100 Days of NLP
1.0.0

Es ist nichts Magie an Magie. Der Zauberer versteht nur etwas Einfaches, das für das ungeübte Publikum nicht einfach oder natürlich zu sein scheint. Sobald Sie gelernt haben, wie man eine Karte hält, während Sie Ihre Hand leer aussehen lassen, müssen Sie auch nur vor Ihnen üben. Sie können „Magie machen“. - Jeffrey Friedl im Buch Mastering reguläre Ausdrücke
Hinweis: Bitte geben Sie ein Problem für Vorschläge, Korrekturen und Feedback an.
Die meisten Code -Beispiele werden mit Jupyter -Notizbüchern (mit Colab) durchgeführt. So kann jeder Code unabhängig ausgeführt werden.
Die folgenden Themen wurden untersucht:
Hinweis: Der Schwierigkeitsgrad wurde nach meinem Verständnis zugewiesen.
| Tokenisierung | Worteinbettungen - Word2Vec | Worteinbettungen - Handschuh | Worteinbettungen - Elmo |
| RNN, LSTM, Gru | Verpackung gepackte Sequenzen | Aufmerksamkeitsmechanismus - Luong | Aufmerksamkeitsmechanismus - Bahdanau |
| Zeigernetzwerk | Transformator | GPT-2 | Bert |
| Themenmodellierung - LDA | Hauptkomponentenanalyse (PCA) | Naive Bayes | Datenvergrößerung |
| Satzeinbettungen |
Der Prozess der Konvertierung von Textdaten in Token ist einer der wichtigsten Schritt in NLP. Die Tokenisierung mit den folgenden Methoden wurde untersucht:
Eine Worteinbettung ist eine erlernte Darstellung für Text, bei der Wörter mit der gleichen Bedeutung eine ähnliche Darstellung haben. Es ist dieser Ansatz zur Darstellung von Wörtern und Dokumenten, die als einer der wichtigsten Durchbrüche des tiefen Lernens bei Problemen mit der Verarbeitung natürlicher Sprache angesehen werden können.

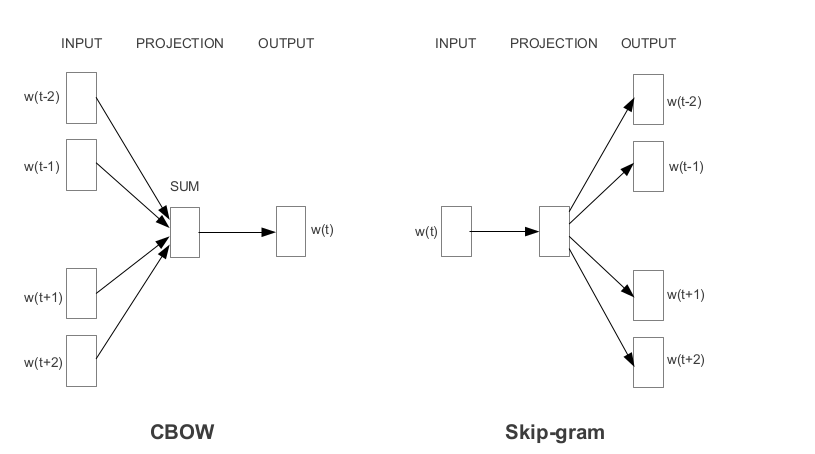
Word2VEC ist eines der beliebtesten, vorbereiteten Worteinbettungen, die von Google entwickelt wurden. Abhängig von der Art und Weise, wie die Einbettungen gelernt werden, wird Word2VEC in zwei Ansätze eingeteilt:
Handschuh ist eine weitere häufig verwendete Methode zur Erlangung von Vorausbettungen. Handschuh zielt darauf ab, zwei Ziele zu erreichen:
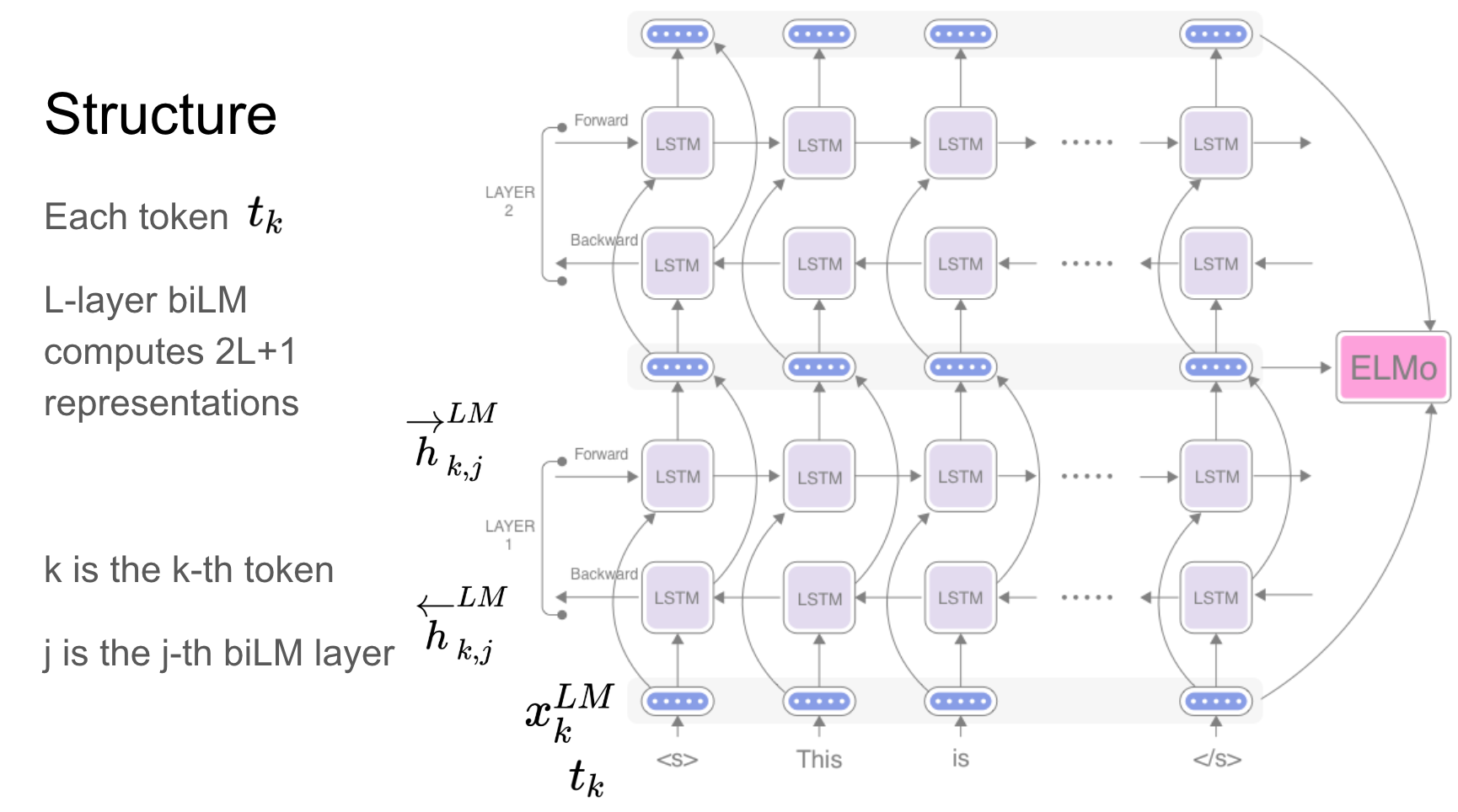
Elmo ist eine tiefe kontextualisierte Wortrepräsentation, die modelliert:
Diese Wortvektoren sind erlernte Funktionen der internen Zustände eines tiefen bidirektionalen Sprachmodells (BILM), das auf einem großen Textkorpus vorgebracht ist.
Wiederkehrende Netzwerke - RNN, LSTM, Gru haben sich aufgrund ihrer Architektur als eine der wichtigsten Einheiten in NLP -Anwendungen erwiesen. Es gibt viele Probleme, bei denen die Sequenz -Natur in Erinnerung bleiben muss, um eine Emotion in der Szene vorherzusagen. Frühere Szenen müssen in Erinnerung bleiben.

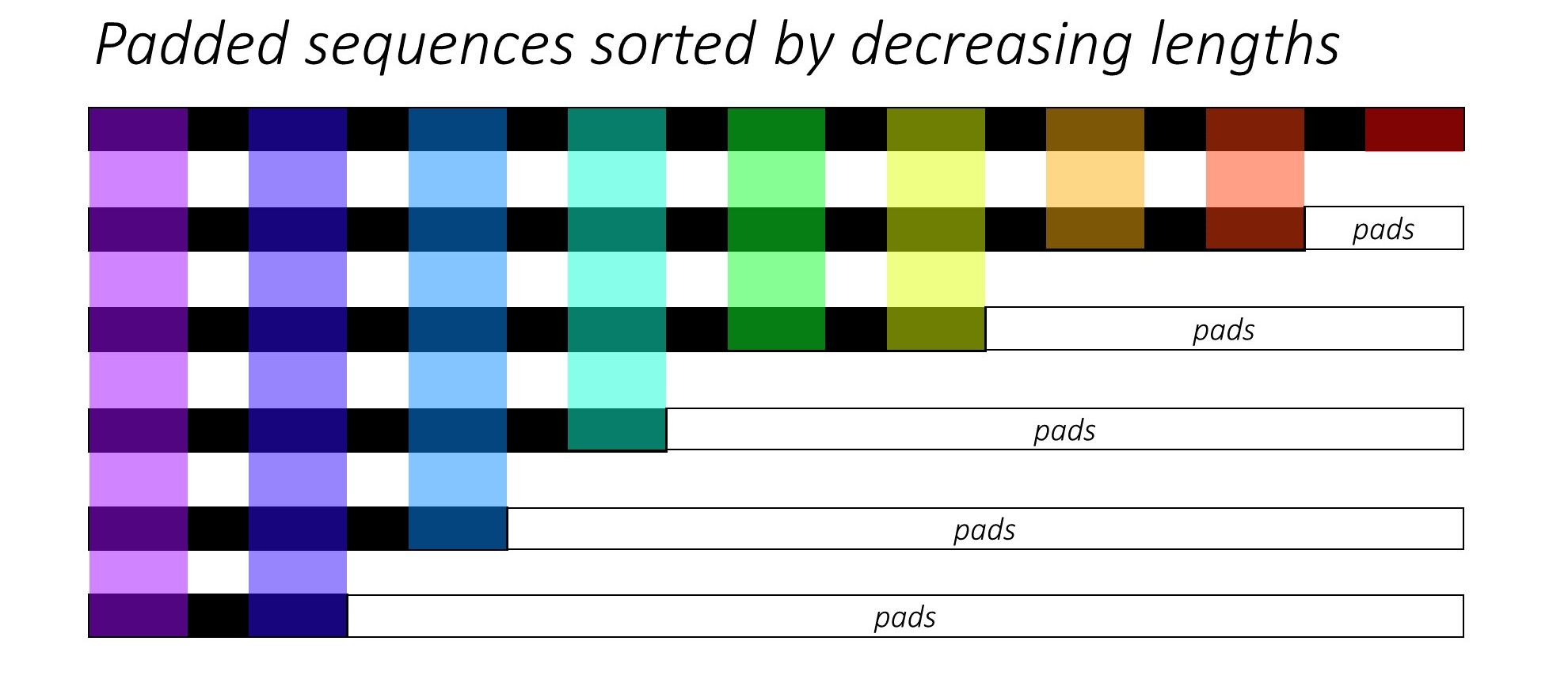
Beim Training von RNN (LSTM oder GRU oder Vanille-RNN) ist es schwierig, die Sequenzen mit variabler Länge zu beenden. Idealerweise padeln wir alle Sequenzen auf eine feste Länge und führen am Ende unnötige Berechnungen durch. Wie können wir das überwinden? Pytorch bietet die Funktionalität pack_padded_sequences .
Der Aufmerksamkeitsmechanismus wurde geboren, um sich lange Quellsätze in der neuronalen Maschinenübersetzung (NMT) auswendig zu merken. Anstatt einen einzelnen Kontextvektor aus dem letzten versteckten Zustand des Encoders zu erstellen, wird die Aufmerksamkeit verwendet, um sich mehr auf die relevanten Teile der Eingabe zu konzentrieren, während er einen Satz entschlüsselt. Der Kontextvektor wird erstellt, indem Encoder -Ausgänge und die current output des Decoder -RNN genommen werden.

Die Aufmerksamkeitsbewertung kann auf drei Arten berechnet werden. dot , general und concat .
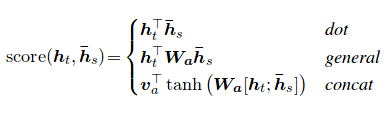
Der Hauptunterschied zwischen Bahdanau und Luong ist die Art und Weise, wie der Kontextvektor geschaffen wird. Der Kontextvektor wird erstellt, indem Encoder -Ausgänge und der previous hidden state des Decoder RNN eingenommen werden. Wo ist in der Aufmerksamkeit des Kontextvektors durch die Einnahme von Encoder -Ausgängen und der current hidden state des Decoder -RNN erstellt.
Sobald der Kontext berechnet wurde, wird er mit der Einbettung von Decoder -Eingaben kombiniert und als Eingabe in Decoder RNN gefüttert.

Die Aufmerksamkeit von Bahdanau wird auch als additive Aufmerksamkeit bezeichnet.
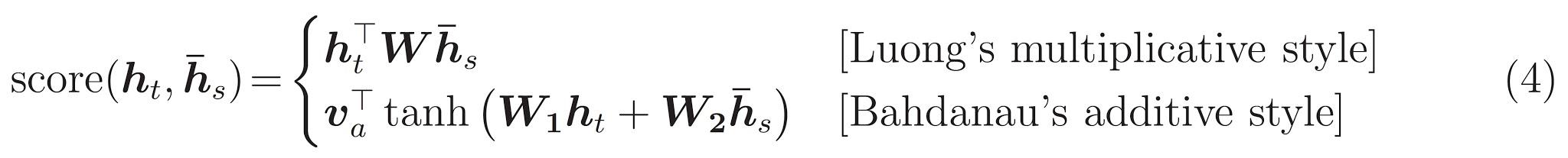
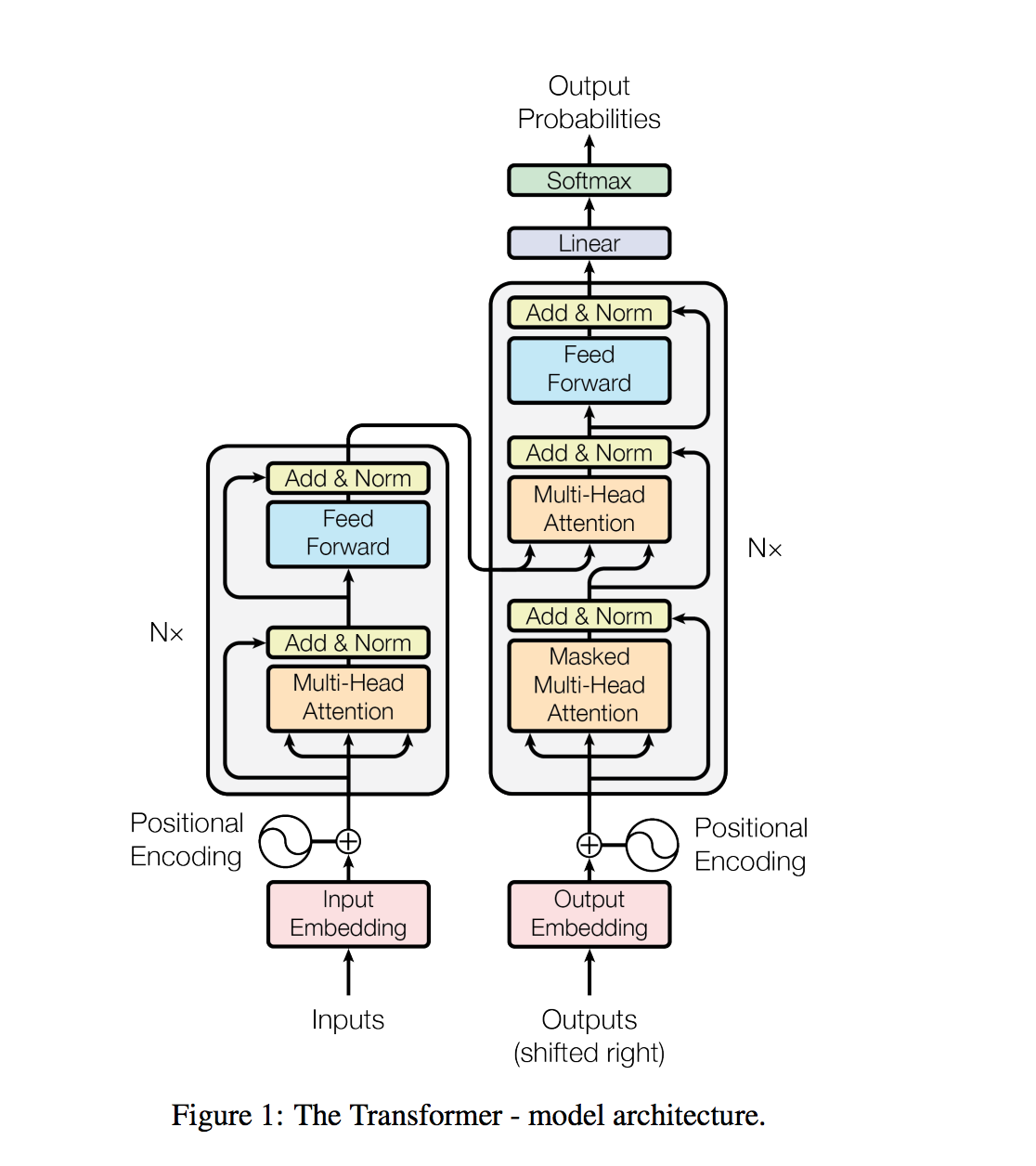
Der Transformator, eine Modellarchitektur, meidet das Wiederauftreten und stützt sich stattdessen vollständig auf einen Aufmerksamkeitsmechanismus, um globale Abhängigkeiten zwischen Eingabe und Ausgabe zu ziehen.
Aufgaben der natürlichen Sprachverarbeitung, wie die Beantwortung von Fragen, die maschinelle Übersetzung, das Leseverständnis und die Zusammenfassung, werden typischerweise mit überwachtem Lernen auf TASKSPecific -Datensätzen angegangen. Wir zeigen, dass Sprachmodelle diese Aufgaben ohne explizite Aufsicht lernen, wenn sie auf einem neuen Datensatz von Millionen von Webseiten namens WebText trainiert werden. Unser größtes Modell, GPT-2, ist ein 1,5B-Parametertransformator, der auf 7 von 8 getesteten Sprachmodellierungsdatensätzen in einer Null-Shot-Einstellung auf dem neuesten Stand der Technik erzielt wird, aber dennoch dem WebText unterenthält. Die Proben aus dem Modell spiegeln diese Verbesserungen wider und enthalten kohärente Textabsätze. Diese Ergebnisse deuten auf einen vielversprechenden Weg zum Aufbau von Sprachverarbeitungssystemen hin, die lernen, Aufgaben aus ihren natürlich vorkommenden Demonstrationen auszuführen.
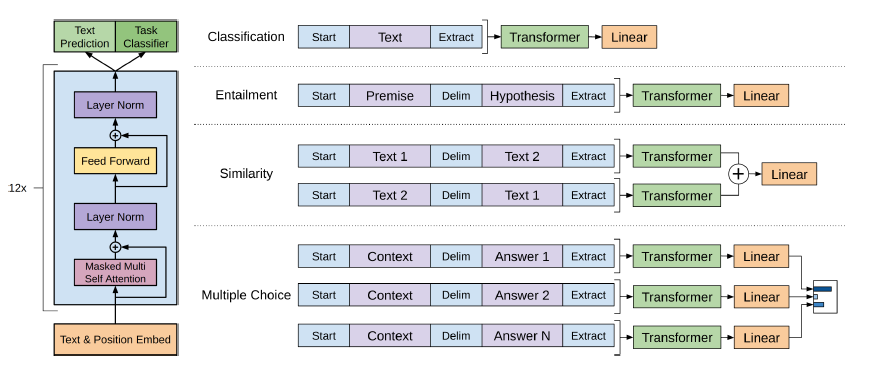
Das GPT-2 verwendet eine 12-layer-Decoder-Transformatorarchitektur.
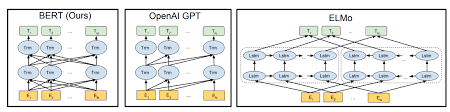
Bert verwendet die Transformer -Architektur für Codierung von Sätzen.
Die Ausgabe von Zeigernetzen ist diskret und entspricht Positionen in der Eingangssequenz
Die Anzahl der Zielklassen in jedem Schritt des Ausgangs hängt von der Länge des Eingangs ab, was variabel ist.
Es unterscheidet sich von den vorherigen Aufmerksamkeitsversuchen darin, anstatt die Aufmerksamkeit für die Mischung versteckter Einheiten eines Encoders zu einem Kontextvektor bei jedem Decoder -Schritt zu verwenden, und es wird Aufmerksamkeit als Zeiger verwendet, um ein Mitglied der Eingabesequenz als Ausgabe auszuwählen.

