100 Days of NLP
1.0.0

ไม่มีอะไรมหัศจรรย์เกี่ยวกับเวทมนตร์ นักมายากลเข้าใจสิ่งที่เรียบง่ายซึ่งดูเหมือนจะไม่ง่ายหรือเป็นธรรมชาติสำหรับผู้ชมที่ไม่ได้รับการฝึกฝน เมื่อคุณเรียนรู้วิธีถือการ์ดในขณะที่ทำให้มือของคุณดูว่างเปล่าคุณก็ต้องฝึกฝนก่อนที่คุณจะ“ ทำเวทมนตร์” ได้เช่นกัน - Jeffrey Friedl ในหนังสือเรียนรู้การแสดงออกปกติ
หมายเหตุ: โปรดยกประเด็นสำหรับคำแนะนำการแก้ไขและข้อเสนอแนะใด ๆ
ตัวอย่างรหัสส่วนใหญ่ทำโดยใช้สมุดบันทึก Jupyter (ใช้ colab) ดังนั้นแต่ละรหัสสามารถทำงานได้อย่างอิสระ
มีการสำรวจหัวข้อต่อไปนี้:
หมายเหตุ: ระดับความยากได้รับการกำหนดตามความเข้าใจของฉัน
| การทำให้โทเค็น | Word Embeddings - Word2Vec | Word Embeddings - ถุงมือ | Word Embeddings - Elmo |
| rnn, lstm, gru | บรรจุลำดับเบาะ | กลไกความสนใจ - Luong | กลไกความสนใจ - Bahdanau |
| เครือข่ายตัวชี้ | หม้อแปลงไฟฟ้า | GPT-2 | เบิร์ต |
| การสร้างแบบจำลองหัวข้อ - LDA | การวิเคราะห์องค์ประกอบหลัก (PCA) | เบย์ไร้เดียงสา | การเพิ่มข้อมูล |
| ประโยคฝังตัว |
กระบวนการแปลงข้อมูลข้อความเป็นโทเค็นเป็นหนึ่งในขั้นตอนที่สำคัญที่สุดใน NLP โทเค็นโดยใช้วิธีการต่อไปนี้ได้รับการสำรวจ:
การฝังคำเป็นตัวแทนที่เรียนรู้สำหรับข้อความที่คำที่มีความหมายเหมือนกันมีการแสดงที่คล้ายกัน มันเป็นวิธีการนี้ในการเป็นตัวแทนของคำและเอกสารที่อาจได้รับการพิจารณาว่าเป็นหนึ่งในความก้าวหน้าที่สำคัญของการเรียนรู้อย่างลึกซึ้งเกี่ยวกับปัญหาการประมวลผลภาษาธรรมชาติที่ท้าทาย

Word2vec เป็นหนึ่งในคำที่ได้รับความนิยมมากที่สุดในการฝังตัวที่พัฒนาโดย Google ขึ้นอยู่กับวิธีการเรียนรู้การฝังตัว Word2vec แบ่งออกเป็นสองวิธี:
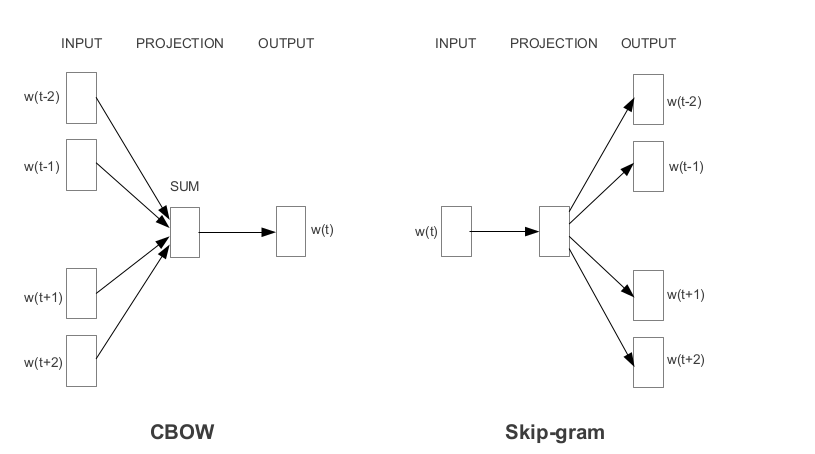
ถุงมือเป็นอีกวิธีหนึ่งที่ใช้กันทั่วไปในการได้รับการฝังตัวที่ผ่านการฝึกอบรมมาก่อน ถุงมือมีจุดมุ่งหมายเพื่อให้บรรลุเป้าหมายสองประการ:
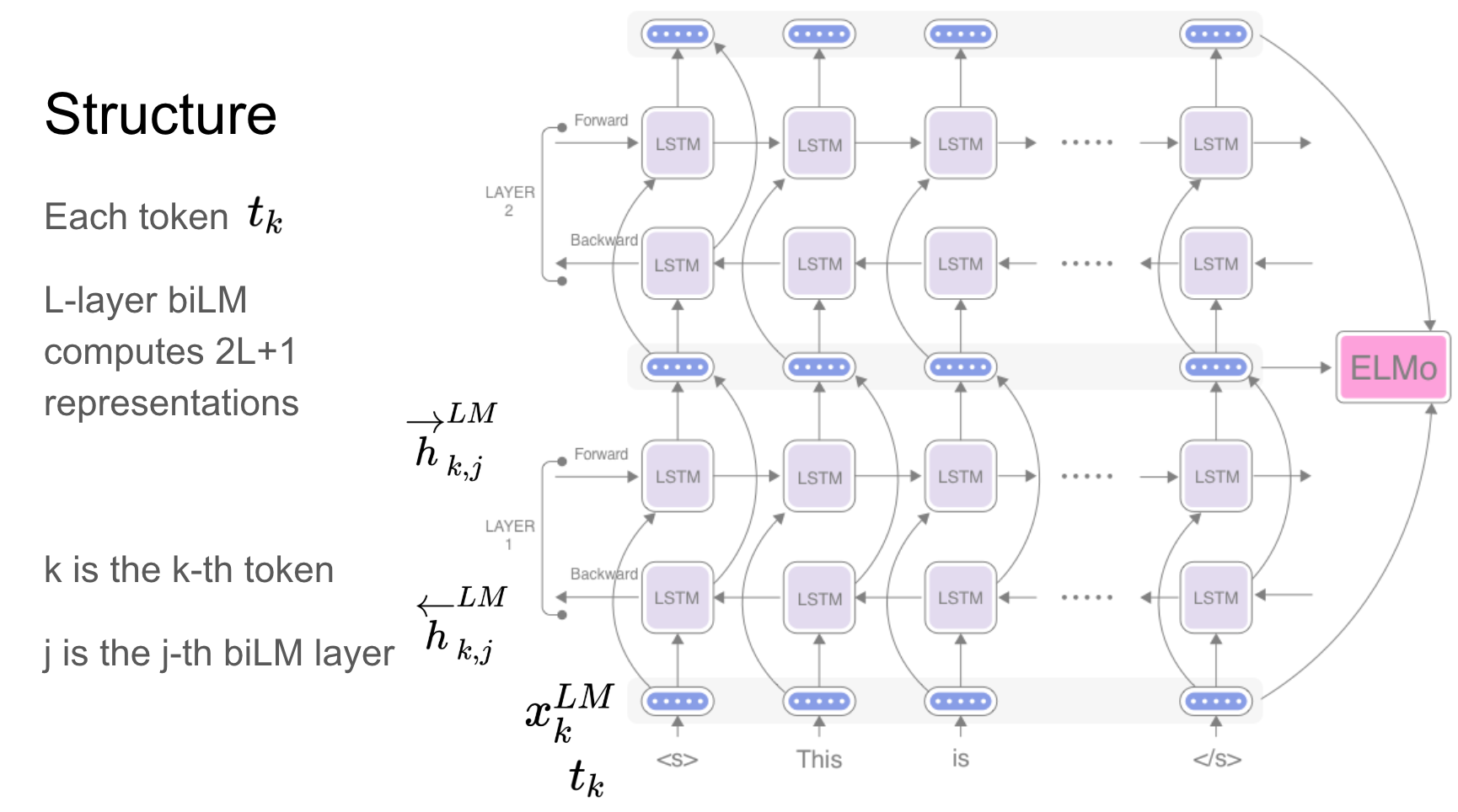
Elmo เป็นการแสดงคำบริบทที่ลึกล้ำซึ่งเป็นแบบจำลอง:
เวกเตอร์คำเหล่านี้เรียนรู้ฟังก์ชั่นของสถานะภายในของแบบจำลองภาษาสองทิศทางลึก (BILM) ซึ่งได้รับการฝึกอบรมล่วงหน้าบนคลังข้อความขนาดใหญ่
เครือข่ายกำเริบ - RNN, LSTM, GRU ได้พิสูจน์แล้วว่าเป็นหนึ่งในหน่วยที่สำคัญที่สุดในแอปพลิเคชัน NLP เนื่องจากสถาปัตยกรรมของพวกเขา มีปัญหามากมายที่ต้องจดจำธรรมชาติของลำดับเช่นเพื่อทำนายอารมณ์ในฉากฉากก่อนหน้านี้จะต้องจดจำ

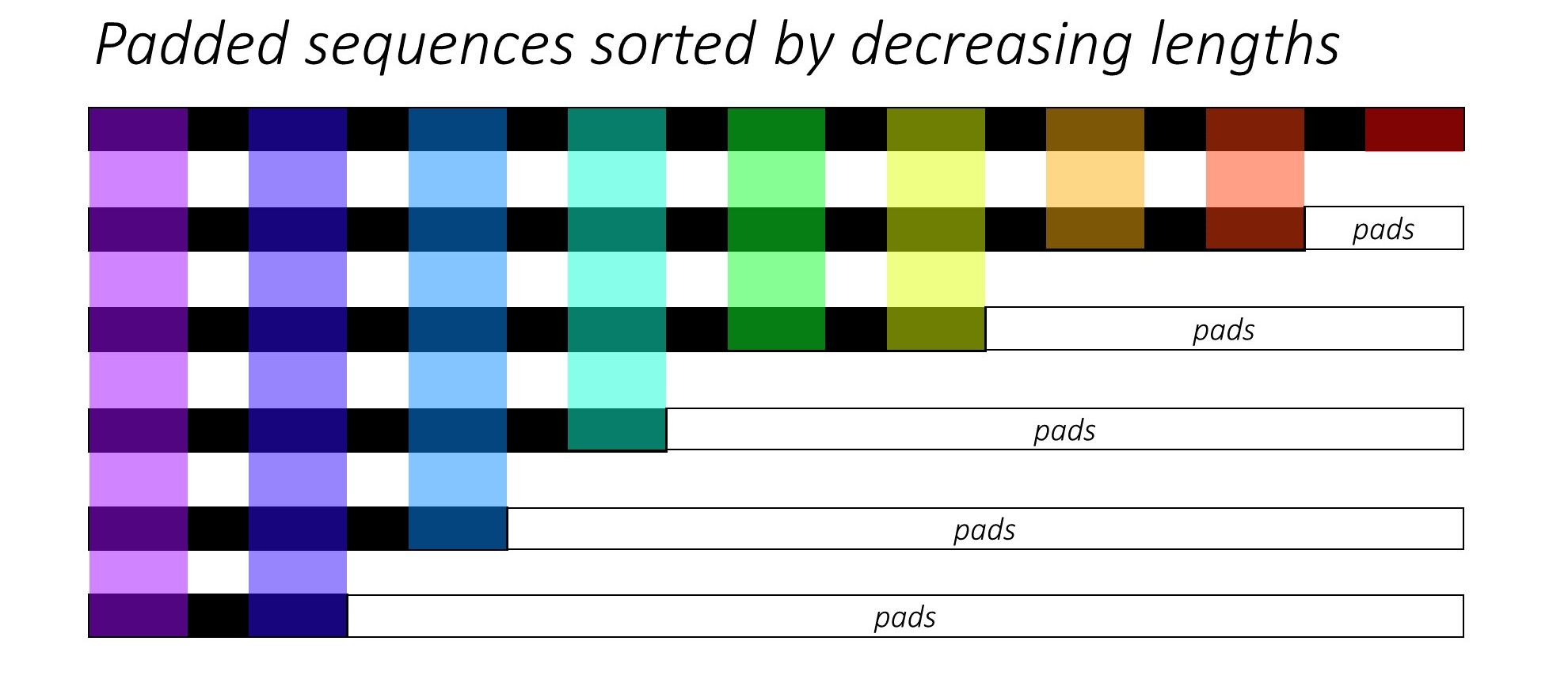
เมื่อการฝึกอบรม RNN (LSTM หรือ GRU หรือ Vanilla-RNN) มันเป็นเรื่องยากที่จะสร้างชุดลำดับความยาวตัวแปร เป็นการดีที่เราจะเพิ่มลำดับทั้งหมดให้มีความยาวคงที่และจบลงด้วยการคำนวณที่ไม่จำเป็น เราจะเอาชนะสิ่งนี้ได้อย่างไร? Pytorch จัดเตรียมฟังก์ชั่น pack_padded_sequences
กลไกความสนใจเกิดขึ้นเพื่อช่วยจดจำประโยคแหล่งที่มายาวในการแปลเครื่องประสาท (NMT) แทนที่จะสร้างเวกเตอร์บริบทเดียวจากสถานะที่ซ่อนอยู่สุดท้ายของเข้ารหัสความสนใจจะถูกใช้เพื่อมุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของอินพุตในขณะที่ถอดรหัสประโยค เวกเตอร์บริบทจะถูกสร้างขึ้นโดยใช้เอาต์พุตตัวเข้ารหัสและ current output ของตัวถอดรหัส RNN

คะแนนความสนใจสามารถคำนวณได้สามวิธี dot , general และ concat
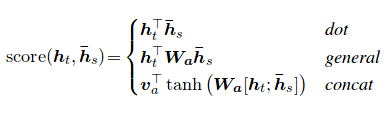
ความแตกต่างที่สำคัญระหว่างความสนใจของ Bahdanau และ Luong คือวิธีที่เวกเตอร์บริบทถูกสร้างขึ้น เวกเตอร์บริบทจะถูกสร้างขึ้นโดยใช้เอาต์พุตตัวเข้ารหัสและ previous hidden state ของตัวถอดรหัส RNN ที่อยู่ในความสนใจของ Luong เวกเตอร์บริบทจะถูกสร้างขึ้นโดยการใช้เอาท์พุทตัวเข้ารหัสและ current hidden state ของตัวถอดรหัส RNN
เมื่อบริบทถูกคำนวณจะรวมกับการฝังอินพุตตัวถอดรหัสและป้อนเป็นอินพุตไปยังตัวถอดรหัส RNN

ความสนใจของ Bahdanau เรียกอีกอย่างว่าเป็นความสนใจ additive
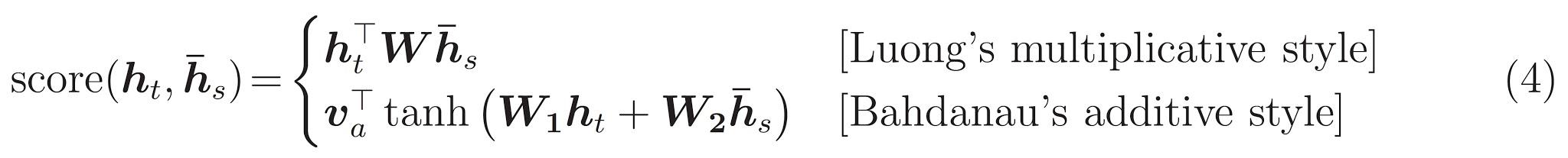
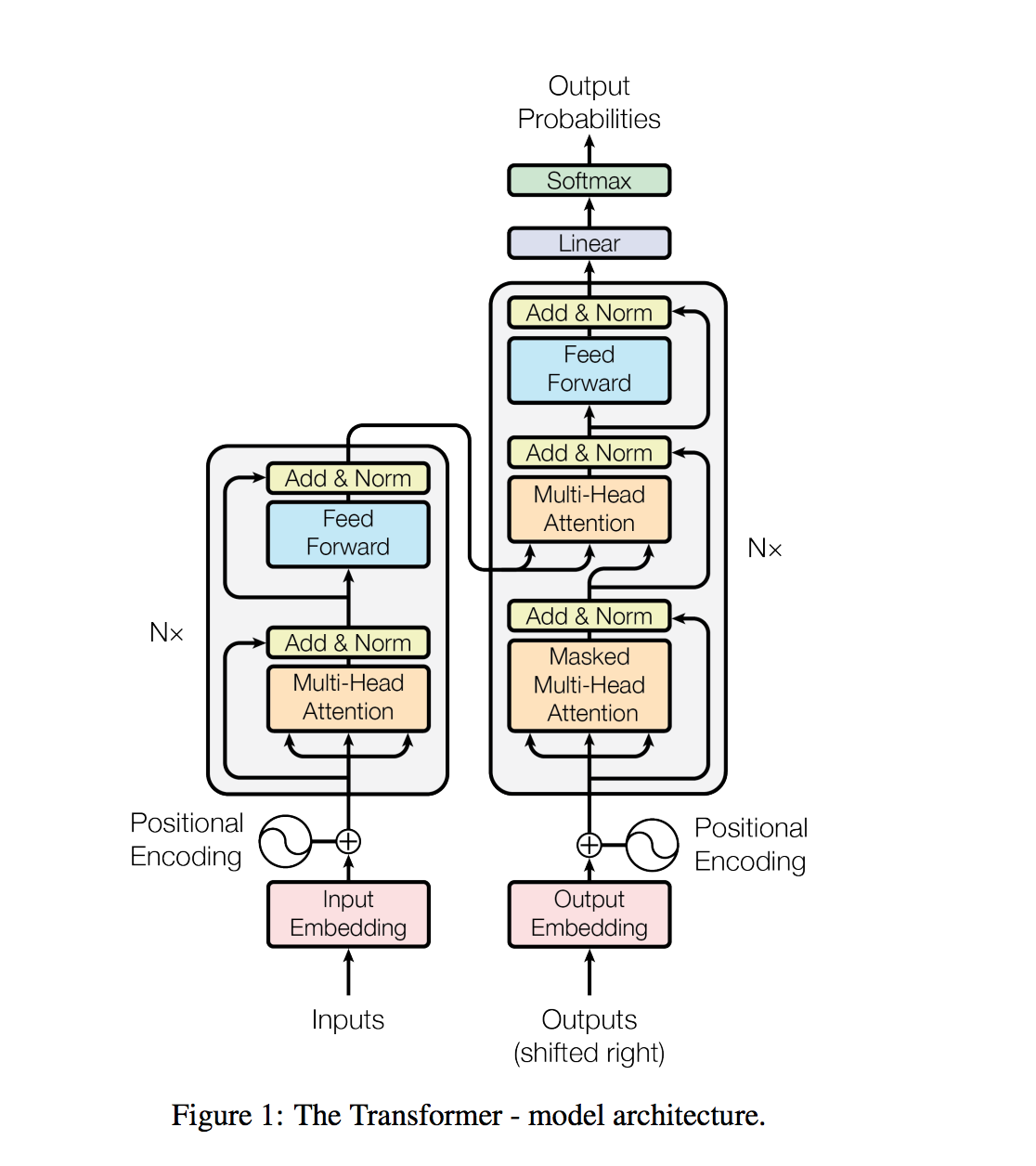
หม้อแปลงสถาปัตยกรรมแบบจำลองละทิ้งการเกิดซ้ำและแทนที่จะพึ่งพากลไกความสนใจทั้งหมดเพื่อดึงการพึ่งพาทั่วโลกระหว่างอินพุตและเอาต์พุต
งานการประมวลผลภาษาธรรมชาติเช่นการตอบคำถามการแปลเครื่องการอ่านความเข้าใจและการสรุปมักจะเข้าหาด้วยการเรียนรู้ภายใต้การดูแลของชุดข้อมูลเฉพาะงาน เราแสดงให้เห็นว่าแบบจำลองภาษาเริ่มเรียนรู้งานเหล่านี้โดยไม่มีการกำกับดูแลที่ชัดเจนเมื่อได้รับการฝึกฝนในชุดข้อมูลใหม่ของหน้าเว็บหลายล้านหน้าเว็บที่เรียกว่า WebText โมเดลที่ใหญ่ที่สุดของเราคือ GPT-2 เป็นหม้อแปลงพารามิเตอร์ 1.5B ที่ได้รับผลลัพธ์ที่ทันสมัยในชุดข้อมูลการสร้างแบบจำลองภาษาที่ผ่านการทดสอบ 7 ใน 8 ชุดในการตั้งค่าแบบไม่มีการยิง แต่ยังคงอยู่ใต้เว็บข้อความ ตัวอย่างจากแบบจำลองสะท้อนการปรับปรุงเหล่านี้และมีย่อหน้าที่สอดคล้องกันของข้อความ การค้นพบนี้แนะนำเส้นทางที่มีแนวโน้มในการสร้างระบบการประมวลผลภาษาที่เรียนรู้ที่จะปฏิบัติงานจากการสาธิตที่เกิดขึ้นตามธรรมชาติ
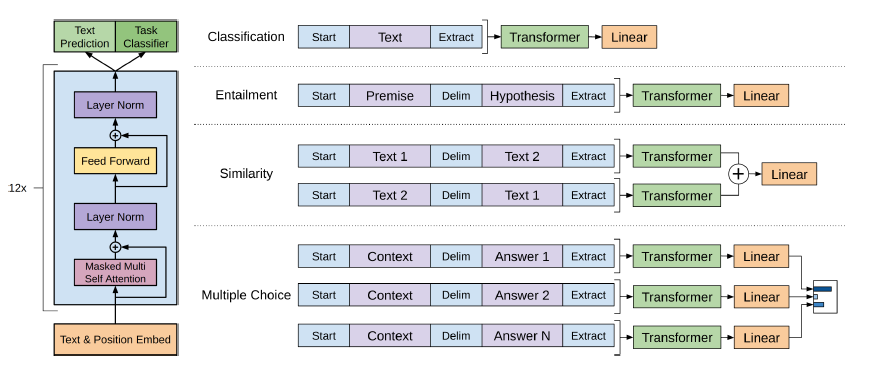
GPT-2 ใช้ตัวถอดรหัส 12 ชั้นเท่านั้นสถาปัตยกรรมหม้อแปลง
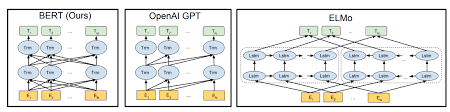
เบิร์ตใช้สถาปัตยกรรมหม้อแปลงสำหรับการเข้ารหัสประโยค
เอาต์พุตของเครือข่ายตัวชี้ไม่ต่อเนื่องและสอดคล้องกับตำแหน่งในลำดับอินพุต
จำนวนคลาสเป้าหมายในแต่ละขั้นตอนของเอาต์พุตขึ้นอยู่กับความยาวของอินพุตซึ่งเป็นตัวแปร
มันแตกต่างจากความสนใจก่อนหน้านี้ในสิ่งนั้นแทนที่จะใช้ความสนใจในการผสมผสานหน่วยที่ซ่อนอยู่ของตัวเข้ารหัสเข้ากับเวกเตอร์บริบทในแต่ละขั้นตอนถอดรหัสมันใช้ความสนใจเป็นตัวชี้เพื่อเลือกสมาชิกของลำดับอินพุตเป็นเอาต์พุต

