100 Days of NLP
1.0.0

لا يوجد شيء سحر حول السحر. يسهم الساحر فقط شيئًا بسيطًا لا يبدو أنه بسيط أو طبيعي للجمهور غير المدربين. بمجرد أن تتعلم كيفية عقد بطاقة أثناء جعل يدك تبدو فارغة ، فأنت بحاجة فقط إلى التدريب قبل أن تفعل أيضًا "سحر". - جيفري فريدل في كتاب يتقن التعبيرات العادية
ملاحظة: يرجى إثارة مشكلة لأي اقتراحات وتصحيحات وتعليقات.
تتم معظم عينات التعليمات البرمجية باستخدام دفاتر Jupyter (باستخدام Colab). لذلك يمكن تشغيل كل رمز بشكل مستقل.
تم استكشاف الموضوعات التالية:
ملاحظة: تم تعيين مستوى الصعوبة وفقًا لفهمي.
| الرمز المميز | كلمات الكلمات - Word2Vec | تضمينات الكلمات - القفاز | تضمينات الكلمات - إلمو |
| RNN ، LSTM ، جرو | تعبئة تسلسل مبطن | آلية الانتباه - Luong | آلية الانتباه - بحدانو |
| شبكة المؤشر | محول | GPT-2 | بيرت |
| نمذجة الموضوع - LDA | تحليل المكون الرئيسي (PCA) | بايز ساذجة | زيادة البيانات |
| التضمينات الجملة |
تعد عملية تحويل البيانات النصية إلى الرموز ، واحدة من أهم خطوة في NLP. تم استكشاف الرمز المميز باستخدام الطرق التالية:
كلمة تضمين هي تمثيل مستفاد للنص حيث يكون للكلمات التي لها نفس المعنى تمثيل مماثل. هذا النهج لتمثيل الكلمات والمستندات التي يمكن اعتبارها واحدة من الاختراقات الرئيسية للتعلم العميق حول تحدي مشاكل معالجة اللغة الطبيعية.

Word2Vec هي واحدة من أكثر تدمسينات Word PretRained شعبية من قبل Google. اعتمادًا على الطريقة التي يتم بها تعلم التضمينات ، يتم تصنيف Word2Vec إلى نهجين:
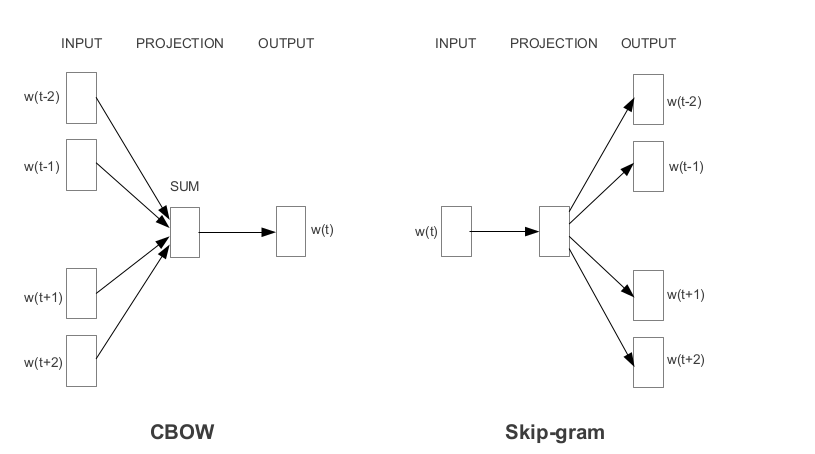
القفازات هي طريقة أخرى شائعة الاستخدام للحصول على التضمينات التي تم تدريبها مسبقًا. يهدف القفاز إلى تحقيق هدفين:
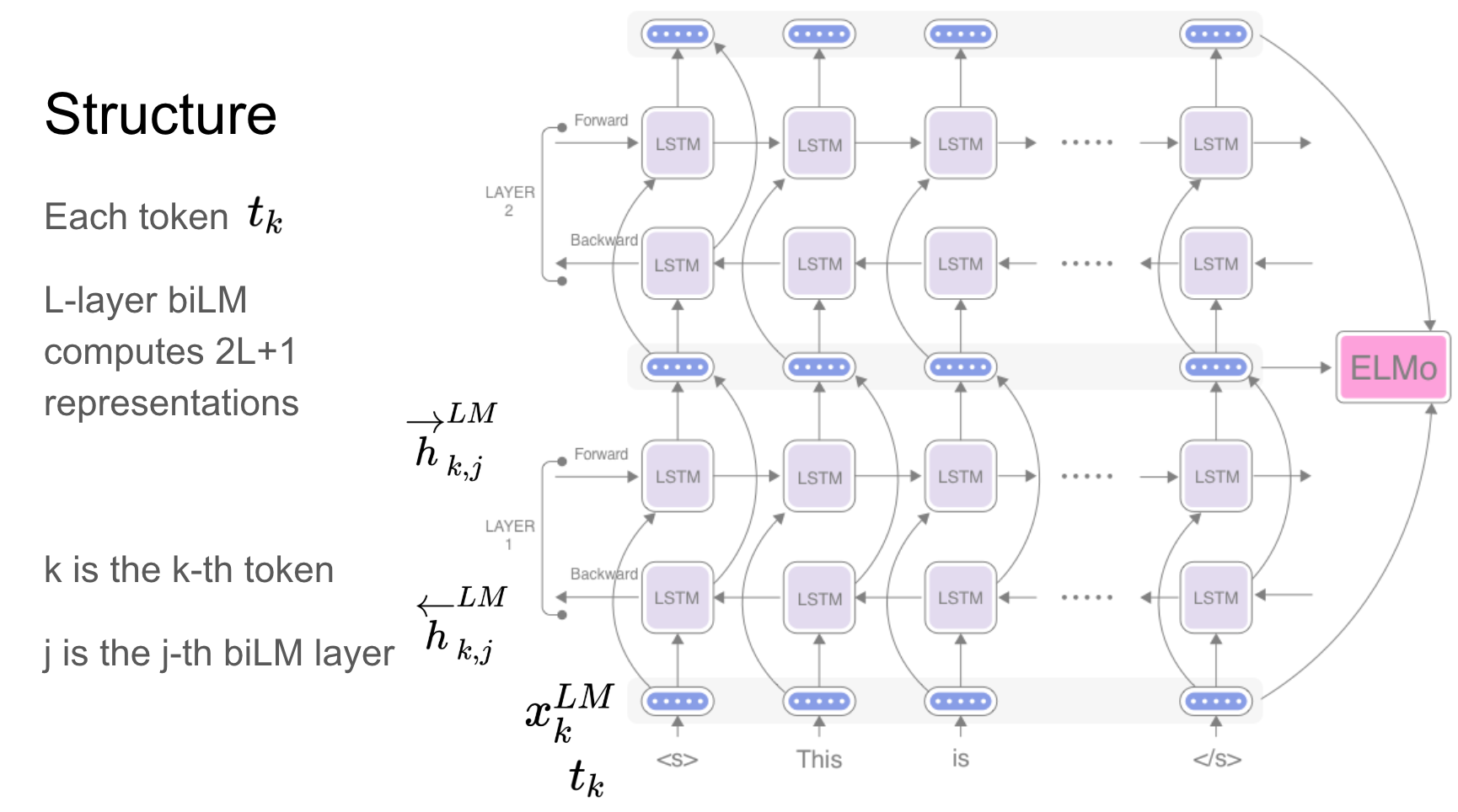
Elmo هو تمثيل عميق للسياق سياق نماذج:
يتم تعلم ناقلات الكلمات هذه وظائف للحالات الداخلية لنموذج اللغة ثنائية الاتجاه العميقة (BILM) ، والتي يتم تدريبها مسبقًا على مجموعة نصية كبيرة.
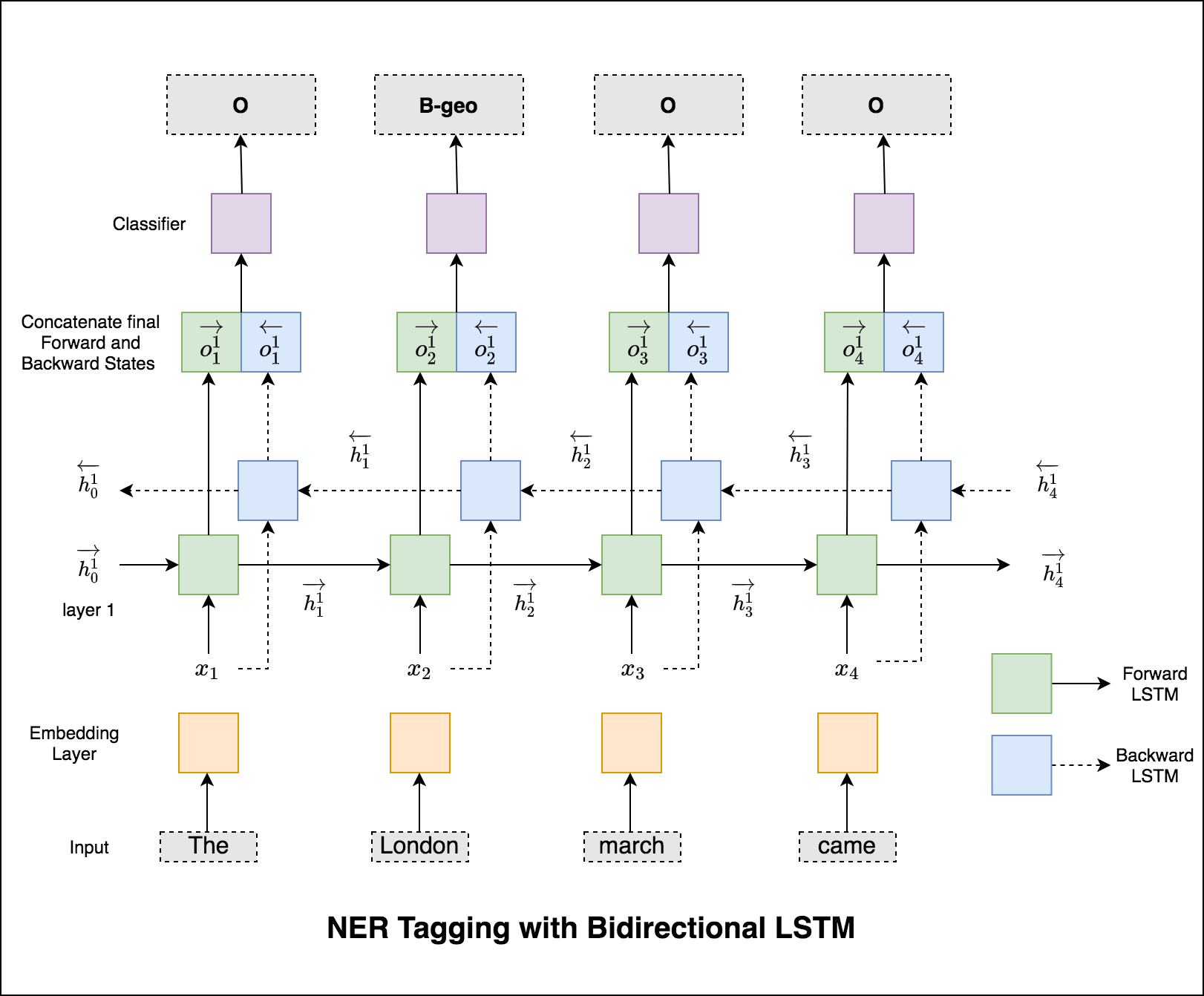
أثبتت الشبكات المتكررة - RNN ، LSTM ، GRU أنها واحدة من أهم الوحدة في تطبيقات NLP بسبب بنيةها. هناك العديد من المشكلات التي يجب أن تتذكرها طبيعة التسلسل كما للتنبؤ بوجود المشاعر في المشهد ، يجب تذكر المشاهد السابقة.

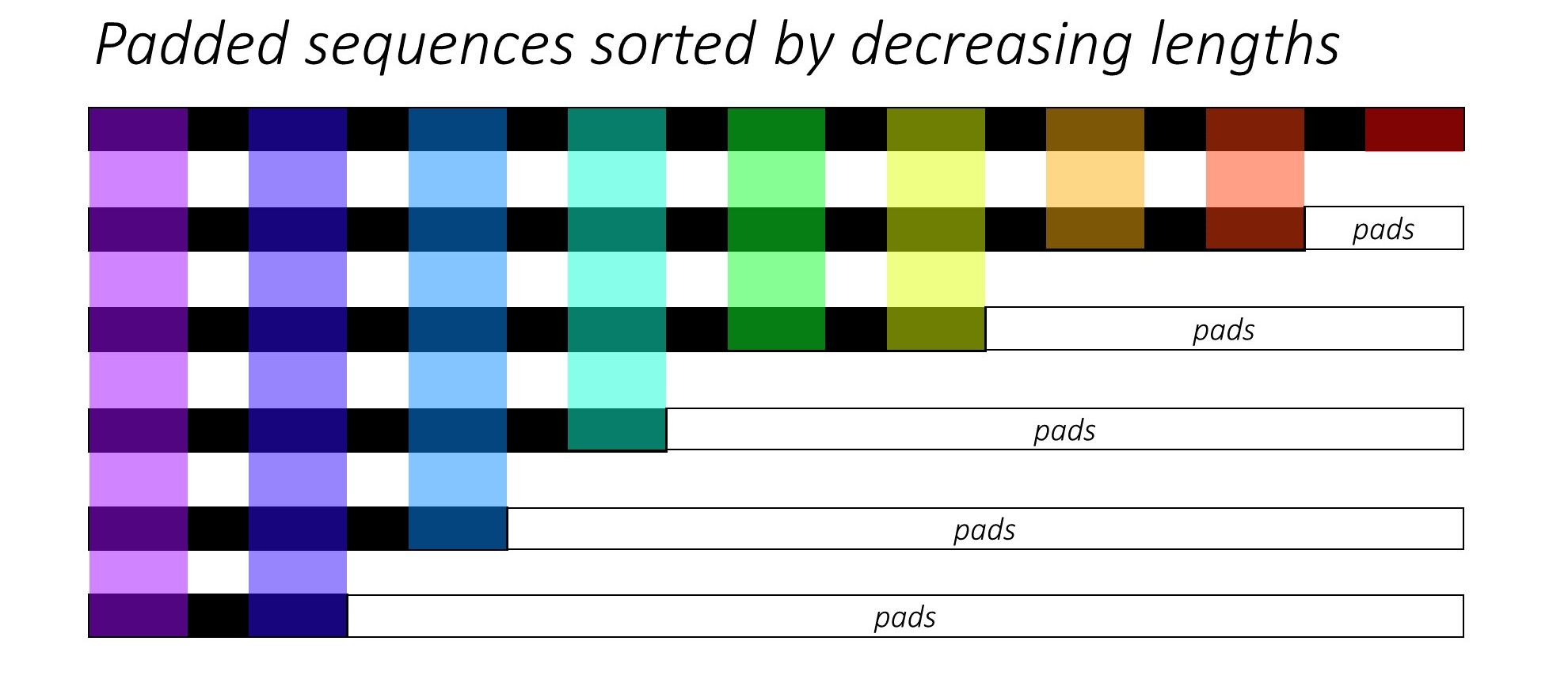
عند تدريب RNN (LSTM أو GRU أو Vanilla-RNN) ، يكون من الصعب دفع تسلسل الطول المتغير. من الناحية المثالية ، سنقوم بتوصيل جميع التسلسلات بطول ثابت وينتهي بنا الأمر إلى إجراء حسابات غير ضرورية. كيف يمكننا التغلب على هذا؟ يوفر Pytorch وظيفة pack_padded_sequences .
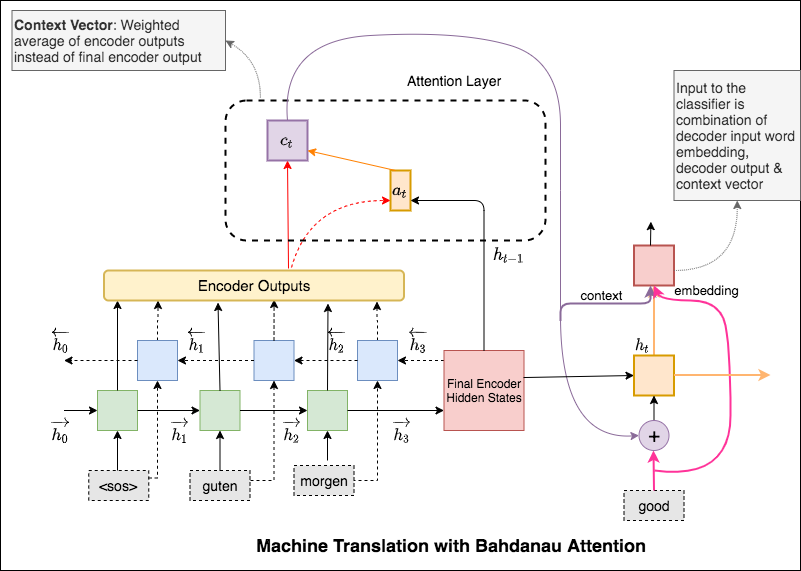
ولدت آلية الانتباه للمساعدة في حفظ جمل المصدر الطويلة في الترجمة الآلية العصبية (NMT). بدلاً من بناء ناقل سياق واحد من آخر حالة مخفية للمشفر ، يتم استخدام الاهتمام للتركيز أكثر على الأجزاء ذات الصلة من المدخلات مع فك تشفير الجملة. سيتم إنشاء متجه السياق عن طريق أخذ مخرجات التشفير current output من وحدة فك الترميز RNN.

يمكن حساب درجة الانتباه بثلاث طرق. dot ، general concat .
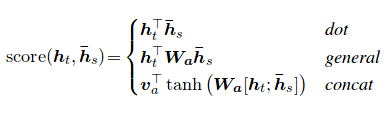
الفرق الرئيسي بين الاهتمام Bahdanau & Luong هو الطريقة التي يتم بها إنشاء ناقل السياق. سيتم إنشاء متجه السياق عن طريق أخذ مخرجات التشفير previous hidden state لـ Decoder RNN. أين هو في Luong ، سيتم إنشاء متجه السياق من خلال أخذ مخرجات التشفير current hidden state لـ Decoder RNN.
بمجرد حساب السياق ، يتم دمجه مع تضمين مدخلات وحدة فك الترميز وتغذية كمدخلات لفك تشفير RNN.

