sense2vec
v2.0.2
Sense2Vec (Trask et. Al, 2015) es un buen giro en Word2vec que le permite aprender vectores de palabras más interesantes y detallados. Esta biblioteca es una implementación simple de Python para la carga, consulta y entrenamiento de modelos Sense2Vec. Para más detalles, consulte nuestra publicación de blog. Para explorar las similitudes semánticas en todos los comentarios de Reddit de 2015 y 2019, vea la demostración interactiva.
? Versión 2.0 (para Spacy V3) ahora! Lea las notas de la versión aquí.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ Tenga en cuenta que este ejemplo describe el uso con Spacy V3. Para el uso con Spacy V2, descarguesense2vec==1.0.3y consulte la ramav1.xde este repositorio.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]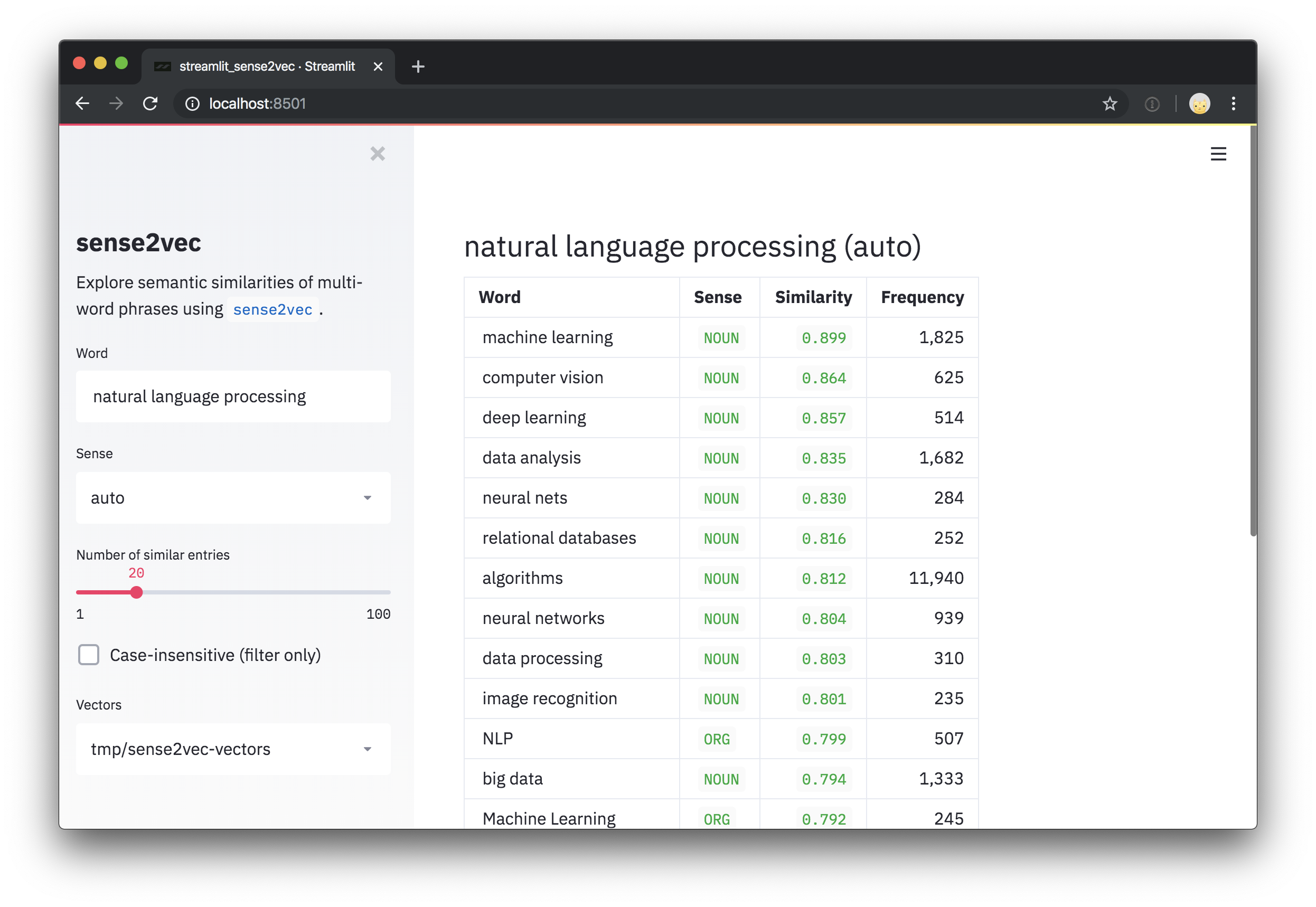
Para probar nuestros vectores previos a la petróleo entrenados en comentarios de Reddit, consulte la demostración interactiva Sense2Vec.
