sense2vec
v2.0.2
Sense2Vec(Trask等,2015)是Word2Vec的一个不错的转折,使您可以学习更多有趣且详细的单词矢量。该库是用于加载,查询和培训Sense2Vec模型的简单python实现。有关更多详细信息,请查看我们的博客文章。要探讨2015年和2019年所有Reddit评论中的语义相似性,请参见互动演示。
? 2.0版(用于Spacy V3)现在!在此处阅读发行说明。

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
配x 请注意,此示例描述了Spacy V3的用法。对于使用Spacy V2的使用,请下载sense2vec==1.0.3并查看此存储库的v1.x分支。
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]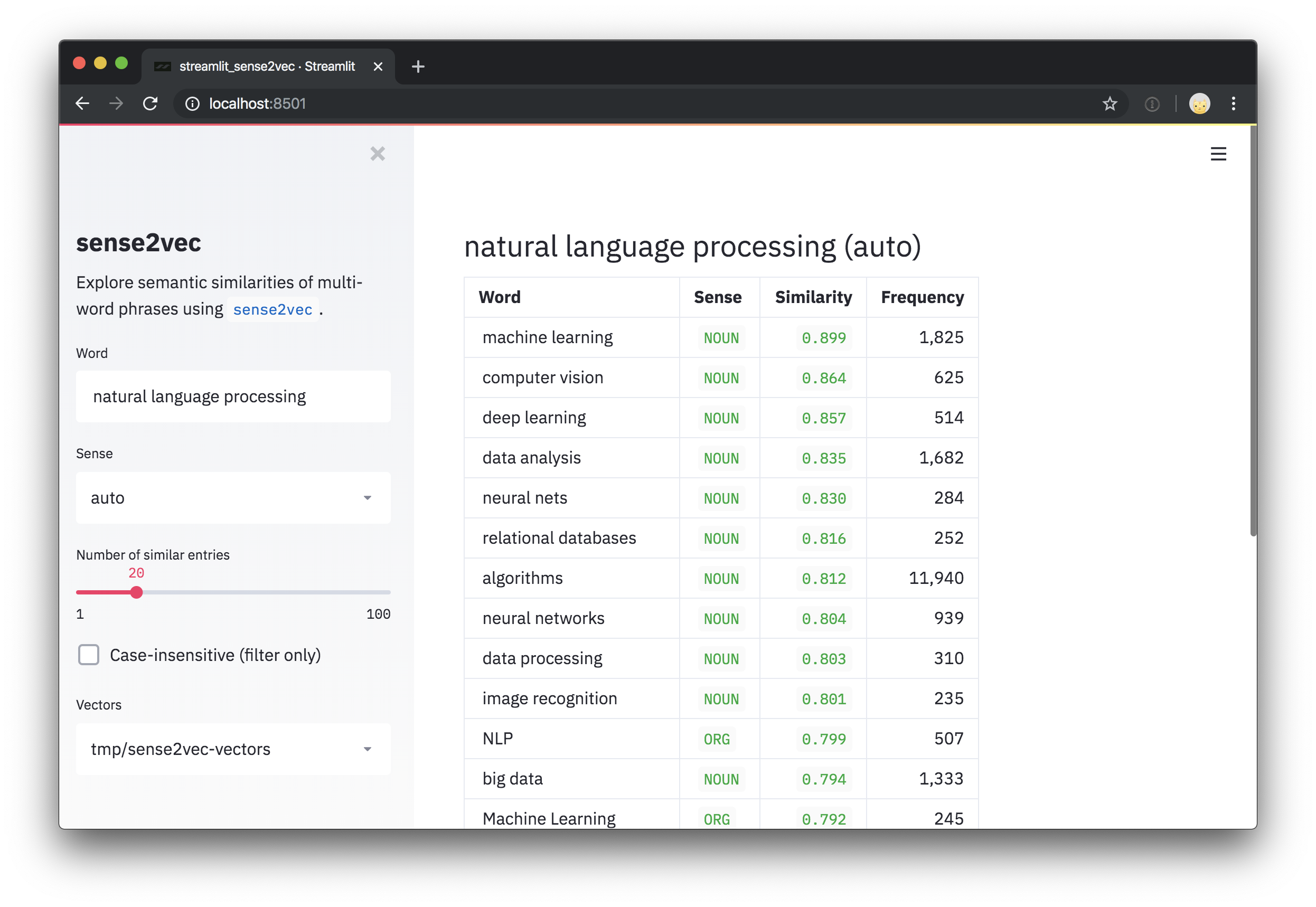
要尝试我们经过Reddit评论训练的载体,请查看Interactive Sense2Vec演示。
此存储库还包括一个简化的演示脚本,用于探索向量和最相似的短语。安装streamlit后,您可以使用streamlit run的脚本运行脚本,并在命令行上作为定位参数,一条或多个途径或多个路径。例如:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors要使用向量,请下载档案库,然后将提取的目录传递到Sense2Vec.from_disk或Sense2VecComponent.from_disk 。向量文件附加到GitHub版本。大文件已分为多部分下载。
| 向量 | 尺寸 | 描述 | ?下载(拉链) |
|---|---|---|---|
s2v_reddit_2019_lg | 4GB | Reddit评论2019(01-07) | 第1部分,第2部分,第3部分 |
s2v_reddit_2015_md | 573 MB | Reddit评论2015 | 第1部分 |
要合并多部分档案,您可以运行以下内容:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzSense2Vec版本可在PIP上获得:
pip install sense2vec要使用预告片的向量,请下载一个矢量包,请拆卸.tar.gz档案和from_disk点到提取的数据目录:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )使用库和向量的最简单方法是将其插入您的Spacy管道中。 sense2vec软件包公开了Sense2VecComponent ,该软件包可以用共享词汇初始化,并将其添加到Spacy管道中,作为自定义管道组件。默认情况下,将组件添加到管道末端,这是该组件的建议位置,因为它需要访问依赖项解析,并且(如果可用)命名实体。
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )该组件将为Spacy的Token和Span对象添加几个扩展属性和方法,这些属性可让您检索向量和频率以及大多数相似的术语。
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )对于实体,实体标签用作“ siense”(而不是令牌的词性词性标签):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 )以下扩展属性通过._属性在Doc对象上暴露:
| 姓名 | 属性类型 | 类型 | 描述 |
|---|---|---|---|
s2v_phrases | 财产 | 列表 | 所有Sense2Vec兼容的Doc (名词短语,命名实体)。 |
以下属性可通过Token和Span对象的._属性可用 - 例如token._.in_s2v :
