100 Days of NLP
1.0.0

魔法について魔法は何もありません。魔術師は、訓練されていない聴衆にとってはシンプルまたは自然ではないように見えるシンプルなものを単に理解しているだけです。手を空にしながらカードを保持する方法を学ぶと、あなたも「魔法をかける」ことができる前に練習する必要があります。 - ジェフリー・フリードルは、定期的な表現をマスターする本の中で
注:提案、修正、フィードバックについて問題を提起してください。
ほとんどのコードサンプルは、jupyterノートブック(colabを使用)を使用して行われます。そのため、各コードは独立して実行できます。
次のトピックが検討されています。
注:難易度は、私の理解に従って割り当てられています。
| トークン化 | Word Embeddings -Word2vec | ワード埋め込み - グローブ | 単語埋め込み - エルモ |
| RNN、LSTM、Gru | パッド付きシーケンスのパッキング | 注意メカニズム - ルオン | 注意メカニズム - バダナウ |
| ポインターネットワーク | トランス | GPT-2 | バート |
| トピックモデリング-LDA | 主成分分析(PCA) | 素朴なベイズ | データ増強 |
| 文の埋め込み |
テキストデータをトークンに変換するプロセスは、NLPの最も重要なステップの1つです。次の方法を使用したトークン化が検討されています。
単語の埋め込みは、同じ意味を持つ単語が同様の表現を持っているテキストの学習表現です。これは、挑戦的な自然言語処理の問題に関する深い学習の重要なブレークスルーの1つと考えられる可能性のある単語や文書を表すためのこのアプローチです。

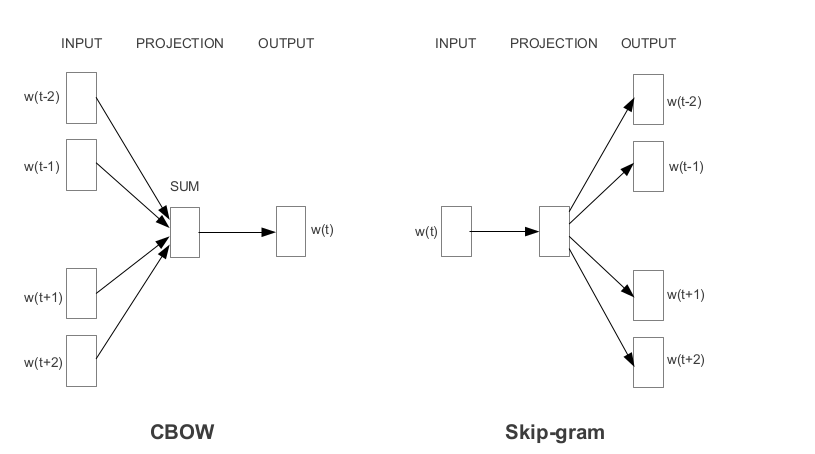
Word2vecは、Googleが開発した最も人気のある優先ワード埋め込みの1つです。埋め込みの方法に応じて、Word2vecは2つのアプローチに分類されます。
グローブは、事前に訓練された埋め込みを取得するもう1つの一般的に使用される方法です。グローブは、2つの目標を達成することを目指しています。
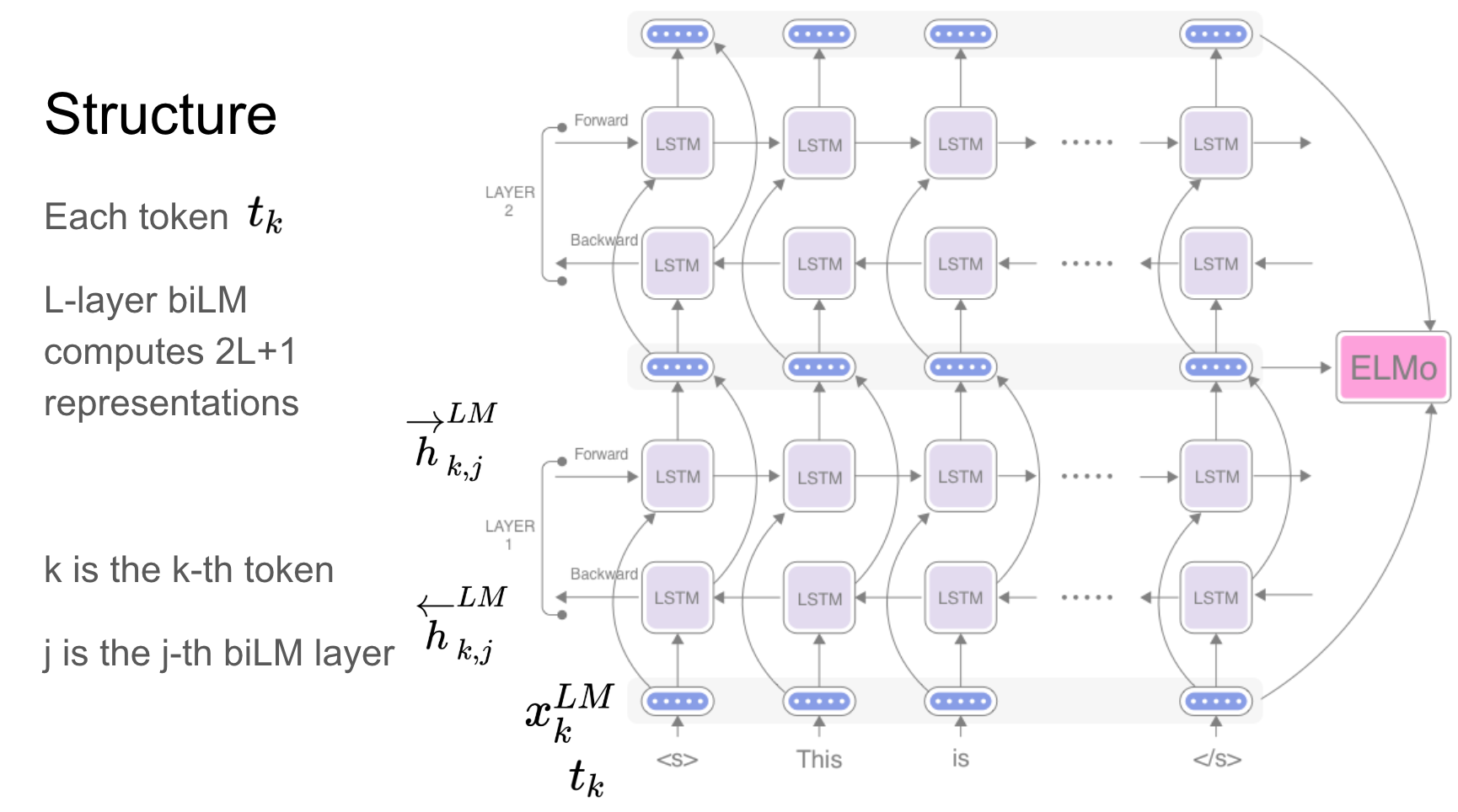
Elmoは、モデル化する深い文脈化された単語表現です。
これらの単語ベクトルは、大きなテキストコーパスで事前に訓練されている深い双方向言語モデル(BILM)の内部状態の関数を学習しています。
Recurrent Networks -RNN、LSTM、GRUは、アーキテクチャのため、NLPアプリケーションで最も重要なユニットの1つであることが証明されています。シーンの感情を予測するために、シーケンスの性質を記憶する必要がある多くの問題があります。以前のシーンを覚えておく必要があります。

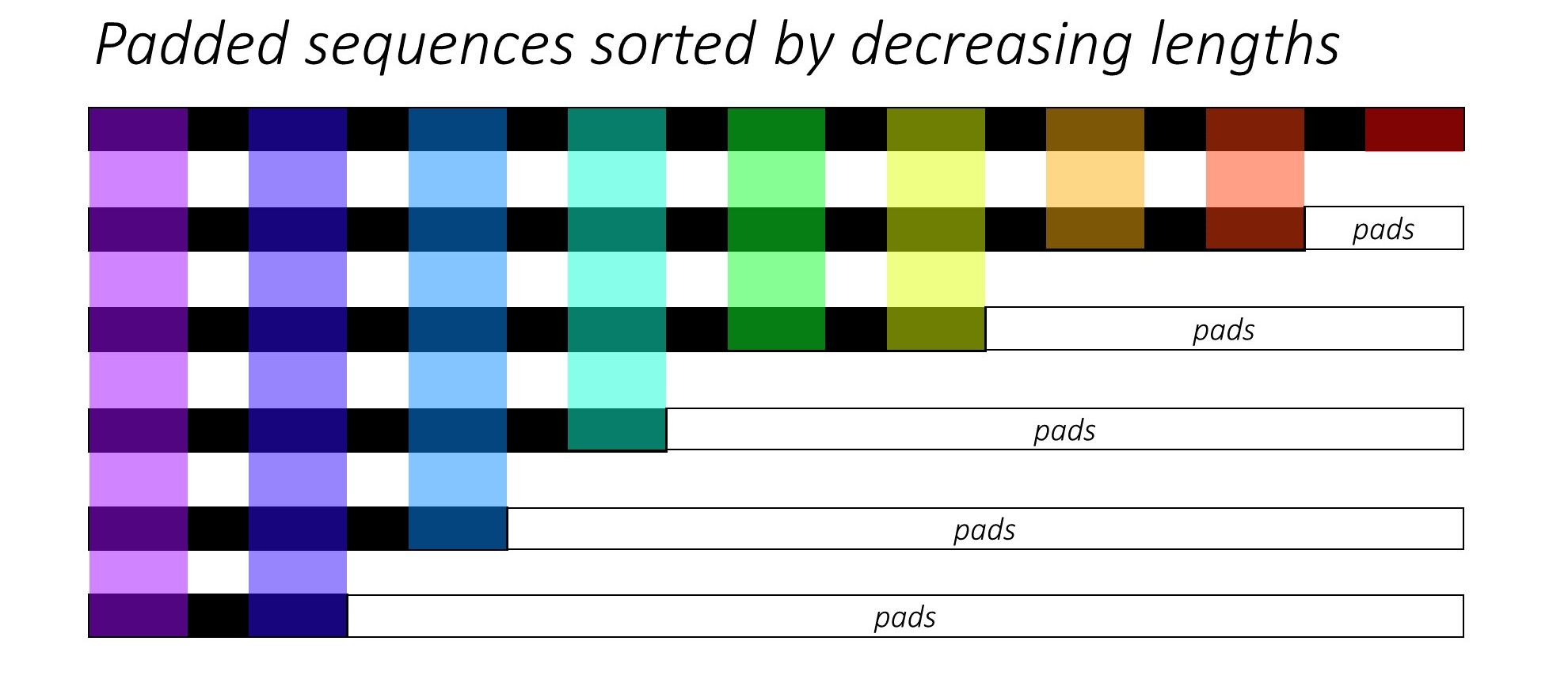
RNN(LSTMまたはGRUまたはVanilla-RNN)をトレーニングする場合、可変長シーケンスをバッチすることは困難です。理想的には、すべてのシーケンスを固定長にパッドし、最終的には不要な計算を実行します。どうすればこれを克服できますか? Pytorchは、 pack_padded_sequences機能を提供します。
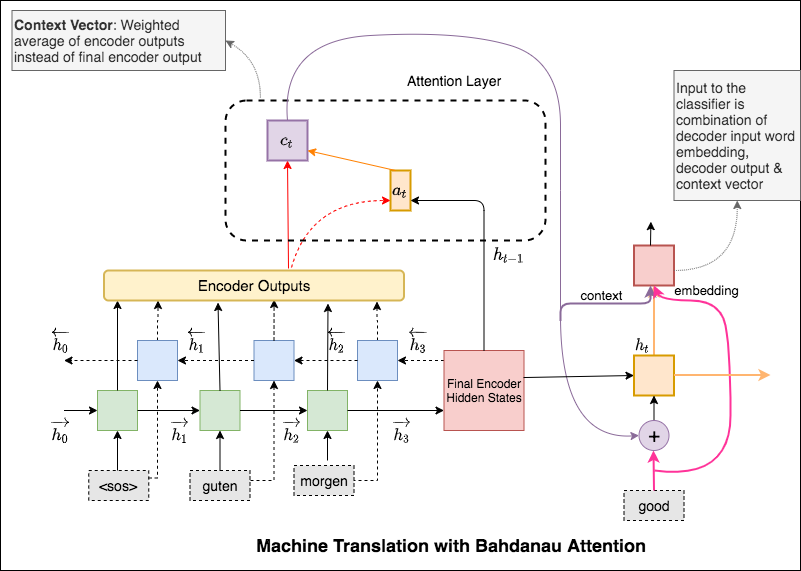
注意メカニズムは、神経機械翻訳(NMT)の長いソース文を記憶するのを助けるために生まれました。エンコーダの最後の隠された状態から単一のコンテキストベクトルを構築するのではなく、文をデコードしながら入力の関連部分により多くの焦点を合わせるために注意が使用されます。コンテキストベクトルは、エンコーダー出力とデコーダーRNNのcurrent outputを取得することにより作成されます。

注意スコアは3つの方法で計算できます。 dot 、 general 、 concat 。
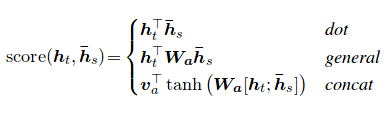
BahdanauとLuongの注意の大きな違いは、コンテキストベクトルの作成方法です。コンテキストベクトルは、エンコーダー出力とデコーダーRNNのprevious hidden stateを取得することにより作成されます。ここで、注意してください。エンコーダー出力とデコーダーRNNのcurrent hidden stateを取得することにより、コンテキストベクトルが作成されます。
コンテキストが計算されると、デコーダー入力埋め込みと組み合わされ、デコーダーRNNへの入力として供給されます。

Bahdanauの注意は、 additive注意とも呼ばれます。
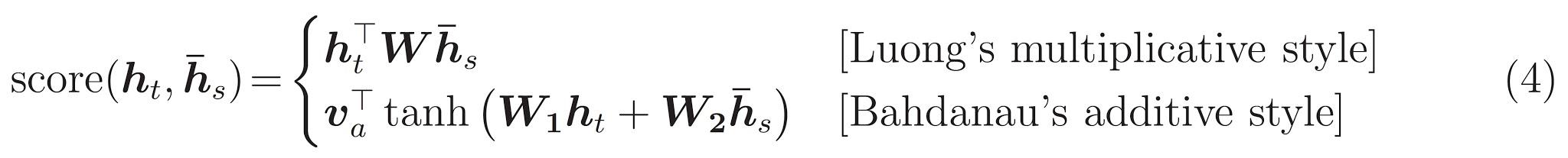
変圧器は、再発を避け、代わりに入力と出力の間にグローバルな依存関係を引き出すための注意メカニズムに完全に依存しています。
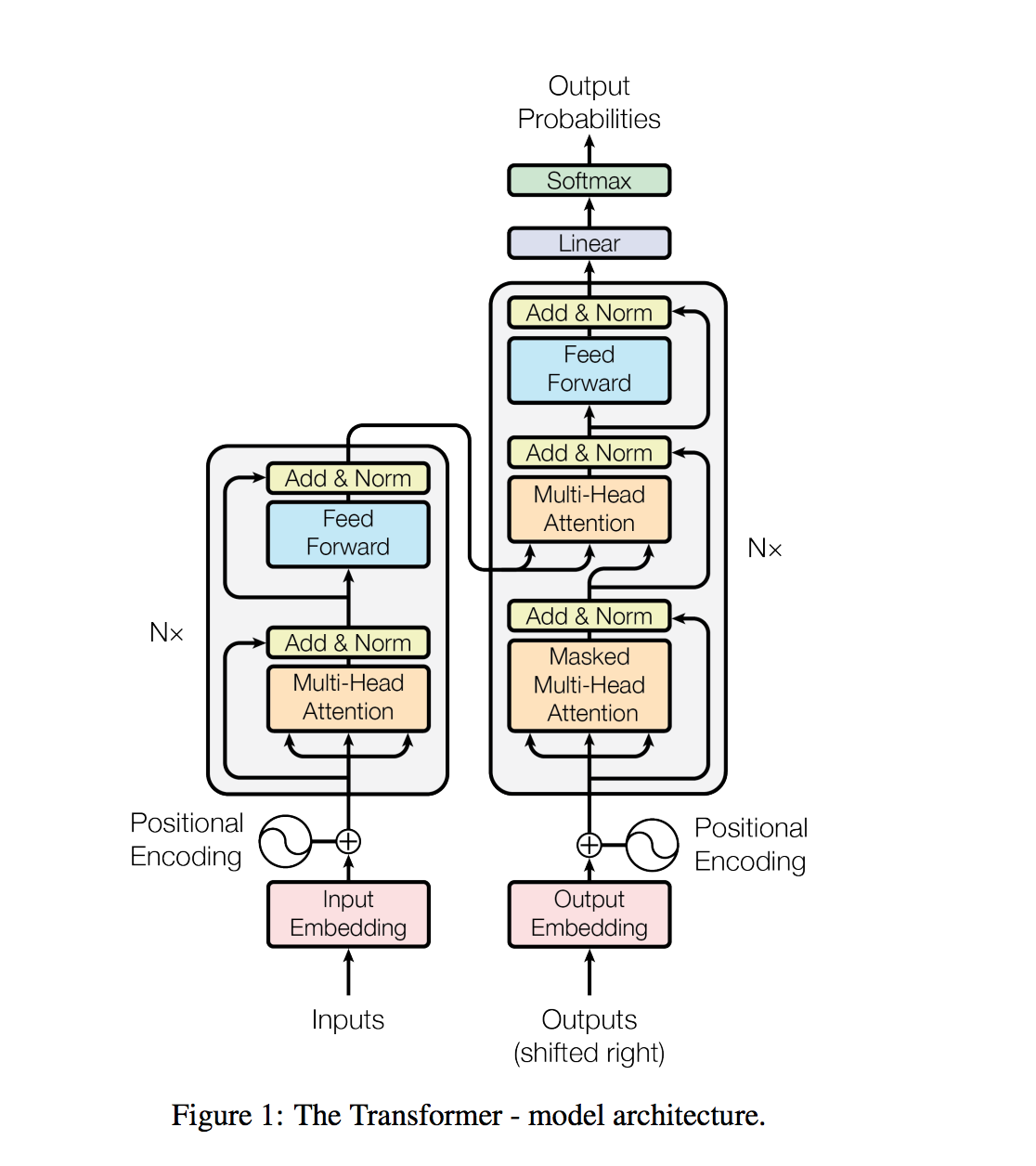
質問の回答、機械の翻訳、読解、要約などの自然言語処理タスクは、タスク特有のデータセットでの監視された学習で通常、アプローチされます。 WeBtextと呼ばれる数百万のウェブページの新しいデータセットで訓練されたとき、言語モデルは明示的な監督なしでこれらのタスクを学習し始めることを実証します。当社の最大のモデルであるGPT-2は、ゼロショット設定でテストされた8つの言語モデリングデータセットのうち7で最先端の結果を達成する1.5Bパラメータートランスですが、それでもwebtextです。モデルからのサンプルは、これらの改善を反映し、テキストの一貫した段落を含んでいます。これらの調査結果は、自然に発生するデモンストレーションからタスクを実行することを学ぶ言語処理システムを構築するための有望な道を示唆しています。
GPT-2は、12層デコーダーのみのトランスアーキテクチャを使用しています。
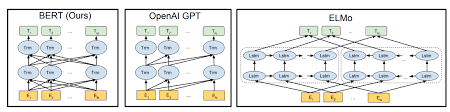
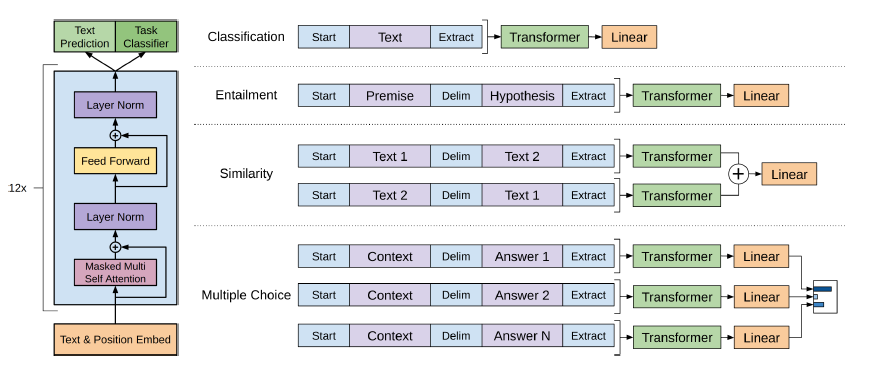
Bertは、文章をエンコードするためにトランスアーキテクチャを使用しています。
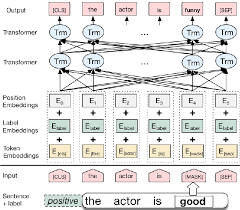
ポインターネットワークの出力は個別であり、入力シーケンス内の位置に対応しています
出力の各ステップのターゲットクラスの数は、入力の長さに依存します。これは可変です。
それは、各デコーダーステップでエンコーダの非表示ユニットをコンテキストベクトルにブレンドしてエンコーダユニットをブレンドするのではなく、ポインターとして注意を使用して出力として選択を使用します。

