sense2vec
v2.0.2
Sense2VEC (Trask et. Al, 2015) - хороший поворот в Word2VEC, который позволяет вам изучать более интересные и подробные слова. Эта библиотека представляет собой простую реализацию Python для загрузки, запросов и обучения моделей Sense2VEC. Для получения более подробной информации, ознакомьтесь с нашим сообщением в блоге. Чтобы исследовать семантическое сходство во всех комментариях Reddit 2015 и 2019 годов, см. Интерактивную демонстрацию.
? Версия 2.0 (для Spacy v3) сейчас! Прочитайте заметки о выпуске здесь.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ Обратите внимание, что этот пример описывает использование с Spacy v3. Для использования со Spacy V2 загрузитеsense2vec==1.0.3и ознакомьтесь с ветвьюv1.xэтого репо.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]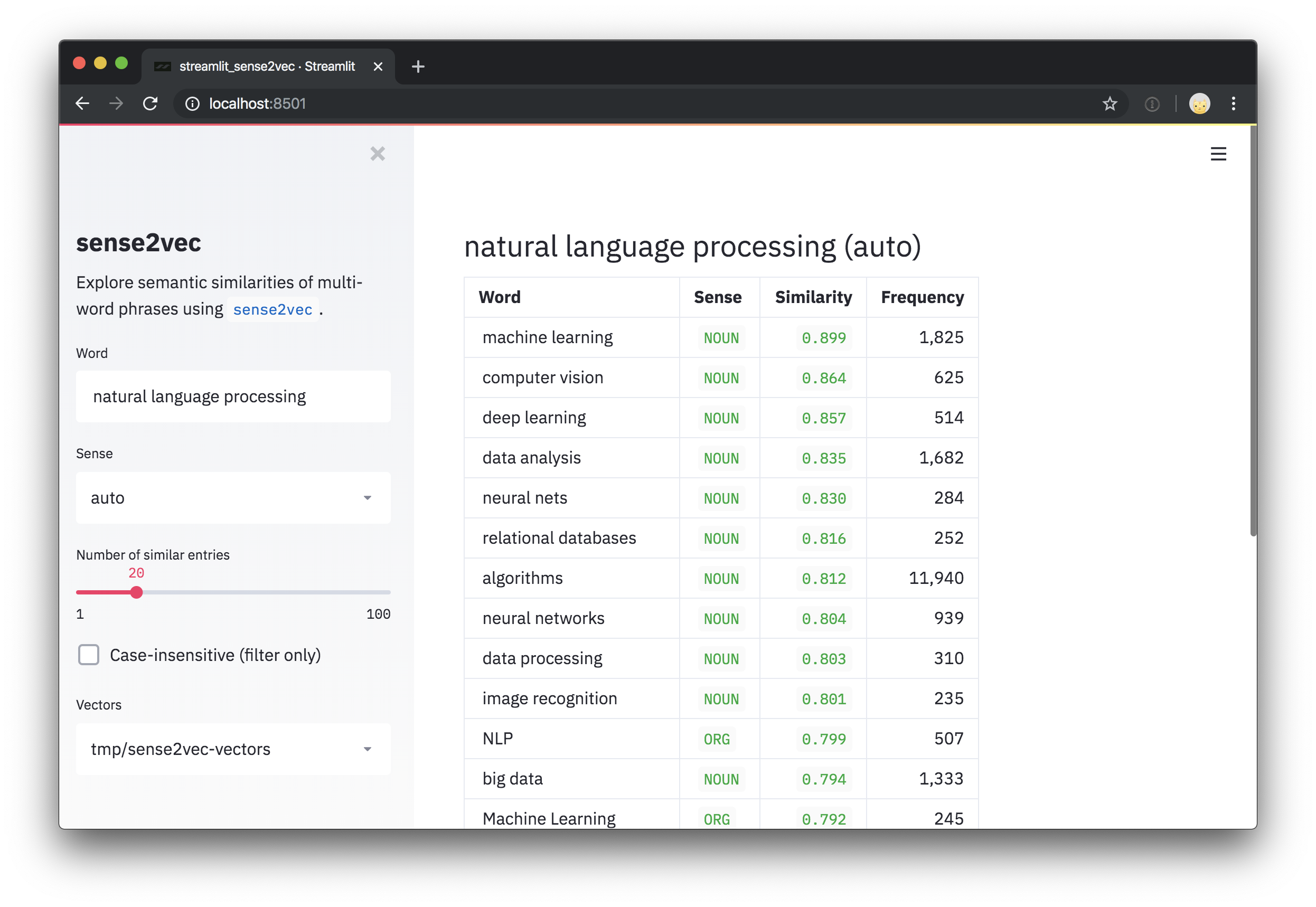
Чтобы попробовать наши предварительные векторы, обученные в комментариях Reddit, ознакомьтесь с демонстрацией интерактивного Sense2VEC.