|名称|属性类型|返回类型|描述| | ---------------------- | ---------------- | ---------------------- | -------------------------------------------------------------------------------------------------------------- | ------------------ | ------- | | in_s2v |属性|布尔|矢量图中是否存在密钥。 | | s2v_key |属性| Unicode |给定对象的Sense2Vec键,例如"duck | NOUN" 。 | | s2v_vec |属性| ndarray[float32] |给定密钥的向量。 | | s2v_freq |属性| int |给定键的频率。 | | s2v_other_senses |属性|列表|可用的其他感官,例如"duck | VERB"作为"duck | NOUN" 。 | | s2v_most_similar |方法|列表|获取n最相似的术语。返回((word, sense), score)元组的列表。 | | s2v_similarity |方法|浮点|获得与另一个Token或Span相似性。 |
配x 关于跨度属性的注释:在引擎盖下,doc.ents中的实体是Span对象。这就是为什么管道组件还为跨度而不仅仅是令牌添加属性和方法的原因。但是,不建议在文档的任意切片上使用Sense2Vec属性,因为该模型可能不会为各自的文本提供键。Span对象也没有词性词性标签,因此,如果没有实体标签,则“ siense”默认为词根的词性词性标签。
如果您要培训和包装Spacy管道,并希望在其中包含Sense2Vec组件,则可以通过培训配置的[initialize]块加载数据:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md "您也可以直接使用基础Sense2Vec类,并使用from_disk方法在向量中加载。有关可用的API方法,请参见下文。
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
配x 重要说明:要查找向量表中的条目,键需要遵循phrase_text|SENSE的方案(请注意_而不是spaces,而在标签或标签之前|) - 例如,machine_learning|NOUN。另请注意,底层矢量表对病例敏感。
Sense2Vec具有矢量,字符串和频率的独立Sense2Vec对象。
Sense2Vec.__init__初始化Sense2Vec对象。
| 争论 | 类型 | 描述 |
|---|---|---|
shape | 元组 | 向量形状。默认为(1000, 128) 。 |
strings | spacy.strings.StringStore | 可选的字符串商店。如果不存在,将创建。 |
senses | 列表 | 所有可用感官的可选列表。用于产生最佳理智或其他感官的方法。 |
vectors_name | Unicode | 可选的名称要分配给向Vectors ,以防止冲突。默认为"sense2vec" 。 |
overrides | dict | 可选的自定义功能要使用,映射到通过注册表注册的名称,例如{"make_key": "custom_make_key"} 。 |
| 返回 | Sense2Vec | 新构造的对象。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__向量表中的行数。
| 争论 | 类型 | 描述 |
|---|---|---|
| 返回 | int | 向量表中的行数。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__检查键是否在向量表中。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的钥匙。 |
| 返回 | 布尔 | 钥匙是否在表中。 |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__检索给定键的向量。如果键不在表中,则返回无。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的钥匙。 |
