sense2vec
v2.0.2
Sense2Vec (Trask et al, 2015)는 더 흥미롭고 상세한 단어 벡터를 배울 수있는 Word2Vec의 멋진 트위스트입니다. 이 라이브러리는 Sense2VEC 모델로드, 쿼리 및 교육을위한 간단한 파이썬 구현입니다. 자세한 내용은 블로그 게시물을 확인하십시오. 2015 년과 2019 년의 모든 Reddit 의견에서 시맨틱 유사성을 탐색하려면 대화식 데모를 참조하십시오.
? 버전 2.0 (Spacy v3 용) 지금! 여기에서 릴리스 노트를 읽으십시오.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
켈 이 예제는 Spacy v3의 사용법을 설명합니다. Spacy v2를 사용하려면sense2vec==1.0.3다운로드 하고이 repo의v1.x지점을 확인하십시오.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]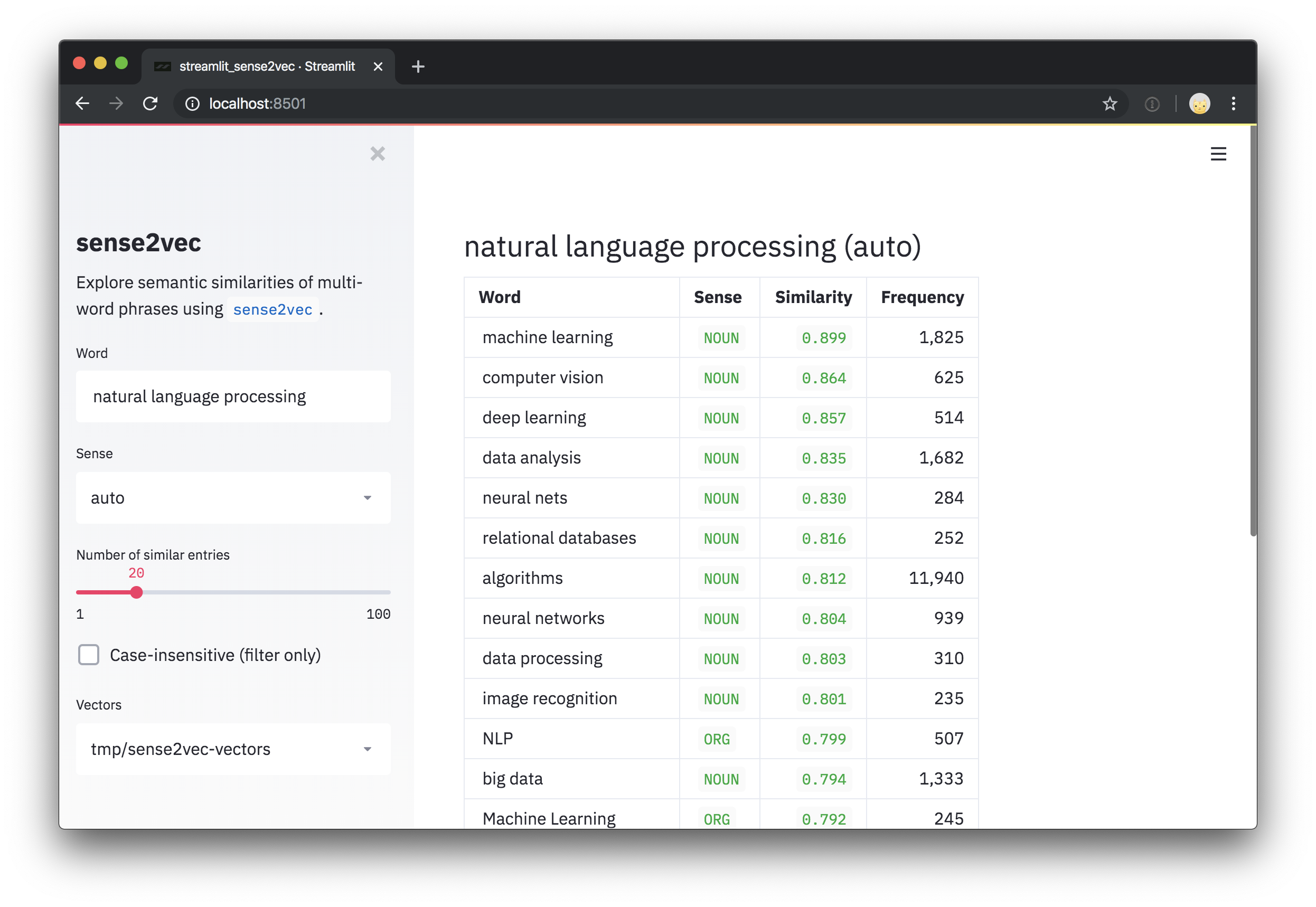
Reddit 주석에 대해 훈련 된 사전 취사 벡터를 시험해 보려면 Interactive Sense2Vec 데모를 확인하십시오.
