100 Days of NLP
1.0.0

魔術沒有什麼魔術。魔術師只是理解一些簡單的東西,對於未經訓練的觀眾來說似乎並不簡單或自然。一旦您學習瞭如何在使手看起來空的同時握住卡,那麼您只需要練習才能“做魔術”。 - 杰弗裡·弗里德爾(Jeffrey Friedl)在書中掌握正則表達式
注意:請提出任何建議,更正和反饋的問題。
大多數代碼樣本都是使用Jupyter筆記本(使用COLAB)完成的。因此每個代碼可以獨立運行。
已經探討了以下主題:
注意:難度水平是根據我的理解分配的。
| 令牌化 | 單詞嵌入 - word2vec | 單詞嵌入 - 手套 | 單詞嵌入 - elmo |
| RNN,LSTM,Gru | 包裝襯墊序列 | 注意機制-Luong | 注意機制-Bahdanau |
| 指針網絡 | 變壓器 | GPT-2 | 伯特 |
| 主題建模 - LDA | 主成分分析(PCA) | 天真的貝葉斯 | 數據增強 |
| 句子嵌入 |
將文本數據轉換為令牌的過程是NLP中最重要的一步之一。使用以下方法進行了代幣化:
單詞嵌入是文本的學習表示,其中具有相同含義的單詞具有相似的表示形式。正是這種代表單詞和文檔的方法可能被認為是挑戰自然語言處理問題的深度學習的關鍵突破之一。

Word2Vec是Google開發的最受歡迎的預貼單詞嵌入之一。根據學習嵌入的方式,Word2Vec分為兩種方法:
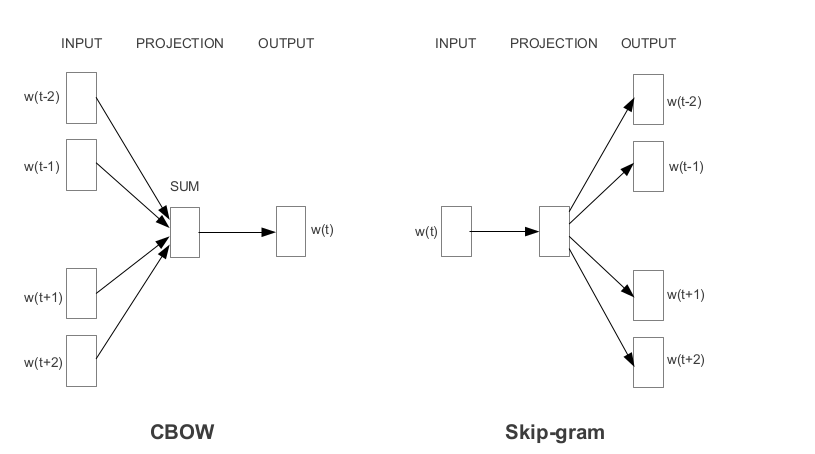
手套是獲得預訓練的嵌入的另一種常用方法。手套旨在實現兩個目標:
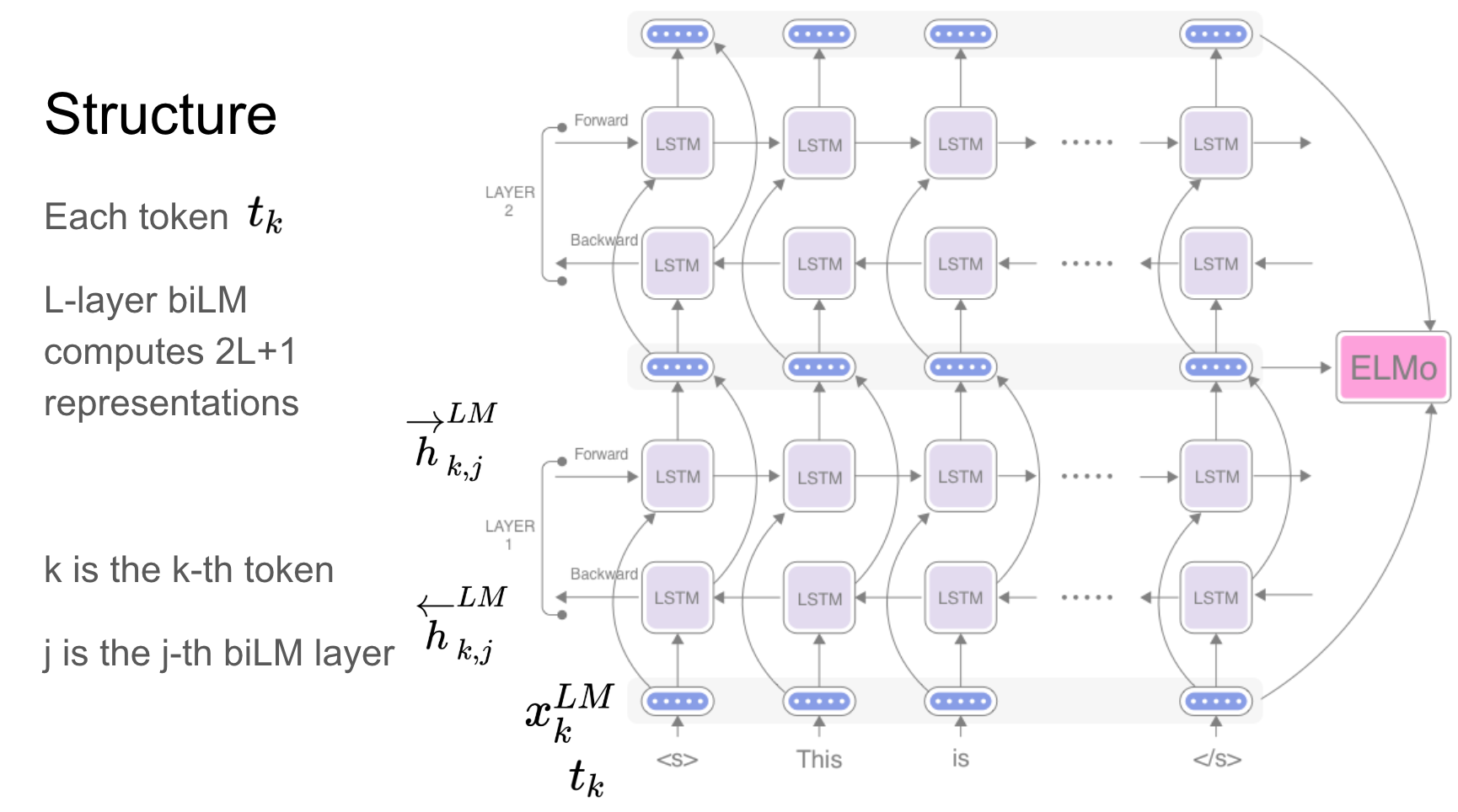
Elmo是一個建模的深層上下文化的單詞表示形式:
這些單詞向量是深層雙向語言模型(BILM)的內部狀態的函數,該功能已在大型文本語料庫中進行了預培訓。
經常性網絡-RNN,LSTM,GRU已被證明是NLP應用程序中最重要的單元之一,因為它們的架構。在許多問題上,需要像預測場景中的情緒一樣需要記住序列性質,需要記住以前的場景。

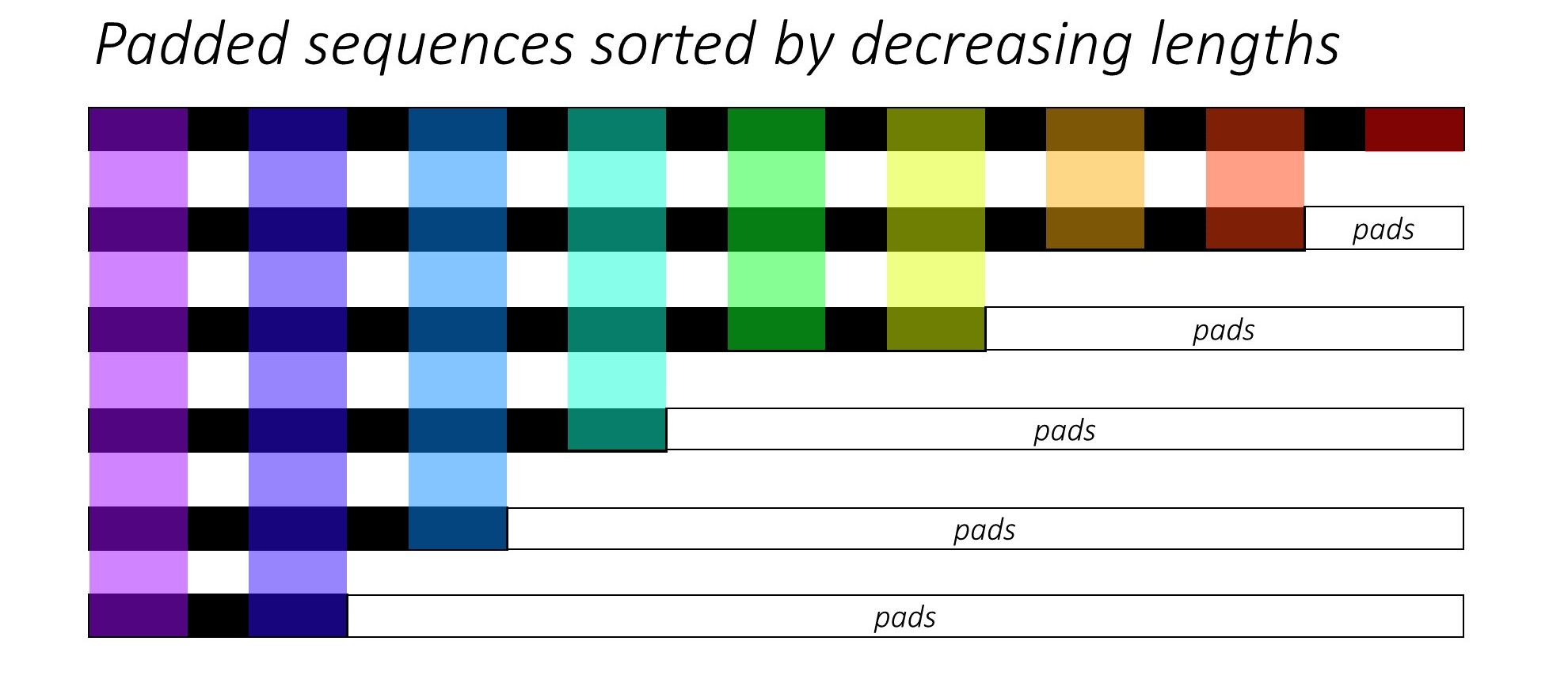
當訓練RNN(LSTM,GRU或VANILLA-RNN)時,很難批量批次序列。理想情況下,我們將把所有序列都放在固定的長度上,並最終進行不必要的計算。我們如何克服這一點? Pytorch提供pack_padded_sequences功能。
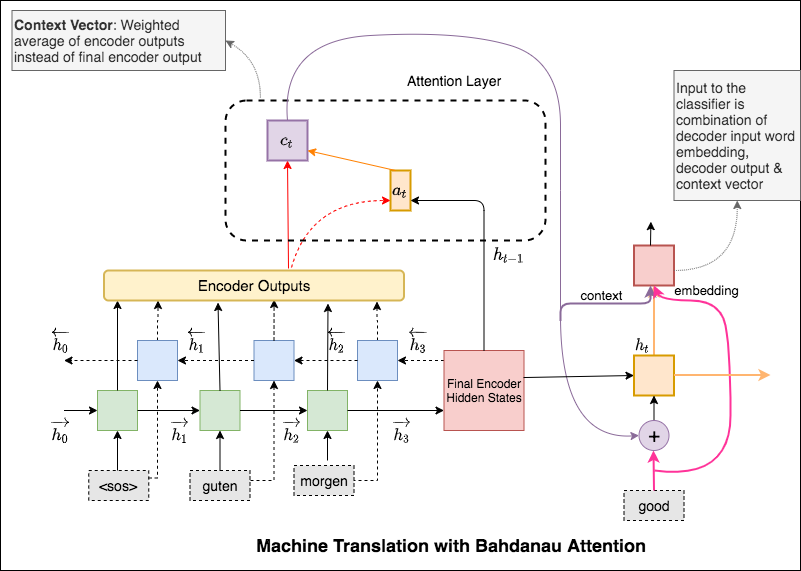
注意機制誕生是為了幫助記住神經機器翻譯(NMT)中的長源句子。與其從編碼器的最後一個隱藏狀態中構建單個上下文向量,不如在解碼句子時更多地專注於輸入的相關部分。將通過獲取編碼器輸出和解碼器RNN的current output來創建上下文向量。

注意力評分可以通過三種方式計算。 dot , general和concat 。
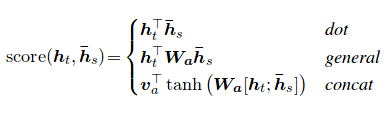
Bahdanau和Luong關注之間的主要區別在於上下文向量的創建方式。上下文向量將通過取編碼器輸出和解碼器RNN的previous hidden state創建。在Luong注意的位置,將通過取編碼器輸出和解碼器RNN的current hidden state來創建上下文向量。
一旦計算上下文,它將與解碼器輸入嵌入並作為解碼器RNN輸入。

Bahdanau的關注也被稱為additive 。
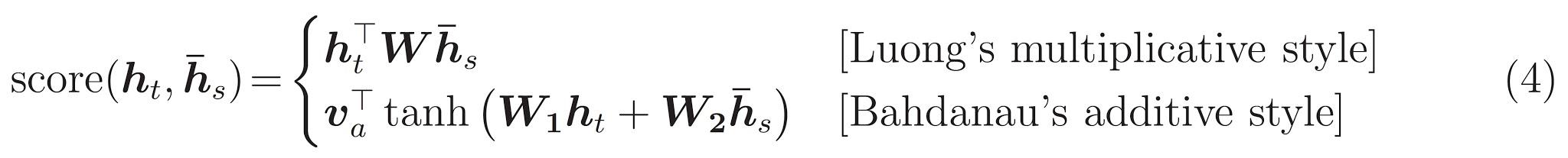
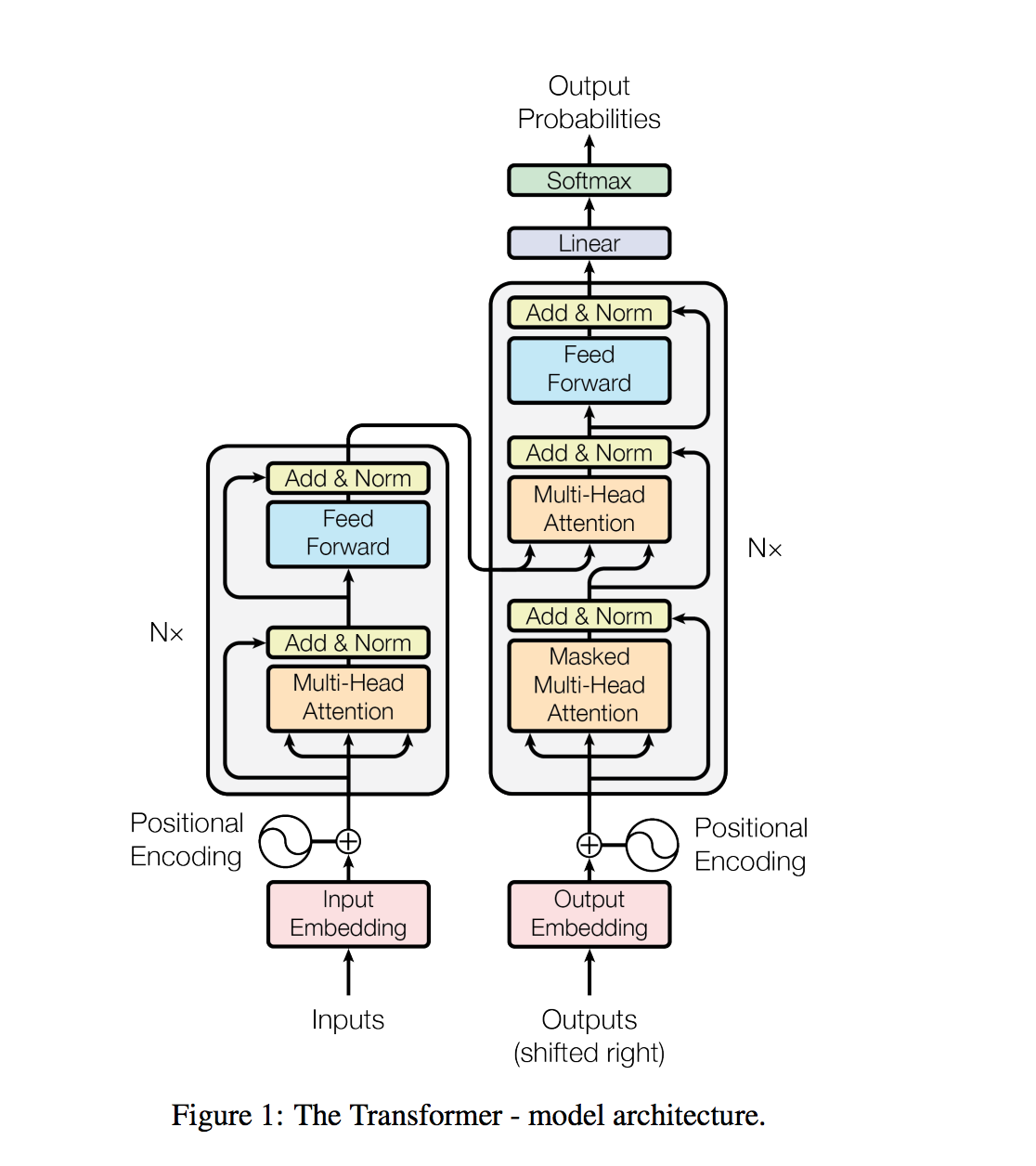
變壓器是一種模型體系結構避免復發,而是完全依靠注意機制在輸入和輸出之間吸引全局依賴性。
通常,在任務規定的數據集中進行監督學習,通常會接近自然語言處理任務,例如問答,機器翻譯,閱讀理解和摘要。我們證明,當在新的名為WebText的新網頁上培訓時,語言模型開始學習這些任務而沒有任何明確的監督。我們最大的型號GPT-2是1.5B參數變壓器,在8個測試的語言建模數據集中有7個以零拍設置的方式實現了最先進的結果,但仍未擬合WebText。該模型的樣本反映了這些改進,並包含文本的連貫段落。這些發現提出了建立語言處理系統的有希望的途徑,該途徑學會從其自然發生的演示中執行任務。
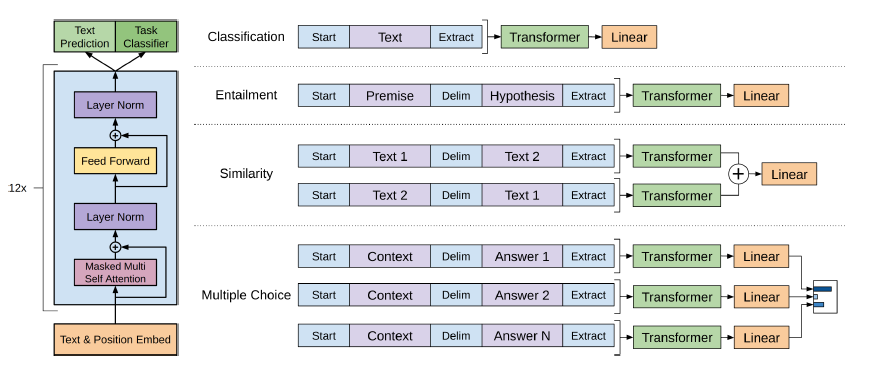
GPT-2利用了僅12層解碼器的變壓器體系結構。
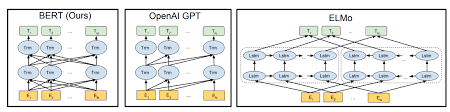
伯特使用變壓器體系結構來編碼句子。
指針網絡的輸出是離散的,對應於輸入序列中的位置
輸出每個步驟中目標類的數量取決於輸入的長度,這是可變的。
它與以前的注意力嘗試不同,而不是使用注意力將編碼器的隱藏單元與每個解碼器步驟的上下文向量進行混合,而是將注意力用作指針來選擇輸入序列的成員作為輸出。