Eine der Hauptanwendungen der Verarbeitung natürlicher Sprache besteht darin, automatisch zu extrahieren, welche Themen Menschen aus großen Textvolumina diskutieren. Einige Beispiele für großen Text können Feeds von sozialen Medien, Kundenbewertungen von Hotels, Filmen usw., Benutzerfeedbacks, Nachrichten, E-Mails von Kundenbeschwerden usw. sein.
Zu wissen, wovon Menschen ihre Probleme und Meinungen sprechen und sie verstehen, ist für Unternehmen, Administratoren und politische Kampagnen von großer Bedeutung. Und es ist wirklich schwer, so große Bände manuell durchzulesen und die Themen zu erstellen.
Daher ist ein automatisierter Algorithmus erforderlich, der die Textdokumente durchlesen und die besprochenen Themen automatisch ausgeben kann.
In diesem Notebook werden wir ein echtes Beispiel für den 20 Newsgroups -Datensatz nennen und LDA verwenden, um die natürlich diskutierten Themen zu extrahieren.
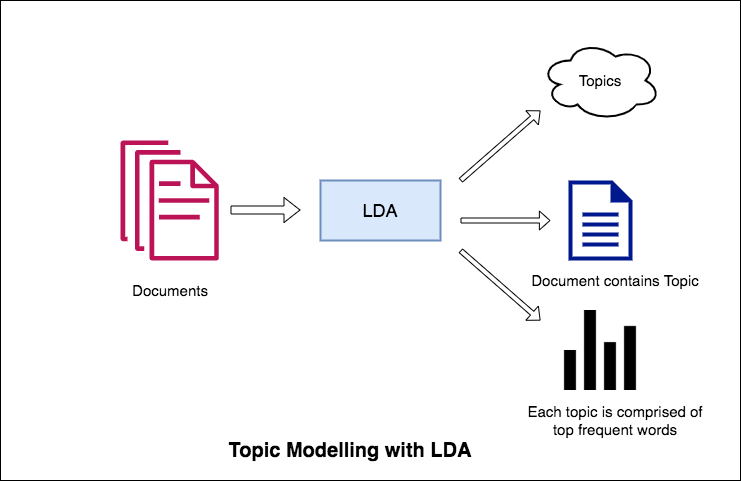
Der Ansatz der LDA zur Themenmodellierung ist, dass jedes Dokument als eine Sammlung von Themen in einem bestimmten Verhältnis betrachtet wird. Und jedes Thema als Sammlung von Schlüsselwörtern wieder in einem bestimmten Verhältnis.
Sobald Sie den Algorithmus mit der Anzahl der Themen zur Verfügung gestellt haben, ordnen Sie die Themenverteilung innerhalb der Dokumente und Schlüsselwörter innerhalb der Themen um, um eine gute Komposition der Verteilung der Themenschlüsselwörter zu erhalten.
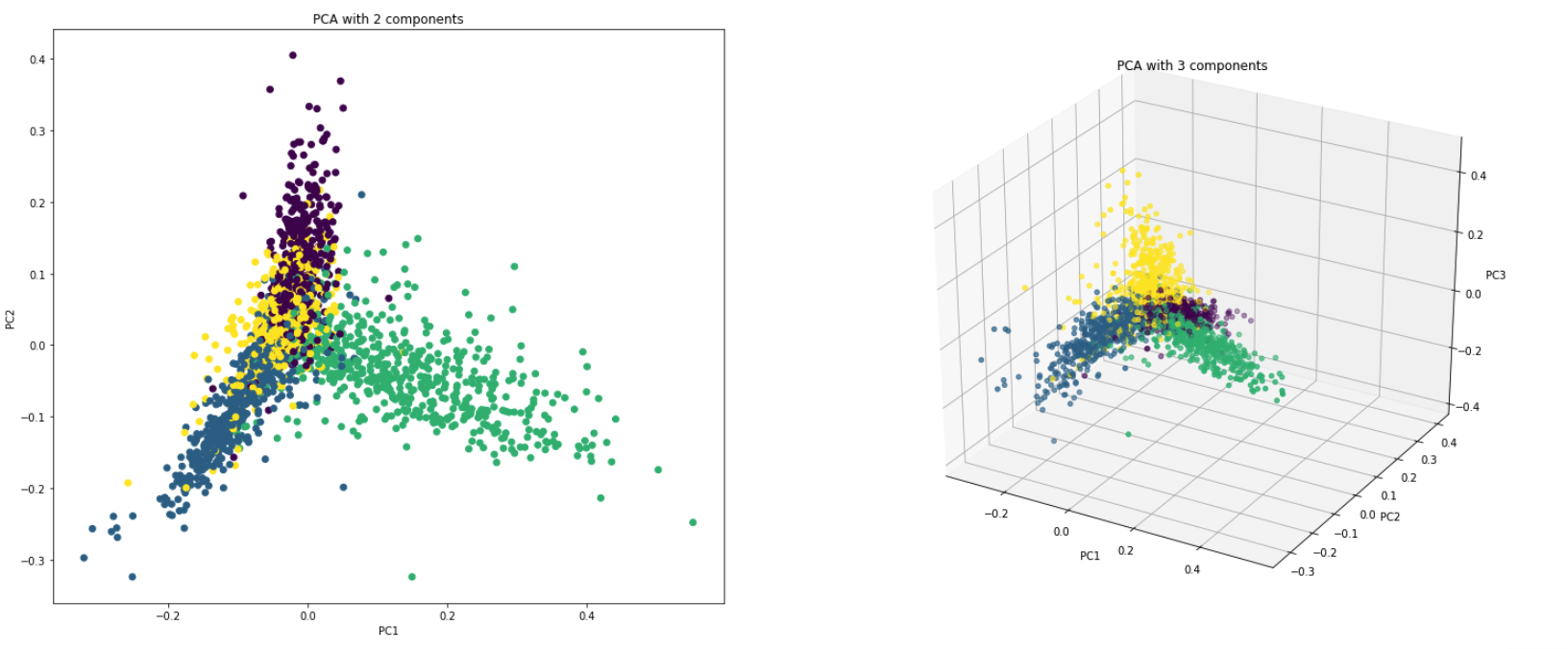
PCA ist im Grunde eine Dimensionalitätsreduktionstechnik, die die Spalten eines Datensatzes in eine neue Set -Funktion verwandelt. Dies geschieht, indem es einen neuen Satz von Anweisungen (wie X- und Y -Achsen) finden, die die maximale Variabilität in den Daten erklären. Diese neuen Systemkoordinatenachsen werden als Hauptkomponenten (PCS) bezeichnet.
Praktisch wird PCA aus zwei Gründen verwendet:
Dimensionality Reduction : Die über eine Vielzahl von Spalten verteilten Informationen werden in Hauptkomponenten (PC) umgewandelt, so dass die ersten PCs einen großen Teil der Gesamtinformation (Varianz) erklären können. Diese PCs können als erklärende Variablen in maschinellen Lernmodellen verwendet werden.
Visualize Data : Die Visualisierung der Trennung von Klassen (oder Clustern) ist für Daten mit mehr als 3 Dimensionen (Merkmalen) schwierig. Bei den ersten beiden PCs selbst ist es normalerweise möglich, eine klare Trennung zu erkennen.
Ein naiver Bayes -Klassifizierer ist ein probabilistisches maschinelles Lernmodell, das für die Klassifizierungsaufgabe verwendet wird. Der Kern des Klassifikators basiert auf dem Bayes -Theorem.
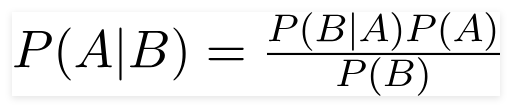
Mit Bayes Theorem können wir die Wahrscheinlichkeit eines Ereignisses feststellen, da B aufgetreten ist. Hier ist B der Beweis und A ist die Hypothese. Die hier getroffene Annahme ist, dass die Prädiktoren/Merkmale unabhängig sind. Das Vorhandensein eines bestimmten Merkmals wirkt sich nicht auf das andere aus. Daher heißt es naiv.
Arten von naiven Bayes -Klassifikator :
Multinomial Naive Bayes : Dies wird hauptsächlich verwendet, wenn die Variablen diskret sind (wie Wörter). Die vom Klassifikator verwendeten Merkmale/Prädiktoren sind die Häufigkeit der im Dokument vorhandenen Wörter.
Gaussian Naive Bayes : Wenn die Prädiktoren einen kontinuierlichen Wert aufnehmen und nicht diskret sind, gehen wir davon aus, dass diese Werte aus einer Gaußschen Verteilung abgetastet werden.
Bernoulli Naive Bayes : Dies ähnelt dem multinomialen naiven Bayes, aber die Prädiktoren sind booleale Variablen. Die Parameter, die wir verwenden, um die Klassenvariable vorherzusagen, werden nur mit Ja oder Nein bewertet, beispielsweise wenn ein Wort im Text auftritt oder nicht.
Unter Verwendung von 20NewsGroup -Datensatz wird der Naive Bayes -Algorithmus untersucht, um die Klassifizierung durchzuführen.
Die Datenvergrößerung mit den folgenden Techniken wird untersucht:

Eine neue Architektur namens Sbert wurde untersucht. Die siamesische Netzwerkarchitektur ermöglicht es, dass Vektoren mit fester Größe für Eingabesätze abgeleitet werden können. Unter Verwendung eines Ähnlichkeitsmaßes wie Cosinesimilarity oder Manhatten / euklidischer Entfernung können semantisch ähnliche Sätze gefunden werden.

| Stimmungsanalyse - IMDB | Stimmungsklassifizierung - Hinglish | Dokumentklassifizierung |
| Doppelte Fragepaarklassifizierung - Quora | POS -Tagging | Inferenz der natürlichen Sprache - SNLI |
| Klassifizierung giftiger Kommentare | Grammatikalisch korrekter Satz - Cola | Ner -Tagging |
Die Sentiment -Analyse bezieht sich auf die Verwendung von Verarbeitung natürlicher Sprache, Textanalyse, rechnerischer Linguistik und Biometrie, um affektive Zustände und subjektive Informationen systematisch zu identifizieren, zu extrahieren, zu quantifizieren und zu studieren.
Die folgenden Varizen wurden untersucht:
RNN wird zur Verarbeitung und Identifizierung des Gefühls verwendet.

Nach dem Versuch des grundlegenden RNN, der eine Test_ -Akz. weniger als 50% verleiht, wurden die folgenden Techniken experimentiert, und es wird eine test_accuracy über 88% erreicht.
Verwendete Techniken:

Die Aufmerksamkeit hilft dabei, sich auf die relevante Eingabe zu konzentrieren, wenn die Stimmung der Eingabe vorhersagt. Die Aufmerksamkeit von Bahdanau wurde verwendet, als die Ausgaben von LSTM und die Verkettung des endgültigen Vorwärts- und Rückwärtsversteckstatus zu verkettet wurden. Ohne die vorgebreiteten Worteinbettungen zu verwenden, wird eine Testgenauigkeit von 88% erreicht.
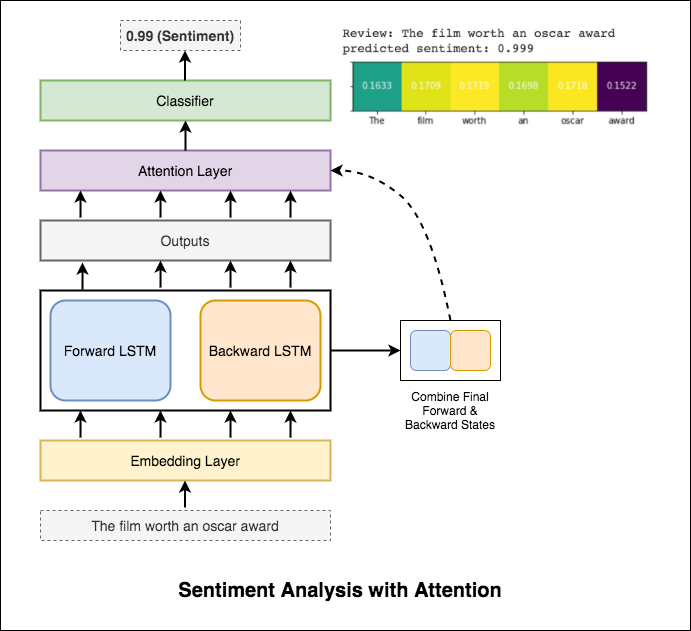
Bert erzielt neue Ergebnisse der Kunst bei elf natürlichen Sprachverarbeitungsaufgaben. Das Transferlernen in NLP hat nach der Freisetzung des Bert -Modells ausgelöst. Die Verwendung von Bert zum Durchführung der Stimmungsanalyse wird untersucht.

Das Mischen von Sprachen, auch als Code-Mixing bekannt, ist eine Norm in mehrsprachigen Gesellschaften. Mehrsprachige Menschen, die nicht einheimische englische Sprecher sind, neigen dazu, Mixe mit der phonetischen Typisierung von englischen Basis und der Insertion von Anglizismen in ihre Hauptsprache zu codieren.
Die Aufgabe besteht darin, das Gefühl eines bestimmten Code-Mixed-Tweet vorherzusagen. Die Stimmungsbezeichnungen sind positiv, negativ oder neutral, und die Code-Mischsprachen sind englischhindi. (Sentimix)
Die folgenden Varizen wurden untersucht:
Unter Verwendung des einfachen MLP -Modells wurde F1 score of 0.58 für Testdaten erreicht

Nach der Erforschung des grundlegenden MLP -Modells wurde das LSTM -Modell für die Vorhersage der Stimmung verwendet und der F1 -Score von 0.57 erreicht.

Die Ergebnisse waren tatsächlich geringer im Vergleich zu einem grundlegenden MLP -Modell. Einer der Gründe könnte sein, dass LSTM aufgrund der sehr unterschiedlichen Art der Code-Misch-Daten nicht in der Lage ist, die Beziehungen zwischen den Wörtern in einem Satz zu lernen.
Da die LSTM aufgrund der sehr unterschiedlichen Art der Code-Misch-Daten nicht in der Lage ist, die Beziehungen zwischen den Wörtern in einem Code-Mixed-Satz zu lernen, und keine vorgebauten Einbettungen verwendet werden, ist die F1-Punktzahl geringer.
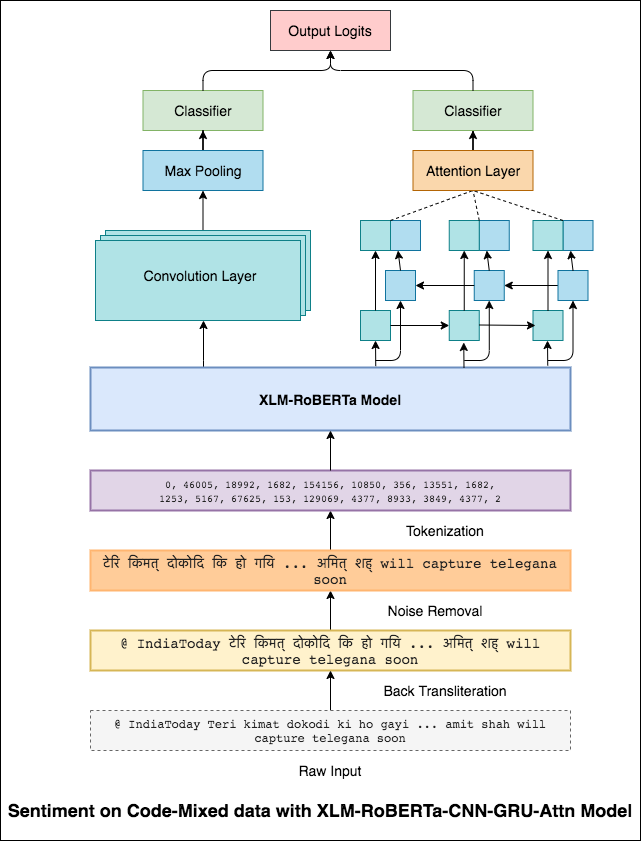
Um dieses Problem zu lindern, wird das XLM-Roberta-Modell (das auf 100 Sprachen vorgeschrieben wurde) verwendet, um den Satz zu codieren. Um das XLM-Roberta-Modell zu verwenden, muss der Satz in einer richtigen Sprache sein. Zuerst müssen die Hinglish -Wörter in die Hindi -Form (Devanagari) umgewandelt werden.
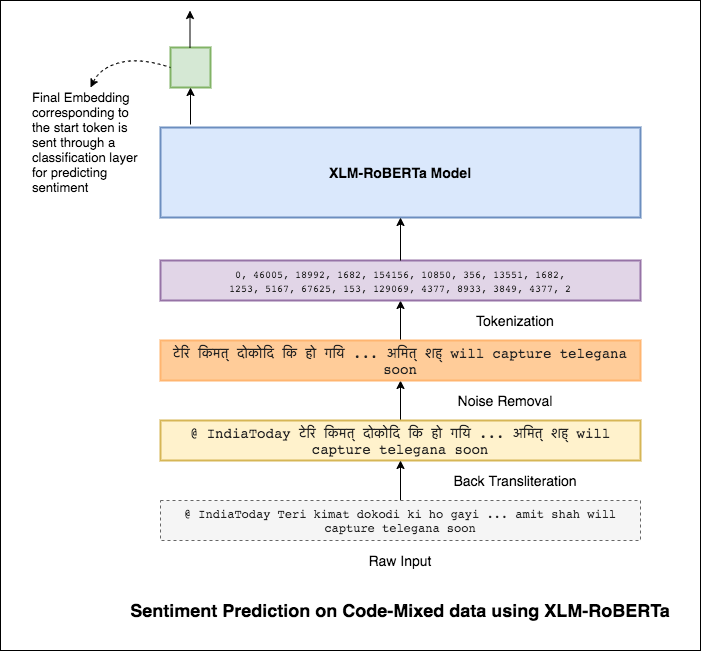
Ein F1 -Score von 0.59 wurde erreicht. Methoden, um dies zu verbessern, werden später untersucht.
Die endgültige Ausgabe aus dem XLM-Roberta-Modell wurde als Eingangsempfindungen zum bidirektionalen LSTM-Modell verwendet. Eine Aufmerksamkeitsschicht, die die Ausgänge aus der LSTM -Schicht nimmt, erzeugt eine gewichtete Darstellung des Eingangs, der dann einen Klassifikator zur Vorhersage des Satzes des Satzes durchgesetzt wird.

