100 Days of NLP
1.0.0

Il n'y a rien de magique dans la magie. Le magicien comprend simplement quelque chose de simple qui ne semble pas simple ou naturel pour le public non formé. Une fois que vous avez appris à tenir une carte tout en rendant votre main vide, vous n'avez besoin que de pratiquer avant vous aussi de «faire de la magie». - Jeffrey Friedl dans le livre Mastering Expressions régulières
Remarque: veuillez soulever un problème pour toute suggestion, correction et commentaires.
La plupart des échantillons de code sont effectués à l'aide de cahiers Jupyter (à l'aide de Colab). Ainsi, chaque code peut être exécuté indépendamment.
Les sujets suivants ont été explorés:
Remarque: Le niveau de difficulté a été attribué selon ma compréhension.
| Tokenisation | Word Embeddings - Word2Vec | Incorporation de mots - gant | Word Embeddings - Elmo |
| RNN, LSTM, GRU | Emballage des séquences rembourrées | Mécanisme d'attention - Luong | Mécanisme d'attention - Bahdanau |
| Réseau de pointes | Transformateur | Gpt-2 | Bert |
| Modélisation des sujets - LDA | Analyse des composants principaux (PCA) | Bayes naïf | Augmentation des données |
| Entretien de phrases |
Le processus de conversion des données textuelles en jetons est l'une des étapes les plus importantes de la PNL. La tokenisation utilisant les méthodes suivantes a été explorée:
Un mot incorporé est une représentation apprise pour le texte où les mots qui ont la même signification ont une représentation similaire. C'est cette approche pour représenter des mots et des documents qui peuvent être considérés comme l'une des principales percées de l'apprentissage en profondeur sur les problèmes de traitement du langage naturel difficiles.

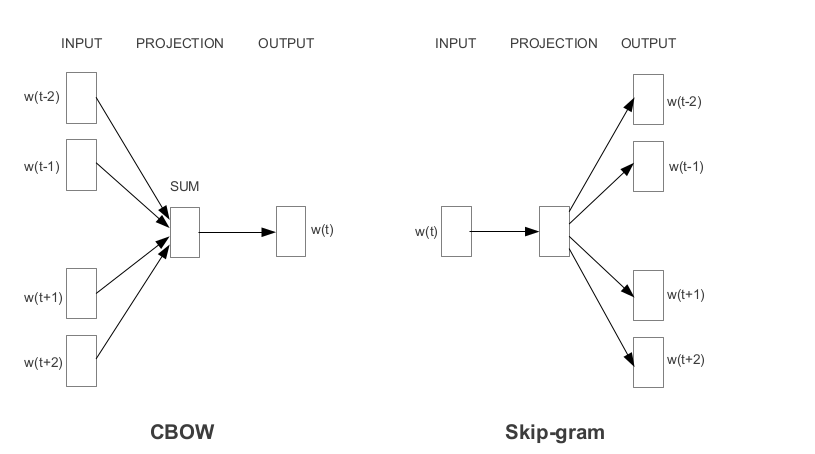
Word2Vec est l'un des incorporations de mots pré-entraînées les plus populaires développées par Google. Selon la façon dont les intérêts sont apprises, Word2Vec est classé en deux approches:
Le gant est une autre méthode couramment utilisée pour obtenir des intérêts pré-formés. Glove vise à atteindre deux objectifs:
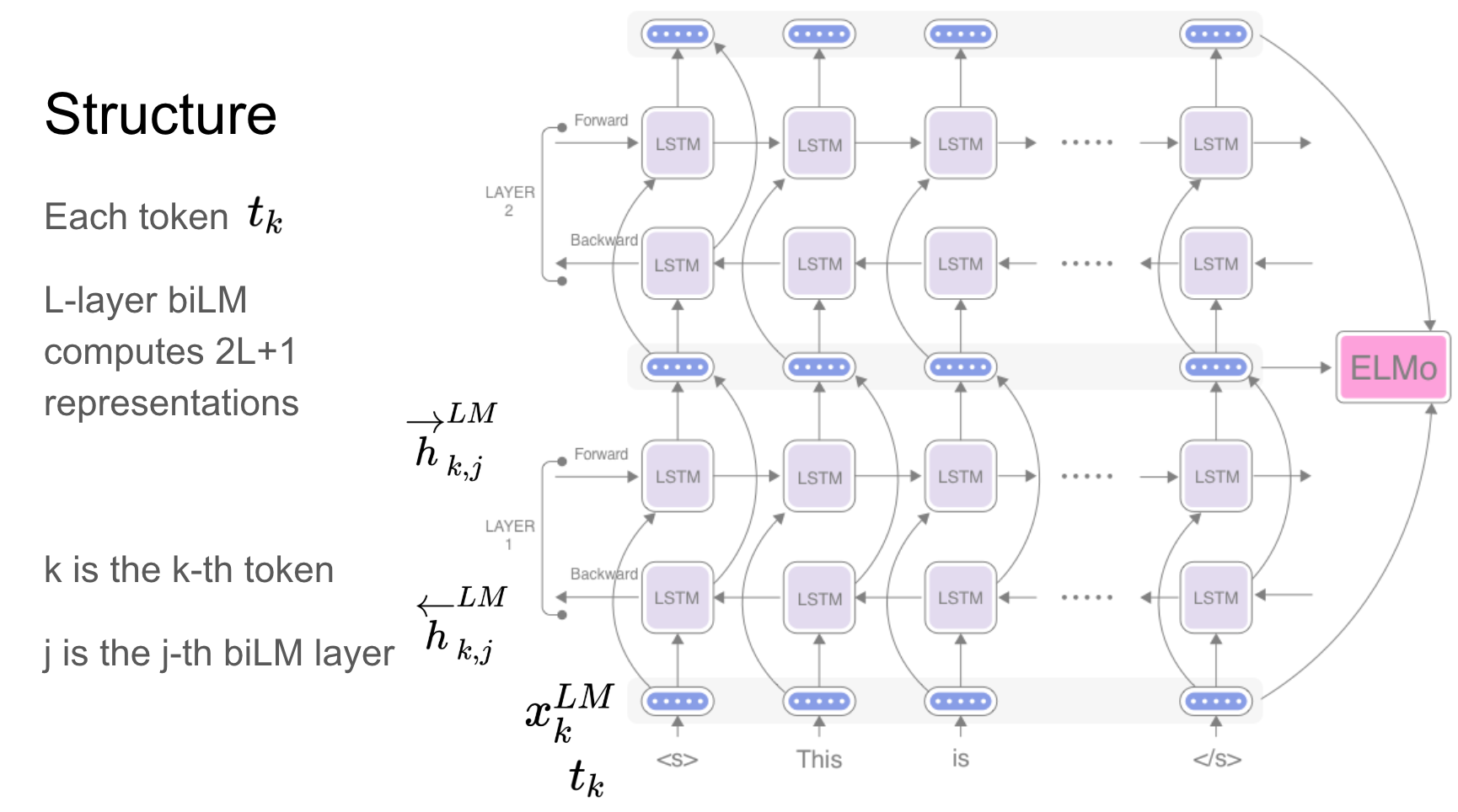
Elmo est une représentation de mots contextualisée profonde qui modèle:
Ces vecteurs de mots sont des fonctions apprises des états internes d'un modèle de langage bidirectionnel profond (BILM), qui est pré-formé sur un grand corpus de texte.
Réseaux récurrents - RNN, LSTM, GRU s'est avéré être l'une des applications les plus importantes des applications PNL en raison de leur architecture. Il y a de nombreux problèmes où la nature de la séquence doit être rappelée comme pour prédire une émotion dans la scène, les scènes précédentes doivent être rappelées.

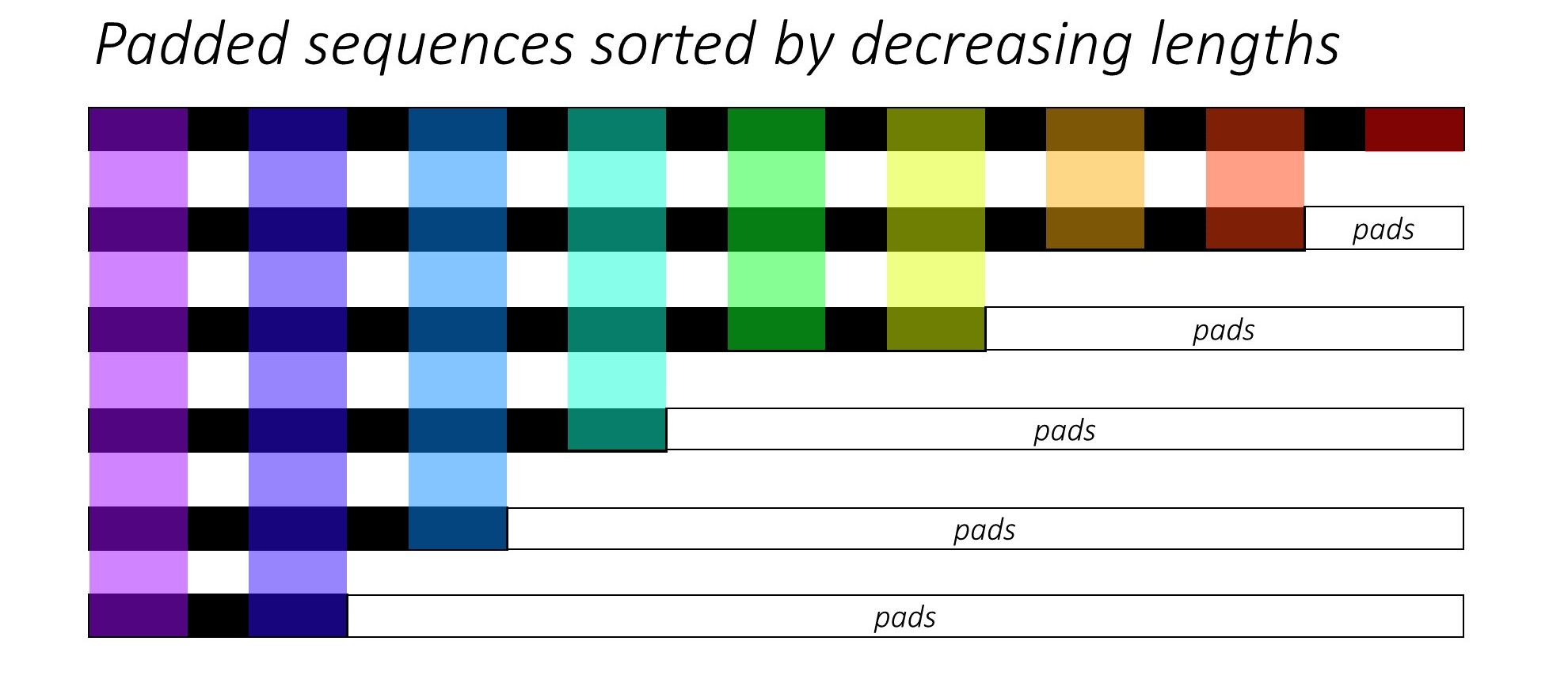
Lors de l'entraînement RNN (LSTM ou GRU ou Vanilla-RNN), il est difficile de lancer les séquences de longueur variable. Idéalement, nous remporterons toutes les séquences sur une longueur fixe et finirons par faire des calculs inutiles. Comment pouvons-nous surmonter cela? Pytorch fournit la fonctionnalité pack_padded_sequences .
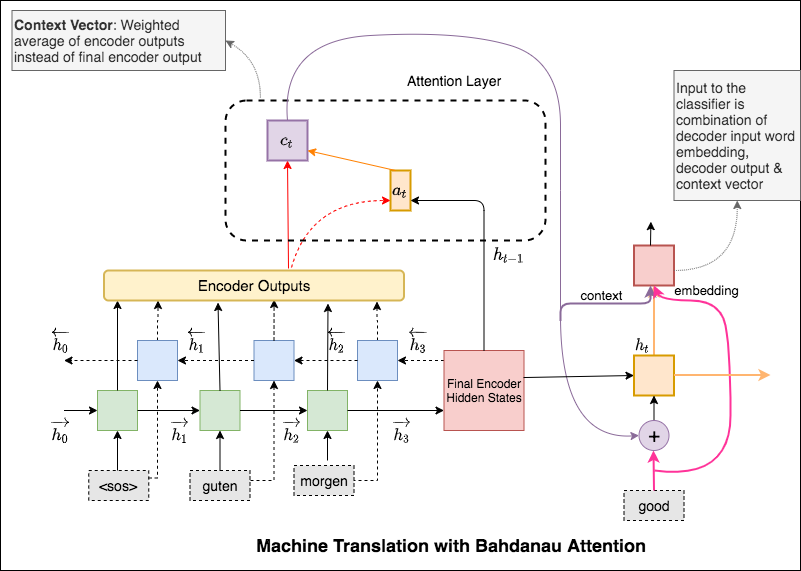
Le mécanisme d'attention est né pour aider à mémoriser des phrases à longue source dans la traduction des machines neuronales (NMT). Plutôt que de construire un seul vecteur de contexte à partir du dernier état caché de l'encodeur, l'attention est utilisée pour se concentrer davantage sur les parties pertinentes de l'entrée tout en décodant une phrase. Le vecteur de contexte sera créé en prenant des sorties d'encodeur et la current output du décodeur RNN.

Le score d'attention peut être calculé de trois manières. dot , general et concat .
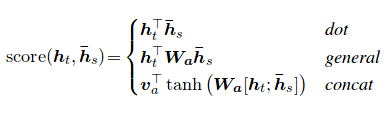
La principale différence entre l'attention de Bahdanau et Luong est la façon dont le vecteur de contexte est créé. Le vecteur de contexte sera créé en prenant des sorties d'encodeur et à l' previous hidden state du décodeur RNN. Où est dans l'attention de Luong, le vecteur de contexte sera créé en prenant des sorties d'encodeur et à l' current hidden state du décodeur RNN.
Une fois le contexte calculé, il est combiné avec l'intégration d'entrée de décodeur et nourri comme entrée au RNN de décodeur.

L'attention de Bahdanau est également appelée attention additive .
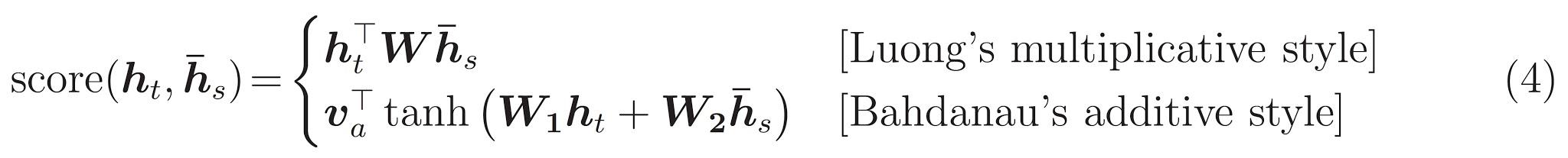
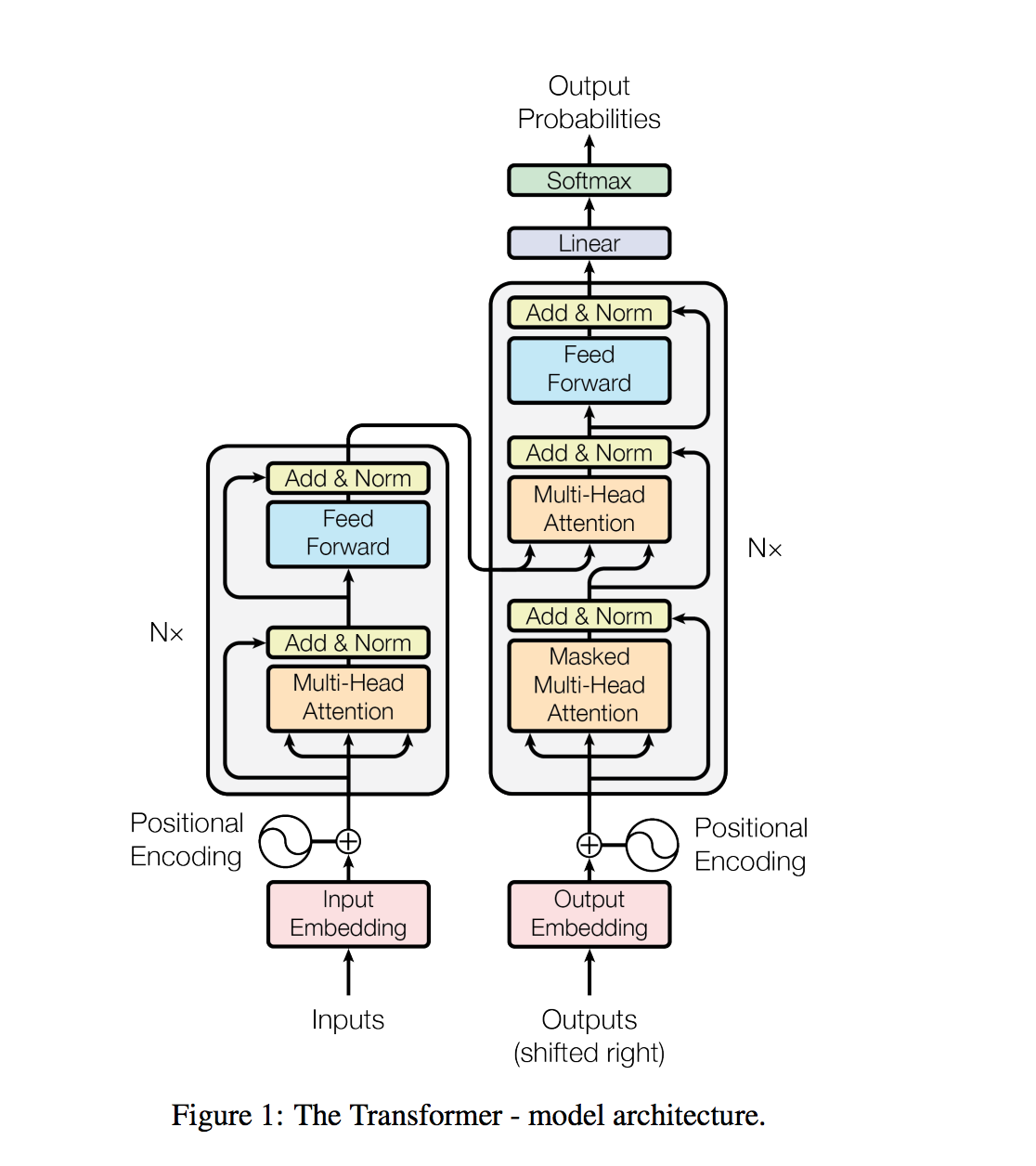
Le transformateur, une architecture de modèle évitant la récidive et s'appuyant plutôt sur un mécanisme d'attention pour attirer les dépendances globales entre l'entrée et la sortie.
Les tâches de traitement du langage naturel, telles que la réponse aux questions, la traduction machine, la compréhension de la lecture et le résumé, sont généralement approchées avec un apprentissage supervisé sur les ensembles de données spécifiques aux tâches. Nous démontrons que les modèles de langue commencent à apprendre ces tâches sans aucune supervision explicite lorsqu'elle est formée sur un nouvel ensemble de données de millions de pages Web appelé WebText. Notre plus grand modèle, GPT-2, est un transformateur de paramètres de 1,5b qui obtient des résultats ultramodernes sur 7 sur 7 ensembles de données de modélisation du langage testés dans un paramètre à tirs zéro mais sous-fiche toujours WebText. Les échantillons du modèle reflètent ces améliorations et contiennent des paragraphes cohérents de texte. Ces résultats suggèrent une voie prometteuse vers la construction de systèmes de traitement du langage qui apprennent à effectuer des tâches à partir de leurs démonstrations naturelles.
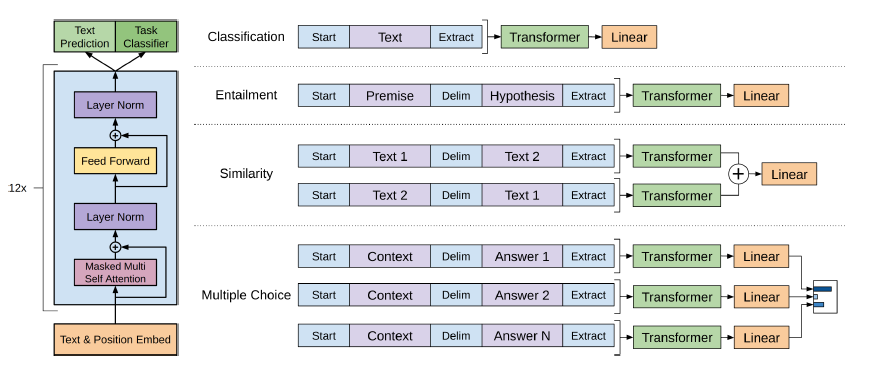
Le GPT-2 utilise une architecture de transformateur uniquement de décodeur à 12 couches.
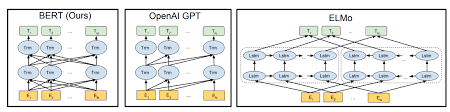
Bert utilise l'architecture du transformateur pour les phrases de codage.
La sortie des réseaux de pointeurs est discret et correspond à des positions dans la séquence d'entrée
Le nombre de classes cibles à chaque étape de la sortie dépend de la longueur de l'entrée, qui est variable.
Il diffère des tentatives d'attention précédentes en ce que, au lieu d'utiliser l'attention pour mélanger les unités cachées d'un encodeur à un vecteur de contexte à chaque étape de décodeur, il utilise l'attention comme pointeur pour sélectionner un membre de la séquence d'entrée comme sortie.