| 返回 | numpy.ndarray | 向量或None 。 |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__为给定键设置向量。如果键不存在,将会引起错误。要添加新条目,请使用Sense2Vec.add 。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 钥匙。 |
vector | numpy.ndarray | 要设置的向量。 |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.add将新向量添加到表中。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 要添加的关键。 |
vector | numpy.ndarray | 向量要添加。 |
freq | int | 可选频率计数。用于寻找最佳匹配感。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freq获取给定键的频率计数。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 查找的钥匙。 |
default | - | 如果没有发现频率,则返回默认值。 |
| 返回 | int | 频率计数。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freq为给定键设置频率计数。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 设置计数的关键。 |
freq | int | 频率计数。 |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.items迭代向量表中的条目。
| 争论 | 类型 | 描述 |
|---|---|---|
| 产量 | 元组 | 表中的字符串键和矢量对。 |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keys迭代桌子中的键。
| 争论 | 类型 | 描述 |
|---|---|---|
| 产量 | Unicode | 表中的字符串键。 |
all_keys = list ( s2v . keys ())Sense2Vec.values迭代桌子中的向量。
| 争论 | 类型 | 描述 |
|---|---|---|
| 产量 | numpy.ndarray | 桌子中的向量。 |
all_vecs = list ( s2v . values ())Sense2Vec.senses表中的可用感官,例如"NOUN"或"VERB" (在初始化时添加)。
| 争论 | 类型 | 描述 |
|---|---|---|
| 返回 | 列表 | 可用的感官。 |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequencies表中键的频率按顺序下降。
| 争论 | 类型 | 描述 |
|---|---|---|
| 返回 | 列表 | (key, freq)乘以频率,下降。 |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarity对两个键或两组键进行语义相似性估计。默认估计是使用平均向量的余弦相似性。
| 争论 | 类型 | 描述 |
|---|---|---|
keys_a | unicode / int / itoser | 字符串或整数键。 |
keys_b | unicode / int / itoser | 另一个字符串或整数键。 |
| 返回 | 漂浮 | 相似得分。 |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similar获取表中最相似的条目。如果提供了多个密钥,则使用向量的平均值。为了使此方法更快,请参见脚本以预先计算最近的邻居的缓存。
| 争论 | 类型 | 描述 |
|---|---|---|
keys | unicode / int / itoser | 将字符串或整数键进行比较。 |
n | int | 返回的类似键的数量。默认为10 。 |
batch_size | int | 批次大小要使用。默认为16 。 |
