sense2vec
v2.0.2
Sense2Vec (Trask et. AL, 2015) est une belle tournure sur Word2Vec qui vous permet d'apprendre des vecteurs de mots plus intéressants et détaillés. Cette bibliothèque est une simple implémentation Python pour le chargement, l'interrogation et la formation Sense2Vec. Pour plus de détails, consultez notre article de blog. Pour explorer les similitudes sémantiques à travers tous les commentaires de Reddit de 2015 et 2019, voir la démo interactive.
? Version 2.0 (pour Spacy v3) Out maintenant! Lisez les notes de communication ici.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ Notez que cet exemple décrit l'utilisation avec Spacy V3. Pour une utilisation avec Spacy V2, téléchargezsense2vec==1.0.3et consultez la branchev1.xde ce référentiel.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]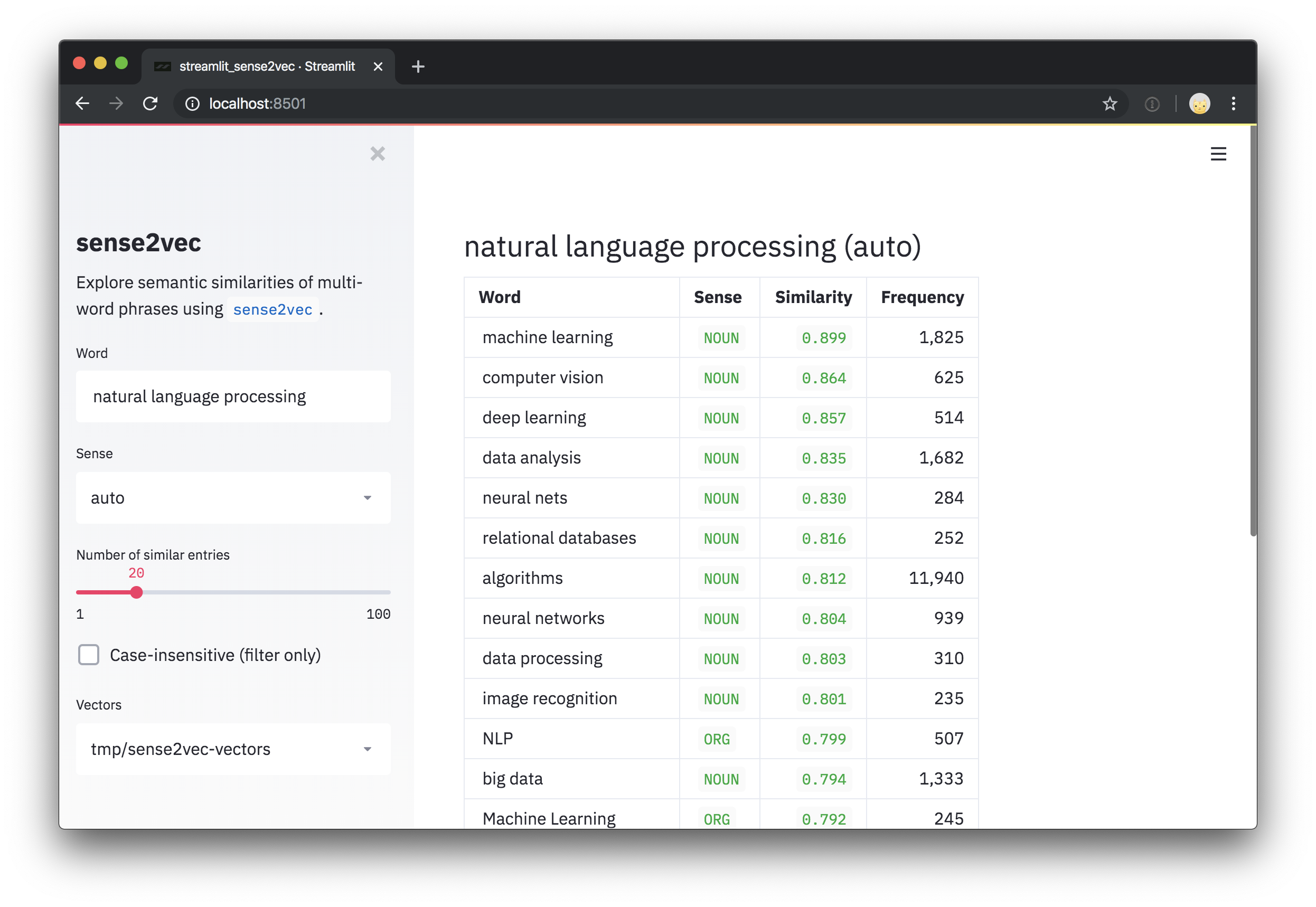
Pour essayer nos vecteurs pré-entraînés formés aux commentaires de Reddit, consultez la démo interactive Sense2Vec.
