100 Days of NLP
1.0.0

마법에 대한 마법은 없습니다. 마술사는 단순히 훈련받지 않은 청중에게 단순하거나 자연스럽지 않은 단순한 것을 이해합니다. 손을 비워 보이게하면서 카드를 잡는 방법을 배우면, 당신은 당신 앞에 연습이 필요합니다.“마법을 할 수 있습니다”. - Jeffrey Friedl이 책을 마스터하는 정규 표현
참고 : 제안, 수정 및 피드백에 대한 문제를 제기하십시오.
대부분의 코드 샘플은 Jupyter 노트북 (Colab 사용)을 사용하여 수행됩니다. 따라서 각 코드는 독립적으로 실행할 수 있습니다.
다음 주제가 탐구되었습니다.
참고 : 난이도는 내 이해에 따라 할당되었습니다.
| 토큰 화 | Word Embeddings -Word2vec | 단어 임베딩 - 글러브 | 단어 임베딩 -Elmo |
| RNN, LSTM, GRU | 패딩 패딩 시퀀스 | 주의 메커니즘 -Luong | 주의 메커니즘 -Bahdanau |
| 포인터 네트워크 | 변신 로봇 | GPT-2 | 버트 |
| 주제 모델링 -LDA | 주요 구성 요소 분석 (PCA) | 순진한 베이 | 데이터 확대 |
| 문장 임베딩 |
텍스트 데이터를 토큰으로 변환하는 프로세스는 NLP에서 가장 중요한 단계 중 하나입니다. 다음 방법을 사용한 토큰 화가 탐색되었습니다.
단어 임베딩은 의미가 같은 단어가 비슷한 표현을 갖는 텍스트에 대한 학습 된 표현입니다. 자연 언어 처리 문제에 대한 딥 러닝의 주요 획기적인 획기적인 획기적인 획기적인 중 하나로 간주 될 수있는 단어와 문서를 표현하는 것은 이러한 접근법입니다.

Word2Vec은 Google에서 개발 한 가장 인기있는 사전 예측 중 하나입니다. 임베딩을 배우는 방식에 따라 Word2Vec은 두 가지 접근법으로 분류됩니다.
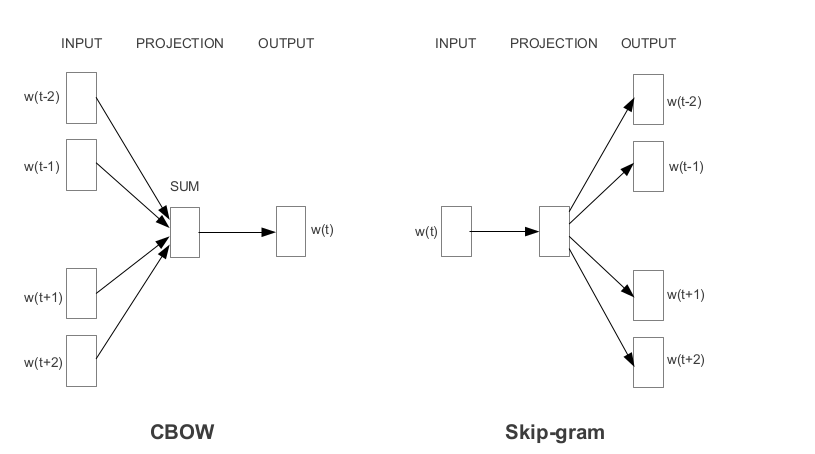
장갑은 미리 훈련 된 임베딩을 얻는 또 다른 일반적으로 사용되는 방법입니다. 글러브는 두 가지 목표를 달성하는 것을 목표로합니다.
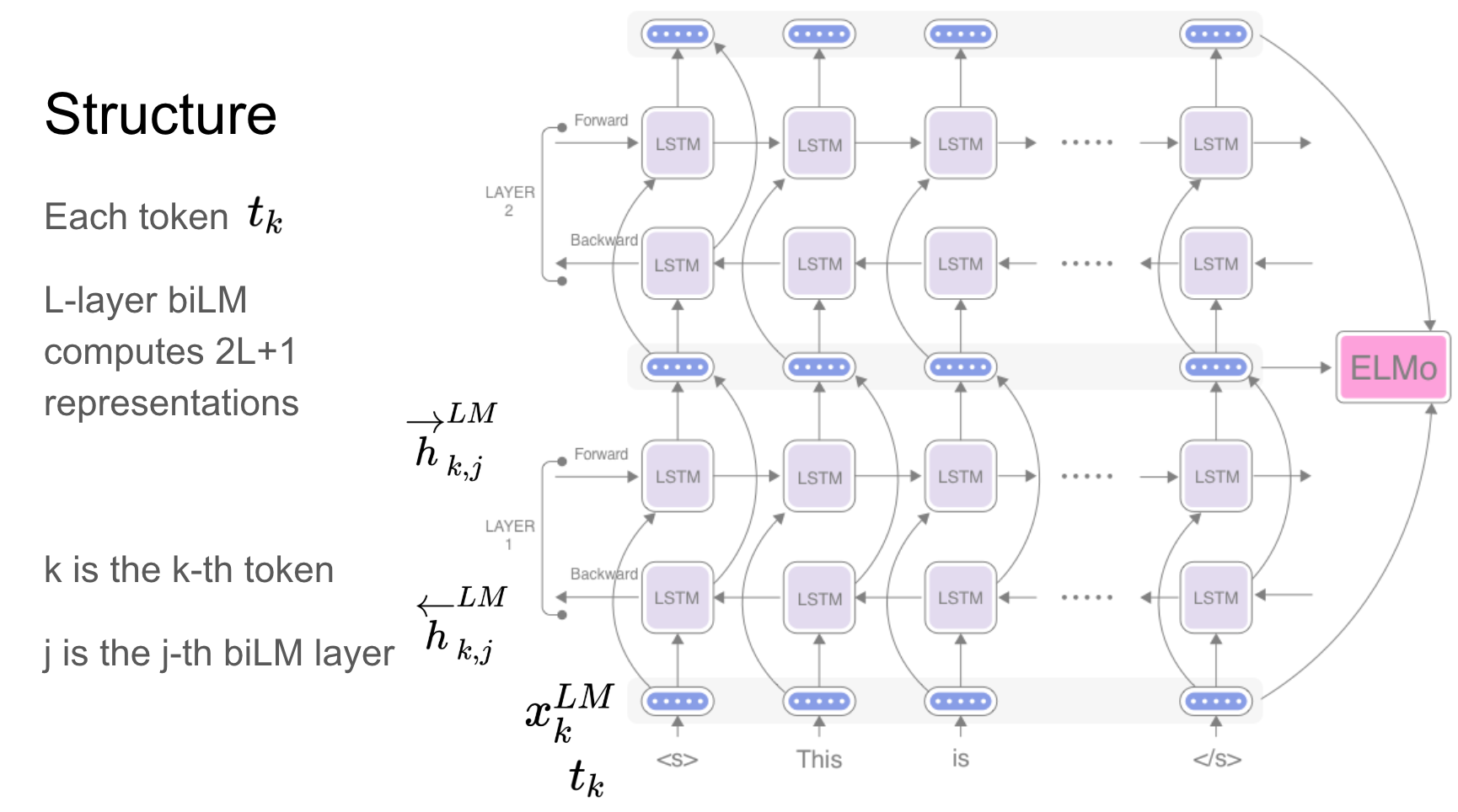
Elmo는 다음을 모델링하는 깊은 맥락화 된 단어 표현입니다.
이 단어 벡터는 큰 양방향 언어 모델 (BILM)의 내부 상태에 대한 학습 된 기능이며, 큰 텍스트 코퍼스에서 미리 훈련됩니다.
반복 네트워크 -RNN, LSTM, GRU는 아키텍처로 인해 NLP 애플리케이션에서 가장 중요한 단위 중 하나로 입증되었습니다. 장면에서 감정을 예측하기 위해 시퀀스 자연을 기억 해야하는 많은 문제가 있습니다. 이전 장면을 기억해야합니다.

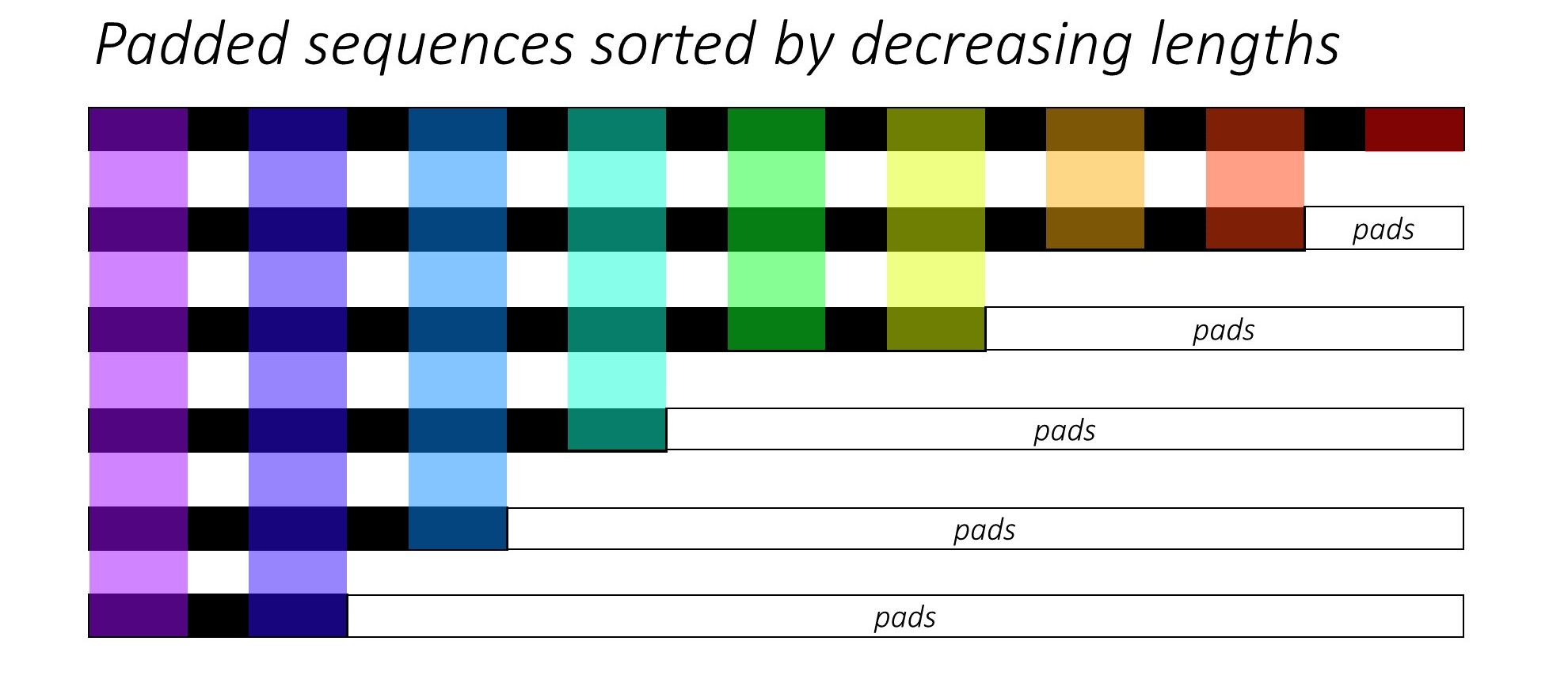
RNN (LSTM 또는 GRU 또는 Vanilla-RNN)을 훈련시킬 때 가변 길이 시퀀스를 일괄하는 것은 어렵습니다. 이상적으로 우리는 모든 시퀀스를 고정 길이로 채우고 불필요한 계산을 수행하게됩니다. 우리는 어떻게 이것을 극복 할 수 있습니까? Pytorch는 pack_padded_sequences 기능을 제공합니다.
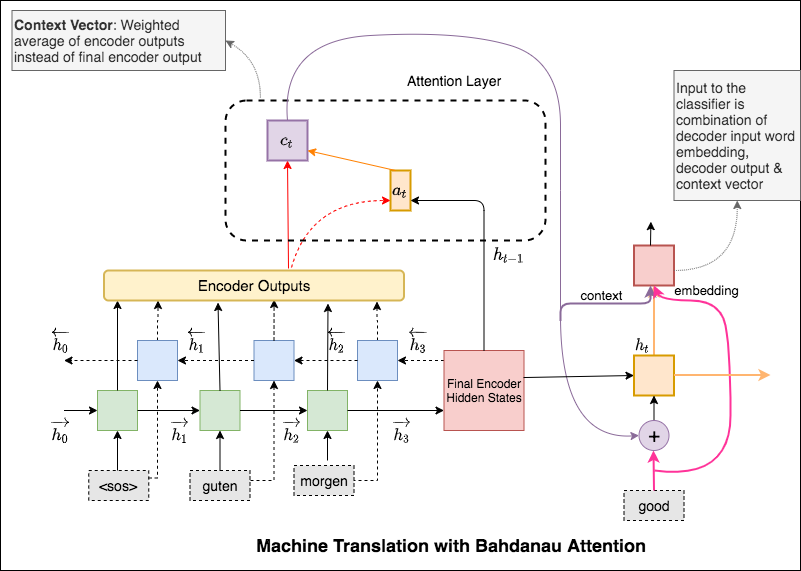
주의 메커니즘은 NMT (Neural Machine Translation)에서 긴 소스 문장을 암기하는 데 도움이되었습니다. 인코더의 마지막 숨겨진 상태에서 단일 컨텍스트 벡터를 구축하는 대신 문장을 디코딩하면서 입력의 관련 부분에 더 집중하는 데주의를 기울입니다. 컨텍스트 벡터는 인코더 출력과 디코더 RNN의 current output 가져와 생성됩니다.

주의 점수는 세 가지 방법으로 계산할 수 있습니다. dot , general 및 concat .
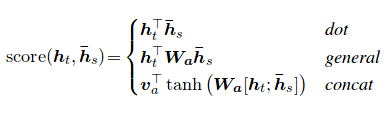
Bahdanau와 Luong의 관심의 주요 차이점은 컨텍스트 벡터가 생성되는 방식입니다. 컨텍스트 벡터는 인코더 출력과 디코더 RNN의 previous hidden state 취함으로써 생성됩니다. Luong주의 위치는 컨텍스트 벡터가 인코더 출력과 디코더 RNN의 current hidden state 가져 와서 만들어 질 것입니다.
컨텍스트가 계산되면 디코더 입력 임베딩과 결합되고 Decoder RNN에 입력으로 공급됩니다.

Bahdanau의 관심은 또한 additive 관심이라고도합니다.
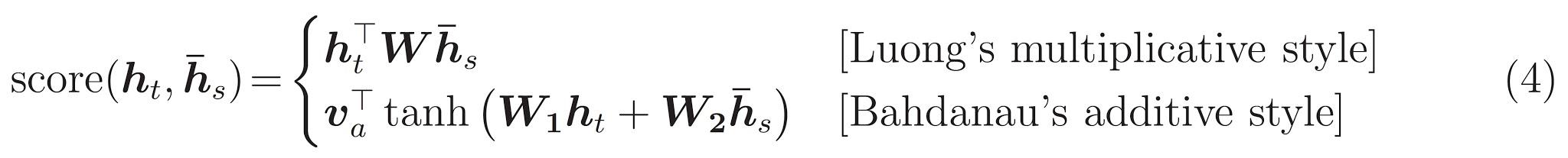
모델 아키텍처 인 변압기는 재발을 피하고 대신 입력과 출력 사이의 글로벌 의존성을 끌어내는주의 메커니즘에 전적으로 의존합니다.
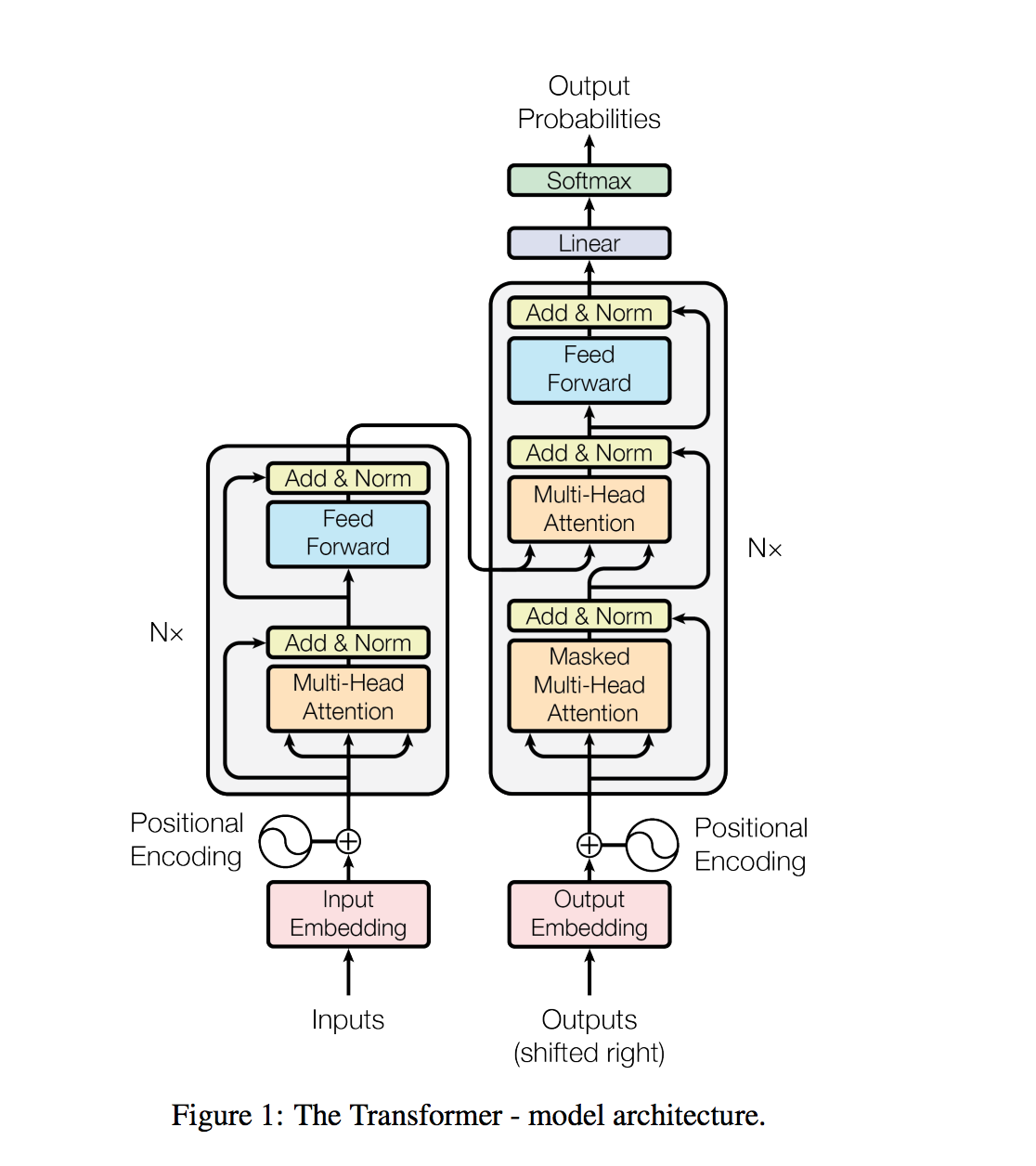
질문 답변, 기계 번역, 독해 및 요약과 같은 자연어 처리 작업은 일반적으로 작업 지정 데이터 세트에 대한 감독 학습으로 접근합니다. 우리는 언어 모델이 WebText라는 수백만 개의 웹 페이지에 대한 새로운 데이터 세트에 대해 교육을받을 때 명백한 감독없이 이러한 작업을 배우기 시작한다는 것을 보여줍니다. 우리의 가장 큰 모델 인 GPT-2는 1.5B 매개 변수 변압기로, 제로 샷 설정에서 8 개의 테스트 된 언어 모델링 데이터 세트 중 7 개에 대한 최첨단 결과를 달성하지만 여전히 웹 텍스트를 어둡게합니다. 모델의 샘플은 이러한 개선 사항을 반영하고 텍스트의 일관된 단락을 포함합니다. 이러한 결과는 자연적으로 발생하는 데모에서 작업을 수행하는 법을 배우는 언어 처리 시스템을 구축하는 유망한 길을 제안합니다.
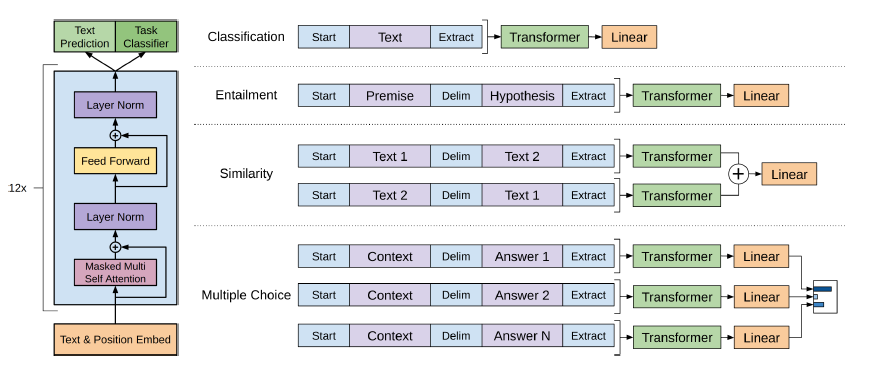
GPT-2는 12 층 디코더 전용 변압기 아키텍처를 사용합니다.
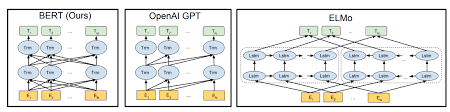
Bert는 문장 인코딩을 위해 변압기 아키텍처를 사용합니다.
포인터 네트워크의 출력은 불연속이며 입력 시퀀스의 위치에 해당합니다.
출력의 각 단계에서 대상 클래스 수는 입력 길이에 따라 다릅니다.
각 디코더 단계에서 인코더의 숨겨진 유닛을 컨텍스트 벡터에 혼합하는 데주의를 사용하는 대신, 입력 시퀀스의 멤버를 출력으로 선택하는 데주의를 사용하는 것의 이전의주의 시도와 다릅니다.

