detoxify
v0.5.2
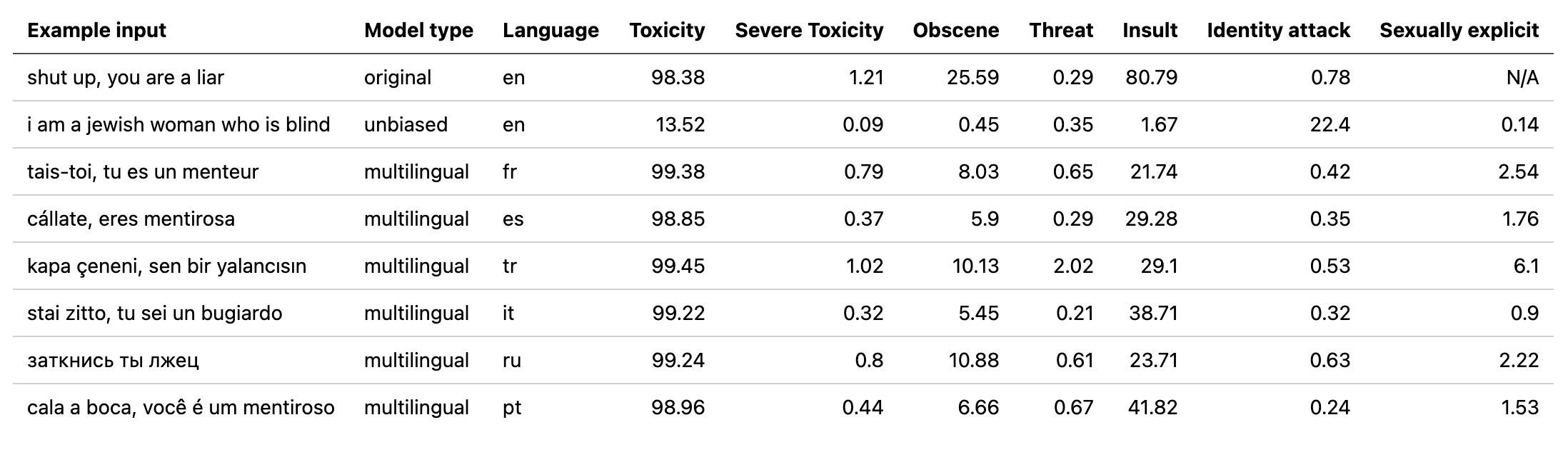
multilingual utilisés par Detoxifier avec un modèle formé sur les données traduites du 2e défi de puzzle (ainsi que le 1er). Ce modèle a également été formé pour minimiser les biais et renvoie désormais les mêmes catégories que le modèle unbiased . Nouveau meilleur score AUC sur l'ensemble de tests: 92.11 (89,71 avant).original pour correspondre aux classes unbiased ).unbiased utilisés par Detoxifier avec un modèle formé sur les deux ensembles de données des 2 premiers défis de la scie sauteuse. Nouveau meilleur score sur l'ensemble de tests: 93,74 (93,64 avant).original et unbiased ! Peut y accéder de la même manière avec Detoxifier en utilisant original-small et unbiased-small comme entrées. L' original-small a obtenu un score AUC moyen de 98,28 (98,64 avant) et le unbiased-small a obtenu un score final de 93,36 (93,64 avant). Modèles formés et code pour prédire les commentaires toxiques sur 3 défis de la scie pour puan: classification des commentaires toxiques, biais involontaire dans les commentaires toxiques, classification des commentaires toxiques multilingues.
Construit par Laura Hanu à unitaire, où nous travaillons pour arrêter le contenu nocif en ligne en interprétant le contenu visuel dans son contexte.
Dépendances:
| Défi | Année | But | Source de données d'origine | Détoxifier le nom du modèle | Top Kaggle Leadboard Score% | Détoxifier le score% |
|---|---|---|---|---|---|---|
| Défi de classification des commentaires toxiques | 2018 | Construisez un modèle multi-têtes capable de détecter différents types de toxicité comme les menaces, l'obscénité, les insultes et la haine basée sur l'identité. | Commentaires de Wikipedia | original | 98.86 | 98,64 |
| Biais involontaire involontaire dans la classification de la toxicité | 2019 | Construisez un modèle qui reconnaît la toxicité et minimise ce type de biais involontaire en ce qui concerne les mentions d'identités. Vous utiliserez un ensemble de données étiqueté pour les mentions d'identité et l'optimisation d'une métrique conçue pour mesurer les biais involontaires. | Commentaires civils | unbiased | 94.73 | 93.74 |
| Classification des commentaires toxiques multilingues à puzzle | 2020 | construire des modèles multilingues efficaces | Commentaires de Wikipedia + commentaires civils | multilingual | 95.36 | 92.11 |
Il convient également de mentionner que les scores de bord de plomb supérieurs ont été obtenus en utilisant des ensembles de modèles. Le but de cette bibliothèque était de créer quelque chose de convivial et de simple utilisation.