이 repo에는 벡터를 탐색하기위한 간단한 데모 스크립트와 가장 유사한 문구도 포함되어 있습니다. streamlit 설치 한 후에는 streamlit run 사용하여 스크립트를 실행할 수 있으며 명령 줄의 위치 인수 로 사전에 사전 처리 된 벡터로의 하나 이상의 경로를 실행할 수 있습니다. 예를 들어:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors 벡터를 사용하려면 아카이브를 다운로드하고 추출 된 디렉토리를 Sense2Vec.from_disk 또는 Sense2VecComponent.from_disk 로 전달하십시오. 벡터 파일은 Github 릴리스에 연결 됩니다. 대형 파일은 다중 부분 다운로드로 분할되었습니다.
| 벡터 | 크기 | 설명 | ? 다운로드 (ZIPPER) |
|---|---|---|---|
s2v_reddit_2019_lg | 4GB | Reddit Comments 2019 (01-07) | 1 부, 2 부, 3 부 |
s2v_reddit_2015_md | 573MB | Reddit 의견 2015 | 1 부 |
멀티 파트 아카이브를 병합하려면 다음을 실행할 수 있습니다.
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzSENSE2VEC 릴리스는 PIP에서 사용할 수 있습니다.
pip install sense2vec 사전 처리 된 벡터를 사용하려면 벡터 패키지 중 하나를 다운로드하고 .tar.gz 아카이브를 풀고 추출 된 데이터 디렉토리로 from_disk 포인트를 포장하십시오.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) 라이브러리와 벡터를 사용하는 가장 쉬운 방법은 Spacy 파이프 라인에 연결하는 것입니다. sense2vec 패키지는 Sense2VecComponent 노출시켜 공유 어휘로 초기화하고 사용자 지정 파이프 라인 구성 요소로 스파이 파이프 라인에 추가 할 수 있습니다. 기본적으로 구성 요소는 파이프 라인의 끝에 추가됩니다.이 구성 요소의 권장 위치는 종속성 구문 분석 및 사용 가능한 경우 엔티티의 이름을 지정해야 하므로이 구성 요소의 권장 위치입니다.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) 구성 요소는 벡터와 주파수를 검색 할 수있는 벡터와 주파수를 검색 할 수있는 객체의 Token 및 Span 객체에 여러 확장 속성과 메소드를 추가합니다.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )엔터티의 경우 엔티티 레이블은 "토큰의 부상 태그 대신에"감지 "로 사용됩니다.
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) 다음 확장 속성은 ._ 속성을 통해 Doc 객체에 노출됩니다.
| 이름 | 속성 유형 | 유형 | 설명 |
|---|---|---|---|
s2v_phrases | 재산 | 목록 | 주어진 Doc 의 모든 sense2Vec 호환 문구 (명사 문구, 명명 된 엔티티). |
다음 속성은 Token 및 Span 객체의 ._ 속성을 통해 사용할 수 있습니다 (예 : token._.in_s2v :
| 이름 | 속성 유형 | 반환 유형 | 설명 | | ---------------- | ------------- | ---------------- | --------------------------------------------------------------------------- | --------------- | ------- | | in_s2v | 속성 | 부 | 벡터 맵에 키가 존재하는지 여부. | | s2v_key | 속성 | 유니 코드 | 주어진 객체의 Sense2Vec 키, 예를 들어 "duck | NOUN" . | | s2v_vec | 속성 | ndarray[float32] | 주어진 키의 벡터. | | s2v_freq | 속성 | int | 주어진 키의 빈도. | | s2v_other_senses | 속성 | 목록 | "duck | VERB" "duck | NOUN" , 예를 들어 다른 감각을 이용할 수 있습니다. | | s2v_most_similar | 방법 | 목록 | 가장 유사한 n 얻으십시오. ((word, sense), score) 튜플 목록을 반환합니다. | | s2v_similarity | 방법 | 플로트 | 다른 Token 이나 Span 과 유사하게 유사합니다. |
켈 스팬 속성에 대한 메모 : 후드 아래에서doc.ents의 엔티티는Span객체입니다. 그렇기 때문에 파이프 라인 구성 요소가 토큰뿐만 아니라 스팬에 속성과 방법을 추가하는 이유입니다. 그러나 모델에 각 텍스트의 키가 없을 가능성이 있기 때문에 문서의 임의의 슬라이스에 Sense2Vec 속성을 사용하는 것이 좋습니다.Span객체에는 또한 말하기 태그가 없으므로 엔티티 레이블이없는 경우 "Sense"기본값은 루트의 부품 태그에 기본적으로 표시됩니다.
Spacy 파이프 라인을 교육하고 포장하고 Sense2VEC 구성 요소를 포함하려면 교육 구성의 [initialize] 블록을 통해 데이터를로드 할 수 있습니다.
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " 또한 기본 Sense2Vec 클래스를 직접 사용하고 from_disk 메소드를 사용하여 벡터에로드 할 수도 있습니다. 사용 가능한 API 방법은 아래를 참조하십시오.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
켈 중요 참고 : 벡터 테이블에서 항목을 찾으려면 키는phrase_text|SENSE(공백 대신_를 참고 및 태그 또는 레이블 이전의|machine_learning|NOUN)를 따라야합니다. 또한 기본 벡터 테이블은 대소 문자에 민감합니다.
Sense2Vec 벡터, 문자열 및 주파수를 보유하는 독립형 Sense2Vec 객체.