หนึ่งในแอปพลิเคชั่นหลักของการประมวลผลภาษาธรรมชาติคือการแยกหัวข้อที่ผู้คนพูดถึงโดยอัตโนมัติจากข้อความจำนวนมาก ตัวอย่างของข้อความขนาดใหญ่อาจเป็นฟีดจากโซเชียลมีเดียความคิดเห็นของลูกค้าเกี่ยวกับโรงแรมภาพยนตร์ ฯลฯ คำติชมของผู้ใช้เรื่องราวข่าวอีเมลของการร้องเรียนของลูกค้า ฯลฯ
การรู้ว่าสิ่งที่ผู้คนกำลังพูดถึงและทำความเข้าใจปัญหาและความคิดเห็นของพวกเขานั้นมีค่าสูงสำหรับธุรกิจผู้ดูแลระบบแคมเปญทางการเมือง และมันยากมากที่จะอ่านด้วยตนเองผ่านปริมาณมากเช่นนี้และรวบรวมหัวข้อ
ดังนั้นจึงจำเป็นต้องมีอัลกอริทึมอัตโนมัติที่สามารถอ่านผ่านเอกสารข้อความและส่งออกหัวข้อที่กล่าวถึงโดยอัตโนมัติ
ในสมุดบันทึกนี้เราจะเป็นตัวอย่างที่แท้จริงของชุดข้อมูล 20 Newsgroups และใช้ LDA เพื่อแยกหัวข้อที่กล่าวถึงตามธรรมชาติ
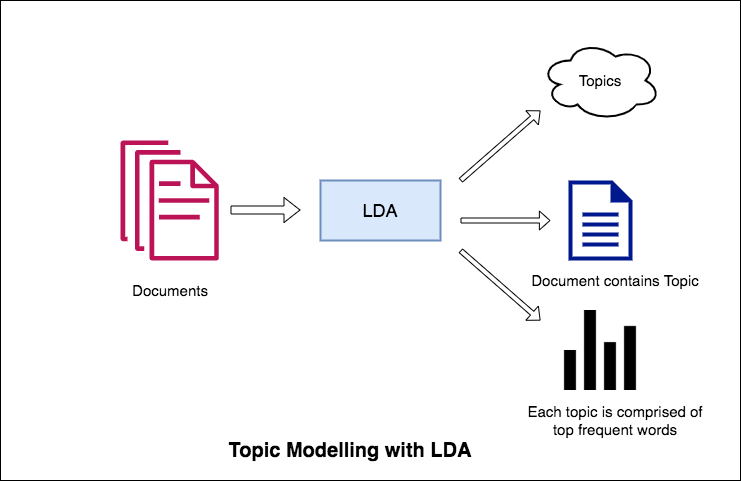
วิธีการของ LDA ในการสร้างแบบจำลองหัวข้อคือการพิจารณาแต่ละเอกสารเป็นชุดของหัวข้อในสัดส่วนที่แน่นอน และแต่ละหัวข้อเป็นคอลเลกชันของคำหลักอีกครั้งในสัดส่วนที่แน่นอน
เมื่อคุณให้จำนวนอัลกอริทึมที่มีจำนวนหัวข้อแล้วทั้งหมดจะทำเพื่อจัดเรียงการกระจายหัวข้อใหม่ภายในเอกสารและการแจกแจงคำหลักภายในหัวข้อเพื่อให้ได้องค์ประกอบที่ดีของการแจกแจงหัวข้อคำพูด
PCA เป็นเทคนิคการลดขนาดโดยพื้นฐานที่แปลงคอลัมน์ของชุดข้อมูลให้เป็นคุณสมบัติชุดใหม่ มันทำได้โดยการค้นหาชุดทิศทางใหม่ (เช่นแกน x และ y) ที่อธิบายความแปรปรวนสูงสุดในข้อมูล แกนประสานงานระบบใหม่นี้เรียกว่าส่วนประกอบหลัก (พีซี)
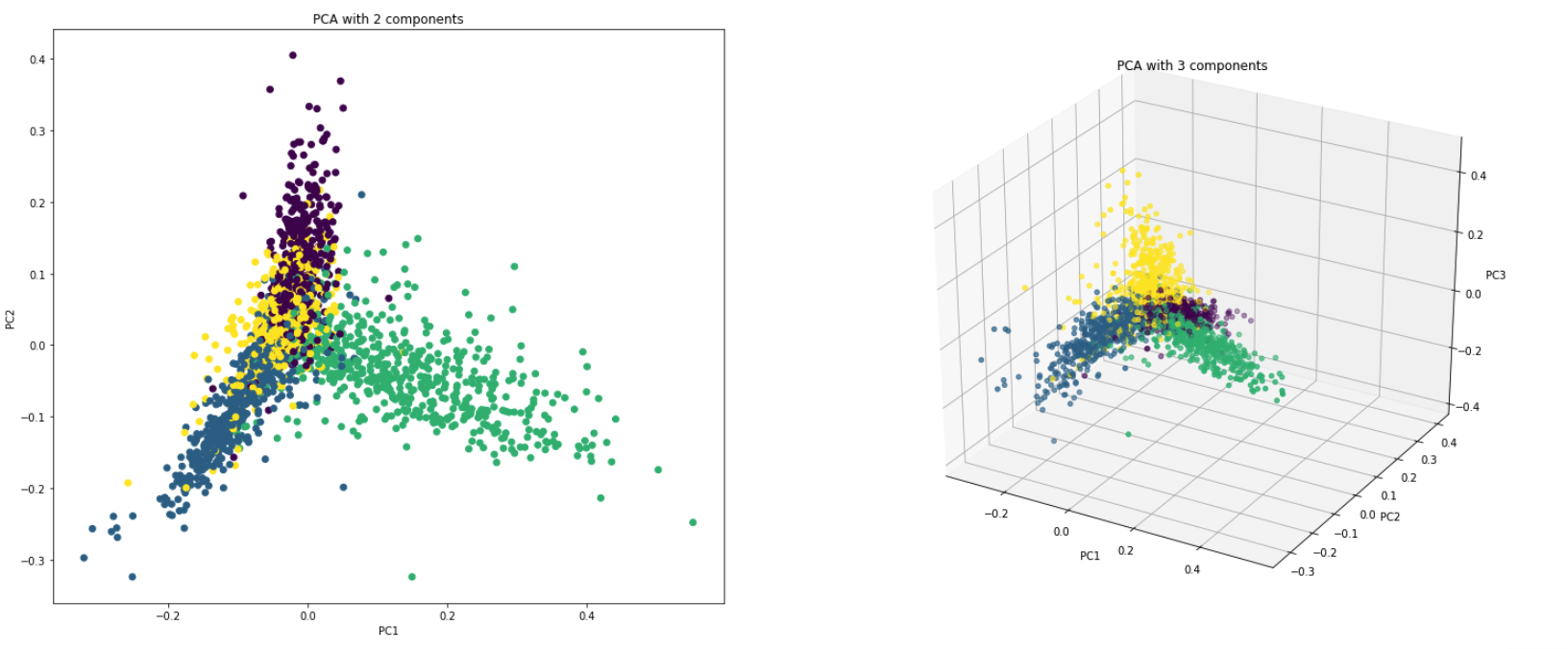
PCA ใช้จริงด้วยเหตุผลสองประการ:
Dimensionality Reduction : ข้อมูลที่กระจายไปทั่วคอลัมน์จำนวนมากจะถูกเปลี่ยนเป็นส่วนประกอบหลัก (PC) เพื่อให้พีซีสองสามตัวแรกสามารถอธิบายชิ้นส่วนใหญ่ของข้อมูลทั้งหมด (ความแปรปรวน) พีซีเหล่านี้สามารถใช้เป็นตัวแปรอธิบายในรูปแบบการเรียนรู้ของเครื่อง
Visualize Data : การแสดงภาพการแยกคลาส (หรือกลุ่ม) นั้นยากสำหรับข้อมูลที่มีมากกว่า 3 มิติ (คุณสมบัติ) ด้วยพีซีสองเครื่องแรกนั้นมักจะเป็นไปได้ที่จะเห็นการแยกที่ชัดเจน
ตัวจําแนกที่ไร้เดียงสาเบย์เป็นรูปแบบการเรียนรู้ของเครื่องที่น่าจะเป็นที่ใช้สำหรับงานการจำแนกประเภท ปมของตัวจําแนกขึ้นอยู่กับทฤษฎีบทของเบย์
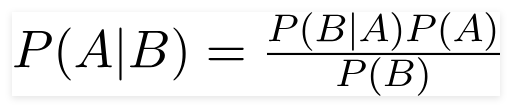
การใช้ทฤษฎีบท Bayes เราสามารถค้นหาความน่าจะเป็นของการเกิดขึ้นเนื่องจาก B เกิดขึ้น ที่นี่ B คือหลักฐานและเป็นสมมติฐาน สมมติฐานที่ทำไว้ที่นี่คือตัวทำนาย/คุณสมบัติมีความเป็นอิสระ นั่นคือการปรากฏตัวของคุณสมบัติหนึ่งโดยเฉพาะไม่ส่งผลกระทบต่อสิ่งอื่น ๆ ดังนั้นจึงเรียกว่าไร้เดียงสา
ประเภทของตัวแยกประเภท Bayes ไร้เดียงสา :
Multinomial Naive Bayes : ส่วนใหญ่จะใช้เมื่อตัวแปรไม่ต่อเนื่อง (เช่นคำ) คุณสมบัติ/ตัวทำนายที่ใช้โดยตัวจําแนกคือความถี่ของคำที่มีอยู่ในเอกสาร
Gaussian Naive Bayes : เมื่อผู้ทำนายใช้ค่าต่อเนื่องและไม่ต่อเนื่องเราคิดว่าค่าเหล่านี้จะถูกสุ่มตัวอย่างจากการแจกแจงแบบเกาส์
Bernoulli Naive Bayes : นี่คล้ายกับ Bayes ไร้เดียงสาพหุคูณ แต่ตัวทำนายเป็นตัวแปรบูลีน พารามิเตอร์ที่เราใช้ในการทำนายตัวแปรคลาสจะใช้ค่าเพียงค่าใช่หรือไม่เช่นหากคำที่เกิดขึ้นในข้อความหรือไม่
ใช้ชุดข้อมูล 20NewSGroup อัลกอริทึมไร้เดียงสาเบย์จะถูกสำรวจเพื่อทำการจำแนกประเภท
การเพิ่มข้อมูลโดยใช้เทคนิคต่อไปนี้มีการสำรวจ:

สถาปัตยกรรมใหม่ที่ชื่อว่า Sbert ถูกสำรวจ สถาปัตยกรรมเครือข่ายสยามช่วยให้สามารถรับเวกเตอร์ขนาดคงที่สำหรับประโยคอินพุตได้ การใช้การวัดความคล้ายคลึงกันเช่น Cosinesimilarity หรือ Manhatten / Euclidean ระยะทางสามารถพบประโยคที่คล้ายคลึงกันเชิงความหมาย

| การวิเคราะห์ความเชื่อมั่น - IMDB | การจำแนกความเชื่อมั่น - Hinglish | การจำแนกเอกสาร |
| การจำแนกคู่คำถามซ้ำ - Quora | การติดแท็ก POS | การอนุมานภาษาธรรมชาติ - SNLI |
| การจำแนกความคิดเห็นที่เป็นพิษ | ประโยคที่ถูกต้องตามหลักไวยากรณ์ - โคล่า | การติดแท็ก |
การวิเคราะห์ความเชื่อมั่นหมายถึงการใช้การประมวลผลภาษาธรรมชาติการวิเคราะห์ข้อความภาษาศาสตร์การคำนวณและชีวภาพเพื่อระบุการแยกปริมาณและการศึกษาสถานะทางอารมณ์และข้อมูลอัตนัยอย่างเป็นระบบ
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
RNN ใช้สำหรับการประมวลผลและระบุความเชื่อมั่น

หลังจากลองใช้ RNN พื้นฐานซึ่งให้การทดสอบ _curacy น้อยกว่า 50% แล้วมีการทดลองเทคนิคต่อไปนี้และการทดสอบ _curacy สูงกว่า 88% จะทำได้
เทคนิคที่ใช้:

ความสนใจช่วยในการมุ่งเน้นไปที่อินพุตที่เกี่ยวข้องเมื่อทำนายความเชื่อมั่นของอินพุต Bahdanau ให้ความสนใจกับการใช้เอาต์พุตของ LSTM และเชื่อมต่อสถานะที่ซ่อนเร้นไปข้างหน้าและถอยหลังครั้งสุดท้าย โดยไม่ต้องใช้คำที่ผ่านการฝึกอบรมมาก่อนการทดสอบความแม่นยำของการทดสอบ 88% จะทำได้
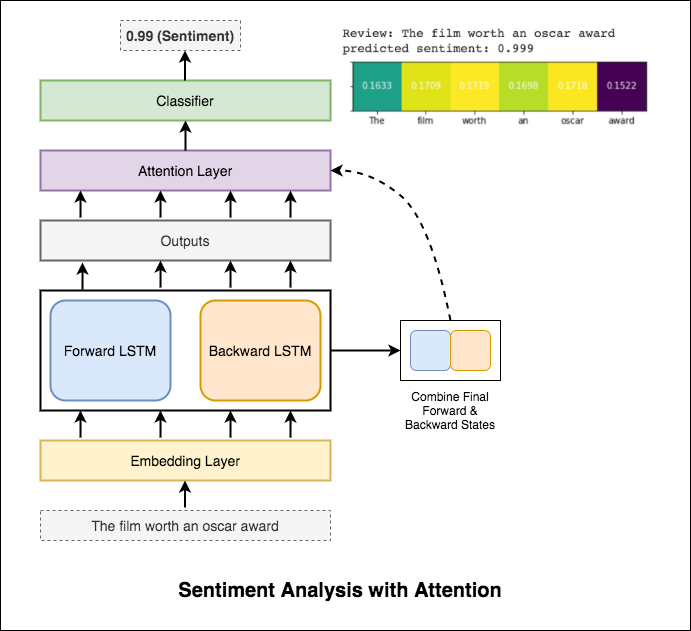
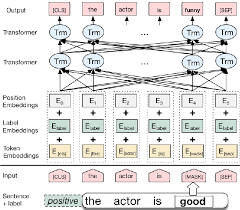
เบิร์ตได้รับผลลัพธ์ที่ทันสมัยใหม่ในงานการประมวลผลภาษาธรรมชาติสิบเอ็ด การถ่ายโอนการเรียนรู้ใน NLP ได้กระตุ้นหลังจากการเปิดตัวของรุ่น Bert การใช้ Bert เพื่อทำการวิเคราะห์ความเชื่อมั่น

ภาษาผสมหรือที่เรียกว่าการผสมโค้ดเป็นบรรทัดฐานในสังคมหลายภาษา คนหลายภาษาซึ่งเป็นผู้พูดภาษาอังกฤษที่ไม่ใช่เจ้าของภาษามีแนวโน้มที่จะผสมรหัสโดยใช้การพิมพ์ออกเสียงที่ใช้ภาษาอังกฤษและการแทรกของ anglicisms ในภาษาหลักของพวกเขา
งานคือการทำนายความเชื่อมั่นของทวีตผสมโค้ดที่กำหนด ฉลากความเชื่อมั่นเป็นภาษาบวกลบหรือเป็นกลางและภาษาผสมรหัสจะเป็นภาษาอังกฤษ-ฮินดี (Sentimix)
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
การใช้โมเดล MLP อย่างง่าย F1 score of 0.58 ทำได้จากข้อมูลการทดสอบ

หลังจากสำรวจโมเดล MLP พื้นฐานแล้วโมเดล LSTM ถูกนำมาใช้สำหรับการทำนายความเชื่อมั่นและคะแนน F1 ที่ 0.57

ผลลัพธ์นั้นน้อยกว่าเมื่อเทียบกับโมเดล MLP พื้นฐาน หนึ่งในเหตุผลอาจเป็น LSTM ไม่สามารถเรียนรู้ความสัมพันธ์ระหว่างคำในประโยคเนื่องจากลักษณะที่หลากหลายของข้อมูลผสมรหัส
เนื่องจาก LSTM ไม่สามารถเรียนรู้ความสัมพันธ์ระหว่างคำในประโยคผสมโค้ดเนื่องจากลักษณะที่หลากหลายของข้อมูลผสมรหัสและไม่มีการใช้การฝังตัวที่ผ่านการฝึกอบรมมาก่อนคะแนน F1 จึงน้อยกว่า
เพื่อบรรเทาปัญหานี้รุ่น XLM-Roberta (ซึ่งได้รับการฝึกอบรมล่วงหน้าใน 100 ภาษา) กำลังถูกใช้เพื่อเข้ารหัสประโยค ในการใช้โมเดล XLM-Roberta ประโยคจะต้องเป็นภาษาที่เหมาะสม ดังนั้นก่อนอื่นคำ Hinglish จะต้องถูกแปลงเป็นรูปแบบภาษาฮินดี (Devanagari)
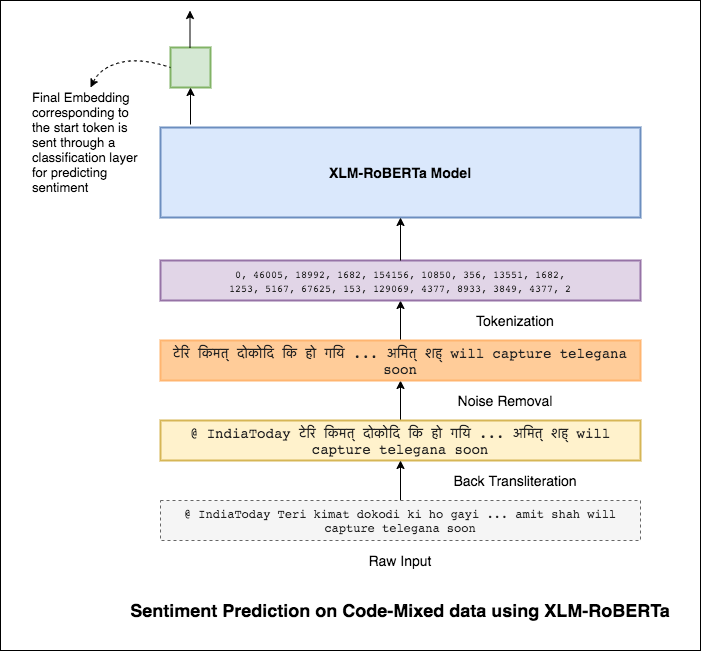
คะแนน F1 ที่ 0.59 ประสบความสำเร็จ วิธีการปรับปรุงสิ่งนี้จะได้รับการสำรวจในภายหลัง
เอาต์พุตสุดท้ายจากโมเดล XLM-Roberta ถูกใช้เป็นอินพุตฝังตัวไปยังรุ่น LSTM แบบสองทิศทาง เลเยอร์ความสนใจซึ่งใช้เอาต์พุตจากเลเยอร์ LSTM จะสร้างการแสดงถ่วงน้ำหนักของอินพุตซึ่งจะผ่านตัวจําแนกสำหรับการทำนายความเชื่อมั่นของประโยค

