100 Days of NLP
1.0.0

В магии нет ничего волшебного. Маг просто понимает что -то простое, что не кажется простым или естественным для неподготовленной аудитории. Как только вы узнаете, как держать карту, заставляя вашу руку выглядеть пустой, вам нужна практика только перед вами, прежде чем вы можете «сделать магию». - Джеффри Фридл в книге «Освоение регулярных выражений
Примечание. Пожалуйста, поднимите проблему для любых предложений, исправлений и обратной связи.
Большинство образцов кода выполняются с использованием ноутбуков Jupyter (с использованием colab). Таким образом, каждый код может быть запущен независимо.
Следующие темы были изучены:
Примечание: уровень сложности был назначен в соответствии с моим пониманием.
| Токенизация | Слово внедрения - Word2VEC | Слово встраивание - перчатка | Слово встраивание - Эльмо |
| RNN, LSTM, Gru | Упаковочные последовательности | Механизм внимания - Луонг | Механизм внимания - Бахданау |
| По указатель сеть | Трансформатор | GPT-2 | БЕРТ |
| Тематическое моделирование - LDA | Анализ основных компонентов (PCA) | Наивный Байес | Увеличение данных |
| Предложение встраивалось |
Процесс преобразования текстовых данных в токены является одним из наиболее важных шагов в НЛП. Токенизация с использованием следующих методов была исследована:
Слово внедрение - это изученное представление для текста, где слова, которые имеют одинаковое значение, имеют одинаковое представление. Именно этот подход к представлению слов и документов может считаться одним из ключевых прорывов глубокого обучения на сложные проблемы обработки естественного языка.

Word2VEC - одно из самых популярных предварительно предварительно проведенных встроенных слов, разработанных Google. В зависимости от того, как изучаются вставки, Word2VEC классифицируется на два подхода:
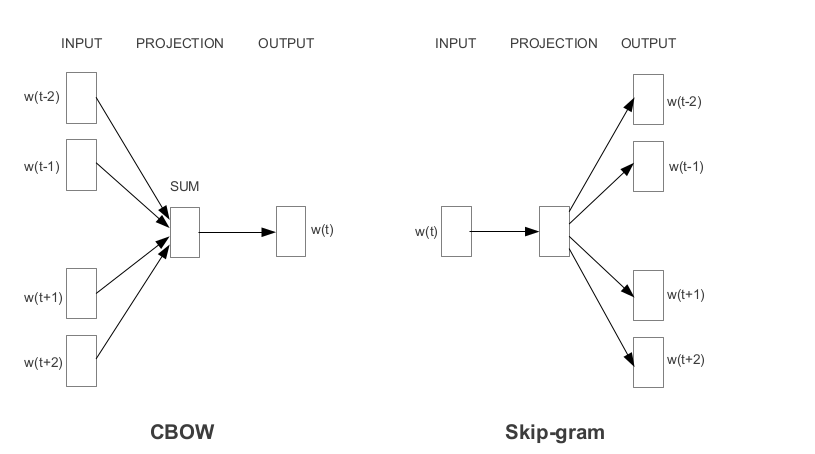
Перчатка является еще одним часто используемым методом получения предварительно обученных встраиваний. Перчатка стремится к достижению двух целей:
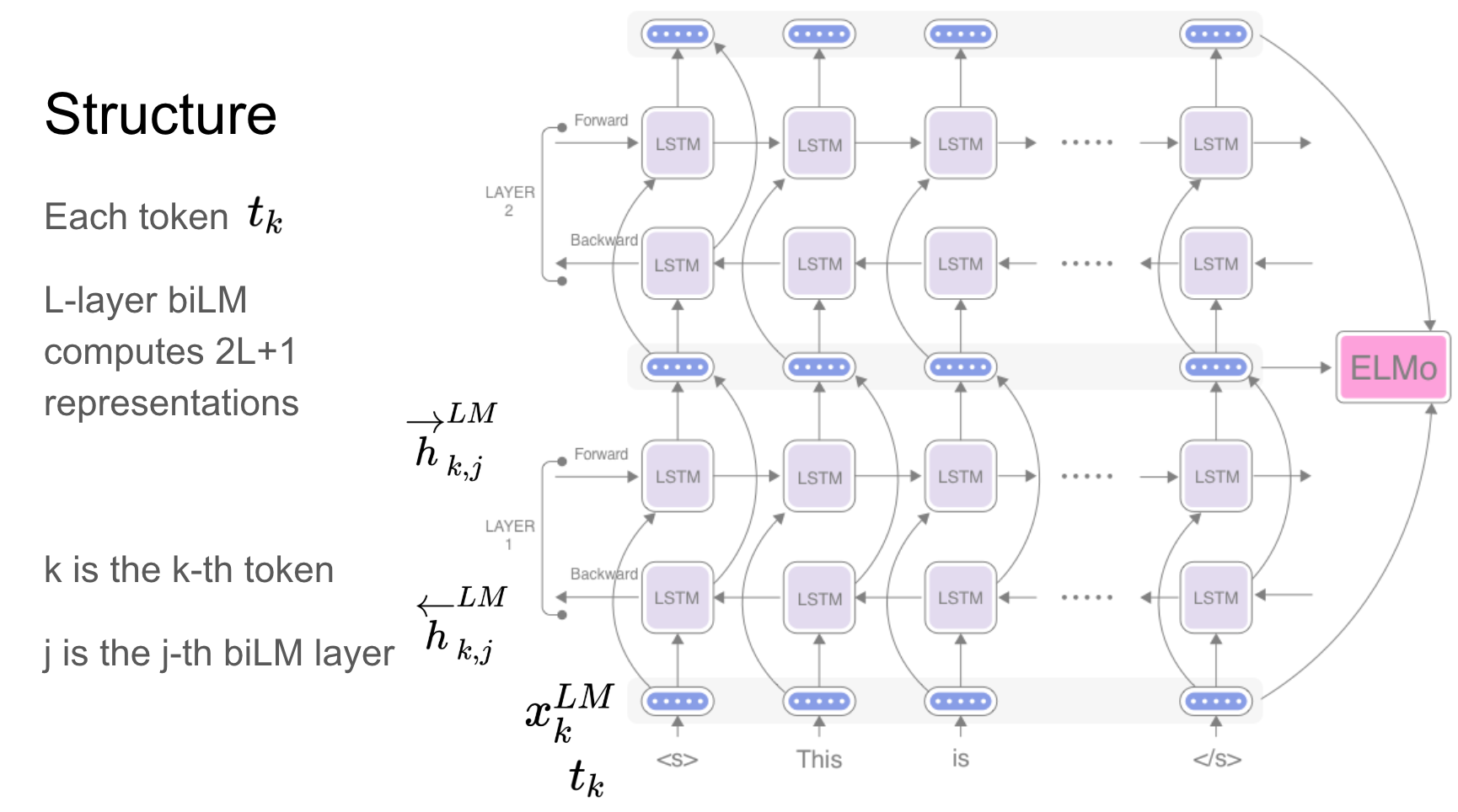
Elmo - это глубокое контекстуализированное представление слов, которое модели:
Эти векторы слов являются изученными функциями внутренних состояний глубокой двунаправленной языковой модели (BILM), которая предварительно обучена на большом текстовом корпусе.
Рецидивирующие сети - RNN, LSTM, GRU оказались одной из наиболее важных единиц в приложениях NLP из -за их архитектуры. Есть много проблем, когда нужно помнить о природе последовательности, чтобы предсказать эмоции на сцене, предыдущие сцены должны быть запоминаются.

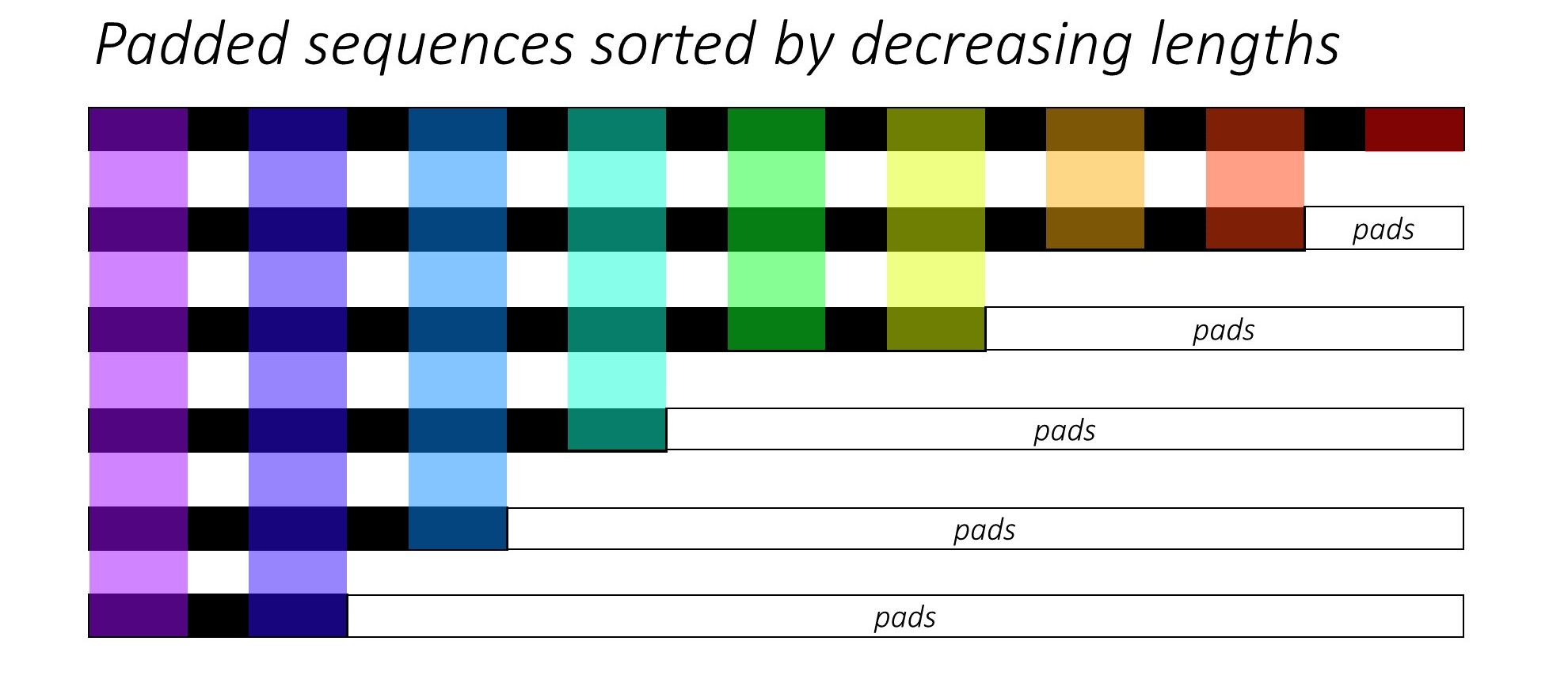
При обучении RNN (LSTM или GRU или Vanilla-rnn) трудно выровнять последовательности переменной длины. В идеале мы будем наладить все последовательности в фиксированную длину и в конечном итоге делать нереховые вычисления. Как мы можем преодолеть это? Pytorch предоставляет функциональность pack_padded_sequences .
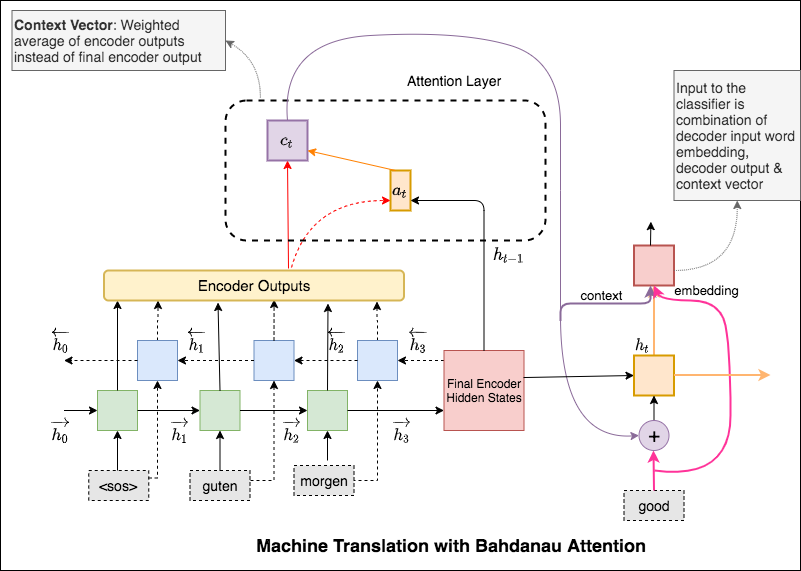
Механизм внимания был рожден, чтобы помочь запомнить длинные исходные предложения в переводе нервной машины (NMT). Вместо того, чтобы построить один контекстный вектор из последнего скрытого состояния энкодера, внимание используется, чтобы больше сосредоточиться на соответствующих частях ввода при декодировании предложения. Вектор контекста будет создан путем принятия выходов энкодера и current output декодера RNN.

Оценка внимания может быть рассчитана тремя способами. dot , general и concat .
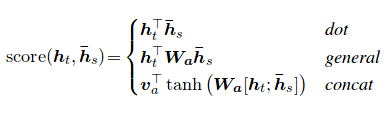
Основное различие между вниманием Бахданау и Луонга заключается в том, как создается контекстный вектор. Вектор контекста будет создан путем получения выходов энкодера и previous hidden state декодера RNN. Где в внимании, контекстный вектор будет создан путем получения выходов энкодера и current hidden state декодера RNN.
Как только контекст рассчитывается, он объединяется с вводом декодера и подается в качестве входных данных в декодер RNN.

Внимание Бахданау также называется additive вниманием.
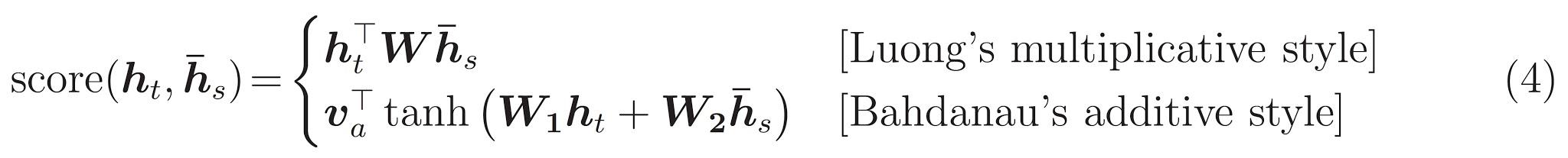
Трансформатор, модельная архитектура, избегая рецидива и вместо этого полностью полагается на механизм внимания для проведения глобальных зависимостей между вводом и выводом.
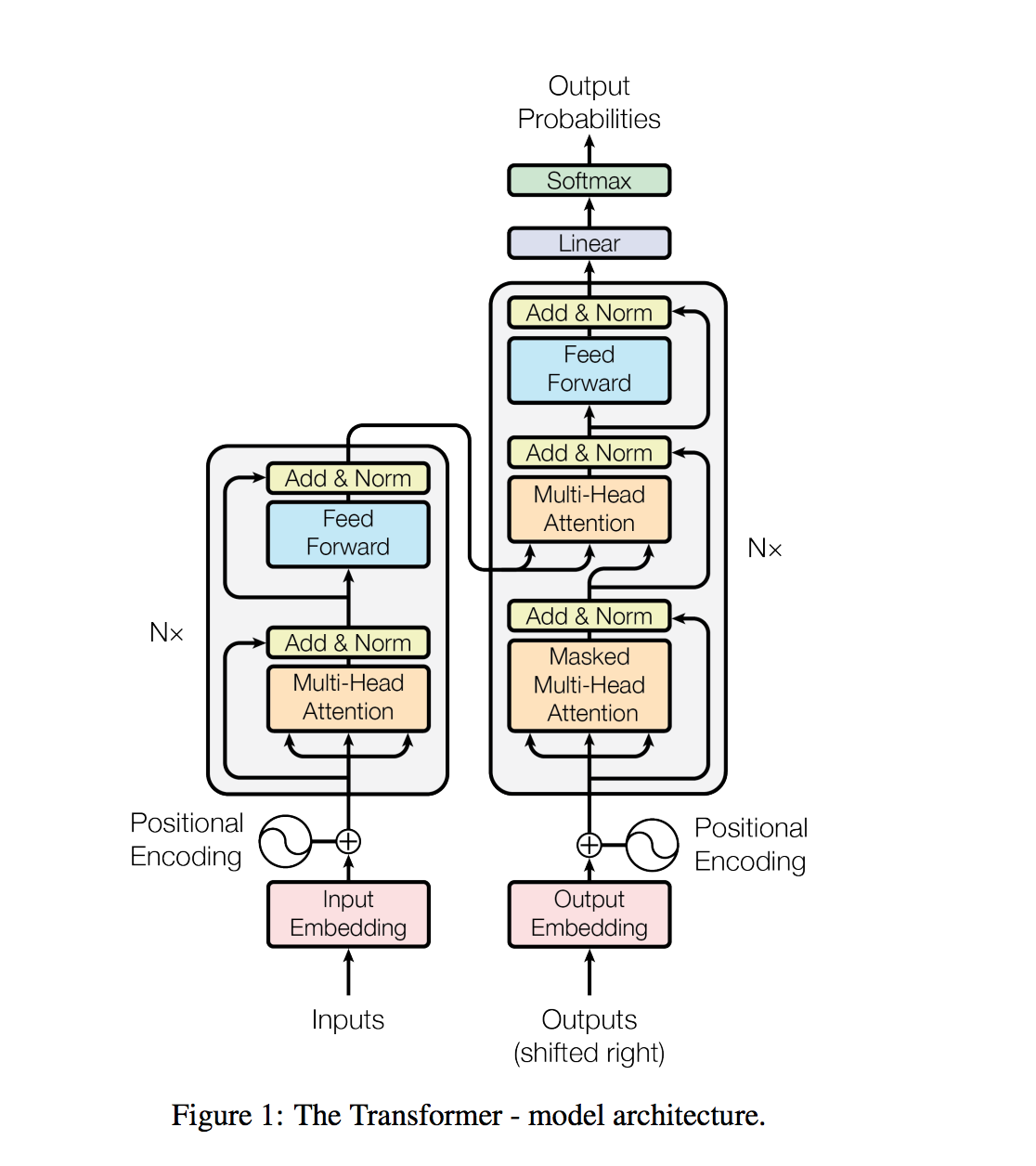
Задачи обработки естественного языка, такие как ответ на вопросы, машинный перевод, понимание прочитанного и суммирование, обычно подходят с контролируемым обучением по специальным наборам данных. Мы демонстрируем, что языковые модели начинают изучать эти задачи без какого -либо явного контроля при обучении на новом наборе данных с миллионами веб -страниц, называемых WebText. Наша самая большая модель, GPT-2, представляет собой трансформатор параметров 1,5B, который достигает современных результатов на 7 из 8 тестируемых наборов данных по моделированию языка в настройке с нулевым выстрелом, но все еще недостаточно настраивает веб-текст. Образцы из модели отражают эти улучшения и содержат последовательные абзацы текста. Эти результаты предполагают многообещающий путь к созданию систем обработки языка, которые учатся выполнять задачи из их естественных демонстраций.
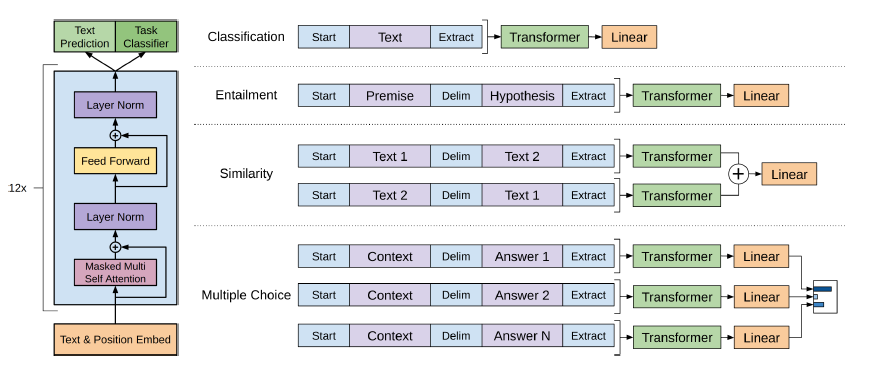
GPT-2 использует 12-слойную архитектуру трансформатора.
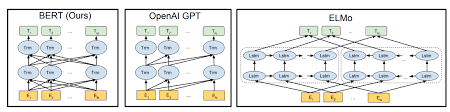
Берт использует архитектуру трансформатора для кодирования предложений.
Вывод сетей указателей дискретен и соответствует позициям в входной последовательности
Количество целевых классов на каждом этапе выхода зависит от длины входа, которая является переменной.
Он отличается от предыдущих попыток внимания, поскольку вместо того, чтобы использовать внимание для смешивания скрытых единиц кодера с вектором контекста на каждом этапе декодера, он использует внимание в качестве указателя, чтобы выбрать член входной последовательности в качестве вывода.