Sense2Vec.__init__ Sense2Vec 객체를 초기화하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
shape | 튜플 | 벡터 모양. 기본값 (1000, 128) . |
strings | spacy.strings.StringStore | 선택적 문자열 저장소. 존재하지 않으면 생성됩니다. |
senses | 목록 | 사용 가능한 모든 감각의 선택적 목록. 최상의 의미 또는 기타 감각을 생성하는 방법에 사용됩니다. |
vectors_name | 유니 코드 | 충돌을 방지하기 위해 Vectors 테이블에 할당 할 선택 이름. "sense2vec" 에 대한 기본값. |
overrides | DITT | 사용할 선택적 사용자 정의 기능, 레지스트리를 통해 등록 된 이름에 매핑됩니다 (예 {"make_key": "custom_make_key"} . |
| 보고 | Sense2Vec | 새로 구성된 물체. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__벡터 테이블의 행 수.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 보고 | int | 벡터 테이블의 행 수. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__키가 벡터 테이블에 있는지 확인하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 찾는 열쇠. |
| 보고 | 부 | 키가 테이블에 있는지 여부. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__주어진 키에 대한 벡터를 검색하십시오. 키가 테이블에없는 경우 아무것도 반환합니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 찾는 열쇠. |
| 보고 | numpy.ndarray | 벡터 또는 None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ 주어진 키에 대한 벡터를 설정하십시오. 키가 존재하지 않으면 오류가 발생합니다. 새 항목을 추가하려면 Sense2Vec.add 사용하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 열쇠. |
vector | numpy.ndarray | 설정할 벡터. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.add테이블에 새 벡터를 추가하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 추가 할 키. |
vector | numpy.ndarray | 추가 할 벡터. |
freq | int | 선택적 주파수 수. 가장 잘 어울리는 감각을 찾는 데 사용됩니다. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freq주어진 키의 주파수 수를 얻으십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 찾는 열쇠. |
default | - | 주파수가없는 경우 반환 할 기본값. |
| 보고 | int | 주파수 수. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freq주어진 키에 대한 주파수 수를 설정하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 카운트를 설정하는 열쇠. |
freq | int | 주파수 수. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.items벡터 테이블의 항목을 반복하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 수율 | 튜플 | 테이블의 문자열 키 및 벡터 쌍. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keys테이블의 키를 반복하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 수율 | 유니 코드 | 테이블의 문자열 키. |
all_keys = list ( s2v . keys ())Sense2Vec.values테이블의 벡터를 반복하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 수율 | numpy.ndarray | 테이블의 벡터. |
all_vecs = list ( s2v . values ())Sense2Vec.senses 표에서 사용 가능한 감각 (예 : "NOUN" 또는 "VERB" (초기화시 추가).
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 보고 | 목록 | 사용 가능한 감각. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequencies테이블의 키 주파수, 내림차순 순서.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 보고 | 목록 | (key, freq) 튜플은 주파수로 내려갑니다. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarity두 키 또는 두 개의 키 세트의 의미 론적 유사성 추정치를 만듭니다. 기본 추정치는 평균 벡터를 사용하여 코사인 유사성입니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
keys_a | 유니 코드 / int / 반복 가능 | 문자열 또는 정수 키. |
keys_b | 유니 코드 / int / 반복 가능 | 다른 문자열 또는 정수 키. |
| 보고 | 뜨다 | 유사성 점수. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similar테이블에서 가장 유사한 항목을 얻으십시오. 둘 이상의 키가 제공되면 벡터의 평균이 사용됩니다. 이 방법을 더 빨리 만들려면 가장 가까운 이웃의 캐시를 미리 컴퓨팅하려면 스크립트를 참조하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
keys | 유니 코드 / int / 반복 가능 | 비교할 문자열 또는 정수 키. |
n | int | 반환 할 비슷한 키의 수. 기본값은 10 까지. |
batch_size | int | 사용할 배치 크기. 기본값 16 . |
| 보고 | 목록 | 가장 유사한 벡터의 (key, score) 튜플. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses "duck|VERB" 에 대한 "duck|NOUN" 같은 다른 의미로 같은 단어에 대한 다른 항목을 찾으십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
key | 유니 코드 / int | 확인하는 열쇠. |
ignore_case | 부 | 대문자, 소문자 및 Titlecase를 확인하십시오. 기본값은 True . |
| 보고 | 목록 | 다른 감각을 가진 다른 항목의 문자열 키. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense 사용 가능한 감각과 빈도 수를 기반으로 주어진 단어에 대한 가장 좋은 일치 의미를 찾으십시오. 일치가 없으면 None 반환하지 않습니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
word | 유니 코드 | 확인해야 할 단어. |
senses | 목록 | 검색을 제한 할 감각 목록. 설정 / 비어 있지 않으면 벡터의 모든 감각이 사용됩니다. |
ignore_case | 부 | 대문자, 소문자 및 Titlecase를 확인하십시오. 기본값은 True . |
| 보고 | 유니 코드 | 최고의 일치 키 또는 없음. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Sense2Vec 객체를 바이 테스트로 직렬화하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
exclude | 목록 | 제외 할 직렬화 필드의 이름. |
| 보고 | 바이트 | 직렬화 된 Sense2Vec 객체. |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Bytestring에서 Sense2Vec 객체를로드하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
bytes_data | 바이트 | 로드 할 데이터. |
exclude | 목록 | 제외 할 직렬화 필드의 이름. |
| 보고 | Sense2Vec | 로드 된 물체. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Sense2Vec 객체를 디렉토리로 직렬화하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
path | 유니 코드 / Path | 길. |
exclude | 목록 | 제외 할 직렬화 필드의 이름. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk 디렉토리에서 Sense2Vec 객체를로드하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
path | 유니 코드 / Path | 로드하는 길 |
exclude | 목록 | 제외 할 직렬화 필드의 이름. |
| 보고 | Sense2Vec | 로드 된 물체. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponent파이프 라인 구성 요소는 Sness2Vec를 스파이 파이프 라인에 추가합니다.