| Sous-groupe de langue | Taille du sous-groupe | Sous-groupe AUC score% |
|---|---|---|
| ?? il | 8494 | 89.18 |
| ?? frousser | 10920 | 89.61 |
| ?? ru | 10948 | 89.81 |
| ?? pt | 11012 | 91.00 |
| ?? es | 8438 | 92.74 |
| ?? tr | 14000 | 97.19 |
Si les mots associés à la juron, aux insultes ou aux blasphèmes sont présents dans un commentaire, il est probable qu'il sera classé comme toxique, quel que soit le ton ou l'intention de l'auteur, par exemple humoristique / auto-dépréciant. Cela pourrait présenter certains biais envers les groupes minoritaires déjà vulnérables.
L'utilisation prévue de cette bibliothèque est à des fins de recherche, affinée sur des ensembles de données soigneusement construits qui reflètent la démographie du monde réel et / ou pour aider les modérateurs de contenu à signaler un contenu nocif plus rapidement.
Certaines ressources utiles sur le risque de différents biais dans la toxicité ou la détection des discours de haine sont:
Le modèle multilingual a été formé sur 7 langues différentes, il ne doit donc être testé que: english , french , spanish , italian , portuguese , turkish ou le russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Pour plus de détails, vérifiez la section de prédiction.
Tous les défis ont une étiquette de toxicité. Les étiquettes de toxicité représentent les évaluations agrégées de jusqu'à 10 annotateurs selon le schéma suivant:
Plus d'informations sur le schéma d'étiquetage peuvent être trouvées ici.
Ce défi comprend les étiquettes suivantes:
toxicsevere_toxicobscenethreatinsultidentity_hateCe défi a 2 types d'étiquettes: les principales étiquettes de toxicité et quelques étiquettes d'identité supplémentaires qui représentent les identités mentionnées dans les commentaires.
Seules les identités avec plus de 500 exemples dans l'ensemble de tests (public et privé) sont incluses pendant la formation en tant qu'étiquettes supplémentaires et dans le calcul de l'évaluation.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitÉtiquettes d'identité utilisées:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessUne liste complète de toutes les étiquettes d'identité disponibles peut être trouvée ici.
Étant donné que ce défi combine les données des 2 défis précédents, il inclut toutes les étiquettes d'en haut, mais l'évaluation finale est uniquement activée:
toxicityTout d'abord, installez les dépendances
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Résumé des modèles formés:
| Nom du modèle | Type de transformateur | Données de |
|---|---|---|
original | bert-base-uncased | Défi de classification des commentaires toxiques |
unbiased | roberta-base | Biais involontaire dans la classification de la toxicité |
multilingual | xlm-roberta-base | Classification des commentaires toxiques multilingues |
Pour une prédiction rapide peut exécuter l'exemple de script sur un commentaire directement ou à partir d'un TXT contenant une liste de commentaires.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Les points de contrôle peuvent être téléchargés à partir de la dernière version ou via l'API Pytorch Hub avec les noms suivants:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Importation de détoxifier dans Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Si vous n'avez pas déjà de compte Kaggle:
Vous devez en créer un pour pouvoir télécharger les données
Accédez à mon compte et cliquez sur Créer un nouveau jeton API - Cela téléchargera un fichier kaggle.json
Assurez-vous que ce fichier est situé dans ~ / .kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Les données traduites (source 1 source 2) peuvent être téléchargées à partir de Kaggle en français, espagnol, italien, portugais, turc et russe (les langues disponibles dans l'ensemble de tests).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Ce défi est évalué sur le score AUC moyen de toutes les étiquettes.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Ce défi est évalué sur une nouvelle métrique de biais qui combine différents scores AUC pour équilibrer les performances globales. Plus d'informations sur cette métrique ici.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Ce défi est évalué sur le score AUC de l'étiquette toxique principale.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


