detoxify
v0.5.2
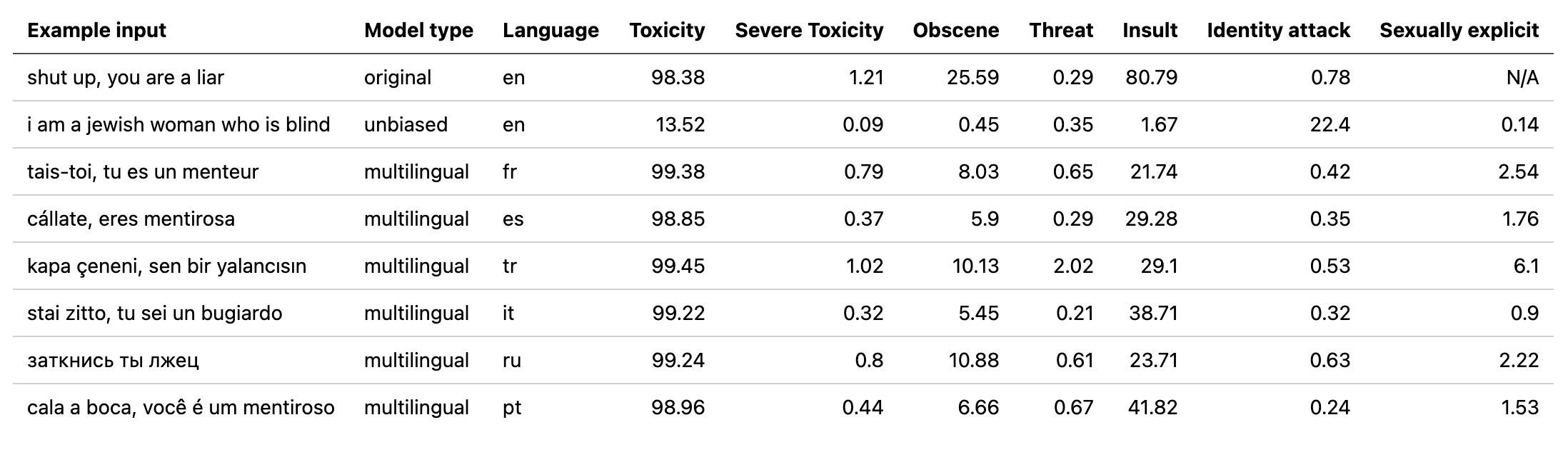
multilingual модели, используемые Detoxify с помощью модели, обученной переведенным данным из 2 -й проблемы с призовом (а также 1 -й). Эта модель также была обучена минимизации смещения и теперь возвращает те же категории, что и unbiased модель. Новый лучший показатель AUC на тестовом наборе: 92.11 (89,71 до).original модели в соответствии с unbiased классами).unbiased веса модели, используемые Detoxify с помощью модели, обученной обоим наборам данных из первых 2 задач. Новый лучший результат на наборе тестирования: 93,74 (93,64 ранее).original и unbiased моделей! Можно получить доступ к ним так же с помощью детоксикации, используя original-small и unbiased-small в качестве входов. original-small достиг среднего балла AUC 98,28 (98,64 ранее), а unbiased-small достиг окончательного балла 93,36 (93,64 ранее). Обученные модели и код для прогнозирования токсичных комментариев по 3 задачам зажимания: токсическая классификация комментариев, непреднамеренное смещение в токсичных комментариях, многоязычная классификация токсичных комментариев.
Построенный Лорой Хану в Unitary, где мы работаем над тем, чтобы остановить вредный контент в Интернете, интерпретируя визуальный контент в контексте.