Sense2VecComponent.__init__파이프 라인 구성 요소를 초기화하십시오.
| 논쟁 | 유형 | 설명 |
|---|---|---|
vocab | Vocab | 공유 Vocab . 주로 공유 StringStore 에 사용됩니다. |
shape | 튜플 | 벡터 모양. |
merge_phrases | 부 | Sense2Vec 문구를 하나의 토큰으로 병합할지 여부. 기본값으로 False . |
lemmatize | 부 | 벡터에서 사용할 수있는 경우 항상 Lemmas를 찾아보십시오. 기본값으로 False . |
overrides | 레지스트리를 통해 등록 된 이름에 매핑 된 선택적 사용자 정의 함수 (예 {"make_key": "custom_make_key"} . | |
| 보고 | Sense2VecComponent | 새로 구성된 물체. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp NLP 객체에서 구성 요소를 초기화하십시오. 입구 포인트의 구성 요소 공장 (Setup.cfg 참조) 및 @spacy.component decorator를 통해 자동 등록에 주로 사용됩니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
nlp | Language | nlp 객체. |
**cfg | - | 선택적 구성 매개 변수. |
| 보고 | Sense2VecComponent | 새로 구성된 물체. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ 구성 요소로 Doc 객체를 처리하십시오. 일반적으로 스파이 파이프 라인의 일부로 만 호출되며 직접적으로는 아닙니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
doc | Doc | 처리 할 문서. |
| 보고 | Doc | 처리 된 문서. |
Sense2Vec.init_component구성 요소 별 확장 속성을 여기에 등록하고 구성 요소가 파이프 라인에 추가되어 사용 된 경우에만 등록하십시오. 그렇지 않으면 토큰은 구성 요소 만 생성되어 추가되지 않더라도 속성을 얻게됩니다.
Sense2VecComponent.to_bytes 구성 요소를 바이 테스트로 직렬화하십시오. 구성 요소가 파이프 라인에 추가되고 nlp.to_bytes 실행할 때도 호출됩니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
| 보고 | 바이트 | 직렬화 된 구성 요소. |
Sense2VecComponent.from_bytes 바이 테스트에서 구성 요소를로드하십시오. nlp.from_bytes 실행할 때도 호출됩니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
bytes_data | 바이트 | 로드 할 데이터. |
| 보고 | Sense2VecComponent | 로드 된 물체. |
Sense2VecComponent.to_disk 구성 요소를 디렉토리로 직렬화하십시오. 구성 요소가 파이프 라인에 추가되고 nlp.to_disk 실행할 때도 호출됩니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
path | 유니 코드 / Path | 길. |
Sense2VecComponent.from_disk 디렉토리에서 Sense2Vec 객체를로드하십시오. nlp.from_disk 실행할 때도 호출됩니다.
| 논쟁 | 유형 | 설명 |
|---|---|---|
path | 유니 코드 / Path | 로드하는 길 |
| 보고 | Sense2VecComponent | 로드 된 물체. |
registry 기능 레지스트리 ( catalogue 로 구동) 키와 문구를 생성하는 데 사용되는 기능을 쉽게 사용자 정의합니다. 사용자 정의 기능을 장식하고 이름을 지정하고 모델을 저장할 때 사용자 정의 기능을 교체하고 사용자 정의 이름을 직렬화 할 수 있습니다. 다음 레지스트리 옵션을 사용할 수 있습니다.
| 이름 | 설명 | | --------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | | registry.make_key | word 와 sense 주어지면 "word | sense". | | registry.split_key | 문자열 키가 주어지면 A (word, sense) 튜플을 반환하십시오. | | registry.make_spacy_key | 스파크 객체 ( Token 또는 Span )와 부울 prefer_ents 키워드 인수 (단일 토큰의 엔티티 레이블을 선호할지 여부)를 주어지면 A (word, sense) 튜플을 반환하십시오. 확장 속성에 사용되어 토큰 및 스팬의 키를 생성합니다. | | | registry.get_phrases | Spacy Doc 이 주어지면 Sense2Vec 문구 (일반적으로 명사 문구 및 명명 된 엔티티)에 사용되는 Span 객체 목록을 반환하십시오. | | registry.merge_phrases | Spacy Doc 주어지면 모든 Sense2Vec 문구를 가져 와서 단일 토큰으로 통합하십시오. |
각 레지스트리에는 기능 데코레이터로 사용할 수있는 register 메소드가 있으며 사용자 정의 기능의 이름 인 하나의 인수를 취합니다.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Sense2Vec 객체를 초기화 할 때 이제 사용자 정의 등록 기능의 이름으로 재정의 사전을 전달할 수 있습니다.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )이를 통해 다양한 전략을 실험하고 전략을 평범한 문자열로 직렬화 할 수 있습니다 (기능 자체를 전달하거나/또는 피클하는 대신).
/scripts 디렉토리에는 텍스트를 전처리하고 자신의 벡터를 훈련하기위한 명령 줄 유틸리티가 포함되어 있습니다.