Ce repo comprend également un script de démonstration rationalisé pour explorer les vecteurs et les phrases les plus similaires. Après avoir installé streamlit , vous pouvez exécuter le script avec streamlit run et un ou plusieurs chemins vers des vecteurs prétraités comme arguments de position sur la ligne de commande. Par exemple:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors Pour utiliser les vecteurs, téléchargez les archives et passez le répertoire extrait à Sense2Vec.from_disk ou Sense2VecComponent.from_disk . Les fichiers vectoriels sont joints à la version github . Les fichiers volumineux ont été divisés en téléchargements en plusieurs parties.
| Vecteurs | Taille | Description | ? Télécharger (zippé) |
|---|---|---|---|
s2v_reddit_2019_lg | 4 Go | Reddit Commentaires 2019 (01-07) | Partie 1, partie 2, partie 3 |
s2v_reddit_2015_md | 573 MB | Reddit Commentaires 2015 | partie 1 |
Pour fusionner les archives en plusieurs parties, vous pouvez exécuter ce qui suit:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzLes versions Sense2Vec sont disponibles sur PIP:
pip install sense2vec Pour utiliser des vecteurs pré-entraînés, téléchargez l'un des packages vectoriels, déballez l'archive et le point .tar.gz from_disk au répertoire de données extrait:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) La façon la plus simple d'utiliser la bibliothèque et les vecteurs est de le brancher sur votre pipeline spacy. Le package sense2vec expose un Sense2VecComponent , qui peut être initialisé avec le vocabulaire partagé et ajouté à votre pipeline Spacy en tant que composant de pipeline personnalisé. Par défaut, des composants sont ajoutés à la fin du pipeline , qui est la position recommandée pour ce composant, car il a besoin d'accès à l'analyse de dépendance et, si disponible, des entités nommées.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) Le composant ajoutera plusieurs attributs et méthodes d'extension aux objets Token et Span de Spacy qui vous permettent de récupérer des vecteurs et des fréquences, ainsi que la plupart des termes similaires.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )Pour les entités, les étiquettes d'entité sont utilisées comme "sens" (au lieu de la balise de la partie de la parole du jeton):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) Les attributs d'extension suivants sont exposés sur l'objet Doc via la propriété ._ :
| Nom | Type d'attribut | Taper | Description |
|---|---|---|---|
s2v_phrases | propriété | liste | Toutes les phrases compatibles Sense2Vec dans le Doc donné (phrases nominales, entités nommées). |
Les attributs suivants sont disponibles via la propriété ._ des objets Token et Span - par exemple token._.in_s2v :
| Nom | Type d'attribut | Type de retour | Description | | ------------------ | -------------- | ------------------ | ---------------------------------------------------------------------------------- | --------------- | ------- | | in_s2v | propriété | bool | Si une clé existe sur la carte vectorielle. | | s2v_key | propriété | Unicode | La clé Sense2vec de l'objet donné, par exemple "duck | NOUN" . | | s2v_vec | propriété | ndarray[float32] | Le vecteur de la clé donnée. | | s2v_freq | propriété | int | La fréquence de la clé donnée. | | s2v_other_senses | propriété | Liste | Disponible d'autres sens, par exemple "duck | VERB" pour "duck | NOUN" . | | s2v_most_similar | Méthode | Liste | Obtenez les n termes les plus similaires. Renvoie une liste de tuples ((word, sense), score) . | | s2v_similarity | Méthode | Float | Obtenez la similitude avec un autre Token ou une autre Span . |
️ Une note sur les attributs Span: sous le capot, les entités dedoc.entssont des objetsSpan. C'est pourquoi le composant de pipeline ajoute également des attributs et des méthodes aux portes et pas seulement à des jetons. Cependant, il n'est pas recommandé d'utiliser les attributs Sense2Vec sur les tranches arbitraires du document, car le modèle n'aura probablement pas de clé pour le texte respectif. Les objetsSpann'ont pas non plus de balise de discours, donc si aucune étiquette d'entité n'est présente, le "Sense" par défaut la balise de la parole de la racine.
Si vous entraînez et emballez un pipeline Spacy et que vous souhaitez y inclure un composant SENSE2VEC, vous pouvez charger dans les données via le bloc [initialize] de la configuration de formation:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " Vous pouvez également utiliser directement la classe Sense2Vec sous-jacente et se charger dans les vecteurs à l'aide de la méthode from_disk . Voir ci-dessous pour les méthodes API disponibles.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ Remarque importante: Pour rechercher les entrées dans la table des vecteurs, les touches doivent suivre le schéma dephrase_text|SENSE(notez le_au lieu des espaces et le|avant l'étiquette ou l'étiquette) - par exemple,machine_learning|NOUN. Notez également que la table vectorielle sous-jacente est sensible à la casse.
Sense2Vec classe2vec L'objet Sense2Vec autonome qui contient les vecteurs, les chaînes et les fréquences.
Sense2Vec.__init__ Initialisez l'objet Sense2Vec .
| Argument | Taper | Description |
|---|---|---|
shape | tuple | La forme vectorielle. Par défaut (1000, 128) . |
strings | spacy.strings.StringStore | Magasin de chaînes en option. Sera créé s'il n'existe pas. |
senses | liste | Liste facultative de tous les sens disponibles. Utilisé dans les méthodes qui génèrent le meilleur sens ou d'autres sens. |
vectors_name | unicode | Nom facultatif à affecter à la table Vectors , pour éviter les affrontements. Par défaut "sense2vec" . |
overrides | diction | Fonctions personnalisées facultatives à utiliser, mappées sur des noms enregistrés via le registre, par exemple {"make_key": "custom_make_key"} . |
| Rendements | Sense2Vec | L'objet nouvellement construit. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__Le nombre de lignes dans la table des vecteurs.
| Argument | Taper | Description |
|---|---|---|
| Rendements | int | Le nombre de lignes dans la table des vecteurs. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__Vérifiez si une clé se trouve dans la table des vecteurs.
