100 Days of NLP
1.0.0

No hay nada de magia sobre la magia. El mago simplemente entiende algo simple que no parece ser simple o natural para la audiencia no entrenada. Una vez que aprende a sostener una tarjeta mientras hace que su mano se vea vacía, solo necesita práctica antes que usted, también puede "hacer magia". - Jeffrey Friedl en el libro Mastering Expresiones regulares
Nota: plantee un problema para cualquier sugerencia, corrección y retroalimentación.
La mayoría de las muestras de código se realizan con cuadernos Jupyter (usando Colab). Para que cada código se pueda ejecutar de forma independiente.
Se han explorado los siguientes temas:
Nota: El nivel de dificultad se ha asignado de acuerdo con mi comprensión.
| Tokenización | Incrustaciones de palabras - word2vec | Incrustaciones de palabras - guante | Incrustaciones de palabras - Elmo |
| RNN, LSTM, Gru | Empaque secuencias acolchadas | Mecanismo de atención - Luong | Mecanismo de atención - Bahdanau |
| Red de puntero | Transformador | GPT-2 | Bert |
| Modelado de temas - LDA | Análisis de componentes principales (PCA) | Bayes ingenuos | Aumento de datos |
| Incrustaciones de oraciones |
El proceso de convertir datos textuales en tokens es uno de los pasos más importantes en la PNL. Se ha explorado la tokenización utilizando los siguientes métodos:
Una incrustación de palabras es una representación aprendida para el texto donde las palabras que tienen el mismo significado tienen una representación similar. Es este enfoque para representar palabras y documentos el que puede considerarse uno de los avances clave del aprendizaje profundo en problemas desafiantes de procesamiento del lenguaje natural.

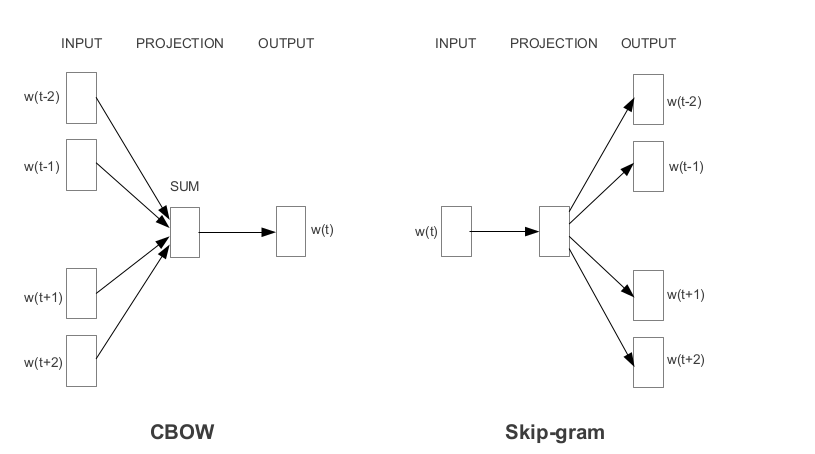
Word2Vec es una de las incrustaciones de palabras previas a la aparición más populares desarrolladas por Google. Dependiendo de la forma en que se aprenden los incrustaciones, Word2Vec se clasifica en dos enfoques:
El guante es otro método de uso común para obtener incrustaciones previamente capacitadas. Glove tiene como objetivo lograr dos objetivos:
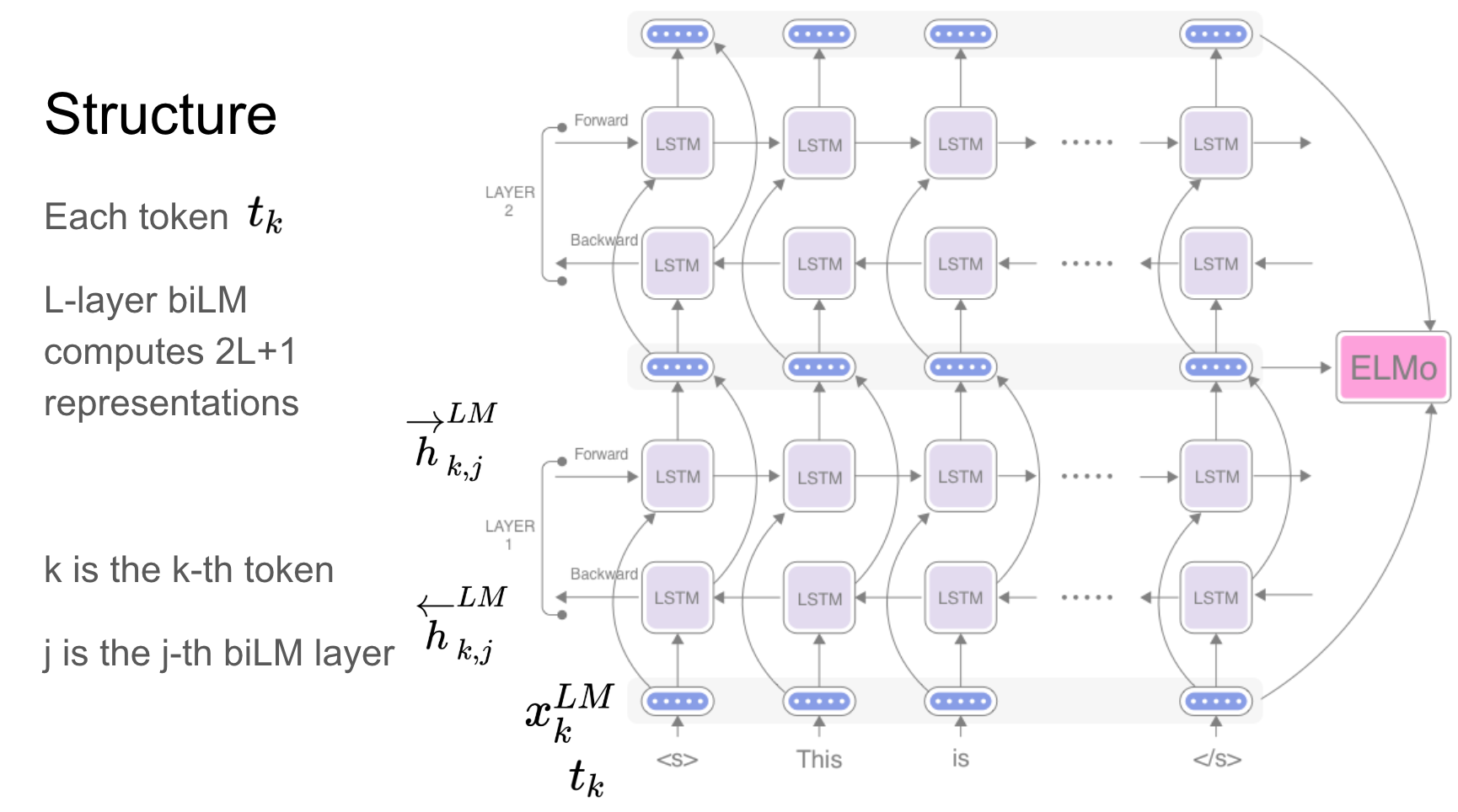
Elmo es una representación de palabras contextualizada profunda que modela:
Estos vectores de palabras son funciones aprendidas de los estados internos de un modelo de lenguaje bidireccional profundo (BILM), que se entrena previamente en un gran corpus de texto.
Redes recurrentes: RNN, LSTM, Gru han demostrado ser una de las unidades más importantes en las aplicaciones de PNL debido a su arquitectura. Hay muchos problemas en los que la naturaleza de la secuencia debe recordarse como para predecir una emoción en la escena, las escenas anteriores deben ser recordadas.

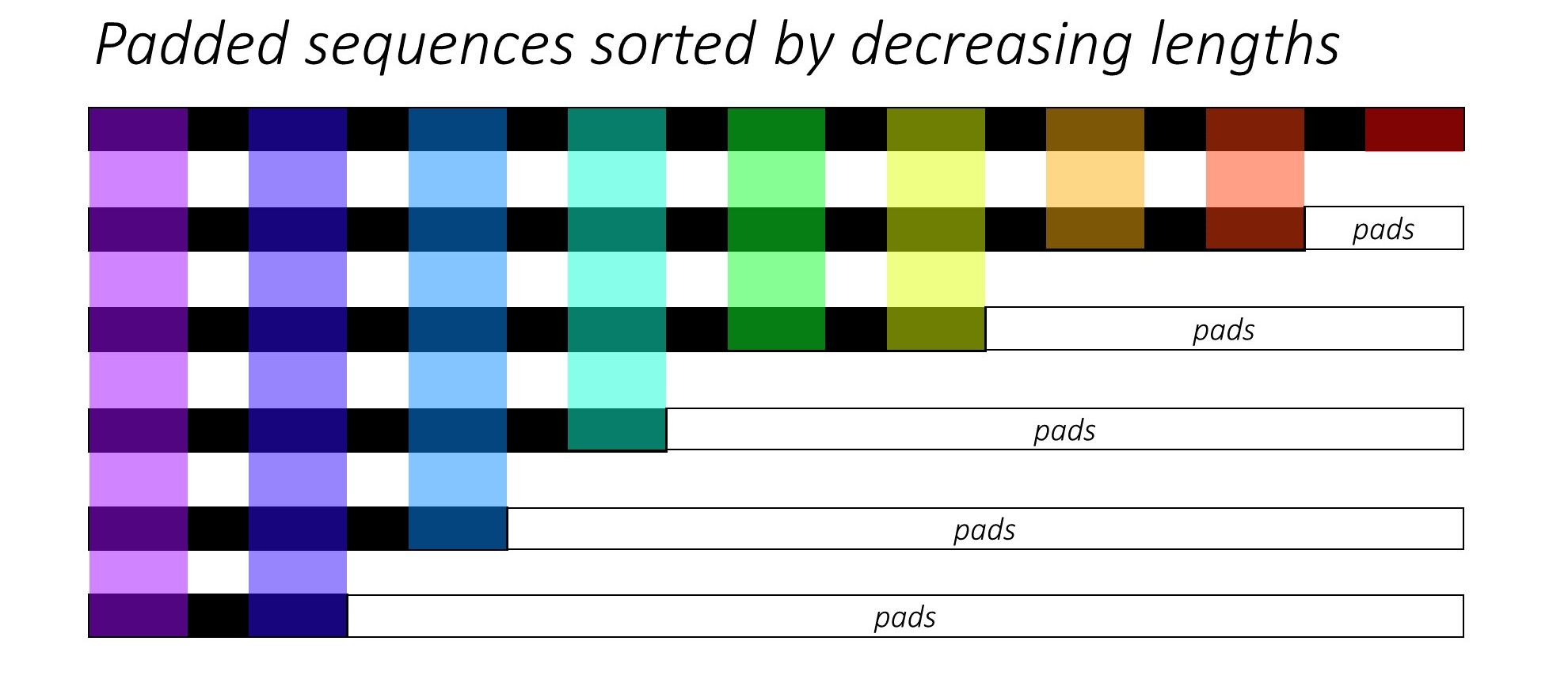
Al entrenar RNN (LSTM o GRU o Vanilla-RNN), es difícil por lote las secuencias de longitud variable. Idealmente, rellenaremos todas las secuencias a una longitud fija y terminaremos haciendo cálculos no necesarios. ¿Cómo podemos superar esto? Pytorch proporciona la funcionalidad pack_padded_sequences .
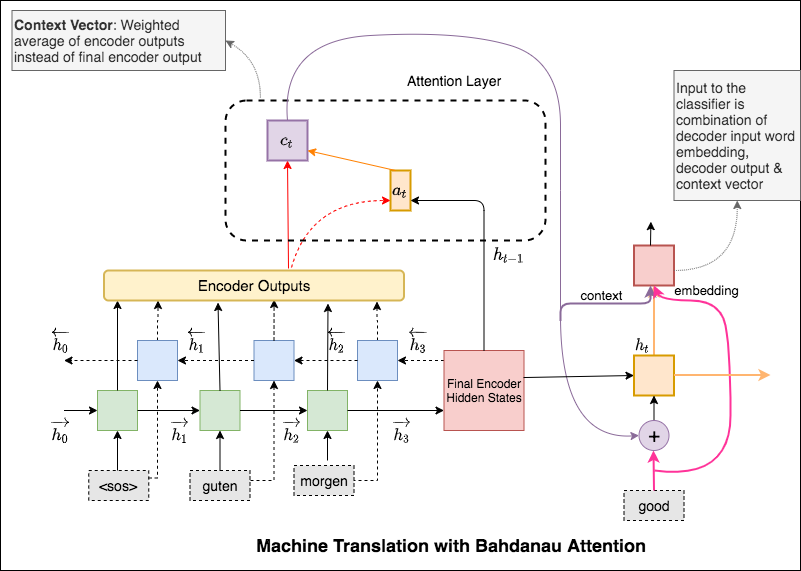
El mecanismo de atención nació para ayudar a memorizar oraciones de origen largo en la traducción del automóvil neuronal (NMT). En lugar de construir un solo vector de contexto a partir del último estado oculto del codificador, la atención se utiliza para centrarse más en las partes relevantes de la entrada mientras decodifica una oración. El vector de contexto se creará tomando salidas del codificador y la current output del decodificador RNN.

El puntaje de atención se puede calcular de tres maneras. dot , general y concat .
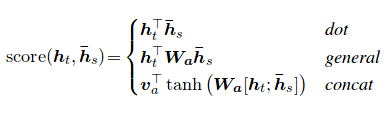
La principal diferencia entre la atención de Bahdanau y Luong es la forma en que se crea el vector de contexto. El vector de contexto se creará tomando salidas del codificador y el previous hidden state del decodificador RNN. Donde está en Luong la atención el vector de contexto se creará tomando salidas del codificador y el current hidden state del decodificador RNN.
Una vez que se calcula el contexto, se combina con la incorporación de entrada del decodificador y se alimenta como entrada al decodificador RNN.

La atención de Bahdanau también se llama atención additive .
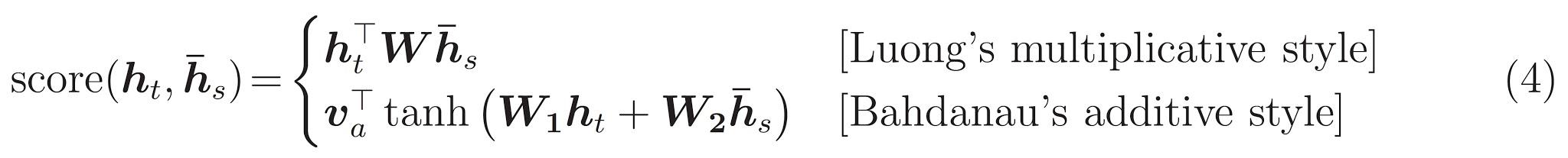
El transformador, una arquitectura modelo evita la recurrencia y, en su lugar, se basa completamente en un mecanismo de atención para atraer dependencias globales entre entrada y salida.
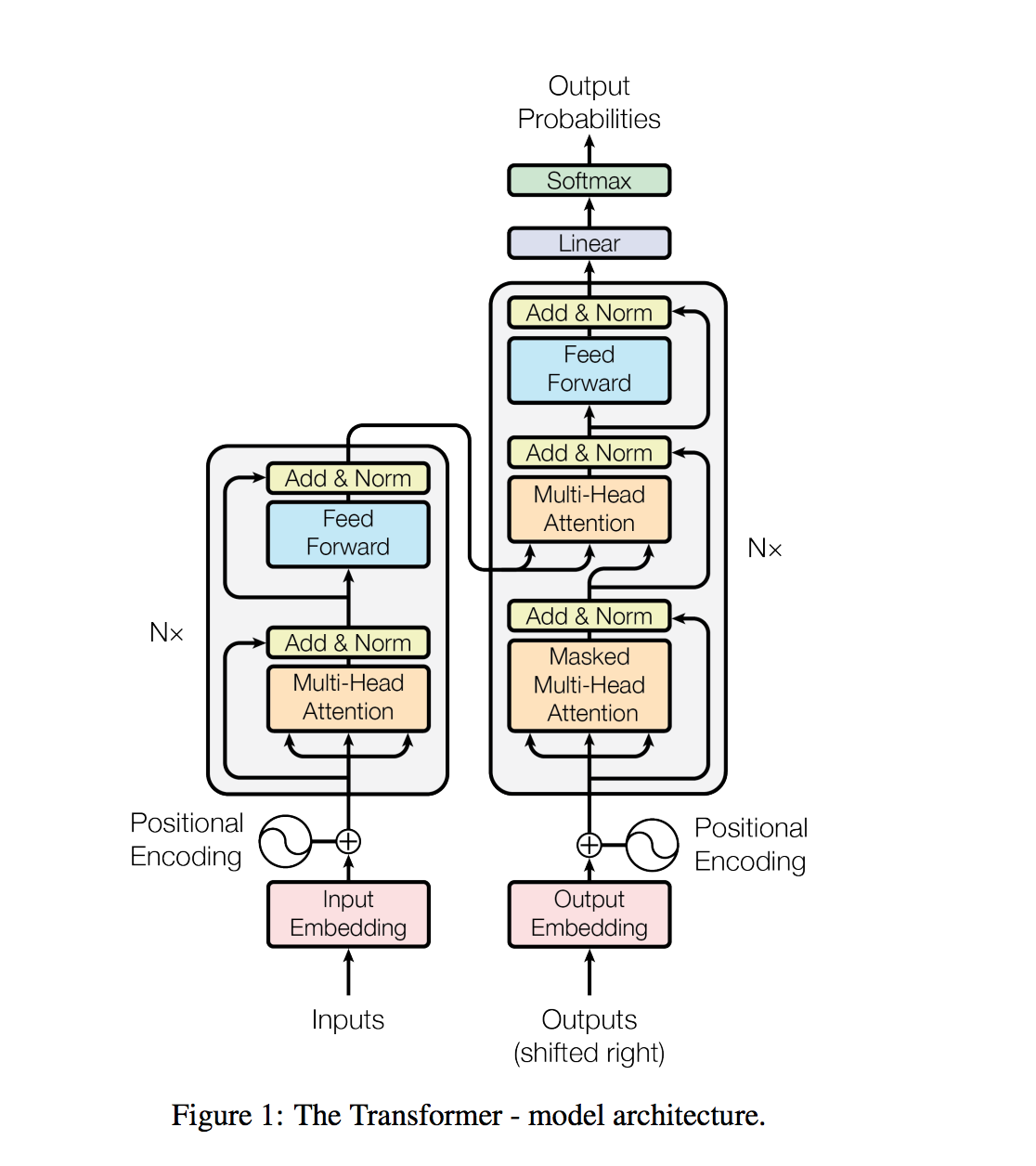
Las tareas de procesamiento del lenguaje natural, como la respuesta a las preguntas, la traducción automática, la comprensión de lectura y el resumen, generalmente se abordan con el aprendizaje supervisado en conjuntos de datos específicos de la tarea. Demostramos que los modelos de idiomas comienzan a aprender estas tareas sin ninguna supervisión explícita cuando se capacitan en un nuevo conjunto de datos de millones de páginas web llamada WebText. Nuestro modelo más grande, GPT-2, es un transformador de parámetros de 1.5B que logra los resultados de última generación en 7 de 8 conjuntos de datos de modelado de lenguaje probado en una configuración de disparo cero, pero aún no encadena webText. Las muestras del modelo reflejan estas mejoras y contienen párrafos coherentes de texto. Estos hallazgos sugieren un camino prometedor hacia la construcción de sistemas de procesamiento del lenguaje que aprenden a realizar tareas de sus demostraciones naturales.
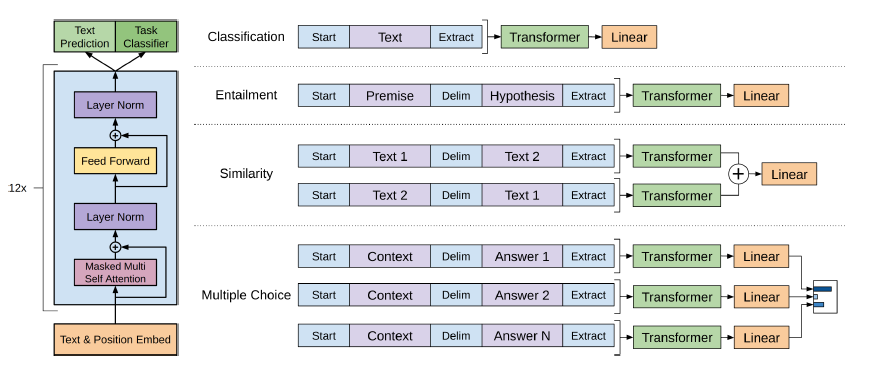
El GPT-2 utiliza una arquitectura del transformador de decodificador de 12 capas.
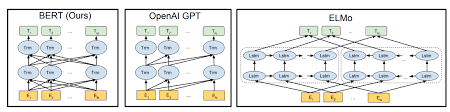
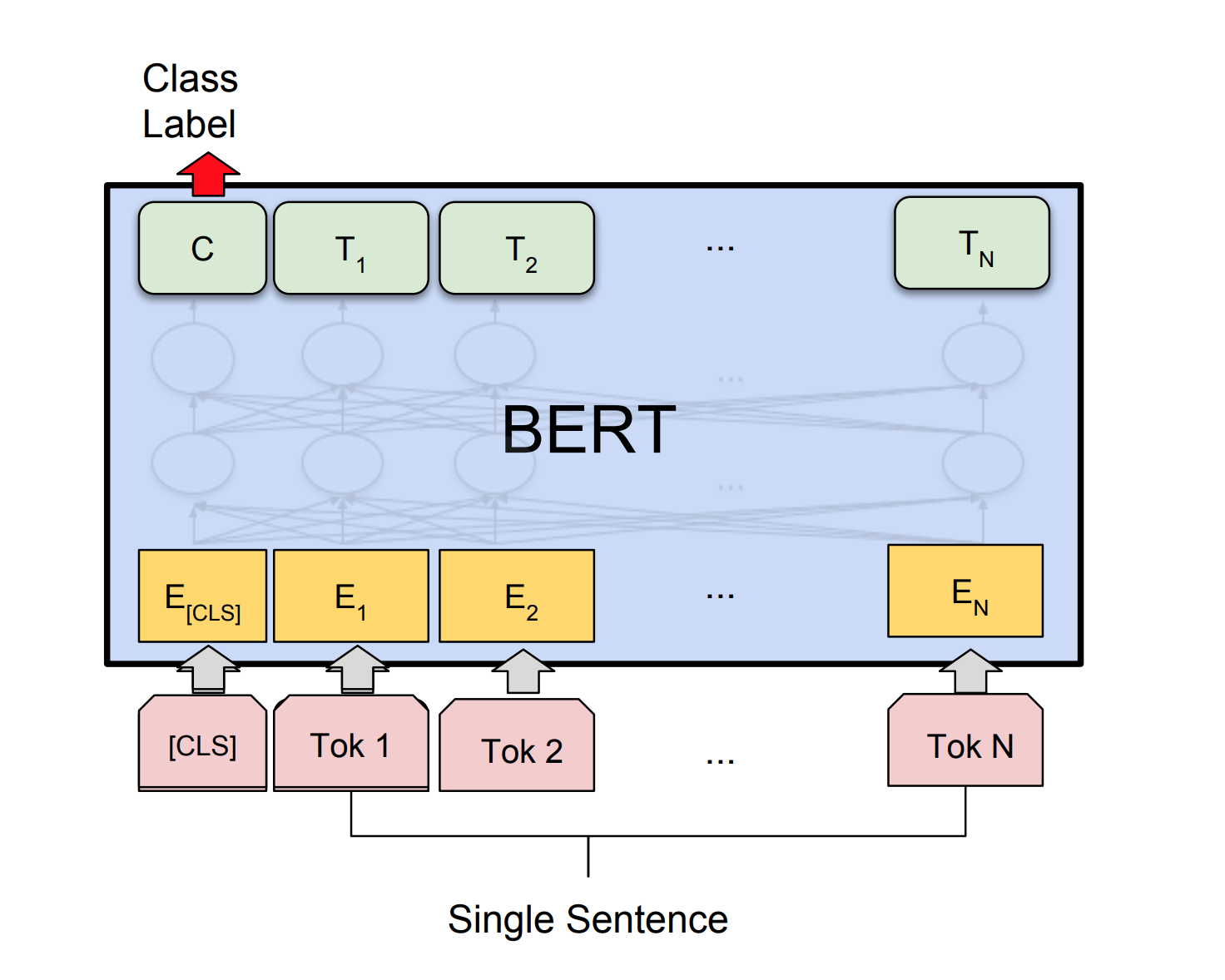
Bert usa la arquitectura del transformador para codificar oraciones.
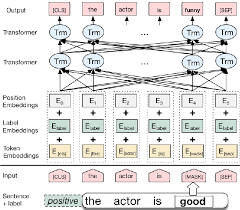
La salida de las redes de puntero es discreta y corresponde a posiciones en la secuencia de entrada
El número de clases de destino en cada paso de la salida depende de la longitud de la entrada, que es variable.
Se diferencia de los intentos de atención anteriores en que, en lugar de usar la atención para combinar las unidades ocultas de un codificador a un vector de contexto en cada paso del decodificador, utiliza la atención como un puntero para seleccionar un miembro de la secuencia de entrada como salida.