Ein F1 -Score von 0.64 wurde erreicht.
Auf die gleiche Weise, wie ein 3x3-Filter über einen Patch eines Bildes schauen kann, kann ein 1x2-Filter in einem Textstück über 2 aufeinanderfolgende Wörter schauen, dh ein BI-Gramm. In diesem CNN-Modell verwenden wir stattdessen mehrere Filter verschiedener Größen, die die BI-Gramm (ein 1x2-Filter), Tri-Grams (1x3-Filter) und/oder N-Gramm (1xn-Filter) im Text untersuchen.
Die Intuition hier ist, dass das Erscheinen bestimmter Bi-Gramm, Tri-Grams und N-Gramm innerhalb der Überprüfung ein guter Hinweis auf die endgültige Stimmung sein wird.
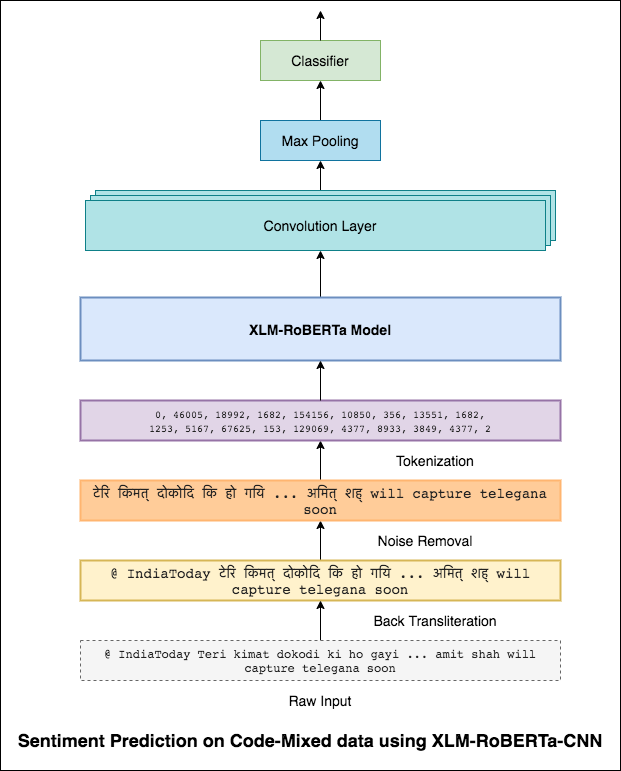
Ein F1 -Score von 0.69 wurde erreicht.
CNN erfasst die lokalen Abhängigkeiten, bei denen RNN die globalen Abhängigkeiten erfasst. Durch die Kombination beider können wir die Daten besser verstehen. Das Ensemblieren des CNN-Modells und des bidirektionalen Gru-Beeinträchtigungsmodells führt die anderen aus.
Ein F1 -Score von 0.71 wurde erreicht. (Top 5 in der Rangliste).
Die Kategorisierung der Dokumentenklassifizierung oder Dokumente ist ein Problem in der Bibliothekswissenschaft, Informationswissenschaft und Informatik. Die Aufgabe besteht darin, einem oder mehreren Klassen oder Kategorien ein Dokument zuzuweisen.
Die folgenden Varizen wurden untersucht:
Ein hierarchisches Aufmerksamkeitsnetzwerk (HAN) berücksichtigt die hierarchische Struktur von Dokumenten (Dokument - Sätze - Wörter) und enthält einen Aufmerksamkeitsmechanismus, der in der Lage ist, die wichtigsten Wörter und Sätze in einem Dokument zu finden, während der Kontext berücksichtigt wird.
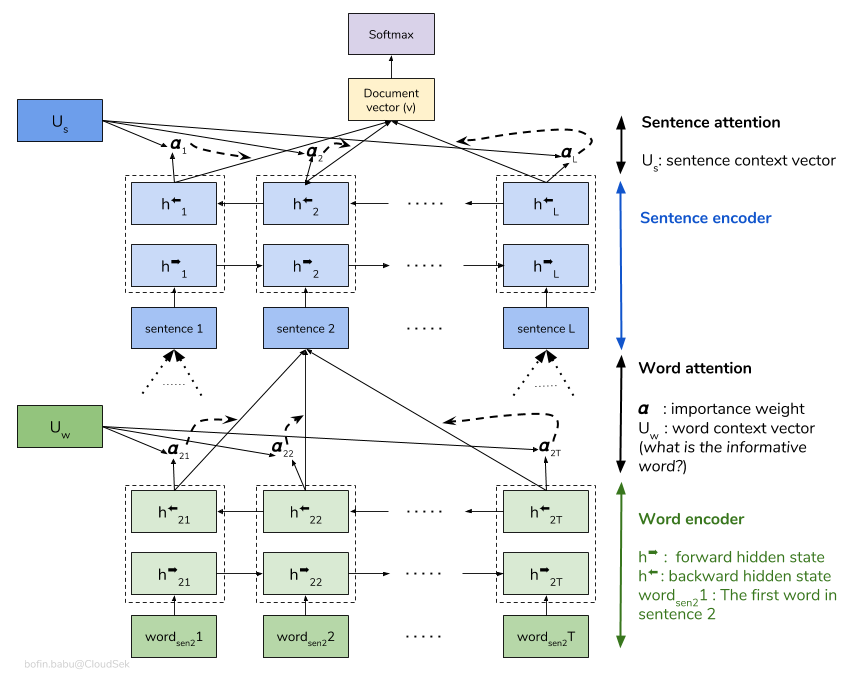
Das grundlegende Han -Modell ist schnell übertroffen. Um dies zu überwinden, werden Techniken wie Embedding Dropout und Locked Dropout untersucht. Es gibt noch eine weitere Technik namens Weight Dropout die nicht implementiert wird (lassen Sie mich wissen, ob es gute Ressourcen gibt, um dies zu implementieren). Anstelle einer zufälligen Initialisierung werden ebenfalls vorgeschaltete Wort- Glove verwendet. Da die Aufmerksamkeit auf Satzebene und Wortebene erfolgt, können wir visualisieren, welche Wörter in einem Satz wichtig sind und welche Sätze in einem Dokument wichtig sind.



QQP steht für Quora -Fragepaare. Das Ziel der Aufgabe ist für ein bestimmtes Paar von Fragen; Wir müssen herausfinden, ob diese Fragen einander semantisch ähnlich sind oder nicht.
Die folgenden Varizen wurden untersucht:
Der Algorithmus muss das Paar von Fragen als Eingabe annehmen und sollte ihre Ähnlichkeit ausgeben. Ein siamesisches Netzwerk wird verwendet. Ein Siamese neural network (manchmal als Doppel -neuronales Netzwerk bezeichnet) ist ein künstliches neuronales Netzwerk, das die same weights verwendet, während sie gleichzeitig an zwei verschiedenen Eingangsvektoren arbeiten, um vergleichbare Ausgangsvektoren zu berechnen.

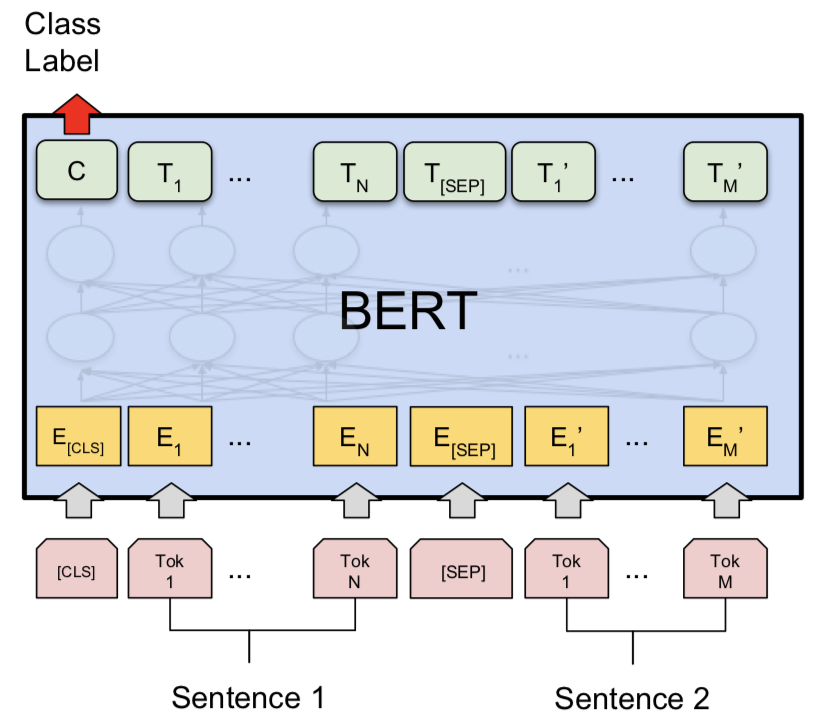
Nach dem Versuch des siamesischen Modells wurde Bert untersucht, um die Erkennung von Quora -doppelten Fragenpaaren durchzuführen. Bert nimmt die Frage 1 und Frage 2 als Eingabe von [SEP] -Token getrennt und die Klassifizierung wurde unter Verwendung der endgültigen Darstellung von [CLS] -Token durchgeführt.
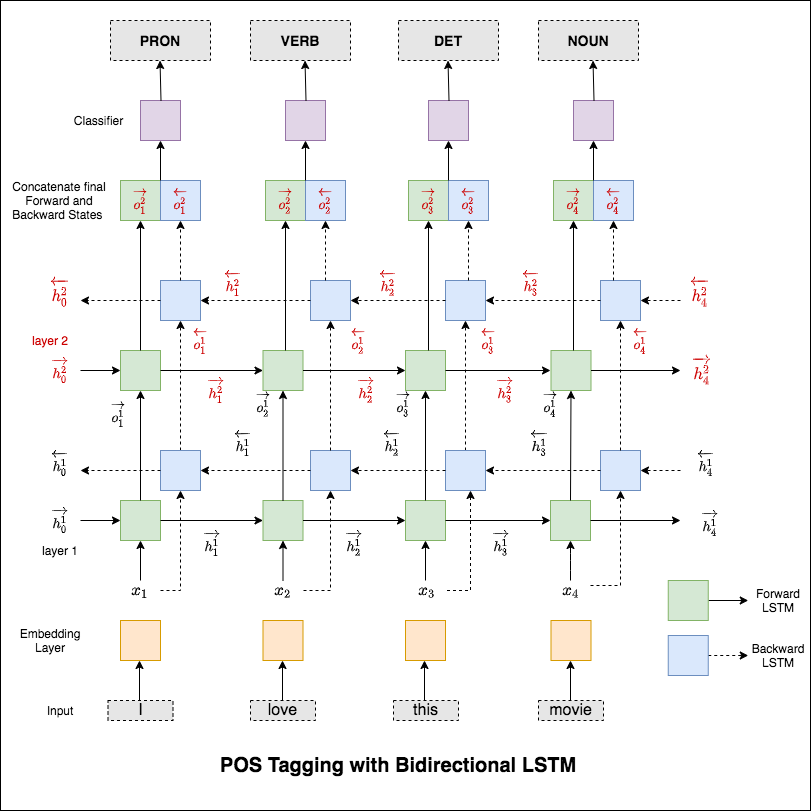
Teil des Sprachaussagens (POS) ist eine Aufgabe, jedes Wort in einem Satz mit seinem geeigneten Teil der Sprache zu kennzeichnen.
Die folgenden Varizen wurden untersucht:
Dieser Code deckt den grundlegenden Workflow ab. Wir erfahren, wie Sie Daten laden, Zug-/Test-/Validierungs -Spaltungen erstellen, ein Wortschatz erstellen, Daten Iteratoren erstellen, ein Modell definieren und das Tagging für Zug-/Evaluieren-/Testschleife (Laufzeit (Inferenz) implementieren.
Das verwendete Modell ist ein bidirektionales Multi-Layer-LSTM-Netzwerk
Nach dem Versuch des RNN -Ansatzes wird POS -Tagging mit transformatorischer Architektur untersucht. Da der Transformator sowohl Encoder als auch Decoder enthält, und für die Sequenz -Kennzeichnungsaufgabe ist nur Encoder ausreichend. Da die Daten mit 6 Schichten von Encoder gering sind, übertreiben Sie die Daten. Daher wurde ein 3-Layer-Transformator-Encodermodell verwendet.

Nach dem Ausprobieren von POS-Tagging mit Transformator-Encoder wird POS-Tagging mit vorgebildetem Bert-Modell genutzt. Es erreichte eine Testgenauigkeit von 91% .