Este repositorio también incluye un script de demostración a simpatización para explorar vectores y las frases más similares. Después de instalar streamlit , puede ejecutar el script con streamlit run y una o más rutas a los vectores previos a la aparición como argumentos posicionales en la línea de comando. Por ejemplo:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors Para usar los vectores, descargue el archivo (s) y pase el directorio extraído a Sense2Vec.from_disk o Sense2VecComponent.from_disk . Los archivos vectoriales se adjuntan a la versión de GitHub . Los archivos grandes se han dividido en descargas de varias partes.
| Vectores | Tamaño | Descripción | ? Descargar (con cremallera) |
|---|---|---|---|
s2v_reddit_2019_lg | 4 GB | Comentarios de Reddit 2019 (01-07) | Parte 1, Parte 2, Parte 3 |
s2v_reddit_2015_md | 573 MB | Comentarios de Reddit 2015 | Parte 1 |
Para fusionar los archivos de varias partes, puede ejecutar lo siguiente:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzLos lanzamientos de Sense2Vec están disponibles en PIP:
pip install sense2vec Para usar vectores previos a la aparición, descargue uno de los paquetes vectoriales, desempaquete el archivo .tar.gz y apunte from_disk al directorio de datos extraído:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) La forma más fácil de usar la biblioteca y los vectores es enchufarla a su tubería Spacy. El paquete sense2vec expone un Sense2VecComponent , que se puede inicializar con el vocabulario compartido y agregar a su tubería de Spacy como un componente de tubería personalizado. Por defecto, los componentes se agregan al final de la tubería , que es la posición recomendada para este componente, ya que necesita acceso al análisis de dependencia y, si está disponible, entidades nombradas.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) El componente agregará varios atributos y métodos de extensión a los objetos Token y Span de Spacy que le permiten recuperar vectores y frecuencias, así como los términos más similares.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )Para las entidades, las etiquetas de las entidades se usan como "sentido" (en lugar de la etiqueta de parte del voz del token):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) Los siguientes atributos de extensión están expuestos en el objeto Doc a través de la propiedad ._ :
| Nombre | Tipo de atributo | Tipo | Descripción |
|---|---|---|---|
s2v_phrases | propiedad | lista | Todas las frases compatibles con Sense2Vec en el Doc dados (frases nominal, entidades nombradas). |
Los siguientes atributos están disponibles a través de la propiedad ._ de los objetos Token y Span , por ejemplo token._.in_s2v :
| Nombre | Tipo de atributo | Tipo de retorno | Descripción | | ------------------ | -------------- | ------------------ | ---------------------------------------------------------------------------------- | --------------- | ------- | | in_s2v | propiedad | bool | Si existe una clave en el mapa de vector. | | s2v_key | propiedad | Unicode | La clave Sense2Vec del objeto dado, por ejemplo, "duck | NOUN" . | | s2v_vec | propiedad | ndarray[float32] | El vector de la clave dada. | | s2v_freq | propiedad | int | La frecuencia de la clave dada. | | s2v_other_senses | propiedad | Lista | Disponible otros sentidos, por ejemplo "duck | VERB" para "duck | NOUN" . | | s2v_most_similar | Método | Lista | Obtenga los n más similares. Devuelve una lista de ((word, sense), score) tuples. | | s2v_similarity | Método | flotante | Obtenga la similitud con otra Token o Span . |
️ Una nota sobre los atributos del tramo:Spandel capó, las entidades endoc.ents. Esta es la razón por la cual el componente de la tubería también agrega atributos y métodos a los tramos y no solo a las fichas. Sin embargo, no se recomienda utilizar los atributos Sense2Vec en cortes arbitrarios del documento, ya que el modelo probablemente no tendrá una clave para el texto respectivo. Los objetosSpantampoco tienen una etiqueta de parte de voz, por lo que si no hay etiqueta de entidad presente, el "sentido" predeterminado a la etiqueta de parte del voz de la raíz.
Si está entrenando y empaquetando una tubería de Spacy y desea incluir un componente Sense2Vec en él, puede cargar en los datos a través del bloque [initialize] de la configuración de entrenamiento:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " También puede usar la clase Sense2Vec subyacente directamente y cargar en los vectores utilizando el método from_disk . Consulte a continuación los métodos API disponibles.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ Nota importante: para buscar entradas en la tabla de vectores, las teclas deben seguir el esquema dephrase_text|SENSE(tenga en cuenta el_en lugar de los espacios y el|antes de la etiqueta o la etiqueta), por ejemplo,machine_learning|NOUN. También tenga en cuenta que la tabla vectorial subyacente es sensible a la caja.
Sense2Vec El objeto Sense2Vec independiente que contiene los vectores, cadenas y frecuencias.
Sense2Vec.__init__ Inicializar el objeto Sense2Vec .
| Argumento | Tipo | Descripción |
|---|---|---|
shape | tupla | La forma del vector. Predeterminado a (1000, 128) . |
strings | spacy.strings.StringStore | Tienda de cadenas opcional. Se creará si no existe. |
senses | lista | Lista opcional de todos los sentidos disponibles. Utilizado en métodos que generan el mejor sentido u otros sentidos. |
vectors_name | unicode | Nombre opcional para asignar a la tabla Vectors , para evitar enfrentamientos. El valor predeterminado es "sense2vec" . |
overrides | dictarse | Funciones personalizadas opcionales para usar, asignadas a nombres registrados a través del registro, por ejemplo {"make_key": "custom_make_key"} . |
| Devolución | Sense2Vec | El objeto recién construido. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__El número de filas en la tabla de vectores.
| Argumento | Tipo | Descripción |
|---|---|---|
| Devolución | intencionalmente | El número de filas en la tabla de vectores. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__Compruebe si una clave está en la tabla de vectores.