Una de las aplicaciones principales del procesamiento del lenguaje natural es extraer automáticamente los temas que las personas discuten de grandes volúmenes de texto. Algunos ejemplos de texto grande podrían ser alimentos de las redes sociales, revisiones de los clientes de hoteles, películas, etc., comentarios de los usuarios, noticias, correos electrónicos de quejas de los clientes, etc.
Saber de qué están hablando la gente y comprender sus problemas y opiniones es muy valioso para las empresas, administradores, campañas políticas. Y es realmente difícil leer manualmente a través de volúmenes tan grandes y compilar los temas.
Por lo tanto, se requiere un algoritmo automatizado que pueda leer los documentos de texto y generar automáticamente los temas discutidos.
En este cuaderno, tomaremos un ejemplo real del conjunto de datos 20 Newsgroups y usaremos LDA para extraer los temas discutidos naturalmente.
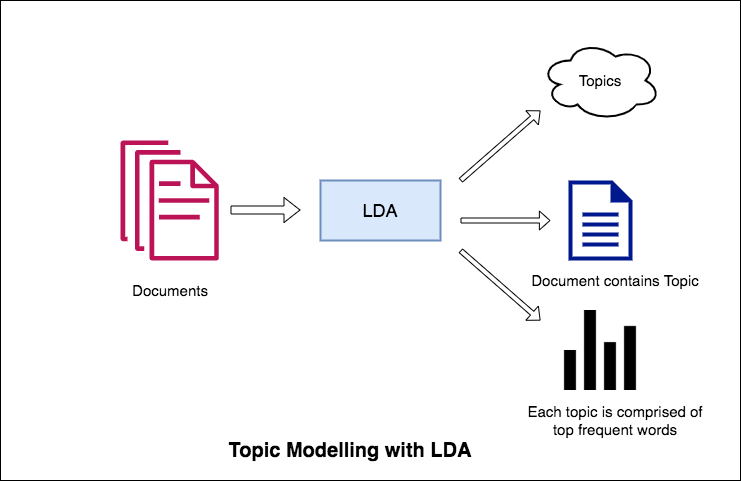
El enfoque de LDA para el modelado de temas es que considera cada documento como una colección de temas en una determinada proporción. Y cada tema como una colección de palabras clave, nuevamente, en una determinada proporción.
Una vez que proporciona al algoritmo la cantidad de temas, todo lo que lo hace para reorganizar la distribución de temas dentro de los documentos y la distribución de palabras clave dentro de los temas para obtener una buena composición de la distribución de palabras de temas.
PCA es fundamentalmente una técnica de reducción de dimensionalidad que transforma las columnas de un conjunto de datos en un nuevo conjunto de características. Lo hace al encontrar un nuevo conjunto de direcciones (como los ejes X e Y) que explican la máxima variabilidad en los datos. Este nuevo sistema de coordenadas del sistema se llama componentes principales (PC).
Prácticamente PCA se usa por dos razones:
Dimensionality Reduction : la información distribuida en una gran cantidad de columnas se transforma en componentes principales (PC) de modo que las primeras PC pueden explicar una parte considerable de la información total (varianza). Estas PC se pueden usar como variables explicativas en modelos de aprendizaje automático.
Visualize Data : visualizar la separación de clases (o grupos) es difícil para los datos con más de 3 dimensiones (características). Con las dos primeras PC, generalmente es posible ver una separación clara.
Un clasificador ingenuo de Bayes es un modelo de aprendizaje automático probabilístico que se utiliza para la tarea de clasificación. El quid del clasificador se basa en el teorema de Bayes.
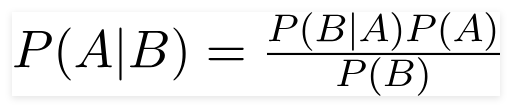
Usando el teorema de Bayes, podemos encontrar la probabilidad de que ocurra, dado que B ha ocurrido. Aquí, B es la evidencia y A es la hipótesis. La suposición hecha aquí es que los predictores/características son independientes. Es decir, la presencia de una característica particular no afecta a la otra. Por lo tanto, se llama ingenuo.
Tipos de clasificador ingenuo de Bayes :
Multinomial Naive Bayes : esto se usa principalmente cuando las variables son discretas (como las palabras). Las características/predictores utilizados por el clasificador son la frecuencia de las palabras presentes en el documento.
Gaussian Naive Bayes : cuando los predictores toman un valor continuo y no son discretos, suponemos que estos valores se muestrean de una distribución gaussiana.
Bernoulli Naive Bayes : esto es similar a los Bayes ingenuos multinomiales, pero los predictores son variables booleanas. Los parámetros que usamos para predecir la variable de clase toman solo valores sí o no, por ejemplo, si una palabra ocurre en el texto o no.
Utilizando el conjunto de datos 20NewsGroup, se explora el algoritmo Naive Bayes para hacer la clasificación.
Se explora el aumento de datos utilizando las siguientes técnicas:

Se exploró una nueva arquitectura llamada Sbert. La arquitectura de red siamese permite derivar vectores de tamaño fijo para oraciones de entrada. Utilizando una medida de similitud como la cosinesimilaridad o la distancia de Manhatten / Euclidiana, se pueden encontrar oraciones semánticamente similares.

| Análisis de sentimientos - IMDB | Clasificación de sentimientos - Hinglish | Clasificación de documentos |
| Clasificación de pares de preguntas duplicados - Quora | Etiquetado POS | Inferencia del lenguaje natural - SNLI |
| Clasificación de comentarios tóxicos | Oración gramaticalmente correcta - cola | Etiquetado ner |
El análisis de sentimientos se refiere al uso del procesamiento del lenguaje natural, el análisis de texto, la lingüística computacional y la biometría para identificar, extraer, cuantificar y estudiar sistemáticamente estados afectivos e información subjetiva.
Se han explorado los siguientes varios:
RNN se usa para procesar e identificar el sentimiento.

Después de probar el RNN básico que da una Test_accuración menos del 50%, se han experimentado las siguientes técnicas y se logra una test_accury por encima del 88%.
Técnicas utilizadas:

La atención ayuda a centrarse en la entrada relevante al predecir el sentimiento de la entrada. La atención de Bahdanau se utilizó para tomar las salidas de LSTM y concatenar el estado final y el estado oculto hacia atrás. Sin usar las incrustaciones de palabras previamente capacitadas, se logra la precisión de la prueba del 88% .
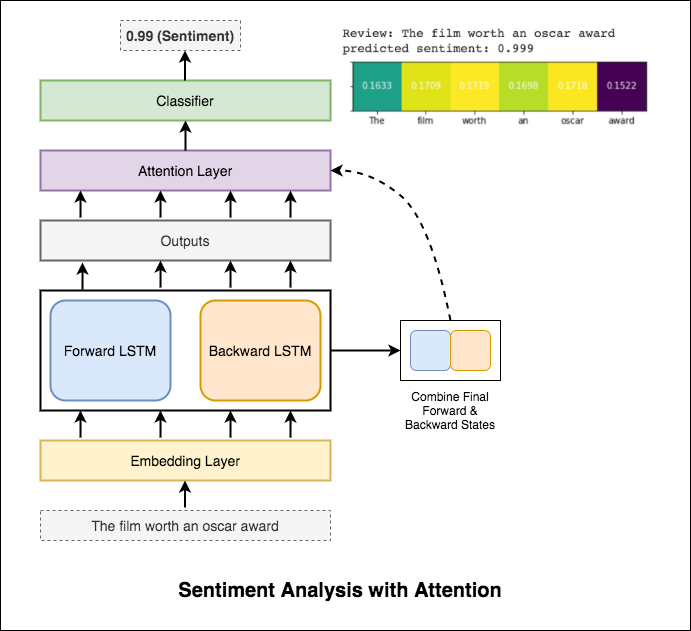
Bert obtiene nuevos resultados de vanguardia en once tareas de procesamiento del lenguaje natural. El aprendizaje de transferencia en PNL se ha activado después de la liberación del modelo Bert. Se explora el uso de Bert para hacer el análisis de sentimientos.

Mezclar idiomas, también conocidos como mezcla de código, es una norma en las sociedades multilingües. Las personas multilingües, que son hablantes de inglés no nativos, tienden a mezclar con código utilizando la tipificación fonética basada en el inglés y la inserción de los anglicismos en su idioma principal.
La tarea es predecir el sentimiento de un tweet mezclado con código dado. Las etiquetas de los sentimientos son positivas, negativas o neutrales, y los idiomas mezclados con código serán hindi de inglés. (Sentimix)
Se han explorado los siguientes varios:
Usando el modelo MLP simple, F1 score of 0.58 se logró en los datos de prueba

Después de explorar el modelo MLP básico, el modelo LSTM se usó para la predicción de sentimientos y se logró la puntuación F1 de 0.57 .

Los resultados fueron en realidad menos en comparación con un modelo MLP básico. Una de las razones que podría ser LSTM no puede aprender las relaciones entre las palabras en una oración debido a la naturaleza altamente diversa de los datos mezclados con código.
Como el LSTM no puede aprender las relaciones entre las palabras en una oración mezclada con código debido a la naturaleza altamente diversa de los datos mezclados con código y no se utilizan incrustaciones previamente entrenadas, el puntaje F1 es menor.
Para aliviar este problema, se está utilizando el modelo XLM-Roberta (que se ha capacitado en 100 idiomas) para codificar la oración. Para usar el modelo XLM-Roberta, la oración debe estar en un idioma adecuado. Entonces, primero las palabras de Hinglish deben convertirse en la forma hindi (Devanagari).
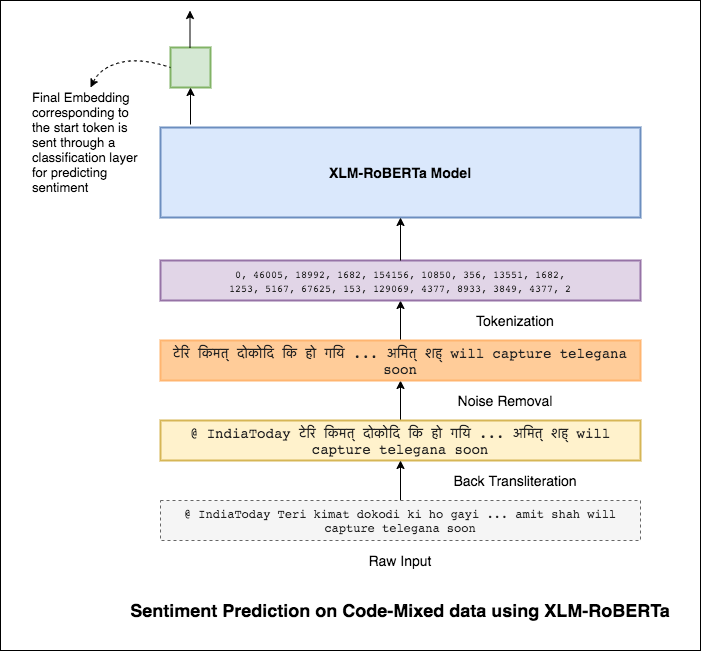
Se logró un puntaje F1 de 0.59 . Los métodos para mejorar esto se explorarán más adelante.
La salida final del modelo XLM-Roberta se usó como incrustaciones de entrada al modelo LSTM bidireccional. Una capa de atención, que toma las salidas de la capa LSTM, produce una representación ponderada de la entrada, que luego se pasa a través de un clasificador para predecir el sentimiento de la oración.

