sense2vec
v2.0.2
Sense2vec (Trask et al., 2015) é uma boa reviravolta no Word2vec que permite aprender vetores de palavras mais interessantes e detalhados. Esta biblioteca é uma implementação simples do Python para carregamento, consulta e treinamento de modelos Sense2Vec. Para mais detalhes, consulte a nossa postagem no blog. Para explorar as semelhanças semânticas em todos os comentários do Reddit de 2015 e 2019, consulte a demonstração interativa.
? Versão 2.0 (para Spacy V3) agora! Leia as notas de lançamento aqui.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ Observe que este exemplo descreve o uso com Spacy V3. Para uso com Spacy V2, faça o downloadsense2vec==1.0.3e confira a ramificaçãov1.xdeste repo.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]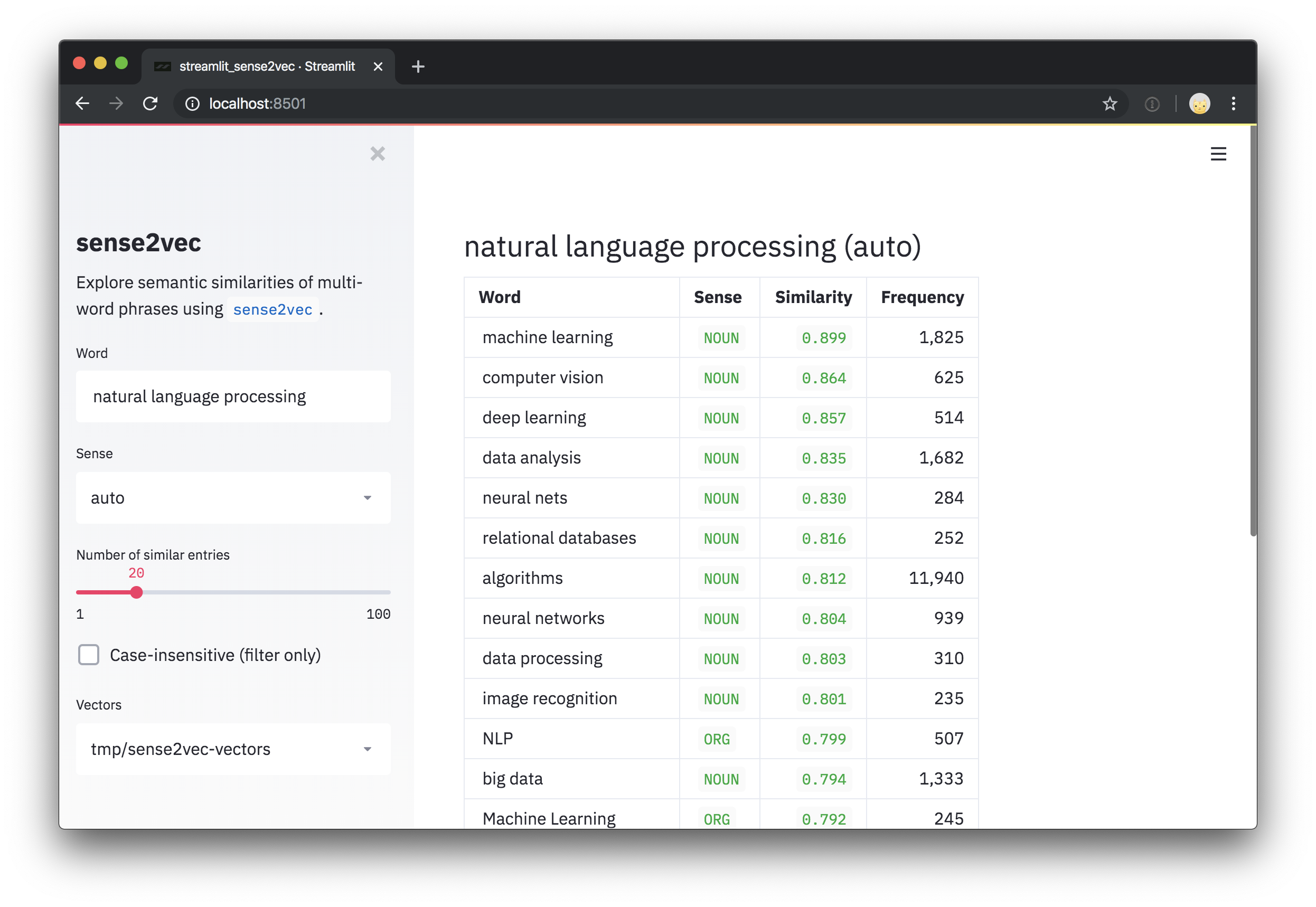
Para experimentar nossos vetores pré -treinados treinados em comentários do Reddit, confira a demonstração interativa do Sense2vec.