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para buscar. |
| Devolución | bool | Si la clave está en la tabla. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__Recupere un vector para una clave dada. No devuelve ninguno si la clave no está en la tabla.
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para buscar. |
| Devolución | numpy.ndarray | El vector o None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ Establezca un vector para una clave dada. Aumentará un error si la clave no existe. Para agregar una nueva entrada, use Sense2Vec.add .
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La llave. |
vector | numpy.ndarray | El vector para establecer. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addAgregue un nuevo vector a la mesa.
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para agregar. |
vector | numpy.ndarray | El vector para agregar. |
freq | intencionalmente | Recuento de frecuencia opcional. Se usa para encontrar los mejores sentidos coincidentes. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqObtenga el recuento de frecuencia para una clave determinada.
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para buscar. |
default | - | Valor predeterminado para devolver si no se encuentra ninguna frecuencia. |
| Devolución | intencionalmente | El recuento de frecuencia. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqEstablezca un recuento de frecuencia para una clave dada.
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para establecer el recuento. |
freq | intencionalmente | El recuento de frecuencia. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsIterar sobre las entradas en la tabla de vectores.
| Argumento | Tipo | Descripción |
|---|---|---|
| Rendimientos | tupla | La tecla de cadena y los pares de vectores en la tabla. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysIterar sobre las llaves de la mesa.
| Argumento | Tipo | Descripción |
|---|---|---|
| Rendimientos | unicode | Las teclas de cadena en la tabla. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesIterar sobre los vectores en la mesa.
| Argumento | Tipo | Descripción |
|---|---|---|
| Rendimientos | numpy.ndarray | Los vectores en la mesa. |
all_vecs = list ( s2v . values ())Sense2Vec.senses Los sentidos disponibles en la tabla, por ejemplo, "NOUN" o "VERB" (agregado en la inicialización).
| Argumento | Tipo | Descripción |
|---|---|---|
| Devolución | lista | Los sentidos disponibles. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesLas frecuencias de las claves en la tabla, en orden descendente.
| Argumento | Tipo | Descripción |
|---|---|---|
| Devolución | lista | Las tuplas (key, freq) por frecuencia, descendiendo. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityHaga una estimación de similitud semántica de dos claves o dos conjuntos de claves. La estimación predeterminada es la similitud de coseno utilizando un promedio de vectores.
| Argumento | Tipo | Descripción |
|---|---|---|
keys_a | unicode / int / ITerable | La cadena o la tecla (s) entera (s). |
keys_b | unicode / int / ITerable | La otra cadena o tecla (s) entera (s). |
| Devolución | flotar | El puntaje de similitud. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarObtenga las entradas más similares en la mesa. Si se proporciona más de una clave, se usa el promedio de los vectores. Para hacer este método más rápido, consulte el script para precomputar un caché de los vecinos más cercanos.
| Argumento | Tipo | Descripción |
|---|---|---|
keys | unicode / int / ITerable | La cadena o las teclas enteras para comparar. |
n | intencionalmente | El número de claves similares para devolver. El valor predeterminado a 10 . |
batch_size | intencionalmente | El tamaño del lote para usar. Predeterminado a 16 . |
| Devolución | lista | Las tuplas (key, score) de los vectores más similares. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses Encuentre otras entradas para la misma palabra con un sentido diferente, por ejemplo "duck|VERB" para "duck|NOUN" .
| Argumento | Tipo | Descripción |
|---|---|---|
key | unicode / int | La clave para verificar. |
ignore_case | bool | Verifique si hay mayúsculas, minúsculas y titleCase. El valor predeterminado es True . |
| Devolución | lista | Las teclas de cadena de otras entradas con diferentes sentidos. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense Encuentre el mejor sentido de coincidencia para una palabra dada basada en los sentidos y recuentos de frecuencia disponibles. No devuelve None si no se encuentra ninguna coincidencia.
| Argumento | Tipo | Descripción |
|---|---|---|
word | unicode | La palabra para verificar. |
senses | lista | Lista opcional de sentidos para limitar la búsqueda. Si no se establece / vacía, se usan todos los sentidos en los vectores. |
ignore_case | bool | Verifique si hay mayúsculas, minúsculas y titleCase. El valor predeterminado es True . |
| Devolución | unicode | La clave de mejor coincidencia o ninguna. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Serializa un objeto Sense2Vec a un bytestring.
| Argumento | Tipo | Descripción |
|---|---|---|
exclude | lista | Nombres de campos de serialización para excluir. |
| Devolución | bytes | El objeto Sense2Vec serializado. |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Cargue un objeto Sense2Vec de un bytestring.