Одним из основных применений обработки естественного языка является автоматическое извлечение того, что люди обсуждают из больших объемов текста. Некоторые примеры большого текста могут быть каналами из социальных сетей, отзывов клиентов о отелях, фильмах и т. Д., Отзывы пользователей, новости, электронные письма о жалобах клиентов и т. Д.
Знание того, о чем говорят люди, и понимают свои проблемы и мнения, очень полезно для предприятий, администраторов, политических кампаний. И очень трудно прочитать такие большие объемы и составить темы.
Таким образом, требуется автоматический алгоритм, который может прочитать текстовые документы и автоматически выводить обсуждаемые темы.
В этой записной книжке мы приведем реальный пример набора данных 20 Newsgroups и используем LDA для извлечения естественных обсуждаемых тем.
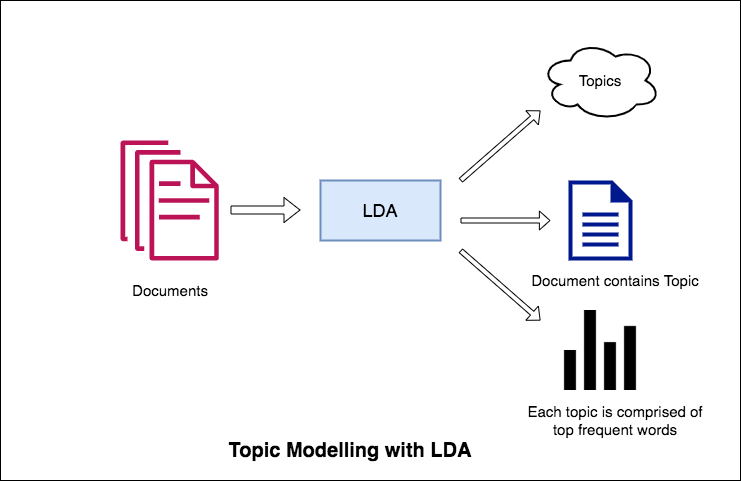
Подход LDA к моделированию темы заключается в том, что он рассматривает каждый документ как набор тем в определенную пропорцию. И каждая тема как коллекция ключевых слов, опять же, в определенной пропорции.
После того, как вы предоставите алгоритм количество тем, все, что он делает, чтобы изменить распределение тем в документах и распределение ключевых слов в рамках тем, чтобы получить хорошую композицию распределения тематических слов.
PCA в основном является методом сокращения размерности, которая превращает столбцы набора данных в новые функции набора. Это происходит путем поиска нового набора направлений (например, оси x и y), которые объясняют максимальную изменчивость в данных. Эта новая система координат системы называется основными компонентами (ПК).
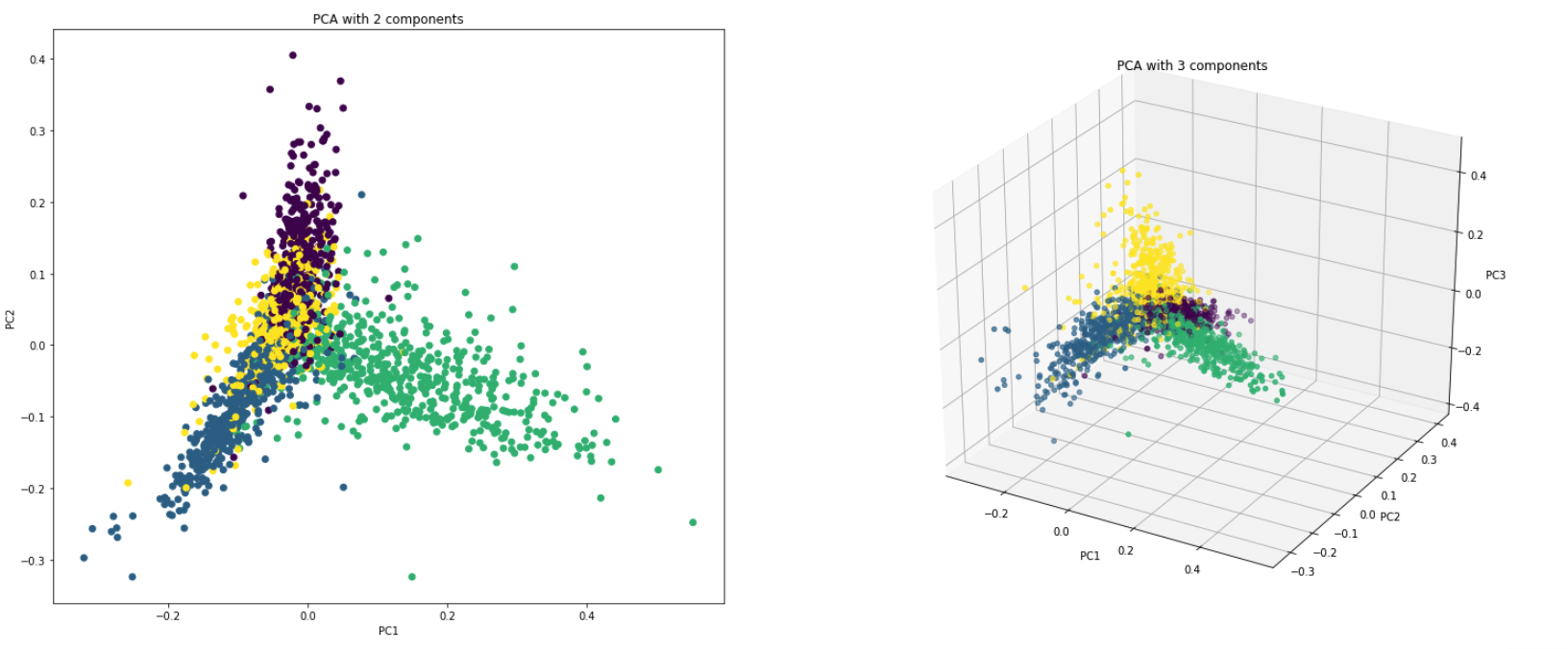
Практически PCA используется по двум причинам:
Dimensionality Reduction : информация, распределенная по большому количеству столбцов, преобразуется в основные компоненты (ПК), так что первые несколько ПК могут объяснить значительную часть общей информации (дисперсия). Эти ПК можно использовать в качестве объяснительных переменных в моделях машинного обучения.
Visualize Data : визуализация разделения классов (или кластеров) трудно для данных с более чем 3 измерениями (функциями). С первыми двумя ПК, обычно можно увидеть четкое разделение.
Наивный классификатор Байеса - это вероятностная модель машинного обучения, которая используется для задачи классификации. Суть классификатора основана на теореме Байеса.
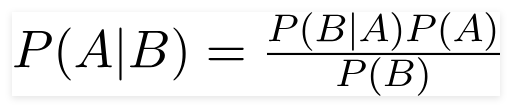
Используя теорему Байеса, мы можем найти вероятность происходящего, учитывая, что B произошел. Здесь B является доказательством, а a - гипотеза. Предполагается, что предикторы/функции являются независимыми. То есть присутствие одной конкретной функции не влияет на другую. Следовательно, это называется наивным.
Типы наивного байеса классификатора :
Multinomial Naive Bayes : это в основном используется, когда переменные дискретные (как слова). Особенности/предикторы, используемые классификатором, являются частотой слов, присутствующих в документе.
Gaussian Naive Bayes : когда предикторы получают непрерывное значение и не являются дискретными, мы предполагаем, что эти значения отображаются из гауссового распределения.
Bernoulli Naive Bayes : это похоже на многономиальную наивную байесу, но предикторы являются логическими переменными. Параметры, которые мы используем для прогнозирования переменной класса, принимают только значения да или нет, например, если слово происходит в тексте или нет.
Используя набор данных 20newsgroup, для выполнения классификации исследуется наивный байесовский алгоритм.
Изучено увеличение данных с использованием следующих методов:

Была исследована новая архитектура под названием Sbert. Архитектура сиамской сети позволяет получить векторы фиксированного размера для входных предложений. Используя меру сходства, такую как Cosinesimilality или Manhatten / Euclidean Distance, можно найти сходные предложения.

| Анализ настроений - IMDB | Классификация настроений - Хинглиш | Классификация документов |
| Дубликатная классификация пары вопросов - Quora | POS -метка | Вывод естественного языка - snli |
| Токсичная классификация комментариев | Грамматически правильное предложение - кола | NER Tagging |
Анализ настроений относится к использованию обработки естественного языка, анализа текста, вычислительной лингвистики и биометрии для систематического идентификации, извлечения, количественной оценки и изучения аффективных состояний и субъективной информации.
Были исследованы следующие разности:
RNN используется для обработки и определения настроения.

После попытки базового RNN, который дает Test_Accuracy менее 50%, экспериментированы с использованием методов, и Test_accuracy выше 88% достигается.
Используются методы:

Внимание помогает сосредоточиться на соответствующем входе при прогнозировании настроения ввода. Внимание Бахданау использовалось с получением результатов LSTM и объединением окончательного скрытого состояния вперед и назад. Без использования предварительно обученных вторжений слов достигается точность теста 88% .
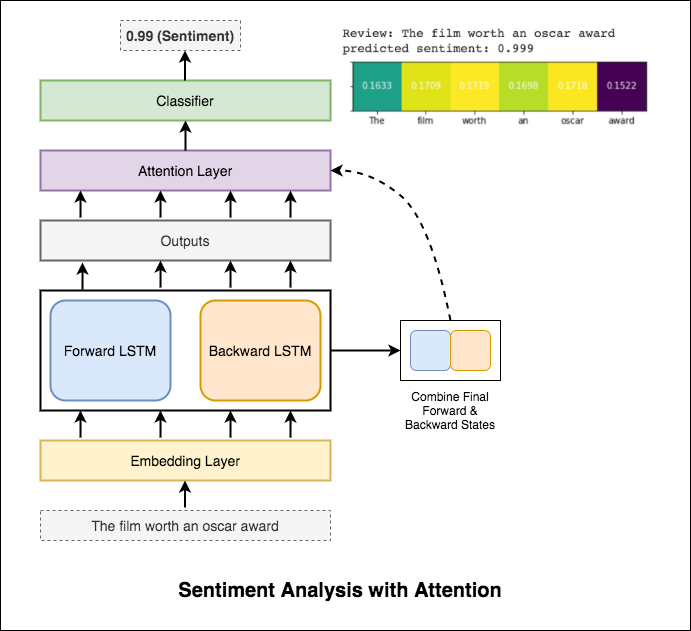
Берт получает новые современные результаты по одиннадцать задач обработки естественного языка. Переносное обучение в НЛП вызвало после выпуска модели BERT. Использование BERT для выполнения анализа настроений исследуется.

Языки смешивания, также известные как смешивание кода, является нормой в многоязычных обществах. Многоязычные люди, которые являются неродными носителями английского языка, имеют тенденцию к кодовому смешиванию, используя английский фонетический типинг и введение англиков на их основной язык.
Задача состоит в том, чтобы предсказать настроение данного твита, смешанного с кодом. Метки настроения являются положительными, отрицательными или нейтральными, а языки, смешанные с кодом, будут английскими-хинди. (Sentimix)
Были исследованы следующие разности:
Используя простую модель MLP, F1 score of 0.58 был достигнут по данным тестирования

После изучения основной модели MLP модель LSTM использовалась для прогнозирования настроений, и был достигнут оценка F1 0.57 .

Результаты были на самом деле меньше по сравнению с основной моделью MLP. Одной из причин может быть LSTM, не может изучить отношения между словами в предложении из-за очень разнообразной природы данных смешанных кода.
Поскольку LSTM не может изучать отношения между словами в смешанном коде предложении из-за очень разнообразной природы данных, смешанных кодом, и не используются предварительно обученные встраивания, оценка F1 меньше.
Чтобы облегчить эту проблему модели XLM-Roberta (которая была предварительно обучена на 100 языках) используется для кодирования предложения. Чтобы использовать модель XLM-Roberta, предложение должно быть на правильном языке. Итак, сначала хиндисты должны быть преобразованы в форму хинди (деванагари).
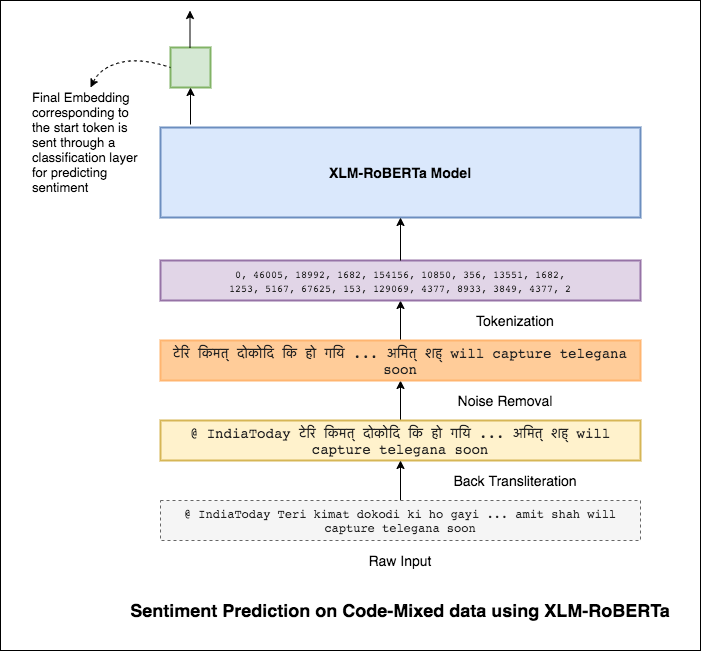
Был достигнут оценка F1 0.59 . Методы улучшения этого будут изучены позже.
Окончательный выход из модели XLM-Roberta был использован в качестве входных встроений в двунаправленную модель LSTM. Уровень внимания, который берет выходы от слоя LSTM, создает взвешенное представление входного ввода, которое затем передается через классификатор для прогнозирования настроения предложения.

Был достигнут оценка F1 0.64 .
Точно так же, как фильтр 3x3 может просмотреть пятно изображения, фильтр 1x2 может просмотреть 2 последовательные слова в кусочке текста, то есть би-грамм. В этой модели CNN мы вместо этого будем использовать несколько фильтров разных размеров, которые будут рассмотреть BI-граммы (фильтр 1x2), три-граммы (фильтр 1x3) и/или n-граммы (фильтр 1xn) в тексте.
Интуиция здесь заключается в том, что появление некоторых би-граммов, три-граммов и N-граммов в рамках обзора будет хорошим признаком окончательного настроения.
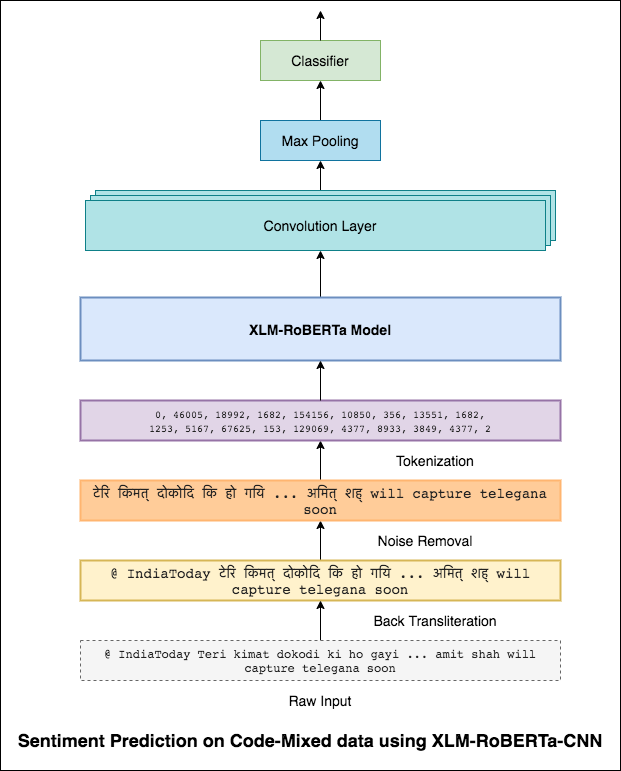
Был достигнут оценка F1 0.69 .
CNN отражает местные зависимости, где RNN захватывает глобальные зависимости. Объединив оба, мы можем лучше понять данные. Ансамблирование модели CNN и модели двунаправленного привязанного подщения выполняют другие.
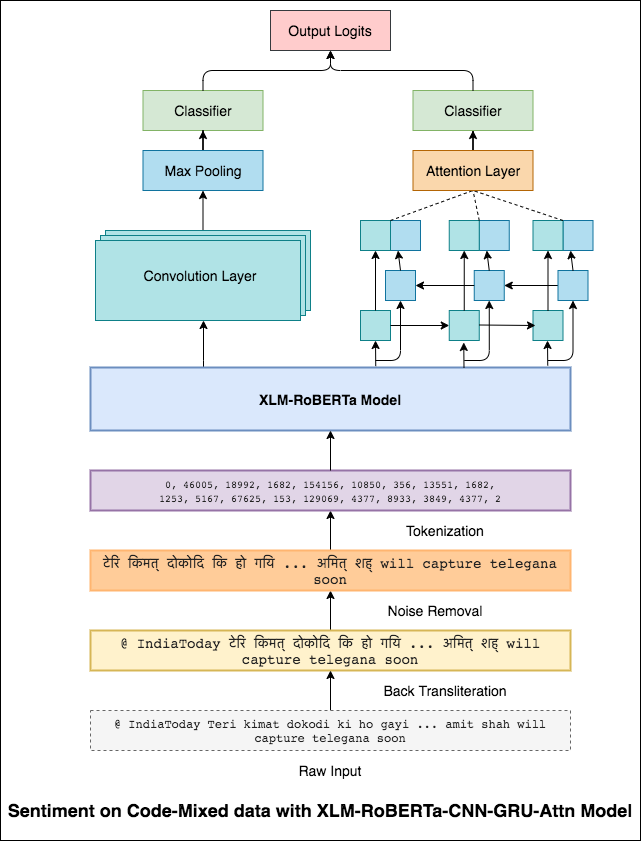
Был достигнут оценка F1 0.71 . (Топ -5 в таблице лидеров).
Классификация документов или категоризация документов является проблемой в библиотечной науке, информационной науке и информатике. Задача состоит в том, чтобы назначить документ одному или нескольким классам или категориям.
Были исследованы следующие разности:
Иерархическая сеть внимания (HAN) рассматривает иерархическую структуру документов (документ - предложения - слова) и включает механизм внимания, способный найти наиболее важные слова и предложения в документе, принимая во внимание контекст.
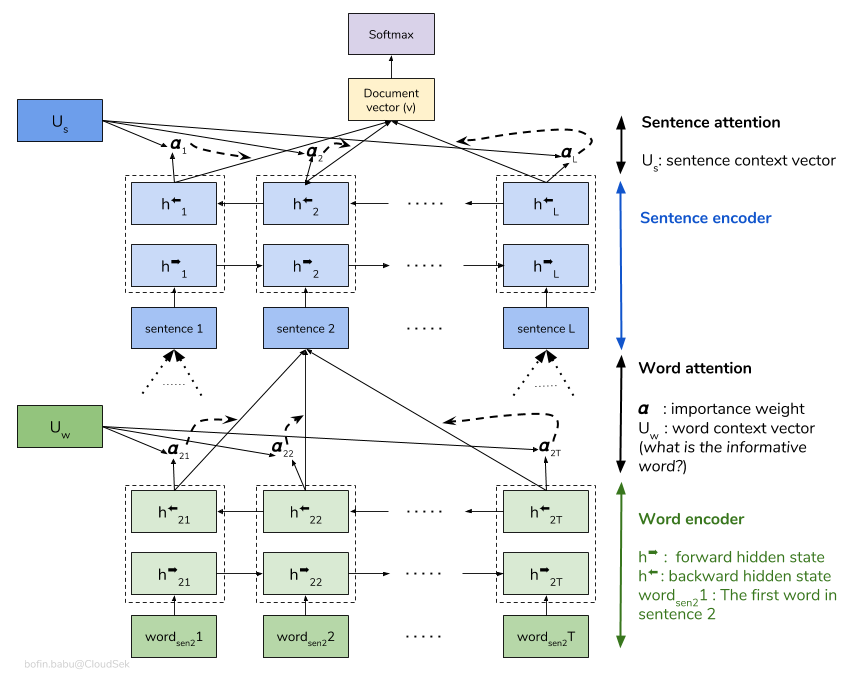
Основная модель Хана быстро переживает. Чтобы преодолеть это, исследуются методы, такие как Embedding Dropout , Locked Dropout . Есть еще одна другая техника, называемая Weight Dropout , который не реализован (дайте мне знать, если есть какие -либо хорошие ресурсы для этого). Предварительно обученные встроенные Glove также используются вместо случайной инициализации. Поскольку внимание может быть сделано на уровне предложений и уровне слов, мы можем визуализировать, какие слова важны в предложении, а какие предложения важны в документе.