自然語言處理的主要應用之一是自動提取人們從大量文本中討論的主題。一些大文本的示例可能是社交媒體,酒店,電影等客戶評論,用戶反饋,新聞報導,客戶投訴的電子郵件等。
了解人們在說什麼,並理解他們的問題和觀點對企業,管理人員和政治運動非常有價值。而且很難手動閱讀如此大的捲並編譯主題。
因此,需要一種自動化算法,該算法可以通過文本文檔讀取並自動輸出所討論的主題。
在此筆記本中,我們將以20 Newsgroups數據集的真實示例,並使用LDA提取自然討論的主題。
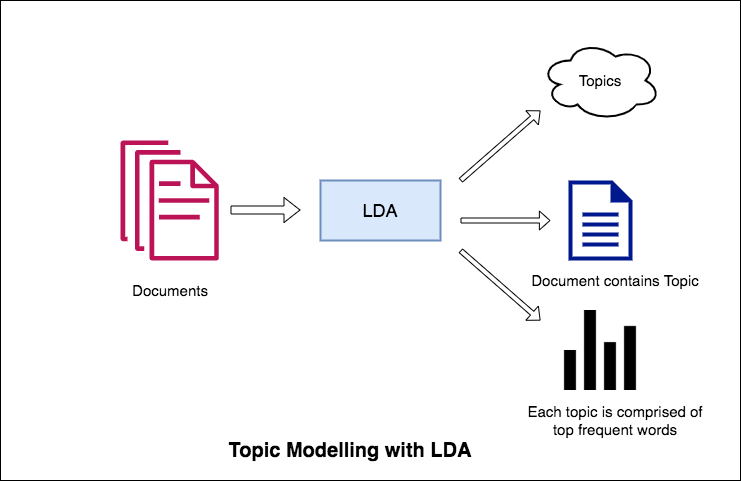
LDA的主題建模方法是將每個文檔視為一定比例的主題集合。並且每個主題都是關鍵字集合,並以一定比例的比例。
一旦您提供了主題數量的算法,就可以將文檔和關鍵字分佈中的主題分佈重新排列,以獲得主題鍵單詞分佈的良好組成。
從根本上講,PCA是一種減少維度的技術,可將數據集的列轉換為新集合功能。它通過找到一組新的方向(例如X和Y軸)來解釋數據中的最大可變性。這個新的系統坐標軸稱為主組件(PC)。
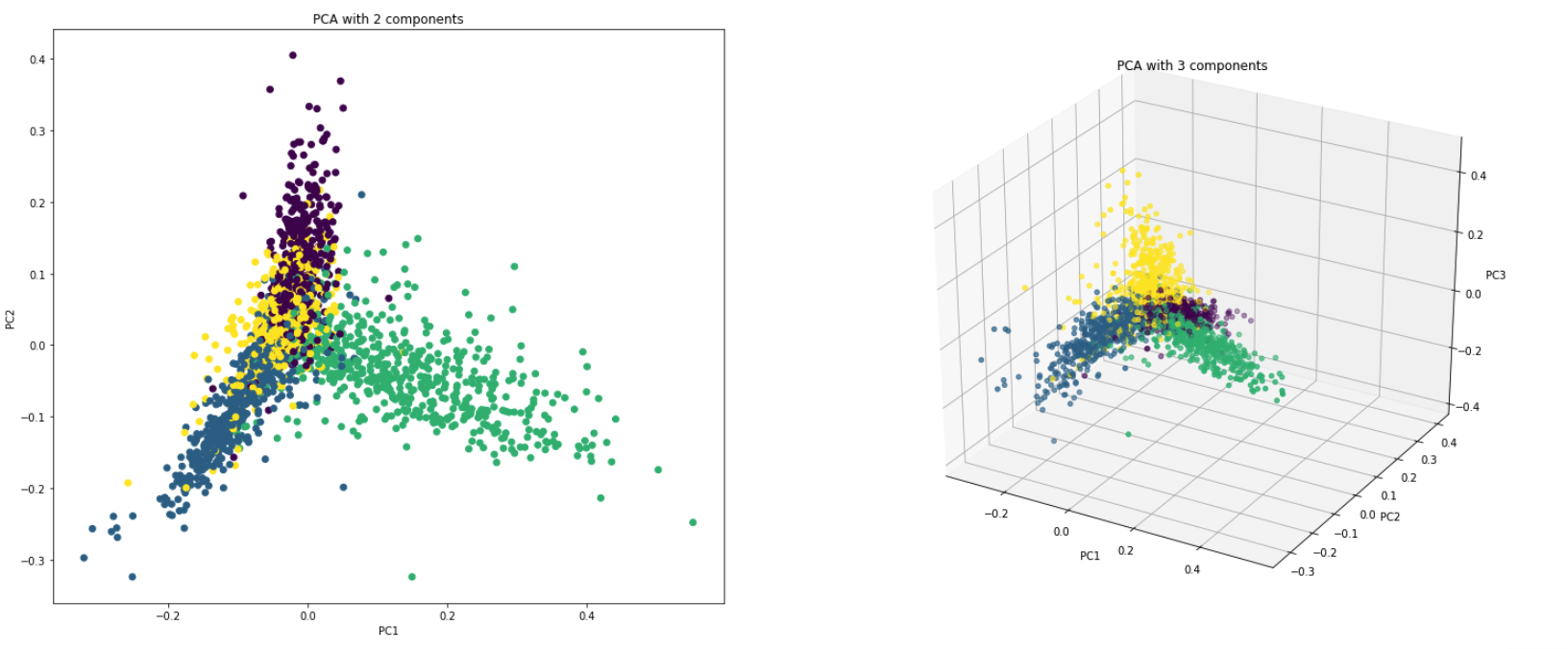
實際上,PCA的使用有兩個原因:
Dimensionality Reduction :分佈在大量列中的信息被轉換為主組件(PC),以便前幾個PC可以解釋總信息的相當大部分(方差)。這些PC可以用作機器學習模型中的解釋變量。
Visualize Data :可視化類(或群集)的分離很難具有超過3個維度(功能)的數據。對於前兩台PC本身,通常可以看到明確的分離。
天真的貝葉斯分類器是用於分類任務的概率機器學習模型。分類器的關鍵基於貝葉斯定理。
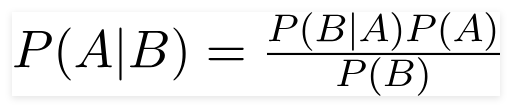
考慮到B發生了B,使用貝葉斯定理,我們可以找到發生A的可能性。在這裡,B是證據,A是假設。這裡提出的假設是預測因素/特徵是獨立的。那就是一個特定特徵的存在不會影響另一個特徵。因此,它被稱為天真。
天真貝葉斯分類器的類型:
Multinomial Naive Bayes :這主要是當變量離散(如單詞)時使用的。分類器使用的功能/預測指標是文檔中存在的單詞的頻率。
Gaussian Naive Bayes :當預測變量佔據連續值並且不是離散的值時,我們假設這些值是從高斯分佈中採樣的。
Bernoulli Naive Bayes :這與多項式幼稚的貝葉斯相似,但預測因子是布爾變量。我們用來預測類變量的參數僅佔用值是或否,例如,是否在文本中出現單詞。
使用20NewSgroup數據集,探索了Naive Bayes算法進行分類。
探索了使用以下技術的數據增強:

探索了一個名為Sbert的新建築。暹羅網絡體系結構可以派生用於輸入句子的固定尺寸向量。使用諸如餘弦或曼哈頓 /歐幾里得距離之類的相似性度量,可以找到語義上相似的句子。

| 情感分析-IMDB | 情感分類 - hinglish | 文檔分類 |
| 重複的問題對分類 - Quora | POS標籤 | 自然語言推論-SNLI |
| 有毒評論分類 | 語法正確的句子 - 可樂 | NER標記 |
情感分析是指使用自然語言處理,文本分析,計算語言學和生物識別技術來系統地識別,提取,量化和研究情感狀態和主觀信息。
探索了以下變體:
RNN用於處理和識別情感。

在嘗試了基本的RNN後,test_accuracy的基本RNN少於50%,已經實驗了以下技術,並實現了超過88%的test_accuracy。
使用的技術:

在預測輸入情緒時,注意力有助於關注相關輸入。 Bahdanau的注意力被用來吸收LSTM的輸出,並串聯了最終的前進和向後隱藏狀態。不使用預訓練的單詞嵌入,可以達到88%的測試準確性。
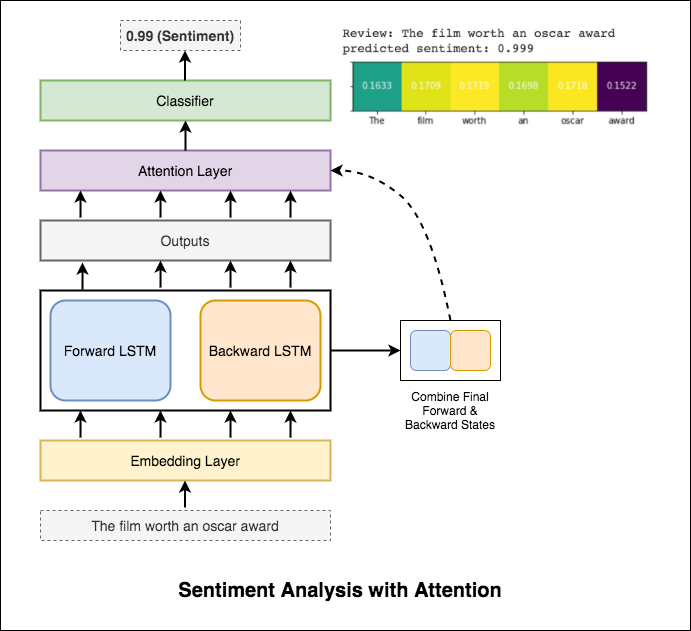
伯特(Bert)在11個自然語言處理任務上獲得了新的最新結果。 NLP中的轉移學習在發布BERT模型後觸發。探索了使用BERT進行情感分析。

混合語言(也稱為混合代碼)是多語言社會的規範。多語言的人是非母語英語的人,他們傾向於使用基於英語的語音鍵入和插入英語的主語言來代碼混音。
任務是預測給定代碼混合推文的情感。情感標籤是正面,負面或中立的,而混合的語言將是英語印度語。 (Sentimix)
探索了以下變體:
使用簡單的MLP模型,在測試數據上達到了F1 score of 0.58

探索基本MLP模型後,將LSTM模型用於情感預測,並實現了F1分數為0.57 。

實際上,與基本MLP模型相比,結果較小。原因之一可能是LSTM由於代碼混合數據的高度多樣性而無法學習句子中單詞之間的關係。
由於LSTM由於代碼混合數據的高度多樣性而無法使用代碼混合句子中的單詞之間的關係,並且不使用預訓練的嵌入,因此F1分數較小。
為了減輕此問題,XLM-Roberta模型(已在100種語言上進行了預培訓)用於編碼句子。為了使用XLM-Roberta模型,該句子需要使用適當的語言。因此,首先需要將Hinglish單詞轉換為印地語(Devanagari)形式。
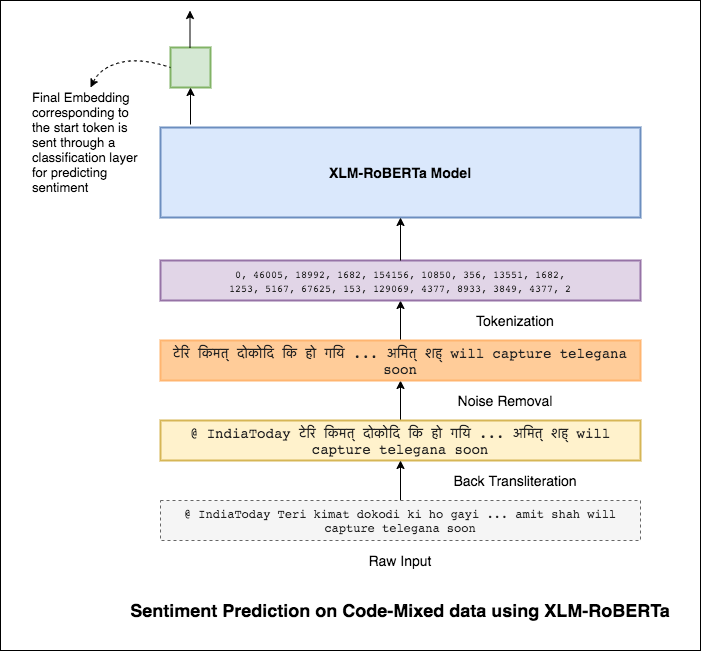
達到0.59的F1分數。改進的方法將在稍後進行。
XLM-Roberta模型的最終輸出用作雙向LSTM模型的輸入嵌入。從LSTM層中獲取輸出的注意力層產生輸入的加權表示,然後通過分類器通過分類器來預測句子的情感。

達到0.64的F1分數。
就像3x3濾波器可以瀏覽圖像的斑塊一樣,1x2濾波器可以在文本中瀏覽兩個順序單詞,即Bi-gram。在此CNN模型中,我們將使用不同尺寸的多個過濾器,這些過濾器將查看BI-GRAM(1x2濾波器),Tri-gram(1x3濾波器)和/或N-Grams(1xn filtr)(1倍濾波器)。
此處的直覺是,審查中某些Bi-gram,Tri-grams和n-grams的外觀將很好地表明最終情感。
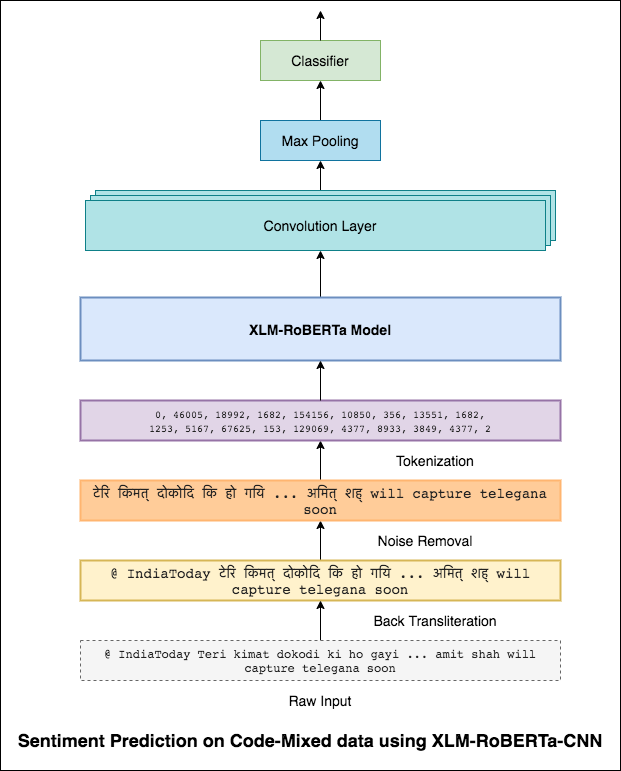
達到0.69的F1分數。
CNN捕獲了RNN捕獲全球依賴性的本地依賴性。通過組合兩者,我們可以更好地了解數據。 CNN模型和雙向牽引模型的結合執行了其他模型。
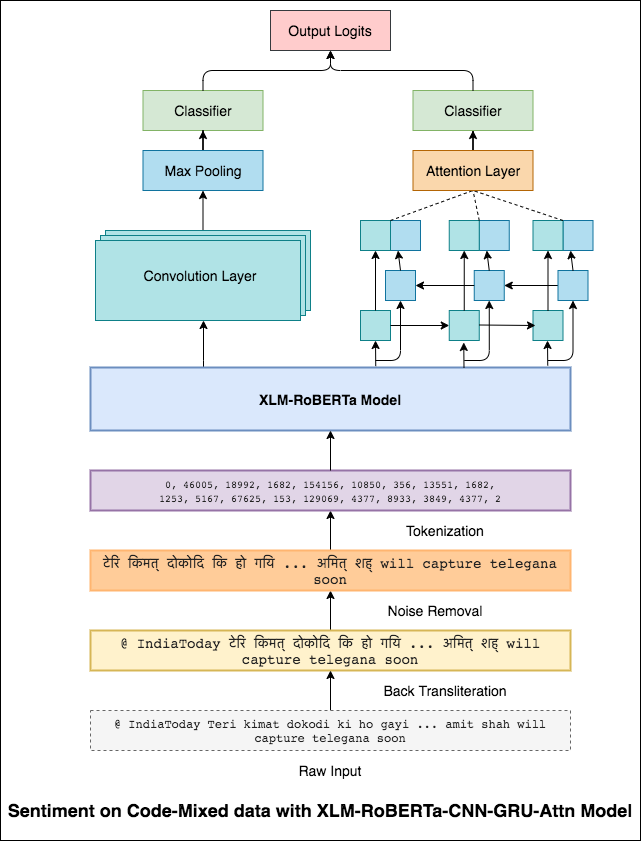
達到0.71的F1分數。 (排名前5位)。
文檔分類或文檔分類是圖書館科學,信息科學和計算機科學中的一個問題。任務是將文檔分配給一個或多個類或類別。
探索了以下變體:
分層注意力網絡(HAN)考慮文檔的層次結構(文檔 - 句子 - 單詞),並包括一種注意機制,該機制能夠在考慮上下文時在文檔中找到最重要的單詞和句子。
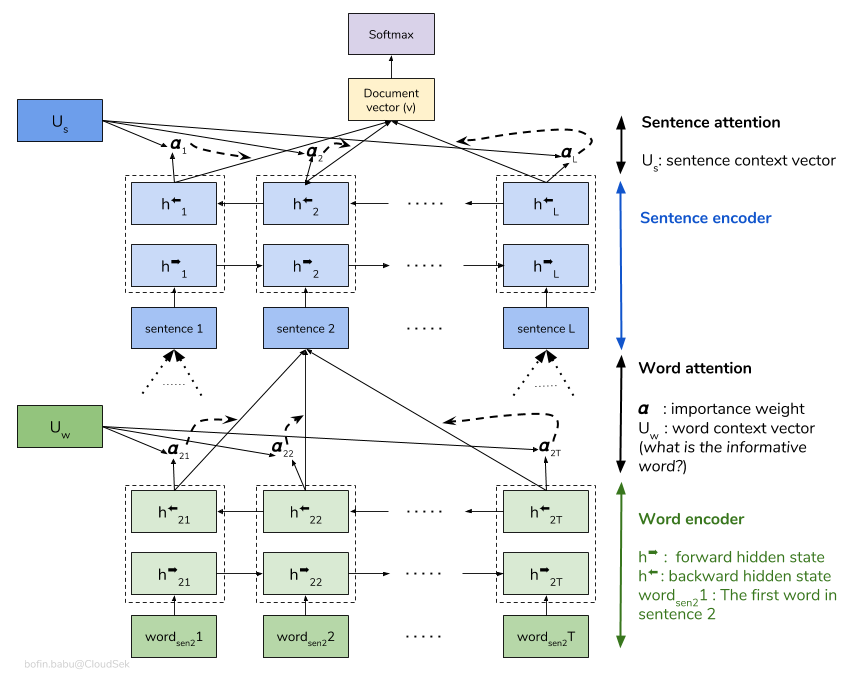
基本的HAN模型迅速擬合。為了克服這一問題,探索了Embedding Dropout的技術,探索了Locked Dropout 。還有另一種稱為Weight Dropout的技術,該技術未實施(讓我知道是否有任何實施此功能的資源)。還使用預訓練的單詞嵌入Glove代替隨機初始化。由於可以在句子級別和單詞級別上進行注意,因此我們可以看到哪些單詞在句子中很重要,哪些句子在文檔中很重要。