Este repositório também inclui um script de demonstração de streamlit para explorar vetores e as frases mais semelhantes. Após a instalação streamlit , você pode executar o script com streamlit run e um ou mais caminhos para vetores pré -teriam como argumentos posicionais na linha de comando. Por exemplo:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors Para usar os vetores, faça o download do (s) arquivo (s) e passe no diretório extraído para Sense2Vec.from_disk ou Sense2VecComponent.from_disk . Os arquivos vetoriais estão anexados à liberação do GitHub . Arquivos grandes foram divididos em downloads de várias partes.
| Vetores | Tamanho | Descrição | ? Download (com zíper) |
|---|---|---|---|
s2v_reddit_2019_lg | 4GB | Comentários do Reddit 2019 (01-07) | Parte 1, Parte 2, Parte 3 |
s2v_reddit_2015_md | 573 MB | Comentários do Reddit 2015 | Parte 1 |
Para mesclar os arquivos de várias partes, você pode executar o seguinte:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzOs lançamentos do Sense2vec estão disponíveis no PIP:
pip install sense2vec Para usar vetores pré -gravados, faça o download de um dos pacotes de vetores, descompacte o arquivo .tar.gz e ponto from_disk até o diretório de dados extraído:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) A maneira mais fácil de usar a biblioteca e os vetores é conectá -la ao seu pipeline espacial. O pacote sense2vec expõe um Sense2VecComponent , que pode ser inicializado com o vocabulário compartilhado e adicionado ao seu pipeline spacy como um componente de pipeline personalizado. Por padrão, os componentes são adicionados ao final do pipeline , que é a posição recomendada para este componente, pois precisa de acesso à análise de dependência e, se disponível, nomeadas entidades.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) O componente adicionará vários atributos e métodos de extensão ao Token de Spacy e Span objetos que permitem recuperar vetores e frequências, bem como termos mais semelhantes.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )Para as entidades, os rótulos das entidades são usados como o "sentido" (em vez da tag de parte da fala do token):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) Os seguintes atributos de extensão são expostos no objeto Doc através da propriedade ._ :
| Nome | Tipo de atributo | Tipo | Descrição |
|---|---|---|---|
s2v_phrases | propriedade | lista | Todas as frases compatíveis com Sense2vec nas Doc especificados (frases substantivos, entidades nomeadas). |
Os seguintes atributos estão disponíveis através da propriedade ._ de Token e Span Objetos - por exemplo token._.in_s2v :
| Nome | Tipo de atributo | Tipo de retorno | Descrição | | -------------------- | -------------- | -------------------- | ---------------------------------------------------------------------------------- | ----------------- | ------- | | in_s2v | propriedade | bool | Se existe uma chave no mapa vetorial. | | s2v_key | propriedade | unicode | A chave Sense2vec do objeto dado, por exemplo "duck | NOUN" . | | s2v_vec | propriedade | ndarray[float32] | O vetor da chave dada. | | s2v_freq | propriedade | int | A frequência da chave fornecida. | | s2v_other_senses | propriedade | Lista | Disponível outros sentidos, por exemplo "duck | VERB" para "duck | NOUN" . | | s2v_most_similar | método | Lista | Obtenha os n mais semelhantes. Retorna uma lista de tuplas ((word, sense), score) . | | s2v_similarity | método | flutuar | Obtenha a semelhança com outro Token ou Span . |
️ Uma nota nos atributos de span: sob o capô, as entidades emdoc.entssão objetosSpan. É por isso que o componente do pipeline também adiciona atributos e métodos aos vãos e não apenas nos tokens. No entanto, não é recomendável usar os atributos Sense2vec em fatias arbitrárias do documento, pois o modelo provavelmente não terá uma chave para o respectivo texto. Os objetosSpantambém não possuem uma tag de parte do fala; portanto, se nenhum rótulo de entidade estiver presente, o "Sense" padronizará a tag de parte da fala da raiz.
