detoxify
v0.5.2
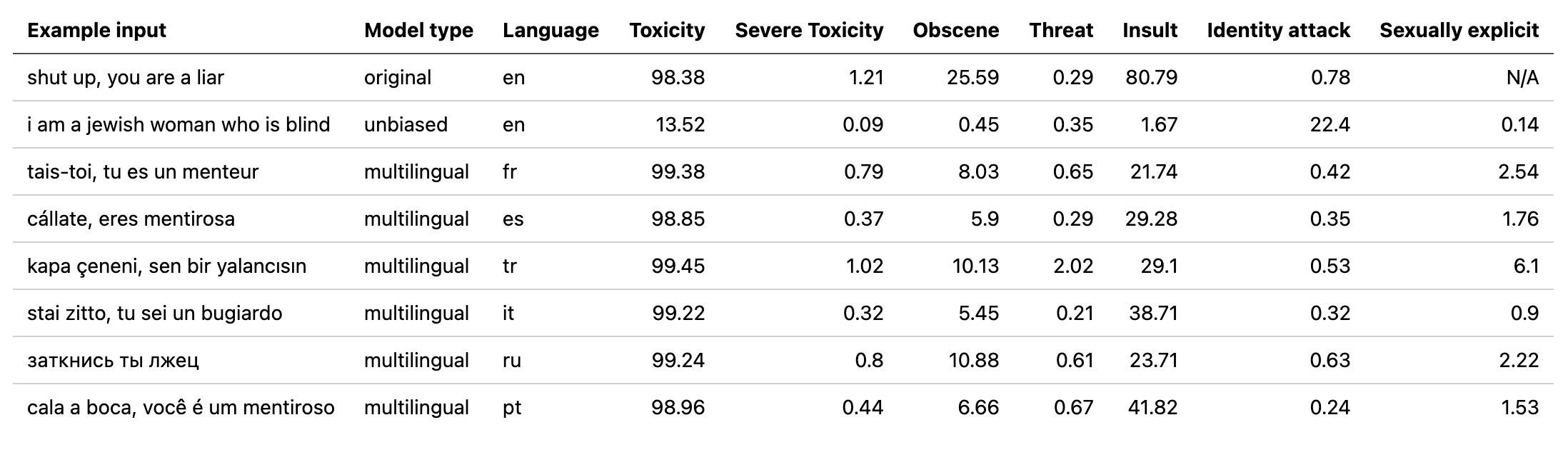
multilingualモデルの重みを更新しました。2番目のJigsawチャレンジ(および1番目)の翻訳されたデータでトレーニングされたモデルで使用されました。このモデルは、バイアスを最小限に抑えるためにトレーニングされており、現在はunbiasedモデルと同じカテゴリを返しています。テストセットでの新しいベストAUCスコア:92.11(89.71前)。unbiasedクラスに一致するように、 originalモデルの「ID_Hate」を置き換えます)。unbiasedモデルの重みを更新しました。最初の2つのジグソーパンの課題から両方のデータセットでトレーニングされたモデルで使用されました。テストセットの新しいベストスコア:93.74(93.64前)。originalとunbiasedモデルのためにアルバートで訓練された小さなモデルを追加しました!入力としてoriginal-small unbiased-smallを使用して、デトキシファイを使用して同じ方法でこれらにアクセスできます。 original-small平均AUCスコア98.28(前の98.64)を達成し、 unbiased-small 93.36(93.64の前)の最終スコアを達成しました。 3つのジグソーパドの課題に対する有毒なコメントを予測するための訓練されたモデルとコード:有毒なコメント分類、有毒コメントの意図しないバイアス、多言語の毒性コメント分類。
Laura HanuによってUnitaryで建設されました。そこでは、視覚的なコンテンツをコンテキストで解釈することにより、有害なコンテンツをオンラインで停止するために取り組んでいます。
依存関係:
| チャレンジ | 年 | ゴール | 元のデータソース | モデル名を解毒します | トップKaggleリーダーボードスコア% | スコア%を解毒する |
|---|---|---|---|---|---|---|
| 有毒なコメント分類課題 | 2018年 | 脅威、わいせつ、in辱、アイデンティティベースの憎しみなど、さまざまな種類の毒性を検出できる多目的モデルを構築します。 | ウィキペディアのコメント | original | 98.86 | 98.64 |
| 毒性分類における意図しないバイアスのジグソー | 2019年 | 毒性を認識し、アイデンティティの言及に関してこのタイプの意図しないバイアスを最小化するモデルを構築します。アイデンティティの言及のためにラベル付けされたデータセットを使用し、意図しないバイアスを測定するように設計されたメトリックを最適化します。 | 市民のコメント | unbiased | 94.73 | 93.74 |
| Jigsaw多言語の毒性コメント分類 | 2020 | 効果的な多言語モデルを構築します | ウィキペディアのコメント +市民のコメント | multilingual | 95.36 | 92.11 |
また、モデルアンサンブルを使用してトップリードボードのスコアが達成されたことに言及することも注目に値します。このライブラリの目的は、使用するためにユーザーフレンドリーで簡単なものを構築することでした。
| 言語サブグループ | サブグループサイズ | サブグループAUCスコア%% |
|---|---|---|
| ??それ | 8494 | 89.18 |
| ?? fr | 10920 | 89.61 |
| ?? ru | 10948 | 89.81 |
| ?? pt | 11012 | 91.00 |
| ?? es | 8438 | 92.74 |
| ?? tr | 14000 | 97.19 |
宣誓、in辱、または冒とくに関連する言葉がコメントに存在する場合、著者の意図やユーモラスな/自己非難など、トーンや意図に関係なく、それは有毒として分類される可能性があります。これは、すでに脆弱な少数派グループにいくつかのバイアスを提示する可能性があります。
このライブラリの意図された使用は、研究目的であり、現実世界の人口統計を反映した慎重に構築されたデータセットを微調整したり、有害なコンテンツをより早くフラグを立てるのを支援するための慎重に構築されたデータセットを微調整します。
毒性または憎悪の発話検出における異なるバイアスのリスクに関するいくつかの有用なリソースは次のとおりです。