Se logró una puntuación F1 de 0.64 .
De la misma manera que un filtro 3x3 puede mirar sobre un parche de una imagen, un filtro 1x2 puede mirar sobre 2 palabras secuenciales en una pieza de texto, es decir, un bi-gramo. En este modelo CNN, en su lugar, usaremos múltiples filtros de diferentes tamaños que analizarán los bi-grams (un filtro 1x2), tri-grams (un filtro 1x3) y/o n-gramos (un filtro 1xn) dentro del texto.
La intuición aquí es que la aparición de ciertos bi-gramos, tri-gramos y n-gramos dentro de la revisión será una buena indicación del sentimiento final.
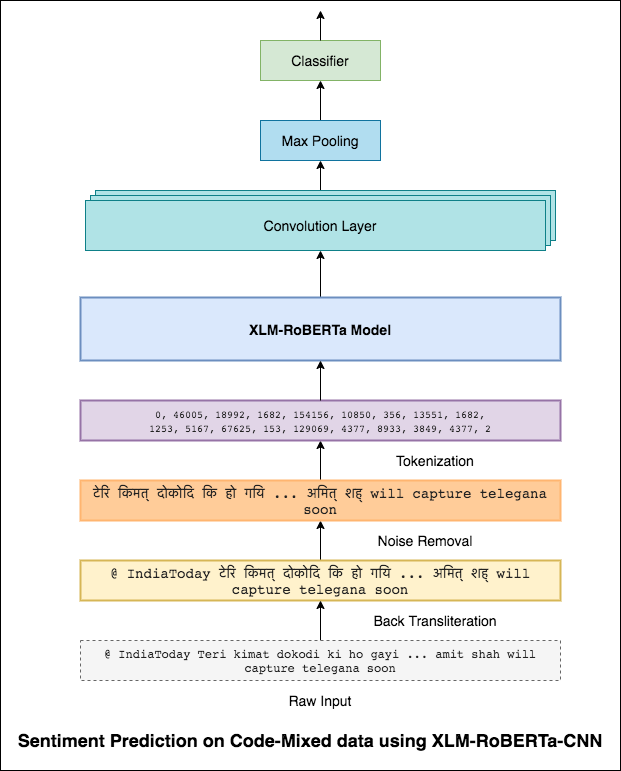
Se logró una puntuación F1 de 0.69 .
CNN captura las dependencias locales donde RNN captura las dependencias globales. Al combinar ambos podemos obtener una mejor comprensión de los datos. El conjunto del modelo CNN y el modelo de asistencia bidireccional-gru realizan los otros.
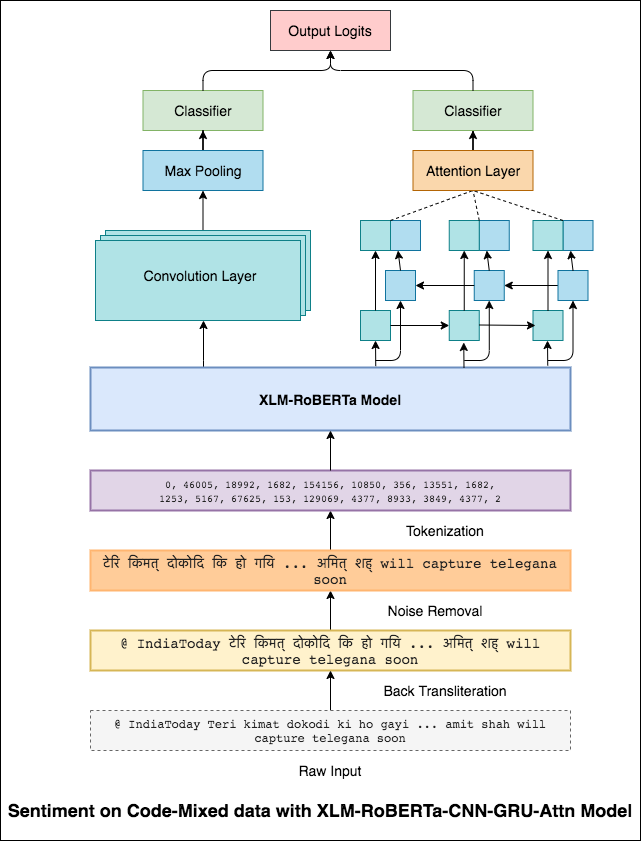
Se logró una puntuación F1 de 0.71 . (Top 5 en la clasificación).
La clasificación de documentos o la categorización de documentos es un problema en la biblioteca, ciencias de la información e informática. La tarea es asignar un documento a una o más clases o categorías.
Se han explorado los siguientes varios:
Una red de atención jerárquica (HAN) considera la estructura jerárquica de los documentos (documento - oraciones - palabras) e incluye un mecanismo de atención que puede encontrar las palabras y oraciones más importantes en un documento mientras toma el contexto en consideración.
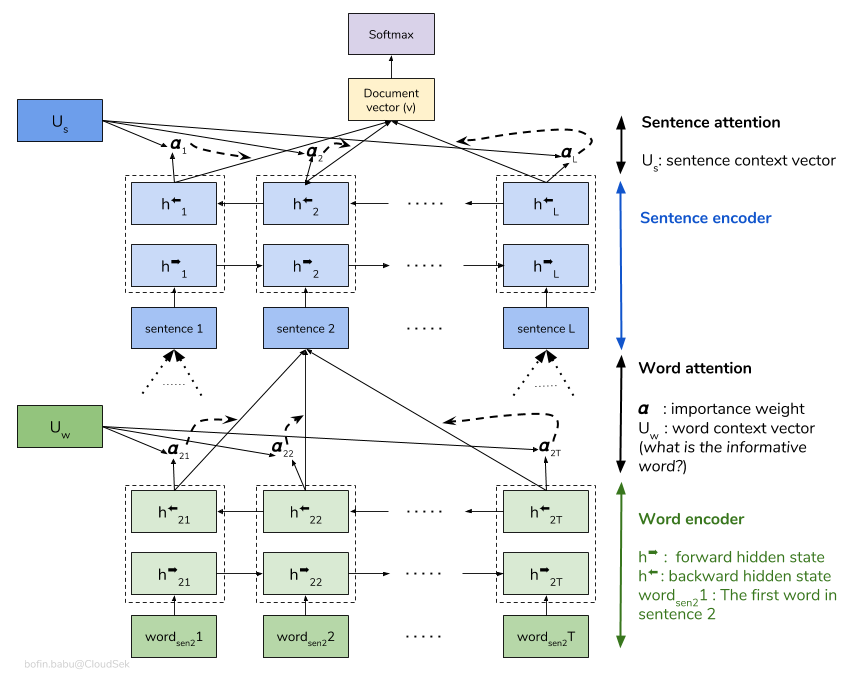
El modelo HAN básico está sobrecilladamente rápidamente. Para superar esto, se exploran técnicas como Embedding Dropout , se exploran Locked Dropout . Hay una otra técnica más llamada Weight Dropout que no se implementa (avíseme si hay buenos recursos para implementar esto). También se usan Glove incrustaciones de palabras previamente capacitadas en lugar de inicialización aleatoria. Dado que la atención se puede hacer en el nivel de oración y el nivel de palabras, podemos visualizar qué palabras son importantes en una oración y qué oraciones son importantes en un documento.



QQP significa pares de preguntas de Quora. El objetivo de la tarea es para un par dado de preguntas; Necesitamos encontrar si esas preguntas son semánticamente similares entre sí o no.
Se han explorado los siguientes varios:
El algoritmo debe tomar el par de preguntas como entrada y debe generar su similitud. Se utiliza una red siamesa. Una Siamese neural network (a veces llamada una red neuronal gemela) es una red neuronal artificial que utiliza los same weights mientras trabaja en conjunto en dos vectores de entrada diferentes para calcular vectores de salida comparables.

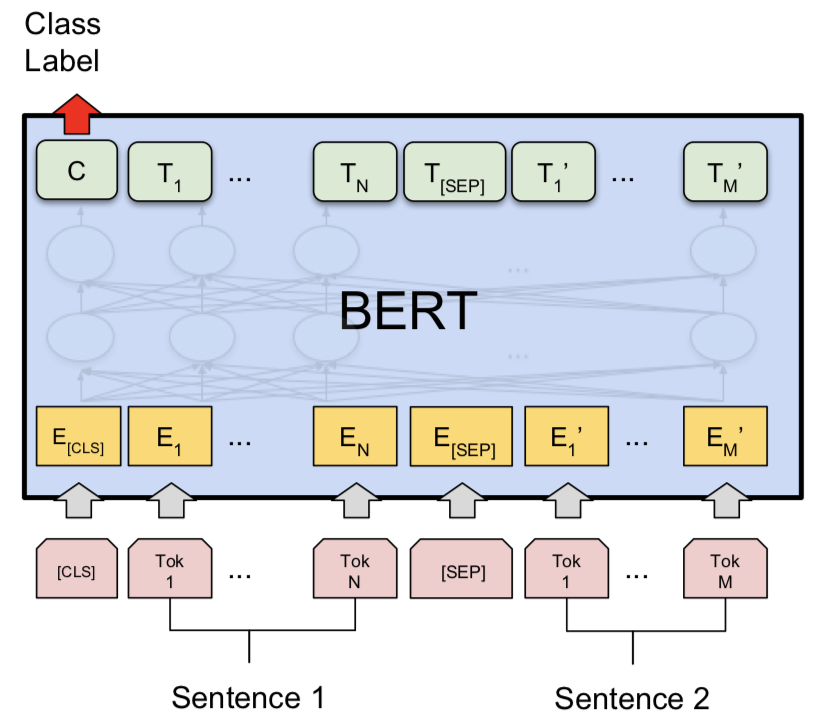
Después de probar el modelo siamés, Bert fue explorado para hacer la detección de pares de preguntas duplicados de Quora. Bert toma la pregunta 1 y la pregunta 2 como la entrada separada por el token [SEP] y la clasificación se realizó utilizando la representación final del token [CLS] .
El etiquetado de parte de voz (POS) es una tarea de etiquetar cada palabra en una oración con su parte apropiada del discurso.
Se han explorado los siguientes varios:
Este código cubre el flujo de trabajo básico. Aprenderemos cómo: Cargar datos, crear divisiones de trenes/pruebas/validación, crear un vocabulario, crear iteradores de datos, definir un modelo e implementar el etiquetado de trenes/evaluación/prueba y tiempo de ejecución (inferencia).
El modelo utilizado es una red LSTM bidireccional múltiple
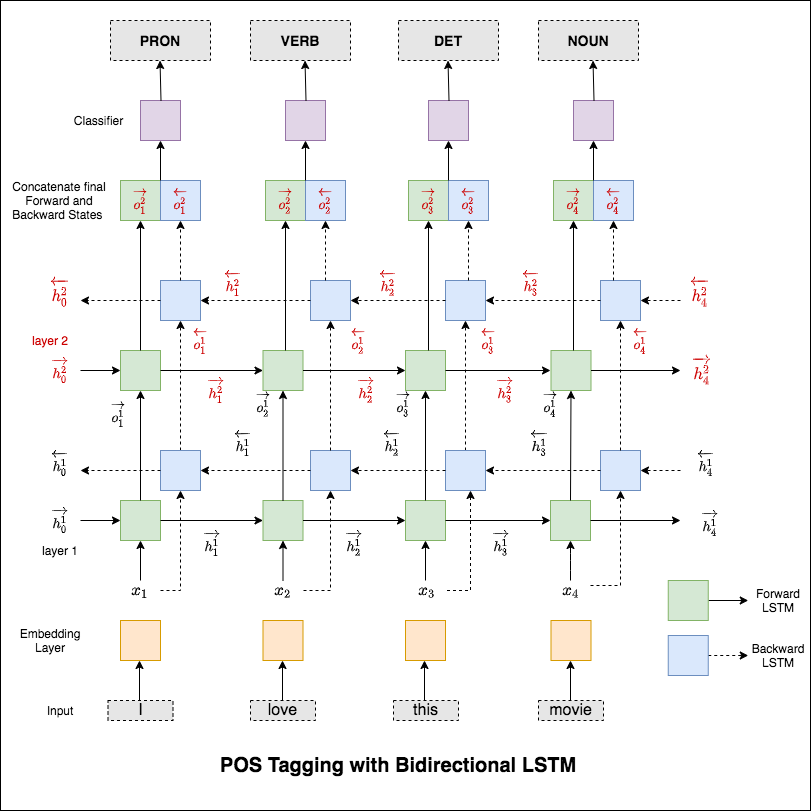
Después de probar el enfoque RNN, se explora el etiquetado POS con arquitectura basada en transformador. Dado que el transformador contiene codificador y decodificador y para la tarea de etiquetado de secuencia, solo Encoder será suficiente. Como los datos son pequeños, tener 6 capas de codificador sobrevalorarán los datos. Entonces se utilizó un modelo de codificador de transformador de 3 capas.

Después de probar el etiquetado POS con el codificador de transformador, se explota el etiquetado POS con el modelo Bert previamente capacitado. Logró una precisión de la prueba del 91% .

El objetivo de la inferencia del lenguaje natural (NLI), una tarea de procesamiento del lenguaje natural ampliamente estudiada, es determinar si una declaración dada (una premisa) implica semánticamente otra declaración dada (una hipótesis).
Se han explorado los siguientes varios:
Se implementa un modelo básico con la red siamesa bilstm
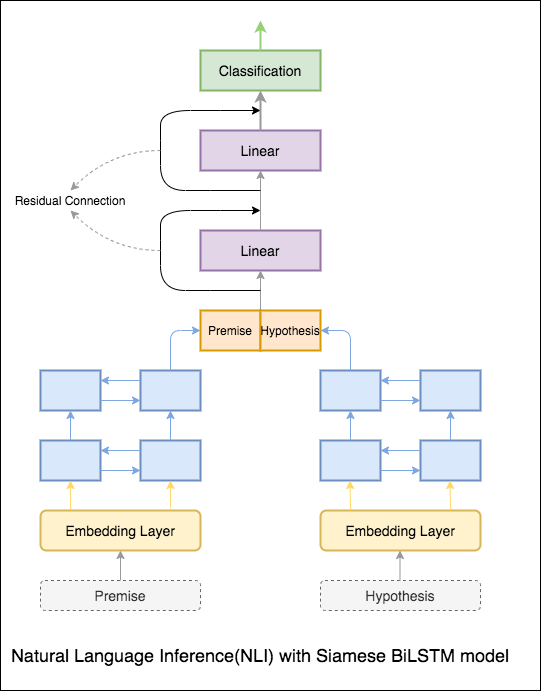
Esto puede tratarse como configuración de línea base. Se logró una precisión de prueba del 76.84% .
En el cuaderno anterior, los estados ocultos finales de premisa e hipótesis como representaciones de LSTM. Ahora, en lugar de tomar los estados ocultos finales, se calculará la atención en todos los tokens de entrada y se toma un vector ponderado final como la representación de la premisa y la hipótesis.
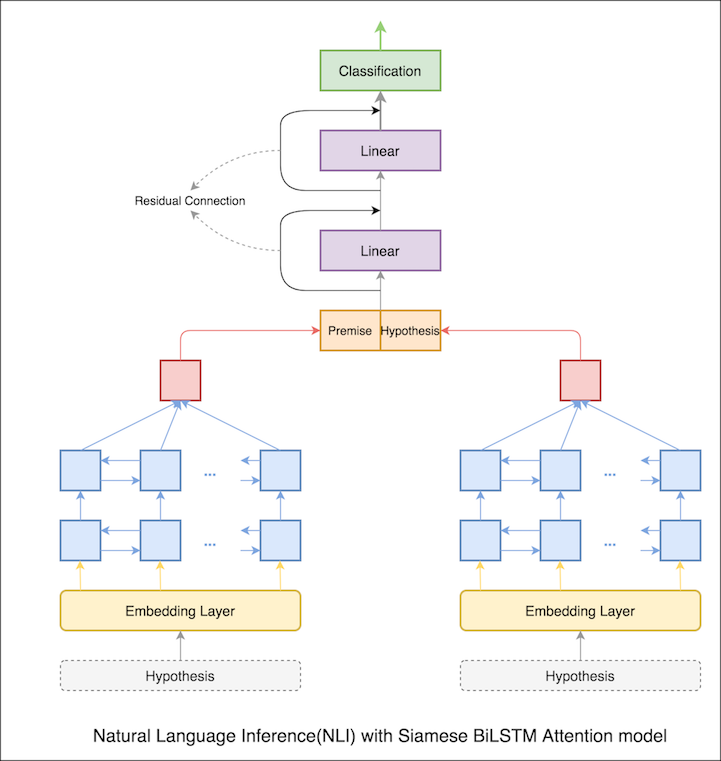
La precisión de la prueba aumentó de 76.84% a 79.51% .
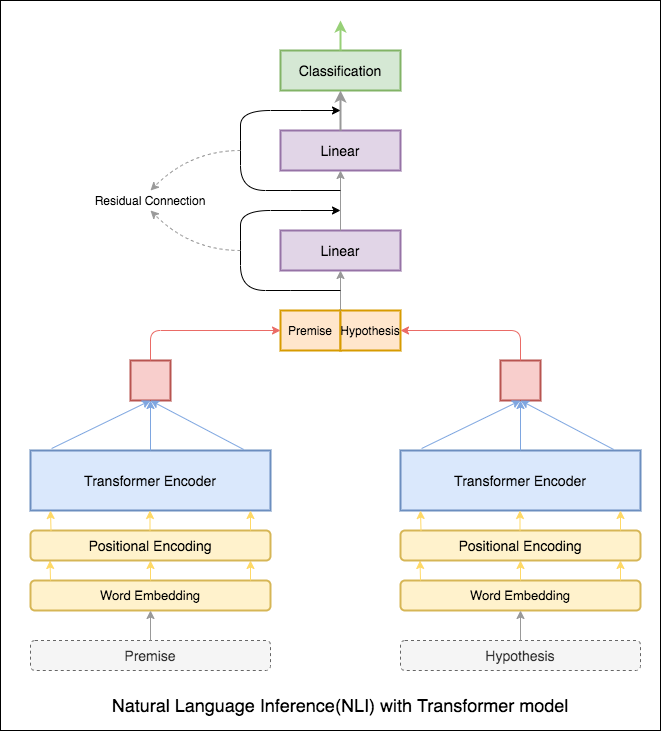
El codificador del transformador se usó para codificar la premisa y la hipótesis. Una vez que la oración se pasa a través del codificador, la suma de todos los tokens se considera la representación final (se pueden explorar otras variantes). La precisión del modelo es menor en comparación con las variantes RNN.
Se exploró el NLI con el modelo base Bert. Bert toma la premisa y la hipótesis como entradas separadas por el token [SEP] y la clasificación se realizó utilizando la representación final del token [CLS] .
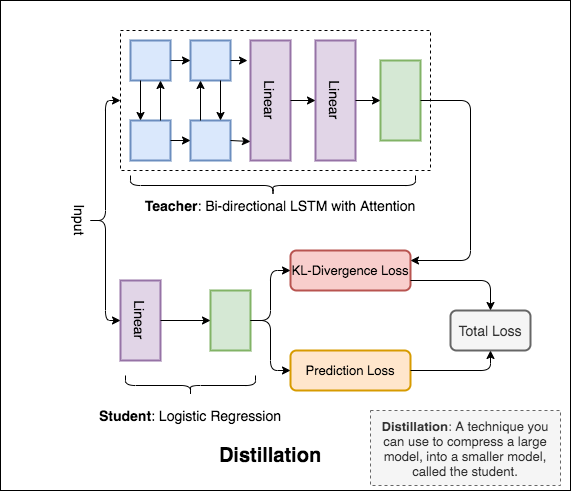
Distillation : una técnica que puede usar para comprimir un modelo grande, llamado teacher , en un modelo más pequeño, llamado student . Después del estudiante, los modelos de maestros se utilizan para realizar la destilación en NLI.
Discutir cosas que le importan puede ser difícil. La amenaza de abuso y acoso en línea significa que muchas personas dejan de expresarse y renuncian a buscar opiniones diferentes. Las plataformas luchan para facilitar efectivamente las conversaciones, lo que lleva a muchas comunidades a limitar o cerrar completamente los comentarios de los usuarios.
Se le proporciona una gran cantidad de comentarios de Wikipedia que han sido etiquetados por los evaluadores humanos para el comportamiento tóxico. Los tipos de toxicidad son:
Se han explorado los siguientes varios:
El modelo utilizado es una red Gru bidireccional.
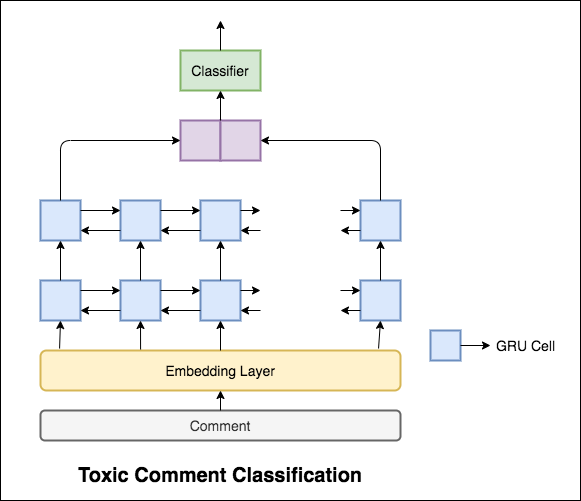
Se logró una precisión de prueba del 99.42% . Dado que el 90% de los datos no están etiquetados en ninguna de la toxicidad, simplemente predecir todos los datos como no tóxicos ofrece un modelo preciso del 90%. Por lo tanto, la precisión no es una métrica confiable. Se implementó un ROC AUC diferente.
Con Categorical Cross Entropy como pérdida, se logra la puntuación ROC_AUC de 0.5 . Al cambiar la pérdida a Binary Cross Entropy y también modificar un poco el modelo agregando capas de agrupación (máxima, media), la puntuación ROC_AUC mejoró a 0.9873 .
Convertido la clasificación de comentarios tóxicos en una aplicación usando Streamlit. El modelo previamente capacitado está disponible ahora.
¿Pueden las redes neuronales artificiales tener la capacidad de juzgar la aceptabilidad gramatical de una oración? Para explorar esta tarea, se utiliza el conjunto de datos de la aceptabilidad lingüística (COLA). Cola es un conjunto de oraciones etiquetadas como gramaticalmente correctas o incorrectas.
Se han explorado los siguientes varios:
Bert obtiene nuevos resultados de vanguardia en once tareas de procesamiento del lenguaje natural. El aprendizaje de transferencia en PNL se ha activado después de la liberación del modelo Bert. En este cuaderno, exploraremos cómo usar Bert para clasificar si una oración es gramaticalmente correcta o no que usa el conjunto de datos COLA.
Se logró una precisión del coeficiente de correlación del 85% y Matthews (MCC) de 64.1 .
Distillation : una técnica que puede usar para comprimir un modelo grande, llamado teacher , en un modelo más pequeño, llamado student . Después del estudiante, los modelos de maestros se utilizan para realizar la destilación en COLA.