Этот репо также включает в себя демонстрационный скрипт для изучения векторов и самые похожие фразы. После установки streamlit вы можете запустить сценарий с помощью streamlit run и одного или нескольких путей к предварительному векторам в качестве позиционных аргументов в командной строке. Например:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors Чтобы использовать векторы, загрузите архив (ы) и передайте извлеченный каталог Sense2Vec.from_disk или Sense2VecComponent.from_disk . Векторные файлы прикреплены к выпуску GitHub . Большие файлы были разделены на многочасовые загрузки.
| Векторы | Размер | Описание | ? Скачать (ZIPPED) |
|---|---|---|---|
s2v_reddit_2019_lg | 4ГБ | Комментарии Reddit 2019 (01-07) | Часть 1, часть 2, часть 3 |
s2v_reddit_2015_md | 573 МБ | Reddit Comments 2015 | Часть 1 |
Чтобы объединить многочасовые архивы, вы можете запустить следующее:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzВыпуски Sense2VEC доступны на PIP:
pip install sense2vec Чтобы использовать предварительные векторы, загрузите один из векторных пакетов, распаковать архив .tar.gz и точка from_disk до извлеченного каталога данных:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) Самый простой способ использования библиотеки и векторов - подключить ее к трубопроводу Spacy. Пакет sense2vec раскрывает Sense2VecComponent , который может быть инициализирован с помощью общего слока и добавлен в ваш трубопровод Spacy в качестве пользовательского компонента трубопровода. По умолчанию компоненты добавляются к окончанию трубопровода , который является рекомендуемой позицией для этого компонента, поскольку он нуждается в доступе к обработке зависимости и, если доступно, названные объекты.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) Компонент добавит несколько атрибутов и методов расширения в Token Spacy и Span объекты, которые позволяют вам получить векторы и частоты, а также большинство аналогичных терминов.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )Для сущностей этикетки сущности используются в качестве «смысла» (вместо тега токена со стороны речи):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) Следующие атрибуты расширения выставлены на объекте Doc через свойство ._ :
| Имя | Тип атрибута | Тип | Описание |
|---|---|---|---|
s2v_phrases | свойство | список | Все смысл2VEC-совместимых фраз в данном Doc (существительные фразы, названные сущности). |
token._.in_s2v атрибуты доступны Span Token ._
| Имя | Тип атрибута | Возврат тип | Описание | | ------------------ | -------------- | ------------------ | ------------------------------------------------------------------------------ | --------------- | ------- | | in_s2v | собственность | Bool | Существует ли ключ в векторной карте. | | s2v_key | собственность | Unicode | Sense2VEC Ключ от данного объекта, например "duck | NOUN" . | | s2v_vec | собственность | ndarray[float32] | Вектор данного ключа. | | s2v_freq | собственность | int | Частота данного ключа. | | s2v_other_senses | собственность | список | Доступны другие чувства, например "duck | VERB" для "duck | NOUN" . | | s2v_most_similar | Метод | список | Получите n похожие термины. Возвращает список ((word, sense), score) . | | s2v_similarity | Метод | Поплавок | Получите сходство с другим Token или Span . |
️ Примечание по атрибутам SPAN: под капотом объекты вdoc.entsявляются объектамиSpan. Вот почему компонент трубопровода также добавляет атрибуты и методы для пролета, а не только токены. Тем не менее, не рекомендуется использовать атрибуты Sense2VEC на произвольных срезах документа, поскольку модель, вероятно, не будет иметь ключа для соответствующего текста. ОбъектыSpanтакже не имеют тега части речи, поэтому, если этикетки объекта не присутствуют, «смысл» по умолчанию к тегу части речи корня.
Если вы тренируете и упаковываете трубопровод Spacy и хотите включить в него компонент Sense2VEC, вы можете загрузить в данные через блок [initialize] тренировочной конфигурации:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " Вы также можете напрямую использовать базовый класс Sense2Vec и загрузить в векторы, используя метод from_disk . См. Ниже для доступных методов API.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ Важное примечание: чтобы посмотреть записи в таблице векторов, ключи должны следовать схемеphrase_text|SENSE(обратите внимание на_вместо пространств и|перед тегом или меткой) - например,machine_learning|NOUN. Также обратите внимание, что базовая векторная таблица чувствительна к случаям.
Sense2Vec Автономный объект Sense2Vec , который содержит векторы, строки и частоты.
Sense2Vec.__init__ Инициализируйте объект Sense2Vec .
| Аргумент | Тип | Описание |
|---|---|---|
shape | кортеж | Векторная форма. По умолчанию (1000, 128) . |
strings | spacy.strings.StringStore | Дополнительный магазин строк. Будет создан, если его не существует. |
senses | список | Необязательный список всех доступных чувств. Используется в методах, которые генерируют наилучший смысл или другие чувства. |
vectors_name | Unicode | Необязательное имя для назначения таблице Vectors , чтобы предотвратить столкновения. По умолчанию "sense2vec" . |
overrides | диктат | Необязательные пользовательские функции для использования, сопоставлены с именами, зарегистрированными через реестр, например {"make_key": "custom_make_key"} . |
| Возврат | Sense2Vec | Недавно построенный объект. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__Количество рядов в таблице векторов.
| Аргумент | Тип | Описание |
|---|---|---|
| Возврат | инт | Количество рядов в таблице векторов. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__Проверьте, находится ли ключ в таблице векторов.
