sense2vec
v2.0.2
Sense2Vec(Trask等,2015)是Word2Vec的一個不錯的轉折,使您可以學習更多有趣且詳細的單詞矢量。該庫是用於加載,查詢和培訓Sense2Vec模型的簡單python實現。有關更多詳細信息,請查看我們的博客文章。要探討2015年和2019年所有Reddit評論中的語義相似性,請參見互動演示。
? 2.0版(用於Spacy V3)現在!在此處閱讀發行說明。

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
配x 請注意,此示例描述了Spacy V3的用法。對於使用Spacy V2的使用,請下載sense2vec==1.0.3並查看此存儲庫的v1.x分支。
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]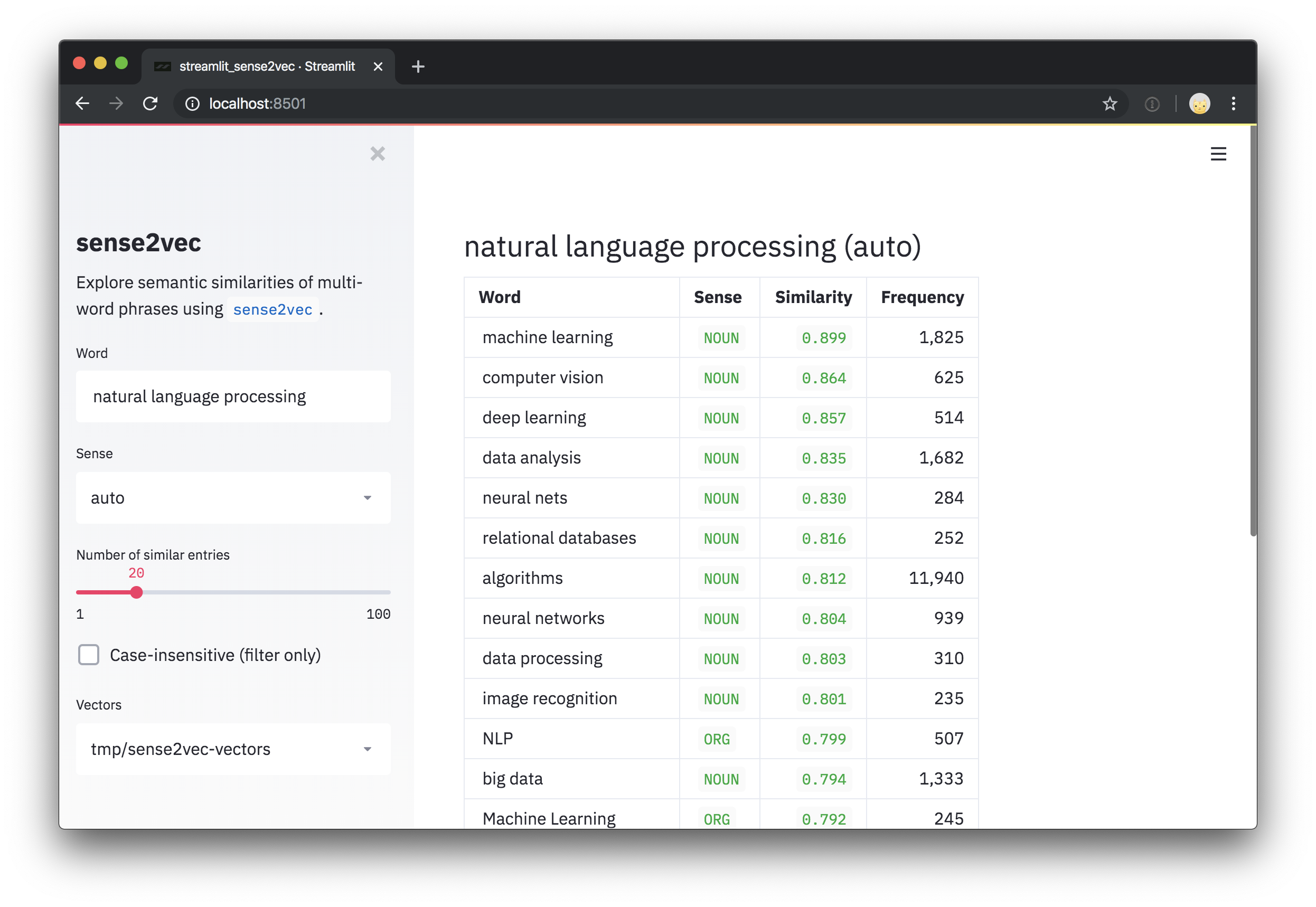
要嘗試我們經過Reddit評論訓練的載體,請查看Interactive Sense2Vec演示。
此存儲庫還包括一個簡化的演示腳本,用於探索向量和最相似的短語。安裝streamlit後,您可以使用streamlit run的腳本運行腳本,並在命令行上作為定位參數,一條或多個途徑或多個路徑。例如:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors要使用向量,請下載檔案庫,然後將提取的目錄傳遞到Sense2Vec.from_disk或Sense2VecComponent.from_disk 。向量文件附加到GitHub版本。大文件已分為多部分下載。
| 向量 | 尺寸 | 描述 | ?下載(拉鍊) |
|---|---|---|---|
s2v_reddit_2019_lg | 4GB | Reddit評論2019(01-07) | 第1部分,第2部分,第3部分 |
s2v_reddit_2015_md | 573 MB | Reddit評論2015 | 第1部分 |
要合併多部分檔案,您可以運行以下內容:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzSense2Vec版本可在PIP上獲得:
pip install sense2vec要使用預告片的向量,請下載一個矢量包,請拆卸.tar.gz檔案和from_disk點到提取的數據目錄:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )使用庫和向量的最簡單方法是將其插入您的Spacy管道中。 sense2vec軟件包公開了Sense2VecComponent ,該軟件包可以用共享詞彙初始化,並將其添加到Spacy管道中,作為自定義管道組件。默認情況下,將組件添加到管道末端,這是該組件的建議位置,因為它需要訪問依賴項解析,並且(如果可用)命名實體。
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )該組件將為Spacy的Token和Span對象添加幾個擴展屬性和方法,這些屬性可讓您檢索向量和頻率以及大多數相似的術語。
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )對於實體,實體標籤用作“ siense”(而不是令牌的詞性詞性標籤):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 )以下擴展屬性通過._屬性在Doc對像上暴露:
| 姓名 | 屬性類型 | 類型 | 描述 |
|---|---|---|---|
s2v_phrases | 財產 | 列表 | 所有Sense2Vec兼容的Doc (名詞短語,命名實體)。 |
以下屬性可通過Token和Span對象的._屬性可用 - 例如token._.in_s2v :
