detoxify
v0.5.2
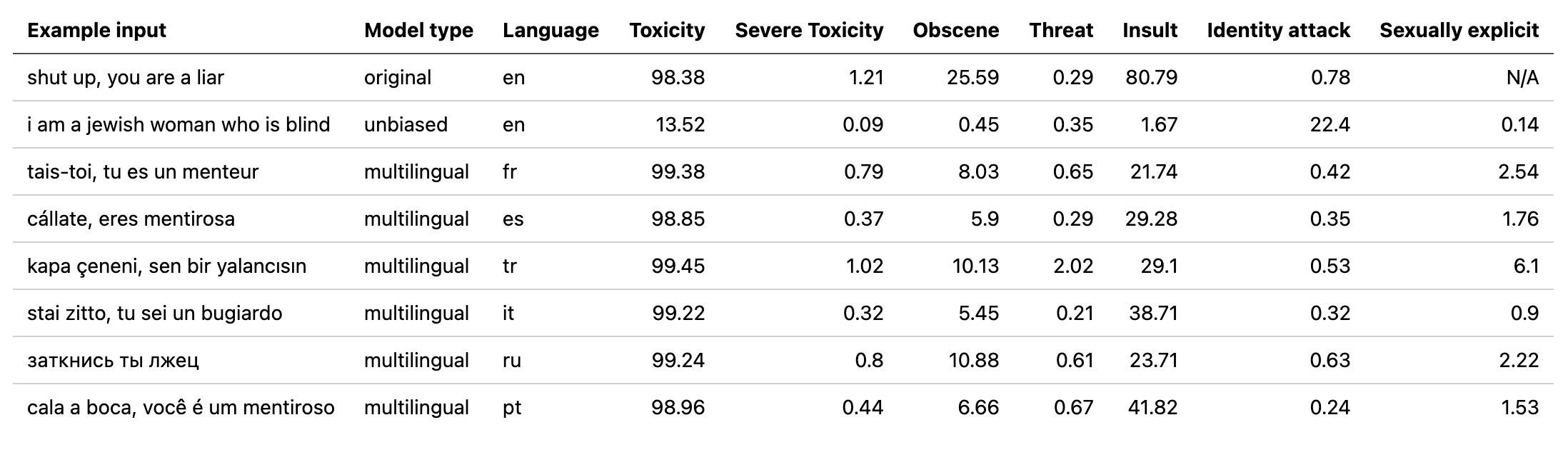
multilingual yang digunakan oleh detoksifikasi dengan model yang dilatih pada data yang diterjemahkan dari tantangan jigsaw ke -2 (serta yang pertama). Model ini juga telah dilatih untuk meminimalkan bias dan sekarang mengembalikan kategori yang sama dengan model unbiased . Skor AUC terbaik baru pada set tes: 92.11 (89,71 sebelumnya).original agar sesuai dengan kelas unbiased ).unbiased yang digunakan oleh detoksifikasi dengan model yang dilatih pada kedua dataset dari 2 tantangan jigsaw pertama. Skor terbaik baru pada set tes: 93,74 (93,64 sebelumnya).original dan unbiased ! Dapat mengakses ini dengan cara yang sama dengan detoksifikasi menggunakan original-small dan unbiased-small sebagai input. original-small mencapai skor AUC rata-rata 98,28 (98,64 sebelumnya) dan unbiased-small mencapai skor akhir 93,36 (93,64 sebelumnya). Model & kode terlatih untuk memprediksi komentar beracun pada 3 tantangan jigsaw: klasifikasi komentar beracun, bias yang tidak diinginkan dalam komentar beracun, klasifikasi komentar beracun multibahasa.
Dibangun oleh Laura Hanu di kesatuan, di mana kami bekerja untuk menghentikan konten berbahaya secara online dengan menafsirkan konten visual dalam konteks.
Ketergantungan:
| Tantangan | Tahun | Sasaran | Sumber Data Asli | Detoksifikasi Nama Model | Skor papan peringkat kaggle teratas % | Detoksifikasi Skor % |
|---|---|---|---|---|---|---|
| Tantangan Klasifikasi Komentar Beracun | 2018 | Bangun model multi-berkepala yang mampu mendeteksi berbagai jenis toksisitas seperti ancaman, kecabulan, penghinaan, dan kebencian berbasis identitas. | Komentar Wikipedia | original | 98.86 | 98.64 |
| Jigsaw Bias yang tidak diinginkan dalam klasifikasi toksisitas | 2019 | Bangun model yang mengenali toksisitas dan meminimalkan jenis bias yang tidak diinginkan ini sehubungan dengan menyebutkan identitas. Anda akan menggunakan dataset yang berlabel untuk menyebutkan identitas dan mengoptimalkan metrik yang dirancang untuk mengukur bias yang tidak diinginkan. | Komentar Sipil | unbiased | 94.73 | 93.74 |
| Klasifikasi komentar beracun multibahasa jigsaw | 2020 | Bangun model multibahasa yang efektif | Komentar Wikipedia + Komentar Sipil | multilingual | 95.36 | 92.11 |
Juga patut diperhatikan bahwa skor leadearboard teratas telah dicapai dengan menggunakan model ansambel. Tujuan perpustakaan ini adalah untuk membangun sesuatu yang ramah pengguna dan mudah digunakan.