คะแนน F1 ที่ 0.64 ประสบความสำเร็จ
ในทำนองเดียวกับที่ตัวกรอง 3x3 สามารถดูแพทช์ของภาพตัวกรอง 1x2 สามารถดูคำ 2 คำต่อเนื่องในข้อความส่วนหนึ่งนั่นคือ bi-gram ในรุ่น CNN นี้เราจะใช้ตัวกรองหลายตัวที่มีขนาดต่างกันซึ่งจะดูที่ bi-grams (ตัวกรอง 1x2), tri-grams (ตัวกรอง 1x3) และ/หรือ N-Grams (ตัวกรอง 1xn) ภายในข้อความ
สัญชาตญาณที่นี่คือการปรากฏตัวของ bi-grams, tri-grams และ N-grams ภายในการตรวจสอบจะเป็นข้อบ่งชี้ที่ดีของความเชื่อมั่นสุดท้าย
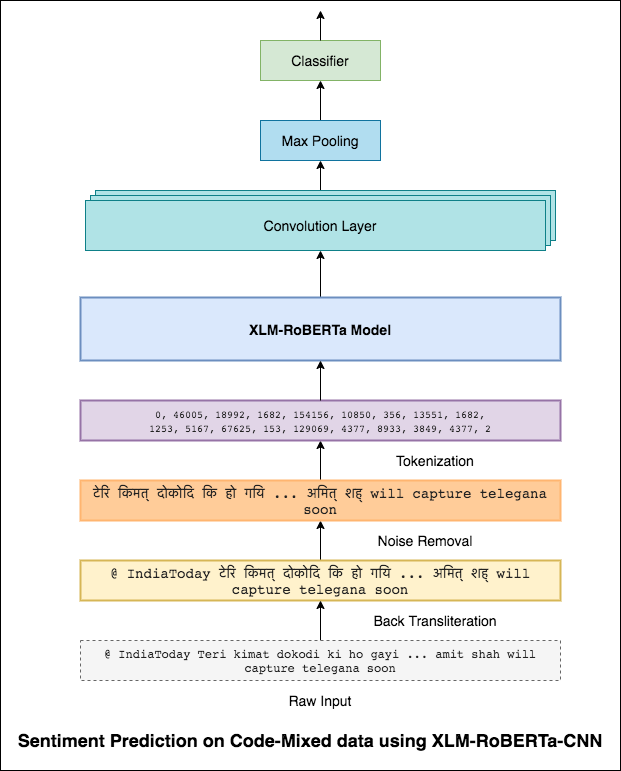
คะแนน F1 ที่ 0.69 ประสบความสำเร็จ
CNN จับการพึ่งพาในท้องถิ่นซึ่งเป็น RNN จับการพึ่งพาทั่วโลก โดยการรวมทั้งสองเราจะได้รับความเข้าใจข้อมูลที่ดีขึ้น วงดนตรีของโมเดล CNN และแบบจำลองความสนใจแบบสองทิศทางการทำงานออกมาดำเนินการอื่น ๆ
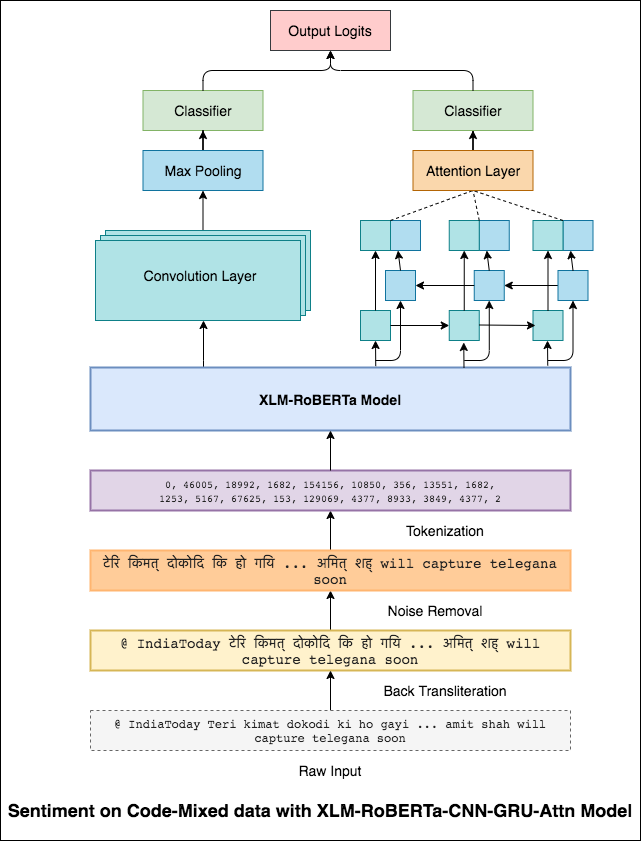
คะแนน F1 ที่ 0.71 ประสบความสำเร็จ (5 อันดับแรกในกระดานผู้นำ)
การจำแนกประเภทเอกสารหรือการจัดหมวดหมู่เอกสารเป็นปัญหาในวิทยาศาสตร์ห้องสมุดวิทยาศาสตร์สารสนเทศและวิทยาศาสตร์คอมพิวเตอร์ ภารกิจคือการกำหนดเอกสารให้กับคลาสหรือหมวดหมู่อย่างน้อยหนึ่งคลาส
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
เครือข่ายความสนใจแบบลำดับชั้น (HAN) พิจารณาโครงสร้างลำดับชั้นของเอกสาร (เอกสาร - ประโยค - คำ) และรวมถึงกลไกความสนใจที่สามารถค้นหาคำและประโยคที่สำคัญที่สุดในเอกสารในขณะที่นำบริบทมาพิจารณา
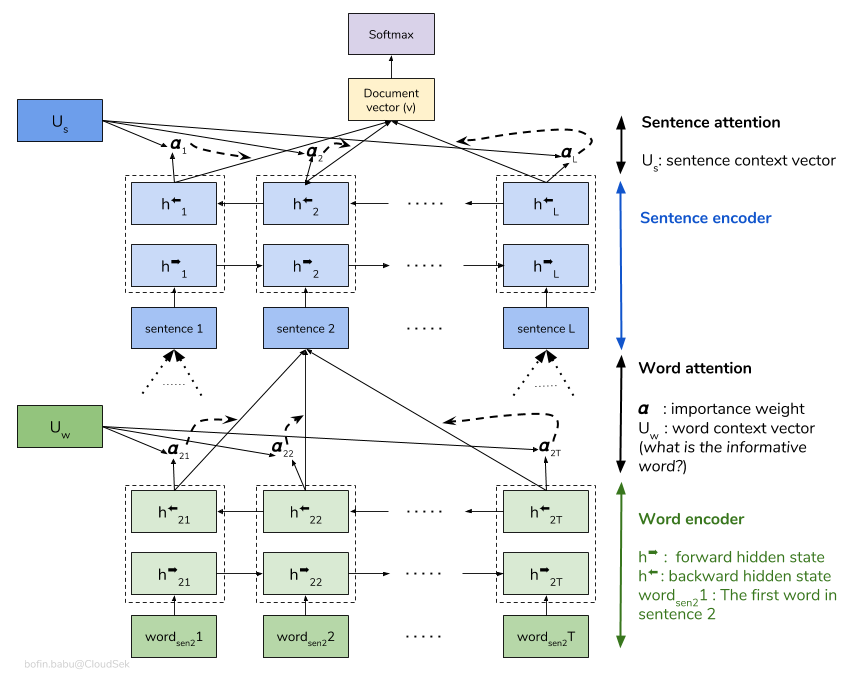
โมเดลฮันพื้นฐานกำลังล้นอย่างรวดเร็ว เพื่อที่จะเอาชนะสิ่งนี้ได้เทคนิคเช่น Embedding Dropout จะมีการสำรวจ Locked Dropout มีอีกหนึ่งเทคนิคอื่น ๆ ที่เรียกว่า Weight Dropout ซึ่งไม่ได้ใช้งาน (แจ้งให้เราทราบหากมีทรัพยากรที่ดีในการใช้งานนี้) Glove ฝังคำที่ผ่านการฝึกอบรมมาก่อนยังใช้แทนการเริ่มต้นแบบสุ่ม เนื่องจากความสนใจสามารถทำได้ในระดับประโยคและระดับคำเราจึงสามารถมองเห็นได้ว่าคำใดที่มีความสำคัญในประโยคและประโยคใดที่มีความสำคัญในเอกสาร



qqp ย่อมาจากคู่คำถาม Quora วัตถุประสงค์ของงานสำหรับคำถามคู่ที่กำหนด เราจำเป็นต้องค้นหาว่าคำถามเหล่านั้นมีความคล้ายคลึงกันหรือไม่
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
อัลกอริทึมจำเป็นต้องใช้คำถามคู่เป็นอินพุตและควรส่งออกความคล้ายคลึงกัน ใช้เครือข่ายสยาม Siamese neural network (บางครั้งเรียกว่าเครือข่ายประสาทคู่) เป็นเครือข่ายประสาทเทียมที่ใช้ same weights ในขณะที่ทำงานควบคู่กับเวกเตอร์อินพุตสองตัวที่แตกต่างกันเพื่อคำนวณเวกเตอร์เอาท์พุทเทียบเท่า

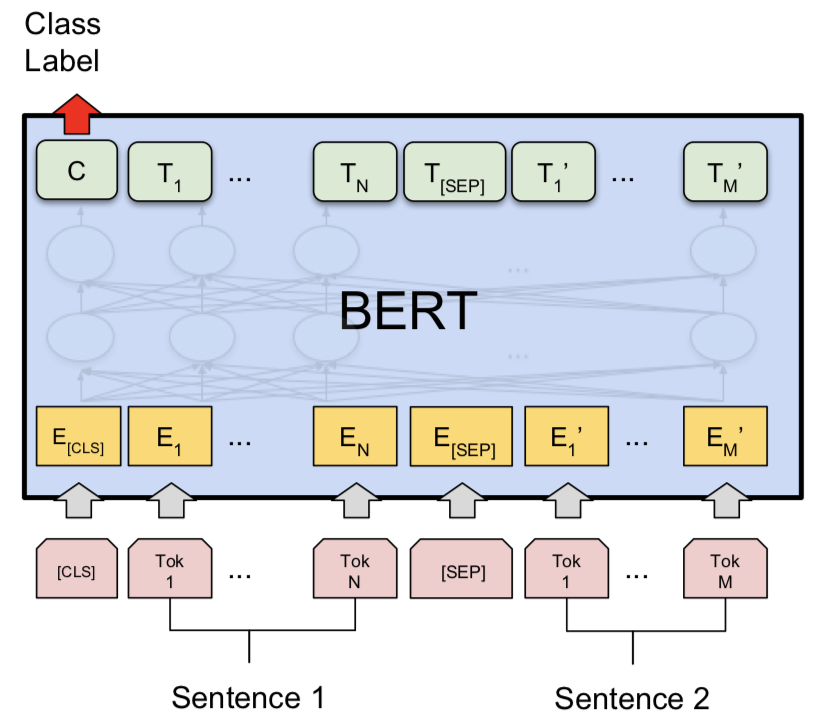
หลังจากลองใช้โมเดลสยามเบิร์ตได้รับการสำรวจเพื่อทำการตรวจจับคู่คำถามที่ซ้ำกันของ Quora เบิร์ตใช้คำถามที่ 1 และคำถามที่ 2 เป็นอินพุตคั่นด้วยโทเค็น [SEP] และการจำแนกประเภทได้ดำเนินการโดยใช้การเป็นตัวแทนขั้นสุดท้ายของโทเค็น [CLS]
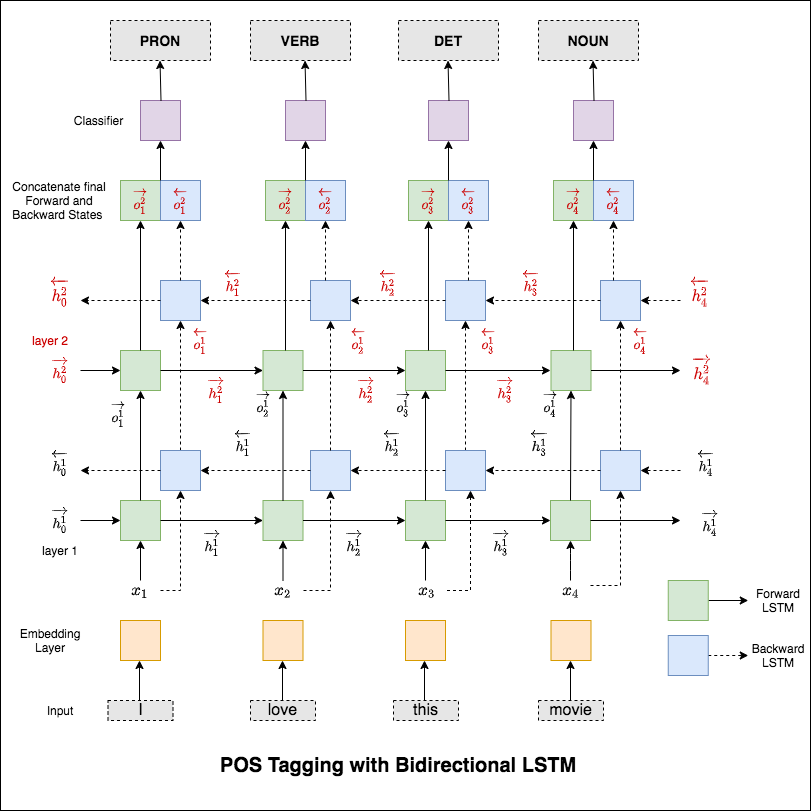
การติดแท็กส่วนหนึ่งของคำพูด (POS) เป็นหน้าที่ของการติดฉลากแต่ละคำในประโยคที่มีส่วนที่เหมาะสมของการพูด
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
รหัสนี้ครอบคลุมเวิร์กโฟลว์พื้นฐาน เราจะเรียนรู้วิธีการ: โหลดข้อมูลสร้างการแยกรถไฟ/ทดสอบ/ตรวจสอบความถูกต้องสร้างคำศัพท์สร้างตัววนซ้ำข้อมูลกำหนดรูปแบบและใช้งานรถไฟ/ประเมิน/ทดสอบลูปและการติดแท็กเวลา (การอนุมาน)
โมเดลที่ใช้คือเครือข่าย LSTM สองชั้นแบบสองชั้น
หลังจากลองใช้วิธีการ RNN แล้วให้ทำการสำรวจ POS ด้วยสถาปัตยกรรมที่ใช้หม้อแปลง เนื่องจากหม้อแปลงมีทั้งตัวเข้ารหัสและตัวถอดรหัสและสำหรับงานการติดฉลากลำดับเท่านั้น Encoder จะเพียงพอ เนื่องจากข้อมูลมีขนาดเล็กที่มีตัวเข้ารหัส 6 ชั้นจะทำให้ข้อมูลเกินจริง ดังนั้นจึงใช้โมเดลเครื่องเข้ารหัสหม้อแปลงขนาด 3 ชั้น

หลังจากลองใช้การติดแท็ก POS ด้วยตัวเข้ารหัสหม้อแปลงแล้วการติดแท็ก POS ด้วยโมเดล Bert ที่ผ่านการฝึกอบรมมาก่อนจะถูกนำไปใช้ มันบรรลุความแม่นยำในการทดสอบ 91%