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ, чтобы посмотреть вверх. |
| Возврат | буль | Является ли ключ в таблице. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__Получить вектор для данного ключа. Возвращает нет, если ключа нет в таблице.
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ, чтобы посмотреть вверх. |
| Возврат | numpy.ndarray | Вектор или None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ Установите вектор для данного ключа. Вынесет ошибку, если ключ не существует. Чтобы добавить новую запись, используйте Sense2Vec.add .
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ. |
vector | numpy.ndarray | Вектор для установки. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addДобавьте новый вектор в таблицу.
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ к добавлению. |
vector | numpy.ndarray | Вектор, чтобы добавить. |
freq | инт | Необязательное количество частот. Используется, чтобы найти лучшие подходящие чувства. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqПолучите количество частот для данного ключа.
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ, чтобы посмотреть вверх. |
default | - | Значение по умолчанию, чтобы вернуть, если частота не найдена. |
| Возврат | инт | Количество частот. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqУстановите количество частот для данного ключа.
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ, чтобы установить количество для. |
freq | инт | Количество частот. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsИтерация над записями в таблице векторов.
| Аргумент | Тип | Описание |
|---|---|---|
| Доходность | кортеж | Строковая ключа и векторные пары в таблице. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysИтерация над ключами в столе.
| Аргумент | Тип | Описание |
|---|---|---|
| Доходность | Unicode | Клавиши струны в таблице. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesИтерация над векторами в столе.
| Аргумент | Тип | Описание |
|---|---|---|
| Доходность | numpy.ndarray | Векторы в таблице. |
all_vecs = list ( s2v . values ())Sense2Vec.senses имущества2VEC.Senses Доступные чувства в таблице, например, "NOUN" или "VERB" (добавлено при инициализации).
| Аргумент | Тип | Описание |
|---|---|---|
| Возврат | список | Доступные чувства. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequencies НАБОЧКАЧастоты ключей в таблице, в порядке убывания.
| Аргумент | Тип | Описание |
|---|---|---|
| Возврат | список | (key, freq) ПУЛЕЙ по частоте, спуска. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityСделайте семантическую оценку сходства с двумя ключами или двумя наборами ключей. Оценка по умолчанию является сходство косинуса с использованием среднего значения векторов.
| Аргумент | Тип | Описание |
|---|---|---|
keys_a | Unicode / int / iterable | Строка или целочисленный ключ (ы). |
keys_b | Unicode / int / iterable | Другая строка или целочисленное ключ (ы). |
| Возврат | плавать | Оценка сходства. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarПолучите самые похожие записи в таблице. Если предоставляется более одного ключа, используется среднее значение векторов. Чтобы сделать этот метод быстрее, см. Сценарий для предварительного выпуска кеша ближайших соседей.
| Аргумент | Тип | Описание |
|---|---|---|
keys | Unicode / int / iterable | Строка или целочисленное ключ для сравнения. |
n | инт | Количество аналогичных ключей для возврата. По умолчанию до 10 . |
batch_size | инт | Размер партии для использования. По умолчанию до 16 . |
| Возврат | список | (key, score) кортежи самых похожих векторов. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses Найдите другие записи для одного и того же слова с другим смыслом, например "duck|VERB" для "duck|NOUN" .
| Аргумент | Тип | Описание |
|---|---|---|
key | Unicode / Int | Ключ для проверки. |
ignore_case | буль | Проверьте на наличие прописного, нижнего регистра и титлека. По умолчанию к True . |
| Возврат | список | Клавиши струн других записей с разными чувствами. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense Найдите лучшее смысл для данного слова на основе доступных чувств и частоты. Возвращает None , если совпадение не найдено.
| Аргумент | Тип | Описание |
|---|---|---|
word | Unicode | Слово, чтобы проверить. |
senses | список | Необязательный список чувств, чтобы ограничить поиск. Если не установлено / пустое, все чувства в векторах используются. |
ignore_case | буль | Проверьте на наличие прописного, нижнего регистра и титлека. По умолчанию к True . |
| Возврат | Unicode | Лучший ключ или нет. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Сериализуйте Sense2Vec объект на байетс.
| Аргумент | Тип | Описание |
|---|---|---|
exclude | список | Названия полей сериализации, чтобы исключить. |
| Возврат | байты | Сериализованный объект Sense2Vec . |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Загрузите объект Sense2Vec от Bytestring.
| Аргумент | Тип | Описание |
|---|---|---|
bytes_data | байты | Данные для загрузки. |
exclude | список | Названия полей сериализации, чтобы исключить. |
| Возврат | Sense2Vec | Загруженный объект. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Сериализуйте объект Sense2Vec в каталог.
| Аргумент | Тип | Описание |
|---|---|---|
path | Unicode / Path | Путь. |
exclude | список | Названия полей сериализации, чтобы исключить. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk Загрузите объект Sense2Vec из каталога.
| Аргумент | Тип | Описание |
|---|---|---|
path | Unicode / Path | Путь к загрузке из |
exclude | список | Названия полей сериализации, чтобы исключить. |
| Возврат | Sense2Vec | Загруженный объект. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentКомпонент трубопровода для добавления Sense2VEC в трубопроводы Spacy.