QQP代表Quora問題對。該任務的目的是給定的問題;我們需要找到這些問題在語義上是否彼此相似。
探索了以下變體:
該算法需要將這對問題作為輸入,並應輸出它們的相似性。使用暹羅網絡。 Siamese neural network (有時稱為雙神經網絡)是一個人工神經網絡,在兩個不同的輸入向量的同時使用same weights來計算可比的輸出向量。

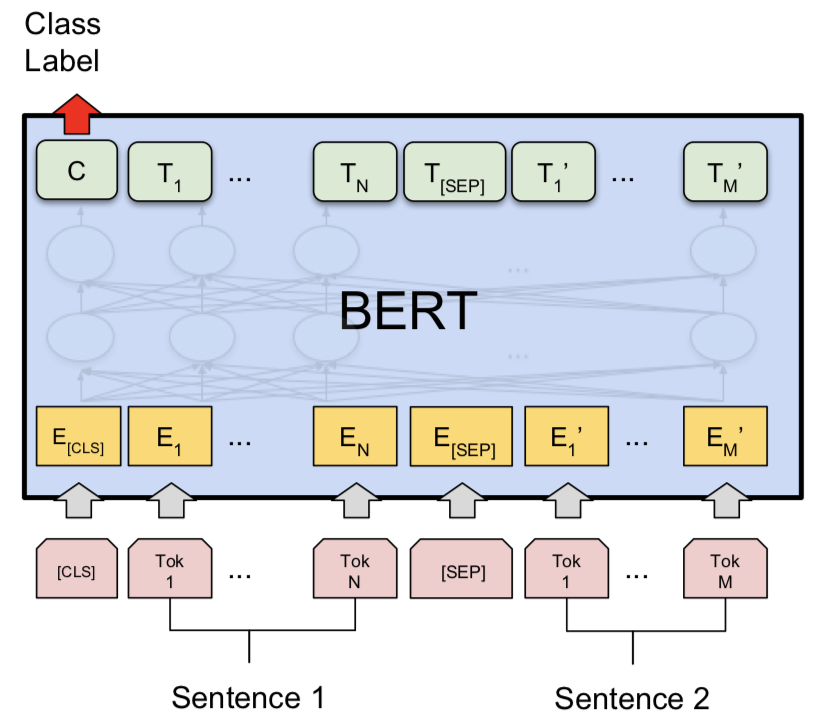
嘗試暹羅模型後,探索了Bert進行Quora重複問題對檢測。伯特(Bert)將問題1和問題2作為輸入,由[SEP]令牌分開,分類是使用[CLS]令牌的最終表示。
詞性(POS)標記是一項任務,是在句子中標記每個單詞,並具有適當的語音部分。
探索了以下變體:
此代碼涵蓋基本工作流程。我們將學習如何:加載數據,創建火車/測試/驗證拆分,構建詞彙,創建數據迭代器,定義模型並實現火車/評估/測試環和運行時間(推理)標記。
使用的模型是多層雙向LSTM網絡
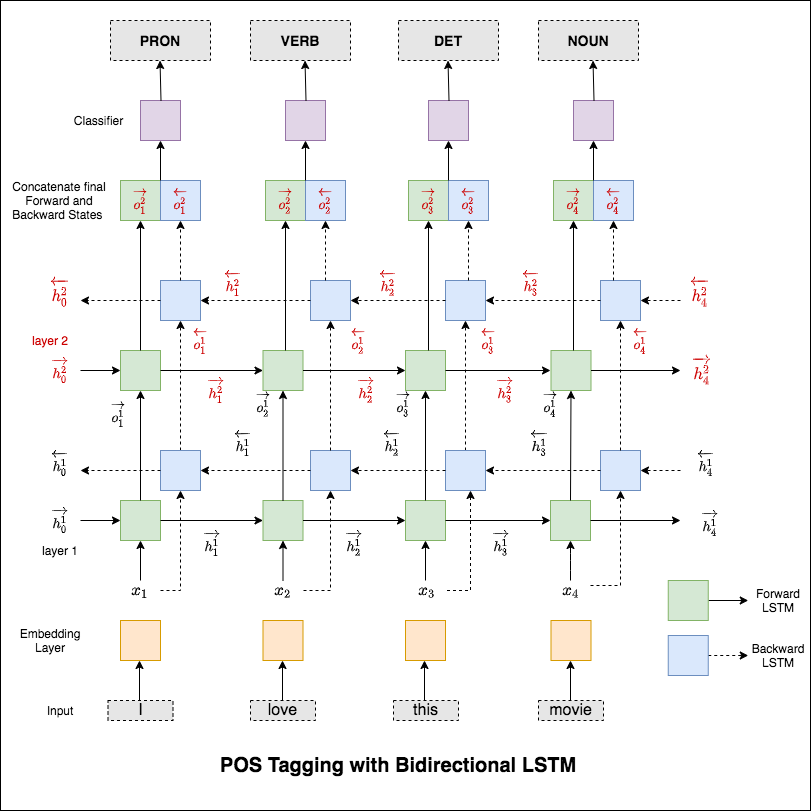
嘗試RNN方法後,探索了具有基於變壓器的體系結構的POS標記。由於變壓器同時包含編碼器和解碼器,並且對於序列標記任務,僅Encoder就足夠了。由於數據很小,因此具有6層編碼器的數據將過度擬合數據。因此使用了三層變壓器編碼器模型。

嘗試使用變壓器編碼器進行POS標記後,利用了預訓練的BERT模型的POS標記。它達到了91%的測試準確性。

自然語言推理(NLI)的目標是一項廣泛研究的自然語言處理任務,是確定一個給定的語句(前提)是否在語義上需要另一個給定的陳述(假設)。
探索了以下變體:
帶有暹羅Bilstm網絡的基本模型已插入
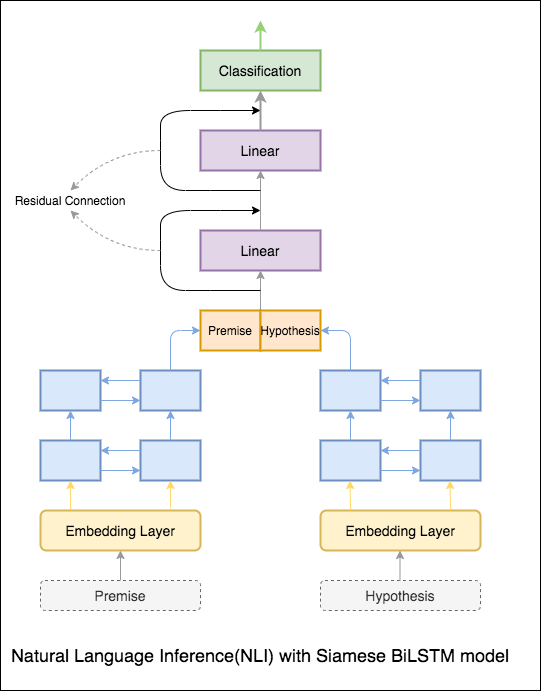
這可以視為基線設置。實現了76.84%的測試精度。
在上一個筆記本中,前提和假設的最終隱藏狀態是LSTM的表示。現在,將在所有輸入令牌上計算注意力,而不是採取最終的隱藏狀態,並將最終加權向量作為前提和假設的表示。
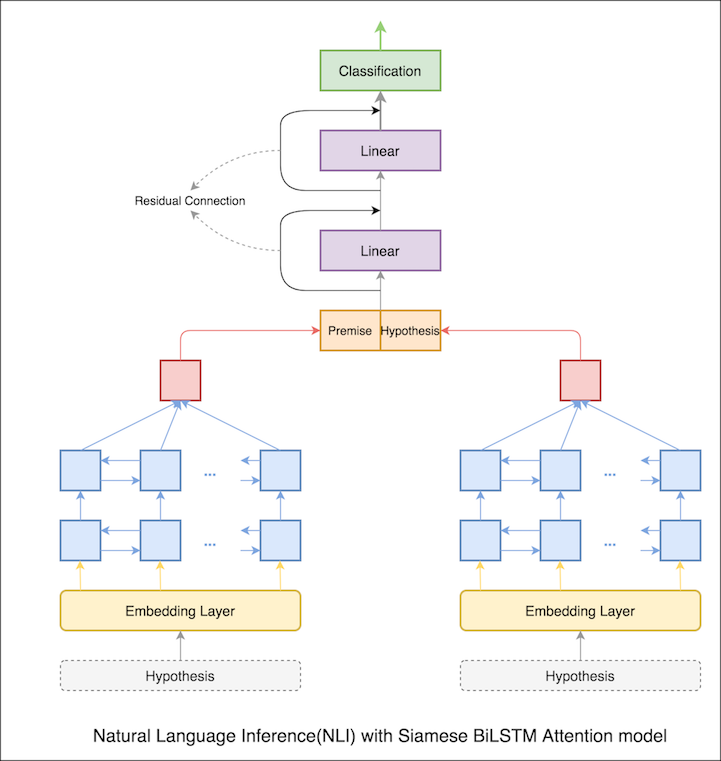
測試準確性從76.84%提高到79.51% 。
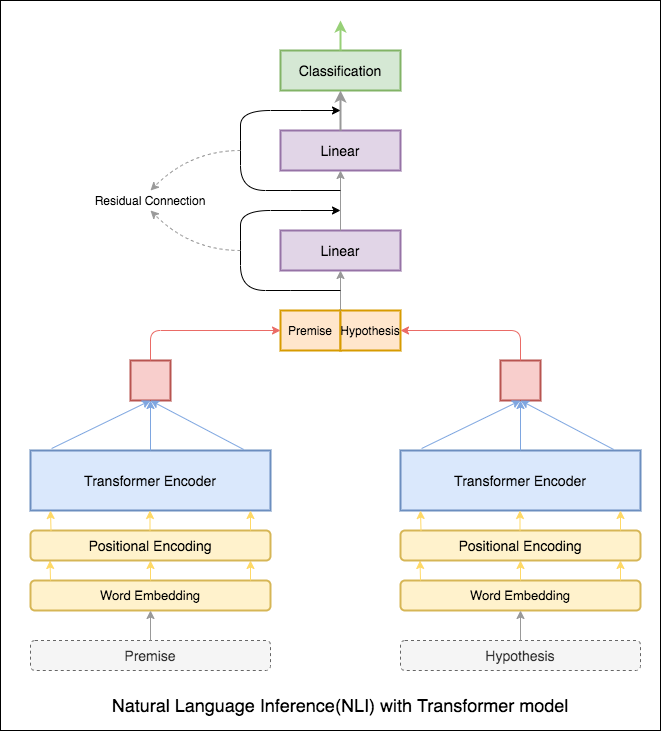
變壓器編碼器用於編碼前提和假設。一旦句子通過編碼器,所有令牌的求和被視為最終表示(可以探索其他變體)。與RNN變體相比,模型精度較低。
探索了帶有BERT基本模型的NLI。伯特(Bert)將前提和假設作為[SEP]令牌分開的輸入,並使用[CLS]令牌的最終表示進行了分類。
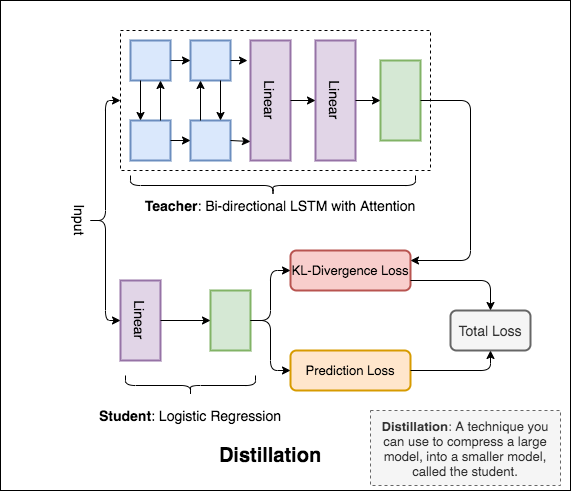
Distillation :您可以用來將一種稱為teacher的大型模型壓縮成一個較小的模型,稱為student 。以下學生,使用教師模型來對NLI進行蒸餾。
討論您關心的事情可能很困難。在線虐待和騷擾的威脅意味著許多人停止表達自己並放棄尋求不同的意見。平台難以有效地促進對話,導致許多社區限製或完全關閉用戶評論。
為您提供了大量的Wikipedia評論,這些評論已被人類對有毒行為的評估者標記。毒性的類型是:
探索了以下變體:
使用的模型是雙向GRU網絡。
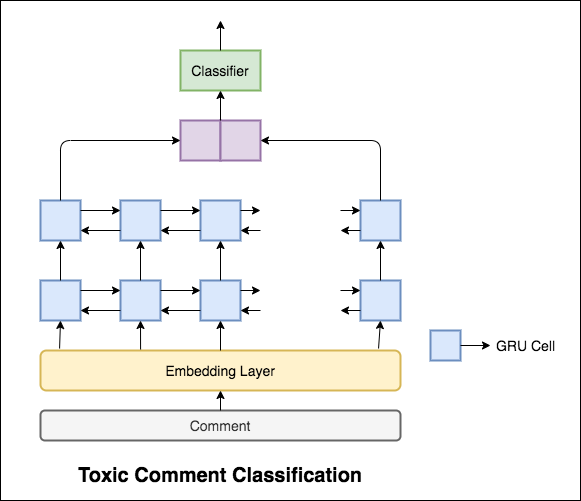
實現了99.42%的測試精度。由於90%的數據未標記為任何毒性,因此僅將所有數據預測為無毒的數據提供了90%的準確模型。因此,準確性不是可靠的指標。實施了不同的ROC AUC。
由於Categorical Cross Entropy作為損失,ROC_AUC得分為0.5 。通過將損失更改為Binary Cross Entropy ,並通過添加池層(最大值,平均值)來修改模型,ROC_AUC得分提高到0.9873 。
使用簡化將有毒評論分類轉換為應用程序。預先訓練的模型現已可用。
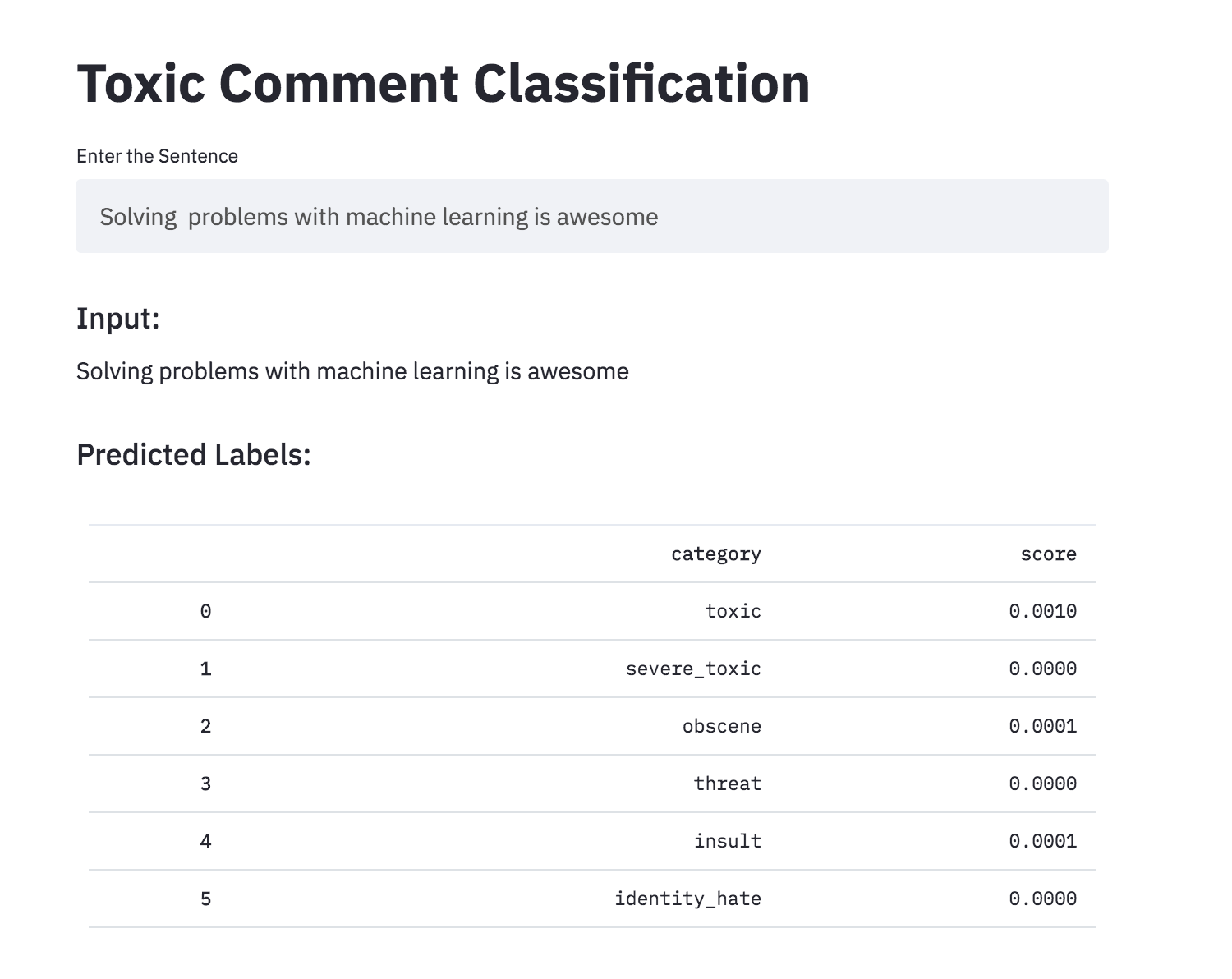
人工神經網絡能夠判斷句子的語法可接受性嗎?為了探索此任務,使用語言可接受性(COLA)數據集。可樂是一組標記為語法正確或不正確的句子。
探索了以下變體:
伯特(Bert)在11個自然語言處理任務上獲得了新的最新結果。 NLP中的轉移學習在發布BERT模型後觸發。在本筆記本中,我們將探討如何使用BERT對句子進行分類是否正確使用COLA數據集。
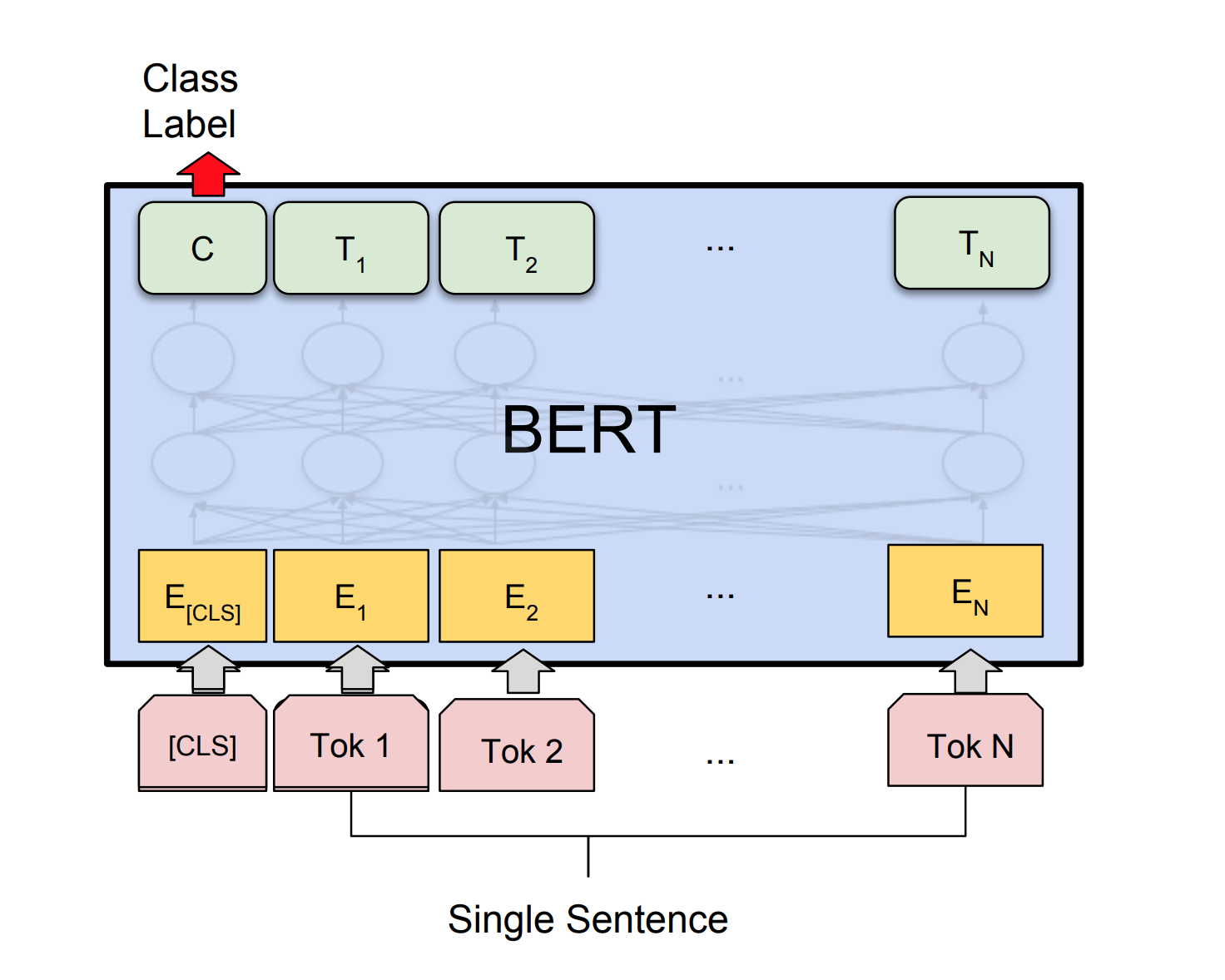
達到85%的準確性,Matthews相關係數(MCC)達到了64.1 。
Distillation :您可以用來將一種稱為teacher的大型模型壓縮成一個較小的模型,稱為student 。以下學生,使用教師模型來對可樂進行蒸餾。