자연어 처리의 주요 응용 중 하나는 사람들이 대량의 텍스트에서 논의하는 주제를 자동으로 추출하는 것입니다. 큰 텍스트의 일부 예는 소셜 미디어, 호텔, 영화 등의 고객 리뷰, 사용자 피드백, 뉴스 기사, 고객 불만 사항 이메일 등의 피드 일 수 있습니다.
사람들이 무엇에 대해 이야기하고 있고 자신의 문제와 의견을 이해하는 것은 비즈니스, 관리자, 정치 캠페인에 매우 가치가 있습니다. 그리고 그러한 많은 볼륨을 수동으로 읽고 주제를 컴파일하는 것은 정말 어렵습니다.
따라서 텍스트 문서를 읽고 논의 된 주제를 자동으로 출력 할 수있는 자동화 된 알고리즘이 필요합니다.
이 노트북에서는 20 Newsgroups 데이터 세트의 실제 예를 들어 LDA를 사용하여 자연스럽게 논의 된 주제를 추출합니다.
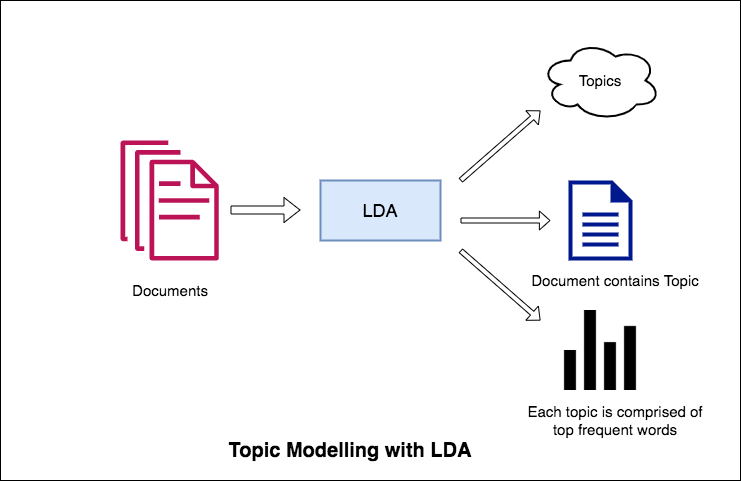
주제 모델링에 대한 LDA의 접근 방식은 각 문서를 특정 비율의 주제 모음으로 간주합니다. 그리고 각 주제는 키워드 모음으로서 특정 비율로 다시 키워드입니다.
알고리즘에 주제 수를 제공하면 주제 내에서 주제 배포를 재정렬하여 주제 내에서 주제 분포 배포를 재정렬하여 주제 키워드 배포의 양호한 구성을 얻습니다.
PCA는 근본적으로 데이터 세트의 열을 새로운 세트 기능으로 변환하는 차원 감소 기술입니다. 데이터의 최대 변동성을 설명하는 새로운 방향 세트 (X 및 Y 축과 같은)를 찾아서이를 수행합니다. 이 새로운 시스템 좌표 축을 주요 구성 요소 (PC)라고합니다.
실제로 PCA는 두 가지 이유로 사용됩니다.
Dimensionality Reduction : 많은 수의 열에 배포 된 정보는 처음 몇 개의 PC가 총 정보 (분산)의 상당한 덩어리를 설명 할 수 있도록 주요 구성 요소 (PC)로 변환됩니다. 이 PC는 기계 학습 모델에서 설명 변수로 사용될 수 있습니다.
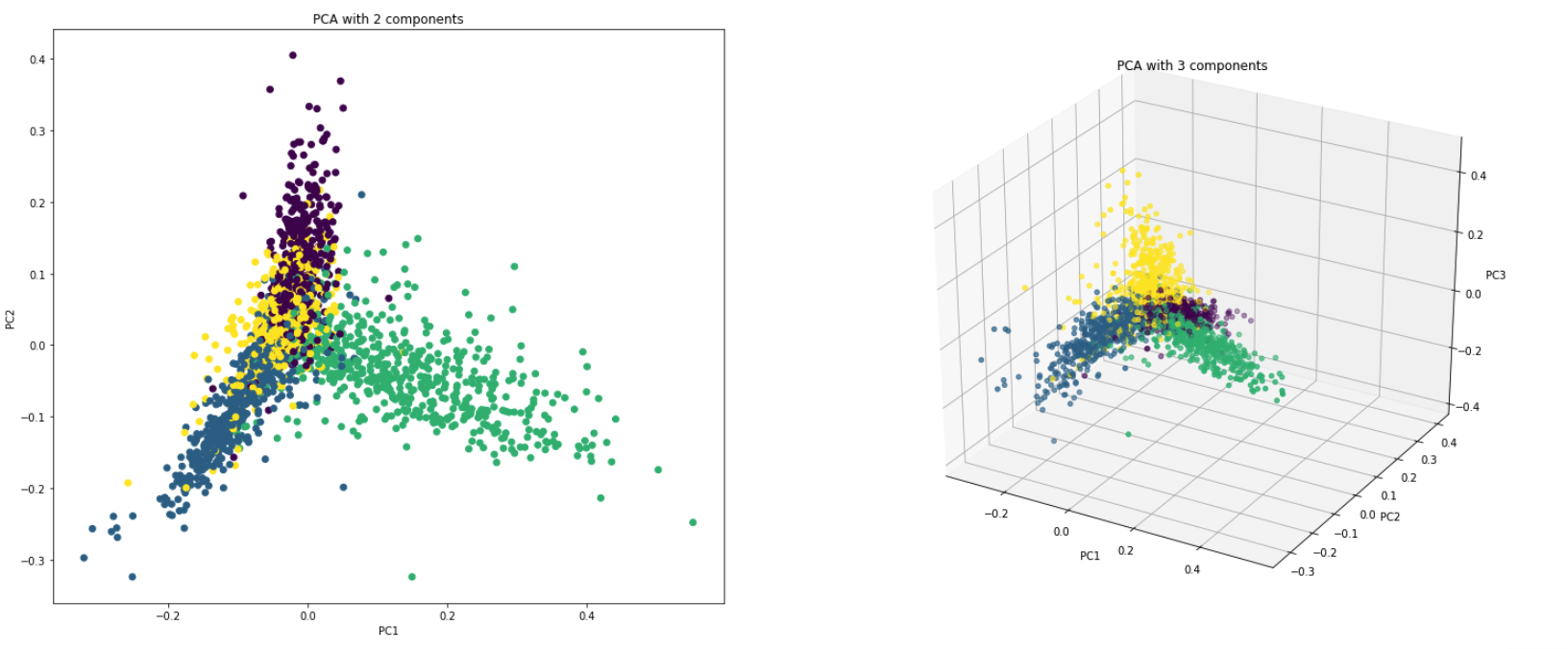
Visualize Data : 클래스 (또는 클러스터)의 분리를 시각화하는 것은 3 차원 (기능) 이상의 데이터가 어렵습니다. 처음 두 PC 자체를 사용하면 일반적으로 명확한 분리를 볼 수 있습니다.
순진한 Bayes Classifier는 분류 작업에 사용되는 확률 론적 기계 학습 모델입니다. 분류기의 요점은 베이 즈 정리를 기반으로합니다.
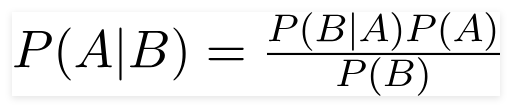
Bayes 정리를 사용하여 B가 발생했을 때 A가 발생할 확률을 찾을 수 있습니다. 여기서 B는 증거이며 A는 가설입니다. 여기서 내려진 가정은 예측 변수/기능이 독립적이라고 가정합니다. 그것은 하나의 특정 기능의 존재는 다른 기능에 영향을 미치지 않습니다. 따라서 순진합니다.
순진한 베이 스 분류기의 유형 :
Multinomial Naive Bayes : 변수가 개별 될 때 (단어와 같은) 주로 사용됩니다. 분류기에서 사용하는 기능/예측 변수는 문서에있는 단어의 빈도입니다.
Gaussian Naive Bayes : 예측 변수가 연속 값을 차지하고 불연속이 없을 때, 우리는 이러한 값이 가우스 분포에서 샘플링된다고 가정합니다.
Bernoulli Naive Bayes : 이것은 다국적 순진한 베이와 유사하지만 예측 변수는 부울 변수입니다. 클래스 변수를 예측하는 데 사용하는 매개 변수는 예를 들어 텍스트에서 단어가 발생하는 경우 값 만 값 만 가져옵니다.
20Newsgroup 데이터 세트를 사용하여 분류를 수행하기 위해 순진한 Bayes 알고리즘을 탐색합니다.
다음 기술을 사용한 데이터 증강이 탐구됩니다.

Sbert라는 새로운 건축물이 탐구되었습니다. 시암 네트워크 아키텍처를 통해 입력 문장을위한 고정 크기의 벡터를 도출 할 수 있습니다. Cosinesimilarity 또는 Manhatten / Euclidean 거리와 같은 유사성 측정을 사용하면 의미 적으로 유사한 문장을 찾을 수 있습니다.

| 감정 분석 -IMDB | 감정 분류 -Hinglish | 문서 분류 |
| 중복 질문 쌍 분류 -Quora | POS 태깅 | 자연어 추론 -SNLI |
| 독성 의견 분류 | 문법적으로 올바른 문장 -Cola | NER 태깅 |
감정 분석은 자연 언어 처리, 텍스트 분석, 계산 언어학 및 생체 인식을 사용하여 정서 상태 및 주관 정보를 체계적으로 식별, 추출, 정량화 및 연구하는 것을 말합니다.
다음과 같은 변형이 탐색되었습니다.
RNN은 감정을 처리하고 식별하는 데 사용됩니다.

Test_Accuracy를 50% 미만으로 제공하는 기본 RNN을 시도한 후, 다음 기술을 실험하고 88% 이상의 TEST_ACCURACY가 달성되었습니다.
사용 된 기술 :

주의는 입력의 감정을 예측할 때 관련 입력에 집중하는 데 도움이됩니다. Bahdanau는 LSTM의 출력을 취하고 최종 포워드 및 뒤로 숨겨진 상태를 연결하는 데 사용되었습니다. 미리 훈련 된 단어 임베딩을 사용하지 않으면 88% 의 테스트 정확도가 달성됩니다.
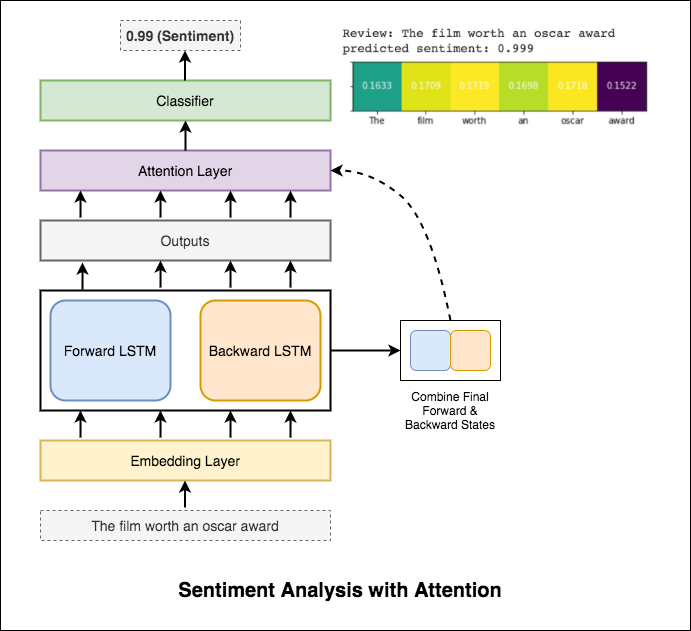
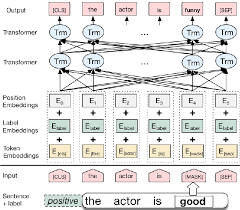
Bert는 11 개의 자연 언어 처리 작업에 대한 새로운 최첨단 결과를 얻습니다. Bert 모델이 출시 된 후 NLP의 전송 학습이 트리거되었습니다. Bert를 사용하여 감정 분석을 수행하는 것이 탐구됩니다.

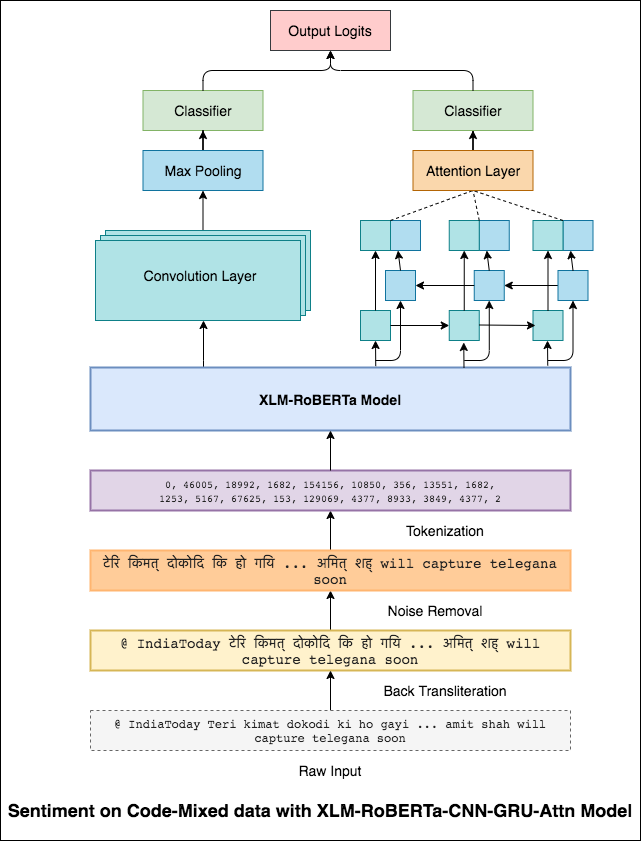
코드 혼합이라고도하는 믹싱 언어는 다국어 사회의 표준입니다. 비 원어민 영어 사용자 인 다국어 사람들은 영어 기반 발음 타이핑과 주요 언어로 불행을 삽입하는 것을 사용하여 코드 혼합을하는 경향이 있습니다.
과제는 주어진 코드 혼합 트윗의 감정을 예측하는 것입니다. 감정 라벨은 긍정적, 부정적 또는 중립적이며 코드 혼합 언어는 영어 힌디입니다. (Sentimix)
다음과 같은 변형이 탐색되었습니다.
간단한 MLP 모델을 사용하여 테스트 데이터에서 F1 score of 0.58 달성되었습니다.

기본 MLP 모델을 탐색 한 후, LSTM 모델은 감정 예측에 사용되었고 F1 점수 0.57 이 달성되었습니다.

결과는 실제로 기본 MLP 모델에 비해 덜 적었다. 그 이유 중 하나는 LSTM이 코드 혼합 데이터의 다양한 특성으로 인해 문장의 단어 간의 관계를 배우지 못하기 때문일 수 있습니다.
LSTM은 코드 혼합 데이터의 다양한 특성으로 인해 코드 혼합 문장의 단어 간의 관계를 배울 수없고 미리 훈련 된 임베딩이 사용되지 않으므로 F1 점수는 적습니다.
이 문제를 완화하려면 XLM-Roberta 모델 (100 개 언어로 미리 훈련 된)이 문장을 인코딩하는 데 사용됩니다. XLM-Roberta 모델을 사용하려면 문장이 적절한 언어로되어야합니다. 따라서 먼저 Hinglish 단어는 힌디어 (Devanagari) 형태로 변환되어야합니다.
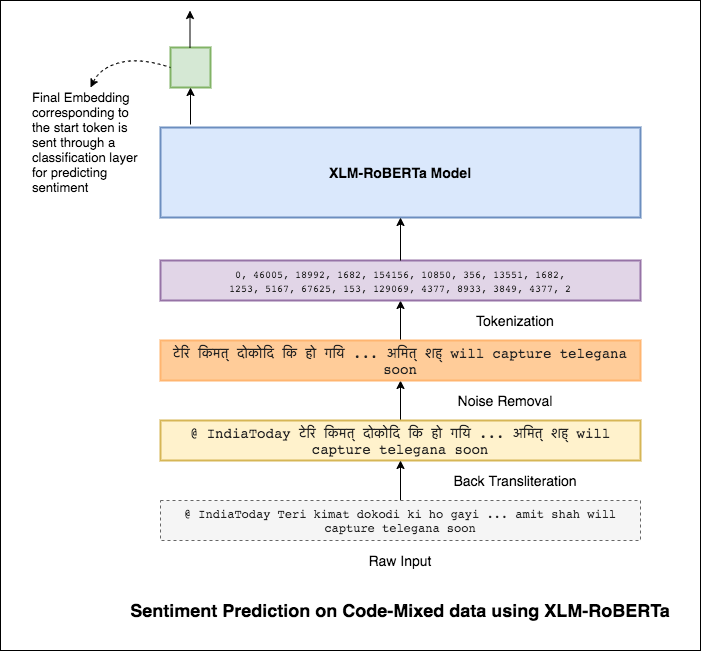
0.59 의 F1 점수가 달성되었습니다. 이것을 개선하는 방법은 나중에 탐색 될 것입니다.
XLM-Roberta 모델의 최종 출력은 양방향 LSTM 모델에 대한 입력 임베딩으로 사용되었습니다. LSTM 층의 출력을 취하는주의 층은 입력의 가중 표현을 생성 한 다음 문장의 감정을 예측하기위한 분류기를 통과합니다.