Se han probado los siguientes experimentos:
84.06 , MCC: 61.582.54 , MCC: 5782.92 , MCC: 57.9 El etiquetado de reconocimiento de entidad (NER) nombrado es una tarea de etiquetar cada palabra en una oración con su entidad apropiada.
Se han explorado los siguientes varios:
Este código cubre el flujo de trabajo básico. Veremos cómo: cargar datos, crear divisiones de trenes/pruebas/validación, crear un vocabulario, crear iteradores de datos, definir un modelo e implementar el bucle de trenes/evaluación/prueba y trenes, probar el modelo.
El modelo utilizado es la red LSTM bidireccional
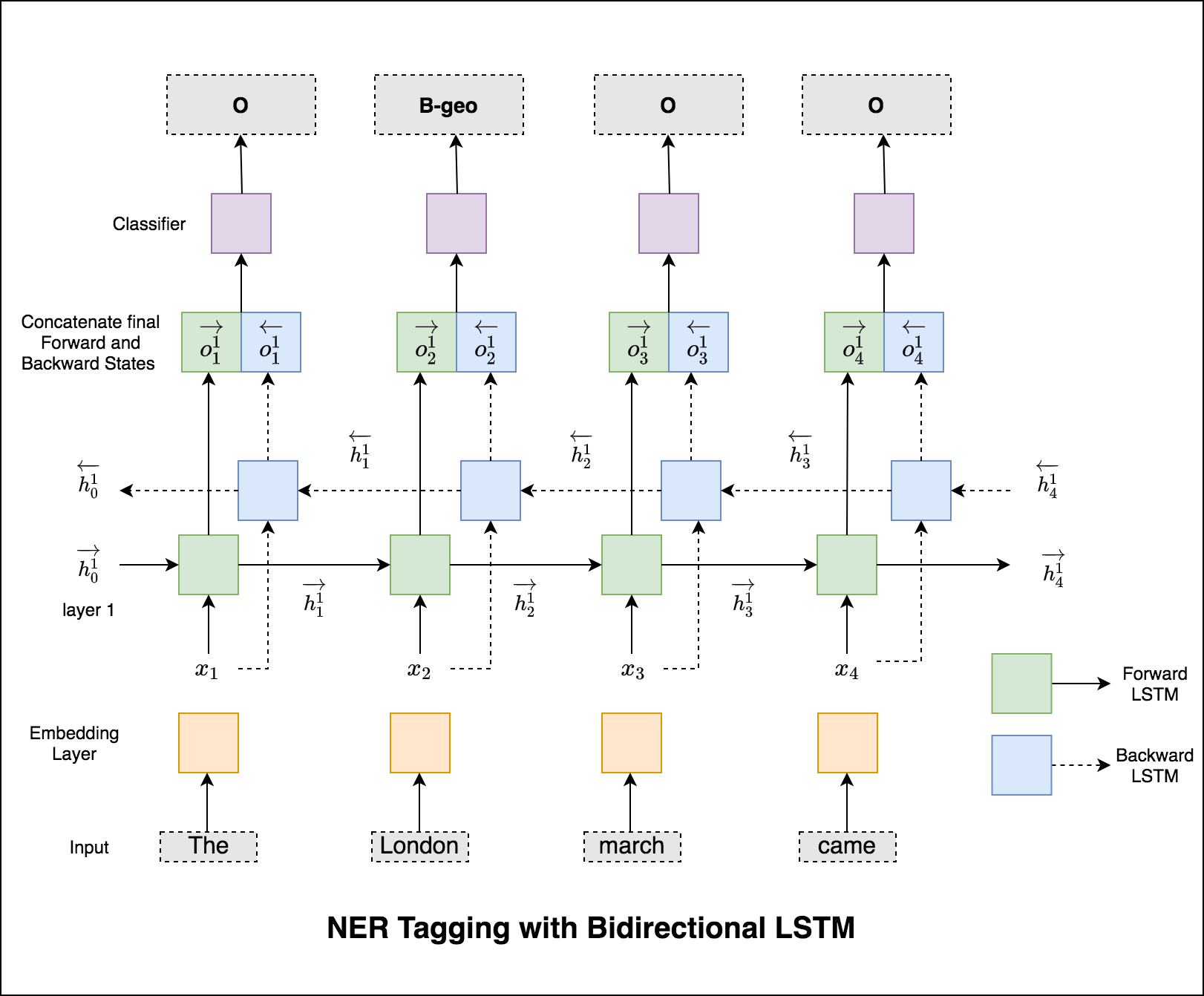
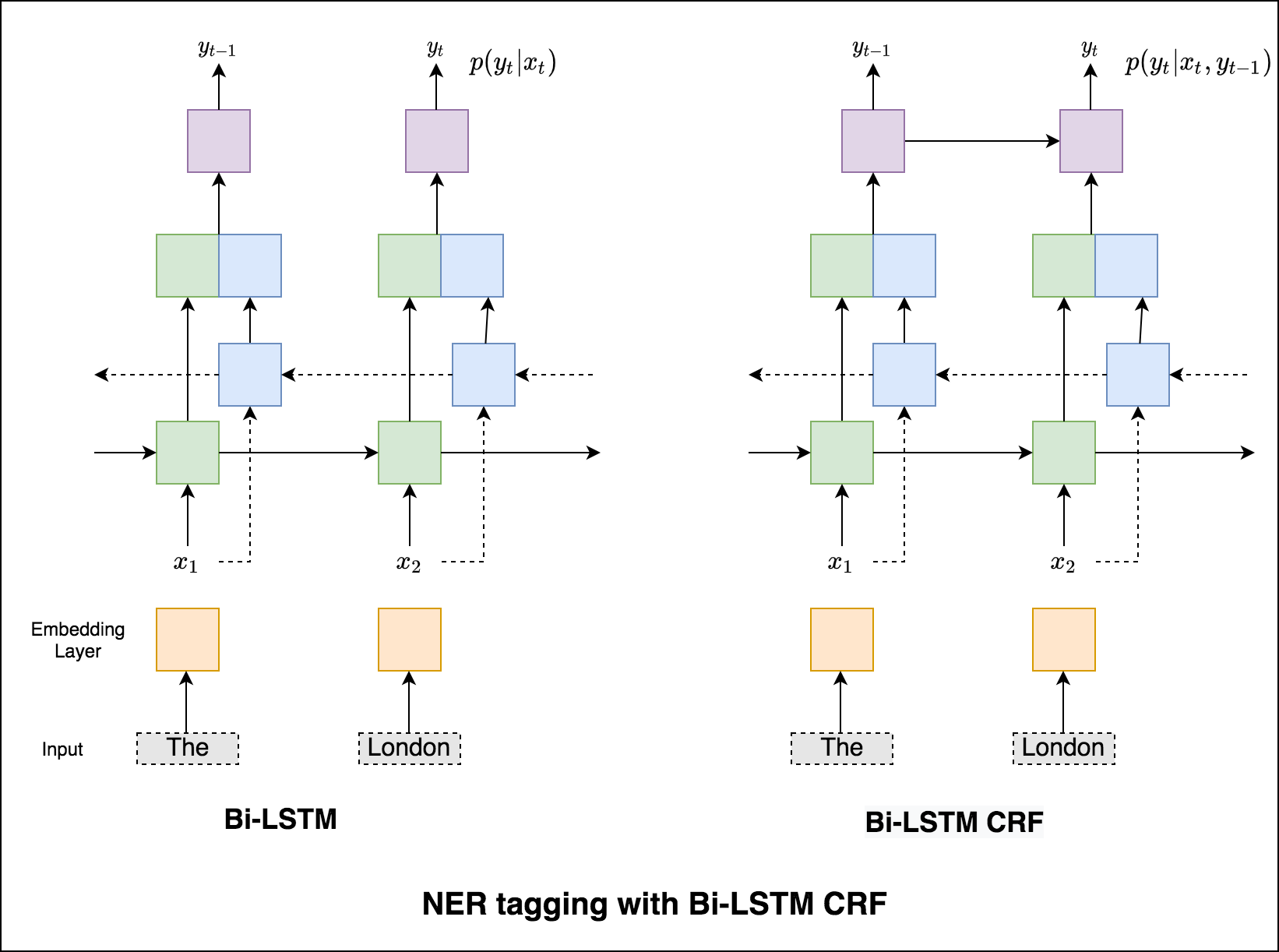
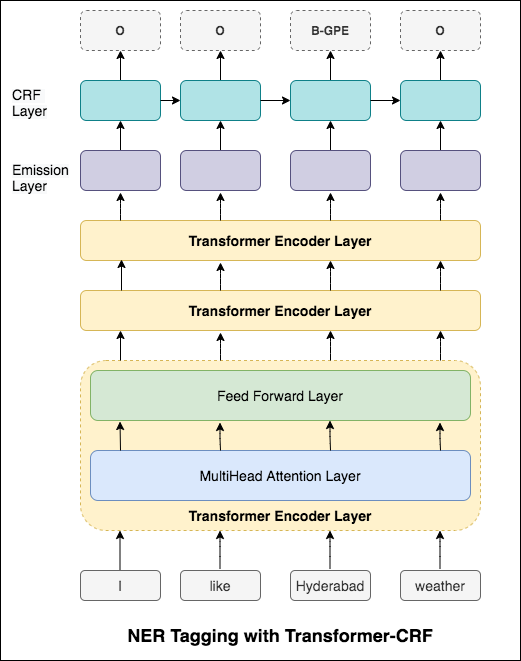
En el caso del etiquetado de secuencia (NER), la etiqueta de una palabra actual podría depender de la etiqueta de palabra anterior. (Ex: Nueva York).
Sin un CRF, simplemente habríamos usado una sola capa lineal para transformar la salida del LSTM bidireccional en puntajes para cada etiqueta. Estos se conocen como emission scores , que son una representación de la probabilidad de que la palabra sea una determinada etiqueta.
Un CRF calcula no solo los puntajes de emisión sino también los transition scores , que son la probabilidad de que una palabra sea una determinada etiqueta considerando que la palabra anterior era una determinada etiqueta. Por lo tanto, los puntajes de transición miden la probabilidad de que la transición de una etiqueta a otra.
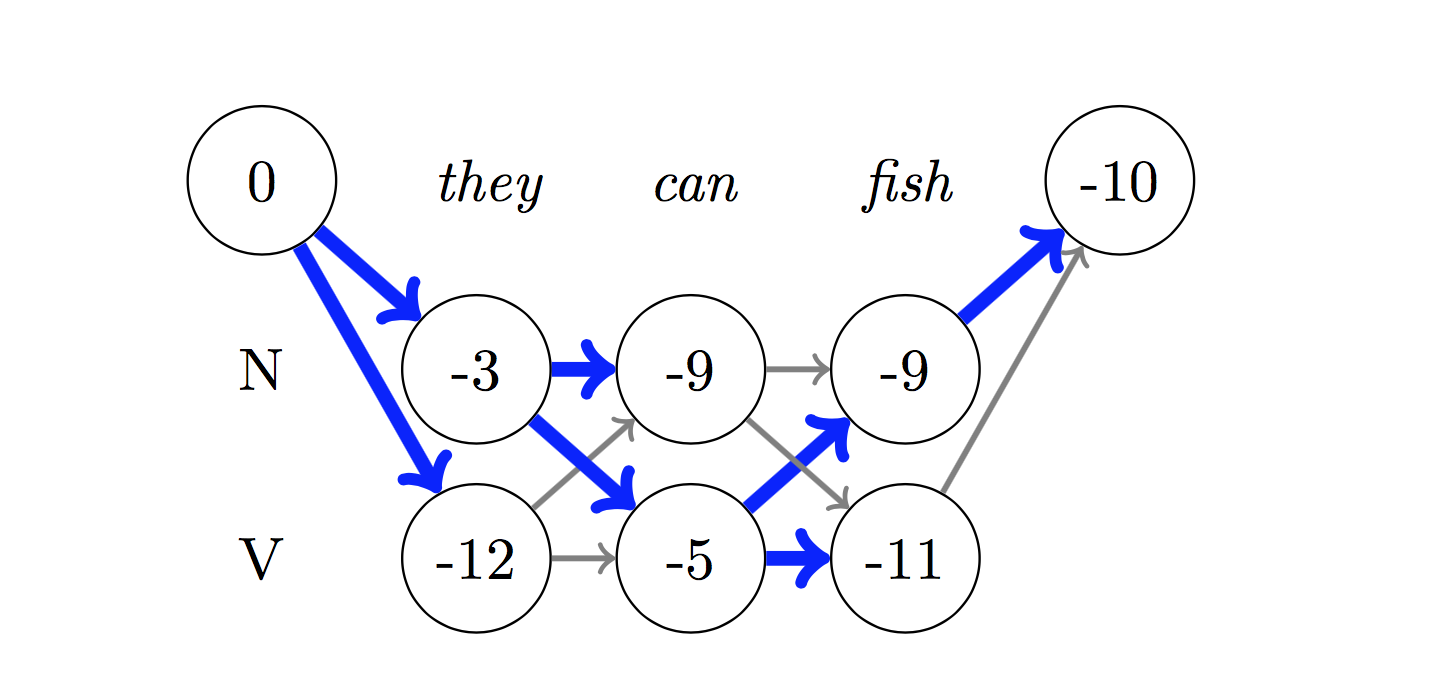
Para la decodificación, se usa el algoritmo Viterbi .
Dado que estamos usando CRF, no estamos prediciendo tanto la etiqueta correcta en cada palabra, ya que estamos prediciendo la secuencia de la etiqueta correcta para una secuencia de palabras. La decodificación de Viterbi es una forma de hacer exactamente esto: encuentre la secuencia de etiqueta más óptima de las puntuaciones calculadas por un campo aleatorio condicional.
Usar información de sub-palabras en nuestra tarea de etiquetado porque puede ser un indicador poderoso de las etiquetas, ya sean partes del habla o las entidades. Por ejemplo, puede aprender que los adjetivos comúnmente terminan con "-y" o "-ul", o que los lugares a menudo terminan con "-land" o "-burg".
Por lo tanto, nuestro modelo de etiquetado de secuencia usa ambos
word-level en forma de incrustaciones de palabras.character-level hasta e incluyendo cada palabra en ambas direcciones. 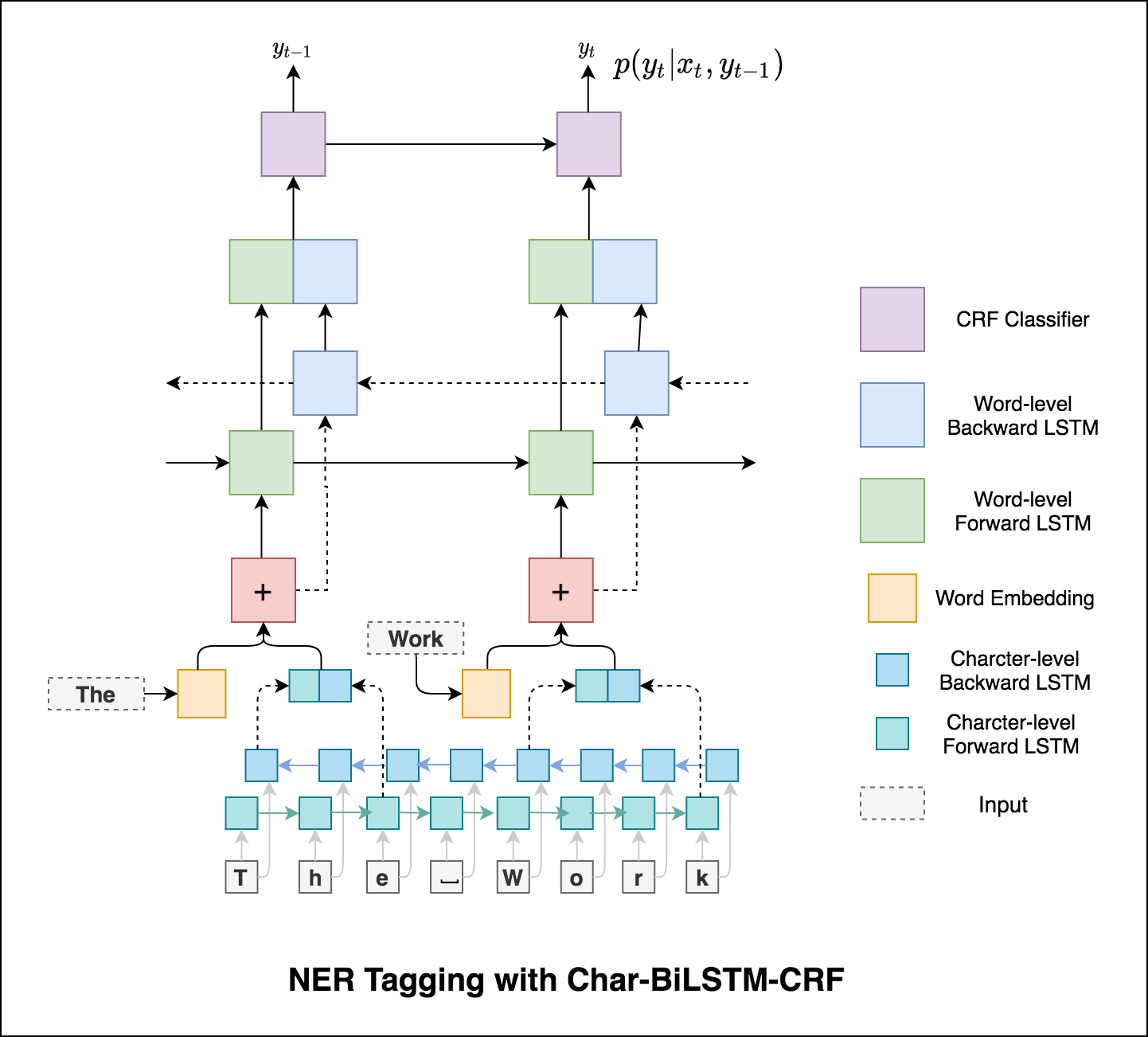
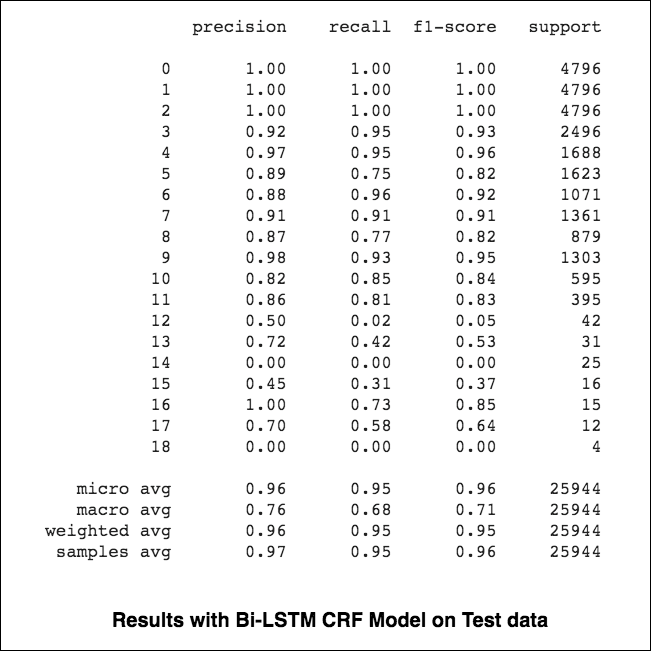
Los micro y los macrovalentes (para cualquier métrica) calcularán cosas ligeramente diferentes y, por lo tanto, su interpretación difiere. Un macro promedio calculará la métrica de forma independiente para cada clase y luego tomará el promedio (por lo tanto, tratando todas las clases por igual), mientras que un microaverazgo agregará las contribuciones de todas las clases para calcular la métrica promedio. En una configuración de clasificación de múltiples clases, es preferible el microverage si sospecha que puede haber un desequilibrio de clase (es decir, puede tener muchos más ejemplos de una clase que de otras clases).