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé pour lever les yeux. |
| Rendements | bool | Si la clé est dans le tableau. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__Récupérez un vecteur pour une clé donnée. Renvoie aucune si la clé n'est pas dans le tableau.
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé pour lever les yeux. |
| Rendements | numpy.ndarray | Le vecteur ou None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ Définissez un vecteur pour une clé donnée. Roulera une erreur si la clé n'existe pas. Pour ajouter une nouvelle entrée, utilisez Sense2Vec.add .
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé. |
vector | numpy.ndarray | Le vecteur à définir. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addAjoutez un nouveau vecteur à la table.
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé à ajouter. |
vector | numpy.ndarray | Le vecteur à ajouter. |
freq | int | Nombre de fréquences facultatif. Utilisé pour trouver les meilleurs sens assortis. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqObtenez le nombre de fréquences pour une clé donnée.
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé pour lever les yeux. |
default | - | Valeur par défaut pour retourner si aucune fréquence n'est trouvée. |
| Rendements | int | Le nombre de fréquences. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqDéfinissez un nombre de fréquences pour une clé donnée.
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé pour définir le décompte pour. |
freq | int | Le nombre de fréquences. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsItérez sur les entrées de la table des vecteurs.
| Argument | Taper | Description |
|---|---|---|
| Rendements | tuple | Clé de chaîne et paires de vecteur dans le tableau. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysItérer sur les clés du tableau.
| Argument | Taper | Description |
|---|---|---|
| Rendements | unicode | Les touches de chaîne dans le tableau. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesItérer sur les vecteurs du tableau.
| Argument | Taper | Description |
|---|---|---|
| Rendements | numpy.ndarray | Les vecteurs du tableau. |
all_vecs = list ( s2v . values ())Sense2Vec.senses Les sens disponibles dans le tableau, par exemple "NOUN" ou "VERB" (ajouté à l'initialisation).
| Argument | Taper | Description |
|---|---|---|
| Rendements | liste | Les sens disponibles. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequencies de propriétéLes fréquences des clés du tableau, par ordre décroissant.
| Argument | Taper | Description |
|---|---|---|
| Rendements | liste | Les tuples (key, freq) par fréquence, descendant. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityFaites une estimation de similitude sémantique de deux clés ou deux ensembles de clés. L'estimation par défaut est la similitude du cosinus en utilisant une moyenne de vecteurs.
| Argument | Taper | Description |
|---|---|---|
keys_a | Unicode / Int / Iteable | La chaîne ou les touches entières (s). |
keys_b | Unicode / Int / Iteable | L'autre chaîne ou clé entière (s). |
| Rendements | flotter | Le score de similitude. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarObtenez les entrées les plus similaires du tableau. Si plusieurs clés sont fournies, la moyenne des vecteurs est utilisée. Pour rendre cette méthode plus rapidement, consultez le script pour précompurer un cache des voisins les plus proches.
| Argument | Taper | Description |
|---|---|---|
keys | Unicode / Int / Iteable | La chaîne ou les touches entières à comparer. |
n | int | Le nombre de clés similaires à retourner. Par défaut est 10 . |
batch_size | int | La taille du lot à utiliser. Par défaut est 16 . |
| Rendements | liste | Les (key, score) des tuples des vecteurs les plus similaires. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses Trouvez d'autres entrées pour le même mot avec un sens différent, par exemple "duck|VERB" pour "duck|NOUN" .
| Argument | Taper | Description |
|---|---|---|
key | Unicode / int | La clé à vérifier. |
ignore_case | bool | Vérifiez les majuscules, les minuscules et les titres. Par défaut est True . |
| Rendements | liste | Les touches de chaîne des autres entrées avec différents sens. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense Trouvez le sens du meilleur match pour un mot donné en fonction des sens et des dénombrements de fréquence disponibles. Renvoie None si aucune correspondance n'est trouvée.
| Argument | Taper | Description |
|---|---|---|
word | unicode | Le mot à vérifier. |
senses | liste | Liste facultative des sens pour limiter la recherche à. S'il n'est pas défini / vide, tous les sens des vecteurs sont utilisés. |
ignore_case | bool | Vérifiez les majuscules, les minuscules et les titres. Par défaut est True . |
| Rendements | unicode | La clé de la meilleure correspondance ou aucune. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Sérialisez un objet Sense2Vec à un bytestring.
| Argument | Taper | Description |
|---|---|---|
exclude | liste | Noms des champs de sérialisation à exclure. |
| Rendements | octets | L'objet Sense2Vec sérialisé. |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Chargez un objet Sense2Vec à partir d'un bytestring.
| Argument | Taper | Description |
|---|---|---|
bytes_data | octets | Les données à charger. |
exclude | liste | Noms des champs de sérialisation à exclure. |
| Rendements | Sense2Vec | L'objet chargé. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Sérialisez un objet Sense2Vec à un répertoire.
| Argument | Taper | Description |
|---|---|---|
path | Unicode / Path | Le chemin. |
exclude | liste | Noms des champs de sérialisation à exclure. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk Chargez un objet Sense2Vec à partir d'un répertoire.
| Argument | Taper | Description |
|---|---|---|
path | Unicode / Path | Le chemin de chargement de |
exclude | liste | Noms des champs de sérialisation à exclure. |
| Rendements | Sense2Vec | L'objet chargé. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentLe composant du pipeline pour ajouter Sense2Vec aux pipelines spacy.