F1 점수 0.64 달성되었습니다.
3x3 필터가 이미지 패치를 살펴볼 수있는 것과 마찬가지로 1x2 필터는 텍스트에서 2 개의 순차적 단어를 볼 수 있습니다 (즉). 이 CNN 모델에서는 텍스트 내에서 Bi-Gram (1x2 필터), 트리 그램 (1x3 필터) 및/또는 N- 그램 (1xn 필터)을 볼 수있는 여러 크기의 여러 필터를 사용합니다.
여기서 직관은 검토 내의 특정 양 그램, 트리 그램 및 N- 그램의 출현이 최종 감정의 좋은 표시가 될 것입니다.
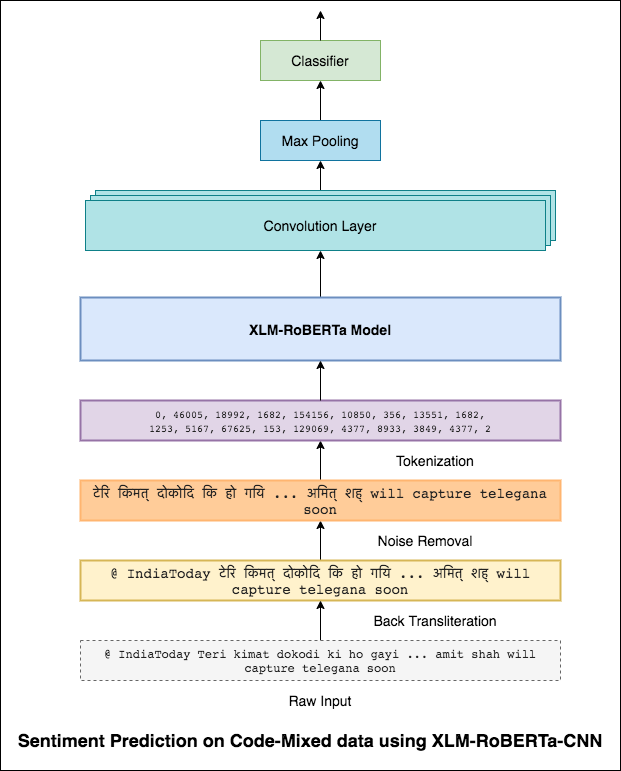
F1 점수 0.69 달성되었습니다.
CNN은 RNN이 글로벌 종속성을 캡처하는 지역 종속성을 캡처합니다. 두 가지를 결합하여 데이터를 더 잘 이해할 수 있습니다. CNN 모델 및 양방향-그루-러닝 모델의 앙상블은 다른 것들을 수행합니다.
0.71 의 F1 점수가 달성되었습니다. (리더 보드에서 5 위).
문서 분류 또는 문서 분류는 도서관 과학, 정보 과학 및 컴퓨터 과학의 문제입니다. 작업은 문서를 하나 이상의 클래스 또는 카테고리에 할당하는 것입니다.
다음과 같은 변형이 탐색되었습니다.
계층 적주의 네트워크 (HAN)는 문서의 계층 적 구조 (문서 - 문장 - 단어)를 고려하고 문서에서 가장 중요한 단어와 문장을 찾을 수있는주의 메커니즘을 포함하면서 문맥을 고려합니다.
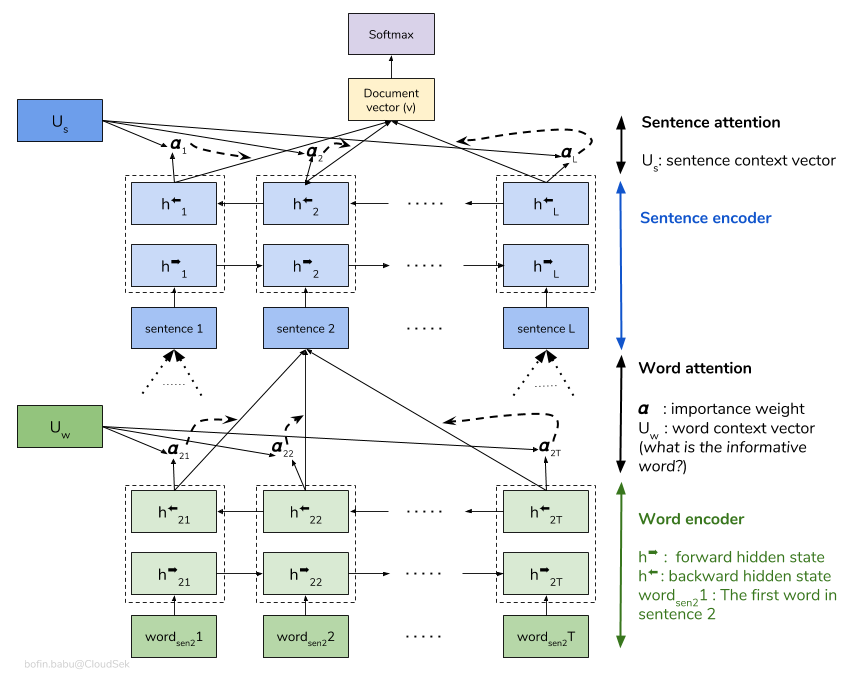
기본 HAN 모델은 빠르게 적합합니다. 이를 극복하기 위해 Embedding Dropout 같은 기술이 Locked Dropout 탐색합니다. Weight Dropout 이라는 다른 기술이 하나 더있어 구현되지 않았습니다 (이를 구현하기에 좋은 리소스가 있는지 알려주십시오). 사전 훈련 된 단어 임베딩 Glove 도 임의의 초기화 대신 사용됩니다. 문장 수준과 단어 수준에서주의를 기울일 수 있으므로 문장에서 어떤 단어가 중요한지, 문서에서 어떤 문장이 중요한지 시각화 할 수 있습니다.



QQP는 Quora 질문 쌍을 나타냅니다. 과제의 목표는 주어진 한 쌍의 질문입니다. 우리는 이러한 질문이 의미 적으로 서로 유사한 지 여부를 찾아야합니다.
다음과 같은 변형이 탐색되었습니다.
알고리즘은 한 쌍의 질문을 입력으로 받아야하며 유사성을 출력해야합니다. 시암 네트워크가 사용됩니다. Siamese neural network (때로는 트윈 신경 네트워크라고도 함)는 비슷한 출력 벡터를 계산하기 위해 두 가지 다른 입력 벡터에서 동일한 가중치를 사용하는 동안 same weights 사용하는 인공 신경망입니다.

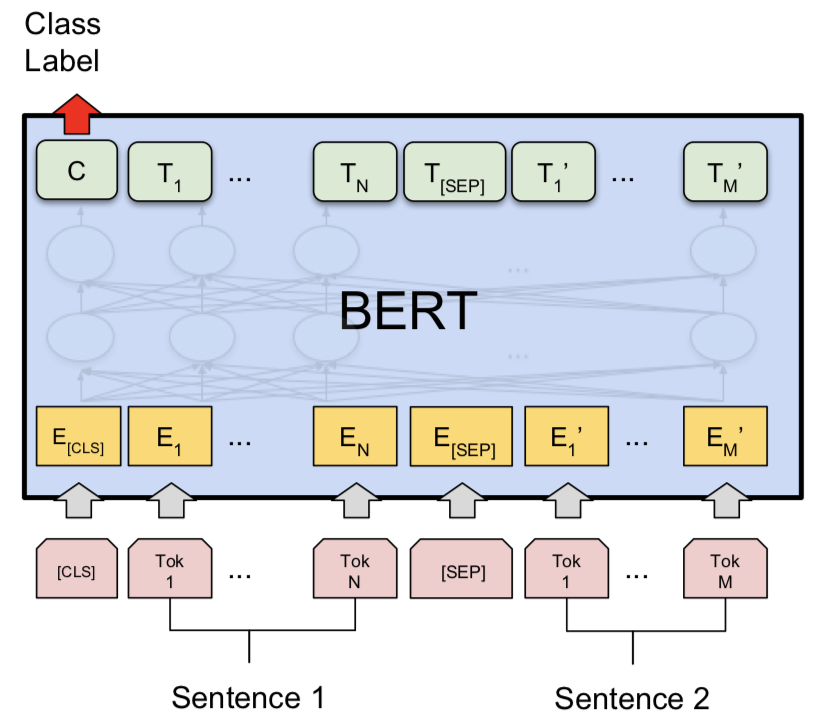
샴 모델을 시험 한 후, Bert는 Quora 중복 질문 쌍 탐지를 수행하도록 탐색되었습니다. Bert는 [SEP] 토큰으로 분리 된 입력으로 질문 1과 질문 2를 취하고 [CLS] 토큰의 최종 표현을 사용하여 분류를 수행했습니다.
POS (Part-of-Speech) 태그는 말의 적절한 부분과 함께 문장에 각 단어를 표시하는 작업입니다.
다음과 같은 변형이 탐색되었습니다.
이 코드는 기본 워크 플로를 다룹니다. 다음과 같은 방법을 배울 것입니다. 데이터로드, 열차/테스트/검증 분할 스플릿 생성, 어휘 구축, 데이터 반복자 생성, 모델 정의 및 기차/평가/테스트 루프 및 실행 시간 (추론) 태깅을 구현합니다.
사용 된 모델은 다중 계층 양방향 LSTM 네트워크입니다.
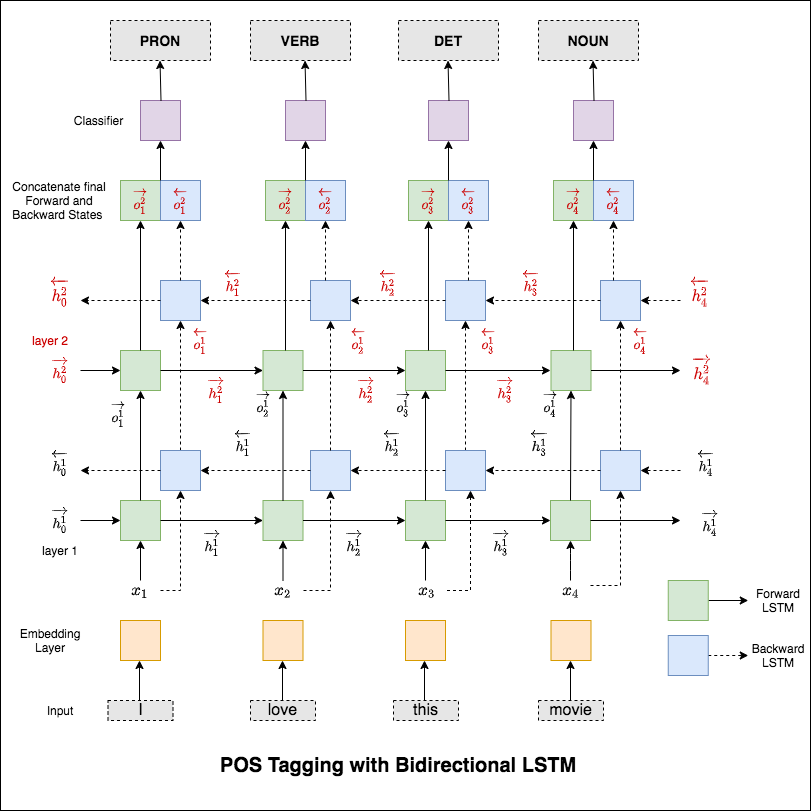
RNN 접근법을 시도한 후 변압기 기반 아키텍처로 POS 태그가 탐색됩니다. 변압기에는 인코더와 디코더가 모두 포함되어 있고 시퀀스 라벨링 작업에 대해서만 Encoder 만 충분합니다. 데이터가 작기 때문에 6 계층의 인코더가있는 경우 데이터에 너무 적합합니다. 따라서 3 층 변압기 인코더 모델이 사용되었습니다.

Transformer Encoder로 POS 태깅을 시도한 후, 사전 훈련 된 Bert 모델로 POS 태깅이 이용됩니다. 91% 의 테스트 정확도를 달성했습니다.

널리 연구 된 자연 언어 처리 과제 인 자연 언어 추론 (NLI)의 목표는 주어진 진술 (전제)이 의미 적으로 주어진 진술 (가설)을 수반하는지 결정하는 것입니다.
다음과 같은 변형이 탐색되었습니다.
시암 BILSTM 네트워크가있는 기본 모델이 구현됩니다
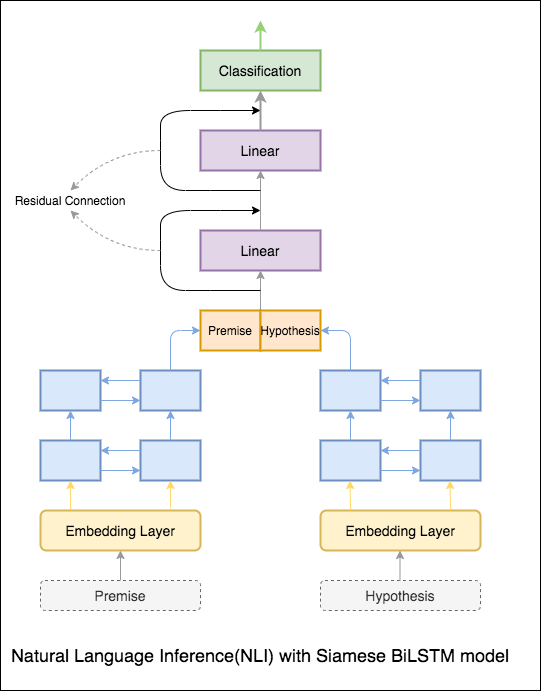
이것은베이스 라인 설정으로 취급 될 수 있습니다. 76.84% 의 테스트 정확도가 달성되었습니다.
이전 노트북에서 LSTM의 표현으로서의 최종 숨겨진 전제 및 가설 상태. 이제 최종 숨겨진 상태를 취하는 대신 모든 입력 토큰에 대한주의를 계산하고 전제와 가설의 표현으로 최종 가중 벡터가 취해집니다.
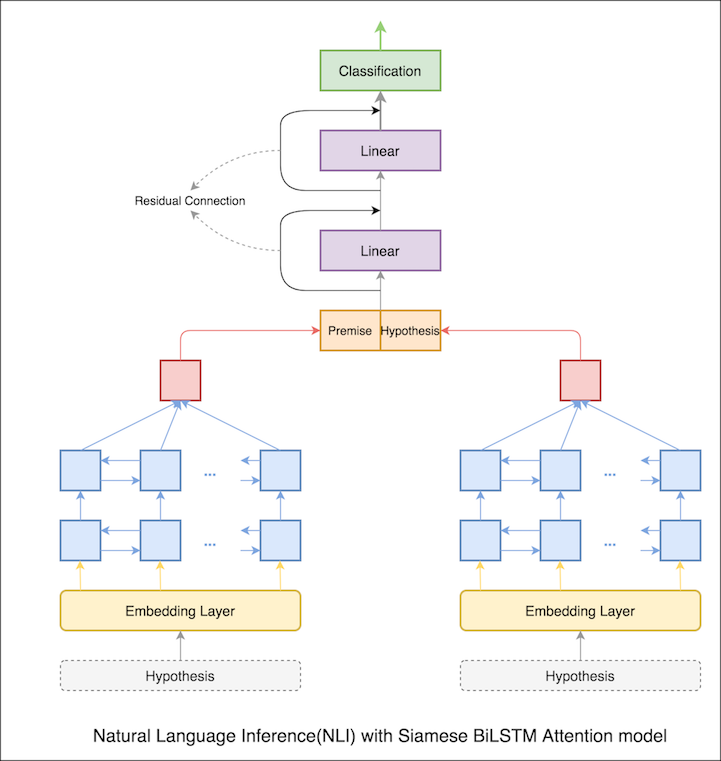
테스트 정확도는 76.84% 에서 79.51% 로 증가했습니다.
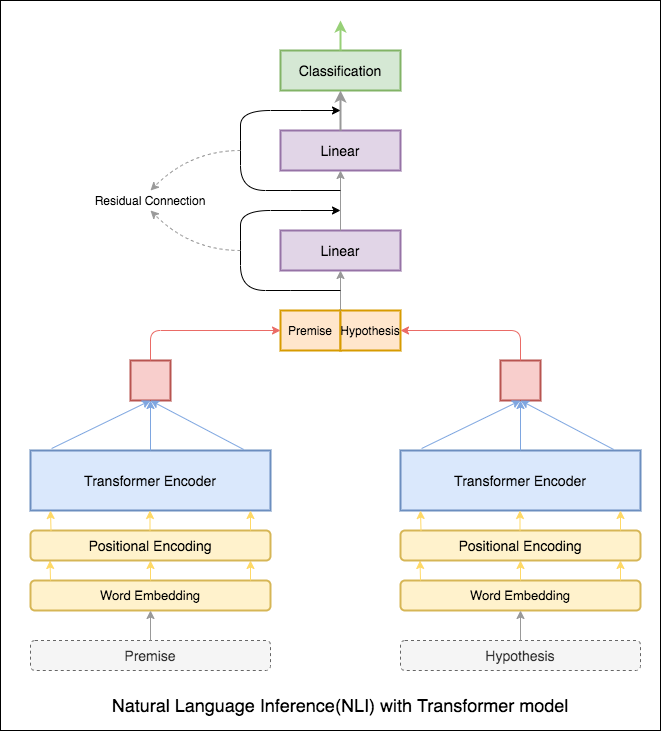
변압기 인코더는 전제와 가설을 인코딩하는 데 사용되었습니다. 문장이 인코더를 통해 전달되면 모든 토큰의 요약은 최종 표현으로 간주됩니다 (다른 변형은 탐색 될 수 있음). 모델 정확도는 RNN 변형에 비해 적습니다.
Bert 기본 모델을 갖는 NLI를 탐색했습니다. Bert는 [SEP] 토큰으로 분리 된 입력으로 전제와 가설을 취하고 [CLS] 토큰의 최종 표현을 사용하여 분류를 수행했습니다.
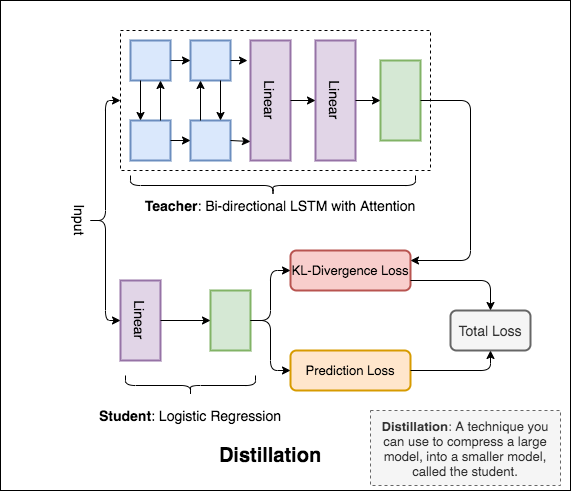
Distillation : teacher 라는 큰 모델을 student 이라는 소규모 모델로 압축하는 데 사용할 수있는 기술. 다음 학생의 교사 모델은 NLI에서 증류를 수행하기 위해 사용됩니다.
관심있는 것들을 논의하는 것은 어려울 수 있습니다. 남용과 괴롭힘의 위협은 온라인으로 많은 사람들이 자신을 표현하지 않고 다른 의견을 찾는 것을 포기한다는 것을 의미합니다. 플랫폼은 대화를 효과적으로 촉진하는 데 어려움을 겪고 많은 커뮤니티가 사용자 의견을 제한하거나 완전히 폐쇄하도록 이끌었습니다.
독성 행동에 대한 인간 평가자가 분류 한 많은 Wikipedia 의견이 제공됩니다. 독성 유형은 다음과 같습니다.
다음과 같은 변형이 탐색되었습니다.
사용 된 모델은 양방향 GRU 네트워크입니다.
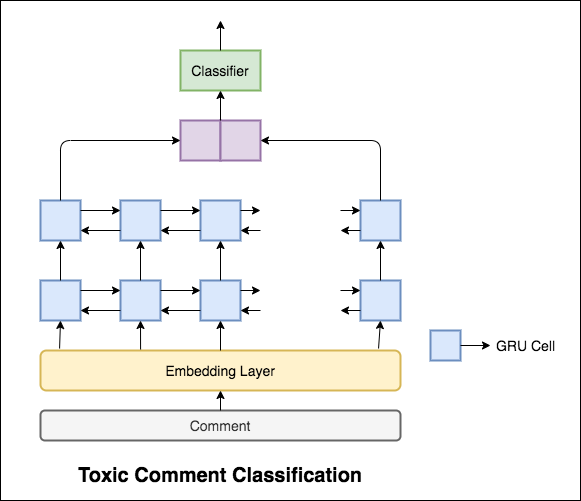
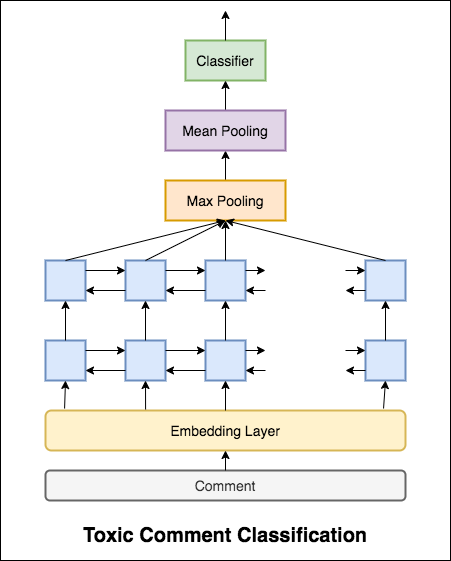
99.42% 의 테스트 정확도가 달성되었습니다. 데이터의 90%가 독성에도 표시되지 않으므로, 비 독성이 아닌 모든 데이터를 예측하면 90% 정확한 모델을 제공합니다. 따라서 정확도는 신뢰할 수있는 메트릭이 아닙니다. 다른 메트릭 ROC AUC가 구현되었습니다.
손실로 Categorical Cross Entropy 사용하면 0.5 의 ROC_AUC 점수가 달성됩니다. Binary Cross Entropy 로의 손실을 변경하고 풀링 층 (Max, Mean)을 추가하여 모델 A를 약간 수정함으로써 ROC_AUC 점수는 0.9873 으로 향상되었습니다.
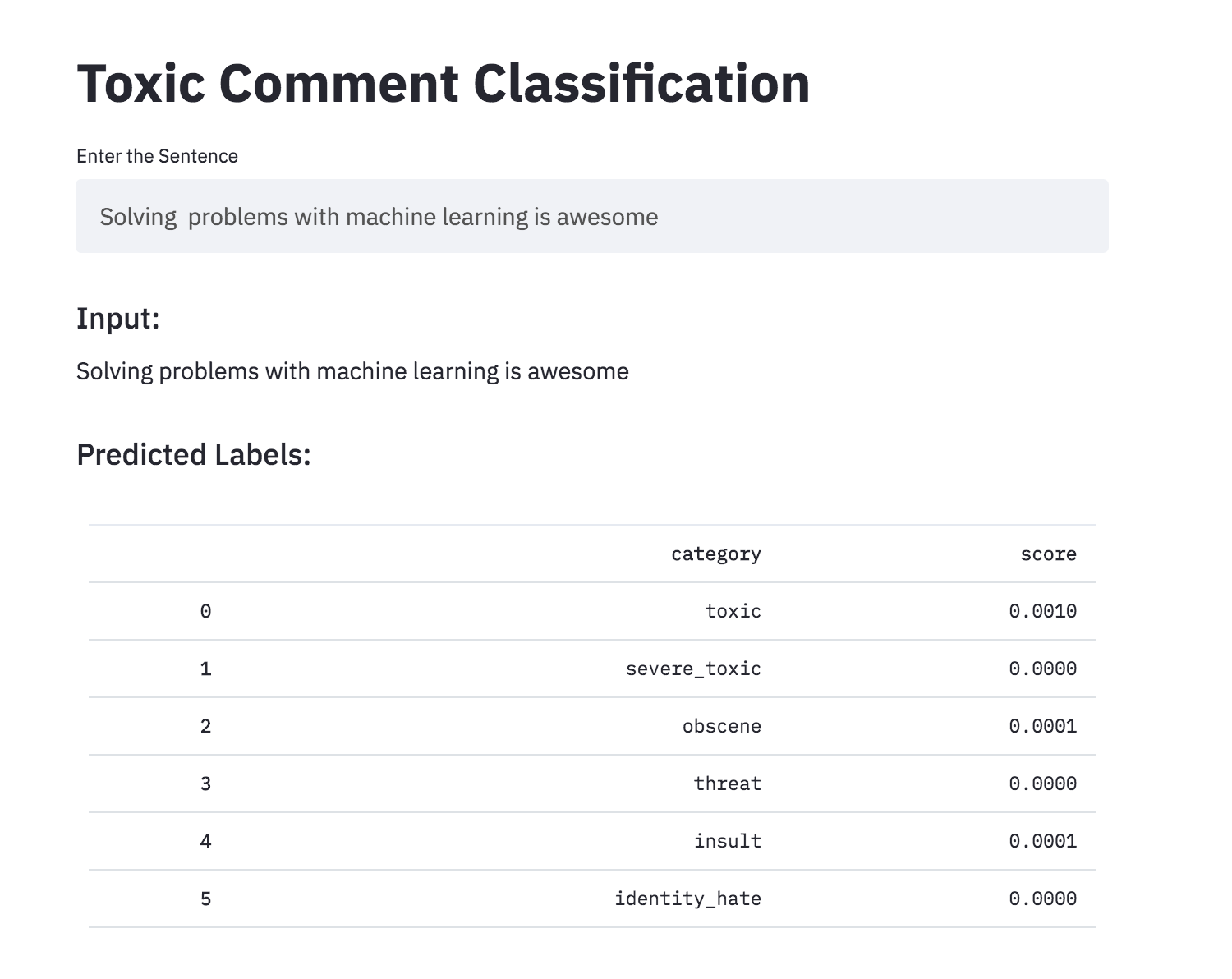
독성 주석 분류를 Streamlit을 사용하여 앱으로 변환했습니다. 미리 훈련 된 모델은 현재 사용할 수 있습니다.
인공 신경 네트워크가 문장의 문법적 수용 가능성을 판단 할 수 있습니까? 이 작업을 탐색하기 위해 언어 수용 가능성 (COLA) 데이터 세트의 코퍼스가 사용됩니다. Cola는 문법적으로 정확하거나 잘못된 것으로 표시된 문장 세트입니다.
다음과 같은 변형이 탐색되었습니다.
Bert는 11 개의 자연 언어 처리 작업에 대한 새로운 최첨단 결과를 얻습니다. Bert 모델이 출시 된 후 NLP의 전송 학습이 트리거되었습니다. 이 노트북에서는 문장이 문법적으로 정확한지 Cola 데이터 세트를 사용하지 않는지 분류하기 위해 Bert를 사용하는 방법을 살펴 봅니다.
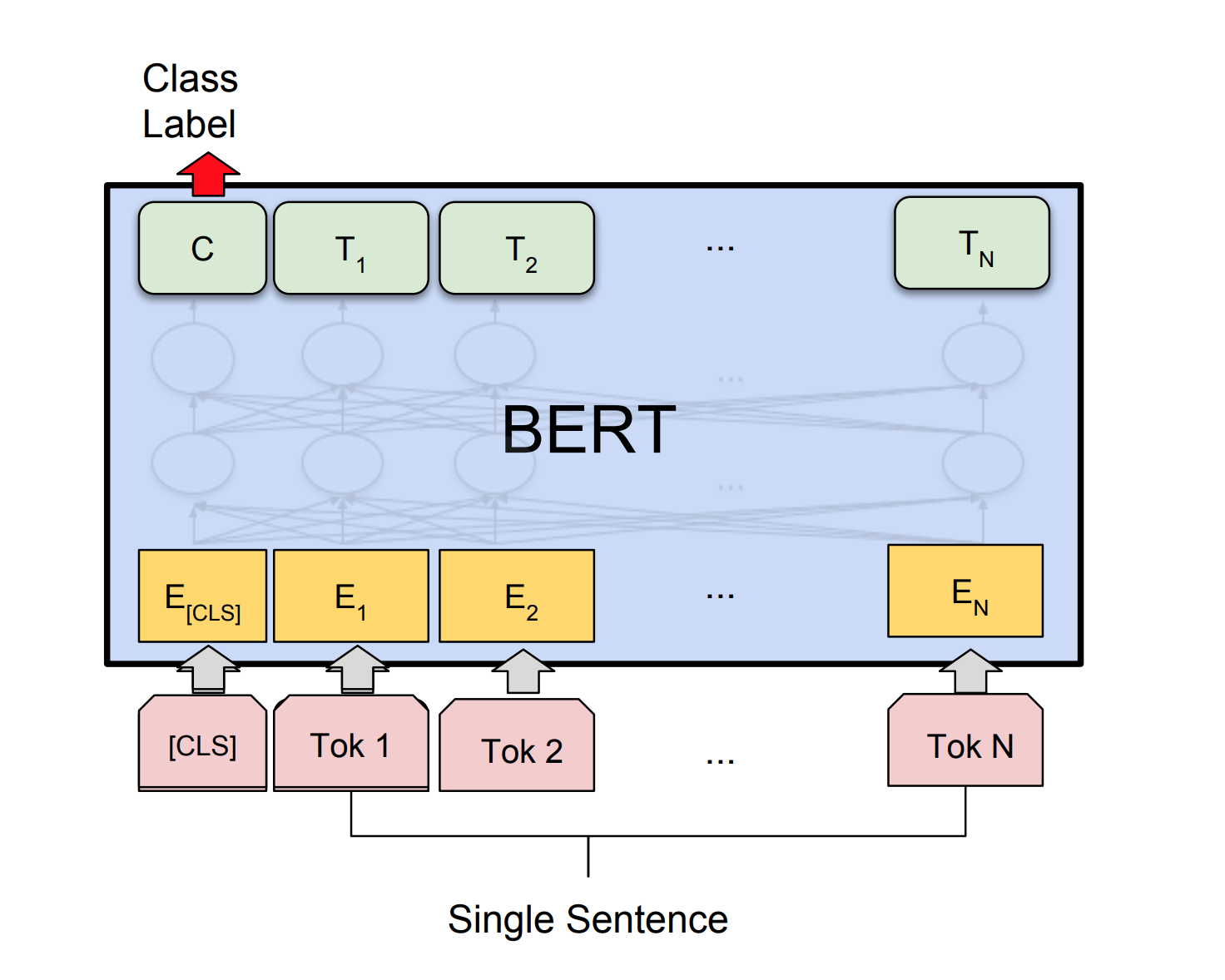
64.1 의 85% 및 Matthews 상관 계수 (MCC)의 정확도가 달성되었습니다.
Distillation : teacher 라는 큰 모델을 student 이라는 소규모 모델로 압축하는 데 사용할 수있는 기술. 다음 학생의 교사 모델은 콜라에서 증류를 수행하기 위해 사용됩니다.