QQP означает пары вопросов Quora. Цель задачи - для данной пары вопросов; Нам нужно обнаружить, семантически похожи друг на друга или нет.
Были исследованы следующие разности:
Алгоритм должен воспринимать пару вопросов в качестве входных данных и должен вывести их сходство. Сиамская сеть используется. Siamese neural network (иногда называемая двойной нейронной сетью) - это искусственная нейронная сеть, которая использует same weights во время работы в тандеме на двух разных входных векторах для вычисления сопоставимых выходных векторов.

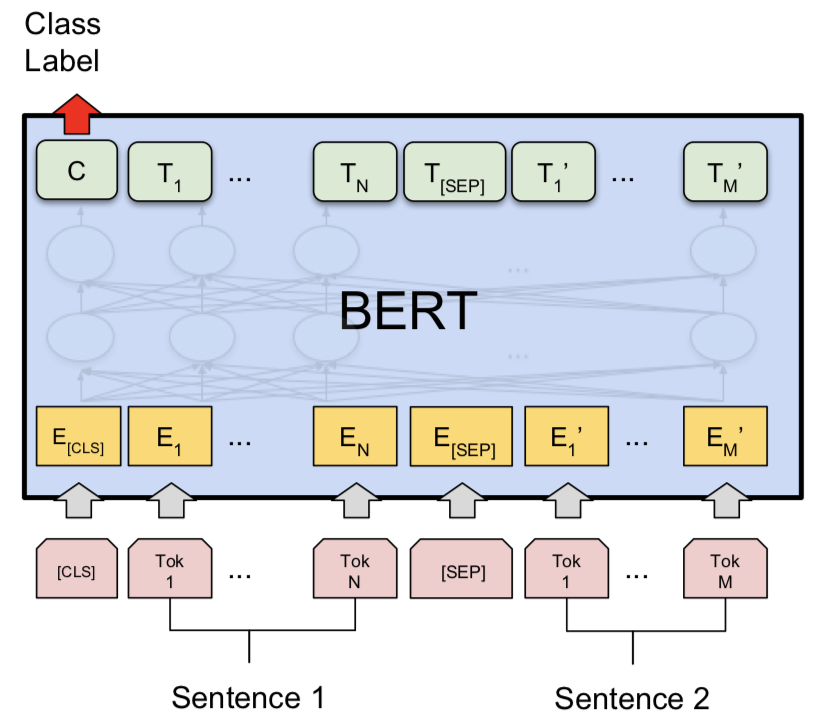
Попробовав сиамскую модель, Берт был исследован, чтобы сделать обнаружение пар в дубликатах Quora. Берт принимает вопрос 1 и вопрос 2 в качестве входных данных, разделенных токеном [SEP] , и классификация была выполнена с использованием окончательного представления токена [CLS] .
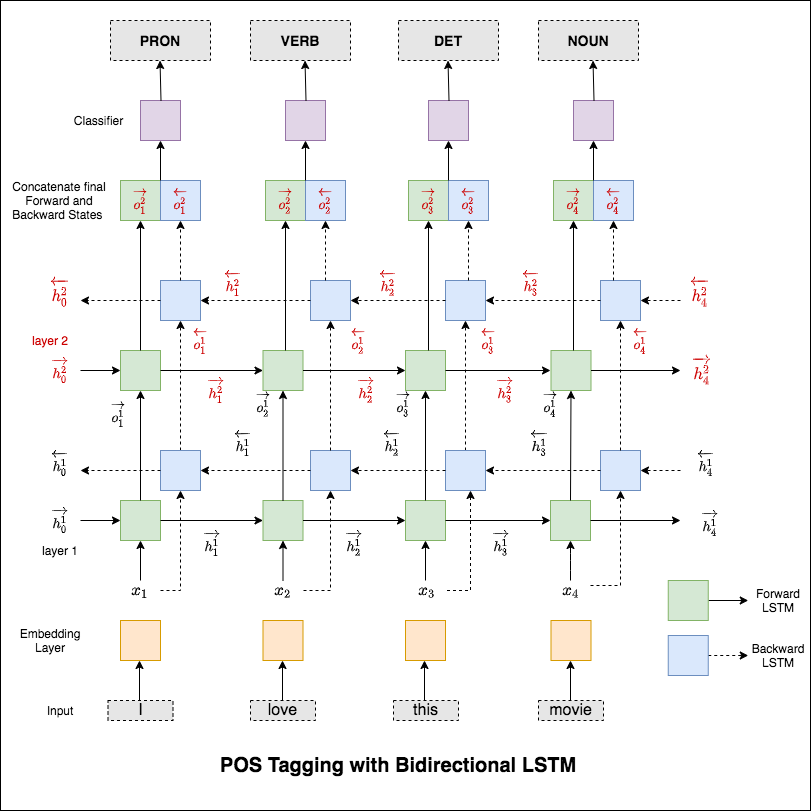
Часть речи (POS), представляет собой задачу маркировки каждого слова в предложении с соответствующей частью речи.
Были исследованы следующие разности:
Этот код охватывает базовый рабочий процесс. Мы узнаем, как: загрузить данные, создавать разделения поезда/тестирования/валидации, создать словарный запас, создавать итераторы данных, определить модель и реализовать тегин поезда/оценка/тест и время выполнения (вывод).
Используемая модель представляет собой многослойную двунаправленную сеть LSTM
После того, как он попробовал подход RNN, исследуются POS -теги с архитектурой на основе трансформатора. Поскольку трансформатор содержит как энкодер, так и декодер, и для задачи маркировки последовательности Encoder будет достаточно. Поскольку данные невелики, имея 6 слоев энкодера, переполнят данные. Таким образом, использовалась трехслойная модель энкодера трансформатора.

После попытки POS-метки с помощью трансформаторного энкодера используется POS-теги с предварительно обученной моделью BERT. Он достиг точности теста 91% .

Целью вывода естественного языка (NLI), широко изученной задачи по обработке естественного языка, является определение того, семантически ли одно заданное заявление (предпосылка) влечет за собой другое заданное утверждение (гипотеза).
Были исследованы следующие разности:
Основная модель с сетью Siamese Bilstm внедрена
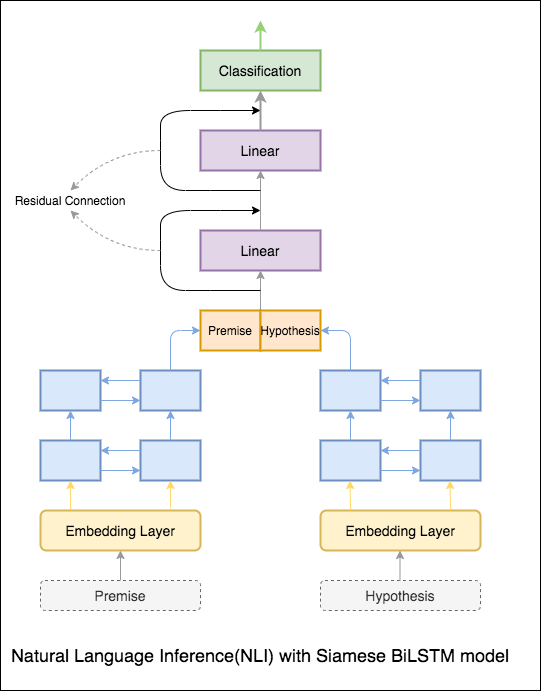
Это можно рассматривать как настройку базовой линии. Точность теста 76.84% была достигнута.
В предыдущей ноутбуке окончательные скрытые состояния предпосылки и гипотезы как представления LSTM. Теперь вместо того, чтобы принимать окончательные скрытые состояния, внимание будет рассчитано на все входные токены, а окончательный взвешенный вектор принимается как представление предпосылки и гипотезы.
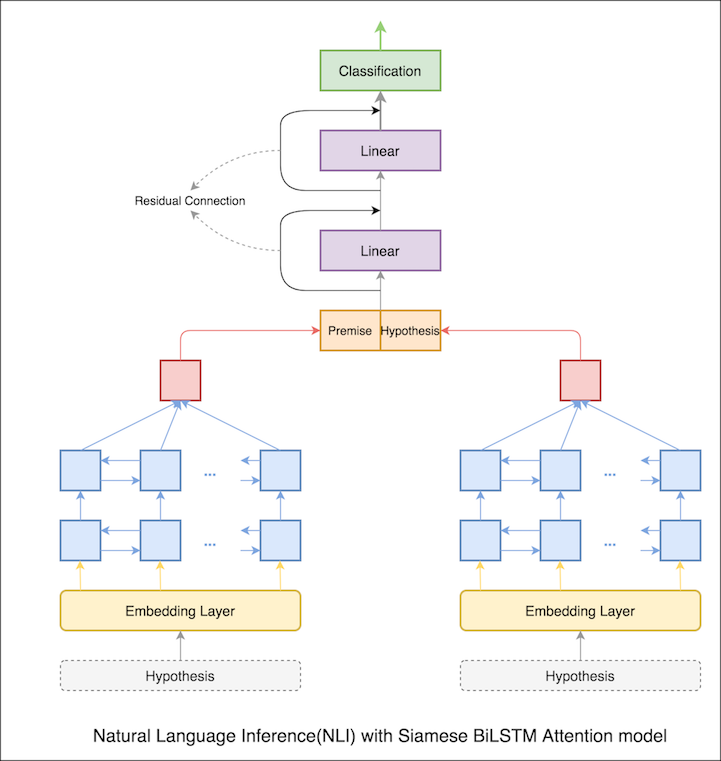
Точность теста увеличилась с 76.84% до 79.51% .
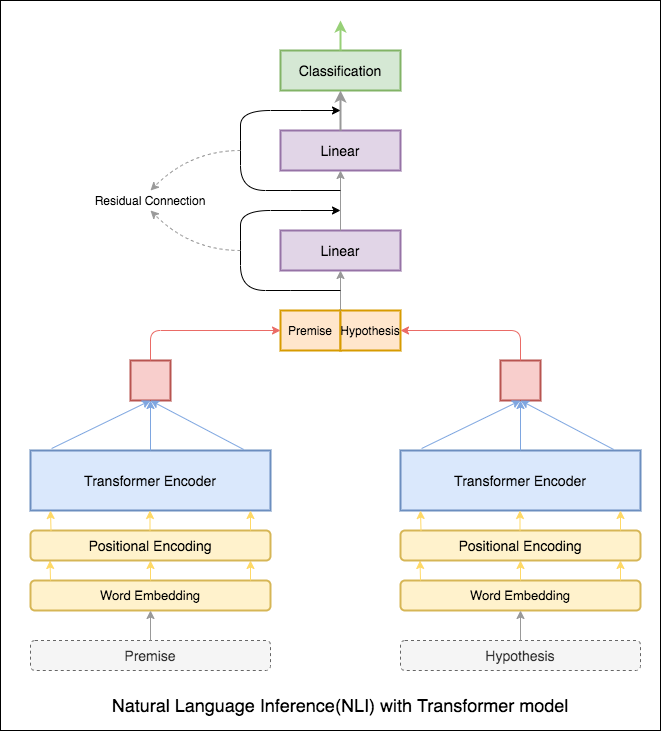
Трансформатор был использован для кодирования предпосылки и гипотезы. Как только предложение будет вынесено через кодировщик, суммирование всех токенов считается окончательным представлением (другие варианты могут быть изучены). Точность модели меньше по сравнению с вариантами RNN.
NLI с базовой моделью Bert была исследована. Берт принимает предпосылку и гипотезу как входные данные, разделенные токеном [SEP] , и классификация была выполнена с использованием окончательного представления токена [CLS] .
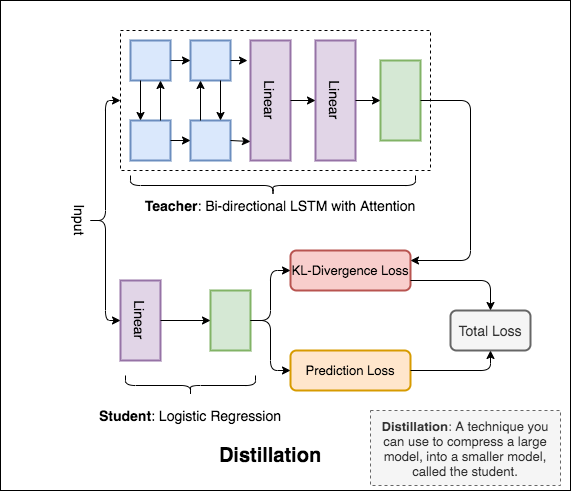
Distillation : техника, которую вы можете использовать для сжатия большой модели, называемой teacher , в меньшую модель, называемую student . После ученика модели учителей используются для выполнения дистилляции на NLI.
Обсудить вещи, о которых вы заботитесь, может быть трудным. Угроза злоупотреблений и домогательств в Интернете означает, что многие люди перестают выражать себя и отказываются от поиска разных мнений. Платформы изо всех сил пытаются эффективно облегчить разговоры, что заставляет многих сообществ ограничить или полностью отключить комментарии пользователей.
Вам предоставляется большое количество комментариев Википедии, которые были помечены оценщиками человека для токсического поведения. Типы токсичности:
Были исследованы следующие разности:
Используемая модель представляет собой двунаправленную сеть GRU.
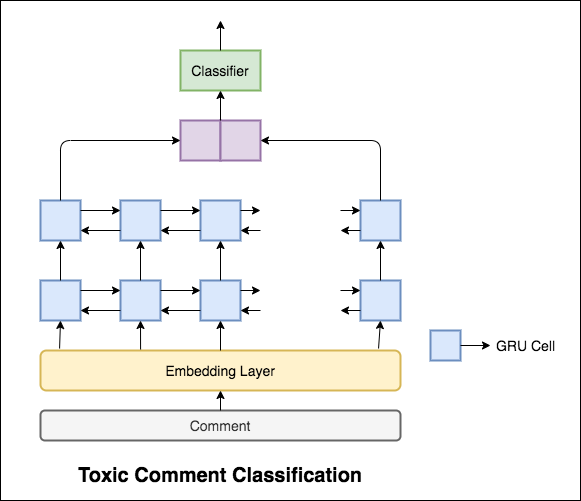
Точность теста 99.42% была достигнута. Поскольку 90% данных не помечены ни в одну из токсичности, просто прогнозирование всех данных как нетоксичных дает 90% точную модель. Таким образом, точность не является надежной метрикой. Был реализован другой метрический ROC AUC.
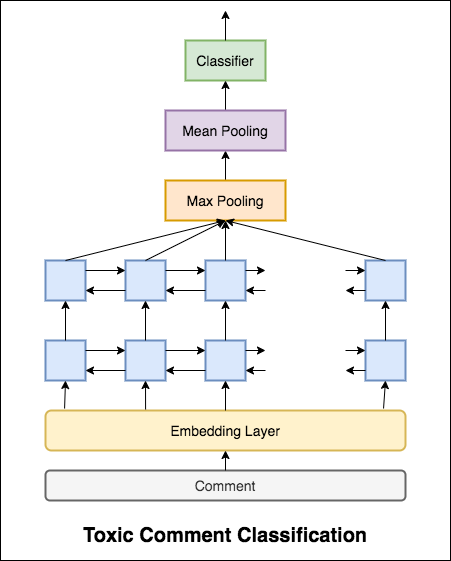
С Categorical Cross Entropy в качестве потери достигается оценка ROC_AUC 0.5 . Изменив потерю на Binary Cross Entropy , а также немного изменяя модель, добавив слои пула (максимум, среднее), оценка ROC_AUC улучшилась до 0.9873 .
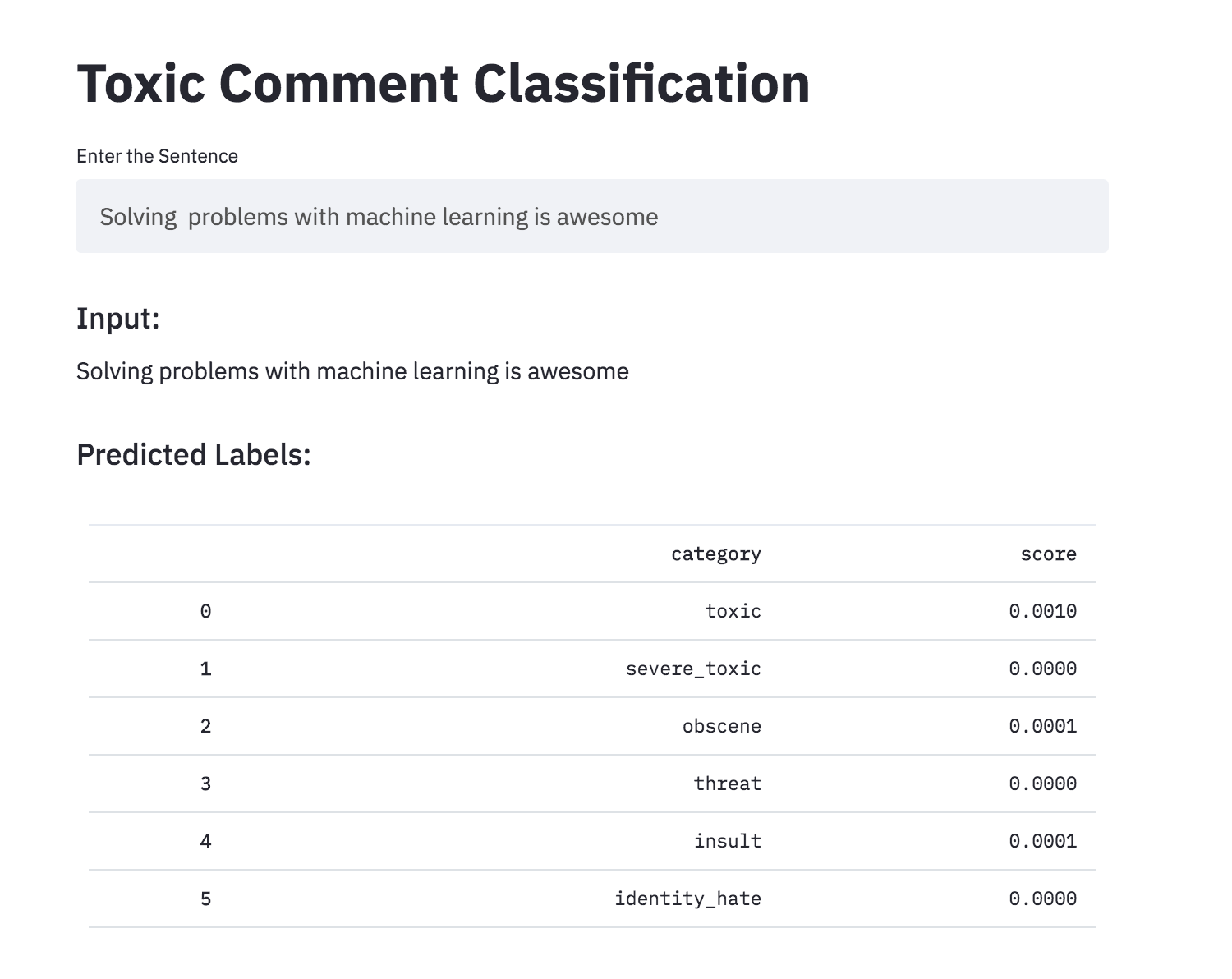
Преобразовал токсичную классификацию комментариев в приложение с использованием стрижки. Предварительно обученная модель доступна сейчас.
Могут ли искусственные нейронные сети иметь возможность судить о грамматической приемлемости предложения? Чтобы изучить эту задачу, используется набор данных Corpus of Linguistic Completibility (COLA). COLA - это набор предложений, помеченных как грамматически правильные или неверные.
Были исследованы следующие разности:
Берт получает новые современные результаты по одиннадцать задач обработки естественного языка. Переносное обучение в НЛП вызвало после выпуска модели BERT. В этой записной книжке мы рассмотрим, как использовать BERT для классификации, является ли предложение грамматически правильным или не использует набор данных COLA.
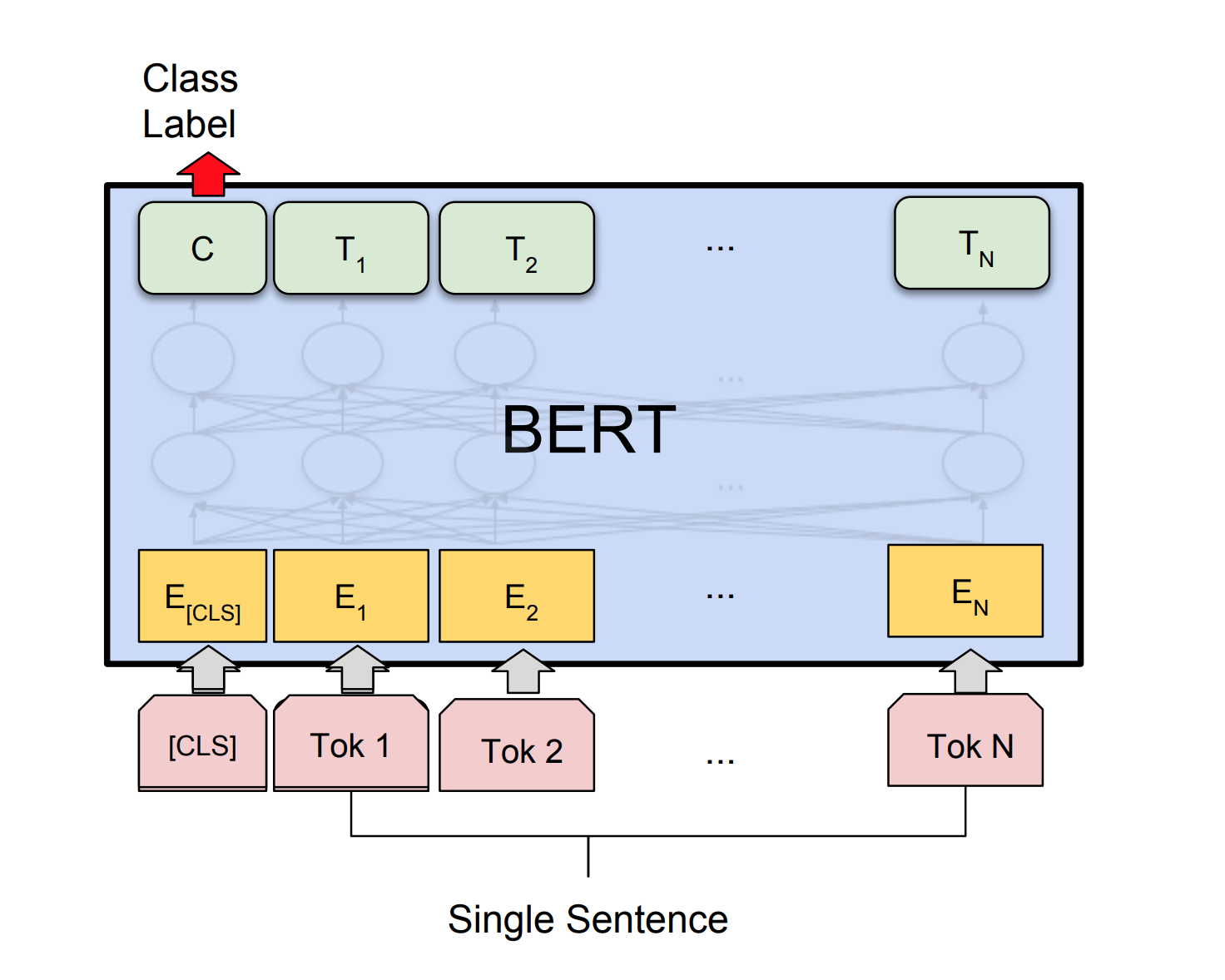
Был достигнут точность 85% и коэффициента корреляции Мэтьюса (MCC) 64.1 .
Distillation : техника, которую вы можете использовать для сжатия большой модели, называемой teacher , в меньшую модель, называемую student . После ученика модели учителей используются для выполнения дистилляции на COLA.