يسمى الانتباه باهداناو أيضا الاهتمام additive .
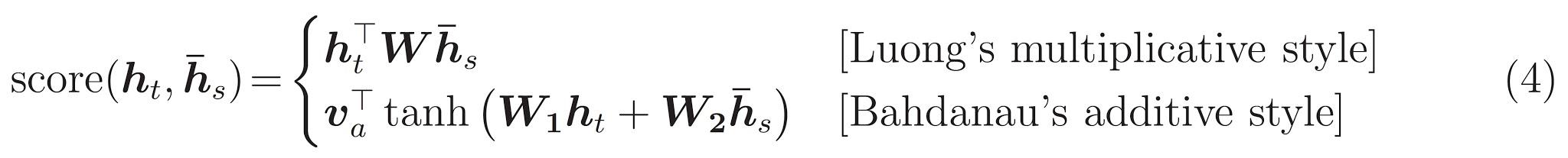
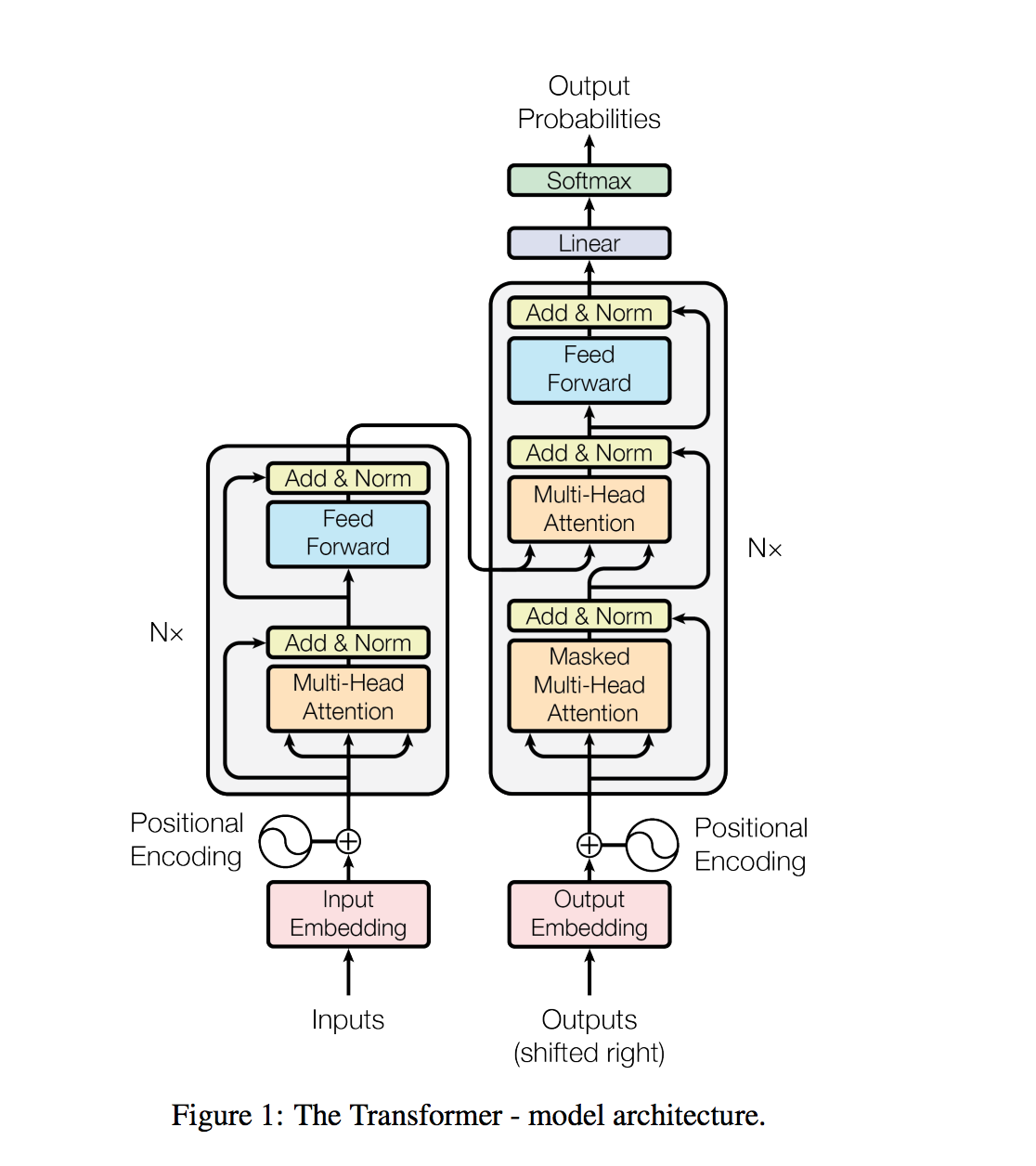
المحول ، وهي بنية نموذجية تتجنب تكرارها وبدلاً من ذلك الاعتماد بالكامل على آلية الانتباه لجذب التبعيات العالمية بين المدخلات والمخرجات.
عادةً ما يتم التعامل مع مهام معالجة اللغة الطبيعية ، مثل الإجابة على الأسئلة ، والترجمة الآلية ، وفهم القراءة ، والتلخيص ، مع التعلم الخاضع للإشراف على مجموعات البيانات المحددة. نوضح أن نماذج اللغة تبدأ في تعلم هذه المهام دون أي إشراف صريح عند تدريبها على مجموعة بيانات جديدة من ملايين صفحات الويب تسمى WebText. أكبر نموذج لدينا ، GPT-2 ، هو محول معلمة 1.5B يحقق نتائج أحدث الأفلام على 7 من أصل 8 مجموعات بيانات نمذجة اللغة المختبرة في إعداد صفري ولكن لا يزال يقلل من webText. تعكس العينات من النموذج هذه التحسينات وتحتوي على فقرات متماسكة من النص. تشير هذه النتائج إلى وجود مسار واعد نحو بناء أنظمة معالجة اللغة التي تتعلم أداء المهام من المظاهرات التي تحدث بشكل طبيعي.
يستخدم GPT-2 وحدة فك ترميز من 12 طبقة فقط.
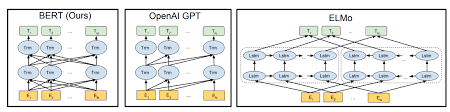
يستخدم بيرت بنية المحولات لتشفير الجمل.
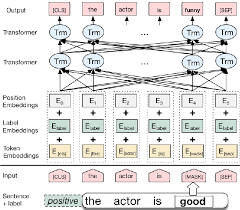
إخراج شبكات المؤشر منفصل ويتوافق مع المواضع في تسلسل الإدخال
يعتمد عدد الفئات المستهدفة في كل خطوة من خطوة الإخراج على طول الإدخال ، وهو متغير.
إنه يختلف عن محاولات الاهتمام السابقة في ذلك ، بدلاً من استخدام الانتباه لمزج الوحدات المخفية للمشفر إلى متجه سياق في كل خطوة فك التشفير ، فإنه يستخدم الانتباه كمؤشر لتحديد عضو في تسلسل الإدخال كمخرج.

يتمثل أحد التطبيقات الأساسية لمعالجة اللغة الطبيعية في استخراج الموضوعات التي يناقشها الأشخاص تلقائيًا من كميات كبيرة من النص. يمكن أن تكون بعض الأمثلة على النص الكبير موجودة من وسائل التواصل الاجتماعي ، ومراجعات العملاء للفنادق ، والأفلام ، وما إلى ذلك ، ملاحظات المستخدمين ، والأخبار ، ورسائل البريد الإلكتروني لشكاوى العملاء ، إلخ.
إن معرفة ما يتحدث عنه الناس وتفهمهم لمشاكلهم وآرائهم أمر ذي قيمة عالية للشركات والمسؤولين والحملات السياسية. ومن الصعب حقًا قراءة مثل هذه المجلدات الكبيرة وتجميع الموضوعات.
وبالتالي ، يلزم وجود خوارزمية آلية يمكنها قراءة المستندات النصية وإخراج الموضوعات التي تمت مناقشتها تلقائيًا.
في دفتر الملاحظات هذا ، سنأخذ مثالًا حقيقيًا على مجموعة بيانات 20 Newsgroups واستخدام LDA لاستخراج الموضوعات التي تمت مناقشتها بشكل طبيعي.
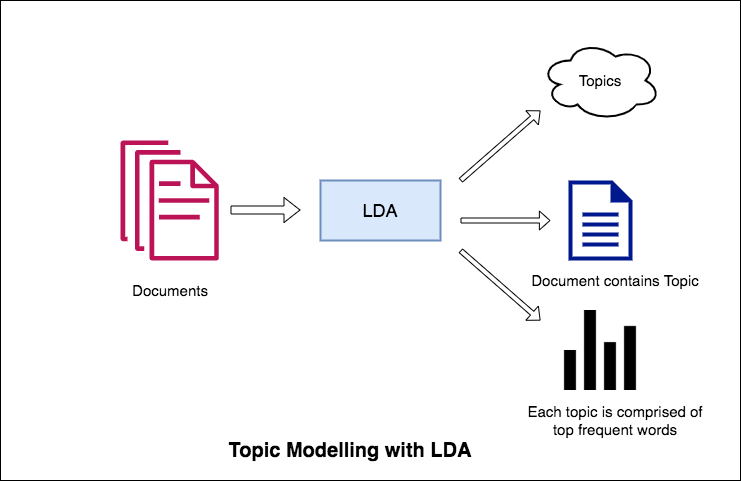
نهج LDA في نمذجة الموضوع هو أنه يعتبر كل مستند كمجموعة من الموضوعات بنسبة معينة. وكل موضوع كمجموعة من الكلمات الرئيسية ، مرة أخرى ، في نسبة معينة.
بمجرد تزويد الخوارزمية بعدد المواضيع ، كل ما يفعله لإعادة ترتيب توزيع الموضوعات داخل المستندات والكلمات الرئيسية في المواضيع للحصول على تكوين جيد لتوزيع كلمات الموضوع.
تعد PCA تقنية تقليل الأبعاد في الأساس تقوم بتحويل أعمدة مجموعة البيانات إلى ميزات مجموعة جديدة. يقوم بذلك عن طريق العثور على مجموعة جديدة من الاتجاهات (مثل محاور X و Y) التي تشرح الحد الأقصى للتغير في البيانات. تسمى محاور إحداثيات النظام الجديدة هذه المكونات الرئيسية (PCS).
يتم استخدام PCA عمليا لسببين:
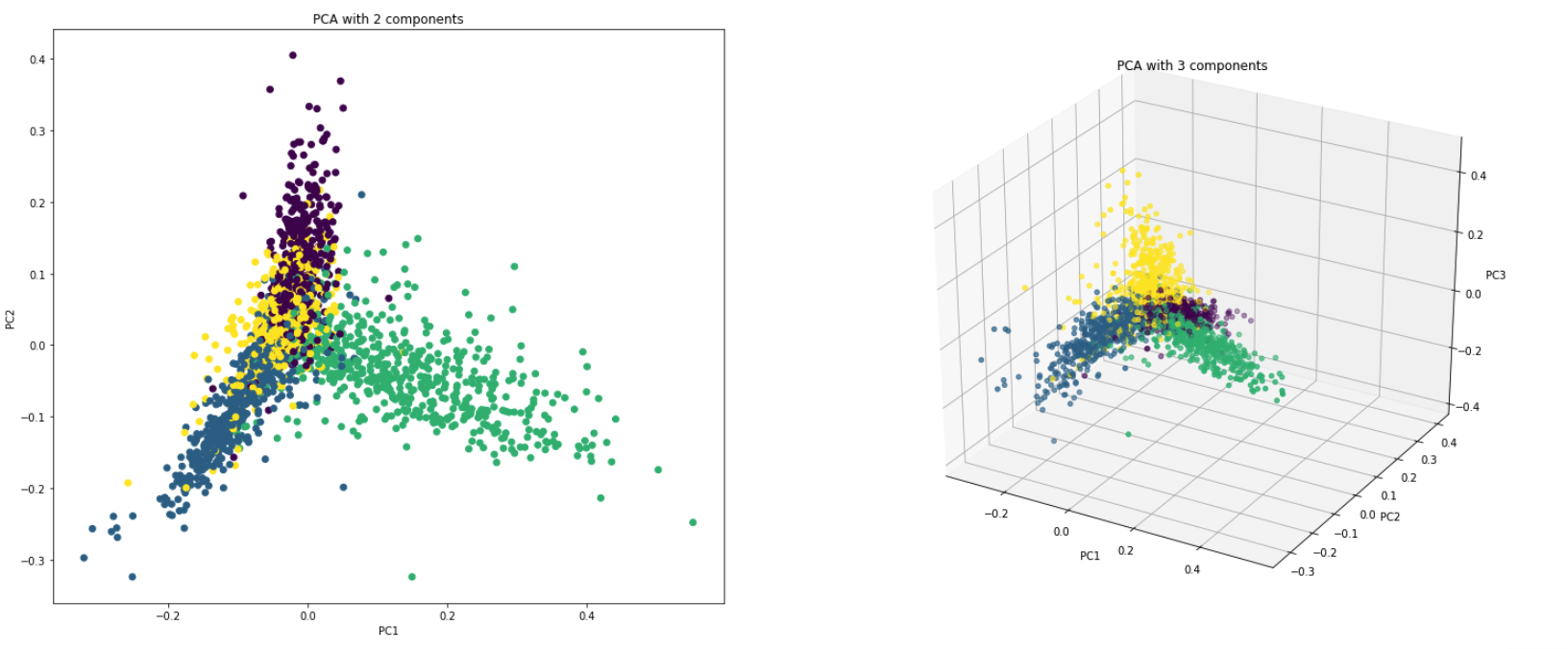
Dimensionality Reduction : يتم تحويل المعلومات الموزعة عبر عدد كبير من الأعمدة إلى مكونات رئيسية (PC) بحيث يمكن أن تفسر أجهزة الكمبيوتر القليلة الأولى قطعة كبيرة من المعلومات الكلية (التباين). يمكن استخدام أجهزة الكمبيوتر هذه كمتغيرات توضيحية في نماذج التعلم الآلي.
Visualize Data : تصور فصل الفئات (أو المجموعات) أمر صعب بالنسبة للبيانات التي تحتوي على أكثر من 3 أبعاد (ميزات). مع الأولين من أجهزة الكمبيوتر الشخصية نفسها ، من الممكن عادةً رؤية فصل واضح.
مصنف Bayes الساذج هو نموذج تعلم آلي احتمالي يستخدم لمهمة التصنيف. يعتمد جوهر المصنف على نظرية بايز.
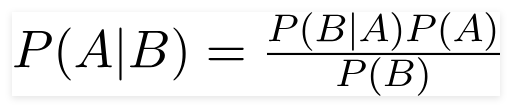
باستخدام نظرية بايز ، يمكننا أن نجد احتمال حدوث ذلك ، بالنظر إلى أن B قد حدث. هنا ، B هو الدليل و A هو الفرضية. الافتراض المقدم هنا هو أن المتنبئين/الميزات مستقلة. هذا هو وجود ميزة معينة لا يؤثر على الآخر. وبالتالي فإنه يسمى ساذجة.
أنواع مصنف بايز الساذج :
Multinomial Naive Bayes : يتم استخدام هذا في الغالب عندما تكون المتغيرات منفصلة (مثل الكلمات). الميزات/التنبؤات المستخدمة من قبل المصنف هي تواتر الكلمات الموجودة في المستند.
Gaussian Naive Bayes : عندما يتوقع المتنبئون قيمة مستمرة وليست منفصلة ، نفترض أن هذه القيم يتم أخذ عينات منها من توزيع غاوسي.
Bernoulli Naive Bayes : هذا مشابه للبايز الساذجة متعددة الحدود ولكن المتنبئين هي متغيرات منطقية. المعلمات التي نستخدمها للتنبؤ بمتغير الفئة تأخذ قيم فقط نعم أو لا ، على سبيل المثال إذا حدثت كلمة في النص أم لا.
باستخدام مجموعة بيانات 20 newsgroup ، يتم استكشاف خوارزمية Bayes الساذجة للقيام بالتصنيف.
يتم استكشاف زيادة البيانات باستخدام التقنيات التالية:

تم استكشاف بنية جديدة تسمى Sbert. تتيح بنية شبكة Siamese أن يمكن اشتقاق المتجهات ذات الحجم الثابت لجمل الإدخال. باستخدام مقياس تشابه مثل مسافة جوني أو مسافة Manhatten / الإقليدية ، يمكن العثور على جمل متشابهة بشكل دلالي.

| تحليل المشاعر - IMDB | تصنيف المشاعر - Hinglish | تصنيف المستند |
| تصنيف زوج أسئلة مكررة - Quora | POS العلامات | استنتاج اللغة الطبيعية - SNLI |
| تصنيف التعليق السام | الجملة الصحيحة من الناحية النحوية - كولا | العلامات ner |
يشير تحليل المشاعر إلى استخدام معالجة اللغة الطبيعية ، وتحليل النص ، واللغويات الحسابية ، والقياسات الحيوية لتحديد الحالات العاطفية والمعلومات الذاتية واستخلاصها ودراستها بشكل منهجي.
تم استكشاف المتغيرات التالية:
يتم استخدام RNN لمعالجة وتحديد المشاعر.

بعد تجربة RNN الأساسي الذي يعطي test_accuracy أقل من 50 ٪ ، تم تجربة التقنيات التالية ويتم تحقيق test_accuracy فوق 88 ٪.
التقنيات المستخدمة:

يساعد الانتباه في التركيز على المدخلات ذات الصلة عند التنبؤ بمشاعر المدخلات. تم استخدام انتباه Bahdanau مع أخذ مخرجات LSTM وتسلسل الحالة النهائية إلى الأمام والخفية للخلف. دون استخدام تضمينات الكلمة التي تم تدريبها مسبقًا ، يتم تحقيق دقة اختبار 88% .
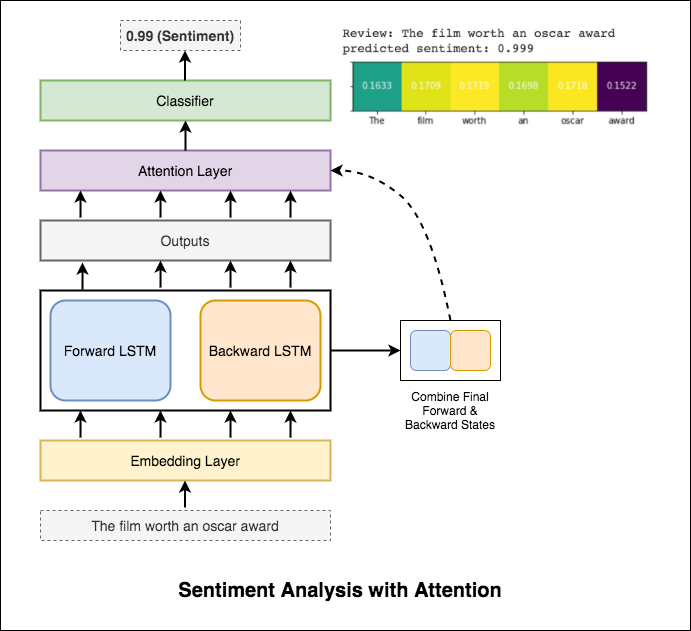
يحصل Bert على نتائج جديدة على أحدث طراز على أحد عشر مهمة معالجة اللغة الطبيعية. انقل التعلم في NLP بعد إطلاق نموذج BERT. يتم استكشاف استخدام Bert للقيام بتحليل المشاعر.

يعد خلط اللغات ، المعروف أيضًا باسم moving الكود ، قاعدة في المجتمعات متعددة اللغات. يميل الأشخاص متعدد اللغات ، الذين هم متحدثون باللغة الإنجليزية غير الأصلية ، إلى رمز MIX باستخدام الكتابة الصوتية القائمة على اللغة الإنجليزية وإدخال الأنجليكمية بلغتهم الرئيسية.
تتمثل المهمة في التنبؤ بعناصر تغريدة معطى من الكود. تكون ملصقات المشاعر إيجابية أو سلبية أو محايدة ، وستكون اللغات المخلوطة بالكود هي اللغة الإنجليزية. (Sentimix)
تم استكشاف المتغيرات التالية:
باستخدام نموذج MLP البسيط ، تم تحقيق F1 score of 0.58 على بيانات الاختبار

بعد استكشاف نموذج MLP الأساسي ، تم استخدام طراز LSTM للتنبؤ بالمشاعر وتم تحقيق درجة F1 البالغة 0.57 .