เป้าหมายของการอนุมานภาษาธรรมชาติ (NLI) ซึ่งเป็นงานประมวลผลภาษาธรรมชาติที่มีการศึกษาอย่างกว้างขวางคือการพิจารณาว่าคำสั่งที่กำหนด (หลักฐาน) มีความหมายเชิงความหมายอีกครั้ง (สมมติฐาน)
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
โมเดลพื้นฐานที่มีเครือข่าย Siamese Bilstm ถูก impleMeted
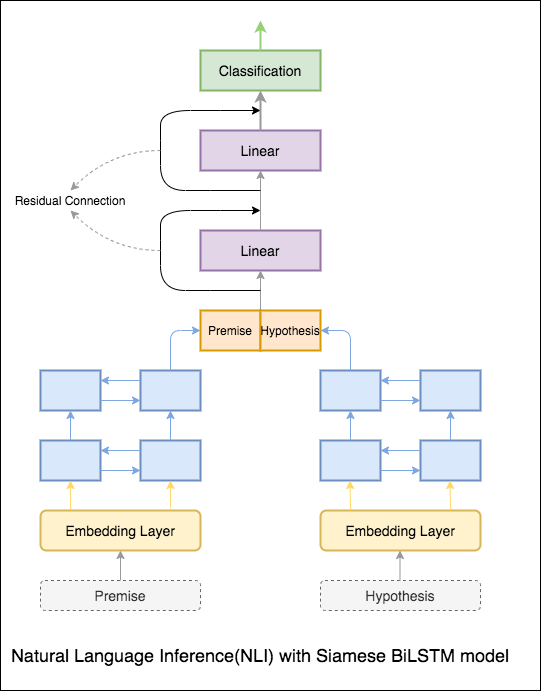
สิ่งนี้สามารถถือว่าเป็นการตั้งค่าพื้นฐาน ความแม่นยำในการทดสอบ 76.84% ประสบความสำเร็จ
ในสมุดบันทึกก่อนหน้านี้สถานะที่ซ่อนอยู่สุดท้ายของหลักฐานและสมมติฐานเป็นตัวแทนจาก LSTM ตอนนี้แทนที่จะใช้สถานะที่ซ่อนอยู่สุดท้ายความสนใจจะถูกคำนวณในโทเค็นอินพุตทั้งหมดและเวกเตอร์ถ่วงน้ำหนักสุดท้ายถูกนำมาเป็นตัวแทนของหลักฐานและสมมติฐาน
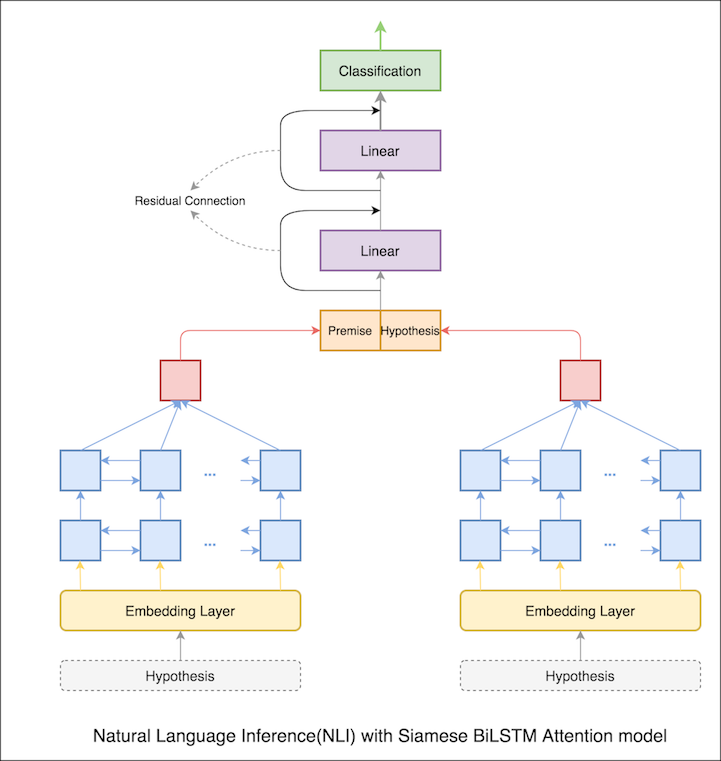
ความแม่นยำในการทดสอบเพิ่มขึ้นจาก 76.84% เป็น 79.51%
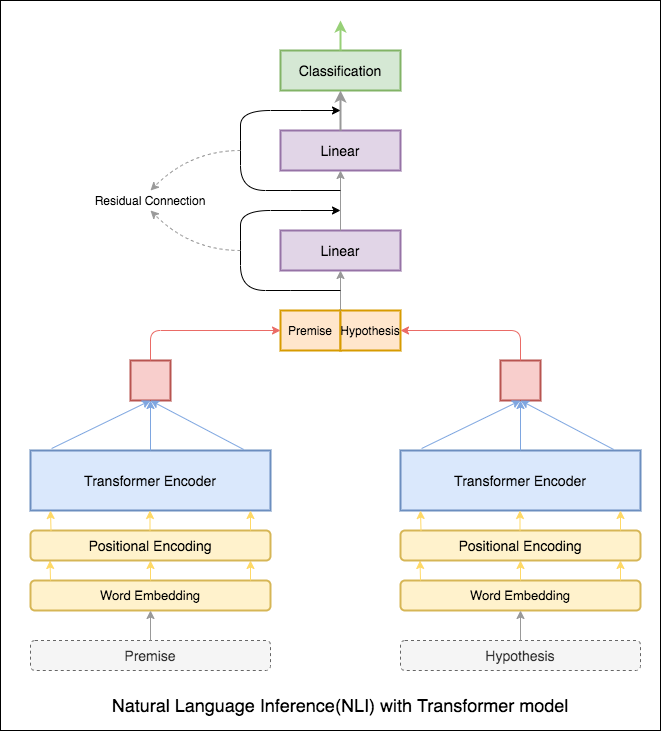
Transformer encoder ถูกใช้เพื่อเข้ารหัสหลักฐานและสมมติฐาน เมื่อประโยคถูกส่งผ่านตัวเข้ารหัสการรวมของโทเค็นทั้งหมดถือเป็นตัวแทนสุดท้าย (สามารถสำรวจตัวแปรอื่น ๆ ได้) ความแม่นยำของแบบจำลองนั้นน้อยกว่าเมื่อเทียบกับตัวแปร RNN
มีการสำรวจ NLI ที่มีโมเดล Bert Base เบิร์ตใช้สมมติฐานและสมมติฐานเป็นอินพุตคั่นด้วยโทเค็น [SEP] และการจำแนกประเภทได้ดำเนินการโดยใช้การเป็นตัวแทนขั้นสุดท้ายของโทเค็น [CLS]
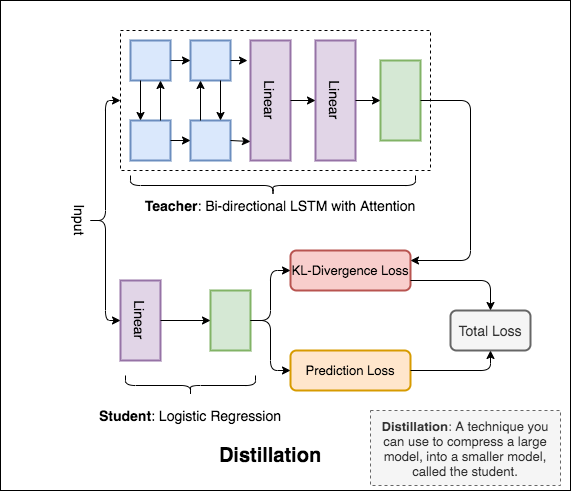
Distillation : เทคนิคที่คุณสามารถใช้ในการบีบอัดโมเดลขนาดใหญ่ที่เรียกว่า teacher เป็นรุ่นเล็ก ๆ เรียกว่า student ต่อไปนี้นักเรียนจะใช้โมเดลครูเพื่อทำการกลั่นใน NLI
การพูดคุยเกี่ยวกับสิ่งที่คุณใส่ใจอาจเป็นเรื่องยาก การคุกคามของการละเมิดและการล่วงละเมิดทางออนไลน์หมายความว่าหลายคนหยุดแสดงออกและยอมแพ้ในการค้นหาความคิดเห็นที่แตกต่างกัน แพลตฟอร์มต่อสู้เพื่ออำนวยความสะดวกในการสนทนาอย่างมีประสิทธิภาพนำชุมชนหลายแห่งให้ จำกัด หรือปิดความคิดเห็นของผู้ใช้อย่างสมบูรณ์
คุณได้รับความคิดเห็น Wikipedia จำนวนมากซึ่งได้รับการติดฉลากโดยผู้ประเมินของมนุษย์สำหรับพฤติกรรมที่เป็นพิษ ประเภทของความเป็นพิษคือ:
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
แบบจำลองที่ใช้เป็นเครือข่าย GRU แบบสองทิศทาง
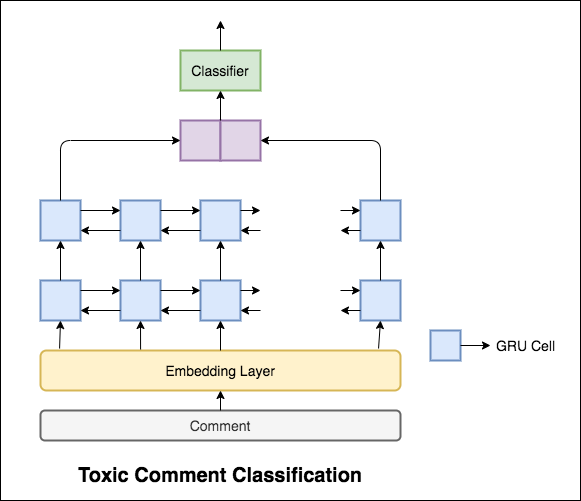
ความแม่นยำในการทดสอบ 99.42% ทำได้ เนื่องจาก 90% ของข้อมูลไม่ได้ระบุไว้ในความเป็นพิษใด ๆ เพียงแค่ทำนายข้อมูลทั้งหมดเป็นที่ไม่เป็นพิษจึงให้แบบจำลองที่แม่นยำ 90% ดังนั้นความแม่นยำจึงไม่ใช่ตัวชี้วัดที่เชื่อถือได้ มีการใช้ตัวชี้วัด ROC AUC ที่แตกต่างกัน
ด้วย Categorical Cross Entropy เช่นการสูญเสียคะแนน ROC_AUC ที่ 0.5 จะทำได้ โดยการเปลี่ยนการสูญเสียเป็น Binary Cross Entropy และปรับเปลี่ยนรุ่นเล็กน้อยโดยการเพิ่มเลเยอร์การรวม (สูงสุด, ค่าเฉลี่ย), คะแนน ROC_AUC ดีขึ้นเป็น 0.9873
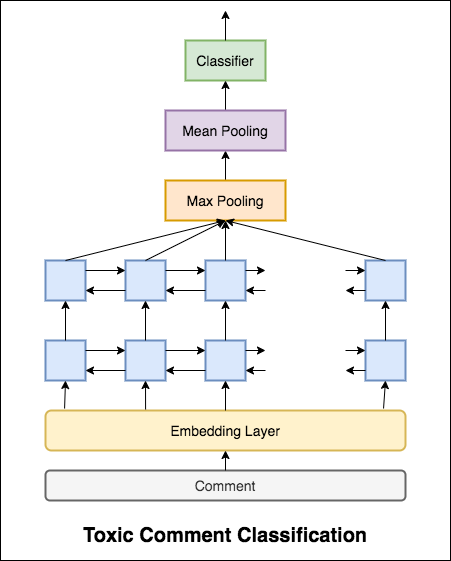
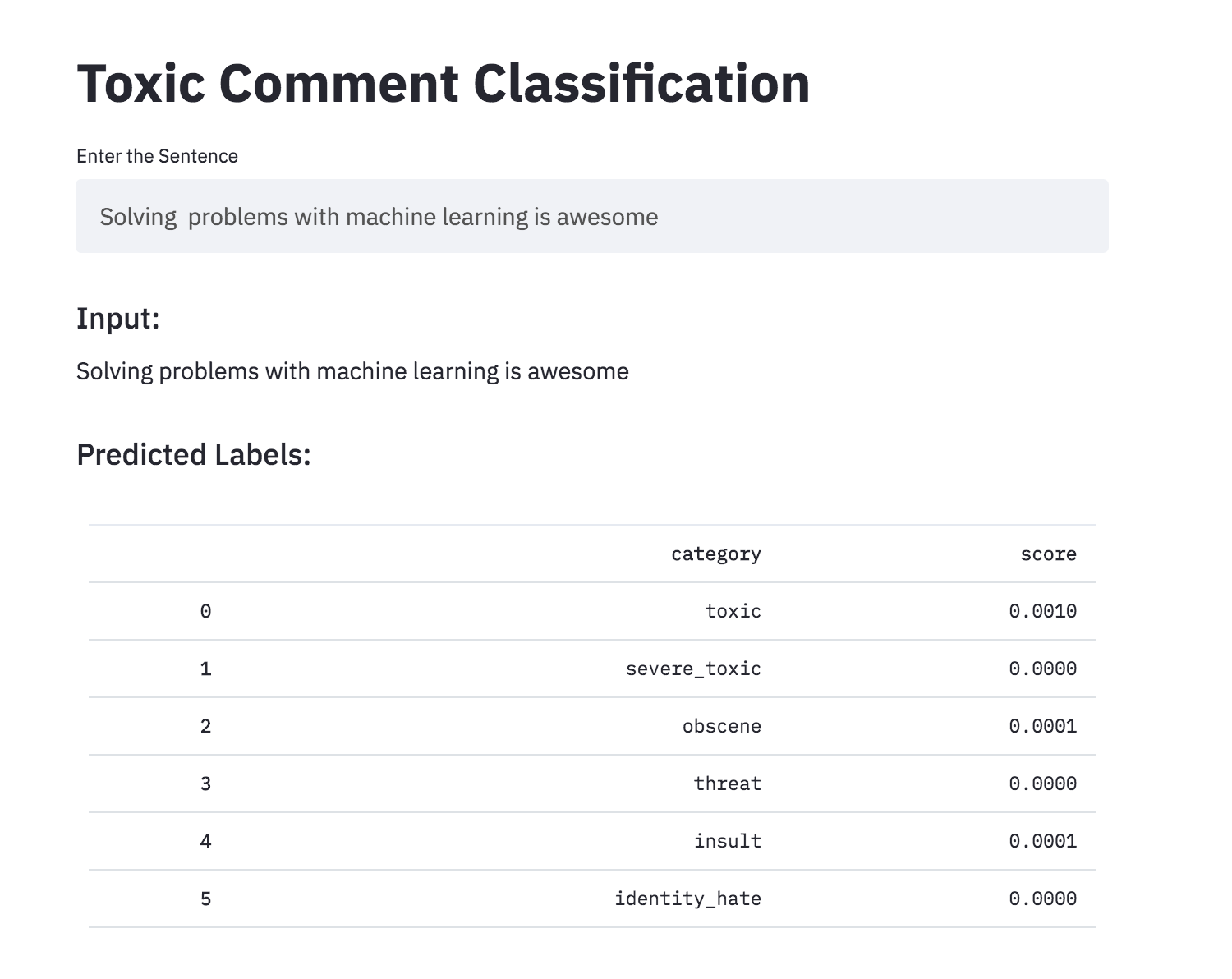
แปลงการจำแนกความคิดเห็นที่เป็นพิษเป็นแอพโดยใช้ Streamlit ตอนนี้รุ่นที่ผ่านการฝึกอบรมมาก่อน
เครือข่ายประสาทเทียมสามารถสามารถตัดสินการยอมรับไวยากรณ์ของประโยคได้หรือไม่? ในการสำรวจงานนี้จะใช้ชุดข้อมูลการยอมรับภาษาศาสตร์ (COLA) (COLA) COLA เป็นชุดของประโยคที่ระบุว่าถูกต้องตามหลักไวยากรณ์หรือไม่ถูกต้อง
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
เบิร์ตได้รับผลลัพธ์ที่ทันสมัยใหม่ในงานการประมวลผลภาษาธรรมชาติสิบเอ็ด การถ่ายโอนการเรียนรู้ใน NLP ได้กระตุ้นหลังจากการเปิดตัวของรุ่น Bert ในสมุดบันทึกนี้เราจะสำรวจวิธีการใช้ BERT เพื่อจำแนกว่าประโยคนั้นถูกต้องตามหลักไวยากรณ์หรือไม่ใช้ชุดข้อมูล COLA
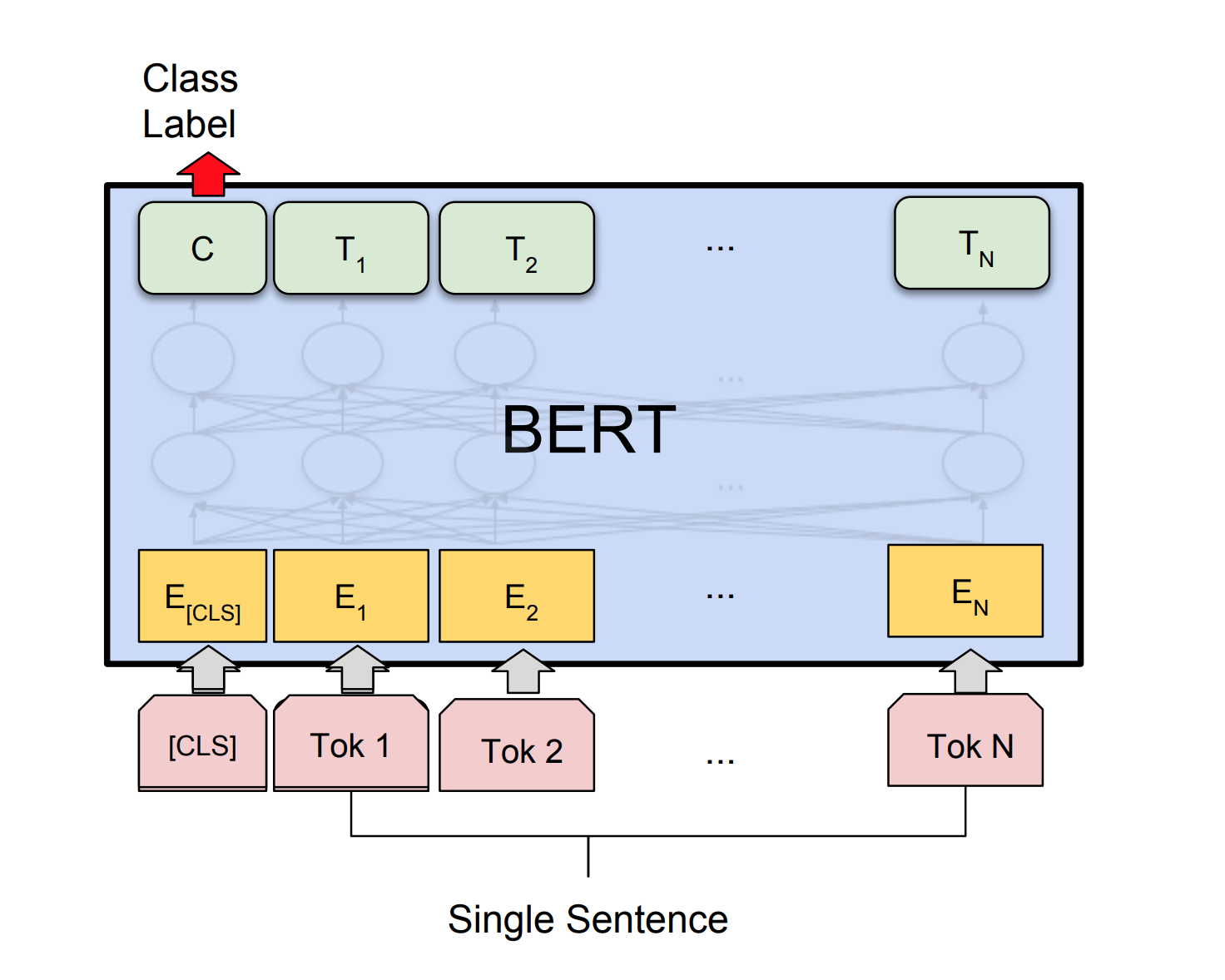
ความแม่นยำของค่าสัมประสิทธิ์สหสัมพันธ์ 85% และ Matthews (MCC) ที่ 64.1 นั้นสำเร็จ
Distillation : เทคนิคที่คุณสามารถใช้ในการบีบอัดโมเดลขนาดใหญ่ที่เรียกว่า teacher เป็นรุ่นเล็ก ๆ เรียกว่า student ต่อไปนี้นักเรียนจะใช้โมเดลครูเพื่อทำการกลั่นที่โคล่า