После экспериментов были опробованы:
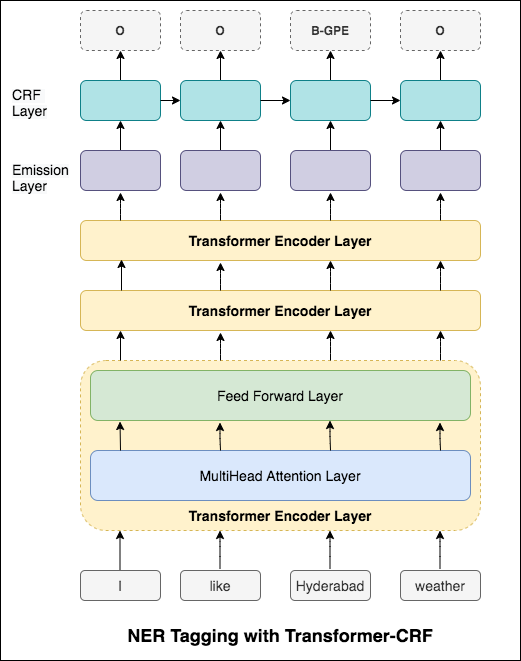
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 Названное познание (NER) Tagring (NER) является задачей маркировки каждого слова в предложении с его подходящей сущностью.
Были исследованы следующие разности:
Этот код охватывает базовый рабочий процесс. Мы посмотрим, как: загрузить данные, создать разделения поезда/тестирования/валидации, создать словарный запас, создать итераторы данных, определить модель и реализовать цикл поезда/оценки/тестирования и поезда, тестируйте модель.
Используемая модель является двунаправленной сетью LSTM
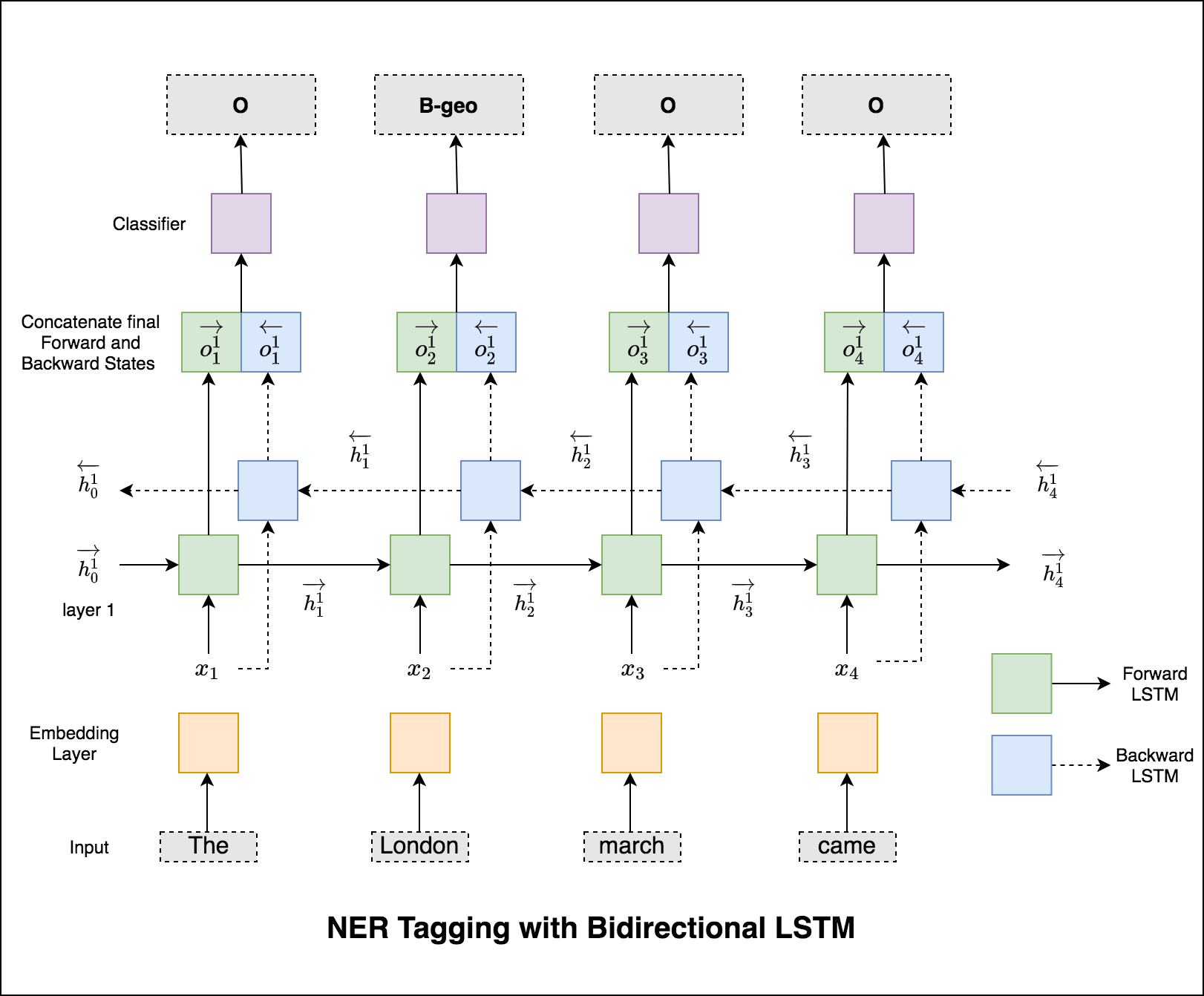
В случае последовательности тега (ner) тег текущего слова может зависеть от тега предыдущего слова. (Пример: Нью -Йорк).
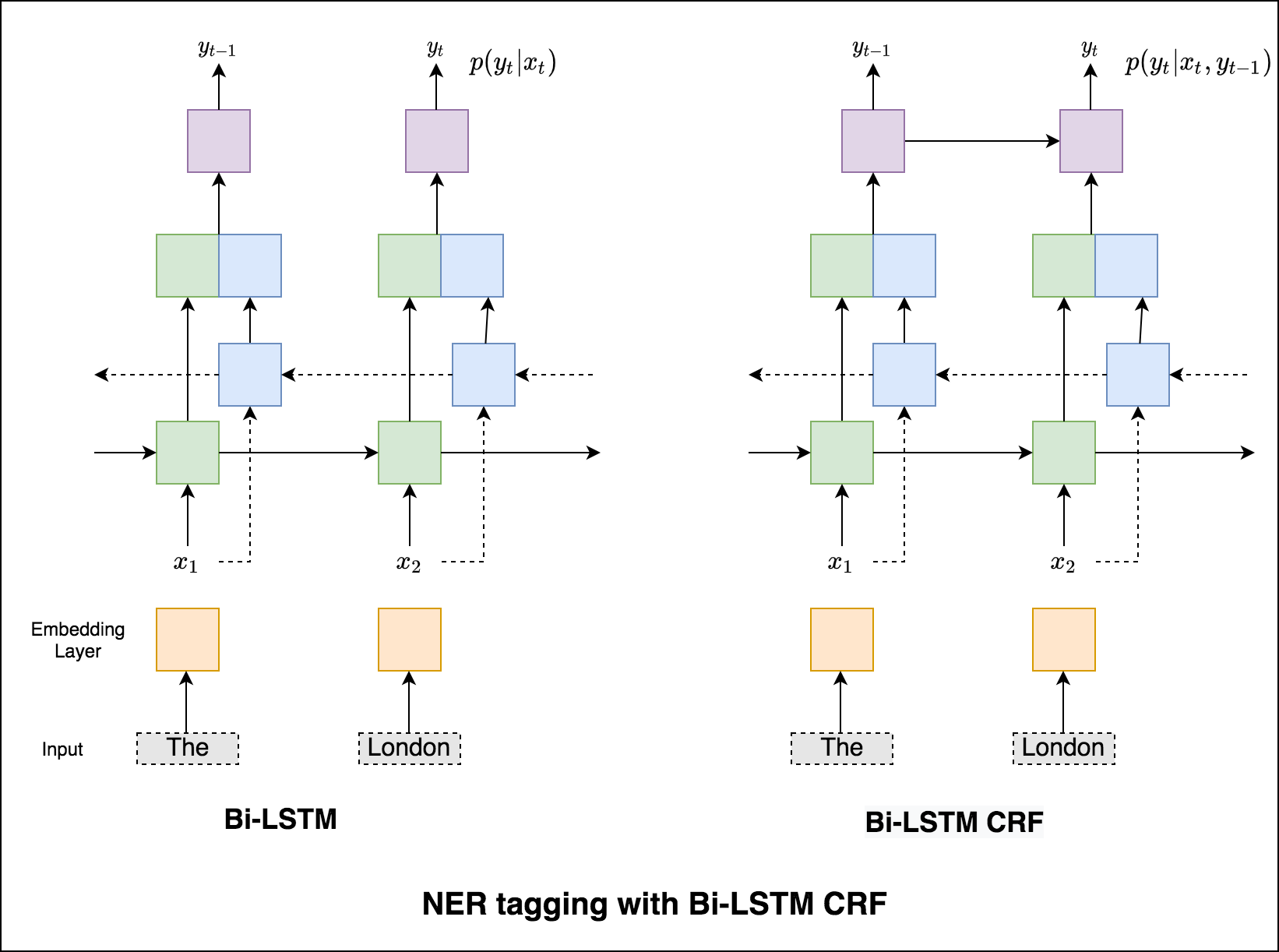
Без CRF мы бы просто использовали один линейный слой для преобразования вывода двунаправленного LSTM в оценки для каждого тега. Они известны как emission scores , которые являются представлением о вероятности того, что слово является определенным тегом.
CRF рассчитывает не только оценки выбросов, но и transition scores , которые являются вероятностью слова, который будет определенным тегом, учитывая, что предыдущее слово было определенным тегом. Поэтому оценки перехода измеряют, насколько вероятно, что это переход от одного тега к другой.
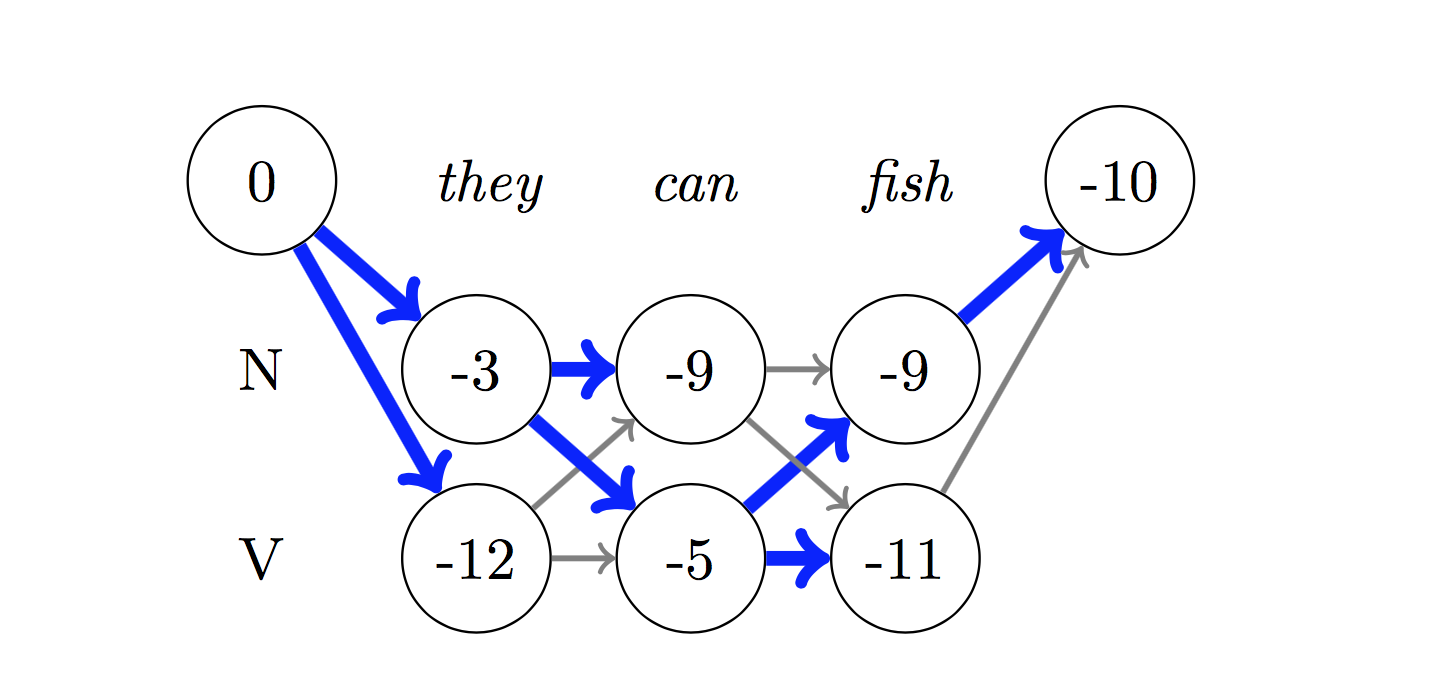
Для декодирования используется алгоритм Viterbi .
Поскольку мы используем CRFS, мы не столько предсказываем правильную метку на каждом словом, сколько прогнозируем правильную последовательность метки для последовательности слов. Декодирование Viterbi - это способ сделать именно это - найти наиболее оптимальную последовательность тегов из баллов, рассчитанных по условному случайному полю.
Использование информации о подлоде в нашей задаче с тегом, потому что это может быть мощным индикатором тегов, будь то части речи или сущностей. Например, он может узнать, что прилагательные обычно заканчиваются «-y» или «-ul», или что места часто заканчиваются «-land» или «-бургом».
Следовательно, наша модель тега последовательности использует оба
word-level в форме встроенных слов.character-level вплоть до каждого слова в обоих направлениях. 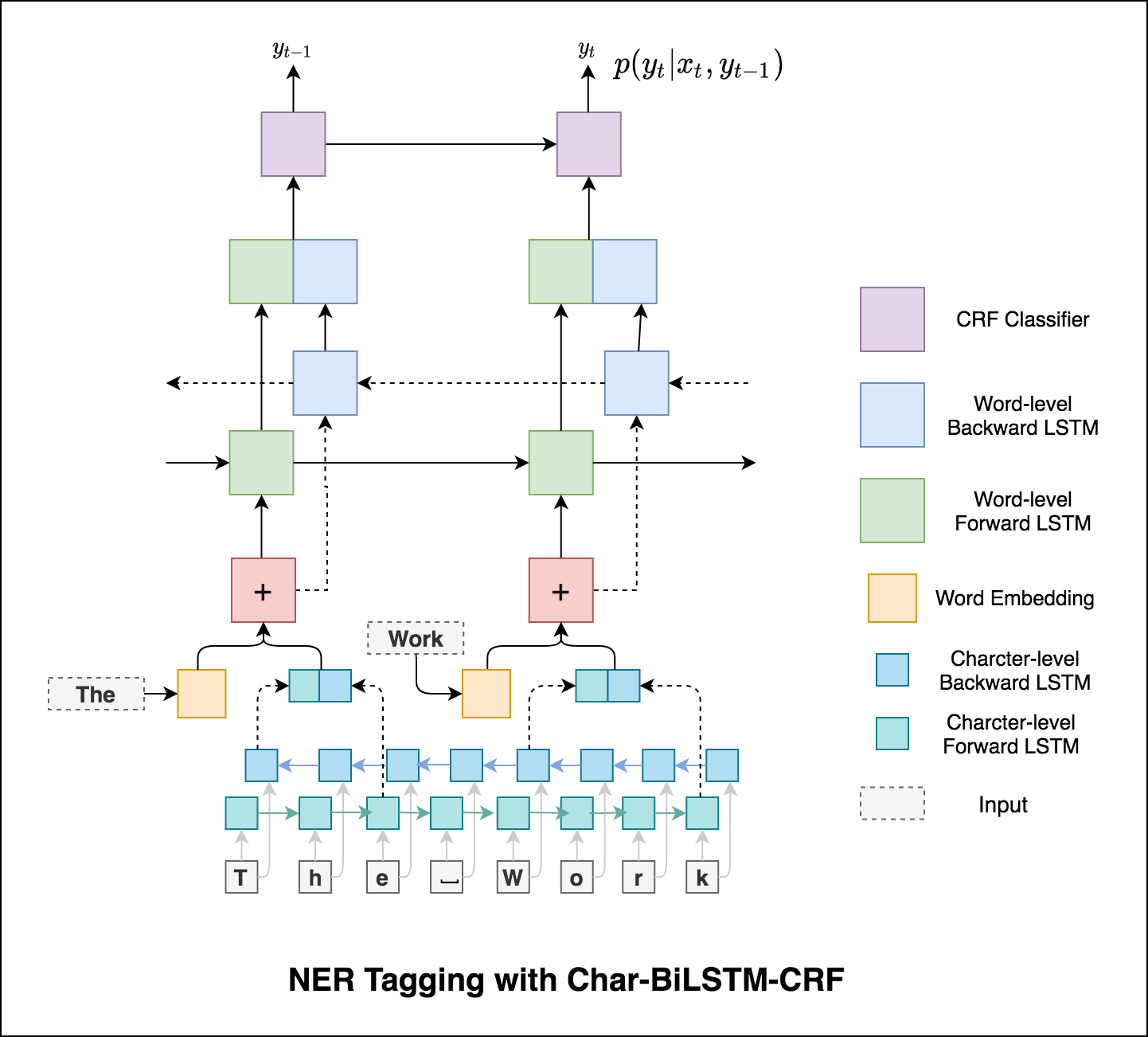
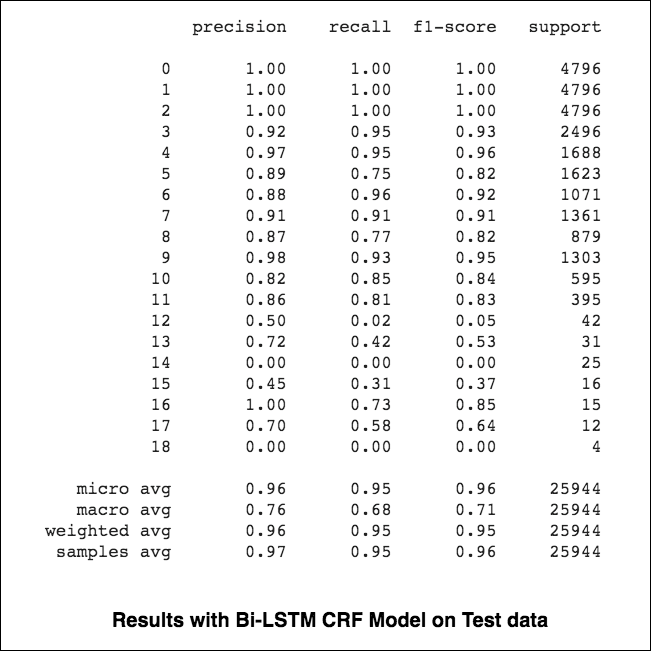
Микро и макросредние (для любой метрики) будут рассчитывать немного разные вещи, и, следовательно, их интерпретация отличается. Макро-среднее будет вычислять метрику независимо для каждого класса, а затем будет принимать среднее значение (следовательно, обработка всех классов одинаково), тогда как микро средний будет объединять вклад всех классов для вычисления средней метрики. В многоклассовой классификационной настройке Micro-среднее предпочтительнее, если вы подозреваете, что может быть дисбаланс класса (то есть у вас может быть гораздо больше примеров одного класса, чем других классов).

