100 Days of NLP
1.0.0

Não há nada de mágica em mágica. O mágico apenas entende algo simples que não parece ser simples ou natural para o público não treinado. Depois de aprender a segurar um cartão enquanto faz com que sua mão pareça vazia, você só precisa de prática antes de você, pode "fazer mágica". - Jeffrey Friedl no livro Dominando expressões regulares
NOTA: Por favor, levante um problema para quaisquer sugestões, correções e feedback.
A maioria das amostras de código é feita usando notebooks Jupyter (usando colab). Portanto, cada código pode ser executado de forma independente.
Os seguintes tópicos foram explorados:
Nota: O nível de dificuldade foi atribuído de acordo com o meu entendimento.
| Tokenização | INCLIMENTOS DE PALAVRAS - Word2vec | Incorporações de palavras - luva | INCLIMENTOS DE PALAVRAS - ELMO |
| RNN, LSTM, GRU | Empacotando sequências acolchoadas | Mecanismo de atenção - luong | Mecanismo de atenção - bahdanau |
| Rede de ponteiros | Transformador | GPT-2 | Bert |
| Modelagem de tópicos - LDA | Análise de componentes principais (PCA) | Bayes ingênuo | Aumentação de dados |
| Incorporações de frase |
O processo de conversão de dados textuais em tokens é uma das etapas mais importantes da PNL. A tokenização usando os seguintes métodos foi explorada:
Uma palavra incorporação é uma representação aprendida para o texto em que as palavras que têm o mesmo significado têm uma representação semelhante. É essa abordagem para representar palavras e documentos que podem ser considerados um dos principais avanços do aprendizado profundo sobre os problemas de processamento de linguagem natural desafiadores.

Word2vec é uma das incorporações de palavras pré -treinadas mais populares desenvolvidas pelo Google. Dependendo da maneira como as incorporações são aprendidas, o Word2vec é classificado em duas abordagens:
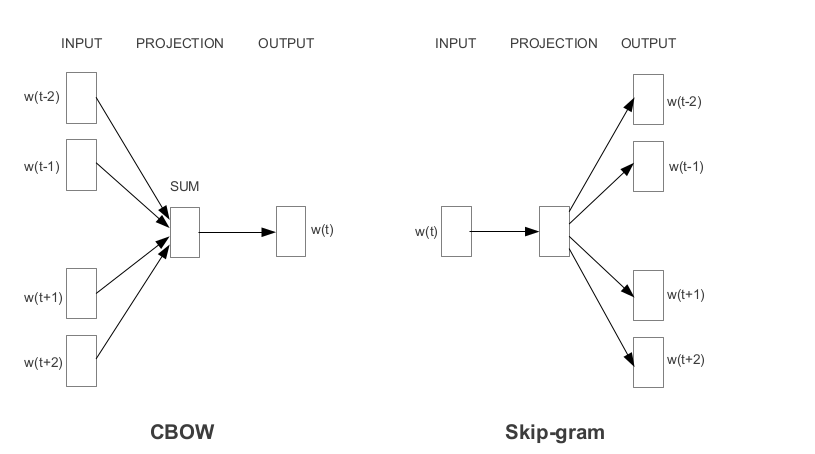
A luva é outro método comumente usado para obter incorporações pré-treinadas. A luva visa atingir dois objetivos:
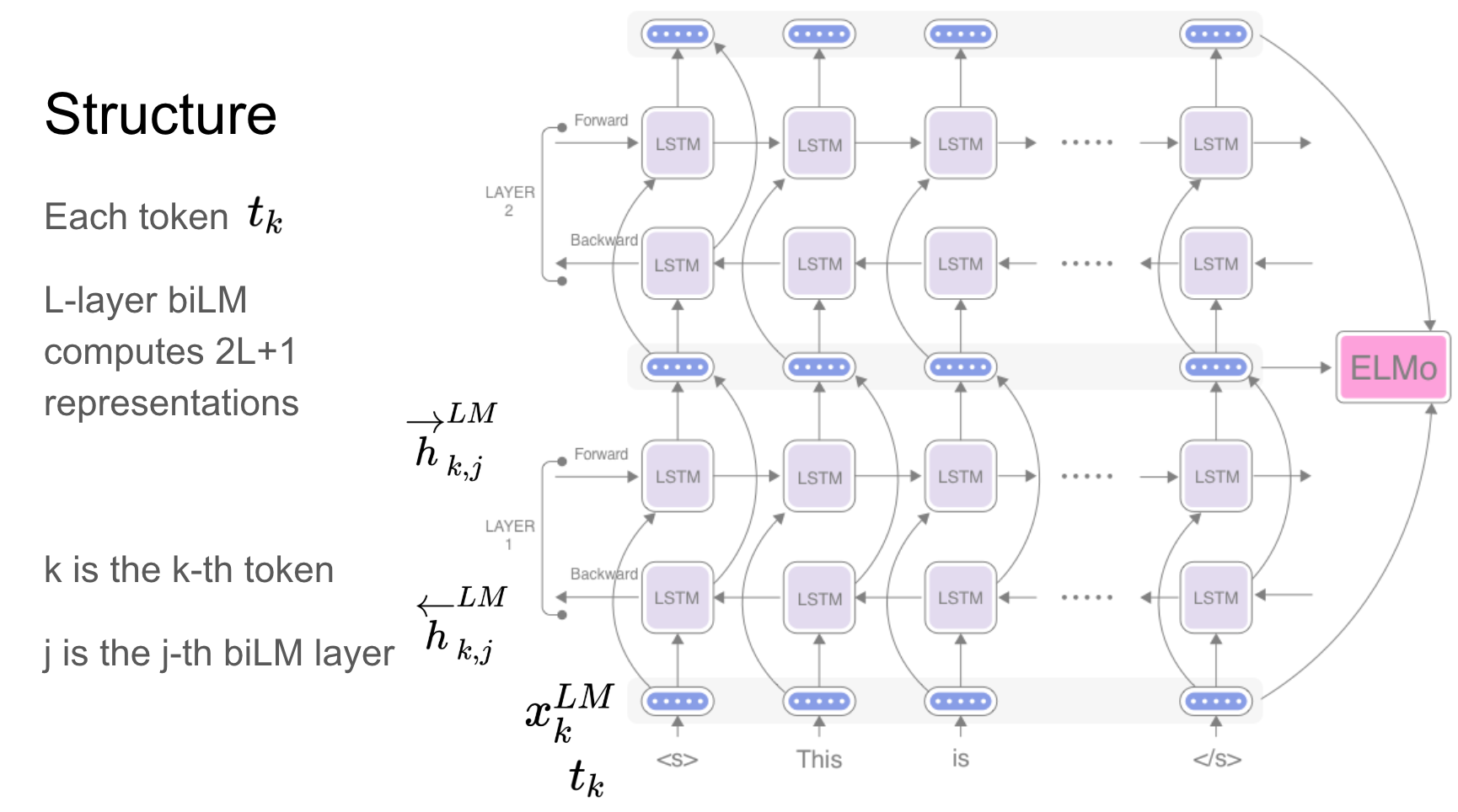
Elmo é uma representação profunda de palavras contextualizada que modela:
Esses vetores de palavras são funções aprendidas dos estados internos de um profundo modelo de linguagem bidirecional (BILM), que é pré-treinado em um grande corpus de texto.
Redes recorrentes - RNN, LSTM, GRU provaram ser uma das unidades mais importantes nos aplicativos de PNL por causa de sua arquitetura. Há muitos problemas em que a natureza da sequência precisa ser lembrada para prever uma emoção na cena, as cenas anteriores precisam ser lembradas.

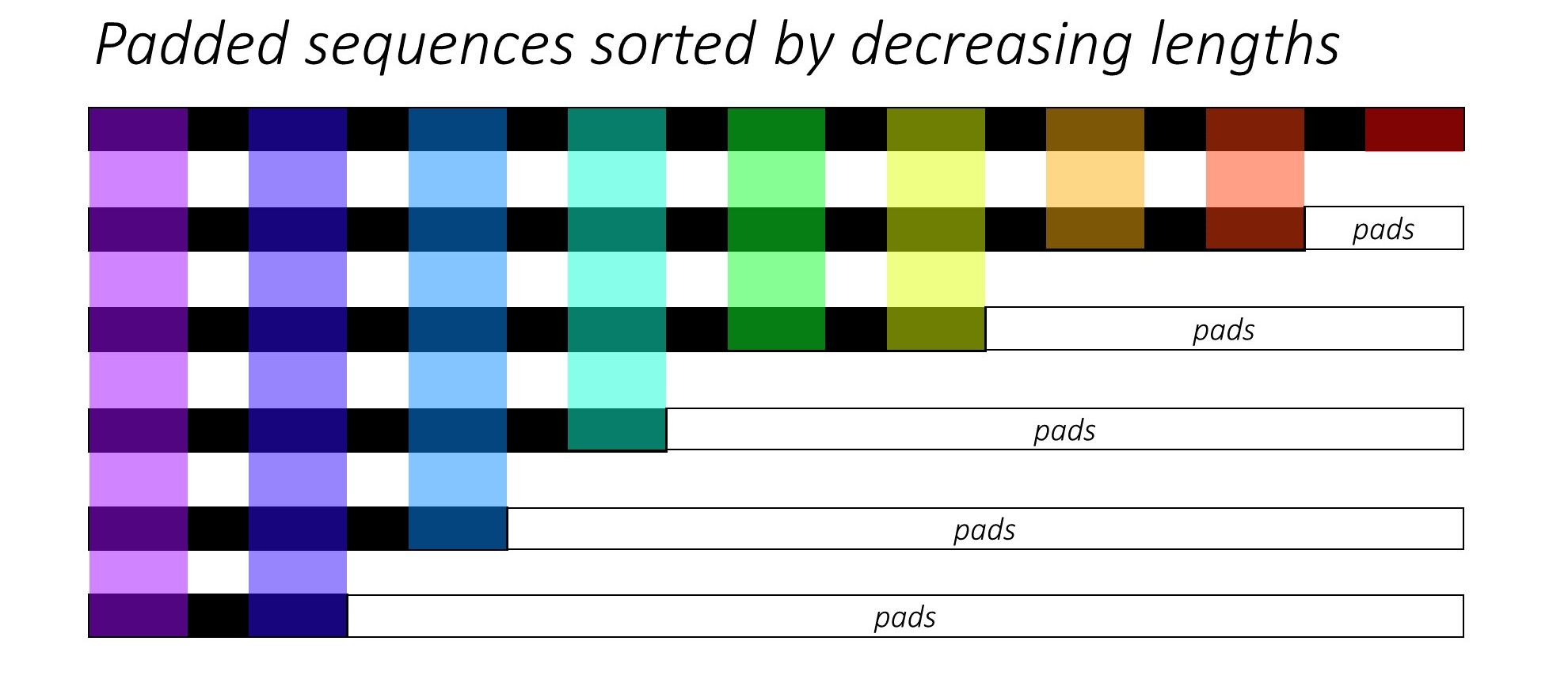
Ao treinar RNN (LSTM ou GRU ou baunilha-rnn), é difícil em lote as seqüências de comprimento variável. Idealmente, encerraremos todas as seqüências para um comprimento fixo e acabaremos fazendo cálculos não necessários. Como podemos superar isso? O Pytorch fornece a funcionalidade pack_padded_sequences .
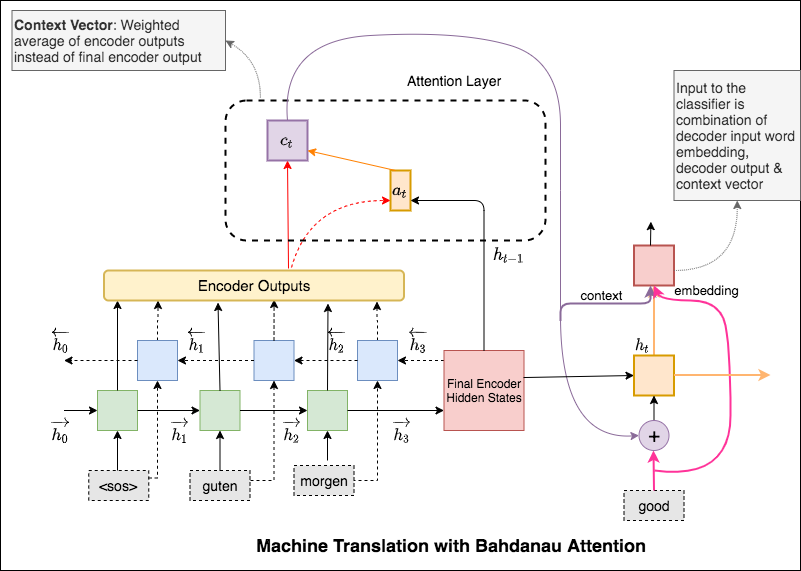
O mecanismo de atenção nasceu para ajudar a memorizar frases de fonte longa na tradução da máquina neural (NMT). Em vez de construir um único vetor de contexto a partir do último estado oculto do codificador, a atenção é usada para se concentrar mais nas partes relevantes da entrada enquanto decodifica uma frase. O vetor de contexto será criado obtendo saídas do codificador e a current output do decodificador RNN.

A pontuação de atenção pode ser calculada de três maneiras. dot , general e concat .
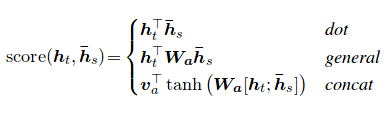
A principal diferença entre a atenção de Bahdanau e Luong é a maneira como o vetor de contexto é criado. O vetor de contexto será criado obtendo saídas do codificador e o previous hidden state do decodificador RNN. Onde está em Luong Atenção O vetor de contexto será criado com saídas do codificador e o current hidden state do decodificador RNN.
Uma vez calculado o contexto, ele é combinado com a incorporação de entrada do decodificador e alimentada como entrada para decodificar o RNN.

A atenção de Bahdanau também é chamada de atenção additive .
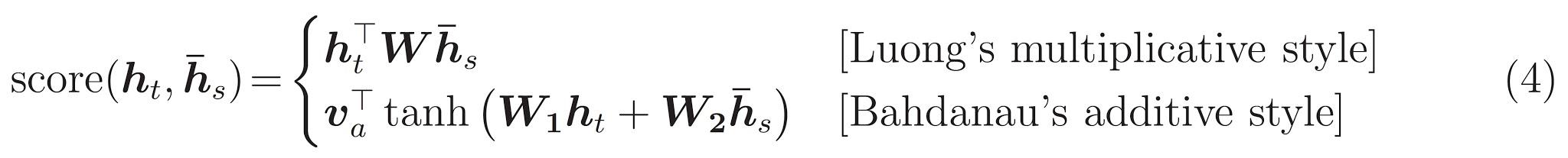
O transformador, uma arquitetura modelo evita a recorrência e, em vez disso, confia inteiramente em um mecanismo de atenção para atrair dependências globais entre entrada e saída.
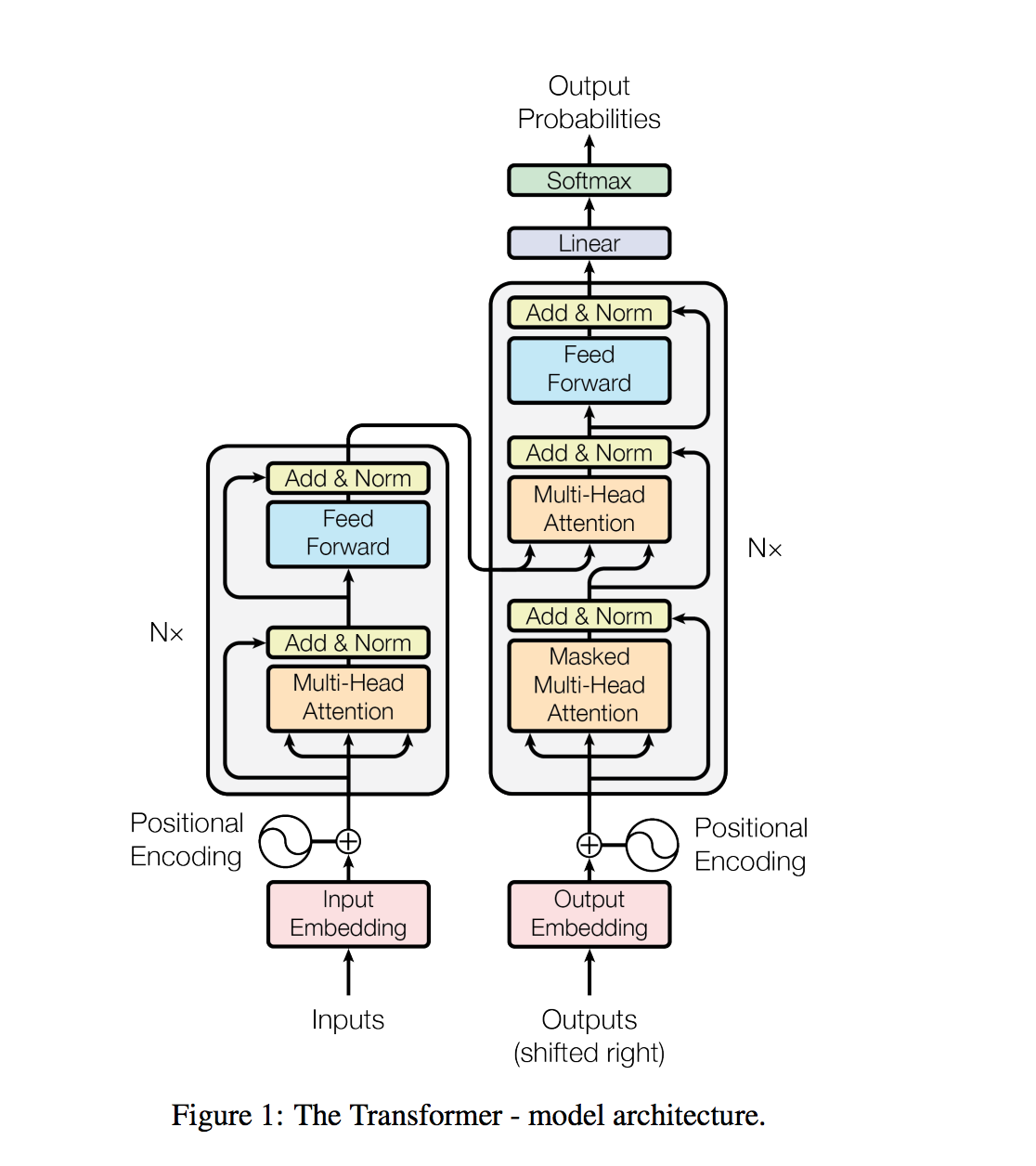
As tarefas de processamento de linguagem natural, como resposta a perguntas, tradução para a máquina, compreensão de leitura e resumo, são normalmente abordadas com o aprendizado supervisionado em conjuntos de dados específicos de tarefas. Demonstramos que os modelos de idiomas começam a aprender essas tarefas sem qualquer supervisão explícita quando treinadas em um novo conjunto de dados de milhões de páginas da Web chamadas WebText. Nosso maior modelo, GPT-2, é um transformador de parâmetros de 1,5b que atinge os resultados da ponta da arte em 7 dos 8 conjuntos de dados de modelagem de idiomas testados em uma configuração de tiro zero, mas ainda estão subfits WebText. As amostras do modelo refletem essas melhorias e contêm parágrafos coerentes de texto. Esses achados sugerem um caminho promissor para a construção de sistemas de processamento de idiomas que aprendem a executar tarefas de suas demonstrações naturais.
O GPT-2 utiliza um decodificador de 12 camadas apenas a arquitetura do transformador.
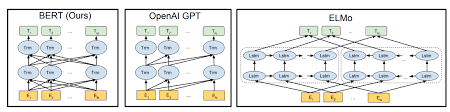
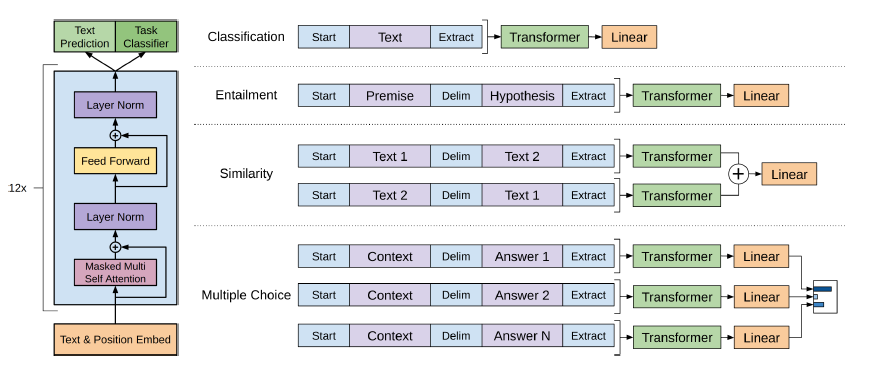
Bert usa a arquitetura do transformador para codificar frases.
A saída das redes de ponteiro é discreta e corresponde a posições na sequência de entrada
O número de classes de destino em cada etapa da saída depende do comprimento da entrada, que é variável.
Difere das tentativas de atenção anteriores, pois, em vez de usar a atenção para misturar unidades ocultas de um codificador a um vetor de contexto em cada etapa do decodificador, usa a atenção como um ponteiro para selecionar um membro da sequência de entrada como saída.