وكانت النتائج في الواقع أقل مقارنة بنموذج MLP الأساسي. قد يكون أحد الأسباب هو LSTM غير قادر على تعلم العلاقات بين الكلمات في جملة بسبب الطبيعة المتنوعة للغاية للبيانات التي تم خلطها.
نظرًا لأن LSTM غير قادر على تعلم العلاقات بين الكلمات في جملة مخططة من الكود بسبب الطبيعة المتنوعة للغاية للبيانات التي تم خلطها رمزًا ولا يتم استخدام أي تضمينات تدريب مسبقًا ، فإن درجة F1 أقل.
للتخفيف من هذه المشكلة ، يتم استخدام نموذج XLM-Roberta (الذي تم تدريبه مسبقًا على 100 لغة) لتشفير الجملة. من أجل استخدام نموذج XLM-Roberta ، يجب أن تكون الجملة بلغة مناسبة. لذا أولاً ، يجب تحويل الكلمات Hinglish إلى شكل الهندية (Devanagari).
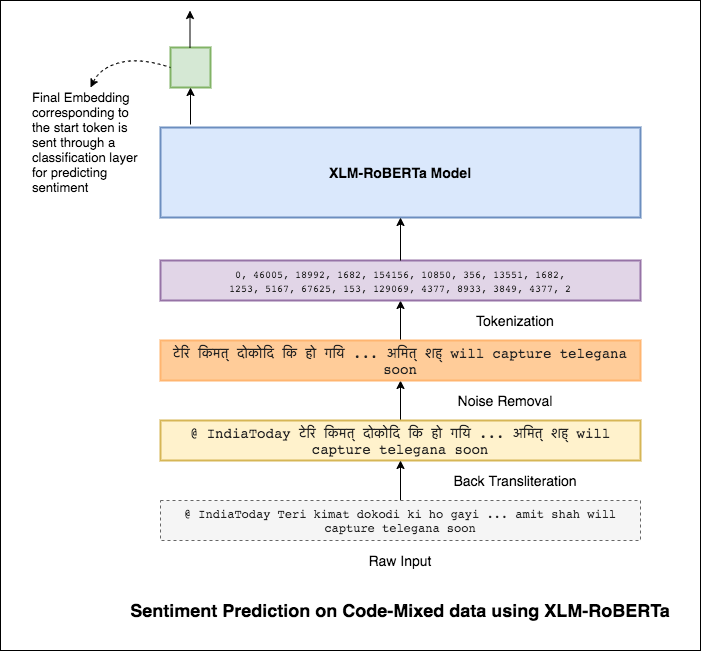
تم تحقيق درجة F1 من 0.59 . سيتم استكشاف طرق لتحسين هذا لاحقًا.
تم استخدام الإخراج النهائي من نموذج XLM-Roberta كضمانات إدخال لنموذج LSTM ثنائي الاتجاه. تنتج طبقة الانتباه ، التي تأخذ المخرجات من طبقة LSTM ، تمثيلًا مرجحًا للمدخلات ، والتي يتم تمريرها بعد ذلك عبر مصنف للتنبؤ بمشاعر الجملة.

تم تحقيق درجة F1 من 0.64 .
بالطريقة نفسها التي يمكن أن ينظر بها مرشح 3 × 3 على رقعة من الصورة ، يمكن للمرشح 1 × 2 أن ينظر إلى كلمتين متتابعتين في نص من النص ، أي ثنائية. في نموذج CNN هذا ، سنستخدم بدلاً من ذلك مرشحات متعددة من أحجام مختلفة ستنظر في الأشكال الثنائية (مرشح 1x2) ، و tre-grams (مرشح 1x3) و/أو n-grams (مرشح 1xn) داخل النص.
الحدس هنا هو أن ظهور بعض الأشكال الثنائية ، والثلاثيات ، و N-grams ضمن المراجعة سيكون مؤشرا جيدا على المشاعر النهائية.
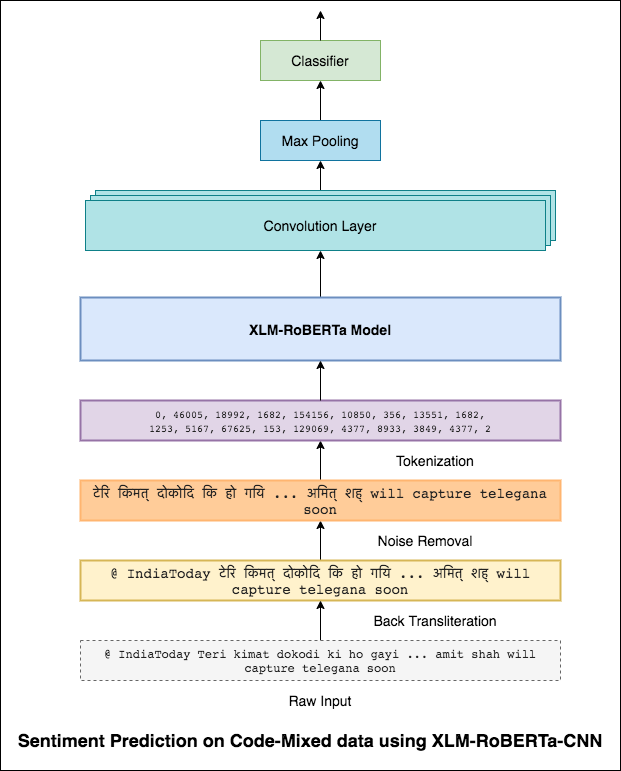
تم تحقيق درجة F1 من 0.69 .
CNN يلتقط التبعيات المحلية حيث يلتقط RNN التبعيات العالمية. من خلال الجمع بين كلاهما يمكننا الحصول على فهم أفضل للبيانات. إن فرقة نموذج CNN ونموذج الاهتمام ثنائي الاتجاه-يؤدي إلى النموذج الآخر.
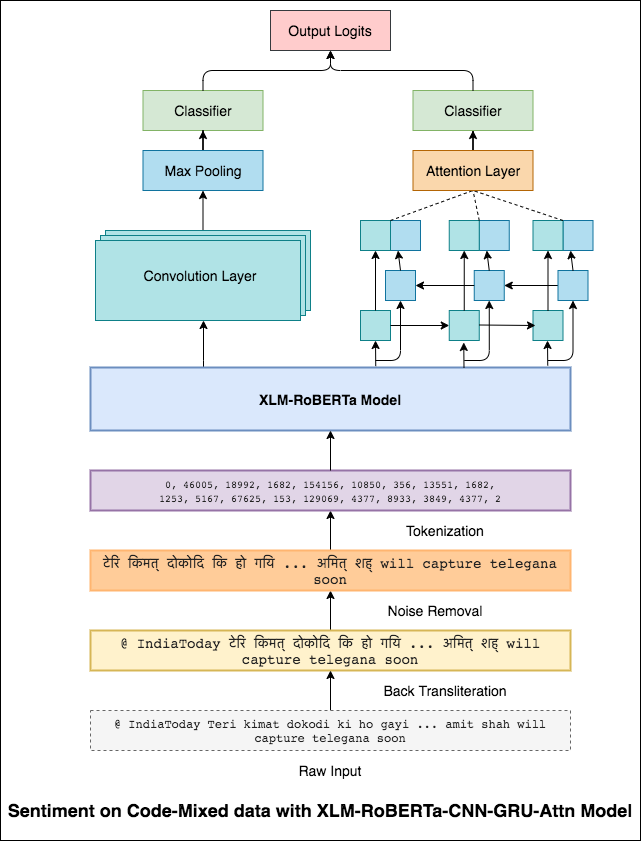
تم تحقيق درجة F1 من 0.71 . (أعلى 5 في المتصدرين).
يعد تصنيف المستندات أو تصنيف المستندات مشكلة في علوم المكتبات وعلوم المعلومات وعلوم الكمبيوتر. المهمة هي تعيين مستند إلى فئة أو فئة واحدة أو أكثر.
تم استكشاف المتغيرات التالية:
تنظر شبكة الاهتمام الهرمية (HAN) في البنية الهرمية للمستندات (المستندات - الجمل - الكلمات) وتتضمن آلية انتباه قادرة على العثور على أهم الكلمات والجمل في وثيقة أثناء أخذ السياق في الاعتبار.
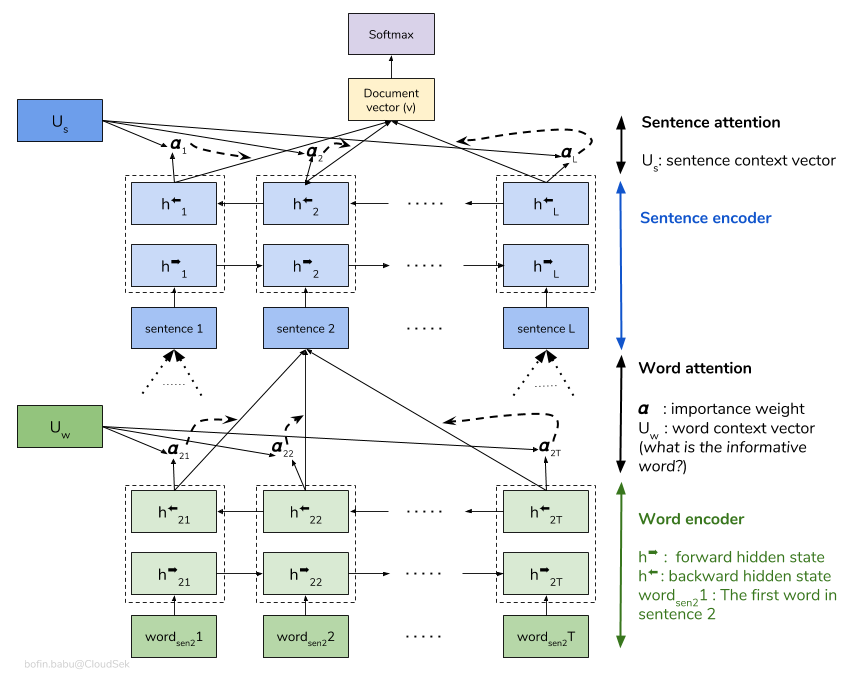
نموذج HAN الأساسي هو المتفاقم بسرعة. من أجل التغلب على هذا ، يتم استكشاف تقنيات مثل Embedding Dropout ، Locked Dropout . هناك تقنية أخرى أخرى تسمى Weight Dropout التي لا يتم تنفيذها (اسمحوا لي أن أعرف ما إذا كانت هناك أي موارد جيدة لتنفيذ هذا). يتم أيضًا استخدام Glove الكلمات المدربة مسبقًا بدلاً من التهيئة العشوائية. نظرًا لأنه يمكن الانتباه على مستوى الجملة ومستوى الكلمات ، يمكننا تصور الكلمات المهمة في الجملة والجمل المهمة في المستند.



QQP تعني أزواج أسئلة Quora. الهدف من المهمة هو لزوج معين من الأسئلة ؛ نحتاج إلى العثور على ما إذا كانت هذه الأسئلة تشبه بشكل دلالي بعضها البعض أم لا.
تم استكشاف المتغيرات التالية:
تحتاج الخوارزمية إلى تناول زوج من الأسئلة كمدخلات ويجب أن تخرج تشابهها. يتم استخدام شبكة سيامي. Siamese neural network (تسمى أحيانًا الشبكة العصبية المزدوجة) هي شبكة عصبية اصطناعية تستخدم same weights أثناء العمل جنبًا إلى جنب على متجهات إدخال مختلفة لحساب متجهات الإخراج المماثلة.

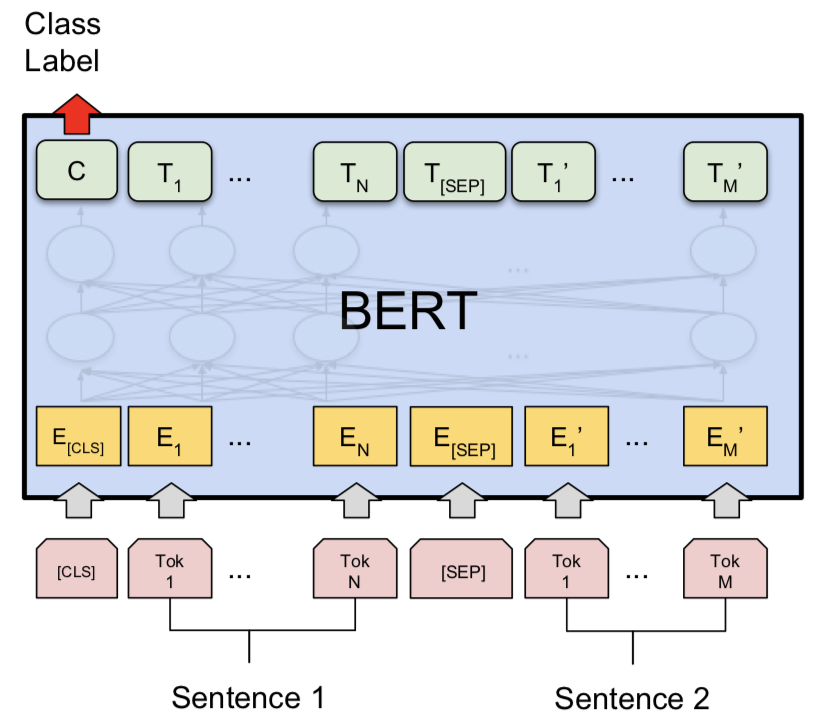
بعد تجربة نموذج Siamese ، تم استكشاف Bert للقيام بالكشف عن أزواج الأسئلة المكررة Quora. يأخذ BERT السؤال 1 والسؤال 2 كمدخلات مفصولة برمز [SEP] وتم التصنيف باستخدام الرمز المميز [CLS] .
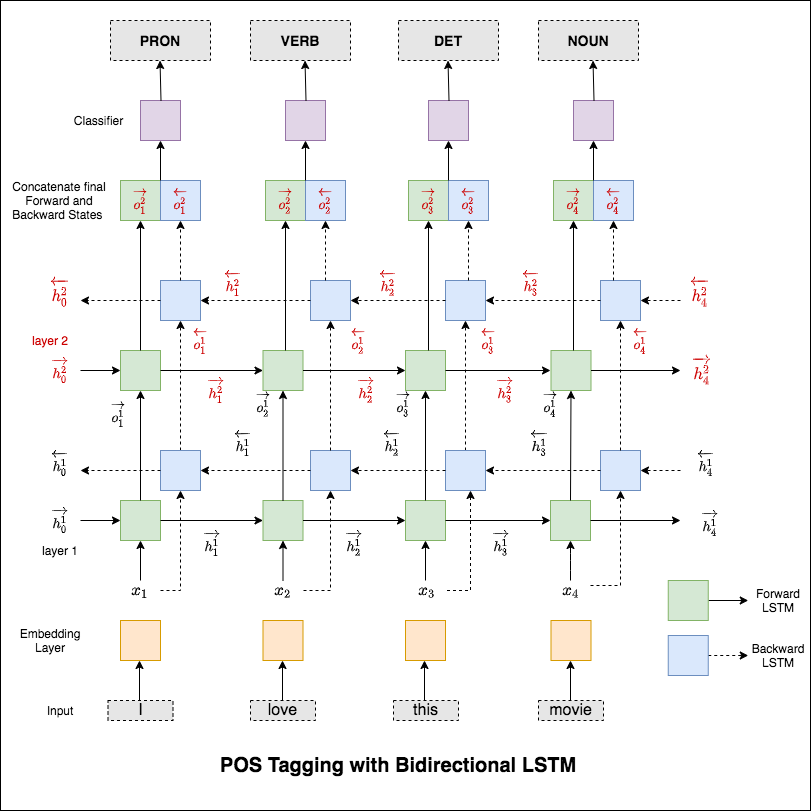
تعتبر وضع العلامات على جزء من الكلام (POS) مهمة لوضع علامة على كل كلمة في جملة مع الجزء المناسب من الكلام.
تم استكشاف المتغيرات التالية:
يغطي هذا الرمز سير العمل الأساسي. سنتعلم كيفية: تحميل البيانات ، وإنشاء تقسيم القطار/الاختبار/التحقق من الصحة ، وبناء مفردات ، وإنشاء تكرار البيانات ، وتحديد نموذج وتنفيذ حلقة القطار/التقييم/اختبار وقت التشغيل (الاستدلال).
النموذج المستخدم هو شبكة LSTM متعددة الطبقة
بعد تجربة نهج RNN ، يتم استكشاف علامات POS مع العمارة القائمة على المحولات. نظرًا لأن المحول يحتوي على كل من التشفير وفك التشفير وللمهمة التسلسلية ، سيكون Encoder فقط كافيًا. نظرًا لأن البيانات صغيرة ، فإن وجود 6 طبقات من التشفير سوف تغلب على البيانات. لذلك تم استخدام نموذج تشفير محول من 3 طبقات.

بعد محاولة وضع علامات POS مع تشفير Transformer ، يتم استغلال علامات POS مع نموذج BERT مسبقًا. حقق دقة الاختبار 91% .