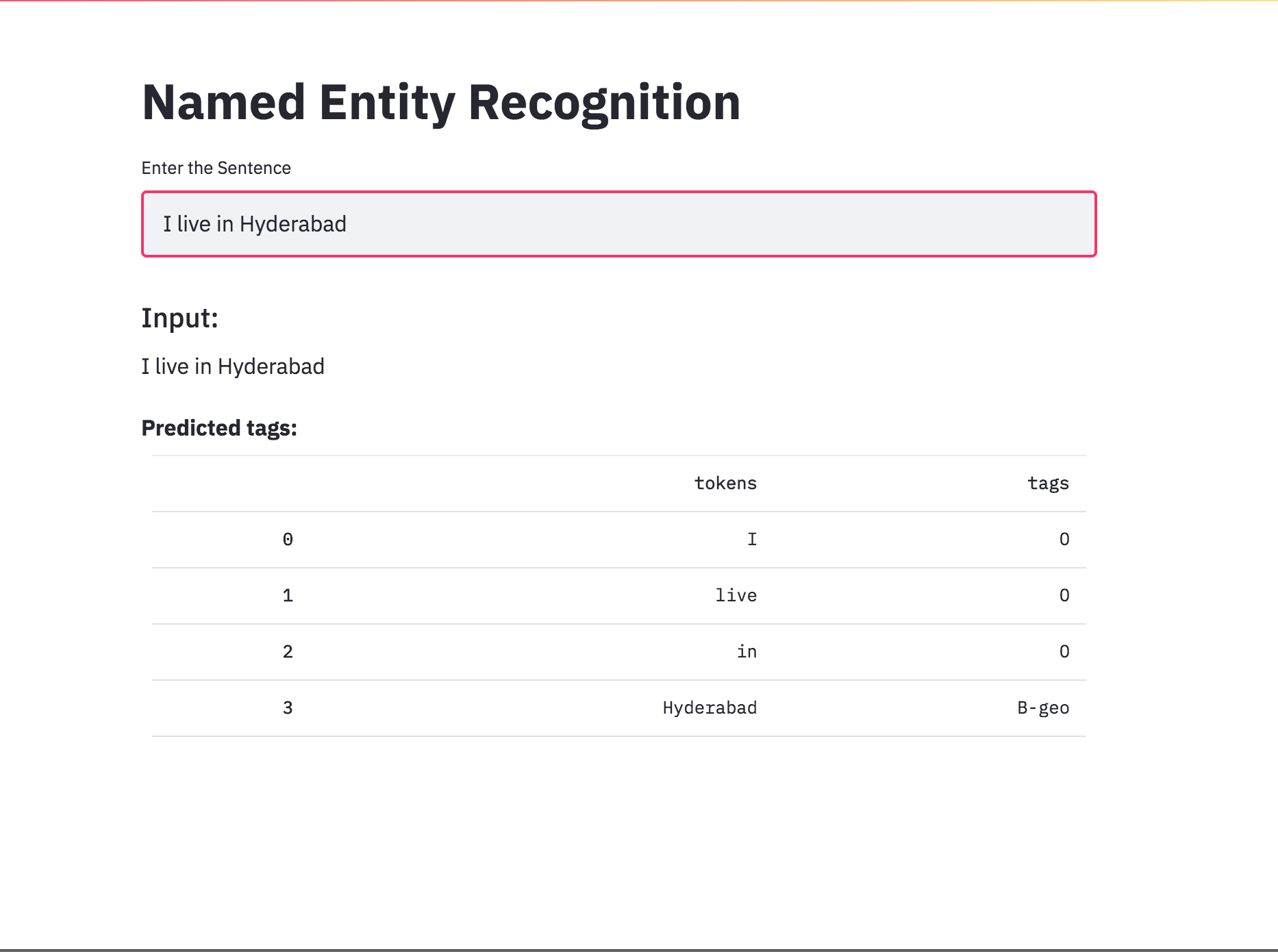
Преобразовал теги NER в приложение, используя StreamLit. Предварительно обученная модель (char-bilstm-crf) доступна сейчас.
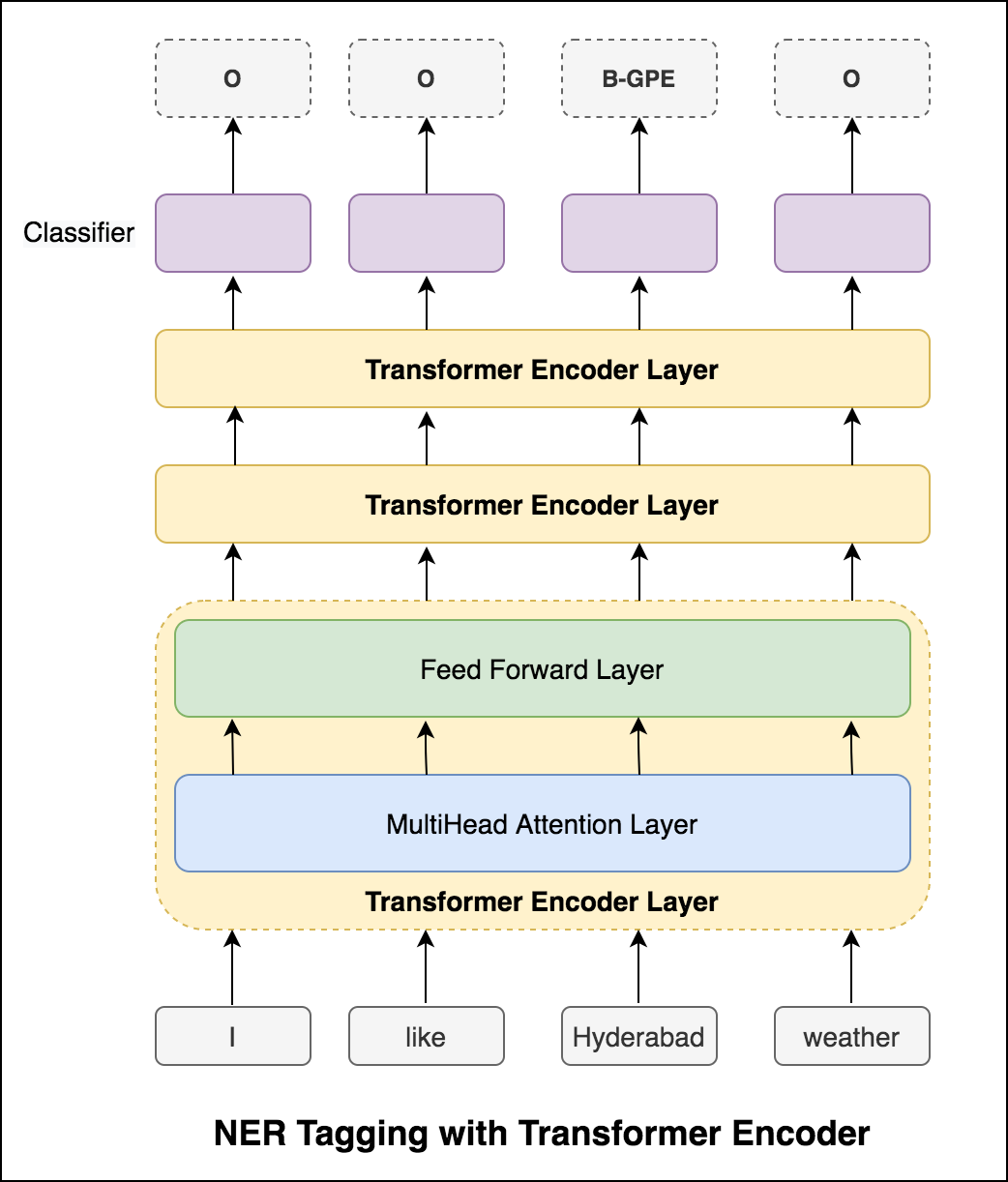
После того, как он попробовал подход RNN, исследуются теги с архитектурой на основе трансформатора. Поскольку трансформатор содержит как энкодер, так и декодер, и для задачи маркировки последовательности Encoder будет достаточно. Была использована трехслойная модель энкодера трансформатора.
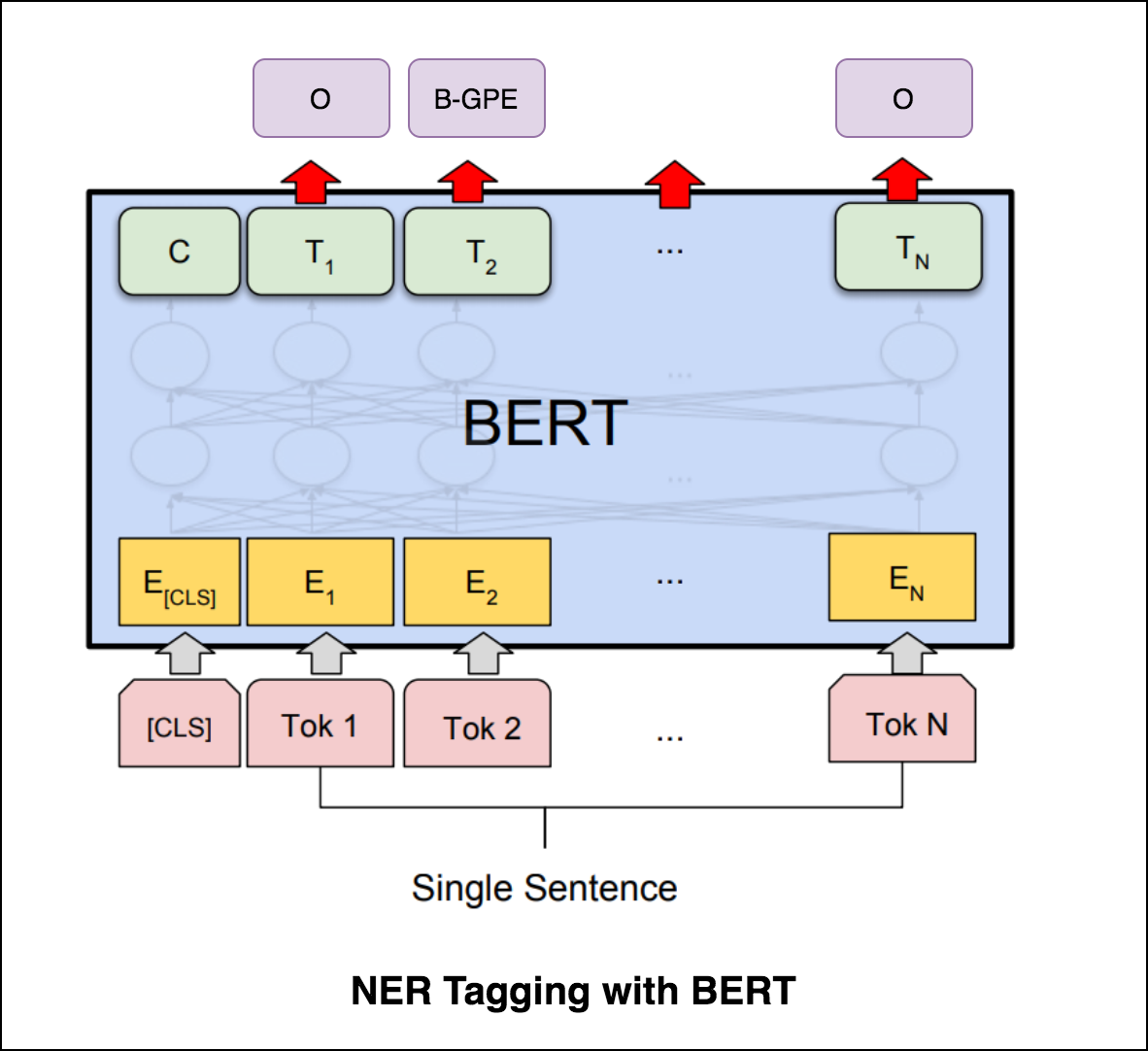
После того, как он попробовал метку NER с помощью Transformer Encoder, исследуется тега NER с предварительно обученной моделью bert-base-cased .
Только трансформатор не дает хороших результатов по сравнению с Bilstm в задаче NER. Увеличение уровня CRF в верхней части трансформатора, которое улучшает результаты по сравнению с автономным трансформатором.
Spacy предоставляет исключительно эффективную статистическую систему для NER в Python, которая может назначать метки группам токенов. Он предоставляет модель по умолчанию, которая может распознавать широкий спектр названных или численных сущностей, которые включают в себя человека, организацию, язык, событие и т. Д.