|名稱|屬性類型|返回類型|描述| | ---------------------- | ---------------- | ---------------------- | -------------------------------------------------------------------------------------------------------------- | ------------------ | ------- | | in_s2v |屬性|布爾|矢量圖中是否存在密鑰。 | | s2v_key |屬性| Unicode |給定對象的Sense2Vec鍵,例如"duck | NOUN" 。 | | s2v_vec |屬性| ndarray[float32] |給定密鑰的向量。 | | s2v_freq |屬性| int |給定鍵的頻率。 | | s2v_other_senses |屬性|列表|可用的其他感官,例如"duck | VERB"作為"duck | NOUN" 。 | | s2v_most_similar |方法|列表|獲取n最相似的術語。返回((word, sense), score)元組的列表。 | | s2v_similarity |方法|浮點|獲得與另一個Token或Span相似性。 |
配x 關於跨度屬性的註釋:在引擎蓋下,doc.ents中的實體是Span對象。這就是為什麼管道組件還為跨度而不僅僅是令牌添加屬性和方法的原因。但是,不建議在文檔的任意切片上使用Sense2Vec屬性,因為該模型可能不會為各自的文本提供鍵。Span對像也沒有詞性詞性標籤,因此,如果沒有實體標籤,則“ siense”默認為詞根的詞性詞性標籤。
如果您要培訓和包裝Spacy管道,並希望在其中包含Sense2Vec組件,則可以通過培訓配置的[initialize]塊加載數據:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md "您也可以直接使用基礎Sense2Vec類,並使用from_disk方法在向量中加載。有關可用的API方法,請參見下文。
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
配x 重要說明:要查找向量表中的條目,鍵需要遵循phrase_text|SENSE的方案(請注意_而不是spaces,而在標籤或標籤之前|) - 例如,machine_learning|NOUN。另請注意,底層矢量表對病例敏感。
Sense2Vec具有矢量,字符串和頻率的獨立Sense2Vec對象。
Sense2Vec.__init__初始化Sense2Vec對象。
| 爭論 | 類型 | 描述 |
|---|---|---|
shape | 元組 | 向量形狀。默認為(1000, 128) 。 |
strings | spacy.strings.StringStore | 可選的字符串商店。如果不存在,將創建。 |
senses | 列表 | 所有可用感官的可選列表。用於產生最佳理智或其他感官的方法。 |
vectors_name | Unicode | 可選的名稱要分配給向Vectors ,以防止衝突。默認為"sense2vec" 。 |
overrides | dict | 可選的自定義功能要使用,映射到通過註冊表註冊的名稱,例如{"make_key": "custom_make_key"} 。 |
| 返回 | Sense2Vec | 新構造的對象。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__向量表中的行數。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 返回 | int | 向量表中的行數。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__檢查鍵是否在向量表中。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的鑰匙。 |
| 返回 | 布爾 | 鑰匙是否在表中。 |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__檢索給定鍵的向量。如果鍵不在表中,則返回無。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的鑰匙。 |