الهدف من الاستنتاج الطبيعي (NLI) ، وهي مهمة معالجة اللغة الطبيعية المدروسة على نطاق واسع ، هو تحديد ما إذا كان أحد البيان المعطى (فرضية) ينطوي بشكل دلالي على بيان آخر (فرضية).
تم استكشاف المتغيرات التالية:
يتم تنفيذ نموذج أساسي مع شبكة Siamese Bilstm
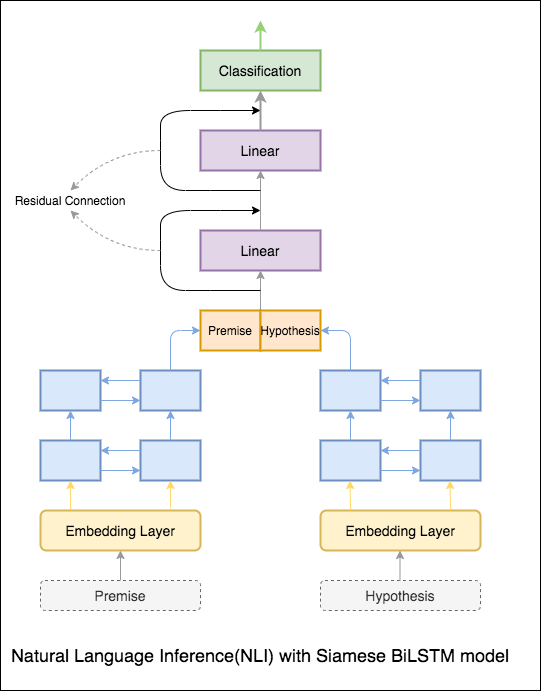
يمكن التعامل مع هذا كإعداد خط الأساس. تم تحقيق دقة اختبار قدرها 76.84% .
في دفتر الملاحظات السابق ، الحالات النهائية المخفية للفرضية والفرضية كتمثيلات من LSTM. الآن بدلاً من أخذ الحالات الخفية النهائية ، سيتم حساب الاهتمام عبر جميع الرموز المميزة للمدخلات ويتم أخذ المتجه المرجح النهائي كتمثيل للفرضية والفرضية.
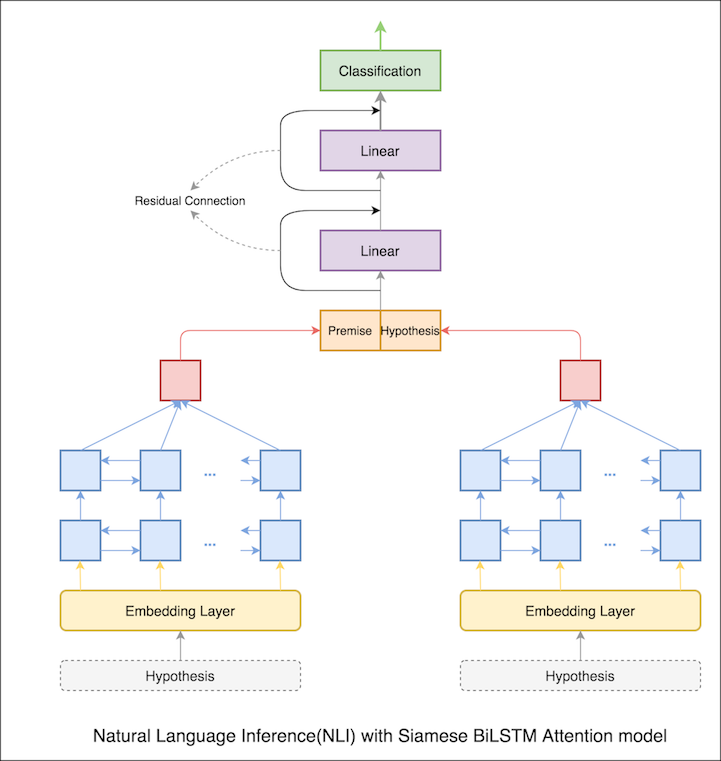
زادت دقة الاختبار من 76.84% إلى 79.51% .
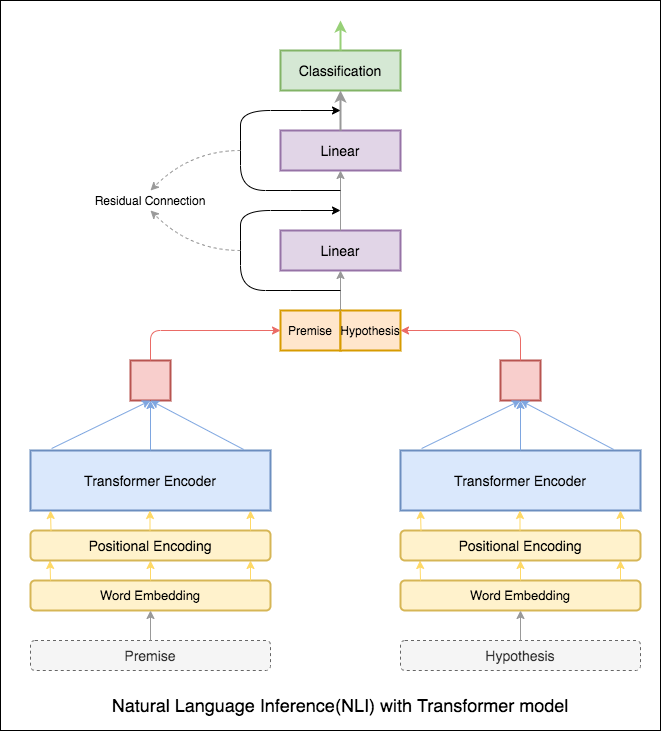
تم استخدام تشفير Transformer لتشفير الفرضية والفرضية. بمجرد تمرير الجملة من خلال المشفر ، يُعتبر ملخص جميع الرموز المميزة التمثيل النهائي (يمكن استكشاف متغيرات أخرى). دقة النموذج أقل مقارنة مع المتغيرات RNN.
تم استكشاف NLI مع نموذج قاعدة Bert. يأخذ Bert الفرضية والفرضية حيث أن المدخلات مفصولة برمز [SEP] وتم إجراء التصنيف باستخدام الرمز المميز [CLS] .
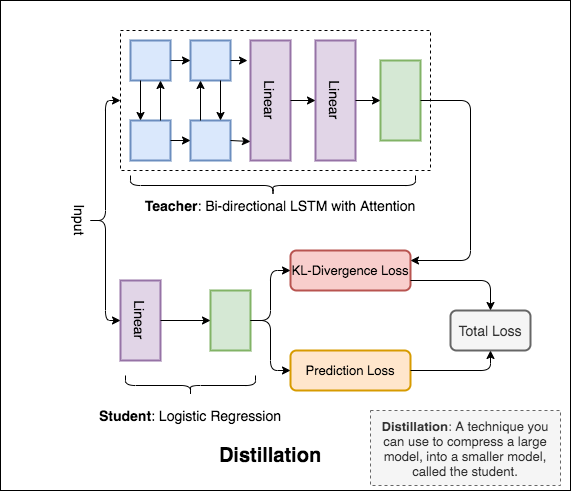
Distillation : تقنية يمكنك استخدامها لضغط نموذج كبير ، يسمى teacher ، إلى نموذج أصغر ، يسمى student . بعد الطالب ، يتم استخدام نماذج المعلمين من أجل إجراء التقطير على NLI.
يمكن أن تكون مناقشة الأشياء التي تهتم بها أمرًا صعبًا. إن تهديد سوء المعاملة والتحرش عبر الإنترنت يعني أن الكثير من الناس يتوقفون عن التعبير عن أنفسهم والتخلي عن البحث عن آراء مختلفة. تكافح المنصات من أجل تسهيل المحادثات بفعالية ، مما يؤدي إلى الحد من المجتمعات إلى الحد من تعليقات المستخدم أو إيقاف تشغيله بالكامل.
يتم تزويدك بعدد كبير من تعليقات Wikipedia التي تم تصنيفها من قبل المقيمين البشريين للسلوك السام. أنواع السمية هي:
تم استكشاف المتغيرات التالية:
النموذج المستخدم هو شبكة GRU ثنائية الاتجاه.
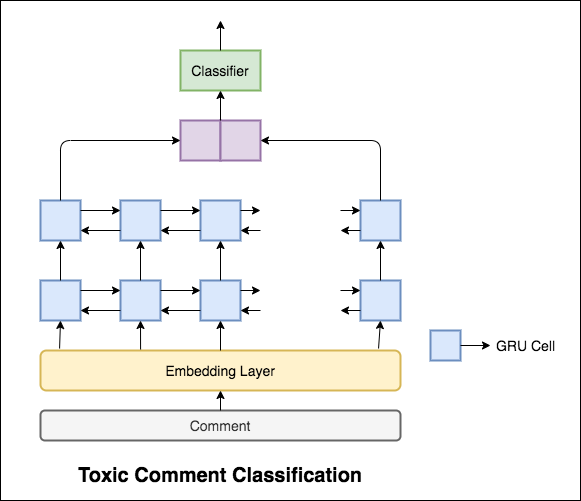
تم تحقيق دقة اختبار قدرها 99.42% . نظرًا لأن 90 ٪ من البيانات لا يتم تصنيفها في أي من السمية ، فإن التنبؤ بكل ما تبقى من البيانات باعتباره غير سامة يعطي نموذجًا دقيقًا بنسبة 90 ٪. لذا فإن الدقة ليست مقياسًا موثوقًا به. تم تنفيذ ROC AUC متري مختلف.
مع Categorical Cross Entropy مثل الخسارة ، يتم تحقيق درجة ROC_AUC البالغة 0.5 . عن طريق تغيير الخسارة إلى Binary Cross Entropy وكذلك تعديل النموذج قليلاً عن طريق إضافة طبقات التجميع (الحد الأقصى ، يعني) ، تحسنت درجة ROC_AUC إلى 0.9873 .
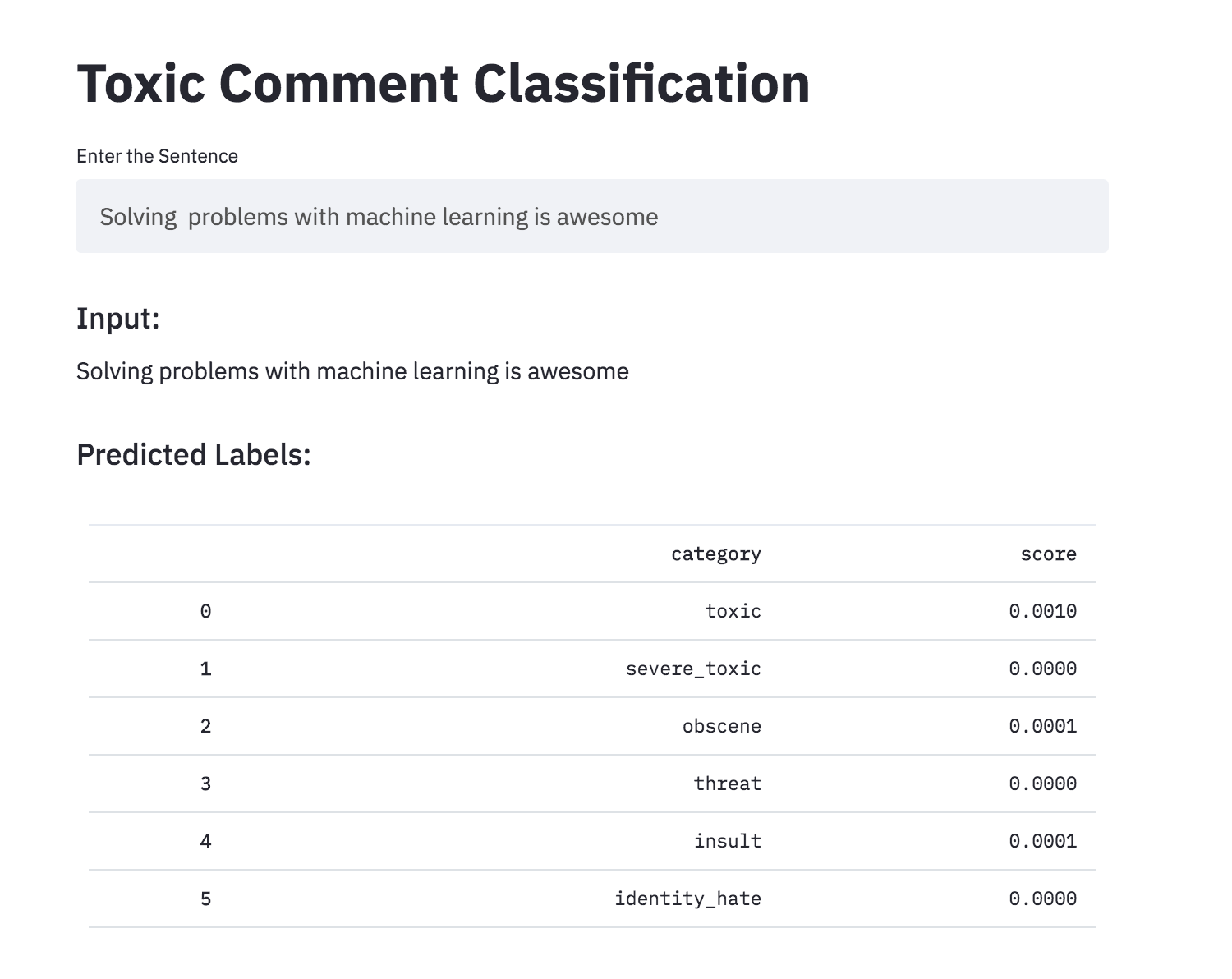
تحويل تصنيف التعليق السام إلى تطبيق باستخدام STIPLELIT. النموذج الذي تم تدريبه مسبقًا متاح الآن.
هل يمكن أن يكون لدى الشبكات العصبية الاصطناعية القدرة على الحكم على القبول النحوي للحكم؟ من أجل استكشاف هذه المهمة ، يتم استخدام مجموعة بيانات قابلية القبول اللغوية (COLA). كولا هي مجموعة من الجمل المسمى على أنها صحيحة أو غير صحيحة.
تم استكشاف المتغيرات التالية:
يحصل Bert على نتائج جديدة على أحدث طراز على أحد عشر مهمة معالجة اللغة الطبيعية. انقل التعلم في NLP بعد إطلاق نموذج BERT. في دفتر الملاحظات هذا ، سوف نستكشف كيفية استخدام BERT لتصنيف ما إذا كانت الجملة صحيحة من الناحية النحوية أم لا تستخدم مجموعة بيانات COLA.
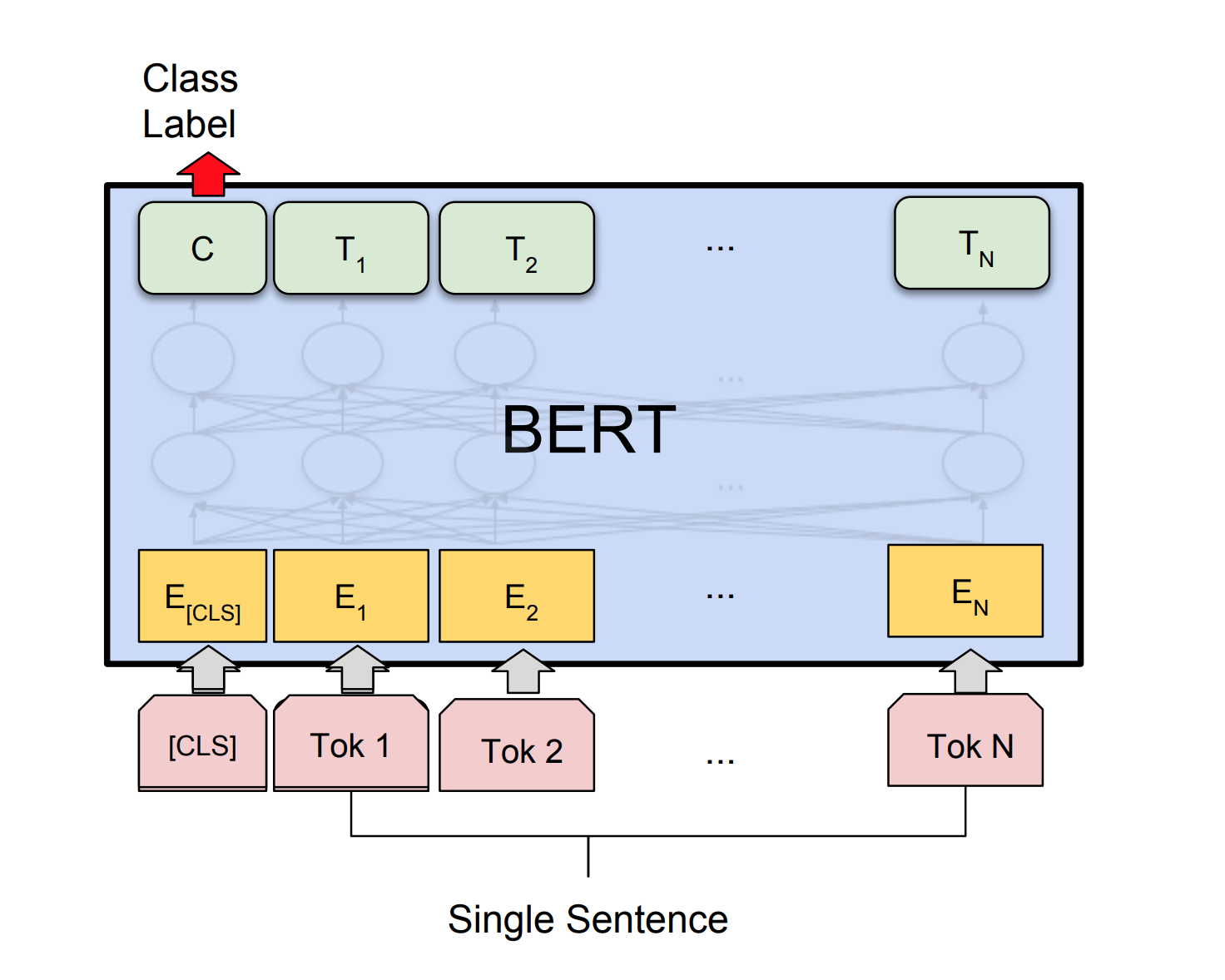
تم تحقيق دقة 85% ومعامل ارتباط ماثيوز (MCC) من 64.1 .
Distillation : تقنية يمكنك استخدامها لضغط نموذج كبير ، يسمى teacher ، إلى نموذج أصغر ، يسمى student . يتبع الطالب ، يتم استخدام نماذج المعلمين من أجل أداء التقطير على كولا.