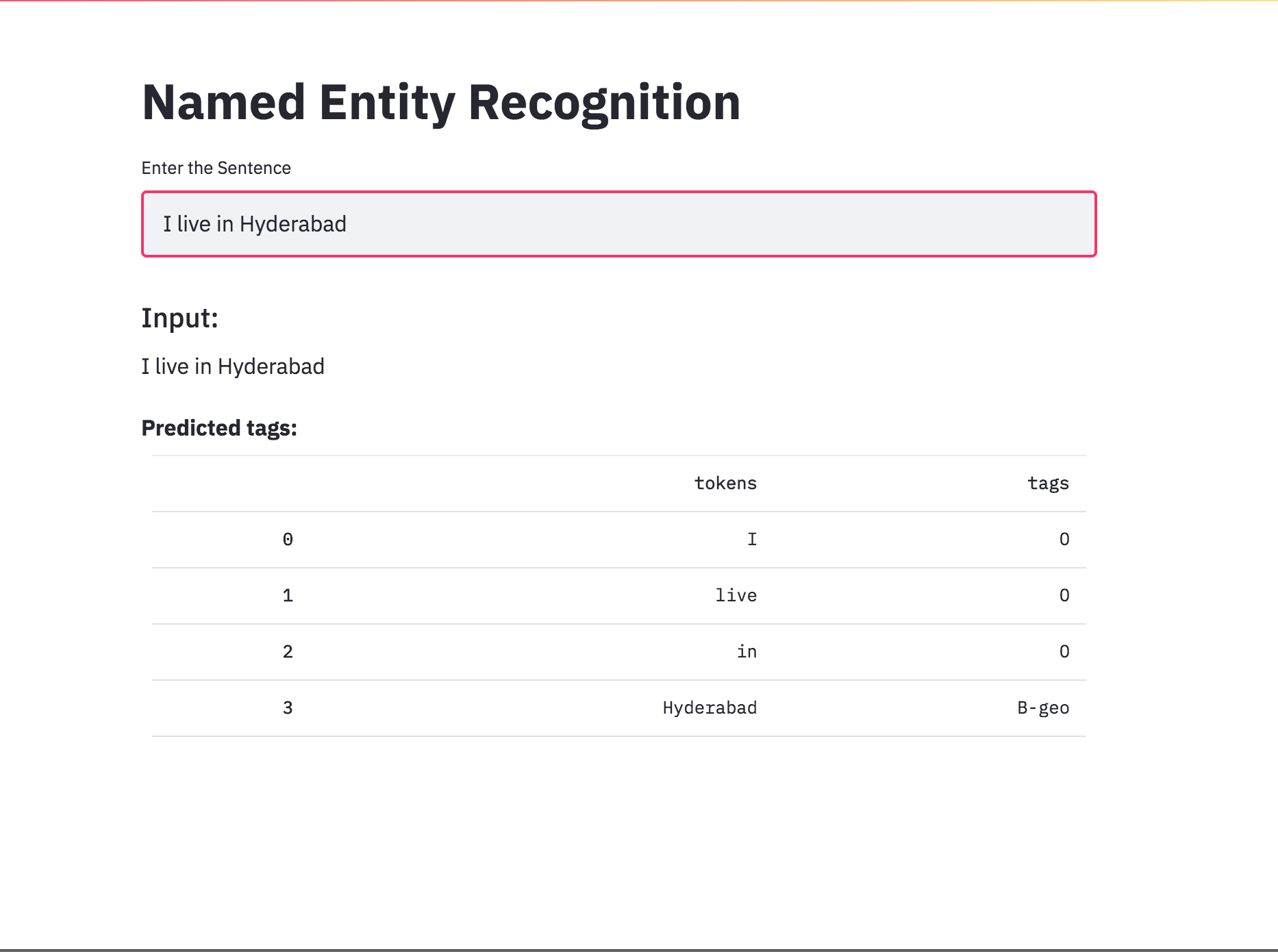
Convertido el etiquetado NER en una aplicación usando Streamlit. El modelo previamente entrenado (Char-BilstM-CRF) ya está disponible.
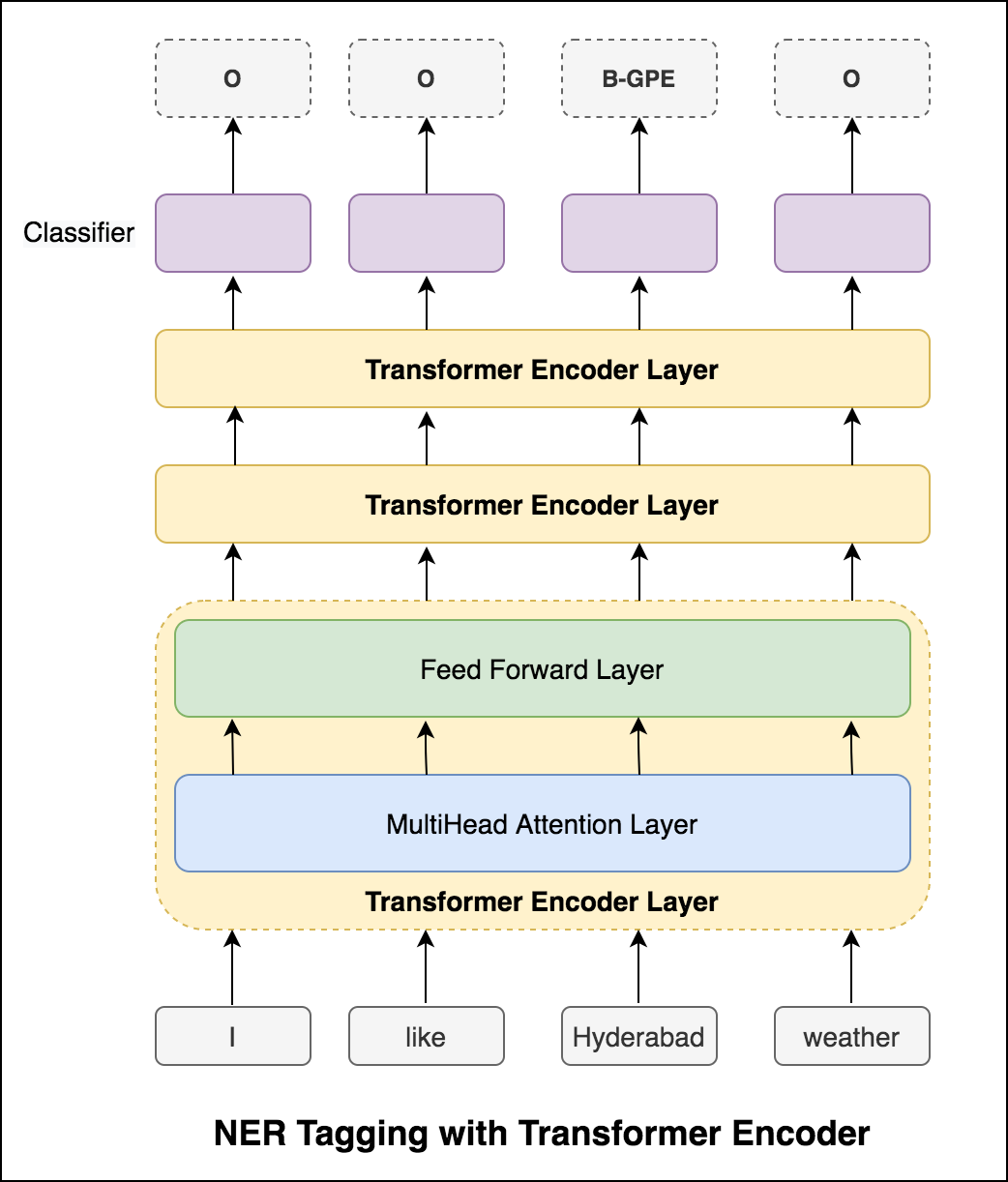
Después de probar el enfoque RNN, se explora el etiquetado NER con arquitectura basada en transformadores. Dado que el transformador contiene codificador y decodificador y para la tarea de etiquetado de secuencia, solo Encoder será suficiente. Se utilizó un modelo de codificador de transformador de 3 capas.
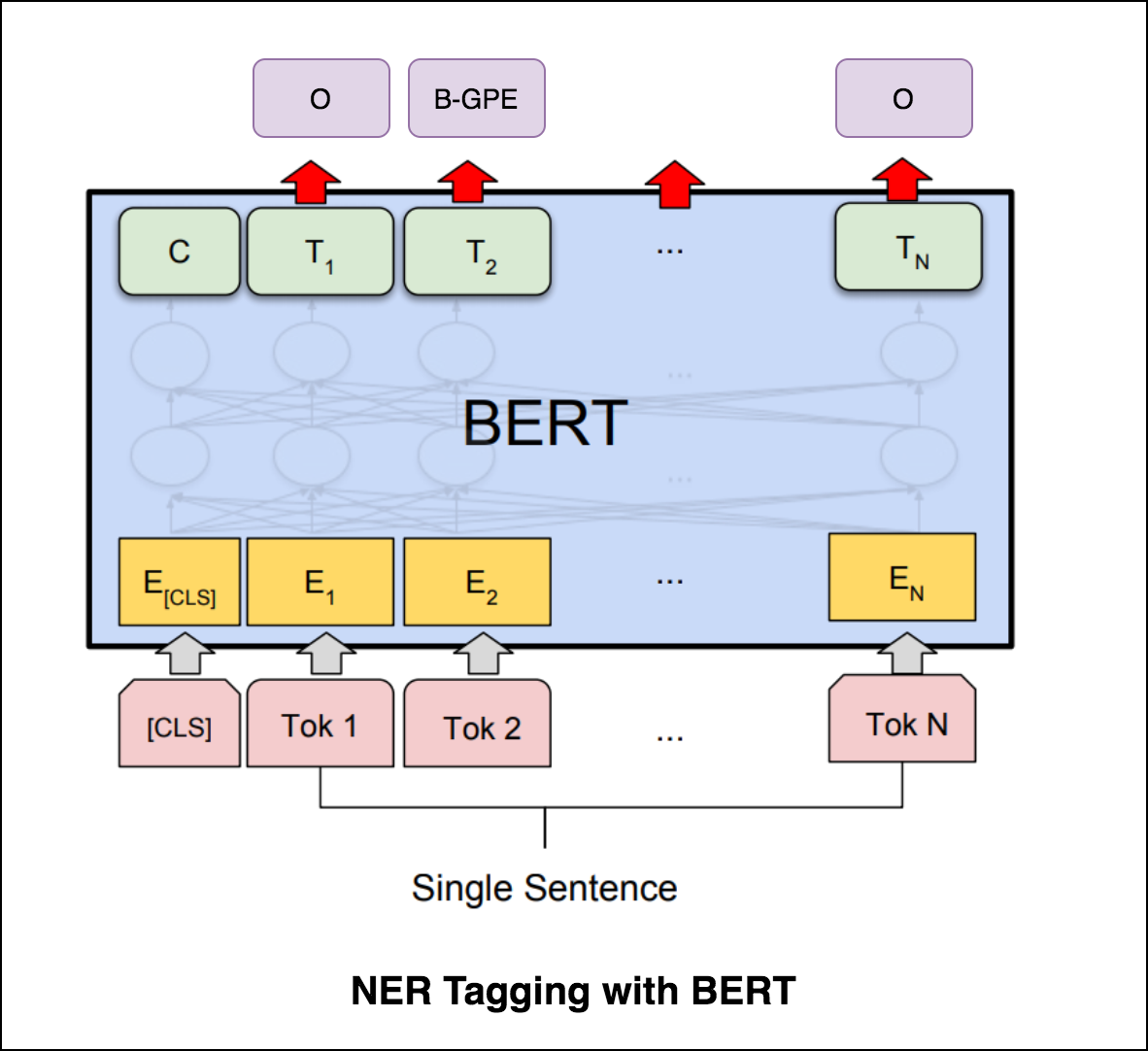
Después de probar el etiquetado NER con el codificador de transformador, se explora el etiquetado NER con el modelo bert-base-cased previamente capacitado.
El transformador solo no está dando buenos resultados en comparación con BILSTM en la tarea de etiquetado NER. Se implementa el aumento de la capa CRF en la parte superior del transformador, lo que mejora los resultados en comparación con el transformador independiente.
Spacy proporciona un sistema estadístico excepcionalmente eficiente para NER en Python, que puede asignar etiquetas a grupos de tokens. Proporciona un modelo predeterminado que puede reconocer una amplia gama de entidades numéricas o nombradas, que incluyen persona, organización, idioma, evento, etc.

Además de estas entidades predeterminadas, Spacy también nos da la libertad de agregar clases arbitrarias al modelo NER, al capacitar al modelo para actualizarlo con ejemplos capacitados más nuevos.
Se crean y capacitan a 2 nuevas entidades llamadas ACTIVITY y SERVICE en un dominio específico (Banco) con pocas muestras de capacitación.

| Generación de nombres | Traducción automática | Generación de enunciado |
| Subtitulación de imágenes | Subtítulos de imagen - Ecuaciones de látex | Resumen de noticias |
| Generación de asignaturas de correo electrónico |
Se utiliza un modelo de lenguaje LSTM a nivel de personaje. Es decir, le daremos al LSTM una gran parte de los nombres y le pediremos que modele la distribución de probabilidad del siguiente carácter en la secuencia dada una secuencia de caracteres anteriores. Esto luego nos permitirá generar un nuevo nombre de un personaje a la vez.

La traducción automática (MT) es la tarea de convertir automáticamente un lenguaje natural en otro, preservar el significado del texto de entrada y producir texto fluido en el lenguaje de salida. Idealmente, una secuencia de lenguaje de origen se traduce en secuencia de lenguaje de destino. La tarea es convertir oraciones de German to English .
Se han explorado los siguientes varios:
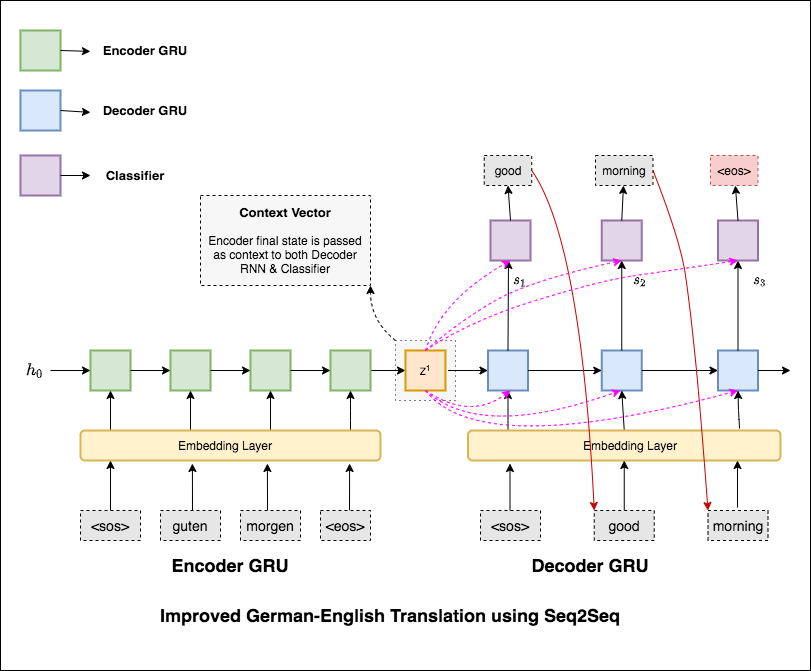
Los modelos más comunes de secuencia a secuencia (SEQ2SEQ) son los modelos de codificadores codificadores, que comúnmente usan una red neuronal recurrente (RNN) para codificar la oración de origen (entrada) en un solo vector. En este cuaderno, nos referiremos a este vector único como un vector de contexto. Podemos pensar que el vector de contexto es una representación abstracta de toda la oración de entrada. Este vector se decodifica mediante un segundo RNN que aprende a generar la oración de destino (salida) generándolo una palabra a la vez.

Después de probar la traducción automática básica que tiene la perplejidad del texto 36.68 , se han experimentado las siguientes técnicas y la perplejidad de la prueba 7.041 .
Consulte el código en la carpeta de applications/generation
El mecanismo de atención nació para ayudar a memorizar oraciones de origen largo en la traducción del automóvil neuronal (NMT). En lugar de construir un solo vector de contexto a partir del último estado oculto del codificador, la atención se utiliza para centrarse más en las partes relevantes de la entrada mientras decodifica una oración. El vector de contexto se creará tomando salidas del codificador y el previous hidden state del decodificador RNN.
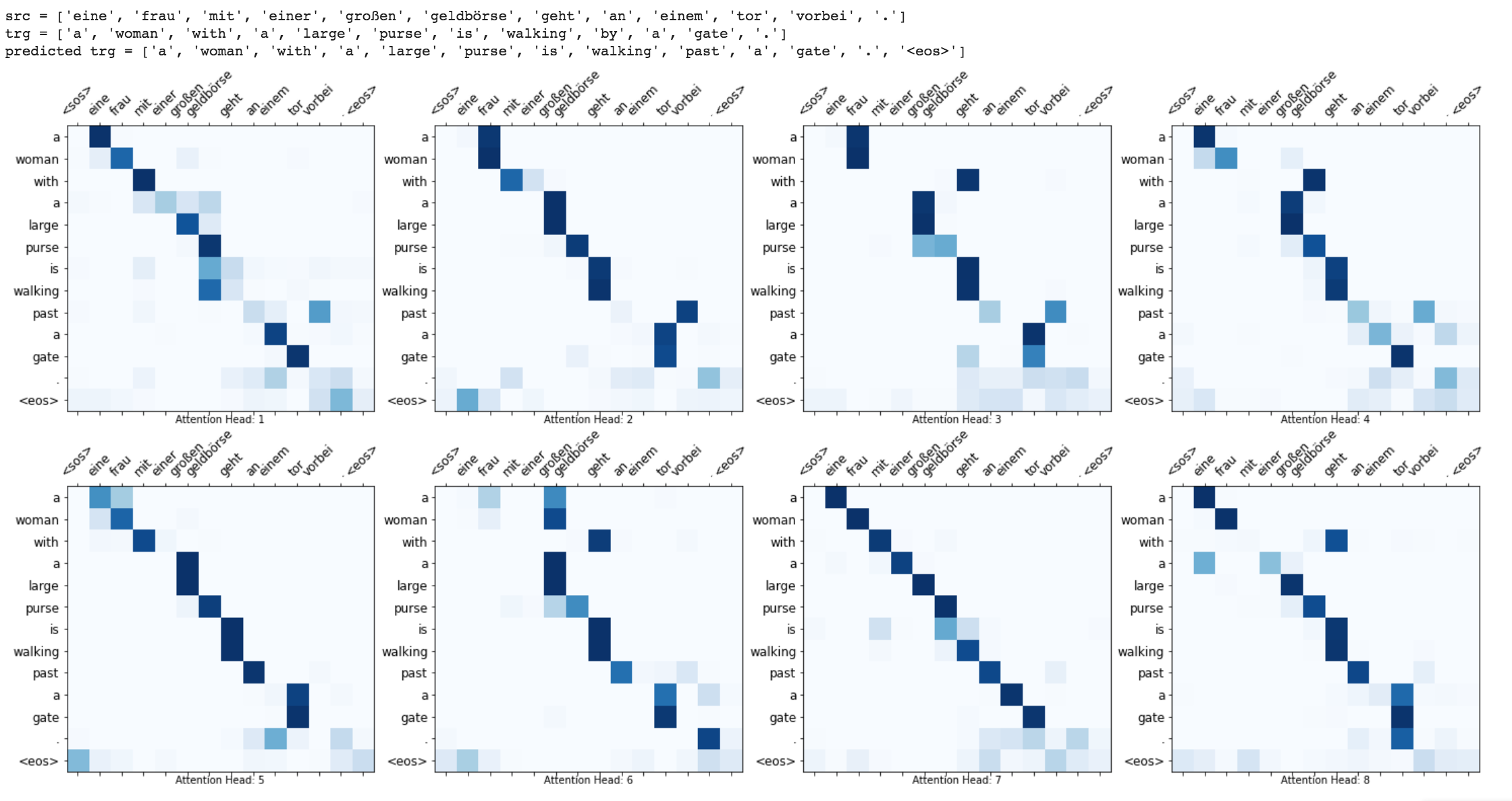
Mejoras como enmascarar (ignorar la atención sobre la entrada acolchada), empacar secuencias acolchadas (para un mejor cálculo), se implementa la visualización de atención y la métrica BLEU en los datos de la prueba.