已嘗試以下實驗:
84.06 ,MCC: 61.582.54 ,MCC: 5782.92 ,MCC: 57.9 命名 - 實體識別(NER)標籤是用適當的實體標記每個單詞的任務。
探索了以下變體:
此代碼涵蓋基本工作流程。我們將查看如何:加載數據,創建火車/測試/驗證拆分,構建詞彙,創建數據迭代器,定義模型並實現火車/評估/測試環和火車,並測試模型。
使用的模型是雙向LSTM網絡
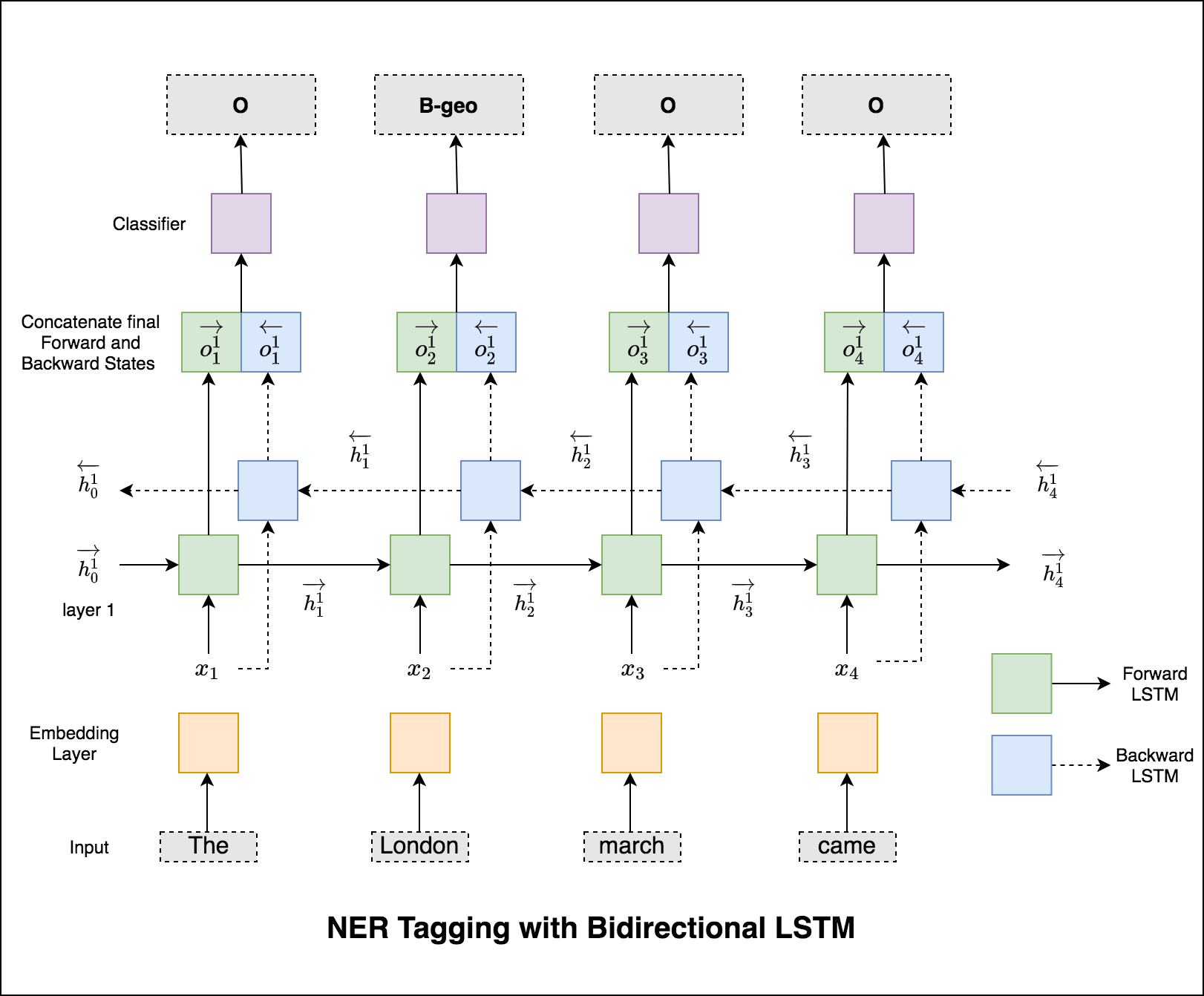
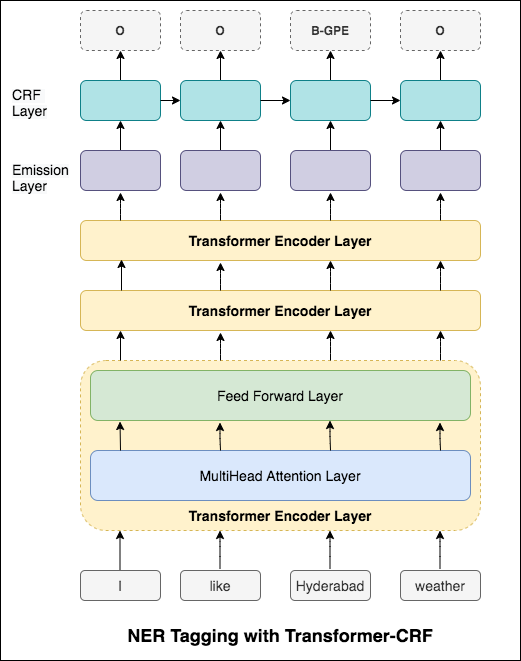
對於序列標記(NER),當前單詞的標籤可能取決於上一個單詞的標籤。 (例如:紐約)。
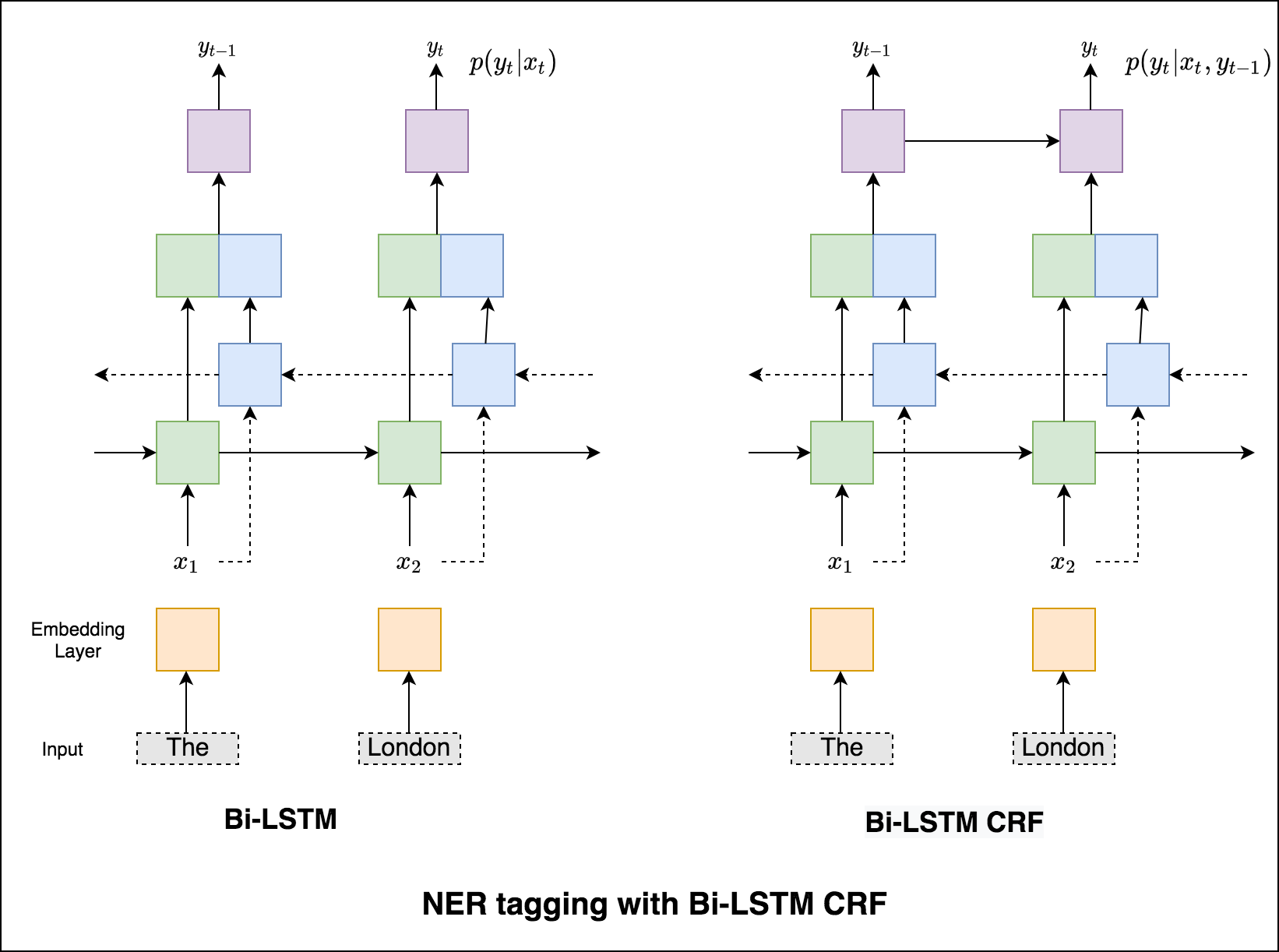
如果沒有CRF,我們只會使用單個線性層將雙向LSTM的輸出轉換為每個標籤的分數。這些被稱為emission scores ,這是單詞為某個標籤的可能性的表示。
CRF不僅計算排放得分,而且還計算transition scores ,這是一個單詞是一個標籤的可能性,因為上一個單詞是某個標籤。因此,過渡分數衡量從一個標籤過渡到另一個標籤的可能性。
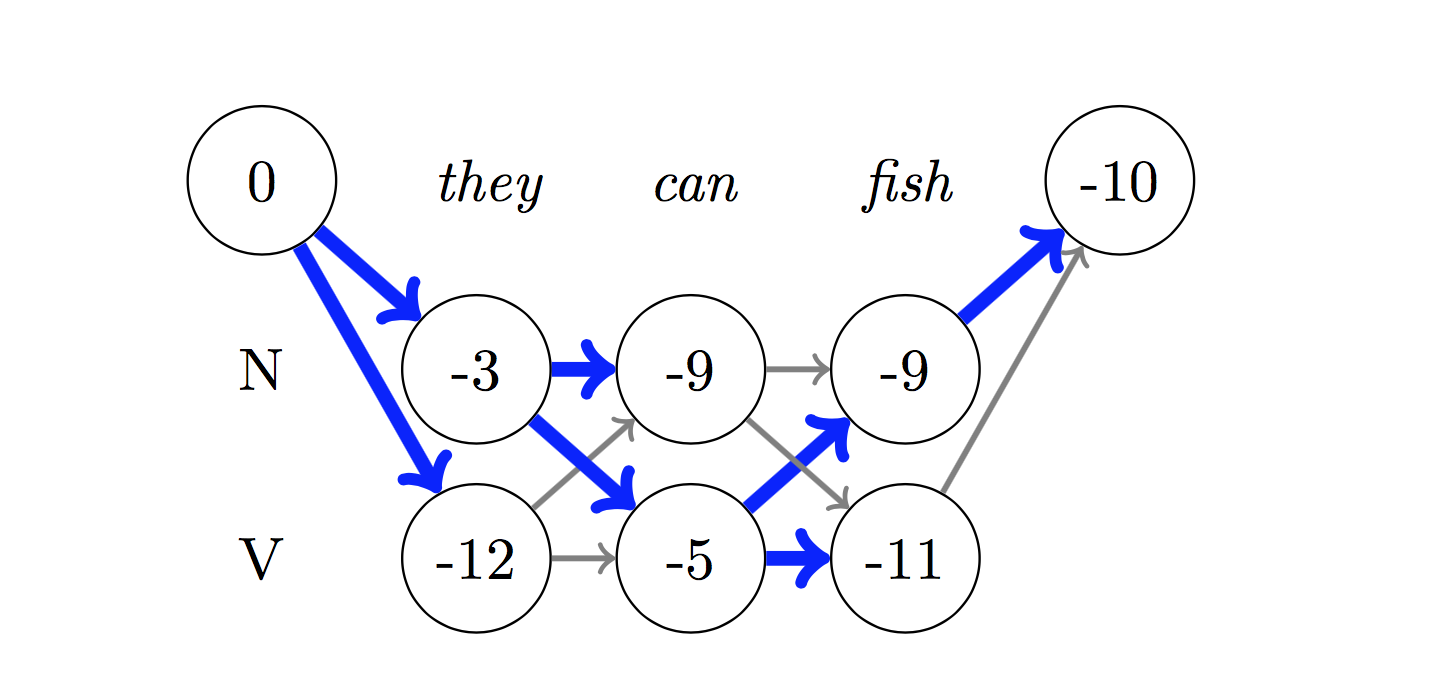
對於解碼,使用Viterbi算法。
由於我們使用的是CRF,因此我們並沒有在每個單詞上預測正確的標籤,而是我們預測單詞序列的正確標籤序列。 Viterbi解碼是一種準確做到這一點的方法 - 從條件隨機場計算出的分數中找到最佳的標籤序列。
在我們的標記任務中使用子字信息,因為它可以是標籤的有力指標,無論它們是語音的一部分還是實體的一部分。例如,它可能會學會形容詞通常以“ -y”或“ -ul”結尾,或者通常以“ -land”或“ -burg”結尾。
因此,我們的序列標記模型都使用
word-level信息。character-level信息直至兩個方向上都包含每個單詞。 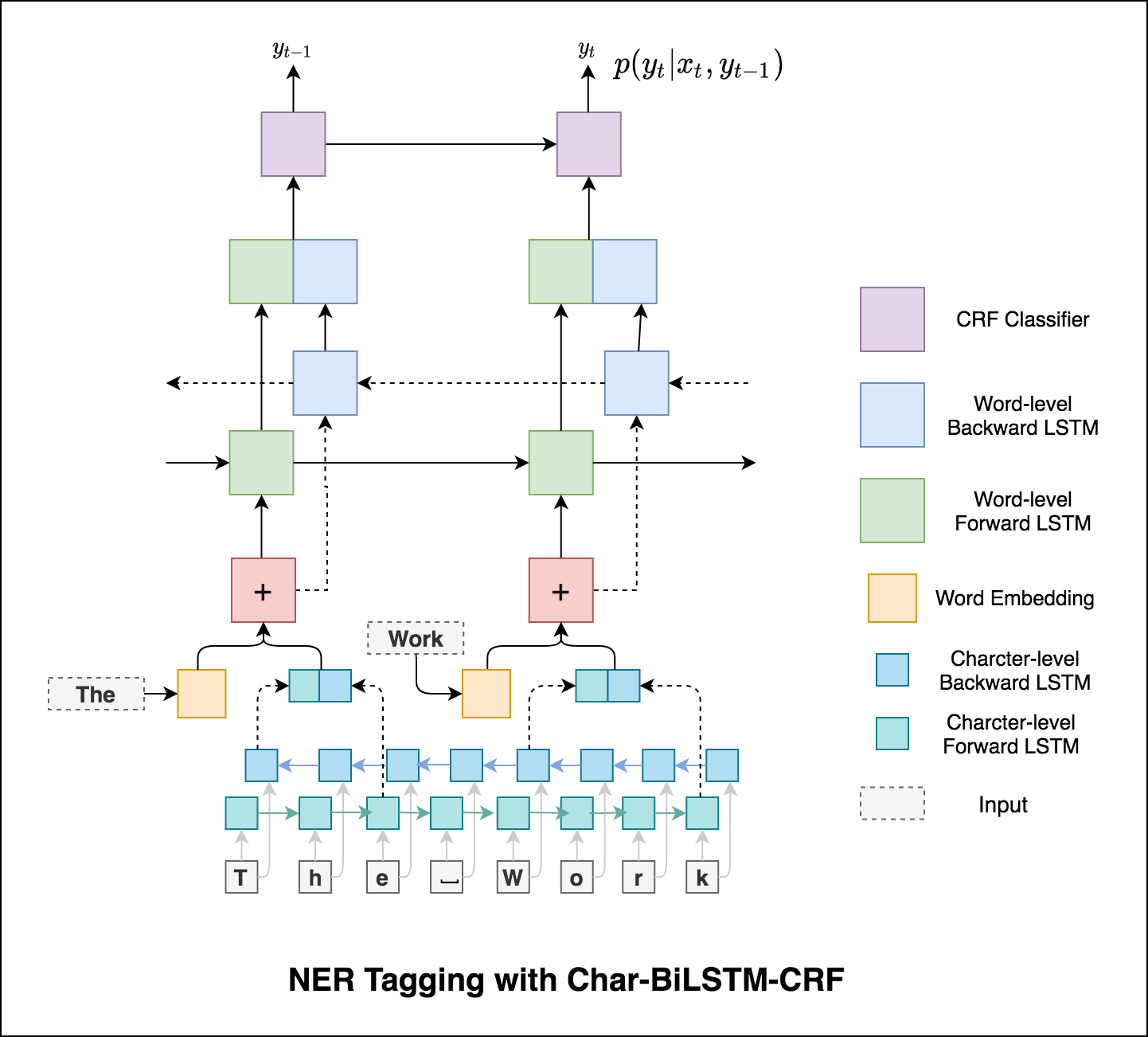
微觀和宏觀大小(對於任何指標)將計算略有不同的事物,因此它們的解釋有所不同。宏觀平均水平將獨立計算每個類別的度量,然後取平均值(因此平均處理所有類),而微平均水平將匯總所有類以計算平均度量的貢獻。在多級分類設置中,如果您懷疑可能存在類不平衡,那麼微平均水平是可取的(即,與其他類別相比,您可能有更多的類示例)。