Uma das principais aplicações do processamento de linguagem natural é extrair automaticamente quais tópicos as pessoas estão discutindo de grandes volumes de texto. Alguns exemplos de texto grande podem ser feeds de mídias sociais, revisões de clientes de hotéis, filmes, etc., feedbacks de usuários, notícias, e-mails de reclamações de clientes etc.
Saber sobre o que as pessoas estão falando e entender seus problemas e opiniões é altamente valioso para empresas, administradores e campanhas políticas. E é realmente difícil ler manualmente os volumes tão grandes e compilar os tópicos.
Assim, é necessário um algoritmo automatizado que possa ler os documentos de texto e gerar automaticamente os tópicos discutidos.
Neste caderno, daremos um exemplo real do conjunto de dados 20 Newsgroups e usaremos o LDA para extrair os tópicos naturalmente discutidos.
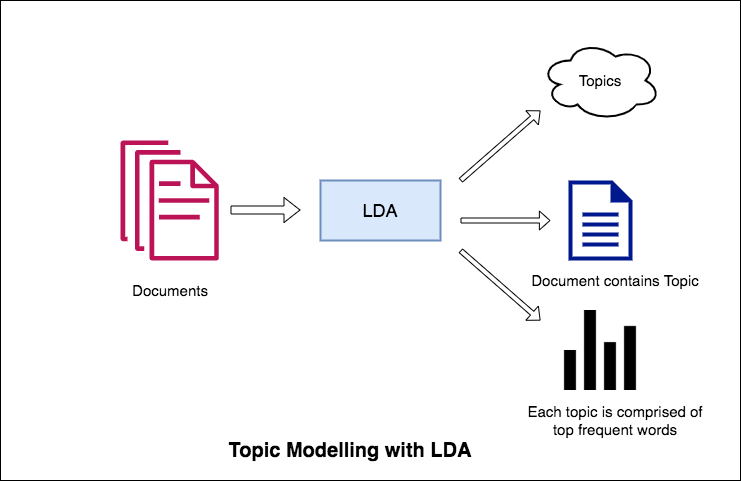
A abordagem da LDA à modelagem de tópicos é que considera cada documento como uma coleção de tópicos em uma certa proporção. E cada tópico como uma coleção de palavras -chave, novamente, em uma certa proporção.
Depois de fornecer ao algoritmo o número de tópicos, tudo o que faz para reorganizar a distribuição de tópicos nos documentos e distribuição de palavras-chave nos tópicos para obter uma boa composição da distribuição de palavras-chave tópicas.
O PCA é fundamentalmente uma técnica de redução de dimensionalidade que transforma as colunas de um conjunto de dados em um novo conjunto de recursos. Faz isso encontrando um novo conjunto de direções (como eixos x e y) que explicam a variabilidade máxima nos dados. Este novo eixo de coordenada do sistema é chamado de componentes principais (PCs).
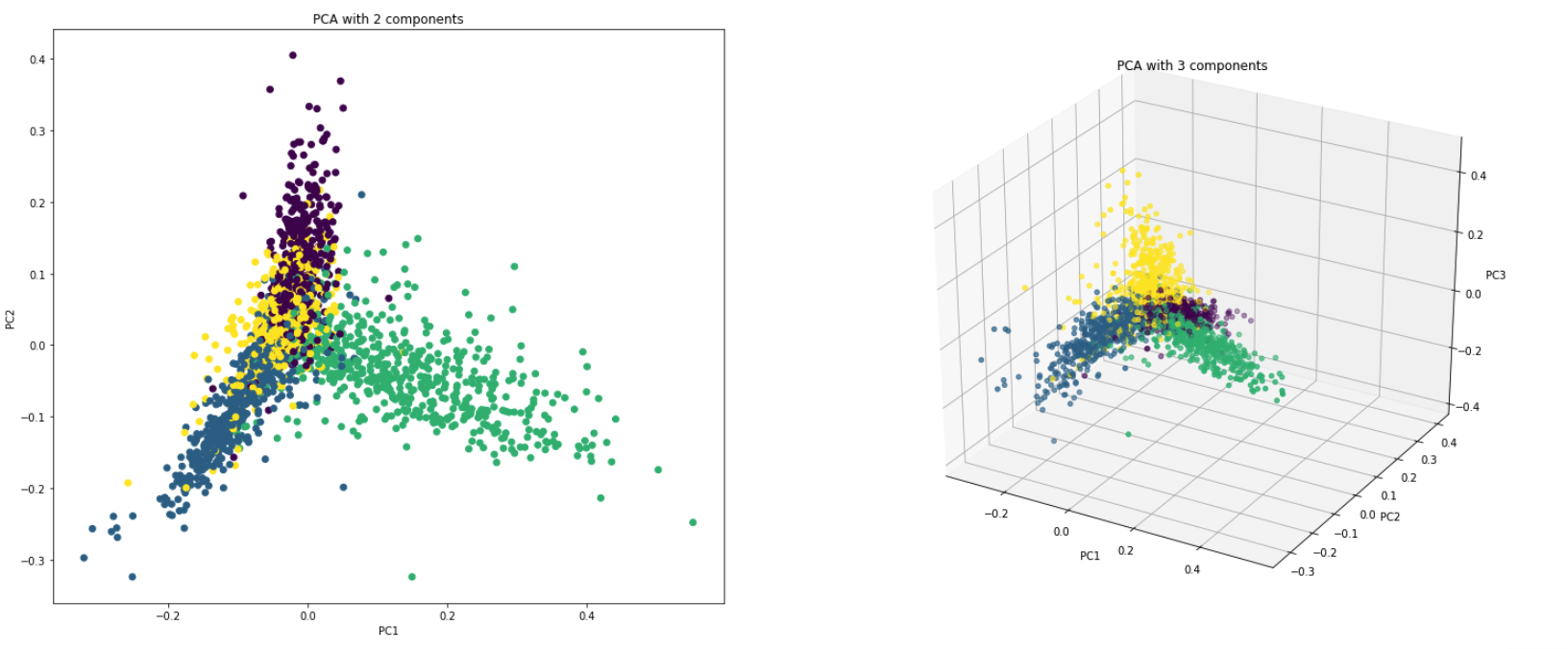
Praticamente o PCA é usado por dois motivos:
Dimensionality Reduction : As informações distribuídas em um grande número de colunas são transformadas em componentes principais (PC), de modo que os primeiros PCs possam explicar um pedaço considerável do total de informações (variação). Esses PCs podem ser usados como variáveis explicativas nos modelos de aprendizado de máquina.
Visualize Data : Visualizar a separação de classes (ou clusters) é difícil para dados com mais de três dimensões (recursos). Com os dois primeiros PCs, geralmente é possível ver uma separação clara.
Um classificador ingênuo de Bayes é um modelo probabilístico de aprendizado de máquina usado para a tarefa de classificação. O ponto crucial do classificador é baseado no teorema de Bayes.
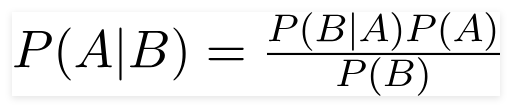
Usando o teorema de Bayes, podemos encontrar a probabilidade de um acontecimento, já que B ocorreu. Aqui, B é a evidência e A é a hipótese. A suposição feita aqui é que os preditores/recursos são independentes. Isso é a presença de um recurso específico não afeta o outro. Portanto, é chamado de ingênuo.
Tipos de classificador ingênuo de Bayes :
Multinomial Naive Bayes : isso é usado principalmente quando as variáveis são discretas (como palavras). Os recursos/preditores usados pelo classificador são a frequência das palavras presentes no documento.
Gaussian Naive Bayes : quando os preditores assumem um valor contínuo e não são discretos, assumimos que esses valores são amostrados a partir de uma distribuição gaussiana.
Bernoulli Naive Bayes : isso é semelhante aos Bayes ingênuos multinomiais, mas os preditores são variáveis booleanas. Os parâmetros que usamos para prever a variável de classe levam apenas o valor sim ou não, por exemplo, se ocorrer uma palavra no texto ou não.
Utilizando o conjunto de dados do 20NewsGroup, o algoritmo NAIVE BAYES é explorado para fazer a classificação.
O aumento de dados usando as seguintes técnicas é explorado:

Uma nova arquitetura chamada Sbert foi explorada. A arquitetura da rede siamesa permite que os vetores de tamanho fixo para sentenças de entrada possam ser derivados. Usando uma medida de similaridade como cosinesimilaridade ou distância de Manhatten / Euclidiana, sentenças semanticamente semelhantes podem ser encontradas.

| Análise de sentimentos - IMDB | Classificação de sentimentos - Hinglish | Classificação de documentos |
| Classificação duplicada do par de perguntas - Quora | Marcação de POS | Inferência de linguagem natural - snli |
| Classificação de comentários tóxicos | Frase gramaticalmente correta - cola | Marcação nerd |
A análise de sentimentos refere -se ao uso do processamento de linguagem natural, análise de texto, lingüística computacional e biometria para identificar, extrair, extrair, quantificar e estudar sistematicamente estados afetivos e informações subjetivas.
A seguir foram explorados variantes:
O RNN é usado para processar e identificar o sentimento.

Depois de experimentar o RNN básico, que fornece uma aceitação de teste inferior a 50%, as seguintes técnicas foram experimentadas e uma aceitação de teste acima de 88% é alcançada.
Técnicas usadas:

A atenção ajuda a focar na entrada relevante ao prever o sentimento da entrada. A atenção de Bahdanau foi usada com a tomada de saídas do LSTM e concatenando o estado oculto final e para trás. Sem usar as incorporações de palavras pré-treinadas, a precisão do teste de 88% é alcançada.
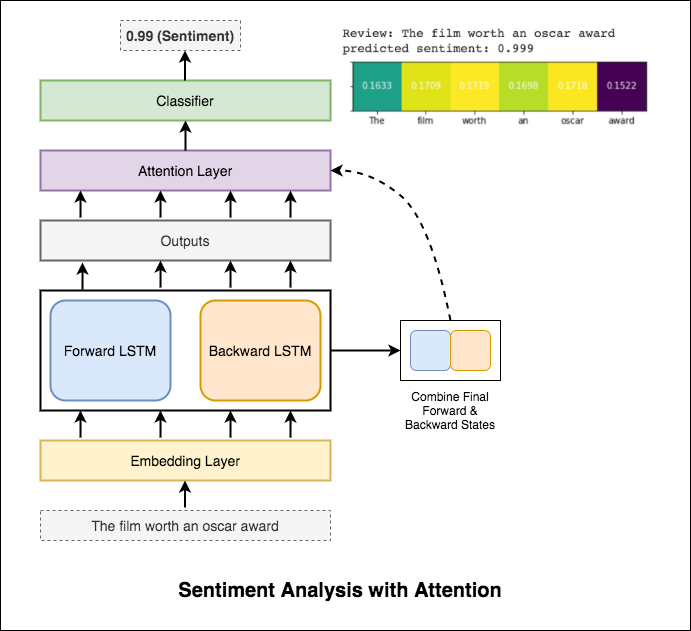
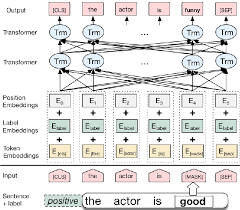
Bert obtém novos resultados de última geração em onze tarefas de processamento de linguagem natural. A aprendizagem de transferência na PNL foi acionada após a liberação do modelo BERT. Usando Bert para fazer a análise de sentimentos é explorado.

Misturar idiomas, também conhecido como mistura de código, é uma norma nas sociedades multilíngues. Pessoas multilíngues, que são falantes de inglês não nativas, tendem a misturar o código usando a digitação fonética em inglês e a inserção de anglicismos em seu idioma principal.
A tarefa é prever o sentimento de um determinado tweet misturado com código. Os rótulos dos sentimentos são positivos, negativos ou neutros, e os idiomas misturados com código serão ingleses-hindi. (Sentimix)
A seguir foram explorados variantes:
Usando o modelo simples de MLP, F1 score of 0.58 foi alcançada nos dados de teste

Depois de explorar o modelo básico de MLP, o modelo LSTM foi usado para previsão de sentimentos e a pontuação de 0,57 de 0.57 foi alcançada.

Os resultados foram realmente menos comparados a um modelo básico de MLP. Um dos motivos pode ser que o LSTM não é capaz de aprender as relações entre as palavras em uma frase devido à natureza altamente diversa dos dados misturados pelo código.
Como o LSTM não é capaz de aprender as relações entre as palavras em uma frase misturada por código devido à natureza altamente diversa dos dados misturados com código e nenhuma incorporação pré-treinada é usada, a pontuação F1 é menor.
Para aliviar esse problema, o modelo XLM-ROBERTA (que foi pré-treinado em 100 idiomas) está sendo usado para codificar a frase. Para usar o modelo XLM-Roberta, a frase precisa estar em um idioma adequado. Então, primeiro as palavras Hinglish precisam ser convertidas para a forma hindi (Devanagari).
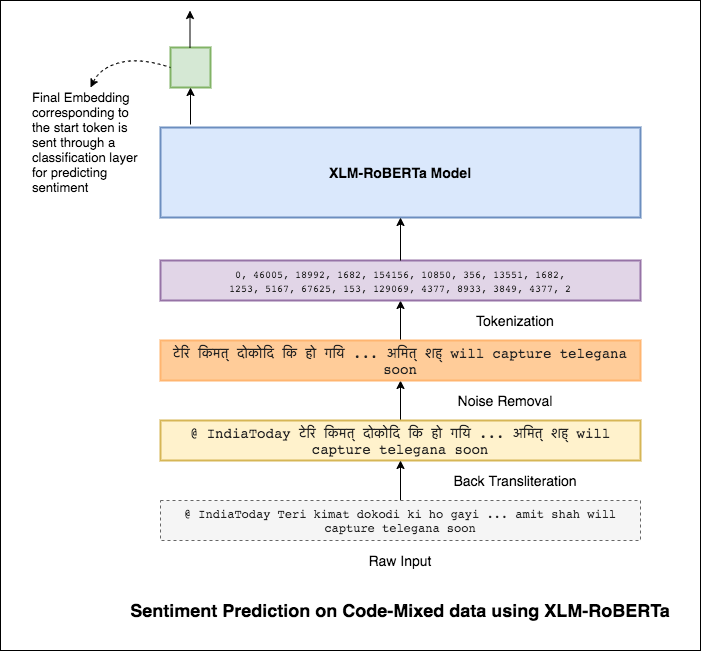
Foi alcançada uma pontuação de 0.59 F1. Métodos para melhorar isso serão explorados posteriormente.
A saída final do modelo XLM-Roberta foi usada como incorporação de entrada no modelo LSTM bidirecional. Uma camada de atenção, que leva as saídas da camada LSTM, produz uma representação ponderada da entrada, que é passada por um classificador para prever o sentimento da frase.

Foi alcançada uma pontuação F1 de 0.64 .
Da mesma forma que um filtro 3x3 pode olhar sobre um patch de uma imagem, um filtro 1x2 pode olhar sobre 2 palavras seqüenciais em um pedaço de texto, ou seja, um bi-gramas. Neste modelo CNN, usaremos vários filtros de tamanhos diferentes que analisarão os bi-gramas (um filtro 1x2), tri-gramas (filtro 1x3) e/ou n-gramas (um filtro 1xn) dentro do texto.
A intuição aqui é que a aparência de certos bi-gramas, tri-gramas e n-gramas na revisão será uma boa indicação do sentimento final.
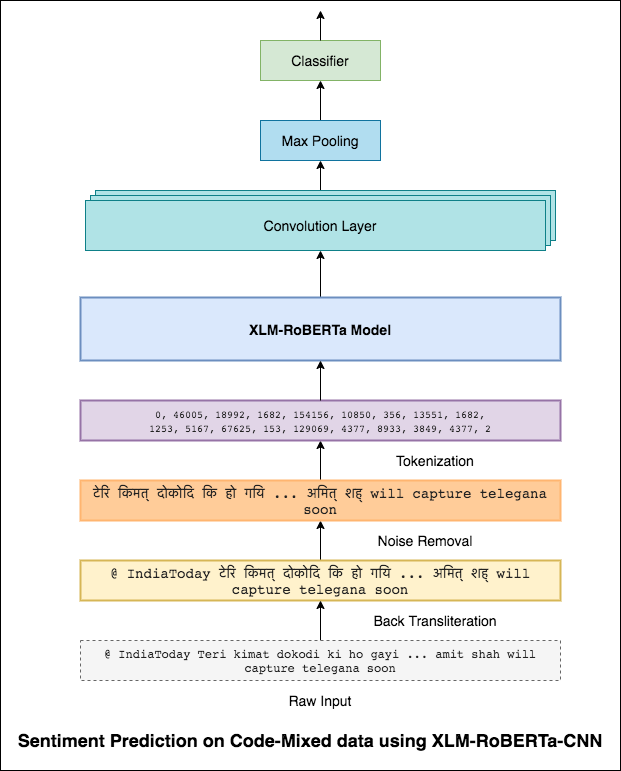
Foi alcançada uma pontuação de 0.69 F1.
A CNN captura as dependências locais, onde, como a RNN, captura as dependências globais. Combinando ambos, podemos entender melhor os dados. O conjunto do modelo da CNN e do modelo bidirecional de atendimento-ação executa os outros.
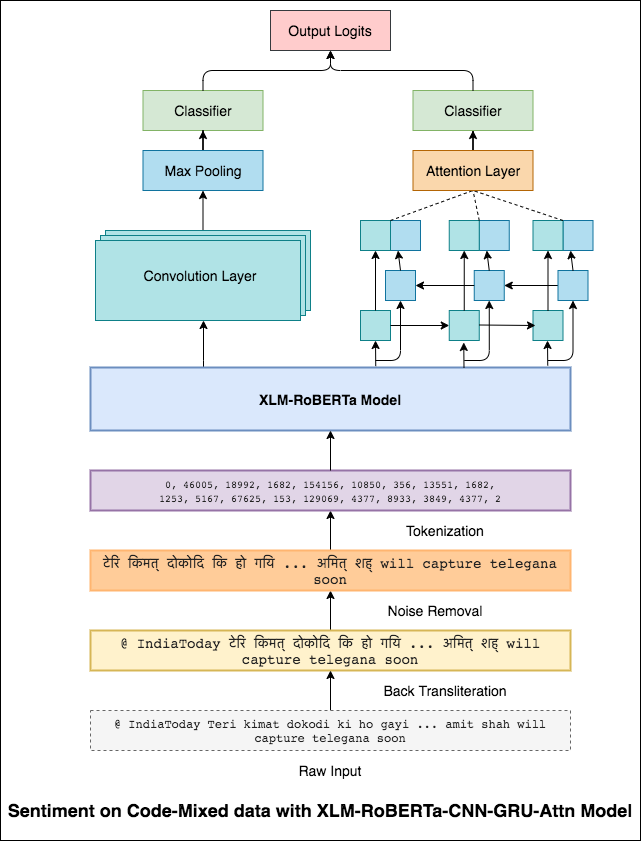
Foi alcançada uma pontuação de 0.71 F1. (Top 5 na tabela de classificação).
Classificação de documentos ou categorização de documentos é um problema na ciência da biblioteca, ciência da informação e ciência da computação. A tarefa é atribuir um documento a uma ou mais classes ou categorias.
A seguir foram explorados variantes:
Uma rede de atenção hierárquica (HAN) considera a estrutura hierárquica dos documentos (Document - frases - palavras) e inclui um mecanismo de atenção capaz de encontrar as palavras e frases mais importantes em um documento, levando em consideração o contexto.
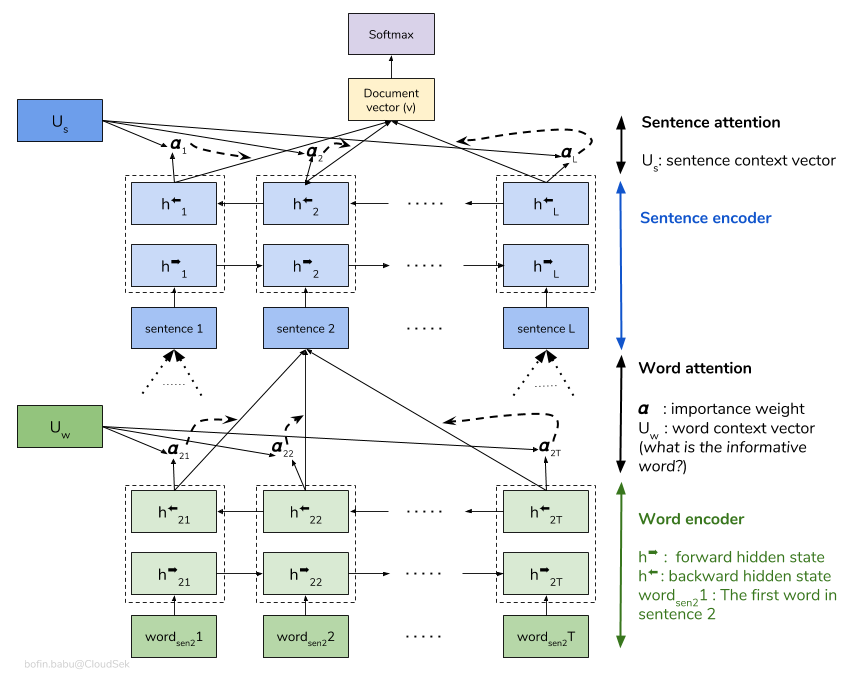
O modelo básico de Han está excessivamente ajustado rapidamente. Para superar isso, técnicas como Embedding Dropout , Locked Dropout são explorados. Há mais uma outra técnica chamada de Weight Dropout que não é implementada (deixe -me saber se houver bons recursos para implementar isso). Glove de incorporação de palavras pré-treinada também é usada em vez de inicialização aleatória. Como a atenção pode ser feita no nível da frase e no nível das palavras, podemos visualizar quais palavras são importantes em uma frase e quais frases são importantes em um documento.