Sense2VecComponent.__init__Инициализировать компонент трубопровода.
| Аргумент | Тип | Описание |
|---|---|---|
vocab | Vocab | Общий Vocab . В основном используется для общего StringStore . |
shape | кортеж | Векторная форма. |
merge_phrases | буль | Собрать ли фразы Sense2VEC в один токен. По умолчанию False . |
lemmatize | буль | Всегда смотрите леммы, если доступны в векторах, в противном случае по умолчанию в оригинальное слово. По умолчанию False . |
overrides | Необязательные пользовательские функции для использования, сопоставленные с именами, регистрируемыми через реестр, например {"make_key": "custom_make_key"} . | |
| Возврат | Sense2VecComponent | Недавно построенный объект. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp Инициализируйте компонент из объекта NLP. В основном используется в качестве компонента заводской для точки входа (см. Setup.cfg) и для автоматической регистрации через декоратор @spacy.component .
| Аргумент | Тип | Описание |
|---|---|---|
nlp | Language | Объект nlp . |
**cfg | - | Необязательные параметры конфигурации. |
| Возврат | Sense2VecComponent | Недавно построенный объект. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ Обработайте объект Doc с компонентом. Обычно называется только как часть трубопровода Spacy, а не напрямую.
| Аргумент | Тип | Описание |
|---|---|---|
doc | Doc | Документ для обработки. |
| Возврат | Doc | обработанный документ. |
Sense2Vec.init_componentЗарегистрируйте атрибуты расширения специфичных для компонента здесь и только в том случае, если компонент добавлен в трубопровод и используется-в противном случае токены все равно получат атрибуты, даже если компонент будет только создан и не добавлен.
Sense2VecComponent.to_bytes Сериализуйте компонент на байтян. Также вызывается, когда компонент добавляется в трубопровод, и вы запускаете nlp.to_bytes .
| Аргумент | Тип | Описание |
|---|---|---|
| Возврат | байты | Сериализованный компонент. |
Sense2VecComponent.from_bytes Загрузите компонент с момента. Также вызвано, когда вы запускаете nlp.from_bytes .
| Аргумент | Тип | Описание |
|---|---|---|
bytes_data | байты | Данные для загрузки. |
| Возврат | Sense2VecComponent | Загруженный объект. |
Sense2VecComponent.to_disk Сериализуйте компонент в каталог. Также вызывается, когда компонент добавляется в трубопровод, и вы запускаете nlp.to_disk .
| Аргумент | Тип | Описание |
|---|---|---|
path | Unicode / Path | Путь. |
Sense2VecComponent.from_disk Загрузите объект Sense2Vec из каталога. Также вызвано, когда вы запускаете nlp.from_disk .
| Аргумент | Тип | Описание |
|---|---|---|
path | Unicode / Path | Путь к загрузке из |
| Возврат | Sense2VecComponent | Загруженный объект. |
registry Реестр функций (питается по catalogue ), чтобы легко настраивать функции, используемые для генерации клавиш и фраз. Позволяет украсить и называть пользовательские функции, обмениваться их и сериализовать пользовательские имена при сохранении модели. Доступны следующие варианты реестра:
| Имя | Описание | | ------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------- | | registry.make_key | Учитывая word и sense , верните строку ключа, например "word | sense". | | registry.split_key | Учитывая строковую клавишу, верните (word, sense) кортеж. | | registry.make_spacy_key | Учитывая объект SPACY ( Token или Span ) и аргумент ключевого слова Boolean prefer_ents (независимо от того, предпочитают ли сущность метку для одиночных токенов), верните (word, sense) . Используется в атрибутах расширения для генерации ключа для токенов и пролетов. | | | registry.get_phrases | Учитывая Doc , верните список объектов Span , используемых для фраз Sense2VEC (обычно существительные фразы и названные объекты). | | registry.merge_phrases | Учитывая Doc Spacy, получите все фразы Sense2VEC и объедините их в одиночные токены. |
Каждый реестр имеет метод register , который можно использовать в качестве декоратора функции, и принимает один аргумент, имя пользовательской функции.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense При инициализации объекта Sense2Vec вы можете пройти в словаре переопределения с именами ваших пользовательских зарегистрированных функций.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )Это позволяет легко экспериментировать с различными стратегиями и сериализовать стратегии как простые строки (вместо того, чтобы пройти и/или марировать сами функции).