L'une des principales applications du traitement du langage naturel est d'extraire automatiquement les sujets que les gens discutent à partir de grands volumes de texte. Quelques exemples de gros texte pourraient être des flux à partir des médias sociaux, des critiques des clients des hôtels, des films, etc., des commentaires des utilisateurs, des reportages, des courriels de plaintes des clients, etc.
Savoir de quoi les gens parlent et comprendre leurs problèmes et leurs opinions sont très précieux pour les entreprises, les administrateurs, les campagnes politiques. Et il est vraiment difficile de lire manuellement de si grands volumes et de compiler les sujets.
Ainsi est requis un algorithme automatisé qui peut lire les documents texte et publier automatiquement les sujets abordés.
Dans ce cahier, nous prendrons un véritable exemple de l'ensemble de données 20 Newsgroups et utiliserons LDA pour extraire les sujets naturellement discutés.
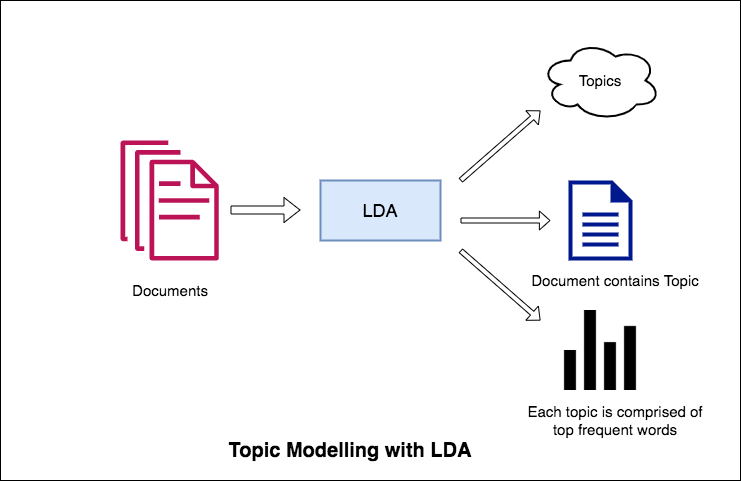
L'approche de LDA à la modélisation des sujets est qu'elle considère chaque document comme une collection de sujets dans une certaine proportion. Et chaque sujet en tant que collection de mots clés, encore une fois, dans une certaine proportion.
Une fois que vous avez fourni à l'algorithme le nombre de sujets, tout ce qu'il fait pour réorganiser la distribution des sujets dans la distribution des documents et des mots clés dans les sujets pour obtenir une bonne composition de la distribution de mots-clés de sujet.
PCA est fondamentalement une technique de réduction de la dimensionnalité qui transforme les colonnes d'un ensemble de données en une nouvelle fonctionnalité. Il le fait en trouvant un nouvel ensemble de directions (comme les axes x et y) qui expliquent la variabilité maximale des données. Ce nouvel axes de coordonnées système est appelé composants principaux (PC).
Pratiquement PCA est utilisé pour deux raisons:
Dimensionality Reduction : les informations distribuées sur un grand nombre de colonnes sont transformées en composants principaux (PC) de sorte que les premiers PC peuvent expliquer un morceau important de l'information totale (variance). Ces PC peuvent être utilisés comme variables explicatives dans les modèles d'apprentissage automatique.
Visualize Data : la visualisation de la séparation des classes (ou des clusters) est difficile pour les données avec plus de 3 dimensions (fonctionnalités). Avec les deux premiers PC lui-même, il est généralement possible de voir une séparation claire.
Un classificateur de Bayes naïf est un modèle d'apprentissage automatique probabiliste utilisé pour la tâche de classification. Le nœud du classificateur est basé sur le théorème de Bayes.
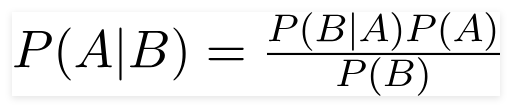
En utilisant le théorème de Bayes, nous pouvons trouver la probabilité d'un événement, étant donné que B s'est produit. Ici, B est la preuve et A est l'hypothèse. L'hypothèse faite ici est que les prédicteurs / fonctionnalités sont indépendants. C'est la présence d'une caractéristique particulière n'affecte pas l'autre. Par conséquent, il est appelé naïf.
Types de classificateur naïf de Bayes :
Multinomial Naive Bayes : Ceci est principalement utilisé lorsque les variables sont discrètes (comme les mots). Les fonctionnalités / prédicteurs utilisés par le classificateur sont la fréquence des mots présents dans le document.
Gaussian Naive Bayes : lorsque les prédicteurs prennent une valeur continue et ne sont pas discrètes, nous supposons que ces valeurs sont échantillonnées à partir d'une distribution gaussienne.
Bernoulli Naive Bayes : Ceci est similaire aux Bayes naïfs multinomiaux mais les prédicteurs sont des variables booléennes. Les paramètres que nous utilisons pour prédire la variable de classe ne prennent que des valeurs oui ou non, par exemple si un mot se produit ou non dans le texte.
En utilisant un ensemble de données 20NewSGroup, l'algorithme naïf de Bayes est exploré pour faire la classification.
L'augmentation des données à l'aide des techniques suivantes est explorée:

Une nouvelle architecture appelée SBERT a été explorée. L'architecture de réseau siamois permet que les vecteurs de taille fixe pour les phrases d'entrée puissent être dérivés. En utilisant une mesure de similitude comme la cosinesimilarité ou la distance de Manhatten / Euclidien, des phrases sémantiquement similaires peuvent être trouvées.

| Analyse des sentiments - IMDB | Classification des sentiments - Hinglish | Classification des documents |
| Classification des paires de questions en double - Quora | Tagging POS | Inférence du langage naturel - SNLI |
| Classification des commentaires toxiques | Phrase grammaticalement correcte - cola | Tagging NER |
L'analyse des sentiments fait référence à l'utilisation du traitement du langage naturel, de l'analyse du texte, de la linguistique informatique et de la biométrie pour identifier, extraire, quantifier et étudier les états affectifs et les informations subjectives.
Les varitifs suivants ont été explorés:
RNN est utilisé pour le traitement et l'identification du sentiment.

Après avoir essayé le RNN de base qui donne un test_actituation inférieur à 50%, les techniques suivantes ont été expérimentées et un test_acuratie supérieur à 88% est atteint.
Techniques utilisées:

L'attention aide à se concentrer sur l'entrée pertinente lors de la prévision du sentiment de l'entrée. L'attention de Bahdanau a été utilisée en prenant les sorties de LSTM et en concaténant l'état caché final et en arrière. Sans utiliser les incorporations de mots pré-formées, une précision de test de 88% est obtenue.
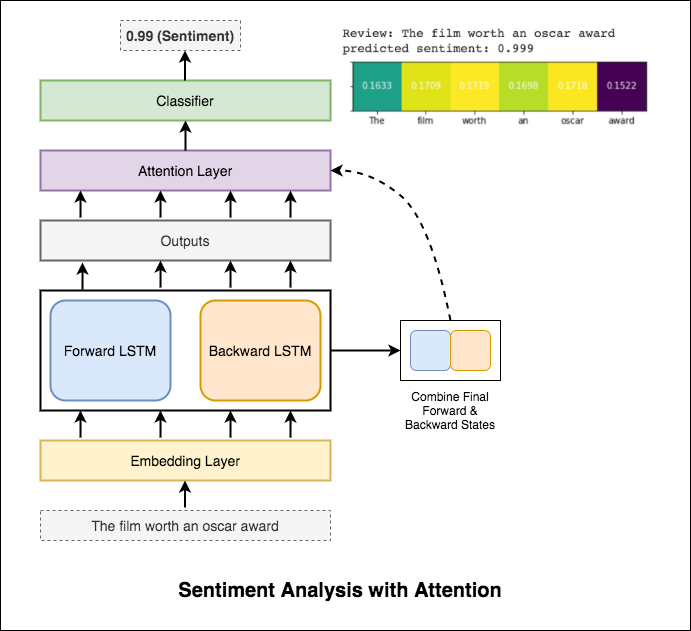
Bert obtient de nouveaux résultats de pointe sur onze tâches de traitement du langage naturel. L'apprentissage du transfert dans la PNL a déclenché après la libération du modèle Bert. L'utilisation de Bert pour faire l'analyse des sentiments est explorée.

Mélanger les langues, également connue sous le nom de mélange de code, est une norme dans les sociétés multilingues. Les personnes multilingues, qui sont des anglophones non natifs, ont tendance à coder en utilisant le frappe phonétique basée en anglais et l'insertion d'anglicismes dans leur langue principale.
La tâche consiste à prédire le sentiment d'un tweet mélangé de code donné. Les étiquettes de sentiment sont positives, négatives ou neutres, et les langues mélangées au code seront anglaises-hindi. (Senmix)
Les varitifs suivants ont été explorés:
En utilisant le modèle MLP simple, F1 score of 0.58 a été obtenu sur les données de test

Après avoir exploré le modèle MLP de base, le modèle LSTM a été utilisé pour la prédiction du sentiment et le score F1 de 0.57 a été obtenu.

Les résultats étaient en fait moins par rapport à un modèle MLP de base. L'une des raisons pourrait être le LSTM n'est pas en mesure d'apprendre les relations entre les mots d'une phrase en raison de la nature très diversifiée des données mélangées par le code.
Comme le LSTM n'est pas en mesure d'apprendre les relations entre les mots d'une phrase mélangée en code en raison de la nature très diversifiée des données mélangées au code et aucune intégration pré-formée n'est utilisée, le score F1 est moindre.
Pour atténuer ce problème, le modèle XLM-Roberta (qui a été formé sur 100 langues) est utilisé pour coder la phrase. Afin d'utiliser le modèle XLM-Roberta, la phrase doit être dans une langue appropriée. Donc, les mots hinglish doivent être convertis en forme hindi (Devanagari).
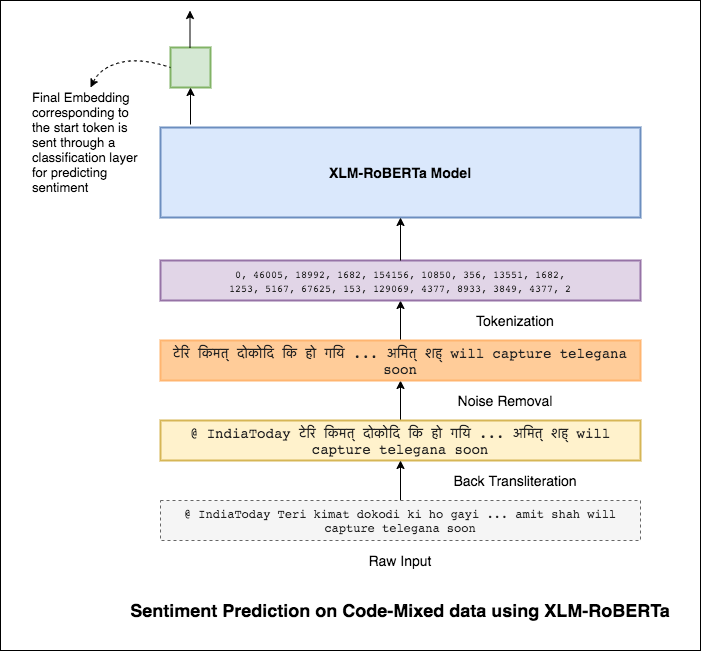
Un score F1 de 0.59 a été atteint. Les méthodes pour améliorer cela seront explorées plus tard.
La sortie finale du modèle XLM-Roberta a été utilisée comme intégration d'entrée au modèle LSTM bidirectionnel. Une couche d'attention, qui prend les sorties de la couche LSTM, produit une représentation pondérée de l'entrée, qui est ensuite transmise par un classificateur pour prédire le sentiment de la phrase.

Un score F1 de 0.64 a été atteint.
De la même manière qu'un filtre 3x3 peut regarder par-dessus un patch d'une image, un filtre 1x2 peut regarder sur 2 mots séquentiels dans un morceau de texte, c'est-à-dire un bi-gramme. Dans ce modèle CNN, nous utiliserons plutôt plusieurs filtres de différentes tailles qui examineront les bi-grammes (filtre 1x2), les tri-grammes (un filtre 1x3) et / ou les n-grammes (un filtre 1xn) dans le texte.
L'intuition ici est que l'apparition de certains bi-grammes, tri-grammes et n-grammes dans la revue sera une bonne indication du sentiment final.
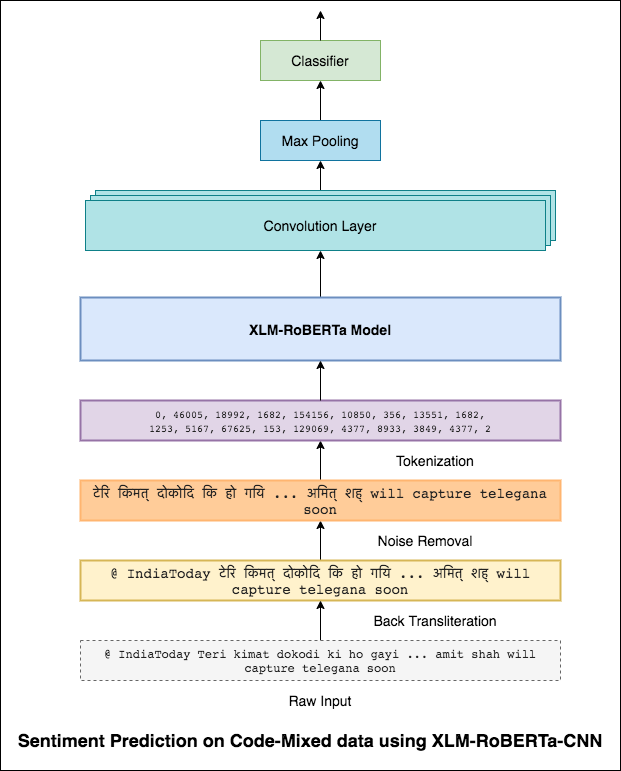
Un score F1 de 0.69 a été atteint.
CNN capture les dépendances locales où RNN capture les dépendances globales. En combinant les deux, nous pouvons mieux comprendre les données. L'ensemble du modèle CNN et du modèle bidirectionnel-gru-attention effectue les autres.
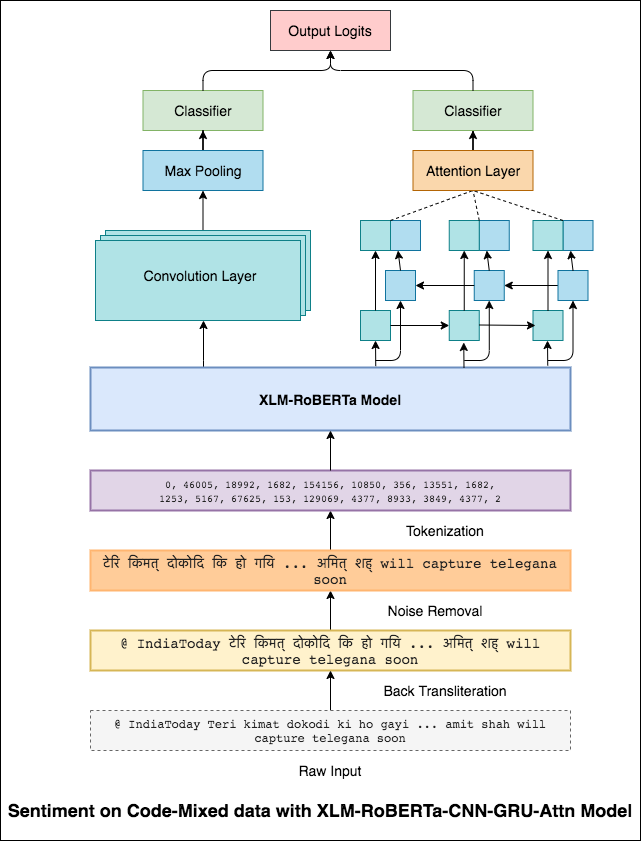
Un score F1 de 0.71 a été atteint. (Top 5 du classement).
La classification des documents ou la catégorisation des documents est un problème dans les sciences des bibliothèques, les sciences de l'information et l'informatique. La tâche consiste à attribuer un document à une ou plusieurs classes ou catégories.
Les varitifs suivants ont été explorés:
Un réseau d'attention hiérarchique (HAN) considère la structure hiérarchique des documents (documents - phrases - mots) et comprend un mécanisme d'attention qui est capable de trouver les mots et les phrases les plus importants dans un document tout en prenant en considération le contexte.
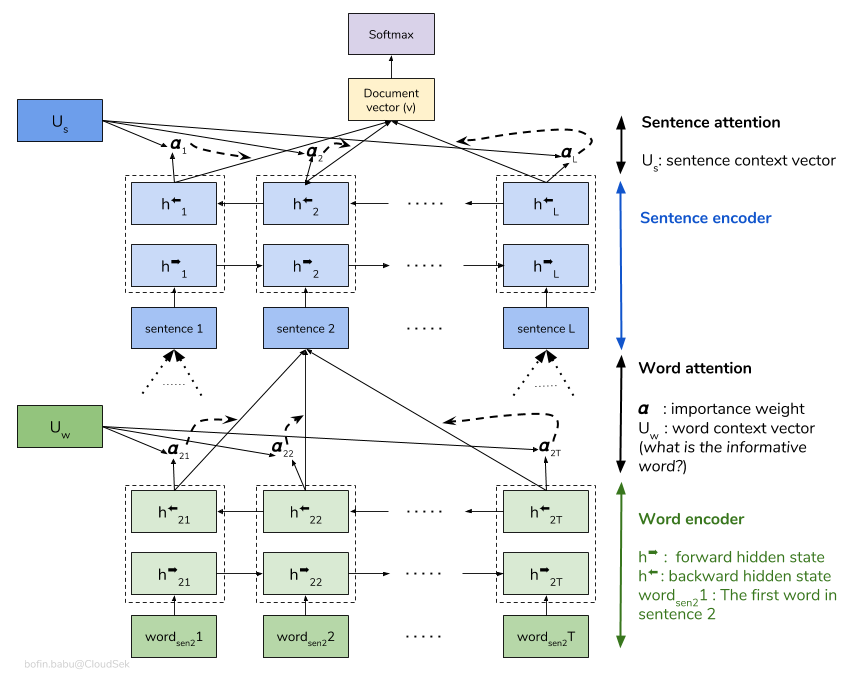
Le modèle HAN de base sur-ajustement rapidement. Afin de surmonter cela, des techniques telles que Embedding Dropout , Locked Dropout sont explorés. Il existe une autre technique appelée Weight Dropout qui n'est pas mise en œuvre (faites-moi savoir s'il existe de bonnes ressources pour implémenter cela). Glove d'incorporation de mots pré-formés sont également utilisés au lieu d'une initialisation aléatoire. Étant donné que l'attention peut être effectuée au niveau de la phrase et au niveau des mots, nous pouvons visualiser quels mots sont importants dans une phrase et quelles phrases sont importantes dans un document.