Sense2VecComponent.__init__Initialisez le composant du pipeline.
| Argument | Taper | Description |
|---|---|---|
vocab | Vocab | Le Vocab partagé. Principalement utilisé pour le StringStore partagé. |
shape | tuple | La forme vectorielle. |
merge_phrases | bool | Que ce soit pour fusionner les phrases Sense2vec en un seul jeton. Par défaut est False . |
lemmatize | bool | Recherchez toujours les lemmes si disponibles dans les vecteurs, sinon par défaut par défaut du mot original. Par défaut est False . |
overrides | Fonctions personnalisées facultatives à utiliser, mappées sur des noms enregistrés via le registre, par exemple {"make_key": "custom_make_key"} . | |
| Rendements | Sense2VecComponent | L'objet nouvellement construit. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp Initialisez le composant à partir d'un objet NLP. Principalement utilisé comme usine de composants pour le point d'entrée (voir setup.cfg) et pour vous inscrire automatiquement via le décorateur @spacy.component .
| Argument | Taper | Description |
|---|---|---|
nlp | Language | L'objet nlp . |
**cfg | - | Paramètres de configuration facultatifs. |
| Rendements | Sense2VecComponent | L'objet nouvellement construit. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ Traitez un objet Doc avec le composant. Généralement, uniquement appelé dans le cadre du pipeline Spacy et non directement.
| Argument | Taper | Description |
|---|---|---|
doc | Doc | Le document à traiter. |
| Rendements | Doc | le document traité. |
Sense2Vec.init_componentEnregistrez les attributs d'extension spécifiques au composant ici et uniquement si le composant est ajouté au pipeline et utilisé - sinon, les jetons obtiendront toujours les attributs même si le composant est uniquement créé et non ajouté.
Sense2VecComponent.to_bytes Sérialisez le composant en un by-atestring. Également appelé lorsque le composant est ajouté au pipeline et que vous exécutez nlp.to_bytes .
| Argument | Taper | Description |
|---|---|---|
| Rendements | octets | Le composant sérialisé. |
Sense2VecComponent.from_bytes Chargez un composant à partir d'un bytestring. Également appelé lorsque vous exécutez nlp.from_bytes .
| Argument | Taper | Description |
|---|---|---|
bytes_data | octets | Les données à charger. |
| Rendements | Sense2VecComponent | L'objet chargé. |
Sense2VecComponent.to_disk Sérialisez le composant dans un répertoire. Également appelé lorsque le composant est ajouté au pipeline et que vous exécutez nlp.to_disk .
| Argument | Taper | Description |
|---|---|---|
path | Unicode / Path | Le chemin. |
Sense2VecComponent.from_disk Chargez un objet Sense2Vec à partir d'un répertoire. Également appelé lorsque vous exécutez nlp.from_disk .
| Argument | Taper | Description |
|---|---|---|
path | Unicode / Path | Le chemin de chargement de |
| Rendements | Sense2VecComponent | L'objet chargé. |
registry des classes Registre des fonctions (alimentée par catalogue ) pour personnaliser facilement les fonctions utilisées pour générer des clés et des phrases. Vous permet de décorer et de nommer des fonctions personnalisées, de les échanger et de sérialiser les noms personnalisés lorsque vous enregistrez le modèle. Les options de registre suivantes sont disponibles:
| Nom | Description | | ------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | | registry.make_key | Étant donné un word et sense , renvoyez une chaîne de la clé, par exemple "word | sense". | | registry.split_key | Étant donné une clé de chaîne, renvoyez un tuple (word, sense) . | | registry.make_spacy_key | Étant donné un objet Spacy ( Token ou Span ) et un argument de mot-clé Boolean prefer_ents (que ce soit pour préférer l'étiquette d'entité pour les jetons simples), renvoyez un tuple (word, sense) . Utilisé dans les attributs d'extension pour générer une clé pour les jetons et les portées. | | | registry.get_phrases | Compte tenu d'un Doc Spacy, renvoyez une liste d'objets Span utilisés pour les phrases Sense2Vec (généralement des phrases nommées et des entités nommées). | | registry.merge_phrases | Compte tenu d'un Doc spacy, obtenez toutes les phrases Sense2Vec et fusionnez-les en jetons simples. |
Chaque registre a une méthode register qui peut être utilisée comme décorateur de fonction et prend un argument, le nom de la fonction personnalisée.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Lors de l'initialisation de l'objet Sense2Vec , vous pouvez désormais transmettre un dictionnaire de remplacements avec les noms de vos fonctions enregistrées personnalisées.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )Cela permet d'expérimenter facilement avec différentes stratégies et de sérialiser les stratégies en tant que chaînes simples (au lieu d'avoir à passer et / ou à pickle les fonctions elles-mêmes).