QQP significa pares de perguntas quora. O objetivo da tarefa é para um determinado par de perguntas; Precisamos descobrir se essas perguntas são semanticamente semelhantes ou não.
A seguir foram explorados variantes:
O algoritmo precisa tomar o par de perguntas como entrada e deve gerar sua semelhança. Uma rede siamesa é usada. Uma Siamese neural network (às vezes chamada de rede neural dupla) é uma rede neural artificial que usa os same weights enquanto trabalha em conjunto em dois vetores de entrada diferentes para calcular vetores de saída comparáveis.

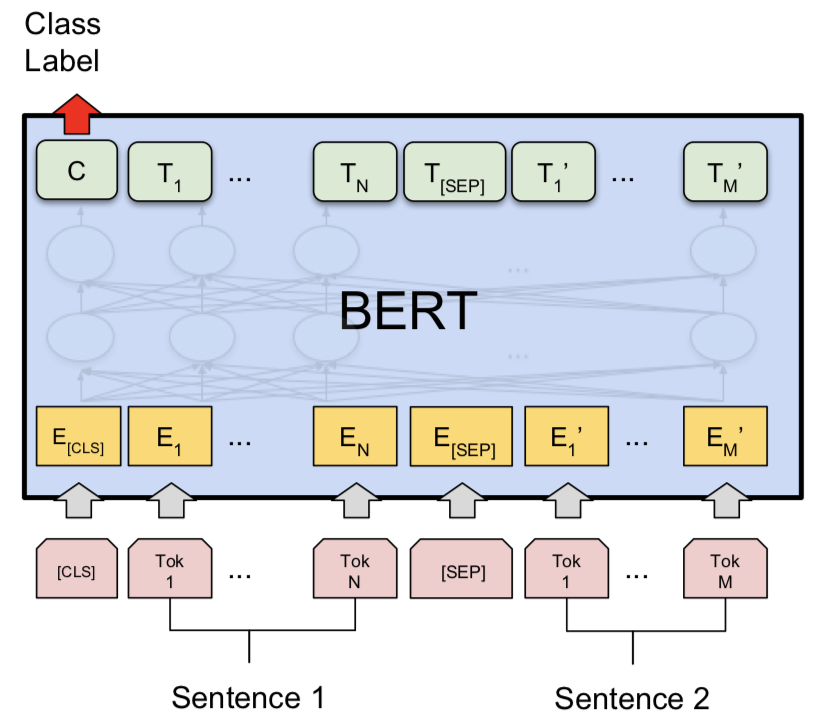
Depois de experimentar o modelo Siamese, Bert foi explorado para fazer a detecção de pares de perguntas do Quora duplicada. Bert pega a pergunta 1 e a pergunta 2 como entrada separada pelo token [SEP] e a classificação foi feita usando a representação final do [CLS] Token.
A marcação de parte da fala (POS) é uma tarefa de rotular cada palavra em uma frase com sua parte apropriada da fala.
A seguir foram explorados variantes:
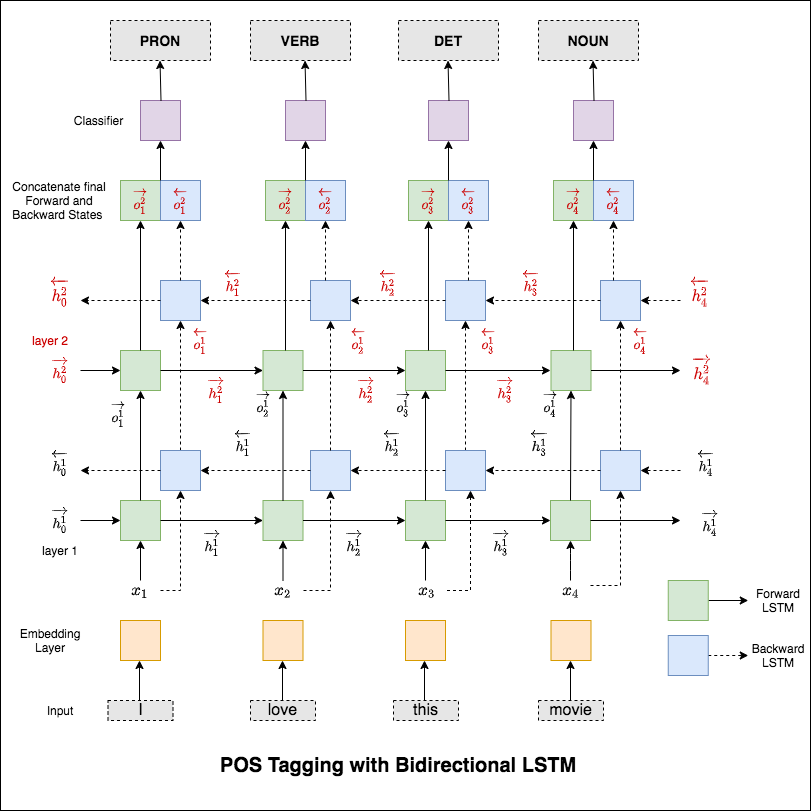
Este código cobre o fluxo de trabalho básico. Aprenderemos como: Carregar dados, criar divisões de trem/teste/validação, criar um vocabulário, criar iteradores de dados, definir um modelo e implementar a marcha de trem/avaliar/teste e tempo de execução (inferência).
O modelo usado é uma rede LSTM bidirecional de várias camadas
Depois de experimentar a abordagem RNN, a marcação de POS com a arquitetura baseada em transformadores é explorada. Como o transformador contém o codificador e o decodificador e para a tarefa de rotulagem de sequência somente Encoder será suficiente. Como os dados são pequenos com 6 camadas de codificador, excederá os dados. Portanto, foi utilizado um modelo de codificador de transformador de 3 camadas.

Depois de experimentar a marcação de POS com o codificador do transformador, a marcação de POS com o modelo BERT pré-treinada é explorada. Atingiu a precisão do teste de 91% .

O objetivo da inferência de linguagem natural (NLI), uma tarefa de processamento de linguagem natural amplamente estudada, é determinar se uma determinada declaração (uma premissa) implica semanticamente outra declaração dada (uma hipótese).
A seguir foram explorados variantes:
Um modelo básico com rede de bilstm siameses está implementado
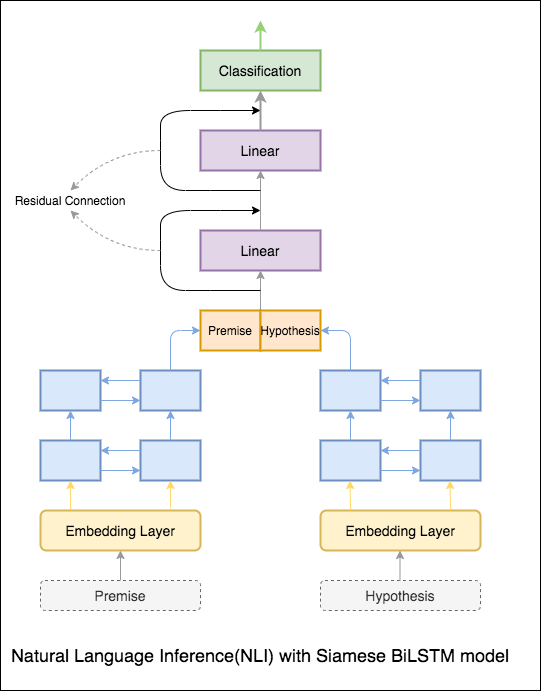
Isso pode ser tratado como configuração da linha de base. Foi alcançada uma precisão de teste de 76.84% .
No caderno anterior, os estados ocultos finais de premissa e hipótese como representações do LSTM. Agora, em vez de tomar os estados ocultos finais, a atenção será calculada em todos os tokens de entrada e um vetor ponderado final é tomado como representação da premissa e da hipótese.
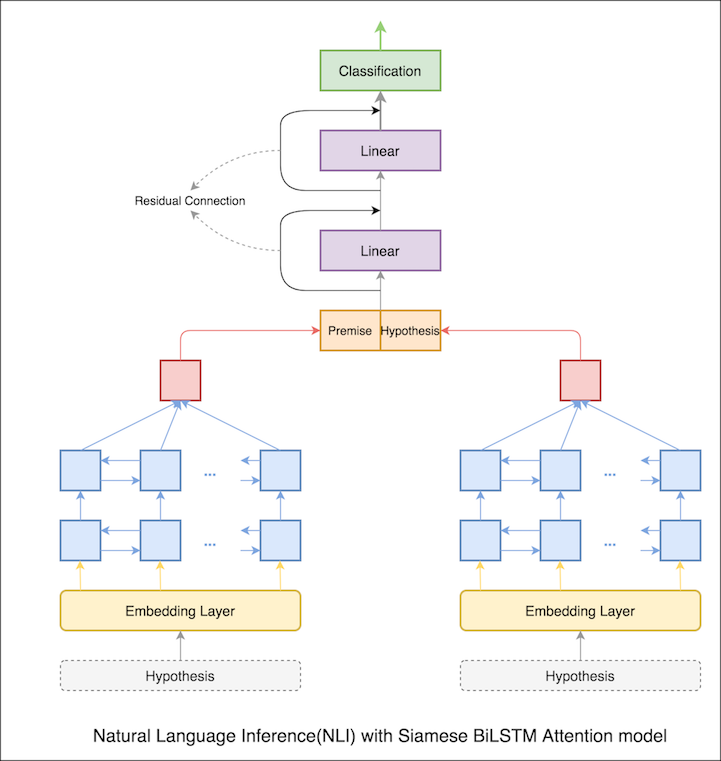
A precisão do teste aumentou de 76.84% para 79.51% .
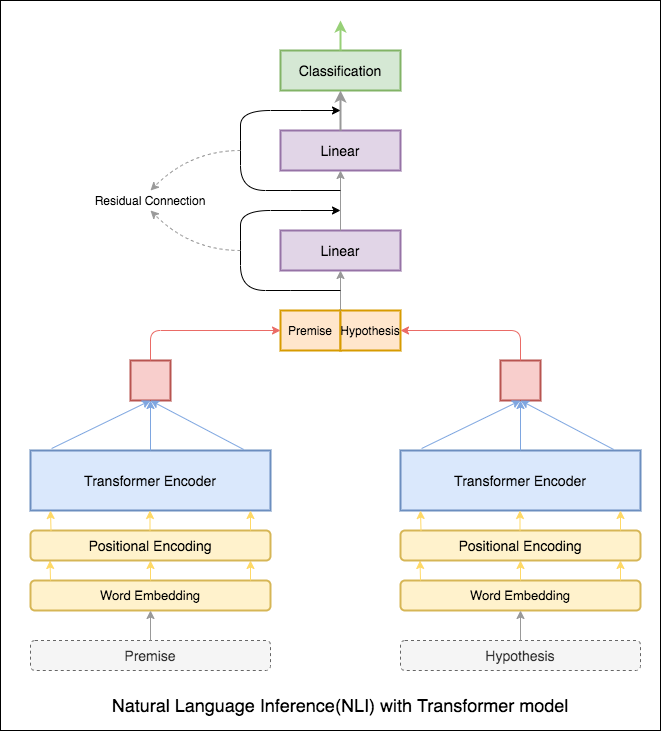
O codificador do transformador foi usado para codificar a premissa e a hipótese. Uma vez que a frase é passada pelo codificador, a soma de todos os tokens é considerada como a representação final (outras variantes podem ser exploradas). A precisão do modelo é menos comparada às variantes RNN.
NLI com modelo base de Bert foi explorado. Bert toma a premissa e a hipótese como entradas separadas pelo token [SEP] e a classificação foi feita usando a representação final do token [CLS] .
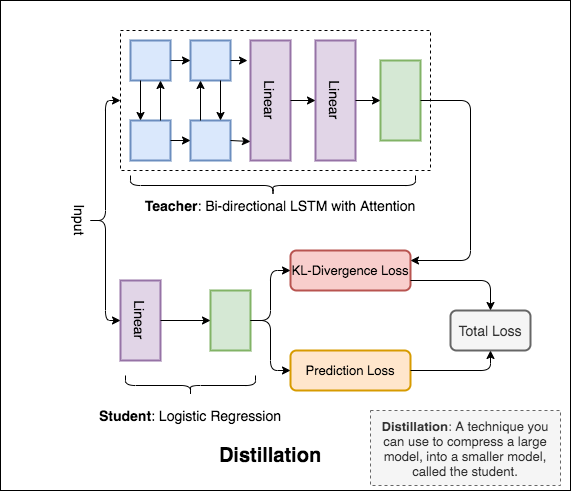
Distillation : uma técnica que você pode usar para comprimir um modelo grande, chamado teacher , em um modelo menor, chamado de student . Após o aluno, os modelos de professores são usados para realizar destilação no NLI.
Discutir coisas com as quais você se importa pode ser difícil. A ameaça de abuso e assédio on -line significa que muitas pessoas param de se expressar e desistem de buscar opiniões diferentes. As plataformas lutam para facilitar efetivamente as conversas, levando muitas comunidades a limitar ou fechar completamente os comentários do usuário.
Você recebe um grande número de comentários da Wikipedia que foram rotulados por avaliadores humanos para comportamento tóxico. Os tipos de toxicidade são:
A seguir foram explorados variantes:
O modelo usado é uma rede GRU bidirecional.
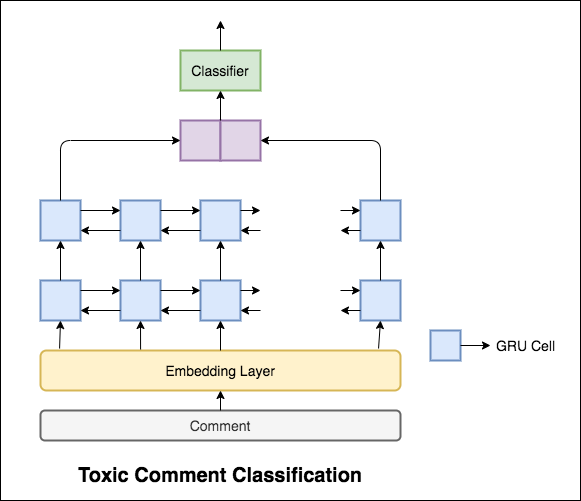
Foi alcançada uma precisão de teste de 99.42% . Como 90% dos dados não são rotulados em nenhuma toxicidade, simplesmente prever todos os dados como não tóxicos fornecem um modelo preciso de 90%. Portanto, a precisão não é uma métrica confiável. Uma AUC de ROC métrica diferente foi implementada.
Com Categorical Cross Entropy como perda, a pontuação ROC_AUC de 0.5 é alcançada. Ao alterar a perda para Binary Cross Entropy e também modificar um pouco o modelo adicionando camadas de agrupamento (max, média), a pontuação ROC_AUC melhorou para 0.9873 .
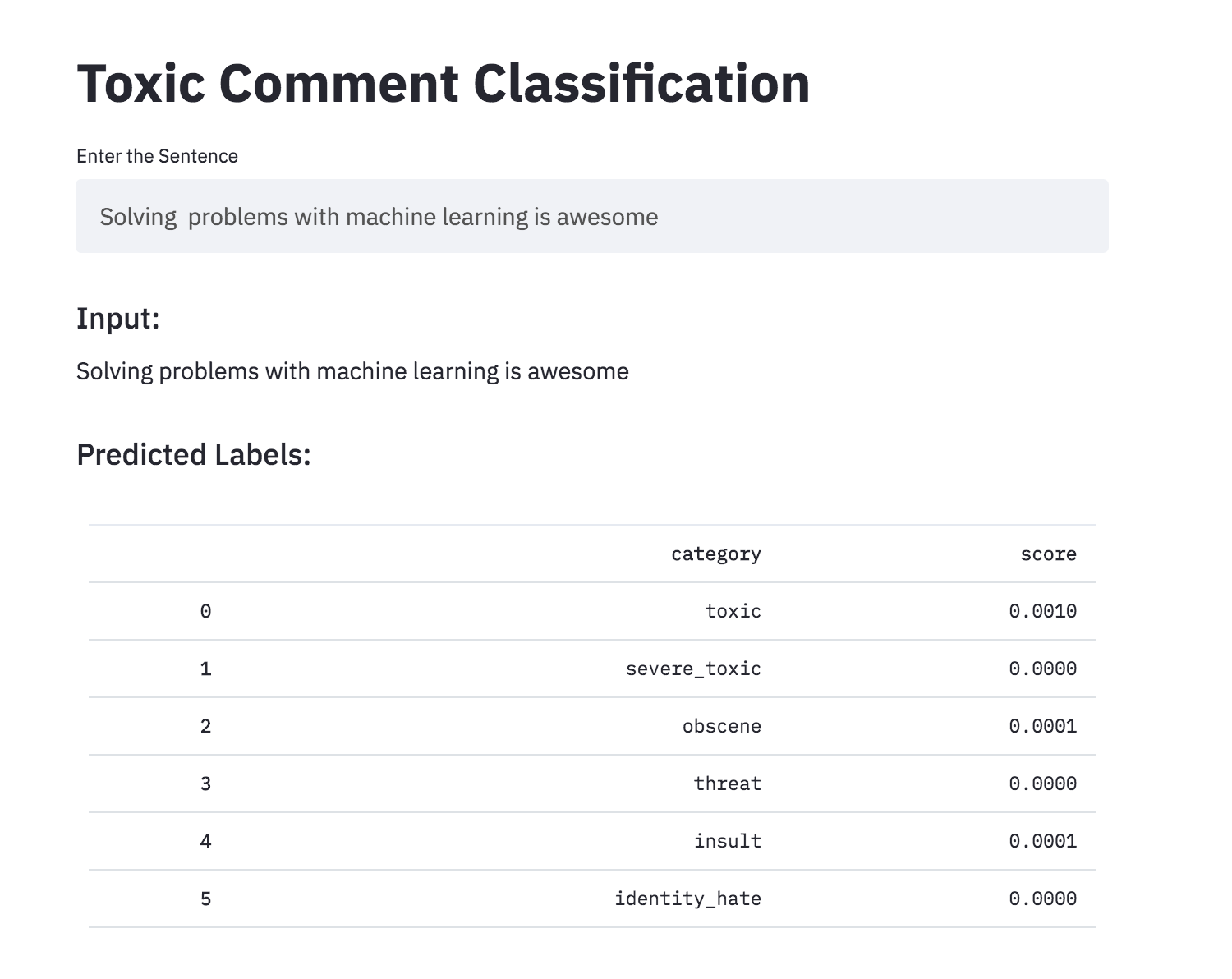
Converteu a classificação de comentários tóxicos em um aplicativo usando o streamlit. O modelo pré-treinado já está disponível.
As redes neurais artificiais podem ter a capacidade de julgar a aceitabilidade gramatical de uma sentença? Para explorar essa tarefa, o conjunto de dados do corpo de aceitabilidade lingüística (COLA) é usado. O Cola é um conjunto de frases rotuladas como gramaticalmente corretas ou incorretas.
A seguir foram explorados variantes:
Bert obtém novos resultados de última geração em onze tarefas de processamento de linguagem natural. A aprendizagem de transferência na PNL foi acionada após a liberação do modelo BERT. Neste caderno, exploraremos como usar o BERT para classificar se uma frase está gramaticalmente correta ou não usando o conjunto de dados Cola.
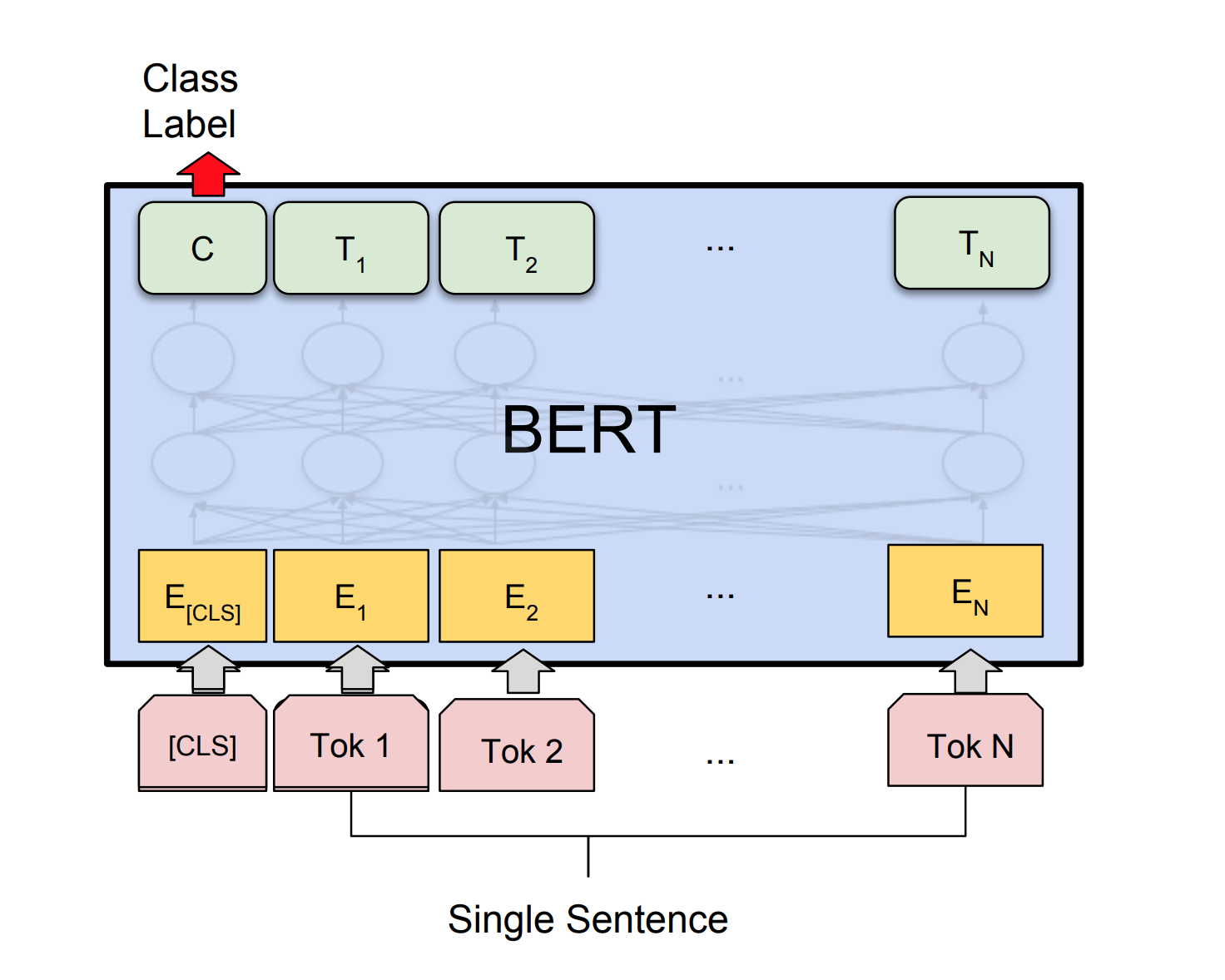
Foi alcançada uma precisão de 85% e o coeficiente de correlação de Matthews (MCC) de 64.1 .
Distillation : uma técnica que você pode usar para comprimir um modelo grande, chamado teacher , em um modelo menor, chamado de student . Após o aluno, os modelos de professores são usados para realizar destilação na cola.