| 返回 | 列表 | 最相似向量的(key, score)元素。 |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses找到具有不同意义的同一单词的其他条目,例如"duck|VERB"作为"duck|NOUN" 。
| 争论 | 类型 | 描述 |
|---|---|---|
key | Unicode / int | 检查的钥匙。 |
ignore_case | 布尔 | 检查大写,小写和滴定酶。默认为True 。 |
| 返回 | 列表 | 具有不同感官的其他条目的字符串键。 |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense根据可用的感官和频率计数,找到给定单词的最佳匹配感。如果找不到匹配,则None返回。
| 争论 | 类型 | 描述 |
|---|---|---|
word | Unicode | 要检查的单词。 |
senses | 列表 | 可选的感官列表以将搜索限制为。如果未设置 /空,则使用向量中的所有感官。 |
ignore_case | 布尔 | 检查大写,小写和滴定酶。默认为True 。 |
| 返回 | Unicode | 最好的匹配键或无。 |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes将Sense2Vec对象序列化为bytestring。
| 争论 | 类型 | 描述 |
|---|---|---|
exclude | 列表 | 排除序列化字段的名称。 |
| 返回 | 字节 | 序列化Sense2Vec对象。 |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes从bytestring加载Sense2Vec对象。
| 争论 | 类型 | 描述 |
|---|---|---|
bytes_data | 字节 | 加载的数据。 |
exclude | 列表 | 排除序列化字段的名称。 |
| 返回 | Sense2Vec | 加载对象。 |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk将Sense2Vec对象序列化为目录。
| 争论 | 类型 | 描述 |
|---|---|---|
path | UNICODE / Path | 路径。 |
exclude | 列表 | 排除序列化字段的名称。 |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk从目录加载Sense2Vec对象。
| 争论 | 类型 | 描述 |
|---|---|---|
path | UNICODE / Path | 从 |
exclude | 列表 | 排除序列化字段的名称。 |
| 返回 | Sense2Vec | 加载对象。 |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponent将Sense2VEC添加到Spacy管道中的管道组件。
Sense2VecComponent.__init__初始化管道组件。
| 争论 | 类型 | 描述 |
|---|---|---|
vocab | Vocab | 共享Vocab 。主要用于共享StringStore 。 |
shape | 元组 | 向量形状。 |
merge_phrases | 布尔 | 是否将Sense2Vec短语合并为一个令牌。默认为False 。 |
lemmatize | 布尔 | 如果在向量中可用,则始终查找引理,否则默认为原始单词。默认为False 。 |
overrides | 可选的自定义函数要使用,映射到通过注册表进行注册的名称,例如{"make_key": "custom_make_key"} 。 | |
| 返回 | Sense2VecComponent | 新构造的对象。 |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp从NLP对象初始化组件。主要用作入口点的组件工厂(请参阅setup.cfg),并通过@spacy.component Decorator自动注册。
| 争论 | 类型 | 描述 |