Das Ziel der Inferenz für natürliche Sprache (NLI), eine weit verbreitete Aufgabe für natürliche Sprachverarbeitung, besteht darin, festzustellen, ob eine gegebene Aussage (eine Prämisse) semantisch eine andere gegebene Aussage (eine Hypothese) beinhaltet.
Die folgenden Varizen wurden untersucht:
Ein Grundmodell mit siamesischen Bilstm -Netzwerk ist implementiert
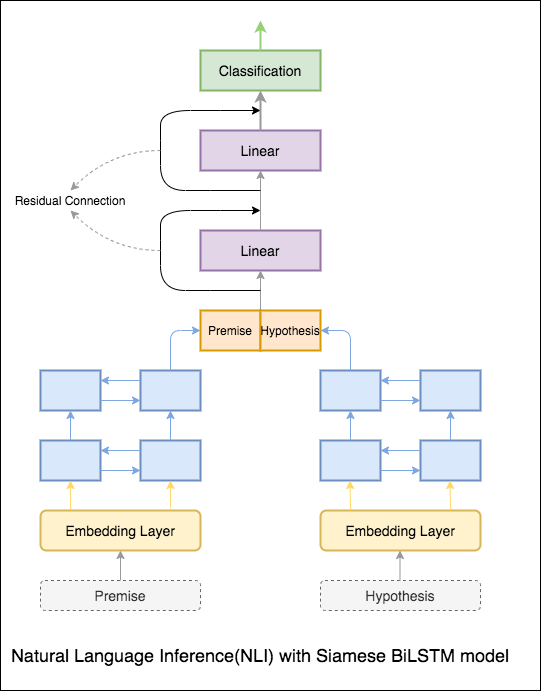
Dies kann als Basislinien-Setup behandelt werden. Eine Testgenauigkeit von 76.84% wurde erreicht.
Im vorherigen Notizbuch haben die endgültigen verborgenen Prämisse und Hypothese als Darstellungen von LSTM. Anstatt die endgültigen versteckten Zustände zu nehmen, wird die Aufmerksamkeit über alle Eingangs -Token berechnet und ein endgültig gewichteter Vektor wird als Darstellung von Prämisse und Hypothese angenommen.
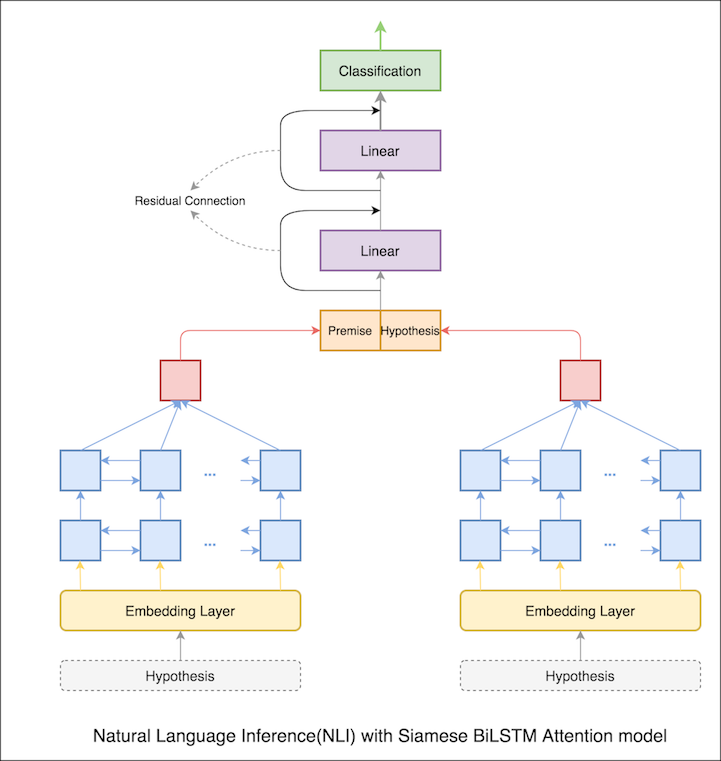
Die Testgenauigkeit stieg von 76.84% auf 79.51% .
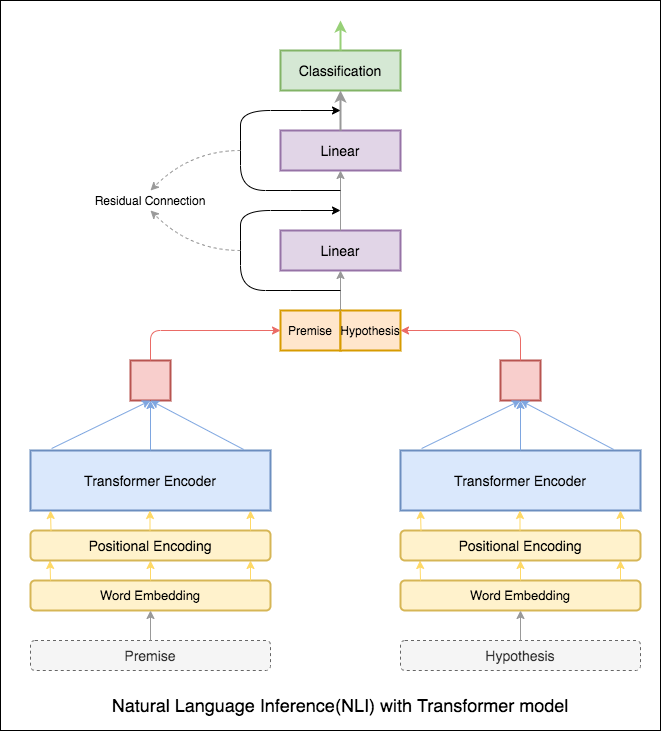
Transformator -Encoder wurde verwendet, um die Prämisse und Hypothese zu codieren. Sobald der Satz durch den Encoder weitergegeben ist, wird die Summe aller Token als endgültige Darstellung angesehen (andere Varianten können untersucht werden). Die Modellgenauigkeit ist im Vergleich zu RNN -Varianten geringer.
NLI mit Bert -Basismodell wurde untersucht. Bert übernimmt die Prämisse und die Hypothese als Eingaben, die durch [SEP] -Token getrennt sind, und die Klassifizierung wurde unter Verwendung der endgültigen Darstellung von [CLS] -Token durchgeführt.
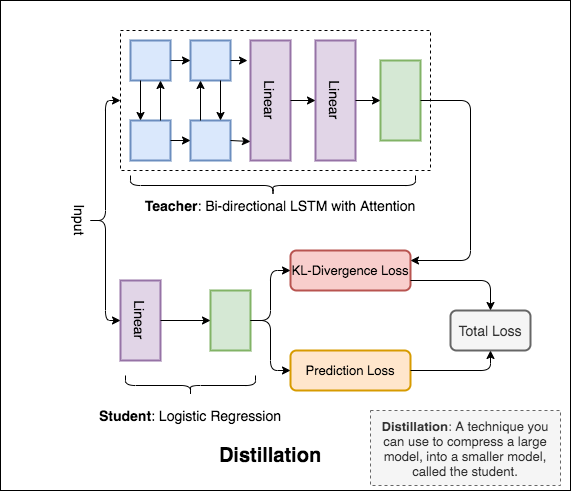
Distillation : Eine Technik, mit der Sie ein großes Modell, das als teacher bezeichnet wird, in ein kleineres Modell, das student genannt wird, komprimiert werden. Im folgenden Schüler werden Lehrermodelle verwendet, um die Destillation auf NLI durchzuführen.
Es kann schwierig sein, Dinge zu diskutieren, die Ihnen wichtig sind. Die Bedrohung durch Missbrauch und Belästigung online bedeutet, dass viele Menschen aufhören, sich selbst auszudrücken und aufzugeben, um verschiedene Meinungen zu suchen. Plattformen haben Schwierigkeiten, Gespräche effektiv zu erleichtern, und führen viele Communitys dazu, Benutzerkommentare einzuschränken oder vollständig zu schließen.
Sie erhalten eine große Anzahl von Wikipedia -Kommentaren, die von menschlichen Bewertern für giftiges Verhalten gekennzeichnet wurden. Die Arten von Toxizität sind:
Die folgenden Varizen wurden untersucht:
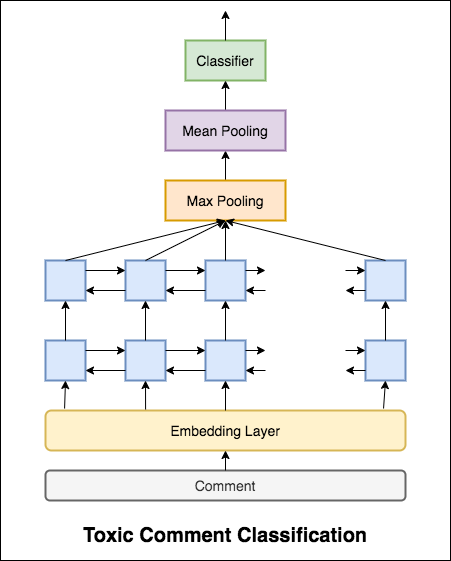
Das verwendete Modell ist ein bidirektionales Gru-Netzwerk.
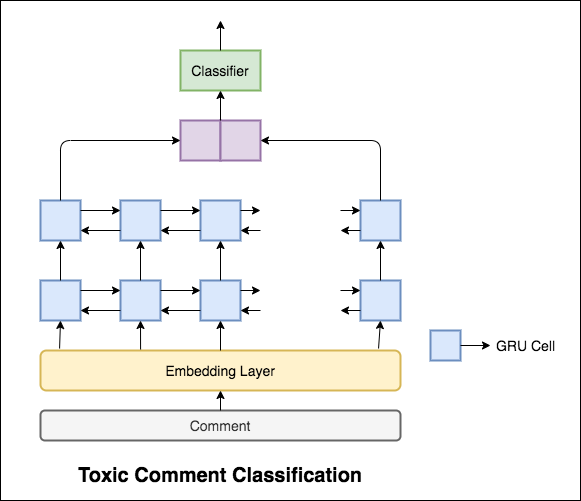
Eine Testgenauigkeit von 99.42% wurde erreicht. Da 90% der Daten nicht in eine der Toxizität markiert sind, ergibt die ledigliche Vorhersage aller Daten als ungiftiges Modell ein genaues Modell von 90%. Genauigkeit ist also keine zuverlässige Metrik. Eine andere metrische ROC AUC wurde implementiert.
Mit Categorical Cross Entropy als Verlust wird der ROC_auc -Score von 0.5 erreicht. Durch Ändern des Verlustes auf Binary Cross Entropy und das Modifizieren des Modells durch Hinzufügen von Poolingschichten (max, Mittelwert) verbesserte sich der ROC_auc -Score auf 0.9873 .
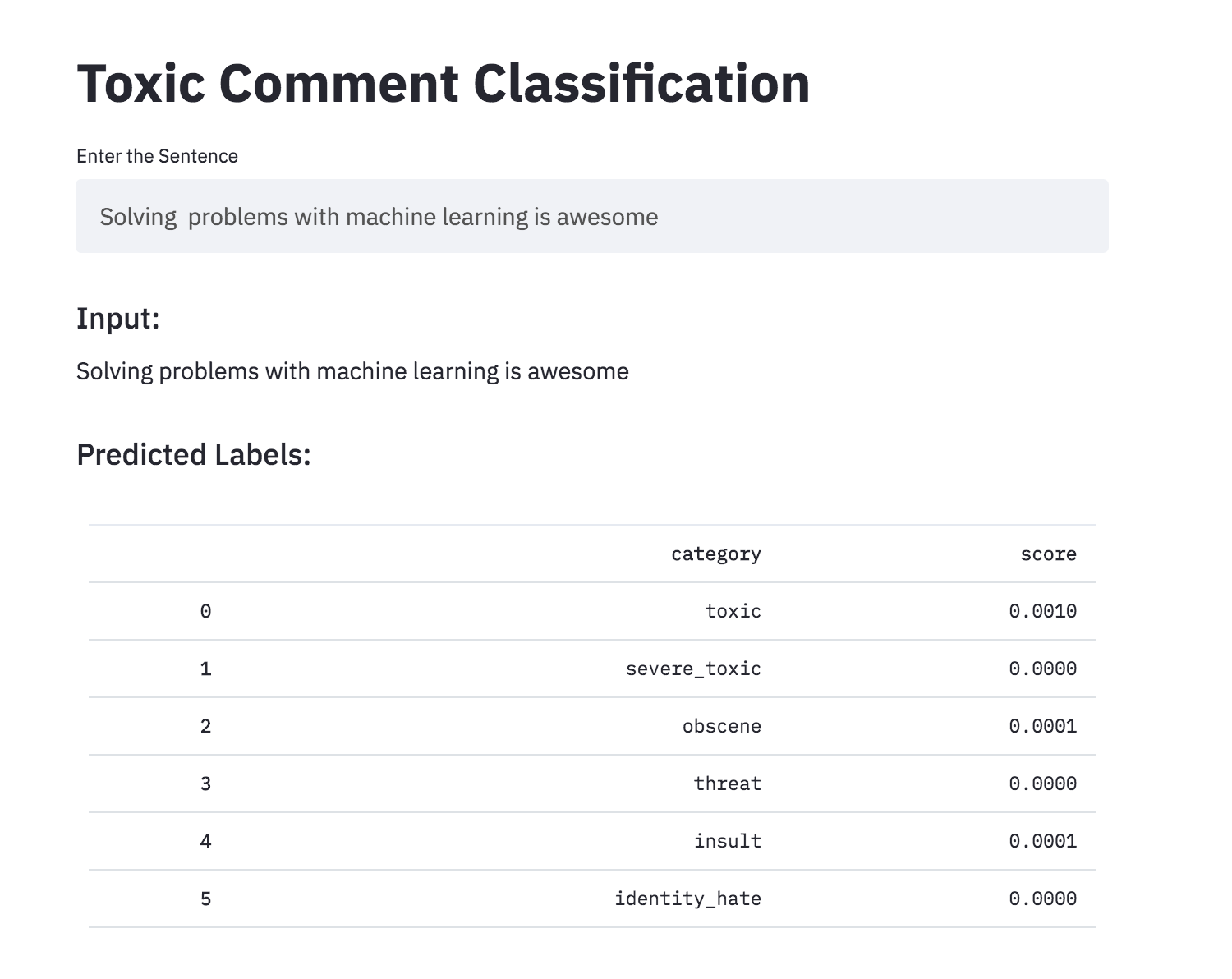
Umgewandelte die giftige Kommentierungsklassifizierung mit Streamlit in eine App. Das vorgebildete Modell ist ab sofort verfügbar.
Können künstliche neuronale Netze die Fähigkeit haben, die grammatikalische Akzeptanz eines Urteils zu beurteilen? Um diese Aufgabe zu untersuchen, wird der Corpus of sprachliche Akzeptanz (COLA) verwendet. Cola ist eine Reihe von Sätzen, die als grammatikalisch korrekt oder falsch bezeichnet werden.
Die folgenden Varizen wurden untersucht:
Bert erzielt neue Ergebnisse der Kunst bei elf natürlichen Sprachverarbeitungsaufgaben. Das Transferlernen in NLP hat nach der Freisetzung des Bert -Modells ausgelöst. In diesem Notebook werden wir untersuchen, wie Bert zur Klassifizierung verwendet wird, ob ein Satz grammatikalisch korrekt ist oder nicht, oder nicht die COLA -Datensatz verwendet.
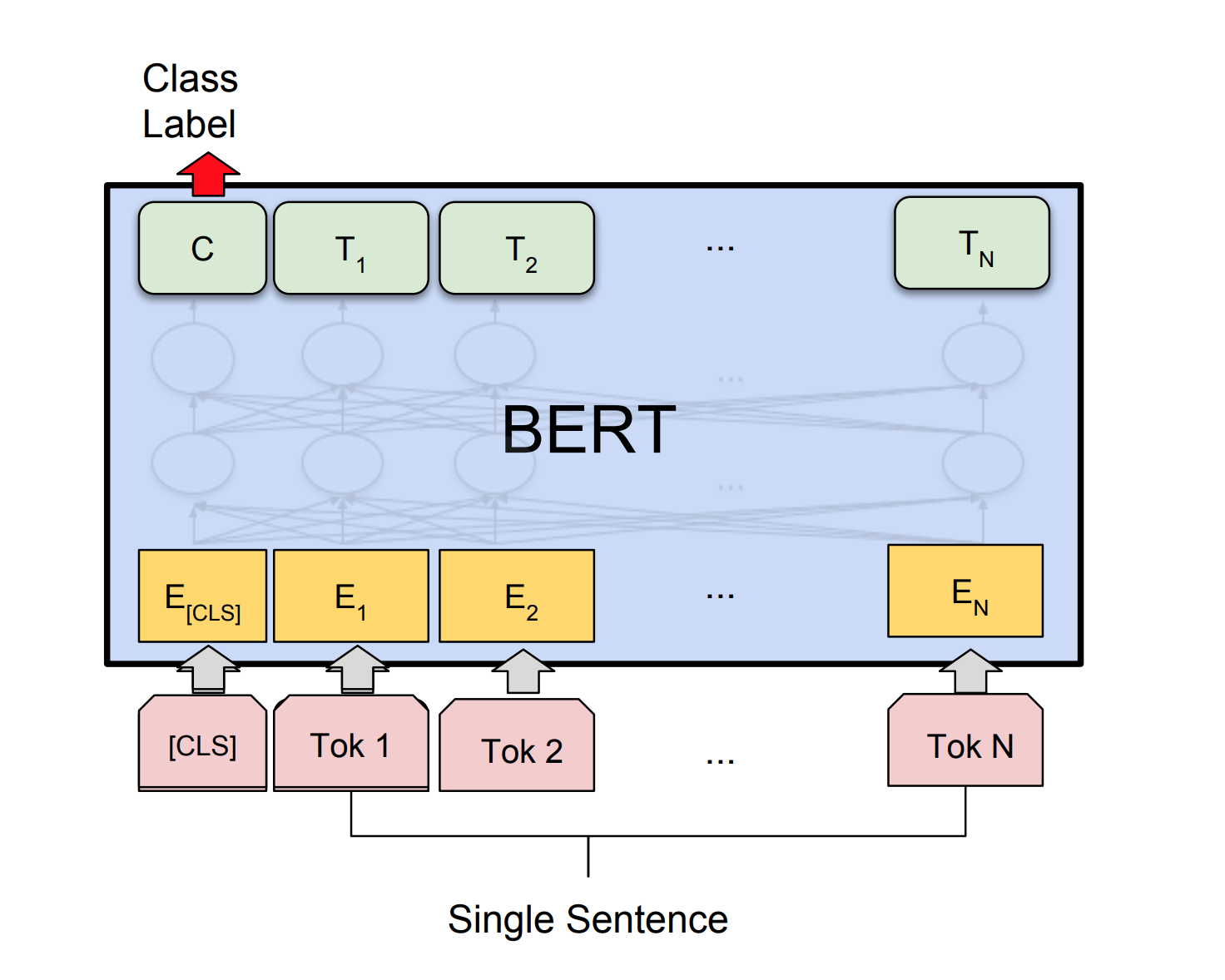
Eine Genauigkeit von 85% und Matthews -Korrelationskoeffizienten (MCC) von 64.1 wurde erreicht.
Distillation : Eine Technik, mit der Sie ein großes Modell, das als teacher bezeichnet wird, in ein kleineres Modell, das student genannt wird, komprimiert werden. Im folgenden Schüler werden Lehrermodelle verwendet, um die Destillation auf Cola durchzuführen.