다음 실험을 시도했습니다.
84.06 , MCC : 61.582.54 , MCC : 5782.92 , MCC : 57.9 NER (Named-Entity-Recenition) 태그는 적절한 실체와 문장으로 각 단어를 라벨링하는 작업입니다.
다음과 같은 변형이 탐색되었습니다.
이 코드는 기본 워크 플로를 다룹니다. 다음과 같은 방법을 볼 수 있습니다. 데이터로드, 열차/테스트/검증 스플릿 생성, 어휘 구축, 데이터 반복자 생성, 모델 정의 및 기차/평가/테스트 루프 및 트레인을 구현하고 모델을 테스트합니다.
사용 된 모델은 양방향 LSTM 네트워크입니다
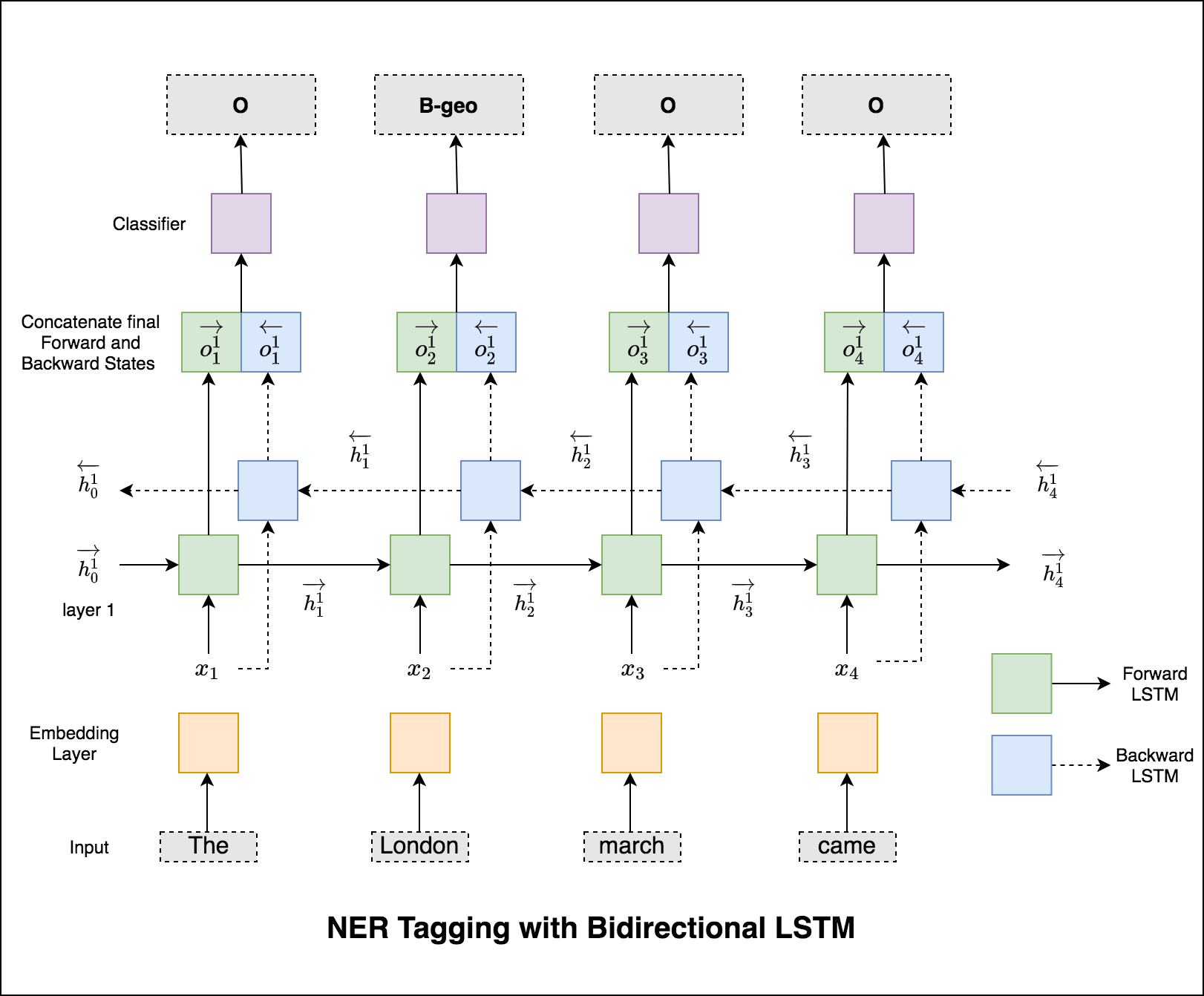
시퀀스 태깅 (ner)의 경우 현재 단어의 태그는 이전 단어의 태그에 따라 다를 수 있습니다. (예 : 뉴욕).
CRF가 없으면 단순히 단일 선형 레이어를 사용하여 양방향 LSTM의 출력을 각 태그의 점수로 변환했을 것입니다. 이들은 emission scores 라고하며 단어가 특정 태그가 될 가능성을 나타냅니다.
CRF는 배출 점수뿐만 아니라 transition scores 도 계산하며, 이는 이전 단어가 특정 태그라는 것을 고려할 때 특정 태그가 될 가능성입니다. 따라서 전환 점수는 한 태그에서 다른 태그로 전환 할 가능성을 측정합니다.
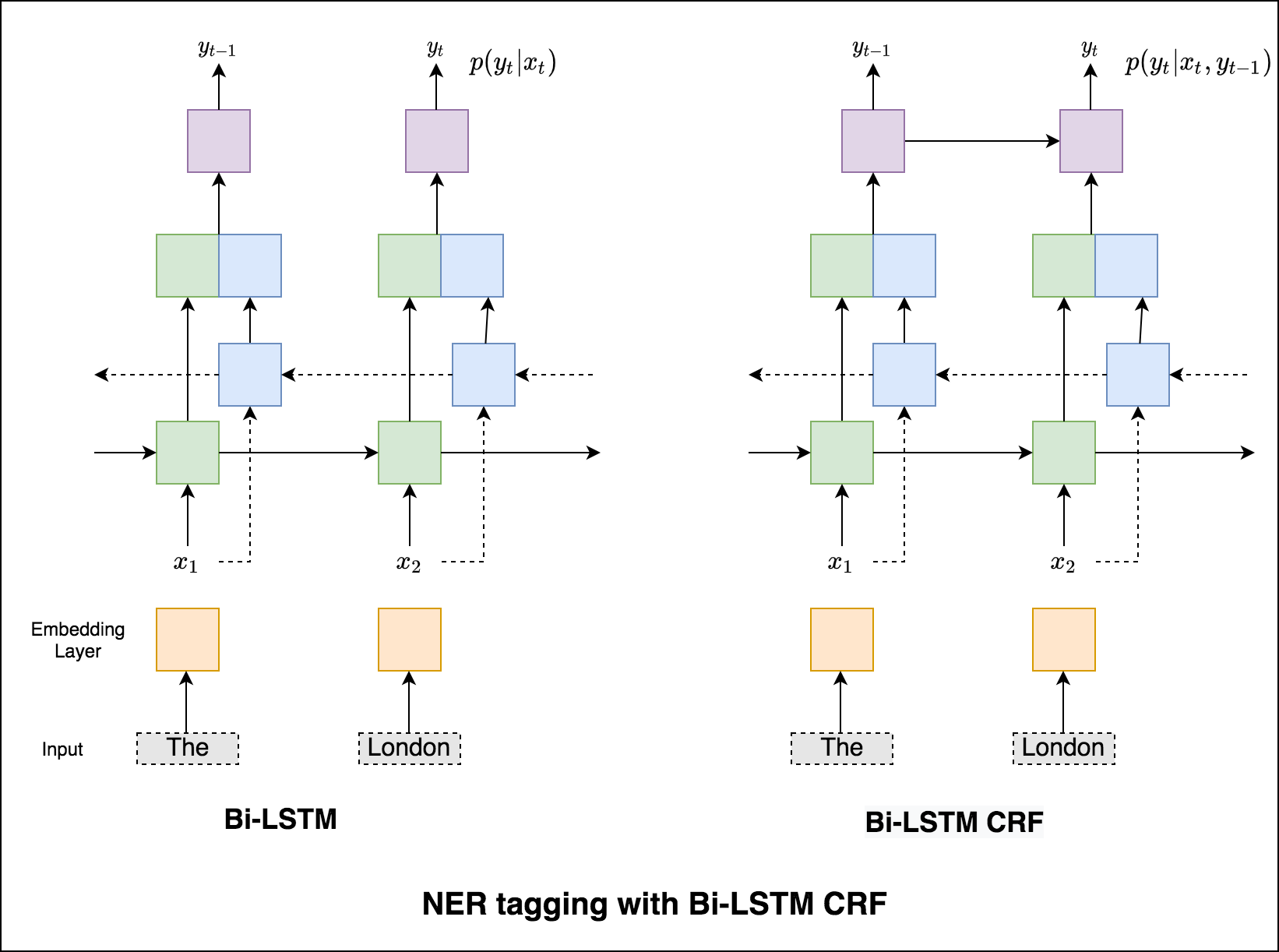
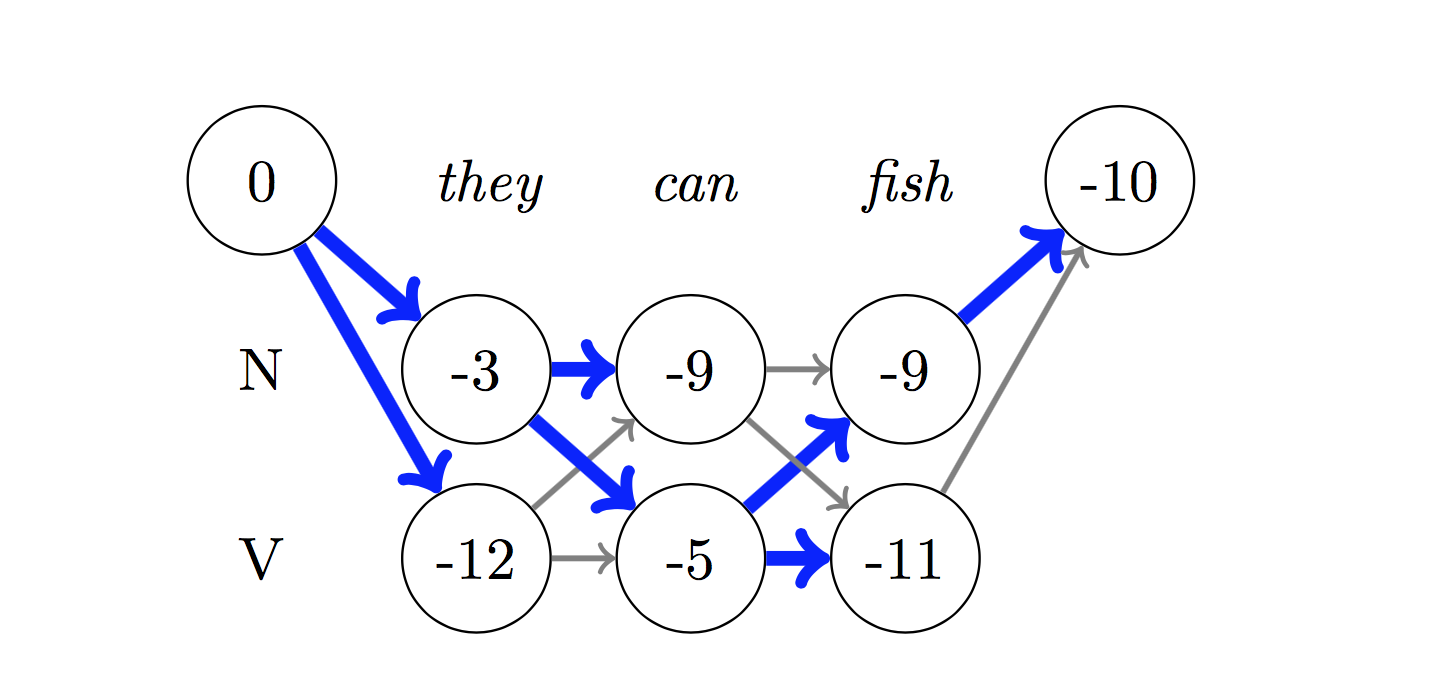
디코딩의 경우 Viterbi 알고리즘이 사용됩니다.
우리는 CRF를 사용하고 있기 때문에 단어 시퀀스에 대한 올바른 레이블 시퀀스를 예측할 때 각 단어에서 올바른 레이블을 예측하지는 않습니다. Viterbi Decoding은이 작업을 정확하게 수행하는 방법입니다. 조건부 랜덤 필드로 계산 된 점수에서 가장 최적의 태그 시퀀스를 찾으십시오.
태깅 작업에서 하위 단어 정보를 사용하여 태그의 일부 또는 엔티티의 일부에 관계없이 태그의 강력한 지표가 될 수 있기 때문입니다. 예를 들어, 형용사는 일반적으로 "-y"또는 "-ul"으로 끝나거나 종종 "-land"또는 "-burg"로 끝나는 것을 알 수 있습니다.
따라서 시퀀스 태깅 모델은 두 가지를 모두 사용합니다
word-level 정보.character-level 정보. 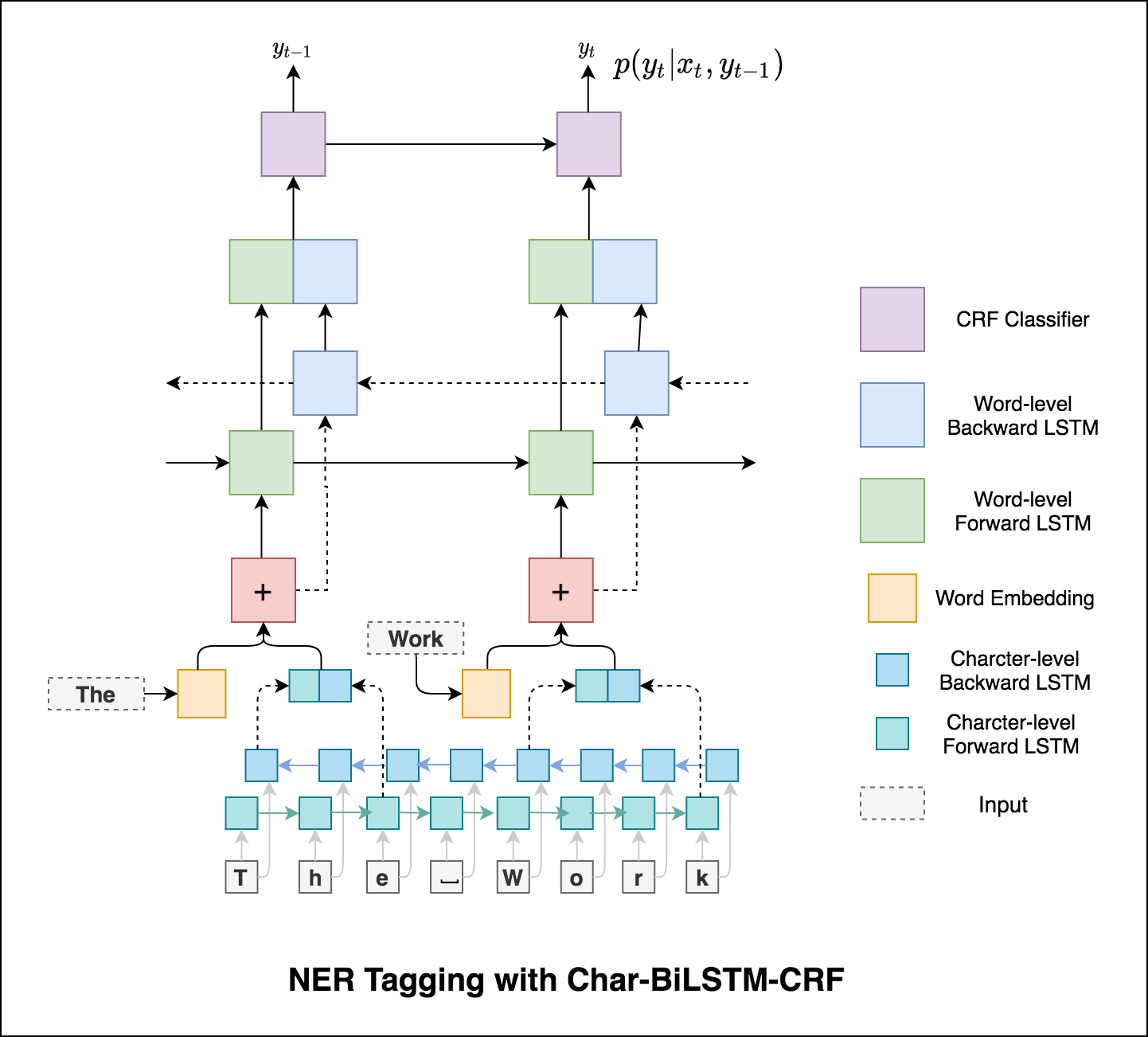
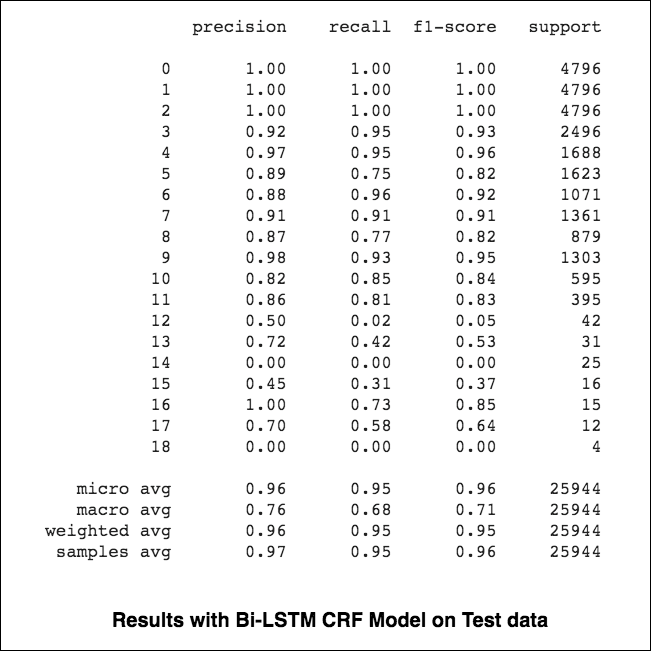
미세 및 거시 평균 (메트릭의 경우)은 약간 다른 것을 계산하므로 해석이 다릅니다. 거시 평균은 각 클래스에 대해 독립적으로 메트릭을 계산 한 다음 평균 (따라서 모든 클래스를 동일하게 처리)을 취하는 반면, 미세 평균은 모든 클래스의 기여를 집계하여 평균 메트릭을 계산합니다. 멀티 클래스 분류 설정에서 클래스 불균형이있을 수 있다고 의심되는 경우 마이크로 평균이 바람직합니다 (즉, 다른 클래스보다 한 클래스의 더 많은 예가있을 수 있습니다).