| 返回 | numpy.ndarray | 向量或None 。 |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__為給定鍵設置向量。如果鍵不存在,將會引起錯誤。要添加新條目,請使用Sense2Vec.add 。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 鑰匙。 |
vector | numpy.ndarray | 要設置的向量。 |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.add將新向量添加到表中。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 要添加的關鍵。 |
vector | numpy.ndarray | 向量要添加。 |
freq | int | 可選頻率計數。用於尋找最佳匹配感。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freq獲取給定鍵的頻率計數。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的鑰匙。 |
default | - | 如果沒有發現頻率,則返回默認值。 |
| 返回 | int | 頻率計數。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freq為給定鍵設置頻率計數。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 設置計數的關鍵。 |
freq | int | 頻率計數。 |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.items迭代向量表中的條目。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 產量 | 元組 | 表中的字符串鍵和矢量對。 |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keys迭代桌子中的鍵。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 產量 | Unicode | 表中的字符串鍵。 |
all_keys = list ( s2v . keys ())Sense2Vec.values迭代桌子中的向量。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 產量 | numpy.ndarray | 桌子中的向量。 |
all_vecs = list ( s2v . values ())Sense2Vec.senses表中的可用感官,例如"NOUN"或"VERB" (在初始化時添加)。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 返回 | 列表 | 可用的感官。 |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequencies表中鍵的頻率按順序下降。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 返回 | 列表 | (key, freq)乘以頻率,下降。 |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarity對兩個鍵或兩組鍵進行語義相似性估計。默認估計是使用平均向量的餘弦相似性。
| 爭論 | 類型 | 描述 |
|---|---|---|
keys_a | unicode / int / itoser | 字符串或整數鍵。 |
keys_b | unicode / int / itoser | 另一個字符串或整數鍵。 |
| 返回 | 漂浮 | 相似得分。 |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similar獲取表中最相似的條目。如果提供了多個密鑰,則使用向量的平均值。為了使此方法更快,請參見腳本以預先計算最近的鄰居的緩存。
| 爭論 | 類型 | 描述 |
|---|---|---|
keys | unicode / int / itoser | 將字符串或整數鍵進行比較。 |