تمت تجربة التجارب التالية:
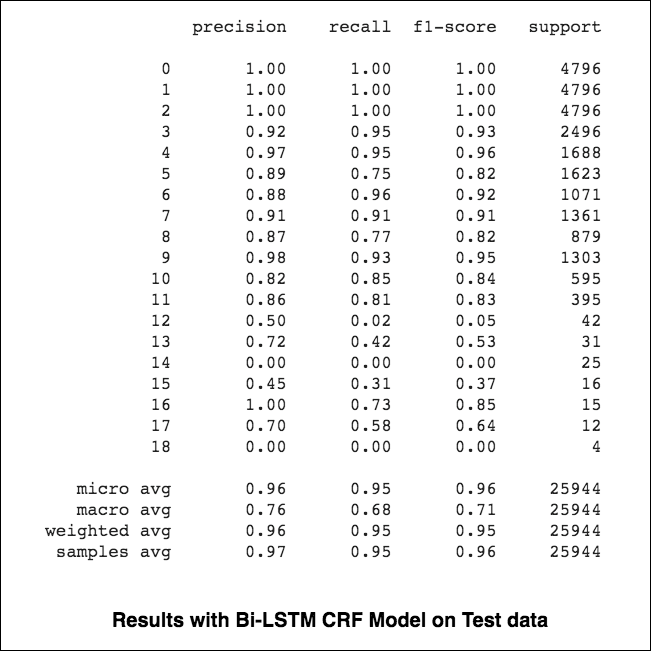
84.06 ، MCC: 61.582.54 ، MCC: 5782.92 ، MCC: 57.9 تعتبر العلامات المسمى-التعرف على العلامات (NER) ، مهمة وضع علامة على كل كلمة في جملة مع كيانها المناسب.
تم استكشاف المتغيرات التالية:
يغطي هذا الرمز سير العمل الأساسي. سنرى كيفية: تحميل البيانات ، وإنشاء تقسيم القطار/الاختبار/التحقق من الصحة ، وإنشاء مفردات ، وإنشاء تكرار البيانات ، وتحديد نموذج وتنفيذ حلقة القطار/التقييم/الاختبار ، واختبار النموذج.
النموذج المستخدم هو شبكة LSTM ثنائية الاتجاه
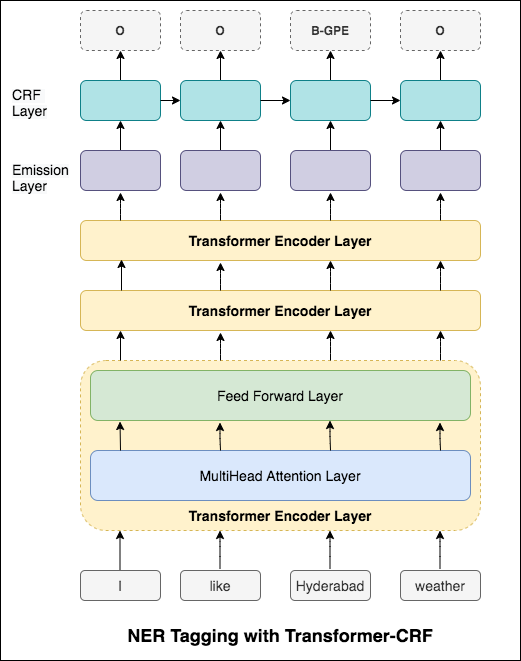
في حالة وضع علامة التسلسل (ner) ، قد تعتمد علامة الكلمة الحالية على علامة الكلمة السابقة. (على سبيل المثال: نيويورك).
بدون CRF ، كنا نستخدم ببساطة طبقة خطية واحدة لتحويل إخراج LSTM ثنائية الاتجاه إلى درجات لكل علامة. تُعرف هذه emission scores ، والتي تمثل احتمال كون الكلمة علامة معينة.
لا يحسب CRF درجات الانبعاثات فحسب ، بل يحسب أيضًا transition scores ، والتي هي احتمال أن تكون كلمة تكون علامة معينة بالنظر إلى أن الكلمة السابقة كانت علامة معينة. لذلك تقيس درجات الانتقال مدى احتمال انتقالها من علامة إلى أخرى.
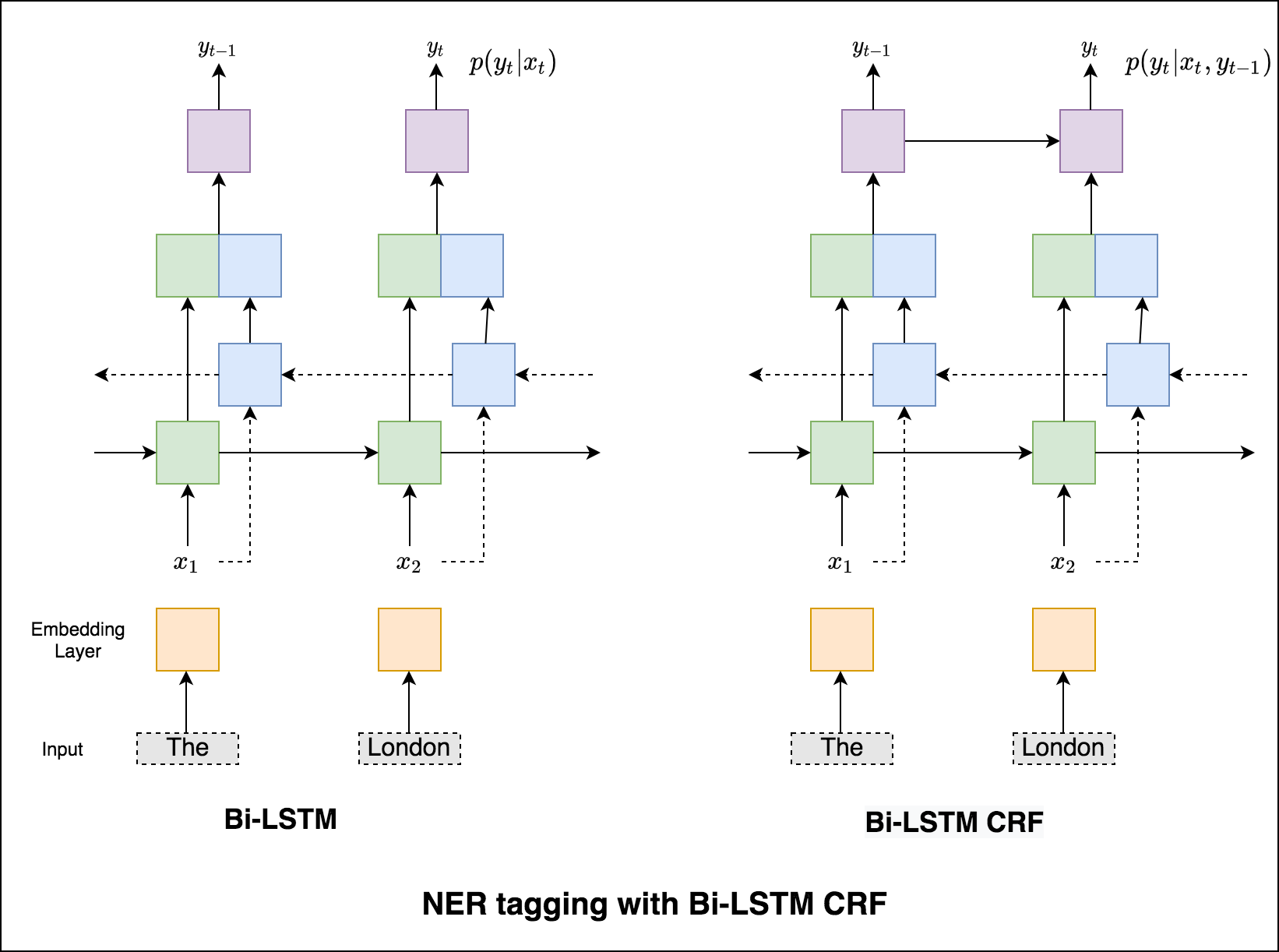
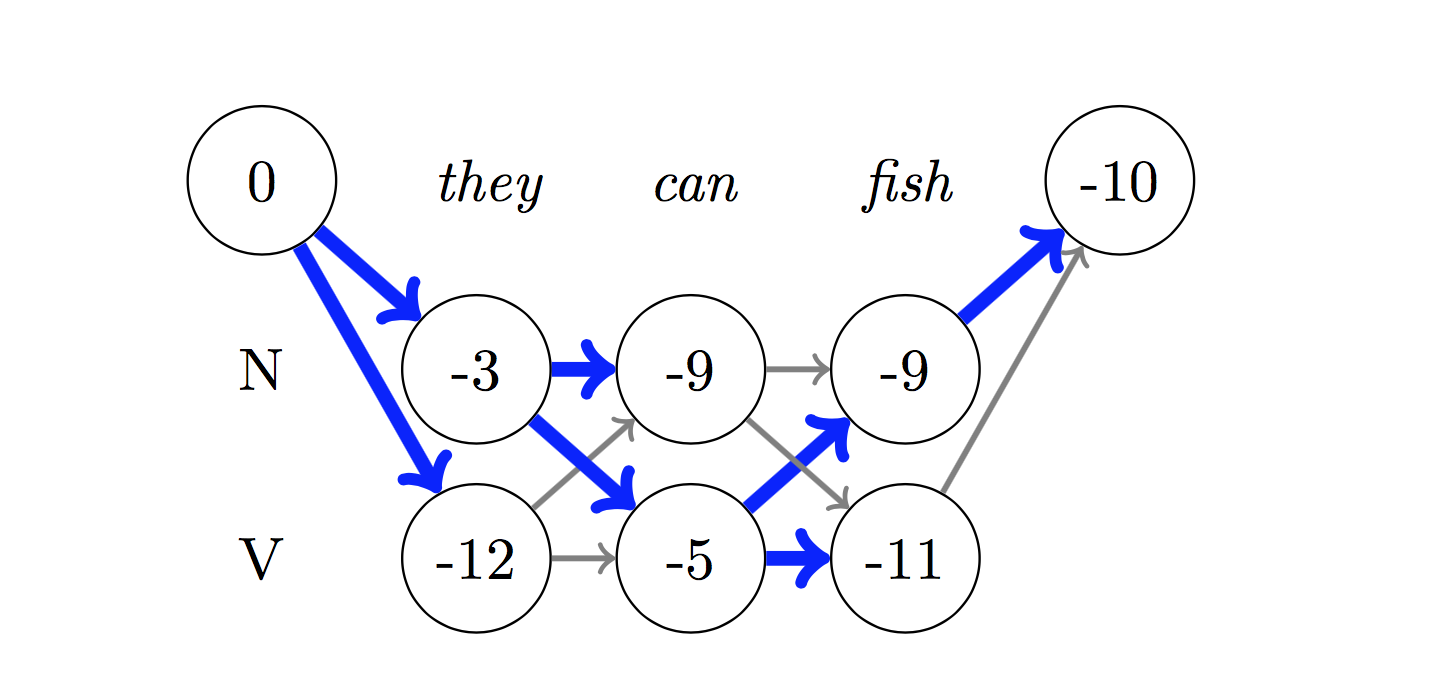
لفك تشفير ، يتم استخدام خوارزمية Viterbi .
نظرًا لأننا نستخدم CRFs ، فإننا لا نتوقع كثيرًا التسمية الصحيحة في كل كلمة بقدر ما نتوقع تسلسل التسمية الصحيح لتسلسل الكلمات. يعد فك تشفير Viterbi وسيلة للقيام بذلك بالضبط - ابحث عن تسلسل العلامة الأكثر مثالية من الدرجات المحسوبة بواسطة حقل عشوائي مشروط.
باستخدام معلومات الكلمات الفرعية في مهمة وضع العلامات الخاصة بنا لأنها يمكن أن تكون مؤشرًا قويًا للعلامات ، سواء كانت أجزاء من الكلام أو الكيانات. على سبيل المثال ، قد يتعلم أن الصفات عادة ما تنتهي بـ "-y" أو "-ul" ، أو أن الأماكن غالباً ما تنتهي بـ "-land" أو "-burg".
لذلك ، يستخدم نموذج وضع العلامات التسلسلي كلاهما
word-level في شكل تضمينات كلمة.character-level تصل إلى كل كلمة في كلا الاتجاهين. 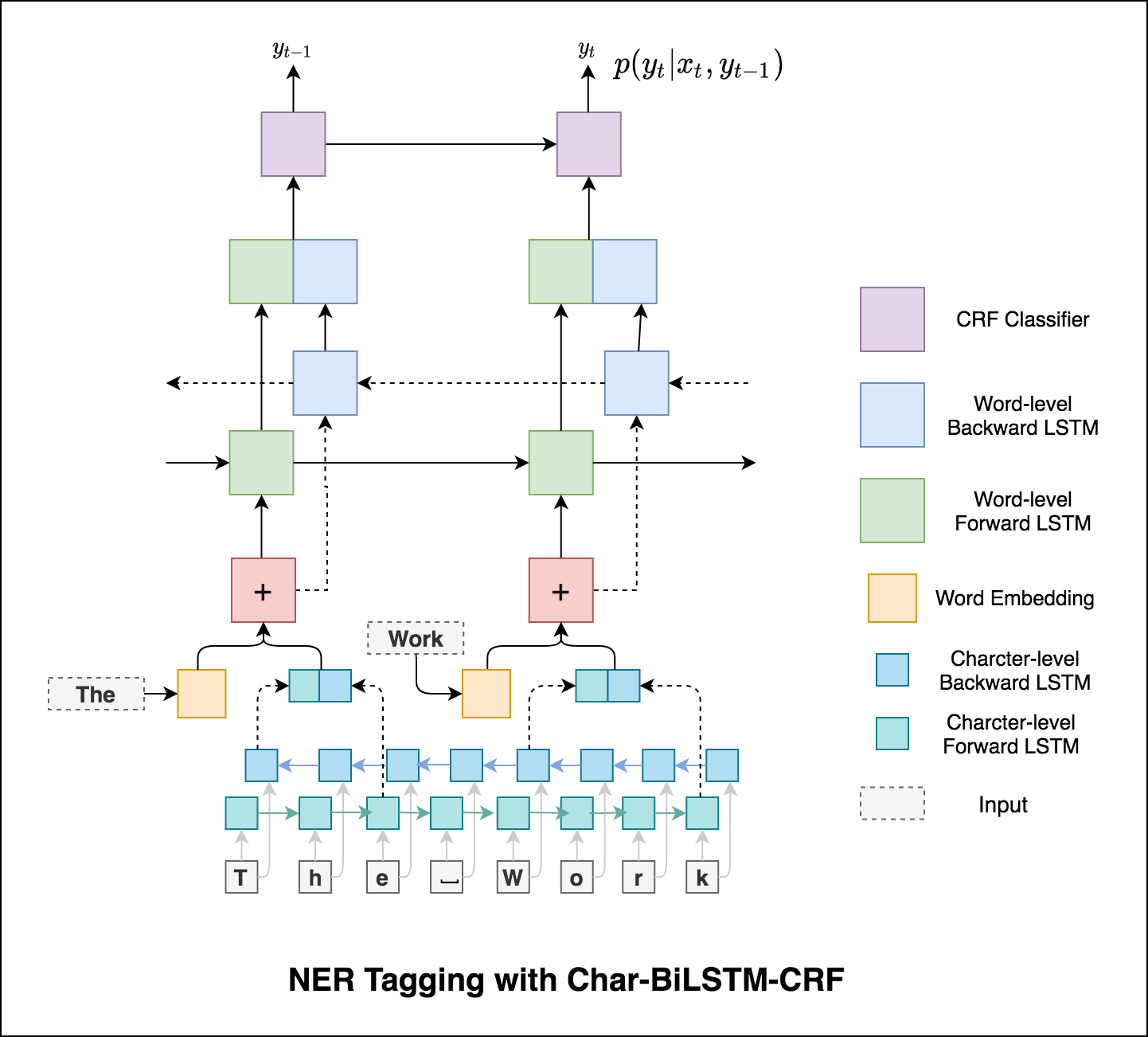
سيحسب المتوسطة الصغيرة والكلية (لأي مقياس) أشياء مختلفة قليلاً ، وبالتالي يختلف تفسيرها. سيحسب متوسط الكلي المقياس المقياس بشكل مستقل لكل فئة ، ثم يأخذ المتوسط (وبالتالي معالجة جميع الفئات بالتساوي) ، في حين أن المتوسط الصغير سوف يجمع مساهمات جميع الفئات لحساب المتوسط المتوسط. في إعداد تصنيف متعدد الطبقات ، يكون المتوسط الصغير هو الأفضل إذا كنت تشك في أنه قد يكون هناك خلل في الفصل (أي قد يكون لديك العديد من الأمثلة على فئة واحدة عن فصول أخرى).

تحويل العلامات NER إلى تطبيق باستخدام SPEREMLIT. النموذج الذي تم تدريبه مسبقًا (char-bilstm-crf) متاح الآن.
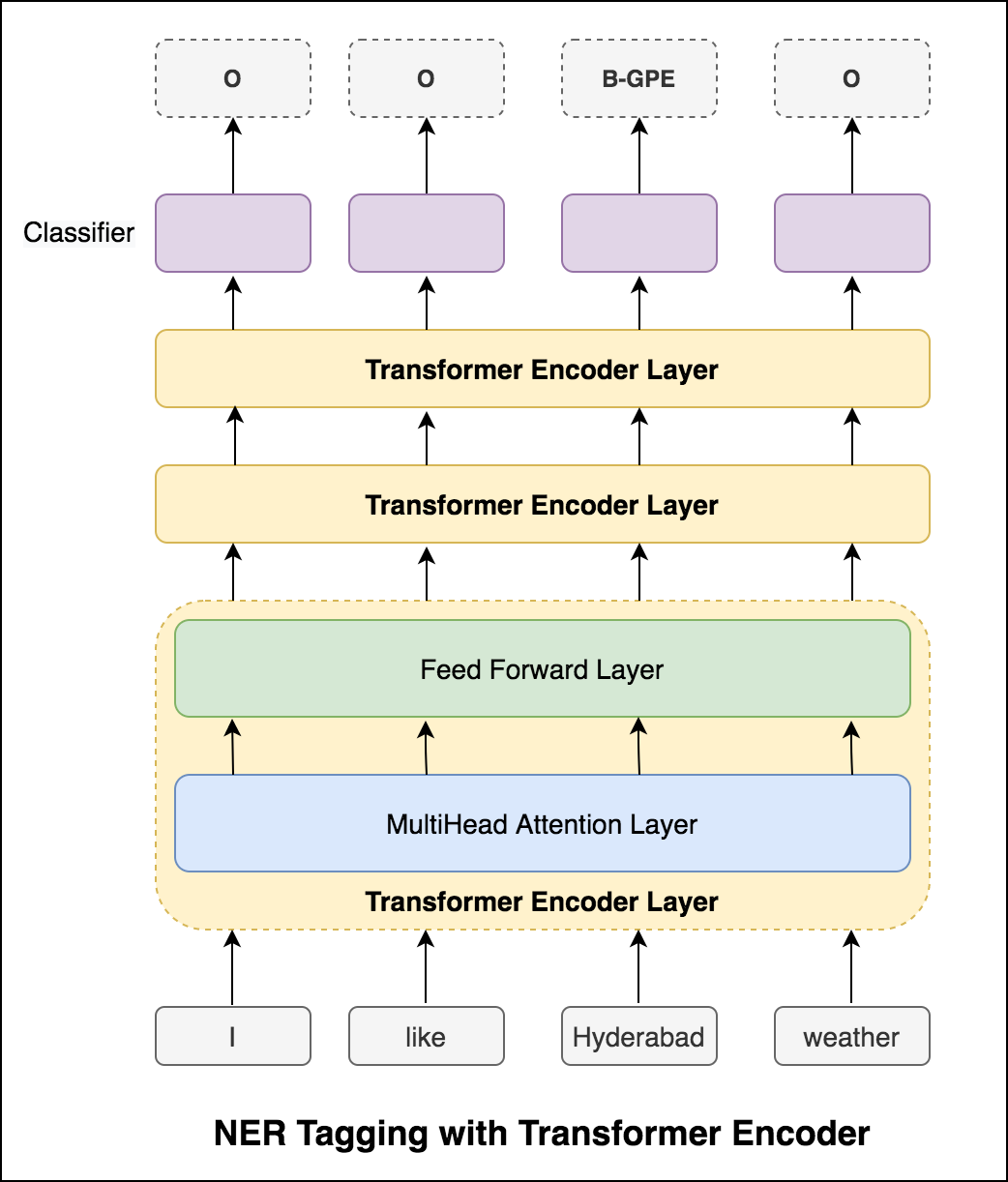
بعد تجربة نهج RNN ، يتم استكشاف العلامات NER مع العمارة القائمة على المحولات. نظرًا لأن المحول يحتوي على كل من التشفير وفك التشفير وللمهمة التسلسلية ، سيكون Encoder فقط كافيًا. تم استخدام نموذج تشفير محول من 3 طبقات.
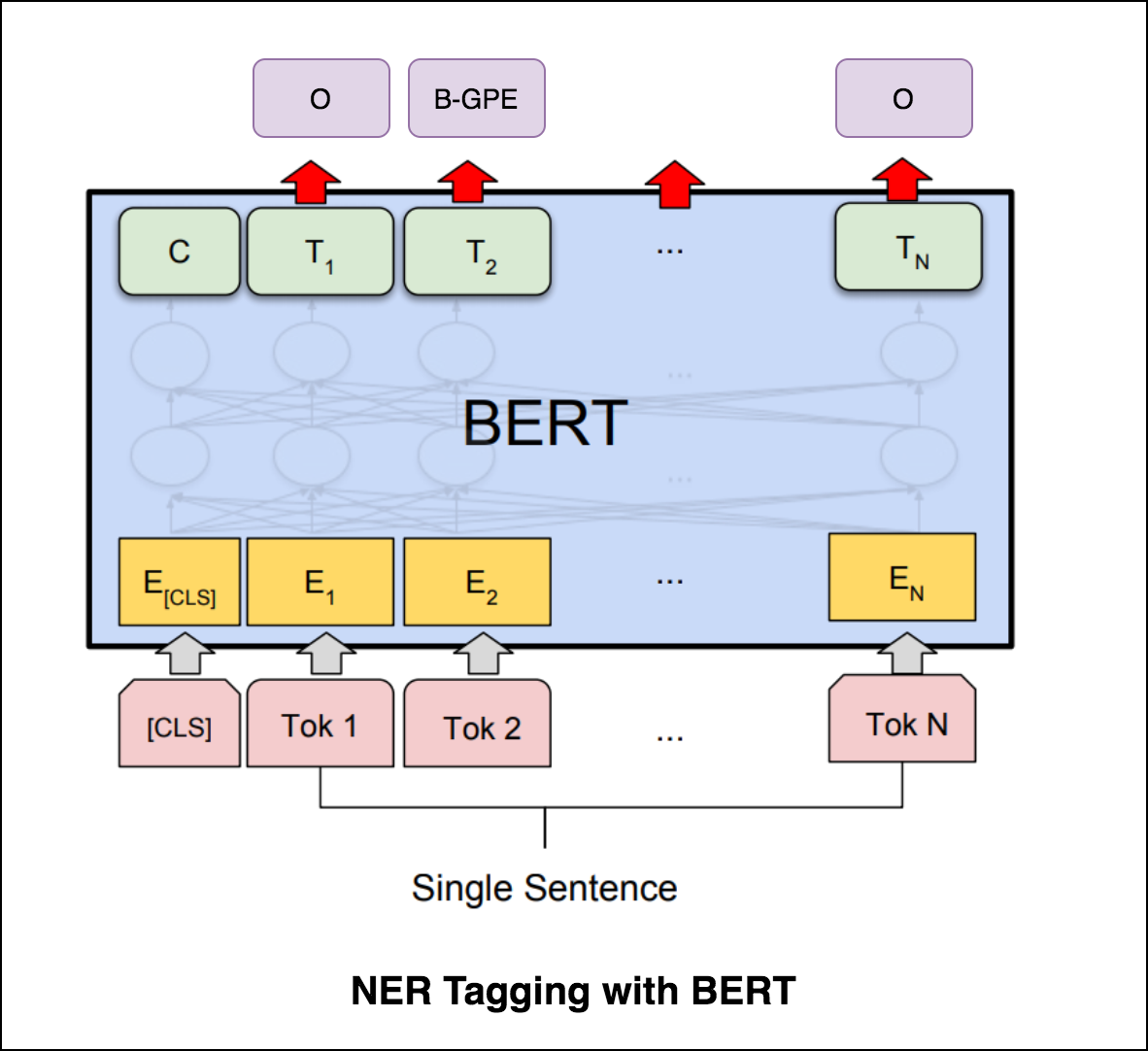
بعد تجربة وضع علامة على NER مع تشفير Transformer ، يتم استكشاف العلامات NER مع نموذج bert-base-cased مسبقًا.
المحول وحده لا يعطي نتائج جيدة مقارنة بـ BILSTM في مهمة وضع العلامات NER. يتم تنفيذ زيادة طبقة CRF أعلى المحول مما يؤدي إلى تحسين النتائج مقارنة بالمحول المستقل.
يوفر Spacy نظامًا إحصائيًا فعالًا بشكل استثنائي لـ NER في Python ، والذي يمكنه تعيين ملصقات لمجموعات من الرموز. يوفر نموذجًا افتراضيًا يمكنه التعرف على مجموعة واسعة من الكيانات المسماة أو العددية ، والتي تشمل الشخص أو المنظمة أو اللغة أو الحدث وما إلى ذلك.