자신의 Sense2Vec 벡터를 훈련하려면 다음이 필요합니다.
doc.noun_chunks 채우는 사전 배치 된 스파이 모델. 필요한 언어가 명사구에 내장 된 구문 반복기를 제공하지 않으면 직접 작성해야합니다. ( doc.noun_chunks 및 doc.ents Sense2VEC가 문구를 결정하는 데 사용하는 것입니다.)make 실행할 수 있어야합니다. 훈련 과정은 주어진 지점에서 재개 할 수 있도록 여러 단계로 나뉩니다. 처리 스크립트는 단일 파일에서 작동하도록 설계되어 작업을 쉽게 평행 할 수 있습니다. 이 repo의 스크립트에는 클론하고 make 위해 필요한 장갑이나 빠른 텍스트가 필요합니다.
FastText의 경우 스크립트에는 생성 된 이진 파일의 경로가 필요합니다. Windows에서 작업하는 경우 cmake 로 빌드하거나 Windows 용 FastText Binary Builds (https://github.com/xiamx/fasttext/releases)와 함께이 비공식 리포의 .exe 파일을 사용할 수 있습니다.
| 스크립트 | 설명 | |
|---|---|---|
| 1. | 01_parse.py | Spacy를 사용하여 Doc 객체의 원시 텍스트 및 출력 바이너리 컬렉션을 구문 분석하십시오 ( DocBin 참조). |
| 2. | 02_preprocess.py | 이전 단계에서 생성 된 구문 분석 된 Doc 객체 모음을로드하고 Sense2Vec 형식으로 출력 텍스트 파일을 선별로로드하십시오 (줄 당 한 문장 및 Senses와 병합 된 문구). |
| 3. | 03_glove_build_counts.py | 장갑을 사용하여 어휘와 계산을 구축하십시오. FastText를 통해 Word2Vec을 사용하는 경우이 단계를 건너 뜁니다. |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | 장갑이나 빠른 텍스트를 사용하여 벡터를 훈련하십시오. |
| 5. | 05_export.py | 벡터와 주파수를로드하고 Sense2Vec.from_disk 통해로드 할 수있는 Sense2Vec 구성 요소를 출력하십시오. |
| 6. | 06_precompute_cache.py | 선택 사항 : 어휘의 모든 항목에 대해 가장 가까운 이웃 쿼리를 전달하여 Sense2Vec.most_similar 더 빨리 만들 수 있습니다. |
스크립트에 대한 자세한 내용을 보려면 소스를 확인하거나 --help 로 실행하십시오. 예를 들어, python scripts/01_parse.py --help .
이 패키지는 또한 Prodigy 주석 도구와 완벽하게 통합되며 Sense2Vec 벡터를 사용하여 다중 단어 문구의 목록 및 부트 스트랩 NER 주석을 신속하게 생성하는 레시피를 노출시킵니다. 레시피를 사용하려면 sense2vec Prodigy와 동일한 환경에 설치해야합니다. 실제 유스 케이스의 예는 다운로드 가능한 데이터 세트가있는이 NER 프로젝트를 확인하십시오.
다음 레시피를 사용할 수 있습니다. 자세한 내용은 아래를 참조하십시오.
| 레시피 | 설명 |
|---|---|
sense2vec.teach | Sense2Vec을 사용하여 용어 목록을 부트 스트랩합니다. |
sense2vec.to-patterns | 문구 데이터 세트를 토큰 기반 매치 패턴으로 변환하십시오. |
sense2vec.eval | 구절 트리플에 대해 묻어 Sense2Vec 모델을 평가하십시오. |