Помимо этих объектов по умолчанию, Spacy также дает нам свободу добавлять произвольные классы в модель NER, обучая модель для обновления ее с помощью более новых обученных примеров.
2 Новые организации, называемые ACTIVITY и SERVICE в определенных данных домена (банк), созданы и обучены с несколькими образцами обучения.

| Имя поколения | Машинный перевод | Генерация высказывания |
| Подпись изображения | Подпись изображения - уравнения латекса | Суммизация новостей |
| По электронной почте генерация субъекта |
Используется языковая модель LSTM на уровне персонажа. То есть мы дадим LSTM огромный кусок имен и попросим его моделировать распределение вероятностей следующего символа в последовательности, с которой приведены последовательность предыдущих символов. Это позволит нам генерировать новое имя по одному персонажу за раз

Машинный перевод (MT) является задачей автоматического преобразования одного естественного языка в другой, сохранения значения входного текста и создания текста бегства на языке вывода. В идеале, последовательность источника языка переводится в целевую языковую последовательность. Задача состоит в том, чтобы преобразовать предложения с German to English .
Были исследованы следующие разности:
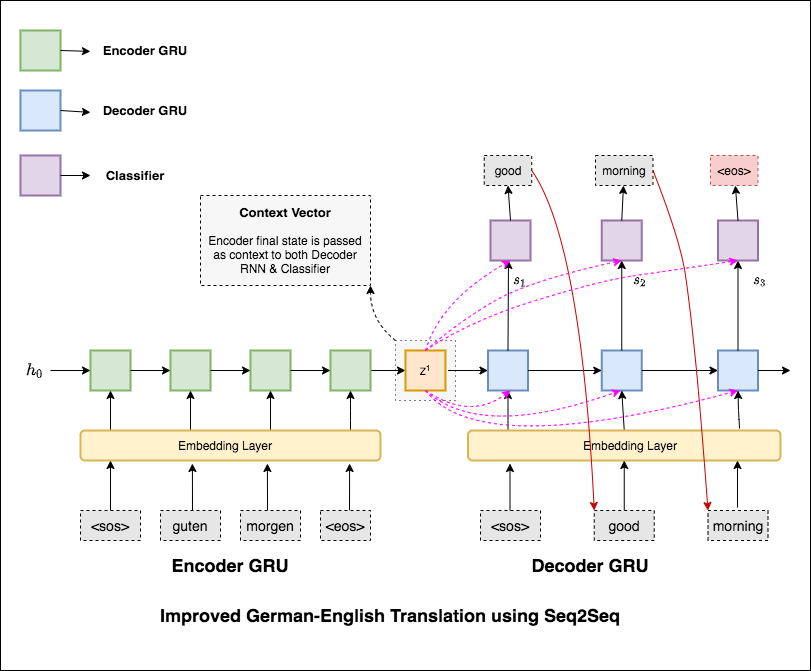
Наиболее распространенными моделями последовательности к последовательности (SEQ2SEQ) являются модели Encoder-Decoder, которые обычно используют рецидивирующую нейронную сеть (RNN) для кодирования предложения источника (вход) в один вектор. В этой записной книжке мы будем называть этот единственный вектор как вектор контекста. Мы можем думать о контекстном векторе как о абстрактном представлении всего входного предложения. Затем этот вектор декодируется вторым RNN, который учится выходить из целевого (выходного) предложения, генерируя его по одному слову за раз.

После попытки основного машинного перевода, который имеет текст недоумения 36.68 , следовать методам экспериментированы и испытательную недоумение 7.041 .
Оформить код в папке applications/generation
Механизм внимания был рожден, чтобы помочь запомнить длинные исходные предложения в переводе нервной машины (NMT). Вместо того, чтобы построить один контекстный вектор из последнего скрытого состояния энкодера, внимание используется, чтобы больше сосредоточиться на соответствующих частях ввода при декодировании предложения. Вектор контекста будет создан путем получения выходов энкодера и previous hidden state декодера RNN.
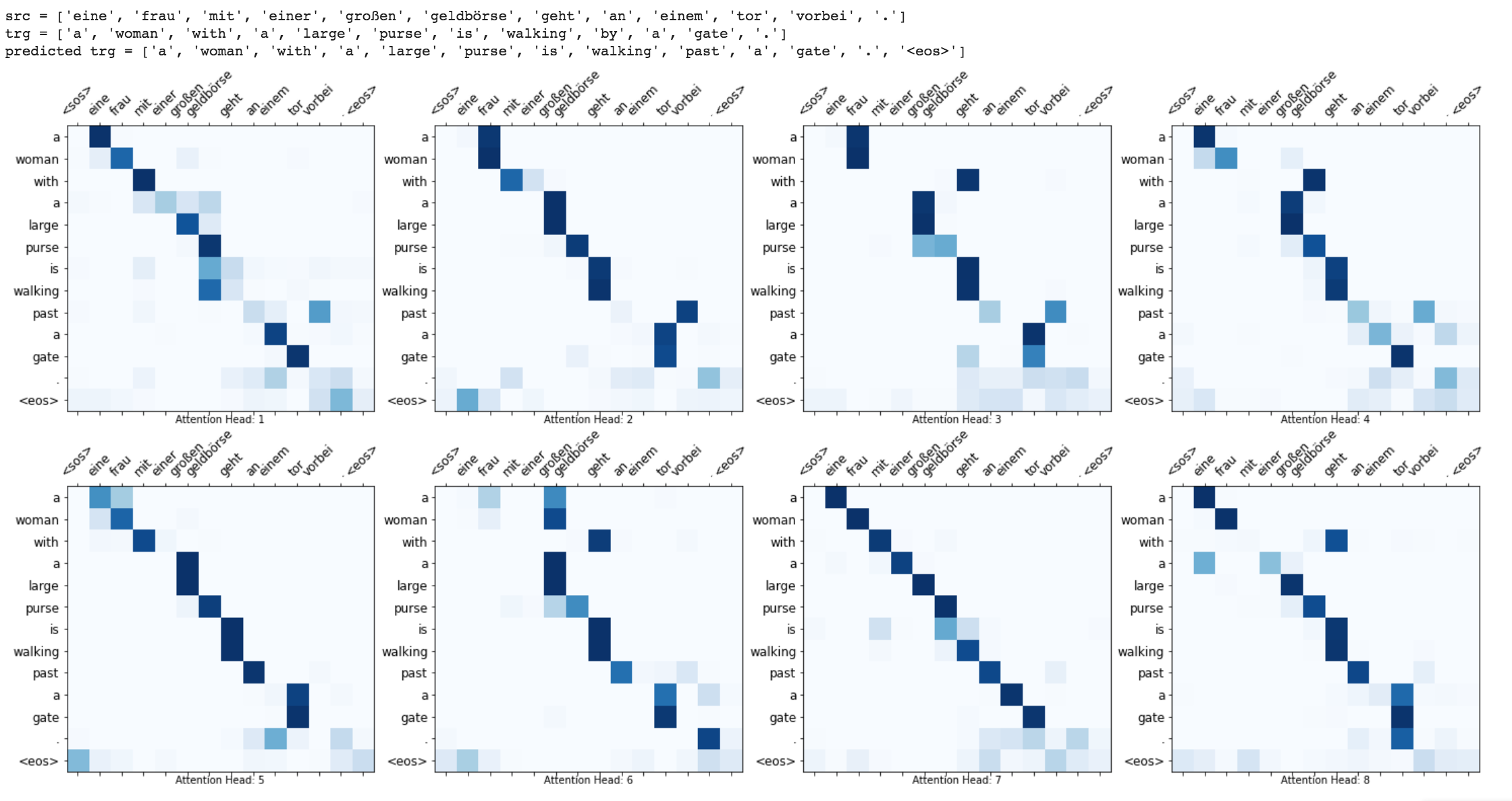
Усовершенствования, такие как маскировка (игнорирование внимания к мягкому вводу), последовательностей упаковки (для лучших вычислений), визуализация внимания и метрика BLEU на тестовых данных.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
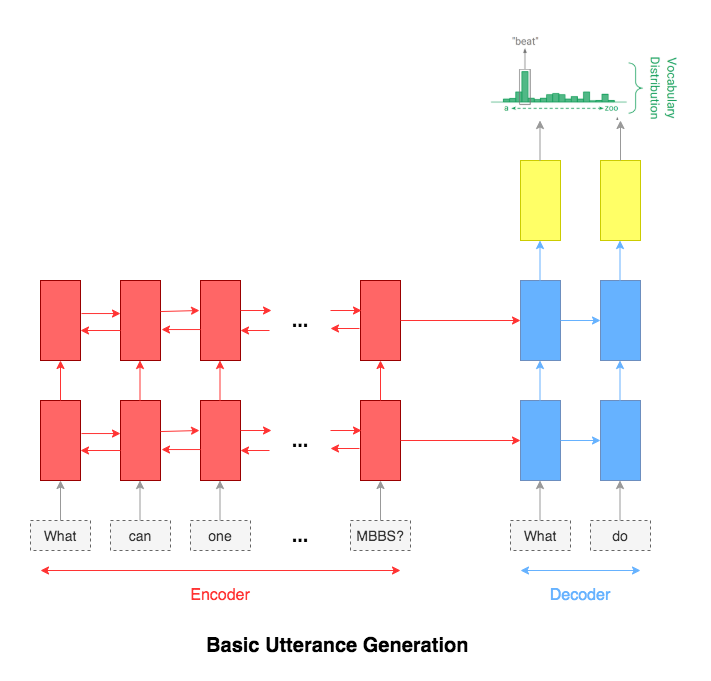
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
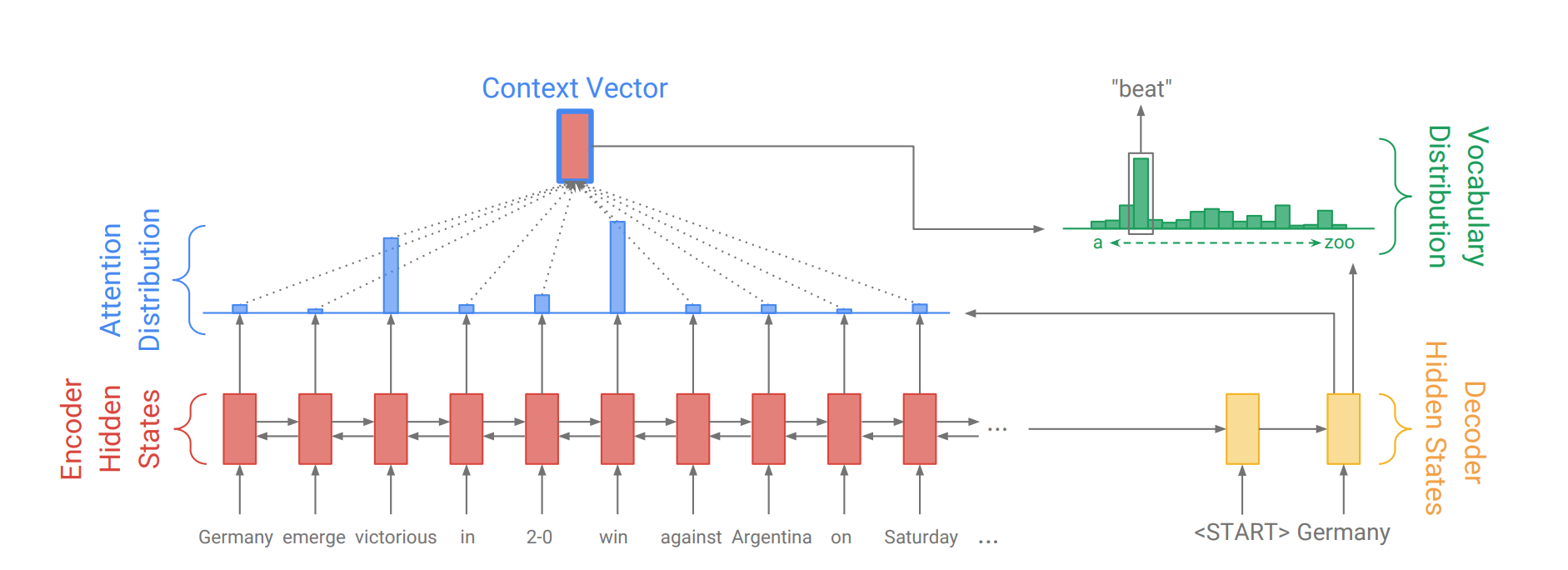
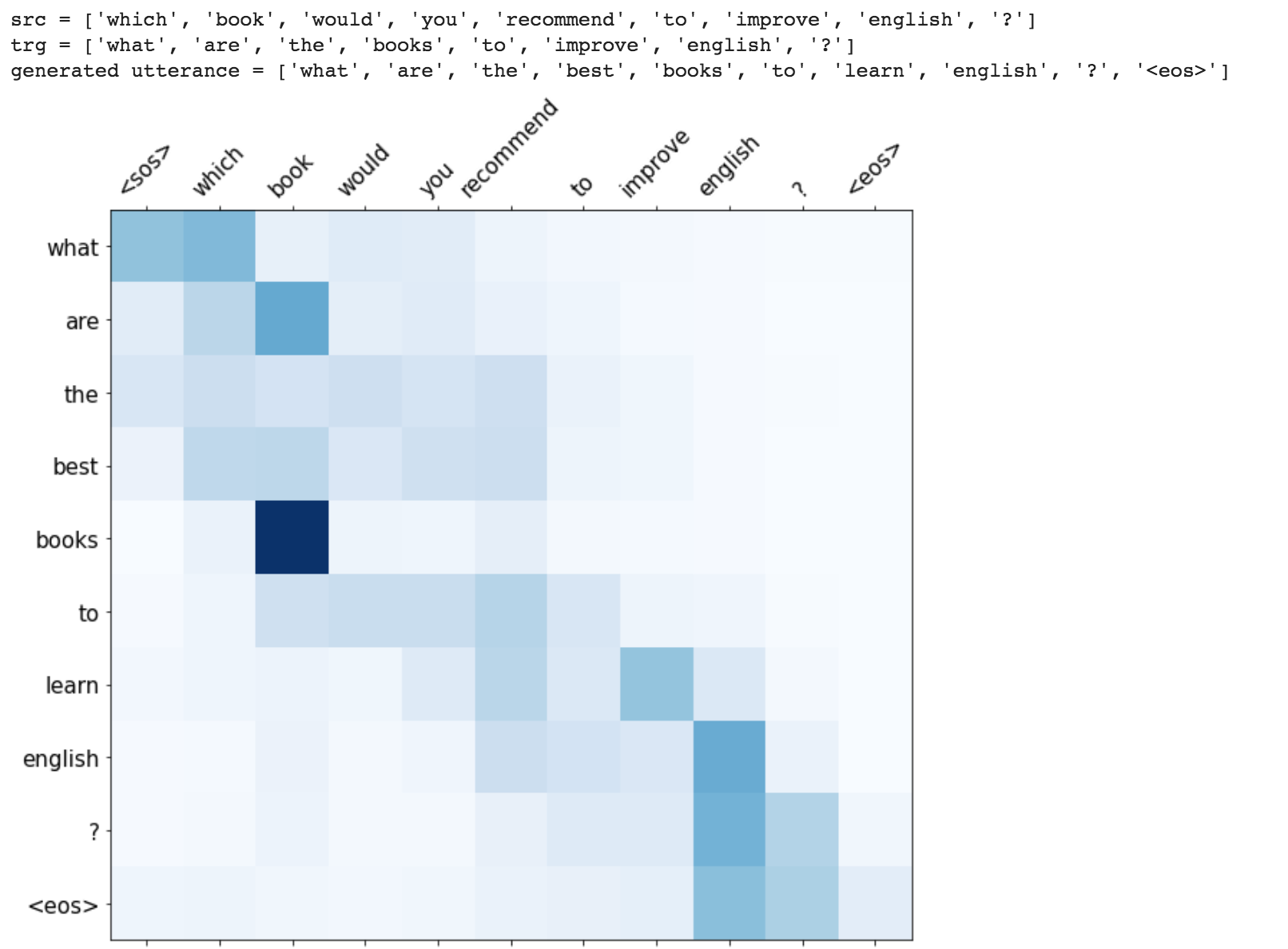
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
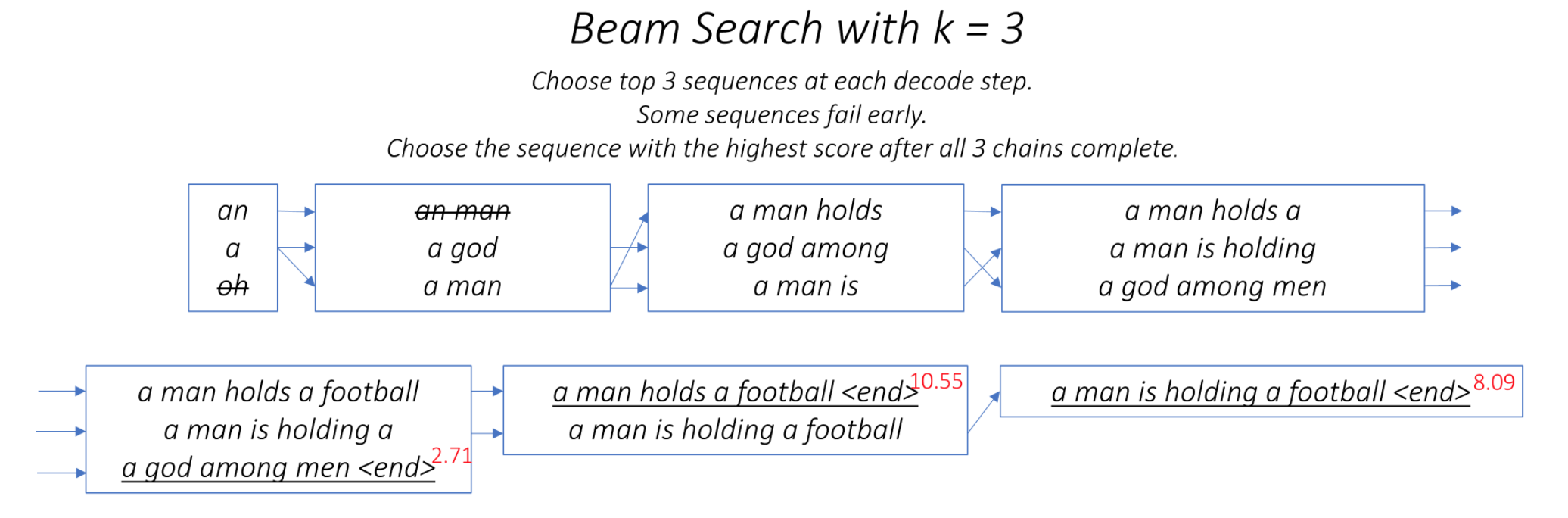
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