| Argumento | Tipo | Descripción |
|---|---|---|
bytes_data | bytes | Los datos para cargar. |
exclude | lista | Nombres de campos de serialización para excluir. |
| Devolución | Sense2Vec | El objeto cargado. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Serializa un objeto Sense2Vec a un directorio.
| Argumento | Tipo | Descripción |
|---|---|---|
path | unicode / Path | El camino. |
exclude | lista | Nombres de campos de serialización para excluir. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk Cargue un objeto Sense2Vec desde un directorio.
| Argumento | Tipo | Descripción |
|---|---|---|
path | unicode / Path | El camino para cargar desde |
exclude | lista | Nombres de campos de serialización para excluir. |
| Devolución | Sense2Vec | El objeto cargado. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentEl componente de la tubería para agregar Sense2Vec a las tuberías de Spacy.
Sense2VecComponent.__init__Inicializar el componente de la tubería.
| Argumento | Tipo | Descripción |
|---|---|---|
vocab | Vocab | El Vocab compartido. Se utiliza principalmente para el StringStore compartido. |
shape | tupla | La forma del vector. |
merge_phrases | bool | Si fusionar frases sense2vec en un token. El valor predeterminado es False . |
lemmatize | bool | Siempre busque lemas si están disponibles en los vectores, de lo contrario, por defecto a la palabra original. El valor predeterminado es False . |
overrides | Funciones personalizadas opcionales para usar, asignadas a nombres registrados a través del registro, por ejemplo {"make_key": "custom_make_key"} . | |
| Devolución | Sense2VecComponent | El objeto recién construido. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp Inicialice el componente desde un objeto NLP. Se utiliza principalmente como la fábrica de componentes para el punto de entrada (ver Setup.cfg) y para registrarse automáticamente a través del decorador @spacy.component .
| Argumento | Tipo | Descripción |
|---|---|---|
nlp | Language | El objeto nlp . |
**cfg | - | Parámetros de configuración opcionales. |
| Devolución | Sense2VecComponent | El objeto recién construido. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ Procese un objeto Doc con el componente. Por lo general, solo se llama parte de la tubería de Spacy y no directamente.
| Argumento | Tipo | Descripción |
|---|---|---|
doc | Doc | El documento para procesar. |
| Devolución | Doc | el documento procesado. |
Sense2Vec.init_componentRegistre los atributos de extensión específicos del componente aquí y solo si el componente se agrega a la tubería y se usa; de lo contrario, los tokens aún obtendrán los atributos incluso si el componente solo se crea y no se agrega.
Sense2VecComponent.to_bytes Serializa el componente a un testigo. También se llama cuando el componente se agrega a la tubería y ejecuta nlp.to_bytes .
| Argumento | Tipo | Descripción |
|---|---|---|
| Devolución | bytes | El componente serializado. |
Sense2VecComponent.from_bytes Cargue un componente desde un testre de bytestring. También llamado cuando ejecuta nlp.from_bytes .
| Argumento | Tipo | Descripción |
|---|---|---|
bytes_data | bytes | Los datos para cargar. |
| Devolución | Sense2VecComponent | El objeto cargado. |
Sense2VecComponent.to_disk Serializa el componente a un directorio. También se llama cuando el componente se agrega a la tubería y ejecuta nlp.to_disk .
| Argumento | Tipo | Descripción |
|---|---|---|
path | unicode / Path | El camino. |
Sense2VecComponent.from_disk Cargue un objeto Sense2Vec desde un directorio. También llamado cuando ejecuta nlp.from_disk .
| Argumento | Tipo | Descripción |
|---|---|---|
path | unicode / Path | El camino para cargar desde |
| Devolución | Sense2VecComponent | El objeto cargado. |
registry de clases Registro de funciones (alimentado por catalogue ) para personalizar fácilmente las funciones utilizadas para generar claves y frases. Le permite decorar y nombrar funciones personalizadas, intercambiarlas y serializar los nombres personalizados cuando guarde el modelo. Las siguientes opciones de registro están disponibles:
| Nombre | Descripción | | ------------------------- | ------------------------------------------------------------------------------- -------- | | registry.make_key | Dada una word y sense , devuelva una cadena de la clave, por ejemplo, "word | sense". | | registry.split_key | Dada una tecla de cadena, devuelva una tupla (word, sense) . | | registry.make_spacy_key | Dado un objeto Spacy ( Token o Span ) y un argumento de palabras clave Boolean prefer_ents (si preferir la etiqueta de la entidad para tokens individuales), devuelve una tupla (word, sense) . Se utiliza en atributos de extensión para generar una clave para tokens y tramos. | | | registry.get_phrases | Dado un Doc Spacy, devuelva una lista de objetos Span utilizados para frases Sense2Vec (típicamente frases de sustantivos y entidades nombradas). | | registry.merge_phrases | Dado un Doc espacial, obtenga todas las frases Sense2Vec y fusionas en tokens individuales. |
Cada registro tiene un método register que se puede utilizar como un decorador de funciones y toma un argumento, el nombre de la función personalizada.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Al inicializar el objeto Sense2Vec , ahora puede pasar un diccionario de anulaciones con los nombres de sus funciones registradas personalizadas.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )Esto hace que sea fácil experimentar con diferentes estrategias y serializar las estrategias como cuerdas simples (en lugar de tener que pasar y/o encoger las funciones en sí).