Die folgenden Experimente wurden ausprobiert:
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 Das Markieren mit dem Namen der Namens-Recognition (NER) ist eine Aufgabe, jedes Wort in einem Satz mit seiner entsprechenden Entität zu kennzeichnen.
Die folgenden Varizen wurden untersucht:
Dieser Code deckt den grundlegenden Workflow ab. Wir werden sehen, wie Sie Daten laden, Zug-/Test-/Validierungsaufenthalte erstellen, ein Wortschatz erstellen, Daten Iteratoren erstellen, ein Modell definieren und die Zug-/Evaluieren-/Testschleife implementieren, das Modell testen, das Modell testen.
Das verwendete Modell ist das bidirektionale LSTM-Netzwerk
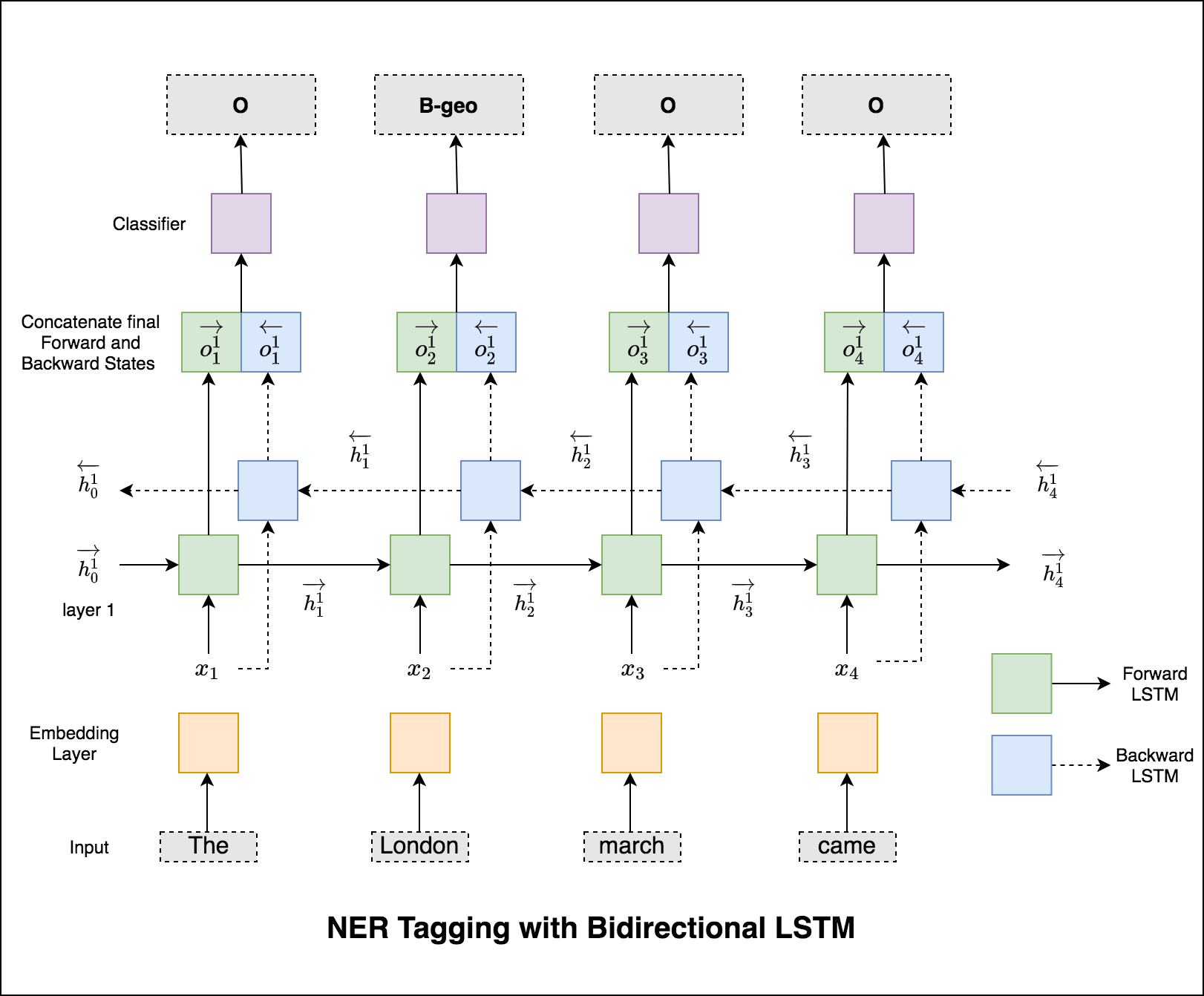
Im Fall von Sequence Tagging (NER) kann das Tag eines aktuellen Wortes vom Tag des vorherigen Wortes abhängen. (Beispiel: New York).
Ohne CRF hätten wir einfach eine einzelne lineare Schicht verwendet, um die Ausgabe des bidirektionalen LSTM für jedes Tag in die Punktzahlen zu verwandeln. Diese sind als emission scores bekannt, die eine Darstellung der Wahrscheinlichkeit darstellen, dass das Wort ein bestimmtes Tag ist.
Ein CRF berechnet nicht nur die Emissionswerte, sondern auch die transition scores , die die Wahrscheinlichkeit eines Wortes sind, ein bestimmtes Tag zu sein, wenn man bedenkt, dass das vorherige Wort ein bestimmtes Tag war. Daher messen die Übergangsbewertungen, wie wahrscheinlich es ist, dass er von einem Tag zum anderen übergeht.
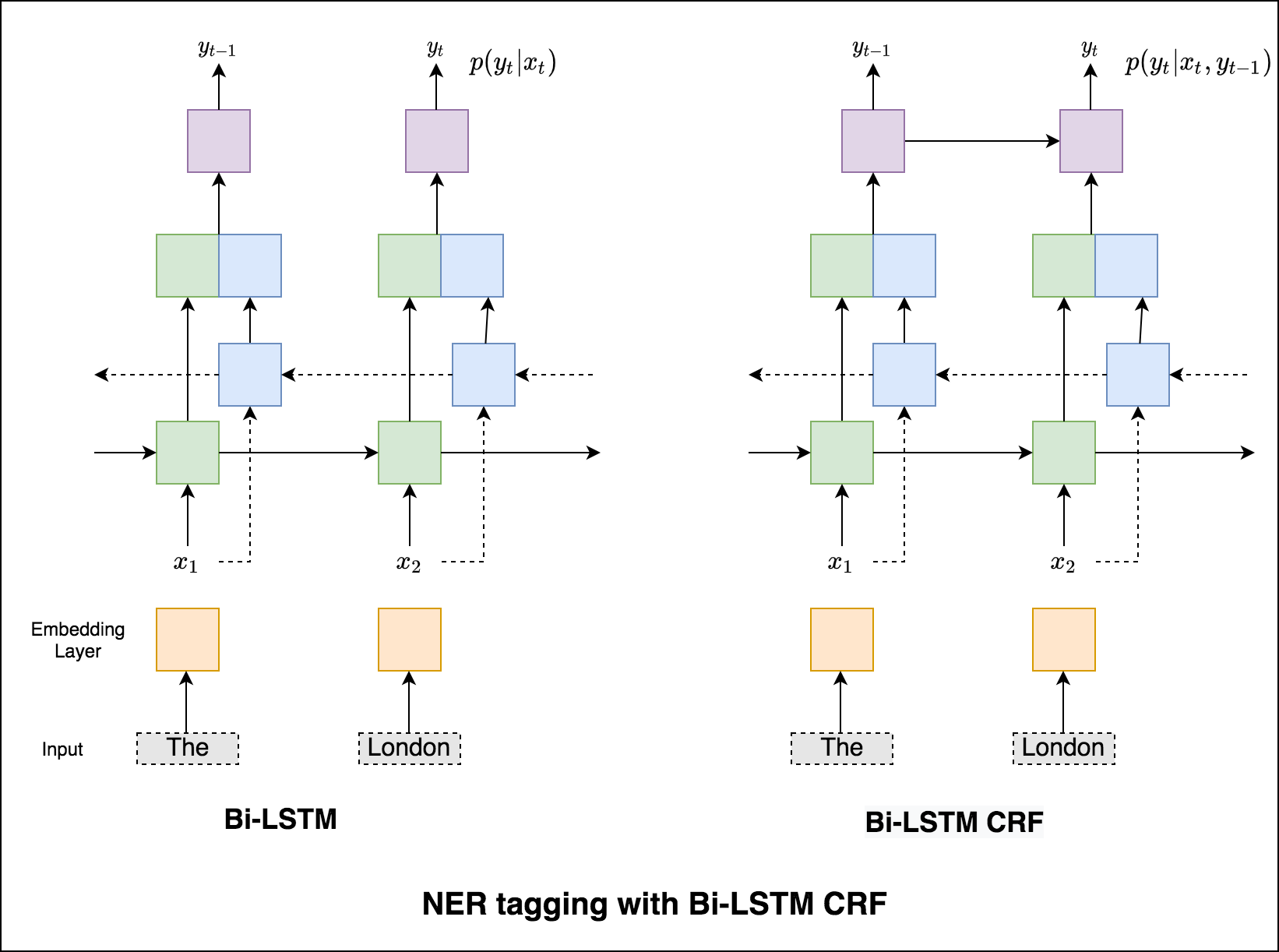
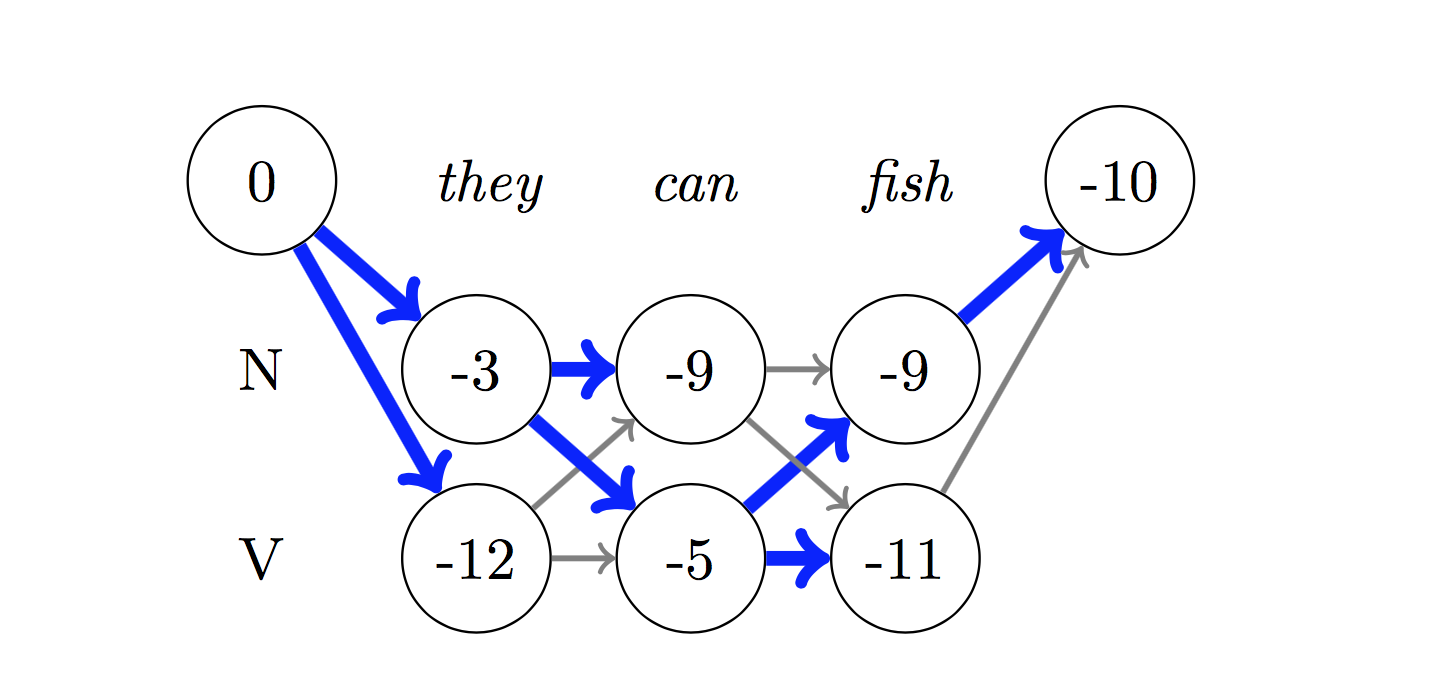
Zum Dekodieren wird der Viterbi -Algorithmus verwendet.
Da wir CRFs verwenden, werden wir bei jedem Wort nicht so sehr das richtige Etikett vorhersagen, da wir die richtige Label -Sequenz für eine Wortsequenz vorhersagen. Viterbi -Dekodierung ist eine Möglichkeit, genau dies zu tun - die optimalste Tag -Sequenz aus den von einem bedingten Zufallsfeld berechneten Bewertungen zu finden.
Verwenden von Unterwortinformationen in unserer Tagging-Aufgabe, da dies ein leistungsstarker Indikator für die Tags sein kann, unabhängig davon, ob es sich um Teile von Sprache oder Entitäten handelt. Zum Beispiel kann es lernen, dass Adjektive üblicherweise mit "-y" oder "-ul" enden oder dass Orte oft mit "Land" oder "-burg" enden.
Daher verwendet unser Sequenz -Tagging -Modell beide
word-level in Form von Worteinbettungen.character-level bis hin zu jedem Wort in beide Richtungen. 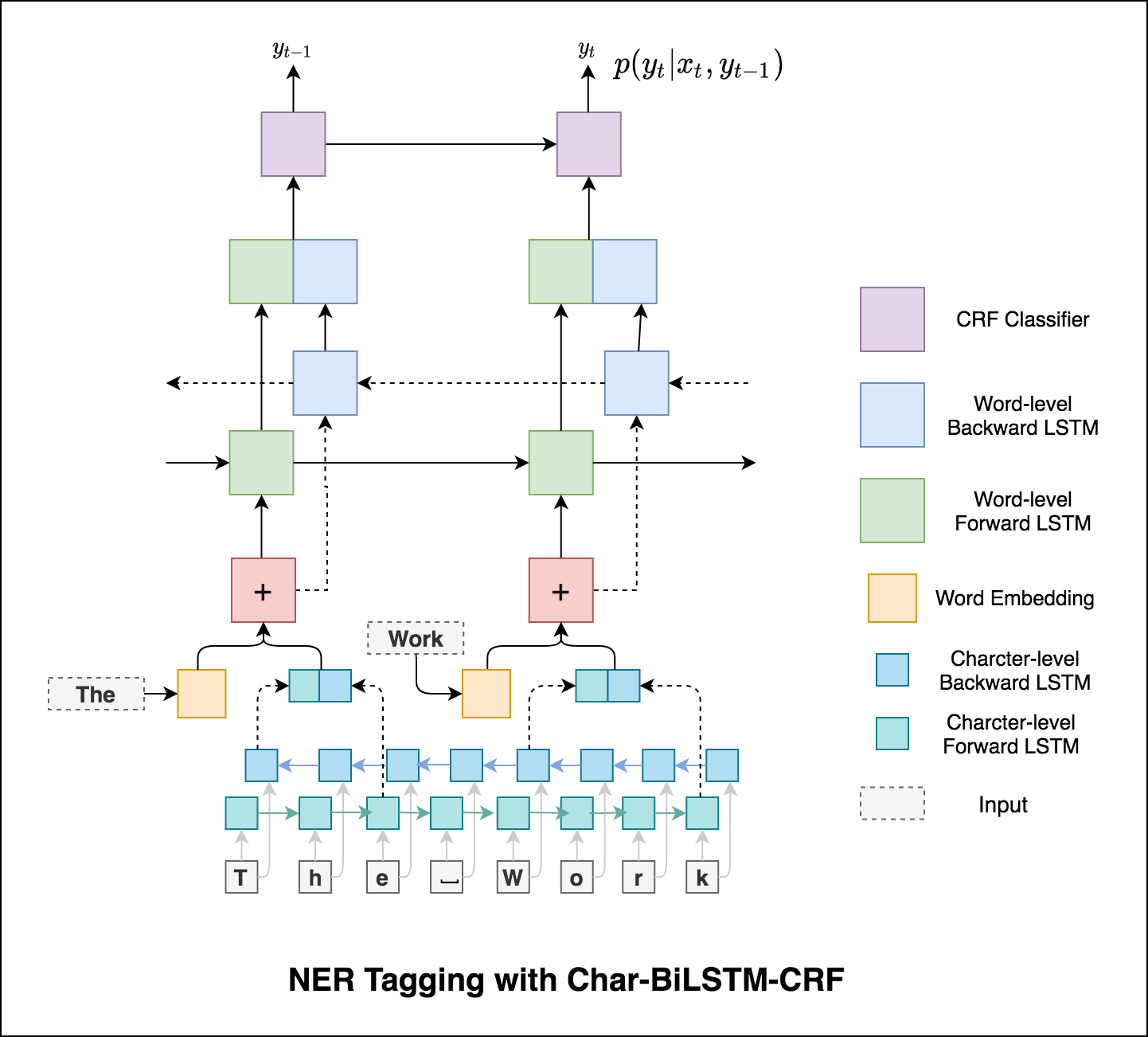
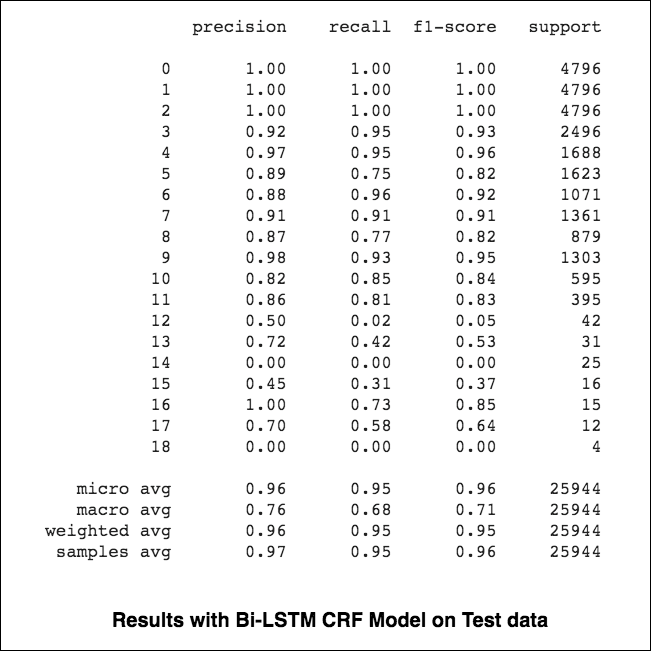
Mikro- und Makroabberichte (für die Metrik) berechnen leicht unterschiedliche Dinge, und daher unterscheidet sich ihre Interpretation. Ein Makro-Durchschnitt berechnet die Metrik für jede Klasse unabhängig und nimmt dann den Durchschnitt (damit die Behandlung aller Klassen gleichermaßen behandelt), während ein Mikro-Durchschnitt die Beiträge aller Klassen zur Berechnung der durchschnittlichen Metrik aggregiert wird. In einem Klassifizierungsaufbau mit mehreren Klassen ist Mikro-durchschnittlich vorzuziehen, wenn Sie vermuten, dass es ein Klassenungleichgewicht gibt (dh Sie haben möglicherweise viele weitere Beispiele für eine Klasse als andere Klassen).

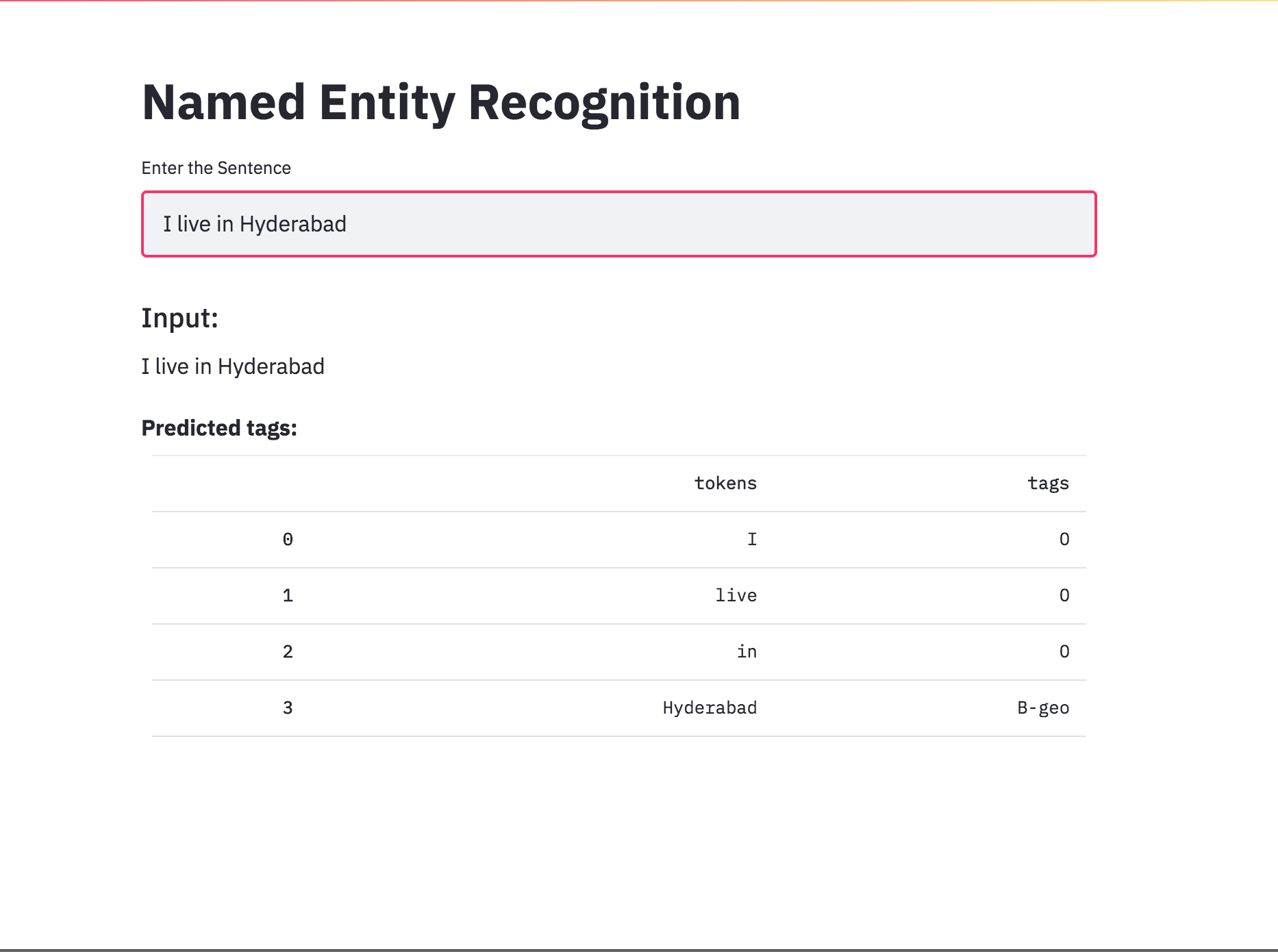
Konvertierte das NER -Tagging mit Streamlit in eine App. Das vorgebildete Modell (Char-Bilstm-CRF) ist ab sofort verfügbar.
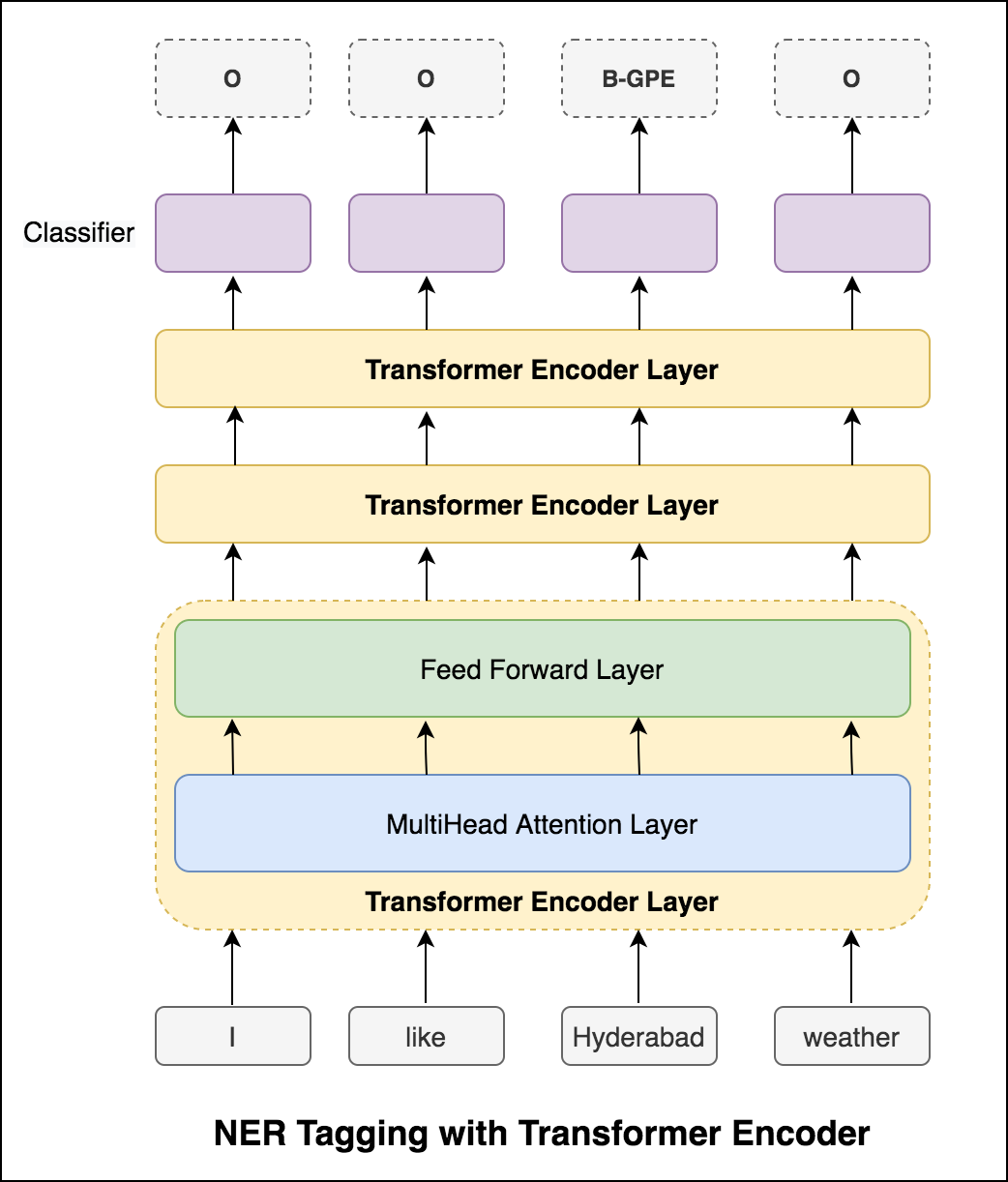
Nach dem Versuch des RNN -Ansatzes wird NER -Tagging mit transformatorischer Architektur untersucht. Da der Transformator sowohl Encoder als auch Decoder enthält, und für die Sequenz -Kennzeichnungsaufgabe ist nur Encoder ausreichend. Es wurde ein 3-Layer-Transformator-Encodermodell verwendet.
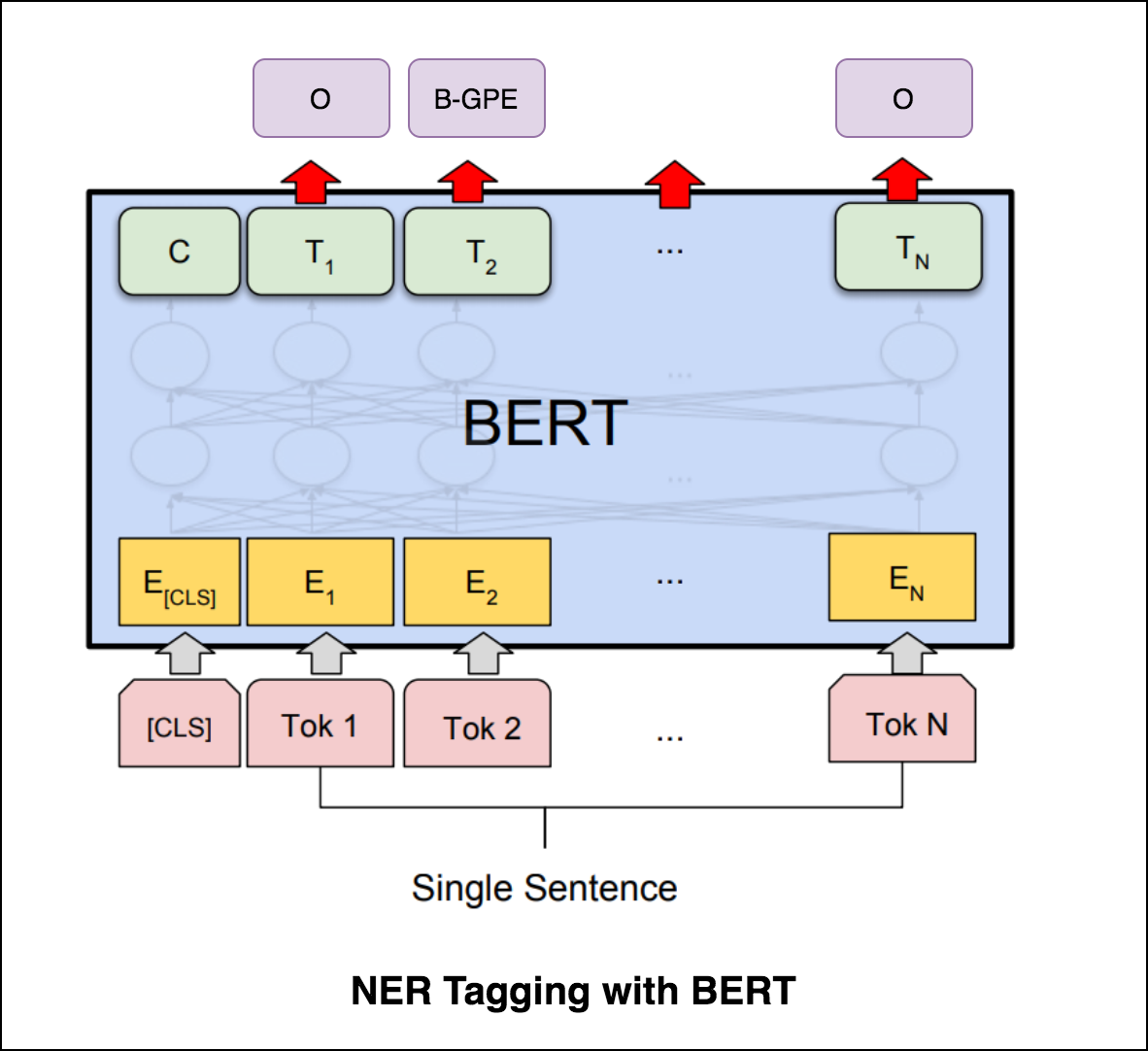
Nach dem Ausprobieren von NER-Tagging mit Transformator-Encoder wird NER-Tagging mit vorgebildetem bert-base-cased Modell untersucht.
Der Transformator allein liefert im Vergleich zu BILSTM in der NER -Tagging -Aufgabe keine guten Ergebnisse. Die Erweiterung der CRF -Schicht auf dem Transformator wird implementiert, was die Ergebnisse im Vergleich zum eigenständigen Transformator verbessert.
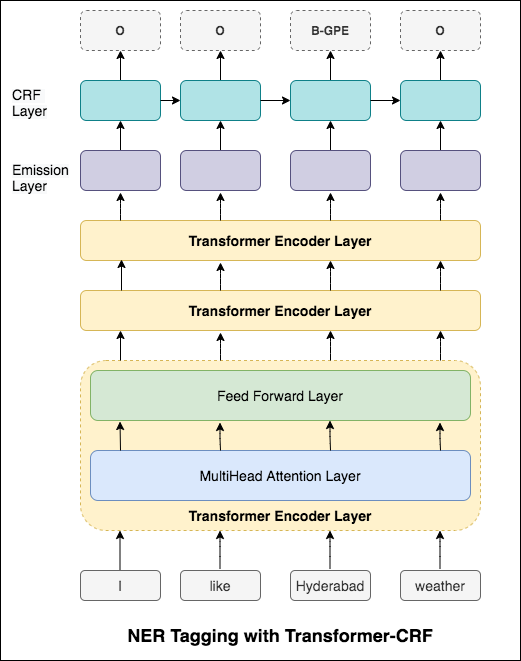
SPACY bietet ein außergewöhnlich effizientes statistisches System für NER in Python, das Tokengruppen Etiketten zuweisen kann. Es bietet ein Standardmodell, das eine breite Palette genannter oder numerischer Einheiten erkennen kann, darunter Person, Organisation, Sprache, Ereignis usw.