|---|---|---|
nlp | Language | nlp对象。 |
**cfg | - | 可选的配置参数。 |
| 返回 | Sense2VecComponent | 新构造的对象。 |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__使用组件处理Doc对象。通常仅称为Spacy管道的一部分而不是直接称为。
| 争论 | 类型 | 描述 |
|---|---|---|
doc | Doc | 要处理的文档。 |
| 返回 | Doc | 处理过的文档。 |
Sense2Vec.init_component在此处注册特定于组件的扩展属性,并且仅当组件被添加到管道中并使用时 - 否则,即使仅创建组件并且未添加组件,代币仍将获得属性。
Sense2VecComponent.to_bytes将组件序列化为bytestring。当将组件添加到管道中并运行nlp.to_bytes时,也将调用。
| 争论 | 类型 | 描述 |
|---|---|---|
| 返回 | 字节 | 序列化组件。 |
Sense2VecComponent.from_bytes从bytestring加载组件。运行nlp.from_bytes时也称为。
| 争论 | 类型 | 描述 |
|---|---|---|
bytes_data | 字节 | 加载的数据。 |
| 返回 | Sense2VecComponent | 加载对象。 |
Sense2VecComponent.to_disk将组件序列化为目录。当将组件添加到管道中并运行nlp.to_disk时,也会调用。
| 争论 | 类型 | 描述 |
|---|---|---|
path | UNICODE / Path | 路径。 |
Sense2VecComponent.from_disk从目录加载Sense2Vec对象。运行nlp.from_disk时也称为。
| 争论 | 类型 | 描述 |
|---|---|---|
path | UNICODE / Path | 从 |
| 返回 | Sense2VecComponent | 加载对象。 |
registry功能注册表(由catalogue供电)轻松自定义用于生成密钥和短语的功能。允许您装饰和命名自定义功能,将其交换并在保存模型时序列化自定义名称。可以使用以下注册表选项:
|名称|描述| | ------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | | registry.make_key |给定一个word和sense ,返回键的字符串,例如"word | sense". | | registry.split_key |给定一个字符串键,返回(word, sense)元组。 | | registry.make_spacy_key |给定一个spacy对象( Token或Span )和一个布尔值prefer_ents关键字参数(是否偏爱单个令牌的实体标签),返回A (word, sense)元组。在扩展属性中用于生成代币和跨度的密钥。 | | | registry.get_phrases |给定一个spacy Doc ,返回用于sense2vec短语(通常是名词短语和命名实体)的Span对象列表。 | | registry.merge_phrases |鉴于spacy Doc ,获取所有Sense2Vec短语,并将它们合并为单个令牌。 |
每个注册表都有一个可以用作函数装饰器的register方法,并采用一个参数,即自定义函数的名称。
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense初始化Sense2Vec对象时,您现在可以将其使用自定义注册功能的名称的覆盖字典传递。
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )这使得可以轻松地尝试不同的策略并将策略序列化为普通字符串(而不是必须传递和/或泡菜功能本身)。
/scripts目录包含用于预处理文本和训练自己的向量的命令行实用程序。
要训练您自己的Sense2Vec向量,您将需要以下内容:
