detoxify
v0.5.2
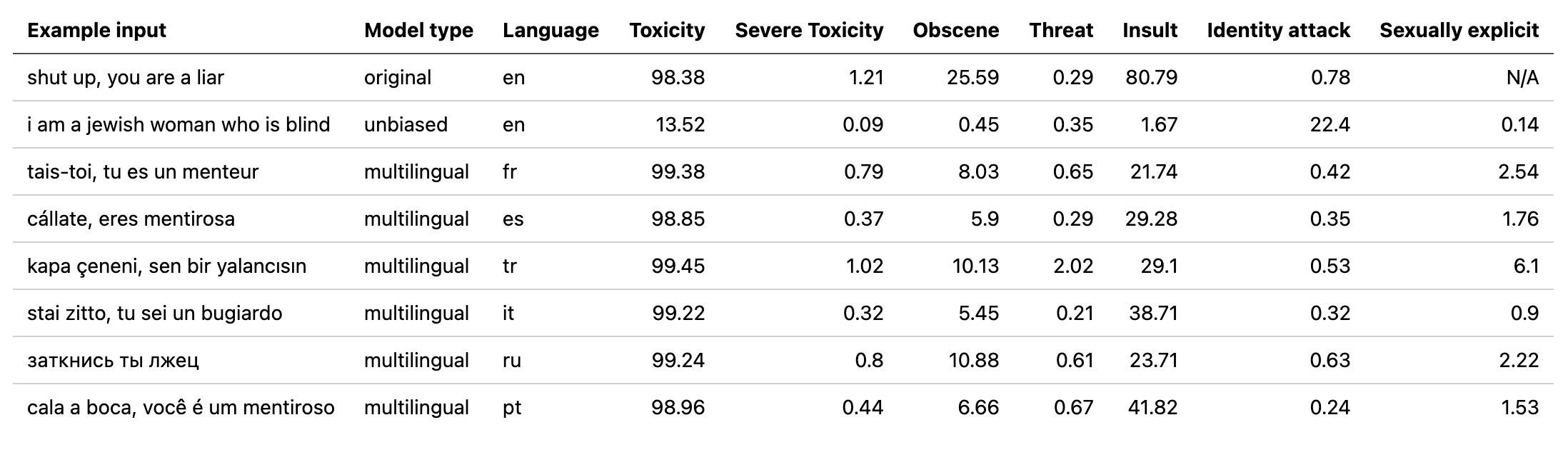
multilingual التي تستخدمها إزالة السموم باستخدام نموذج مدرب على البيانات المترجمة من تحدي Jigsaw الثاني (وكذلك الأول). تم تدريب هذا النموذج أيضًا على تقليل التحيز ويعيد الآن نفس الفئات مثل النموذج unbiased . أفضل درجة AUC الجديدة في مجموعة الاختبار: 92.11 (89.71 من قبل).original لمطابقة الفئات unbiased ).unbiased التي تستخدمها إزالة السموم باستخدام نموذج تم تدريبه على كل من مجموعات البيانات من أول 2 تحديات Jigsaw. أفضل درجة جديدة في مجموعة الاختبار: 93.74 (93.64 من قبل).original unbiased ! يمكن الوصول إلى هذه بالطريقة نفسها مع إزالة السموم باستخدام original-small و unbiased-small مثل المدخلات. حقق original-small درجة متوسط AUC من 98.28 (98.64 من قبل) وحققت unbiased-small درجة نهائية قدرها 93.36 (93.64 من قبل). نماذج ورمز مدرب للتنبؤ بالتعليقات السامة على 3 تحديات بانوراما: تصنيف التعليقات السامة ، التحيز غير المقصود في التعليقات السامة ، تصنيف التعليقات السامة متعددة اللغات.
بنيت من قبل لورا هانو في الوحدة ، حيث نعمل على إيقاف المحتوى الضار عبر الإنترنت من خلال تفسير المحتوى المرئي في السياق.
التبعيات:
| تحدي | سنة | هدف | مصدر البيانات الأصلي | اسم النموذج إزالة السموم | أفضل درجة المتصدرين في Kaggle ٪ | درجة إزالة السموم ٪ |
|---|---|---|---|---|---|---|
| تحدي تصنيف التعليقات السامة | 2018 | قم ببناء نموذج متعدد الرؤوس قادر على اكتشاف أنواع مختلفة من السمية مثل التهديدات والفحش والإهانات والكراهية القائمة على الهوية. | تعليقات ويكيبيديا | original | 98.86 | 98.64 |
| بانوراما تحيز غير مقصود في تصنيف السمية | 2019 | قم ببناء نموذج يتعرف على السمية ويقلل من هذا النوع من التحيز غير المقصود فيما يتعلق بالإشارات من الهويات. ستستخدم مجموعة بيانات مصممة لذكرى الهوية وتحسين مقياسًا مصممًا لقياس التحيز غير المقصود. | التعليقات المدنية | unbiased | 94.73 | 93.74 |
| تصنيف التعليقات السامة متعددة اللغات بانهي | 2020 | بناء نماذج متعددة اللغات فعالة | تعليقات ويكيبيديا + التعليقات المدنية | multilingual | 95.36 | 92.11 |
من الجدير بالذكر أيضًا أن نذكر أنه تم تحقيق أفضل درجات اللوحة الزائدة باستخدام مجموعات النموذج. كان الغرض من هذه المكتبة هو بناء شيء سهل الاستخدام ومباشر للاستخدام.