multilingualモデルは7つの異なる言語でトレーニングされているため、 english 、 french 、 spanish italian 、 portuguese 、 turkish 、 russianのみでテストする必要があります。
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))詳細については、予測セクションを確認してください。
すべての課題には毒性ラベルがあります。毒性ラベルは、次のスキーマに従って、最大10のアノテーターの総評価を表しています。
ラベルスキーマの詳細については、こちらをご覧ください。
この課題には、次のラベルが含まれます。
toxicsevere_toxicobscenethreatinsultidentity_hateこの課題には、主な毒性ラベルと、コメントに記載されているアイデンティティを表すいくつかの追加のアイデンティティラベルの2種類のラベルがあります。
テストセット(パブリックとプライベートの組み合わせ)に500を超える例を持つアイデンティティのみが、トレーニング中に追加のラベルと評価計算に含まれています。
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicit使用されているアイデンティティラベル:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illness利用可能なすべてのIDラベルの完全なリストは、こちらをご覧ください。
この課題は以前の2つの課題からのデータを組み合わせているため、上からのすべてのラベルが含まれていますが、最終的な評価は次のとおりです。
toxicityまず、依存関係をインストールします
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
訓練されたモデルの概要:
| モデル名 | トランスタイプ | からのデータ |
|---|---|---|
original | bert-base-uncased | 有毒なコメント分類課題 |
unbiased | roberta-base | 毒性分類における意図しないバイアス |
multilingual | xlm-roberta-base | 多言語の有毒コメント分類 |
迅速な予測では、コメントの直接またはコメントのリストを含むTXTからサンプルスクリプトを実行できます。
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
チェックポイントは、最新リリースから、または次の名前でPytorch Hub APIからダウンロードできます。
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )PythonでDetoxifyのインポート:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Kaggleアカウントをまだ持っていない場合:
データをダウンロードできるように作成する必要があります
私のアカウントに移動して、新しいAPIトークンの作成をクリックします - これによりkaggle.jsonファイルがダウンロードされます
このファイルが〜/.kaggleにあることを確認してください
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
翻訳されたデータ(ソース1ソース2)は、フランス語、スペイン語、イタリア語、ポルトガル語、トルコ語、ロシア語(テストセットで利用可能な言語)のKaggleからダウンロードできます。
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
この課題は、すべてのラベルの平均AUCスコアで評価されます。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
この課題は、異なるAUCスコアを組み合わせて全体的なパフォーマンスのバランスをとる新しいバイアスメトリックで評価されます。このメトリックの詳細については、こちらをご覧ください。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
この課題は、主な毒性ラベルのAUCスコアで評価されます。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