QQP signifie Quora Question Paires. L'objectif de la tâche est pour une paire de questions donnée; Nous devons découvrir si ces questions sont sémantiquement similaires les unes aux autres ou non.
Les varitifs suivants ont été explorés:
L'algorithme doit prendre la paire de questions en entrée et doit étendre leur similitude. Un réseau siamois est utilisé. Un Siamese neural network (parfois appelé réseau neuronal jumeau) est un réseau neuronal artificiel qui utilise les same weights tout en travaillant en tandem sur deux vecteurs d'entrée différents pour calculer des vecteurs de sortie comparables.

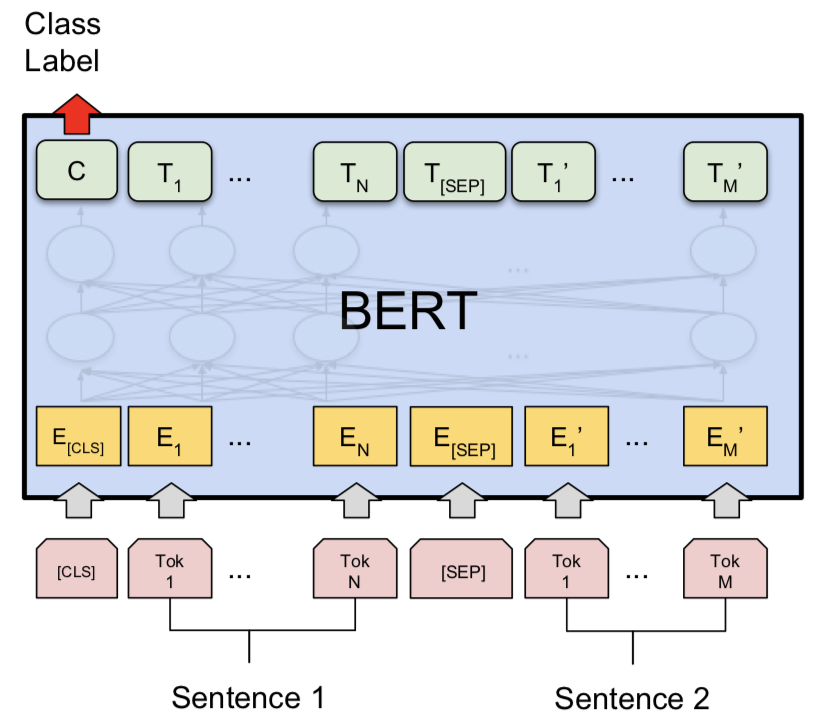
Après avoir essayé le modèle siamois, Bert a été exploré pour faire la détection des paires de questions Quora en double. Bert prend la question 1 et la question 2 en tant qu'entrée séparée par le jeton [SEP] et la classification a été effectuée en utilisant la représentation finale du jeton [CLS] .
Le marquage de la partie de la parole (POS) est une tâche d'étiqueter chaque mot dans une phrase avec sa partie appropriée de la parole.
Les varitifs suivants ont été explorés:
Ce code couvre le flux de travail de base. Nous apprendrons à: charger des données, créer des divisions de train / test / validation, construire un vocabulaire, créer des itérateurs de données, définir un modèle et implémenter la boucle de train / évaluer / tester et le marquage du temps d'exécution (inférence).
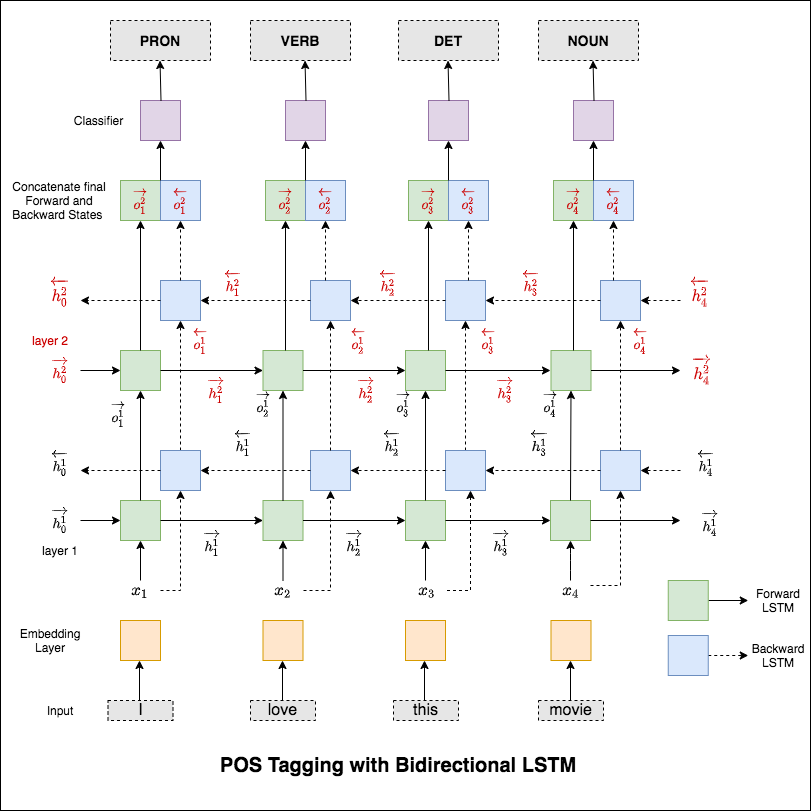
Le modèle utilisé est un réseau LSTM bidirectionnel multi-couche
Après avoir essayé l'approche RNN, le marquage POS avec l'architecture basée sur le transformateur est exploré. Étant donné que le transformateur contient à la fois l'encodeur et le décodeur et pour la tâche d'étiquetage de séquence, seul Encoder sera suffisant. Comme les données sont petites ayant 6 couches d'encodeur surviendront les données. Un modèle d'encodeur de transformateur à 3 couches a donc été utilisé.

Après avoir essayé le balisage POS avec un encodeur de transformateur, le marquage POS avec le modèle BERT pré-formé est expliqué. Il a atteint une précision de test de 91% .

L'objectif de l'inférence du langage naturel (NLI), une tâche de traitement du langage naturel largement étudié, est de déterminer si une déclaration donnée (une prémisse) implique sémantiquement une autre déclaration donnée (une hypothèse).
Les varitifs suivants ont été explorés:
Un modèle de base avec le réseau siamois bilstm est implémait
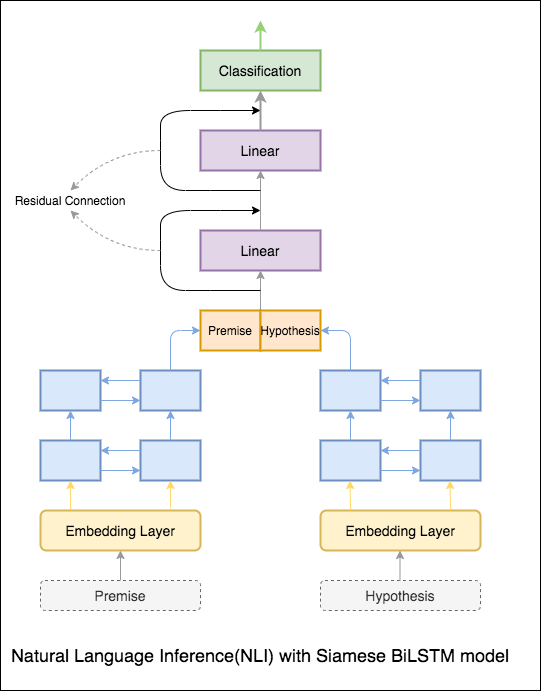
Cela peut être traité comme une configuration de base. Une précision de test de 76.84% a été réalisée.
Dans le cahier précédent, les états finaux cachés de prémisse et d'hypothèse en tant que représentations de LSTM. Maintenant, au lieu de prendre les états cachés finaux, l'attention sera calculée sur tous les jetons d'entrée et un vecteur pondéré final est considéré comme la représentation de la prémisse et de l'hypothèse.
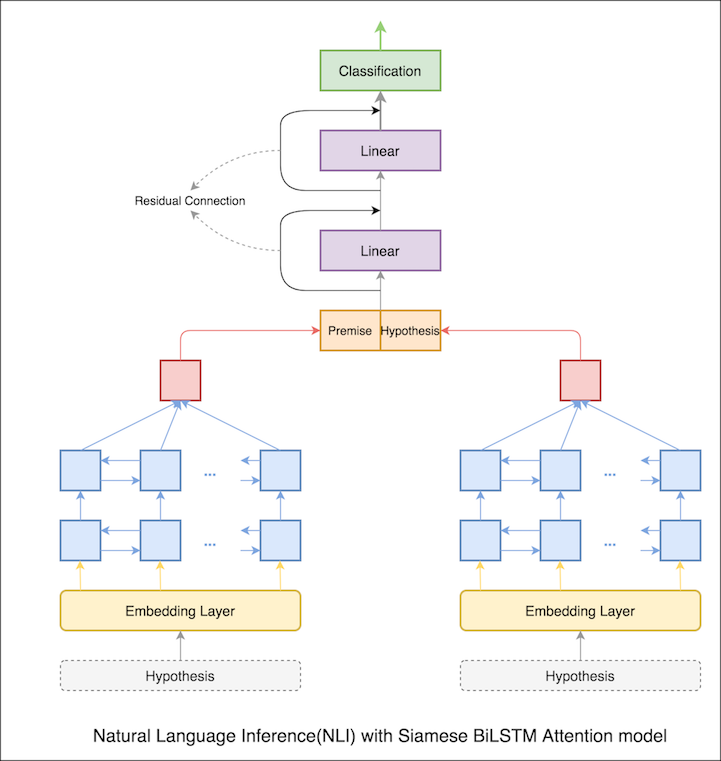
La précision du test est passée de 76.84% à 79.51% .
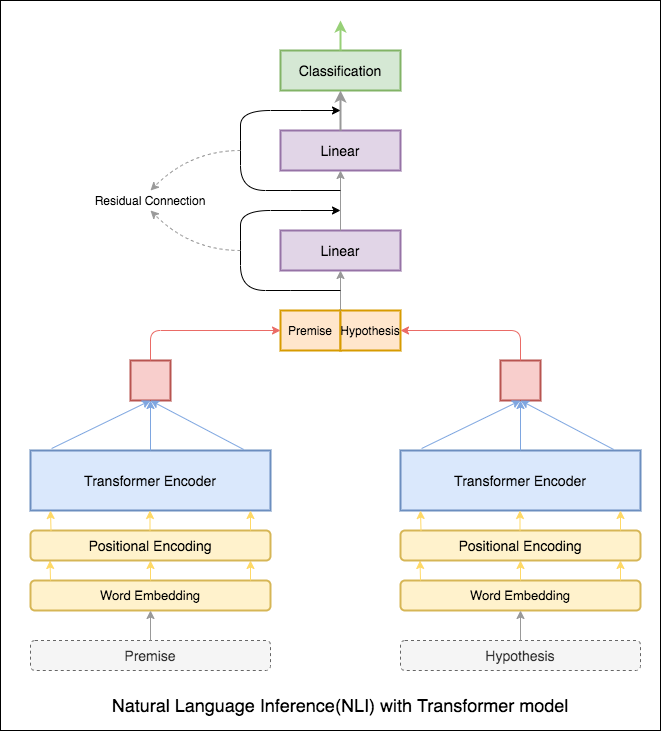
Encodeur de transformateur a été utilisé pour coder la prémisse et l'hypothèse. Une fois la phrase dépassée par le codeur, la sommation de tous les jetons est considérée comme la représentation finale (d'autres variantes peuvent être explorées). La précision du modèle est moindre par rapport aux variantes RNN.
NLI avec modèle de base Bert a été exploré. Bert prend la prémisse et l'hypothèse comme entrées séparées par le jeton [SEP] et la classification a été effectuée en utilisant la représentation finale du jeton [CLS] .
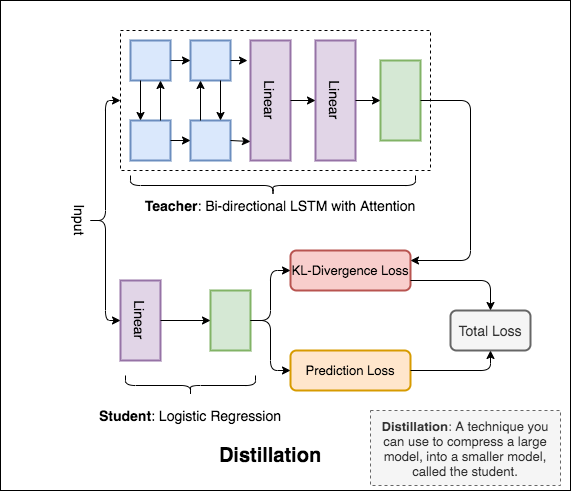
Distillation : une technique que vous pouvez utiliser pour comprimer un grand modèle, appelé l' teacher , dans un modèle plus petit, appelé l' student . Après l'élève, les modèles d'enseignants sont utilisés pour effectuer la distillation sur NLI.
Discuter des choses qui vous intéressent peuvent être difficiles. La menace d'abus et de harcèlement en ligne signifie que de nombreuses personnes cessent de s'exprimer et de renoncer à la recherche de différentes opinions. Les plateformes ont du mal à faciliter efficacement les conversations, ce qui a conduit de nombreuses communautés à limiter ou à arrêter complètement les commentaires des utilisateurs.
Vous bénéficiez d'un grand nombre de commentaires de Wikipedia qui ont été étiquetés par des évaluateurs humains pour un comportement toxique. Les types de toxicité sont:
Les varitifs suivants ont été explorés:
Le modèle utilisé est un réseau GRU bidirectionnel.
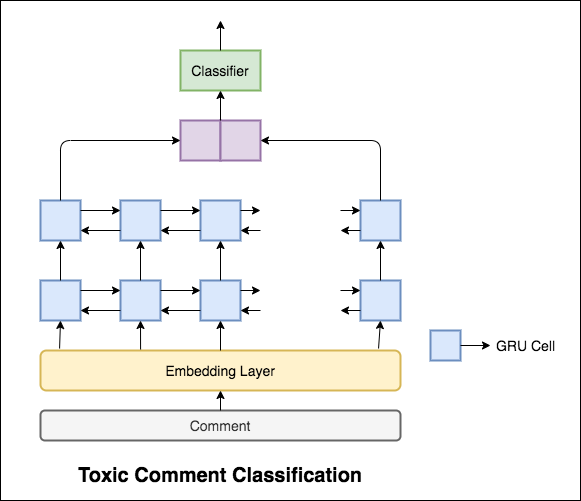
Une précision de test de 99.42% a été réalisée. Étant donné que 90% des données ne sont étiquetées dans aucune de la toxicité, la simple prévision de toutes les données comme non toxique donne un modèle précis à 90%. La précision n'est donc pas une métrique fiable. Une autre ASC métrique ROC a été mise en œuvre.
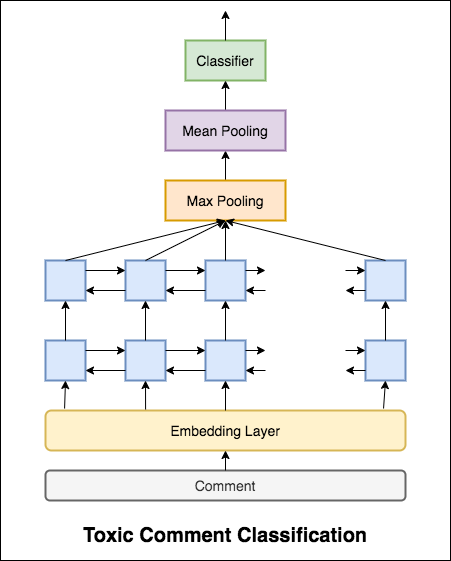
Avec Categorical Cross Entropy comme la perte, le score ROC_AUC de 0.5 est atteint. En modifiant la perte à Binary Cross Entropy et en modifiant un peu le modèle en ajoutant des couches de mise en commun (max, moyenne), le score ROC_AUC s'est amélioré à 0.9873 .
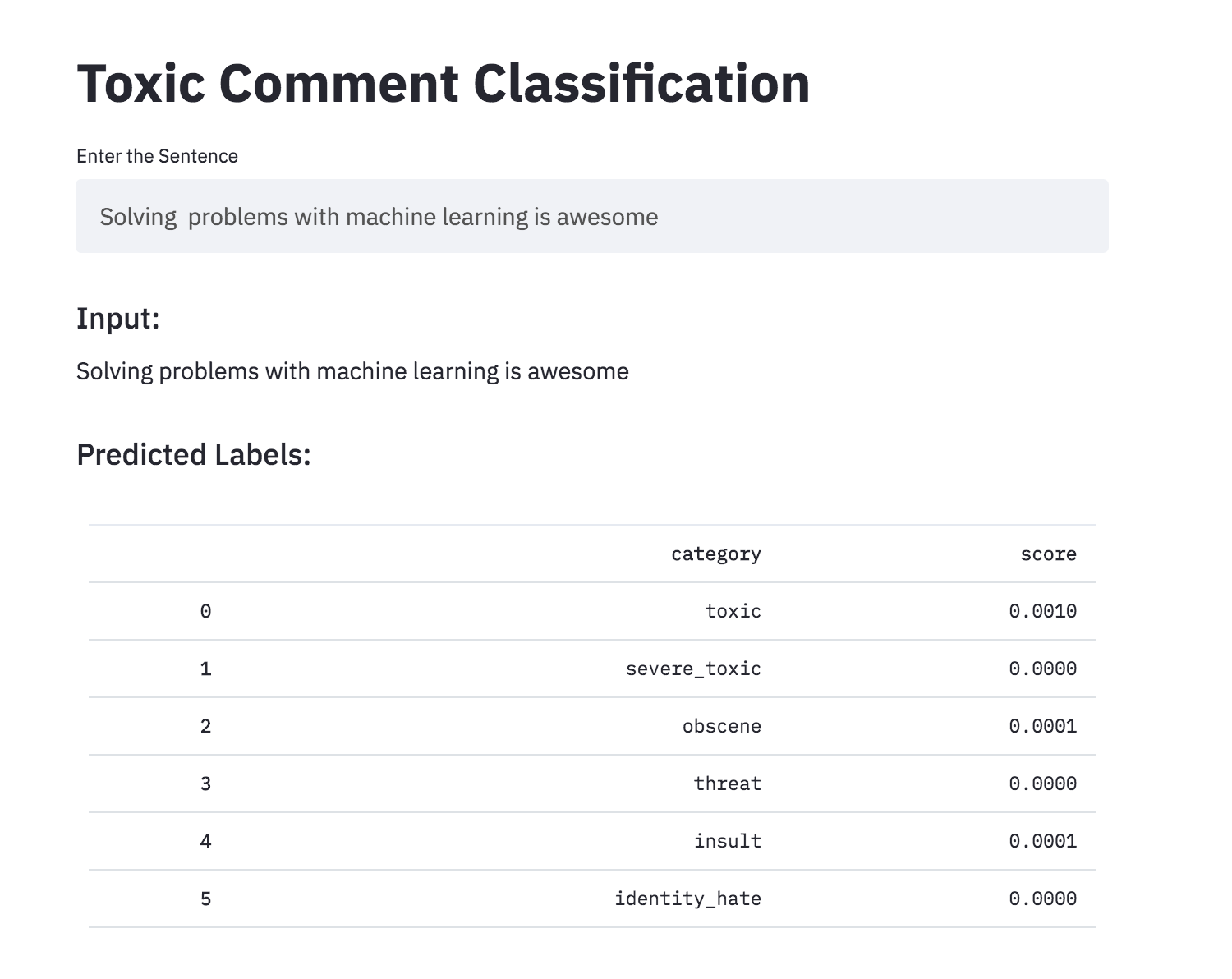
A converti la classification des commentaires toxiques en une application en utilisant Streamlit. Le modèle pré-formé est maintenant disponible.
Les réseaux de neurones artificiels peuvent-ils avoir la capacité de juger de l'acceptabilité grammaticale d'une peine? Afin d'explorer cette tâche, l'ensemble de données du corpus de l'acceptabilité linguistique (COLA) est utilisé. COLA est un ensemble de phrases étiquetées comme grammaticalement correctes ou incorrectes.
Les varitifs suivants ont été explorés:
Bert obtient de nouveaux résultats de pointe sur onze tâches de traitement du langage naturel. L'apprentissage du transfert dans la PNL a déclenché après la libération du modèle Bert. Dans ce cahier, nous explorerons comment utiliser Bert pour classer si une phrase est grammaticalement correcte ou non en utilisant un ensemble de données COLA.
Une précision de 85% et un coefficient de corrélation de Matthews (MCC) de 64.1 ont été obtenues.
Distillation : une technique que vous pouvez utiliser pour comprimer un grand modèle, appelé l' teacher , dans un modèle plus petit, appelé l' student . Après l'élève, les modèles d'enseignants sont utilisés pour effectuer une distillation sur COLA.