El directorio /scripts contiene utilidades de línea de comandos para el texto de preprocesamiento y capacitar a sus propios vectores.
Para entrenar sus propios vectores Sense2Vec, necesitará lo siguiente:
doc.noun_chunks . Si el lenguaje que necesita no proporciona un iterador de sintaxis integrado para frases nomnables, deberá escribir el suyo. ( doc.noun_chunks y doc.ents son lo que Sense2Vec usa para determinar qué es una frase).make en el directorio respectivo. El proceso de capacitación se divide en varios pasos para permitirle reanudar en cualquier punto dado. Los scripts de procesamiento están diseñados para operar en archivos únicos, lo que facilita la paralelización del trabajo. Los scripts en este repositorio requieren guante o FastText que necesita clonar y make .
Para FastText, los scripts requerirán la ruta al archivo binario creado. Si está trabajando en Windows, puede construir con cmake , o alternativamente usar el archivo .exe de este repositorio no oficial con FastText Binary Builds para Windows: https://github.com/xiamx/fastText/Releases.
| Guion | Descripción | |
|---|---|---|
| 1. | 01_parse.py | Use Spacy para analizar las colecciones binarias de texto y salida de objetos Doc (ver DocBin ). |
| 2. | 02_preprocess.py | Cargue una colección de objetos Doc analizados producidos en el paso anterior y los archivos de texto de salida en el formato SENSE2VEC (una oración por línea y frases fusionadas con sentidos). |
| 3. | 03_glove_build_counts.py | Use el guante para construir el vocabulario y cuenta. Omita este paso si está usando Word2Vec a través de FastText. |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | Use Glove o FastText para entrenar vectores. |
| 5. | 05_export.py | Cargue los vectores y frecuencias y emita un componente Sense2Vec que se pueda cargar a través de Sense2Vec.from_disk . |
| 6. | 06_precompute_cache.py | Opcional: Precomputar consultas de vecino más cercano para cada entrada en el vocabulario para hacer Sense2Vec.most_similar más rápido. |
Para obtener una documentación más detallada de los scripts, consulte la fuente o ejecútelos con --help . Por ejemplo, python scripts/01_parse.py --help .
Este paquete también se integra perfectamente con la herramienta de anotación de prodigio y expone recetas para usar vectores Sense2Vec para generar rápidamente listas de frases de múltiples palabras y anotaciones de bootstrap ner. Para usar una receta, sense2vec debe instalarse en el mismo entorno que el prodigio. Para obtener un ejemplo de un caso de uso del mundo real, consulte este proyecto NER con conjuntos de datos descargables.
Las siguientes recetas están disponibles; consulte a continuación los documentos más detallados.
| Receta | Descripción |
|---|---|
sense2vec.teach | Bootstrap Una lista de terminología usando Sense2Vec. |
sense2vec.to-patterns | Convierta el conjunto de datos de frases a patrones de coincidencia basados en tokens. |