Abgesehen von diesen Standardeinheiten gibt uns Spacy auch die Freiheit, dem NER -Modell beliebige Klassen hinzuzufügen, indem wir das Modell mit neueren geschulten Beispielen trainieren.
2 neue Unternehmen, die ACTIVITY und SERVICE in einer bestimmten Domänendaten (Bank) bezeichnet werden, werden mit wenigen Schulungsmuster erstellt und geschult.

| Namensgenerierung | Maschinelle Übersetzung | Äußerungsgenerierung |
| Bildunterschrift | Bildunterschrift - Latexgleichungen | Nachrichtenübersicht |
| E -Mail -Betreff Generation |
Ein LSTM-Sprachmodell auf Charakterebene wird verwendet. Das heißt, wir werden der LSTM einen riesigen Teil der Namen geben und sie bitten, die Wahrscheinlichkeitsverteilung des nächsten Zeichens in der Sequenz bei einer Abfolge früherer Zeichen zu modellieren. Dies ermöglicht uns dann, einen neuen Namen nach dem anderen zu generieren

Maschinelle Übersetzung (MT) ist die Aufgabe, eine natürliche Sprache automatisch in eine andere zu konvertieren, die Bedeutung des Eingangstextes beizubehalten und fließende Text in der Ausgabesprache zu erzeugen. Idealerweise wird eine Quellsprachsequenz in die Zielsprachensequenz übersetzt. Die Aufgabe besteht darin, Sätze vom German to English zu konvertieren.
Die folgenden Varizen wurden untersucht:
Die häufigsten Modelle für Sequence-to-Sequence (SEQ2SQ) sind Encoder-Decoder-Modelle, die üblicherweise ein wiederkehrendes neuronales Netzwerk (RNN) verwenden, um den Quellsatz (Eingabe) in einen einzelnen Vektor zu codieren. In diesem Notebook bezeichnen wir diesen einzelnen Vektor als Kontextvektor. Wir können uns den Kontextvektor als eine abstrakte Darstellung des gesamten Eingabegesatzes vorstellen. Dieser Vektor wird dann von einem zweiten RNN dekodiert, der lernt, den Ziel (Ausgabe) auszugeben, indem er jeweils jeweils ein Wort generiert.

Nach dem Versuch der grundlegenden maschinellen Übersetzung, die Textverfeuchtigkeit 36.68 aufweist, wurden die folgenden Techniken experimentiert und eine Testverfasstigkeit 7.041 .
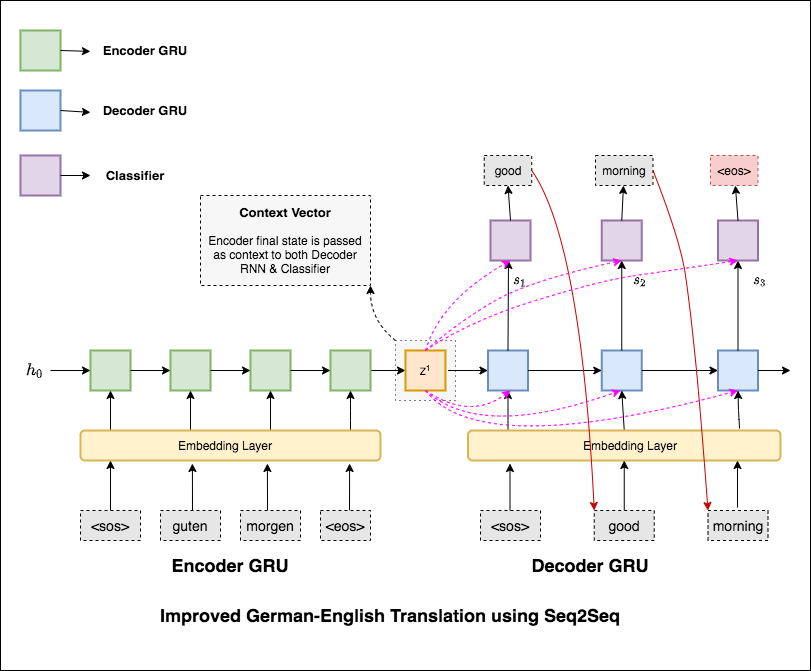
Checkout den Code in applications/generation
Der Aufmerksamkeitsmechanismus wurde geboren, um sich lange Quellsätze in der neuronalen Maschinenübersetzung (NMT) auswendig zu merken. Anstatt einen einzelnen Kontextvektor aus dem letzten versteckten Zustand des Encoders zu erstellen, wird die Aufmerksamkeit verwendet, um sich mehr auf die relevanten Teile der Eingabe zu konzentrieren, während er einen Satz entschlüsselt. Der Kontextvektor wird erstellt, indem Encoder -Ausgänge und der previous hidden state des Decoder RNN eingenommen werden.
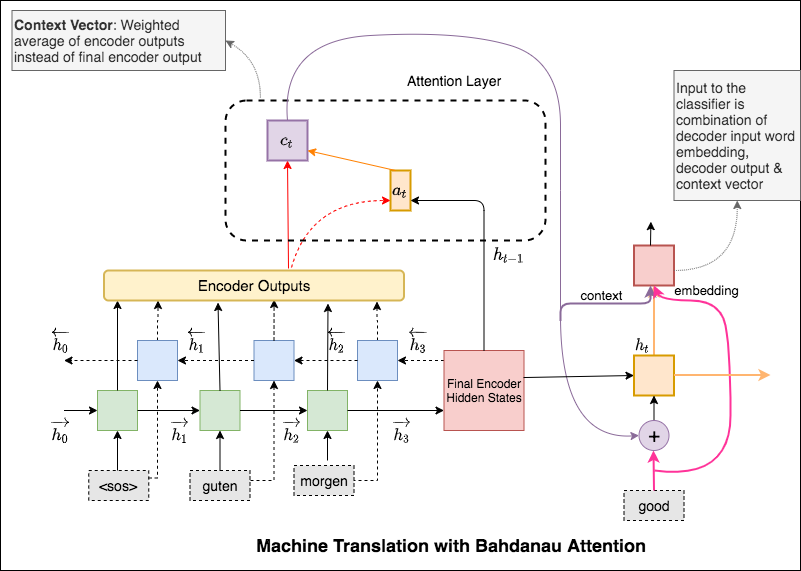
Verbesserungen wie Maskierung (Ignorieren Sie die Aufmerksamkeit über gepolsterte Eingaben), Packungssequenzen (zur besseren Berechnung), die Aufmerksamkeitsvisualisierung und die BLEU -Metrik bei Testdaten.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
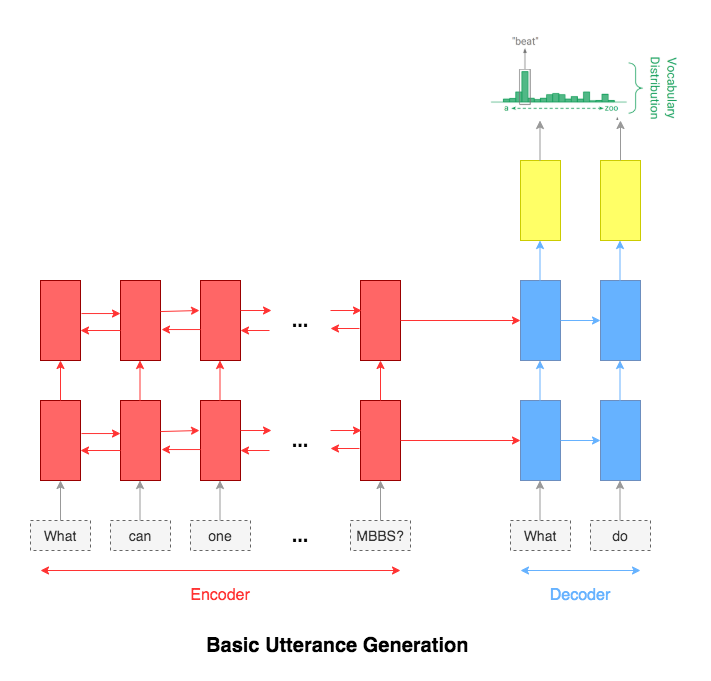
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
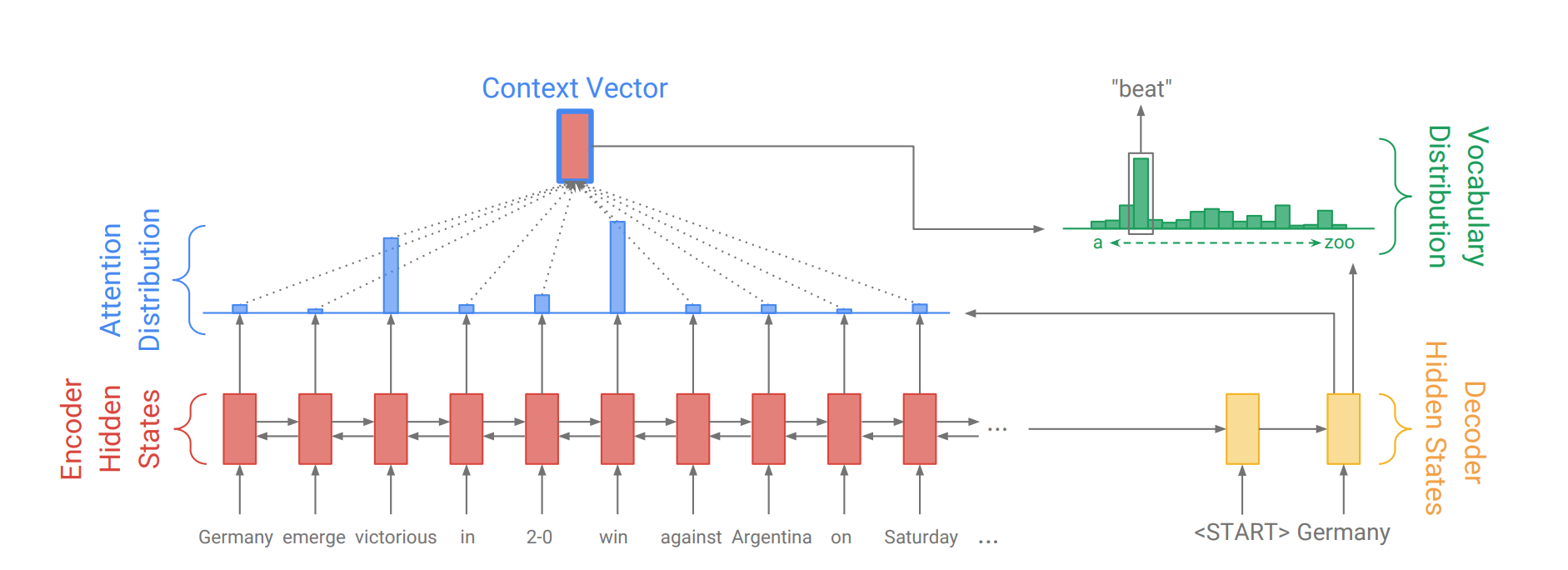
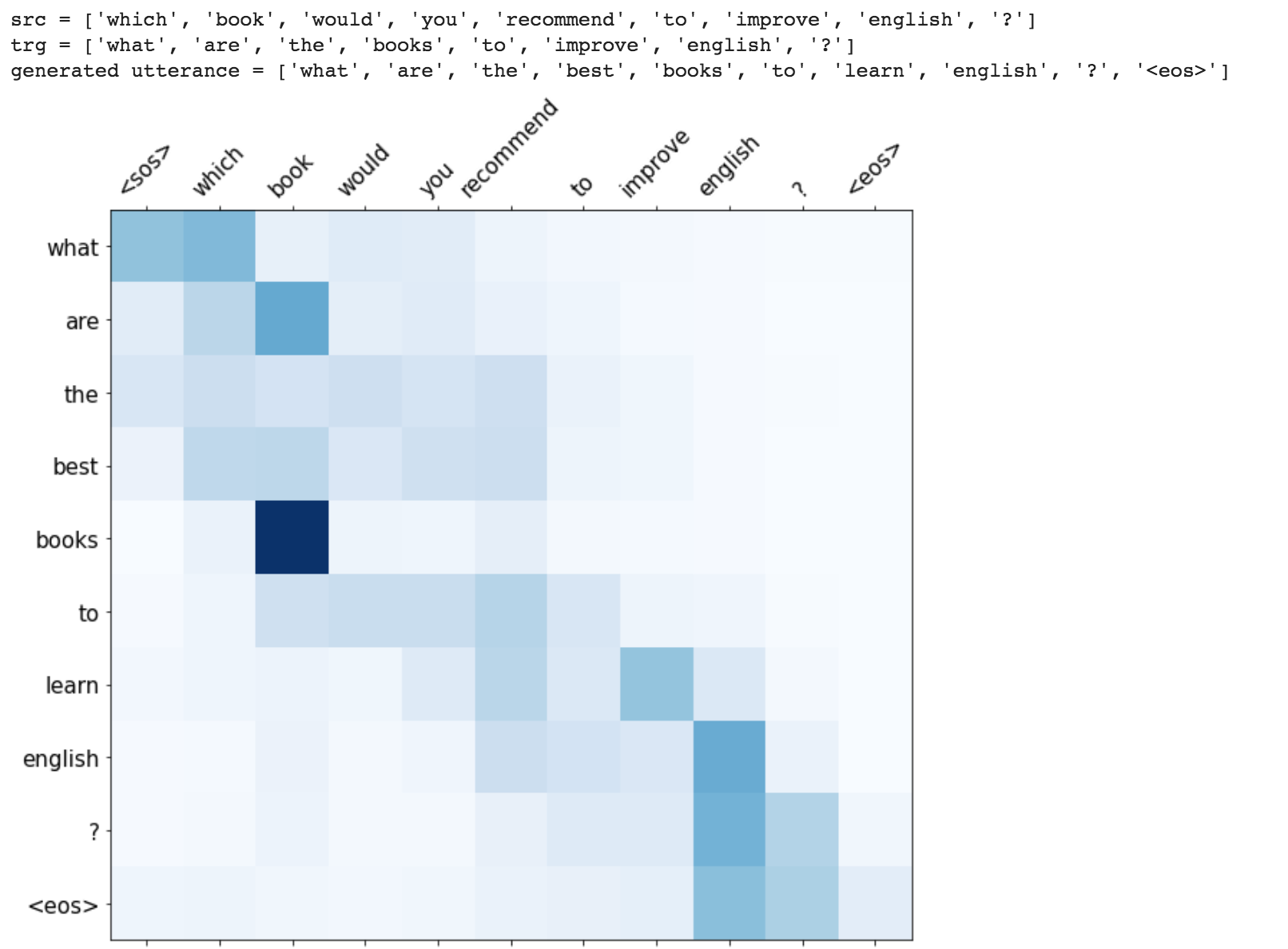
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
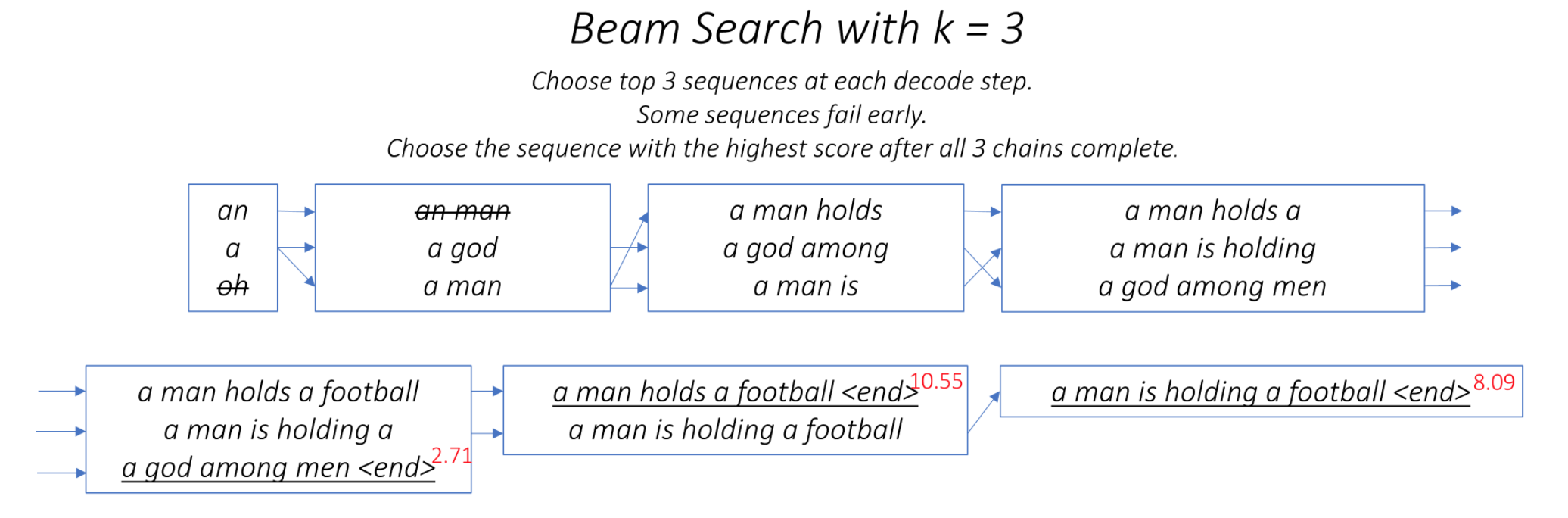
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