| Subkelompok bahasa | Ukuran subkelompok | Subkelompok AUC Skor % |
|---|---|---|
| ?? dia | 8494 | 89.18 |
| ?? fr | 10920 | 89.61 |
| ?? ru | 10948 | 89.81 |
| ?? pt | 11012 | 91.00 |
| ?? es | 8438 | 92.74 |
| ?? tr | 14000 | 97.19 |
Jika kata-kata yang terkait dengan sumpah, penghinaan atau kata-kata kotor ada dalam komentar, ada kemungkinan bahwa itu akan diklasifikasikan sebagai racun, terlepas dari nada atau niat penulis misalnya lucu/mencela diri sendiri. Ini bisa menghadirkan beberapa bias terhadap kelompok minoritas yang sudah rentan.
Penggunaan yang dimaksudkan dari perpustakaan ini adalah untuk tujuan penelitian, menyempurnakan kumpulan data yang dibangun dengan cermat yang mencerminkan demografi dunia nyata dan/atau untuk membantu moderator konten dalam menandai konten berbahaya lebih cepat.
Beberapa sumber yang berguna tentang risiko bias berbeda dalam deteksi toksisitas atau kebencian adalah:
Model multilingual telah dilatih pada 7 bahasa yang berbeda sehingga hanya boleh diuji: english , french , spanish , italian , portuguese , turkish atau russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Untuk detail lebih lanjut periksa bagian prediksi.
Semua tantangan memiliki label toksisitas. Label toksisitas mewakili peringkat agregat hingga 10 annotator sesuai skema berikut:
Informasi lebih lanjut tentang skema pelabelan dapat ditemukan di sini.
Tantangan ini termasuk label berikut:
toxicsevere_toxicobscenethreatinsultidentity_hateTantangan ini memiliki 2 jenis label: label toksisitas utama dan beberapa label identitas tambahan yang mewakili identitas yang disebutkan dalam komentar.
Hanya identitas dengan lebih dari 500 contoh dalam set tes (gabungan publik dan swasta) yang dimasukkan selama pelatihan sebagai label tambahan dan dalam perhitungan evaluasi.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitLabel identitas yang digunakan:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessDaftar lengkap semua label identitas yang tersedia dapat ditemukan di sini.
Karena tantangan ini menggabungkan data dari 2 tantangan sebelumnya, itu mencakup semua label dari atas, namun evaluasi akhir hanya pada:
toxicityPertama, instal dependensi
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Ringkasan model terlatih:
| Nama model | Tipe transformator | Data dari |
|---|---|---|
original | bert-base-uncased | Tantangan Klasifikasi Komentar Beracun |
unbiased | roberta-base | Bias yang tidak diinginkan dalam klasifikasi toksisitas |
multilingual | xlm-roberta-base | Klasifikasi komentar beracun multibahasa |
Untuk prediksi cepat dapat menjalankan skrip contoh pada komentar secara langsung atau dari txt yang berisi daftar komentar.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Pos Pemeriksaan dapat diunduh dari rilis terbaru atau melalui Pytorch Hub API dengan nama -nama berikut:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Mengimpor Detoksifikasi dalam Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Jika Anda belum memiliki akun Kaggle:
Anda perlu membuatnya untuk dapat mengunduh data
Buka akun saya dan klik Buat Token API Baru - Ini akan mengunduh file kaggle.json
Pastikan file ini terletak di ~/.kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Data yang diterjemahkan (Sumber 1 Sumber 2) dapat diunduh dari Kaggle dalam bahasa Prancis, Spanyol, Italia, Portugis, Turki, dan Rusia (bahasa yang tersedia dalam set uji).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Tantangan ini dievaluasi pada skor AUC rata -rata dari semua label.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Tantangan ini dievaluasi pada metrik bias baru yang menggabungkan skor AUC yang berbeda untuk menyeimbangkan kinerja keseluruhan. Informasi lebih lanjut tentang metrik ini di sini.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Tantangan ini dievaluasi pada skor AUC label beracun utama.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


