detoxify
v0.5.2
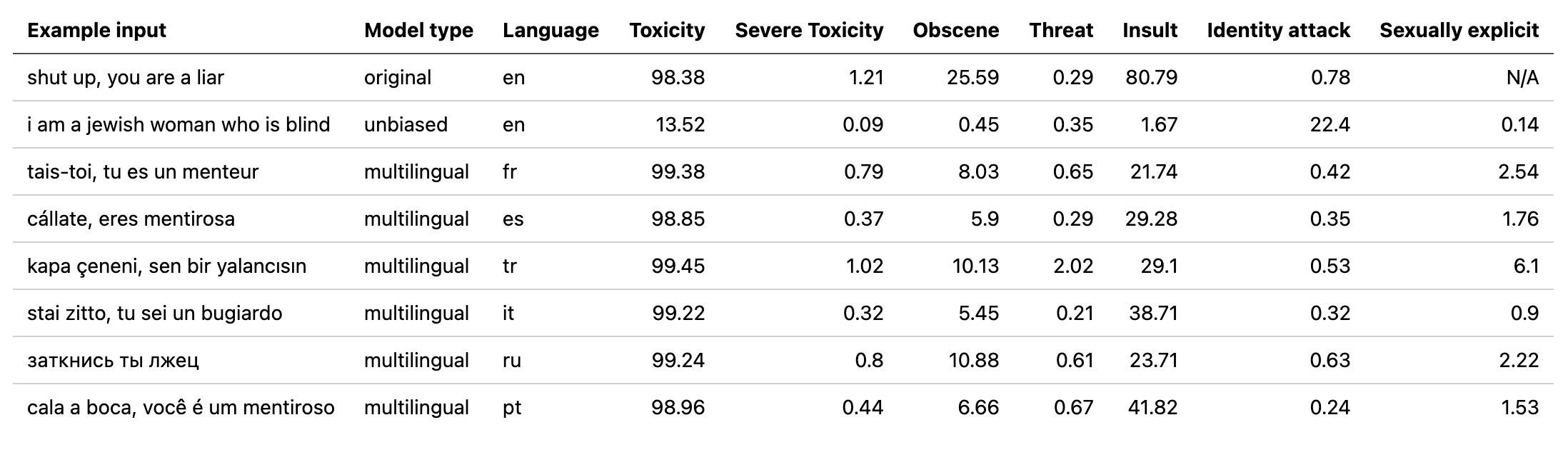
multilingual Modellgewichte, die durch Entgiftung mit einem Modell verwendet wurden, das auf den übersetzten Daten aus der 2. Puzzlebau -Herausforderung (sowie der 1.) trainiert wurde. Dieses Modell wurde auch geschult, um Verzerrungen zu minimieren, und gibt nun die gleichen Kategorien wie das unbiased Modell zurück. Neue beste AUC -Punktzahl im Testsatz: 92.11 (89,71 vorher).original , um den unbiased Klassen zu entsprechen).unbiased Modellgewichte, die durch Entgiftung mit einem Modell verwendet wurden, das auf beiden Datensätzen aus den ersten 2 Puzzlernherausforderungen trainiert wurde. Neue beste Punktzahl im Testsatz: 93,74 (93,64 vorher).original und unbiased Modelle trainiert wurden! Kann auf diese Weise auf diese Weise mit der Entgiftung zugreifen, indem sie original-small und unbiased-small als Eingänge sind. Der original-small erreichte einen mittleren AUC-Score von 98,28 (98,64 vorher) und der unbiased-small erreichte einen Endergebnis von 93,36 (93,64 vorher). Ausgebildete Modelle und Code, um toxische Kommentare zu 3 Puzzlernherausforderungen vorherzusagen: GIXISCHE KOMPENTION -Klassifizierung, unbeabsichtigte Verzerrung in toxischen Kommentaren, mehrsprachige toxische Kommentare.
Erstellt von Laura Hanu bei Unitary, wo wir daran arbeiten, schädliche Inhalte online zu stoppen, indem wir visuelle Inhalte im Kontext interpretieren.
Abhängigkeiten:
| Herausforderung | Jahr | Ziel | Originaldatenquelle | Modellname entgiften | Top Kaggle Rangleichboard erzielt % % | Entgiftung der Punktzahl % |
|---|---|---|---|---|---|---|
| Herausforderung der giftigen Kommentierung Klassifizierung | 2018 | Erstellen Sie ein mehrköpfiges Modell, das verschiedene Arten von Toxizität wie Bedrohungen, Obszönität, Beleidigungen und identitätsbasierten Hass erkennen kann. | Wikipedia kommentiert | original | 98,86 | 98.64 |
| Puzzler unbeabsichtigte Verzerrung in der Toxizitätsklassifizierung | 2019 | Bauen Sie ein Modell auf, das die Toxizität erkennt und diese Art von unbeabsichtigter Verzerrung in Bezug auf die Erwähnungen von Identitäten minimiert. Sie verwenden einen Datensatz, der für Identitätsergebnisse gekennzeichnet und eine Metrik optimiert wird, um unbeabsichtigte Verzerrungen zu messen. | Zivile Kommentare | unbiased | 94.73 | 93.74 |
| Puzzlern mehrsprachige toxische Kommentierung Klassifizierung | 2020 | Bauen Sie effektive mehrsprachige Modelle auf | Wikipedia Kommentare + zivile Kommentare | multilingual | 95.36 | 92.11 |
Es ist auch bemerkenswert zu erwähnen, dass die Top -Leadearboard -Bewertungen unter Verwendung von Modellsembles erzielt wurden. Der Zweck dieser Bibliothek bestand darin, etwas benutzerfreundliches und einfaches zu verwenden.