sense2vec.eval-most-similar | 가장 유사한 항목을 수정하여 Sense2VEC 모델을 평가하십시오. |
sense2vec.eval-ab | 두 개의 사전 여분의 Sense2Vec 벡터 모델에 대한 A/B 평가를 수행하십시오. |
sense2vec.teachSense2Vec을 사용하여 용어 목록을 부트 스트랩합니다. Prodigy는 Sense2Vec의 가장 유사한 문구를 기반으로 비슷한 용어를 제안하며, 유사한 문구를 주석을 달고 받아 들여 제안은 조정됩니다. 각 종자 항에 대해 Sense2Vec 벡터에 따른 가장 일치하는 의미가 사용됩니다.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| 논쟁 | 유형 | 설명 |
|---|---|---|
dataset | 위치 | 주석을 저장하기위한 데이터 세트. |
vectors_path | 위치 | 사전에 미리 감각 2vec 벡터로가는 경로. |
--seeds , -s | 옵션 | 하나 이상의 쉼표로 구분 된 시드 문구. |
--threshold , -t | 옵션 | 유사성 임계 값. 기본값은 0.85 입니다. |
--n-similar , -n | 옵션 | 한 번에 유사한 항목의 수. |
--batch-size , -b | 옵션 | 주석을 제출하기위한 배치 크기. |
--resume , -R | 깃발 | 기존 문구 데이터 세트에서 재개하십시오. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns sense2vec.teach 로 수집 된 문구 데이터 세트를 Spacy의 EntityRuler 또는 ner.match 와 같은 레시피와 함께 사용할 수있는 토큰 기반 일치 패턴으로 변환하십시오. 출력 파일이 지정되지 않으면 패턴이 stdout에 기록됩니다. 예제는 다중 점관 용어가 올바르게 표시되도록 토큰 화됩니다 : {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| 논쟁 | 유형 | 설명 |
|---|---|---|
dataset | 위치 | 변환 할 문구 데이터 세트. |
spacy_model | 위치 | 토큰 화를위한 스파크 모델. |
label | 위치 | 모든 패턴에 적용 할 레이블. |
--output-file , -o | 옵션 | 선택적 출력 파일. 기본값으로 stdout. |
--case-sensitive -CS | 깃발 | 패턴을 케이스에 민감하게 만듭니다. |
--dry , -D | 깃발 | 드라이 런을 수행하고 출력하지 마십시오. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.eval구절 트리플에 대해 묻어 Sense2VEC 모델을 평가하십시오. 단어 A가 단어 B 또는 Word C와 더 유사합니까? 인간이 대부분 모델에 동의하면 벡터 모델이 좋습니다. 레시피는 동일한 의미의 벡터에 대해서만 묻고 다른 예제 선택 전략을 지원합니다.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| 논쟁 | 유형 | 설명 |
|---|---|---|
dataset | 위치 | 주석을 저장하기위한 데이터 세트. |
vectors_path | 위치 | 사전에 미리 감각 2vec 벡터로가는 경로. |
--strategy , -st | 옵션 | 예제 선택 전략. most similar (기본값) 또는 random . |
--senses , -s | 옵션 | 선택을 제한하기위한 쉼표로 구분 된 감각 목록. 설정하지 않으면 벡터의 모든 감각이 사용됩니다. |