A seguir, foram tentados experimentos:
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 A etiqueta de reconhecimento de entrada de entrada (NER) é uma tarefa de rotular cada palavra em uma frase com sua entidade apropriada.
A seguir foram explorados variantes:
Este código cobre o fluxo de trabalho básico. Veremos como: carregar dados, criar divisões de trem/teste/validação, criar um vocabulário, criar iteradores de dados, definir um modelo e implementar o loop de trem/avaliar/testar e treinar, testar o modelo.
O modelo usado é uma rede LSTM bidirecional
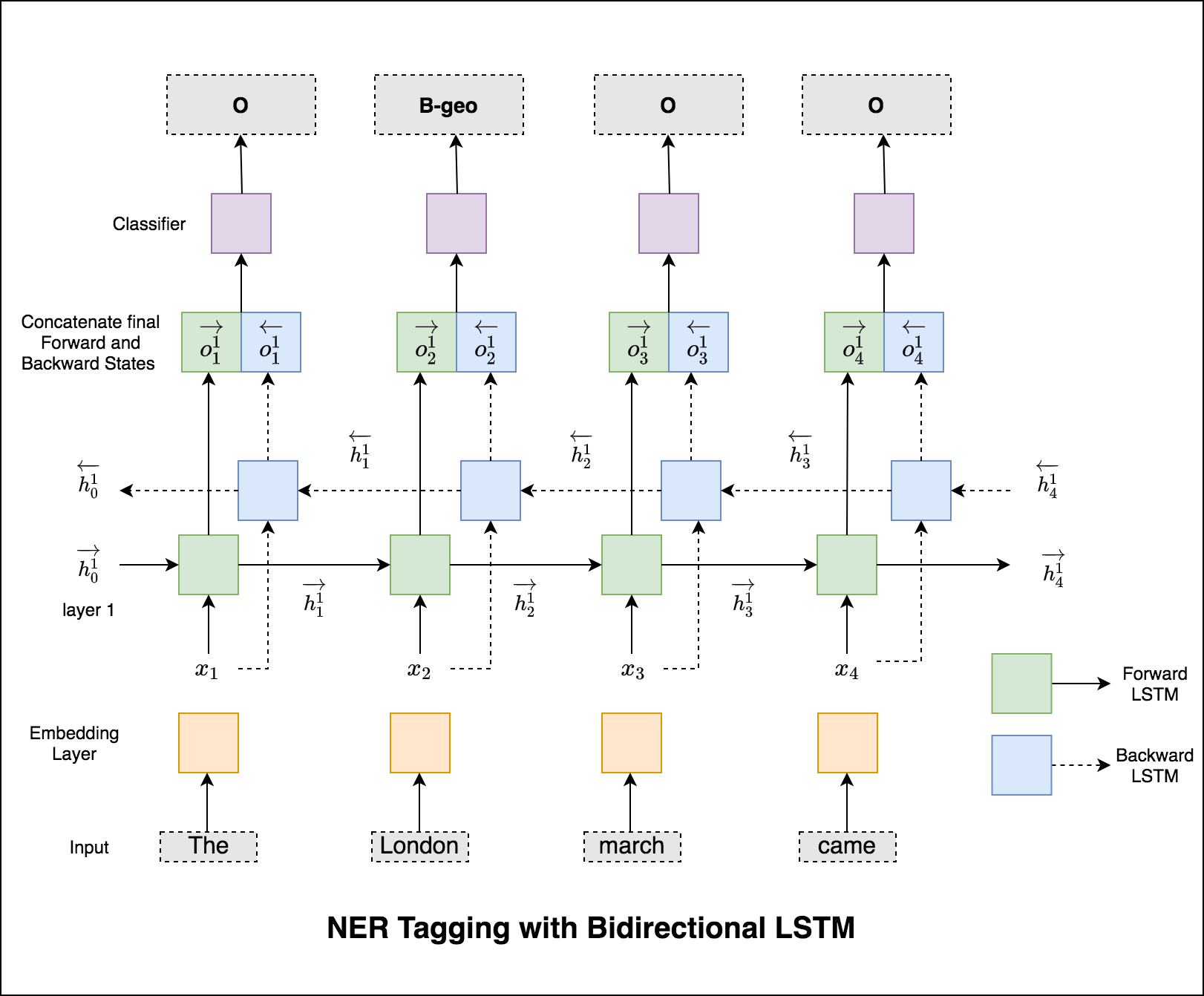
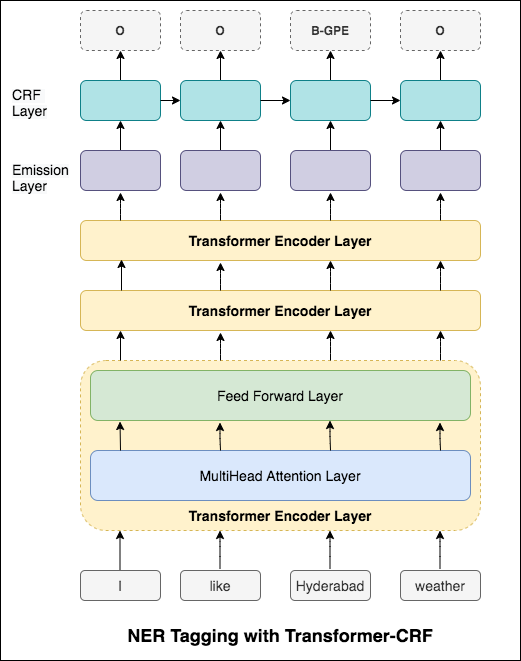
No caso de marcação de sequência (NER), a tag de uma palavra atual pode depender da tag da palavra anterior. (Ex: Nova York).
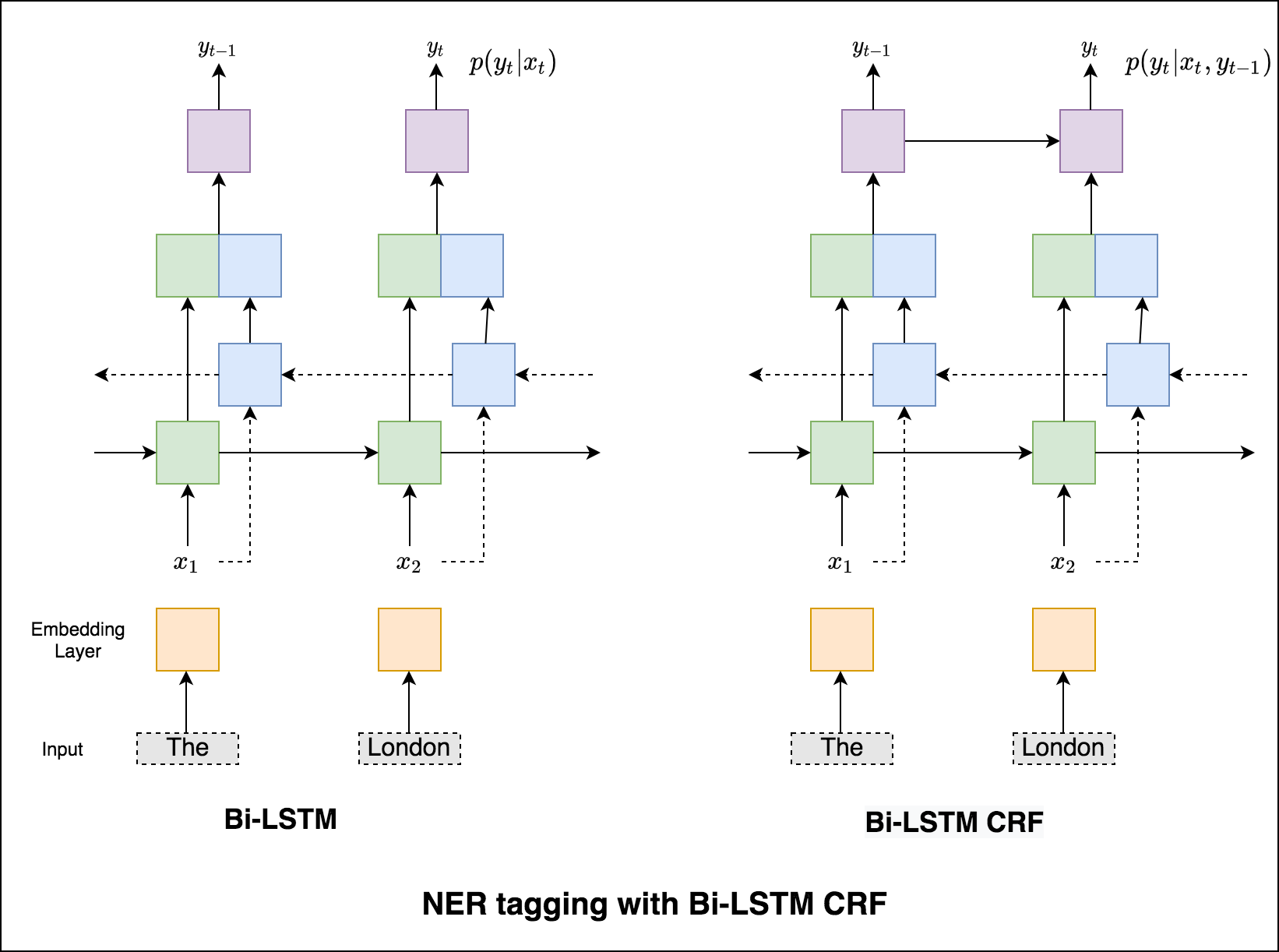
Sem um CRF, teríamos simplesmente usado uma única camada linear para transformar a saída do LSTM bidirecional em pontuações para cada tag. Eles são conhecidos como emission scores , que são uma representação da probabilidade de a palavra ser uma certa etiqueta.
Um CRF calcula não apenas as pontuações de emissão, mas também as transition scores , que são a probabilidade de uma palavra ser uma certa tag, considerando que a palavra anterior era uma certa tag. Portanto, as pontuações de transição medem a probabilidade de fazer a transição de uma etiqueta para outra.
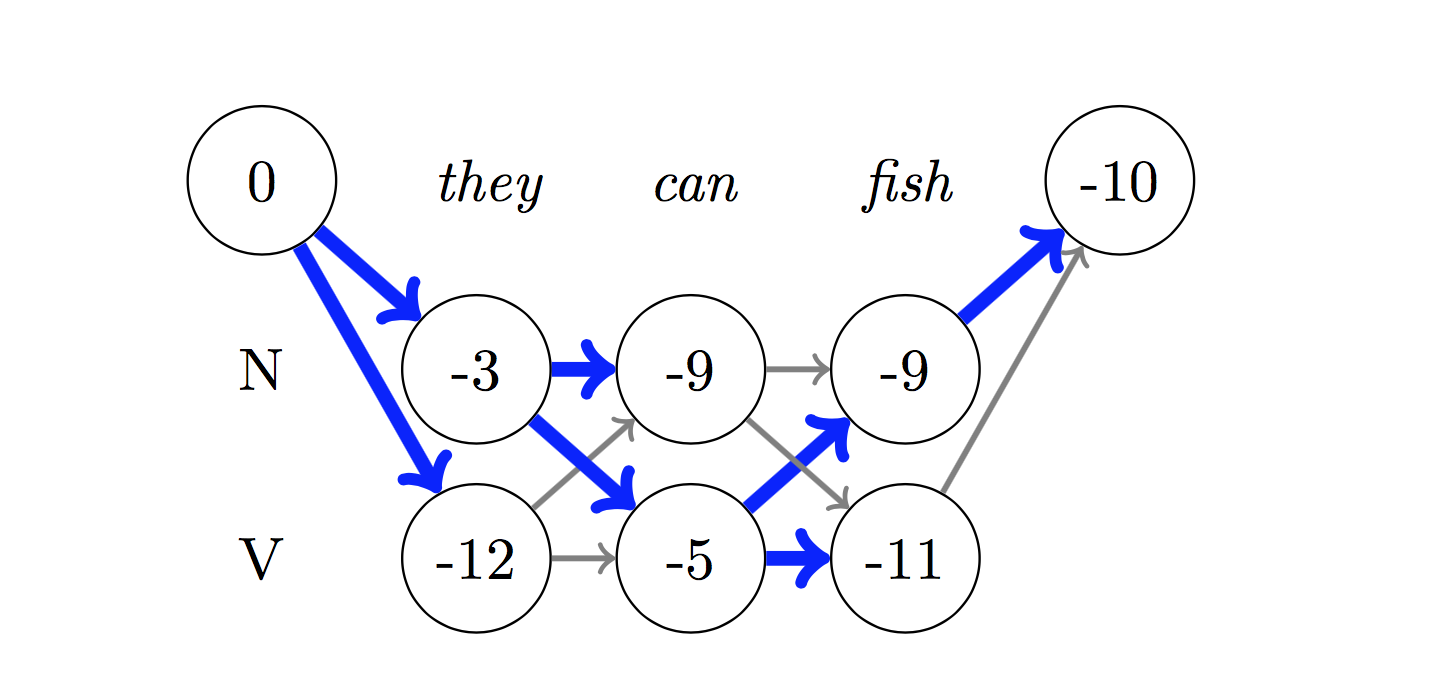
Para decodificar, o algoritmo Viterbi é usado.
Como estamos usando CRFs, não estamos prevendo tanto o rótulo certo em cada palavra quanto prevemos a sequência de etiqueta correta para uma sequência de palavras. A decodificação do Viterbi é uma maneira de fazer exatamente isso - encontre a sequência de tags mais ideal das pontuações calculadas por um campo aleatório condicional.
Usando informações sobre sub-palavras em nossa tarefa de marcação, pois pode ser um indicador poderoso das tags, sejam partes da fala ou entidades. Por exemplo, pode aprender que os adjetivos geralmente terminam com "-y" ou "-ul", ou que os lugares geralmente terminam com "-land" ou "-burg".
Portanto, nosso modelo de marcação de sequência usa os dois
word-level na forma de incorporações de palavras.character-level até e incluindo cada palavra em ambas as direções. 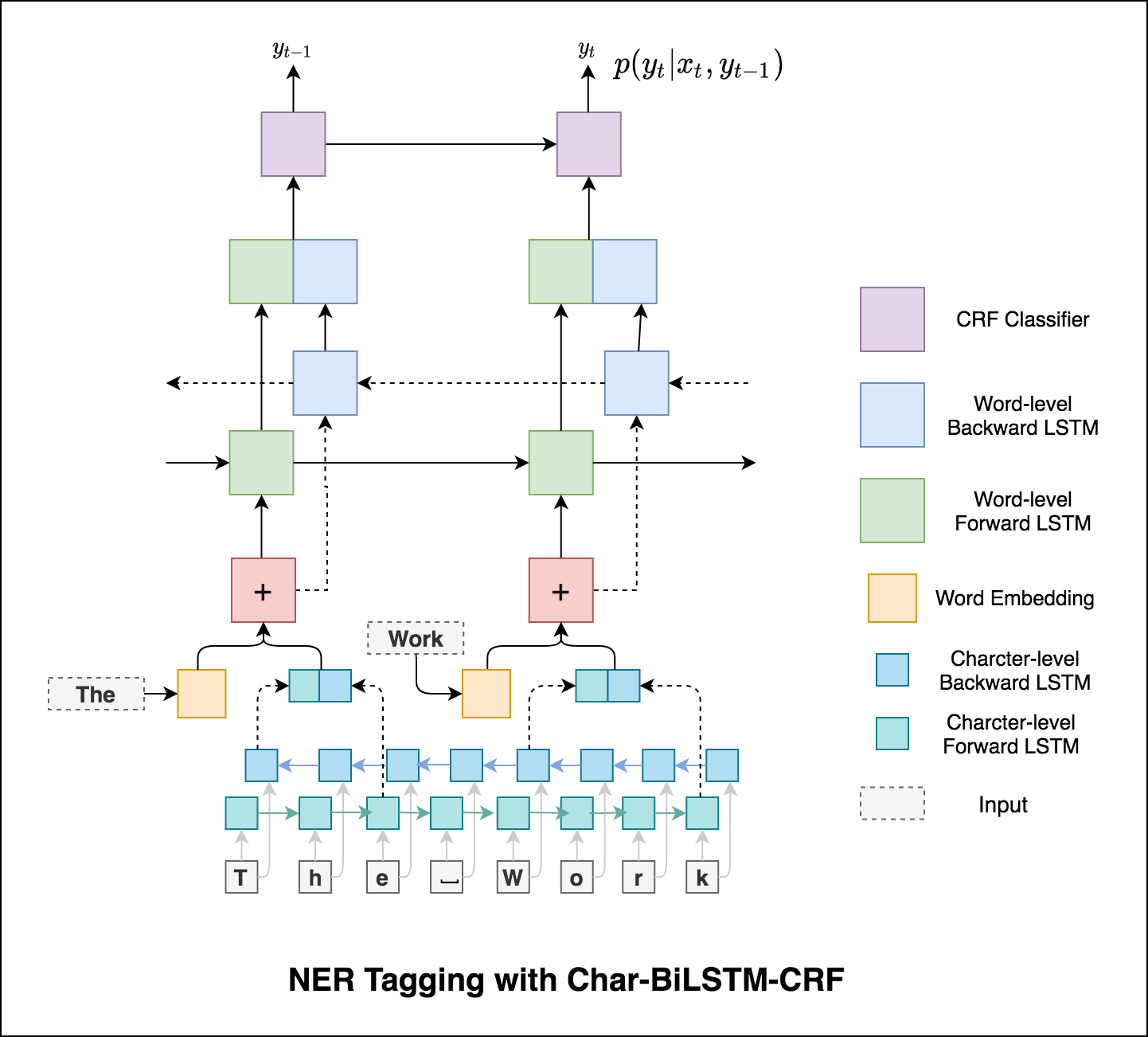
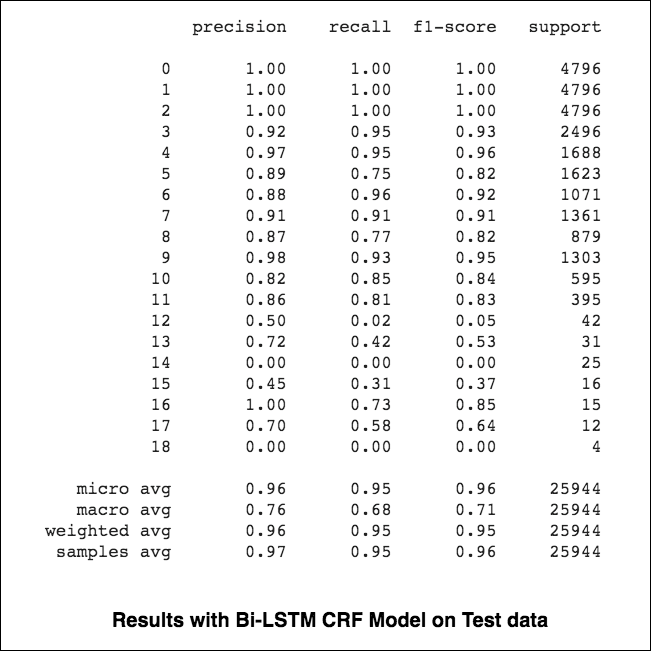
Micro e macro-médias (para qualquer métrica) calcularão coisas ligeiramente diferentes e, portanto, sua interpretação difere. Uma média macro calculará a métrica de forma independente para cada classe e, em seguida, assumirá a média (tratar de forma todas as classes igualmente), enquanto uma micro média agregará as contribuições de todas as classes para calcular a métrica média. Em uma configuração de classificação de várias classes, a micro-média é preferível se você suspeitar que possa haver desequilíbrio de classe (ou seja, você pode ter muito mais exemplos de uma classe do que de outras classes).