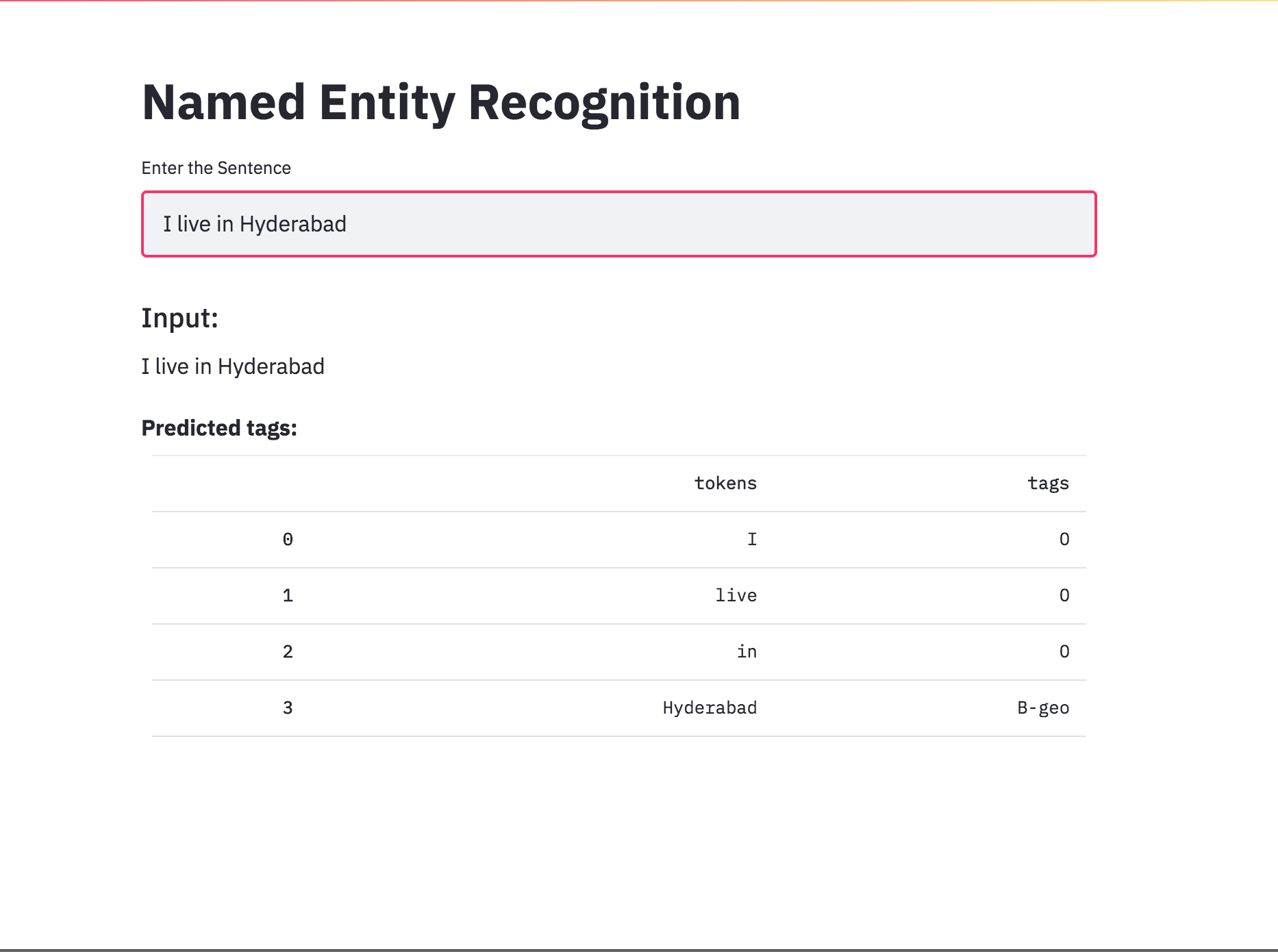
使用簡化將NER標記轉換為應用程序。預訓練模型(CHAR-BILSTM-CRF)現已上市。
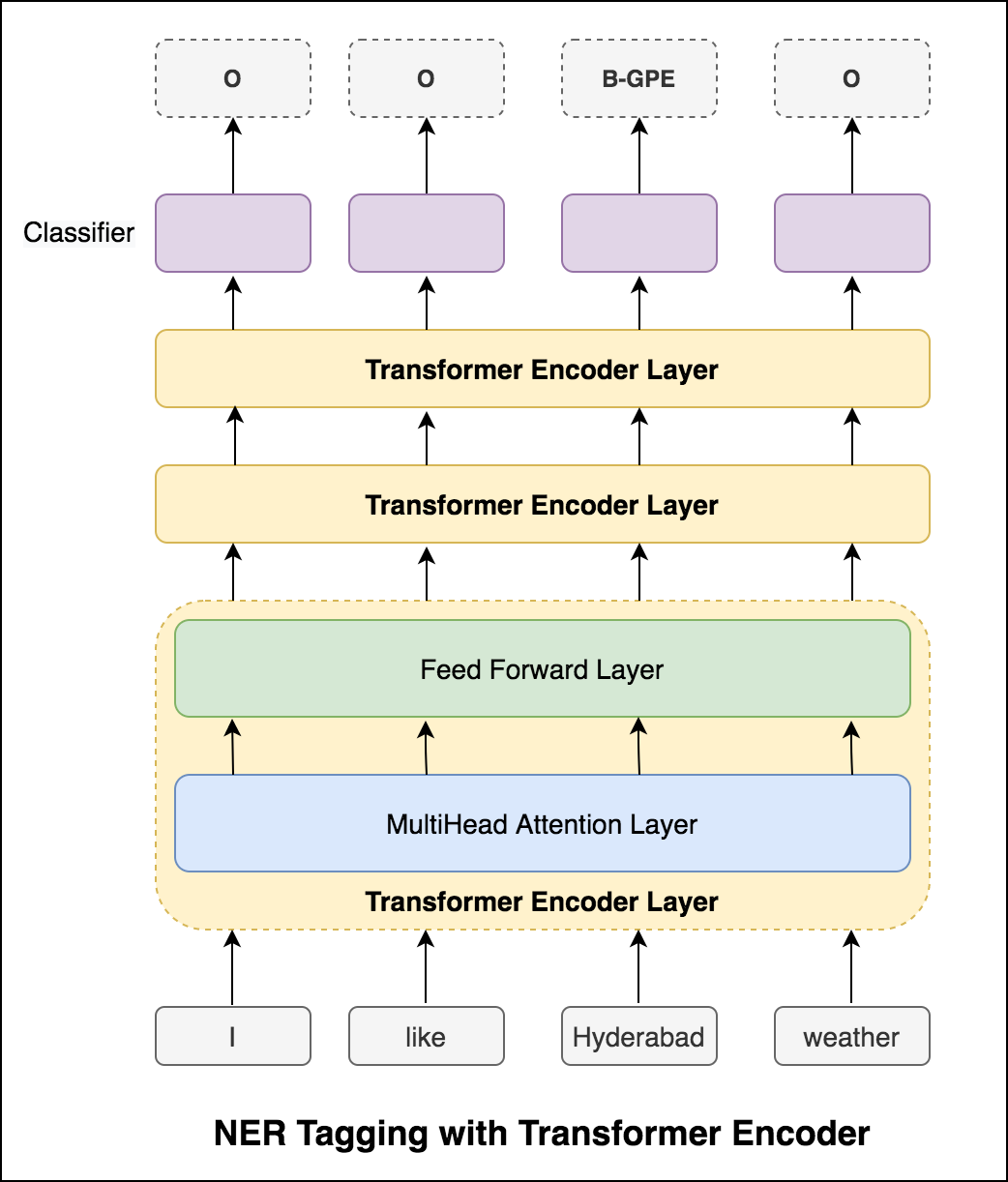
嘗試RNN方法後,探索了使用基於變壓器的體系結構的NER標記。由於變壓器同時包含編碼器和解碼器,並且對於序列標記任務,僅Encoder就足夠了。使用了三層變壓器編碼器模型。
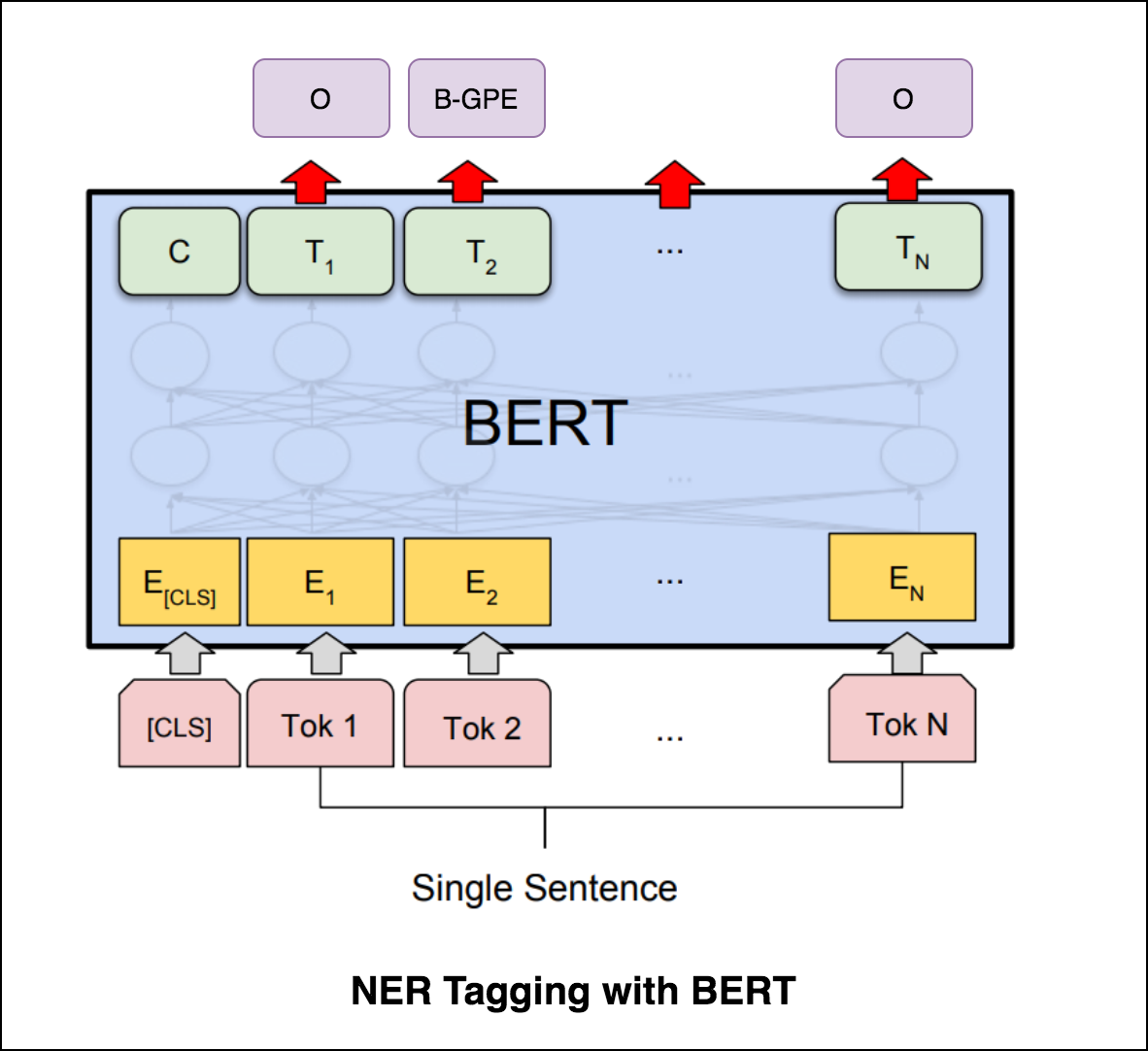
嘗試使用變壓器編碼器進行NER標記後,探索了使用預訓練的bert-base-cased模型的NER標記。
與NER標記任務中的BilstM相比,僅具有變壓器並不能給出良好的結果。與獨立變壓器相比,實現了變壓器頂部上的CRF層,這正在改善結果。
Spacy在Python中為NER提供了一個非常有效的統計系統,該系統可以將標籤分配給令牌組。它提供了一個默認模型,該模型可以識別廣泛的命名或數值實體,包括人,組織,語言,事件等。

除了這些默認實體外,Spacy還通過訓練模型以更新的訓練有素的示例對其進行更新,還使我們可以自由地向NER模型添加任意類別。
在特定領域數據(銀行)中使用的2個稱為ACTIVITY和SERVICE的新實體是由很少的培訓樣本創建和培訓的。

| 名稱生成 | 機器翻譯 | 話語產生 |
| 圖像字幕 | 圖像字幕 - 乳膠方程 | 新聞摘要 |
| 電子郵件主題生成 |
使用字符級LSTM語言模型。也就是說,我們將為LSTM提供大量名稱,並要求它對下一個字符的下一個字符的概率分佈進行建模給定以前的字符的順序。然後,這將使我們一次生成一個新名稱一個字符

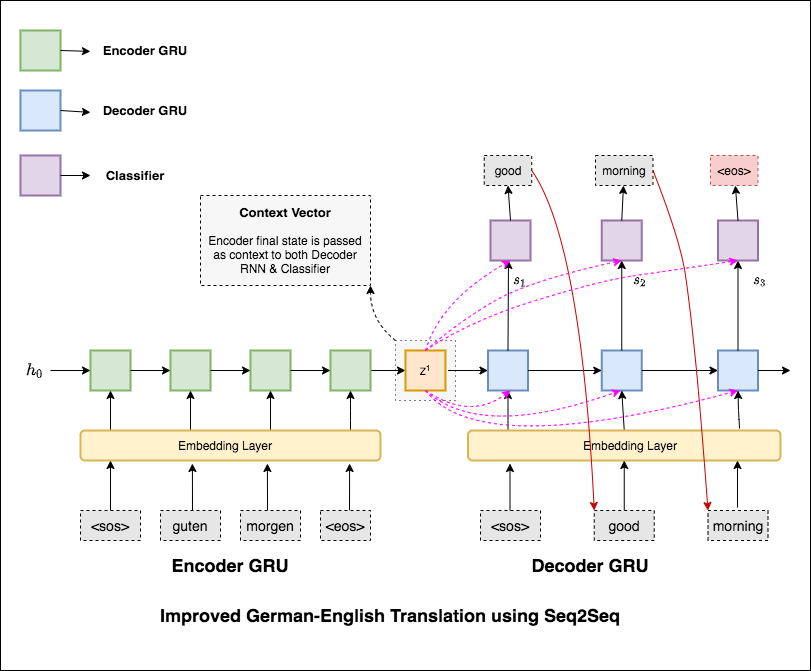
機器翻譯(MT)是將一種自然語言自動轉換為另一種自然語言,保留輸入文本的含義並以輸出語言產生流利的文本的任務。理想情況下,源語言序列被轉化為目標語言序列。任務是將句子從German to English 。
探索了以下變體:
最常見的序列到序列(SEQ2SEQ)模型是編碼器模型,通常使用經常性神經網絡(RNN)將源(輸入)句子編碼為單個向量。在此筆記本中,我們將此單個向量稱為上下文向量。我們可以將上下文向量視為整個輸入句子的抽象表示。然後,該向量由第二個rnn解碼,該載體通過一次生成一個單詞來學習輸出目標(輸出)句子。

在嘗試了具有文本困惑36.68的基本機器翻譯後,已進行了以下技術和測試困惑7.041 。
在applications/generation文件夾中查看代碼
注意機制誕生是為了幫助記住神經機器翻譯(NMT)中的長源句子。與其從編碼器的最後一個隱藏狀態中構建單個上下文向量,不如在解碼句子時更多地專注於輸入的相關部分。上下文向量將通過取編碼器輸出和解碼器RNN的previous hidden state創建。
諸如掩蓋(忽略填充輸入的注意力),包裝填充序列(以更好地計算),注意力可視化和測試數據上的BLEU度量等增強功能。