Les expériences suivantes ont été essayées:
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 Le tagging sur la reconnaissance de l'entité nommée (NER) est une tâche d'étiqueter chaque mot dans une phrase avec son entité appropriée.
Les varitifs suivants ont été explorés:
Ce code couvre le flux de travail de base. Nous verrons comment: charger des données, créer des divisions de train / test / validation, construire un vocabulaire, créer des itérateurs de données, définir un modèle et implémenter la boucle de train / évaluer / tester et se former, tester le modèle.
Le modèle utilisé est le réseau LSTM bidirectionnel
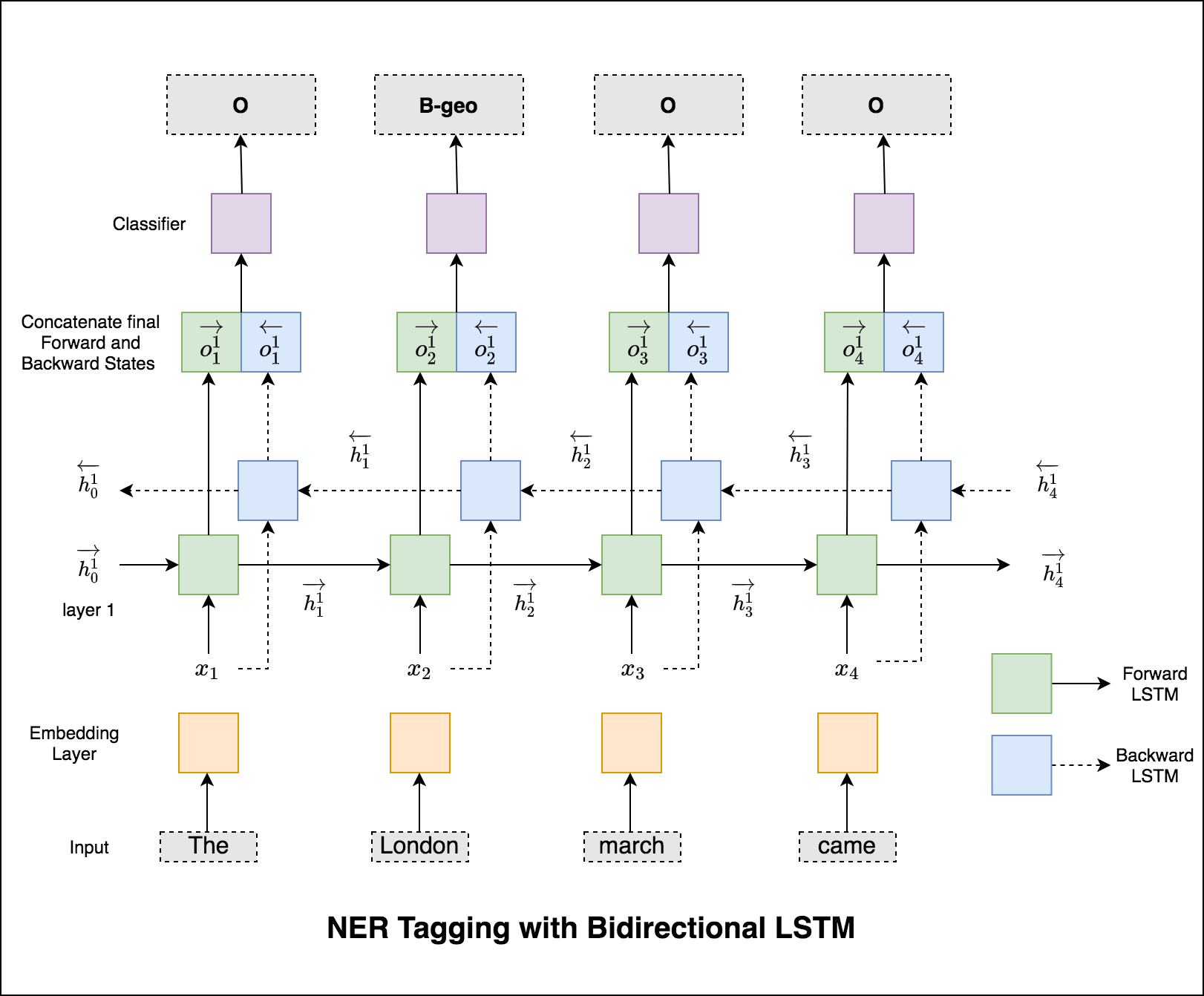
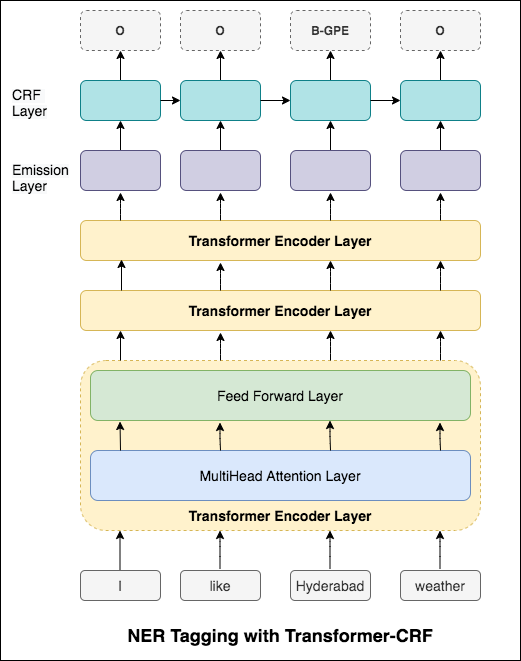
Dans le cas du taggage de séquence (NER), la balise d'un mot actuel peut dépendre de la balise du mot précédent. (Ex: New York).
Sans CRF, nous aurions simplement utilisé une seule couche linéaire pour transformer la sortie du LSTM bidirectionnel en scores pour chaque balise. Ceux-ci sont appelés emission scores , qui sont une représentation de la probabilité que le mot soit une certaine étiquette.
Un CRF calcule non seulement les scores d'émission, mais aussi les transition scores , qui sont la probabilité qu'un mot soit une certaine étiquette étant donné que le mot précédent était une certaine balise. Par conséquent, les scores de transition mesurent dans quelle mesure il est probable de passer d'une étiquette à l'autre.
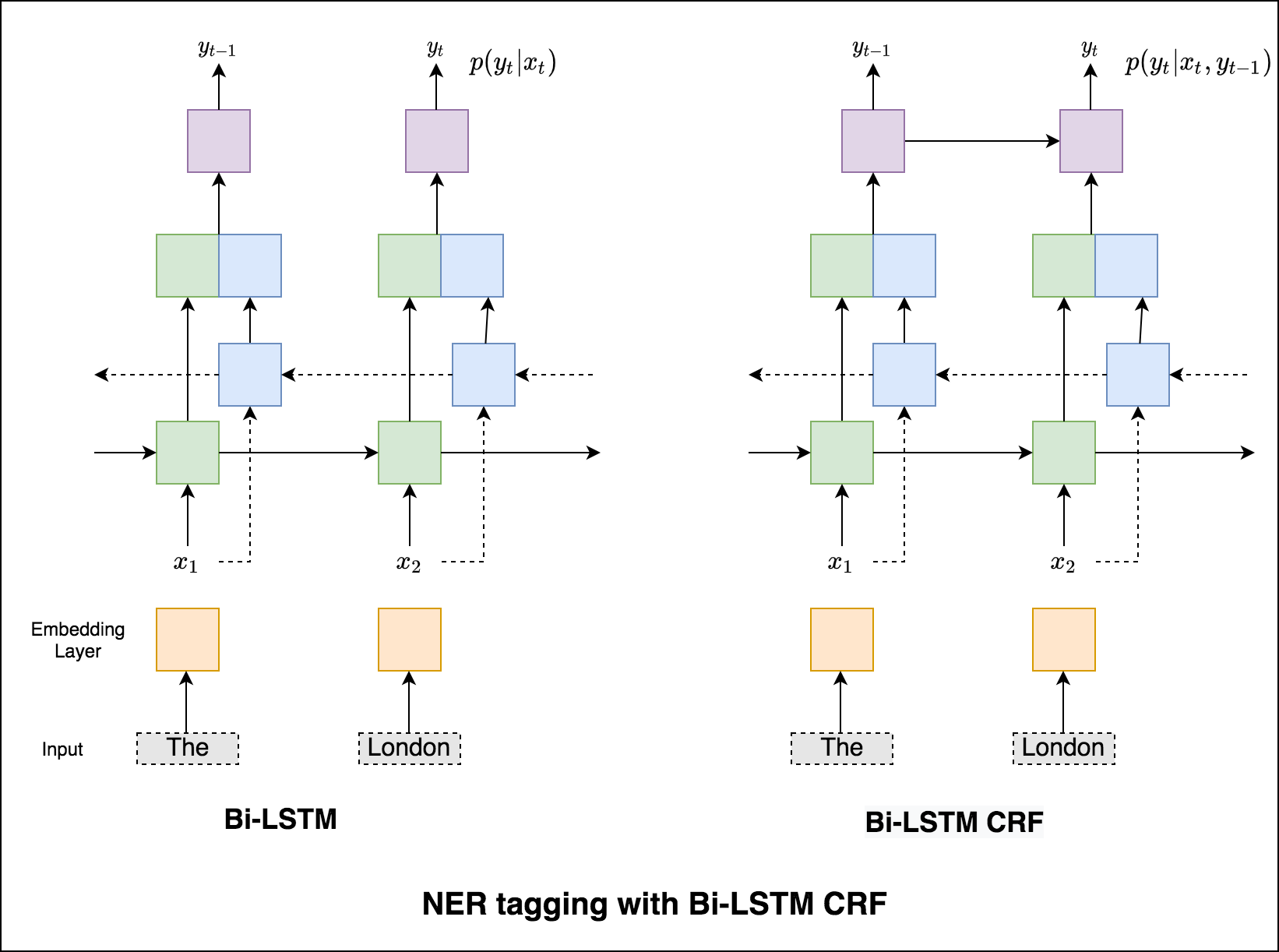
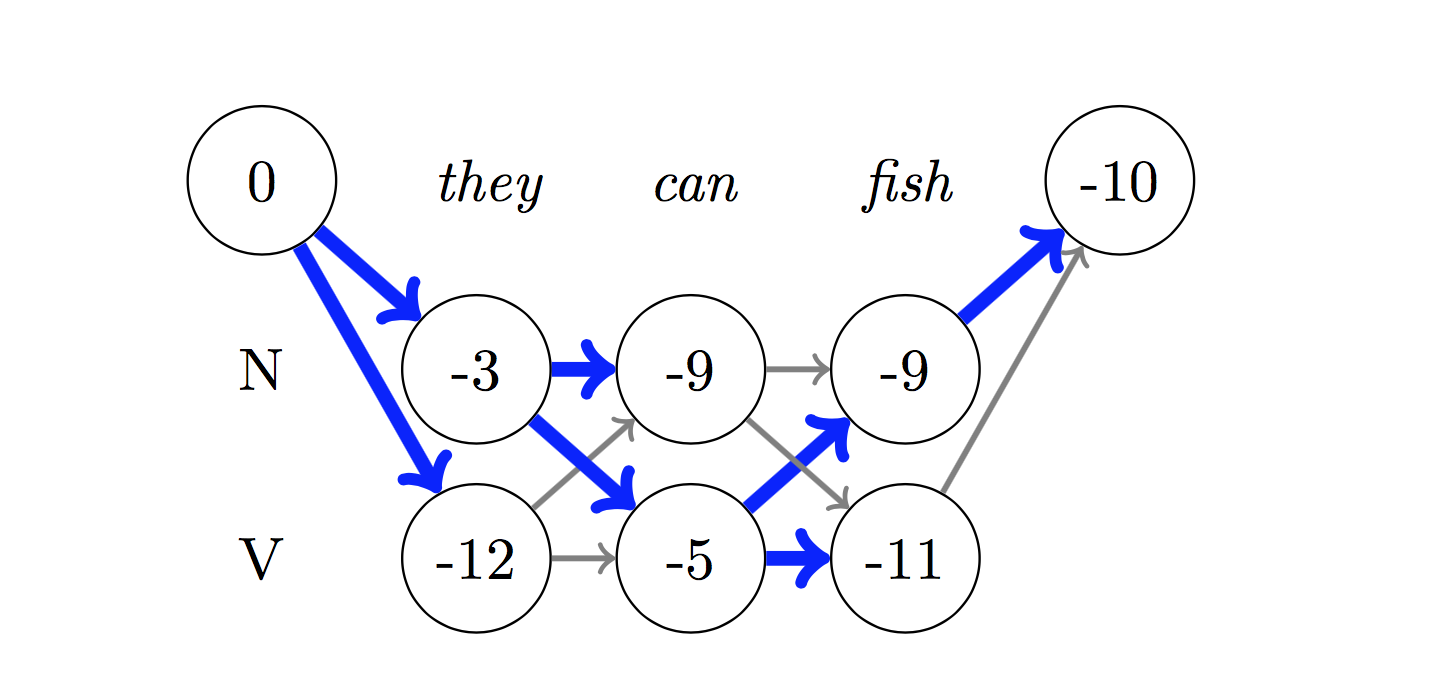
Pour le décodage, l'algorithme Viterbi est utilisé.
Puisque nous utilisons les CRF, nous ne prédisons pas tant la bonne étiquette à chaque mot que nous prédisons la séquence d'étiquette droite pour une séquence de mots. Le décodage viterbi est un moyen de faire exactement cela - trouvez la séquence de balises la plus optimale à partir des scores calculés par un champ aléatoire conditionnel.
Utilisation d'informations de sous-mot dans notre tâche de marquage car elle peut être un indicateur puissant des balises, qu'il s'agisse d'une partie de la parole ou des entités. Par exemple, il peut apprendre que les adjectifs se terminent généralement par "-y" ou "-ul", ou que les lieux se terminent souvent par "-Land" ou "-Burg".
Par conséquent, notre modèle de marquage de séquence utilise les deux
word-level sous la forme d'incorporation de mots.character-level jusqu'à et y compris chaque mot dans les deux sens. 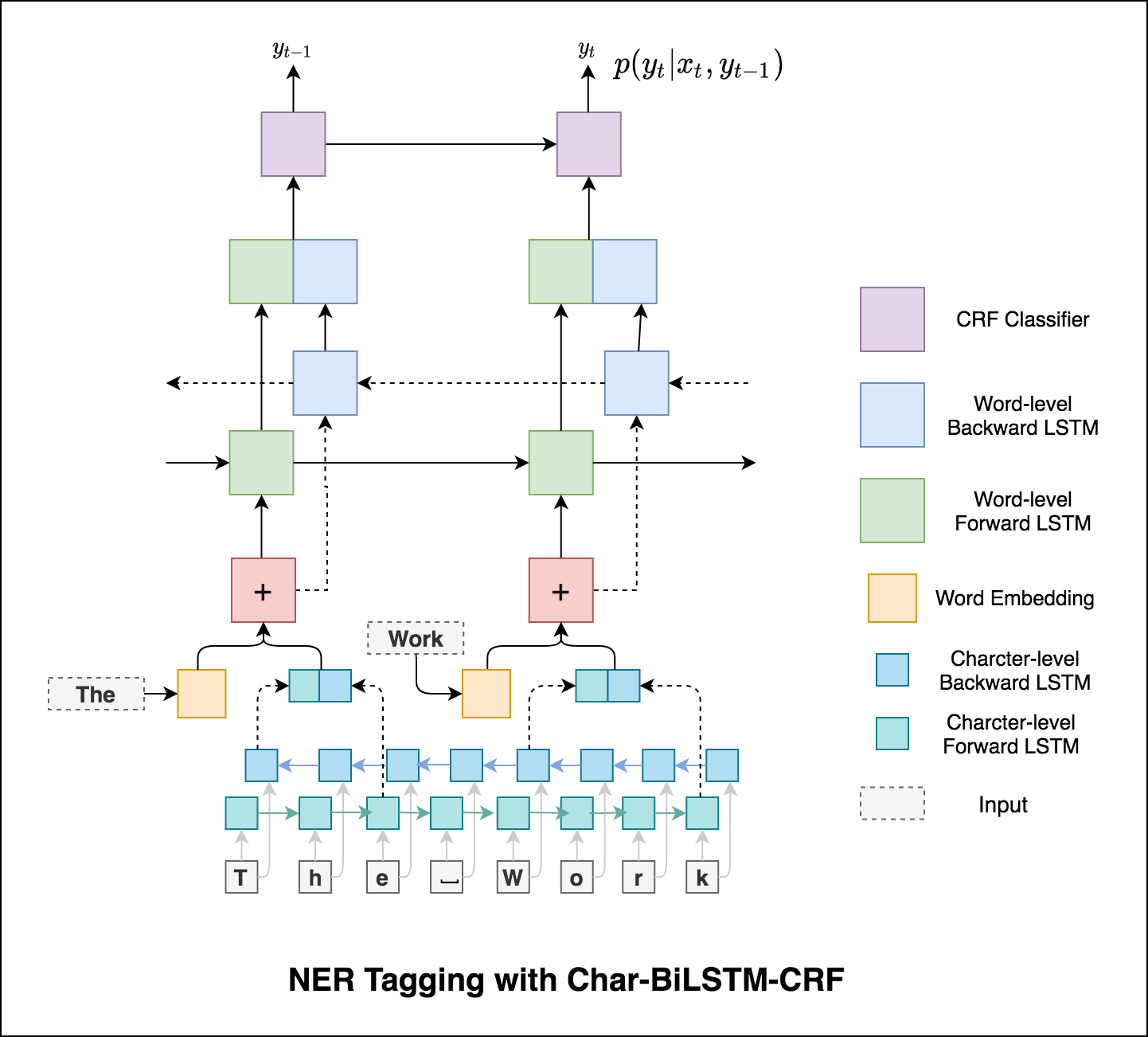
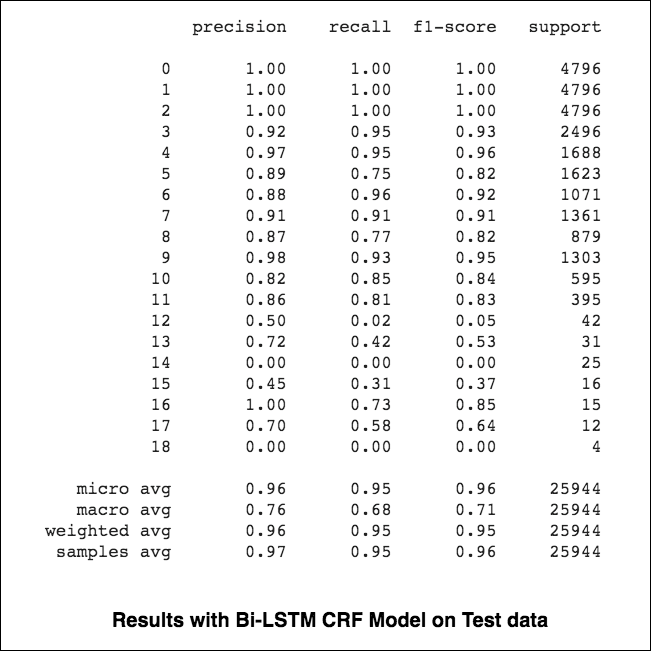
Les micro et macro-moyennes (pour quelle que ce soit la métrique) calculeront des choses légèrement différentes, et donc leur interprétation diffère. Une macro-moyenne calculera la métrique indépendamment pour chaque classe, puis prendra la moyenne (en traitant ainsi toutes les classes également), tandis qu'une micro-moyenne agrégera les contributions de toutes les classes pour calculer la métrique moyenne. Dans une configuration de classification multi-classes, la micro-moyenne est préférable si vous pensez qu'il pourrait y avoir un déséquilibre de classe (c'est-à-dire que vous pouvez avoir beaucoup plus d'exemples d'une classe que d'autres classes).