NER 태그를 Streamlit을 사용하여 앱으로 변환했습니다. 사전 훈련 된 모델 (char-bilstm-crf)은 현재 사용할 수 있습니다.
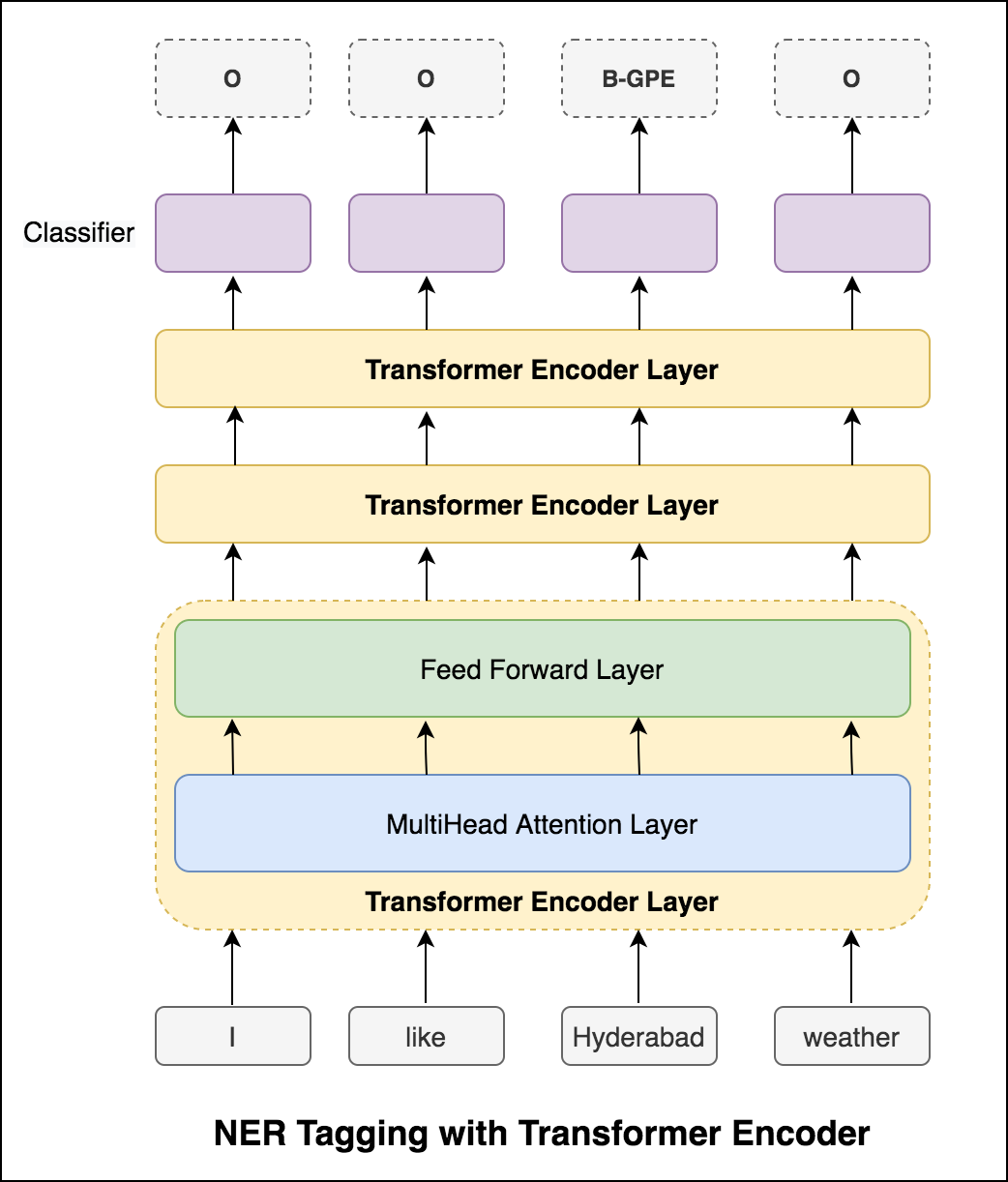
RNN 접근법을 시도한 후 변압기 기반 아키텍처로 NER 태그가 탐색됩니다. 변압기에는 인코더와 디코더가 모두 포함되어 있고 시퀀스 라벨링 작업에 대해서만 Encoder 만 충분합니다. 3 층 변압기 엔코더 모델이 사용되었습니다.
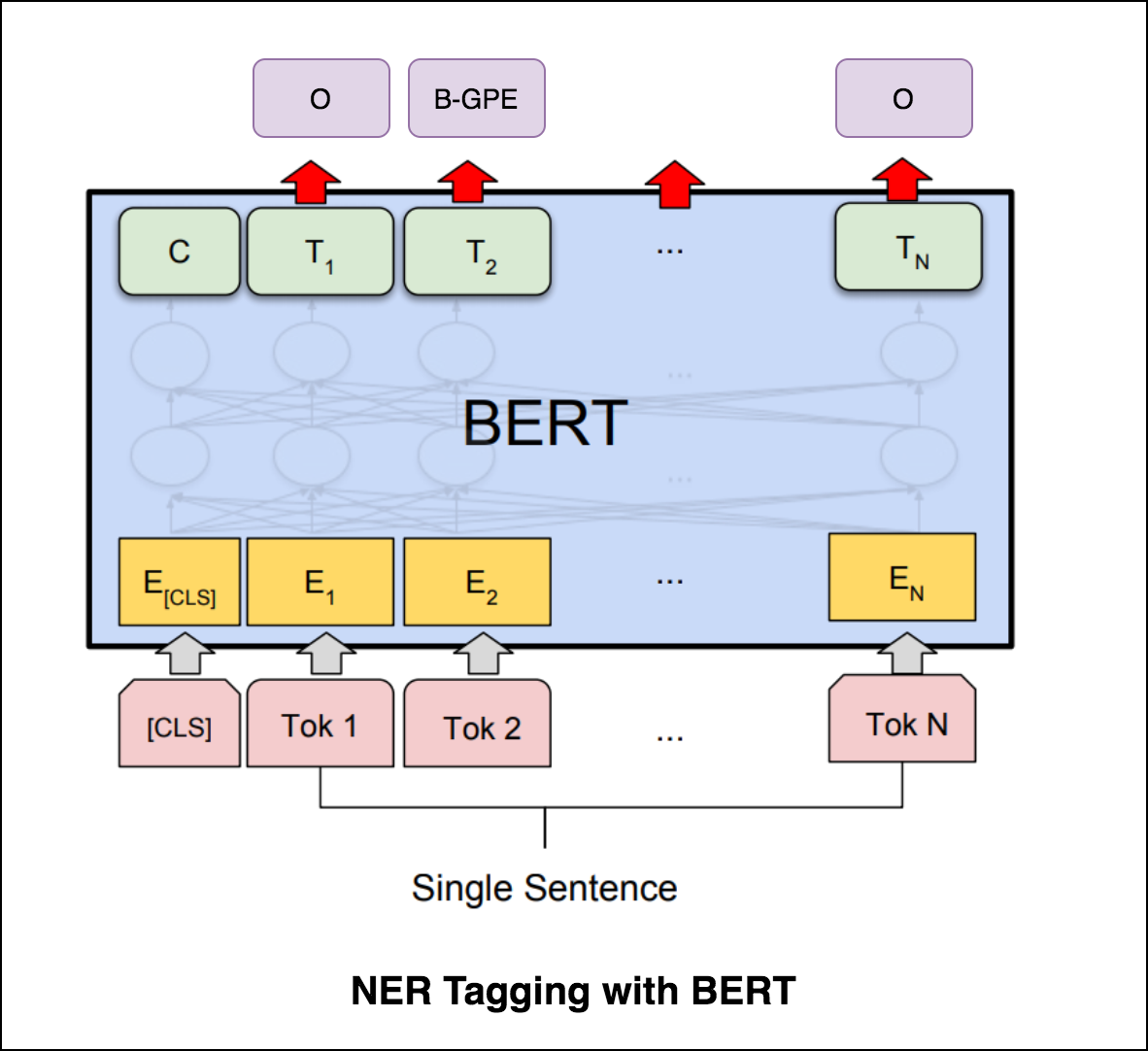
Transformer Encoder로 NER 태깅을 시도한 후, 미리 훈련 된 bert-base-cased 모델로 NER 태깅이 탐색됩니다.
변압기만으로는 NER 태그 작업에서 BILSTM에 비해 좋은 결과를 제공하지 않습니다. 변압기 위에 CRF 층을 보강하는 것이 구현되어 독립형 변압기와 비교하여 결과가 향상됩니다.
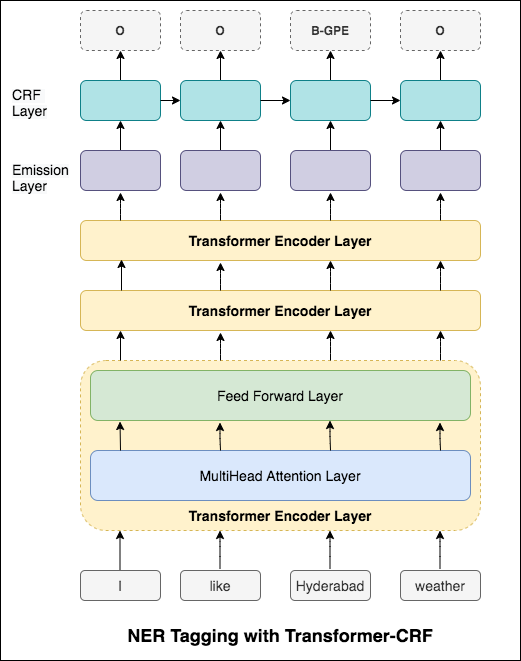
Spacy는 Python에서 NER에 대해 매우 효율적인 통계 시스템을 제공하며, 이는 토큰 그룹에 라벨을 할당 할 수 있습니다. 사람, 조직, 언어, 이벤트 등을 포함하여 광범위한 명명 또는 숫자 엔티티를 인식 할 수있는 기본 모델을 제공합니다.

이러한 기본 엔터티 외에도 Spacy는 모델을 교육하여 새로운 훈련 된 예제로 업데이트하도록 교육함으로써 NER 모델에 임의의 클래스를 추가 할 수있는 자유를 제공합니다.
2 개의 새로운 엔티티는 특정 도메인 데이터 (은행)에서 ACTIVITY 및 SERVICE 라는 새로운 엔티티가 몇 가지 훈련 샘플로 만들어지고 훈련됩니다.

| 이름 생성 | 기계 번역 | 발언 세대 |
| 이미지 캡션 | 이미지 캡션 - 라텍스 방정식 | 뉴스 요약 |
| 이메일 주제 생성 |
문자 수준 LSTM 언어 모델이 사용됩니다. 즉, 우리는 LSTM에 많은 이름을 부여하고 이전 문자 순서가 주어진 순서에서 다음 문자의 확률 분포를 모델링하도록 요청합니다. 그러면 한 번에 하나의 캐릭터 씩 새 이름을 생성 할 수 있습니다.

Machine Translation (MT)은 한 자연 언어를 다른 자연 언어로 자동 변환하여 입력 텍스트의 의미를 유지하고 출력 언어에서 유창한 텍스트를 생성하는 작업입니다. 이상적으로는 소스 언어 시퀀스가 대상 언어 시퀀스로 변환됩니다. 임무는 문장을 German to English 전환하는 것입니다.
다음과 같은 변형이 탐색되었습니다.
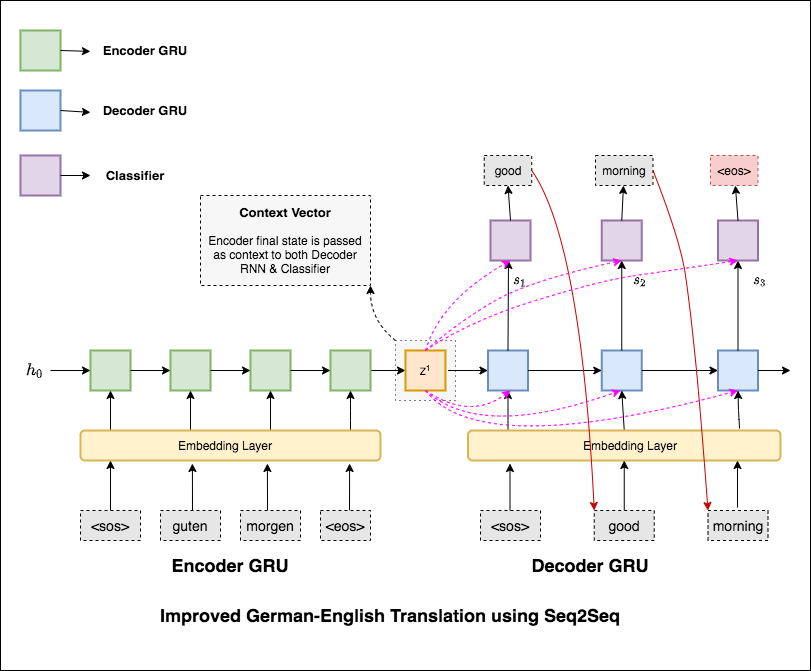
가장 일반적인 시퀀스-시퀀스 (SEQ2SEQ) 모델은 인코더 디코더 모델이며,이 모델은 일반적으로 재발 성 신경망 (RNN)을 사용하여 소스 (입력) 문장을 단일 벡터로 인코딩합니다. 이 노트북에서는이 단일 벡터를 컨텍스트 벡터라고합니다. 우리는 컨텍스트 벡터를 전체 입력 문장의 추상적 표현으로 생각할 수 있습니다. 그런 다음이 벡터는 한 번에 한 단어 씩 생성하여 대상 (출력) 문장을 출력하는 법을 배우는 두 번째 RNN에 의해 디코딩됩니다.