自然言語処理の主なアプリケーションの1つは、大量のテキストから人々が議論しているトピックを自動的に抽出することです。大規模なテキストの例には、ソーシャルメディア、ホテル、映画などの顧客レビュー、ユーザーフィードバック、ニュース記事、顧客の苦情の電子メールなどからのフィードがあります。
人々が何について話しているかを知り、問題や意見を理解することは、企業、管理者、政治キャンペーンにとって非常に価値があります。そして、このような大量を手動で読み取り、トピックを編集することは本当に難しいです。
したがって、テキストドキュメントを読み取り、説明したトピックを自動的に出力できる自動アルゴリズムが必要です。
このノートブックでは、 20 Newsgroups Datasetの実際の例を挙げて、LDAを使用して自然に説明したトピックを抽出します。
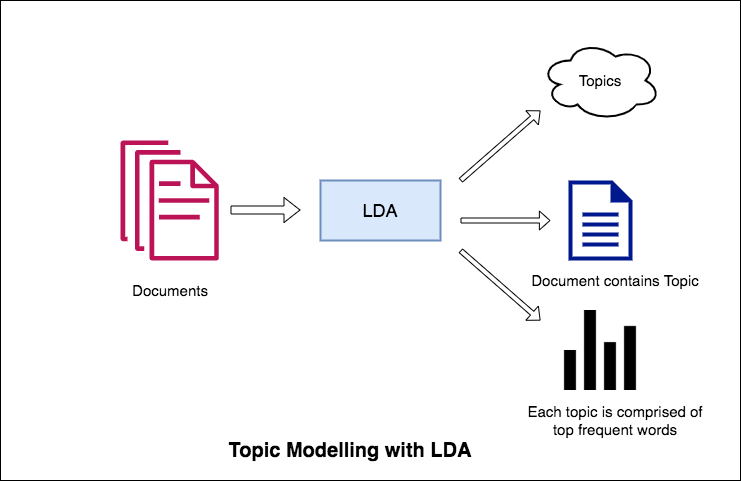
LDAのトピックモデリングへのアプローチは、各ドキュメントを特定の割合のトピックのコレクションと見なすことです。また、各トピックは、キーワードのコレクションとして、繰り返しますが、特定の割合で。
アルゴリズムにトピックの数を提供すると、トピックキーワード分布の適切な構成を取得するために、ドキュメント内のトピック分布とキーワード分布を再配置するためにすべてが行われます。
PCAは、基本的に、データセットの列を新しいセット機能に変換する次元削減手法です。これは、データの最大変動性を説明する新しい方向(x軸やy軸など)を見つけることで行います。この新しいシステム座標軸は、主成分(PC)と呼ばれます。
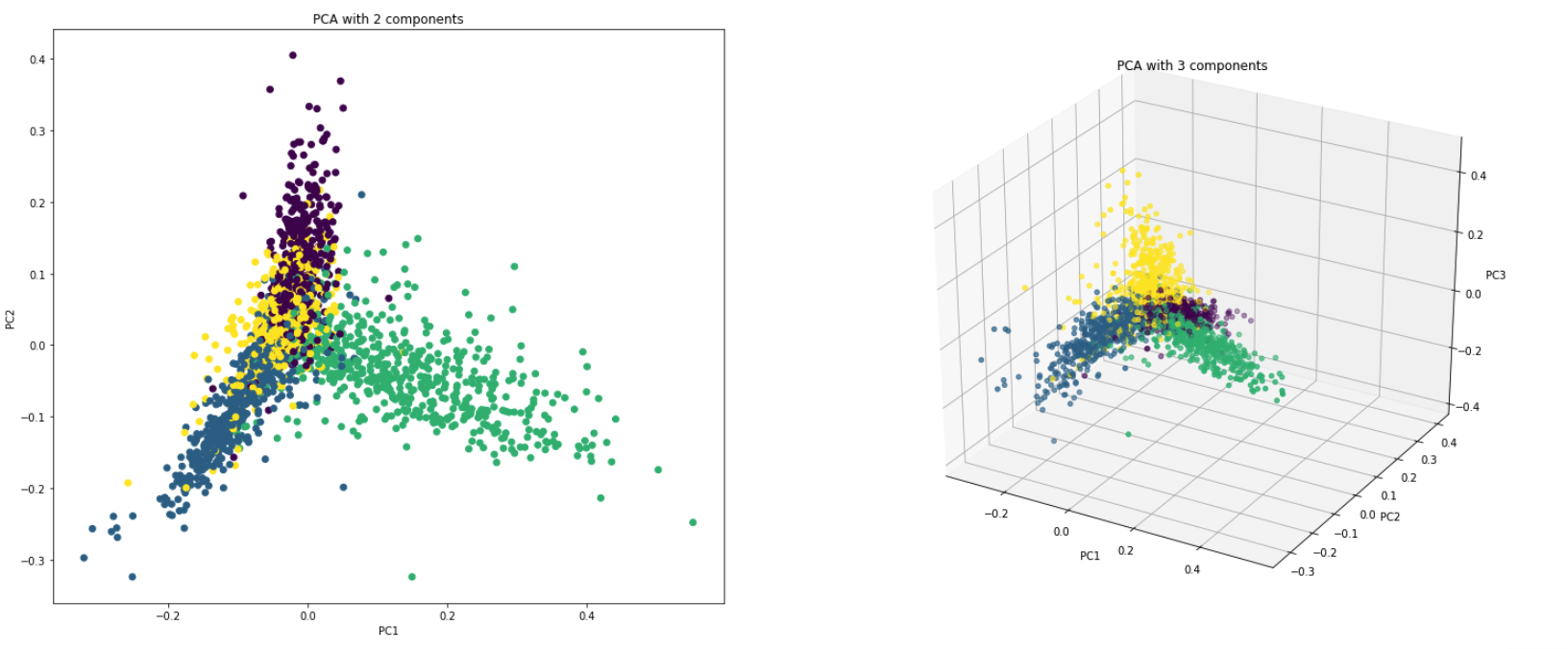
実質的にPCAは2つの理由で使用されます。
Dimensionality Reduction :多数の列に分配された情報は、最初の数個のPCが総情報のかなりの部分を説明できるように、主成分(PC)に変換されます(分散)。これらのPCは、機械学習モデルの説明変数として使用できます。
Visualize Data :クラス(またはクラスター)の分離を視覚化することは、3つ以上の寸法(機能)を持つデータにとって困難です。最初の2つのPC自体では、通常、明確な分離を確認することが可能です。
ナイーブベイズ分類器は、分類タスクに使用される確率的機械学習モデルです。分類器の核心は、ベイズ定理に基づいています。
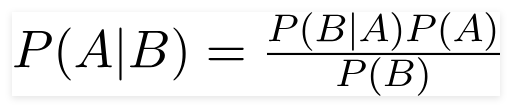
ベイズ定理を使用して、Bが発生したことを考えると、Aが起こる可能性を見つけることができます。ここで、Bは証拠であり、Aは仮説です。ここで行われた仮定は、予測因子/機能が独立しているということです。それは、ある特定の機能の存在が他の機能に影響しないということです。したがって、それはナイーブと呼ばれます。
ナイーブベイズ分類器の種類:
Multinomial Naive Bayes :これは、変数が個別の場合(単語のような)場合に主に使用されます。分類器が使用する機能/予測子は、ドキュメントに存在する単語の頻度です。
Gaussian Naive Bayes :予測因子が連続値を取り、離散しない場合、これらの値はガウス分布からサンプリングされると仮定します。
Bernoulli Naive Bayes :これは多項ナイーブベイズに似ていますが、予測因子はブール変数です。クラス変数を予測するために使用するパラメーターは、テキストで単語が発生するかどうかなど、イエスまたはノーの値のみを占有します。
20NewsGroupデータセットを使用して、ナイーブベイズアルゴリズムを検討して分類を行います。
次の手法を使用したデータ増強については、次のように検討してください。

Sbertと呼ばれる新しいアーキテクチャが探索されました。シアムネットワークアーキテクチャにより、入力文の固定サイズのベクトルを導き出すことができます。 CosinInimilalityやManhatten / Euclideanの距離などの類似性測定を使用して、意味的に類似した文が見つかります。

| 感情分析-IMDB | センチメント分類 - ヒングリッシュ | ドキュメント分類 |
| 重複する質問ペア分類-Quora | POSタグ付け | 自然言語の推論-Snli |
| 有毒なコメント分類 | 文法的に正しい文 - コーラ | nerタグ付け |
感情分析とは、自然言語処理、テキスト分析、計算言語学、および生体認証の使用を指し、感情的な状態と主観的な情報を体系的に識別、抽出、定量化、および研究します。
次の異なるものが調査されています:
RNNは、感情の処理と識別に使用されます。

Test_Accuracyを50%未満にする基本的なRNNを試した後、次の手法が実験され、88%を超えるTest_Accuracyが達成されました。
使用されるテクニック:

注意は、入力の感情を予測するときに、関連する入力に焦点を合わせるのに役立ちます。 Bahdanauの注意は、LSTMの出力を取得し、最終的な前方および後方の隠れた状態を連結することに使用されました。事前に訓練された単語の埋め込みを使用せずに、 88%のテスト精度が達成されます。
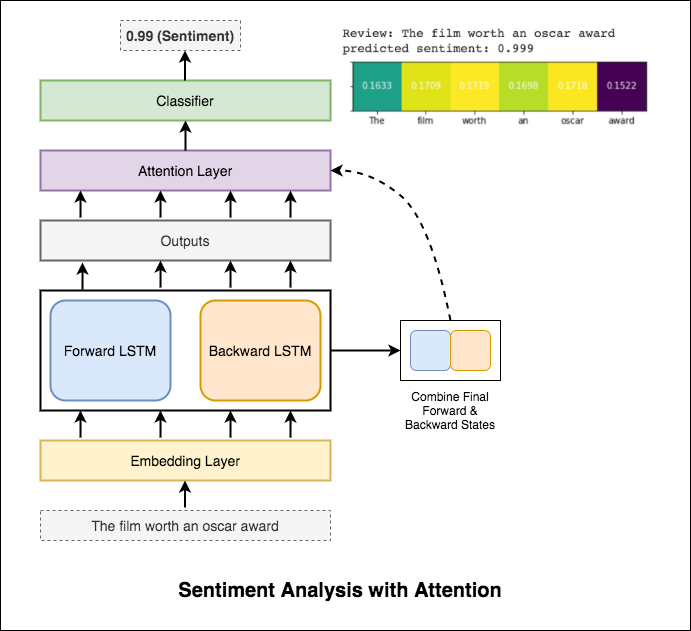
Bertは、11の自然言語処理タスクで新しい最先端の結果を取得します。 NLPでの転送学習は、BERTモデルのリリース後にトリガーされました。 BERTを使用してセンチメント分析を行うことを検討します。

コードミックスとも呼ばれる言語の混合は、多言語社会の標準です。非ネイティブの英語の話者である多言語の人々は、英語ベースの音声タイピングと主要な言語での英国主義の挿入を使用してコードミックスする傾向があります。
タスクは、特定のコードミックスツイートの感情を予測することです。センチメントラベルは肯定的、ネガティブ、またはニュートラルであり、コード混合言語は英語のヒンディになります。 (sentimix)
次の異なるものが調査されています:
単純なMLPモデルを使用して、テストデータでF1 score of 0.58達成しました

基本的なMLPモデルを調査した後、LSTMモデルを使用して感情予測に使用され、F1スコアは0.57達成しました。

結果は、実際には基本的なMLPモデルと比較して少なかった。理由の1つは、LSTMがコード混合データの非常に多様な性質のために、文の単語間の関係を学ぶことができないことです。
LSTMは、コード混合データの非常に多様な性質と事前に訓練された埋め込みのためにコード混合文の単語間の関係を学習できないため、F1スコアは少なくなります。
この問題を軽減するために、XLM-Robertaモデル(100の言語で事前に訓練されています)が、文のエンコードに使用されています。 XLM-Robertaモデルを使用するには、文は適切な言語である必要があります。したがって、最初にヒンジリッシュの言葉をヒンディー語(devanagari)形式に変換する必要があります。
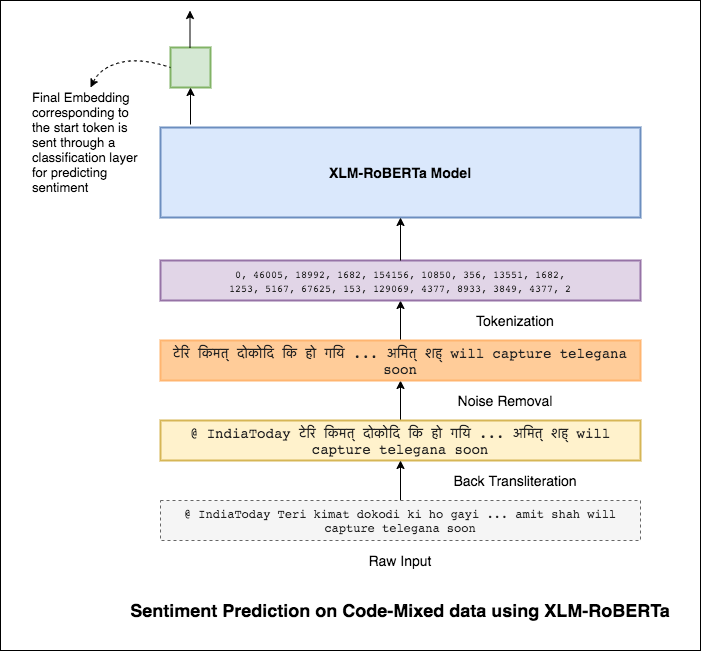
0.59のF1スコアが達成されました。これを改善する方法は、後で検討されます。
XLM-Robertaモデルからの最終出力は、双方向LSTMモデルへの入力埋め込みとして使用されました。 LSTMレイヤーから出力を取得する注意層は、入力の加重表現を生成し、その後、文の感情を予測するために分類器に渡されます。

0.64のF1スコアが達成されました。
3x3フィルターが画像のパッチを見渡すことができるのと同じように、1x2フィルターはテキストの2つのシーケンシャル単語、つまりバイグラムを見ることができます。このCNNモデルでは、テキスト内のBi-Grams(1x2フィルター)、Tri-Grams(1x3フィルター)、および/またはn-Grams(1xnフィルター)を見ることができるさまざまなサイズの複数のフィルターを使用します。
ここでの直感は、レビュー内の特定のバイグラム、トリグラム、nグラムの外観が最終的な感情の適切な兆候になるということです。
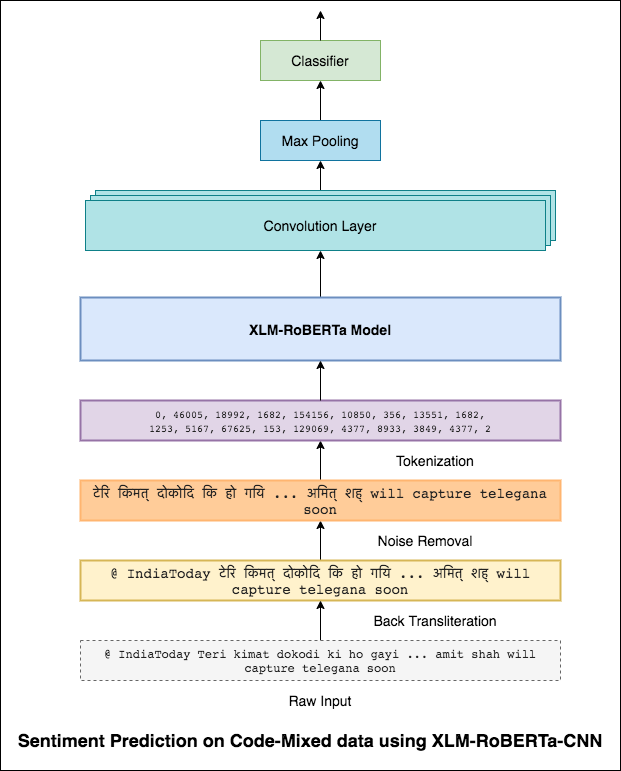
0.69のF1スコアが達成されました。
CNNは、RNNがグローバル依存関係をキャプチャする局所依存関係をキャプチャします。両方を組み合わせることで、データをよりよく理解できます。 CNNモデルと双方向gru-attentionモデルのアンサンベリングは、他のモデルを実行します。
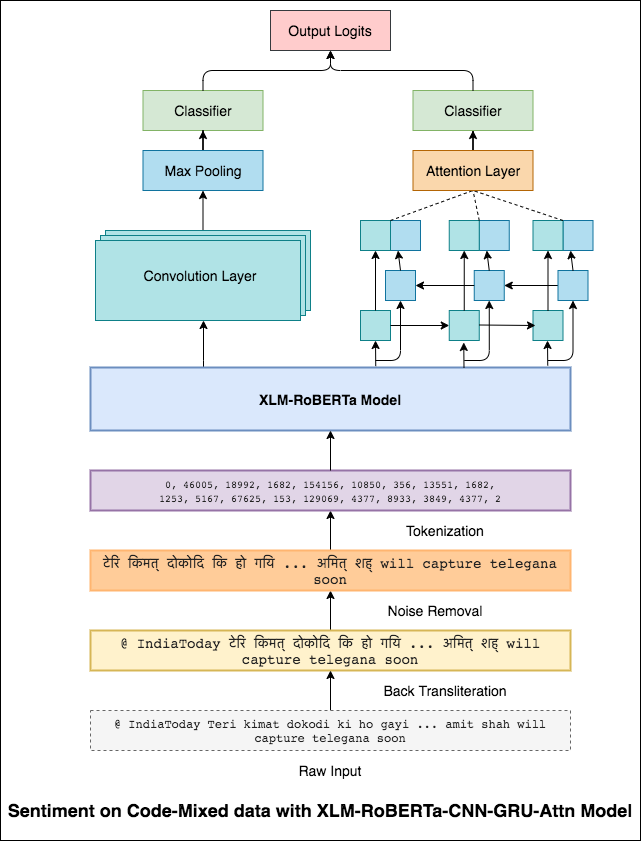
0.71のF1スコアが達成されました。 (リーダーボードのトップ5)。
文書分類または文書の分類は、図書館科学、情報科学、コンピューターサイエンスの問題です。タスクは、ドキュメントを1つ以上のクラスまたはカテゴリに割り当てることです。
次の異なるものが調査されています:
階層的注意ネットワーク(HAN)は、文書の階層構造(文書 - 文章 - 単語)を考慮し、文脈を考慮しながら文書で最も重要な単語と文を見つけることができる注意メカニズムを含みます。
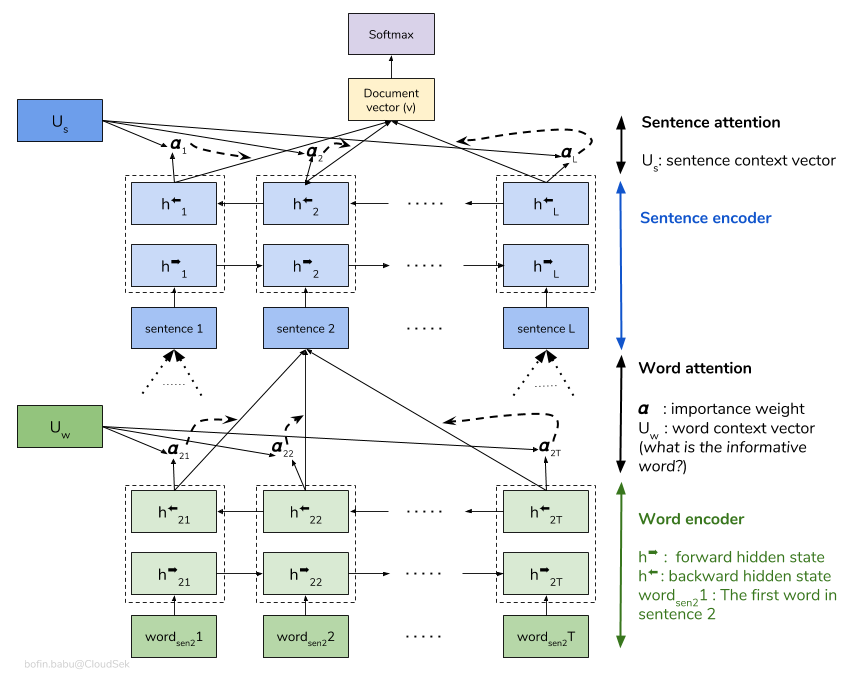
基本的なHANモデルは迅速に過剰に適合しています。これを克服するために、 Embedding Dropout 、 Locked Dropoutなどのテクニックが調査されます。実装されていないWeight Dropoutと呼ばれるもう1つの手法があります(これを実装する良いリソースがあるかどうかを教えてください)。ランダム初期化の代わりに、事前に訓練された単語埋め込みGloveも使用されます。注意は文レベルと単語レベルで行うことができるため、文でどの単語が重要であるか、文書でどの文が重要であるかを視覚化できます。