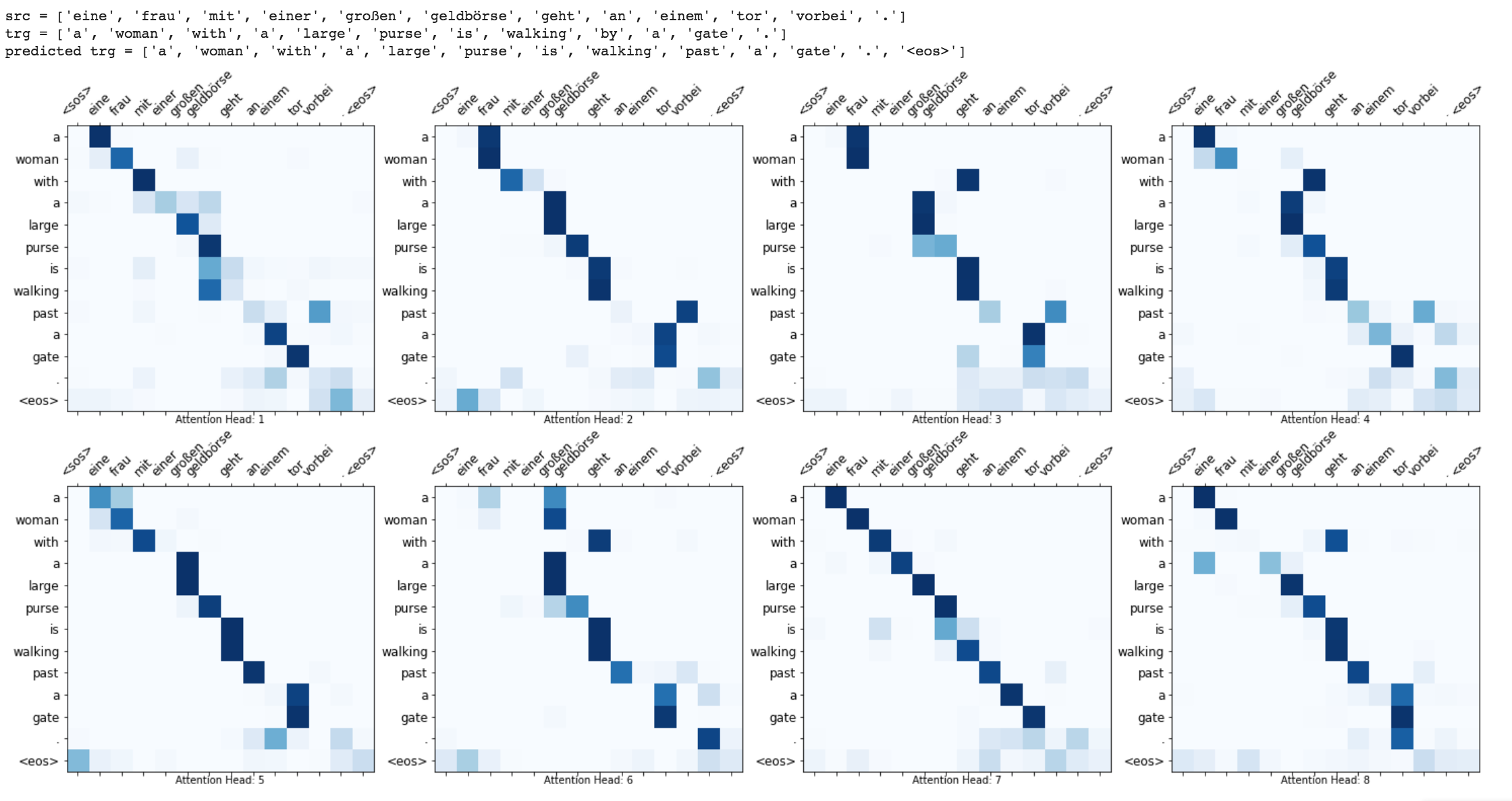
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
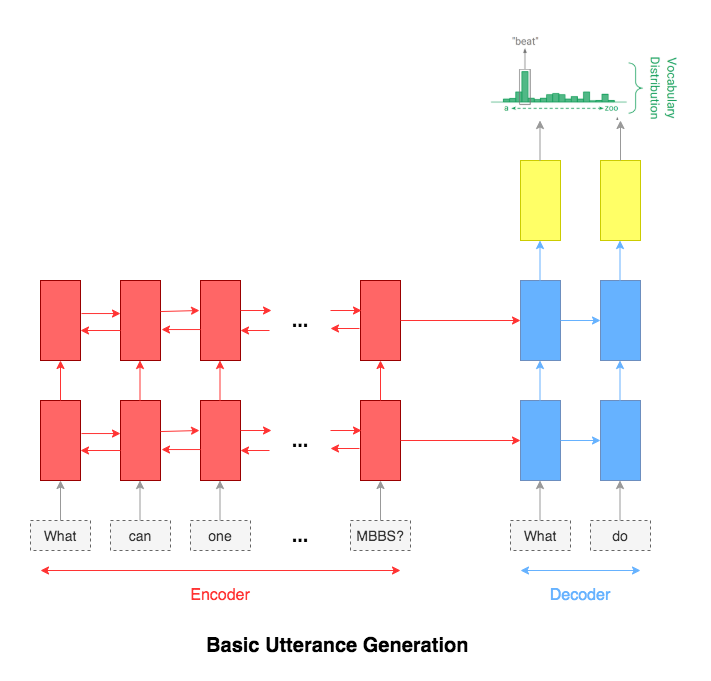
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
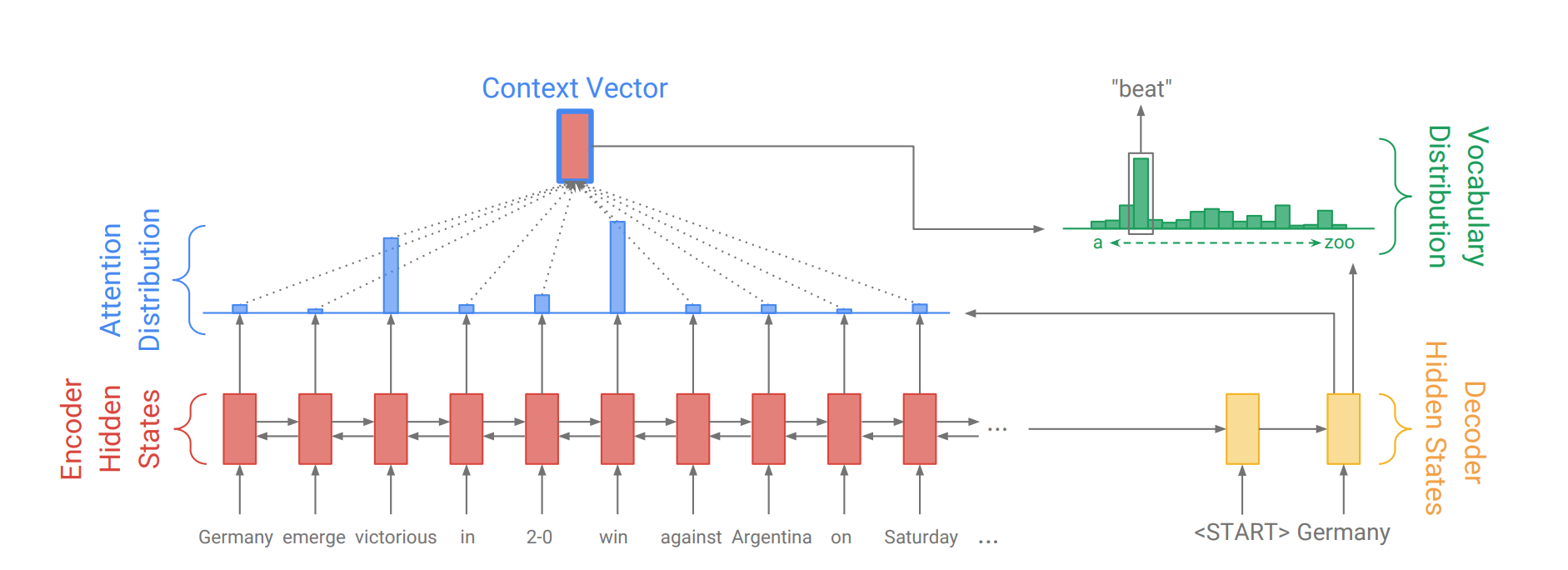
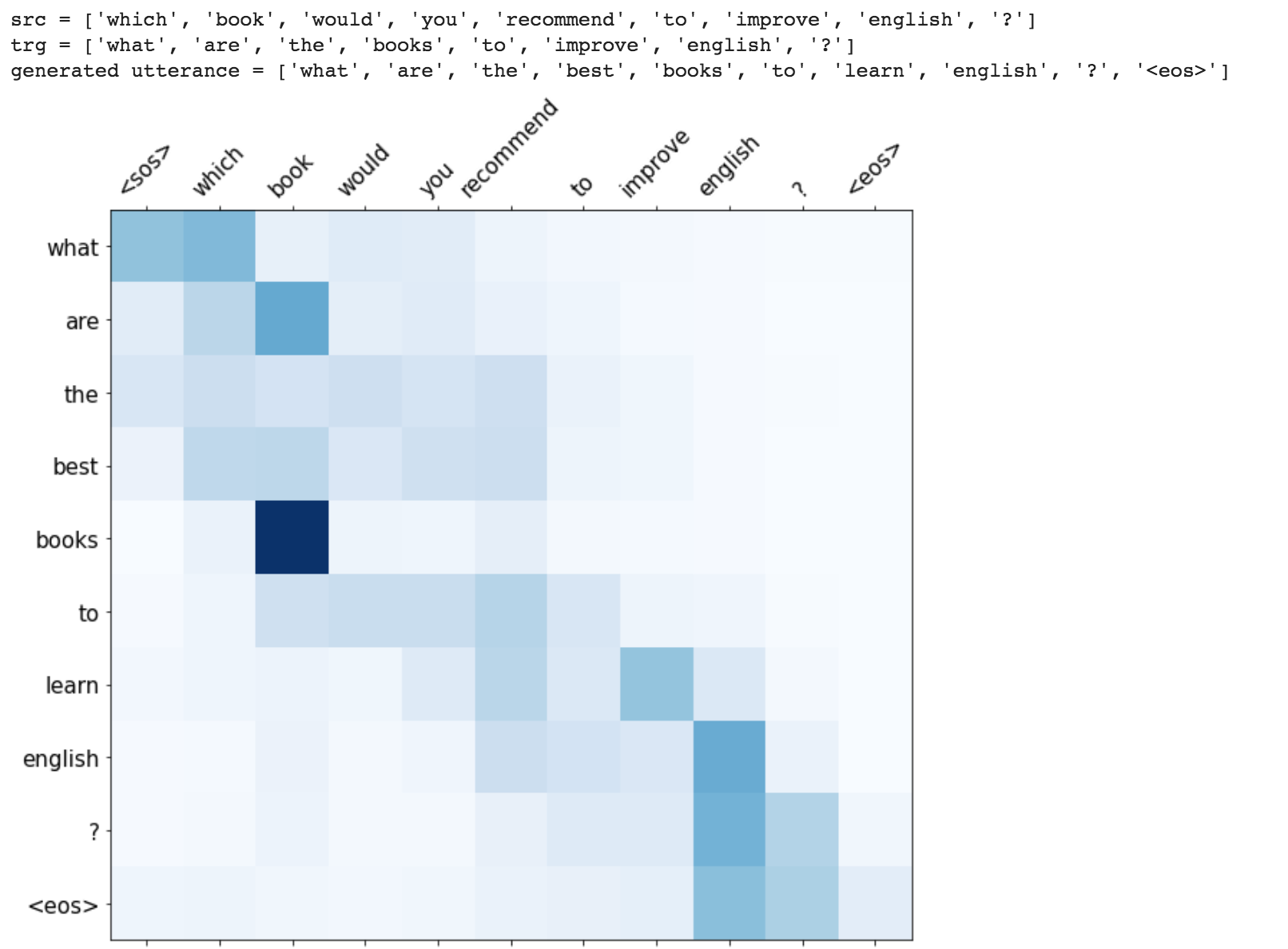
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
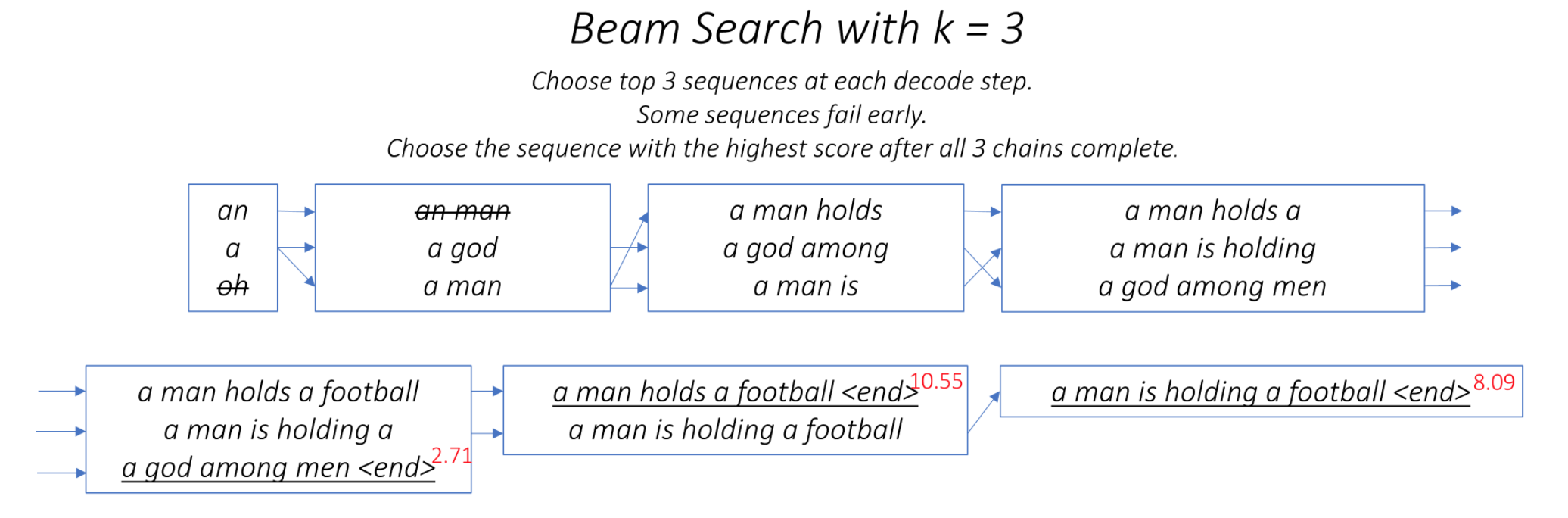
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