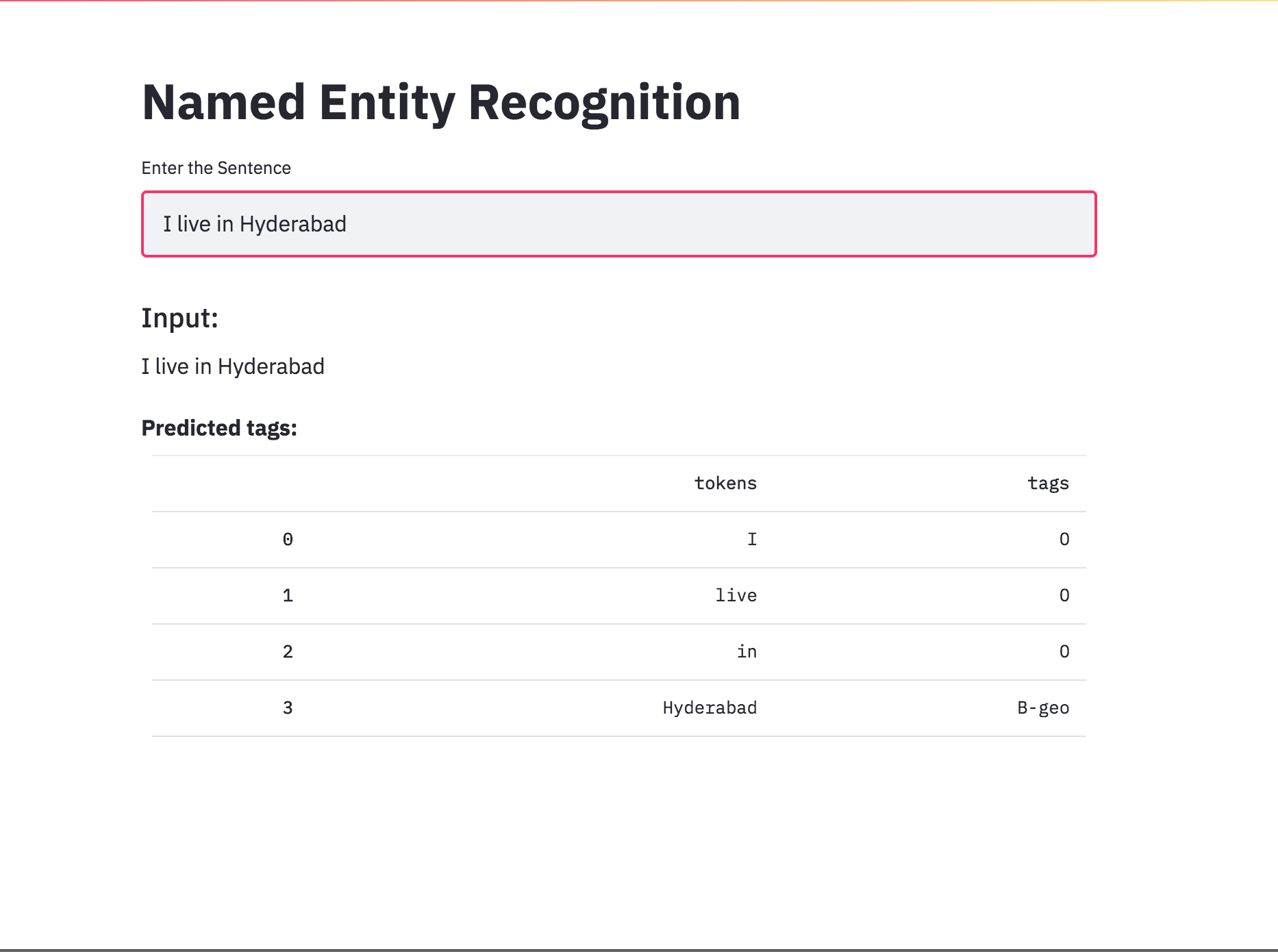
Converteu a marcação NER em um aplicativo usando o Streamlit. O modelo pré-treinado (char-bilstm-CRF) já está disponível.
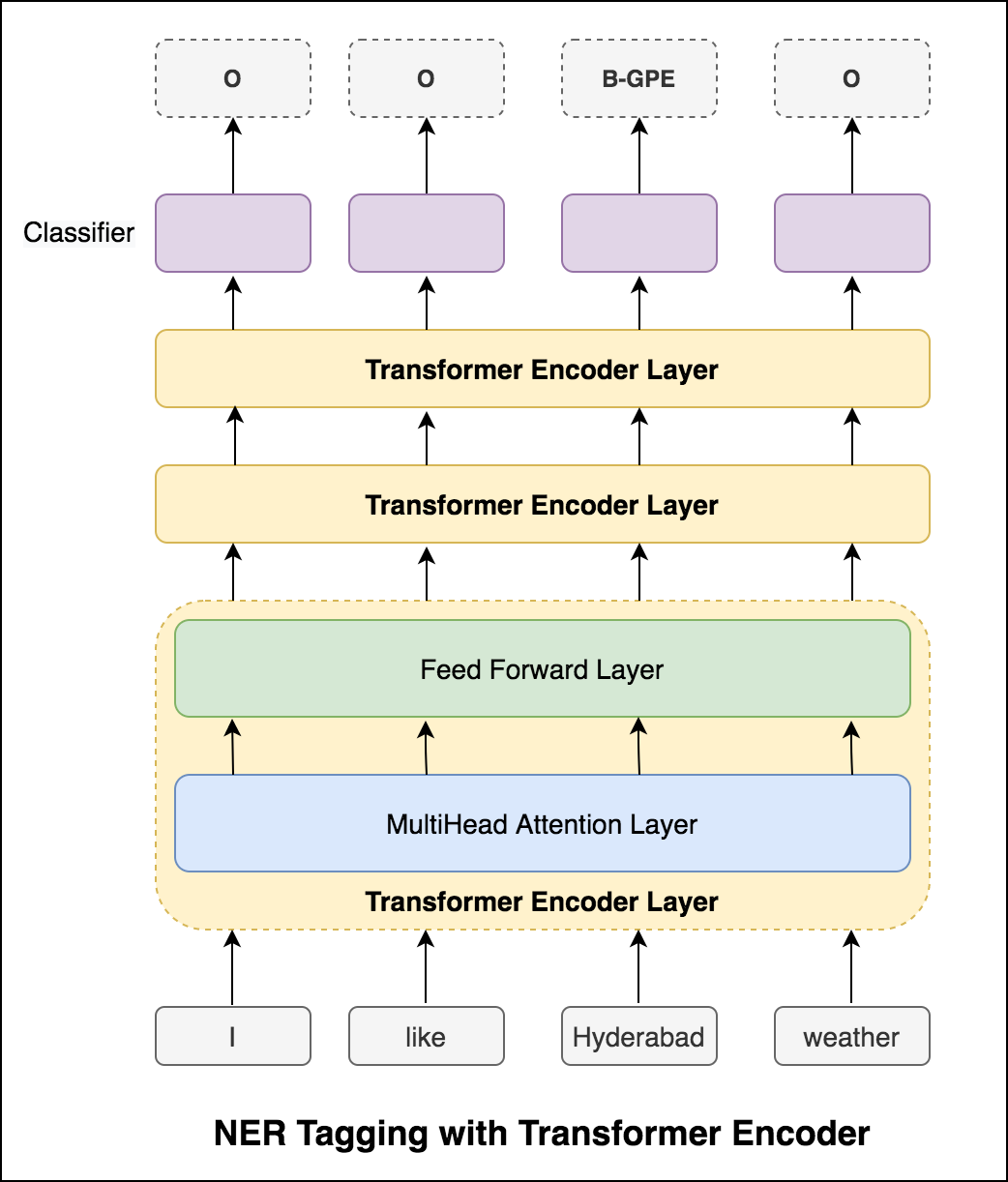
Depois de experimentar a abordagem RNN, a marcação NER com a arquitetura baseada em transformador é explorada. Como o transformador contém o codificador e o decodificador e para a tarefa de rotulagem de sequência somente Encoder será suficiente. Foi utilizado um modelo de codificador de transformador de 3 camadas.
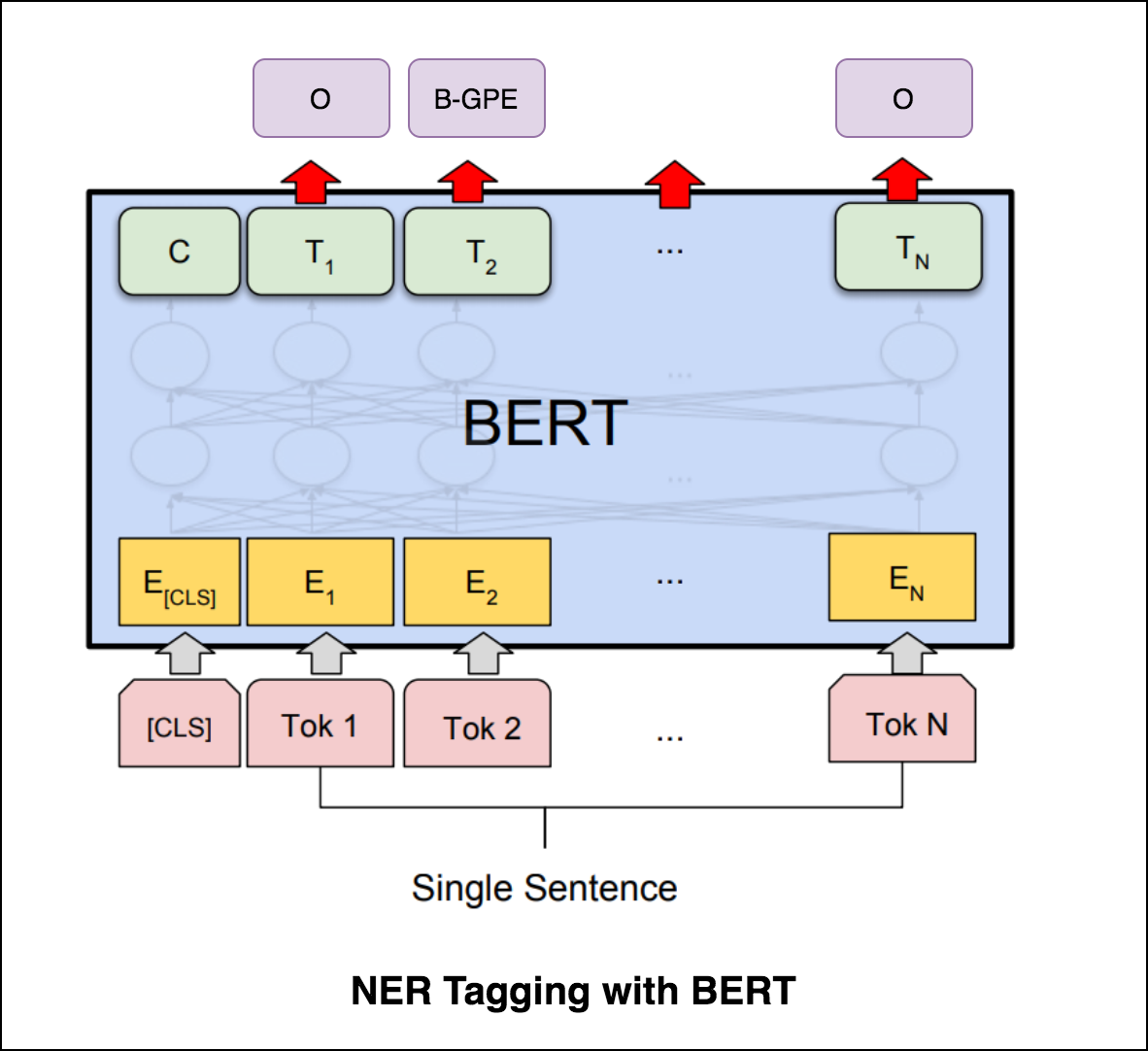
Depois de experimentar a marcação NER com o codificador do transformador, a etiqueta NER com o modelo pré-treinado bert-base-cased é explorada.
Somente o transformador não está dando bons resultados em comparação com o BILSTM na tarefa de etiqueta NER. Aumentando a camada CRF na parte superior do transformador é implementada, o que está melhorando os resultados em comparação com o transformador independente.
O Spacy fornece um sistema estatístico excepcionalmente eficiente para NER no Python, que pode atribuir rótulos a grupos de tokens. Ele fornece um modelo padrão que pode reconhecer uma ampla gama de entidades nomes ou numéricas, que incluem pessoa, organização, idioma, evento etc.