QQPは、Quoraの質問ペアを表しています。タスクの目的は、特定の一対の質問です。これらの質問が意味的に互いに類似しているかどうかを見つける必要があります。
次の異なるものが調査されています:
アルゴリズムは、一対の質問を入力として取得する必要があり、類似性を出力する必要があります。シャムネットワークが使用されています。 Siamese neural network (ツインニューラルネットワークとも呼ばれることもあります)は、2つの異なる入力ベクトルを並行して作業中にsame weightsを使用して、同等の出力ベクトルを計算する人工ニューラルネットワークです。

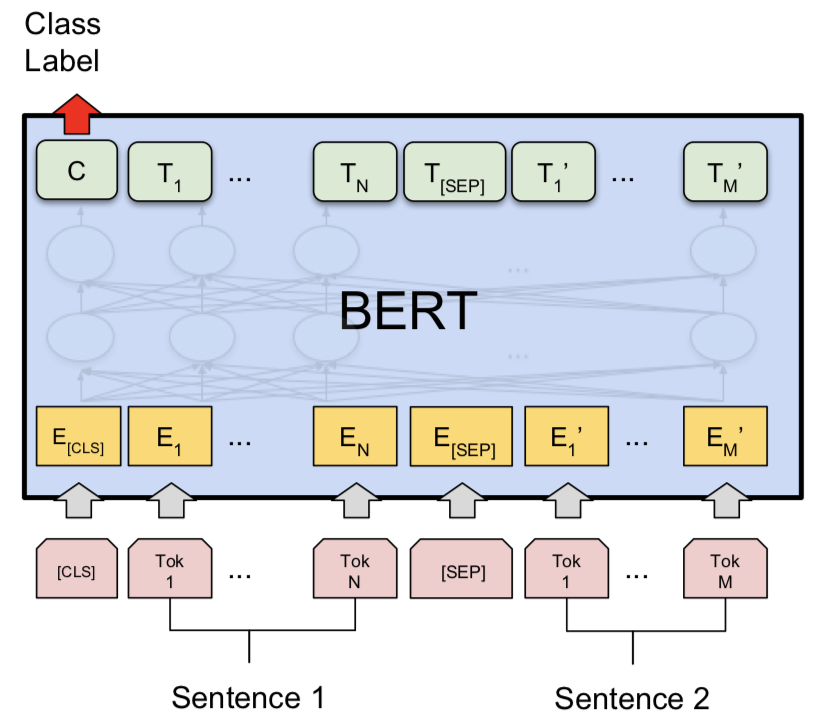
シャムモデルを試した後、バートはQuoraの重複質問ペア検出を行うために探索されました。 Bertは[SEP]トークンで区切られた入力として質問1と質問2を取り、 [CLS]トークンの最終表現を使用して分類が行われました。
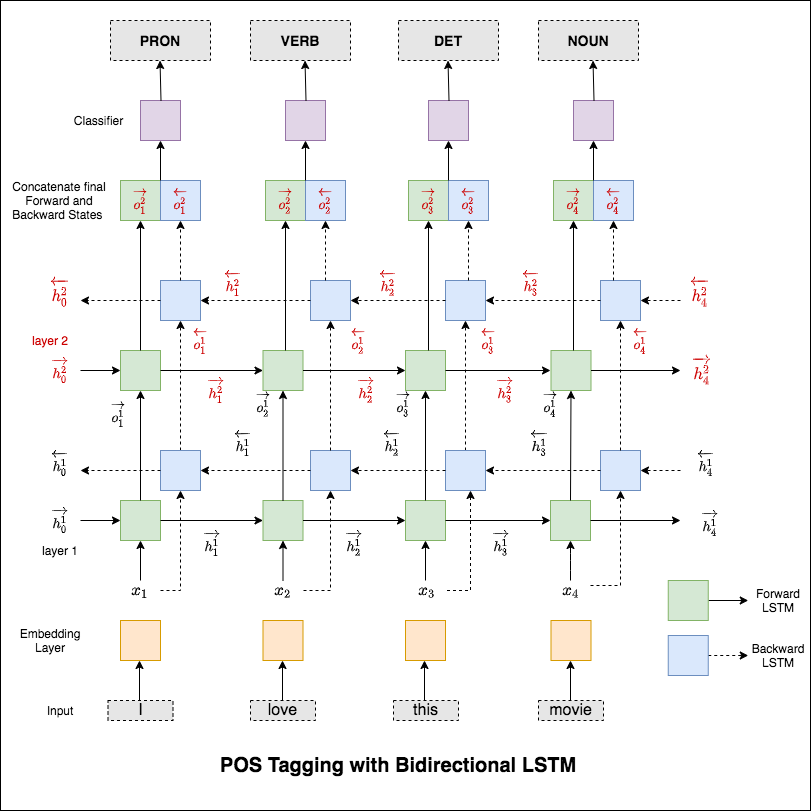
スピーチ(POS)タグ付けは、スピーチの適切な部分を持つ文の各単語にラベルを付けるタスクです。
次の異なるものが調査されています:
このコードは、基本的なワークフローをカバーしています。データの読み込み、トレーニング/テスト/検証の分割の作成、語彙の作成、データの反復者の作成、モデルの定義、トレイン/評価/テストループ、および実行時間(推論)タグ付けを実装する方法を学びます。
使用されるモデルは、多層双方向LSTMネットワークです
RNNアプローチを試した後、トランスベースのアーキテクチャを使用したPOSタグ付けが検討されます。変圧器にはエンコーダーとデコーダーの両方が含まれているため、シーケンスラベリングタスクの場合はEncoderのみで十分です。データは小さいため、6層のエンコーダーがデータに過剰に輝きます。そのため、3層変圧器エンコーダーモデルが使用されました。

トランスエンコーダーでPOSタグ付けを試みた後、事前に訓練されたBERTモデルでPOSタグ付けが悪用されます。 91%のテスト精度を達成しました。

自然言語推論(NLI)の目標は、広く研究されている自然言語処理タスクであり、与えられた声明(前提)が意味的に別の声明(仮説)を意味するかどうかを判断することです。
次の異なるものが調査されています:
シャムBilStmネットワークを備えた基本モデルが実装されています
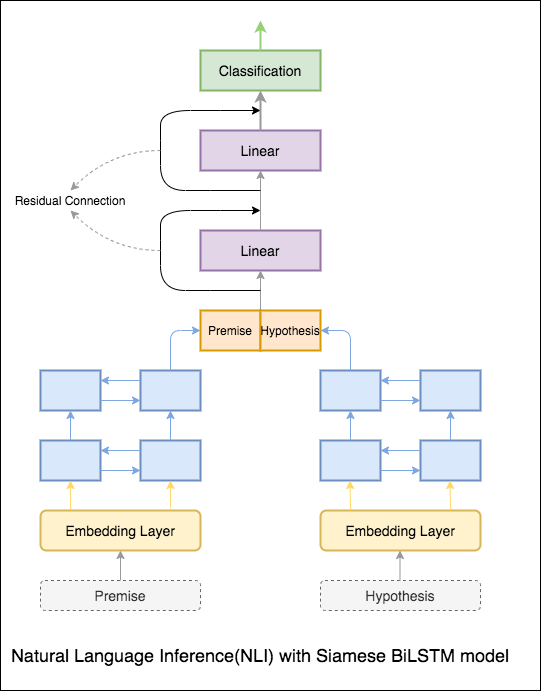
これは、ベースラインのセットアップとして扱うことができます。 76.84%のテスト精度が達成されました。
以前のノートでは、LSTMからの表現としての前提と仮説の最終的な隠された状態。現在、最終的な隠された状態をとる代わりに、すべての入力トークンで注意が計算され、最終的な加重ベクトルが前提と仮説の表現として取られます。
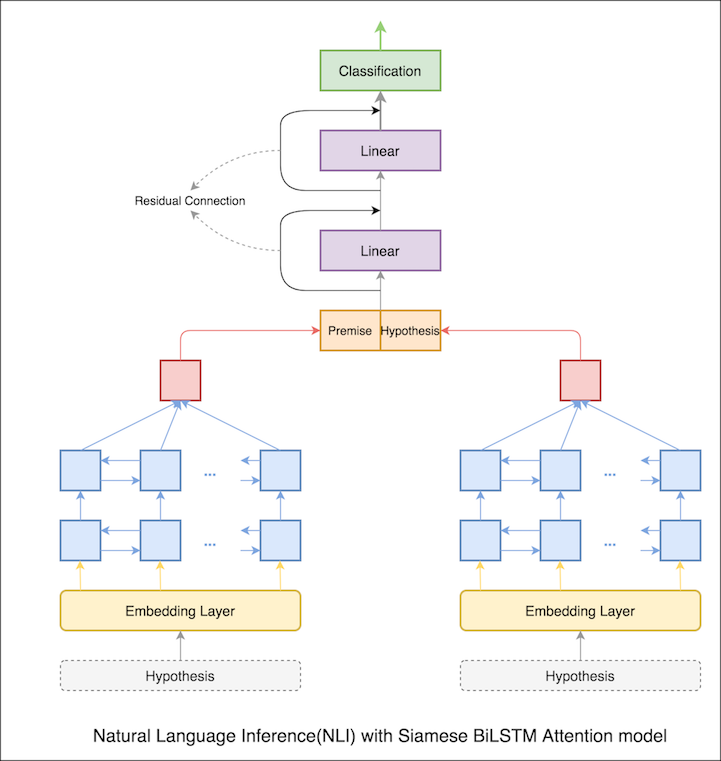
テストの精度は76.84%から79.51%に増加しました。
変圧器エンコーダーを使用して、前提と仮説をエンコードしました。文がエンコーダーに渡されると、すべてのトークンの合計が最終表現と見なされます(その他のバリアントを調査できます)。モデルの精度は、RNNバリアントと比較して少ないです。
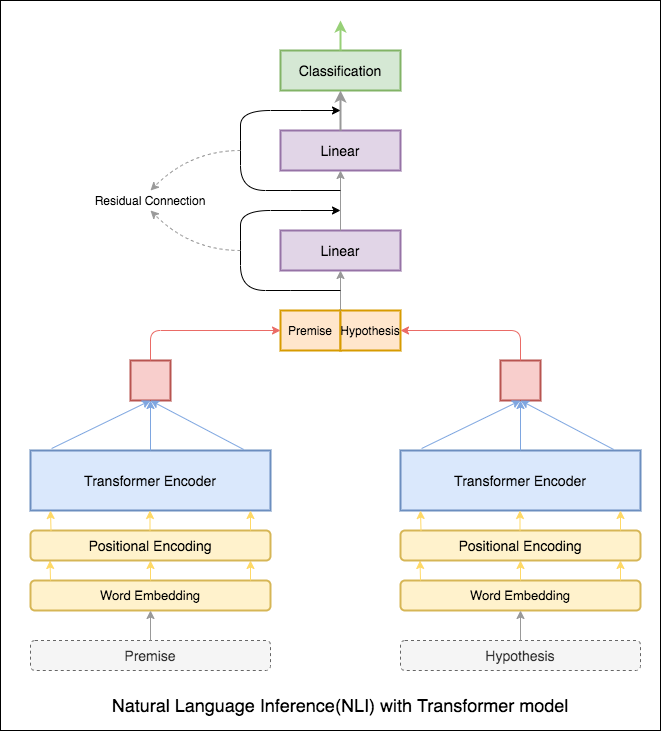
Bert Baseモデルを備えたNLIが調査されました。 Bertは[SEP]トークンで区切られた入力として前提と仮説を取り、 [CLS]トークンの最終表現を使用して分類が行われました。
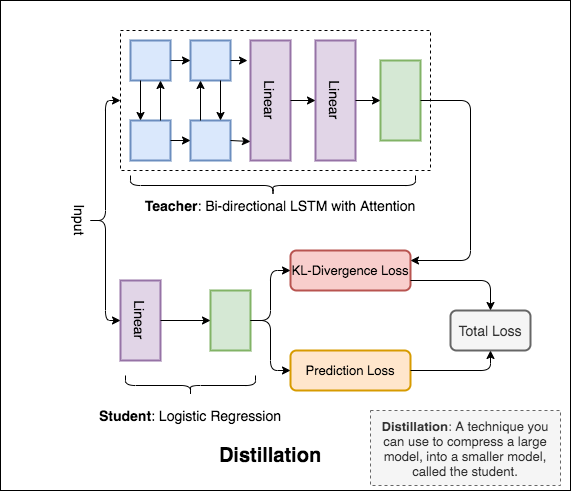
Distillation : teacherと呼ばれる大規模なモデルを、 studentと呼ばれる小さなモデルに圧縮するために使用できる手法。次の生徒は、NLIで蒸留を行うために教師モデルを使用します。
気にかけていることについて話し合うことは難しい場合があります。虐待と嫌がらせのオンラインの脅威は、多くの人々が自分自身を表現するのをやめ、さまざまな意見を求めることをあきらめることを意味します。プラットフォームは、会話を効果的に促進するのに苦労し、多くのコミュニティがユーザーのコメントを制限または完全に閉鎖するように導きます。
あなたは、有毒行動のために人間の評価者によってラベル付けされた多数のウィキペディアのコメントを提供されます。毒性の種類は次のとおりです。
次の異なるものが調査されています:
使用されるモデルは、双方向GRUネットワークです。
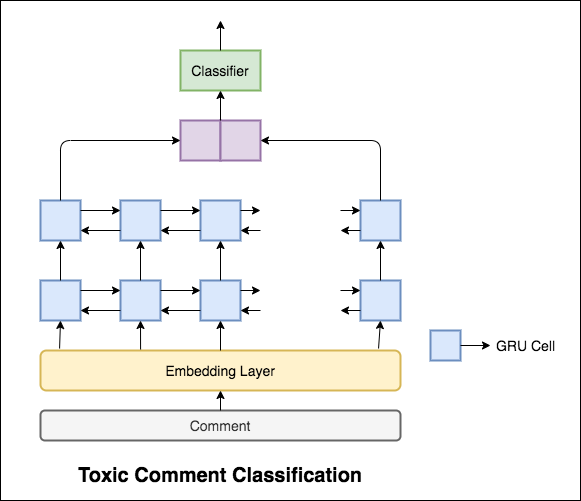
99.42%のテスト精度が達成されました。データの90%は毒性のいずれにもラベル付けされていないため、すべてのデータを非毒性として予測するだけで90%の正確なモデルが得られます。したがって、精度は信頼できるメトリックではありません。別のメトリックROC AUCが実装されました。
損失としてのCategorical Cross Entropyにより、 0.5のROC_AUCスコアが達成されます。損失をBinary Cross Entropyに変更し、プーリングレイヤー(最大、平均)を追加することでモデルを少し変更することにより、ROC_AUCスコアは0.9873に改善されました。
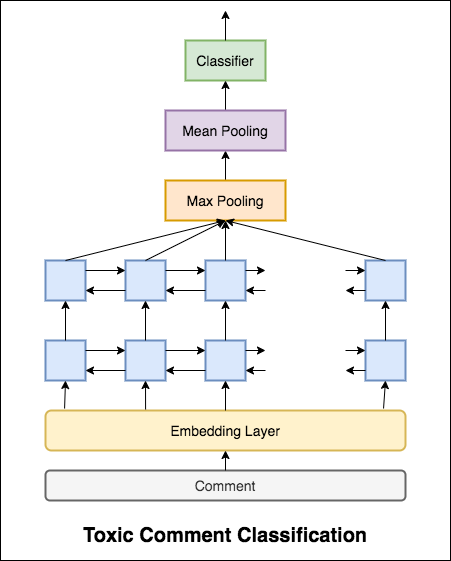
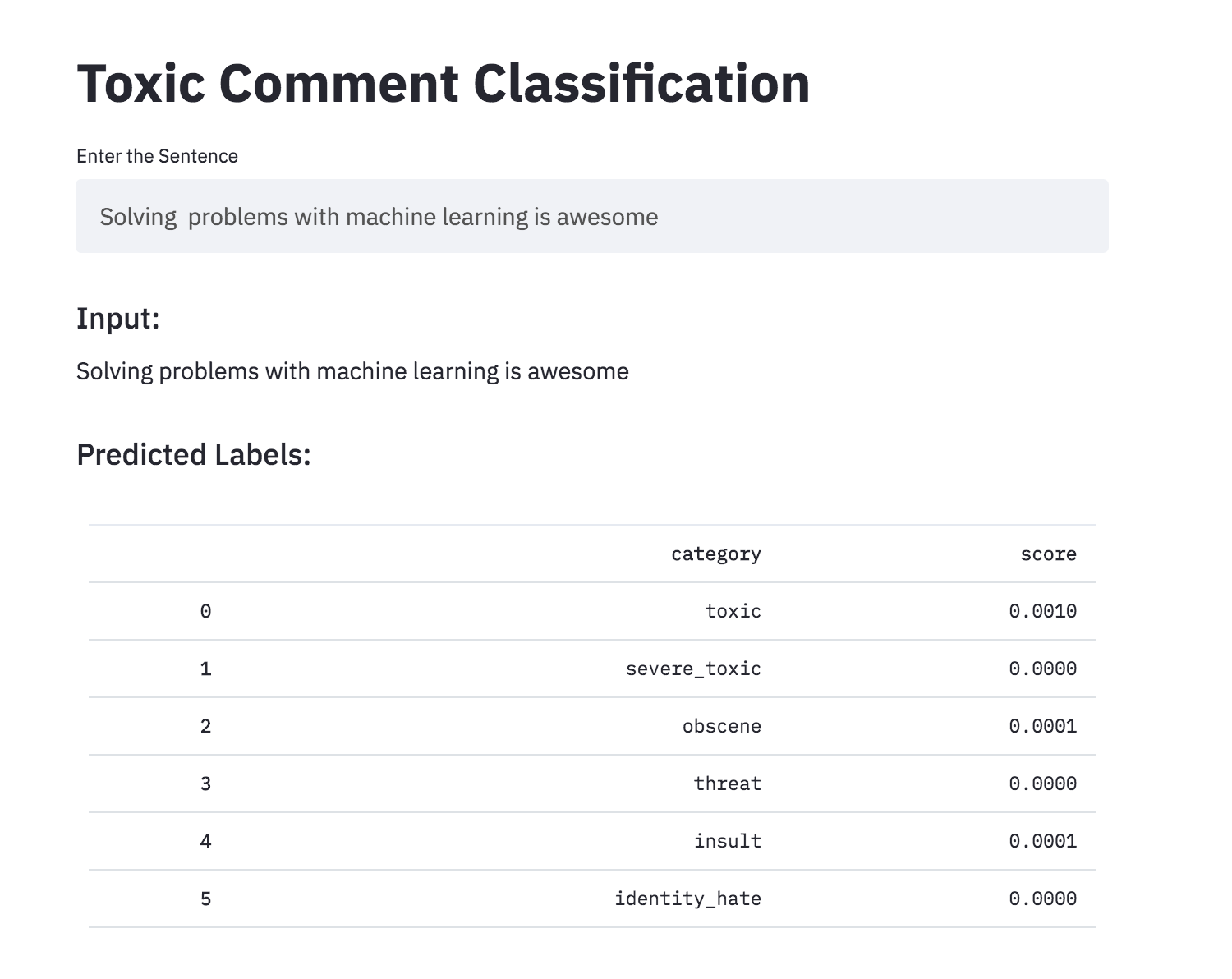
Toxic Commentの分類を、Streamlitを使用してアプリに変換しました。事前に訓練されたモデルは現在入手可能です。
人工ニューラルネットワークには、文の文法的受容性を判断する能力がありますか?このタスクを調査するために、言語受容性(COLA)データセットのコーパスが使用されます。コーラは、文法的に正しいまたは間違っているとラベル付けされた一連の文です。
次の異なるものが調査されています:
Bertは、11の自然言語処理タスクで新しい最先端の結果を取得します。 NLPでの転送学習は、BERTモデルのリリース後にトリガーされました。このノートブックでは、文が文法的に正しいかどうかを分類するためにBERTを使用する方法を検討します。
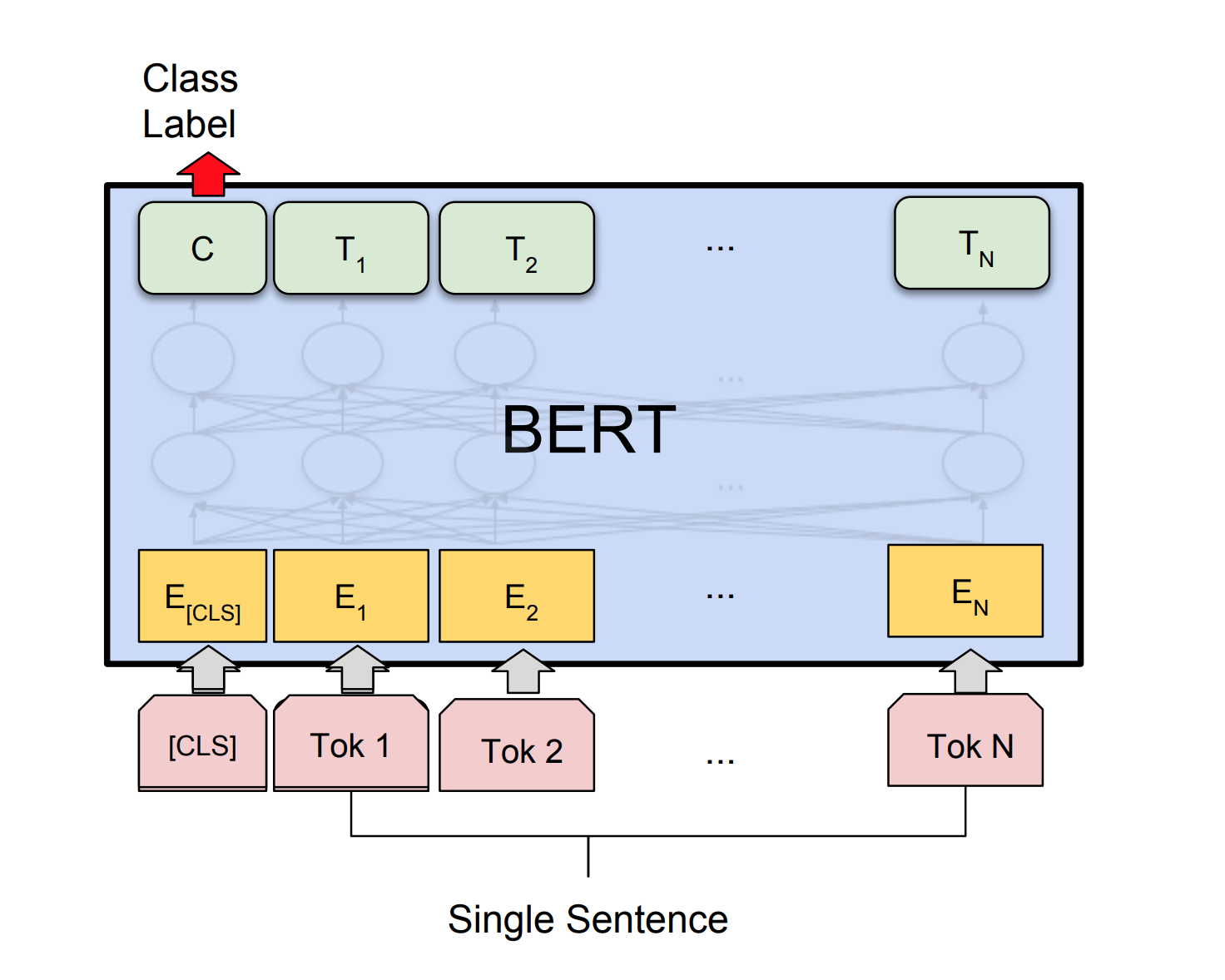
85%の精度と64.1のMatthews相関係数(MCC)が達成されました。
Distillation : teacherと呼ばれる大規模なモデルを、 studentと呼ばれる小さなモデルに圧縮するために使用できる手法。次の生徒は、コーラで蒸留を行うために教師モデルを使用します。

