detoxify
v0.5.2
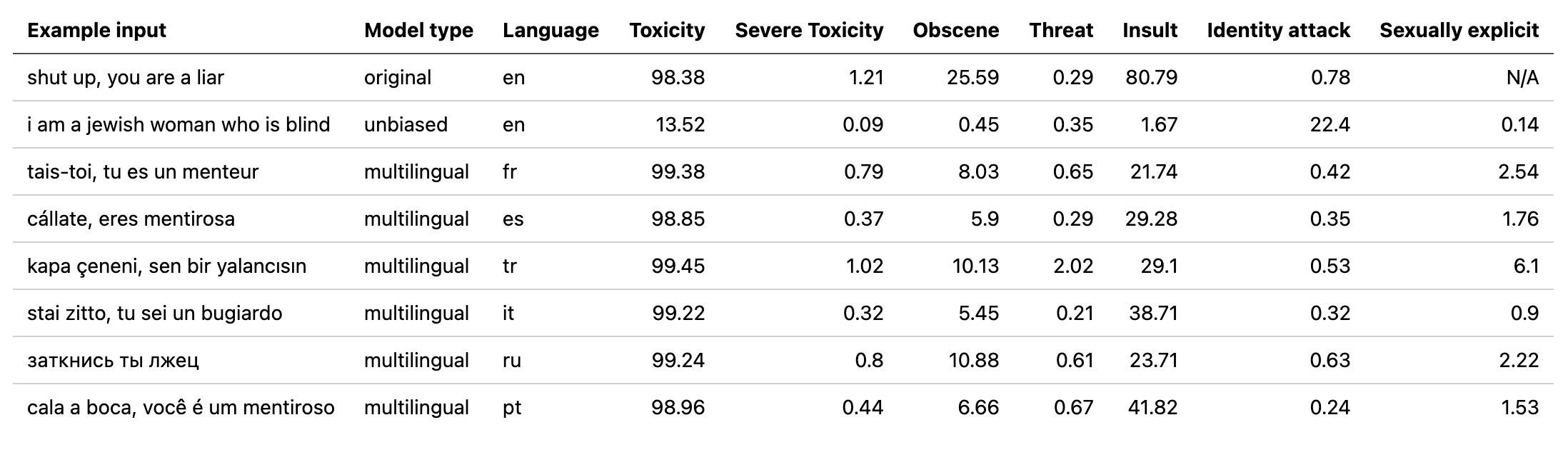
multilingual utilizados por desintoxicar com um modelo treinado nos dados traduzidos do segundo desafio do Jigsaw (bem como no 1º). Esse modelo também foi treinado para minimizar o viés e agora retorna as mesmas categorias que o modelo unbiased . Nova melhor pontuação da AUC no conjunto de testes: 92.11 (89,71 antes).original para corresponder às classes unbiased ).unbiased utilizados por desintoxicar com um modelo treinado nos dois conjuntos de dados dos 2 primeiros desafios do Jigsaw. Nova melhor pontuação no conjunto de testes: 93.74 (93,64 antes).original e unbiased ! Pode acessar-os da mesma maneira com a desintoxica usando original-small unbiased-small como entradas. O original-small alcançou uma pontuação média da AUC de 98,28 (98,64 antes) e o unbiased-small alcançou uma pontuação final de 93,36 (93,64 antes). Modelos e codificação treinados para prever comentários tóxicos sobre 3 desafios de Jigsaw: classificação de comentários tóxicos, viés não intencional em comentários tóxicos, classificação multilíngue de comentários tóxicos.
Construído por Laura Hanu na UNITY, onde estamos trabalhando para interromper o conteúdo prejudicial on -line, interpretando o conteúdo visual no contexto.
Dependências:
| Desafio | Ano | Meta | Fonte de dados original | Desintoxicar o nome do modelo | Top Kaggle Liderboard Score % | Detoxify Score % |
|---|---|---|---|---|---|---|
| Desafio de Classificação de Comentários Tóxicos | 2018 | Construa um modelo de várias cabeças capazes de detectar diferentes tipos de toxicidade, como ameaças, obscenidade, insultos e ódio baseado em identidade. | Comentários da Wikipedia | original | 98.86 | 98.64 |
| Viés não intencional na classificação de toxicidade | 2019 | Construa um modelo que reconheça a toxicidade e minimize esse tipo de viés não intencional em relação às menções das identidades. Você usará um conjunto de dados rotulado para mencionar a identidade e otimizar uma métrica projetada para medir o viés não intencional. | Comentários civis | unbiased | 94.73 | 93.74 |
| Classificação multilíngue de comentários tóxicos multilíngues | 2020 | construir modelos multilíngues eficazes | Comentários da Wikipedia + Comentários Civis | multilingual | 95.36 | 92.11 |
Também é digno de nota mencionar que as principais pontuações do LeadEarboard foram alcançadas usando conjuntos de modelos. O objetivo desta biblioteca era criar algo amigável e simples de usar.