doc.noun_chunks 。如果您需要的语言没有为名词短语提供内置的语法迭代器,则需要编写自己的语法。 ( doc.noun_chunks and doc.ents是Sense2Vec用来确定什么短语的sense2vec。)make 。培训过程分为几个步骤,使您可以在任何给定的点恢复。处理脚本旨在在单个文件上操作,从而可以轻松地对付工作。此存储库中的脚本需要您需要克隆并make手套或fastText。
对于FastText,脚本将需要到达创建的二进制文件的路径。如果您在Windows上工作,则可以使用cmake构建,或者使用FastText二进制构建的Windows builds中的.exe文件使用:https://github.com/xiamx/fasttext/releases。
| 脚本 | 描述 | |
|---|---|---|
| 1。 | 01_parse.py | 使用Spacy解析Doc对象的原始文本和输出二进制集合(请参阅DocBin )。 |
| 2。 | 02_preprocess.py | 加载以Sense2Vec格式(每行句子为一句话,带有感官的句子)中产生的分析的Doc对象集合。 |
| 3。 | 03_glove_build_counts.py | 使用手套来构建词汇和计数。如果您通过FastText使用Word2Vec,则跳过此步骤。 |
| 4。 | 04_glove_train_vectors.py04_fasttext_train_vectors.py | 使用手套或FastText训练向量。 |
| 5。 | 05_export.py | 加载向量和频率,并输出一个可以通过Sense2Vec.from_disk加载的Sense2Vec组件。 |
| 6。 | 06_precompute_cache.py | 可选: vocab中每个条目的最接近的邻居查询,以使Sense2Vec.most_similar更快。 |
有关脚本的更详细的文档,请查看源或使用--help运行它们。例如, python scripts/01_parse.py --help 。
该软件包还与Prodigy注释工具无缝集成,并揭示了使用Sense2Vec向量快速生成多字短语列表和Bootstrap ner注释的食谱。要使用食谱, sense2vec需要安装在与Prodigy相同的环境中。有关真实世界用例的示例,请查看使用可下载数据集的NER项目。
可用以下食谱 - 有关更多详细文档,请参见下文。
| 食谱 | 描述 |
|---|---|
sense2vec.teach | 使用Sense2Vec引导术语列表。 |
sense2vec.to-patterns | 将短语数据集转换为基于令牌的匹配模式。 |
sense2vec.eval | 通过询问短语三元组来评估Sense2VEC模型。 |
sense2vec.eval-most-similar | 通过纠正最相似的条目来评估Sense2VEC模型。 |
sense2vec.eval-ab | 对两个验证的Sense2Vec矢量模型进行A/B评估。 |
sense2vec.teach使用Sense2Vec引导术语列表。神童将根据Sense2Vec的最相似短语提出类似的术语,并在注释并接受相似的短语时调整建议。对于每个种子术语,将使用Sense2Vec向量的最佳匹配感。
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| 争论 | 类型 | 描述 |
|---|---|---|
dataset | 位置 | 数据集以将注释保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途径。 |
--seeds , -s | 选项 | 一个或多个分离的种子短语。 |
--threshold , -t | 选项 | 相似性阈值。默认为0.85 。 |
--n-similar , -n | 选项 | 同时获得类似项目的数量。 |
--batch-size , -b | 选项 | 批次大小用于提交注释。 |