n | int | 返回的類似鍵的數量。默認為10 。 |
batch_size | int | 批次大小要使用。默認為16 。 |
| 返回 | 列表 | 最相似向量的(key, score)元素。 |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses找到具有不同意義的同一單詞的其他條目,例如"duck|VERB"作為"duck|NOUN" 。
| 爭論 | 類型 | 描述 |
|---|---|---|
key | Unicode / int | 檢查的鑰匙。 |
ignore_case | 布爾 | 檢查大寫,小寫和滴定酶。默認為True 。 |
| 返回 | 列表 | 具有不同感官的其他條目的字符串鍵。 |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense根據可用的感官和頻率計數,找到給定單詞的最佳匹配感。如果找不到匹配,則None返回。
| 爭論 | 類型 | 描述 |
|---|---|---|
word | Unicode | 要檢查的單詞。 |
senses | 列表 | 可選的感官列表以將搜索限制為。如果未設置 /空,則使用向量中的所有感官。 |
ignore_case | 布爾 | 檢查大寫,小寫和滴定酶。默認為True 。 |
| 返回 | Unicode | 最好的匹配鍵或無。 |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes將Sense2Vec對象序列化為bytestring。
| 爭論 | 類型 | 描述 |
|---|---|---|
exclude | 列表 | 排除序列化字段的名稱。 |
| 返回 | 位元組 | 序列化Sense2Vec對象。 |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes從bytestring加載Sense2Vec對象。
| 爭論 | 類型 | 描述 |
|---|---|---|
bytes_data | 位元組 | 加載的數據。 |
exclude | 列表 | 排除序列化字段的名稱。 |
| 返回 | Sense2Vec | 加載對象。 |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk將Sense2Vec對象序列化為目錄。
| 爭論 | 類型 | 描述 |
|---|---|---|
path | UNICODE / Path | 路徑。 |
exclude | 列表 | 排除序列化字段的名稱。 |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk從目錄加載Sense2Vec對象。
| 爭論 | 類型 | 描述 |
|---|---|---|
path | UNICODE / Path | 從 |
exclude | 列表 | 排除序列化字段的名稱。 |
| 返回 | Sense2Vec | 加載對象。 |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponent將Sense2VEC添加到Spacy管道中的管道組件。
Sense2VecComponent.__init__初始化管道組件。
| 爭論 | 類型 | 描述 |
|---|---|---|
vocab | Vocab | 共享Vocab 。主要用於共享StringStore 。 |
shape | 元組 | 向量形狀。 |
merge_phrases | 布爾 | 是否將Sense2Vec短語合併為一個令牌。默認為False 。 |
lemmatize | 布爾 | 如果在向量中可用,則始終查找引理,否則默認為原始單詞。默認為False 。 |
overrides | 可選的自定義函數要使用,映射到通過註冊表進行註冊的名稱,例如{"make_key": "custom_make_key"} 。 | |
| 返回 | Sense2VecComponent | 新構造的對象。 |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp從NLP對像初始化組件。主要用作入口點的組件工廠(請參閱setup.cfg),並通過@spacy.component Decorator自動註冊。