| Sprachuntergruppe | Untergruppengröße | Subgruppe AUC Score % |
|---|---|---|
| ? Es | 8494 | 89.18 |
| ? fr | 10920 | 89,61 |
| ? Ru | 10948 | 89,81 |
| ? pt | 11012 | 91.00 |
| ? es | 8438 | 92.74 |
| ? tr | 14000 | 97.19 |
Wenn Wörter, die mit Fluchen, Beleidigungen oder Profanität verbunden sind, in einem Kommentar vorhanden sind, ist es wahrscheinlich, dass es als giftig eingestuft wird, unabhängig vom Ton oder der Absicht des Autors, z. B. humorvoll/selbstironisch. Dies könnte einige Vorurteile gegenüber bereits gefährdeten Minderheitengruppen darstellen.
Die beabsichtigte Verwendung dieser Bibliothek dient zu Forschungszwecken, die sich auf sorgfältig konstruierte Datensätze, die die Demografie der realen Welt widerspiegeln, und/oder in den Moderatoren des Inhalts bei der schnelleren Auswahl schädlicher Inhalte widerspiegeln.
Einige nützliche Ressourcen über das Risiko unterschiedlicher Verzerrungen in der Toxizität oder bei der Erkennung von Hasssprachen sind:
Das multilingual Modell wurde in 7 verschiedenen Sprachen ausgebildet, sodass es nur getestet werden sollte: english , french , spanish , italian , portuguese , turkish oder russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Weitere Informationen finden Sie im Abschnitt Vorhersage.
Alle Herausforderungen haben ein Toxizitätsetikett. Die Toxizitätsbezeichnungen repräsentieren die aggregierten Bewertungen von bis zu 10 Annotatoren gemäß dem folgenden Schema:
Weitere Informationen zum Kennzeichnungsschema finden Sie hier.
Diese Herausforderung umfasst die folgenden Etiketten:
toxicsevere_toxicobscenethreatinsultidentity_hateDiese Herausforderung enthält 2 Arten von Etiketten: die wichtigsten Toxizitätsbezeichnungen und einige zusätzliche Identitätsbezeichnungen, die die in den Kommentaren genannten Identitäten darstellen.
Während des Trainings sind nur Identitäten mit mehr als 500 Beispielen im Testsatz (kombiniert öffentlich und privat) als zusätzliche Etiketten und in der Bewertungsberechnung enthalten.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitVerwendete Identitätsbezeichnungen:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessEine vollständige Liste aller verfügbaren Identitätsbezeichnungen finden Sie hier.
Da diese Herausforderung die Daten aus den vorherigen 2 Herausforderungen kombiniert, enthält sie alle Etiketten von oben. Die endgültige Bewertung ist jedoch nur ein:
toxicityInstallieren Sie zunächst Abhängigkeiten
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
Ausgebildete Models Zusammenfassung:
| Modellname | Transformatortyp | Daten von |
|---|---|---|
original | bert-base-uncased | Herausforderung der giftigen Kommentierung Klassifizierung |
unbiased | roberta-base | Unbeabsichtigte Verzerrung in der Toxizitätsklassifizierung |
multilingual | xlm-roberta-base | Mehrsprachige giftige Kommentierungsklassifizierung |
Für eine schnelle Vorhersage kann das Beispielskript direkt oder aus einem TXT mit einer Liste von Kommentaren in einem Kommentar ausgeführt werden.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
Kontrollpunkte können aus der neuesten Version oder über die Pytorch Hub -API mit den folgenden Namen heruntergeladen werden:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )Entgiftung in Python importieren:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))Wenn Sie noch kein Kaggle -Konto haben:
Sie müssen eine erstellen, um die Daten herunterzuladen
Gehen Sie zu meinem Konto und klicken Sie auf neue API -Token. Dadurch wird eine Kaggle.json -Datei heruntergeladen
Stellen Sie sicher, dass sich diese Datei in ~/.Kaggle befindet
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
Die übersetzten Daten (Quelle 1 Quelle 2) können von Kaggle in Französisch, Spanisch, Italienisch, Portugiesisch, Türkisch und Russisch heruntergeladen werden (die im Testsatz erhältlichen Sprachen).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
Diese Herausforderung wird auf dem mittleren AUC -Score aller Etiketten bewertet.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
Diese Herausforderung wird an einer neuartigen Bias -Metrik bewertet, die verschiedene AUC -Werte kombiniert, um die Gesamtleistung auszugleichen. Weitere Informationen zu dieser Metrik hier.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
Diese Herausforderung wird auf dem AUC -Score des toxischen Hauptetikums bewertet.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