การทดลองหลังจากได้รับการทดลองแล้ว:
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 การติดแท็กการจดจำเอนทิตี้ (NER) ชื่อเป็นงานของการติดฉลากแต่ละคำในประโยคที่มีเอนทิตีที่เหมาะสม
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
รหัสนี้ครอบคลุมเวิร์กโฟลว์พื้นฐาน เราจะเห็นวิธีการ: โหลดข้อมูลสร้างการแยกรถไฟ/ทดสอบ/การตรวจสอบความถูกต้องสร้างคำศัพท์สร้างตัววนซ้ำข้อมูลกำหนดรูปแบบและใช้งานรถไฟ/ประเมิน/ทดสอบลูปและรถไฟทดสอบโมเดล
แบบจำลองที่ใช้คือเครือข่าย LSTM แบบสองทิศทาง
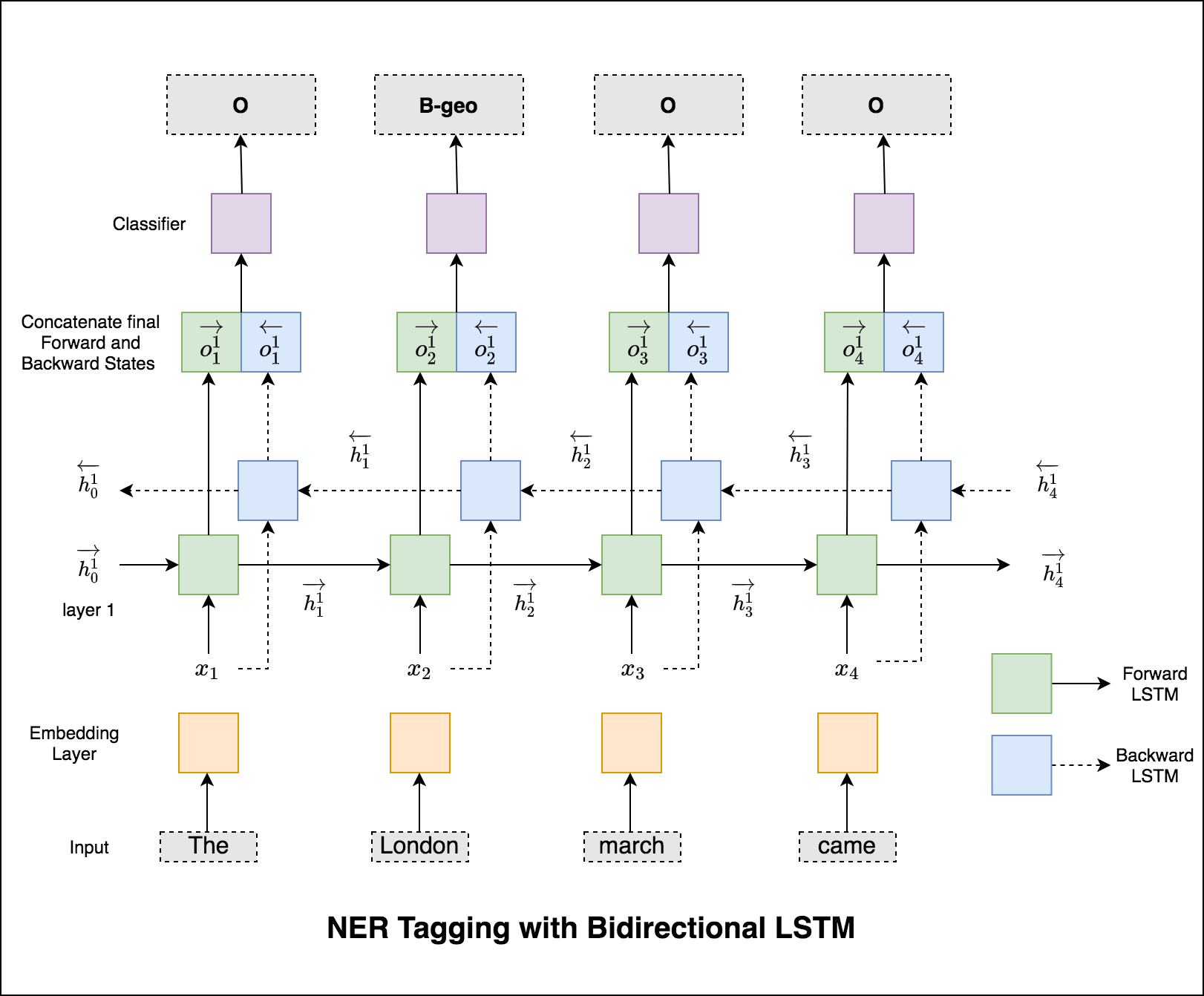
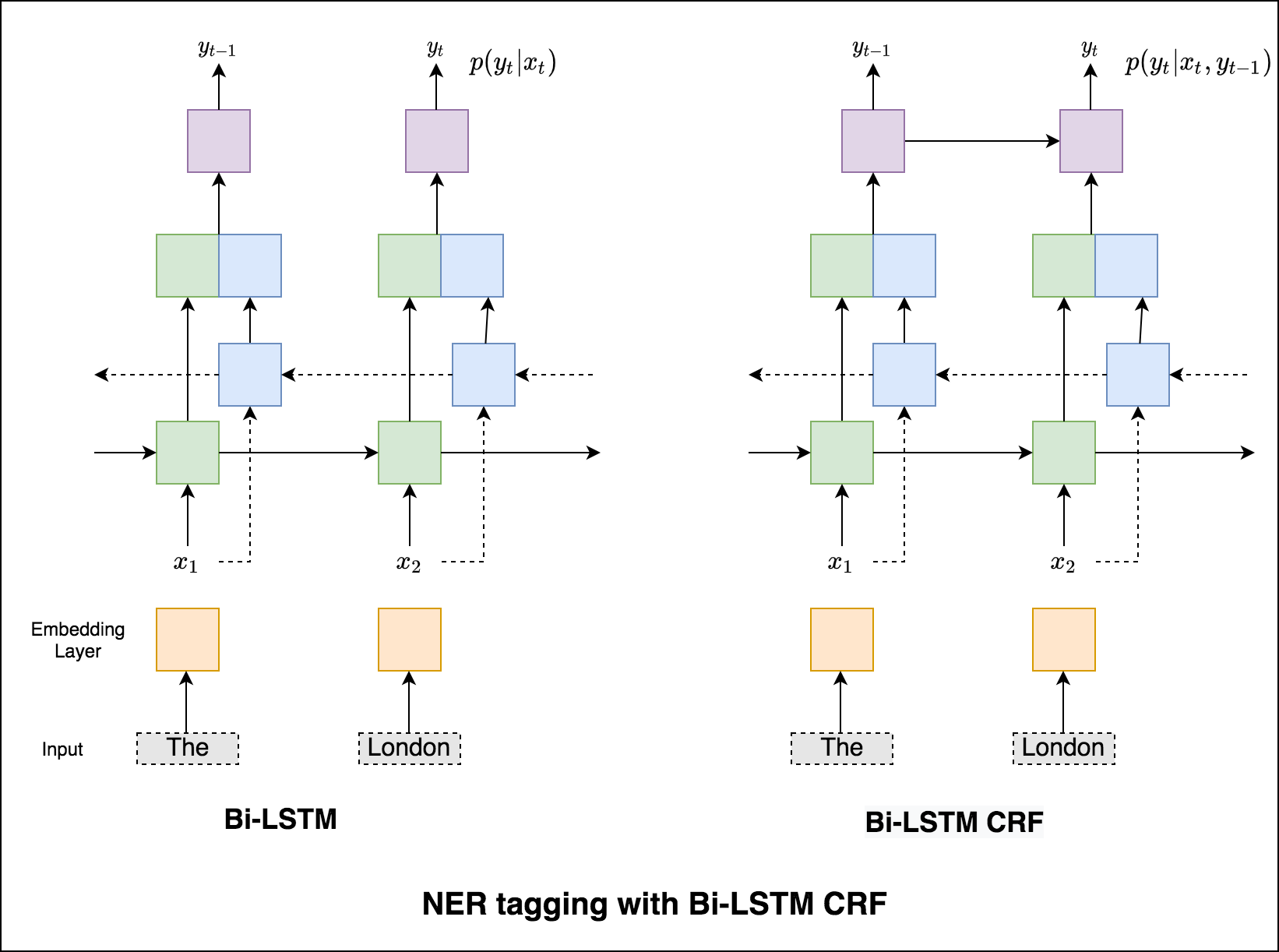
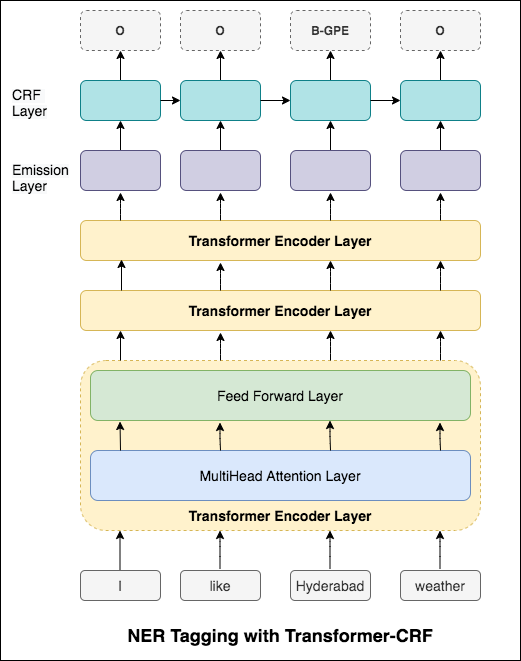
ในกรณีของการติดแท็กลำดับ (NER) แท็กของคำปัจจุบันอาจขึ้นอยู่กับแท็กของคำก่อนหน้า (อดีต: นิวยอร์ก)
หากไม่มี CRF เราจะใช้เลเยอร์เชิงเส้นเดียวเพื่อแปลงเอาต์พุตของ LSTM แบบสองทิศทางเป็นคะแนนสำหรับแต่ละแท็ก สิ่งเหล่านี้เรียกว่า emission scores ซึ่งเป็นตัวแทนของความน่าจะเป็นของคำว่าเป็นแท็กที่แน่นอน
CRF ไม่เพียง แต่คำนวณคะแนนการปล่อยมลพิษ แต่ยังรวมถึง transition scores ซึ่งเป็นโอกาสของคำที่เป็นแท็กที่แน่นอนเมื่อพิจารณาคำก่อนหน้านี้เป็นแท็กที่แน่นอน ดังนั้นคะแนนการเปลี่ยนแปลงจึงวัดว่ามันมีแนวโน้มที่จะเปลี่ยนจากแท็กหนึ่งไปอีกแท็กหนึ่ง
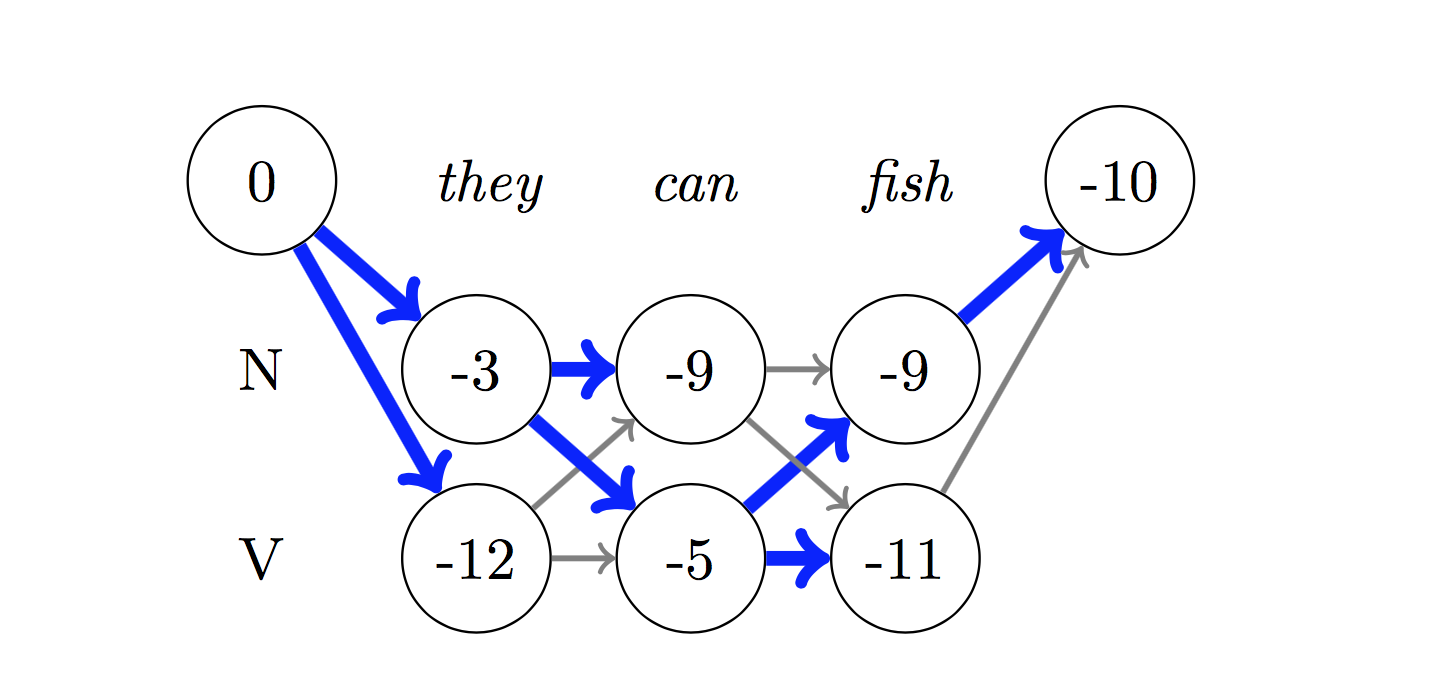
สำหรับการถอดรหัสใช้อัลกอริทึม Viterbi
เนื่องจากเราใช้ CRFs เราไม่ได้ทำนายฉลากที่เหมาะสมมากนักในแต่ละคำในขณะที่เราทำนายลำดับฉลากที่เหมาะสมสำหรับลำดับคำ การถอดรหัส Viterbi เป็นวิธีการทำสิ่งนี้อย่างแน่นอน - ค้นหาลำดับแท็กที่ดีที่สุดจากคะแนนที่คำนวณโดยฟิลด์แบบสุ่มแบบมีเงื่อนไข
การใช้ข้อมูลคำย่อยในงานการติดแท็กของเราเพราะมันอาจเป็นตัวบ่งชี้ที่มีประสิทธิภาพของแท็กไม่ว่าจะเป็นส่วนหนึ่งของคำพูดหรือเอนทิตี ตัวอย่างเช่นอาจเรียนรู้ว่าคำคุณศัพท์มักจะจบลงด้วย "-y" หรือ "-ul" หรือสถานที่นั้นมักจะจบลงด้วย "-land" หรือ "-burg"
ดังนั้นรูปแบบการติดแท็กลำดับของเราจึงใช้ทั้งสองอย่าง
word-level ในรูปแบบของการฝังคำcharacter-level อักขระถึงและรวมถึงแต่ละคำทั้งสองทิศทาง 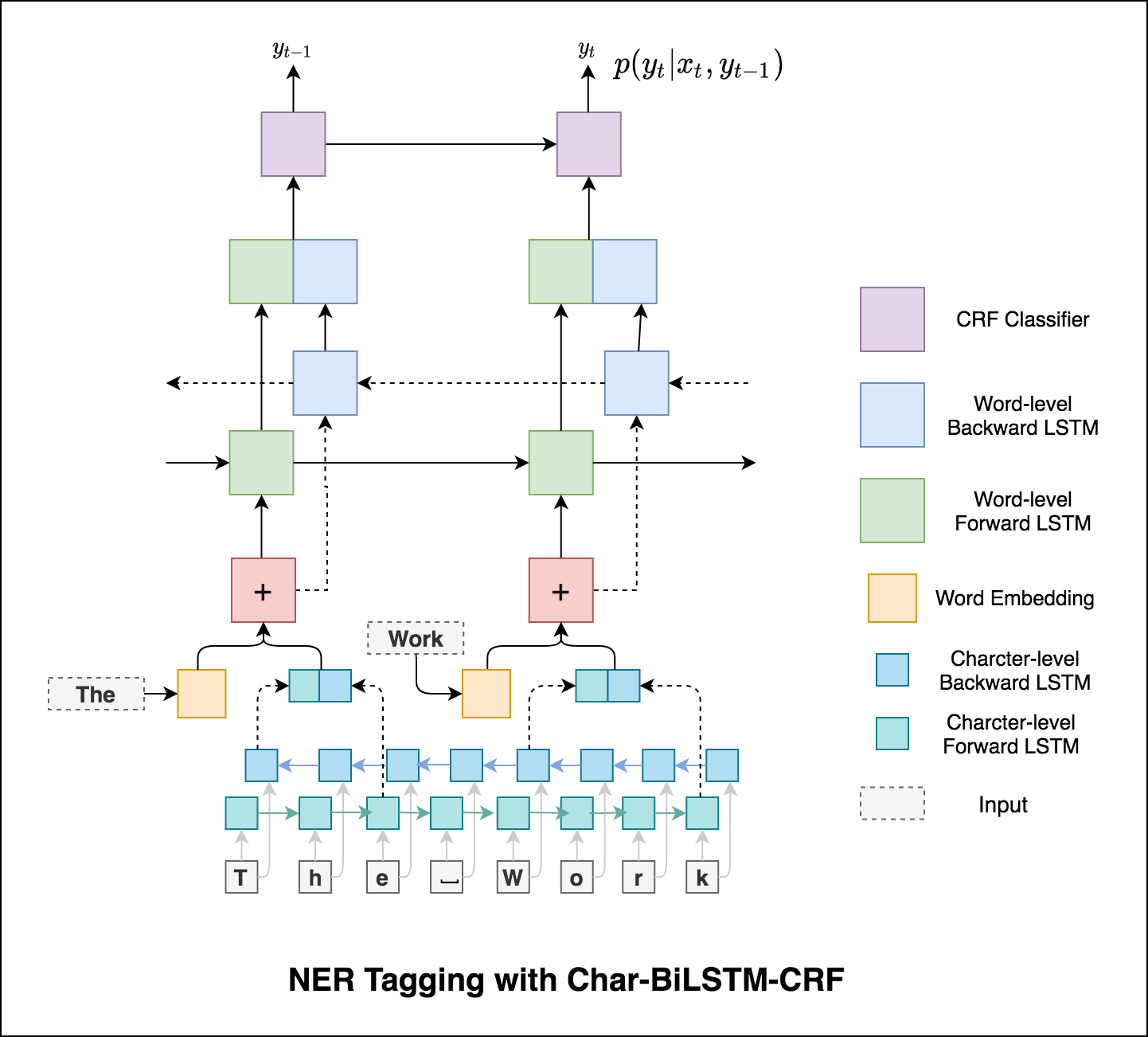
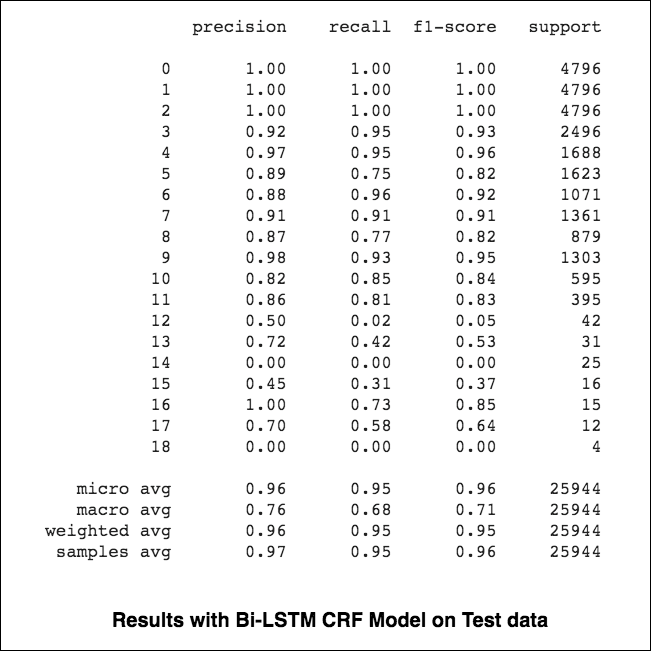
ไมโครและแมโครค่าเฉลี่ย (สำหรับตัวชี้วัดใด ๆ ) จะคำนวณสิ่งที่แตกต่างกันเล็กน้อยและทำให้การตีความของพวกเขาแตกต่างกัน ค่าเฉลี่ยมหภาคจะคำนวณตัวชี้วัดอย่างอิสระสำหรับแต่ละชั้นเรียนจากนั้นใช้ค่าเฉลี่ย (ดังนั้นจึงรักษาทุกคลาสอย่างเท่าเทียมกัน) ในขณะที่ค่าเฉลี่ยไมโครจะรวมการมีส่วนร่วมของคลาสทั้งหมดเพื่อคำนวณการวัดค่าเฉลี่ย ในการตั้งค่าการจำแนกประเภทหลายชั้นค่าเฉลี่ยไมโครจะดีกว่าถ้าคุณสงสัยว่าอาจมีความไม่สมดุลของชั้นเรียน (เช่นคุณอาจมีตัวอย่างของชั้นเรียนหนึ่งชั้นมากกว่าชั้นเรียนอื่น ๆ )

แปลงการติดแท็ก NER เป็นแอพโดยใช้ Streamlit รุ่นที่ผ่านการฝึกอบรมมาก่อน (Char-Bilstm-CRF) พร้อมใช้งานแล้ว
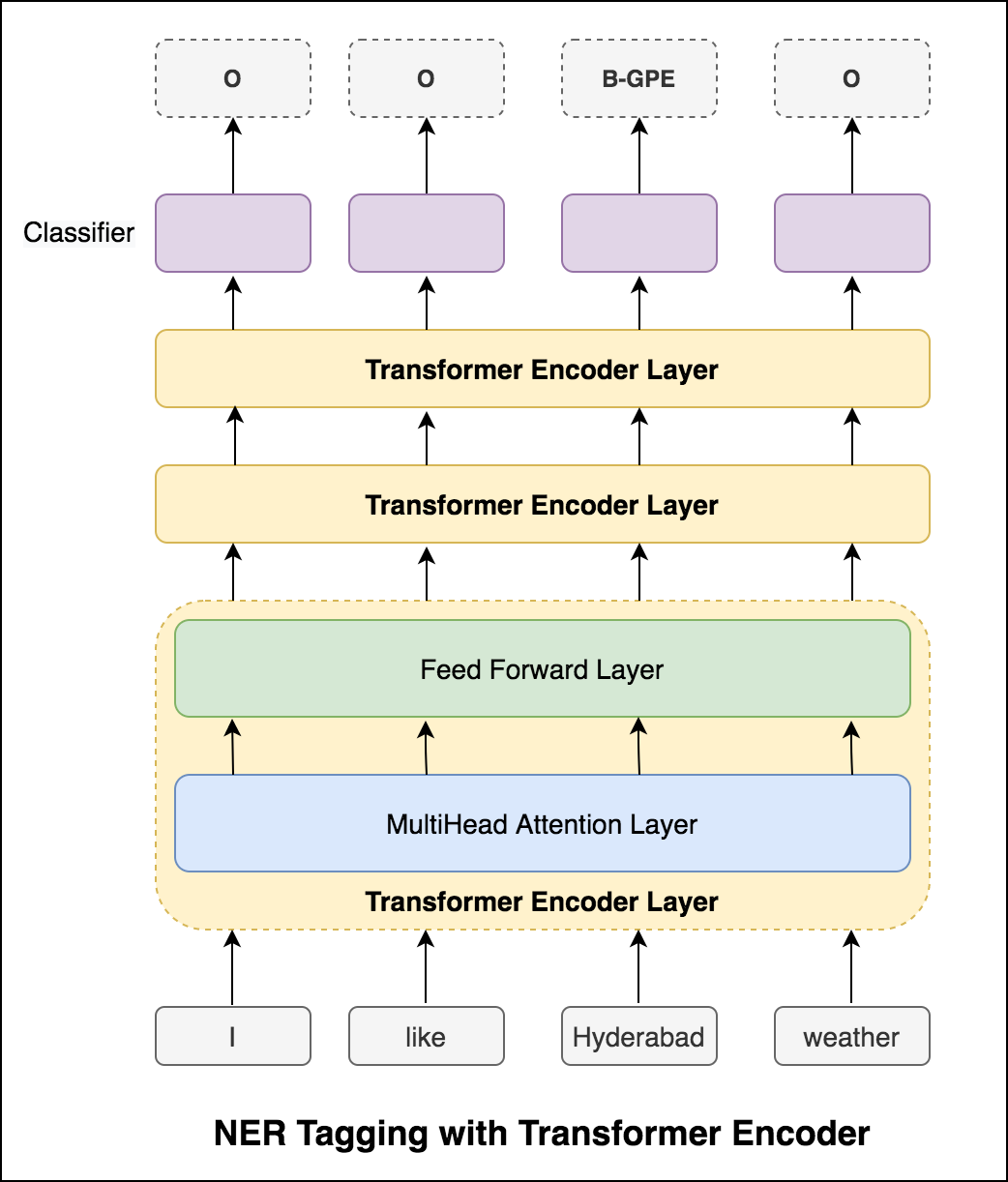
หลังจากลองใช้วิธีการ RNN แล้วจะมีการสำรวจการติดแท็กด้วยสถาปัตยกรรมที่ใช้หม้อแปลง เนื่องจากหม้อแปลงมีทั้งตัวเข้ารหัสและตัวถอดรหัสและสำหรับงานการติดฉลากลำดับเท่านั้น Encoder จะเพียงพอ ใช้โมเดลเครื่องเข้ารหัสหม้อแปลงขนาด 3 ชั้น
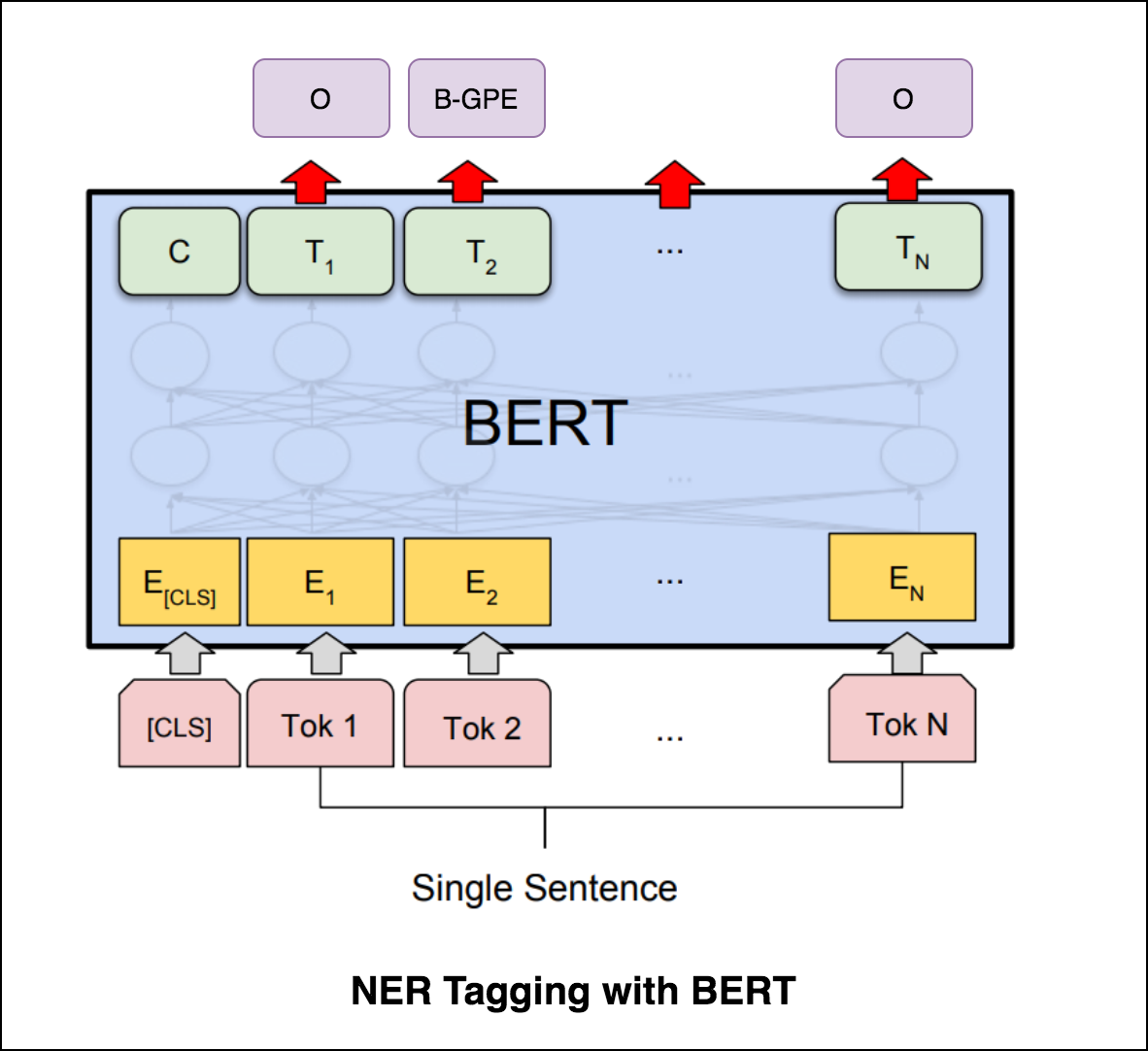
หลังจากลองใช้การติดแท็ก NER ด้วยตัวเข้ารหัสหม้อแปลงแล้วให้สำรวจการติดแท็ก NER ด้วยแบบจำลอง bert-base-cased ที่ผ่านการฝึกอบรมไว้ล่วงหน้า
หม้อแปลงเพียงอย่างเดียวไม่ได้ให้ผลลัพธ์ที่ดีเมื่อเทียบกับ bilstm ในงานการติดแท็ก NER การเพิ่มเลเยอร์ CRF ที่ด้านบนของหม้อแปลงถูกนำมาใช้ซึ่งเป็นการปรับปรุงผลลัพธ์เมื่อเทียบกับหม้อแปลงแบบสแตนด์อโลน
Spacy จัดเตรียมระบบสถิติที่มีประสิทธิภาพเป็นพิเศษสำหรับ NER ใน Python ซึ่งสามารถกำหนดป้ายกำกับให้กับกลุ่มโทเค็น มันมีโมเดลเริ่มต้นซึ่งสามารถรับรู้เอนทิตีที่มีชื่อหรือตัวเลขที่หลากหลายซึ่งรวมถึงบุคคลองค์กร, ภาษา, เหตุการณ์ ฯลฯ