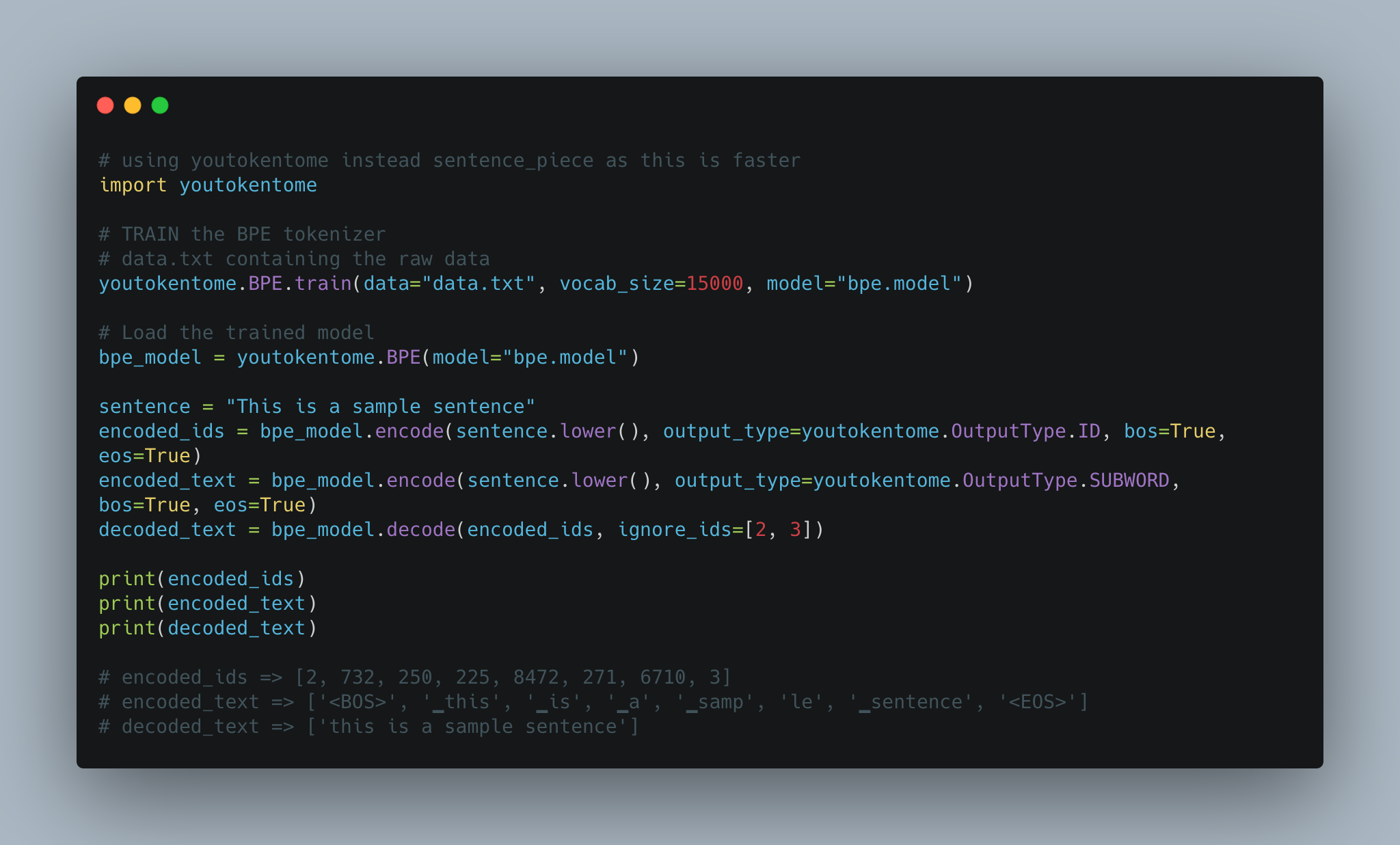
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
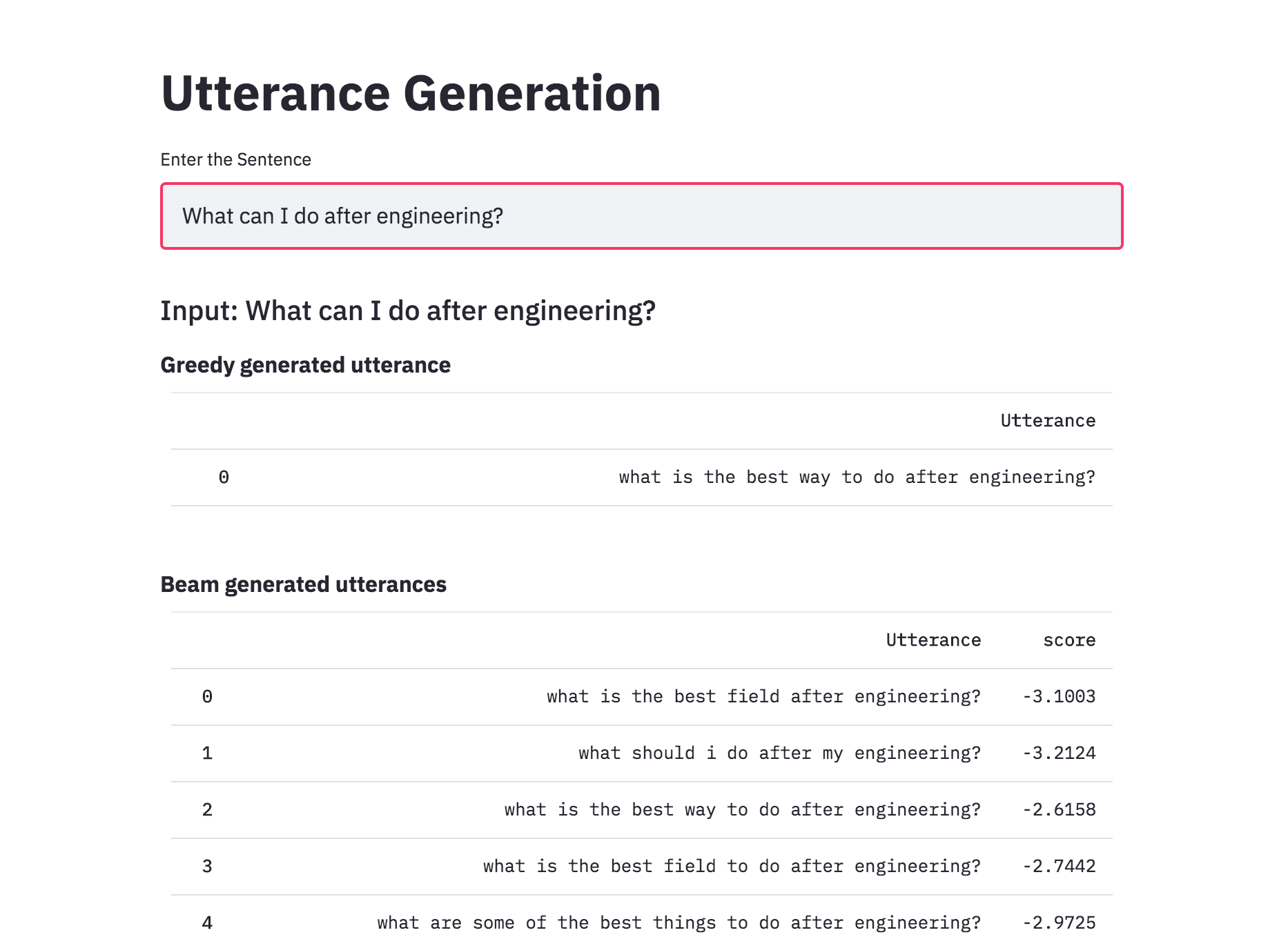
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
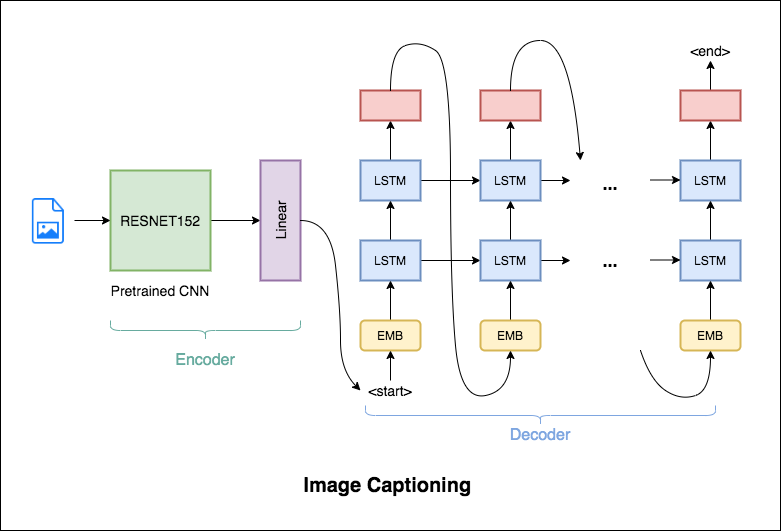
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
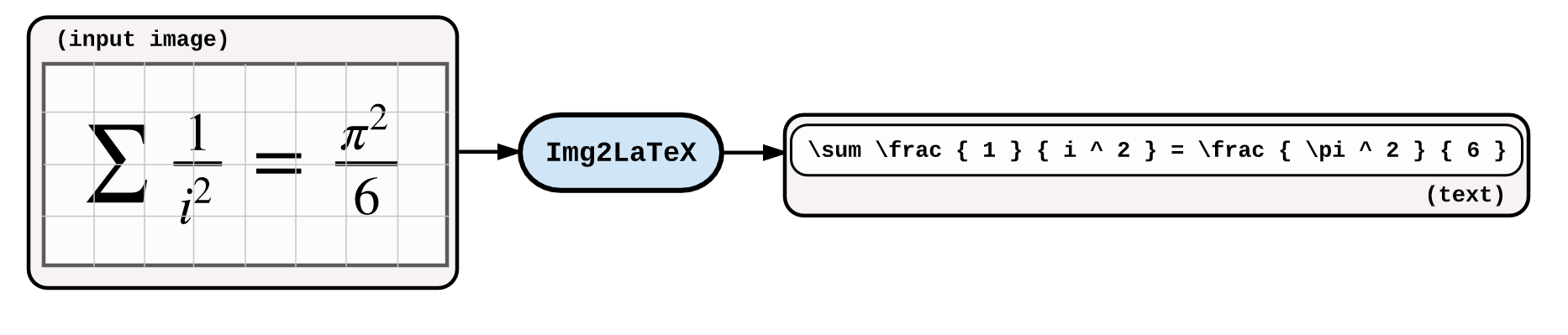
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
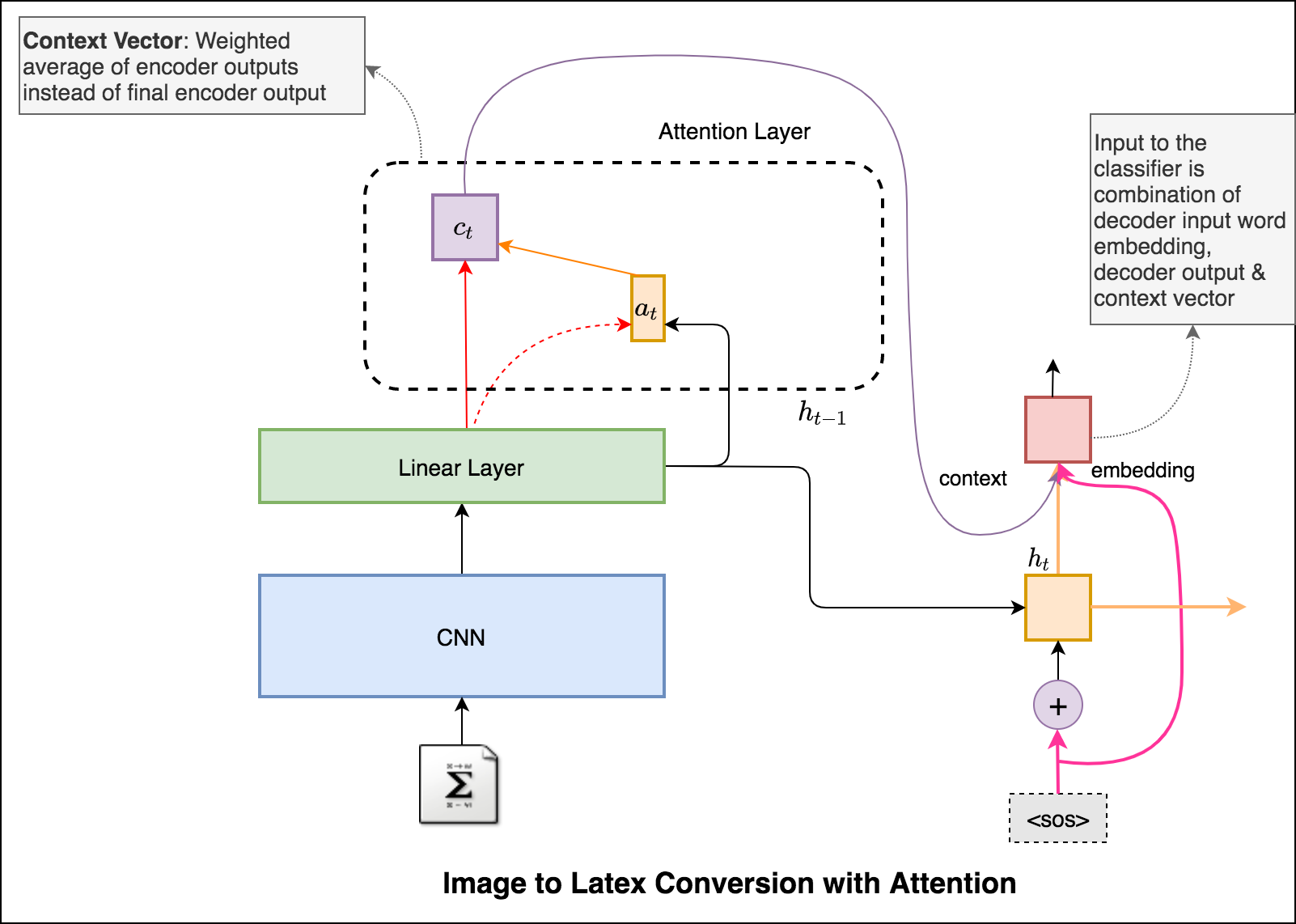
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
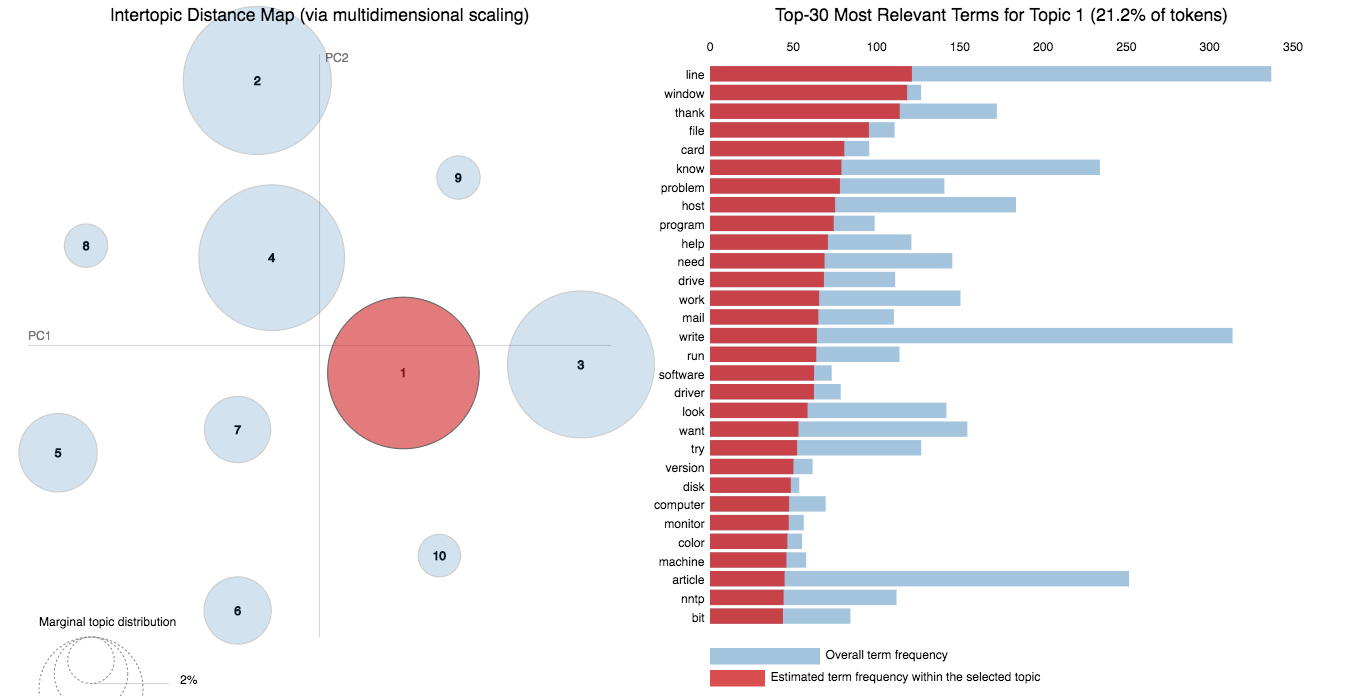
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
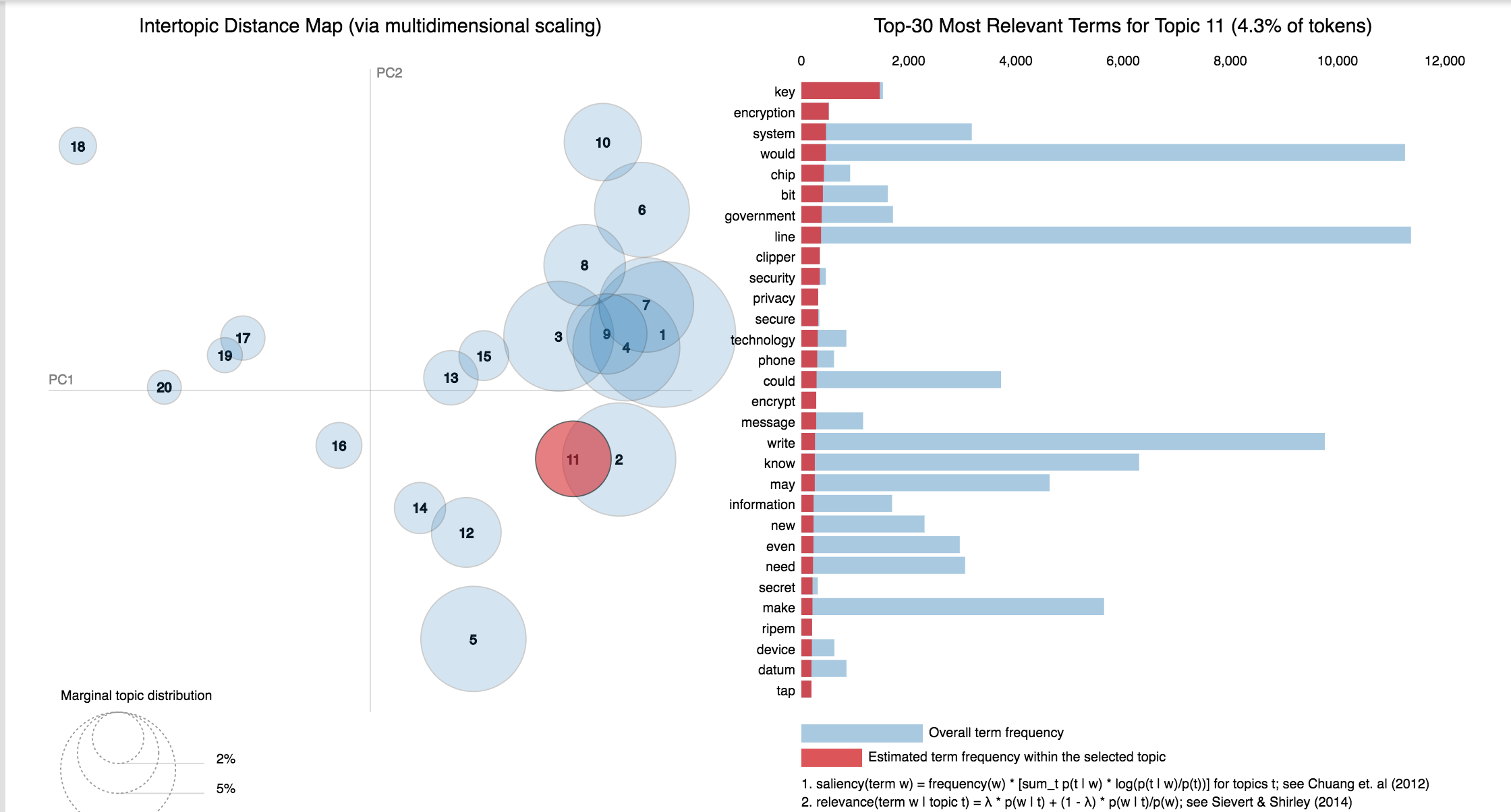