| 爭論 | 類型 | 描述 |
|---|---|---|
nlp | Language | nlp對象。 |
**cfg | - | 可選的配置參數。 |
| 返回 | Sense2VecComponent | 新構造的對象。 |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__使用組件處理Doc對象。通常僅稱為Spacy管道的一部分而不是直接稱為。
| 爭論 | 類型 | 描述 |
|---|---|---|
doc | Doc | 要處理的文檔。 |
| 返回 | Doc | 處理過的文檔。 |
Sense2Vec.init_component在此處註冊特定於組件的擴展屬性,並且僅當組件被添加到管道中並使用時 - 否則,即使僅創建組件並且未添加組件,代幣仍將獲得屬性。
Sense2VecComponent.to_bytes將組件序列化為bytestring。當將組件添加到管道中並運行nlp.to_bytes時,也將調用。
| 爭論 | 類型 | 描述 |
|---|---|---|
| 返回 | 位元組 | 序列化組件。 |
Sense2VecComponent.from_bytes從bytestring加載組件。運行nlp.from_bytes時也稱為。
| 爭論 | 類型 | 描述 |
|---|---|---|
bytes_data | 位元組 | 加載的數據。 |
| 返回 | Sense2VecComponent | 加載對象。 |
Sense2VecComponent.to_disk將組件序列化為目錄。當將組件添加到管道中並運行nlp.to_disk時,也會調用。
| 爭論 | 類型 | 描述 |
|---|---|---|
path | UNICODE / Path | 路徑。 |
Sense2VecComponent.from_disk從目錄加載Sense2Vec對象。運行nlp.from_disk時也稱為。
| 爭論 | 類型 | 描述 |
|---|---|---|
path | UNICODE / Path | 從 |
| 返回 | Sense2VecComponent | 加載對象。 |
registry功能註冊表(由catalogue供電)輕鬆自定義用於生成密鑰和短語的功能。允許您裝飾和命名自定義功能,將其交換並在保存模型時序列化自定義名稱。可以使用以下註冊表選項:
|名稱|描述| | ------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | | registry.make_key |給定一個word和sense ,返回鍵的字符串,例如"word | sense". | | registry.split_key |給定一個字符串鍵,返回(word, sense)元組。 | | registry.make_spacy_key |給定一個spacy對象( Token或Span )和一個布爾值prefer_ents關鍵字參數(是否偏愛單個令牌的實體標籤),返回A (word, sense)元組。在擴展屬性中用於生成代幣和跨度的密鑰。 | | | registry.get_phrases |給定一個spacy Doc ,返回用於sense2vec短語(通常是名詞短語和命名實體)的Span對象列表。 | | registry.merge_phrases |鑑於spacy Doc ,獲取所有Sense2Vec短語,並將它們合併為單個令牌。 |
每個註冊表都有一個可以用作函數裝飾器的register方法,並採用一個參數,即自定義函數的名稱。
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense初始化Sense2Vec對象時,您現在可以將其使用自定義註冊功能的名稱的覆蓋字典傳遞。
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )這使得可以輕鬆地嘗試不同的策略並將策略序列化為普通字符串(而不是必須傳遞和/或泡菜功能本身)。
/scripts目錄包含用於預處理文本和訓練自己的向量的命令行實用程序。
要訓練您自己的Sense2Vec向量,您將需要以下內容:
doc.noun_chunks 。如果您需要的語言沒有為名詞短語提供內置的語法迭代器,則需要編寫自己的語法。 ( doc.noun_chunks and doc.ents是Sense2Vec用來確定什麼短語的sense2vec。)make 。培訓過程分為幾個步驟,使您可以在任何給定的點恢復。處理腳本旨在在單個文件上操作,從而可以輕鬆地對付工作。此存儲庫中的腳本需要您需要克隆並make手套或fastText。
對於FastText,腳本將需要到達創建的二進製文件的路徑。如果您在Windows上工作,則可以使用cmake構建,或者使用FastText二進制構建的Windows builds中的.exe文件使用:https://github.com/xiamx/fasttext/releases。
| 腳本 | 描述 | |
|---|---|---|
| 1。 | 01_parse.py | 使用Spacy解析Doc對象的原始文本和輸出二進制集合(請參閱DocBin )。 |
| 2。 | 02_preprocess.py | 加載以Sense2Vec格式(每行句子為一句話,帶有感官的句子)中產生的分析的Doc對象集合。 |
| 3。 | 03_glove_build_counts.py | 使用手套來構建詞彙和計數。如果您通過FastText使用Word2Vec,則跳過此步驟。 |
| 4。 | 04_glove_train_vectors.py04_fasttext_train_vectors.py | 使用手套或FastText訓練向量。 |
| 5。 | 05_export.py | 加載向量和頻率,並輸出一個可以通過Sense2Vec.from_disk加載的Sense2Vec組件。 |
| 6。 | 06_precompute_cache.py | 可選: vocab中每個條目的最接近的鄰居查詢,以使Sense2Vec.most_similar更快。 |
有關腳本的更詳細的文檔,請查看源或使用--help運行它們。例如, python scripts/01_parse.py --help 。
該軟件包還與Prodigy註釋工具無縫集成,並揭示了使用Sense2Vec向量快速生成多字短語列表和Bootstrap ner註釋的食譜。要使用食譜, sense2vec需要安裝在與Prodigy相同的環境中。有關真實世界用例的示例,請查看使用可下載數據集的NER項目。
可用以下食譜 - 有關更多詳細文檔,請參見下文。
| 食譜 | 描述 |
|---|---|
sense2vec.teach | 使用Sense2Vec引導術語列表。 |
sense2vec.to-patterns | 將短語數據集轉換為基於令牌的匹配模式。 |
sense2vec.eval | 通過詢問短語三元組來評估Sense2VEC模型。 |
sense2vec.eval-most-similar | 通過糾正最相似的條目來評估Sense2VEC模型。 |
sense2vec.eval-ab | 對兩個驗證的Sense2Vec矢量模型進行A/B評估。 |
sense2vec.teach使用Sense2Vec引導術語列表。神童將根據Sense2Vec的最相似短語提出類似的術語,並在註釋並接受相似的短語時調整建議。對於每個種子術語,將使用Sense2Vec向量的最佳匹配感。
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| 爭論 | 類型 | 描述 |
|---|---|---|
dataset | 位置 | 數據集以將註釋保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途徑。 |
--seeds , -s | 選項 | 一個或多個分離的種子短語。 |
--threshold , -t | 選項 | 相似性閾值。默認為0.85 。 |
--n-similar , -n | 選項 | 同時獲得類似項目的數量。 |
--batch-size , -b | 選項 | 批次大小用於提交註釋。 |