sense2vec.eval | Evalúe un modelo Sense2Vec preguntando sobre la frase triples. |
sense2vec.eval-most-similar | Evalúe un modelo Sense2Vec corrigiendo las entradas más similares. |
sense2vec.eval-ab | Realice una evaluación A/B de dos modelos de vectores Sense2VEC previos al detenido. |
sense2vec.teachBootstrap Una lista de terminología usando Sense2Vec. Prodigy sugerirá términos similares basados en las frases más similares de Sense2Vec, y las sugerencias se ajustarán a medida que anotes y acepte frases similares. Para cada término de semilla, se utilizará el mejor sentido coincidente según los vectores Sense2Vec.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| Argumento | Tipo | Descripción |
|---|---|---|
dataset | posicional | Conjunto de datos para guardar anotaciones para. |
vectors_path | posicional | Camino a los vectores de sentido previamente 2Vec. |
--seeds , -s | opción | Una o más frases de semillas separadas por comas. |
--threshold , -t | opción | Umbral de similitud. El valor predeterminado es 0.85 . |
--n-similar , -n | opción | Número de elementos similares para llegar a la vez. |
--batch-size , -b | opción | Tamaño de lote para enviar anotaciones. |
--resume , -R | bandera | Reanude de un conjunto de datos de frases existentes. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns Convierta un conjunto de datos de frases recopiladas con sense2vec.teach a patrones de coincidencia basados en token que se pueden usar con EntityRuler o recetas de Spacy como ner.match . Si no se especifica ningún archivo de salida, los patrones se escriben en STDOUT. Los ejemplos se tokenizan para que los términos múltiples se representen correctamente, por ejemplo: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| Argumento | Tipo | Descripción |
|---|---|---|
dataset | posicional | Frase de datos para convertir. |
spacy_model | posicional | Modelo de Spacy para la tokenización. |
label | posicional | Etiqueta para aplicar a todos los patrones. |
--output-file , -o | opción | Archivo de salida opcional. El valor predeterminado a STDOUT. |
--case-sensitive , -CS | bandera | Hacer patrones sensibles a la caja. |
--dry , -D | bandera | Realice una ejecución seca y no salga nada. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalEvalúe un modelo Sense2Vec preguntando sobre frases triples: ¿es la palabra más similar a la palabra b o a la palabra c? Si el humano está de acuerdo principalmente con el modelo, el modelo de vectores es bueno. La receta solo preguntará sobre los vectores con el mismo sentido y admite diferentes estrategias de selección de ejemplo.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| Argumento | Tipo | Descripción |
|---|---|---|
dataset | posicional | Conjunto de datos para guardar anotaciones para. |
vectors_path | posicional | Camino a los vectores de sentido previamente 2Vec. |
--strategy , -st | opción | Ejemplo de estrategia de selección. most similar (predeterminado) o random . |