Справочник /scripts содержит утилиты командной строки для предварительной обработки текста и обучения ваших собственных векторов.
Чтобы обучить свои собственные векторы Sense2VEC, вам понадобится следующее:
doc.noun_chunks . Если нужный язык не предоставляет встроенный встроенный итератор синтаксиса для существительных фраз, вам нужно написать свой собственный. ( doc.noun_chunks и doc.ents - это то, что Sense2VEC использует для определения фразы.)make в соответствующем каталоге. Процесс обучения разделен на несколько шагов, чтобы вы могли возобновить в любом данном точке. Обработка сценариев предназначена для работы на отдельных файлах, что позволяет легко параллелизировать работу. Сценарии в этом репо требуют либо перчатки, либо перчатки, либо для клонирования, которые вам нужно make .
Для быстрого текста сценариям потребуется путь к созданному двоичному файлу. Если вы работаете над Windows, вы можете построить с помощью cmake или, в качестве альтернативы, использовать файл .exe из этого неофициального репо с помощью Fasttext Binards для Windows: https://github.com/xiamx/fasttext/releases.
| Сценарий | Описание | |
|---|---|---|
| 1 | 01_parse.py | Используйте Spacy, чтобы проанализировать необработанные тексты и вывести бинарные коллекции объектов Doc (см. DocBin ). |
| 2 | 02_preprocess.py | Загрузите коллекцию проанализированных объектов Doc , произведенных в предыдущем шаге и выводится текстовые файлы в формате смысла2VEC (одно предложение на строку и объединенные фразы с чувствами). |
| 3 | 03_glove_build_counts.py | Используйте перчатку, чтобы построить словарный запас и количество. Пропустите этот шаг, если вы используете Word2VEC через FastText. |
| 4 | 04_glove_train_vectors.py04_fasttext_train_vectors.py | Используйте перчатку или быстрый текст для обучения векторов. |
| 5 | 05_export.py | Загрузите векторы и частоты и выводите компонент Sense2VEC, который можно загрузить через Sense2Vec.from_disk . |
| 6 | 06_precompute_cache.py | Необязательно: предварительно выпустить запросы ближайшего соседа для каждой записи в словаре, чтобы провести Sense2Vec.most_similar быстрее. |
Для получения более подробной документации сценария, ознакомьтесь с источником или запустите их с помощью --help . Например, python scripts/01_parse.py --help .
Этот пакет также плавно интегрируется с инструментом аннотаций вутобности и обнаруживает рецепты использования векторов Sense2VEC для быстрого составления списков фраз из нескольких слов и начальных аннотаций. Чтобы использовать рецепт, sense2vec должен быть установлен в той же среде, что и вундеркинд. Для примера реального варианта использования, ознакомьтесь с этим проектом NER с загружаемыми наборами данных.
Доступны следующие рецепты - см. Ниже более подробные документы.
| Рецепт | Описание |
|---|---|
sense2vec.teach | Bootstrap Список терминологий с использованием Sense2VEC. |
