detoxify
v0.5.2
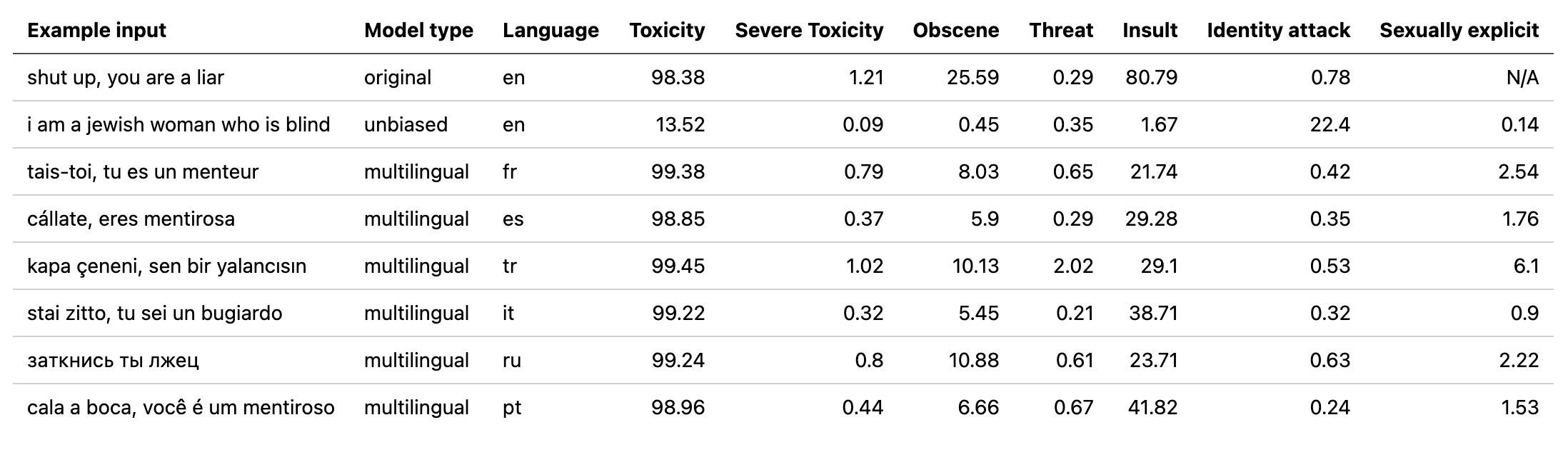
multilingual utilizados por desintoxicación con un modelo entrenado en los datos traducidos del segundo desafío de rompecabezas (así como el 1er). Este modelo también ha sido entrenado para minimizar el sesgo y ahora devuelve las mismas categorías que el modelo unbiased . Nuevo mejor puntaje AUC en el conjunto de pruebas: 92.11 (89.71 antes).original para que coincida con las clases unbiased ).unbiased utilizados por desintoxicación con un modelo entrenado en ambos conjuntos de datos de los primeros 2 desafíos de rompecabezas. Nuevo mejor puntaje en el conjunto de pruebas: 93.74 (93.64 antes).original e unbiased ! Puede acceder a estos de la misma manera con Detoxify usando original-small y unbiased-small como las entradas. La original-small alcanzó una puntuación AUC media de 98.28 (98.64 antes) y la unbiased-small logró un puntaje final de 93.36 (93.64 antes). Modelos y código capacitados para predecir comentarios tóxicos sobre 3 desafíos de rompecabezas: clasificación de comentarios tóxicos, sesgo no deseado en comentarios tóxicos, clasificación multilingüe de comentarios tóxicos.
Construido por Laura Hanu en Unitary, donde estamos trabajando para detener el contenido dañino en línea al interpretar el contenido visual en contexto.
Dependencias:
| Desafío | Año | Meta | Fuente de datos original | Desintoxicar el nombre del modelo | Top Kaggle Roadboard Score % | Desintoxicar el puntaje % |
|---|---|---|---|---|---|---|
| Desafío de clasificación de comentarios tóxicos | 2018 | Construya un modelo de múltiples cabezas que sea capaz de detectar diferentes tipos de toxicidad como amenazas, obscenidad, insultos y odio basado en la identidad. | Comentarios de Wikipedia | original | 98.86 | 98.64 |
| Sesgo no intencionado sesgo en la clasificación de toxicidad | 2019 | Construya un modelo que reconozca la toxicidad y minimice este tipo de sesgo involuntario con respecto a las menciones de identidades. Utilizará un conjunto de datos etiquetado para menciones de identidad y optimizar una métrica diseñada para medir el sesgo no deseado. | Comentarios civiles | unbiased | 94.73 | 93.74 |
| Clasificación de comentarios tóxicos multilingües de Jigsaw | 2020 | construir modelos multilingües efectivos | Comentarios de Wikipedia + Comentarios civiles | multilingual | 95.36 | 92.11 |
También es digno de mención que las puntuaciones superiores de la placa leadear se han logrado utilizando conjuntos de modelos. El propósito de esta biblioteca era construir algo fácil de usar y directo para usar.