--senses , -s | opción | Lista de sentidos separados por comas para limitar la selección a. Si no se establece, se utilizarán todos los sentidos en los vectores. |
--exclude-senses , -es | opción | Lista de sentidos separados por comas para excluir. Ver prodigy_recipes.EVAL_EXCLUDE_SENSES para los valores predeterminados. |
--n-freq , -f | opción | Número de entradas más frecuentes para limitar. |
--threshold , -t | opción | Umbral de similitud mínima para considerar ejemplos. |
--batch-size , -b | opción | Tamaño por lotes para usar. |
--eval-whole , -E | bandera | Evalúe todo el conjunto de datos en lugar de la sesión actual. |
--eval-only , -O | bandera | No anotes, solo evalúe el conjunto de datos actual. |
--show-scores , -S | bandera | Mostrar todos los puntajes para la depuración. |
| Nombre | Descripción |
|---|---|
most_similar | Elija una palabra aleatoria de un sentido aleatorio y obtenga sus entradas más similares del mismo sentido. Pregunte sobre la similitud con la última y media entrada de esa selección. |
most_least_similar | Elija una palabra aleatoria de un sentido aleatorio y obtenga la entrada menos similar de sus entradas más similares, y luego la última entrada más similar de eso. |
random | Elija una muestra aleatoria de 3 palabras del mismo sentido aleatorio. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5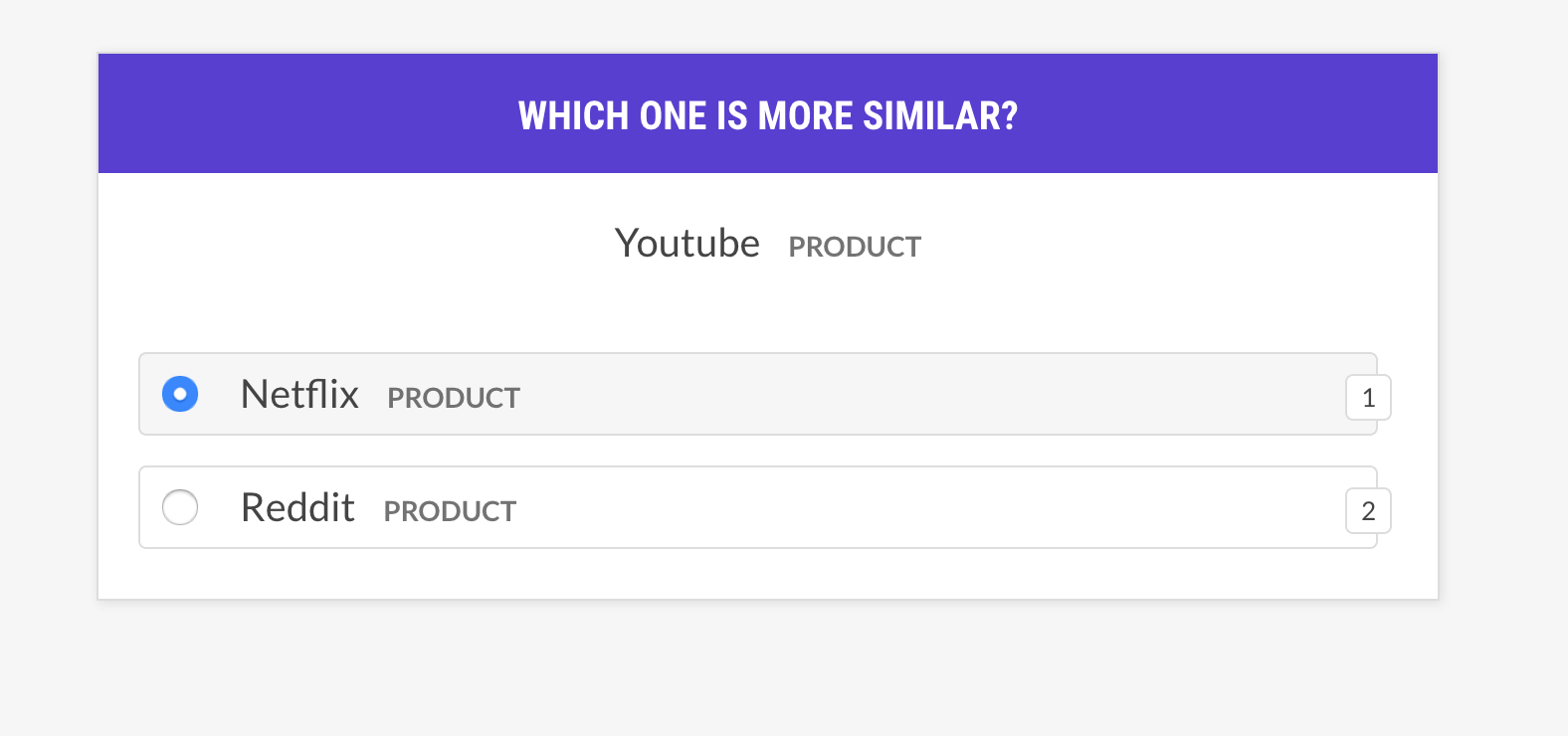
sense2vec.eval-most-similarEvalúe un modelo de vectores observando las entradas más similares que devuelve para una frase aleatoria y sin selección de los errores.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| Argumento | Tipo | Descripción |
|---|---|---|
dataset | posicional | Conjunto de datos para guardar anotaciones para. |
vectors_path | posicional | Camino a los vectores de sentido previamente 2Vec. |
--senses , -s | opción | Lista de sentidos separados por comas para limitar la selección a. Si no se establece, se utilizarán todos los sentidos en los vectores. |
--exclude-senses , -es | opción | Lista de sentidos separados por comas para excluir. Ver prodigy_recipes.EVAL_EXCLUDE_SENSES para los valores predeterminados. |
--n-freq , -f | opción | Número de entradas más frecuentes para limitar. |
--n-similar , -n | opción | Número de artículos similares para verificar. El valor predeterminado a 10 . |
--batch-size , -b | opción | Tamaño por lotes para usar. |
--eval-whole , -E | bandera | Evalúe todo el conjunto de datos en lugar de la sesión actual. |
--eval-only , -O | bandera | No anotes, solo evalúe el conjunto de datos actual. |
--show-scores , -S | bandera | Mostrar todos los puntajes para la depuración. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abRealice una evaluación A/B de dos modelos de vectores Sense2VEC previos al detenido comparando las entradas más similares que devuelven para una frase aleatoria. La interfaz de usuario muestra dos opciones aleatorias con las entradas más similares de cada modelo y destaca las frases que difieren. Al final de la sesión de anotación, se muestran las estadísticas generales y el modelo preferido.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| Argumento | Tipo | Descripción |