นอกเหนือจากเอนทิตีเริ่มต้นเหล่านี้ Spacy ยังให้เสรีภาพแก่เราในการเพิ่มคลาสโดยพลการให้กับโมเดล NER โดยการฝึกอบรมแบบจำลองเพื่ออัปเดตด้วยตัวอย่างที่ผ่านการฝึกอบรมใหม่
2 เอนทิตีใหม่ที่เรียกว่า ACTIVITY และ SERVICE ในข้อมูลโดเมนเฉพาะ (ธนาคาร) ถูกสร้างและฝึกอบรมด้วยตัวอย่างการฝึกอบรมน้อย

| การสร้างชื่อ | การแปลเครื่องจักร | การสร้างคำพูด |
| คำบรรยายภาพ | คำบรรยายภาพ - สมการยางพารา | การสรุปข่าว |
| การสร้างหัวเรื่องอีเมล |
ใช้โมเดลภาษา LSTM ระดับตัวละคร นั่นคือเราจะให้ชื่อ LSTM จำนวนมากและขอให้แบบจำลองการกระจายความน่าจะเป็นของอักขระถัดไปในลำดับที่ได้รับลำดับของอักขระก่อนหน้า สิ่งนี้จะช่วยให้เราสามารถสร้างชื่อใหม่หนึ่งอักขระในแต่ละครั้ง

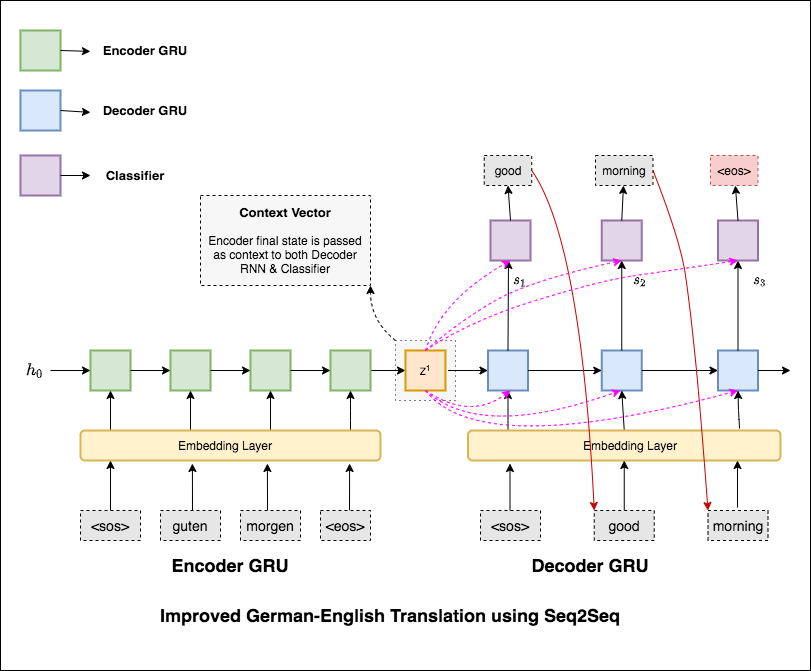
Machine Translation (MT) เป็นหน้าที่ของการแปลงภาษาธรรมชาติหนึ่งเป็นภาษาอื่นโดยอัตโนมัติรักษาความหมายของข้อความอินพุตและสร้างข้อความที่คล่องแคล่วในภาษาเอาท์พุท ตามหลักการแล้วลำดับภาษาต้นฉบับจะถูกแปลเป็นลำดับภาษาเป้าหมาย งานคือการแปลงประโยคจาก German to English
มีการสำรวจตัวแปรต่อไปนี้แล้ว:
โมเดลลำดับต่อลำดับ (SEQ2SEQ) ที่พบมากที่สุดคือโมเดลตัวเข้ารหัส-ตัวพิมพ์ใหญ่ซึ่งโดยทั่วไปจะใช้เครือข่ายประสาทที่เกิดขึ้นซ้ำ (RNN) เพื่อเข้ารหัสประโยคแหล่งที่มา (อินพุต) ลงในเวกเตอร์เดียว ในสมุดบันทึกนี้เราจะอ้างถึงเวกเตอร์เดียวนี้ว่าเป็นเวกเตอร์บริบท เราสามารถนึกถึงบริบทของเวกเตอร์ว่าเป็นตัวแทนนามธรรมของประโยคอินพุตทั้งหมด เวกเตอร์นี้จะถูกถอดรหัสโดย RNN ตัวที่สองซึ่งเรียนรู้ที่จะส่งออกประโยคเป้าหมาย (เอาต์พุต) โดยการสร้างคำทีละคำ

หลังจากลองการแปลของเครื่องพื้นฐานซึ่งมีข้อความที่น่างงงวย 36.68 แล้วเทคนิคดังต่อไปนี้ได้รับการทดลองและทดสอบความงุนงง 7.041
ชำระเงินรหัสใน applications/generation
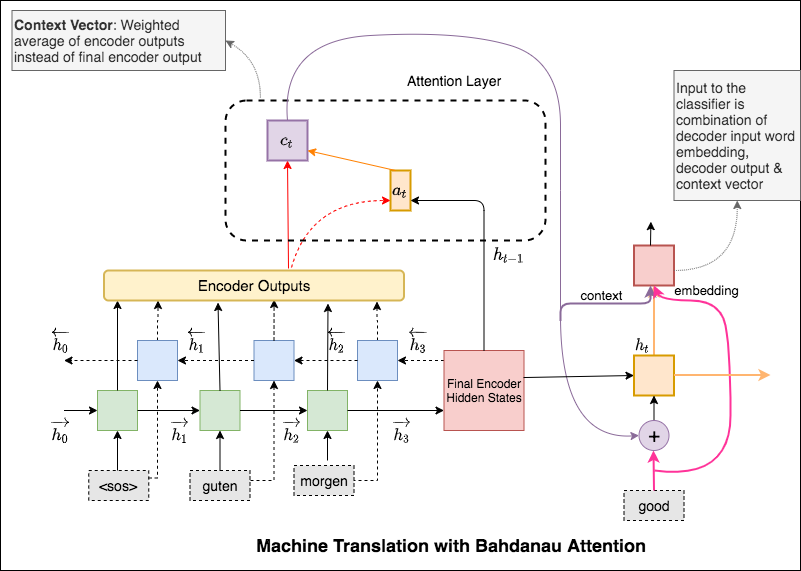
กลไกความสนใจเกิดขึ้นเพื่อช่วยจดจำประโยคแหล่งที่มายาวในการแปลเครื่องประสาท (NMT) แทนที่จะสร้างเวกเตอร์บริบทเดียวจากสถานะที่ซ่อนอยู่สุดท้ายของเข้ารหัสความสนใจจะถูกใช้เพื่อมุ่งเน้นไปที่ส่วนที่เกี่ยวข้องของอินพุตในขณะที่ถอดรหัสประโยค เวกเตอร์บริบทจะถูกสร้างขึ้นโดยใช้เอาต์พุตตัวเข้ารหัสและ previous hidden state ของตัวถอดรหัส RNN
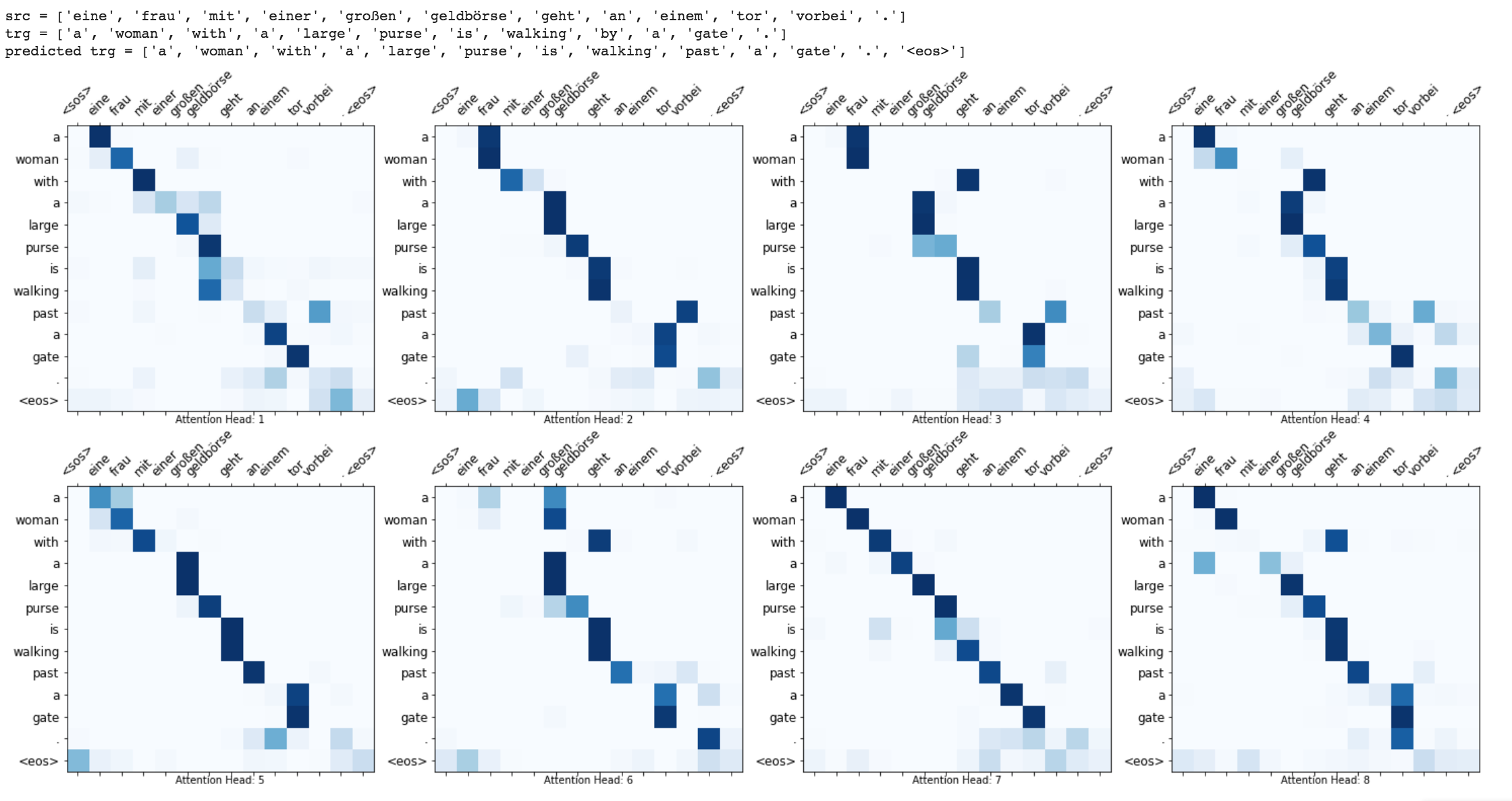
Enhancements like masking (ignoring the attention over padded input), packing padded sequences (for better computation), attention visualization and BLEU metric on test data are implemented.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
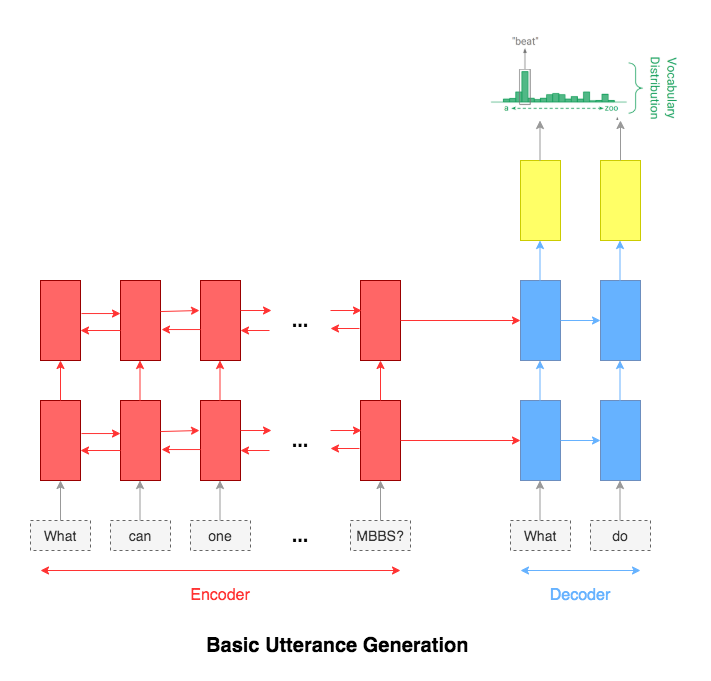
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
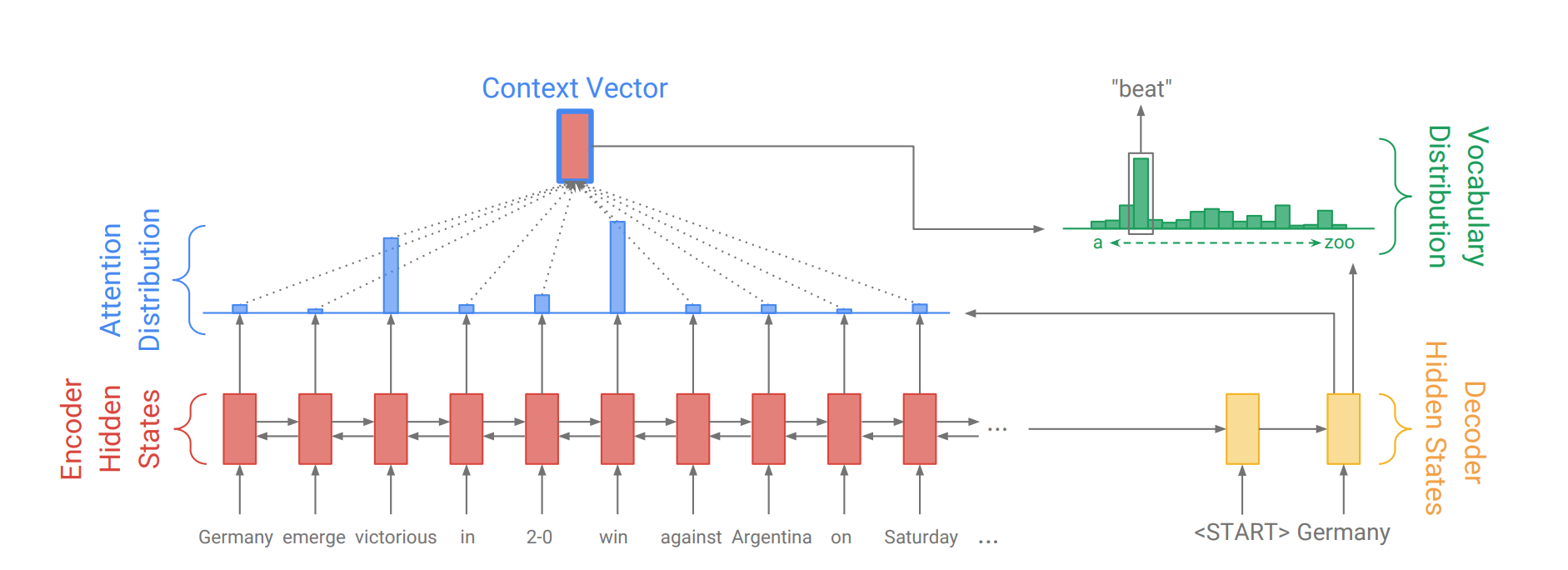
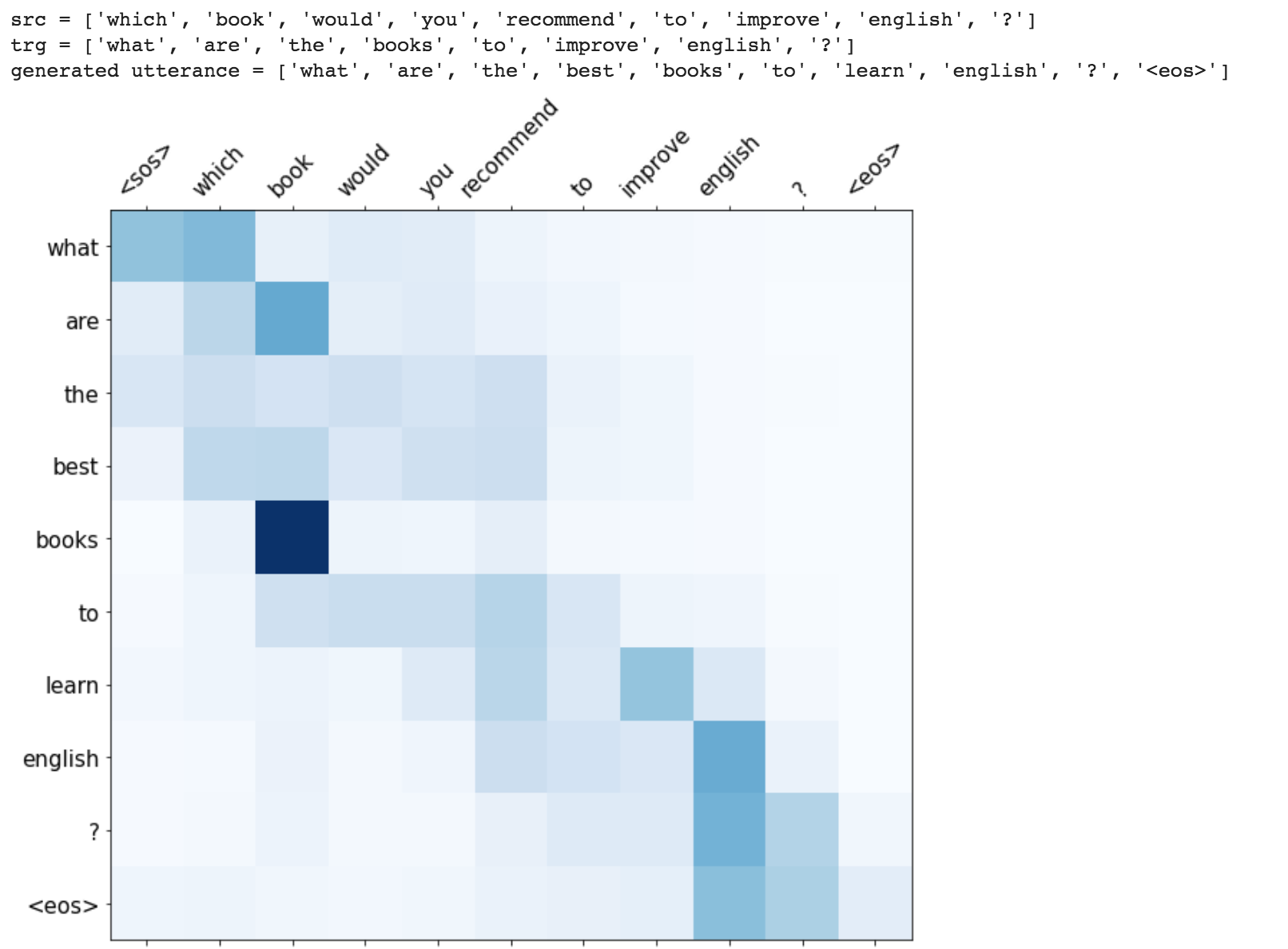
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
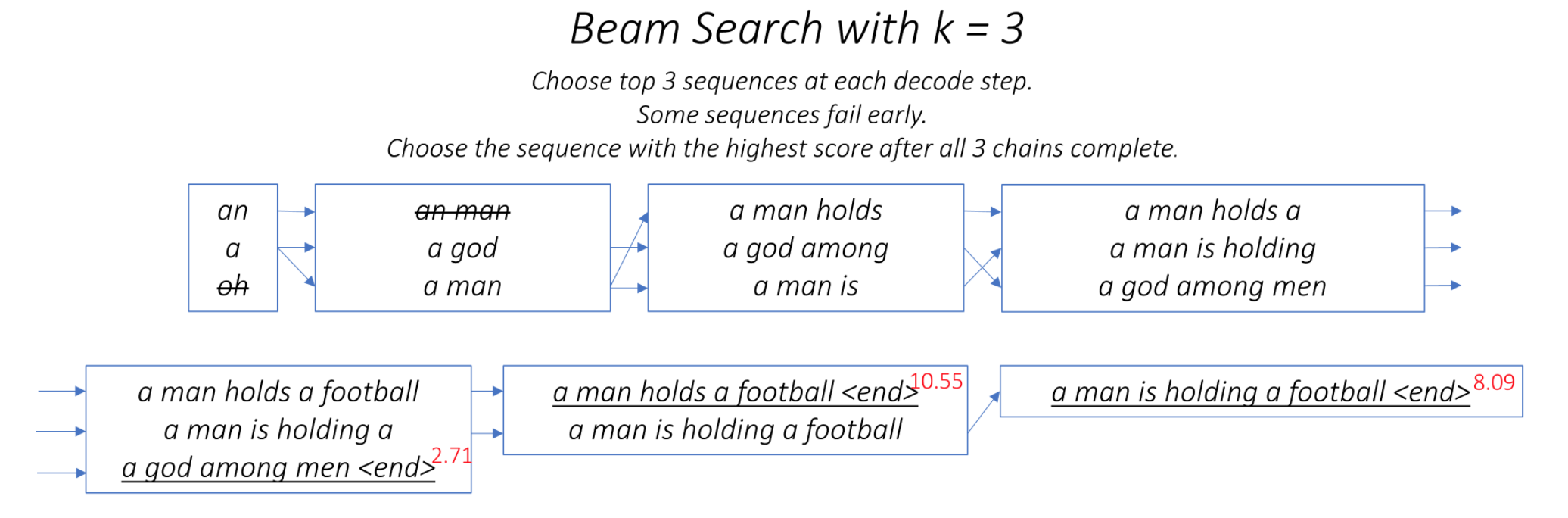
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
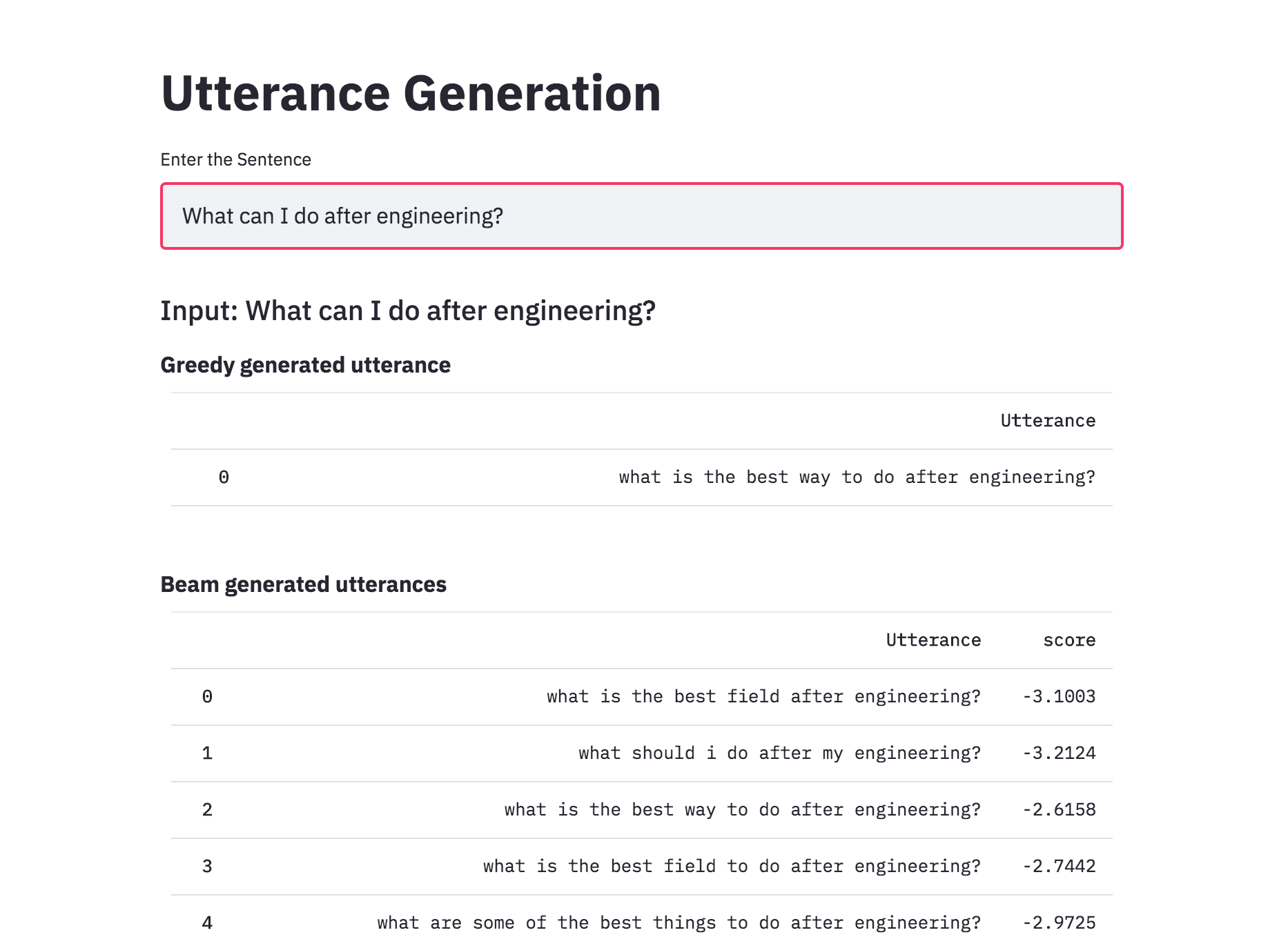
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
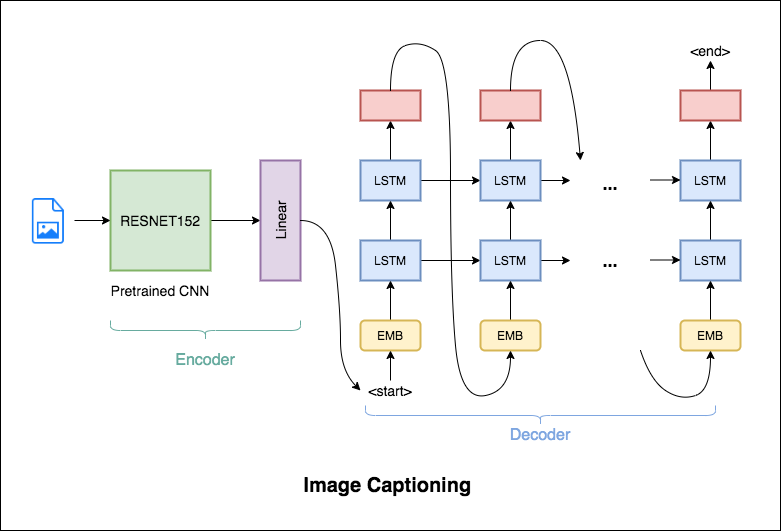
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
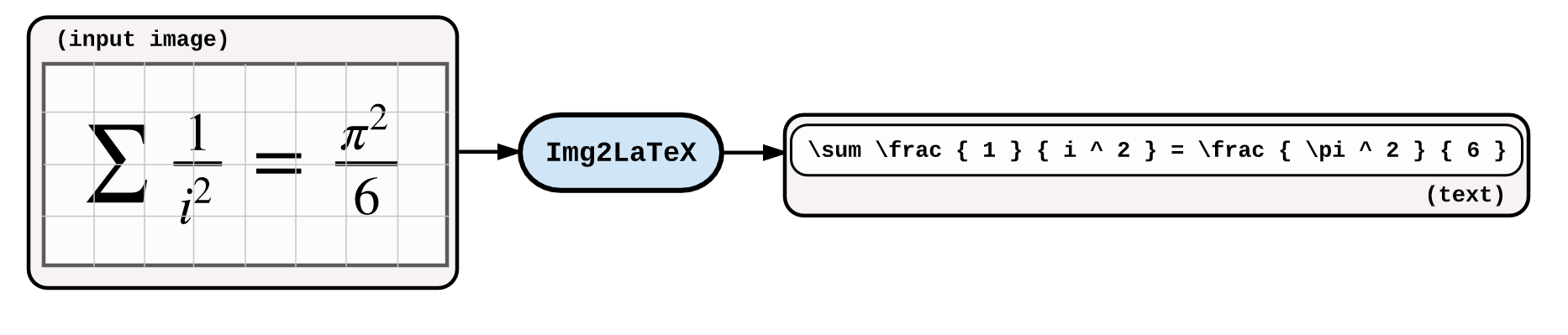
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
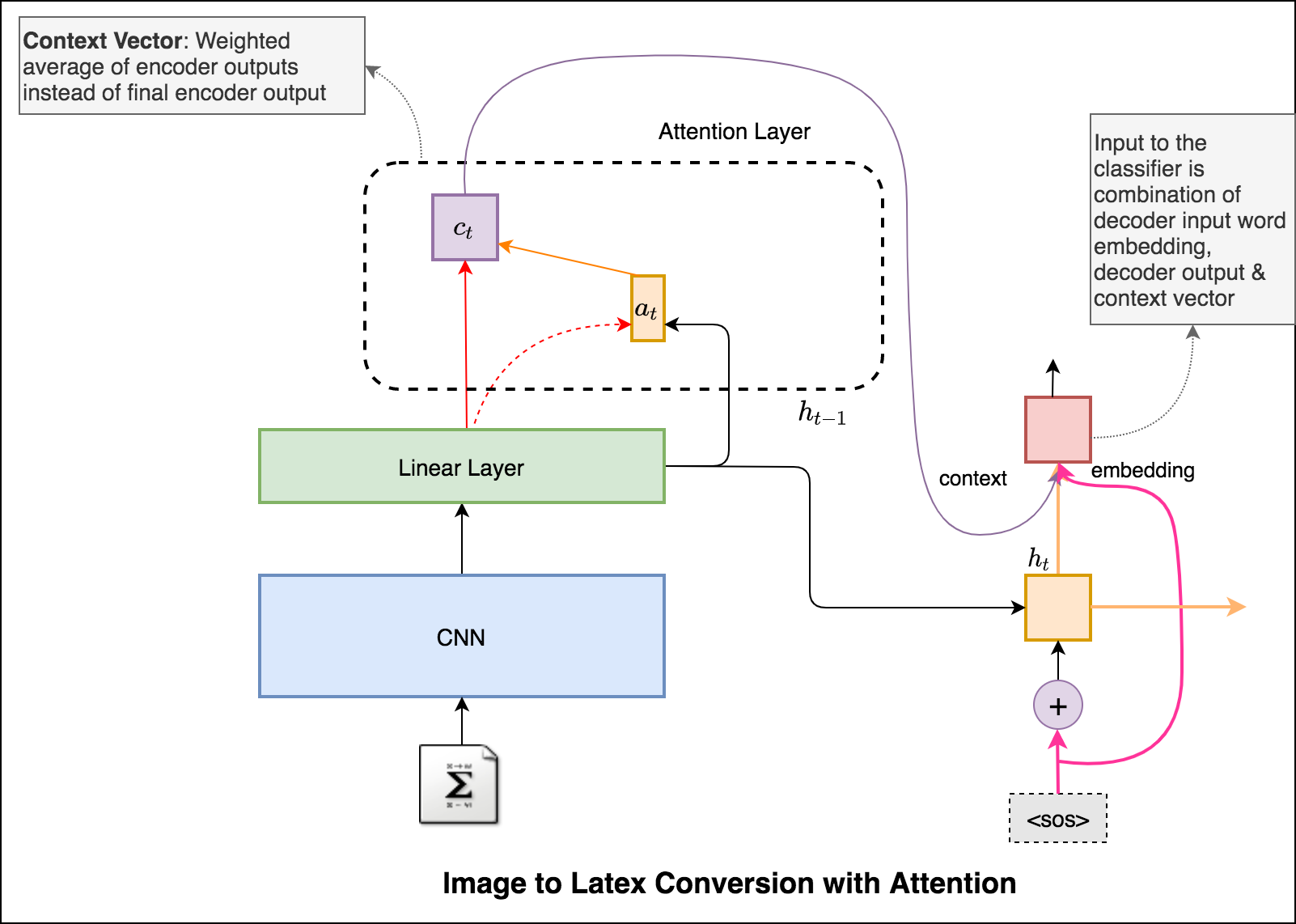
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