The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do Machine translation from German to English

Run time translation (Inference) and attention visualization are added for the transformer based machine translation model.
Utterance generation is an important problem in NLP, especially in question answering, information retrieval, information extraction, conversation systems, to name a few. It could also be used to create synthentic training data for many NLP problems.
Following varients have been explored:
The most common used model for this kind of application is sequence-to-sequence network. A basic 2 layer LSTM was used.
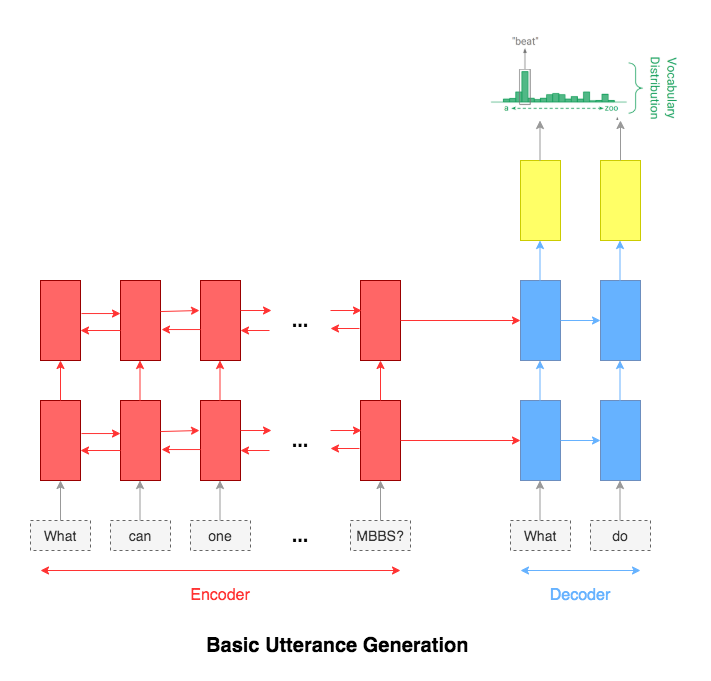
The attention mechanism will help in memorizing long sentences. Rather than building a single context vector out of the encoder's last hidden state, attention is used to focus more on the relevant parts of the input while decoding a sentence. The context vector will be created by taking encoder outputs and the hidden state of the decoder rnn.
After trying the basic LSTM apporach, Utterance generation with attention mechanism was implemented. Inference (run time generation) was also implemented.
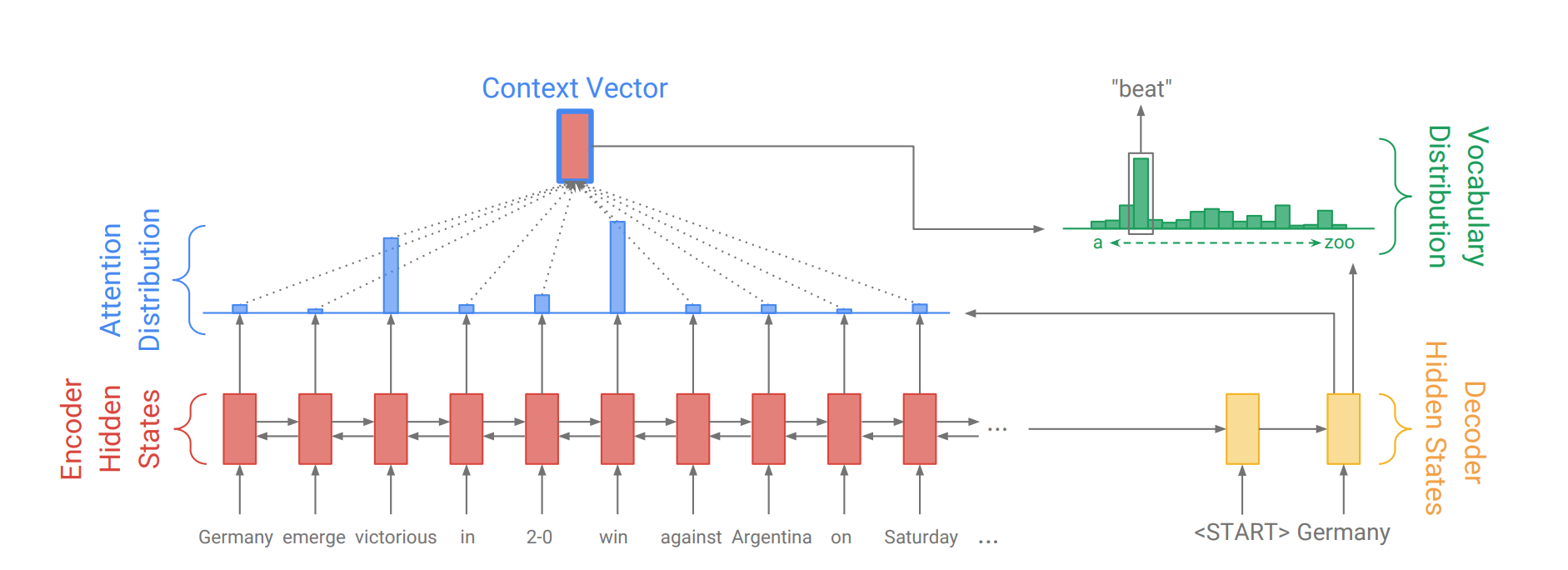
While generating the a word in the utterance, decoder will attend over encoder inputs to find the most relevant word. This process can be visualized.
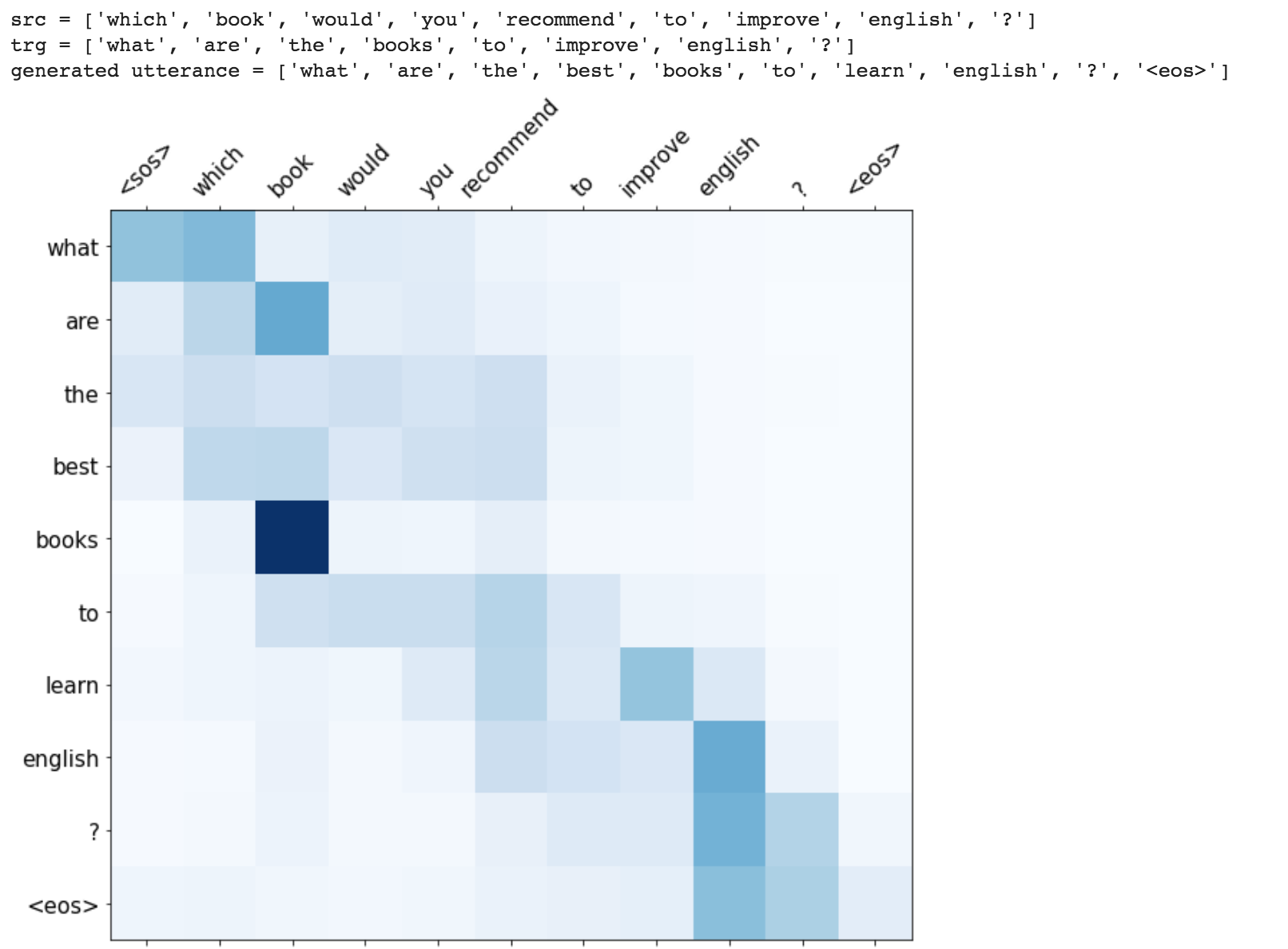
One of the ways to mitigate the repetition in the generation of utterances is to use Beam Search. By choosing the top-scored word at each step (greedy) may lead to a sub-optimal solution but by choosing a lower scored word that may reach an optimal solution.
Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.
Repetition is a common problem for sequenceto-sequence models, and is especially pronounced when generating a multi-sentence text. In coverage model, we maintain a coverage vector c^t , which is the sum of attention distributions over all previous decoder timesteps

This ensures that the attention mechanism's current decision (choosing where to attend next) is informed by a reminder of its previous decisions (summarized in c^t). This should make it easier for the attention mechanism to avoid repeatedly attending to the same locations, and thus avoid generating repetitive text.
The Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output is used to do generate utterance from a given sentence. The training time was also lot faster 4x times compared to RNN based architecture.

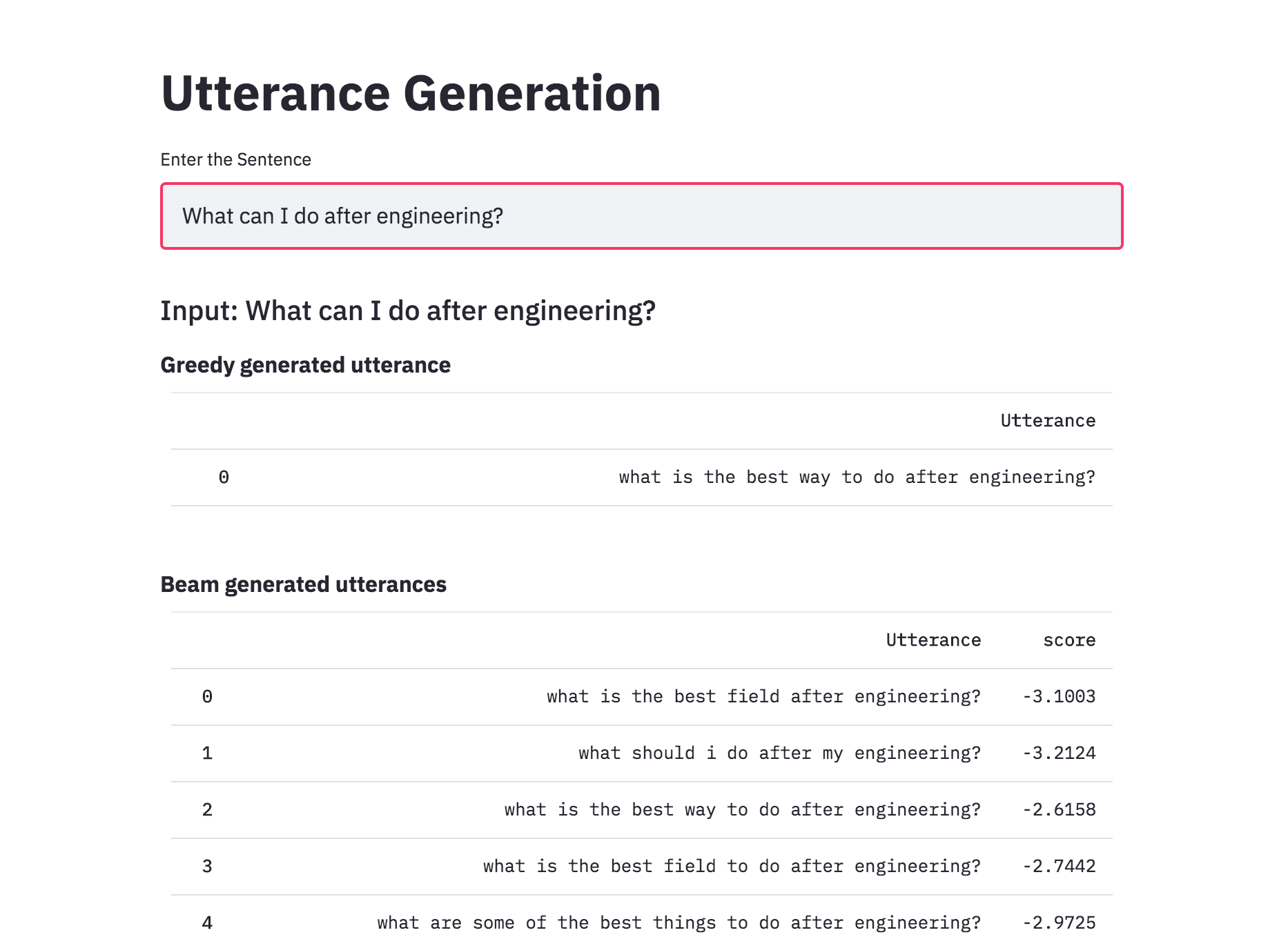
Added beam search to utterance generation with transformers. With beam search, the generated utterances are more diverse and can be more than 1 (which is the case of the greedy approach). This implemented was better than naive one implemented previously.

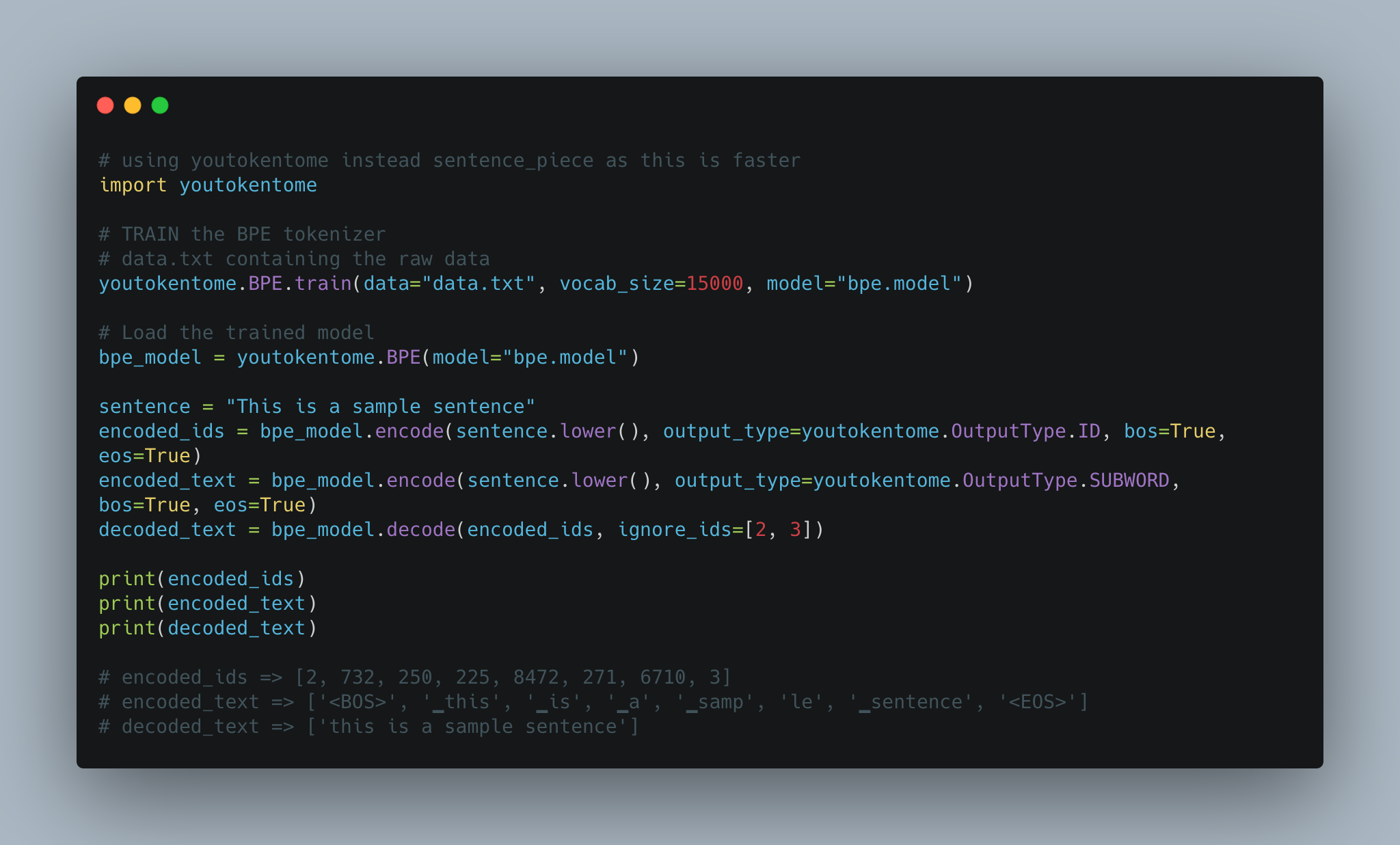
Utterance generation using BPE tokenization instead of Spacy is implemented.
Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
Converted the Utterance Generation into an app using streamlit. The pre-trained model trained on the Quora dataset is available now.
Till now the Utterance Generation is trained using the Quora Question Pairs dataset, which contains sentences in the form of questions. When given a normal sentence (which is not in a question format) the generated utterances are very poor. This is due the bias induced by the dataset. Since the model is only trained on question type sentences, it fails to generate utterances in case of normal sentences. In order to generate utterances for a normal sentence, COCO dataset is used to train the model. 