|---|---|---|
dataset | posicional | Conjunto de datos para guardar anotaciones para. |
vectors_path_a | posicional | Camino a los vectores de sentido previamente 2Vec. |
vectors_path_b | posicional | Camino a los vectores de sentido previamente 2Vec. |
--senses , -s | opción | Lista de sentidos separados por comas para limitar la selección a. Si no se establece, se utilizarán todos los sentidos en los vectores. |
--exclude-senses , -es | opción | Lista de sentidos separados por comas para excluir. Ver prodigy_recipes.EVAL_EXCLUDE_SENSES para los valores predeterminados. |
--n-freq , -f | opción | Número de entradas más frecuentes para limitar. |
--n-similar , -n | opción | Número de artículos similares para verificar. El valor predeterminado a 10 . |
--batch-size , -b | opción | Tamaño por lotes para usar. |
--eval-whole , -E | bandera | Evalúe todo el conjunto de datos en lugar de la sesión actual. |
--eval-only , -O | bandera | No anotes, solo evalúe el conjunto de datos actual. |
--show-mapping , -S | bandera | Muestre qué modelos son la opción 1 y la opción 2 en la UI (para la depuración). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT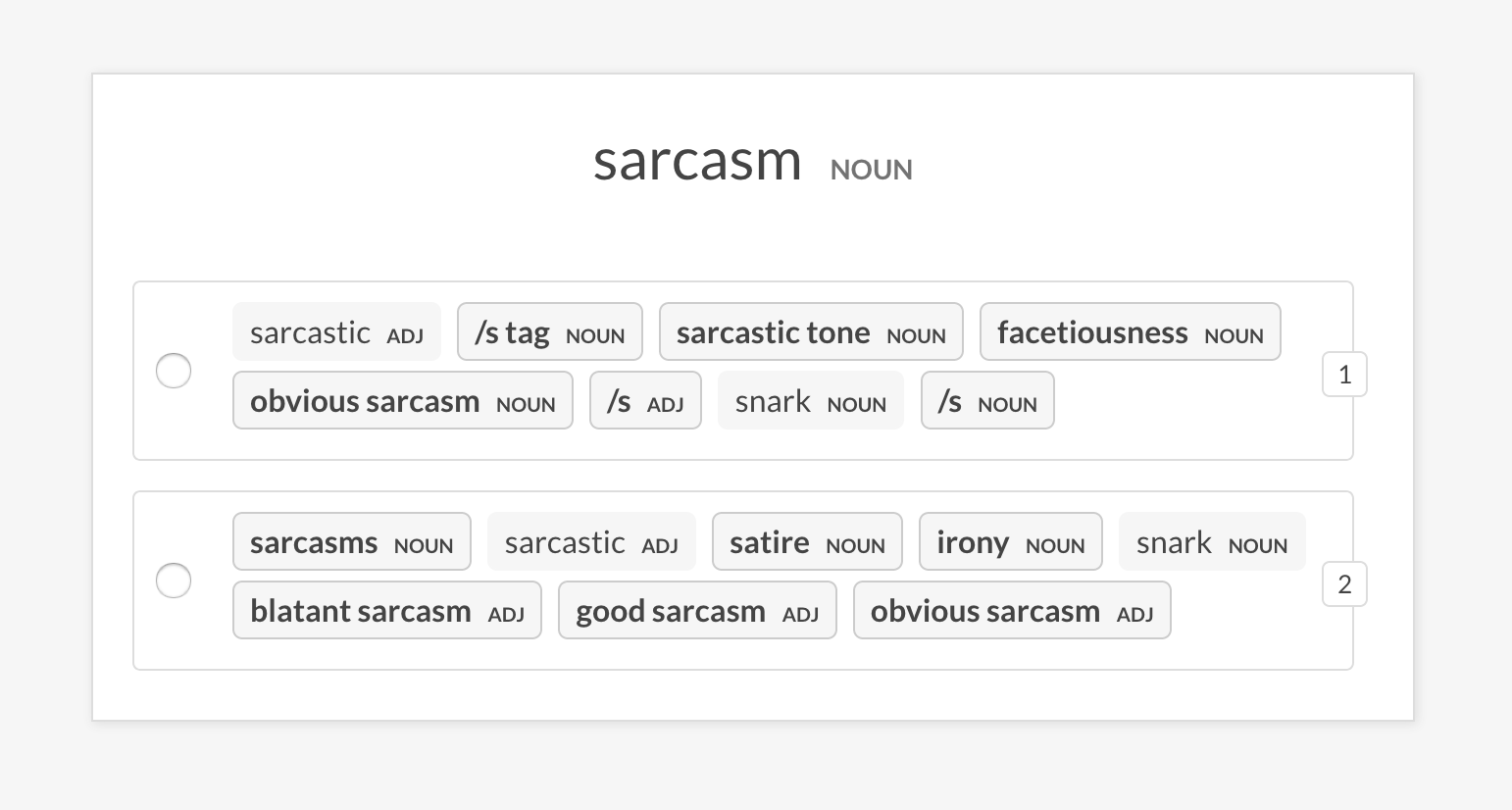
Los vectores Reddit previos al detenido admiten los siguientes "sentidos", ya sea etiquetas de parte de voz o etiquetas de entidad. Para obtener más detalles, consulte Descripción general del esquema de anotación de Spacy.
| Etiqueta | Descripción | Ejemplos |
|---|---|---|
ADJ | adjetivo | grande, viejo, verde |
ADP | adposición | en, a, durante |
ADV | adverbio | muy, mañana, abajo, donde |
AUX | auxiliar | es, ha (hecho), Will (do) |
CONJ | conjunción | y, o, pero |
DET | determinador | a, an, el |
INTJ | interjección | psst, ouch, bravo, hola |
NOUN | sustantivo | niña, gato, árbol, aire, belleza |
NUM | número | 1, 2017, uno, setenta y siete, mmxiv |
PART | partícula | 's, no |
PRON | pronombre | Yo, tú, él, ella, yo mismo, alguien |
PROPN | sustantivo propio | Mary, John, Londres, OTAN, HBO |
PUNCT | puntuación | ,? () |
SCONJ | conjunción subordinante | Si, mientras, eso |
SYM | símbolo | $, %, =, :) ,? |
VERB | verbo | correr, correr, correr, comer, comer, comer |
| Etiqueta de entidad | Descripción |
|---|---|
PERSON | Gente, incluida la ficción. |
NORP | Nacionalidades o grupos religiosos o políticos. |
FACILITY | Edificios, aeropuertos, carreteras, puentes, etc. |
ORG | Empresas, agencias, instituciones, etc. |
GPE | Países, ciudades, estados. |
LOC | Ubicaciones que no son GPE, cadenas montañosas, cuerpos de agua. |
PRODUCT | Objetos, vehículos, alimentos, etc. (no servicios). |
EVENT | Nombrado huracanes, batallas, guerras, eventos deportivos, etc. |
WORK_OF_ART | Títulos de libros, canciones, etc. |
LANGUAGE | Cualquier idioma nombrado. |