Le répertoire /scripts contient des utilitaires de ligne de commande pour le prétraitement du texte et la formation de vos propres vecteurs.
Pour former vos propres vecteurs Sense2Vec, vous aurez besoin de ce qui suit:
doc.noun_chunks . Si le langage dont vous avez besoin ne fournit pas un itérateur de syntaxe intégré pour les phrases nominales, vous devrez écrire le vôtre. (Les doc.noun_chunks et doc.ents sont ce que Sense2Vec utilise pour déterminer ce qu'est une phrase.)make dans le répertoire respectif. Le processus de formation est divisé en plusieurs étapes pour vous permettre de reprendre à un moment donné. Les scripts de traitement sont conçus pour fonctionner sur des fichiers uniques, ce qui facilite la parallèle le travail. Les scripts de ce dépôt nécessitent un gant ou un texte rapide que vous devez cloner et make .
Pour FastText, les scripts nécessiteront le chemin d'accès au fichier binaire créé. Si vous travaillez sur Windows, vous pouvez construire avec cmake , ou utiliser alternativement le fichier .exe à partir de ce référentiel non officiel avec des builds binaires rapides pour Windows: https://github.com/xiamx/fastText/releases.
| Scénario | Description | |
|---|---|---|
| 1 et 1 | 01_parse.py | Utilisez Spacy pour analyser le texte brut et sortir des collections binaires d'objets Doc (voir DocBin ). |
| 2 | 02_preprocess.py | Chargez une collection d'objets Doc analysés produits dans les fichiers de texte d'étape et de sortie précédents au format Sense2Vec (une phrase par ligne et des phrases fusionnées avec des sens). |
| 3 et 3 | 03_glove_build_counts.py | Utilisez Glove pour construire le vocabulaire et compte. Évitez cette étape si vous utilisez Word2Vec via FastText. |
| 4 | 04_glove_train_vectors.py04_fasttext_train_vectors.py | Utilisez Glove ou FastText pour former des vecteurs. |
| 5 | 05_export.py | Chargez les vecteurs et les fréquences et sortez un composant Sense2Vec qui peut être chargé via Sense2Vec.from_disk . |
| 6. | 06_precompute_cache.py | Facultatif: précompute les requêtes les plus proches de l'Eighbor pour chaque entrée du vocabulaire pour rendre Sense2Vec.most_similar plus rapidement. |
Pour une documentation plus détaillée des scripts, consultez la source ou exécutez-les avec --help . Par exemple, python scripts/01_parse.py --help .
Ce package s'intègre également de manière transparente à l'outil d'annotation Prodigy et expose les recettes pour utiliser des vecteurs Sense2Vec pour générer rapidement des listes de phrases multi-mots et d'annotations Bootstrap NER. Pour utiliser une recette, sense2vec doit être installé dans le même environnement que Prodigy. Pour un exemple de cas d'utilisation du monde réel, consultez ce projet NER avec des ensembles de données téléchargeables.
Les recettes suivantes sont disponibles - voir ci-dessous pour des documents plus détaillés.
| Recette | Description |
|---|---|
sense2vec.teach | Bootstrap une liste de terminologie à l'aide de sens2vec. |
sense2vec.to-patterns | Convertir les phrases de données en modèles de correspondance basés sur les jetons. |