--resume , -R | 旗幟 | 從現有短語數據集中恢復。 |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns將用sense2vec.teach收集的短語數據集轉換為基於令牌的匹配模式,該模式可以與Spacy的EntityRuler或ner.match之類的食譜一起使用。如果未指定輸出文件,則將模式寫入Stdout。這些示例已被象徵化,以便正確表示多義術語,例如: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} 。
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| 爭論 | 類型 | 描述 |
|---|---|---|
dataset | 位置 | 短語數據集要轉換。 |
spacy_model | 位置 | 代幣化的Spacy模型。 |
label | 位置 | 標籤適用於所有模式。 |
--output-file , -o | 選項 | 可選輸出文件。默認為stdout。 |
--case-sensitive , -CS | 旗幟 | 使模式對案例敏感。 |
--dry , -D | 旗幟 | 執行乾式跑步,不要輸出任何東西。 |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.eval通過詢問短語三重詞來評估Sense2Vec模型:單詞與單詞B更相似,還是Word C?如果人類主要同意該模型,則矢量模型是好的。該食譜只會詢問具有相同意義的向量,並支持不同的示例選擇策略。
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| 爭論 | 類型 | 描述 |
|---|---|---|
dataset | 位置 | 數據集以將註釋保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途徑。 |
--strategy , -st | 選項 | 示例選擇策略。 most similar (默認)或random 。 |
--senses , -s | 選項 | 逗號分隔的感官列表將選擇限制為。如果未設置,將使用向量中的所有感官。 |
--exclude-senses , -es | 選項 | 逗號分隔的感覺清單排除在外。參見prodigy_recipes.EVAL_EXCLUDE_SENSES從默認值中。 |
--n-freq , -f | 選項 | 限制最常見的條目的數量。 |
--threshold , -t | 選項 | 最小相似性閾值以考慮示例。 |
--batch-size , -b | 選項 | 批次大小要使用。 |
--eval-whole , -E | 旗幟 | 評估整個數據集而不是當前會話。 |
--eval-only , -O | 旗幟 | 不要註釋,只評估當前數據集。 |
--show-scores , -S | 旗幟 | 顯示所有調試分數。 |
| 姓名 | 描述 |
|---|---|
most_similar | 從隨機意義上選擇一個隨機單詞,並獲得相同含義的最相似條目。詢問與該選擇的最後一個和中間條目的相似性。 |
most_least_similar | 從隨機意義上選擇一個隨機單詞,並從其最相似的條目中獲得最小的輸入,然後是最後一個最相似的條目。 |
random | 從相同的隨機意義中選擇3個單詞的隨機樣本。 |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5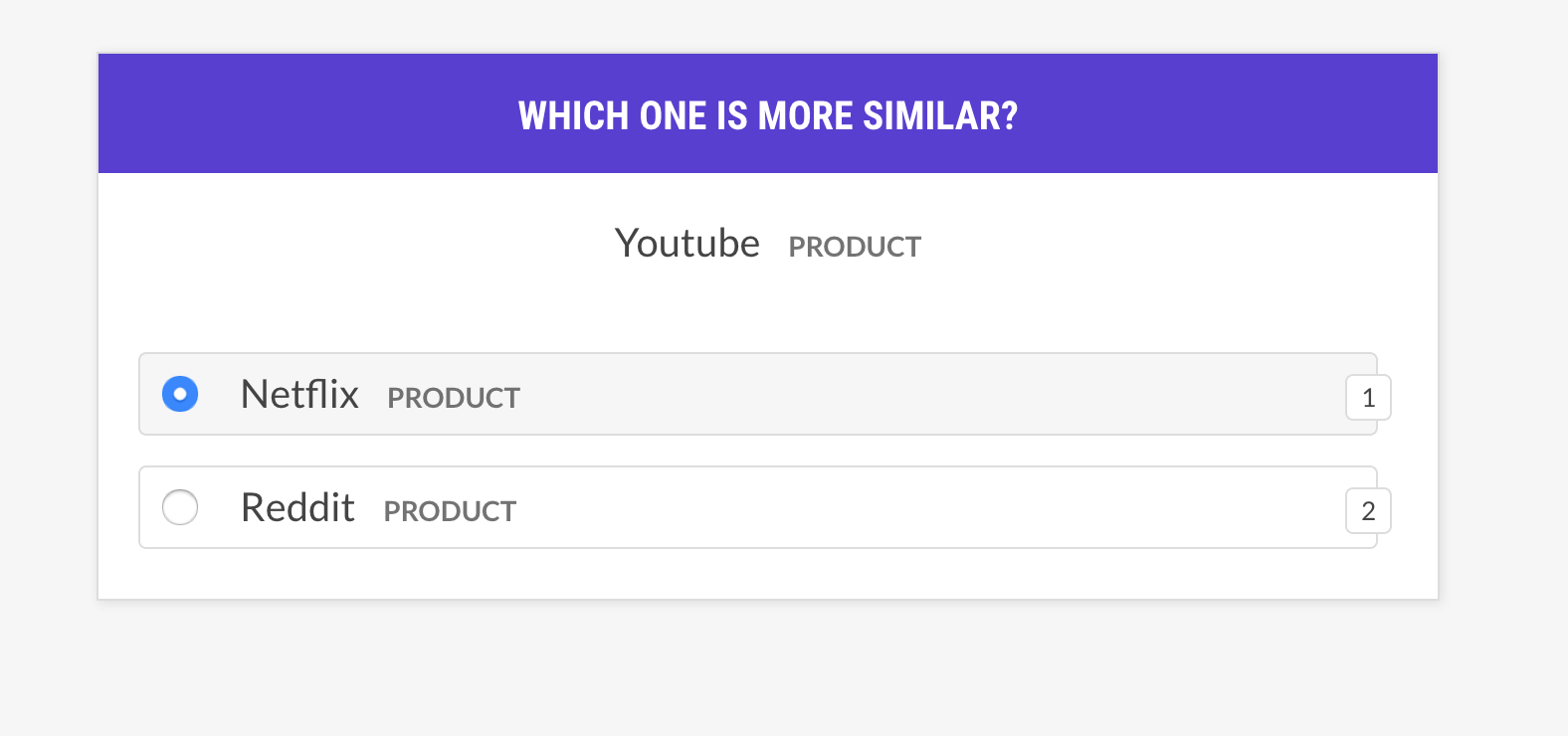
sense2vec.eval-most-similar通過查看最相似的條目來評估矢量模型,它返回的隨機短語並取消了錯誤。
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| 爭論 | 類型 | 描述 |
|---|---|---|
dataset | 位置 | 數據集以將註釋保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途徑。 |
--senses , -s | 選項 | 逗號分隔的感官列表將選擇限制為。如果未設置,將使用向量中的所有感官。 |
--exclude-senses , -es | 選項 | 逗號分隔的感覺清單排除在外。參見prodigy_recipes.EVAL_EXCLUDE_SENSES從默認值中。 |