--exclude-senses , -es | 옵션 | 쉼표로 구분 된 감각 목록. 기본값이있는 prodigy_recipes.EVAL_EXCLUDE_SENSES 참조하십시오. |
--n-freq , -f | 옵션 | 제한 할 가장 빈번한 항목의 수. |
--threshold , -t | 옵션 | 예제를 고려하기위한 최소 유사성 임계 값. |
--batch-size , -b | 옵션 | 사용할 배치 크기. |
--eval-whole , -E | 깃발 | 현재 세션 대신 전체 데이터 세트를 평가하십시오. |
--eval-only , -O | 깃발 | 주석을 달지 말고 현재 데이터 세트 만 평가하십시오. |
--show-scores , -S | 깃발 | 디버깅에 대한 모든 점수를 표시하십시오. |
| 이름 | 설명 |
|---|---|
most_similar | 임의의 의미에서 임의의 단어를 선택하고 같은 의미의 가장 유사한 항목을 얻으십시오. 그 선택에서 마지막 및 중간 항목과 유사성에 대해 물어보십시오. |
most_least_similar | 임의의 의미에서 임의의 단어를 선택하고 가장 유사한 항목에서 가장 유사한 항목을 얻은 다음 마지막으로 가장 유사한 항목을 얻으십시오. |
random | 동일한 임의의 의미에서 3 단어의 무작위 샘플을 선택하십시오. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5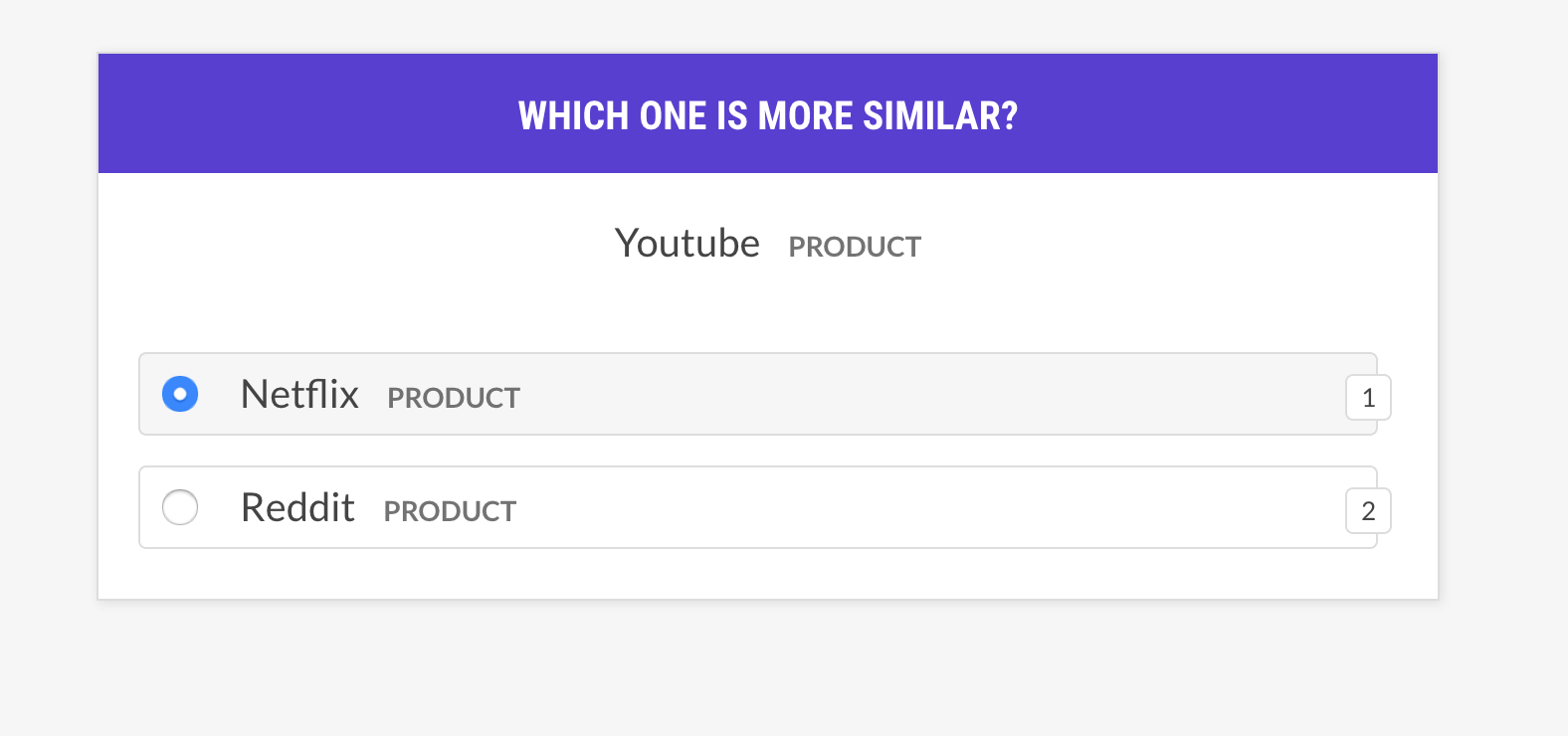
sense2vec.eval-most-similar임의의 문구에 대해 반환하는 가장 유사한 항목을보고 실수를 선택하지 않음으로써 벡터 모델을 평가하십시오.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| 논쟁 | 유형 | 설명 |
|---|---|---|
dataset | 위치 | 주석을 저장하기위한 데이터 세트. |
vectors_path | 위치 | 사전에 미리 감각 2vec 벡터로가는 경로. |
--senses , -s | 옵션 | 선택을 제한하기위한 쉼표로 구분 된 감각 목록. 설정하지 않으면 벡터의 모든 감각이 사용됩니다. |
--exclude-senses , -es | 옵션 | 쉼표로 구분 된 감각 목록. 기본값이있는 prodigy_recipes.EVAL_EXCLUDE_SENSES 참조하십시오. |
--n-freq , -f | 옵션 | 제한 할 가장 빈번한 항목의 수. |
--n-similar , -n | 옵션 | 확인할 유사한 항목 수. 기본값은 10 까지. |
--batch-size , -b | 옵션 | 사용할 배치 크기. |
--eval-whole , -E | 깃발 | 현재 세션 대신 전체 데이터 세트를 평가하십시오. |
--eval-only , -O | 깃발 | 주석을 달지 말고 현재 데이터 세트 만 평가하십시오. |
--show-scores , -S | 깃발 | 디버깅에 대한 모든 점수를 표시하십시오. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-ab임의의 문구에 대해 반환하는 가장 유사한 항목을 비교하여 두 개의 사전 여지가있는 Sense2Vec 벡터 모델의 A/B 평가를 수행하십시오. UI는 각 모델의 가장 유사한 항목을 갖춘 두 가지 무작위 옵션을 보여주고 다른 문구를 강조합니다. 주석 세션이 끝나면 전체 통계 및 선호 모델이 표시됩니다.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| 논쟁 | 유형 | 설명 |