sense2vec.eval | Évaluez un modèle Sense2Vec en interrogeant les triplets de phrases. |
sense2vec.eval-most-similar | Évaluez un modèle SENS2VEC en corrigeant les entrées les plus similaires. |
sense2vec.eval-ab | Effectuer une évaluation A / B de deux modèles vectoriels Sense2Vec pré-entraînés. |
sense2vec.teachBootstrap une liste de terminologie à l'aide de sens2vec. Prodigy suggérera des termes similaires basés sur les phrases les plus similaires de Sense2Vec, et les suggestions seront ajustées lorsque vous annotez et acceptez des phrases similaires. Pour chaque terme de semence, le meilleur sens de correspondance selon les vecteurs Sense2Vec sera utilisé.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| Argument | Taper | Description |
|---|---|---|
dataset | positionnel | Ensemble de données pour enregistrer les annotations. |
vectors_path | positionnel | Chemin vers les vecteurs Sense2vec pré-entraînés. |
--seeds , -s | option | Une ou plusieurs phrases de semences séparées par des virgules. |
--threshold , -t | option | Seuil de similitude. Par défaut à 0.85 . |
--n-similar , -n | option | Nombre d'éléments similaires à obtenir immédiatement. |
--batch-size , -b | option | Taille du lot pour soumettre des annotations. |
--resume , -R | drapeau | Reprendre à partir d'un ensemble de données de phrases existantes. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns Convertissez un ensemble de données de phrases collectées avec sense2vec.teach en modèles de correspondance basés sur les jetons qui peuvent être utilisés avec EntityRuler de Spacy ou des recettes comme ner.match . Si aucun fichier de sortie n'est spécifié, les modèles sont écrits sur stdout. Les exemples sont tokenisés afin que les termes multi-token soient représentés correctement, par exemple: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| Argument | Taper | Description |
|---|---|---|
dataset | positionnel | Ensemble de données de phrase à convertir. |
spacy_model | positionnel | Modèle spacy pour la tokenisation. |
label | positionnel | Étiquetez pour s'appliquer à tous les modèles. |
--output-file , -o | option | Fichier de sortie facultatif. Par défaut est stdout. |
--case-sensitive , -CS | drapeau | Rendre les modèles sensibles à la casse. |
--dry , -D | drapeau | Effectuez une course à sec et ne publiez rien. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalÉvaluez un modèle Sense2Vec en interrogeant les triplets de phrases: le mot est-il plus similaire au mot b, ou au mot c? Si l'humain est principalement d'accord avec le modèle, le modèle des vecteurs est bon. La recette ne pose que des questions sur les vecteurs avec le même sens et prend en charge différentes stratégies de sélection d'exemples.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| Argument | Taper | Description |
|---|---|---|
dataset | positionnel | Ensemble de données pour enregistrer les annotations. |
vectors_path | positionnel | Chemin vers les vecteurs Sense2vec pré-entraînés. |