Converti le marquage NER en une application à l'aide de Streamlit. Le modèle pré-formé (char-bilstm-CRF) est maintenant disponible.
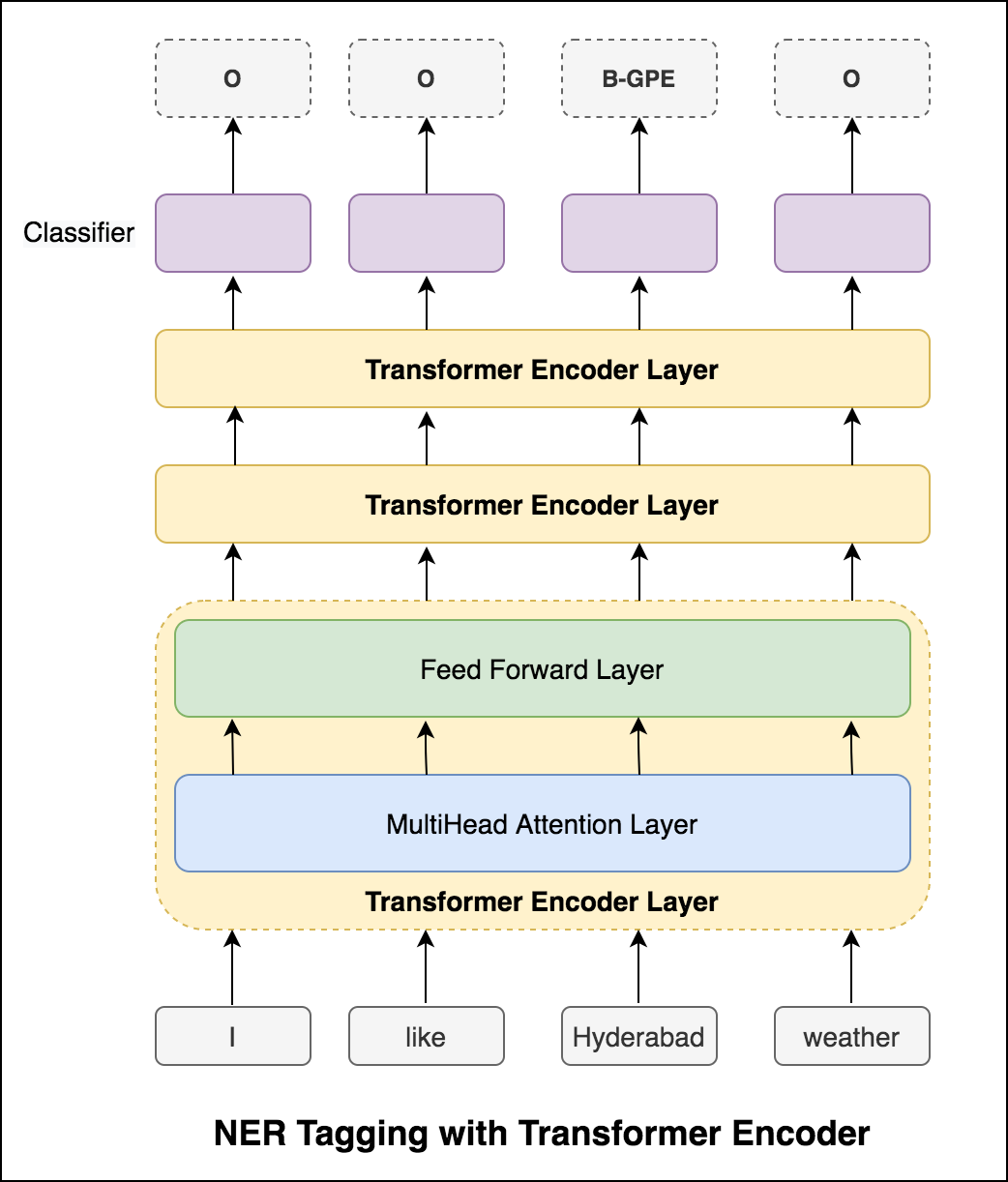
Après avoir essayé l'approche RNN, le marquage NER avec l'architecture basée sur le transformateur est exploré. Étant donné que le transformateur contient à la fois l'encodeur et le décodeur et pour la tâche d'étiquetage de séquence, seul Encoder sera suffisant. Un modèle d'encodeur de transformateur à 3 couches a été utilisé.
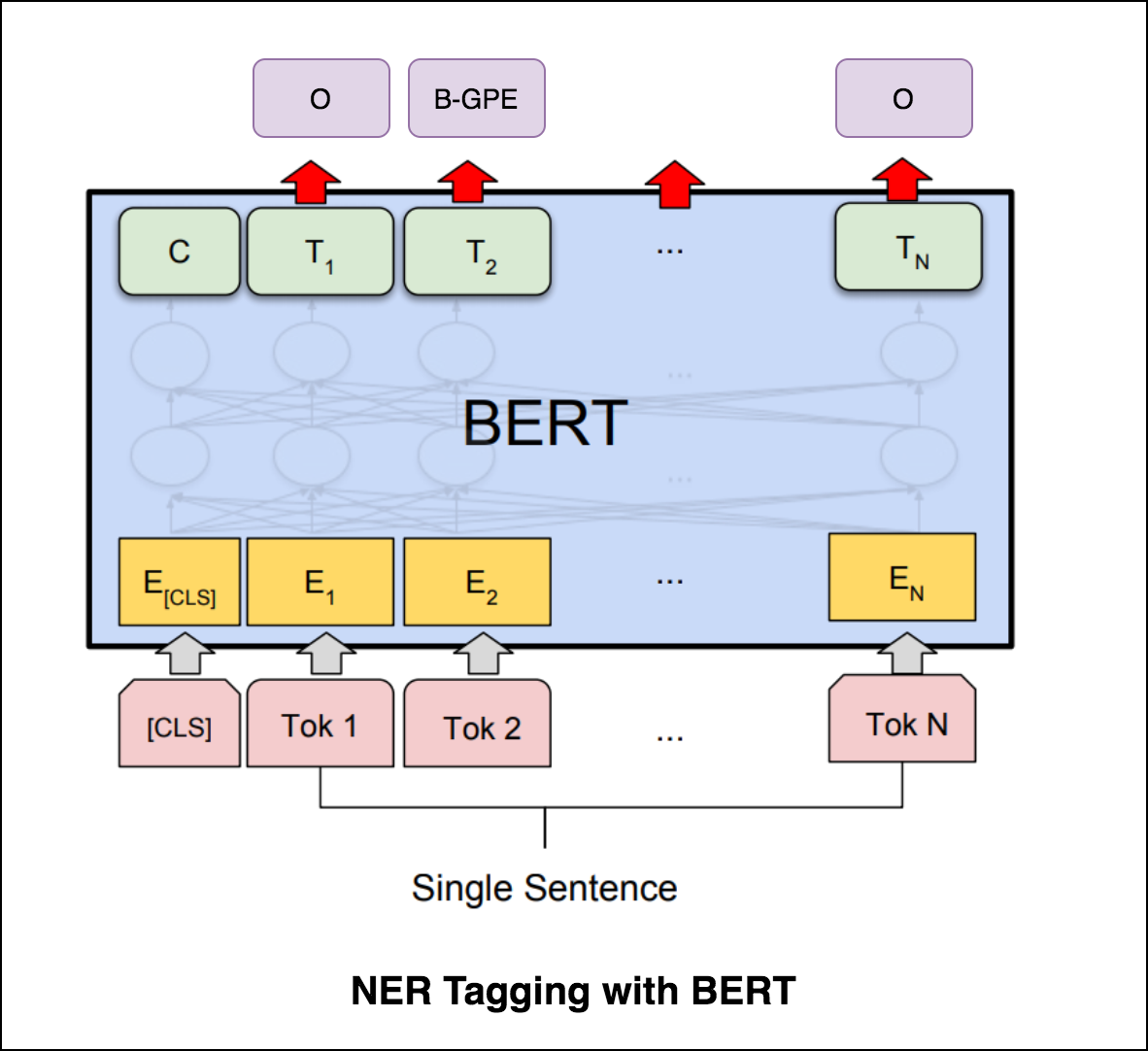
Après avoir essayé le marquage NER avec l'encodeur de transformateur, le marquage NER avec le modèle pré-formé bert-base-cased est exploré.
Le transformateur seul ne donne pas de bons résultats par rapport au bilstm dans la tâche de marquage NER. L'augmentation de la couche CRF au-dessus du transformateur est mise en œuvre, ce qui améliore les résultats par rapport au transformateur autonome.
Spacy fournit un système statistique exceptionnellement efficace pour NER dans Python, qui peut attribuer des étiquettes à des groupes de jetons. Il fournit un modèle par défaut qui peut reconnaître un large éventail d'entités nommées ou numériques, qui incluent la personne, l'organisation, la langue, l'événement, etc.

Outre ces entités par défaut, Spacy nous donne également la liberté d'ajouter des classes arbitraires au modèle NER, en formant le modèle pour le mettre à jour avec de nouveaux exemples formés.
2 nouvelles entités appelées ACTIVITY et SERVICE dans un domaine spécifique (banque) sont créées et formées avec quelques échantillons de formation.

| Génération de noms | Traduction automatique | Génération d'énoncés |
| Sous-titrage d'image | Cabillage d'image - Équations de latex | Résumé des nouvelles |
| Génération de sujets par e-mail |
Un modèle de langue LSTM au niveau des caractères est utilisé. Autrement dit, nous donnerons au LSTM un énorme morceau de noms et lui demanderons de modéliser la distribution de probabilité du caractère suivant dans la séquence étant donné une séquence de caractères précédents. Cela nous permettra alors de générer un nouveau nom un personnage à la fois

La traduction machine (MT) est la tâche de convertir automatiquement un langage naturel en une autre, de préserver la signification du texte d'entrée et de produire du texte fluide dans le langage de sortie. Idéalement, une séquence de langue source est traduite en séquence de langage cible. La tâche consiste à convertir les phrases de German to English .
Les varitifs suivants ont été explorés:
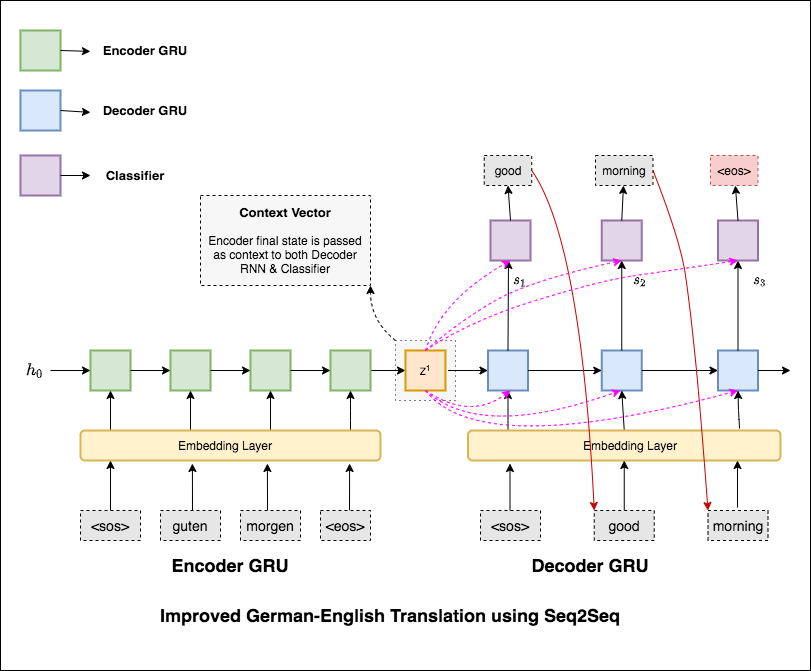
Les modèles de séquence à séquence les plus courants (SEQ2SEQ) sont des modèles de coder-décodeur, qui utilisent couramment un réseau neuronal récurrent (RNN) pour coder la phrase source (entrée) en un seul vecteur. Dans ce cahier, nous nous référerons à ce vecteur unique en tant que vecteur de contexte. Nous pouvons penser que le vecteur de contexte est une représentation abstraite de la phrase d'entrée entière. Ce vecteur est ensuite décodé par un deuxième RNN qui apprend à produire la phrase cible (sortie) en la générant un mot à la fois.

