detoxify
v0.5.2
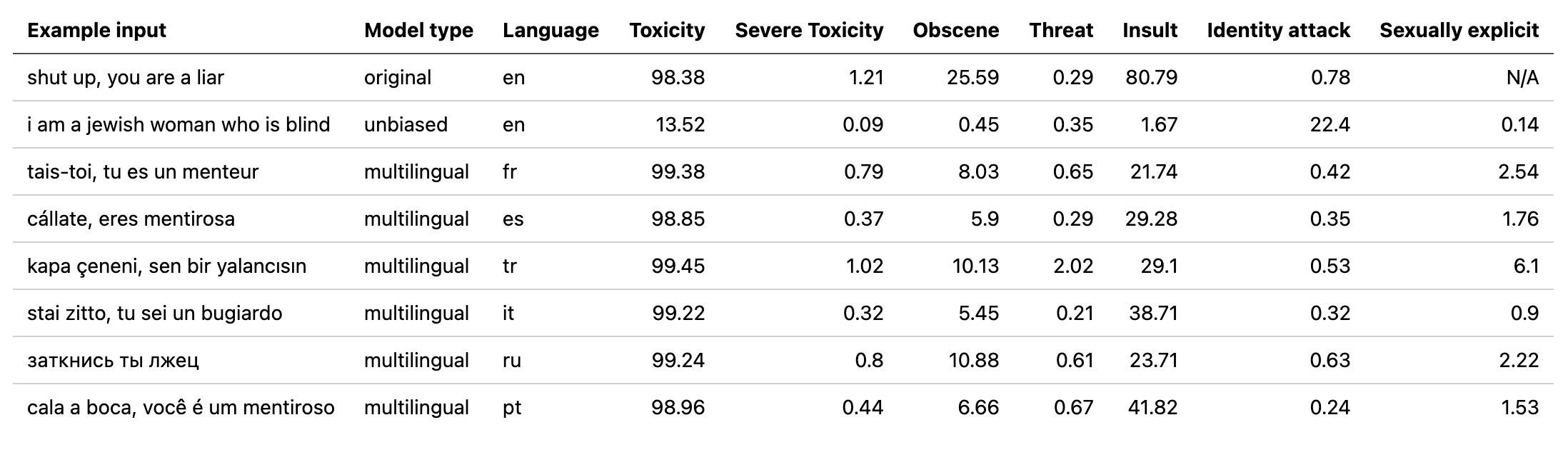
multilingual模型权重,并通过对第二拼图挑战的翻译数据进行了训练的模型(以及第一个)。该模型还接受了训练以最大程度地减少偏差,现在返回与unbiased模型相同的类别。测试集中的新最佳AUC分数:92.11(之前89.71)。original模型中替换“ Identity_hate”以匹配unbiased类)。unbiased模重量。测试集的新最佳分数:93.74(前93.64)。original和unbiased车型培训!可以使用original-small和unbiased-small输入使用排毒的方式以相同的方式访问它们。 original-small平均AUC得分为98.28(98.64), unbiased-small最终成绩为93.36(前93.64)。 受过训练的模型和代码预测有关3个拼图挑战的有毒评论:有毒评论分类,有毒评论中的意外偏见,多语言有毒评论分类。
由Laura Hanu在Unitary建造,我们正在努力通过在上下文中解释视觉内容来停止在线停止有害内容。
依赖性:
| 挑战 | 年 | 目标 | 原始数据源 | 排毒模型名称 | 顶级Kaggle排行榜分数% | 排毒分数% |
|---|---|---|---|---|---|---|
| 有毒评论分类挑战 | 2018 | 建立一个多头模型,能够检测到不同类型的毒性,例如威胁,淫秽,侮辱和基于身份的仇恨。 | 维基百科评论 | original | 98.86 | 98.64 |
| 拼图中意想不到的毒性分类偏见 | 2019 | 建立一个识别毒性并最大程度地减少这种意外偏见的模型。您将使用标记标记的数据集进行身份提及,并优化旨在测量意外偏见的度量标准。 | 民事评论 | unbiased | 94.73 | 93.74 |
| 拼图多语言有毒评论分类 | 2020 | 建立有效的多语言模型 | 维基百科评论 +民事评论 | multilingual | 95.36 | 92.11 |
还值得注意的是,使用模型集合实现了顶级领先板得分。该库的目的是构建用户友好且直接使用的东西。
| 语言子组 | 亚组大小 | 亚组AUC分数% |
|---|---|---|
| ?它 | 8494 | 89.18 |
| ? fr | 10920 | 89.61 |
| ? ru | 10948 | 89.81 |
| ? pt | 11012 | 91.00 |
| ? es | 8438 | 92.74 |
| ? tr | 14000 | 97.19 |
如果在评论中存在与宣誓,侮辱或亵渎相关的单词,那么无论作者的语气或意图如何,它都可能被归类为有毒的词,例如幽默/自我嘲笑。这可能会给已经脆弱的少数群体带来一些偏见。
该库的预期用途是用于研究目的,对经过精心构造的数据集进行了微调,这些数据集反映了现实世界的人口统计数据和/或帮助内容主持人更快地标记有害内容。
关于毒性或仇恨言论检测中不同偏见风险的一些有用资源是:
multilingual模型已经接受了7种不同语言的培训,因此仅应在: english , french , spanish , italian , portuguese , turkish或russian中进行测试。
# install detoxify
pip install detoxify
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify ( 'original' ). predict ( 'example text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to specify the device the model will be allocated on (defaults to cpu), accepts any torch.device input
model = Detoxify ( 'original' , device = 'cuda' )
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))有关更多详细信息,请查看预测部分。
所有挑战都有毒性标签。毒性标签代表最多10个注释者的总额定值:以下模式:
有关标签模式的更多信息,请参见此处。
该挑战包括以下标签:
toxicsevere_toxicobscenethreatinsultidentity_hate这项挑战具有2种类型的标签:主要毒性标签和一些代表评论中提到的身份的其他身份标签。
在培训期间,在测试集中只有500多个示例(合并的公共和私人)的身份作为其他标签和评估计算。
toxicitysevere_toxicityobscenethreatinsultidentity_attacksexual_explicit使用的身份标签:
malefemalehomosexual_gay_or_lesbianchristianjewishmuslimblackwhitepsychiatric_or_mental_illness可以在此处找到所有可用标签的完整列表。
由于此挑战结合了前两个挑战的数据,因此包括上面的所有标签,但是最终评估仅在:
toxicity首先,安装依赖项
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
# or for training
pip install -e ' detoxify[dev] '
cd detoxify
受过训练的模型摘要:
| 模型名称 | 变压器类型 | 来自 |
|---|---|---|