Além dessas entidades padrão, o Spacy também nos dá a liberdade de adicionar classes arbitrárias ao modelo NER, treinando o modelo para atualizá -lo com novos exemplos treinados.
2 Novas entidades chamadas ACTIVITY e SERVICE em um domínio específico (Banco) são criados e treinados com poucas amostras de treinamento.

| Geração de nome | Tradução da máquina | Geração de expressão |
| Legenda da imagem | Legenda de imagem - equações de látex | Resumo de notícias |
| Geração de assuntos por e -mail |
Um modelo de linguagem LSTM no nível do caractere é usado. Ou seja, daremos ao LSTM uma grande parte dos nomes e solicitaremos que ele modele a distribuição de probabilidade do próximo caractere na sequência, dada uma sequência de caracteres anteriores. Isso nos permitirá gerar um novo nome um personagem de cada vez

A tradução da máquina (MT) é a tarefa de converter automaticamente uma linguagem natural em outra, preservar o significado do texto de entrada e produzir texto fluente na linguagem de saída. Idealmente, uma sequência de linguagem de origem é traduzida na sequência de linguagem de destino. A tarefa é converter frases de German to English .
A seguir foram explorados variantes:
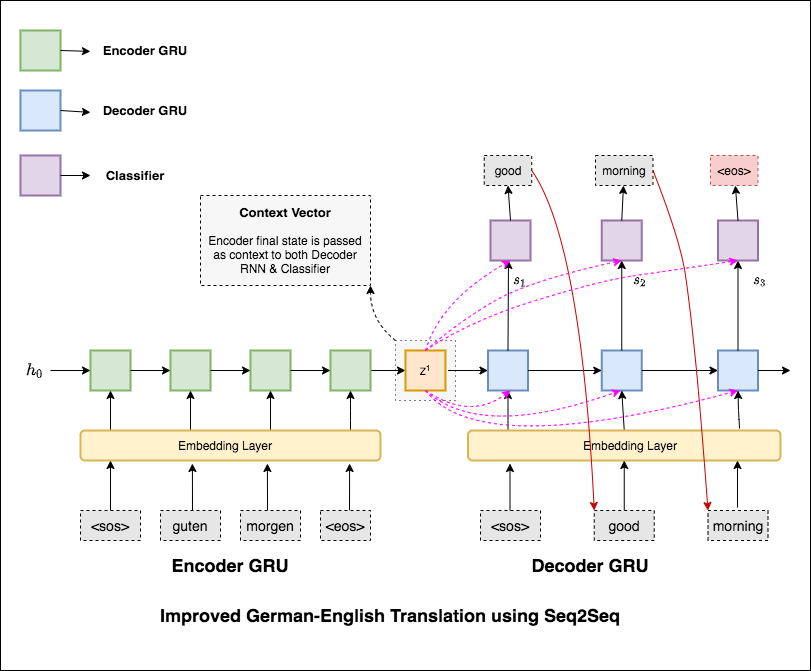
Os modelos de sequência a sequência mais comum (SEQ2SEQ) são os modelos de codificadores-decodificadores, que geralmente usam uma rede neural recorrente (RNN) para codificar a frase de origem (entrada) em um único vetor. Neste caderno, nos referiremos a este único vetor como um vetor de contexto. Podemos pensar no vetor de contexto como uma representação abstrata de toda a frase de entrada. Esse vetor é então decodificado por um segundo RNN que aprende a produzir a frase de destino (saída), gerando uma palavra por vez.

Depois de experimentar a tradução básica da máquina, com o texto perplexidade 36.68 , as seguintes técnicas foram experimentadas e uma perplexidade de teste 7.041 .
Confira o código na pasta applications/generation
O mecanismo de atenção nasceu para ajudar a memorizar frases de fonte longa na tradução da máquina neural (NMT). Em vez de construir um único vetor de contexto a partir do último estado oculto do codificador, a atenção é usada para se concentrar mais nas partes relevantes da entrada enquanto decodifica uma frase. O vetor de contexto será criado obtendo saídas do codificador e o previous hidden state do decodificador RNN.
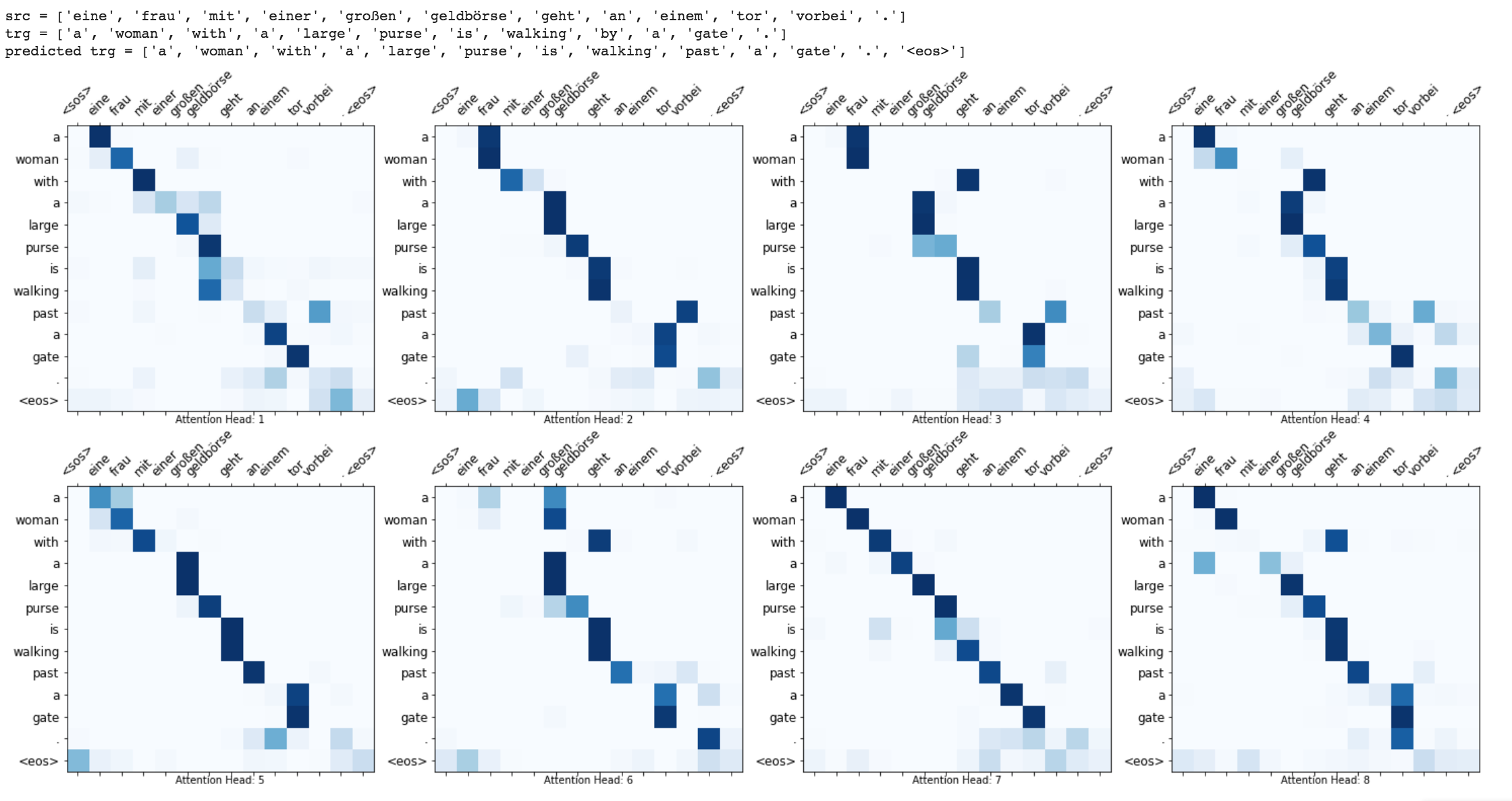
Enhancements like masking (ignoring the attention over padded input), packing padded sequences (for better computation), attention visualization and BLEU metric on test data are implemented.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
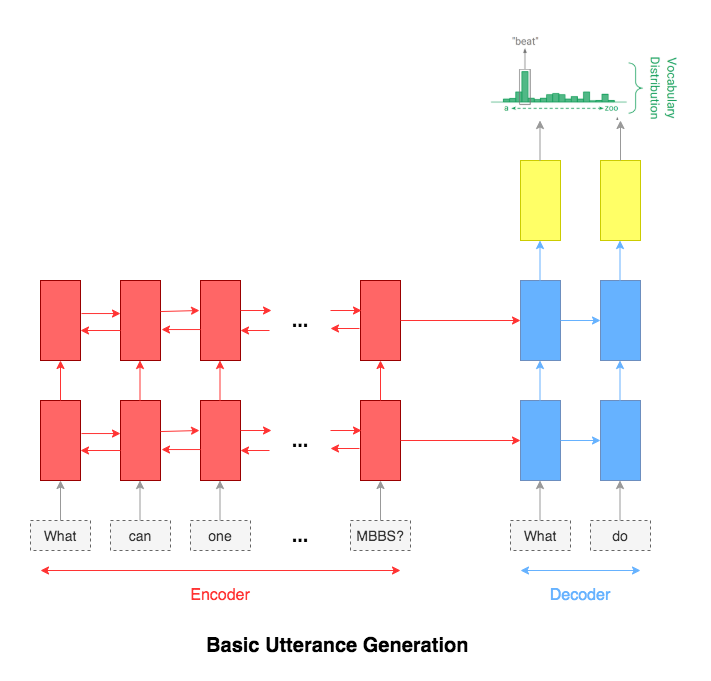
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
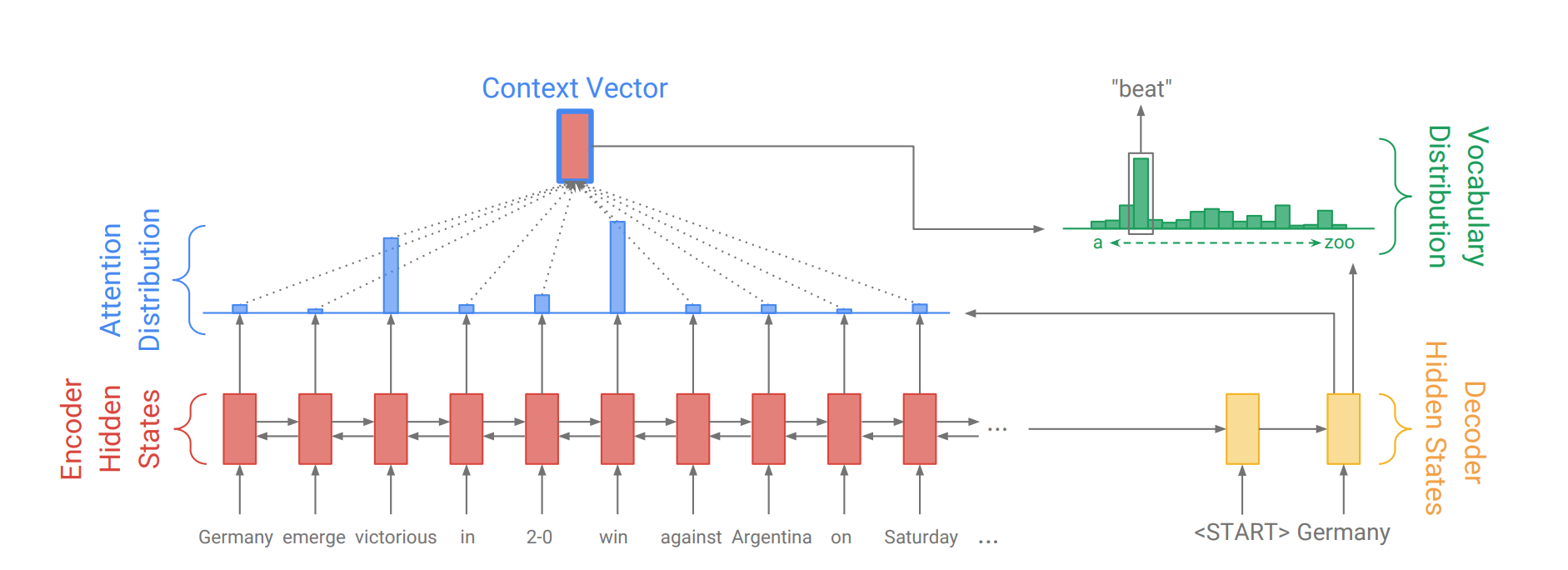
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
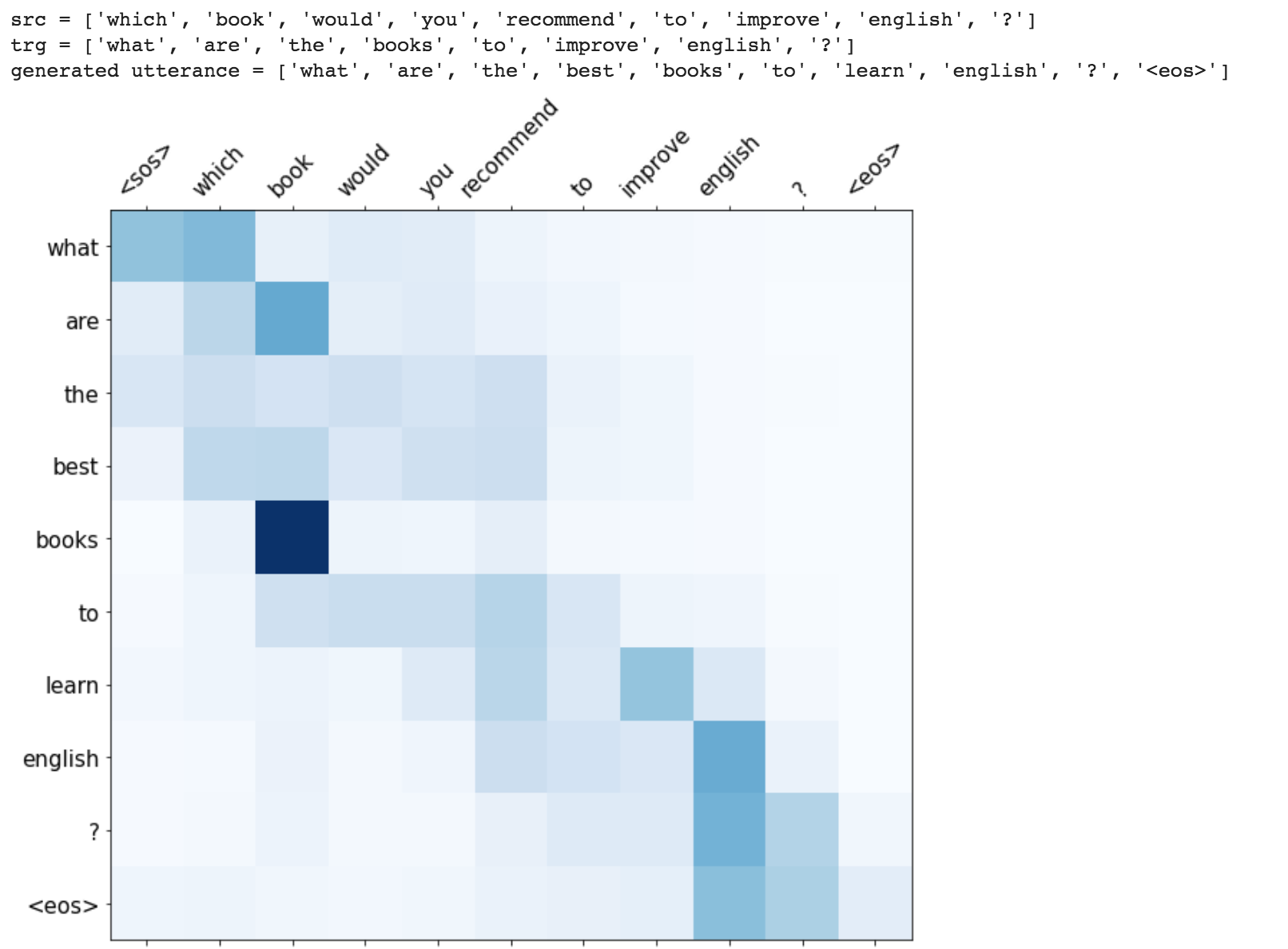
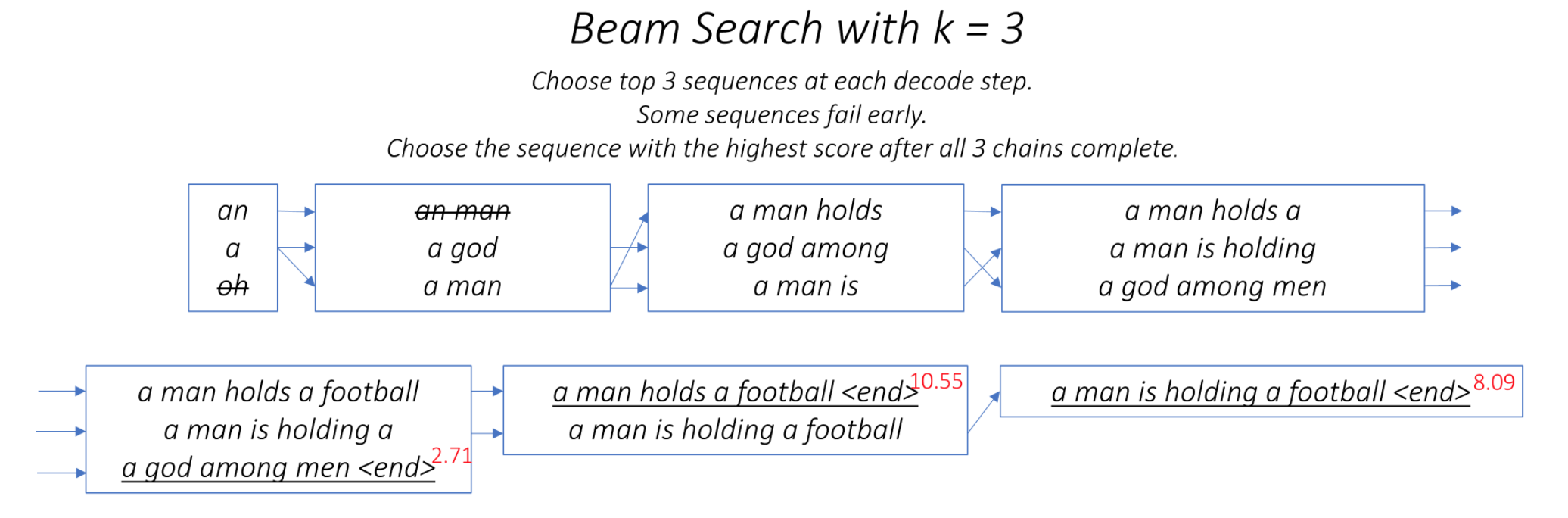
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

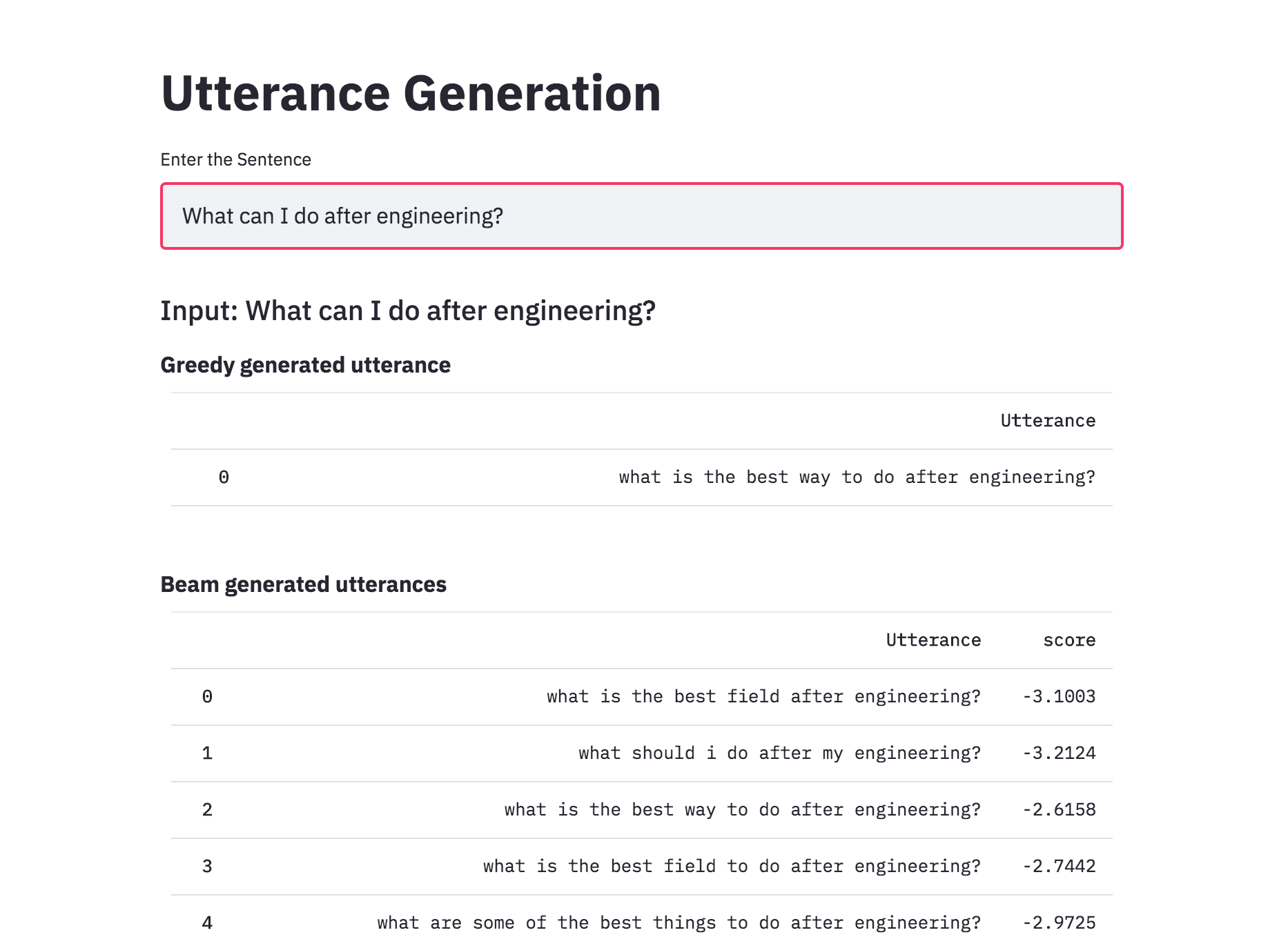
Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