--strategy , -st | option | Exemple de stratégie de sélection. most similar (par défaut) ou random . |
--senses , -s | option | Liste de sens séparée par des virgules pour limiter la sélection à. Si ce n'est pas défini, tous les sens des vecteurs seront utilisés. |
--exclude-senses , -es | option | Liste de sens séparée par des virgules à exclure. Voir prodigy_recipes.EVAL_EXCLUDE_SENSES des paramètres par défaut. |
--n-freq , -f | option | Nombre des entrées les plus fréquentes à limiter. |
--threshold , -t | option | Seuil de similitude minimum pour considérer les exemples. |
--batch-size , -b | option | Taille du lot à utiliser. |
--eval-whole , -E | drapeau | Évaluez l'ensemble de données au lieu de la session actuelle. |
--eval-only , -O | drapeau | N'annotez pas, évaluez uniquement l'ensemble de données actuel. |
--show-scores , -S | drapeau | Montrez tous les scores pour le débogage. |
| Nom | Description |
|---|---|
most_similar | Choisissez un mot aléatoire dans un sens aléatoire et obtenez ses entrées les plus similaires du même sens. Renseignez-vous sur la similitude avec la dernière entrée et intermédiaire de cette sélection. |
most_least_similar | Choisissez un mot aléatoire dans un sens aléatoire et obtenez l'entrée la moins similaire à partir de ses entrées les plus similaires, puis la dernière entrée la plus similaire de cela. |
random | Choisissez un échantillon aléatoire de 3 mots dans le même sens aléatoire. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5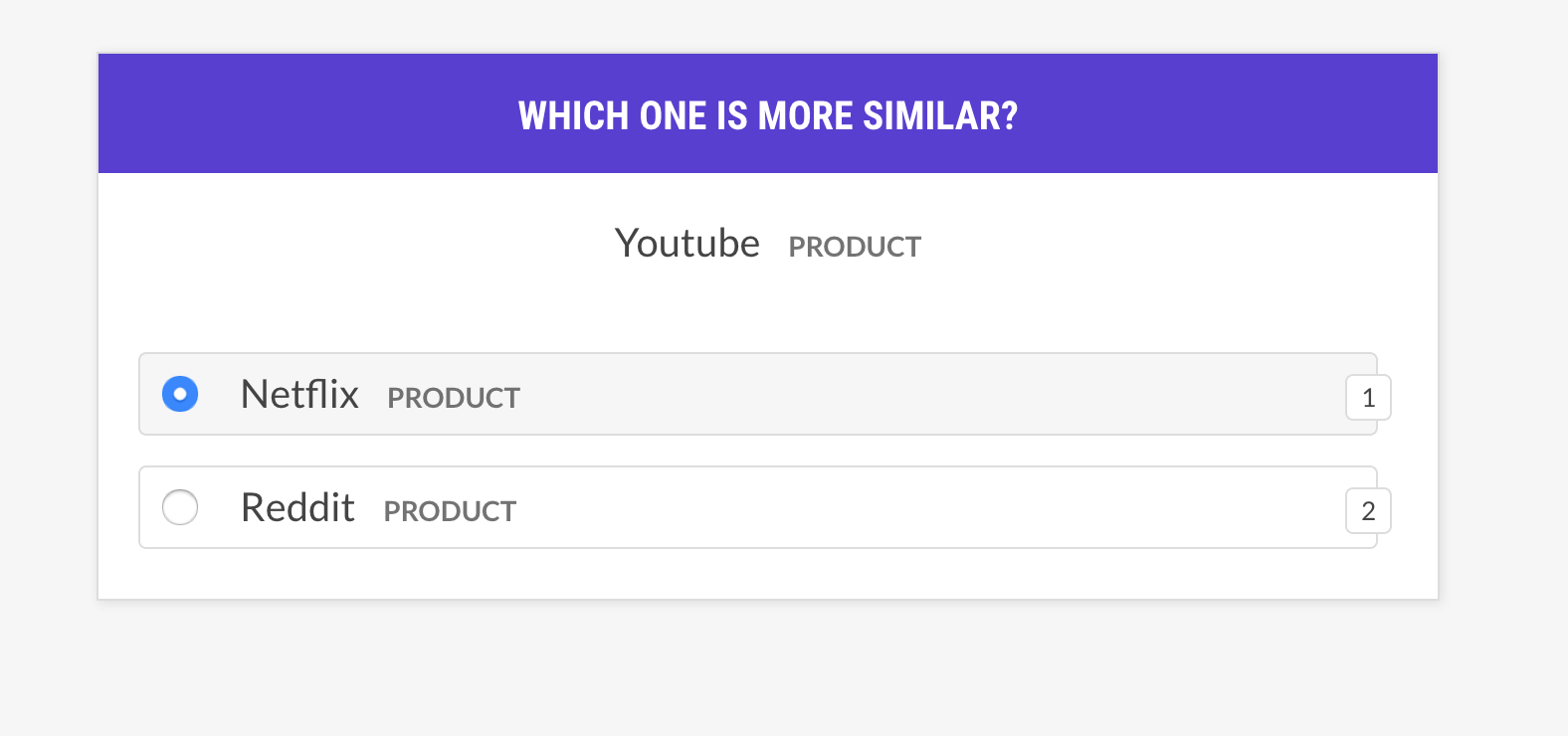
sense2vec.eval-most-similarÉvaluez un modèle de vecteurs en examinant les entrées les plus similaires qu'il renvoie pour une phrase aléatoire et en désempant les erreurs.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| Argument | Taper | Description |
|---|---|---|
dataset | positionnel | Ensemble de données pour enregistrer les annotations. |
vectors_path | positionnel | Chemin vers les vecteurs Sense2vec pré-entraînés. |
--senses , -s | option | Liste de sens séparée par des virgules pour limiter la sélection à. Si ce n'est pas défini, tous les sens des vecteurs seront utilisés. |
--exclude-senses , -es | option | Liste de sens séparée par des virgules à exclure. Voir prodigy_recipes.EVAL_EXCLUDE_SENSES des paramètres par défaut. |
--n-freq , -f | option | Nombre des entrées les plus fréquentes à limiter. |
--n-similar , -n | option | Nombre d'éléments similaires à vérifier. Par défaut est 10 . |
--batch-size , -b | option | Taille du lot à utiliser. |
--eval-whole , -E | drapeau | Évaluez l'ensemble de données au lieu de la session actuelle. |
--eval-only , -O | drapeau | N'annotez pas, évaluez uniquement l'ensemble de données actuel. |
--show-scores , -S | drapeau | Montrez tous les scores pour le débogage. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abEffectuez une évaluation A / B de deux modèles vectoriels Sense2Vec pré-entraînés en comparant les entrées les plus similaires qu'ils renvoient pour une phrase aléatoire. L'interface utilisateur montre deux options randomisées avec les entrées les plus similaires de chaque modèle et met en évidence les phrases qui diffèrent. À la fin de la session d'annotation, les statistiques globales et le modèle préféré sont affichés.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| Argument | Taper | Description |