--resume , -R | 旗帜 | 从现有短语数据集中恢复。 |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns将用sense2vec.teach收集的短语数据集转换为基于令牌的匹配模式,该模式可以与Spacy的EntityRuler或ner.match之类的食谱一起使用。如果未指定输出文件,则将模式写入Stdout。这些示例已被象征化,以便正确表示多义术语,例如: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} 。
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| 争论 | 类型 | 描述 |
|---|---|---|
dataset | 位置 | 短语数据集要转换。 |
spacy_model | 位置 | 代币化的Spacy模型。 |
label | 位置 | 标签适用于所有模式。 |
--output-file , -o | 选项 | 可选输出文件。默认为stdout。 |
--case-sensitive , -CS | 旗帜 | 使模式对案例敏感。 |
--dry , -D | 旗帜 | 执行干式跑步,不要输出任何东西。 |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.eval通过询问短语三重词来评估Sense2Vec模型:单词与单词B更相似,还是Word C?如果人类主要同意该模型,则矢量模型是好的。该食谱只会询问具有相同意义的向量,并支持不同的示例选择策略。
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| 争论 | 类型 | 描述 |
|---|---|---|
dataset | 位置 | 数据集以将注释保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途径。 |
--strategy , -st | 选项 | 示例选择策略。 most similar (默认)或random 。 |
--senses , -s | 选项 | 逗号分隔的感官列表将选择限制为。如果未设置,将使用向量中的所有感官。 |
--exclude-senses , -es | 选项 | 逗号分隔的感觉清单排除在外。参见prodigy_recipes.EVAL_EXCLUDE_SENSES从默认值中。 |
--n-freq , -f | 选项 | 限制最常见的条目的数量。 |
--threshold , -t | 选项 | 最小相似性阈值以考虑示例。 |
--batch-size , -b | 选项 | 批次大小要使用。 |
--eval-whole , -E | 旗帜 | 评估整个数据集而不是当前会话。 |
--eval-only , -O | 旗帜 | 不要注释,只评估当前数据集。 |
--show-scores , -S | 旗帜 | 显示所有调试分数。 |
| 姓名 | 描述 |
|---|---|
most_similar | 从随机意义上选择一个随机单词,并获得相同含义的最相似条目。询问与该选择的最后一个和中间条目的相似性。 |
most_least_similar | 从随机意义上选择一个随机单词,并从其最相似的条目中获得最小的输入,然后是最后一个最相似的条目。 |
random | 从相同的随机意义中选择3个单词的随机样本。 |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5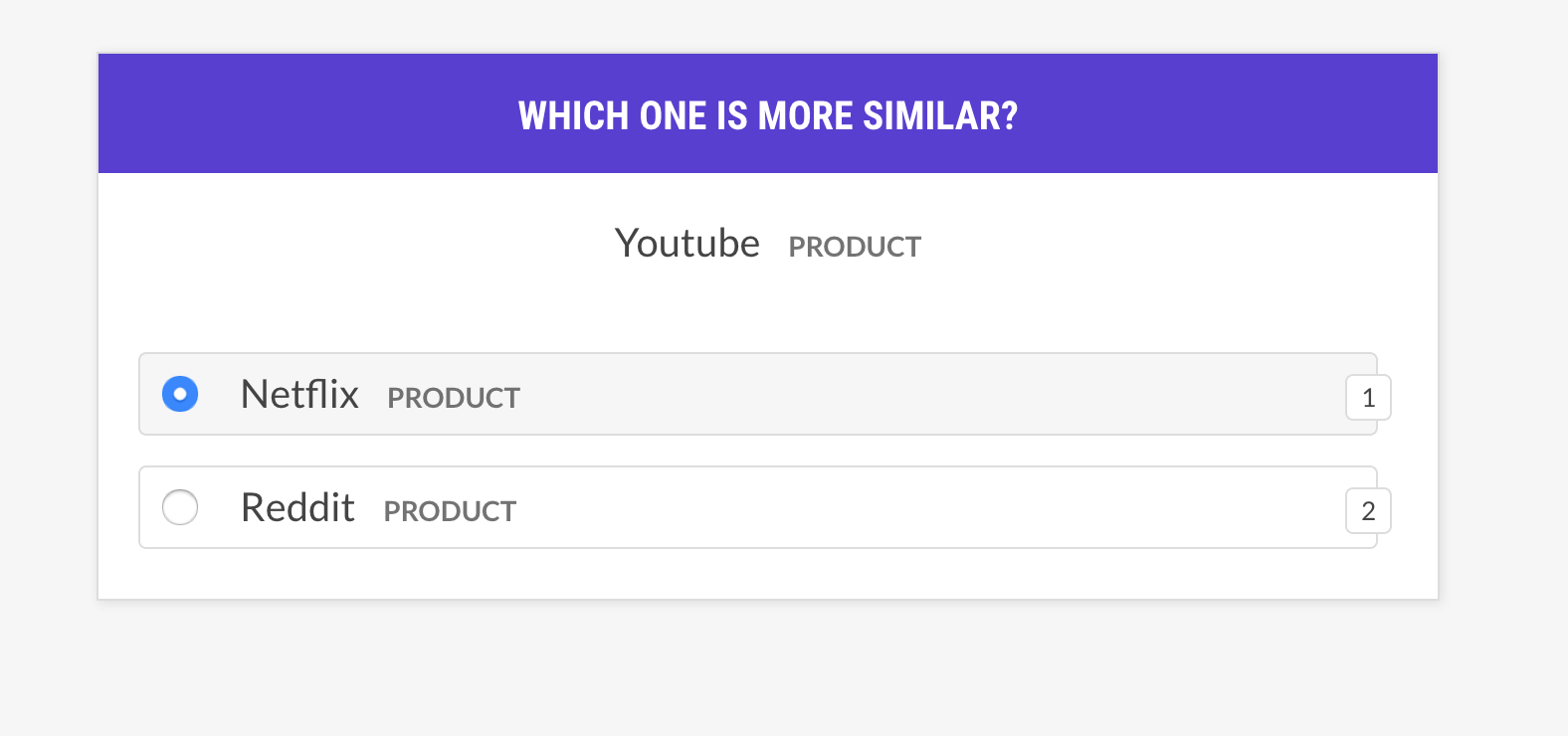
sense2vec.eval-most-similar通过查看最相似的条目来评估矢量模型,它返回的随机短语并取消了错误。
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| 争论 | 类型 | 描述 |
|---|---|---|
dataset | 位置 | 数据集以将注释保存到。 |
vectors_path | 位置 | 通知的Sense2Vec向量的途径。 |
--senses , -s | 选项 | 逗号分隔的感官列表将选择限制为。如果未设置,将使用向量中的所有感官。 |
--exclude-senses , -es | 选项 | 逗号分隔的感觉清单排除在外。参见prodigy_recipes.EVAL_EXCLUDE_SENSES从默认值中。 |