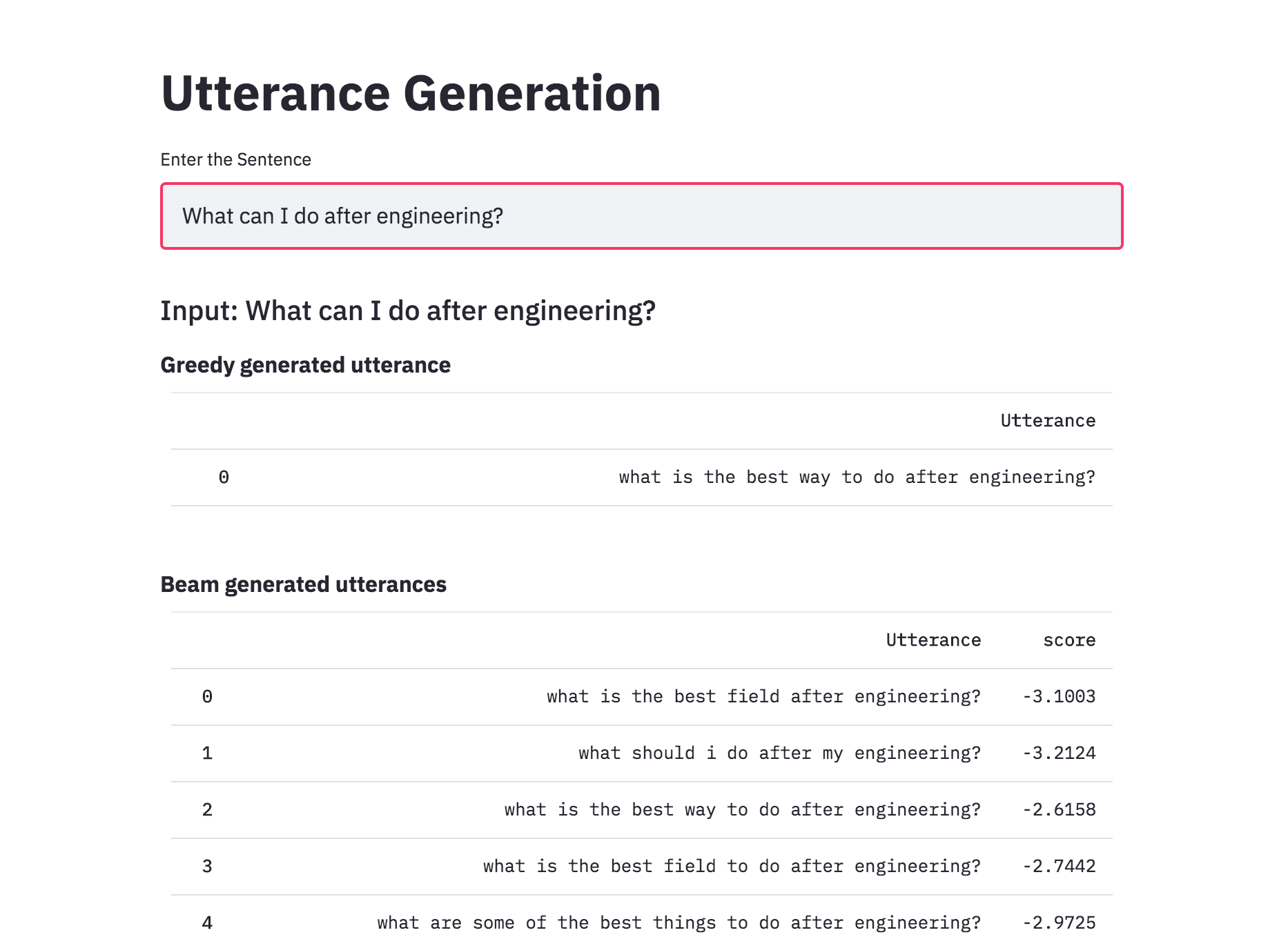
Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
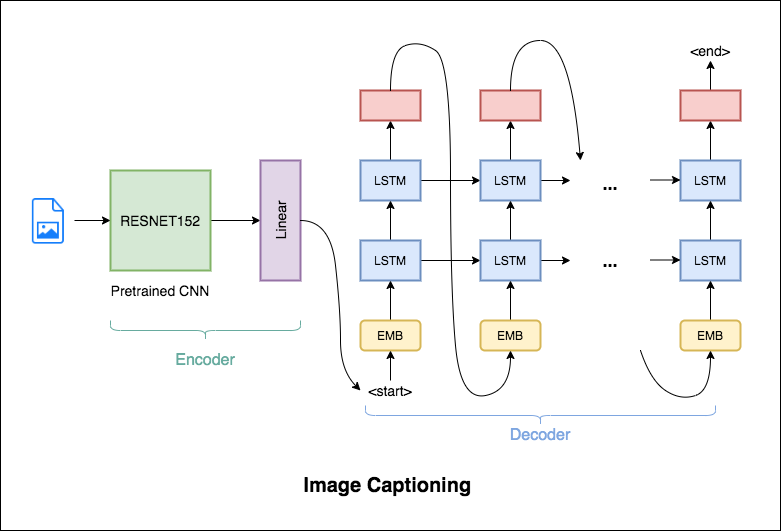
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
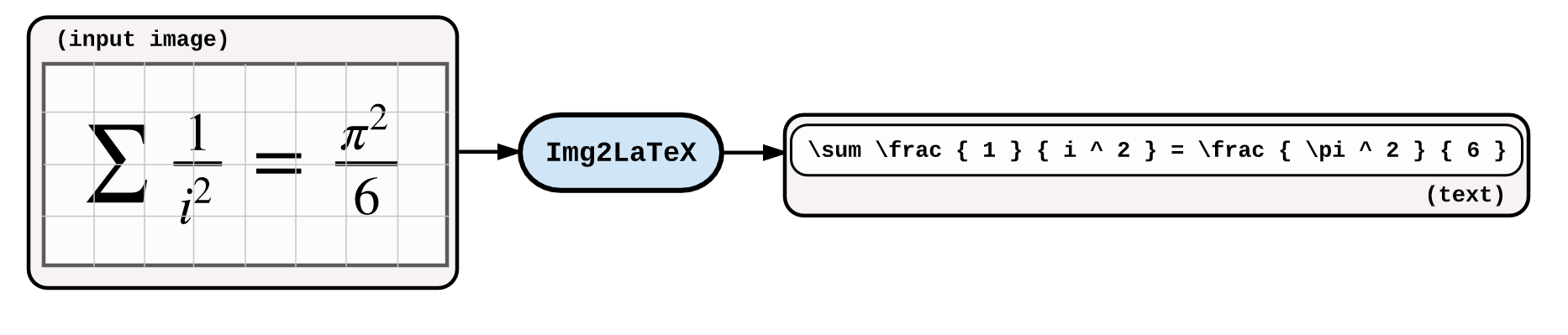
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
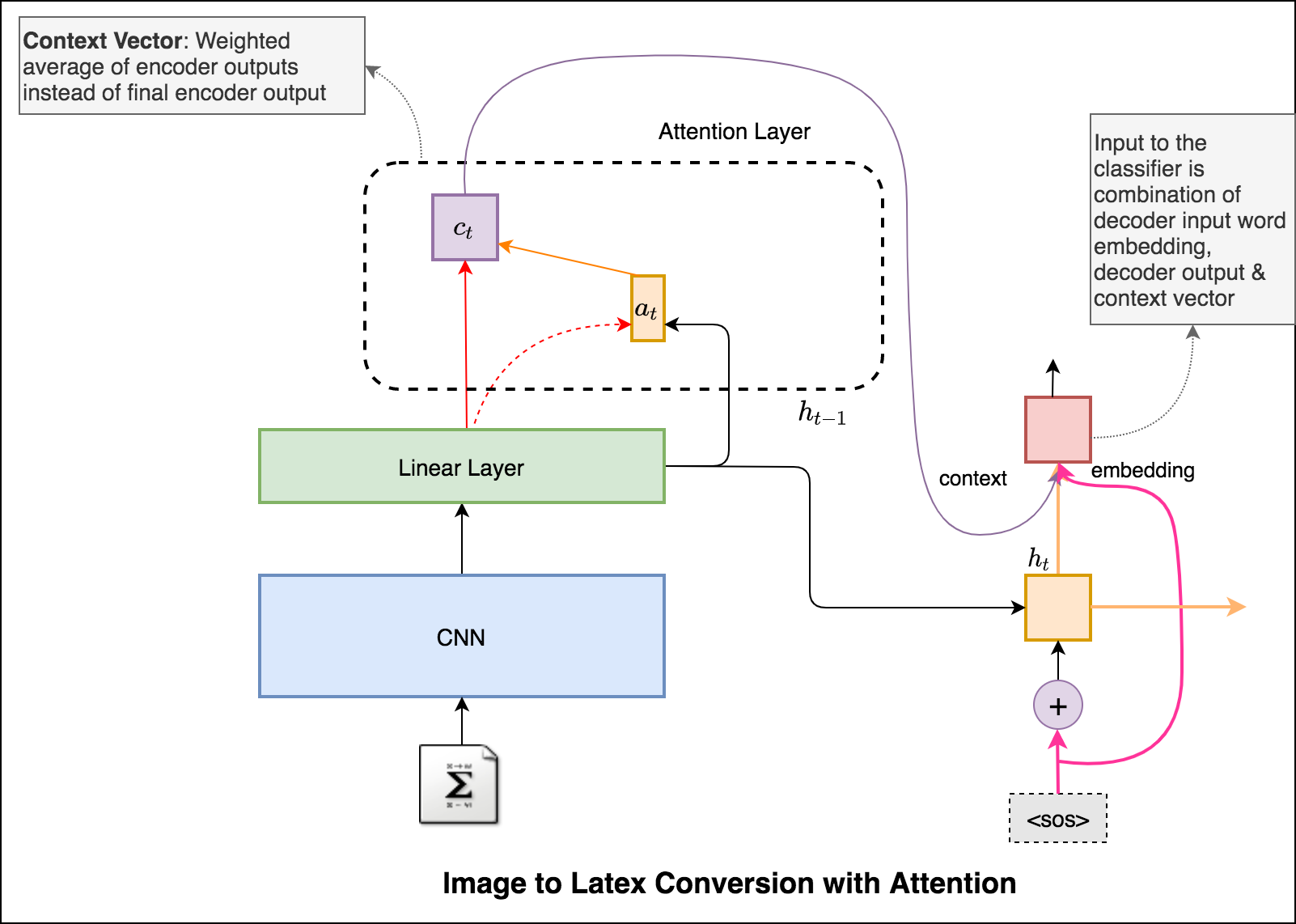
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