次の実験が試みられました:
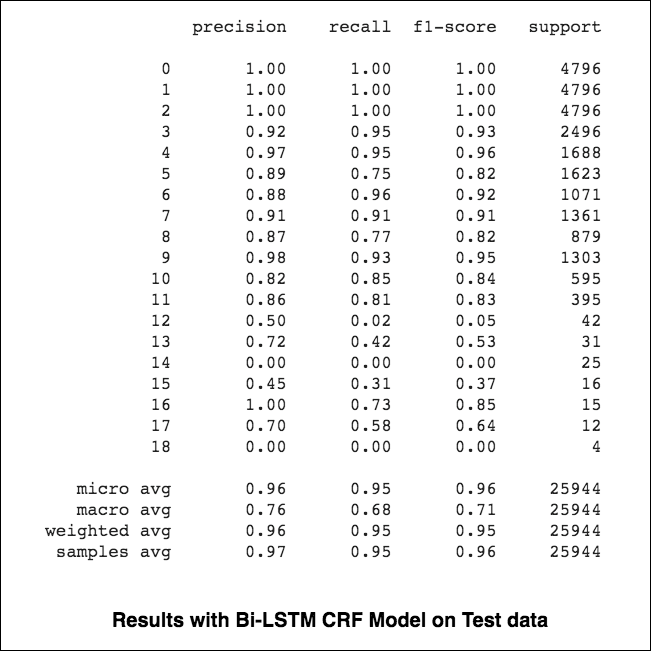
84.06 、MCC: 61.582.54 、MCC: 5782.92 、MCC: 57.9 Named-Entity-Recognition(NER)タグ付けは、適切なエンティティを持つ文の各単語にラベルを付けるタスクです。
次の異なるものが調査されています:
このコードは、基本的なワークフローをカバーしています。データの読み込み、トレーニング/テスト/検証の分割の作成、語彙の作成、データの反復者の作成、モデルの定義、トレイン/評価/テストループとトレーニングの実装、モデルのテスト方法を確認します。
使用されるモデルは、双方向LSTMネットワークです
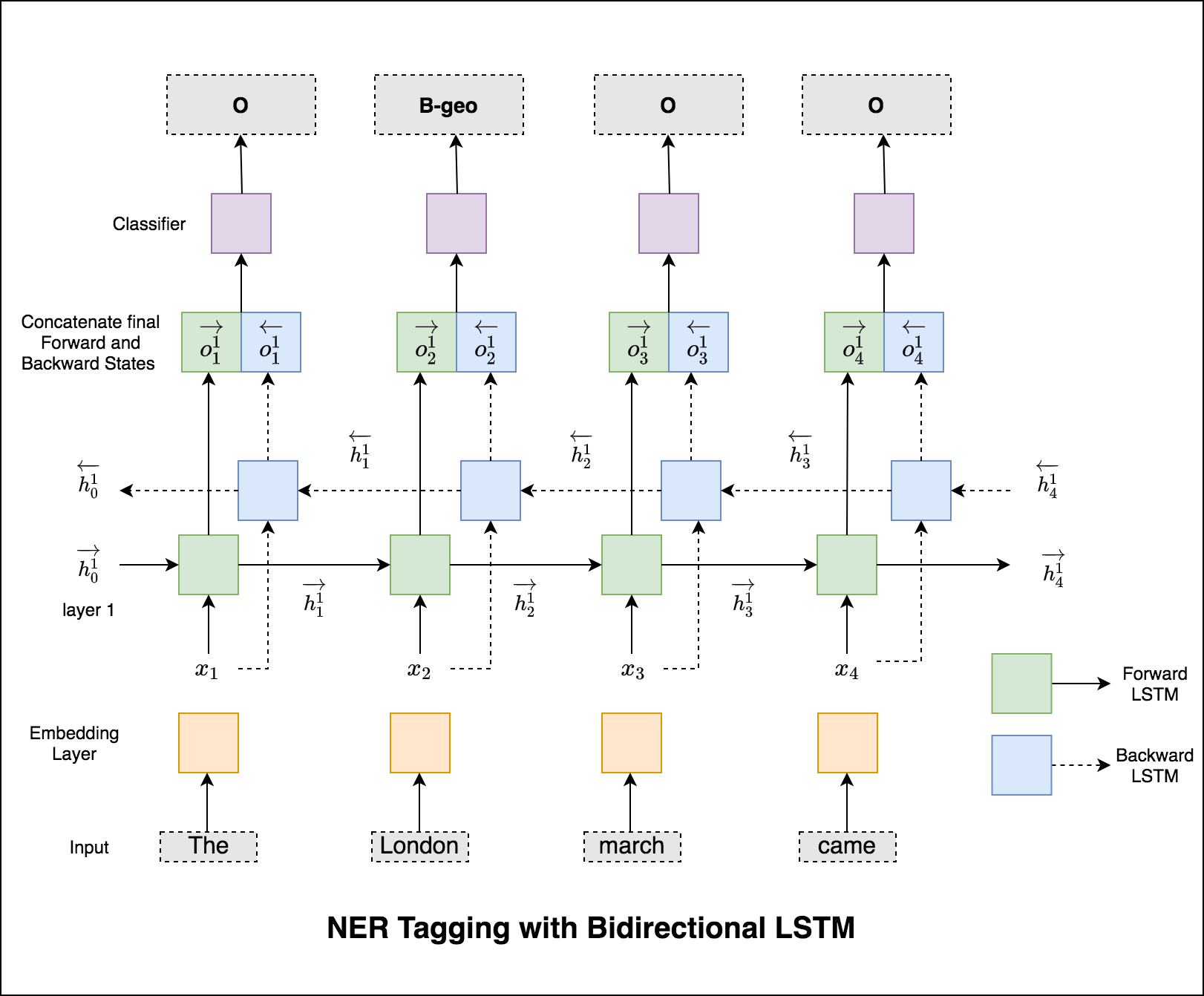
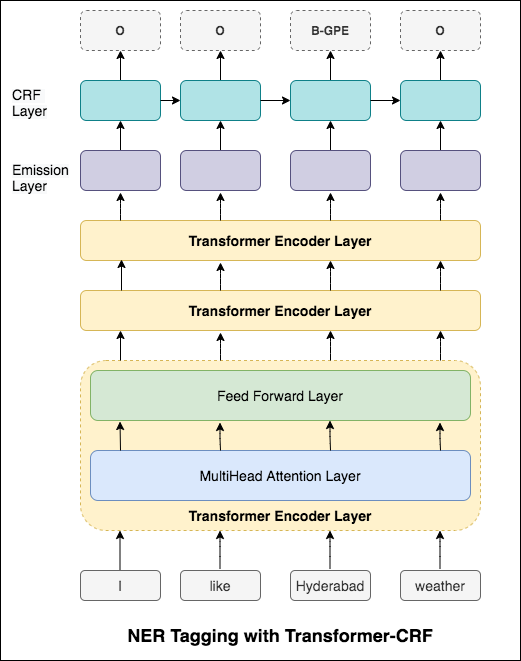
シーケンスタグ付け(NER)の場合、現在の単語のタグは、以前の単語のタグに依存する可能性があります。 (例:ニューヨーク)。
CRFがなければ、単一の線形層を使用して、双方向LSTMの出力を各タグのスコアに変換しただけでした。これらはemission scoresとして知られています。これは、単語が特定のタグである可能性の表現です。
CRFは、排出スコアだけでなく、 transition scoresも計算します。これは、前の単語が特定のタグであることを考慮して、特定のタグである可能性があります。したがって、遷移スコアは、あるタグから別のタグに移行する可能性を測定します。
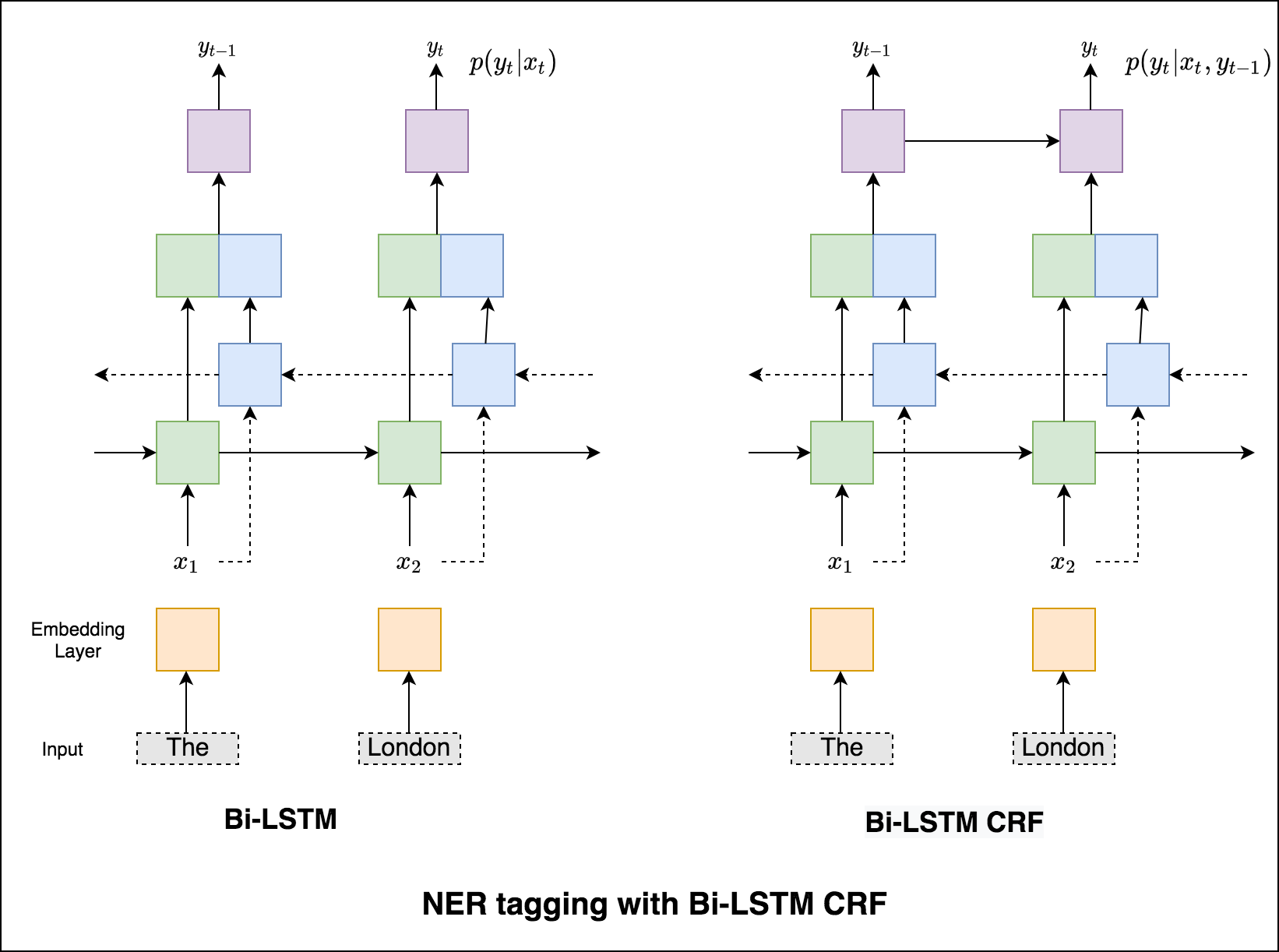
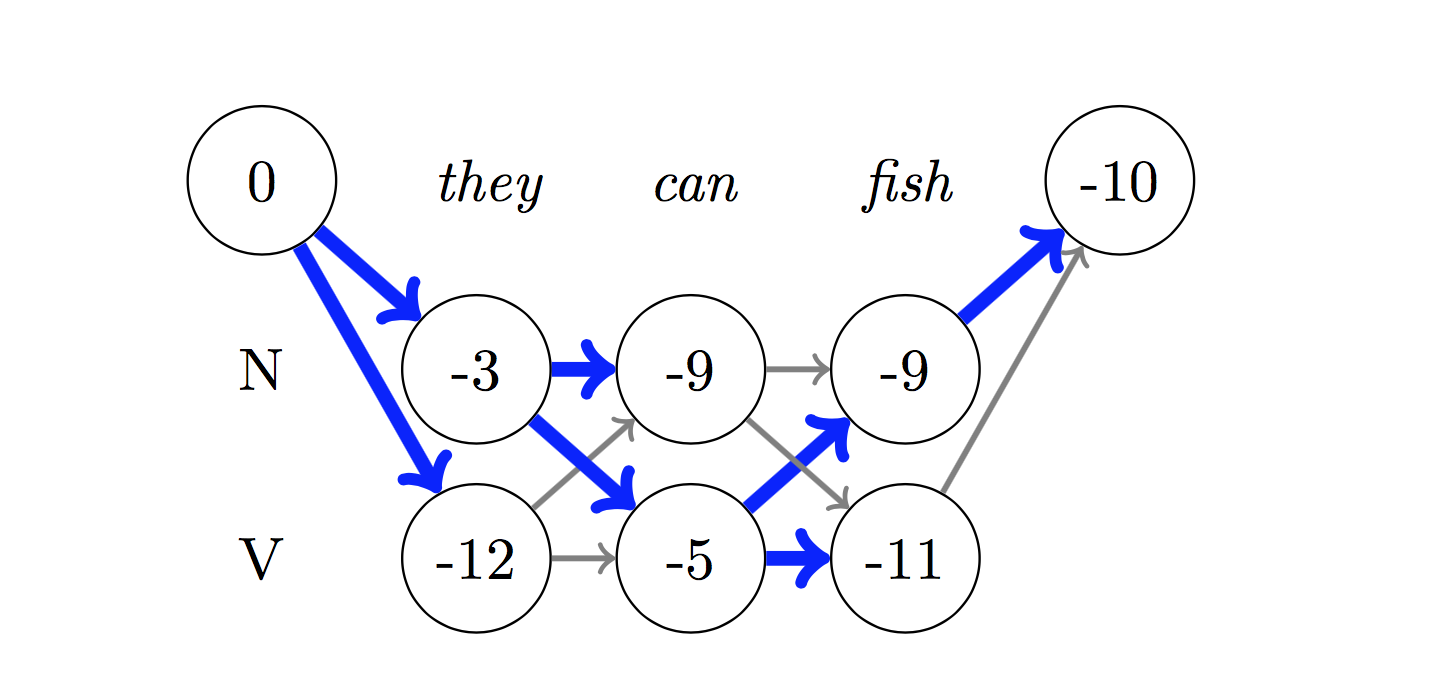
デコードには、 Viterbiアルゴリズムが使用されます。
CRFを使用しているため、単語シーケンスの適切なラベルシーケンスを予測しているので、各単語で正しいラベルを予測することはあまりありません。 ViterBiデコードは、まさにこれを行う方法です。条件付きランダムフィールドによって計算されたスコアから最も最適なタグシーケンスを見つけます。
タグ付けタスクでサブワード情報を使用すると、タグがスピーチの一部であろうとエンティティの一部であろうと、タグの強力な指標になる可能性があるためです。たとえば、形容詞は一般に「-y」または「-ul」で終わるか、しばしば「ランド」または「-burg」で終わることがわかります。
したがって、シーケンスタグモデルは両方を使用します
word-level情報。character-level情報。 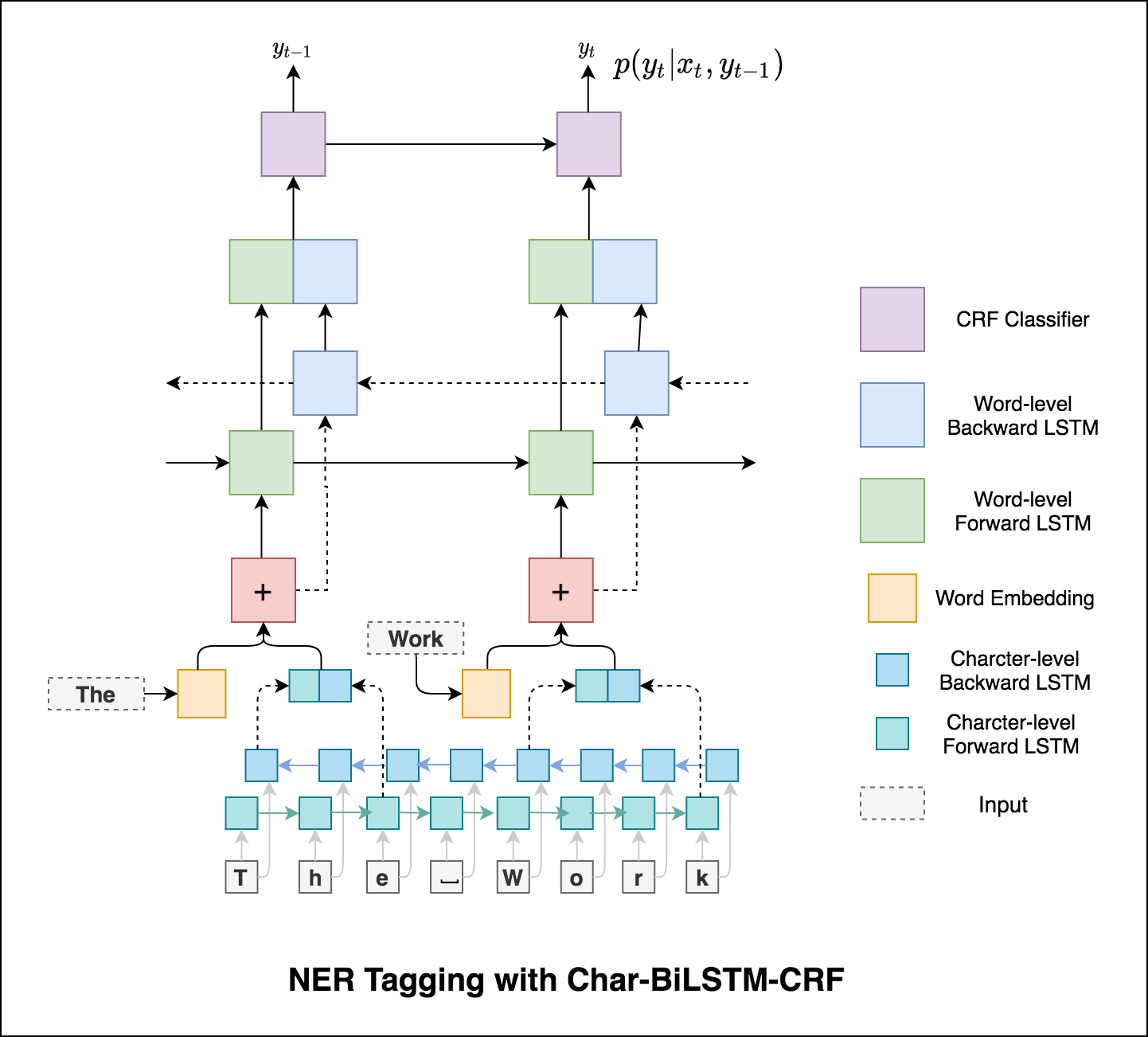
マイクロとマクロ平均(どのメートル法)がわずかに異なるものを計算するため、それらの解釈は異なります。マクロ平均は、各クラスのメトリックを個別に計算し、平均(したがってすべてのクラスを均等に扱う)を取得しますが、マイクロ平均はすべてのクラスの寄与を集約して平均メトリックを計算します。マルチクラスの分類セットアップでは、クラスの不均衡があると思われる場合は、マイクロ平均が望ましいです(つまり、他のクラスよりも多くのクラスの例があるかもしれません)。