بصرف النظر عن هذه الكيانات الافتراضية ، يمنحنا Spacy أيضًا الحرية لإضافة فصول تعسفية إلى نموذج NER ، من خلال تدريب النموذج على تحديثه بأمثلة مدربة أحدث.
يتم إنشاء كيانات جديدة تسمى ACTIVITY SERVICE في بيانات مجال محددة (BANK) وتدريبها مع عدد قليل من عينات التدريب.

| جيل الاسم | الترجمة الآلية | جيل الكلام |
| التسمية التوضيحية للصور | تعليق الصورة - معادلات اللاتكس | تلخيص الأخبار |
| توليد موضوع البريد الإلكتروني |
يتم استخدام نموذج لغة LSTM على مستوى الشخصية. وهذا يعني ، سنعطي LSTM جزءًا كبيرًا من الأسماء ونطلب منه تصميم توزيع احتمال الحرف التالي في التسلسل الممنوح لتسلسل الأحرف السابقة. هذا سيسمح لنا بعد ذلك بإنشاء اسم جديد حرف واحد في وقت واحد

الترجمة الآلية (MT) هي مهمة تحويل لغة طبيعية تلقائيًا إلى لغة أخرى ، والحفاظ على معنى نص الإدخال ، وإنتاج نص بطلاقة في لغة الإخراج. من الناحية المثالية ، يتم ترجمة تسلسل لغة المصدر إلى تسلسل اللغة المستهدف. المهمة هي تحويل الجمل من German to English .
تم استكشاف المتغيرات التالية:
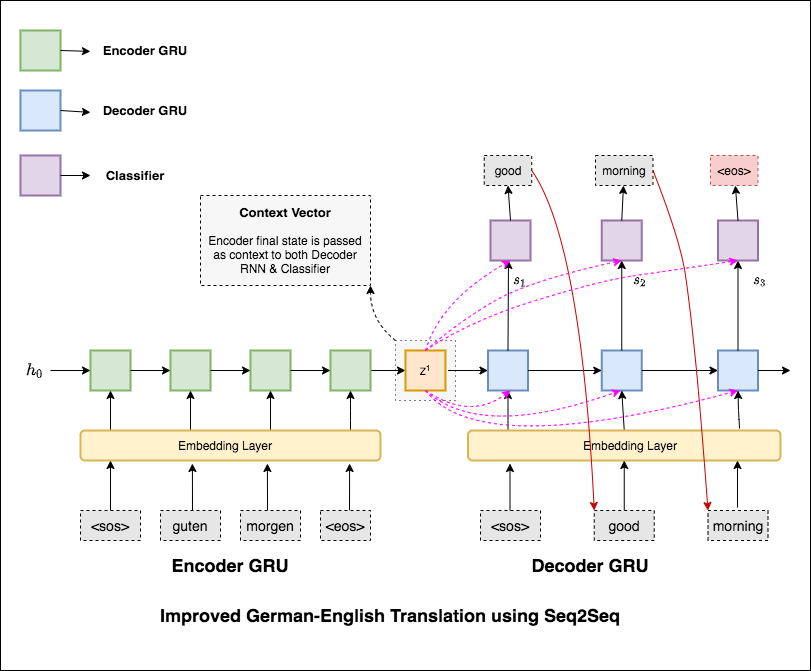
نماذج التسلسل الأكثر شيوعًا إلى التسلسل (SEQ2SEQ) هي نماذج تشفير ترميز ، والتي تستخدم عادة شبكة عصبية متكررة (RNN) لترميز الجملة المصدر (الإدخال) في متجه واحد. في دفتر الملاحظات هذا ، سنشير إلى هذا المتجه الفردي كمتجه سياق. يمكننا أن نفكر في ناقل السياق باعتباره تمثيلًا تجريديًا لجمل الإدخال بأكمله. ثم يتم فك تشفير هذا المتجه بواسطة RNN ثانية يتعلم إخراج الجملة الهدف (الإخراج) عن طريق إنشاء كلمة واحدة في وقت واحد.