| Subgrupo de idiomas | Tamanho do subgrupo | Subgrupo AUC Score % |
|---|---|---|
| ? isto | 8494 | 89.18 |
| ? fr | 10920 | 89.61 |
| ? ru | 10948 | 89.81 |
| ? pt | 11012 | 91.00 |
| ? es | 8438 | 92.74 |
| ? tr | 14000 | 97.19 |
Se as palavras associadas ao juramento, insultos ou palavrões estiverem presentes em um comentário, é provável que seja classificado como tóxico, independentemente do tom ou da intenção do autor, por exemplo, humorístico/autodepreciativo. Isso poderia apresentar alguns preconceitos em relação a grupos minoritários já vulneráveis.
O uso pretendido desta biblioteca é para fins de pesquisa, ajustando finos em conjuntos de dados cuidadosamente construídos que refletem a demografia do mundo real e/ou para ajudar os moderadores de conteúdo a sinalizar mais rápido conteúdo prejudicial.
Alguns recursos úteis sobre o risco de diferentes preconceitos na toxicidade ou na detecção de discursos de ódio são:
O modelo multilingual foi treinado em 7 idiomas diferentes, por isso só deve ser testado: english , french , spanish , italian , portuguese , turkish ou russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Para mais detalhes, verifique a seção de previsão.
Todos os desafios têm um rótulo de toxicidade. Os rótulos de toxicidade representam as classificações agregadas de até 10 anotadores de acordo com o seguinte esquema:
Mais informações sobre o esquema de rotulagem podem ser encontradas aqui.
Este desafio inclui os seguintes rótulos:
toxicsevere_toxicobscenethreatinsultidentity_hateEsse desafio tem 2 tipos de rótulos: os principais rótulos de toxicidade e alguns rótulos adicionais de identidade que representam as identidades mencionadas nos comentários.
Somente identidades com mais de 500 exemplos no conjunto de testes (público e privado combinado) são incluídos durante o treinamento como rótulos adicionais e no cálculo da avaliação.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitEtiquetas de identidade usadas:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessUma lista completa de todos os rótulos de identidade disponíveis pode ser encontrada aqui.
Como esse desafio combina os dados dos 2 desafios anteriores, inclui todos os rótulos de cima, no entanto, a avaliação final está apenas em:
toxicityPrimeiro, instale dependências
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Resumo dos modelos treinados:
| Nome do modelo | Tipo de transformador | Dados de |
|---|---|---|
original | bert-base-uncased | Desafio de Classificação de Comentários Tóxicos |
unbiased | roberta-base | Viés não intencional na classificação de toxicidade |
multilingual | xlm-roberta-base | Classificação multilíngue de comentários tóxicos |
Para uma previsão rápida, pode executar o script de exemplo em um comentário diretamente ou de um TXT contendo uma lista de comentários.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Os pontos de verificação podem ser baixados da versão mais recente ou pela API do Pytorch Hub com os seguintes nomes:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Importar desintoxicar em Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Se você ainda não possui uma conta de kaggle:
Você precisa criar um para poder baixar os dados
Vá para minha conta e clique em Create New API Token - Isso vai baixar um arquivo kaggle.json
Verifique se este arquivo está localizado em ~/.Kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Os dados traduzidos (Fonte 1 Fonte 2) podem ser baixados de Kaggle em francês, espanhol, italiano, português, turco e russo (os idiomas disponíveis no conjunto de testes).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Esse desafio é avaliado na pontuação média da AUC de todos os rótulos.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Esse desafio é avaliado em uma nova métrica de viés que combina diferentes pontuações da AUC para equilibrar o desempenho geral. Mais informações sobre essa métrica aqui.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Esse desafio é avaliado na pontuação da AUC do rótulo tóxico principal.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