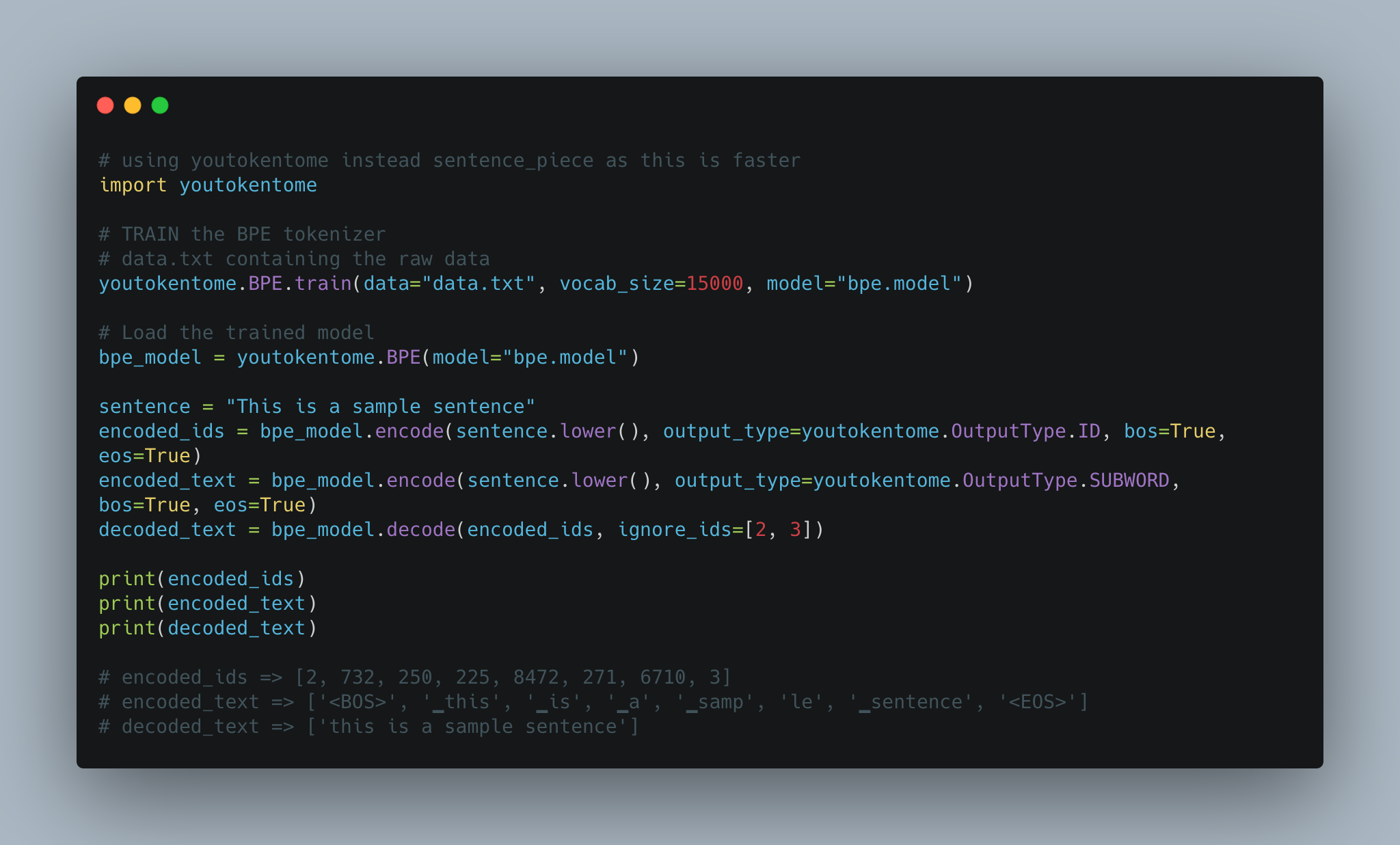
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
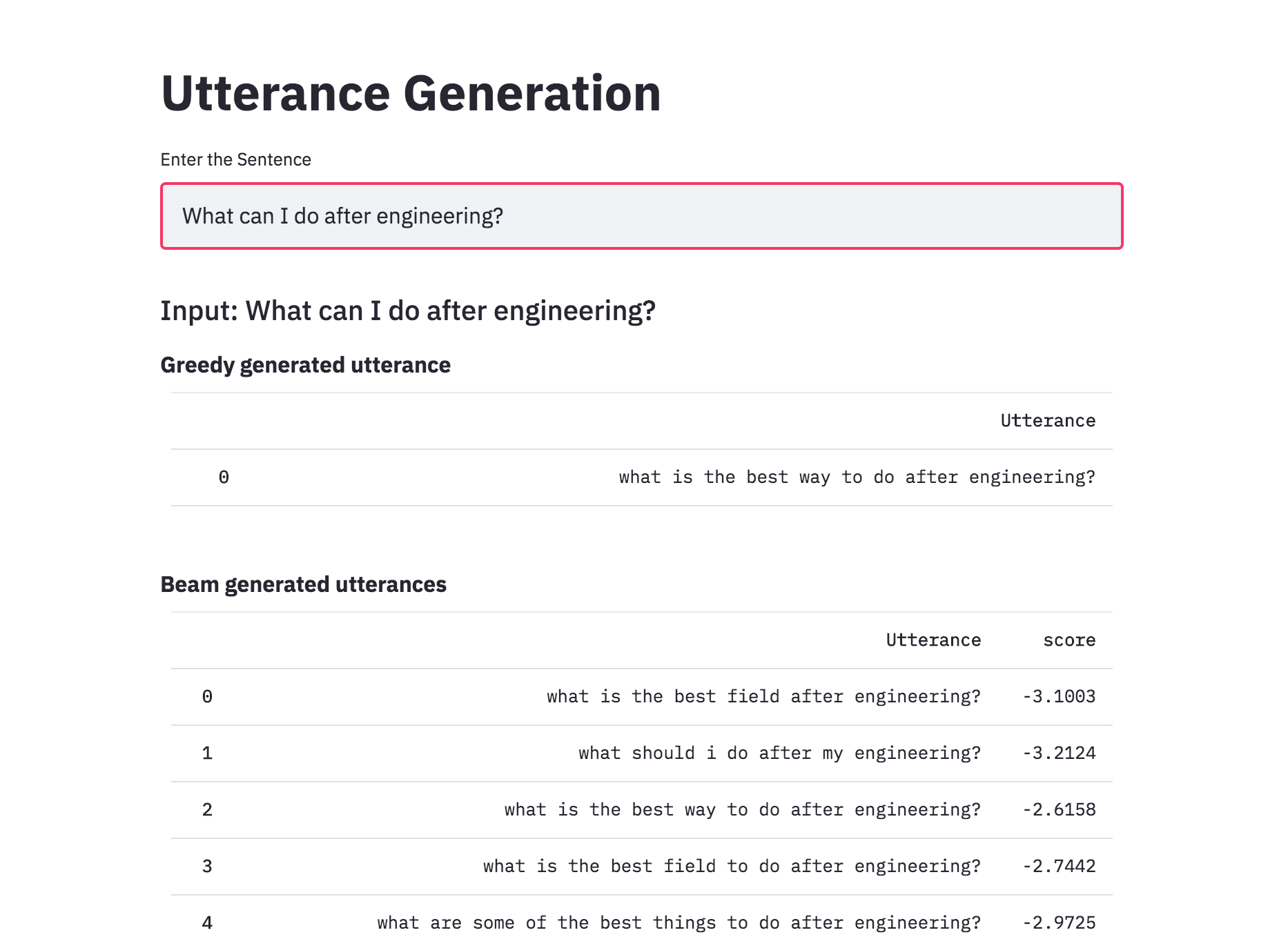
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
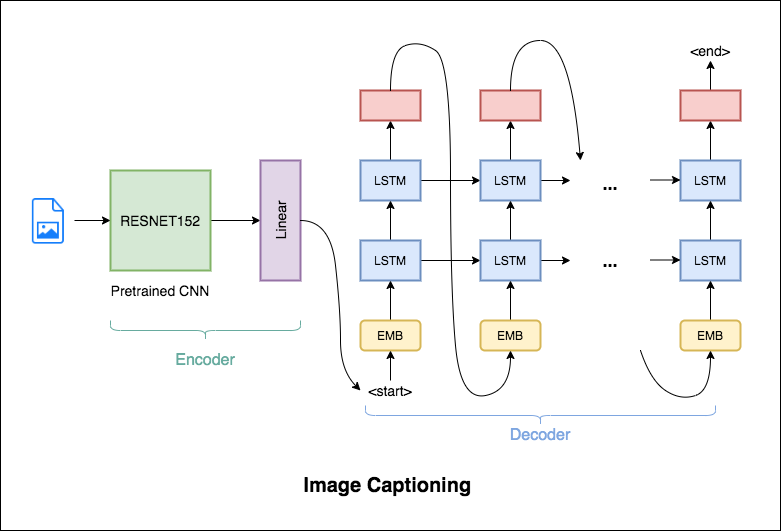
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
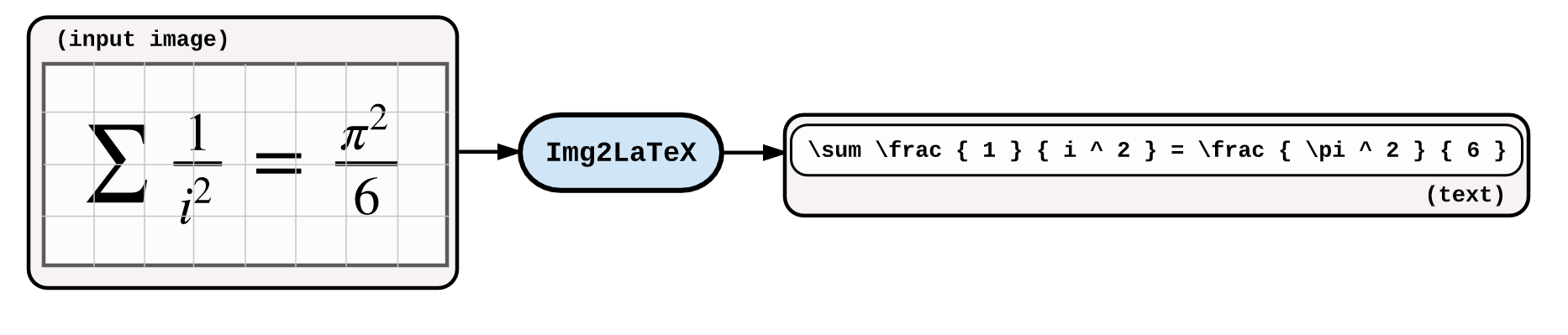
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
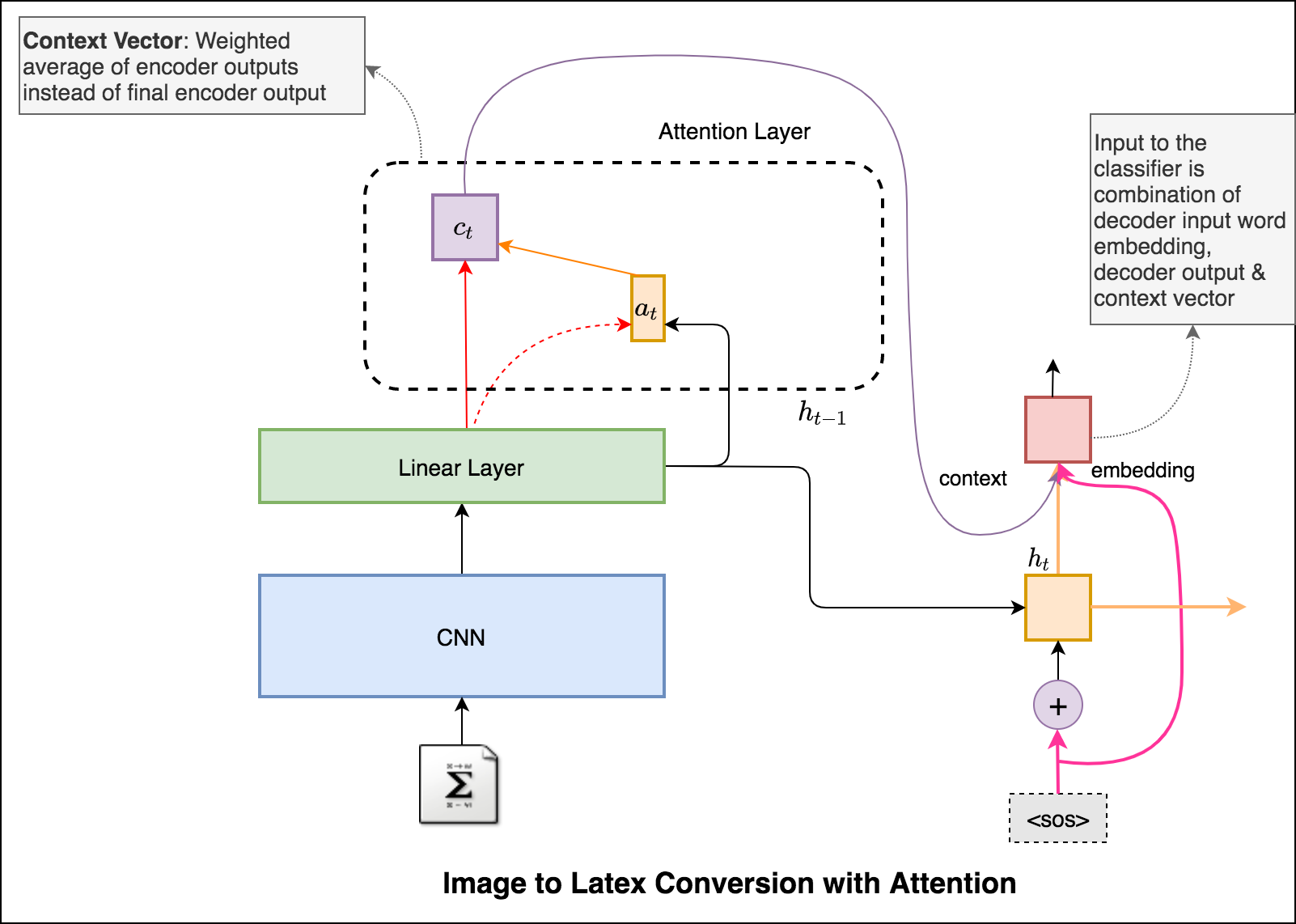
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