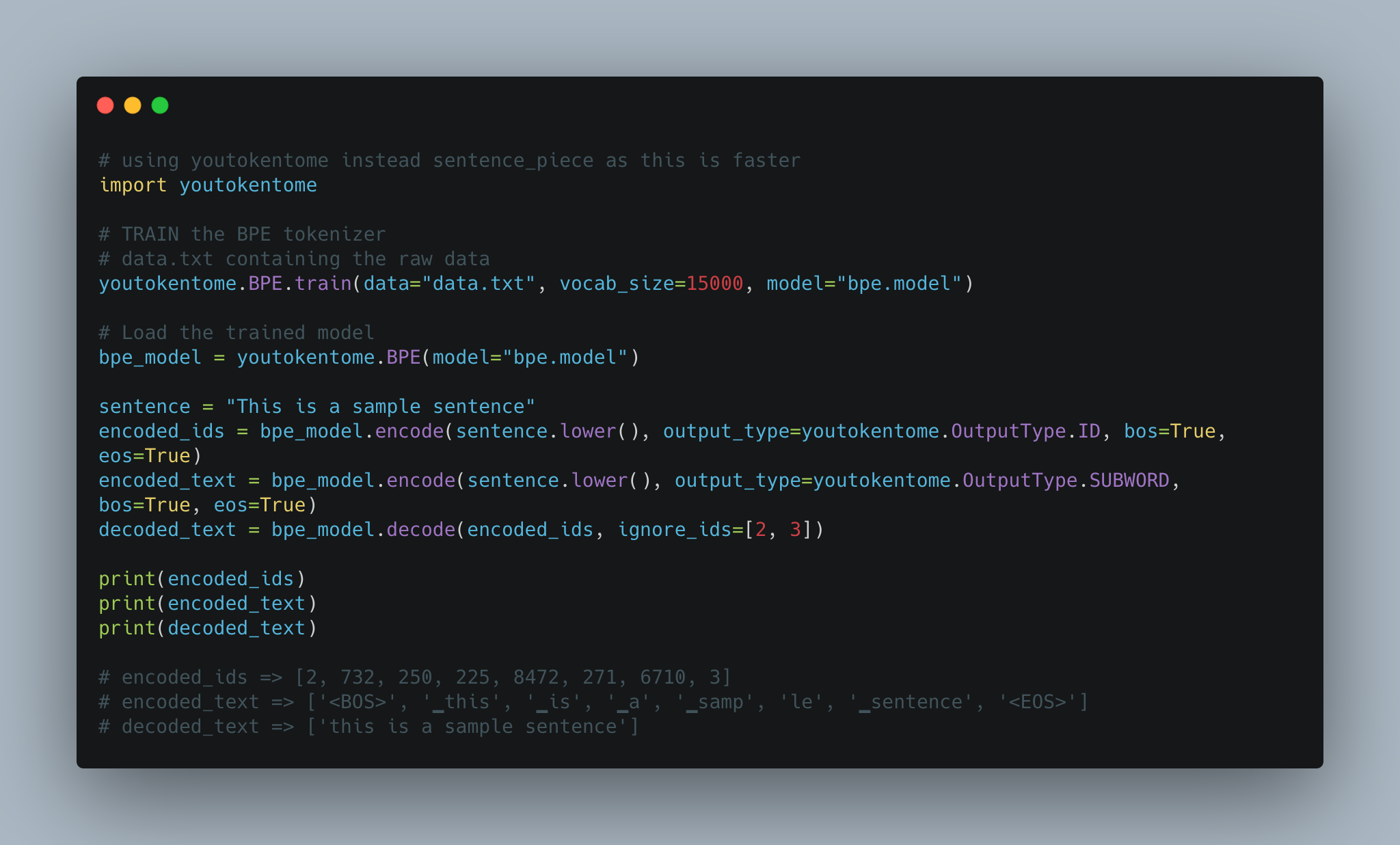
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
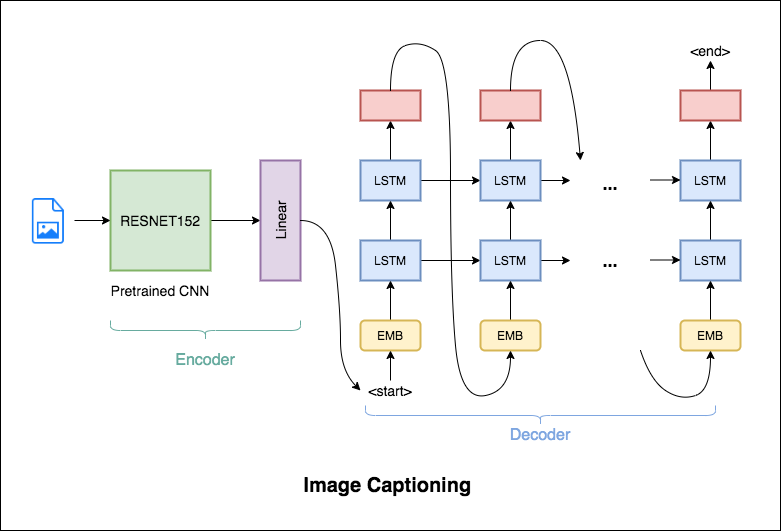
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
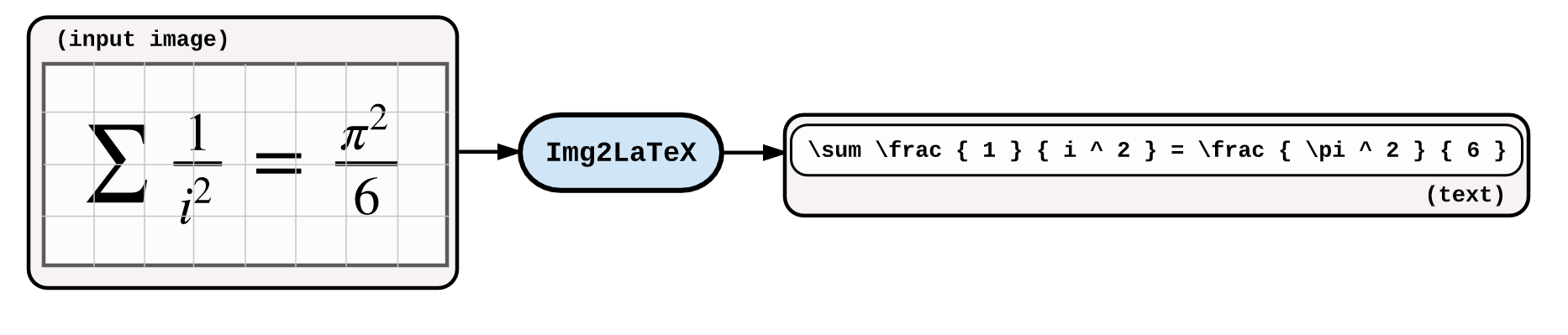
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
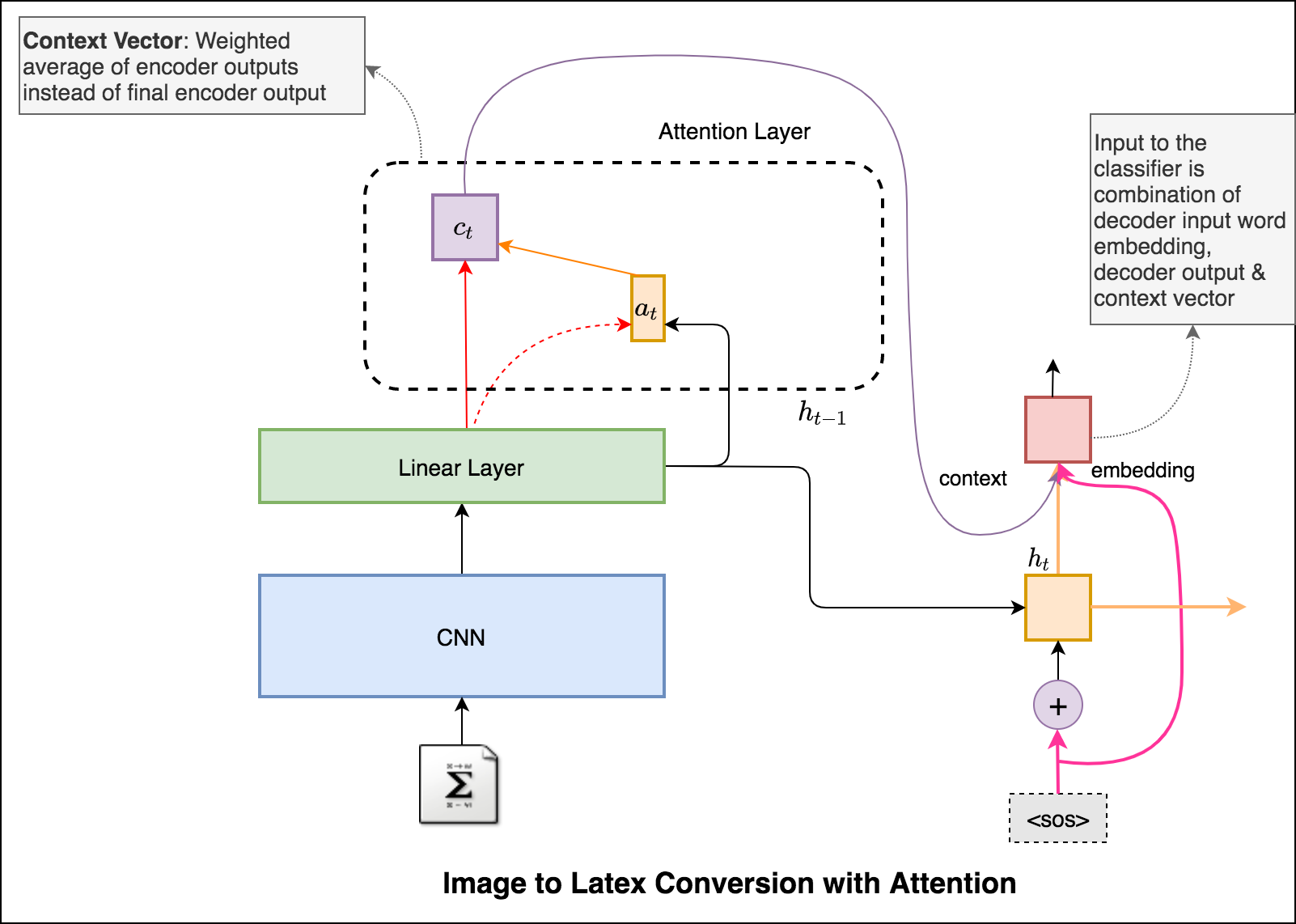
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