Après avoir essayé la traduction machine de base qui a la perplexité du texte 36.68 , les techniques suivantes ont été expérimentées et un test perplexity 7.041 .
Découvrez le code dans le dossier applications/generation
Le mécanisme d'attention est né pour aider à mémoriser des phrases à longue source dans la traduction des machines neuronales (NMT). Plutôt que de construire un seul vecteur de contexte à partir du dernier état caché de l'encodeur, l'attention est utilisée pour se concentrer davantage sur les parties pertinentes de l'entrée tout en décodant une phrase. Le vecteur de contexte sera créé en prenant des sorties d'encodeur et à l' previous hidden state du décodeur RNN.
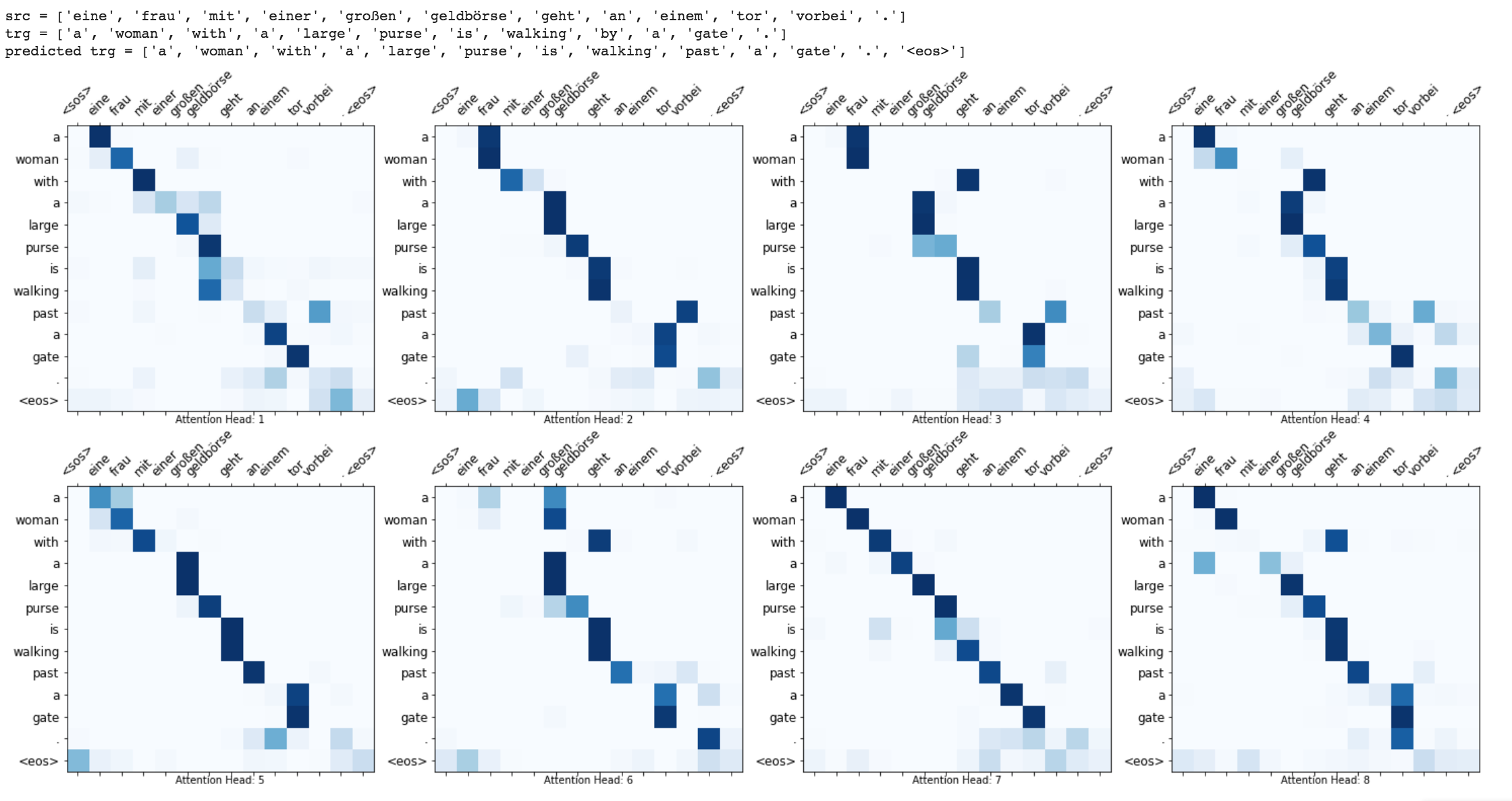
Des améliorations telles que le masquage (ignorer l'attention sur l'entrée rembourrée), l'emballage des séquences rembourrées (pour un meilleur calcul), la visualisation de l'attention et la métrique BLEU sur les données de test sont implémentées.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
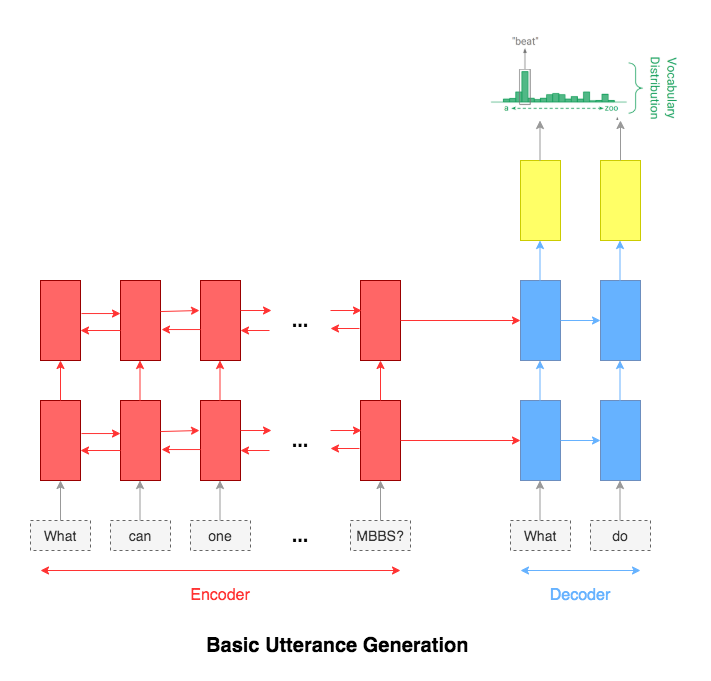
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
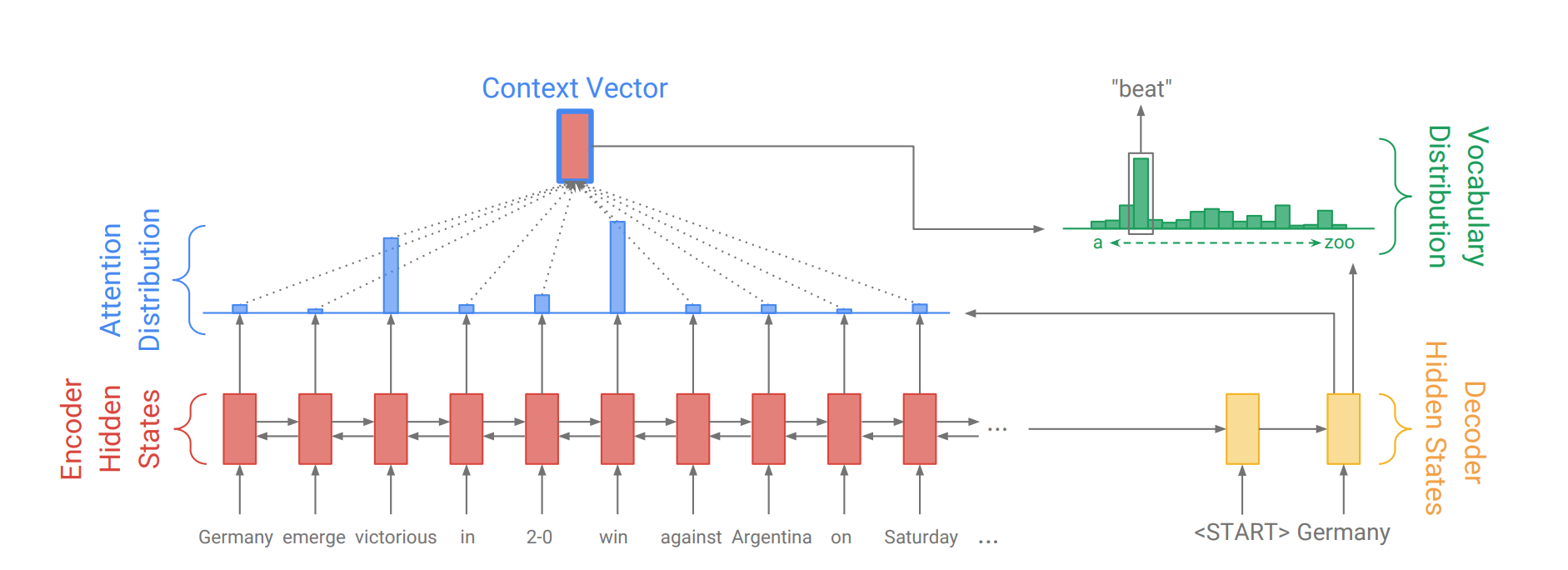
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
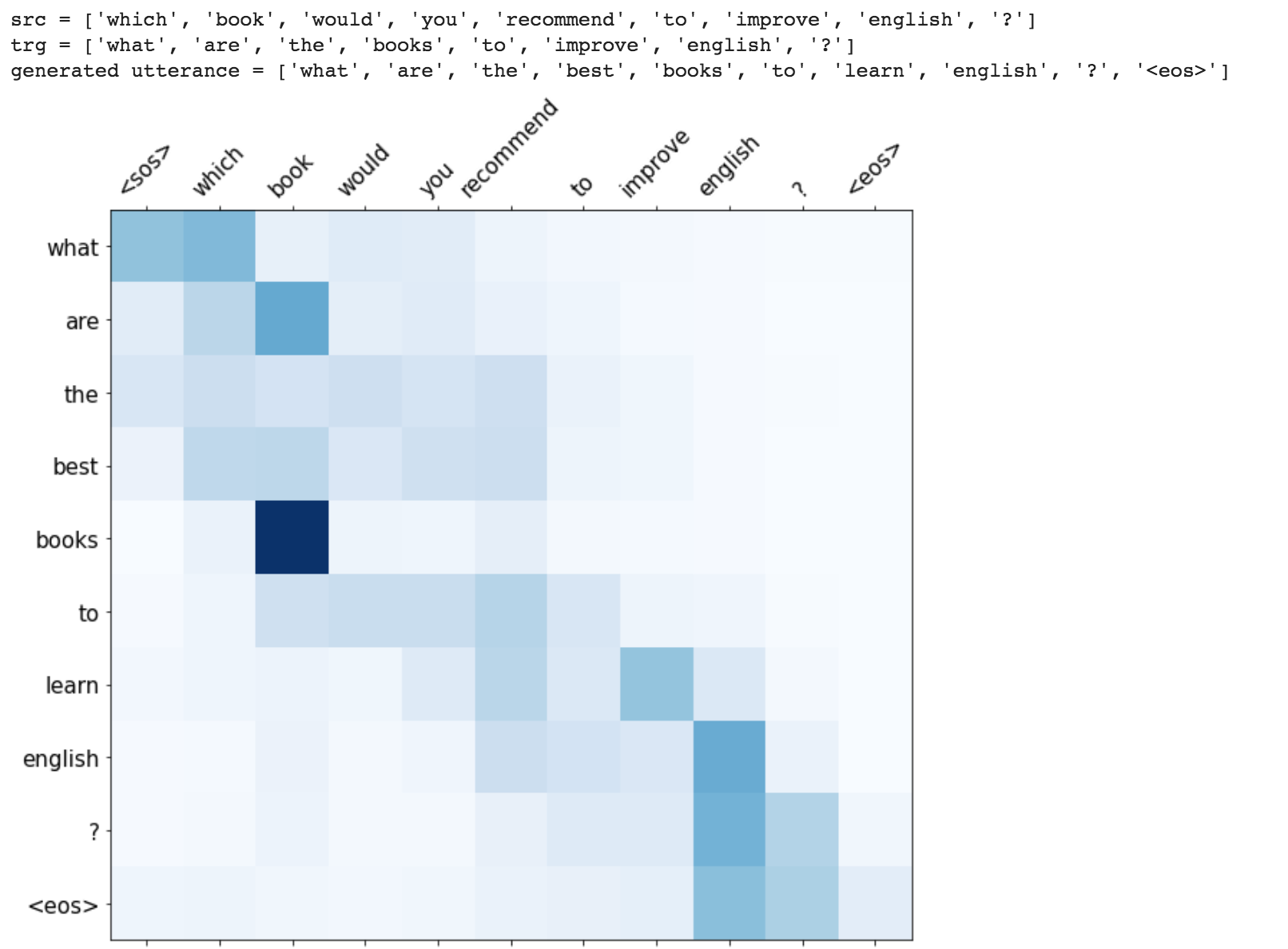
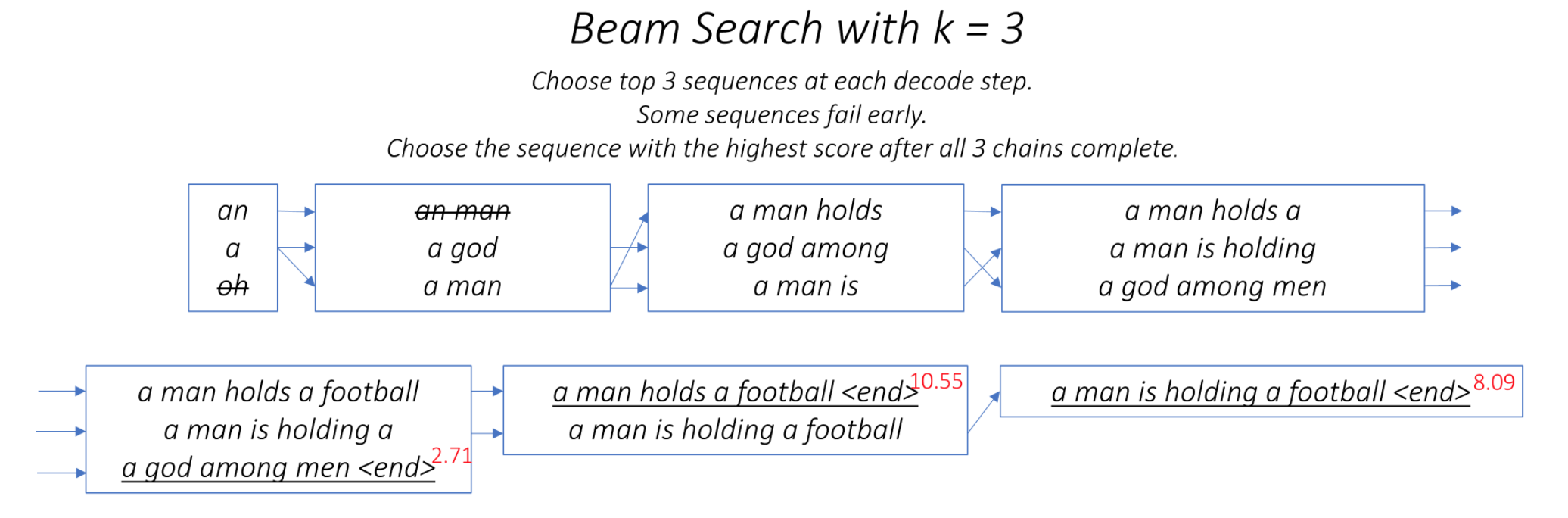
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

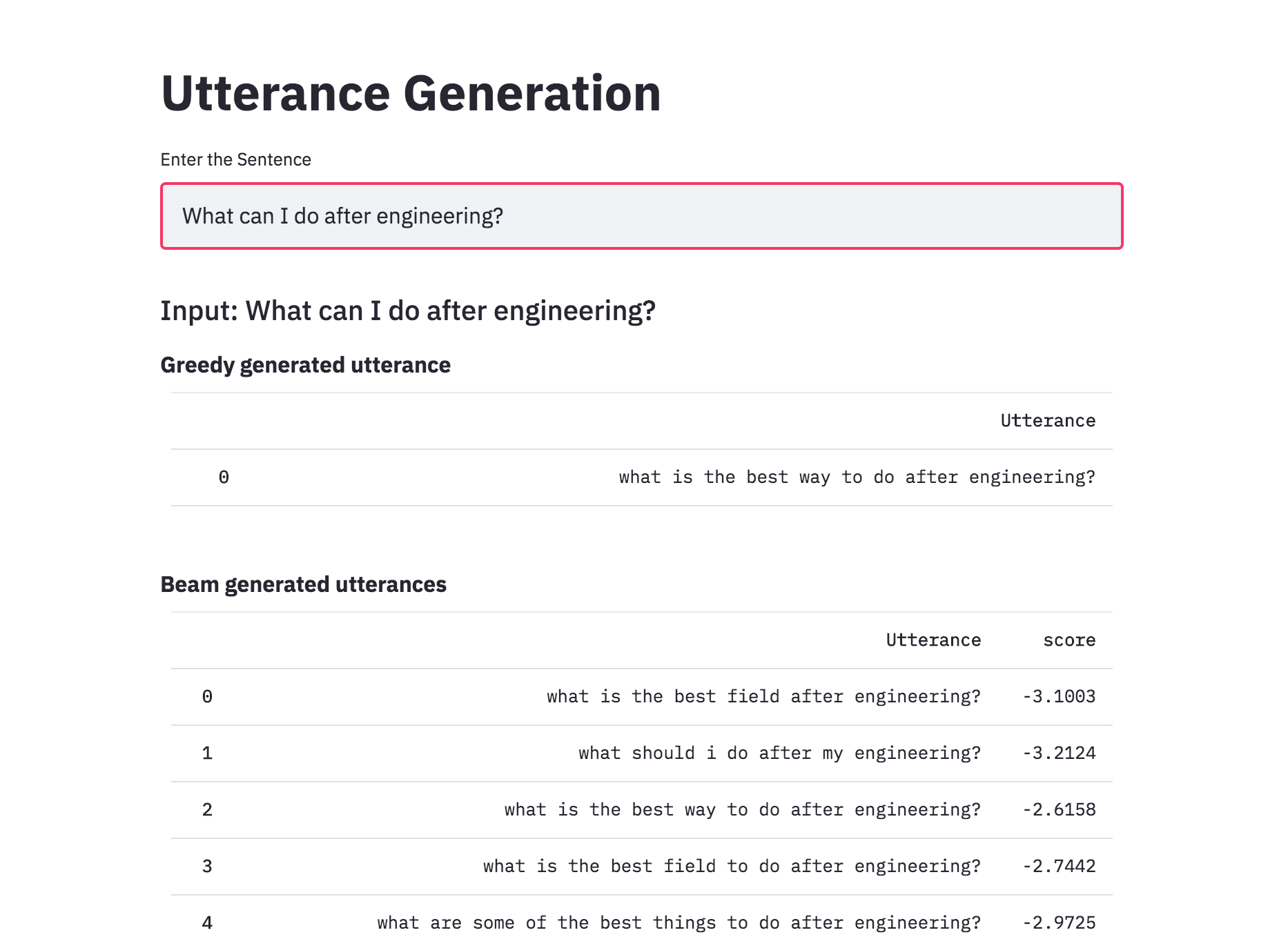
Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