|---|---|---|
dataset | 위치 | 주석을 저장하기위한 데이터 세트. |
vectors_path_a | 위치 | 사전에 미리 감각 2vec 벡터로가는 경로. |
vectors_path_b | 위치 | 사전에 미리 감각 2vec 벡터로가는 경로. |
--senses , -s | 옵션 | 선택을 제한하기위한 쉼표로 구분 된 감각 목록. 설정하지 않으면 벡터의 모든 감각이 사용됩니다. |
--exclude-senses , -es | 옵션 | 쉼표로 구분 된 감각 목록. 기본값이있는 prodigy_recipes.EVAL_EXCLUDE_SENSES 참조하십시오. |
--n-freq , -f | 옵션 | 제한 할 가장 빈번한 항목의 수. |
--n-similar , -n | 옵션 | 확인할 유사한 항목 수. 기본값은 10 까지. |
--batch-size , -b | 옵션 | 사용할 배치 크기. |
--eval-whole , -E | 깃발 | 현재 세션 대신 전체 데이터 세트를 평가하십시오. |
--eval-only , -O | 깃발 | 주석을 달지 말고 현재 데이터 세트 만 평가하십시오. |
--show-mapping , -S | 깃발 | UI의 옵션 1과 옵션 2 인 모델을 표시하십시오 (디버깅의 경우). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT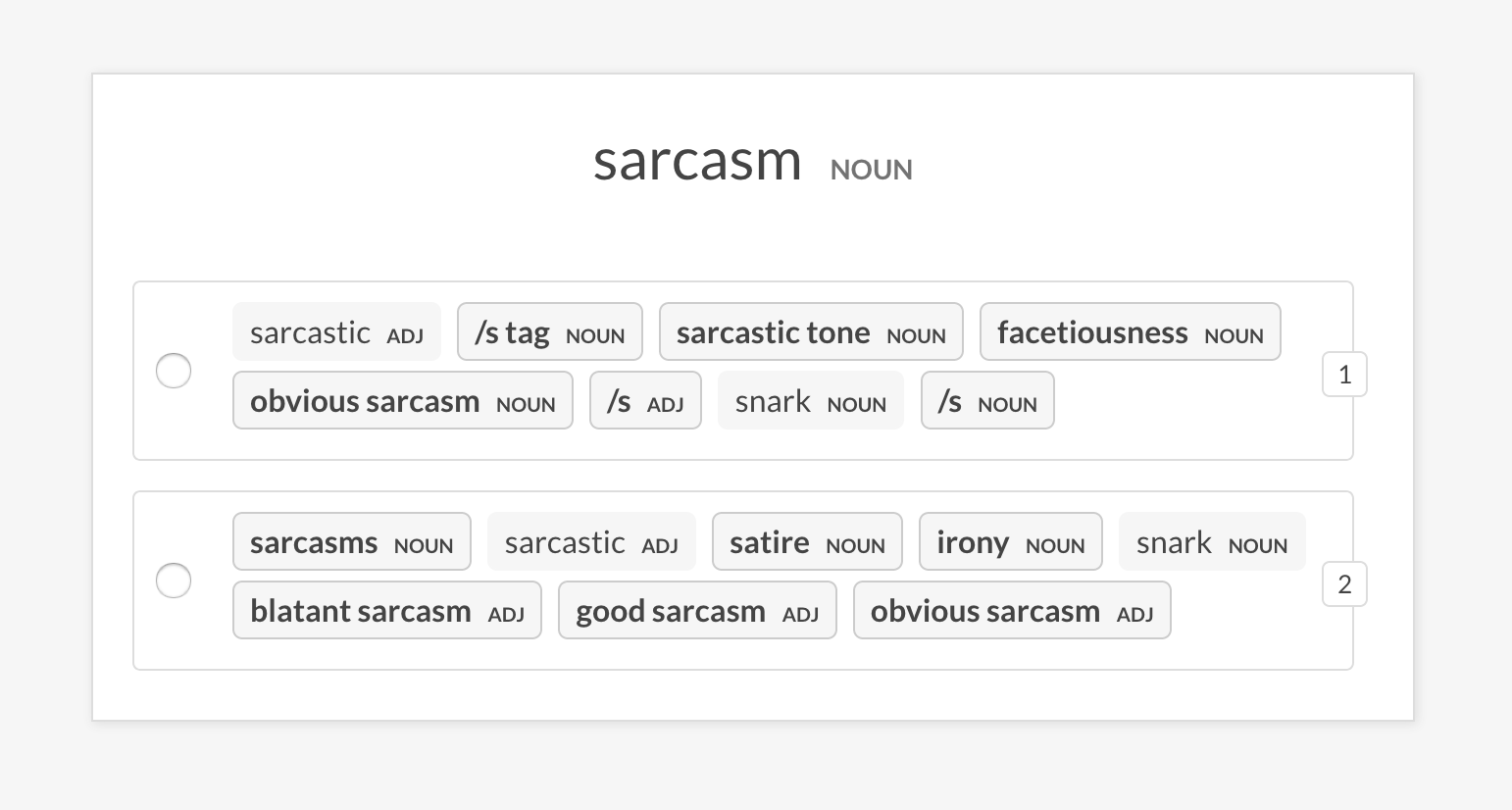
사전 처리 된 Reddit 벡터는 다음과 같은 "감각", 일부 음성 태그 또는 엔터티 레이블을 지원합니다. 자세한 내용은 Spacy의 주석 체계 개요를 참조하십시오.
| 꼬리표 | 설명 | 예 |
|---|---|---|
ADJ | 형용사 | 크고 오래된 녹색 |
ADP | adposition | , |
ADV | 부사 | 아주, 내일, 다운, 어디서 |
AUX | 보조자 | is, has (done), will (do) |
CONJ | 접속사 | 그리고 또는 또는, 그러나 |
DET | 결정자 | a, an, the |
INTJ | 감탄사 | PSST, 아야, 브라보, 안녕하세요 |
NOUN | 명사 | 소녀, 고양이, 나무, 공기, 아름다움 |
NUM | 숫자 | 2017 년 1 월 1 일, 72 세, MMXIV |
PART | 입자 | 아닙니다 |
PRON | 대명사 | 나는 당신, 당신, 그녀, 나 자신, 누군가 |
PROPN | 적절한 명사 | Mary, John, London, NATO, HBO |
PUNCT | 구두 | ,? () |
SCONJ | 종속적 인 결합 | 만약 그렇다면 |
SYM | 상징 | $, %, =, :),? |
VERB | 동사 | 달리기, 달리기, 달리기, 먹고 먹고 먹고 먹는다 |
| 엔티티 레이블 | 설명 |
|---|---|
PERSON | 허구를 포함한 사람들. |
NORP | 국적 또는 종교 또는 정치 그룹. |
FACILITY | 건물, 공항, 고속도로, 교량 등 |
ORG | 회사, 대행사, 기관 등 |
GPE | 국가, 도시, 주. |
LOC | 비 GPE 위치, 산맥, 물 몸체. |
PRODUCT | 물체, 차량, 식품 등 (서비스가 아님) |
EVENT | 허리케인, 전투, 전쟁, 스포츠 이벤트 등이라는 이름. |
WORK_OF_ART | 책, 노래 등의 제목 |
LANGUAGE | 이름이 지정된 언어. |