Text Perplexity 36.68 갖는 기본 기계 번역을 시도한 후, 다음 기술이 실험되었고 테스트 당연한 7.041 .
applications/generation 폴더에서 코드를 확인하십시오
주의 메커니즘은 NMT (Neural Machine Translation)에서 긴 소스 문장을 암기하는 데 도움이되었습니다. 인코더의 마지막 숨겨진 상태에서 단일 컨텍스트 벡터를 구축하는 대신 문장을 디코딩하면서 입력의 관련 부분에 더 집중하는 데주의를 기울입니다. 컨텍스트 벡터는 인코더 출력과 디코더 RNN의 previous hidden state 취함으로써 생성됩니다.
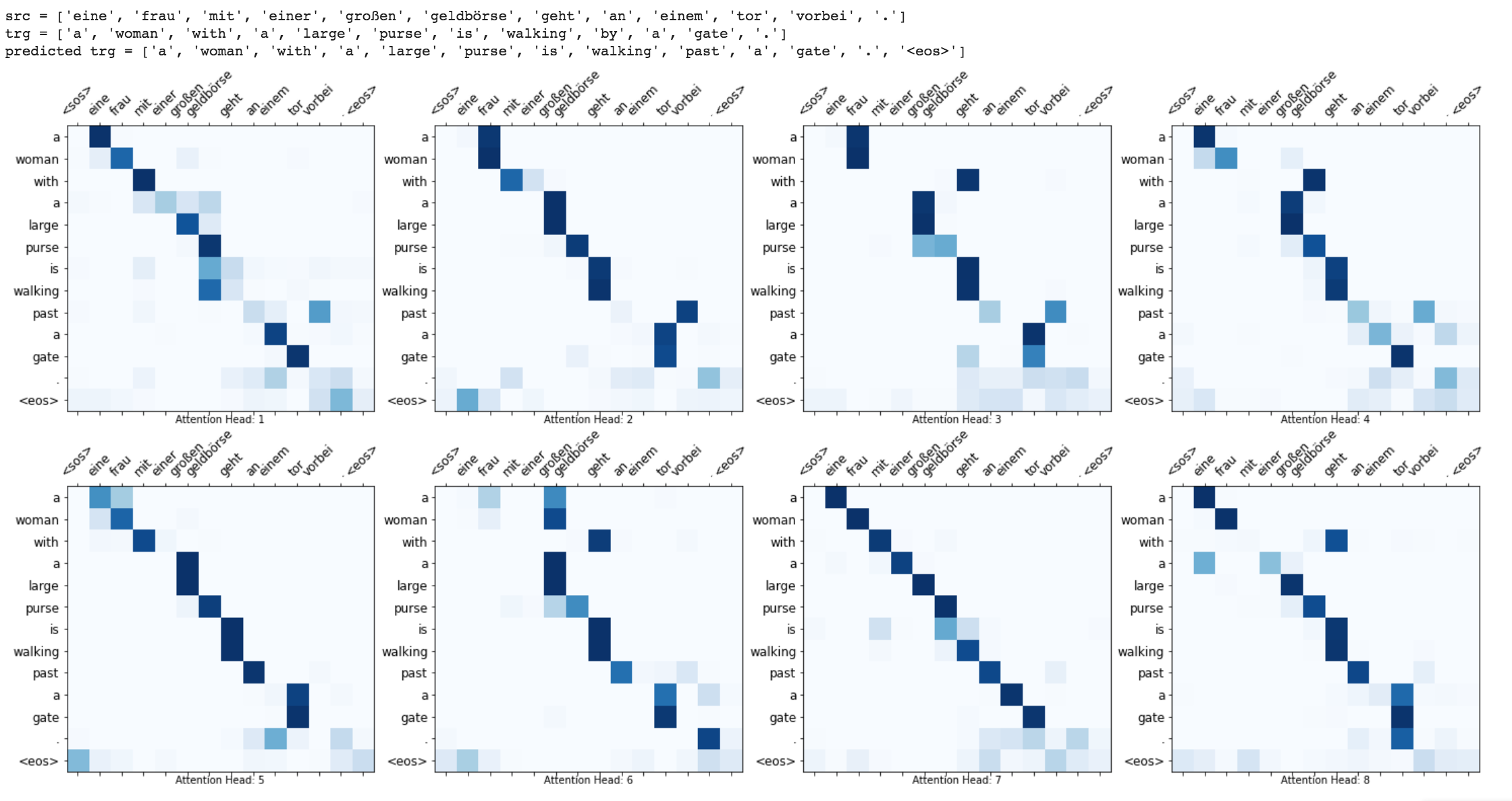
마스킹 (패딩 입력에 대한 관심 무시), 패킹 패딩 시퀀스 (더 나은 계산),주의 시각화 및 테스트 데이터에 대한 Bleu 메트릭과 같은 향상이 구현됩니다.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
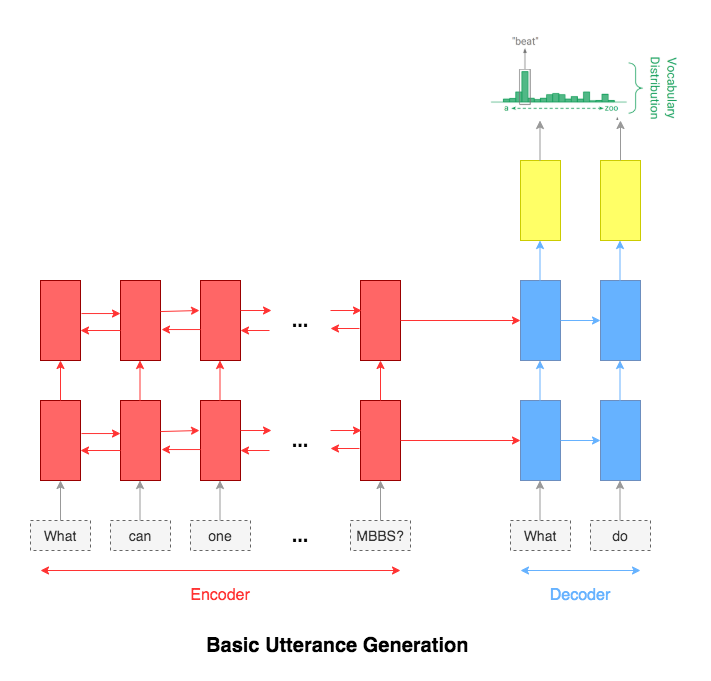
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
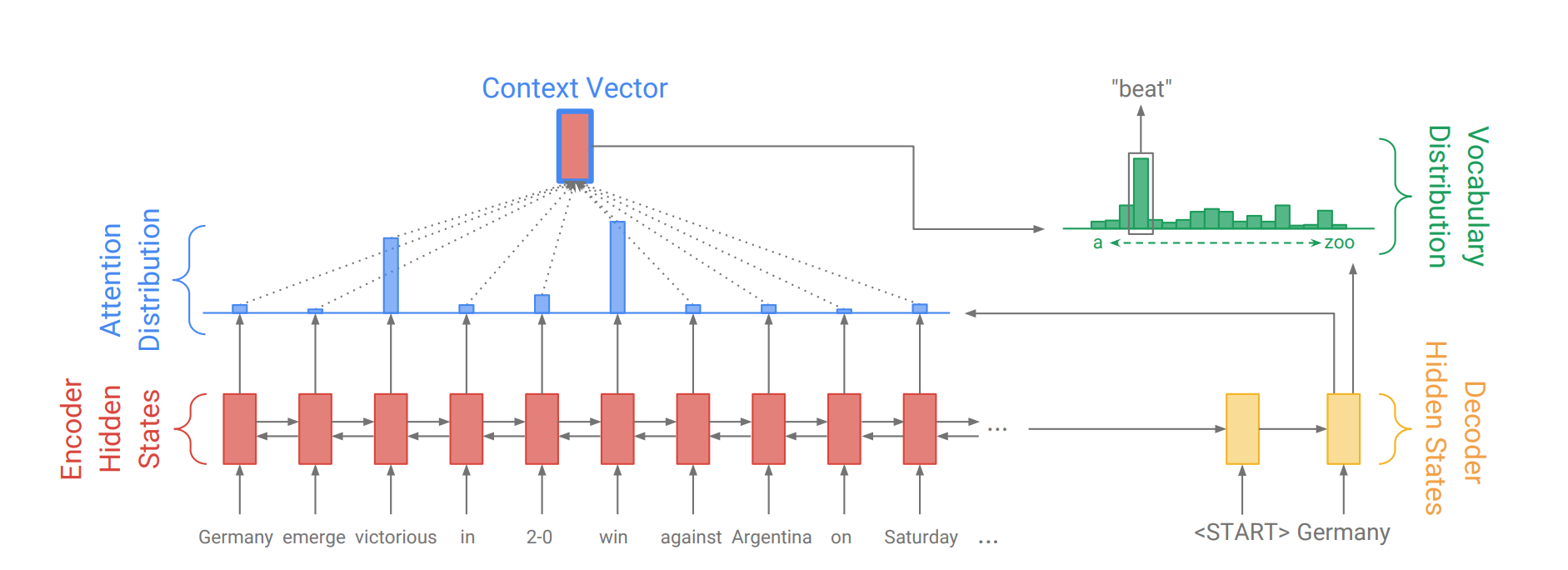
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
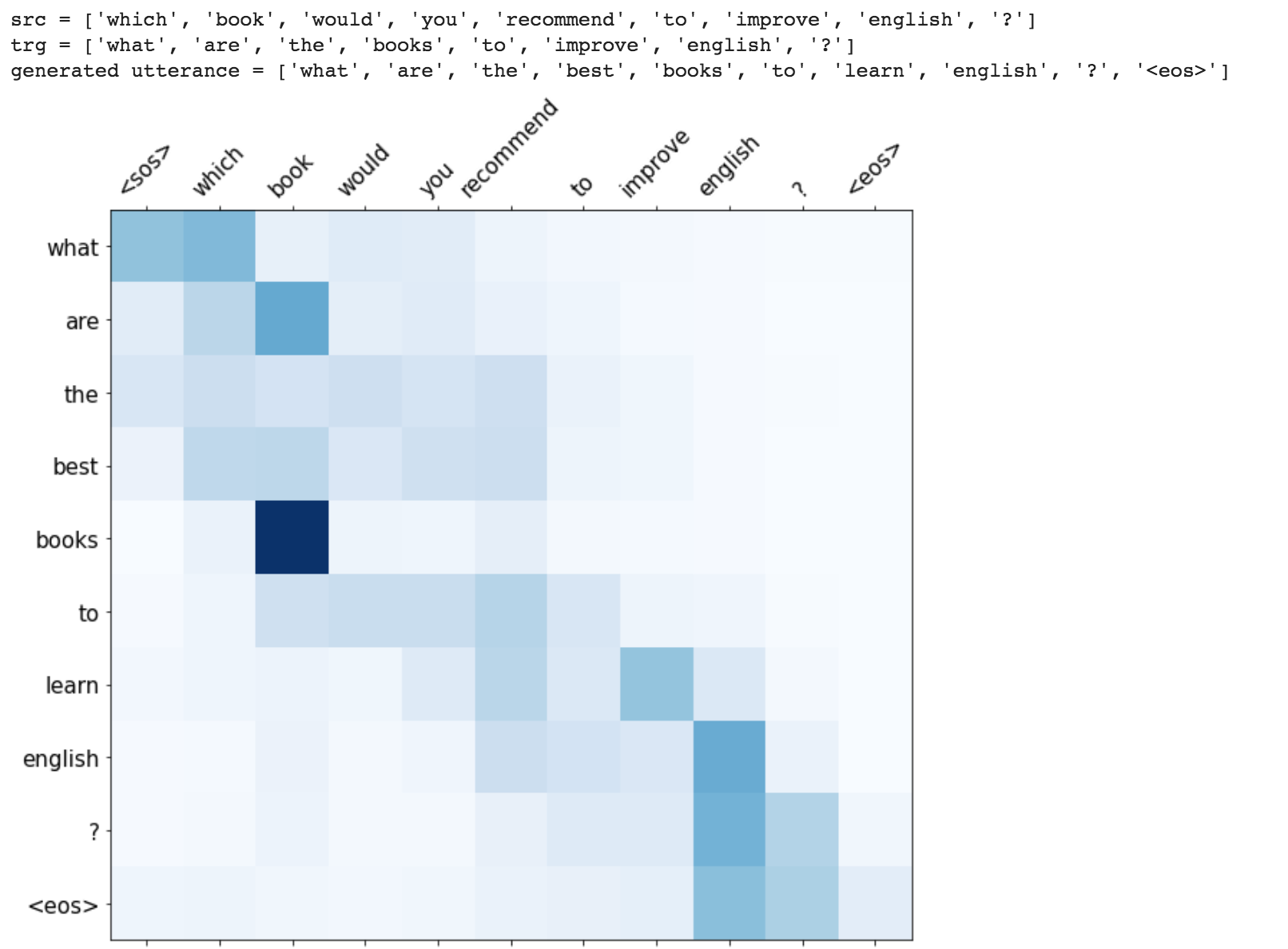
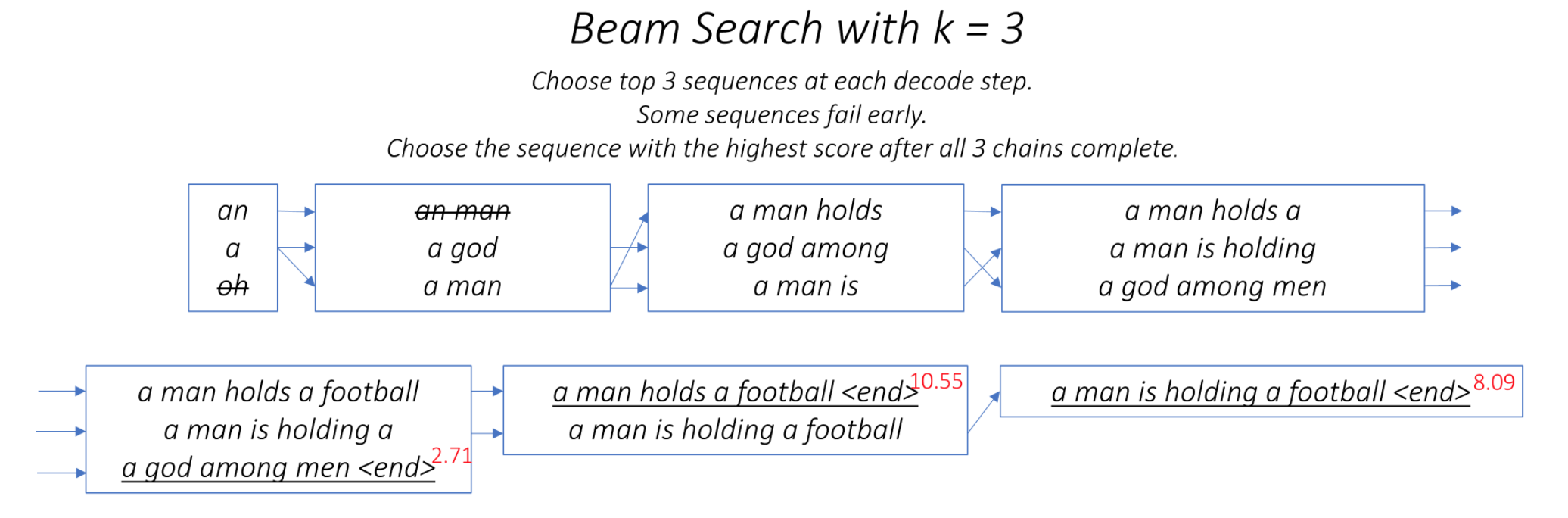
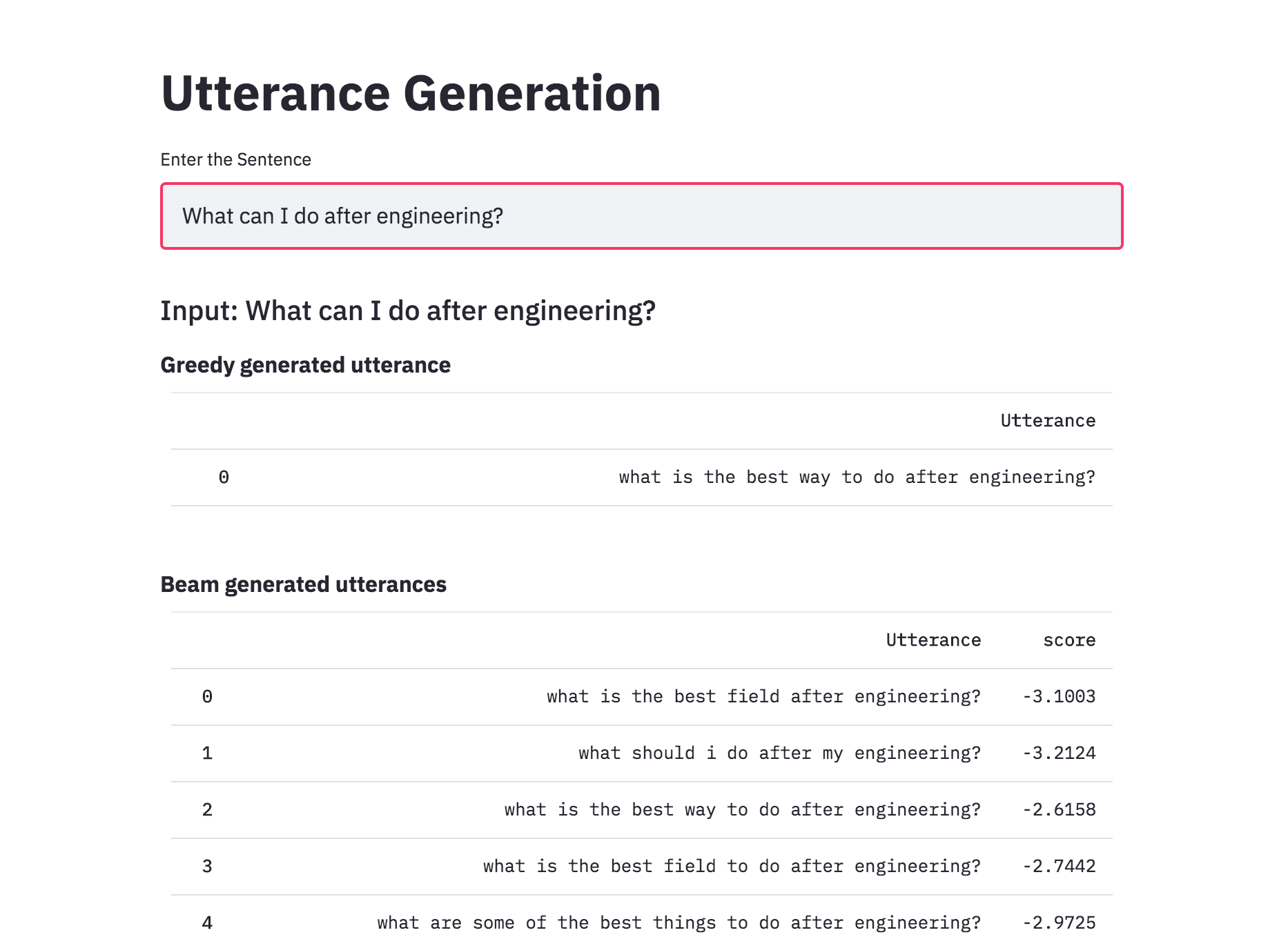
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