sense2vec.to-patterns | Преобразовать набор данных фраз в шаблоны совпадений на основе токенов. |
sense2vec.eval | Оцените модель Sense2VEC, спросив о тройках фразы. |
sense2vec.eval-most-similar | Оцените модель Sense2VEC, исправляя наиболее похожие записи. |
sense2vec.eval-ab | Выполните оценку A/B двух предварительно проведенных векторных моделей Sense2VEC. |
sense2vec.teachBootstrap Список терминологий с использованием Sense2VEC. Prodigy будет предлагать аналогичные термины, основанные на наиболее похожих фразах из Sense2VEC, и предложения будут скорректированы по мере того, как вы аннотируете и принимаете аналогичные фразы. Для каждого семянного термина будет использоваться лучший смысл соответствия в соответствии с векторами Sense2VEC.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| Аргумент | Тип | Описание |
|---|---|---|
dataset | позиционирование | Набор данных для сохранения аннотаций. |
vectors_path | позиционирование | Путь к предварительному Sense2VEC Vectors. |
--seeds , -s | вариант | Одна или несколько разделившихся запятых семян. |
--threshold , -t | вариант | Порог сходства. По умолчанию до 0.85 . |
--n-similar , -n | вариант | Количество аналогичных предметов, чтобы получить сразу. |
--batch-size , -b | вариант | Размер партии для отправки аннотаций. |
--resume , -R | флаг | Резюме из существующего набора данных фраз. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns Преобразуйте набор данных фраз, собранные с sense2vec.teach в токеновые шаблоны совпадений, которые можно использовать с EntityRuler Spacy или рецептами, такими как ner.match . Если выходной файл не указан, шаблоны записываются в Stdout. Примеры токенизированы так, что многократные термины представлены правильно, например: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| Аргумент | Тип | Описание |
|---|---|---|
dataset | позиционирование | Набор данных фразы для преобразования. |
spacy_model | позиционирование | модель SPACY для токенизации. |
label | позиционирование | Метка, чтобы применить все шаблоны. |
--output-file , -o | вариант | Дополнительный выходной файл. По умолчанию в Stdout. |
--case-sensitive , -CS | флаг | Сделайте шаблоны чувствительными к случаям. |
--dry , -D | флаг | Выполните сухой прогон и ничего не выводите. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalОцените модель Sense2VEC, спросив о тройках фразы: более ли слово слово более похоже на слово B или слово C? Если человек в основном согласен с моделью, модель векторов хороша. Рецепт будет спросить только о векторах с одинаковым смыслом и поддерживает различные примеры стратегии выбора.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| Аргумент | Тип | Описание |
|---|---|---|
dataset | позиционирование | Набор данных для сохранения аннотаций. |
vectors_path | позиционирование | Путь к предварительному Sense2VEC Vectors. |