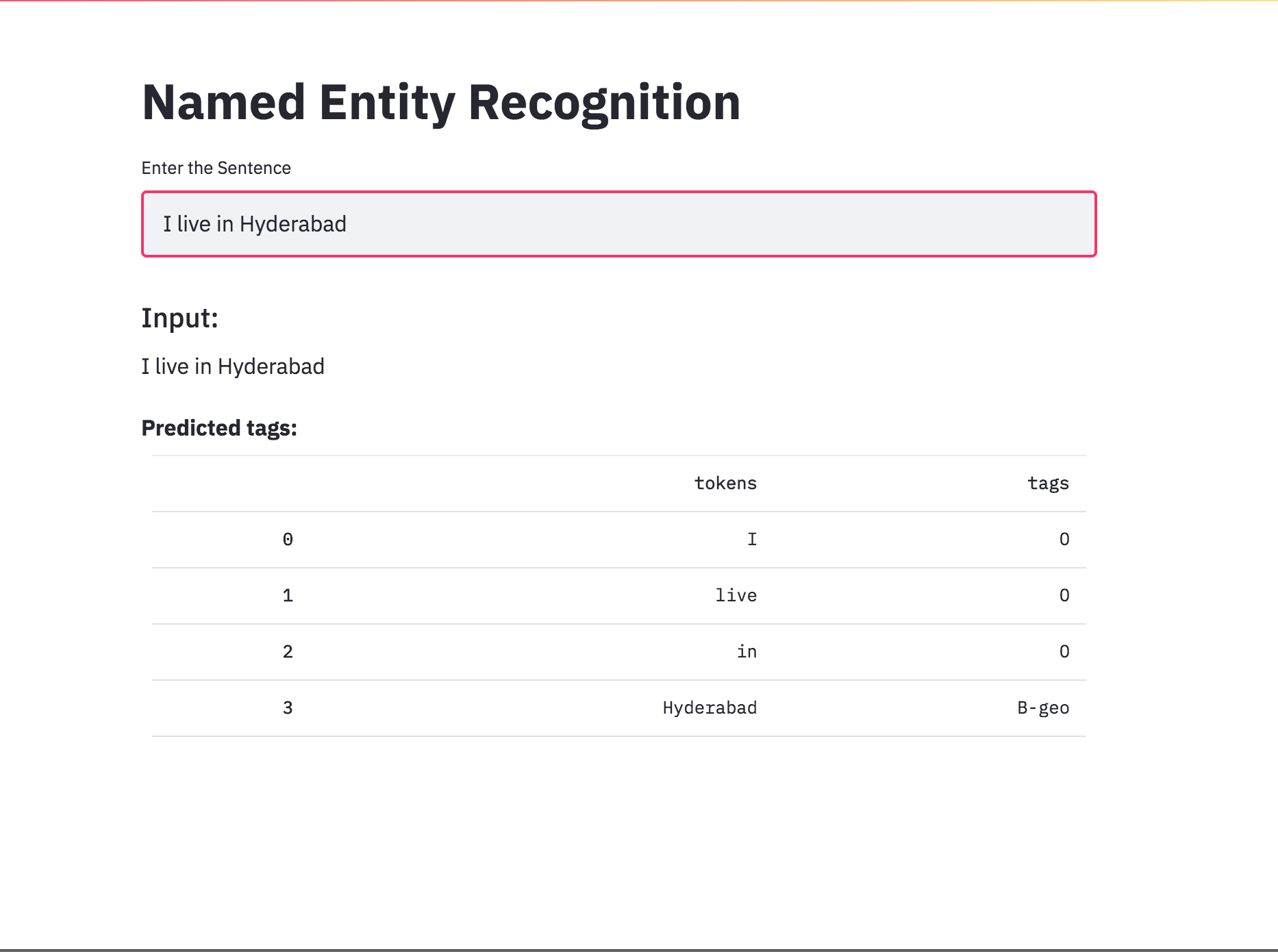
nerタグ付けを、retrylidを使用してアプリに変換しました。事前に訓練されたモデル(char-bilstm-crf)が利用可能になりました。
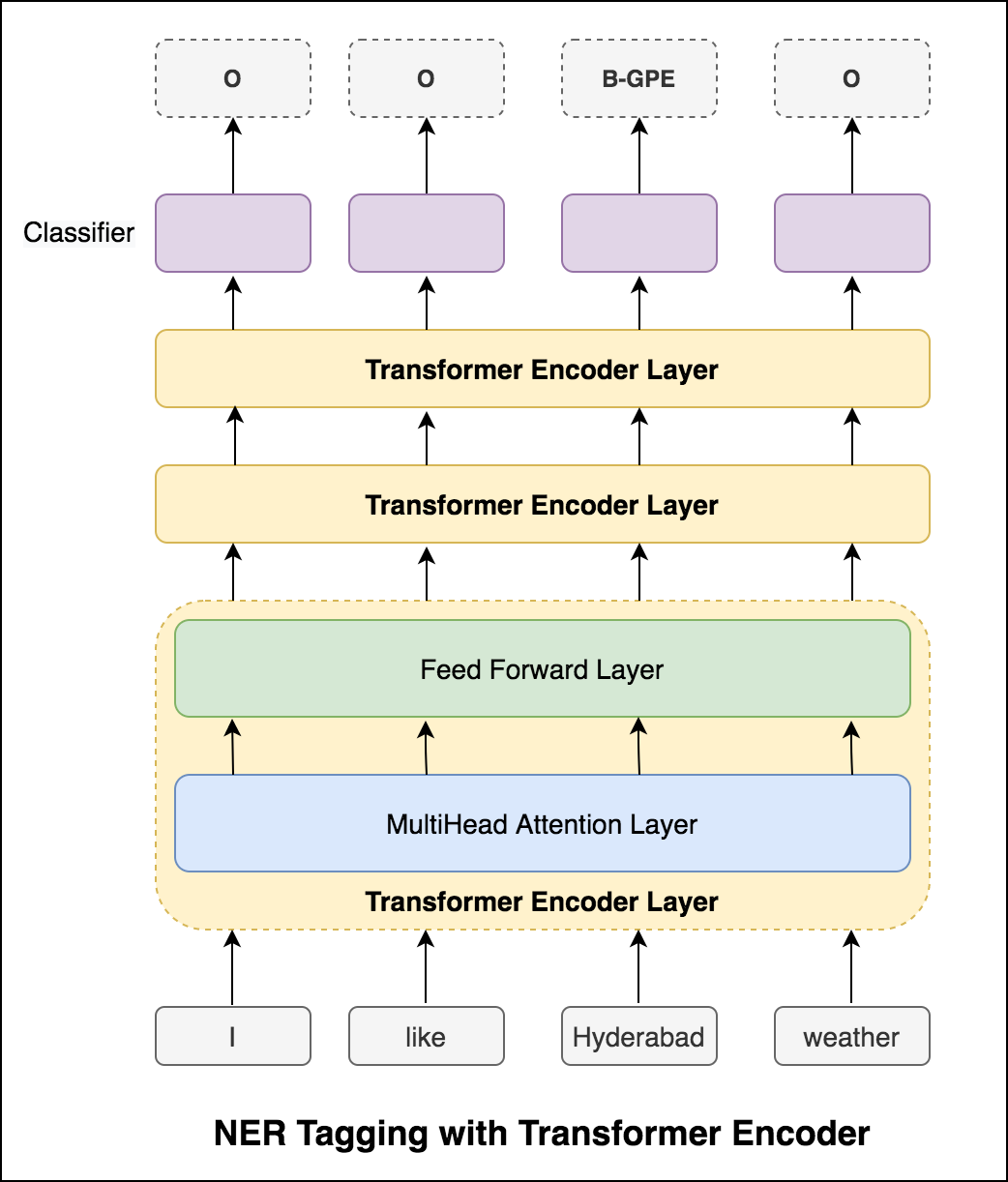
RNNアプローチを試した後、変圧器ベースのアーキテクチャを使用したNERタグ付けが検討されます。変圧器にはエンコーダーとデコーダーの両方が含まれているため、シーケンスラベリングタスクの場合はEncoderのみで十分です。 3層トランスエンコーダーモデルが使用されました。
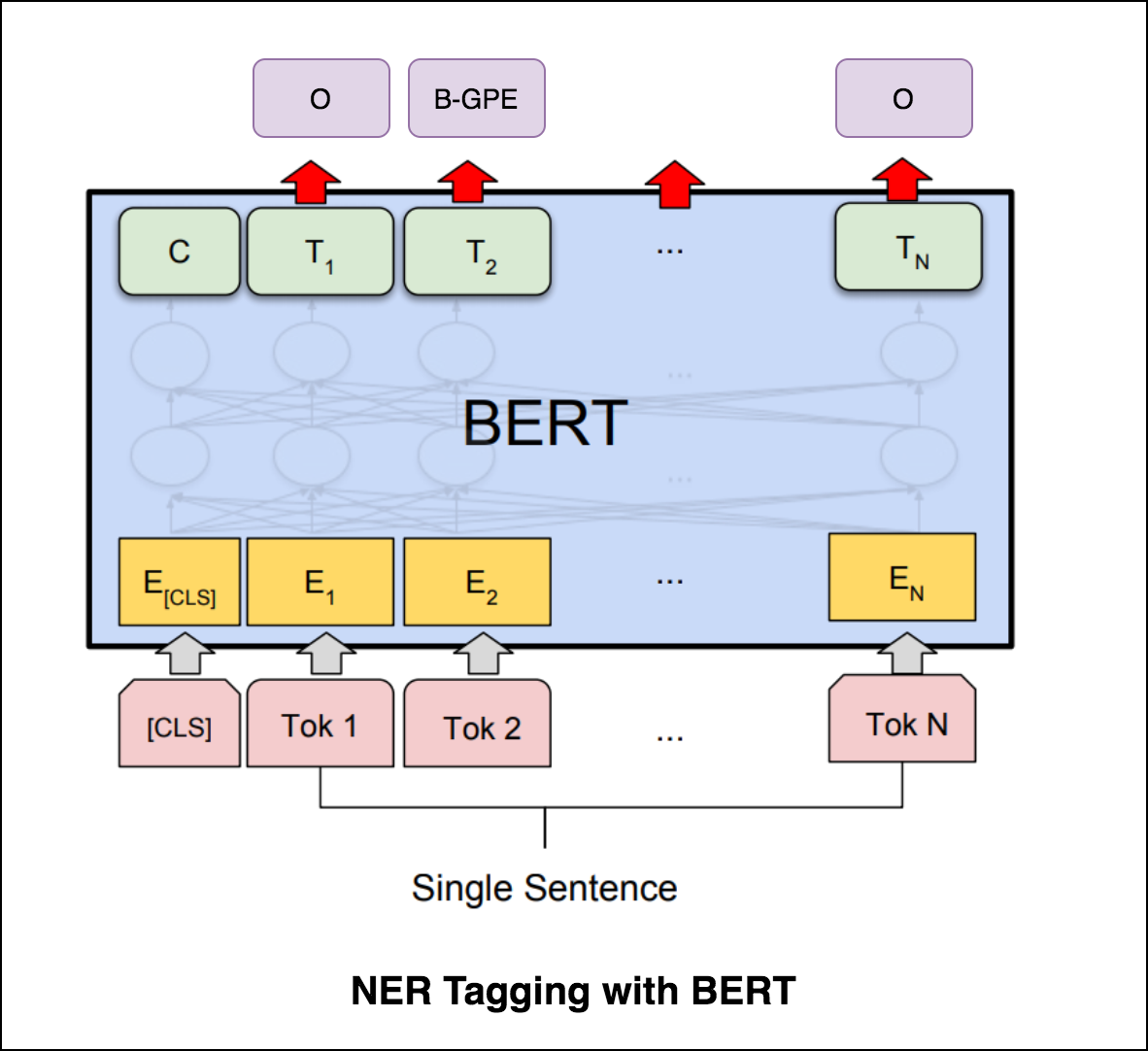
トランスエンコーダーでNERタグ付けを試みた後、事前に訓練されたbert-base-casedモデルを使用したNERタグ付けが検討されています。
トランスだけでは、NERタグ付けタスクのBILSTMと比較して良い結果が得られません。トランスの上部にあるCRF層の拡張が実装されており、スタンドアロントランスと比較して結果が改善されています。
Spacyは、PythonのNERに非常に効率的な統計システムを提供し、トークンのグループにラベルを割り当てることができます。個人、組織、言語、イベントなどを含む、幅広い名前付きまたは数値エンティティを認識できるデフォルトモデルを提供します。

これらのデフォルトエンティティとは別に、Spacyは、新しい訓練された例で更新するためにモデルをトレーニングすることにより、NERモデルに任意のクラスを追加する自由を提供します。
特定のドメインデータ(銀行)のACTIVITYとSERVICEと呼ばれる2つの新しいエンティティは、少数のトレーニングサンプルで作成およびトレーニングされます。

| 名前の生成 | 機械翻訳 | 発話生成 |
| 画像キャプション | 画像キャプション - ラテックス方程式 | ニュース要約 |
| 件名の生成に電子メールを送信します |
文字レベルのLSTM言語モデルが使用されます。つまり、LSTMに膨大な名前の名前を付けて、以前の文字のシーケンスを考慮して、シーケンス内の次の文字の確率分布をモデル化するように依頼します。これにより、一度に1つのキャラクターに新しい名前を生成することができます

機械翻訳(MT)は、ある自然言語を自動的に別の自然言語に変換し、入力テキストの意味を維持し、出力言語で流fluentテキストを作成するタスクです。理想的には、ソース言語シーケンスがターゲット言語シーケンスに変換されます。タスクは、文章をGerman to English変換することです。
次の異なるものが調査されています:
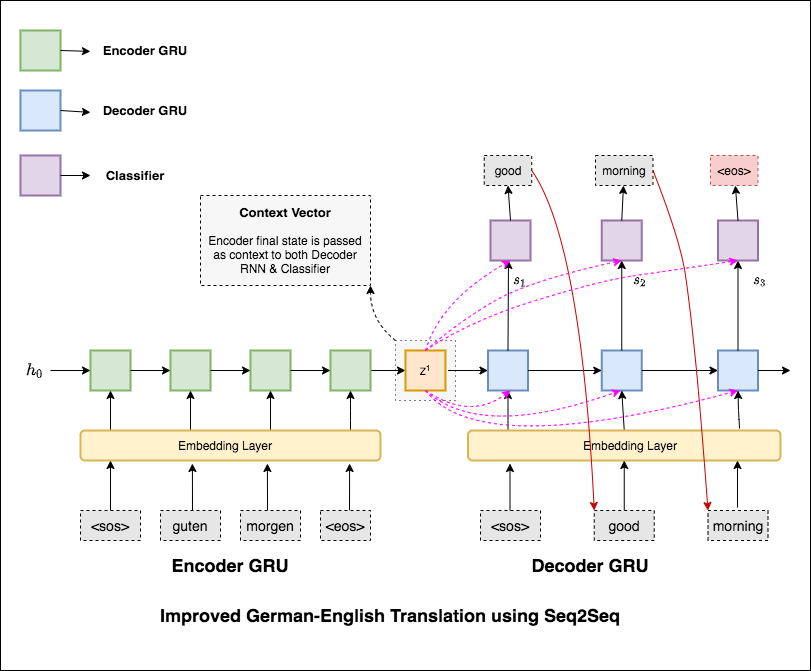
最も一般的なシーケンスからシーケンス(SEQ2SEQ)モデルは、エンコーダーデコーダーモデルであり、一般に再発ニューラルネットワーク(RNN)を使用してソース(入力)文を単一のベクトルにエンコードします。このノートブックでは、この単一のベクトルをコンテキストベクトルと呼びます。コンテキストベクトルは、入力文全体の抽象表現であると考えることができます。次に、このベクトルは、一度に1つの単語を生成することにより、ターゲット(出力)文を出力することを学習する2番目のRNNによってデコードされます。