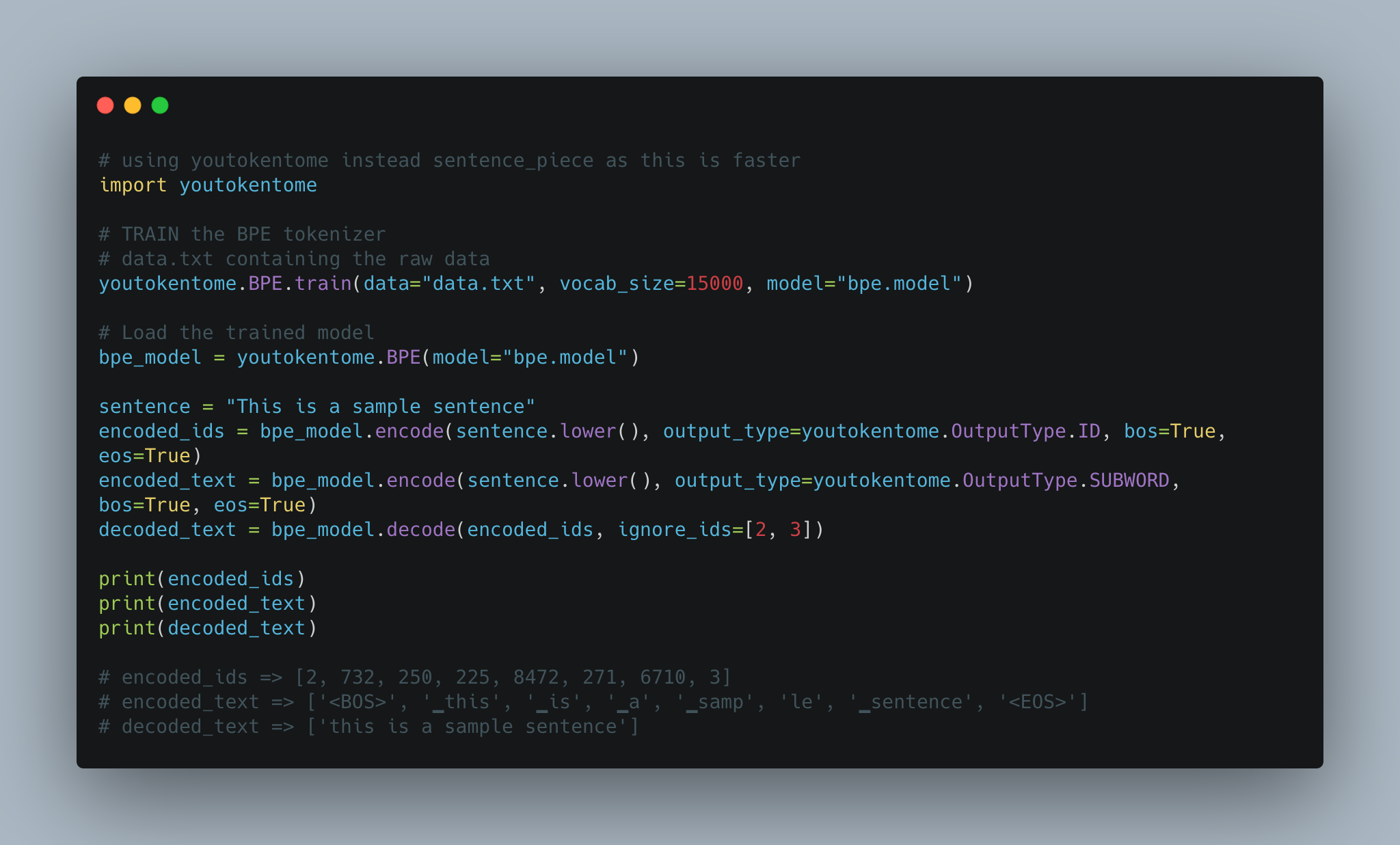
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
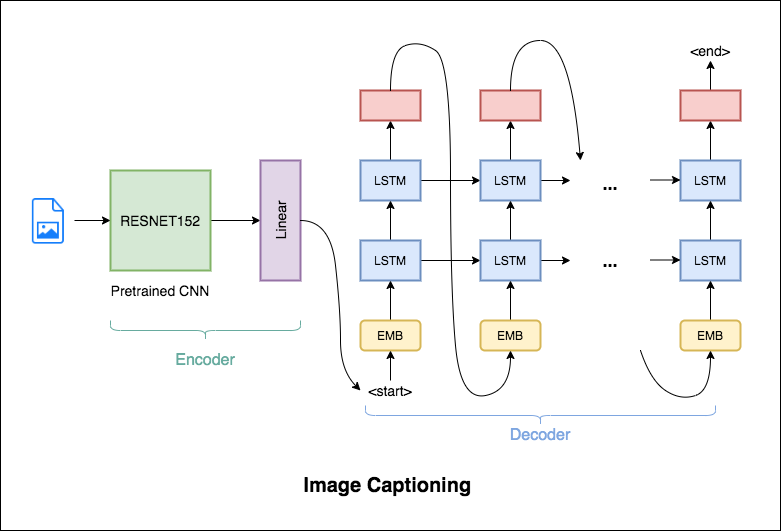
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
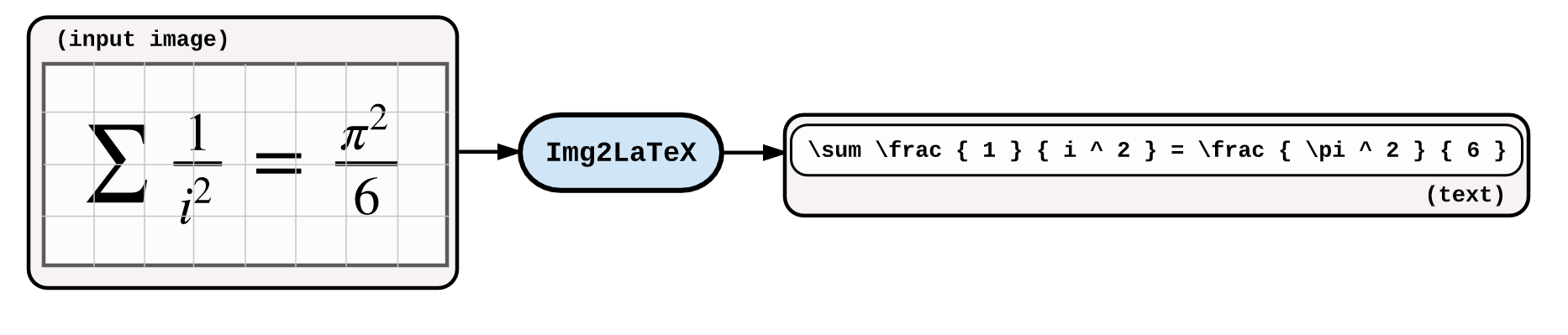
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
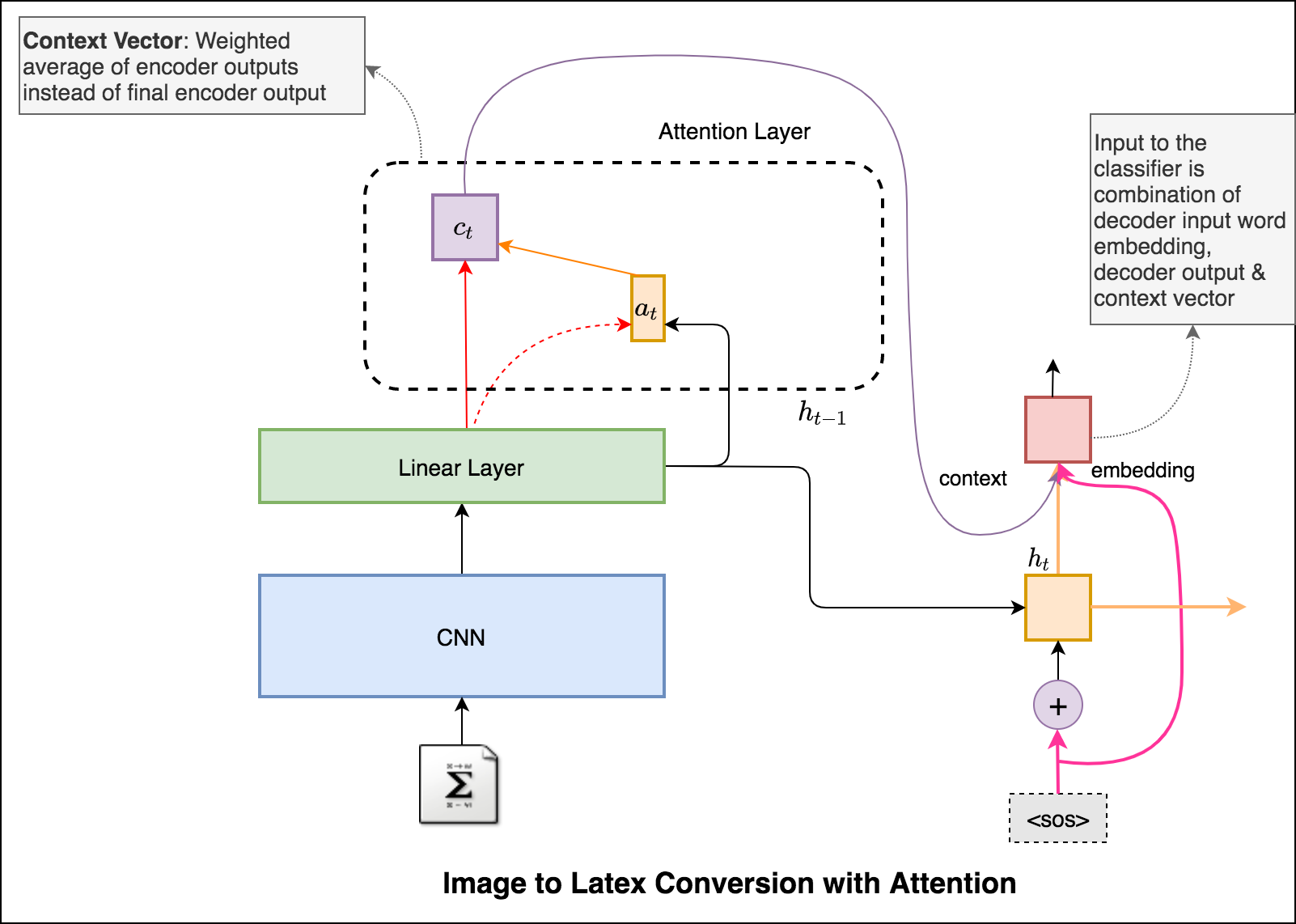
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

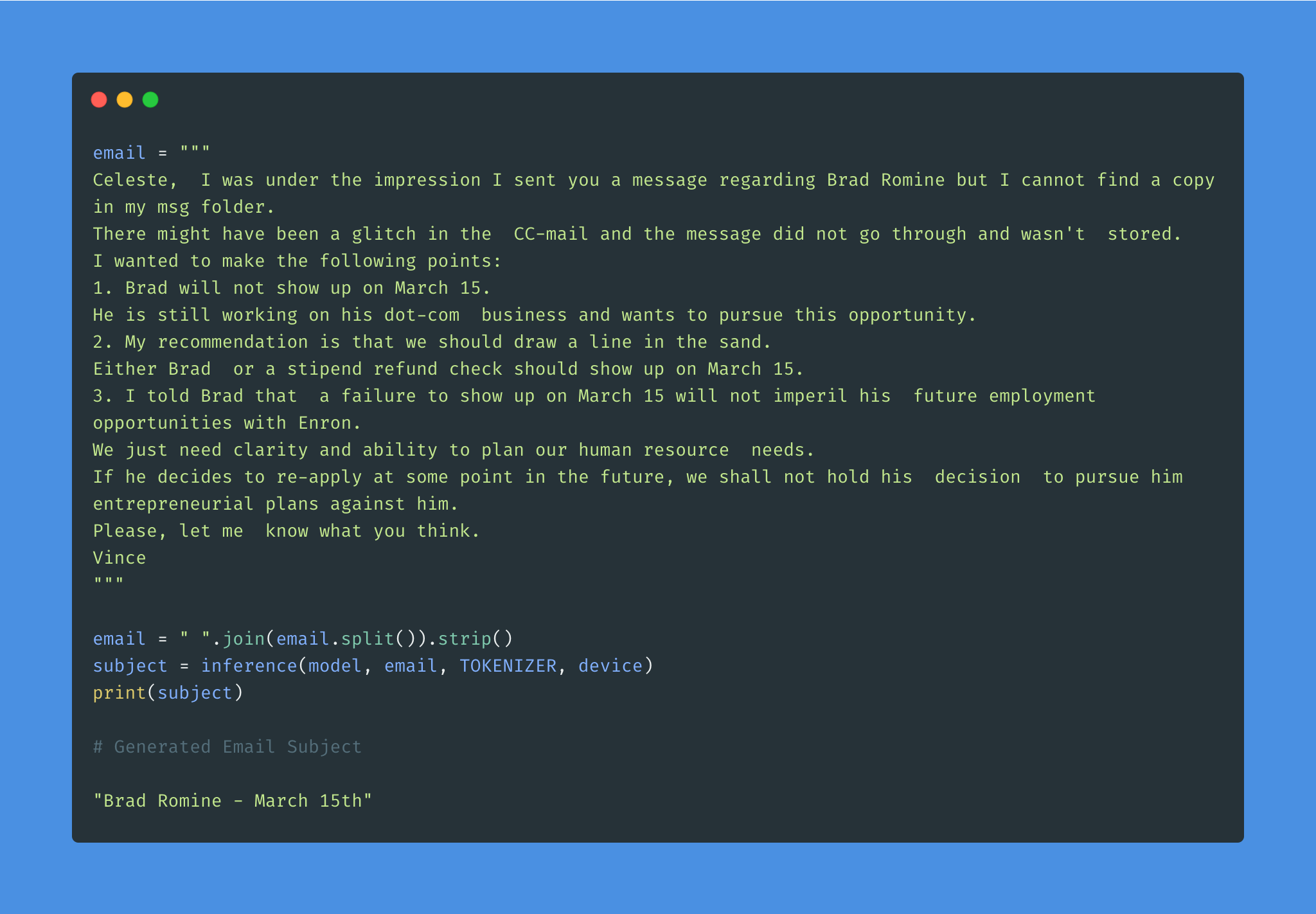
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
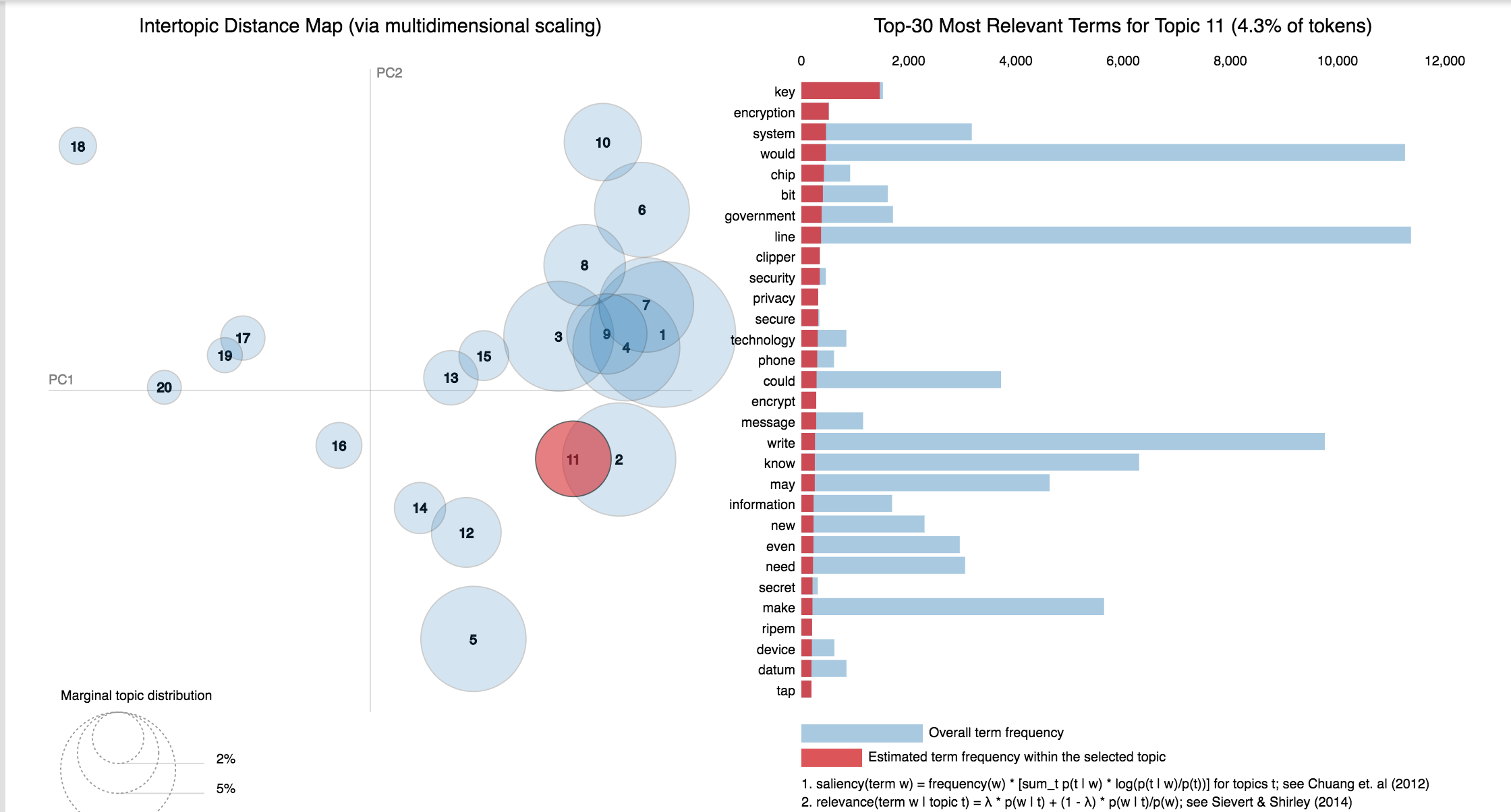
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
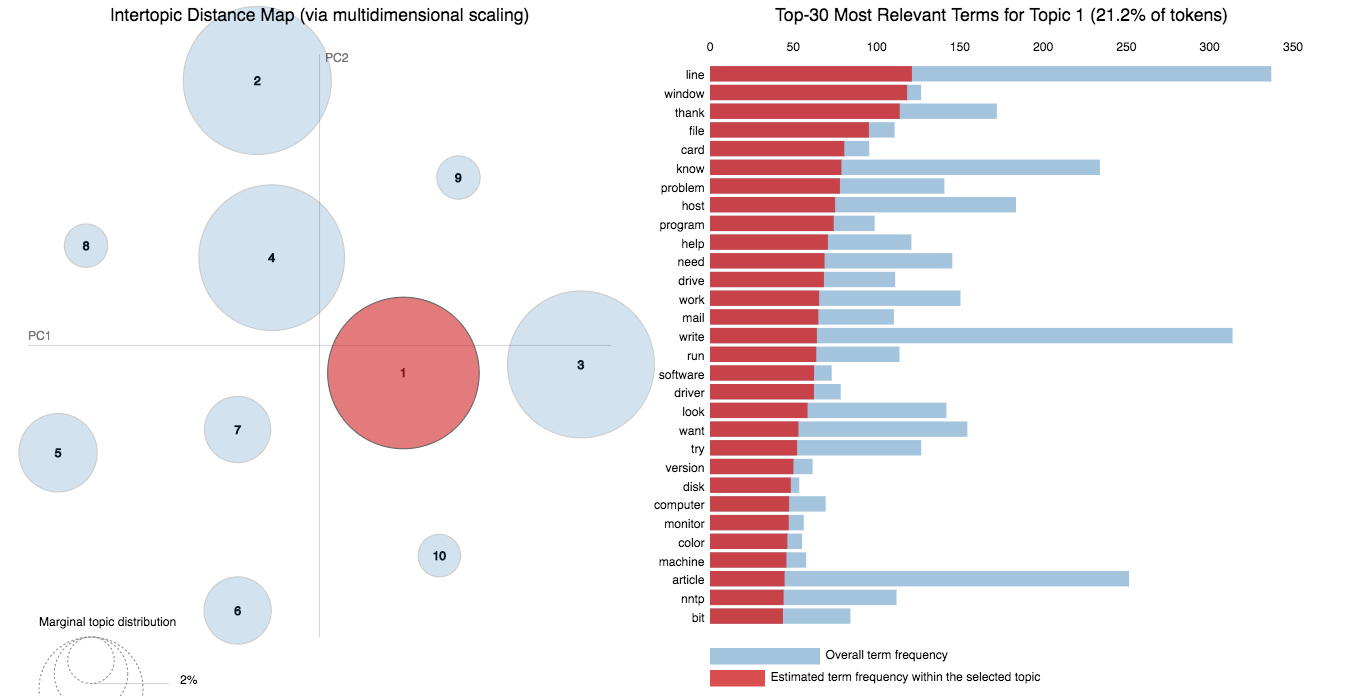
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
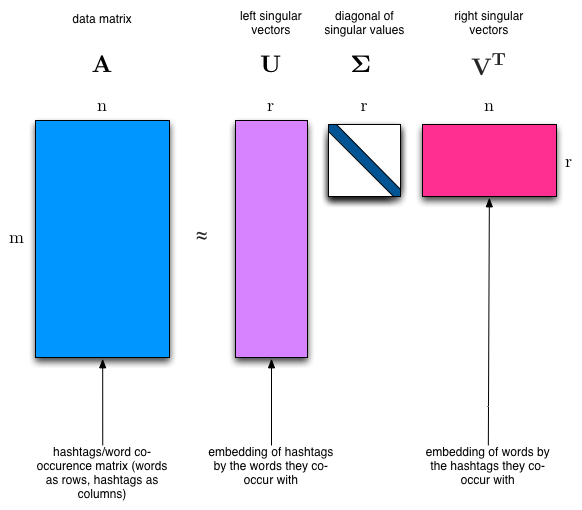
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
참고 :
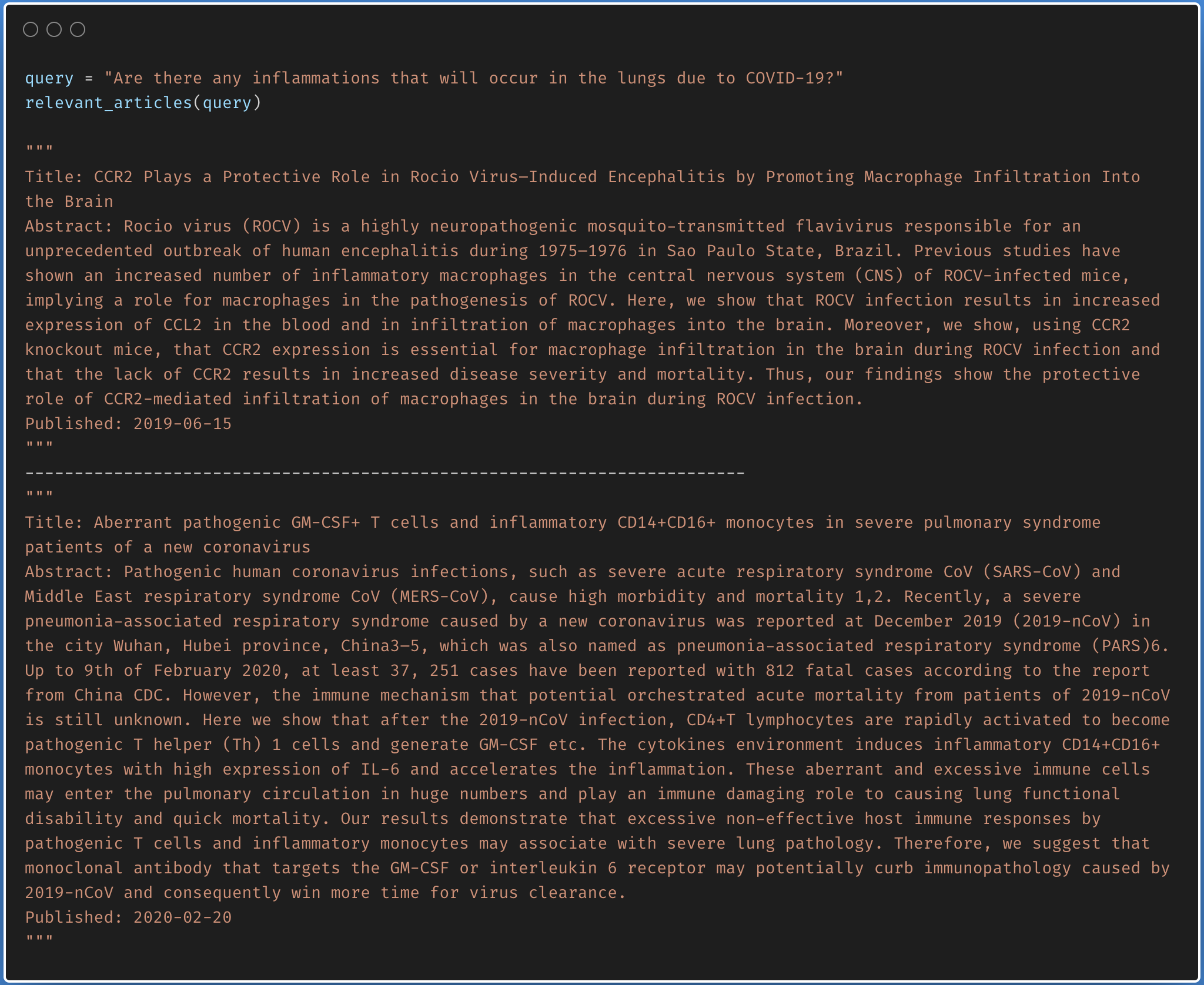
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
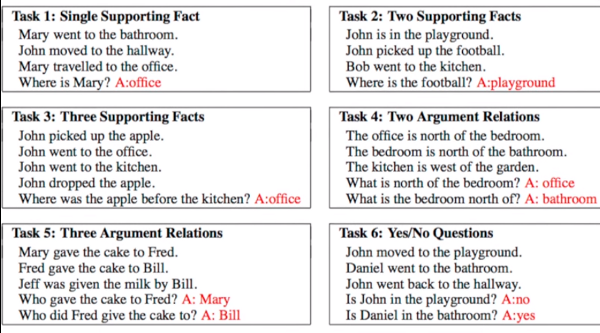
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