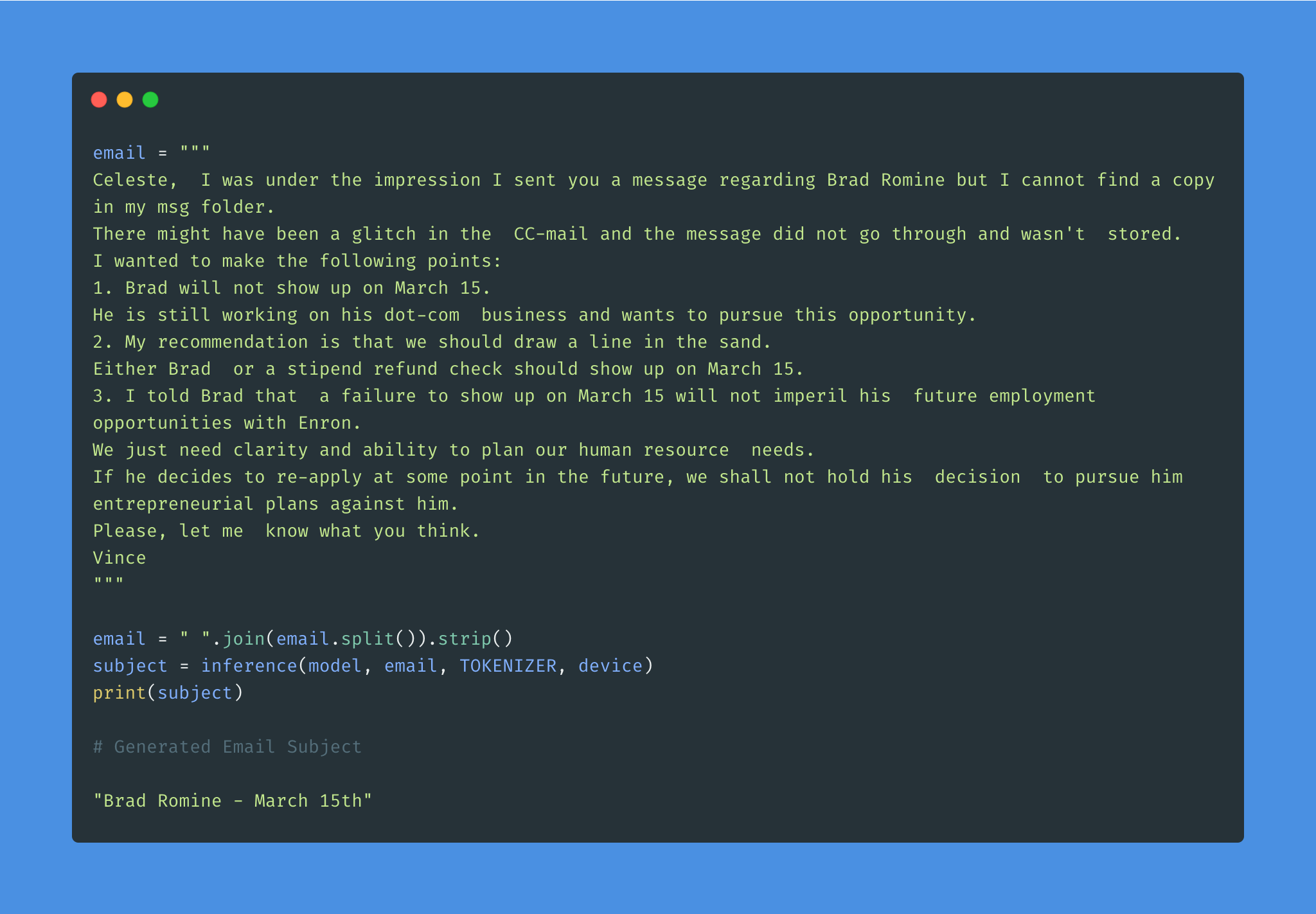
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
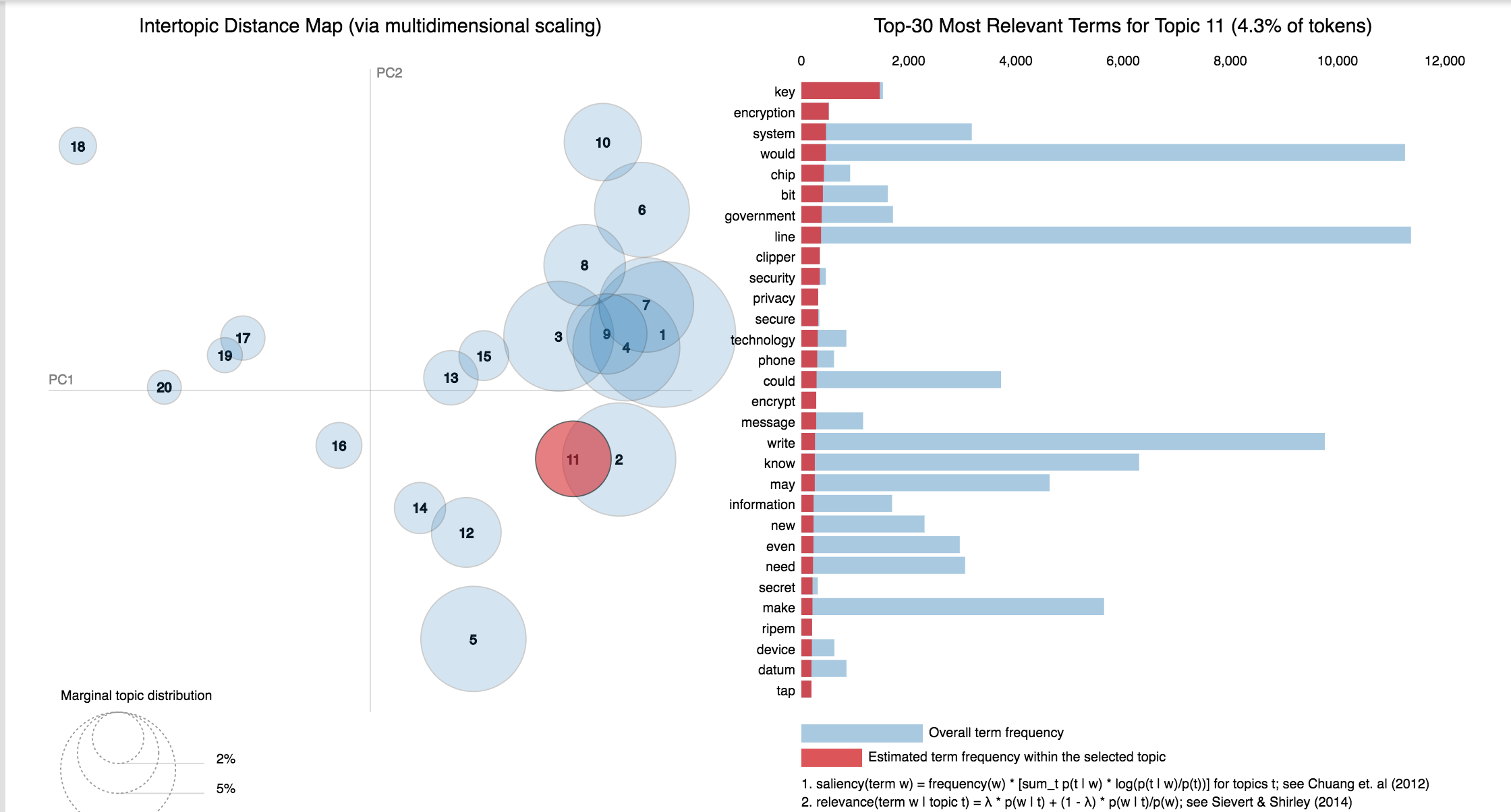
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
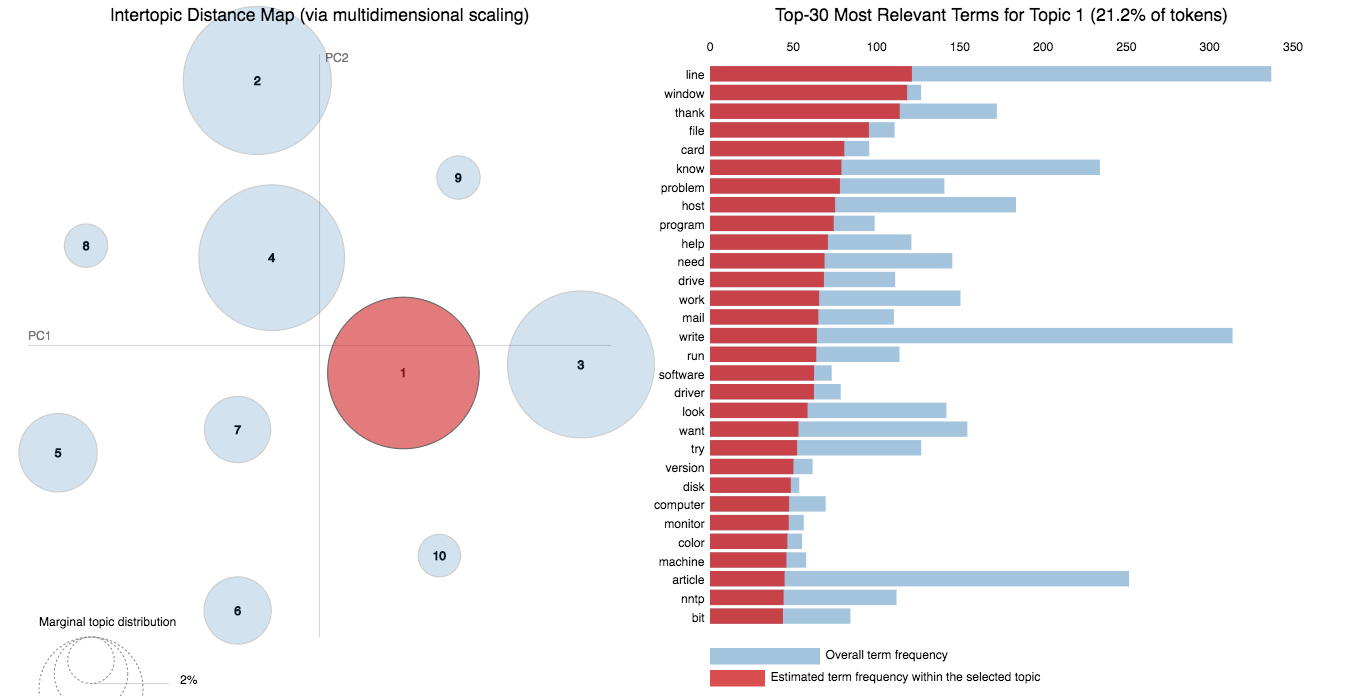
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
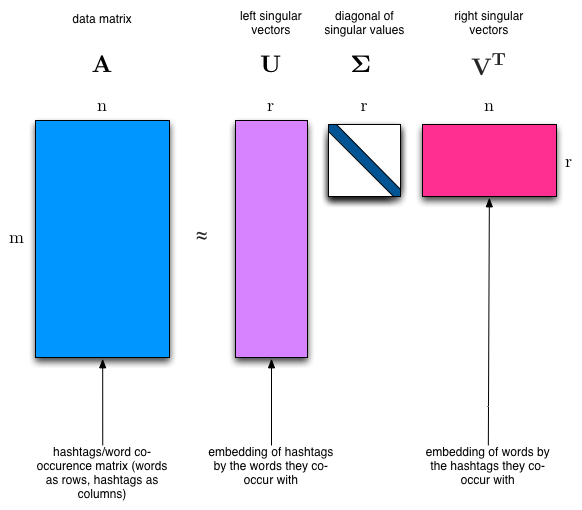
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
หมายเหตุ:
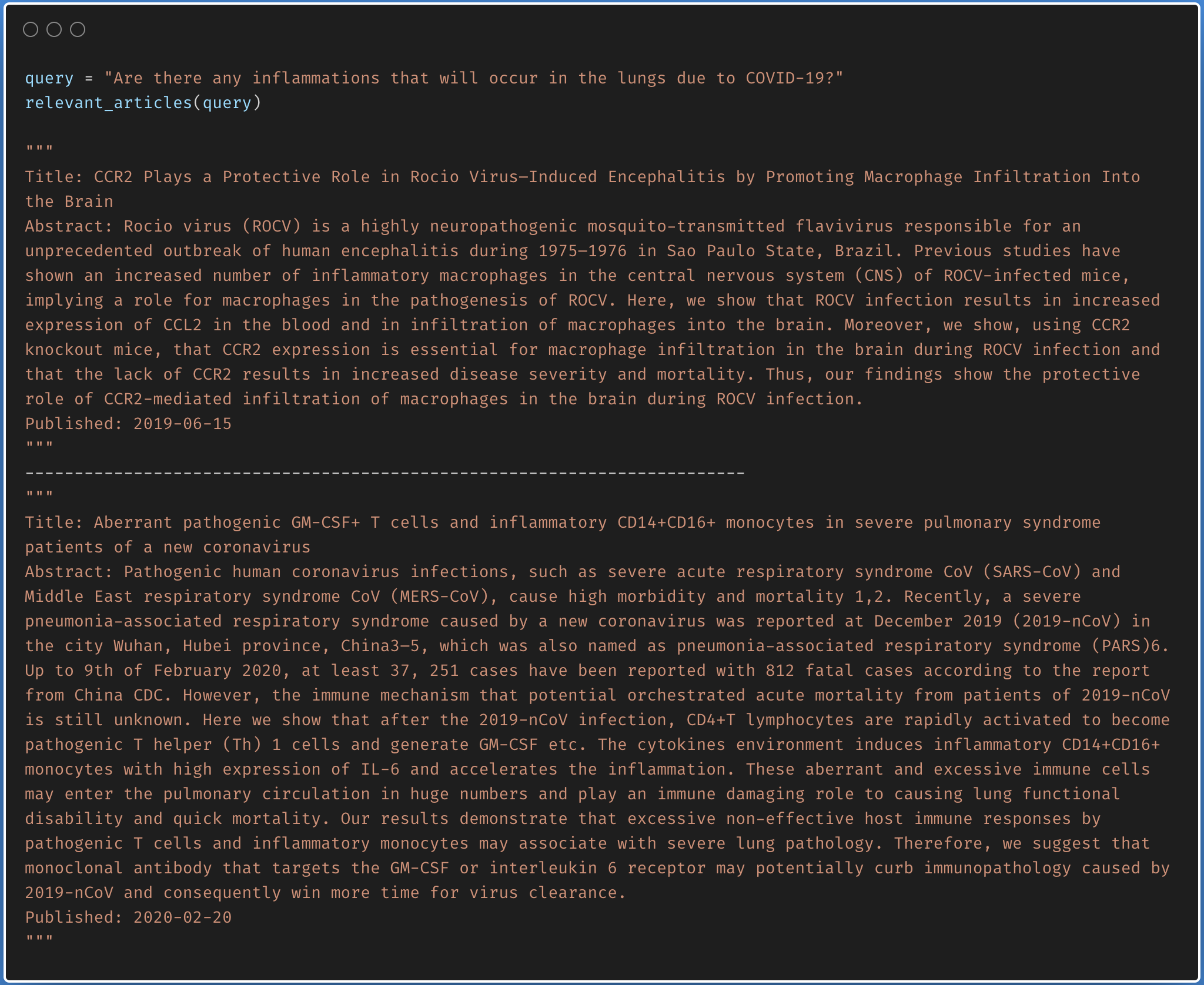
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
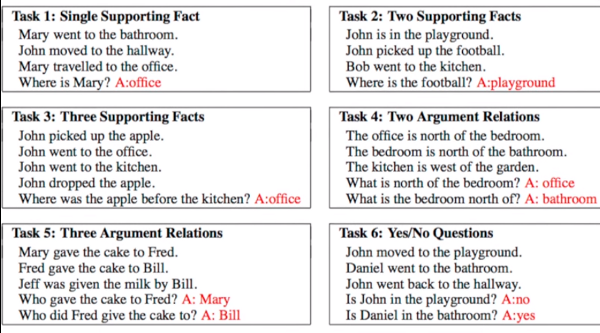
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