|---|---|---|
dataset | positionnel | Ensemble de données pour enregistrer les annotations. |
vectors_path_a | positionnel | Chemin vers les vecteurs Sense2vec pré-entraînés. |
vectors_path_b | positionnel | Chemin vers les vecteurs Sense2vec pré-entraînés. |
--senses , -s | option | Liste de sens séparée par des virgules pour limiter la sélection à. Si ce n'est pas défini, tous les sens des vecteurs seront utilisés. |
--exclude-senses , -es | option | Liste de sens séparée par des virgules à exclure. Voir prodigy_recipes.EVAL_EXCLUDE_SENSES des paramètres par défaut. |
--n-freq , -f | option | Nombre des entrées les plus fréquentes à limiter. |
--n-similar , -n | option | Nombre d'éléments similaires à vérifier. Par défaut est 10 . |
--batch-size , -b | option | Taille du lot à utiliser. |
--eval-whole , -E | drapeau | Évaluez l'ensemble de données au lieu de la session actuelle. |
--eval-only , -O | drapeau | N'annotez pas, évaluez uniquement l'ensemble de données actuel. |
--show-mapping , -S | drapeau | Affichez les modèles qui sont les options 1 et l'option 2 dans l'interface utilisateur (pour le débogage). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT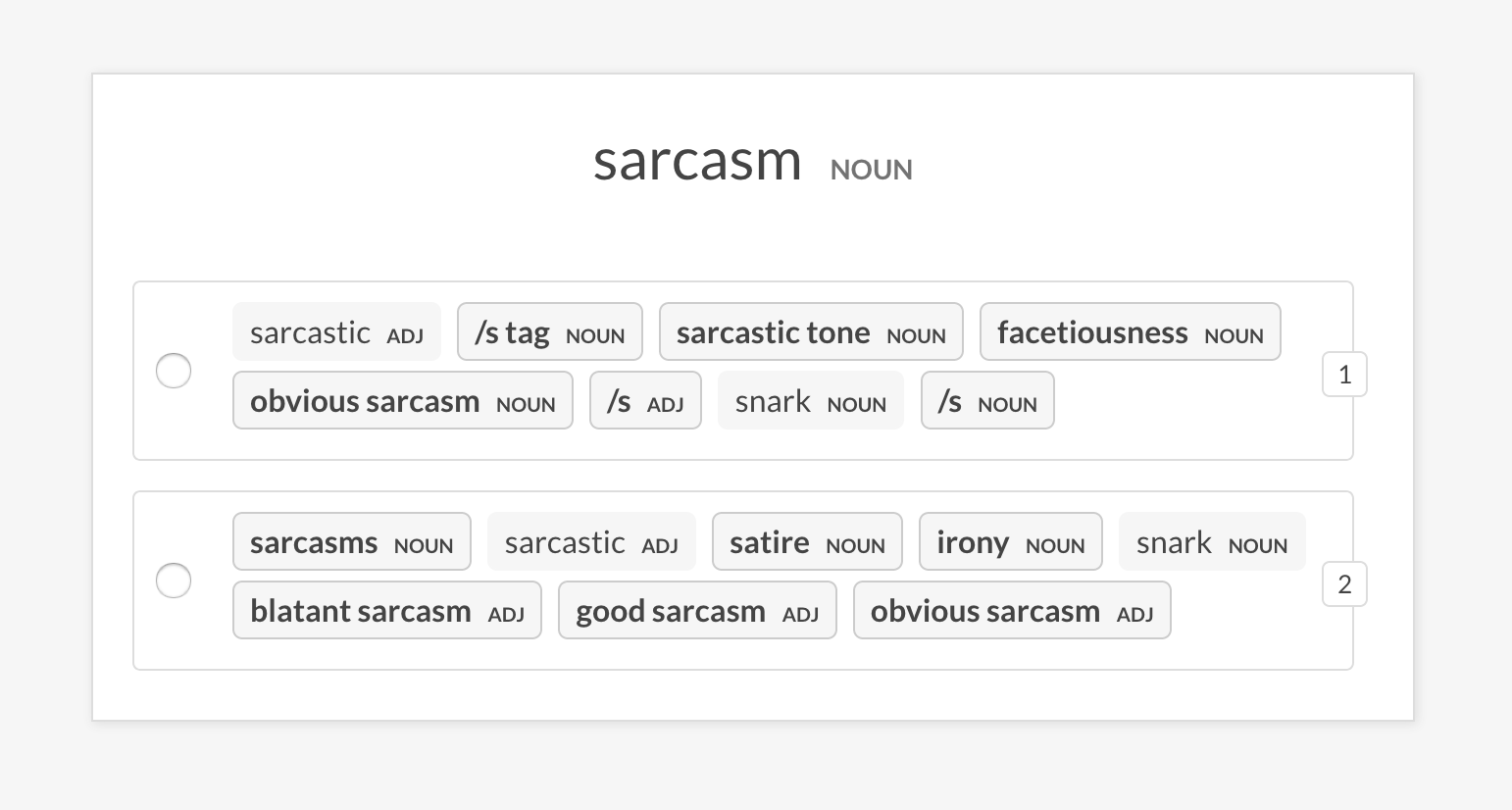
Les vecteurs Reddit pré-entraînés prennent en charge les "sens" suivants, soit des étiquettes de discours ou des étiquettes entités. Pour plus de détails, voir Aperçu du schéma d'annotation de Spacy.
| Étiqueter | Description | Exemples |
|---|---|---|
ADJ | adjectif | Grand, vieux, vert |
ADP | adposition | dans, à, pendant |
ADV | adverbe | Très, demain, en bas, où |
AUX | auxiliaire | est, a (fait), will (faire) |
CONJ | conjonction | et, ou, mais |
DET | déterminant | un, an, le |
INTJ | interjection | psst, aïe, bravo, bonjour |
NOUN | nom | Fille, chat, arbre, air, beauté |
NUM | numéral | 1, 2017, un, soixante-dix-sept, MMXIV |
PART | particule | 's, pas |
PRON | pronom | Moi, toi, lui, elle, moi-même, quelqu'un |
PROPN | nom propre | Mary, John, Londres, OTAN, HBO |
PUNCT | ponctuation | ,? () |
SCONJ | conjonction subordonnée | Si, tandis que c'est |
SYM | symbole | $,%, =, :) ,? |
VERB | verbe | courir, courir, courir, manger, manger, manger |
| Étiquette d'entité | Description |
|---|---|
PERSON | Les gens, y compris fictif. |
NORP | Nationalités ou groupes religieux ou politiques. |
FACILITY | Bâtiments, aéroports, autoroutes, ponts, etc. |
ORG | Entreprises, agences, institutions, etc. |
GPE | Pays, villes, États. |
LOC | Emplacements non GPE, chaînes de montagnes, plans d'eau. |
PRODUCT | Objets, véhicules, aliments, etc. (pas de services.) |
EVENT | Nommé des ouragans, des batailles, des guerres, des événements sportifs, etc. |
WORK_OF_ART | Titres de livres, de chansons, etc. |
LANGUAGE | Toute langue nommée. |