--strategy , -st | вариант | Пример стратегии выбора. most similar (по умолчанию) или random . |
--senses , -s | вариант | Запятый список чувств, чтобы ограничить выбор. Если не установлено, все чувства в векторах будут использоваться. |
--exclude-senses , -es | вариант | Отдельный список чувств, чтобы исключить. См. prodigy_recipes.EVAL_EXCLUDE_SENSES fro по умолчанию. |
--n-freq , -f | вариант | Количество наиболее частых записей, чтобы ограничить. |
--threshold , -t | вариант | Минимальный порог сходства для рассмотрения примеров. |
--batch-size , -b | вариант | Размер партии для использования. |
--eval-whole , -E | флаг | Оцените весь набор данных вместо текущего сеанса. |
--eval-only , -O | флаг | Не аннотируйте, только оценивайте текущий набор данных. |
--show-scores , -S | флаг | Покажите все результаты для отладки. |
| Имя | Описание |
|---|---|
most_similar | Выберите случайное слово из случайного смысла и получите его наиболее похожие записи одного и того же смысла. Спросите о сходстве с последней и средней записью из этого выбора. |
most_least_similar | Выберите случайное слово из случайного смысла и получите наименее похожую запись из его наиболее похожих записей, а затем последнюю наиболее похожую запись этого. |
random | Выберите случайную выборку из 3 слов из того же случайного смысла. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5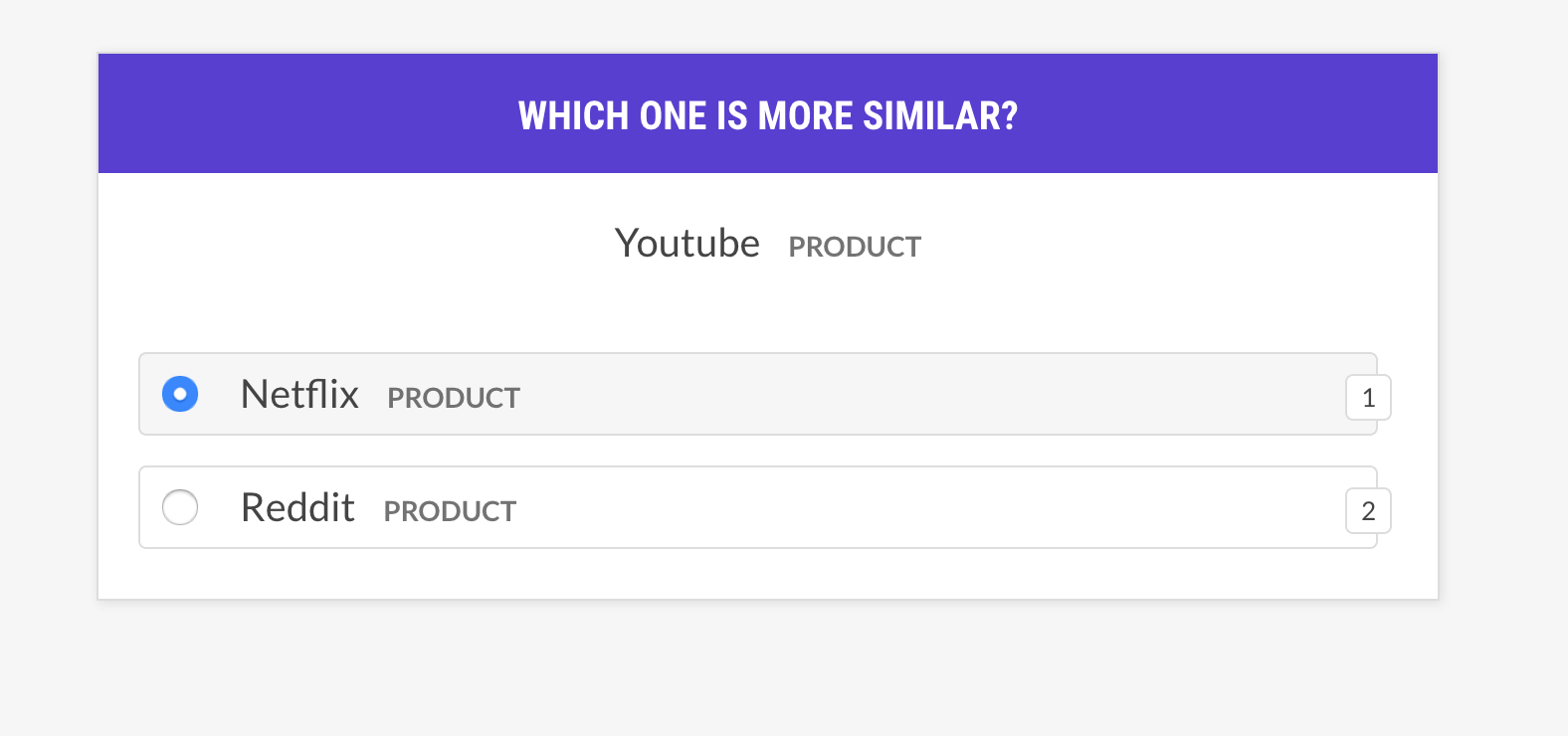
sense2vec.eval-most-similarОцените модель векторов, рассматривая самые похожие записи, которые она возвращает для случайной фразы и не поднимая ошибки.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| Аргумент | Тип | Описание |
|---|---|---|
dataset | позиционирование | Набор данных для сохранения аннотаций. |
vectors_path | позиционирование | Путь к предварительному Sense2VEC Vectors. |
--senses , -s | вариант | Запятый список чувств, чтобы ограничить выбор. Если не установлено, все чувства в векторах будут использоваться. |
--exclude-senses , -es | вариант | Отдельный список чувств, чтобы исключить. См. prodigy_recipes.EVAL_EXCLUDE_SENSES fro по умолчанию. |
--n-freq , -f | вариант | Количество наиболее частых записей, чтобы ограничить. |
--n-similar , -n | вариант | Количество аналогичных элементов для проверки. По умолчанию до 10 . |
--batch-size , -b | вариант | Размер партии для использования. |
--eval-whole , -E | флаг | Оцените весь набор данных вместо текущего сеанса. |
--eval-only , -O | флаг | Не аннотируйте, только оценивайте текущий набор данных. |
--show-scores , -S | флаг | Покажите все результаты для отладки. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abВыполните оценку A/B двух предварительных векторных моделей Sense2VEC, сравнивая наиболее похожие записи, которые они возвращаются для случайной фразы. Пользовательский интерфейс показывает два рандомизированных варианта с наиболее похожими записями каждой модели и выделяют различные фразы. В конце сеанса аннотации показана общая статистика и предпочтительная модель.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| Аргумент | Тип | Описание |