テキストの困惑36.68持つ基本的な機械翻訳を試した後、次の手法が実験され、テスト困惑7.041実験されました。
applications/generationフォルダーのコードをチェックアウトします
注意メカニズムは、神経機械翻訳(NMT)の長いソース文を記憶するのを助けるために生まれました。エンコーダの最後の隠された状態から単一のコンテキストベクトルを構築するのではなく、文をデコードしながら入力の関連部分により多くの焦点を合わせるために注意が使用されます。コンテキストベクトルは、エンコーダー出力とデコーダーRNNのprevious hidden stateを取得することにより作成されます。
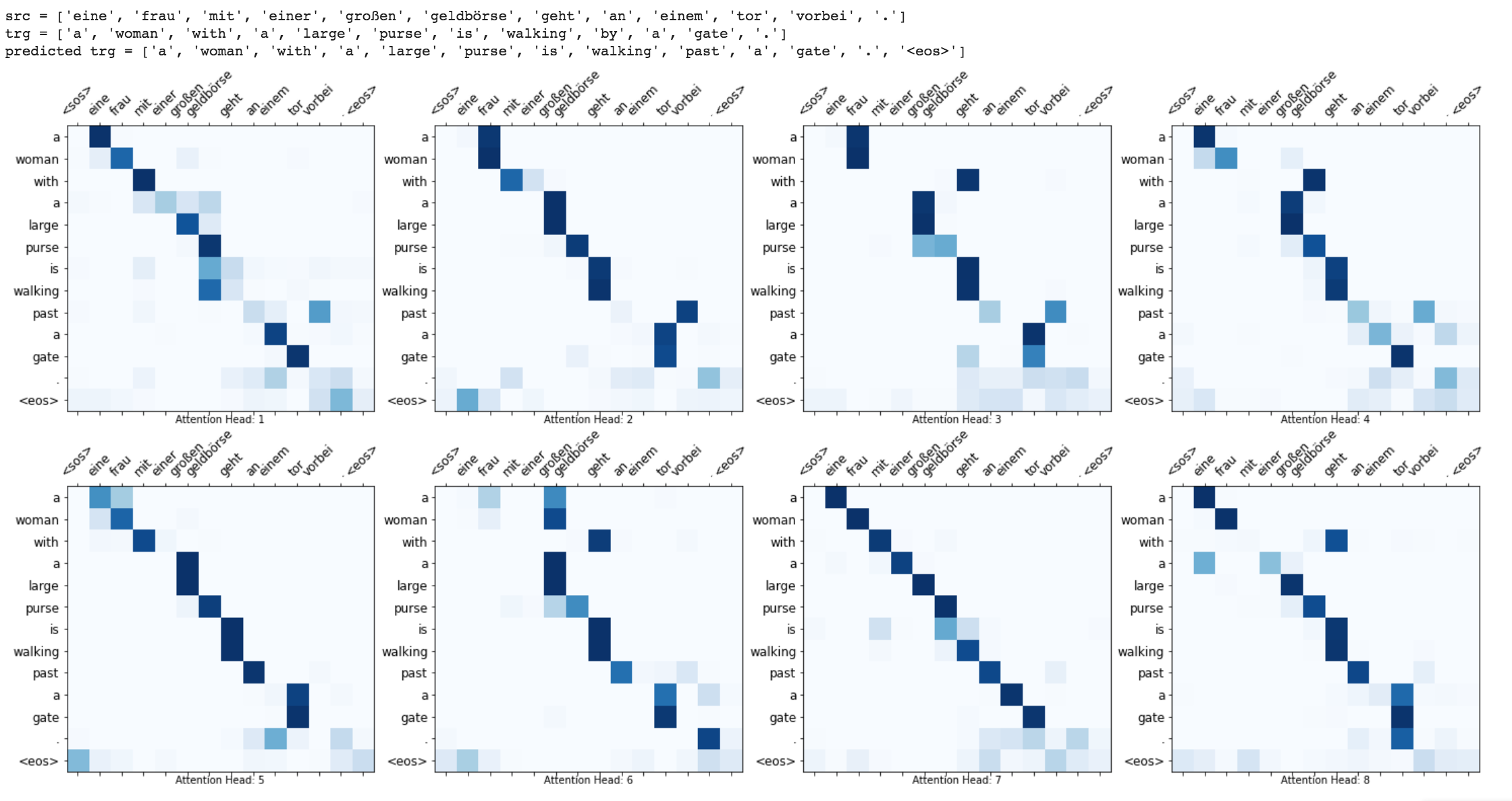
マスキング(パッド入力上の注意を無視する)、パッピングパッド付きシーケンス(より良い計算のため)、テストデータの注意視覚化、ブルーメトリックなどの強化が実装されています。

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
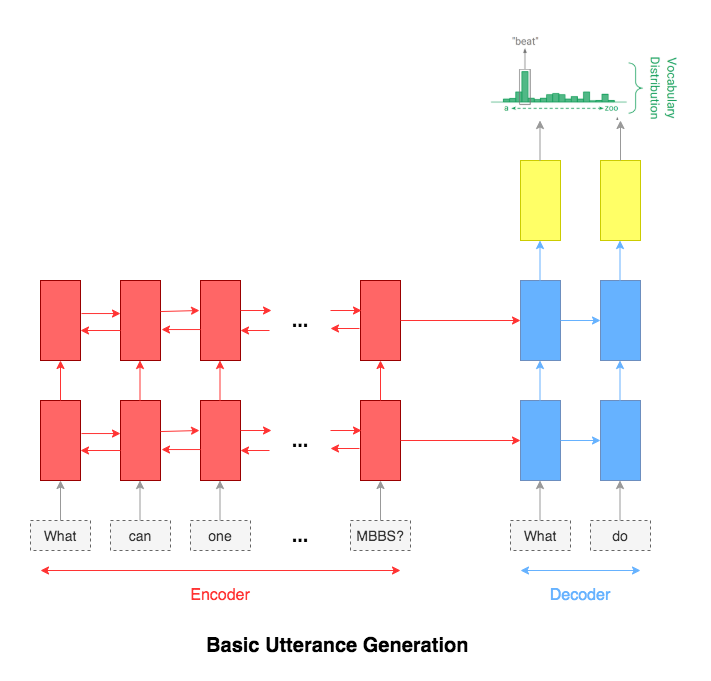
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
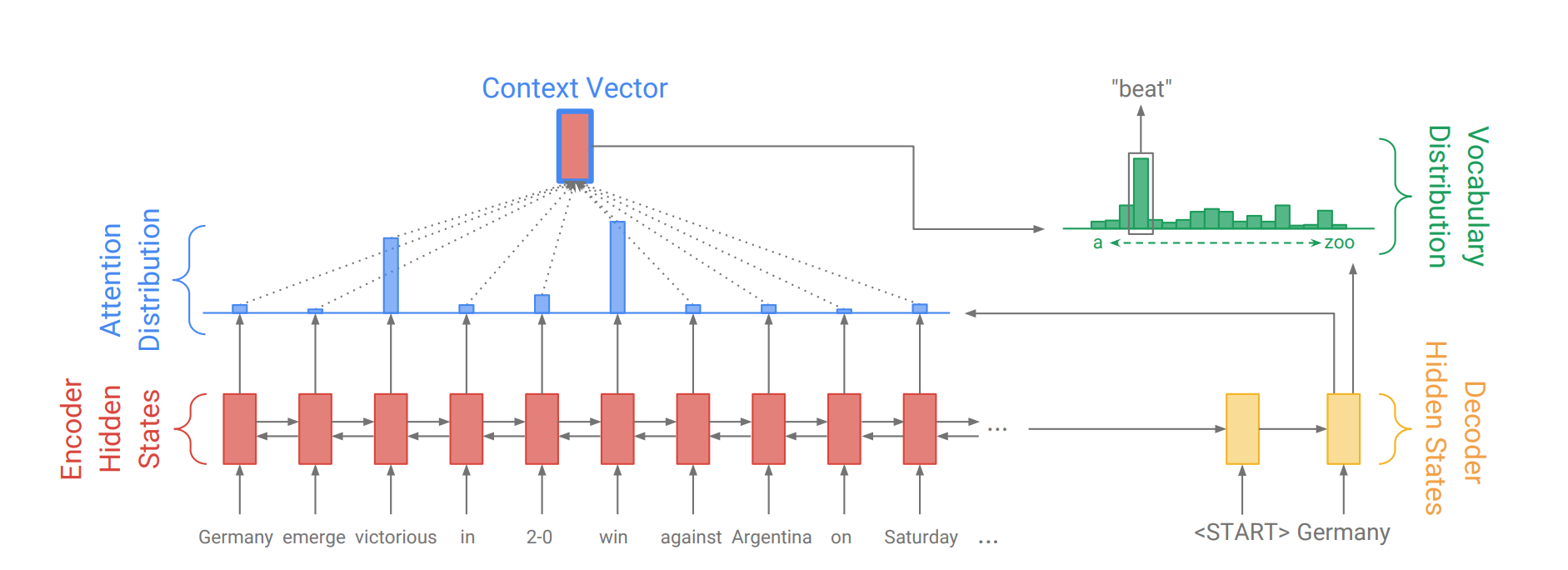
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
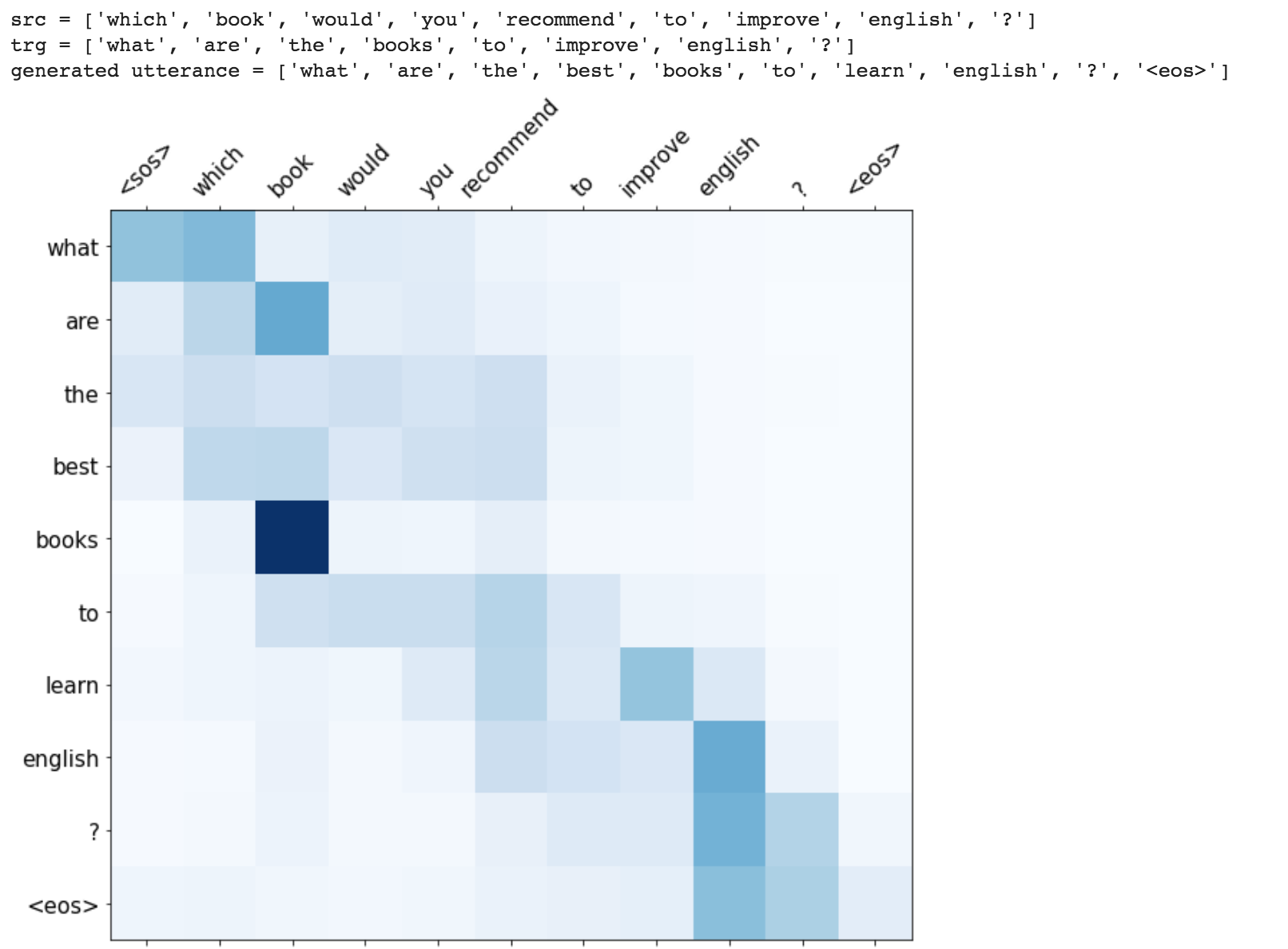
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
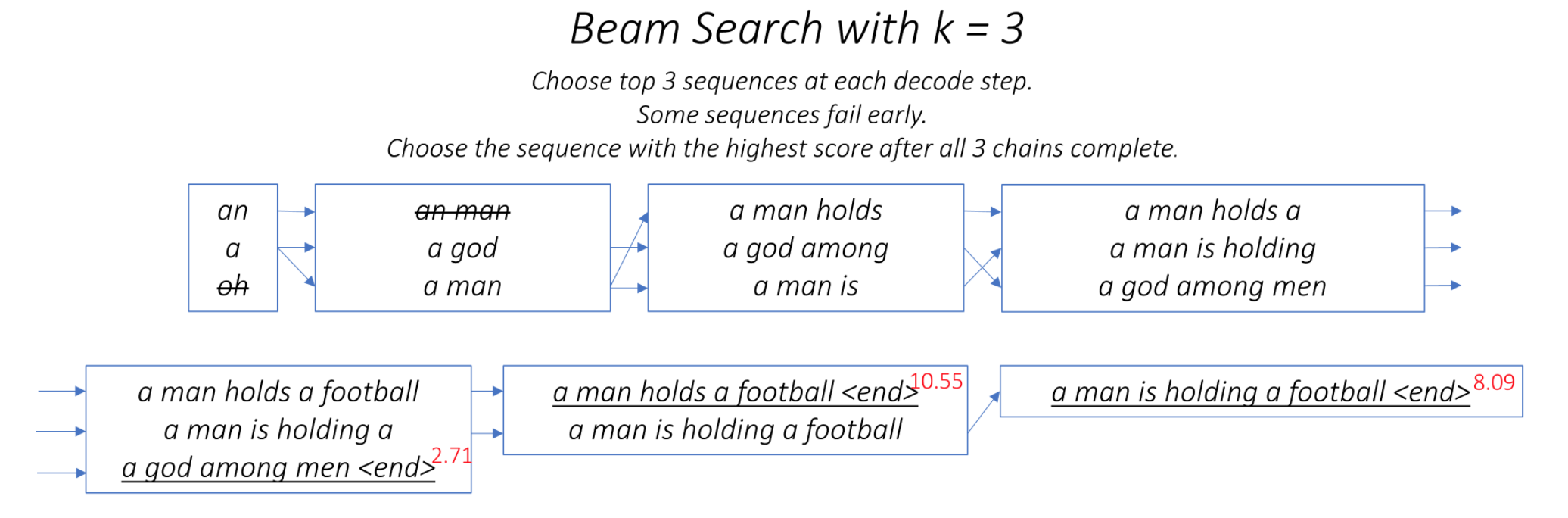
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

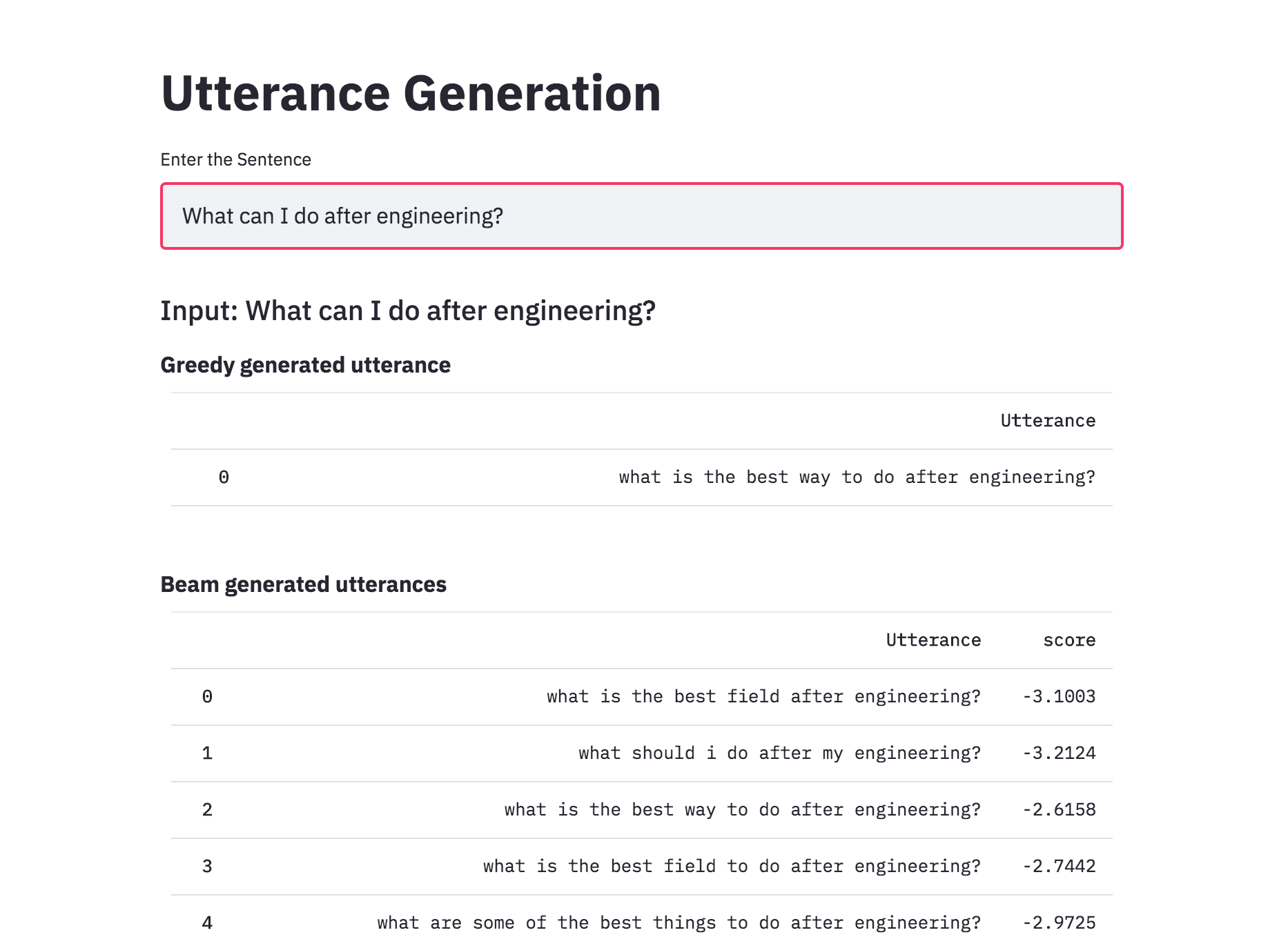
Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