Image Captioning is the process of generating a textual description of an image. It uses both Natural Language Processing and Computer Vision techniques to generate the captions.
Flickr8K dataset is used. It contains 8092 images, each image having 5 captions.
Following varients have been explored:
The encoder-decoder framework is widely used for this task. The image encoder is a convolutional neural network (CNN). The decoder is a recurrent neural network(RNN) which takes in the encoded image and generates the caption.
In this notebook, the resnet-152 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network.
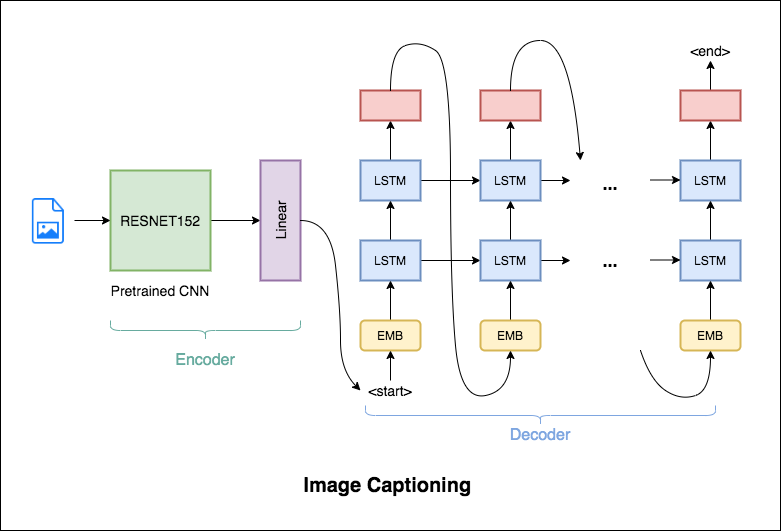
In this notebook, the resnet-101 model pretrained on the ILSVRC-2012-CLS image classification dataset is used as the encoder. The decoder is a long short-term memory (LSTM) network. Attention is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the caption.

Instead of greedily choosing the most likely next step as the caption is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter and controls the number of beams or parallel searches through the sequence of probabilities.

Today, subword tokenization schemes inspired by BPE have become the norm in most advanced models including the very popular family of contextual language models like BERT, GPT-2,RoBERTa, etc.
BPE brings the perfect balance between character and word-level hybrid representations which makes it capable of managing large corpora. This behavior also enables the encoding of any rare words in the vocabulary with appropriate subword tokens without introducing any “unknown” tokens.
BPE was used in order to tokenize the captions instead of using nltk.
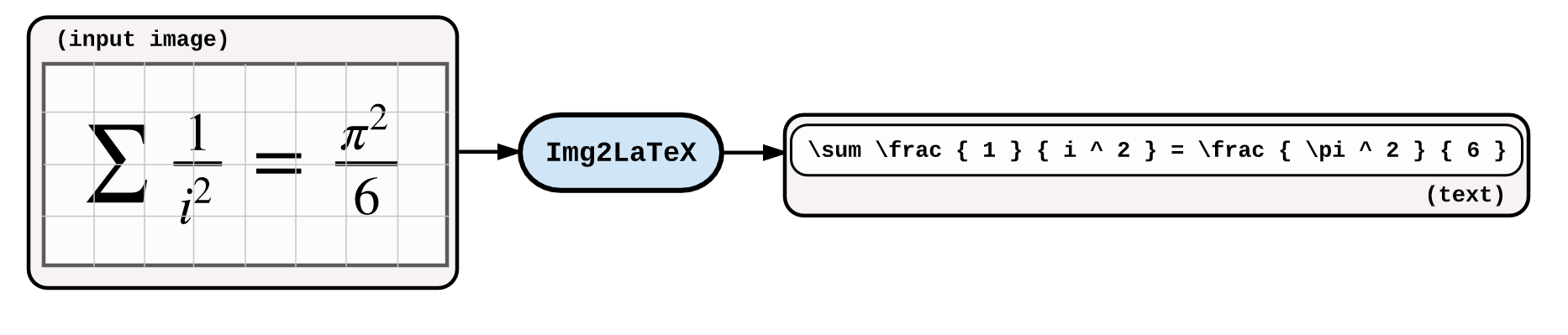
An application of image captioning is to convert the the equation present in the image to latex format.
Following varients have been explored:
An application of image captioning is to convert the the equation present in the image to latex format. Basic Sequence-to-Sequence models is used. CNN is used as encoder and RNN as decoder. Im2latex dataset is used. It contains 100K samples comprising of training, validation and test splits.
Generated formulas are not great. Following notebooks will explore techniques to improve it.
Latex code generation using the attention mechanism is implemented. Instead of the simple average, we use the weighted average across all pixels, with the weights of the important pixels being greater. This weighted representation of the image can be concatenated with the previously generated word at each step to generate the next word of the formula.
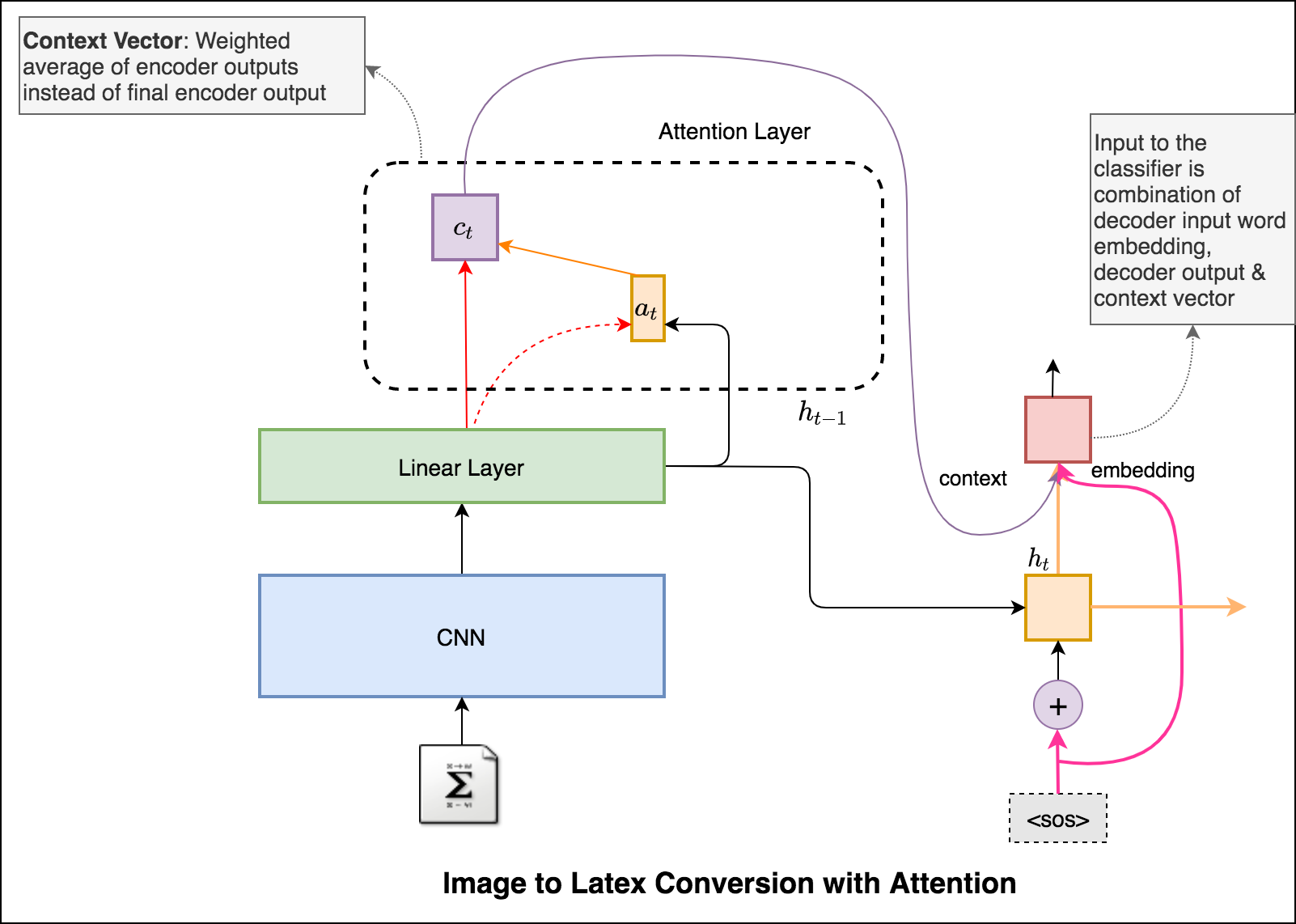
Added beam search in the decoding process. Also added Positional encoding to the input image and learning rate scheduler.
Converted the Latex formula generation into an app using streamlit.

Automatic text summarization is the task of producing a concise and fluent summary while preserving key information content and overall meaning. Have you come across the mobile app inshorts ? It's an innovative news app that converts news articles into a 60-word summary. And that is exactly what we are going to do in this notebook. The model used for this task is T5 .

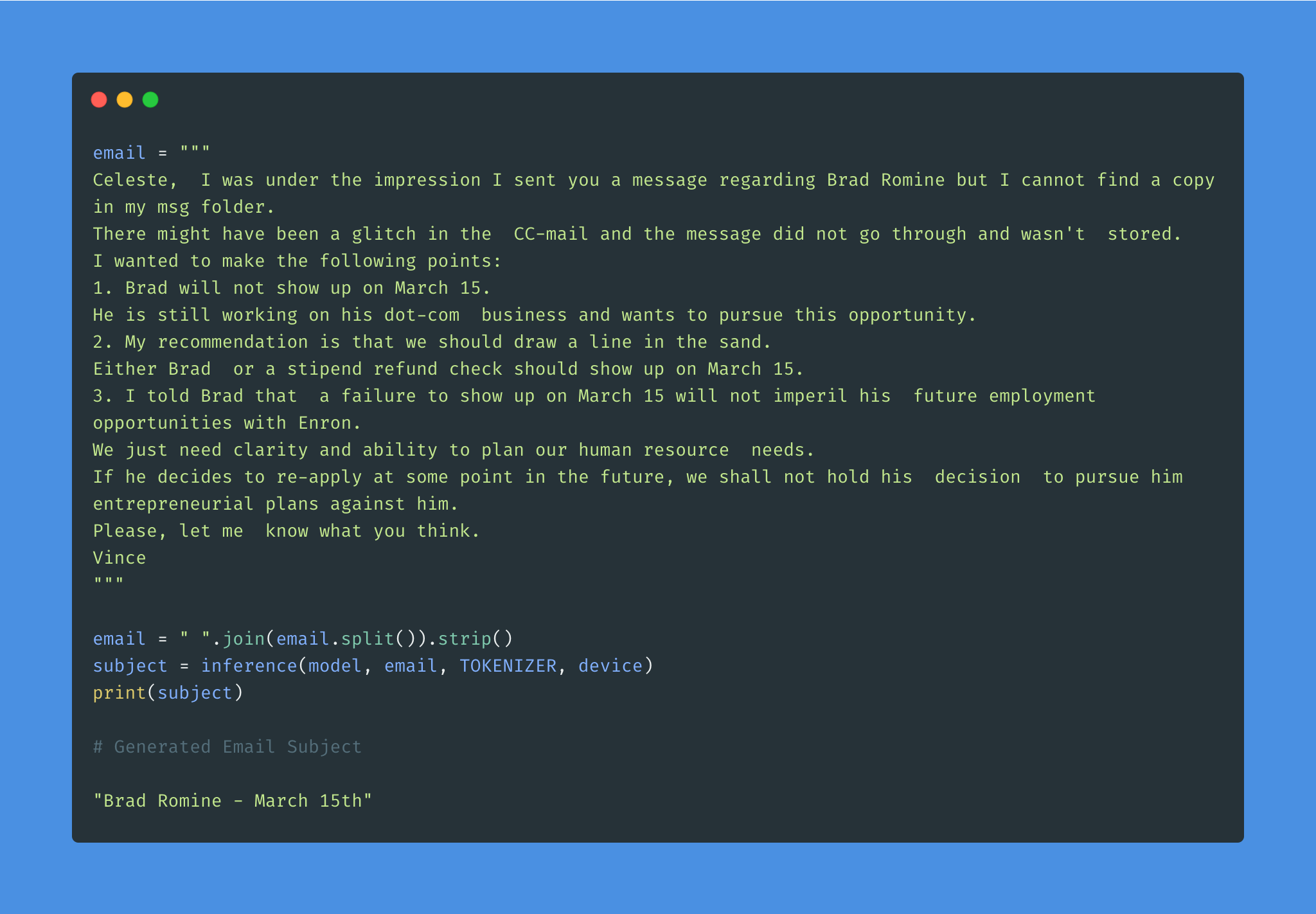
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content.
Email subject generation using T5 model was explored. AESLC dataset was used for this purpose.
| Topic Identification in News | Covid Article finding |
Topic Identification is a Natural Language Processing (NLP) is the task to automatically extract meaning from texts by identifying recurrent themes or topics.
Following varients have been explored:
LDA's approach to topic modeling is it considers each document as a collection of topics in a certain proportion. And each topic as a collection of keywords, again, in a certain proportion.
Once you provide the algorithm with the number of topics, all it does it to rearrange the topics distribution within the documents and keywords distribution within the topics to obtain a good composition of topic-keywords distribution.
20 Newsgroup dataset was used and only the articles are provided to identify the topics. Topic Modelling algorithms will provide for each topic what are the important words. It is upto us to infer the topic name.
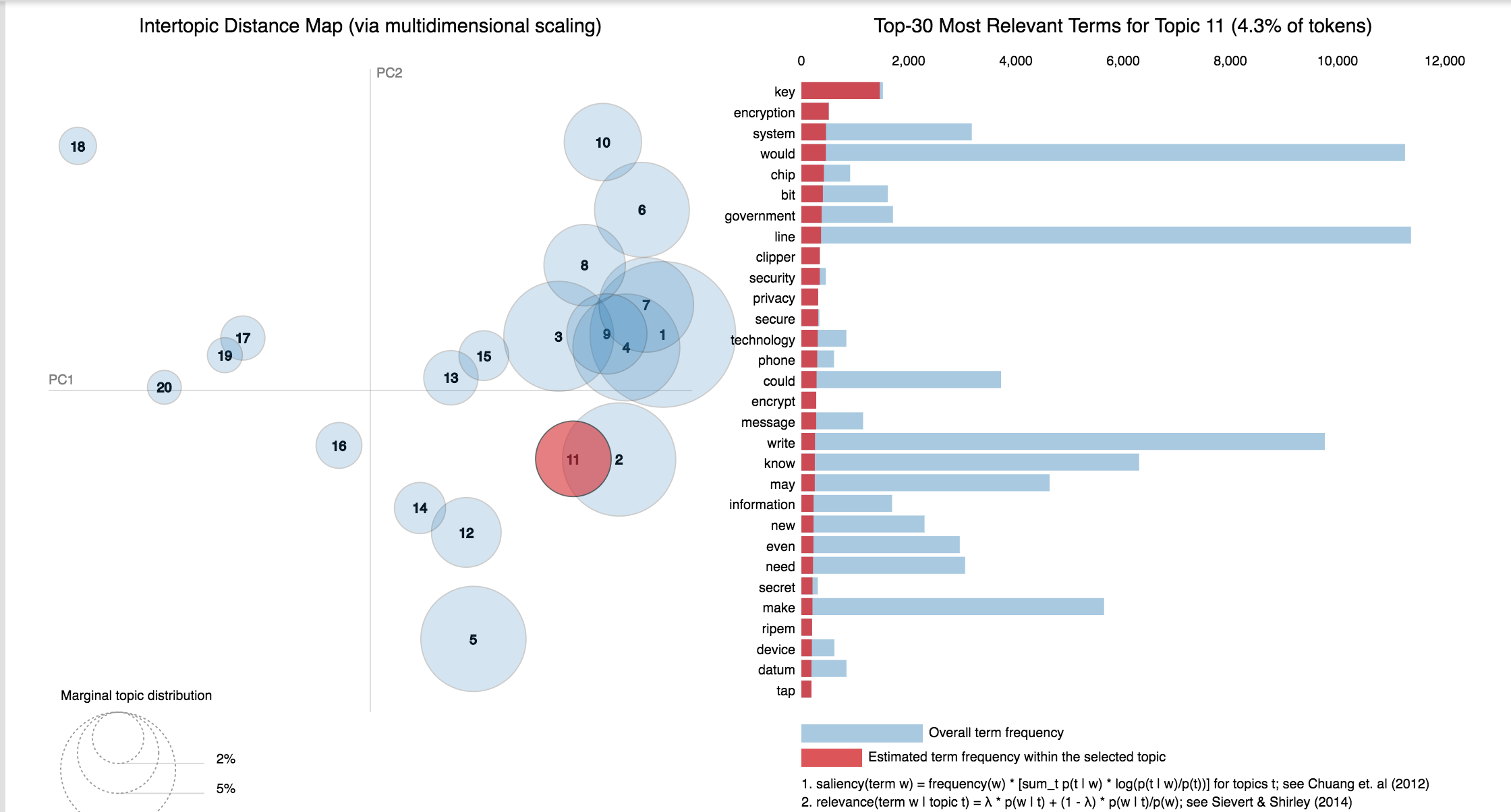
Choosing the number of topics is a difficult job in Topic Modelling. In order to choose the optimal number of topics, grid search is performed on various hypermeters. In order to choose the best model the model having the best perplexity score is choosed.
A good topic model will have non-overlapping, fairly big sized blobs for each topic.
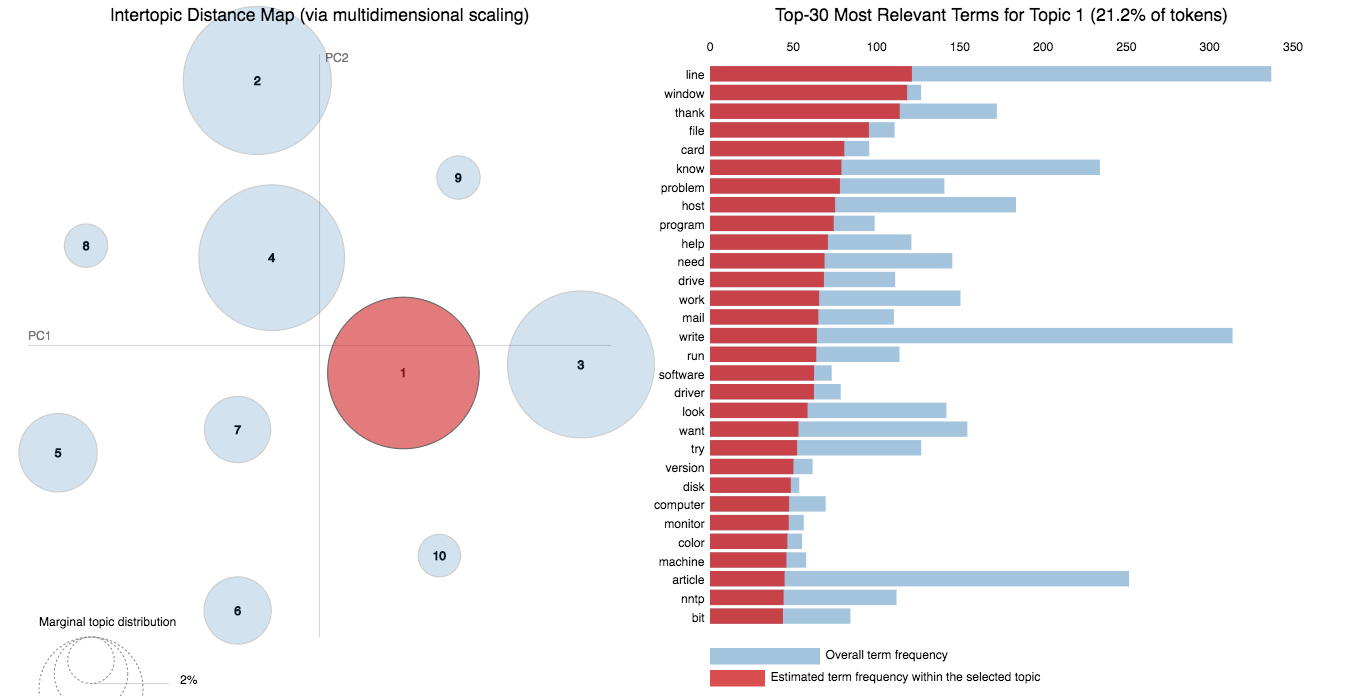
We would clearly expect that the words that appear most frequently in one topic would appear less frequently in the other - otherwise that word wouldn't make a good choice to separate out the two topics. Therefore, we expect the topics to be orthogonal .
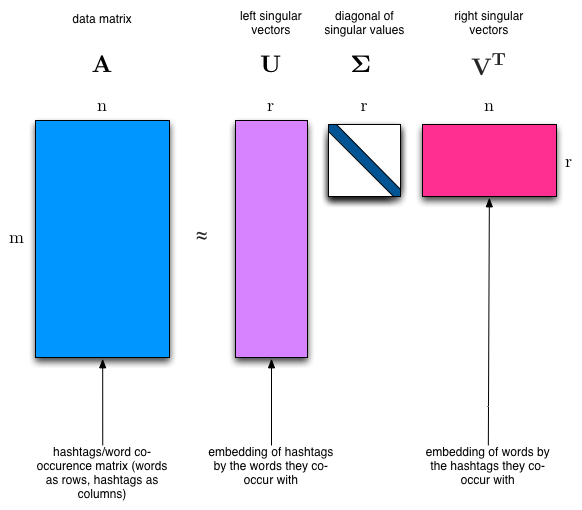
Latent Semantic Analysis (LSA) uses SVD. You will sometimes hear topic modelling referred to as LSA.
The SVD algorithm factorizes a matrix into one matrix with orthogonal columns and one with orthogonal rows (along with a diagonal matrix, which contains the relative importance of each factor).
Notas:
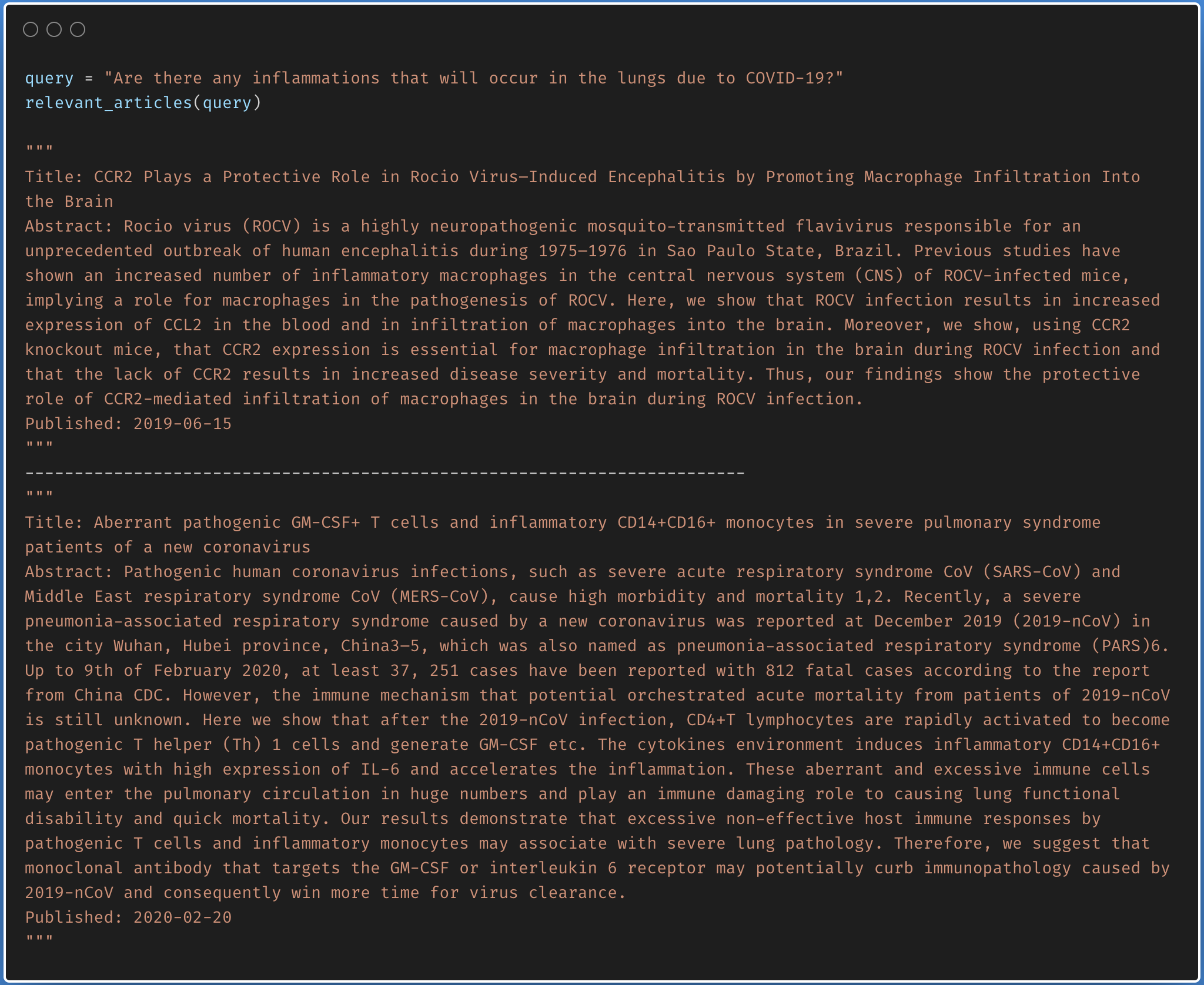
Finding the relevant article from a covid-19 research article corpus of 50K+ documents using LDA is explored.
The documents are first clustered into different topics using LDA. For a given query, dominant topic will be found using the trained LDA. Once the topic is found, most relevant articles will be fetched using the jensenshannon distance.
Only abstracts are used for the LDA model training. LDA model was trained using 35 topics.
| Factual Question Answering | Visual Question Answering | Boolean Question Answering |
| Closed Question Answering |
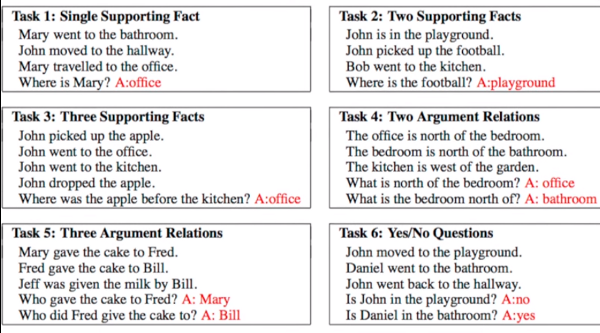
Given a set of facts, question concering them needs to be answered. Dataset used is bAbI which has 20 tasks with an amalgamation of inputs, queries and answers. See the following figure for sample.
Following varients have been explored:
Dynamic Memory Network (DMN) is a neural network architecture which processes input sequences and questions, forms episodic memories, and generates relevant answers.