original | bert-base-uncased | 有毒评论分类挑战 |
unbiased | roberta-base | 毒性分类的意外偏见 |
multilingual | xlm-roberta-base | 多语言有毒评论分类 |
为了快速预测,可以直接在注释上或从包含注释列表的TXT上运行示例脚本。
# load model via torch.hub
python run_prediction.py --input ' example ' --model_name original
# load model from from checkpoint path
python run_prediction.py --input ' example ' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
可以从最新版本或通过Pytorch Hub API下载检查点:
toxic_bertunbiased_toxic_robertamultilingual_toxic_xlm_rmodel = torch.hub.load( ' unitaryai/detoxify ' , ' toxic_bert ' )在Python中导入排毒:
from detoxify import Detoxify
results = Detoxify ( 'original' ). predict ( 'some text' )
results = Detoxify ( 'unbiased' ). predict ([ 'example text 1' , 'example text 2' ])
results = Detoxify ( 'multilingual' ). predict ([ 'example text' , 'exemple de texte' , 'texto de ejemplo' , 'testo di esempio' , 'texto de exemplo' , 'örnek metin' , 'пример текста' ])
# to display results nicely
import pandas as pd
print ( pd . DataFrame ( results , index = input_text ). round ( 5 ))如果您还没有Kaggle帐户:
您需要创建一个才能下载数据
转到我的帐户,然后单击创建新的API令牌 - 这将下载一个kaggle.json文件
确保此文件位于〜/.kaggle中
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
unzip jigsaw-toxic-comment-classification-challenge.zip -d jigsaw-toxic-comment-classification-challenge
find jigsaw-toxic-comment-classification-challenge -name ' *.csv.zip ' | xargs -n1 unzip -d jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
unzip jigsaw-unintended-bias-in-toxicity-classification.zip -d jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
unzip jigsaw-multilingual-toxic-comment-classification.zip -d jigsaw-multilingual-toxic-comment-classification
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-toxic-comment-classification-challenge/test.csv --update_test
python train.py --config configs/Toxic_comment_classification_BERT.jsonpython train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa_combined.json
翻译数据(源1来源2)可以从Kaggle中下载,以法语,西班牙语,意大利语,葡萄牙语,土耳其语和俄语(测试集中可用的语言)下载。
# combine test.csv and test_labels.csv
python preprocessing_utils.py --test_csv jigsaw_data/jigsaw-multilingual-toxic-comment-classification/test.csv --update_test
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
tensorboard --logdir=./saved
对所有标签的平均AUC得分进行了评估。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
对新的偏见度量进行了评估,该挑战将不同的AUC得分结合在一起以平衡整体性能。有关此指标的更多信息。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
对主要有毒标签的AUC评分进行了评估。
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}