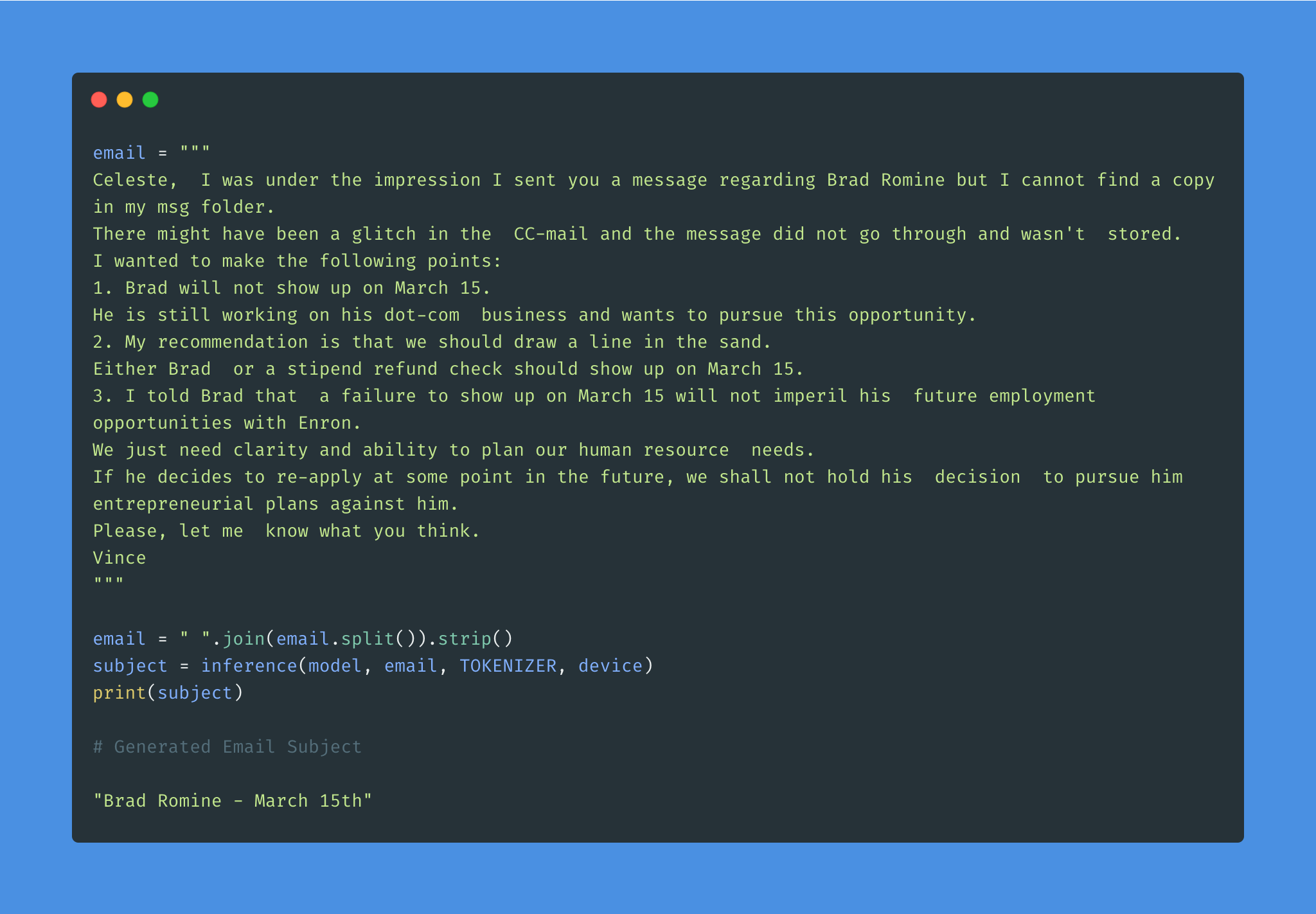
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
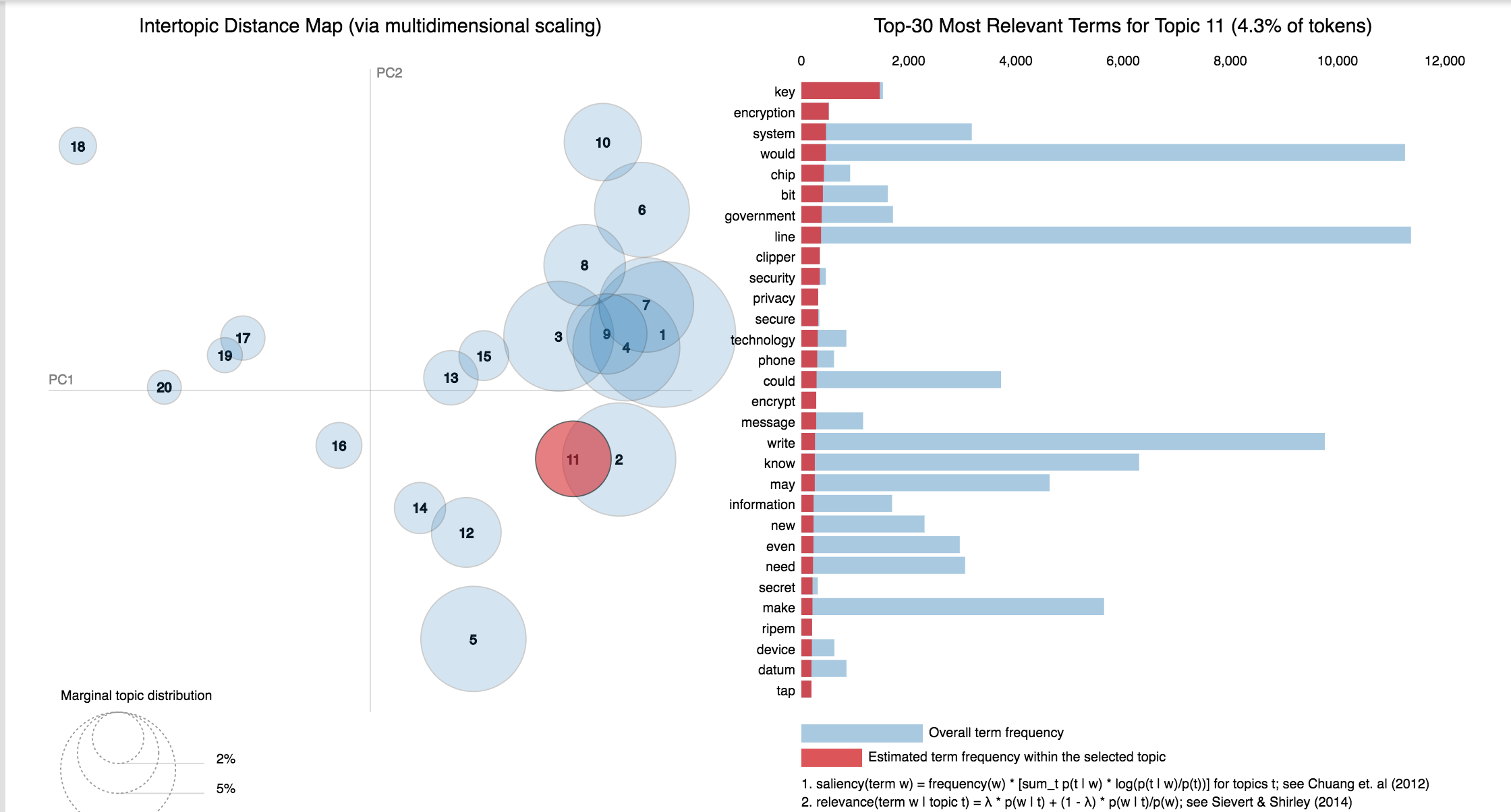
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
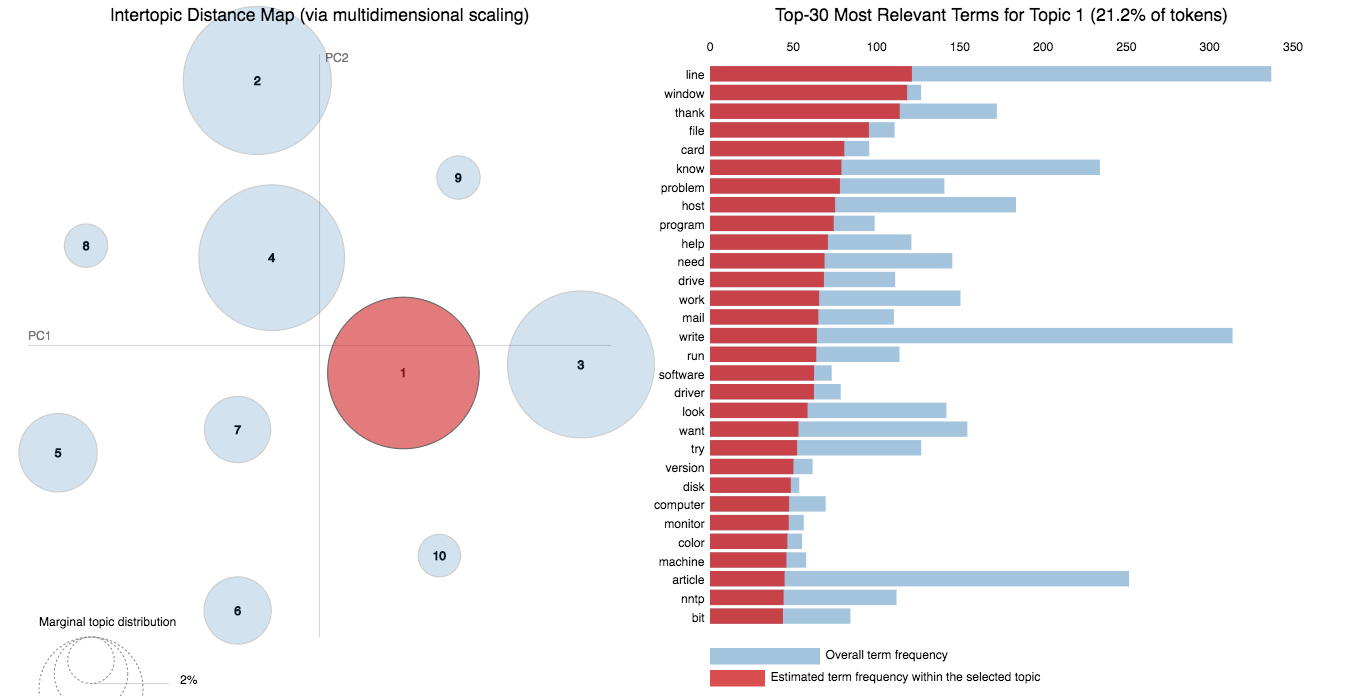
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
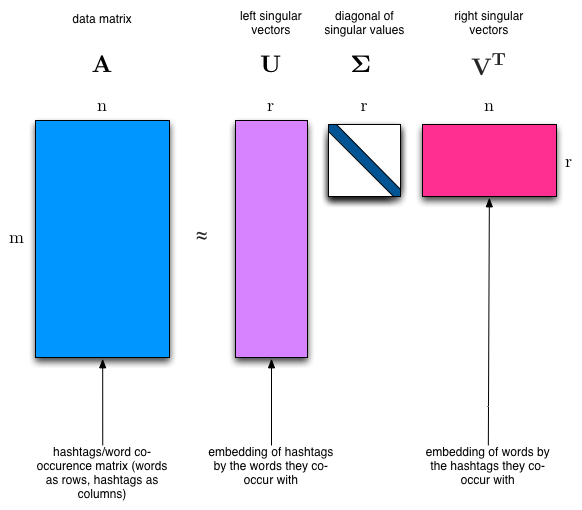
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
Примечания:
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
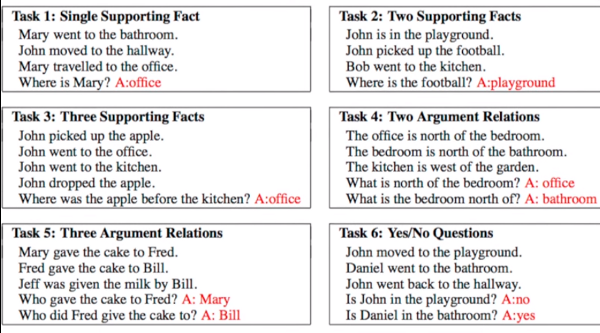
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
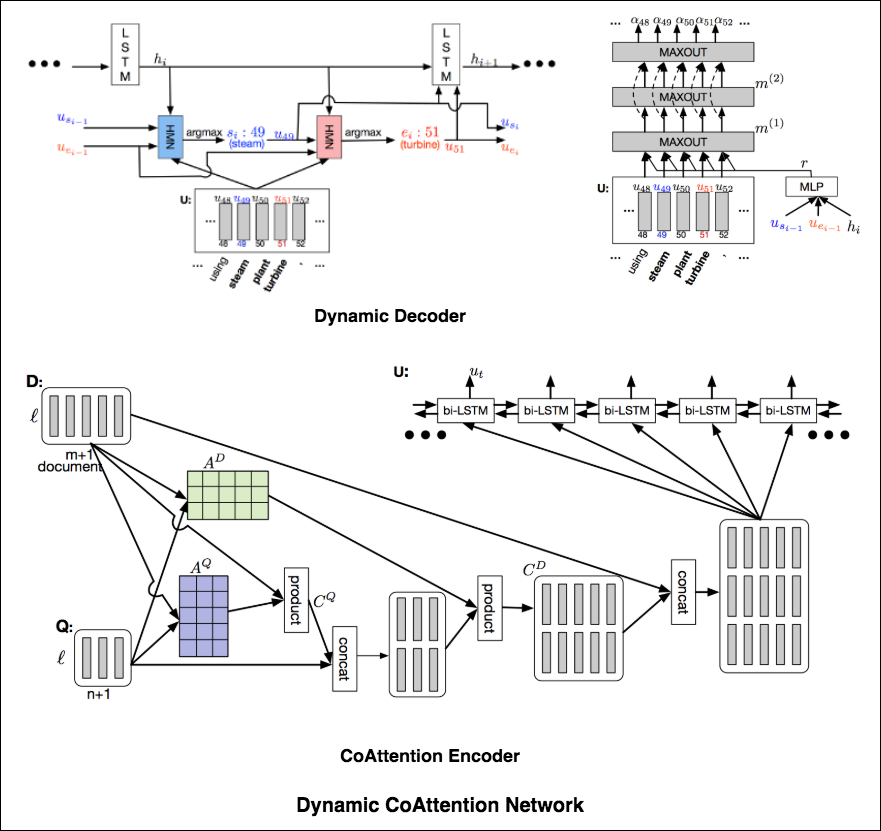
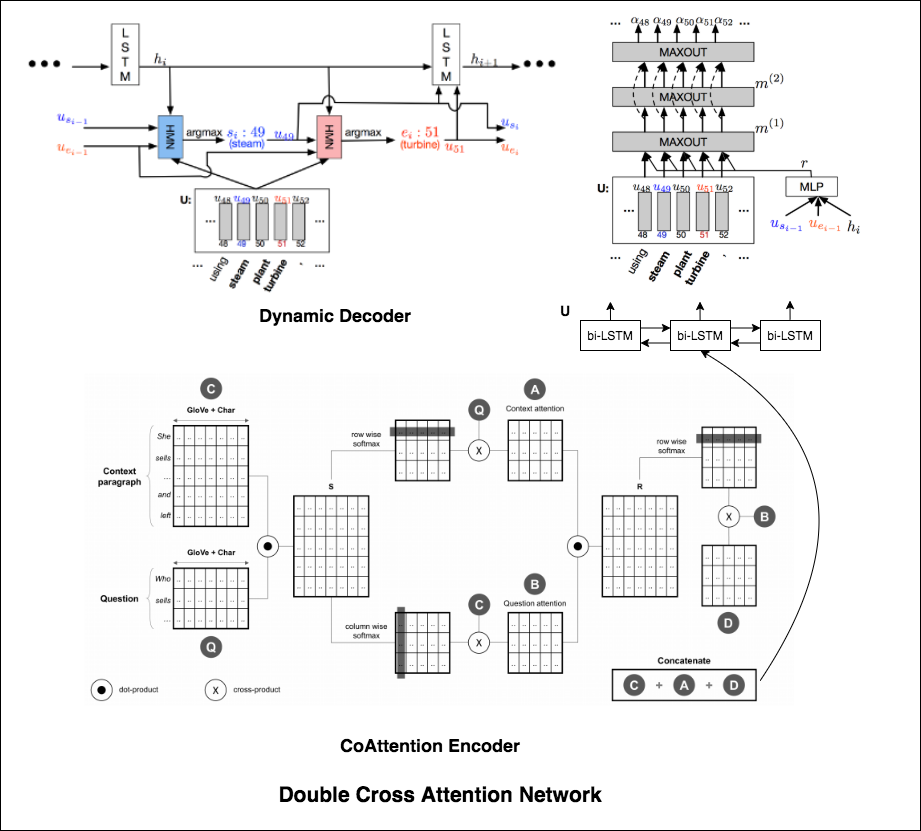
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
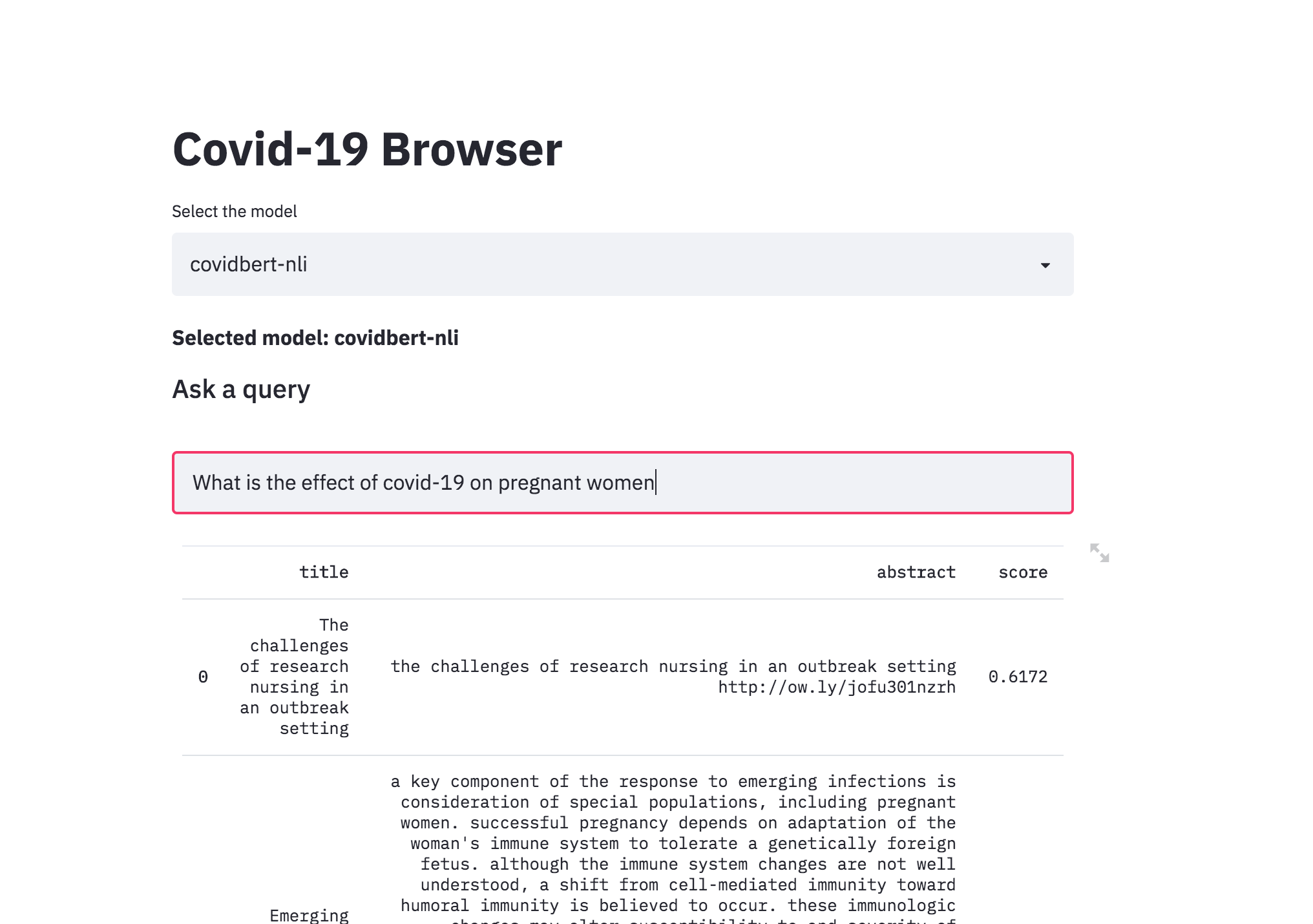
| Covid-19 Browser |
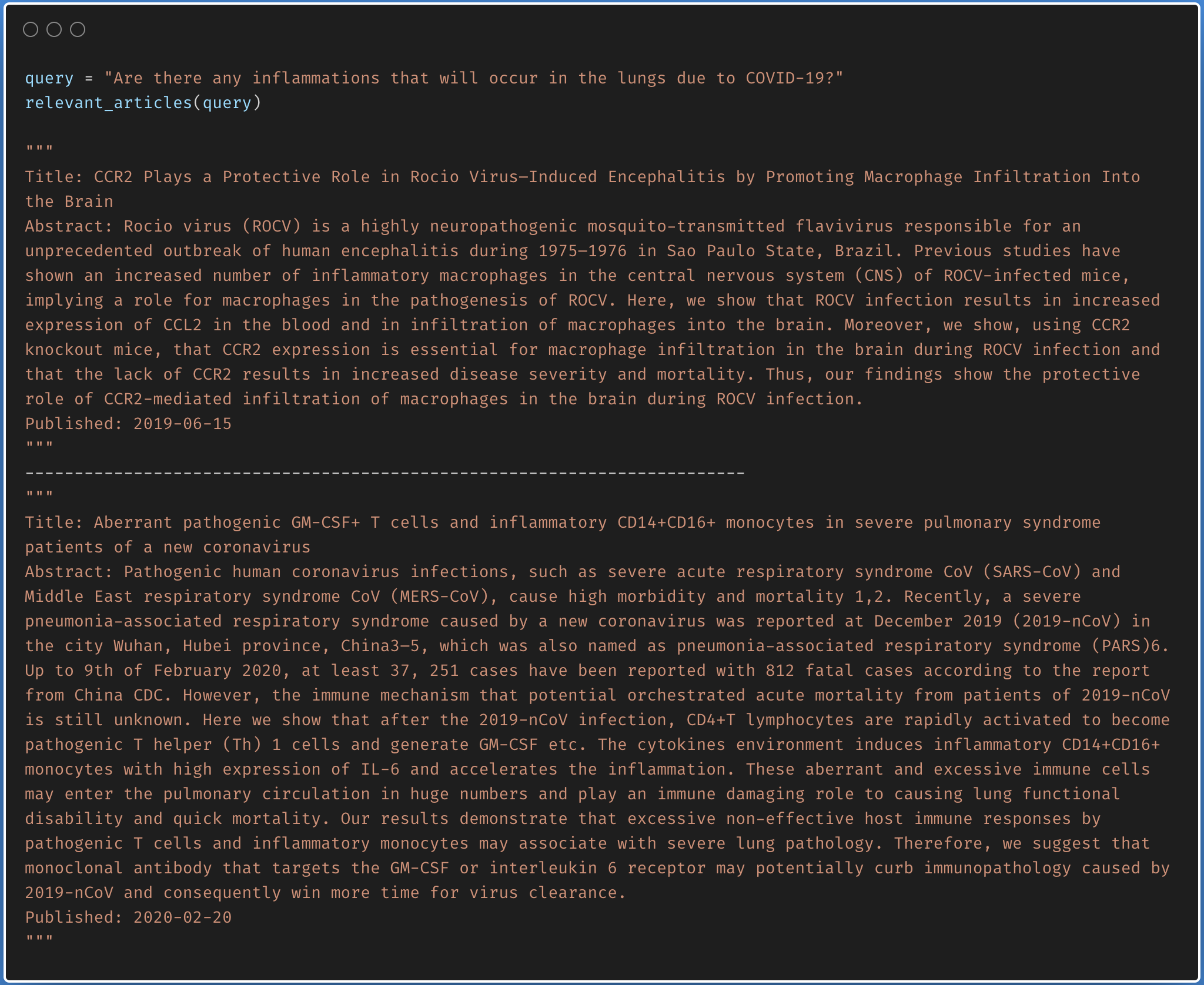
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
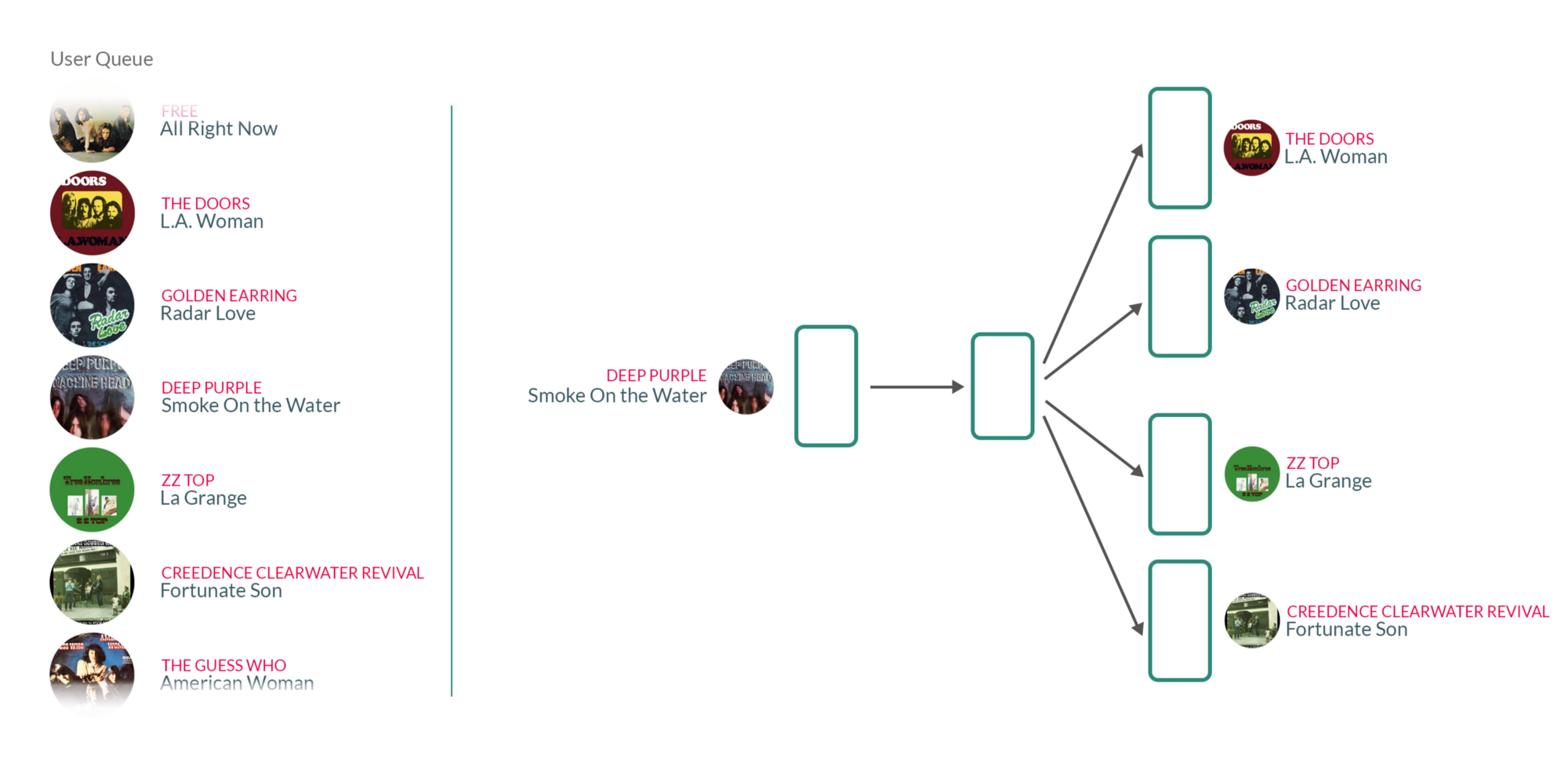
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