Зависимости:
| Испытание | Год | Цель | Исходный источник данных | Детоксифицировать имя модели | Top Kaggle Leader Spoorce % | Детоксифицировать оценку % |
|---|---|---|---|---|---|---|
| Задача классификации токсичных комментариев | 2018 | Создайте многоголовую модель, которая способна обнаружить различные типы токсичности, такие как угрозы, непристойность, оскорбления и ненависть на основе идентичности. | Википедия комментарии | original | 98.86 | 98.64 |
| Непреднамеренный уклон в классификации токсичности в классификации токсичности | 2019 | Создайте модель, которая распознает токсичность и сводит к минимуму этот тип непреднамеренного смещения по отношению к упоминаниям идентичности. Вы будете использовать набор данных, помеченный для упоминаний идентификации, и оптимизировать метрику, предназначенную для измерения непреднамеренного смещения. | Гражданские комментарии | unbiased | 94,73 | 93,74 |
| Классификация многоязычного токсичного комментария | 2020 | Создайте эффективные многоязычные модели | Комментарии Википедии + гражданские комментарии | multilingual | 95,36 | 92.11 |
Также следует отметить, что лучшие оценки на свинцовой доске были достигнуты с использованием модельных ансамблей. Цель этой библиотеки состояла в том, чтобы создать что-то удобное для пользователя и простое использование.
| Языковая подгруппа | Размер подгруппы | Подгруппа AUC оценка % |
|---|---|---|
| ?? это | 8494 | 89.18 |
| ?? фр | 10920 | 89,61 |
| ?? Ру | 10948 | 89,81 |
| ?? пт | 11012 | 91.00 |
| ?? эс | 8438 | 92,74 |
| ?? трэнд | 14000 | 97.19 |
Если в комментарии присутствуют слова, которые связаны с ругательствами, оскорблениями или ненормативностью, вполне вероятно, что они будут классифицированы как токсичные, независимо от тона или намерения автора, например, юмористический/самоуничижительный. Это может представлять некоторые предубеждения в отношении и без того уязвимых групп меньшинств.
Предполагаемое использование этой библиотеки предназначено для исследовательских целей, точная настройка тщательно сконструированных наборов данных, которые отражают демографию реального мира и/или для помощи модераторам контента в более быстром помечении вредного контента.
Некоторые полезные ресурсы о риске различных предубеждений в области токсичности или обнаружения ненавистников:
multilingual модель была обучена на 7 разных языках, поэтому ее следует тестировать только на: english , french , spanish , italian , portuguese , turkish или russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Для получения более подробной информации проверьте раздел прогноза.
Все проблемы имеют токсичность. Метки токсичности представляют собой совокупные оценки до 10 аннотаторов в соответствии с следующей схемой:
Более подробную информацию о схеме маркировки можно найти здесь.
Эта задача включает в себя следующие этикетки:
toxicsevere_toxicobscenethreatinsultidentity_hateЭта задача имеет 2 типа меток: основные этикетки токсичности и некоторые дополнительные метки идентификации, которые представляют идентичности, упомянутые в комментариях.
Только личность с более чем 500 примерами в тестовом наборе (комбинированном государственном и частном) включены во время обучения в качестве дополнительных метков и в расчете оценки.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitИспользуются идентификационные метки:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessПолный список всех доступных идентификационных этикеток можно найти здесь.
Поскольку эта задача объединяет данные из предыдущих 2 проблем, она включает все этикетки сверху, однако окончательная оценка проходит только:
toxicityВо -первых, установите зависимости
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Обученные модели резюме:
| Название модели | Тип трансформатора | Данные от |
|---|---|---|
original | bert-base-uncased | Задача классификации токсичных комментариев |
unbiased | roberta-base | Непреднамеренное смещение в классификации токсичности |
multilingual | xlm-roberta-base | Многоязычная классификация токсичных комментариев |
Для быстрого прогноза может запустить пример сценария на комментарии напрямую или из TXT, содержащего список комментариев.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Контрольные точки можно загрузить с последнего выпуска или через API Pytorch Hub со следующими именами:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Импорт детоксикации в Python:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Если у вас еще нет учетной записи Kaggle:
Вам нужно создать один, чтобы иметь возможность загружать данные
Перейдите к моей учетной записи и нажмите «Создать новый токен API» - он загрузит файл kaggle.json
Убедитесь, что этот файл находится в ~/.Kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Переведенные данные (источник 1 источник 2) можно загрузить с Kaggle на французском, испанском, итальянском, португальском, турецком и русском языках (языки, доступные в тестовом наборе).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Эта проблема оценивается по среднему баллу AUC всех ярлыков.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Эта проблема оценивается на новую метрику смещения, которая сочетает в себе различные оценки AUC, чтобы сбалансировать общую производительность. Более подробная информация об этом метрике здесь.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Эта проблема оценивается по оценке AUC основной токсичной этикетки.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