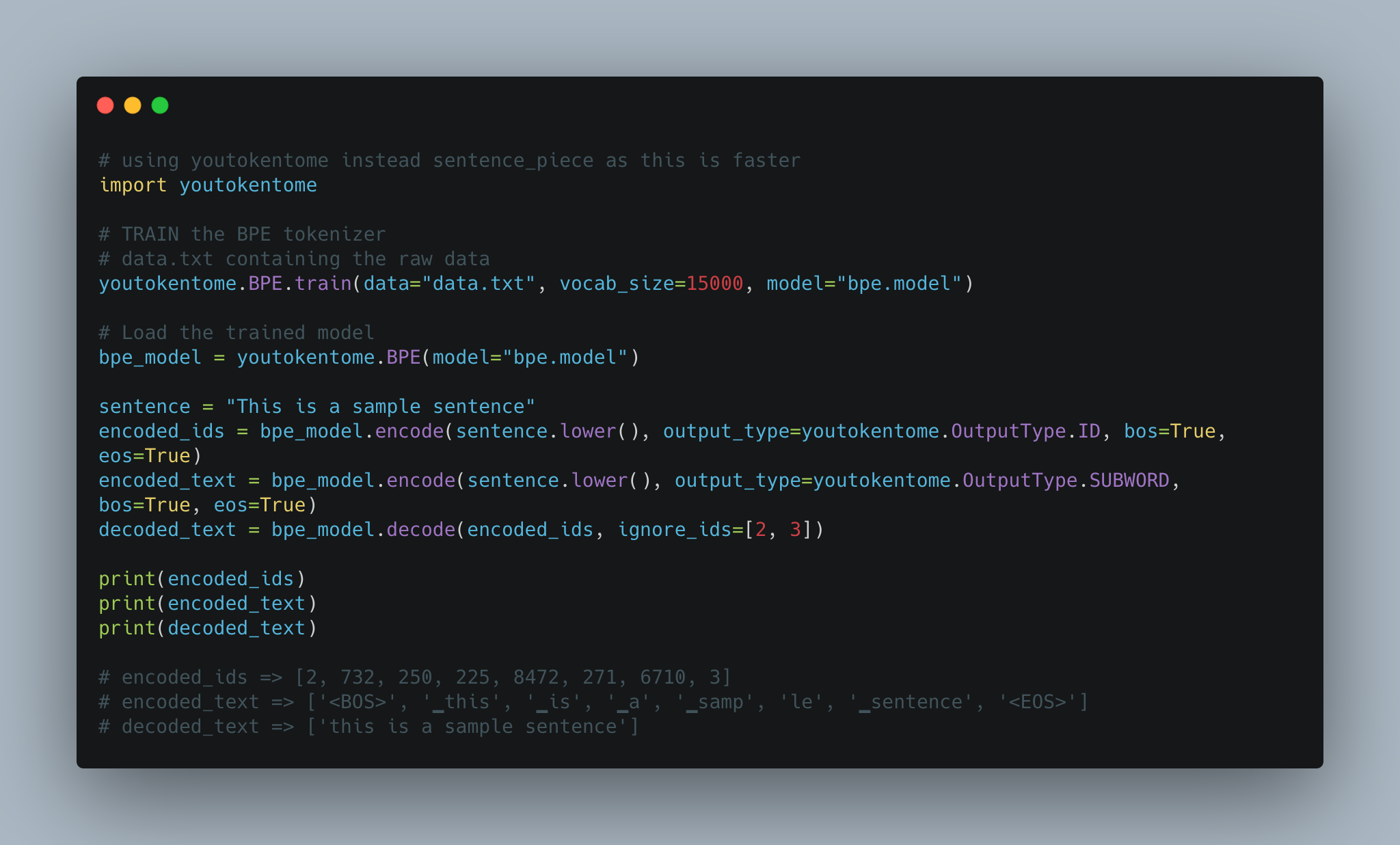
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
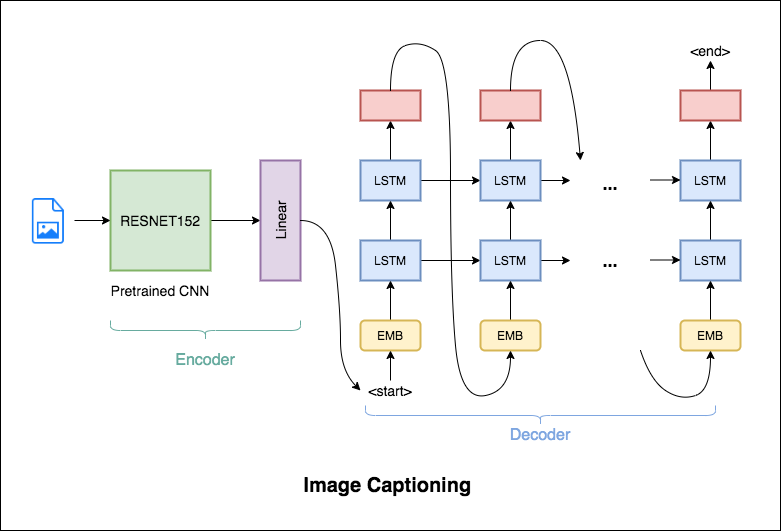
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
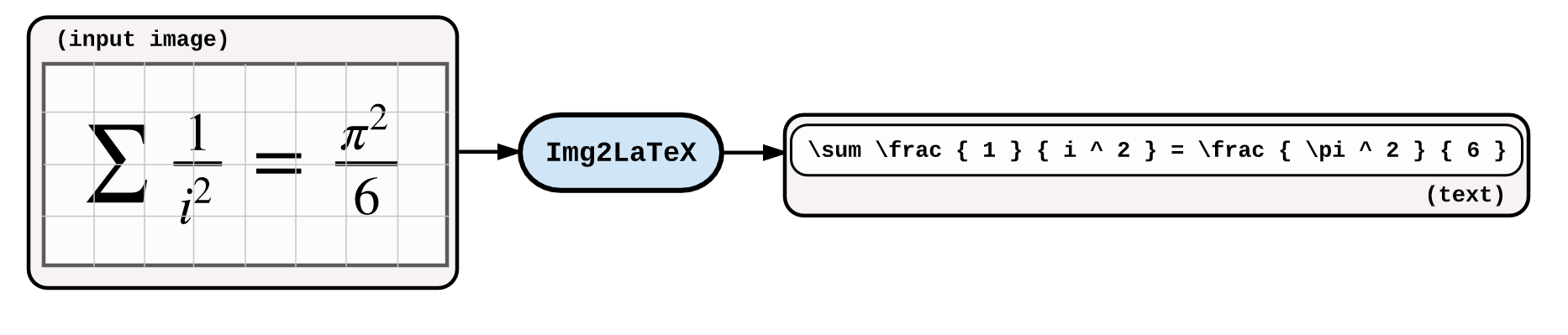
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
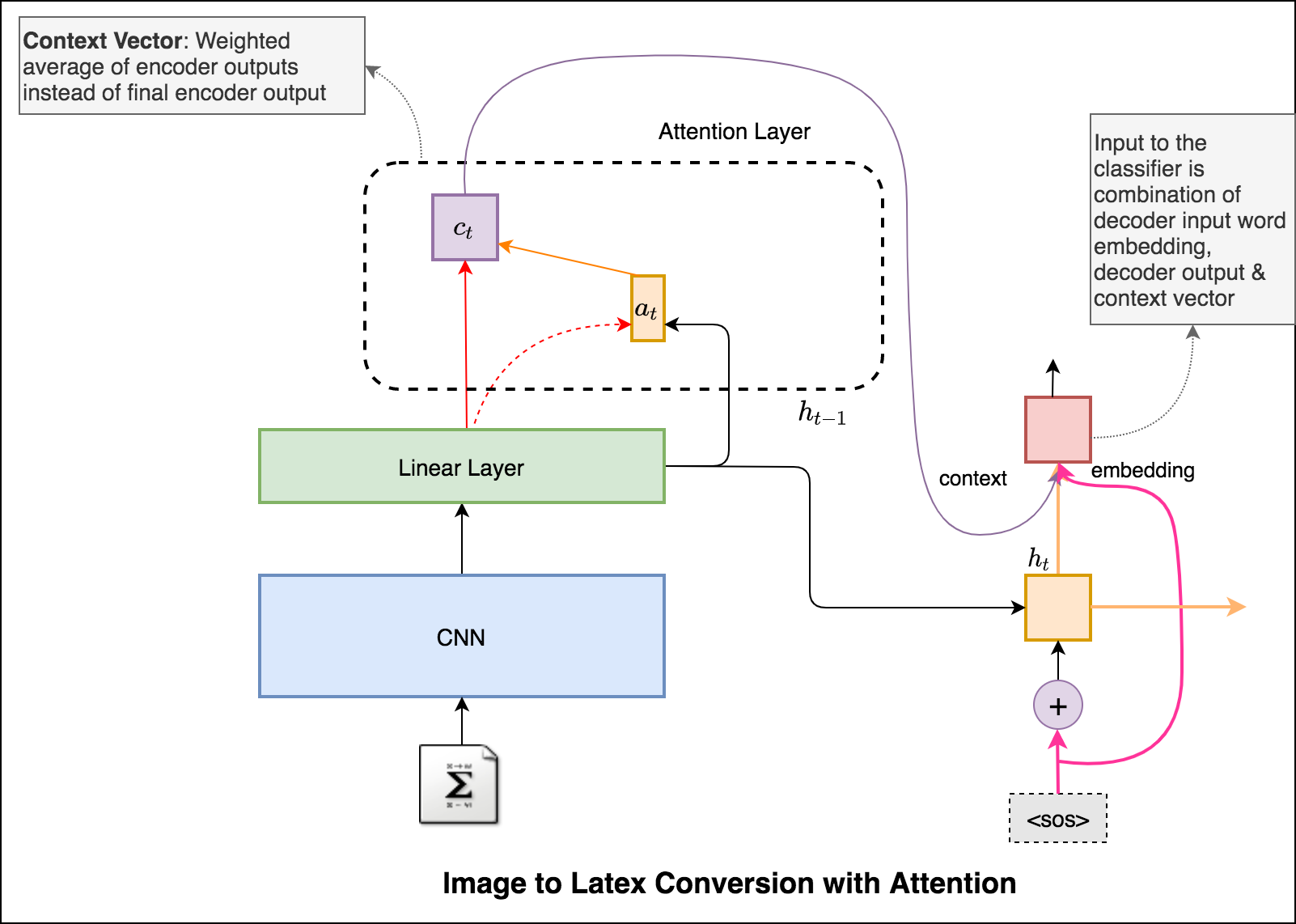
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

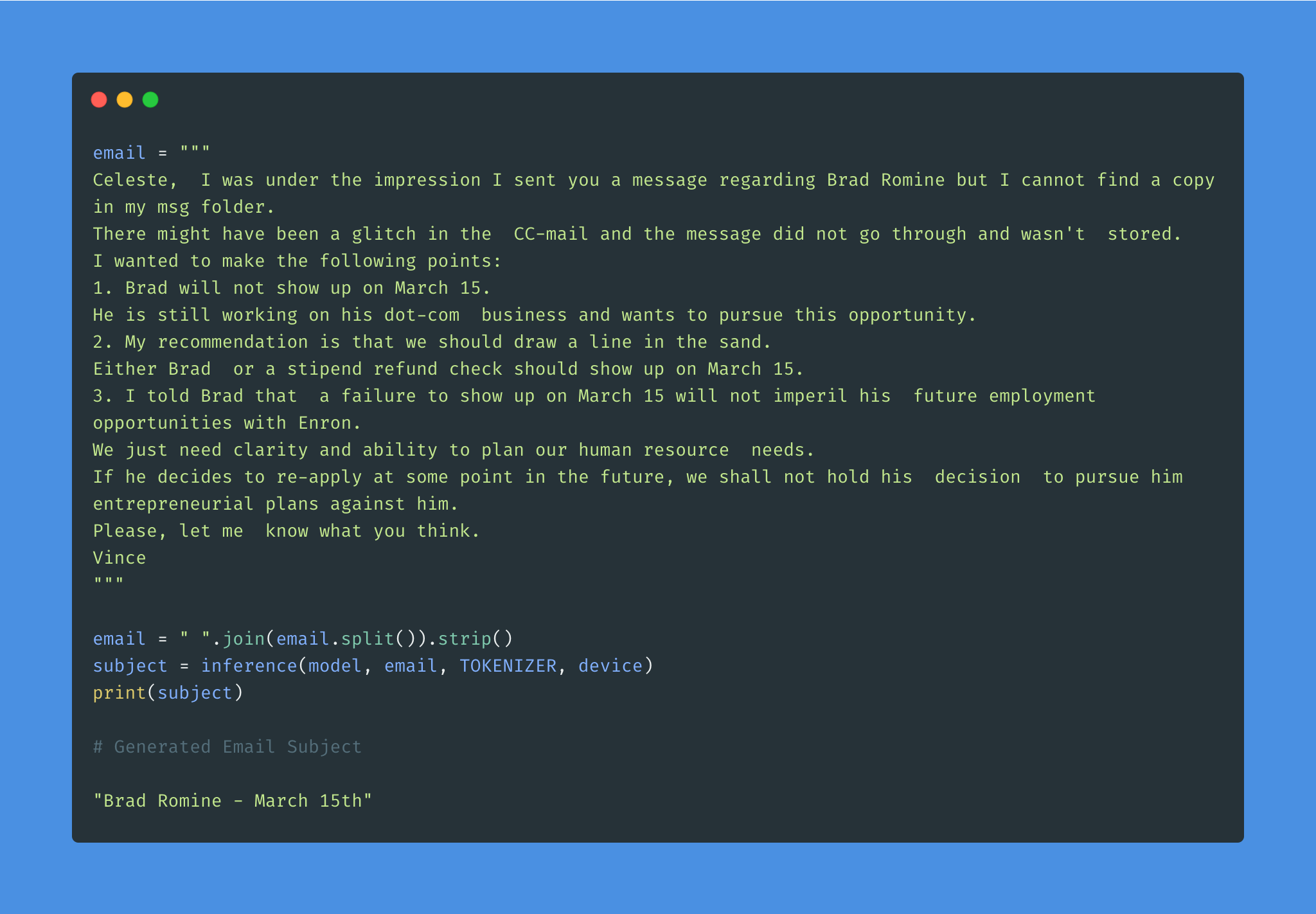
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
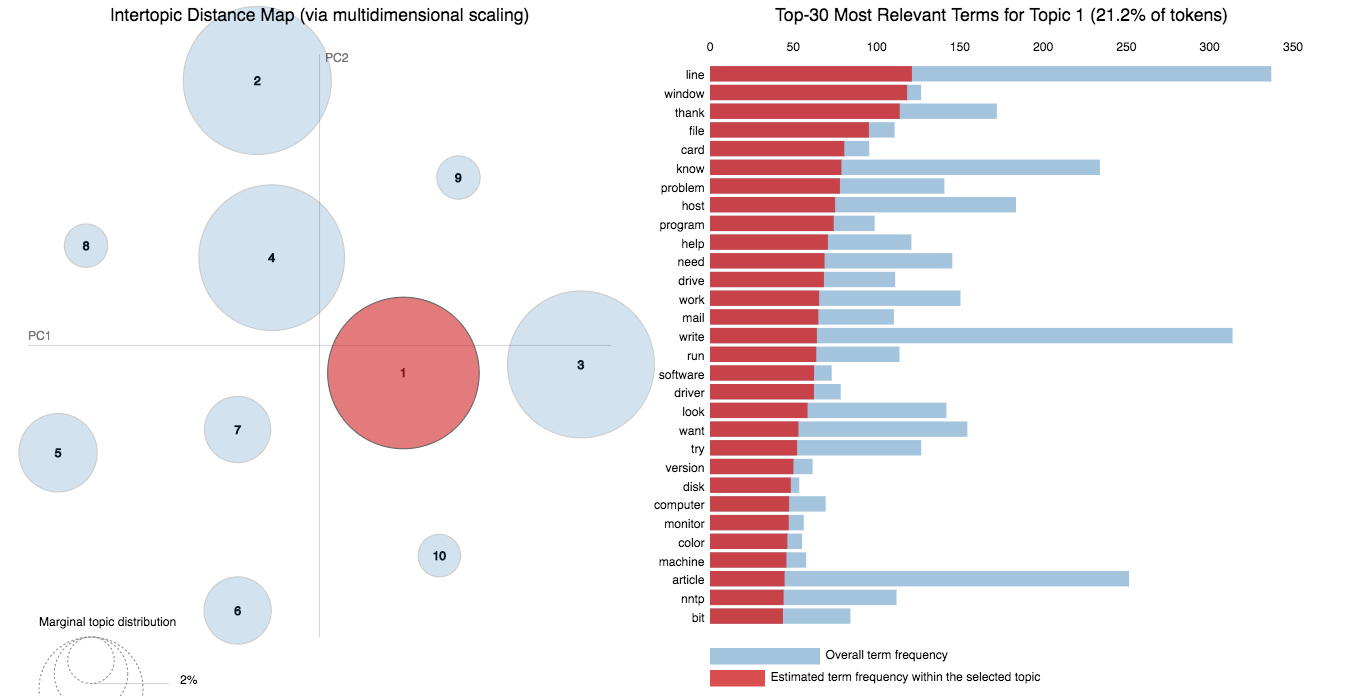
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
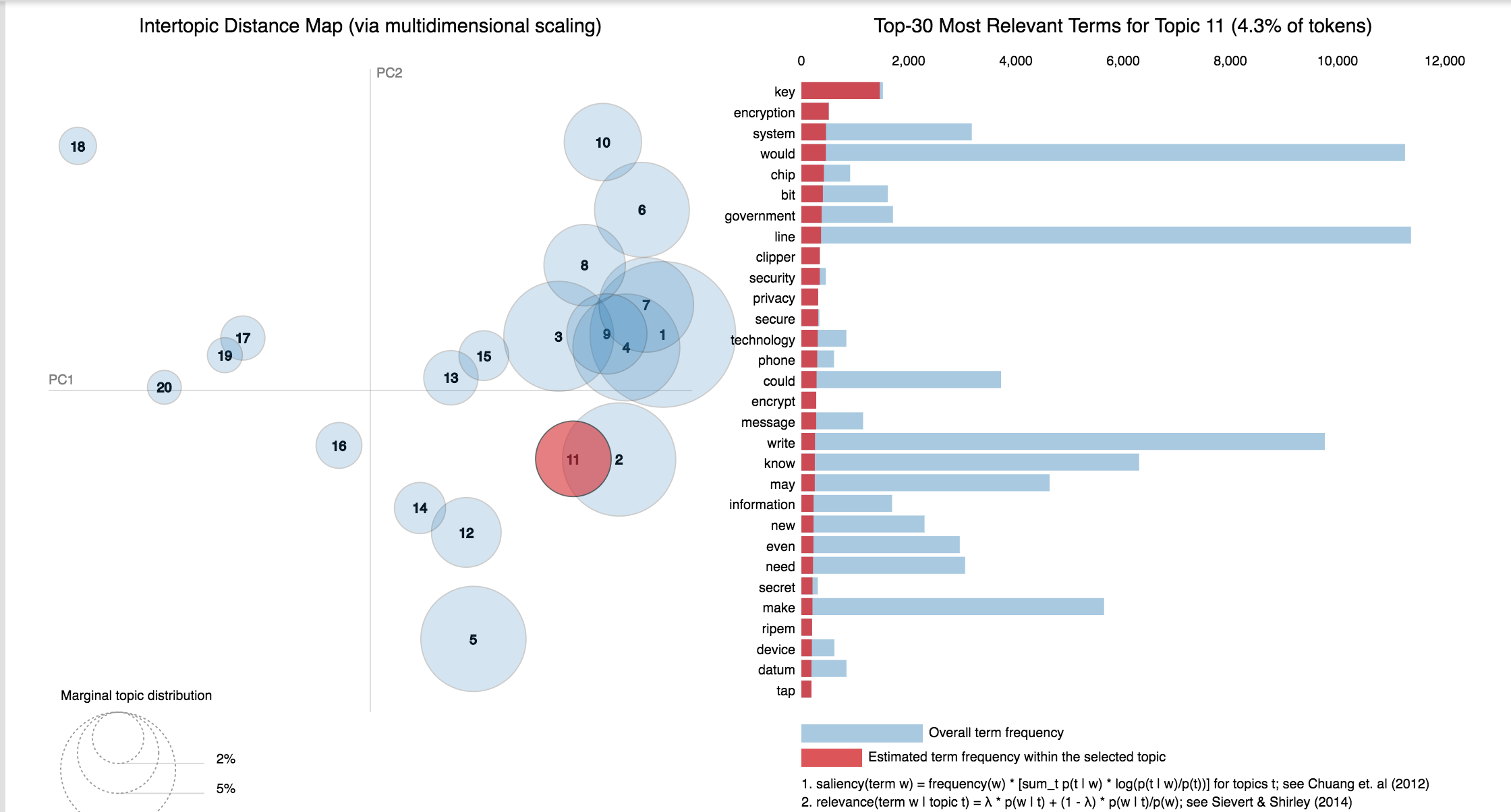
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
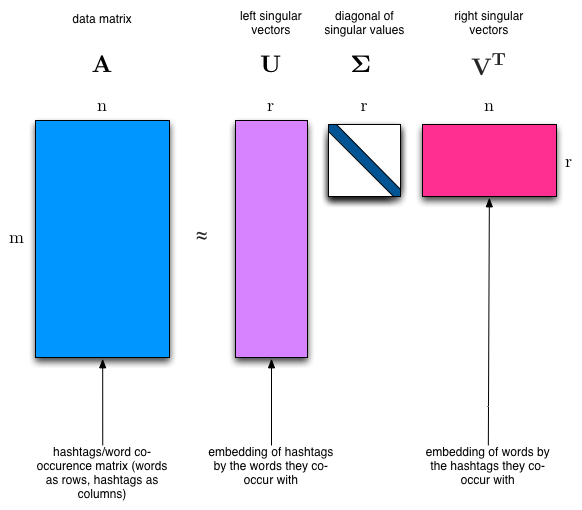
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
注:
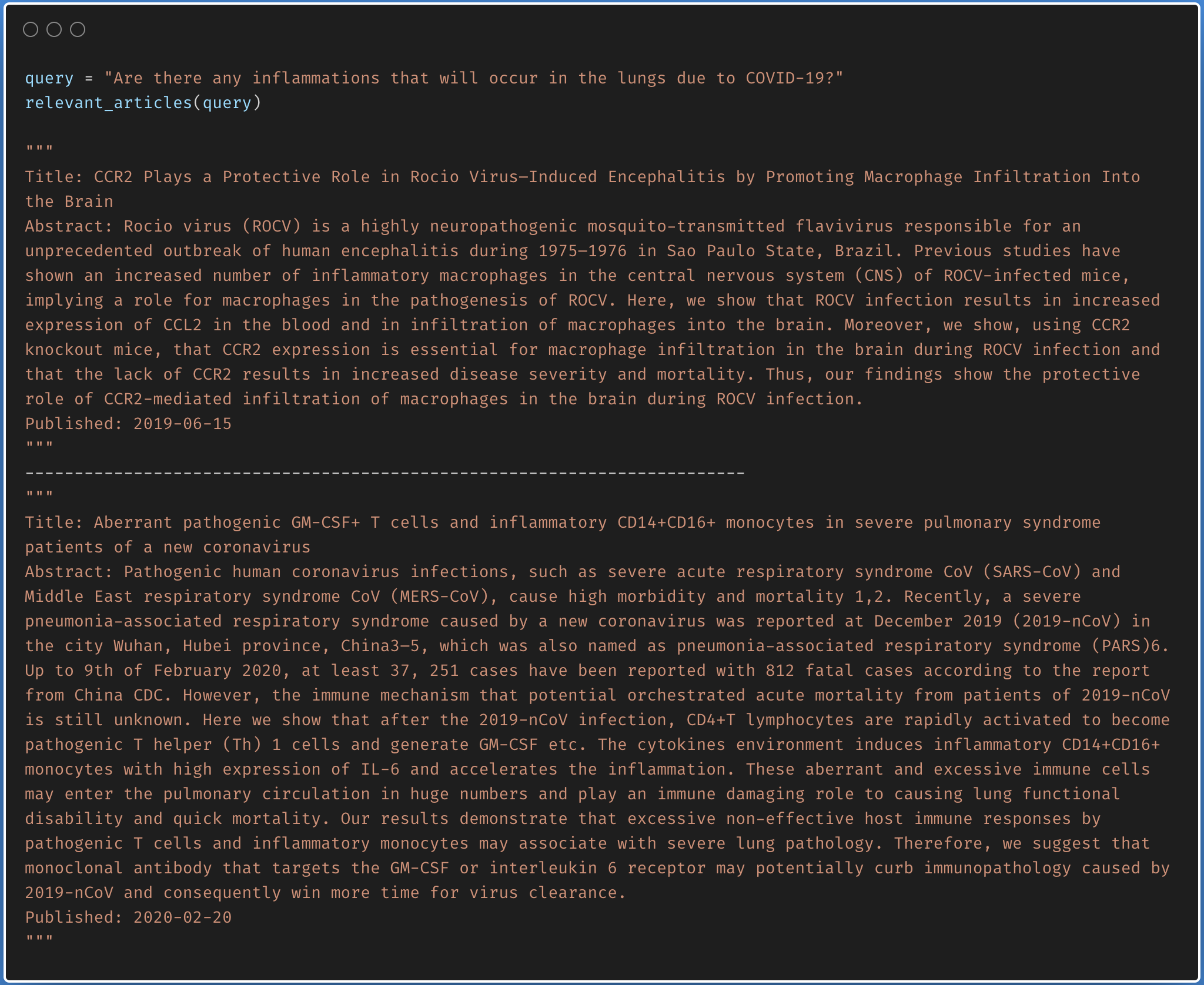
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
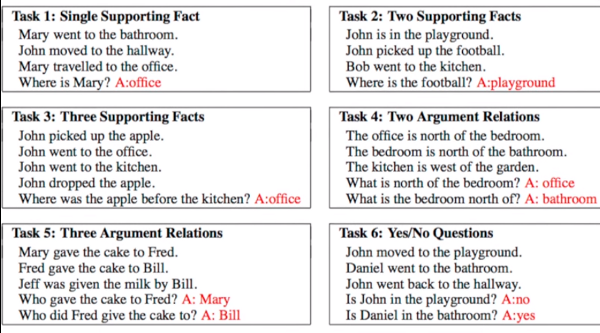
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