Se você está treinando e empacotando um pipeline spacy e deseja incluir um componente Sense2vec nele, pode carregar os dados através do bloco [initialize] da configuração de treinamento:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " Você também pode usar diretamente a classe Sense2Vec subjacente e carregar os vetores usando o método from_disk . Veja abaixo os métodos de API disponíveis.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ NOTA IMPORTANTE: Para procurar entradas na tabela de vetores, as teclas precisam seguir o esquema dephrase_text|SENSE(observe o_em vez de espaços e o|antes da tag ou etiqueta) - por exemplo,machine_learning|NOUN. Observe também que a tabela vetorial subjacente é sensível ao caso.
Sense2Vec O objeto independente Sense2Vec que mantém os vetores, cordas e frequências.
Sense2Vec.__init__ Inicialize o objeto Sense2Vec .
| Argumento | Tipo | Descrição |
|---|---|---|
shape | tupla | A forma do vetor. Padrões para (1000, 128) . |
strings | spacy.strings.StringStore | Armazenamento opcional de string. Será criado se não existir. |
senses | lista | Lista opcional de todos os sentidos disponíveis. Usado em métodos que geram o melhor sentido ou outros sentidos. |
vectors_name | unicode | Nome opcional a ser atribuído à tabela Vectors , para evitar confrontos. Padrões para "sense2vec" . |
overrides | dito | Funções personalizadas opcionais a serem usadas, mapeadas para nomes registrados através do registro, por exemplo {"make_key": "custom_make_key"} . |
| Retorna | Sense2Vec | O objeto recém -construído. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__O número de linhas na tabela de vetores.
| Argumento | Tipo | Descrição |
|---|---|---|
| Retorna | int | O número de linhas na tabela de vetores. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__Verifique se uma chave está na tabela de vetores.
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave para procurar. |
| Retorna | bool | Se a chave está na tabela. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__Recuperar um vetor para uma determinada chave. Retorna nenhum se a chave não estiver na tabela.
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave para procurar. |
| Retorna | numpy.ndarray | O vetor ou None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ Defina um vetor para uma determinada chave. Aumentará um erro se a chave não existir. Para adicionar uma nova entrada, use Sense2Vec.add .
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave. |
vector | numpy.ndarray | O vetor a ser definido. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addAdicione um novo vetor à tabela.
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave a ser adicionada. |
vector | numpy.ndarray | O vetor para adicionar. |
freq | int | Contagem de frequência opcional. Usado para encontrar os melhores sentidos de correspondência. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqObtenha a contagem de frequência para uma determinada chave.
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave para procurar. |
default | - | Valor padrão para retornar se nenhuma frequência for encontrada. |
| Retorna | int | A contagem de frequência. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqDefina uma contagem de frequência para uma determinada chave.
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave para definir a contagem. |
freq | int | A contagem de frequência. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsItera sobre as entradas na tabela de vetores.
| Argumento | Tipo | Descrição |
|---|---|---|
| Rendimentos | tupla | Chave de string e pares de vetores na tabela. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysItera sobre as chaves na mesa.
| Argumento | Tipo | Descrição |
|---|---|---|
| Rendimentos | unicode | As teclas da string na tabela. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesItera sobre os vetores na mesa.
| Argumento | Tipo | Descrição |
|---|---|---|
| Rendimentos | numpy.ndarray | Os vetores na tabela. |
all_vecs = list ( s2v . values ())Sense2Vec.senses Os sentidos disponíveis na tabela, por exemplo, "NOUN" ou "VERB" (adicionado na inicialização).
| Argumento | Tipo | Descrição |
|---|---|---|
| Retorna | lista | Os sentidos disponíveis. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesAs frequências das chaves na tabela, em ordem decrescente.
| Argumento | Tipo | Descrição |
|---|---|---|
| Retorna | lista | As tuplas (key, freq) por frequência, descendente. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityFaça uma estimativa de similaridade semântica de duas chaves ou dois conjuntos de chaves. A estimativa padrão é a similaridade de cosseno usando uma média de vetores.