--n-freq , -f | 選項 | 限制最常見的條目的數量。 |
--n-similar , -n | 選項 | 相似的項目數量。默認為10 。 |
--batch-size , -b | 選項 | 批次大小要使用。 |
--eval-whole , -E | 旗幟 | 評估整個數據集而不是當前會話。 |
--eval-only , -O | 旗幟 | 不要註釋,只評估當前數據集。 |
--show-scores , -S | 旗幟 | 顯示所有調試分數。 |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-ab通過比較它們返回的隨機短語的最相似條目,對兩個預驗證的Sense2Vec矢量模型進行A/B評估。 UI顯示了兩個隨機選項,每個模型中最相似的條目,並突出顯示不同的短語。在註釋會話結束時,顯示了整體統計數據和首選模型。
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| 爭論 | 類型 | 描述 |
|---|---|---|
dataset | 位置 | 數據集以將註釋保存到。 |
vectors_path_a | 位置 | 通知的Sense2Vec向量的途徑。 |
vectors_path_b | 位置 | 通知的Sense2Vec向量的途徑。 |
--senses , -s | 選項 | 逗號分隔的感官列表將選擇限制為。如果未設置,將使用向量中的所有感官。 |
--exclude-senses , -es | 選項 | 逗號分隔的感覺清單排除在外。參見prodigy_recipes.EVAL_EXCLUDE_SENSES從默認值中。 |
--n-freq , -f | 選項 | 限制最常見的條目的數量。 |
--n-similar , -n | 選項 | 相似的項目數量。默認為10 。 |
--batch-size , -b | 選項 | 批次大小要使用。 |
--eval-whole , -E | 旗幟 | 評估整個數據集而不是當前會話。 |
--eval-only , -O | 旗幟 | 不要註釋,只評估當前數據集。 |
--show-mapping , -S | 旗幟 | 在UI中顯示哪些型號是選項1和選項2(用於調試)。 |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT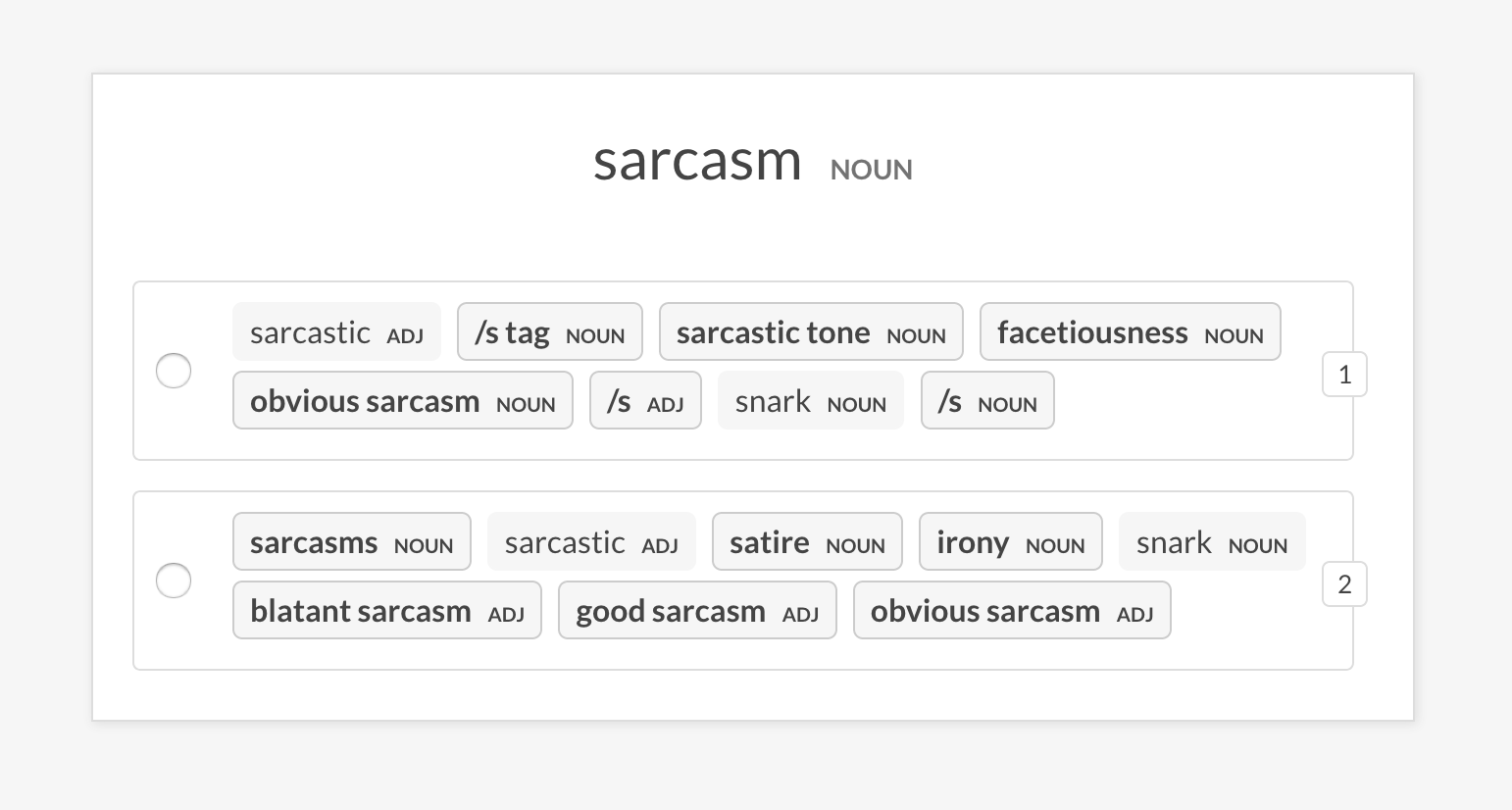
預處理的Reddit矢量支持以下“感官”,無論是詞性的標籤還是實體標籤。有關更多詳細信息,請參見Spacy的註釋方案概述。
| 標籤 | 描述 | 例子 |
|---|---|---|
ADJ | 形容詞 | 大,古老,綠色 |
ADP | 定位 | 在,期間 |
ADV | 副詞 | 非常明天,下來,哪裡 |
AUX | 輔助的 | 是(完成),將(做) |
CONJ | 連詞 | 還有,或者,但是 |
DET | 確定器 | a,an, |
INTJ | 欹 | psst,ouch,bravo,你好 |
NOUN | 名詞 | 女孩,貓,樹,空氣,美麗 |
NUM | 數字 | 1,2017,1,七十七,mmxiv |
PART | 粒子 | 的,不是 |
PRON | 代詞 | 我,你,他,她,我自己,一個人 |
PROPN | 專有名詞 | 瑪麗,約翰,倫敦,北約,HBO |
PUNCT | 標點 | ,? () |
SCONJ | 從屬連詞 | 如果那個 |
SYM | 象徵 | $,%,=,:),? |
VERB | 動詞 | 跑步,跑步,跑步,吃,吃,吃飯 |
| 實體標籤 | 描述 |
|---|---|
PERSON | 人們,包括虛構的人。 |
NORP | 國籍或宗教或政治團體。 |
FACILITY | 建築物,機場,公路,橋樑等 |
ORG | 公司,機構,機構等 |
GPE | 國家,城市,國家。 |
LOC | 非GPE地點,山脈,水體。 |
PRODUCT | 物體,車輛,食物等(不是服務)。 |
EVENT | 命名為颶風,戰鬥,戰爭,體育賽事等。 |
WORK_OF_ART | 書籍,歌曲等的標題。 |
LANGUAGE | 任何命名語言。 |