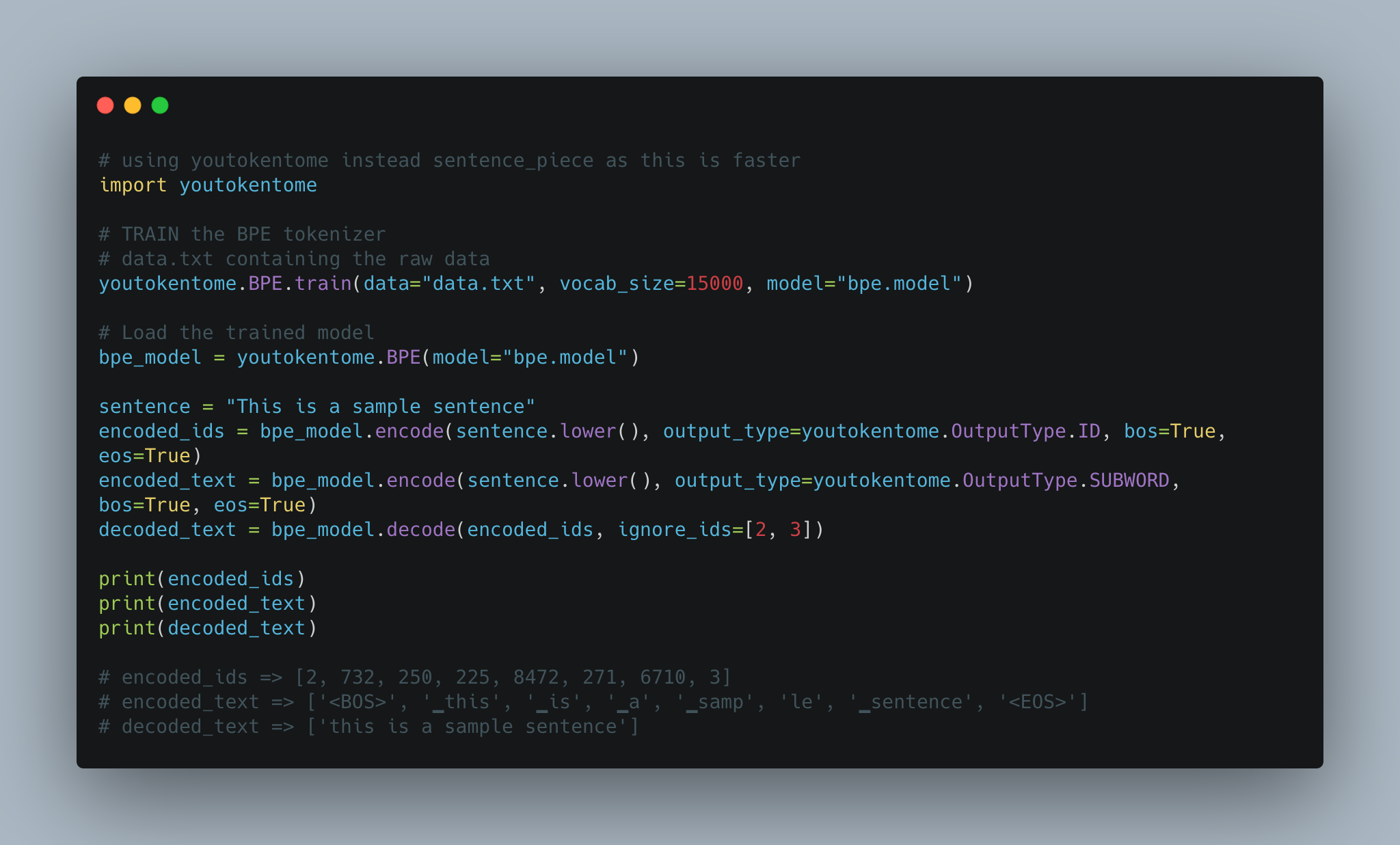
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
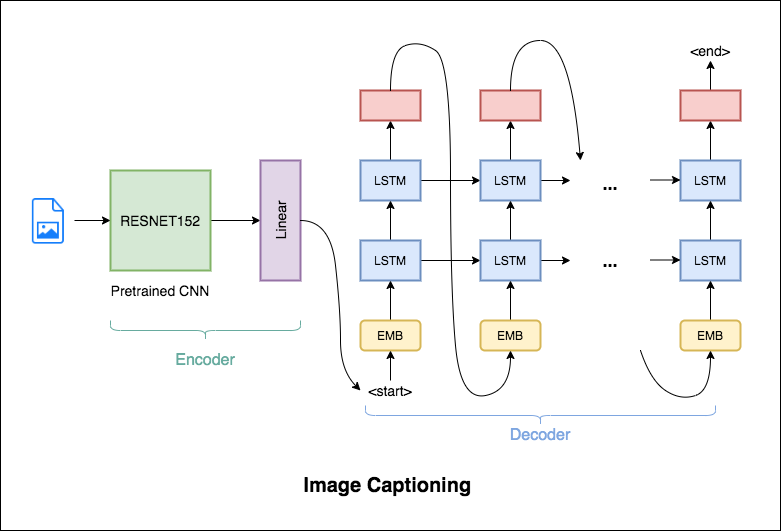
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
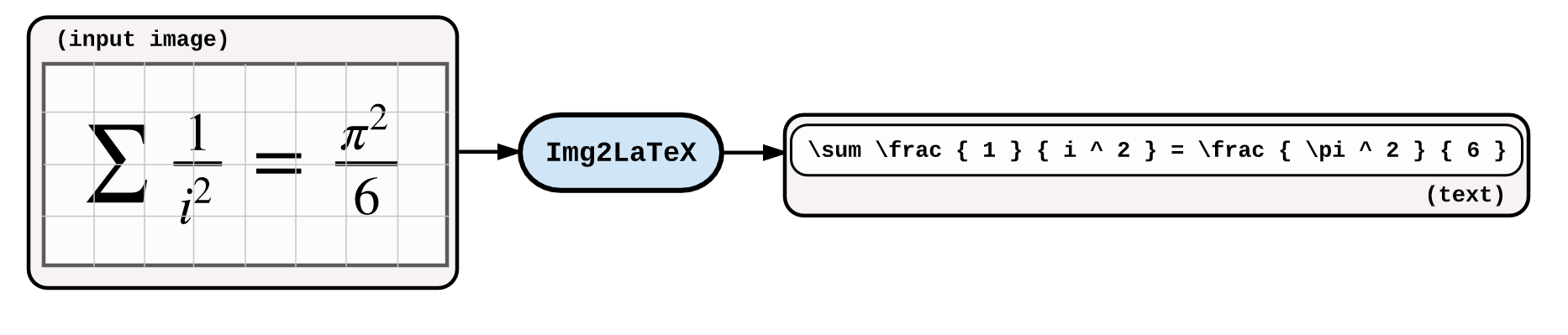
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
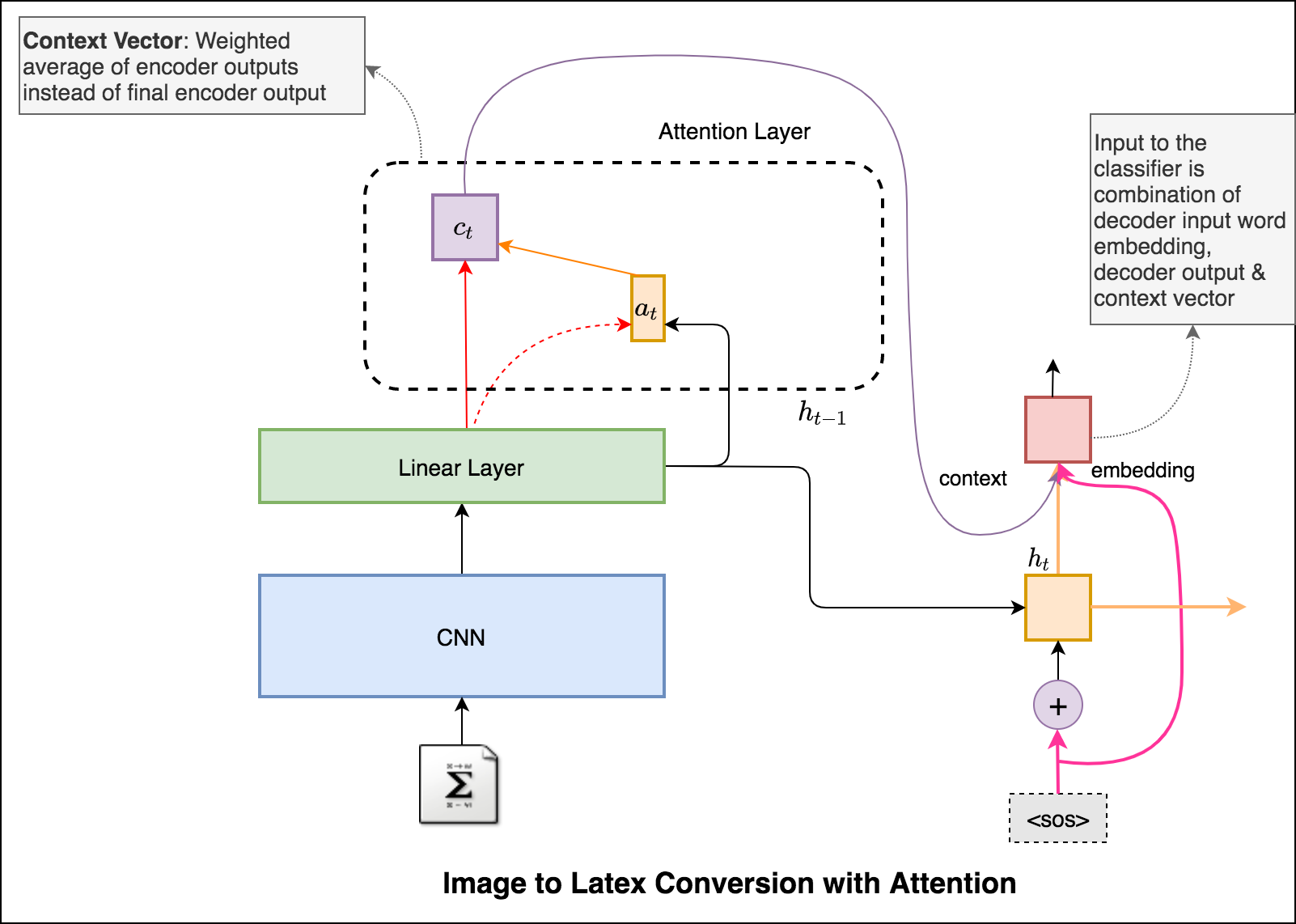
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