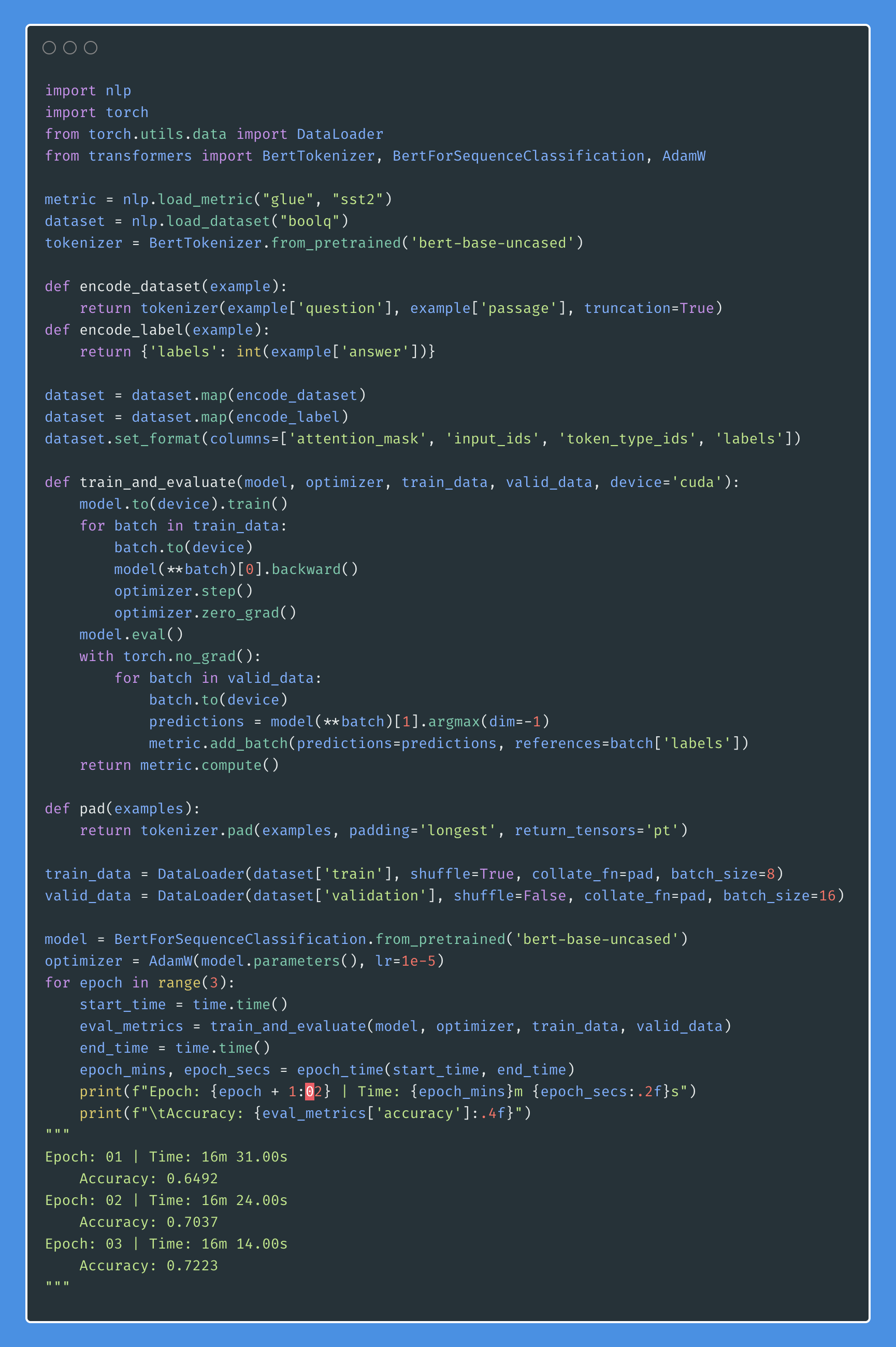
Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
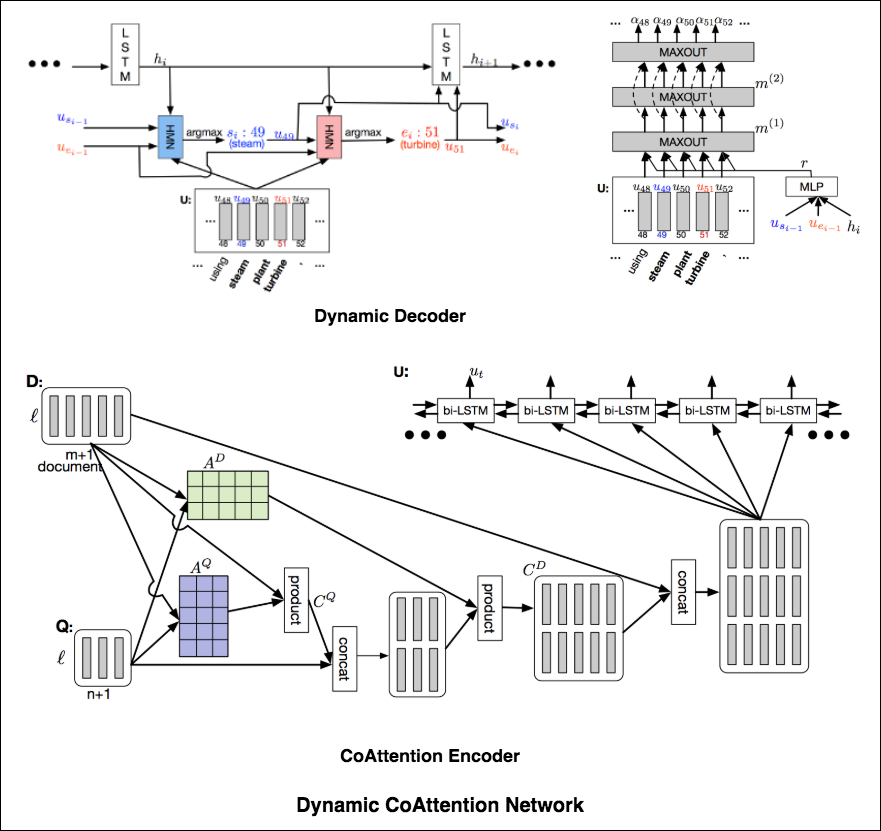
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
| Covid-19 Browser |
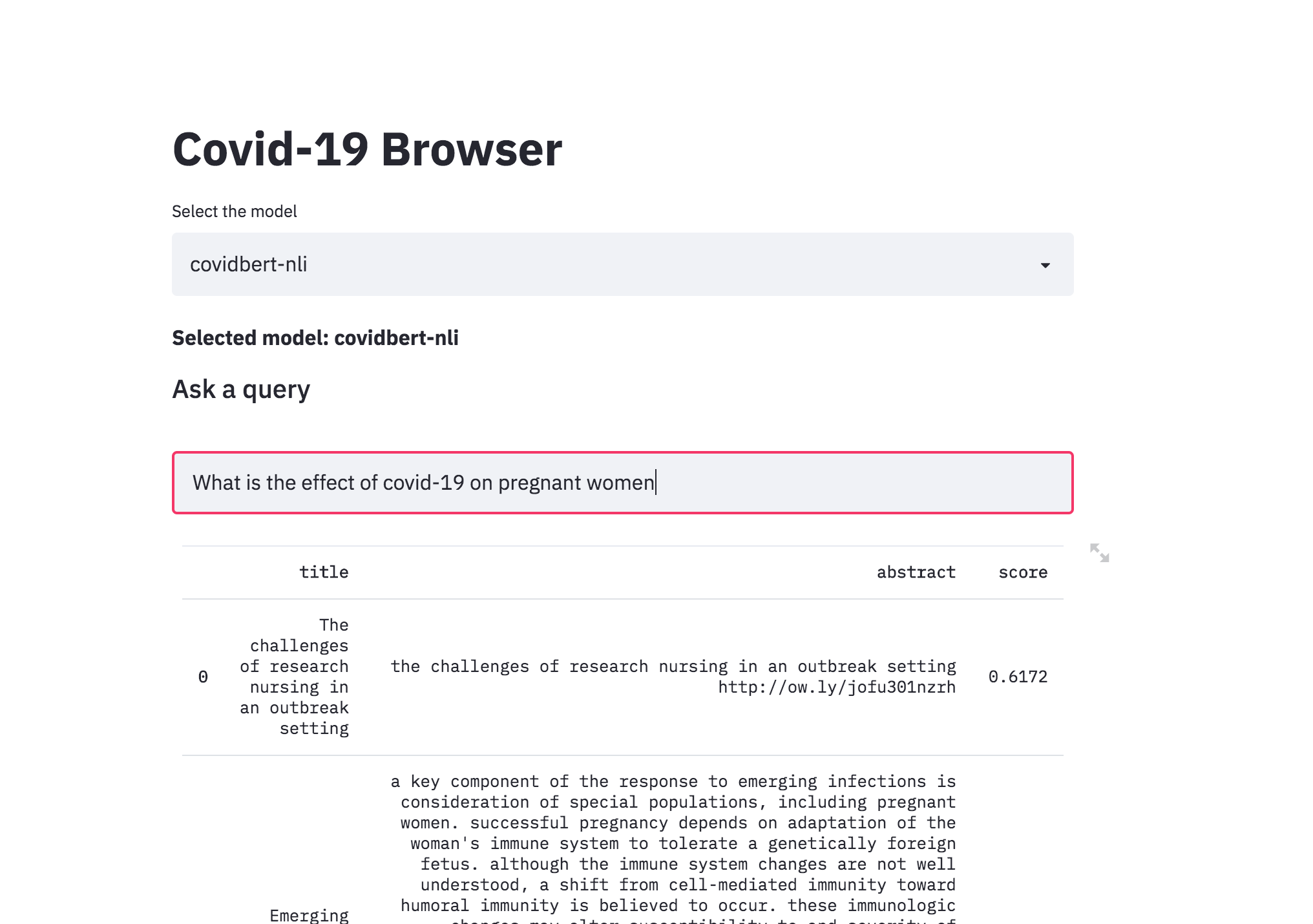
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
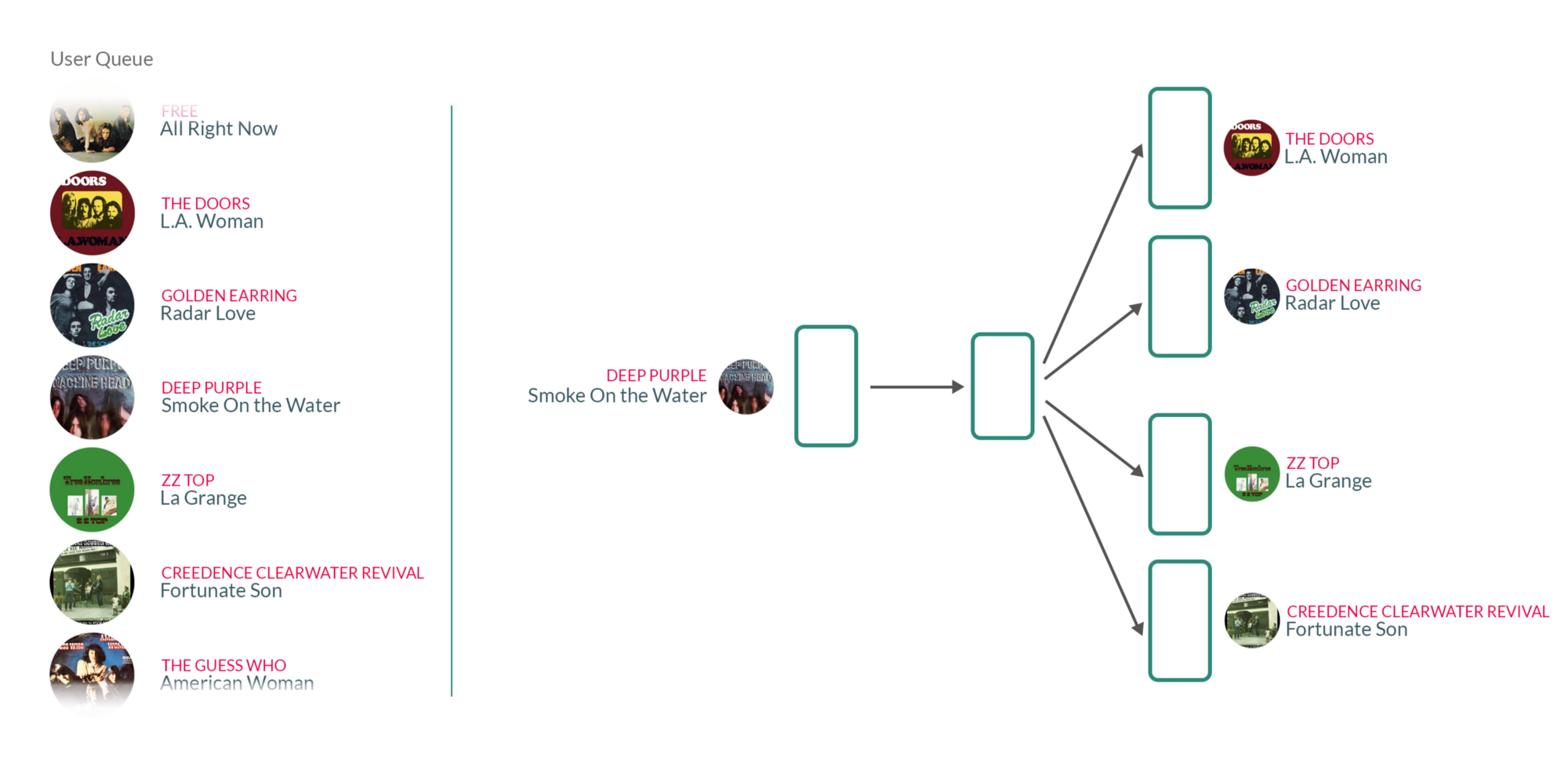
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