| مجموعة فرعية اللغة | حجم المجموعة الفرعية | المجموعة الفرعية AUC ٪ |
|---|---|---|
| ؟ هو - هي | 8494 | 89.18 |
| ؟ الاب | 10920 | 89.61 |
| ؟ رو | 10948 | 89.81 |
| ؟ حزب العمال | 11012 | 91.00 |
| ؟ ES | 8438 | 92.74 |
| ؟ tr | 14000 | 97.19 |
إذا كانت الكلمات المرتبطة بالأقلة أو الإهانات أو الألفاظ النابية موجودة في تعليق ، فمن المحتمل أن يتم تصنيفها على أنها سامة ، بغض النظر عن النغمة أو القصد من المؤلف على سبيل المثال ، الفكاهية/المستندة إلى الذات. هذا يمكن أن يمثل بعض التحيزات تجاه مجموعات الأقليات الضعيفة بالفعل.
الاستخدام المقصود لهذه المكتبة هو لأغراض البحث ، والضبط على مجموعات البيانات التي تم إنشاؤها بعناية والتي تعكس التركيبة السكانية في العالم الحقيقي و/أو لمساعدة المشرفين على المحتوى في وضع علامة على المحتوى الضار بشكل أسرع.
بعض الموارد المفيدة حول خطر التحيزات المختلفة في السمية أو الكشف عن خطاب الكراهية هي:
تم تدريب النموذج multilingual على 7 لغات مختلفة ، لذا يجب اختباره فقط: english ، french ، spanish ، italian ، portuguese ، turkish أو russian .
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))لمزيد من التفاصيل ، تحقق من قسم التنبؤ.
جميع التحديات لها علامة سمية. تمثل ملصقات السمية التقييمات الإجمالية التي تصل إلى 10 مراجعات وفقًا للمخطط التالي:
يمكن العثور على مزيد من المعلومات حول مخطط وضع العلامات هنا.
يتضمن هذا التحدي الملصقات التالية:
toxicsevere_toxicobscenethreatinsultidentity_hateيحتوي هذا التحدي على نوعين من الملصقات: ملصقات السمية الرئيسية وبعض ملصقات الهوية الإضافية التي تمثل الهويات المذكورة في التعليقات.
يتم تضمين الهويات فقط مع أكثر من 500 من الأمثلة في مجموعة الاختبار (مجتمعة وخاصة خاصة) أثناء التدريب كعلامات إضافية وفي حساب التقييم.
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicitتسميات الهوية المستخدمة:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illnessيمكن العثور على قائمة كاملة بجميع ملصقات الهوية المتاحة هنا.
نظرًا لأن هذا التحدي يجمع بين البيانات من التحديين السابقتين ، فإنه يشمل جميع العلامات من الأعلى ، ومع ذلك فإن التقييم النهائي قيد التشغيل فقط:
toxicityأولا ، تثبيت التبعيات
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
ملخص النماذج المدربة:
| اسم النموذج | نوع المحول | البيانات من |
|---|---|---|
original | bert-base-uncased | تحدي تصنيف التعليقات السامة |
unbiased | roberta-base | التحيز غير المقصود في تصنيف السمية |
multilingual | xlm-roberta-base | تصنيف التعليقات السامة متعددة اللغات |
للحصول على تنبؤ سريع ، يمكن تشغيل البرنامج النصي للمثال على تعليق مباشرة أو من TXT يحتوي على قائمة التعليقات.
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
يمكن تنزيل نقاط التفتيش من أحدث إصدار أو عبر واجهة برمجة تطبيقات Pytorch Hub مع الأسماء التالية:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )استيراد إزالة السموم في بيثون:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))إذا لم يكن لديك بالفعل حساب kaggle:
تحتاج إلى إنشاء واحدة لتتمكن من تنزيل البيانات
انتقل إلى حسابي وانقر فوق إنشاء رمز API جديد - سيؤدي ذلك إلى تنزيل ملف kaggle.json
تأكد من وجود هذا الملف في ~/.Kaggle
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
يمكن تنزيل البيانات المترجمة (المصدر 1 المصدر 2) من Kaggle باللغة الفرنسية والإسبانية والإيطالية والبرتغالية والتركية والروسية (اللغات المتاحة في مجموعة الاختبار).
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
يتم تقييم هذا التحدي على متوسط درجة AUC لجميع الملصقات.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
يتم تقييم هذا التحدي على مقياس تحيز جديد يجمع بين درجات AUC المختلفة لتحقيق التوازن بين الأداء العام. مزيد من المعلومات حول هذا المقياس هنا.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
يتم تقييم هذا التحدي على درجة AUC للعلامة السامة الرئيسية.
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