| Subgrupo de idiomas | Tamaño de subgrupo | Puntaje AUC subgrupo % |
|---|---|---|
| ? él | 8494 | 89.18 |
| ? fría | 10920 | 89.61 |
| ? freno | 10948 | 89.81 |
| ? PT | 11012 | 91.00 |
| ? cepalle | 8438 | 92.74 |
| ? TR | 14000 | 97.19 |
Si las palabras que están asociadas con juramentos, insultos o blasfemias están presentes en un comentario, es probable que se clasifique como tóxico, independientemente del tono o la intención del autor, por ejemplo, humorístico/autocrítico. Esto podría presentar algunos sesgos hacia grupos minoritarios ya vulnerables.
El uso previsto de esta biblioteca es para fines de investigación, ajustando los conjuntos de datos cuidadosamente construidos que reflejan la demografía del mundo real y/o para ayudar a los moderadores de contenido a marcar el contenido dañino más rápido.
Algunos recursos útiles sobre el riesgo de diferentes sesgos en toxicidad o detección de discursos de odio son:
El modelo multilingual ha sido entrenado en 7 idiomas diferentes, por lo que solo debe probarse: english , french , spanish , italian , portuguese , turkish o russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Para obtener más detalles, consulte la sección de predicción.
Todos los desafíos tienen una etiqueta de toxicidad. Las etiquetas de toxicidad representan las clasificaciones agregadas de hasta 10 anotadores según el siguiente esquema:
Puede encontrar más información sobre el esquema de etiquetado aquí.
Este desafío incluye las siguientes etiquetas:
toxicsevere_toxicobscenethreatinsultidentity_hateEste desafío tiene 2 tipos de etiquetas: las principales etiquetas de toxicidad y algunas etiquetas de identidad adicionales que representan las identidades mencionadas en los comentarios.
Solo las identidades con más de 500 ejemplos en el conjunto de pruebas (combinado público y privado) se incluyen durante la capacitación como etiquetas adicionales y en el cálculo de la evaluación.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitEtiquetas de identidad utilizadas:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessAquí se puede encontrar una lista completa de todas las etiquetas de identidad disponibles aquí.
Dado que este desafío combina los datos de los 2 desafíos anteriores, incluye todas las etiquetas desde arriba, sin embargo, la evaluación final está en encendido:
toxicityPrimero, instalar dependencias
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Resumen de modelos entrenados:
| Nombre del modelo | Tipo de transformador | Datos de |
|---|---|---|
original | bert-base-uncased | Desafío de clasificación de comentarios tóxicos |
unbiased | roberta-base | Sesgo involuntario en la clasificación de toxicidad |
multilingual | xlm-roberta-base | Clasificación de comentarios tóxicos multilingües |
Para una predicción rápida, puede ejecutar el script de ejemplo en un comentario directamente o desde un txt que contiene una lista de comentarios.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Los puntos de control se pueden descargar de la última versión o a través de la API Pytorch Hub con los siguientes nombres:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Importar desintoxicación en Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Si aún no tiene una cuenta de Kaggle:
Debe crear uno para poder descargar los datos
Vaya a mi cuenta y haga clic en Crear nuevo token API: esto descargará un archivo kaggle.json
Asegúrese de que este archivo esté ubicado en ~/.kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Los datos traducidos (Fuente 1 Fuente 2) se pueden descargar de Kaggle en francés, español, italiano, portugués, turco y ruso (los idiomas disponibles en el conjunto de pruebas).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Este desafío se evalúa en la puntuación media de AUC de todas las etiquetas.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Este desafío se evalúa en una nueva métrica de sesgo que combina diferentes puntajes de AUC para equilibrar el rendimiento general. Más información sobre esta métrica aquí.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Este desafío se evalúa en la puntuación AUC de la etiqueta tóxica principal.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