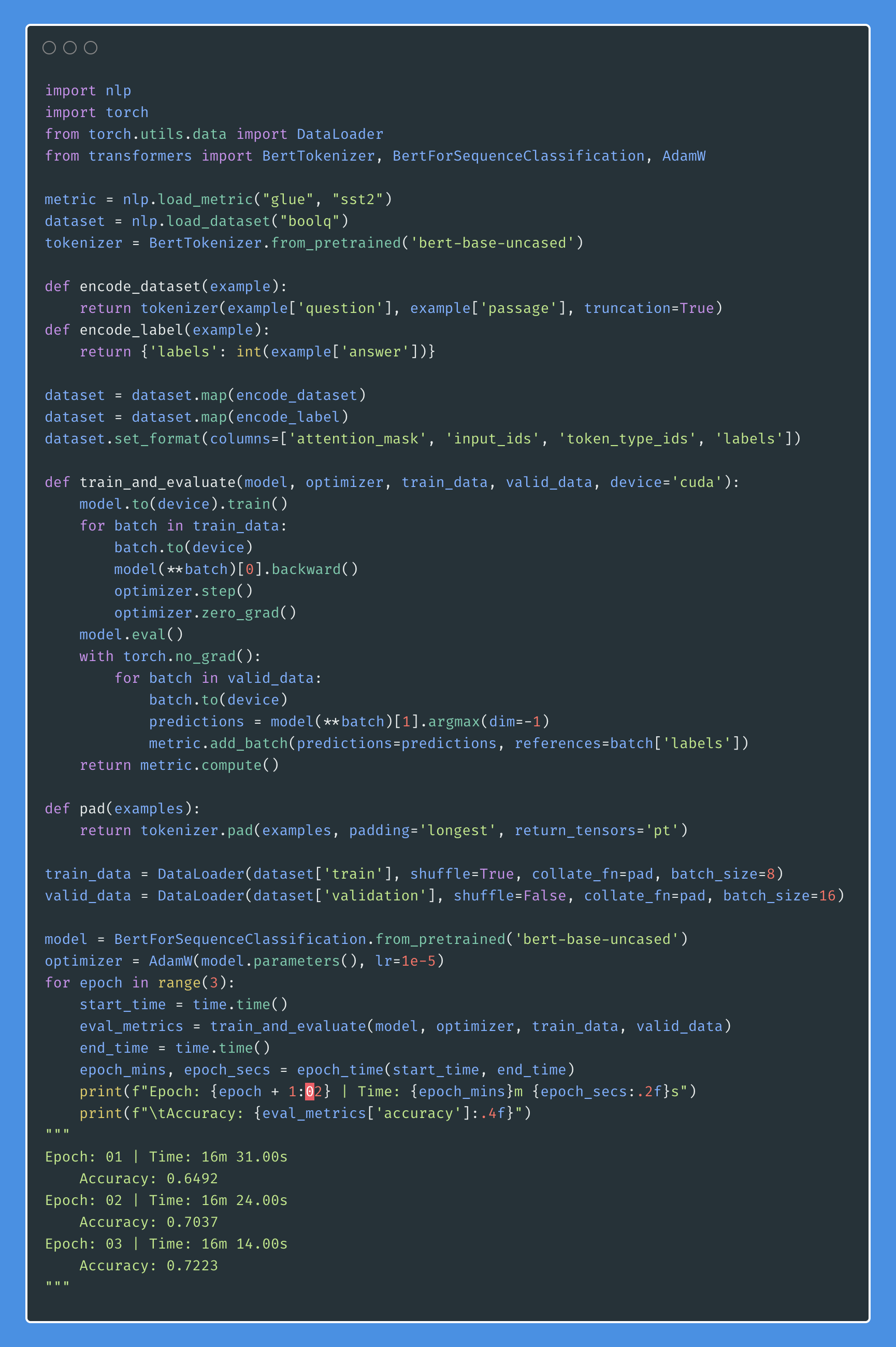
Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
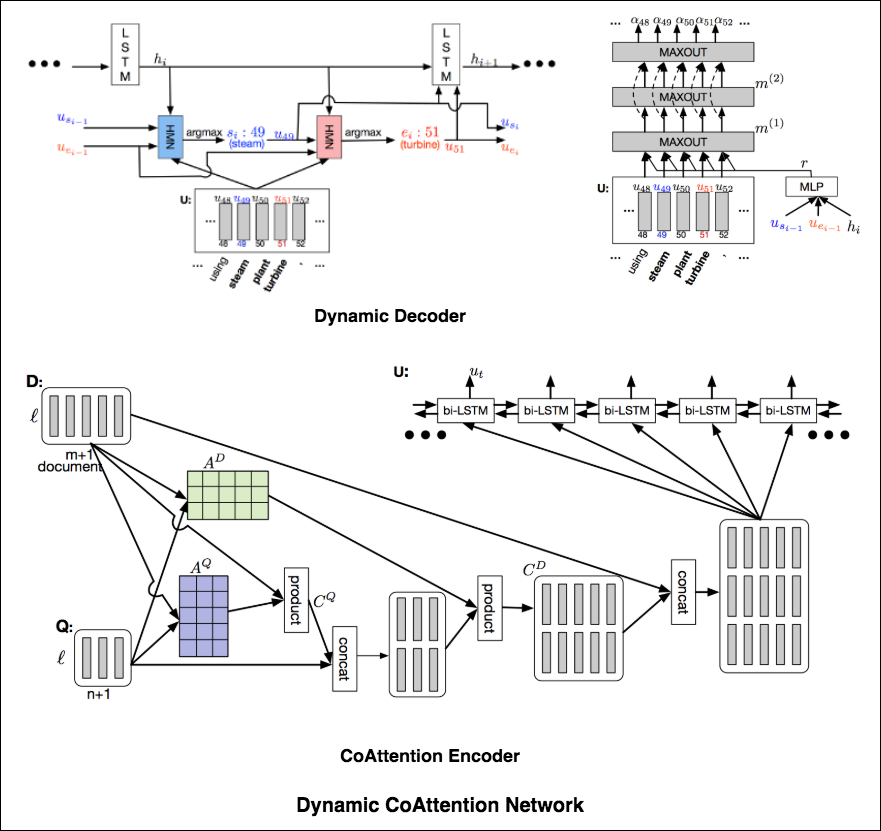
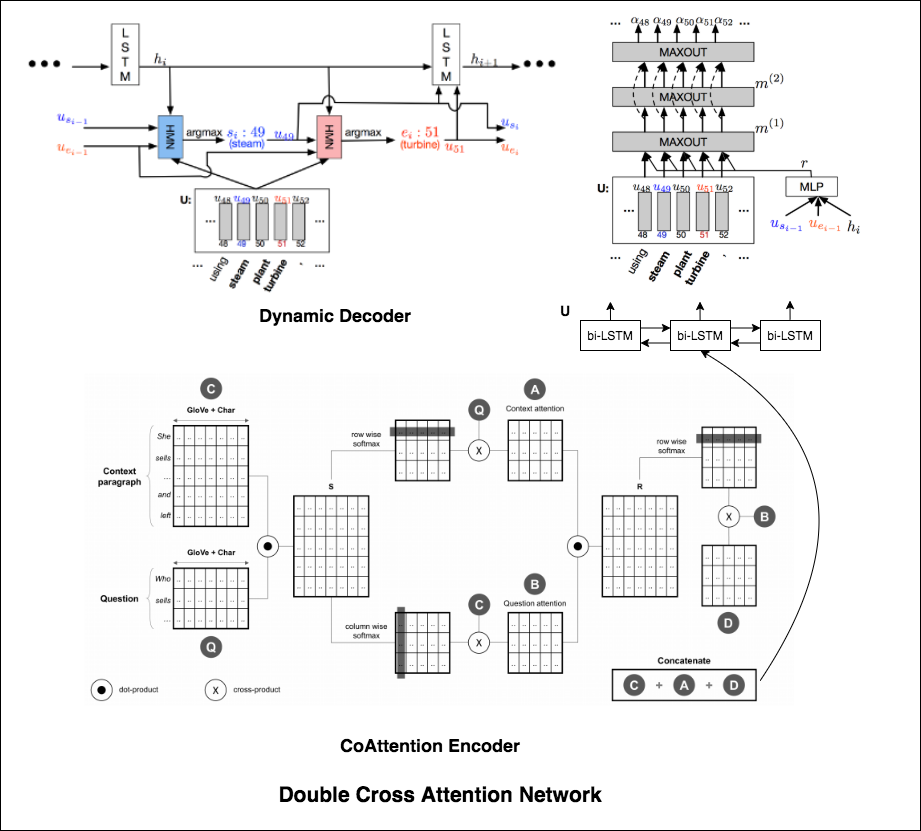
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
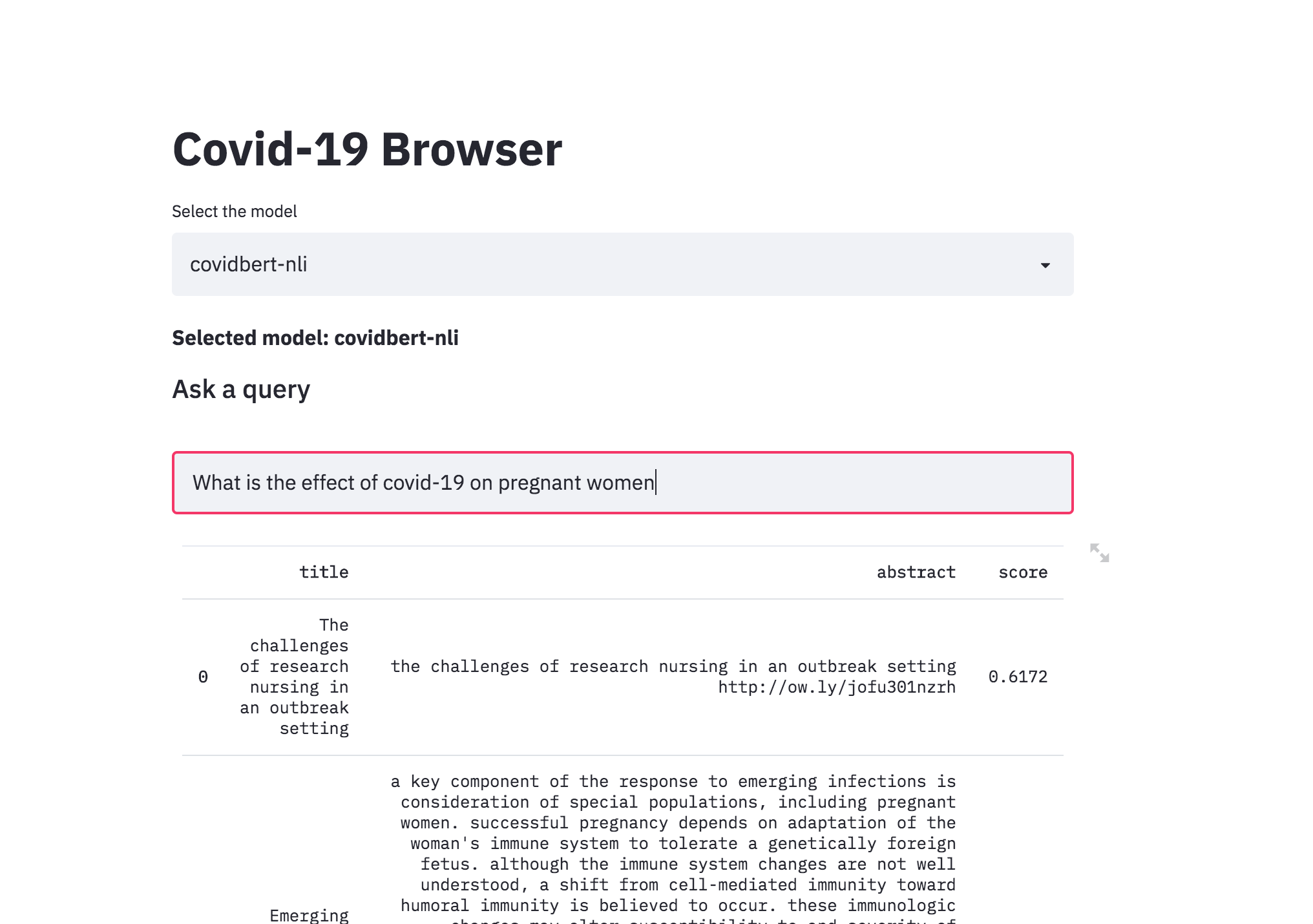
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
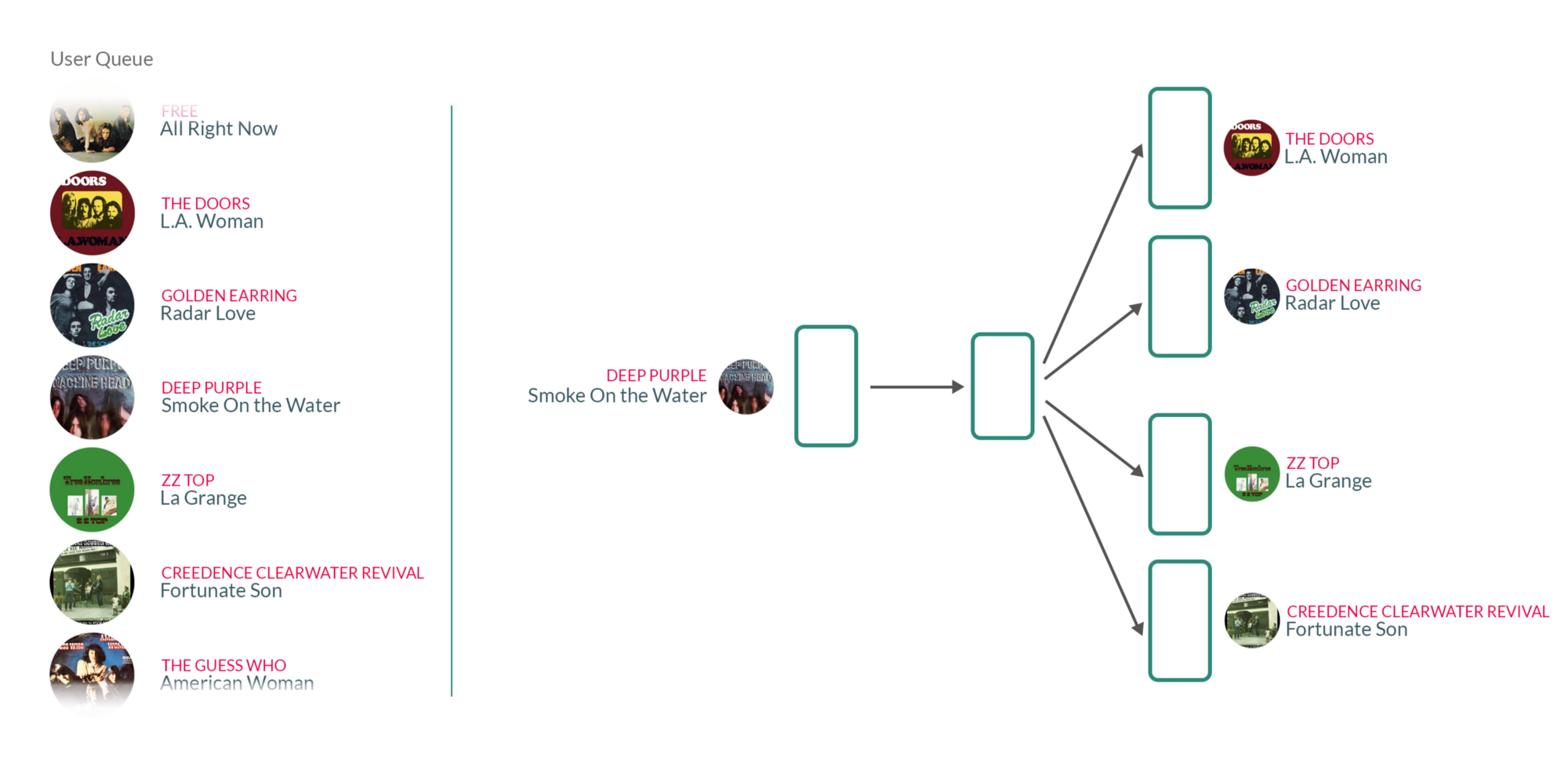
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