The main difference between DMN+ and DMN is the improved InputModule for calculating the facts from input sentences keeping in mind the exchange of information between input sentences using a Bidirectional GRU and a improved version of MemoryModule using Attention based GRU model.

Visual Question Answering (VQA) is the task of given an image and a natural language question about the image, the task is to provide an accurate natural language answer.
Following varients have been explored:

The model uses a two layer LSTM to encode the questions and the last hidden layer of VGGNet to encode the images. The image features are then l_2 normalized. Both the question and image features are transformed to a common space and fused via element-wise multiplication, which is then passed through a fully connected layer followed by a softmax layer to obtain a distribution over answers.
To apply the DMN to visual question answering, input module is modified for images. The module splits an image into small local regions and considers each region equivalent to a sentence in the input module for text.
The input module for VQA is composed of three parts, illustrated in below fig:

Boolean question answering is to answer whether the question has answer present in the given context or not. The BoolQ dataset contains the queries for complex, non-factoid information, and require difficult entailment-like inference to solve.
Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage
Following varients have been explored:
The DCN first fuses co-dependent representations of the question and the document in order to focus on relevant parts of both. Then a dynamic pointing decoder iterates over potential answer spans. This iterative procedure enables the model to recover from initial local maxima corresponding to incorrect answers.
The Dynamic Coattention Network has two major parts: a coattention encoder and a dynamic decoder.
CoAttention Encoder : The model first encodes the given document and question separately via the document and question encoder. The document and question encoders are essentially a one-directional LSTM network with one layer. Then it passes both the document and question encodings to another encoder which computes the coattention via matrix multiplications and outputs the coattention encoding from another bidirectional LSTM network.
Dynamic Decoder : Dynamic decoder is also a one-directional LSTM network with one layer. The model runs the LSTM network through several iterations . In each iteration, the LSTM takes in the final hidden state of the LSTM and the start and end word embeddings of the answer in the last iteration and outputs a new hidden state. Then, the model uses a Highway Maxout Network (HMN) to compute the new start and end word embeddings of the answer in each iteration.
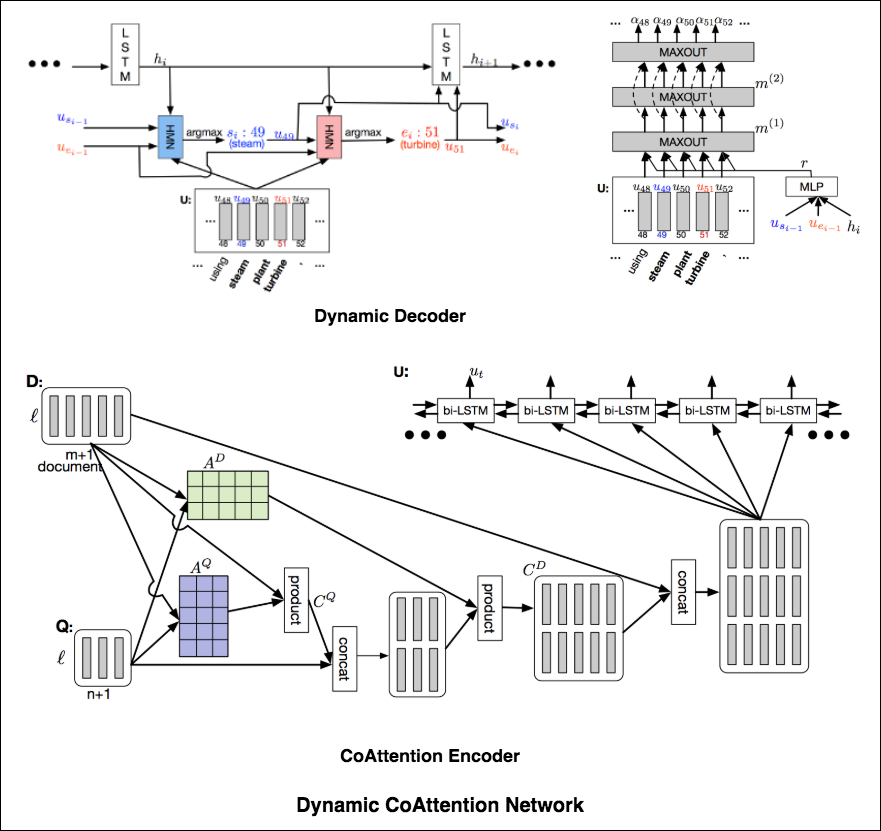
Double Cross Attention (DCA) seems to provide better results compared to both BiDAF and Dynamic Co-Attention Network (DCN). The motivation behind this approach is that first we pay attention to each context and question and then we attend those attentions with respect to each other in a slightly similar way as DCN. The intuition is that if iteratively read/attend both context and question, it should help us to search for answers easily.
I have augmented the Dynamic Decoder part from DCN model in-order to have iterative decoding process which helps finding better answer.
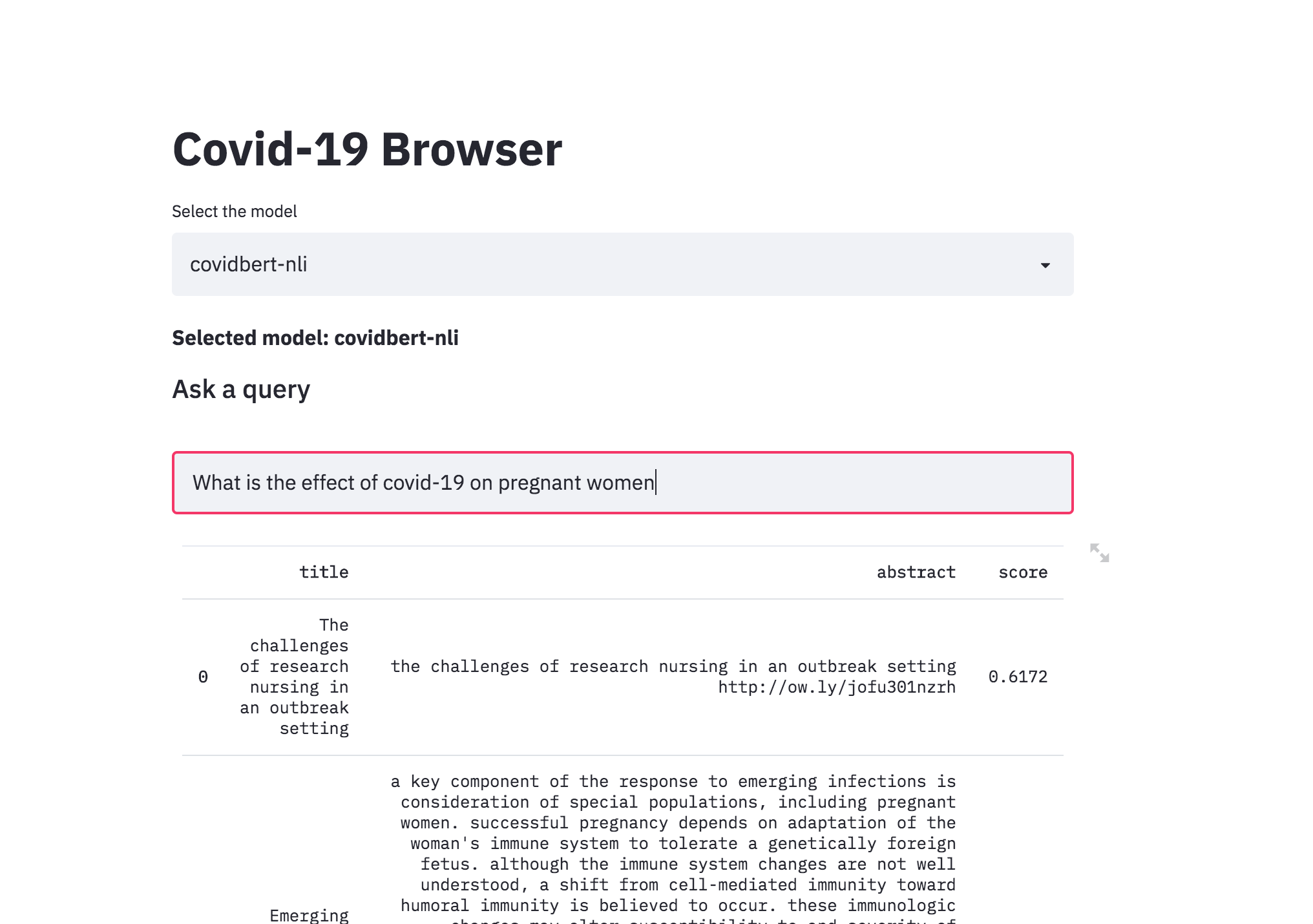
| Covid-19 Browser |
There was a kaggle problem on covid-19 research challenge which has over 1,00,000 + documents. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
The procedure I have taken is to convert the abstracts into a embedding representation using sentence-transformers . When a query is asked, it will converted into an embedding and then ranked across the abstracts using cosine similarity.
| Song Recommendation |
By taking user's listening queue as a sentence, with each word in that sentence being a song that the user has listened to, training the Word2vec model on those sentences essentially means that for each song the user has listened to in the past, we're using the songs they have listened to before and after to teach our model that those songs somehow belong to the same context.
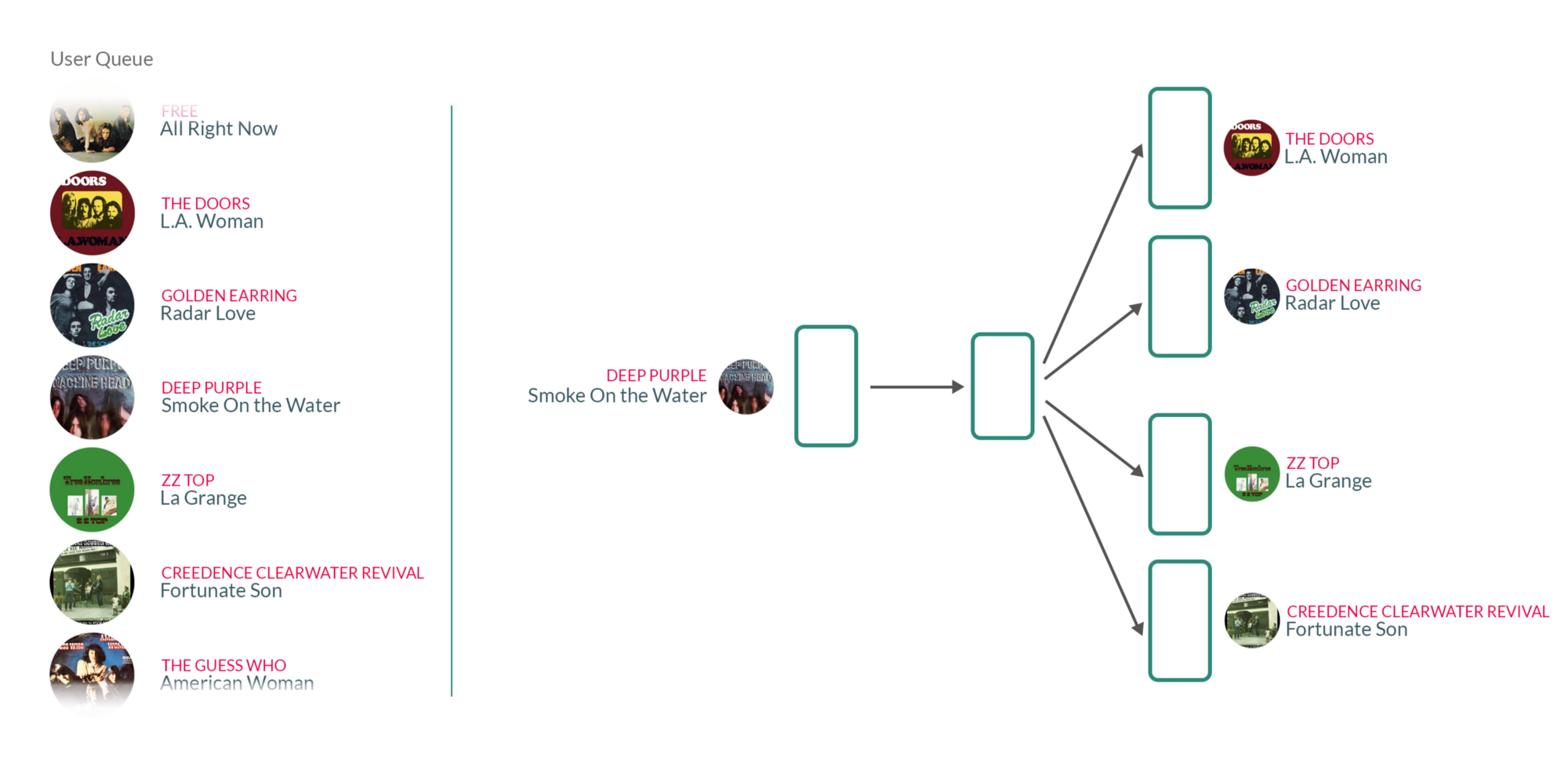
What's interesting about those vectors is that similar songs will have weights that are closer together than songs that are unrelated.