بعد تجربة الترجمة الآلية الأساسية التي لها محير نص 36.68 ، تم تجربة التقنيات التالية واختبار الحيرة 7.041 .
الخروج عن الرمز في مجلد applications/generation
ولدت آلية الانتباه للمساعدة في حفظ جمل المصدر الطويلة في الترجمة الآلية العصبية (NMT). بدلاً من بناء ناقل سياق واحد من آخر حالة مخفية للمشفر ، يتم استخدام الاهتمام للتركيز أكثر على الأجزاء ذات الصلة من المدخلات مع فك تشفير الجملة. سيتم إنشاء متجه السياق عن طريق أخذ مخرجات التشفير previous hidden state لـ Decoder RNN.
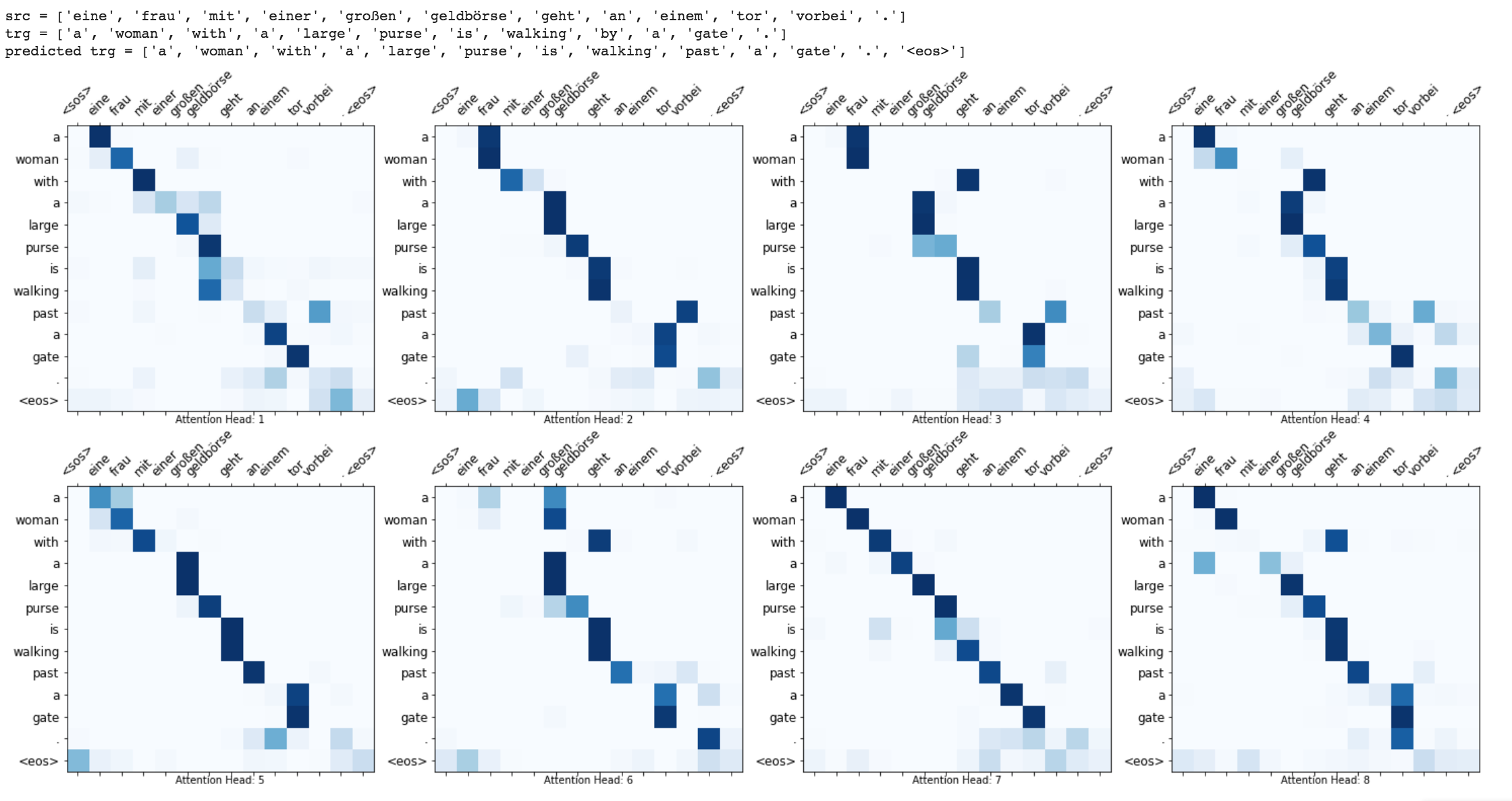
Enhancements like masking (ignoring the attention over padded input), packing padded sequences (for better computation), attention visualization and BLEU metric on test data are implemented.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
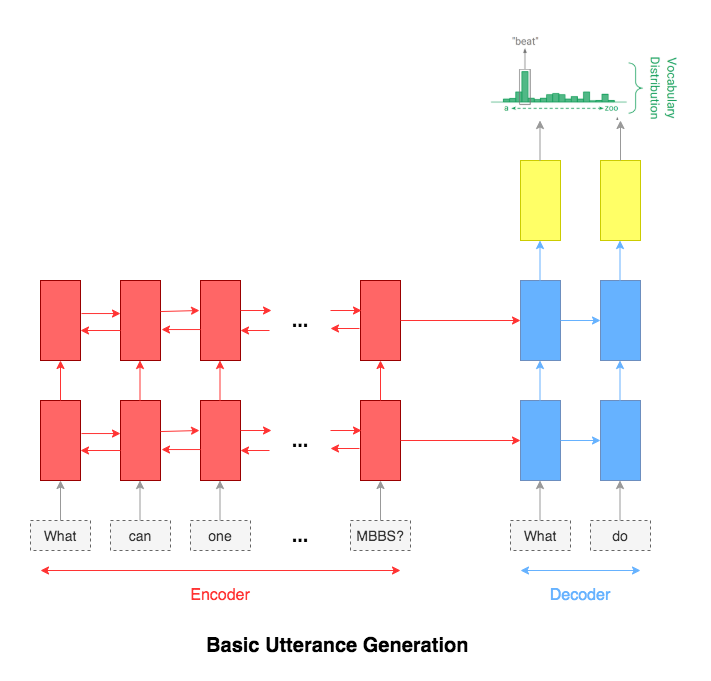
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
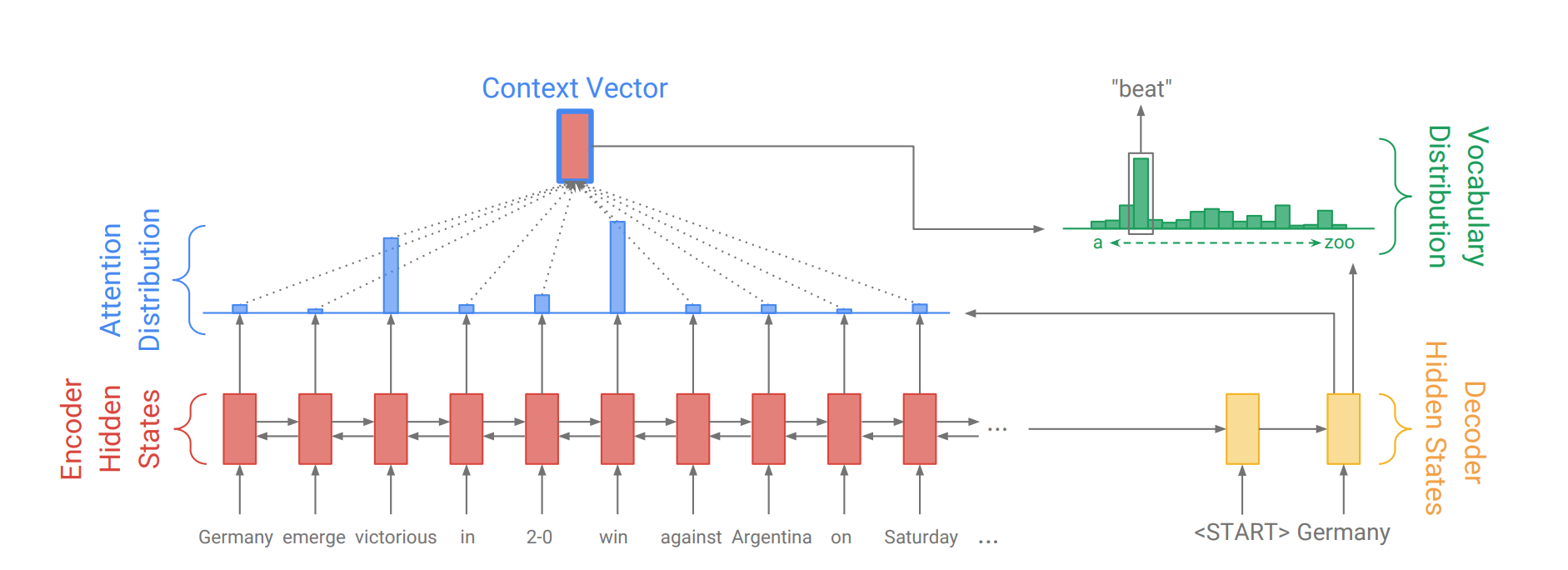
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
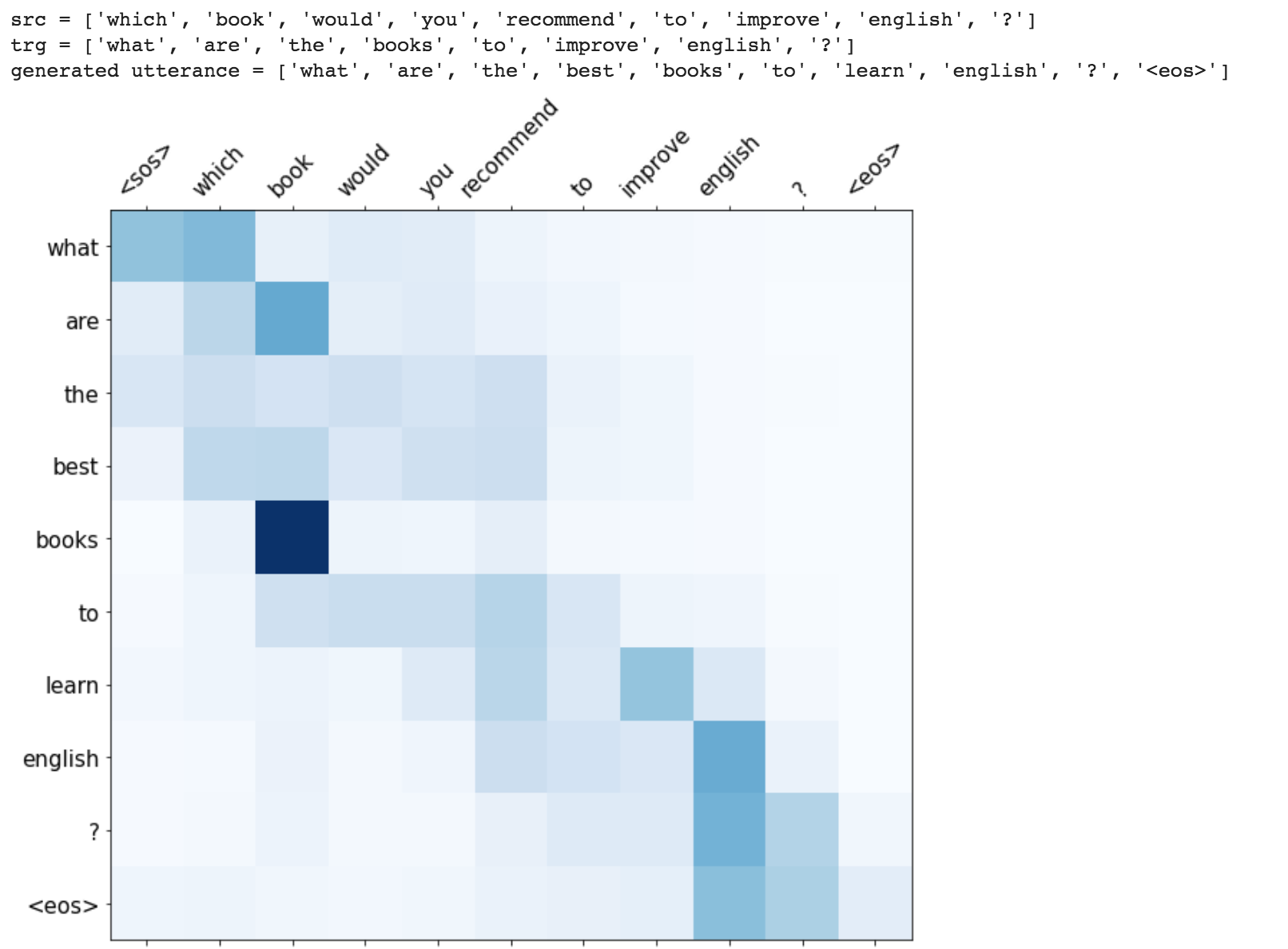
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
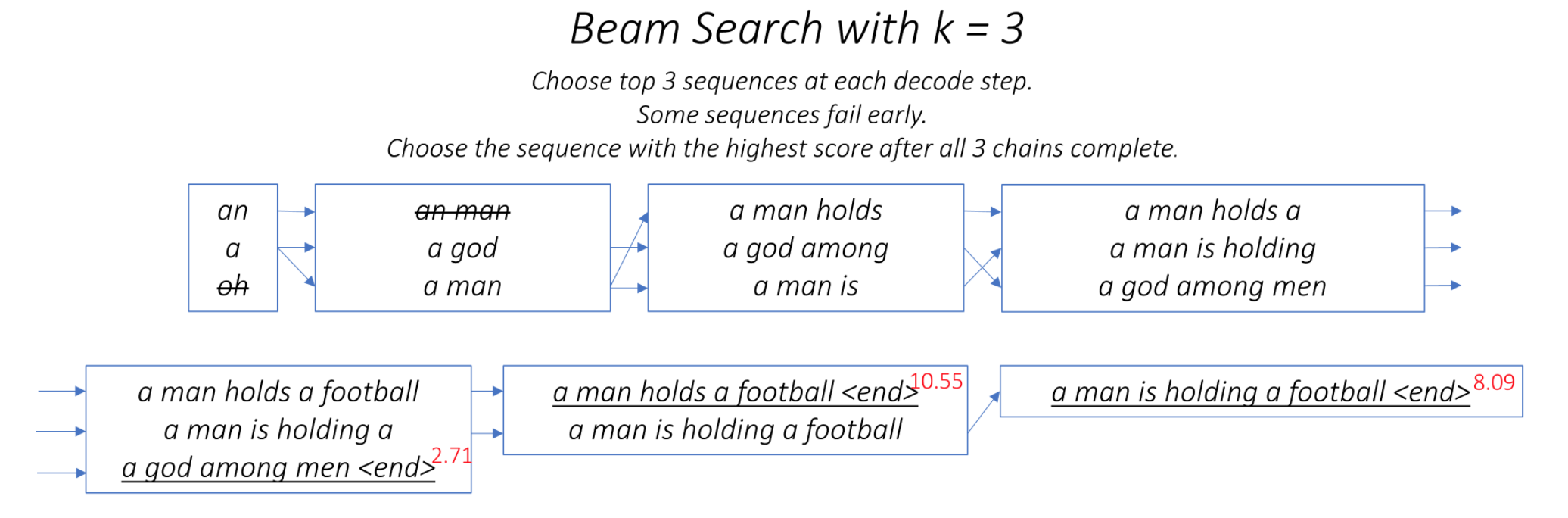
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
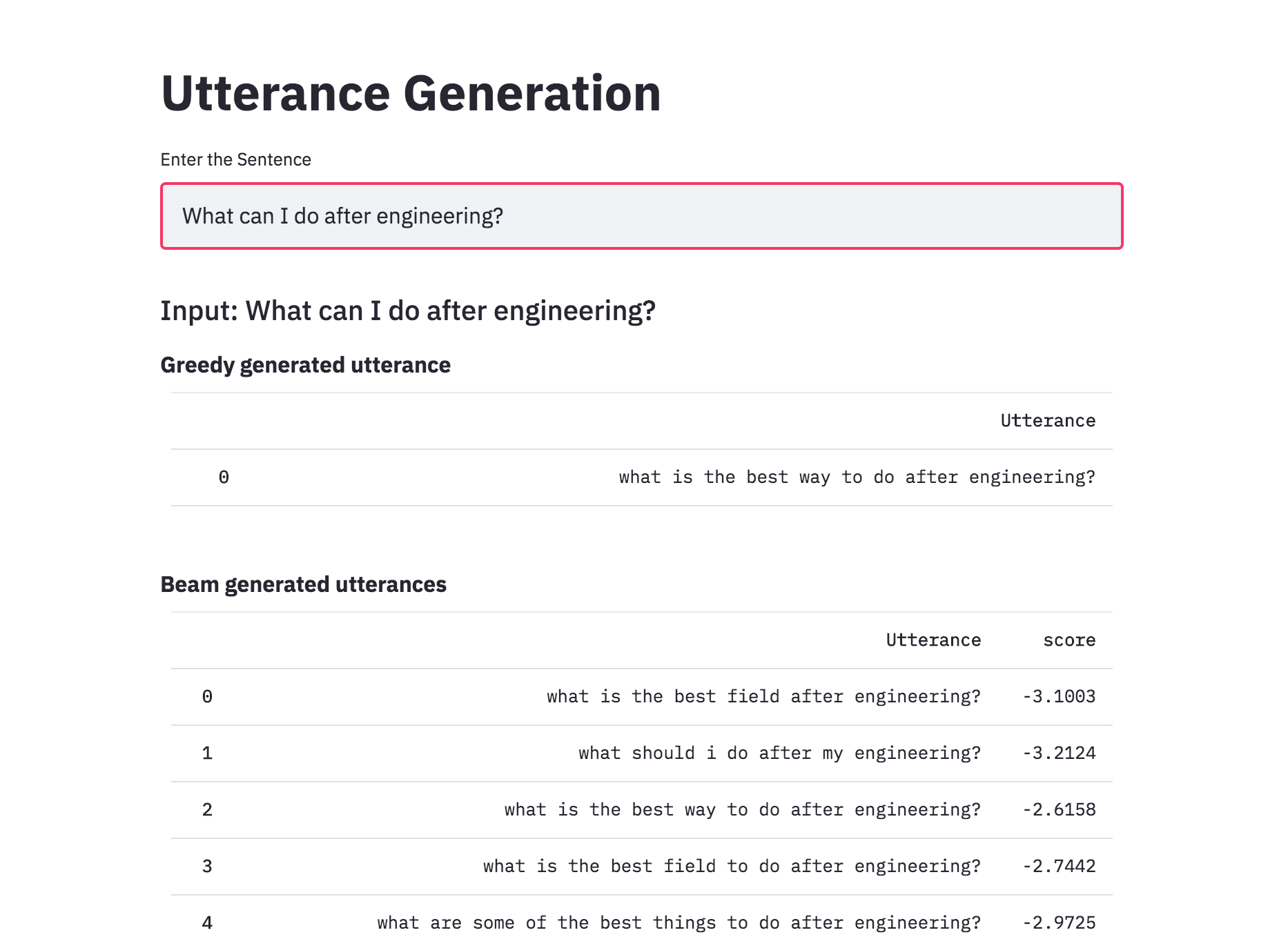