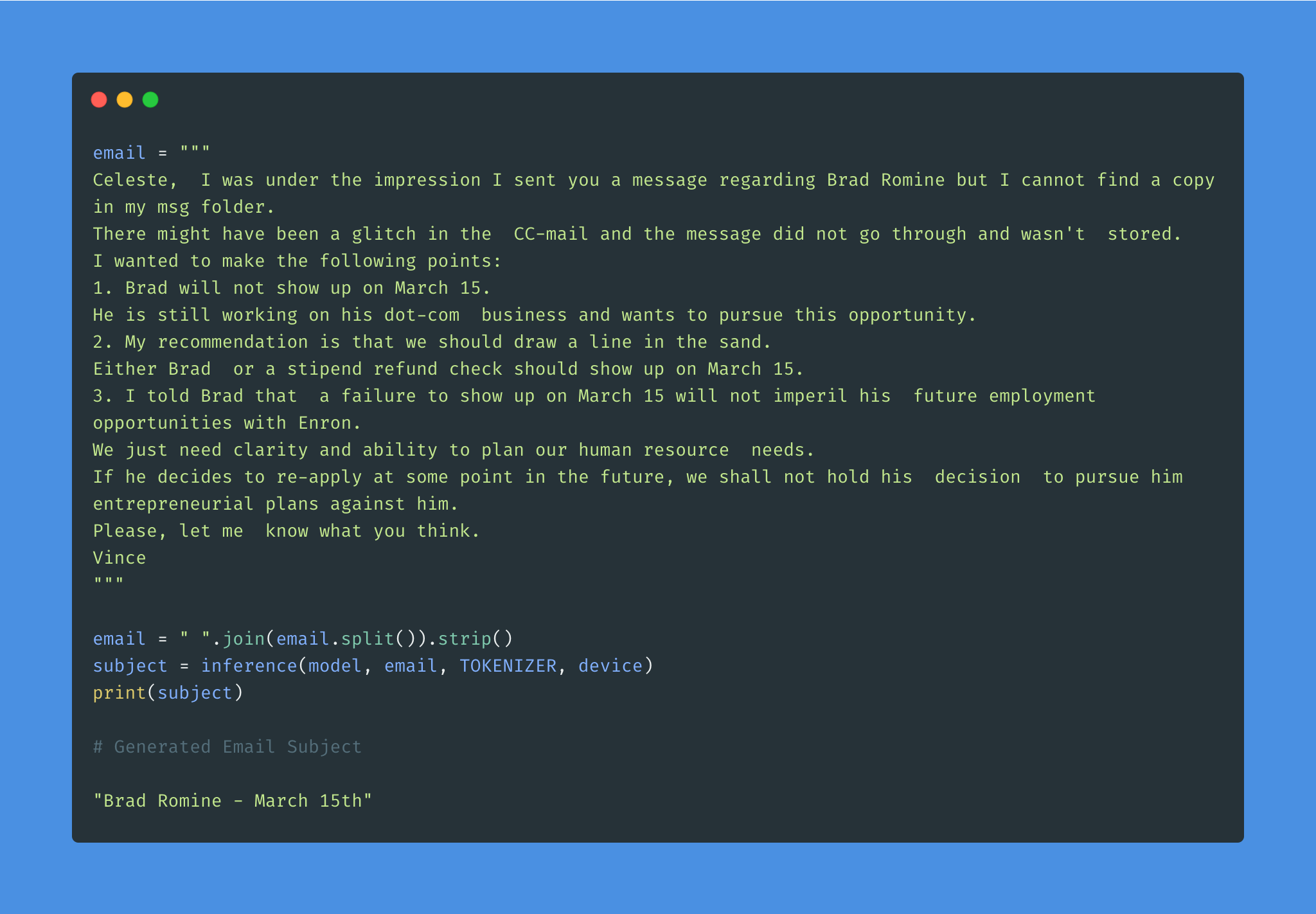
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
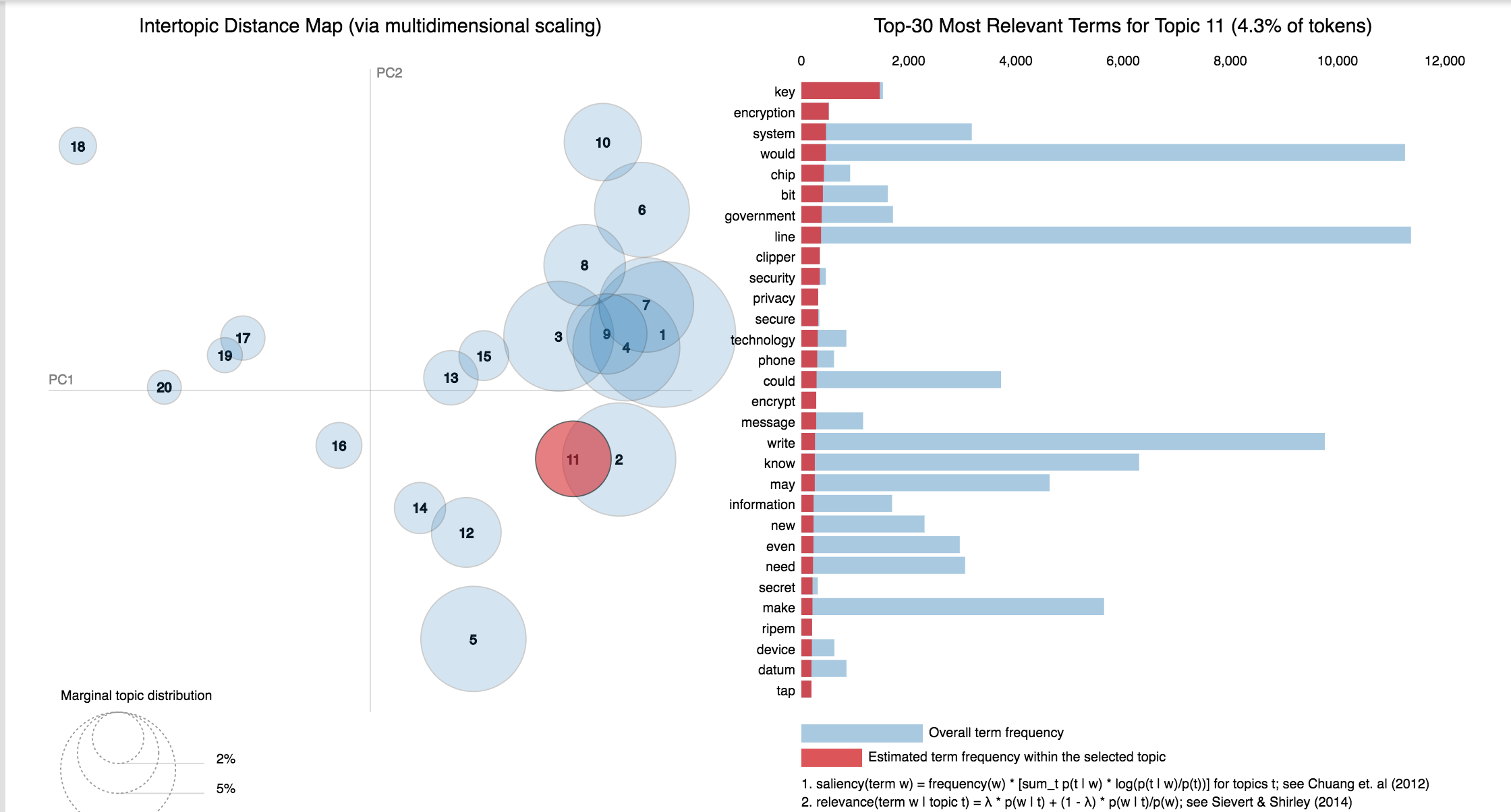
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
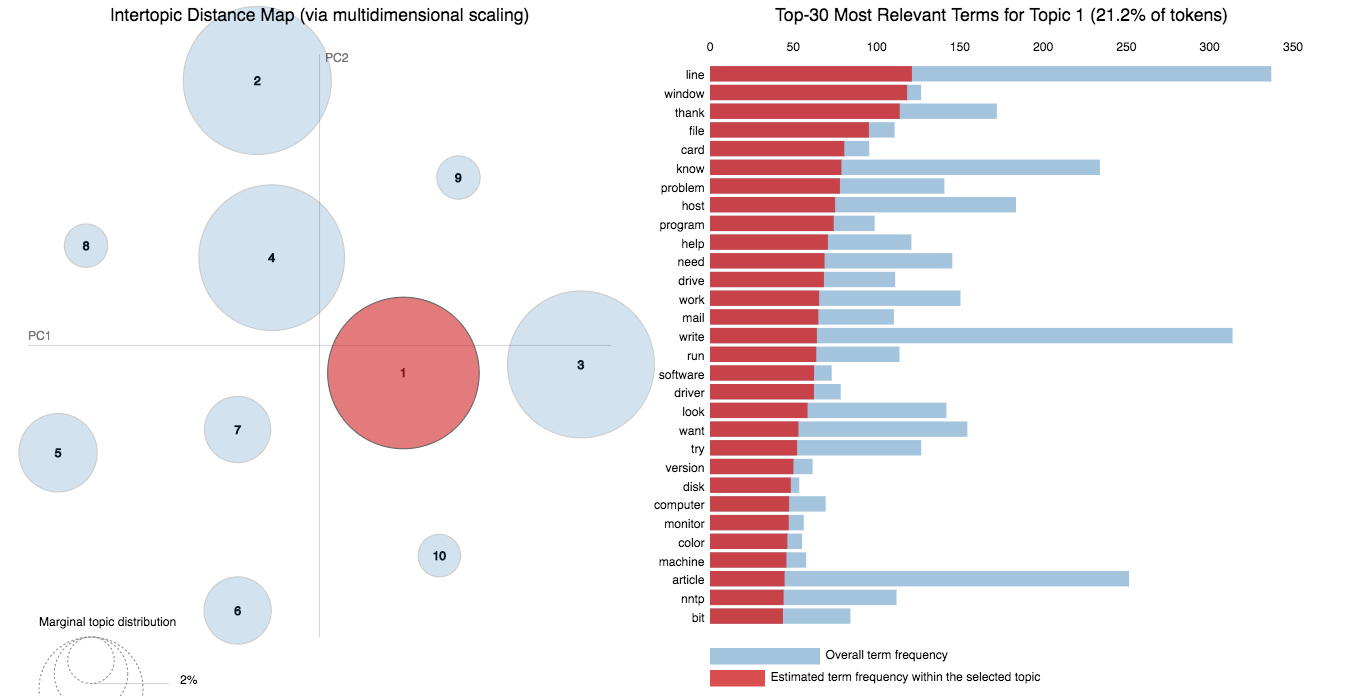
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
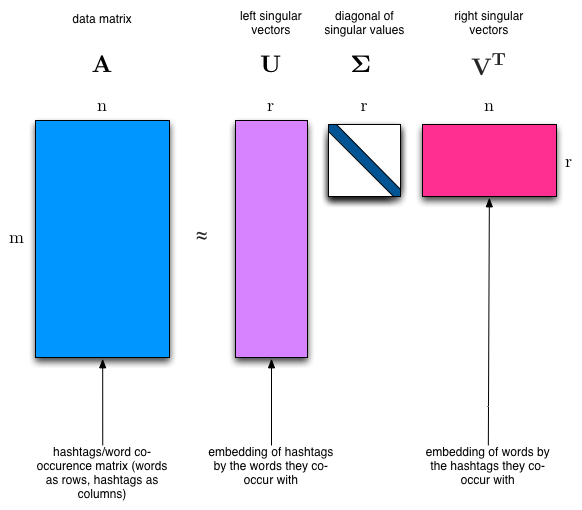
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
Notas:
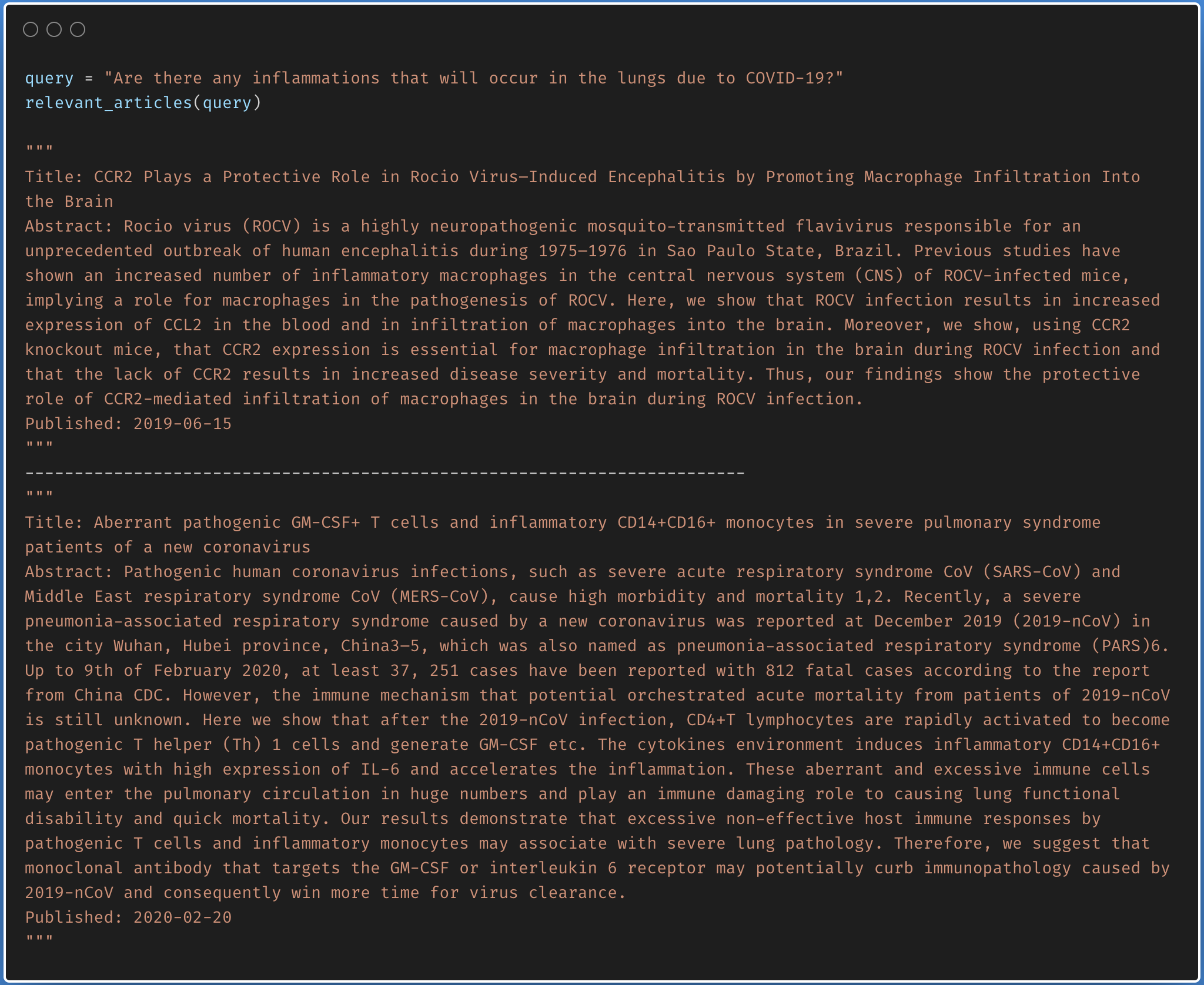
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
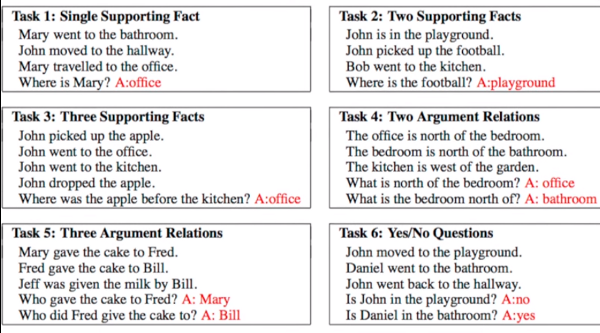
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
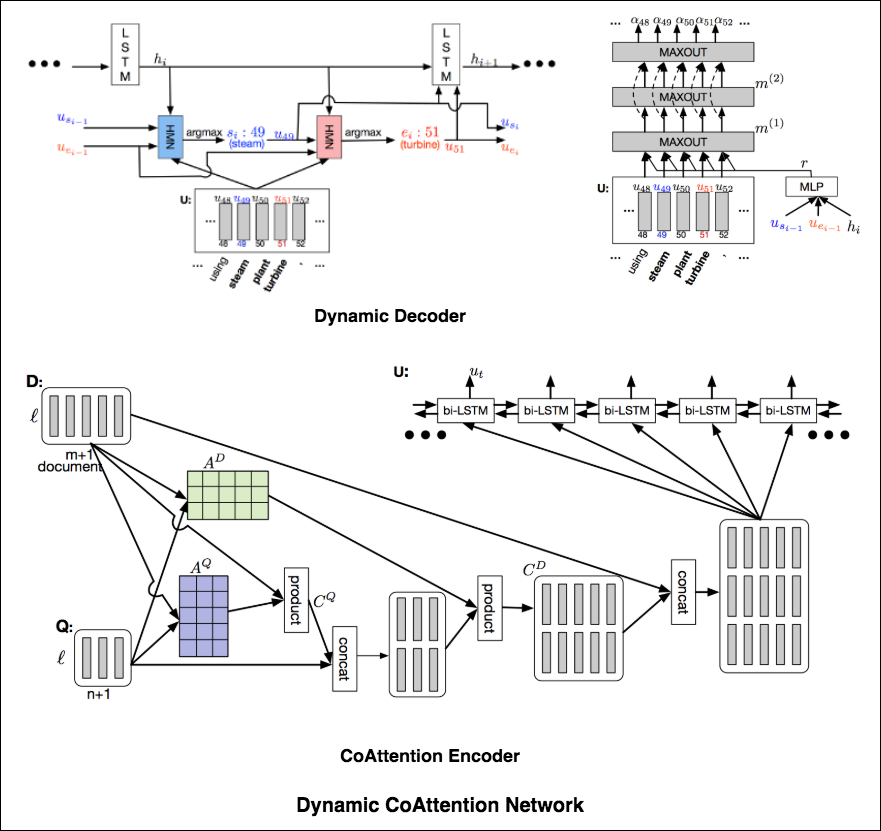
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
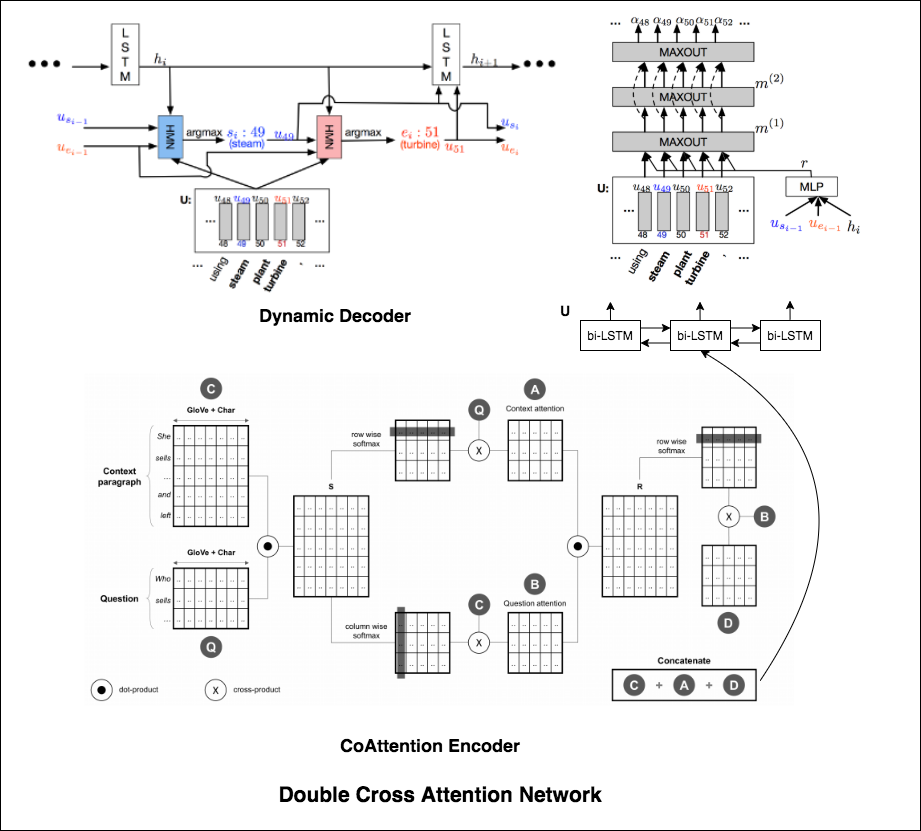
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
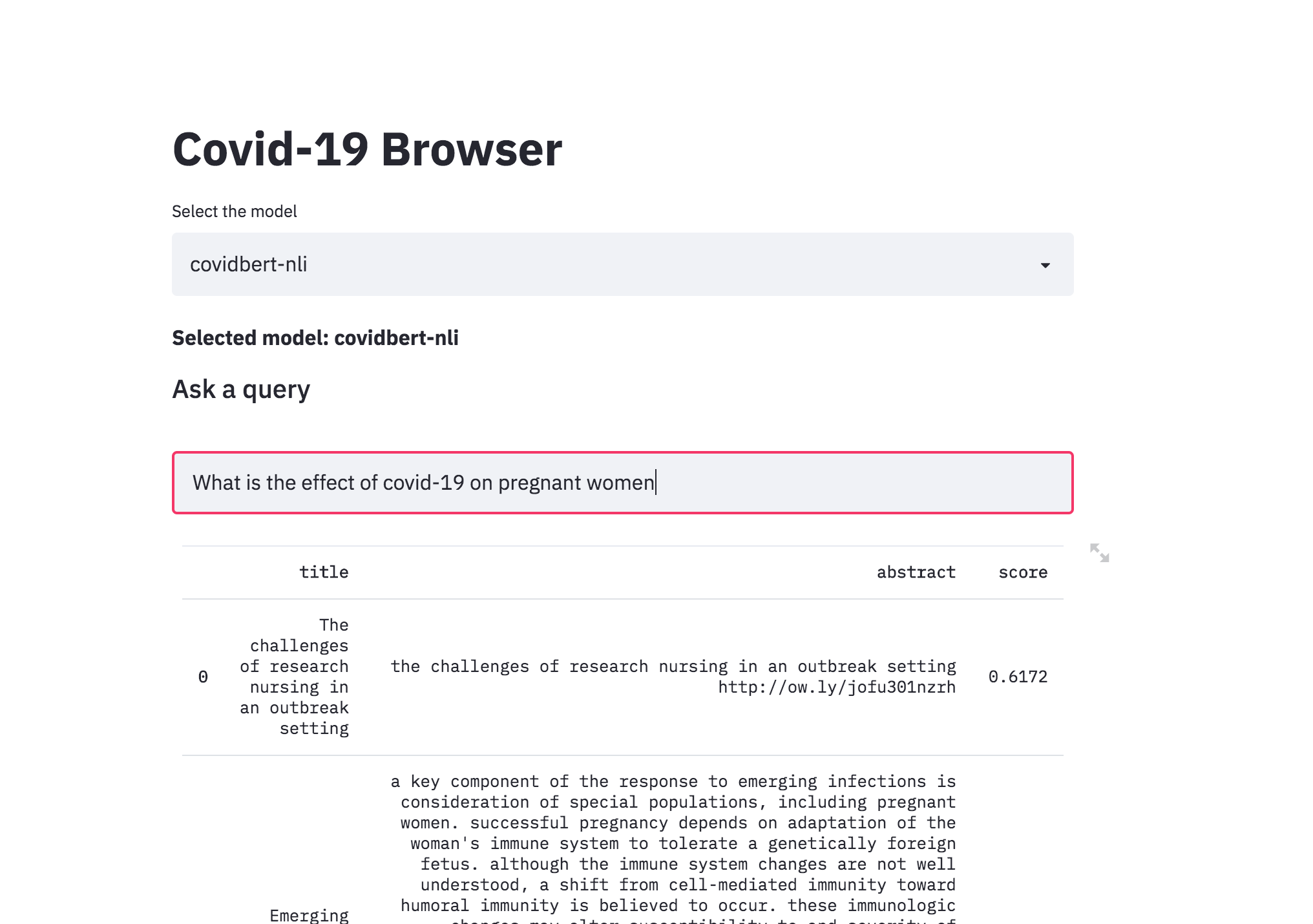
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
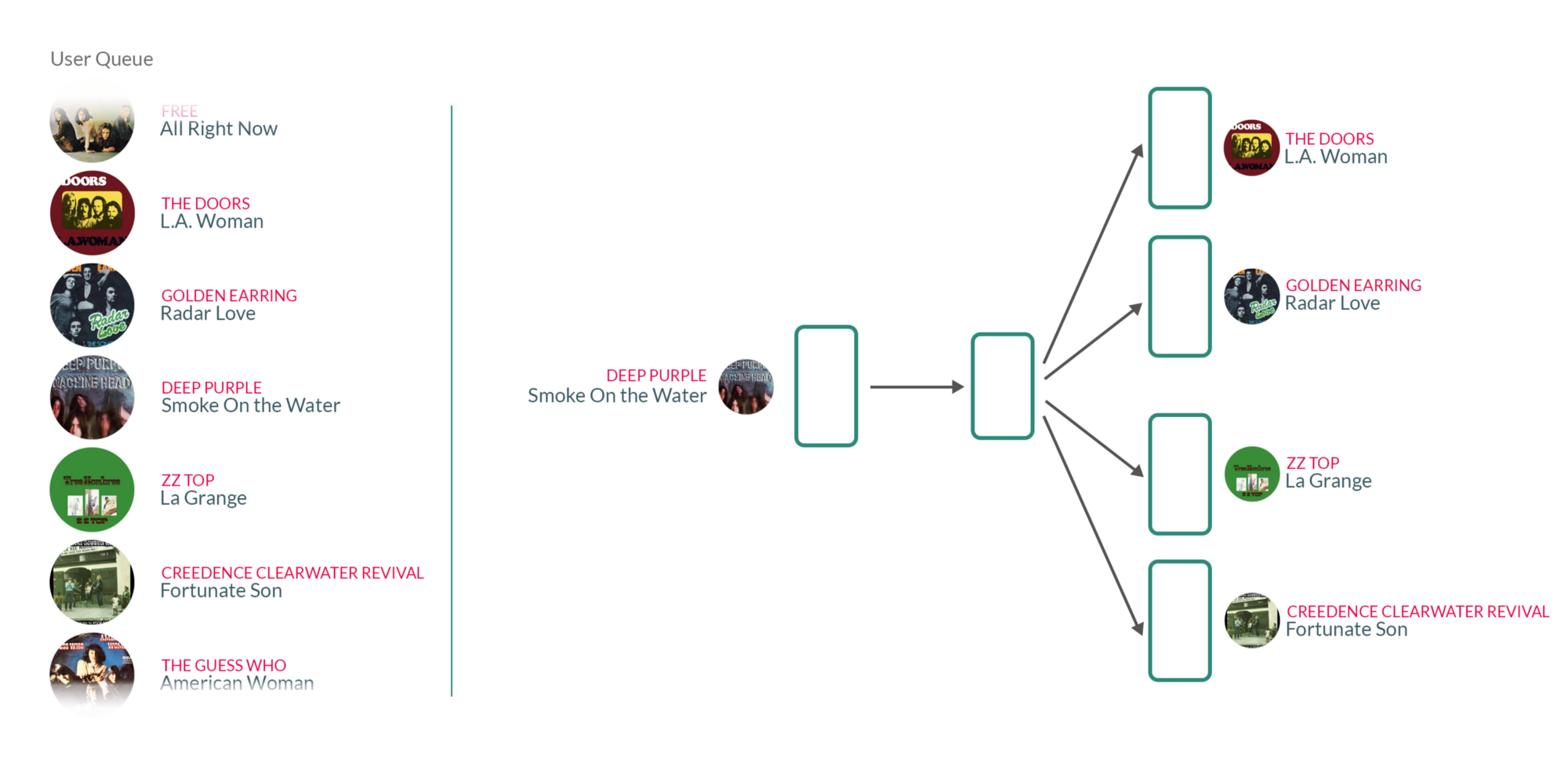
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