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
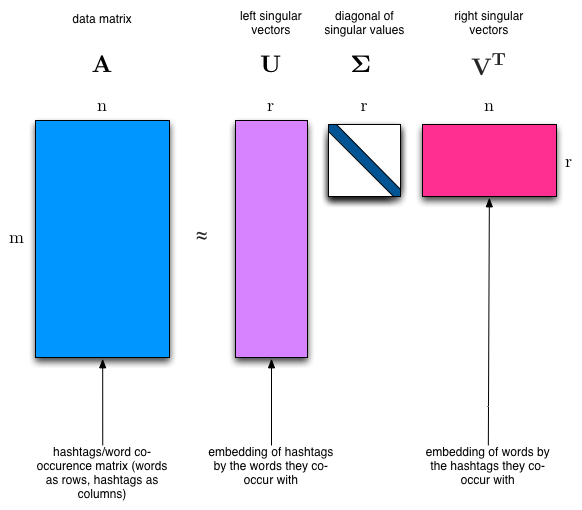
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
Anmerkungen:
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
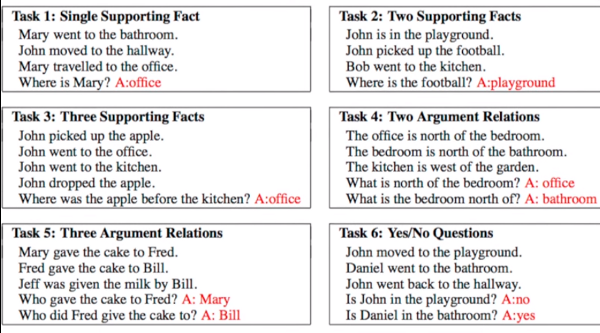
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
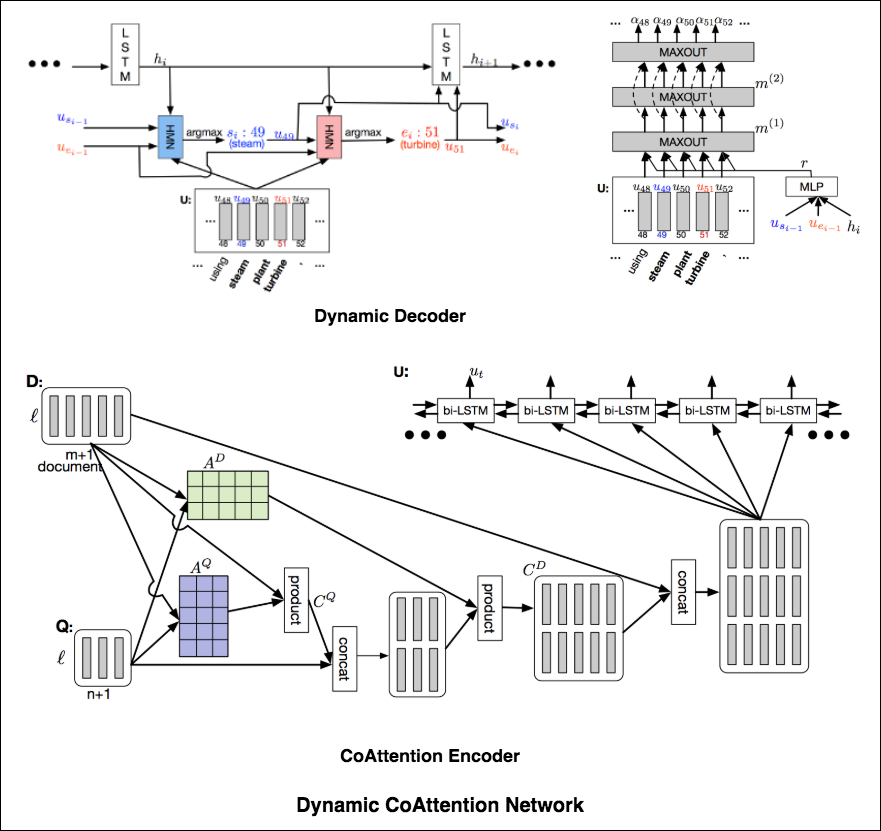
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
| Covid-19 Browser |
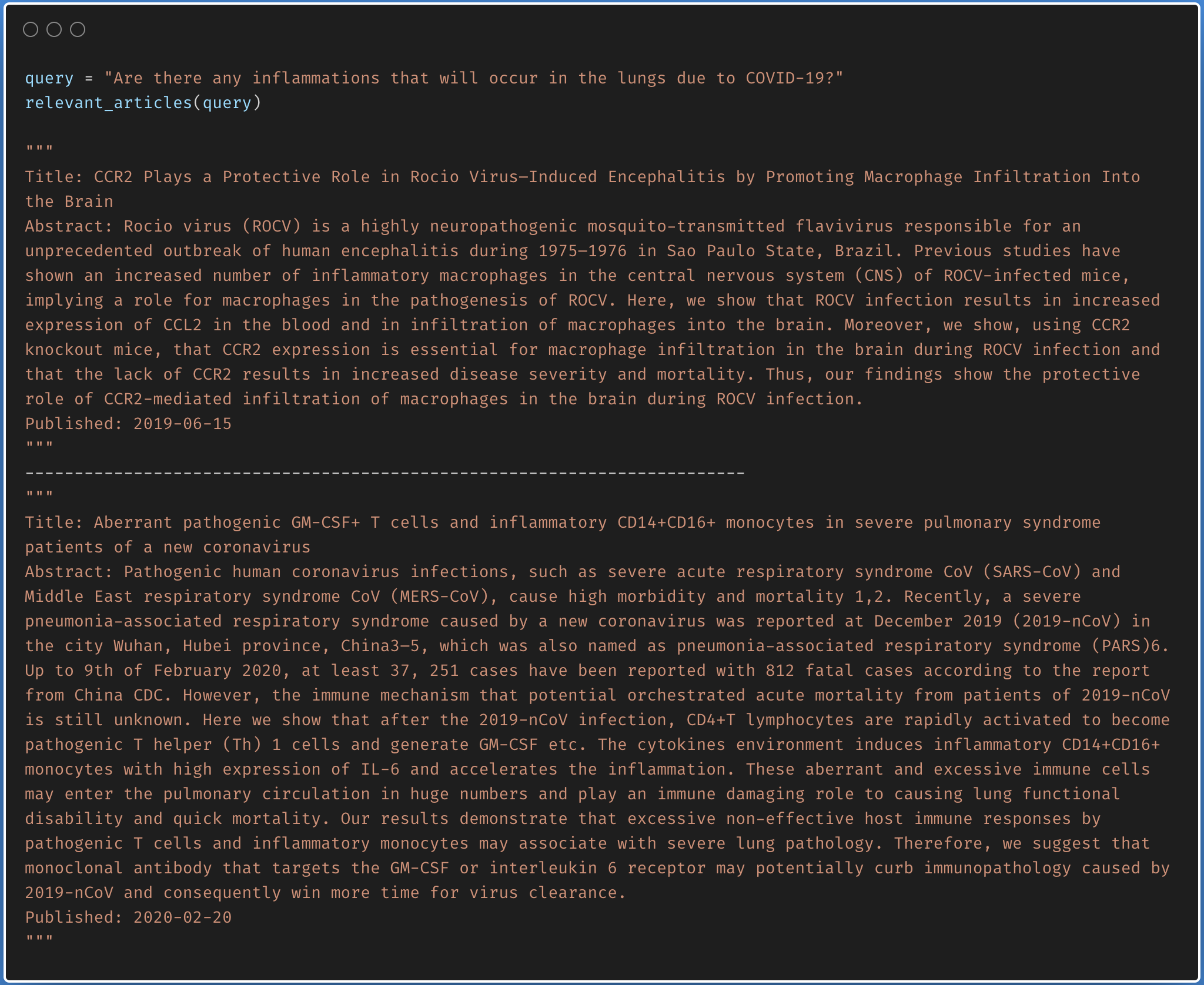
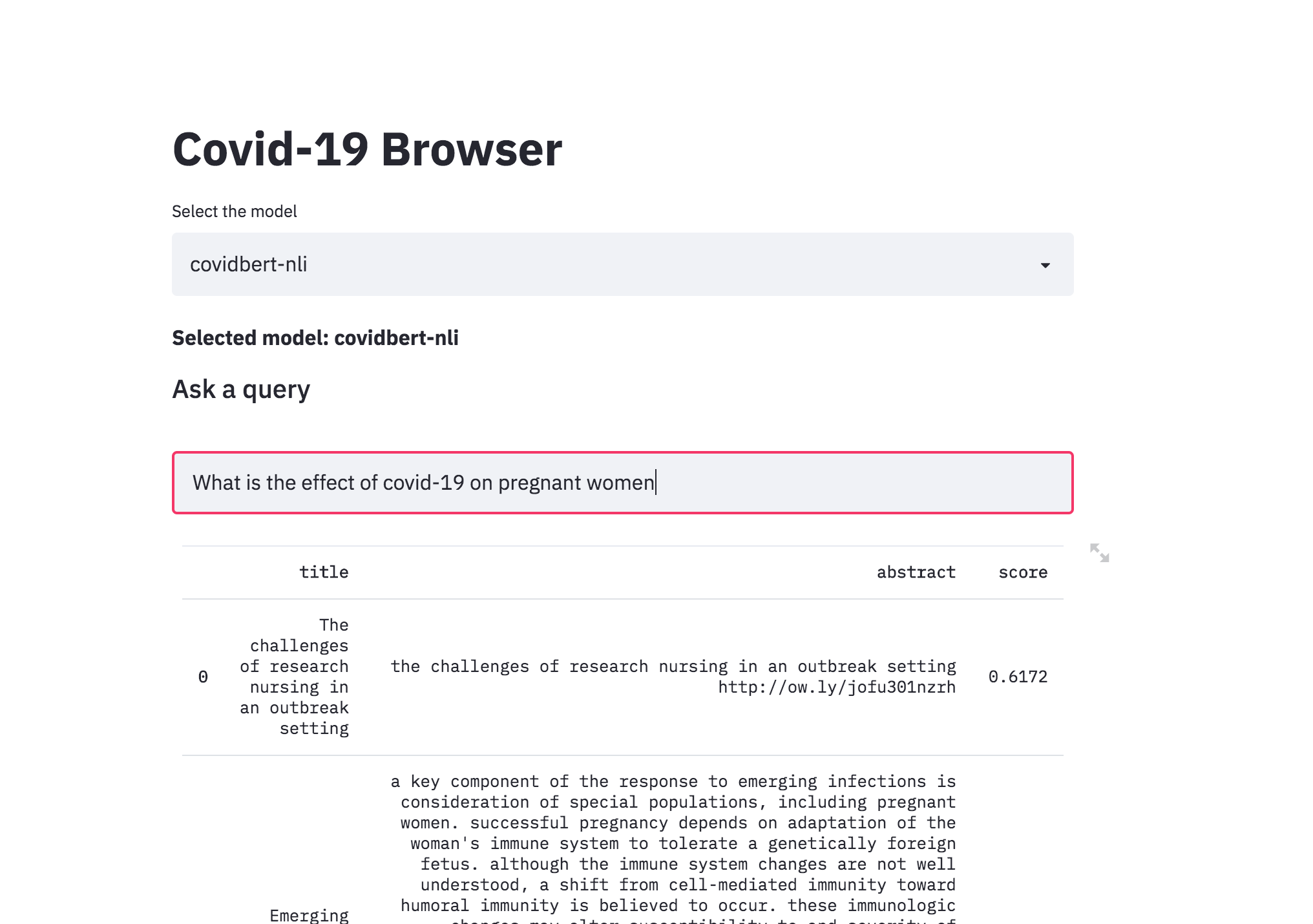
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
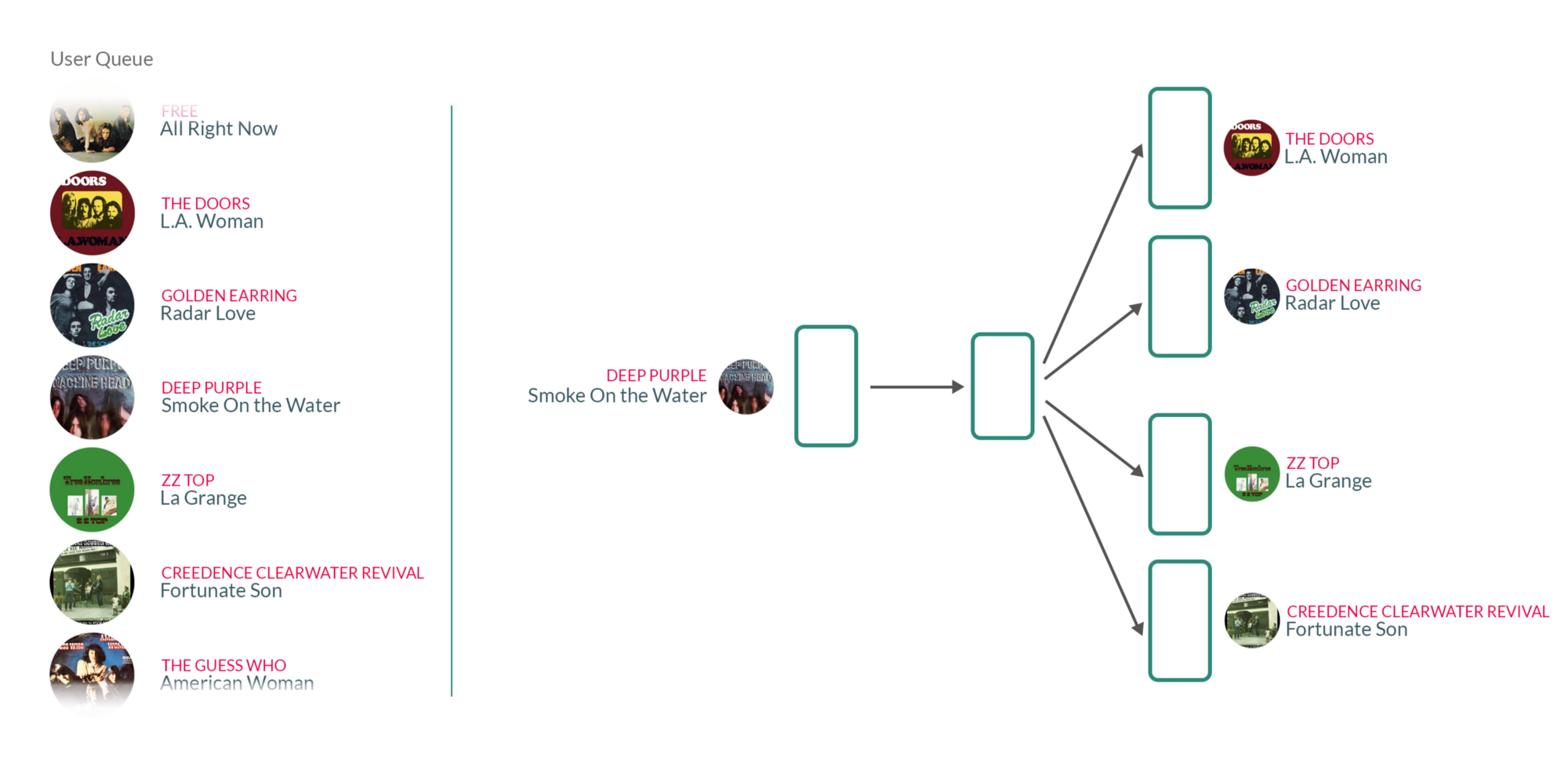
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