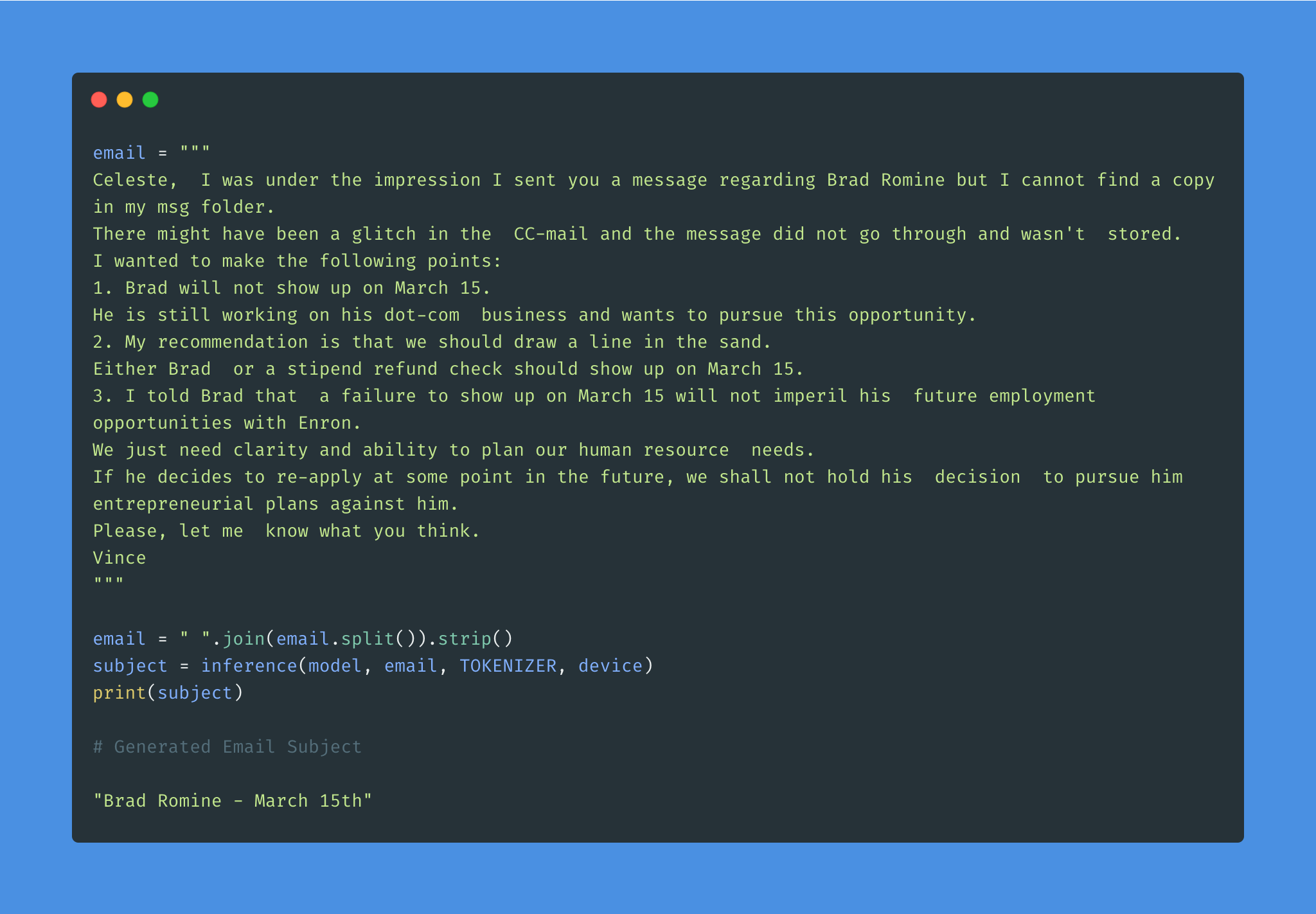
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
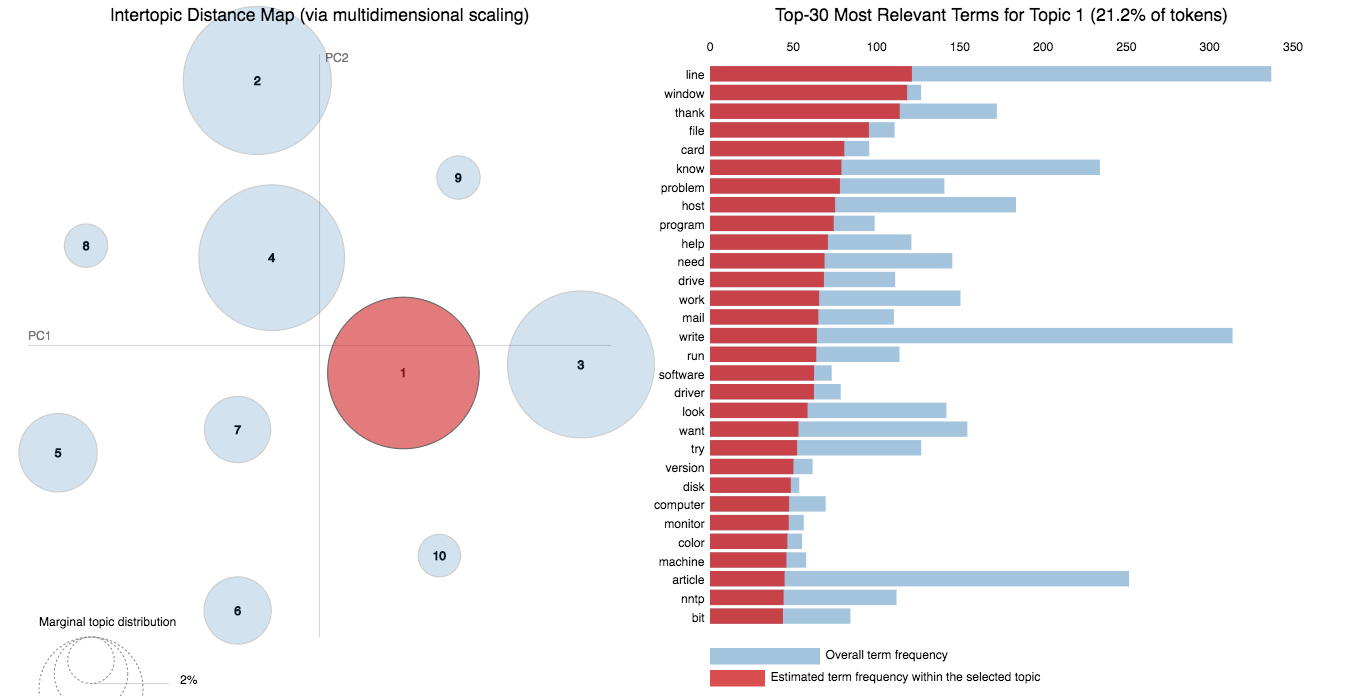
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
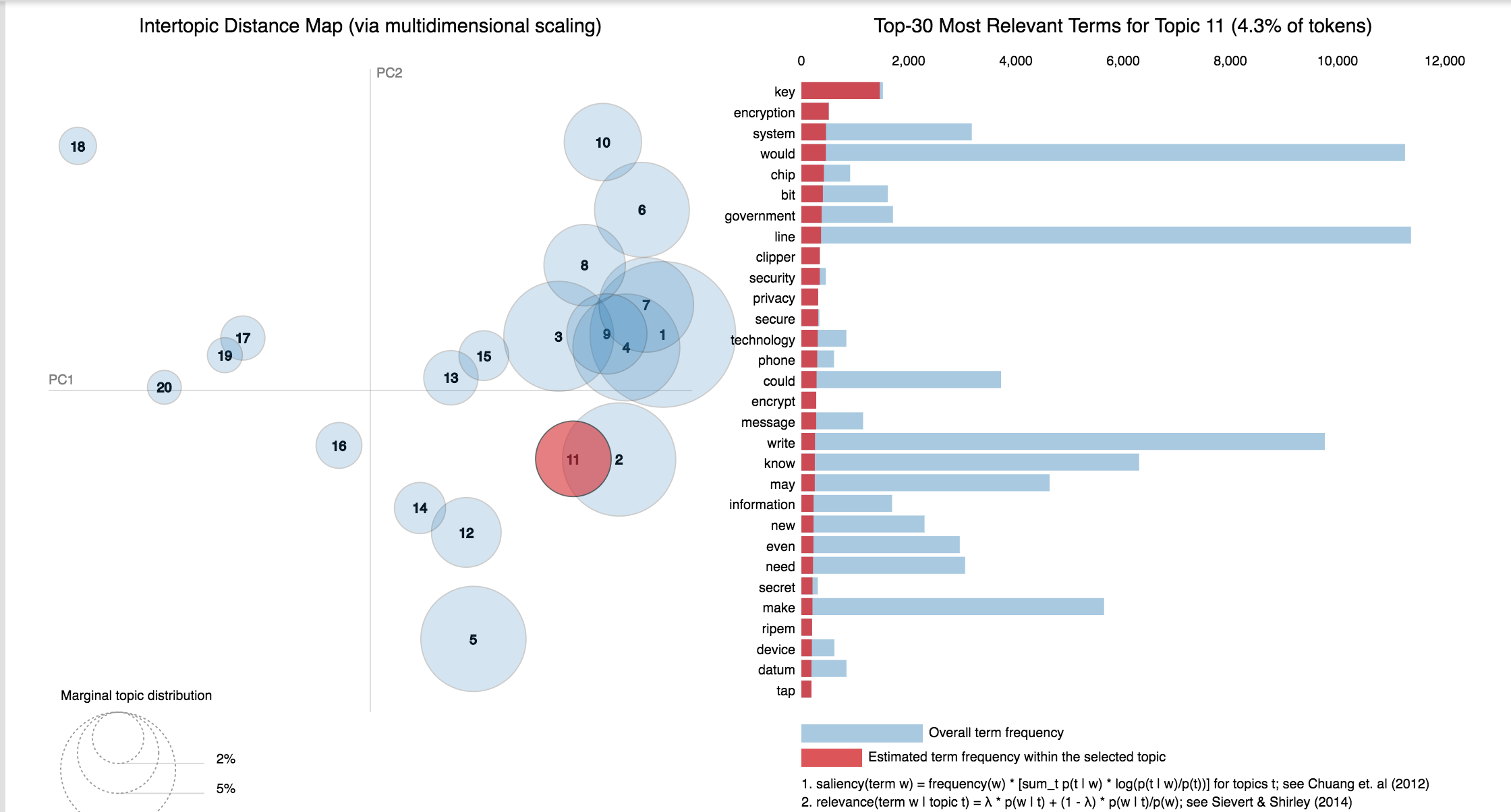
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
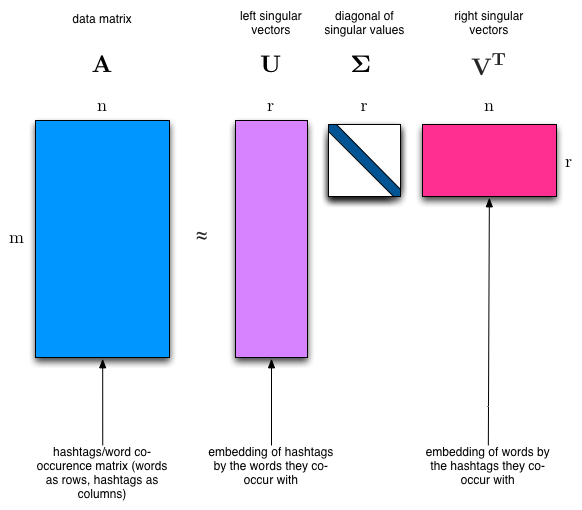
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
Notes:
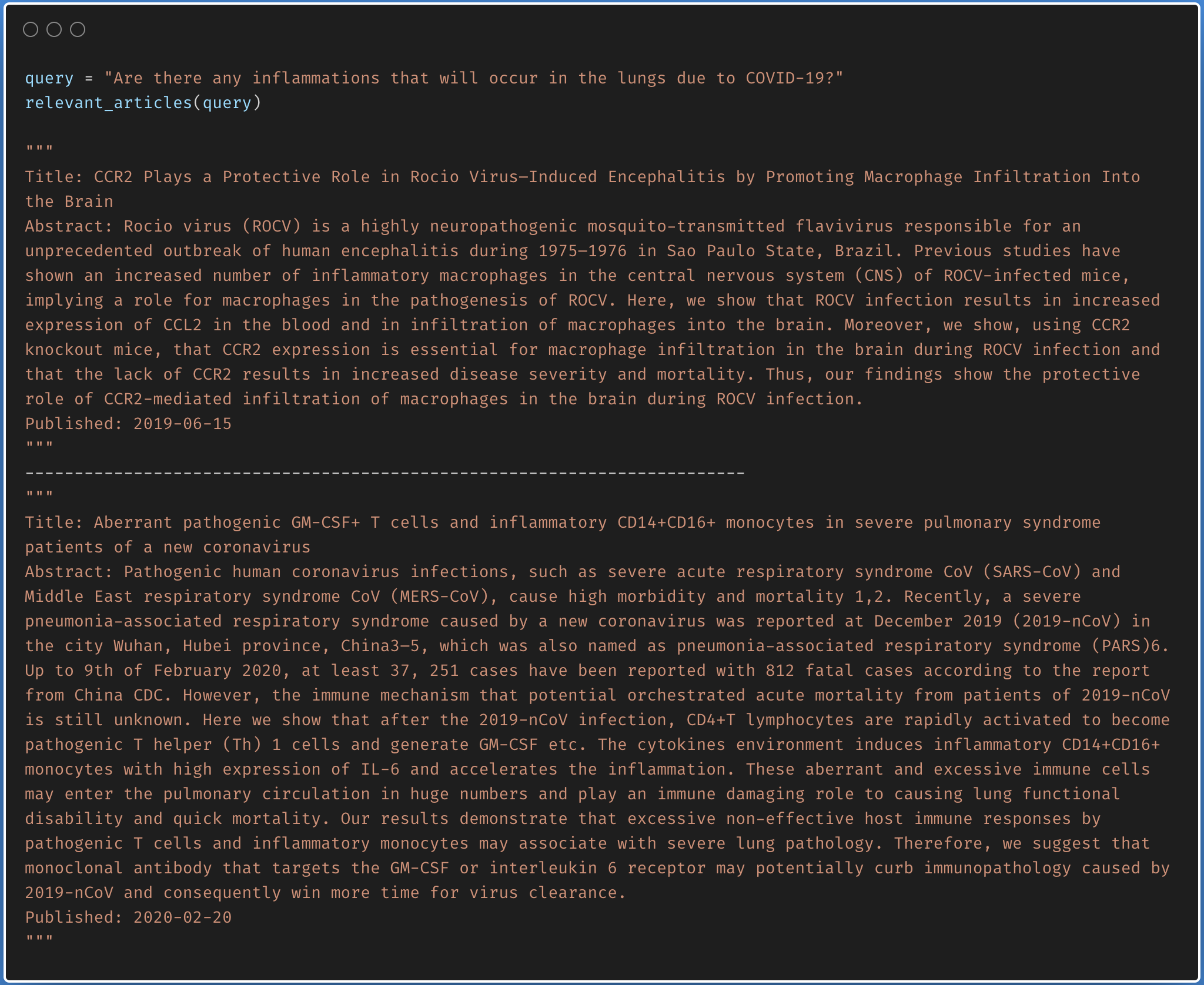
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
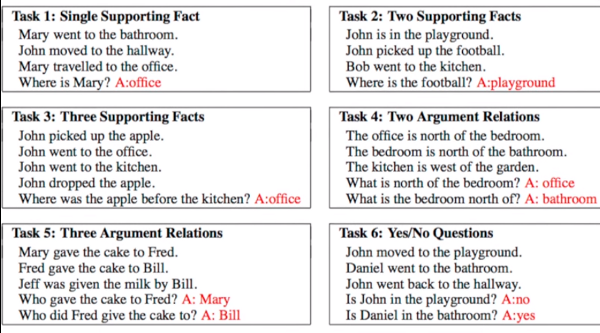
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
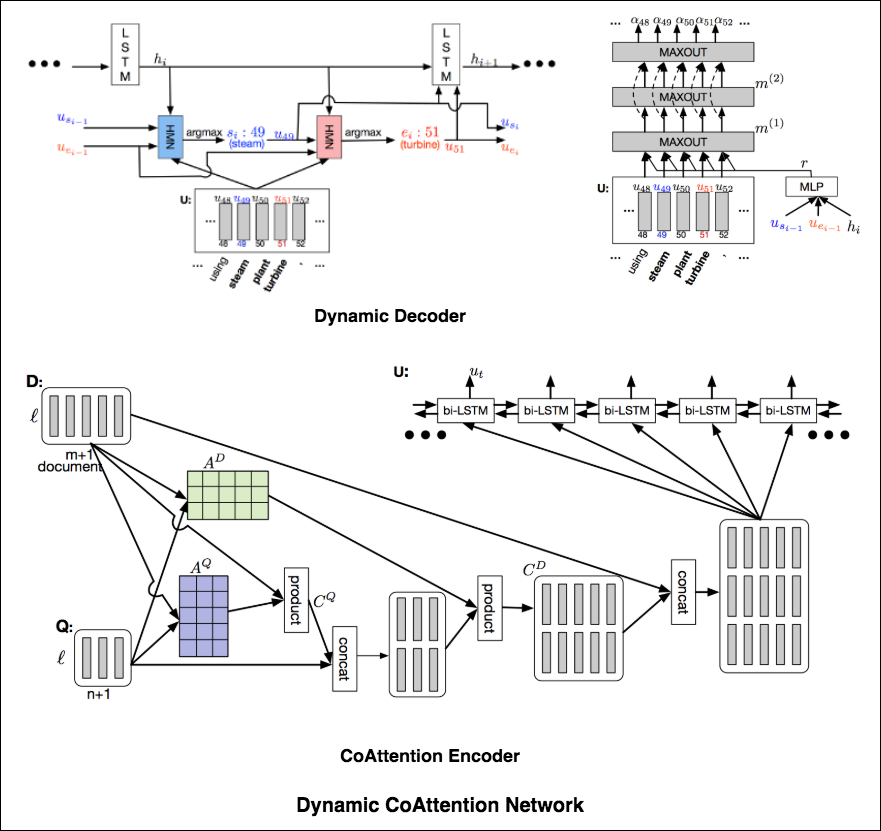
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
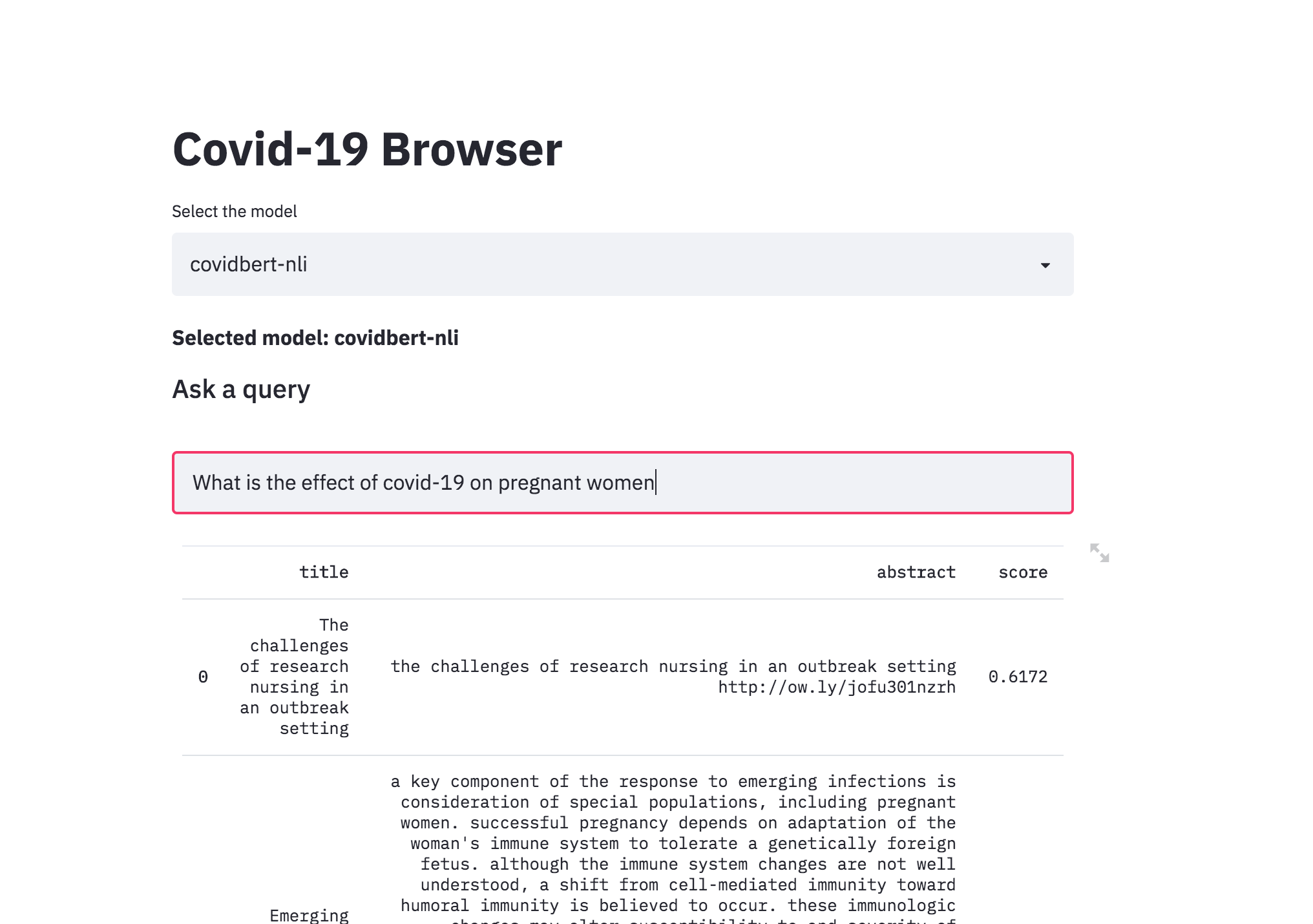
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
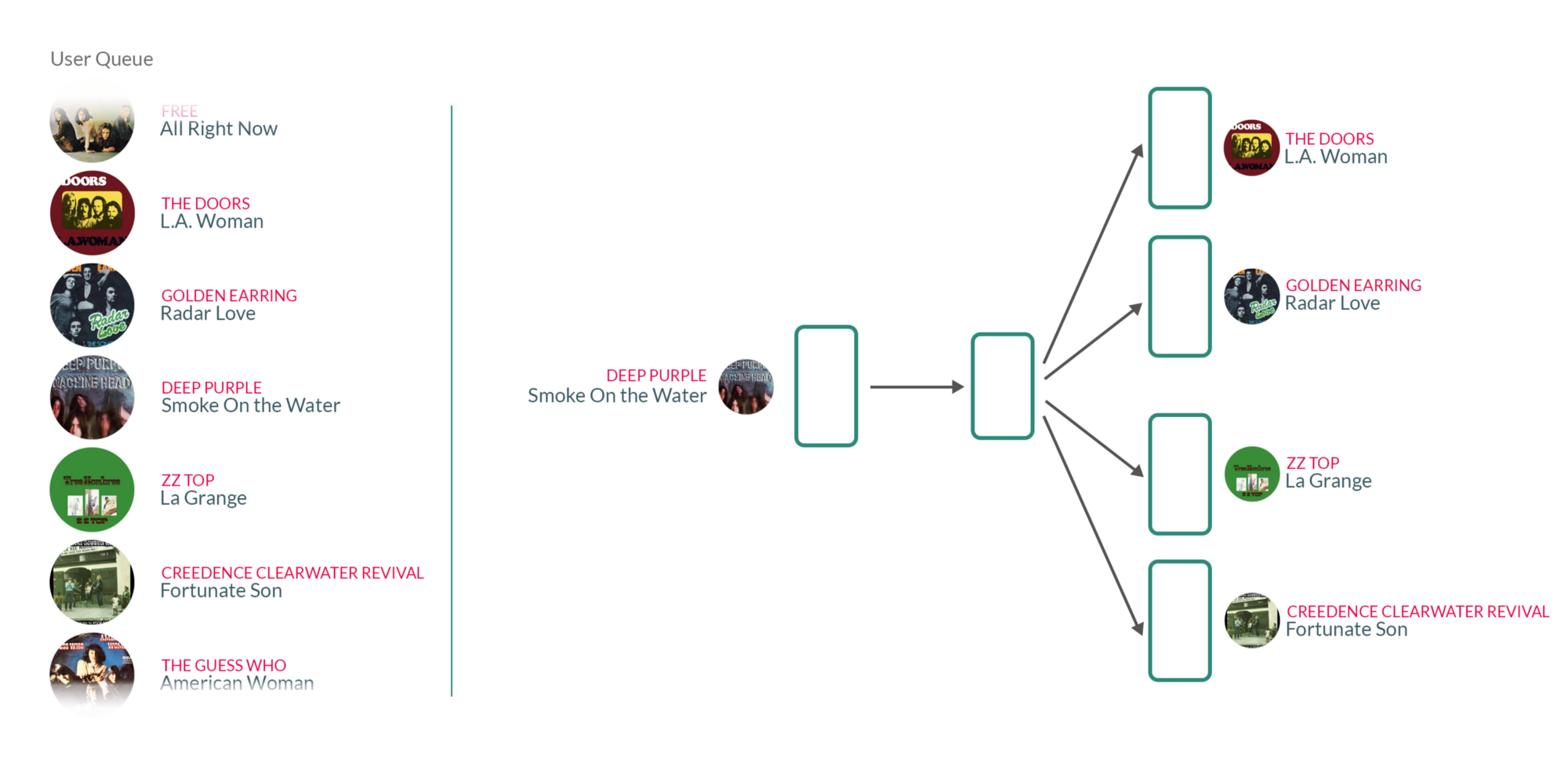
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