|---|---|---|
dataset | позиционирование | Набор данных для сохранения аннотаций. |
vectors_path_a | позиционирование | Путь к предварительному Sense2VEC Vectors. |
vectors_path_b | позиционирование | Путь к предварительному Sense2VEC Vectors. |
--senses , -s | вариант | Запятый список чувств, чтобы ограничить выбор. Если не установлено, все чувства в векторах будут использоваться. |
--exclude-senses , -es | вариант | Отдельный список чувств, чтобы исключить. См. prodigy_recipes.EVAL_EXCLUDE_SENSES fro по умолчанию. |
--n-freq , -f | вариант | Количество наиболее частых записей, чтобы ограничить. |
--n-similar , -n | вариант | Количество аналогичных элементов для проверки. По умолчанию до 10 . |
--batch-size , -b | вариант | Размер партии для использования. |
--eval-whole , -E | флаг | Оцените весь набор данных вместо текущего сеанса. |
--eval-only , -O | флаг | Не аннотируйте, только оценивайте текущий набор данных. |
--show-mapping , -S | флаг | Покажите, какие модели являются вариантом 1 и опцией 2 в пользовательском интерфейсе (для отладки). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT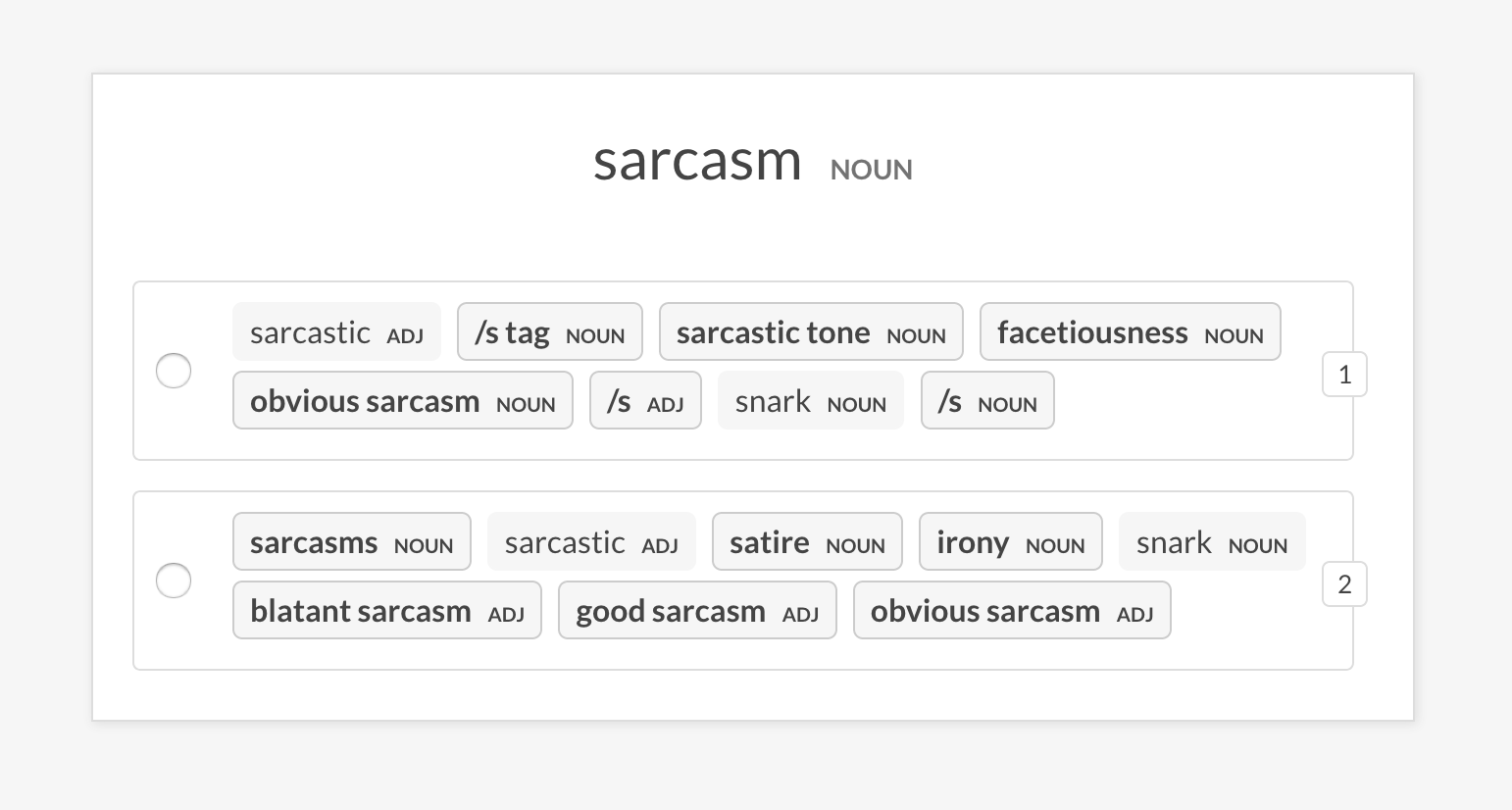
Предварительные векторы Reddit поддерживают следующие «чувства», либо частичные теги или этикетки сущности. Для получения более подробной информации см. Обзор схемы схемы аннотации Spacy.
| Ярлык | Описание | Примеры |
|---|---|---|
ADJ | прилагательное | Большой, старый, зеленый |
ADP | адпозиция | в, во время |
ADV | наречие | Очень, завтра, вниз, где |
AUX | вспомогательный | IS, имеет (сделано), будет (DO) |
CONJ | соединение | и, или, но |
DET | определяющий | а, а |
INTJ | вмешательство | psst, ooch, bravo, привет |
NOUN | существительное | Девушка, кошка, дерево, воздух, красота |
NUM | цифра | 1, 2017, один, семьдесят семь, MMXIV |
PART | частица | S, нет |
PRON | местоимение | Я, ты, он, она, сам, кто -то |
PROPN | Правильное существительное | Мэри, Джон, Лондон, НАТО, HBO |
PUNCT | пунктуация | ,? () |
SCONJ | подчиняющее соединение | Если, пока, это |
SYM | символ | $, %, =, :),? |
VERB | глагол | бегать, бегать, бегать, есть, ели, есть |
| Энтуальная метка | Описание |
|---|---|
PERSON | Люди, в том числе вымышленные. |
NORP | Национальности или религиозные или политические группы. |
FACILITY | Здания, аэропорты, автомагистрали, мосты и т. Д. |
ORG | Компании, агентства, учреждения и т. Д. |
GPE | Страны, города, штаты. |
LOC | Не-GPE местоположения, горные хребты, тела воды. |
PRODUCT | Объекты, транспортные средства, продукты питания и т. Д. (Не услуги.) |
EVENT | Названные ураганы, битвы, войны, спортивные мероприятия и т. Д. |
WORK_OF_ART | Названия книг, песен и т. Д. |
LANGUAGE | Любой названный язык. |