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
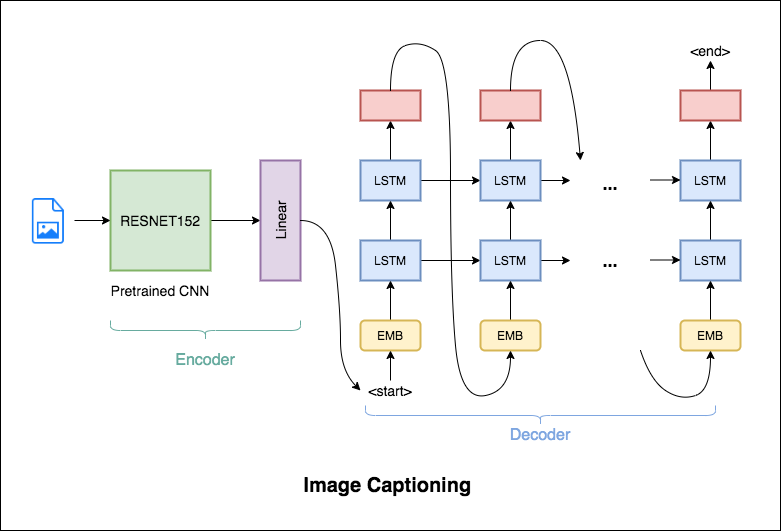
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
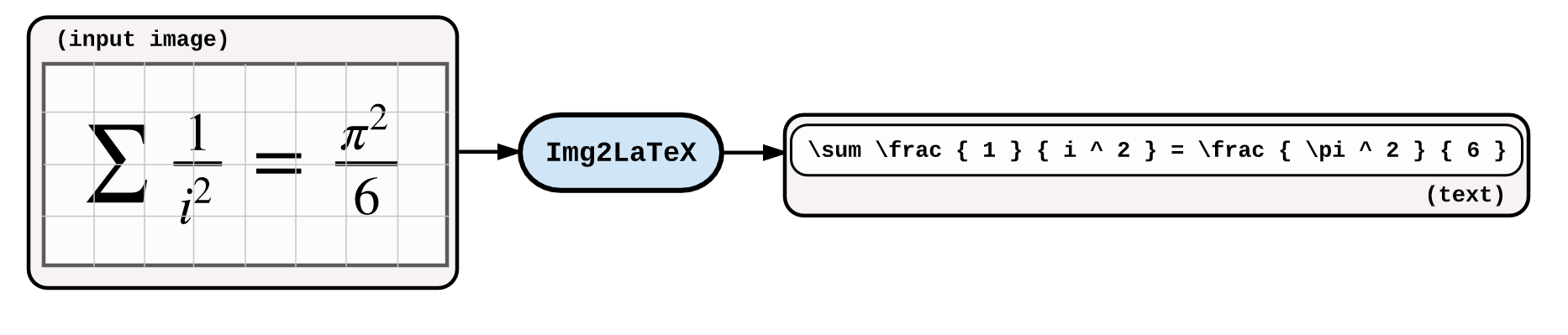
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
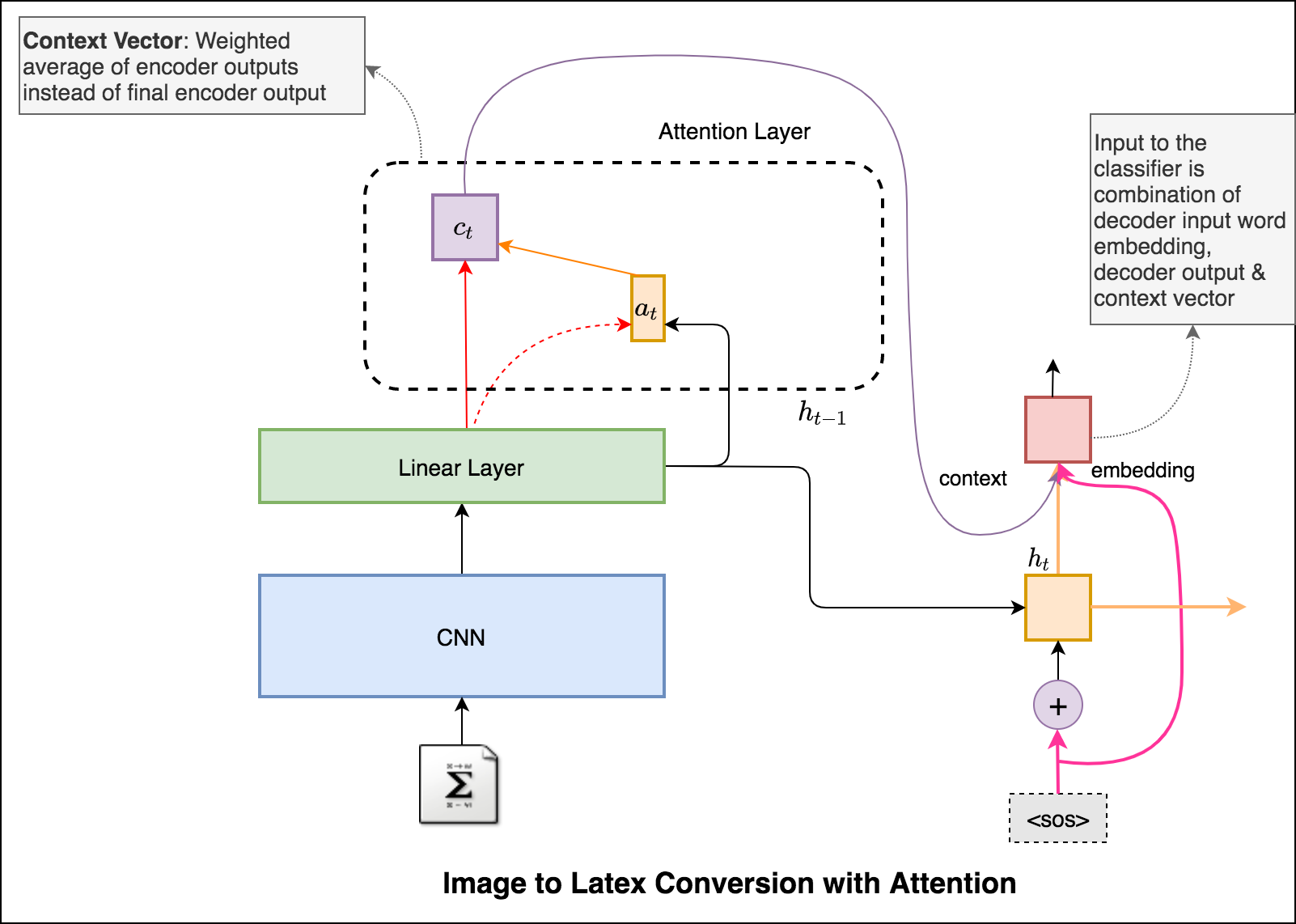
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
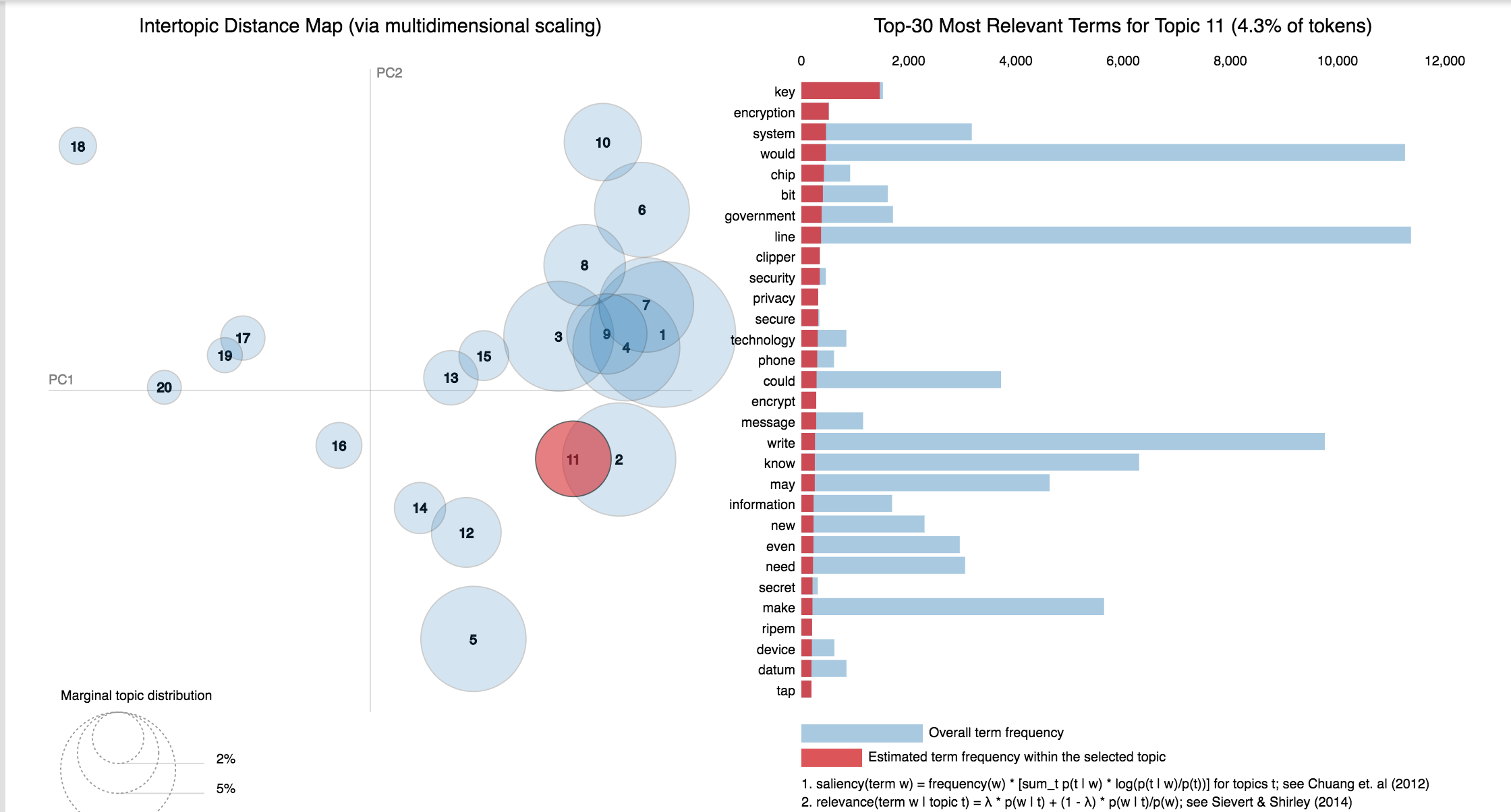
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
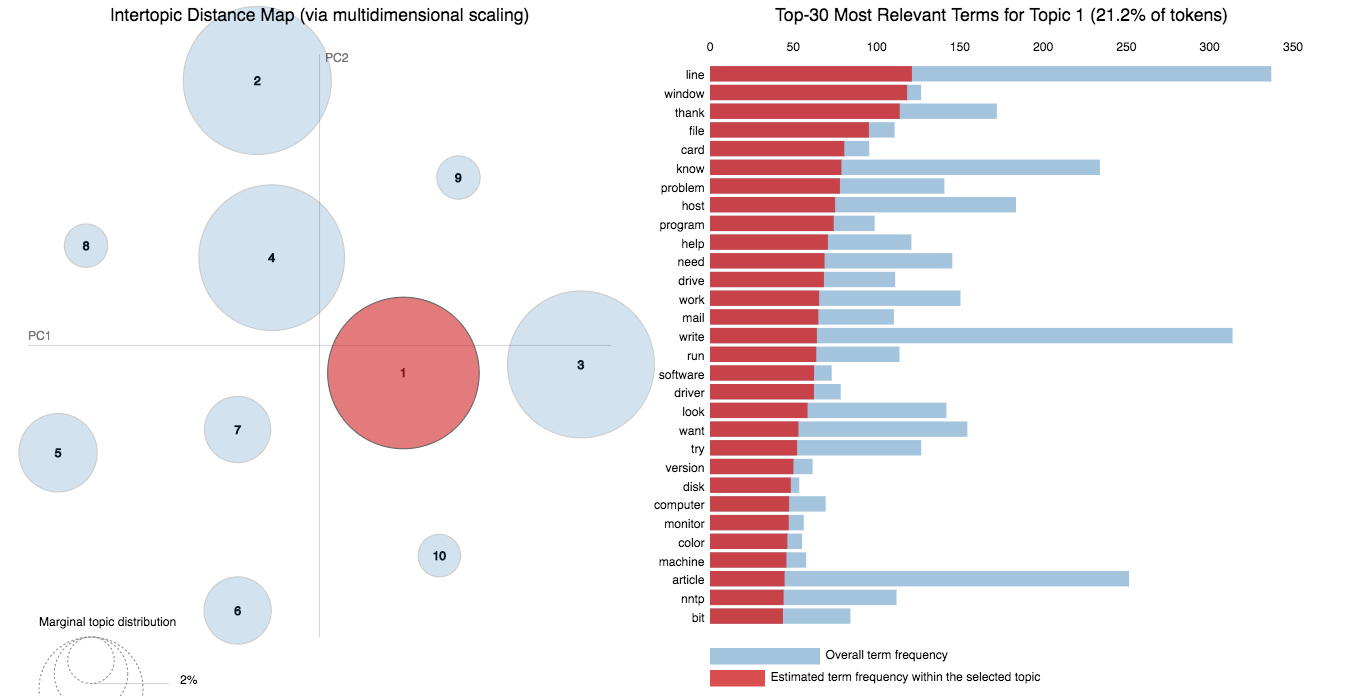
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
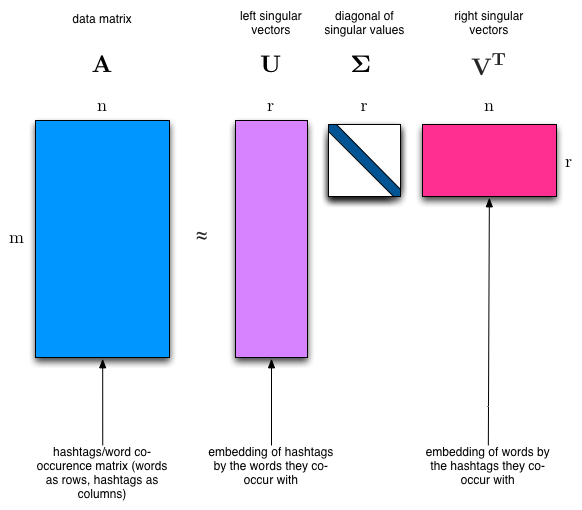
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
ملحوظات:
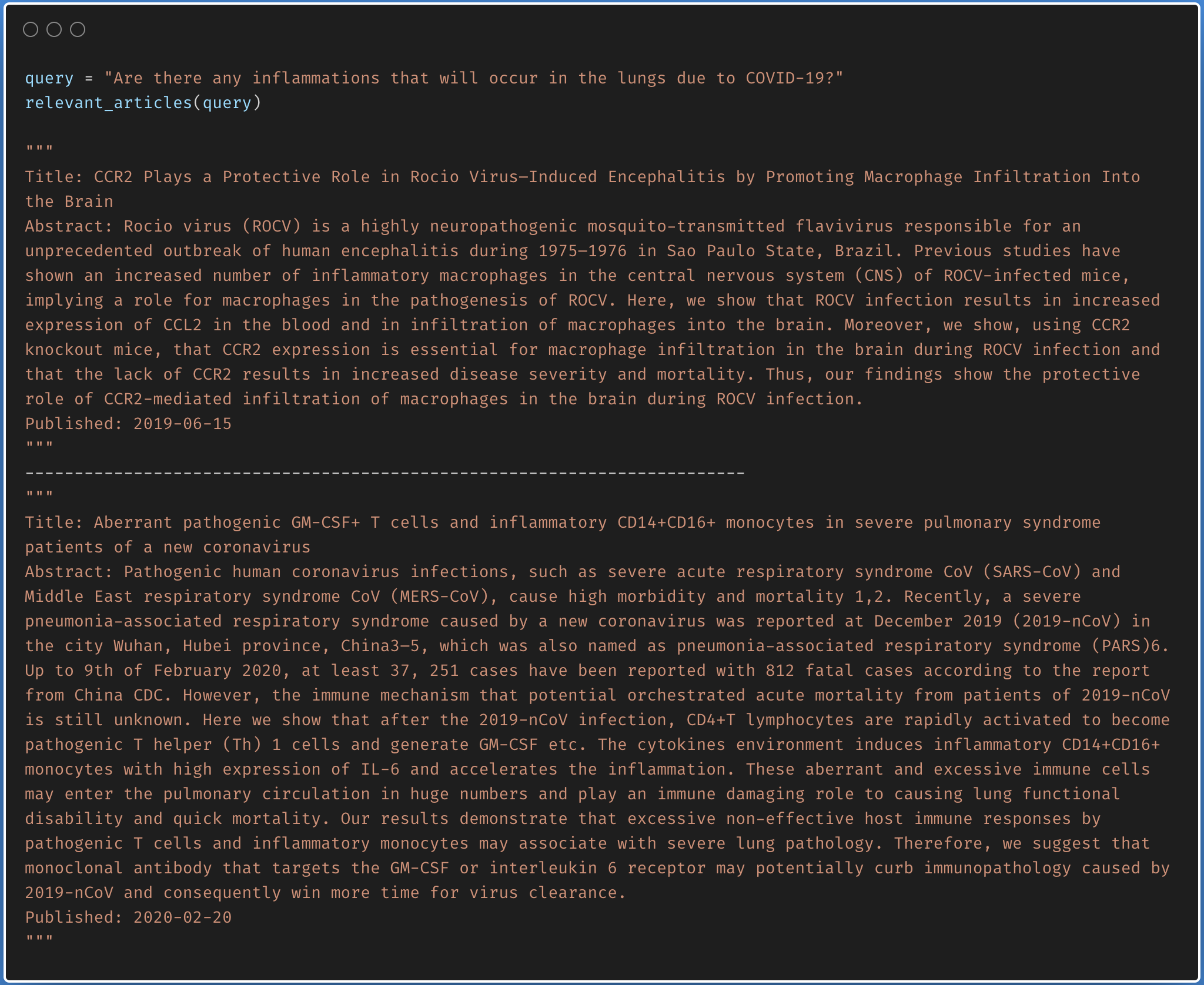
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
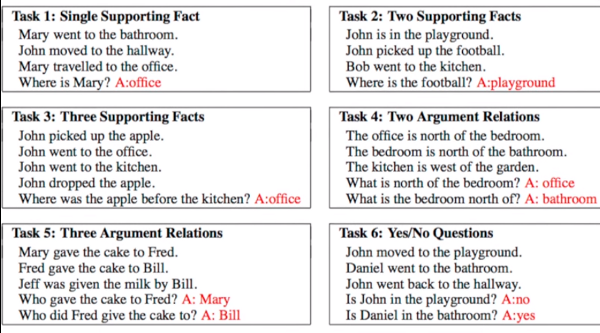
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
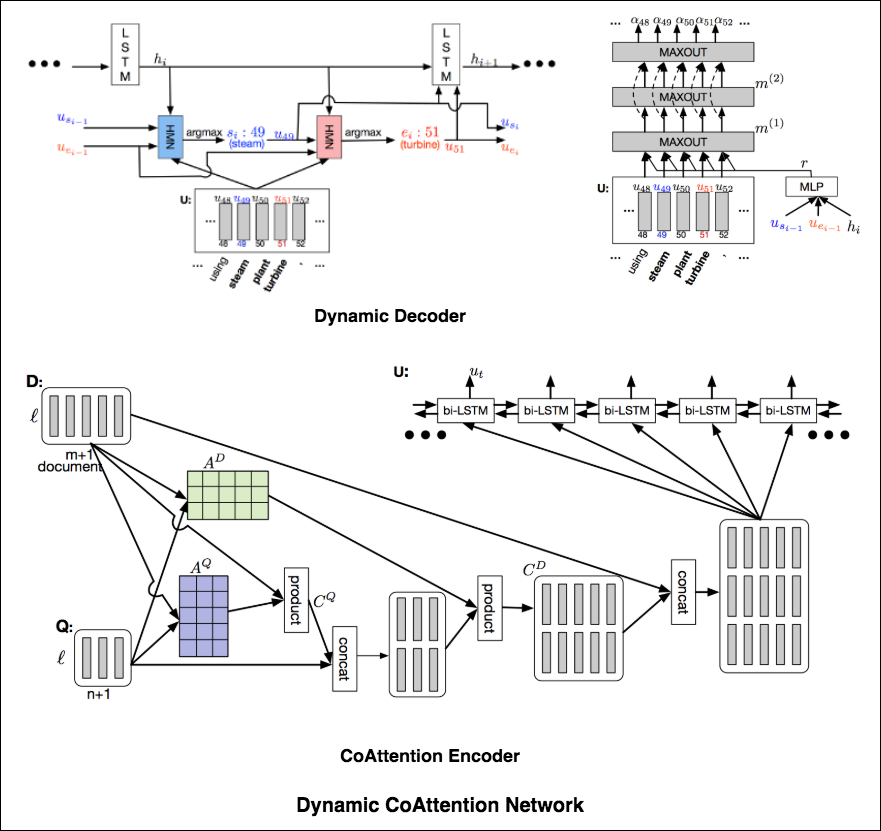
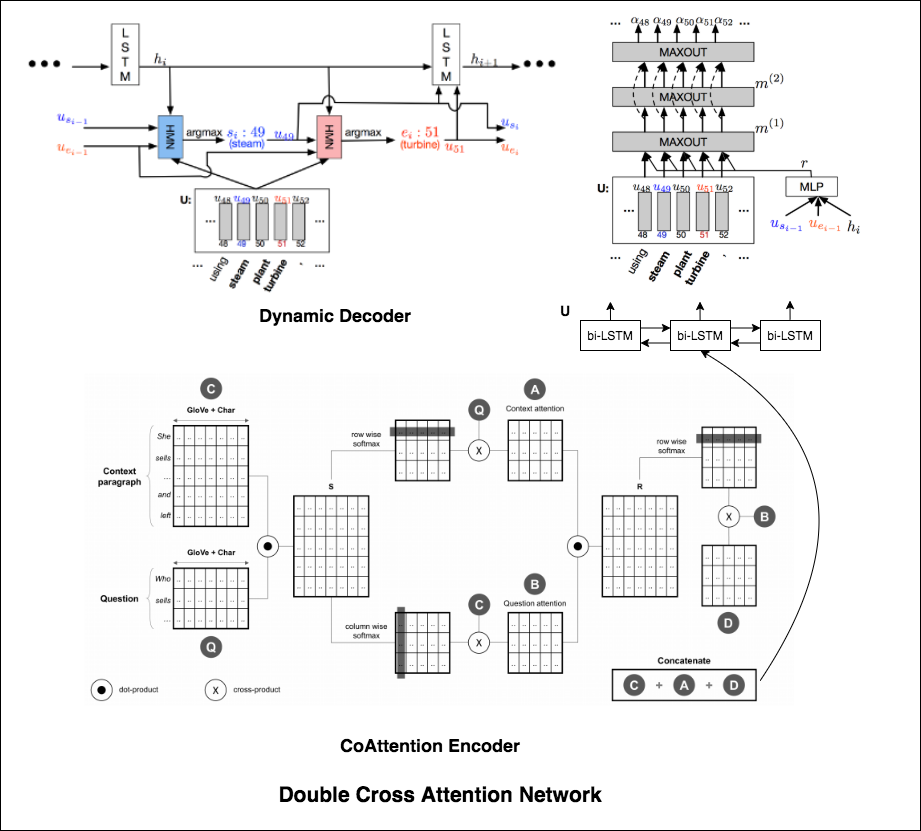
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
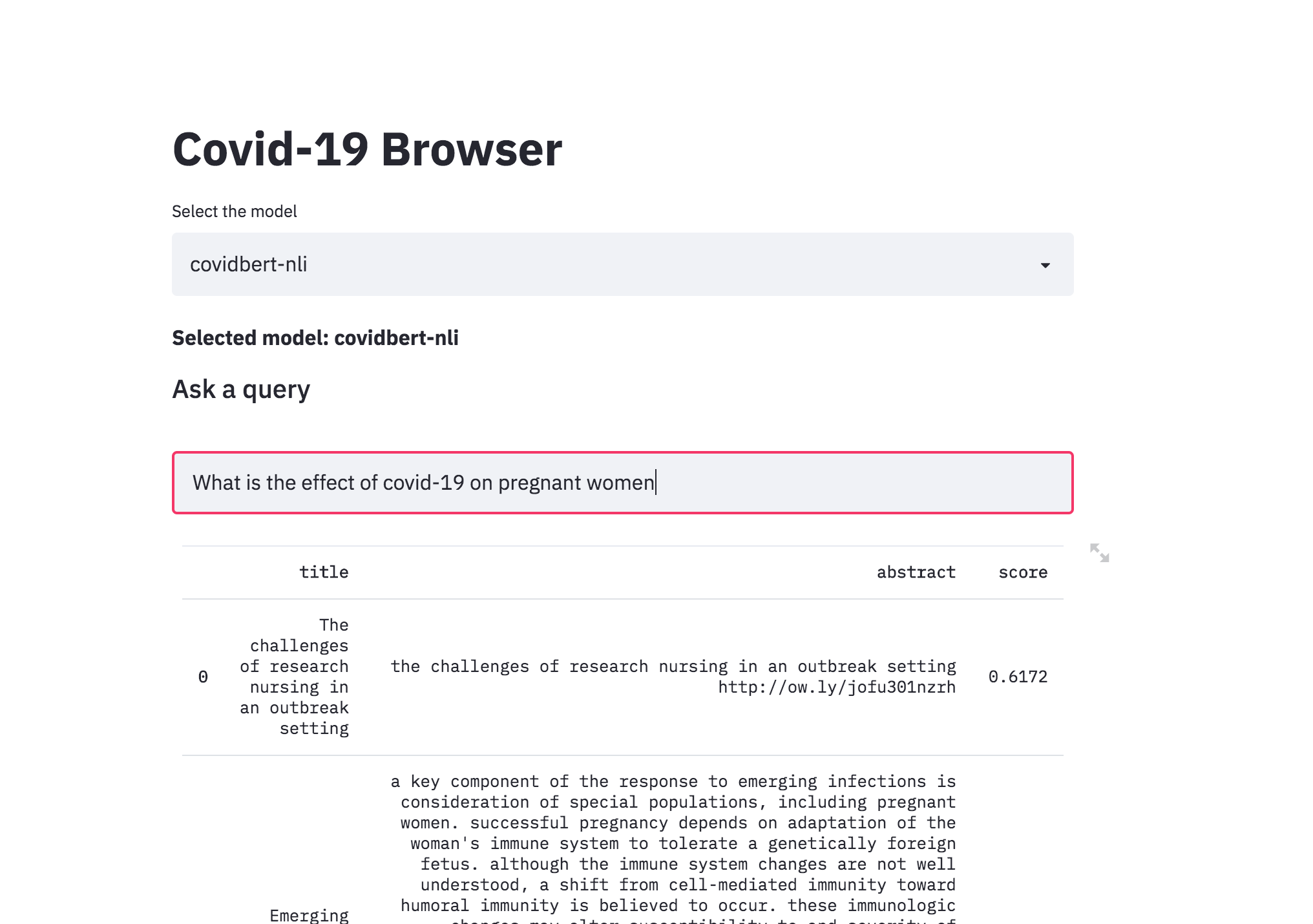
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
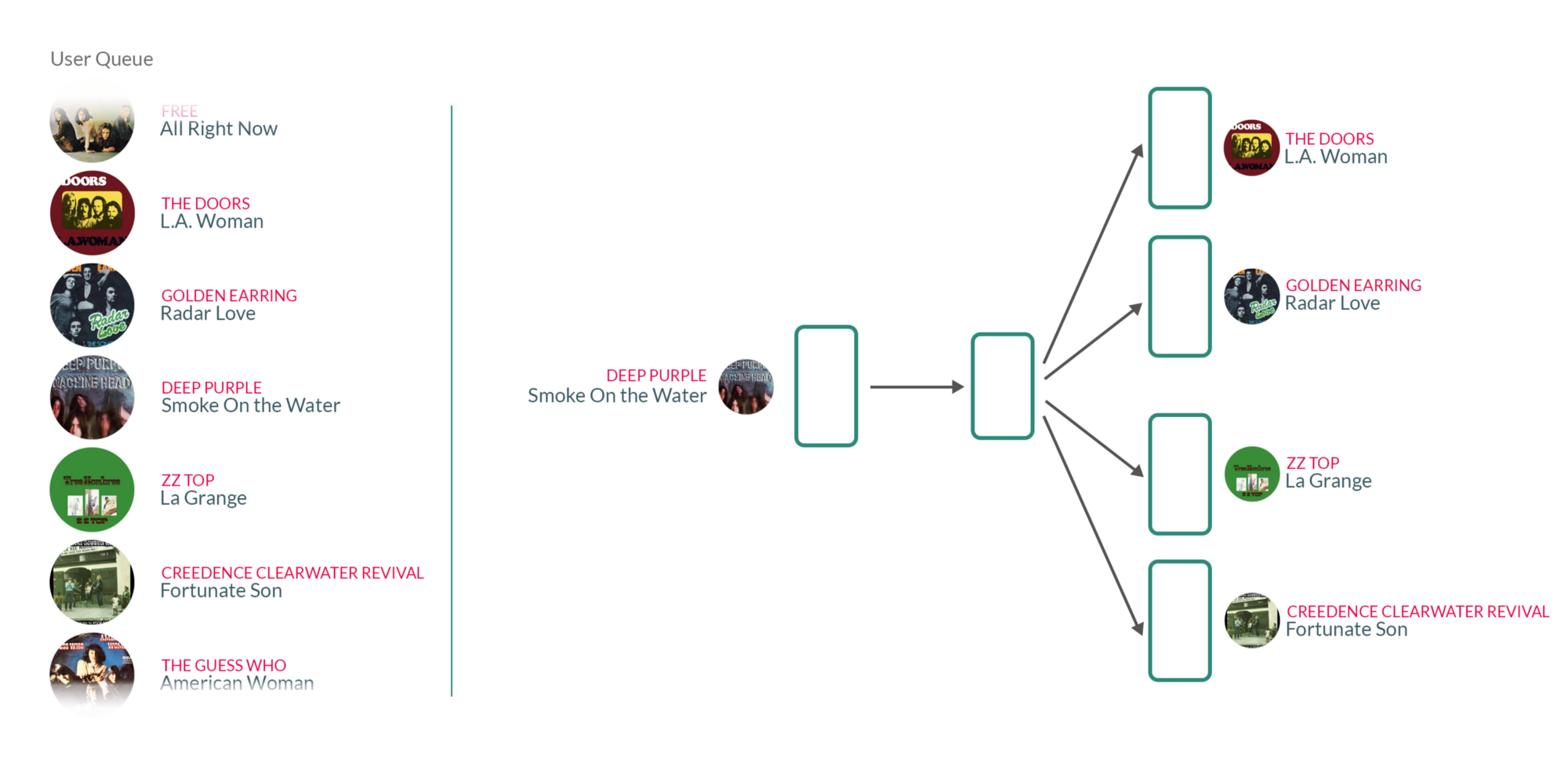
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