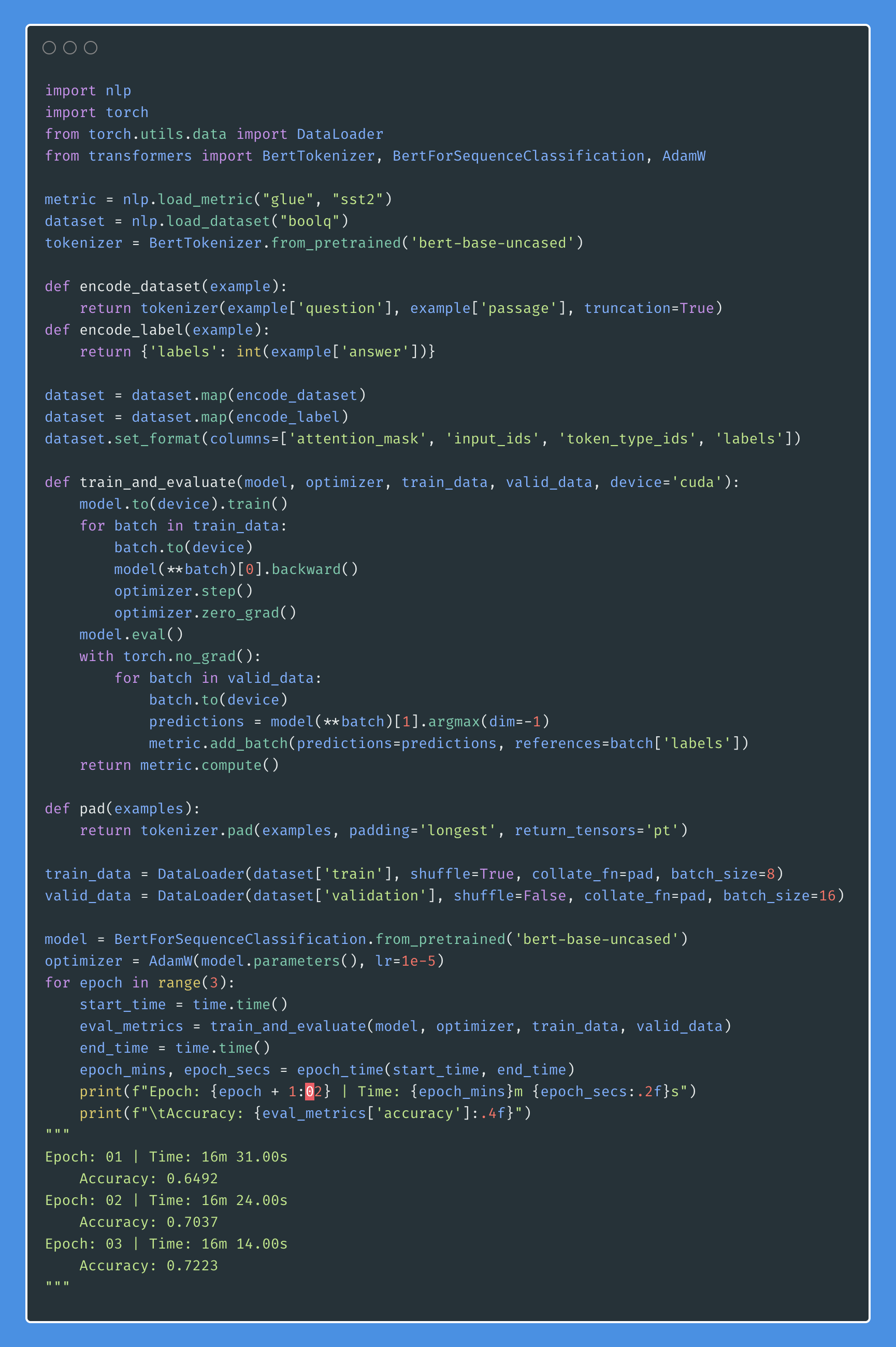
Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
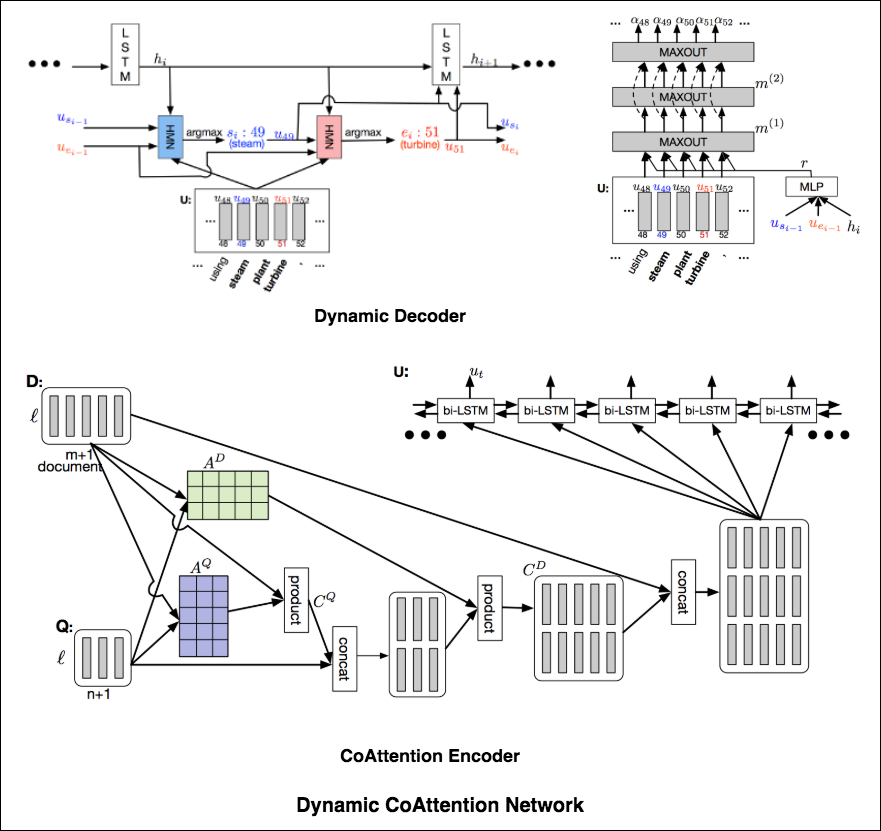
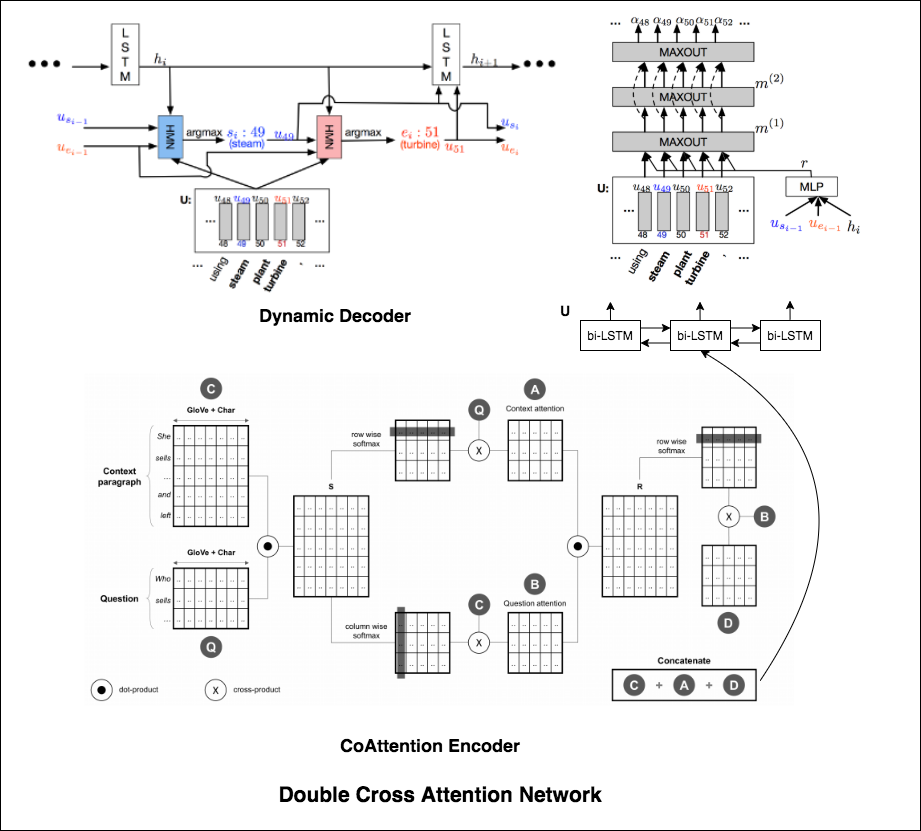
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
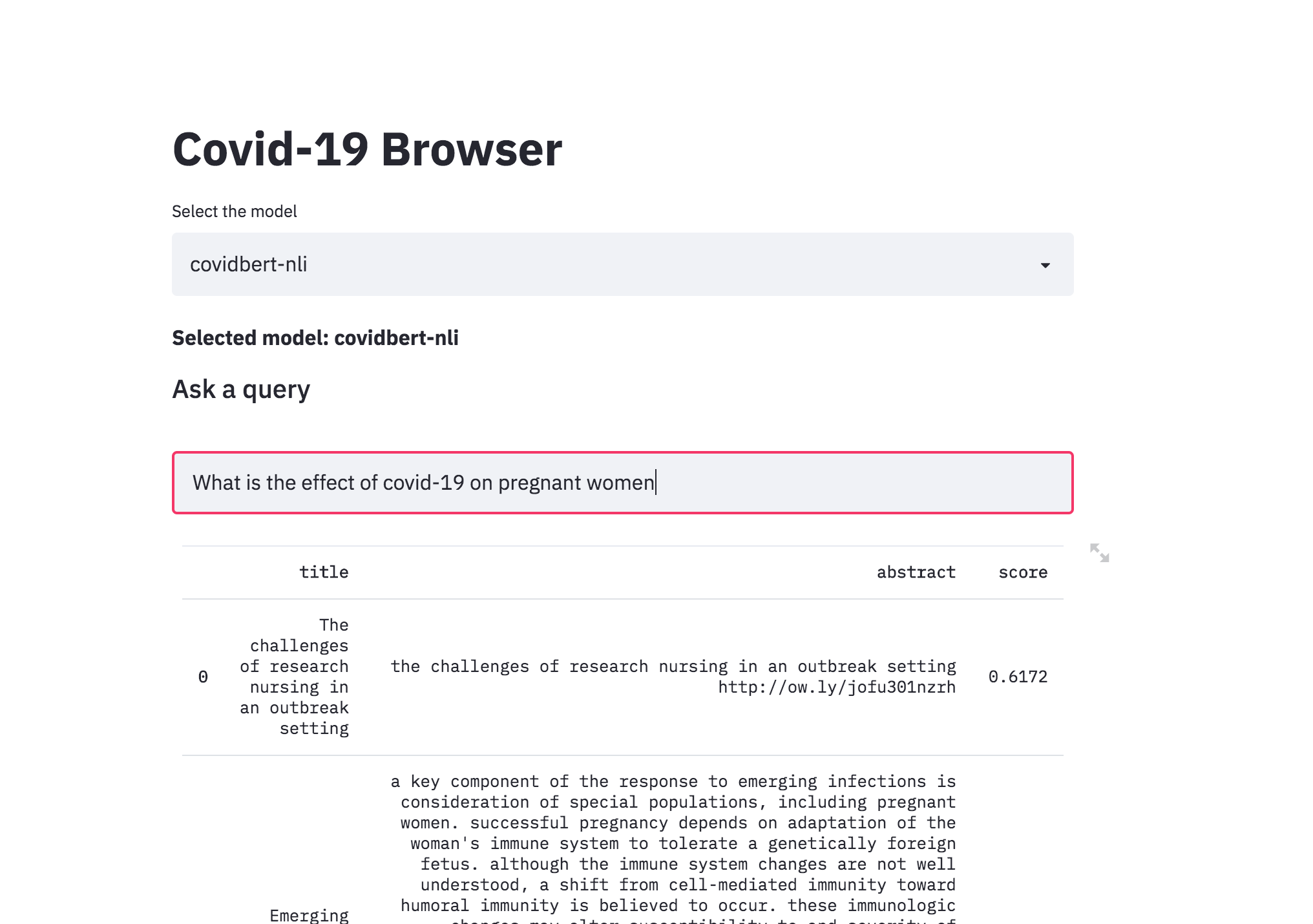
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
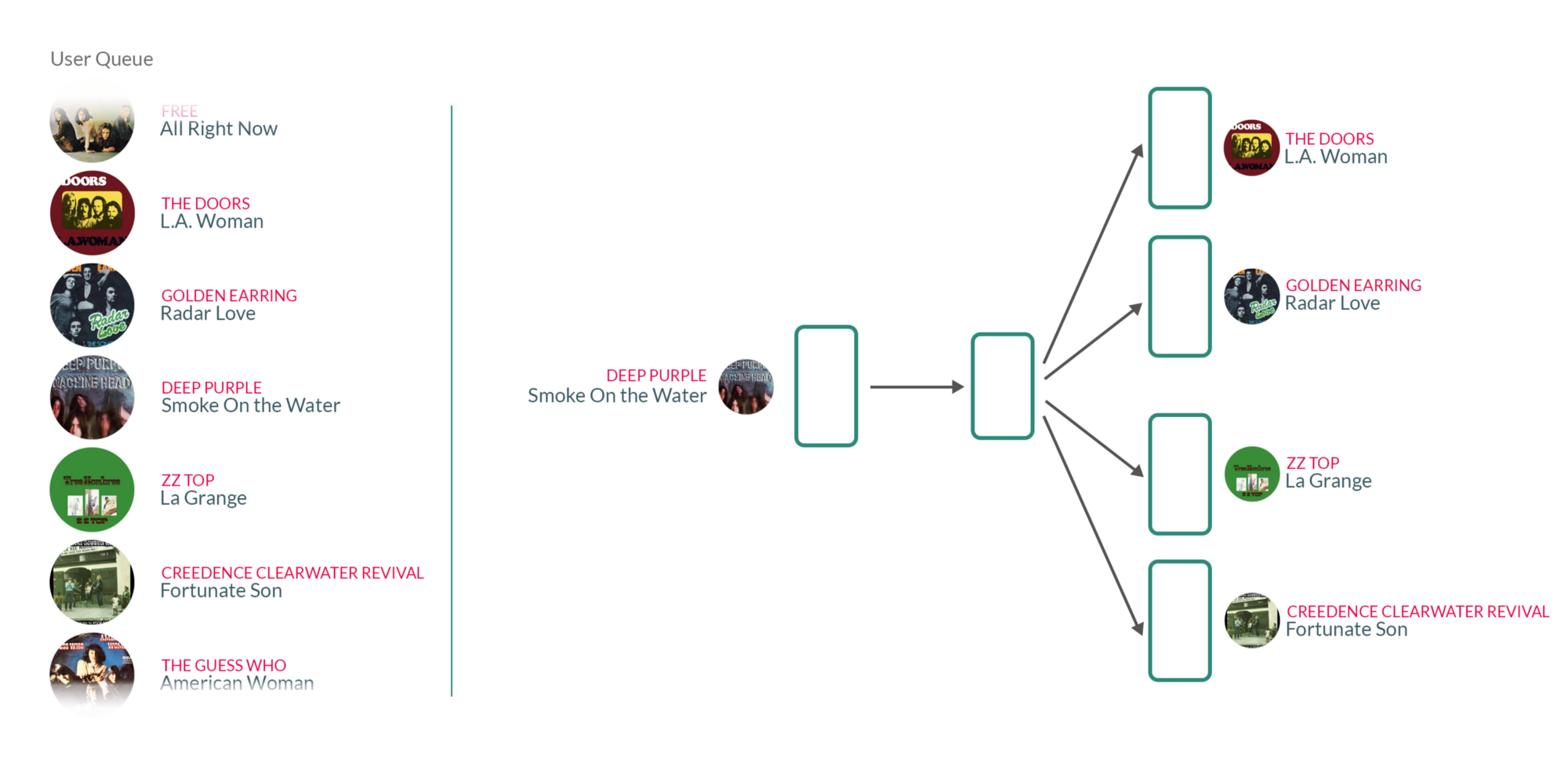
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