--n-freq , -f | 选项 | 限制最常见的条目的数量。 |
--n-similar , -n | 选项 | 相似的项目数量。默认为10 。 |
--batch-size , -b | 选项 | 批次大小要使用。 |
--eval-whole , -E | 旗帜 | 评估整个数据集而不是当前会话。 |
--eval-only , -O | 旗帜 | 不要注释,只评估当前数据集。 |
--show-scores , -S | 旗帜 | 显示所有调试分数。 |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-ab通过比较它们返回的随机短语的最相似条目,对两个预验证的Sense2Vec矢量模型进行A/B评估。 UI显示了两个随机选项,每个模型中最相似的条目,并突出显示不同的短语。在注释会话结束时,显示了整体统计数据和首选模型。
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| 争论 | 类型 | 描述 |
|---|---|---|
dataset | 位置 | 数据集以将注释保存到。 |
vectors_path_a | 位置 | 通知的Sense2Vec向量的途径。 |
vectors_path_b | 位置 | 通知的Sense2Vec向量的途径。 |
--senses , -s | 选项 | 逗号分隔的感官列表将选择限制为。如果未设置,将使用向量中的所有感官。 |
--exclude-senses , -es | 选项 | 逗号分隔的感觉清单排除在外。参见prodigy_recipes.EVAL_EXCLUDE_SENSES从默认值中。 |
--n-freq , -f | 选项 | 限制最常见的条目的数量。 |
--n-similar , -n | 选项 | 相似的项目数量。默认为10 。 |
--batch-size , -b | 选项 | 批次大小要使用。 |
--eval-whole , -E | 旗帜 | 评估整个数据集而不是当前会话。 |
--eval-only , -O | 旗帜 | 不要注释,只评估当前数据集。 |
--show-mapping , -S | 旗帜 | 在UI中显示哪些型号是选项1和选项2(用于调试)。 |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT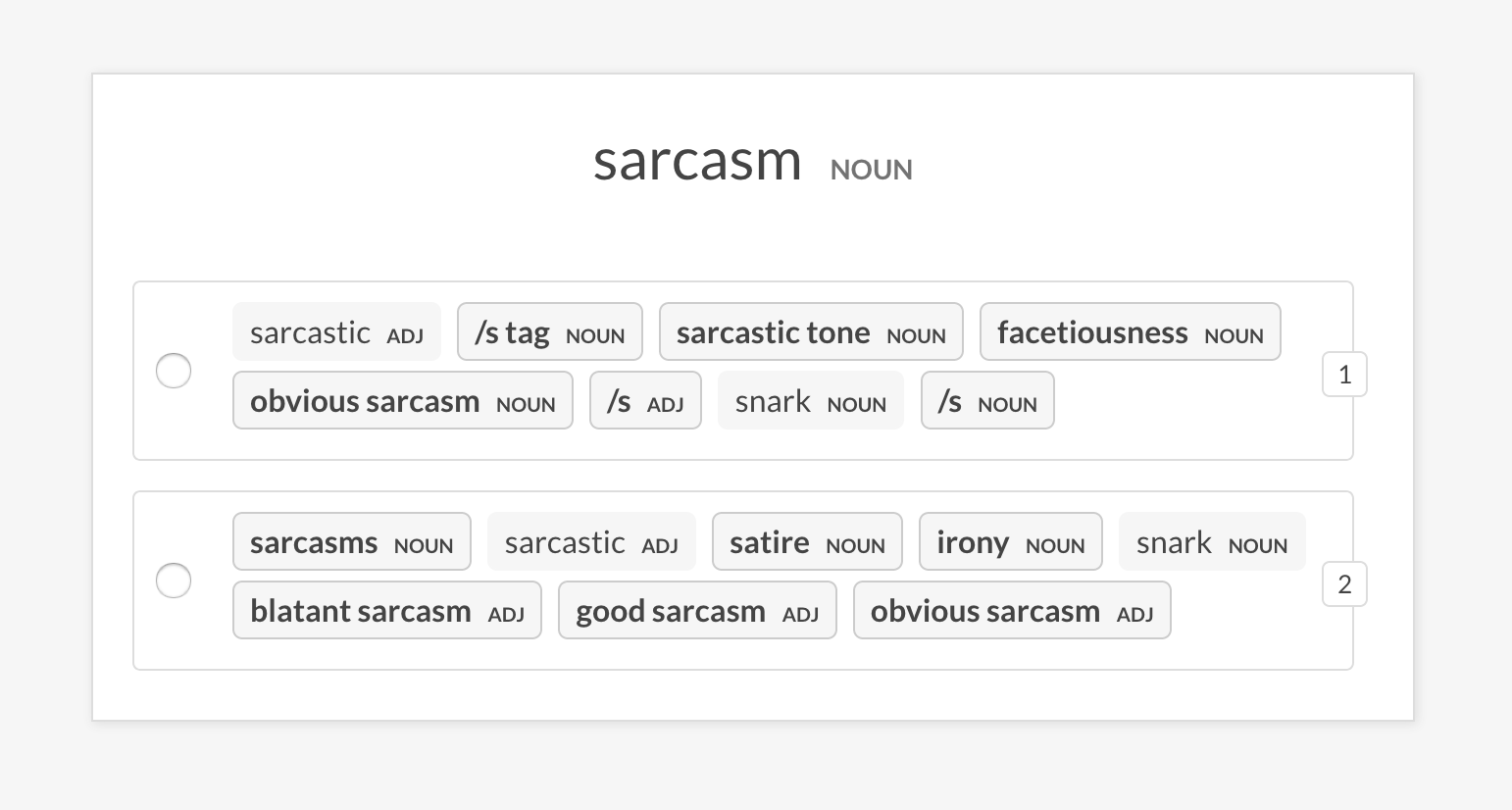
预处理的Reddit矢量支持以下“感官”,无论是词性的标签还是实体标签。有关更多详细信息,请参见Spacy的注释方案概述。
| 标签 | 描述 | 例子 |
|---|---|---|
ADJ | 形容词 | 大,古老,绿色 |
ADP | 定位 | 在,期间 |
ADV | 副词 | 非常明天,下来,哪里 |
AUX | 辅助的 | 是(完成),将(做) |
CONJ | 连词 | 还有,或者,但是 |
DET | 确定器 | a,an, |
INTJ | 欹 | psst,ouch,bravo,你好 |
NOUN | 名词 | 女孩,猫,树,空气,美丽 |
NUM | 数字 | 1,2017,1,七十七,mmxiv |
PART | 粒子 | 的,不是 |
PRON | 代词 | 我,你,他,她,我自己,一个人 |
PROPN | 专有名词 | 玛丽,约翰,伦敦,北约,HBO |
PUNCT | 标点 | ,? () |
SCONJ | 从属连词 | 如果那个 |
SYM | 象征 | $,%,=,:),? |
VERB | 动词 | 跑步,跑步,跑步,吃,吃,吃饭 |
| 实体标签 | 描述 |
|---|---|
PERSON | 人们,包括虚构的人。 |
NORP | 国籍或宗教或政治团体。 |
FACILITY | 建筑物,机场,公路,桥梁等 |
ORG | 公司,机构,机构等 |
GPE | 国家,城市,国家。 |
LOC | 非GPE地点,山脉,水体。 |
PRODUCT | 物体,车辆,食物等(不是服务)。 |
EVENT | 命名为飓风,战斗,战争,体育赛事等。 |
WORK_OF_ART | 书籍,歌曲等的标题。 |
LANGUAGE | 任何命名语言。 |