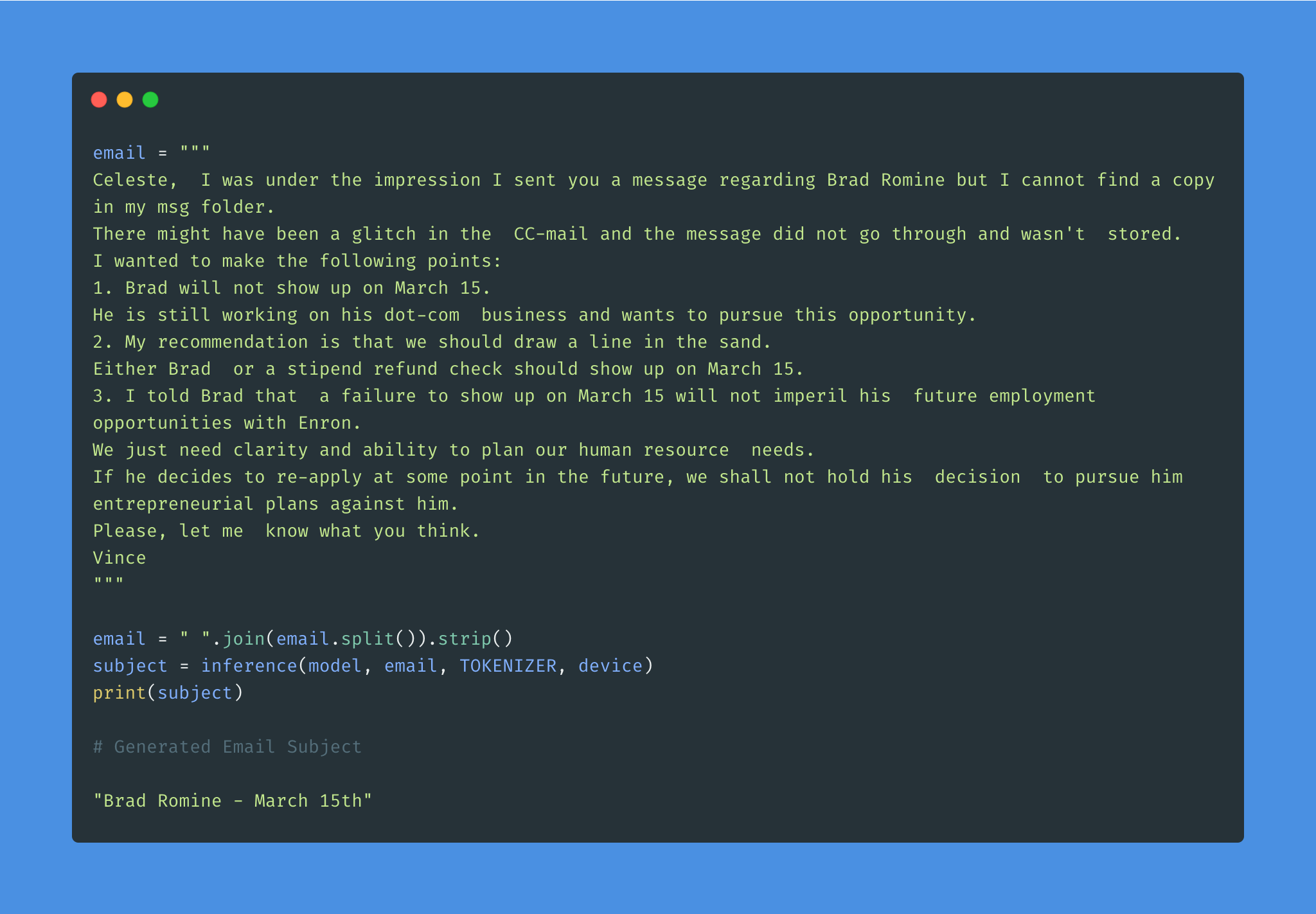
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
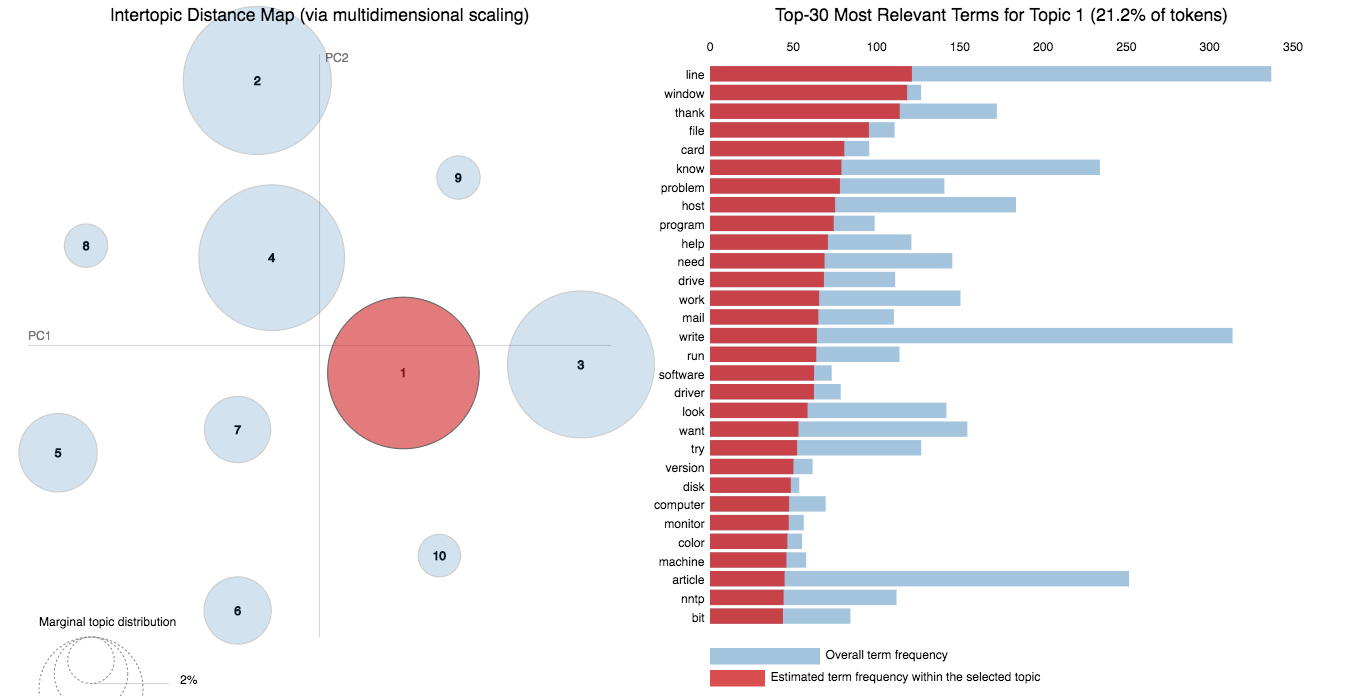
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
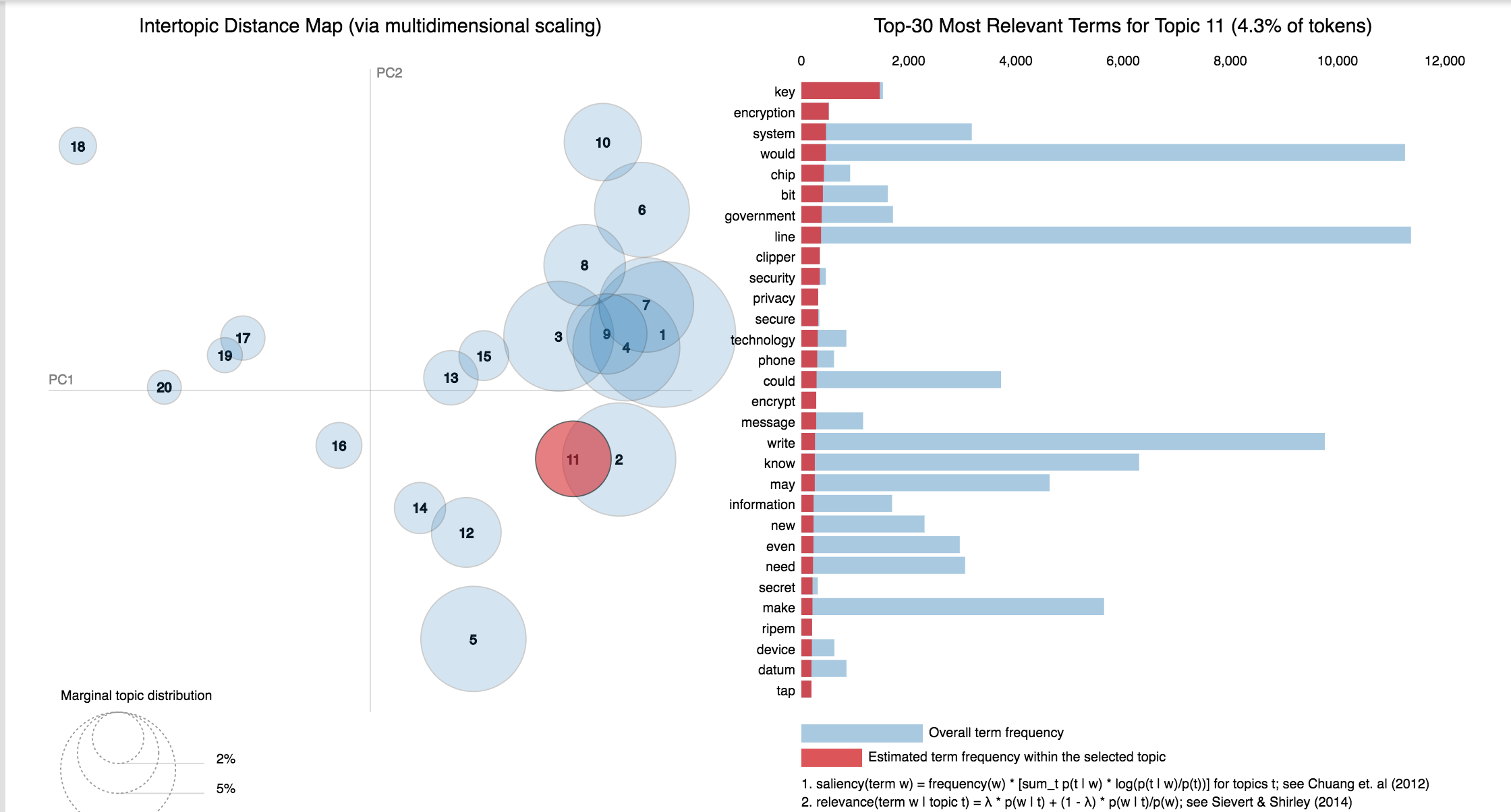
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
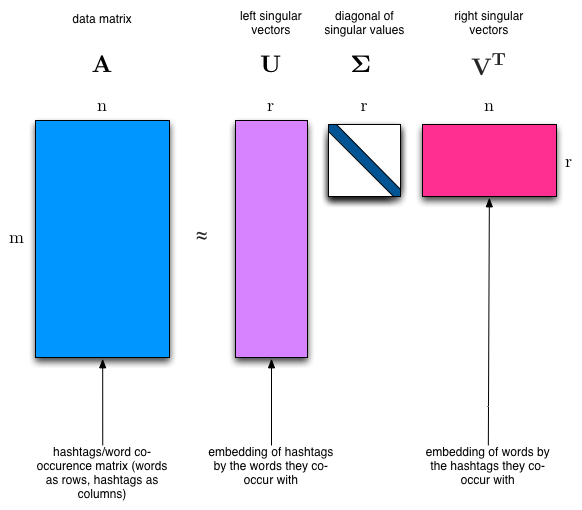
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
筆記:
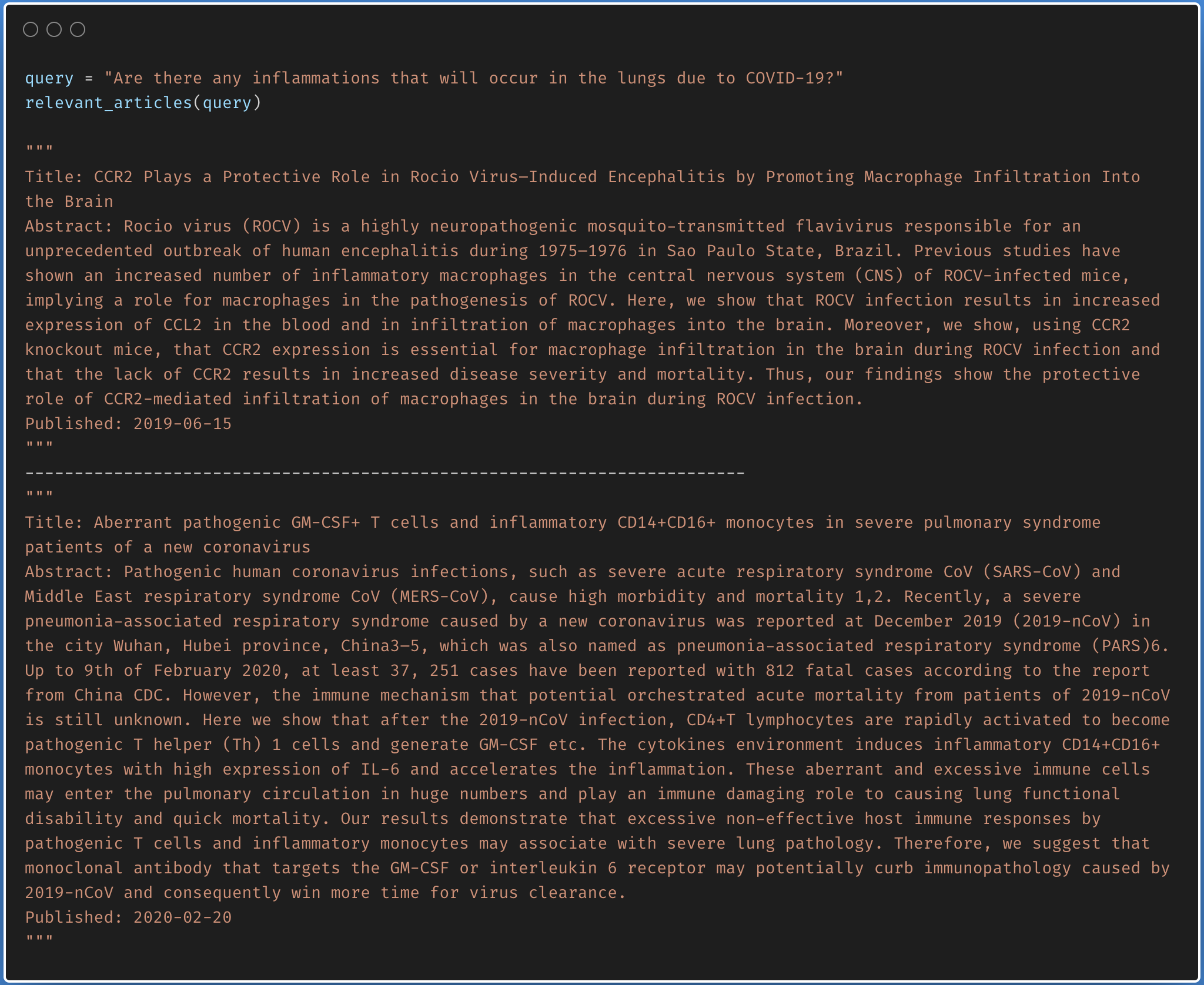
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | 視覺問題回答 | Boolean Question Answering |
| Closed Question Answering |
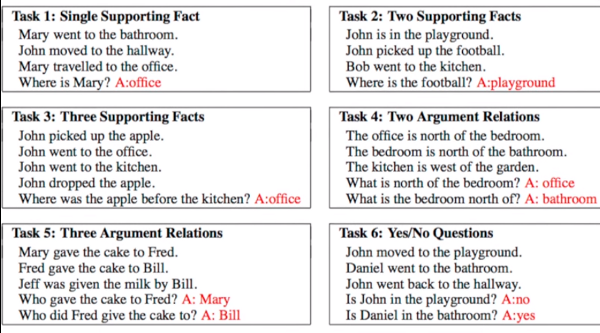
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
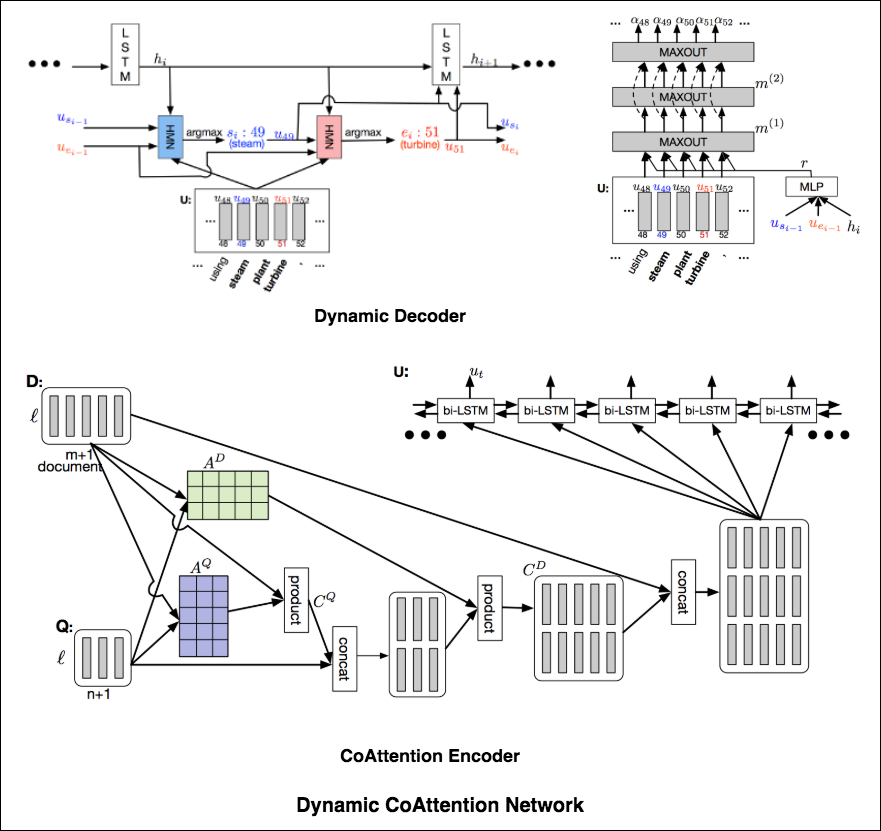
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
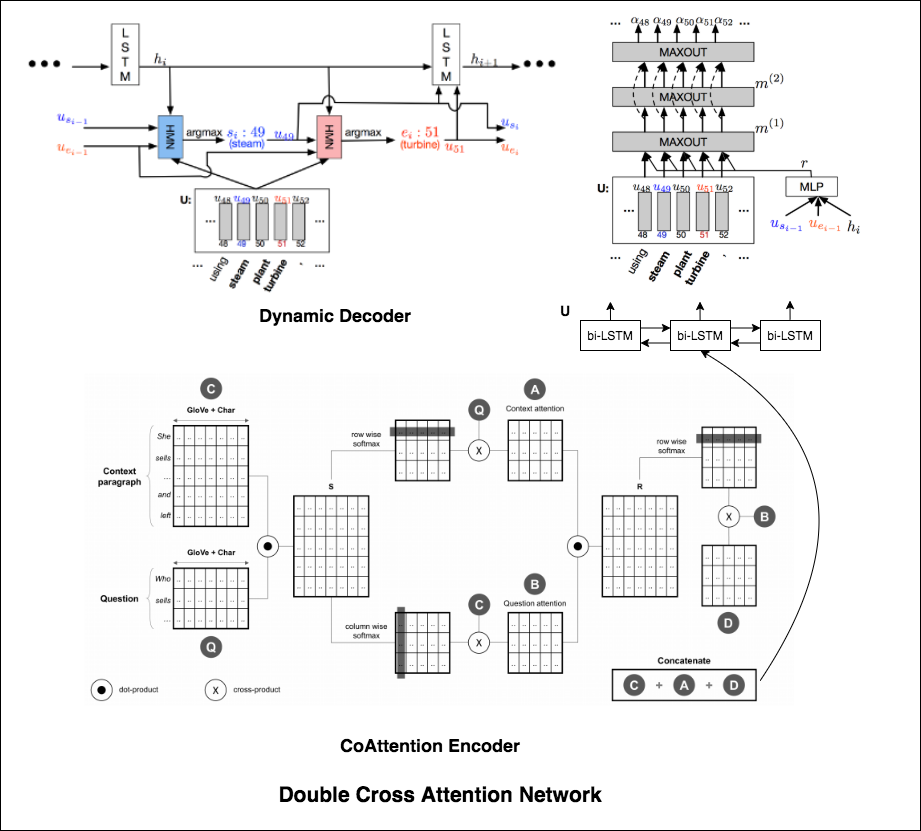
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
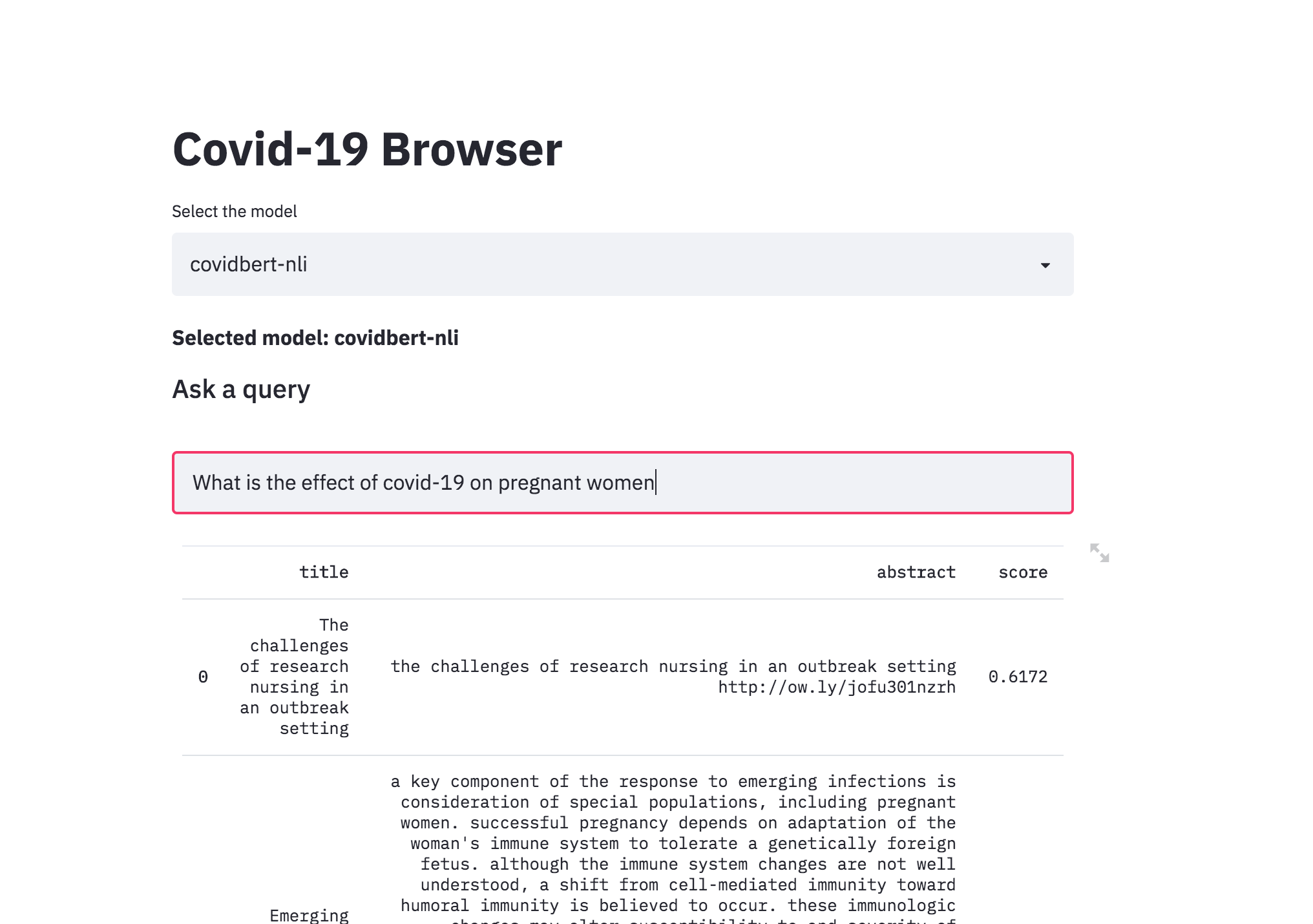
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| 歌曲推薦 |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
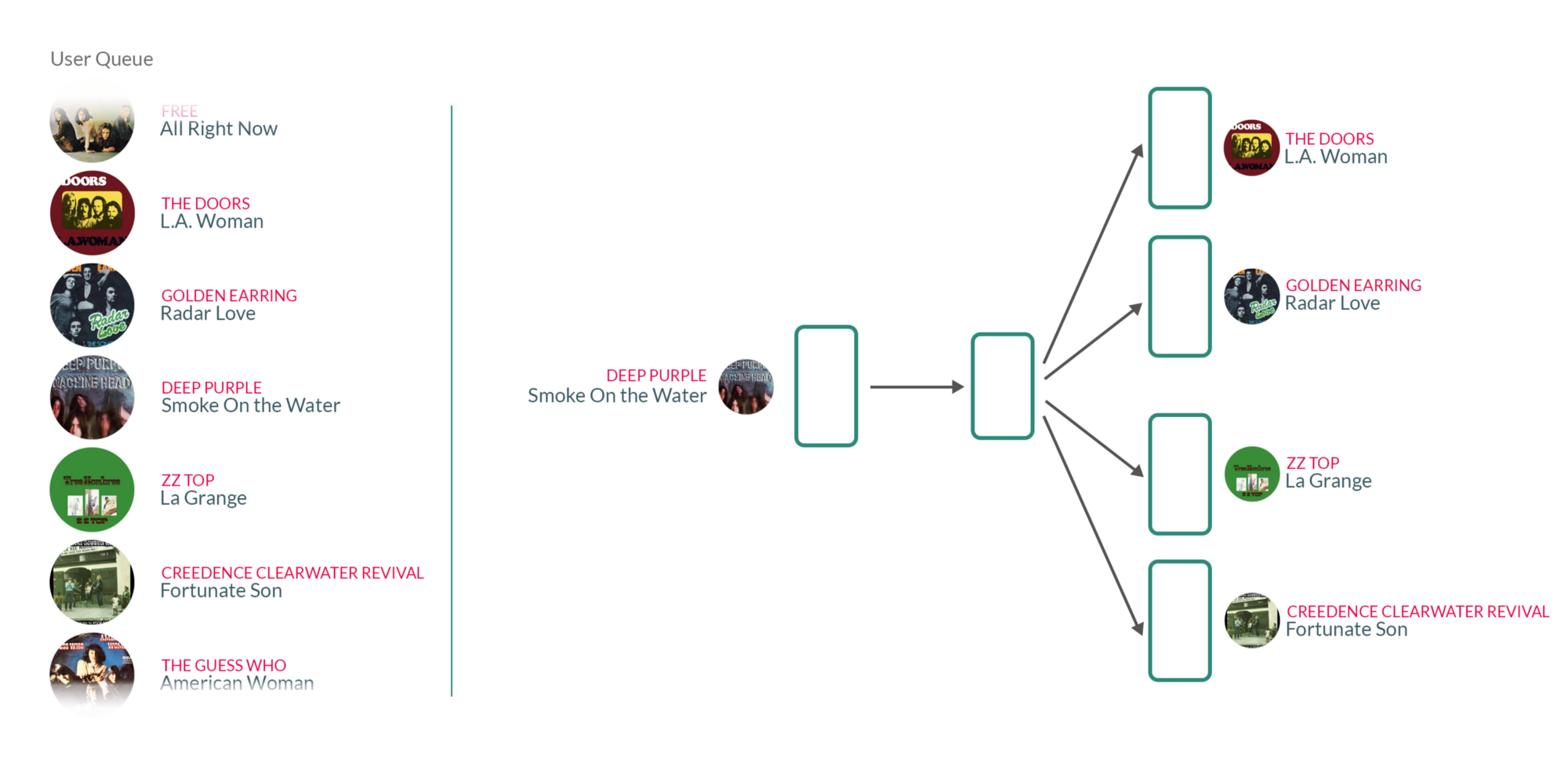
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