| Argumento | Tipo | Descrição |
|---|---|---|
keys_a | unicode / int / iterable | A (s) chave (s) da string ou número inteiro. |
keys_b | unicode / int / iterable | A outra chave de string ou número inteiro (s). |
| Retorna | flutuador | A pontuação de similaridade. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarObtenha as entradas mais semelhantes da tabela. Se mais de uma chave for fornecida, a média dos vetores será usada. Para tornar esse método mais rápido, consulte o script para pré -computar um cache dos vizinhos mais próximos.
| Argumento | Tipo | Descrição |
|---|---|---|
keys | unicode / int / iterable | A (s) chave (s) da string ou inteira para comparar. |
n | int | O número de chaves semelhantes para retornar. Padrões para 10 . |
batch_size | int | O tamanho do lote a ser usado. Padrão para 16 . |
| Retorna | lista | As tuplas (key, score) dos vetores mais semelhantes. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses Encontre outras entradas para a mesma palavra com um sentido diferente, por exemplo "duck|VERB" para "duck|NOUN" .
| Argumento | Tipo | Descrição |
|---|---|---|
key | unicode / int | A chave a verificar. |
ignore_case | bool | Verifique se há maiúsculas, minúsculas e titlecase. Padrões para True . |
| Retorna | lista | As teclas de string de outras entradas com sentidos diferentes. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense Encontre o senso de melhor correspondência para uma determinada palavra com base nos sentidos e contagens de frequência disponíveis. Retorna None se nenhuma correspondência for encontrada.
| Argumento | Tipo | Descrição |
|---|---|---|
word | unicode | A palavra para verificar. |
senses | lista | Lista opcional de sentidos para limitar a pesquisa. Se não estiver definido / vazio, todos os sentidos nos vetores são usados. |
ignore_case | bool | Verifique se há maiúsculas, minúsculas e titlecase. Padrões para True . |
| Retorna | unicode | A chave mais correspondente ou nenhuma. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Serialize um objeto Sense2Vec a um bytestring.
| Argumento | Tipo | Descrição |
|---|---|---|
exclude | lista | Nomes de campos de serialização para excluir. |
| Retorna | bytes | O objeto serializado Sense2Vec . |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Carregue um objeto Sense2Vec de um bytestring.
| Argumento | Tipo | Descrição |
|---|---|---|
bytes_data | bytes | Os dados a serem carregados. |
exclude | lista | Nomes de campos de serialização para excluir. |
| Retorna | Sense2Vec | O objeto carregado. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Serialize um objeto Sense2Vec para um diretório.
| Argumento | Tipo | Descrição |
|---|---|---|
path | unicode / Path | O caminho. |
exclude | lista | Nomes de campos de serialização para excluir. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk Carregue um objeto Sense2Vec de um diretório.
| Argumento | Tipo | Descrição |
|---|---|---|
path | unicode / Path | O caminho para carregar de |
exclude | lista | Nomes de campos de serialização para excluir. |
| Retorna | Sense2Vec | O objeto carregado. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentO componente do pipeline para adicionar sense2vec aos pipelines espaciais.
Sense2VecComponent.__init__Inicialize o componente do pipeline.
| Argumento | Tipo | Descrição |
|---|---|---|
vocab | Vocab | O Vocab compartilhado. Usado principalmente para o StringStore compartilhado. |
shape | tupla | A forma do vetor. |
merge_phrases | bool | Se deve mesclar frases sensoriais2vec em um token. Padrões para False . |
lemmatize | bool | Sempre procure lemas, se disponível nos vetores, de outra forma padrão na palavra original. Padrões para False . |
overrides | Funções personalizadas opcionais a serem usadas, mapeadas para os nomes registrados através do registro, por exemplo {"make_key": "custom_make_key"} . | |
| Retorna | Sense2VecComponent | O objeto recém -construído. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp Inicialize o componente de um objeto PNL. Principalmente usado como fábrica de componentes para o ponto de entrada (consulte Setup.cfg) e para registrar automaticamente o decorador @spacy.component .
| Argumento | Tipo | Descrição |
|---|---|---|
nlp | Language | O objeto nlp . |
**cfg | - | Parâmetros de configuração opcionais. |
| Retorna | Sense2VecComponent | O objeto recém -construído. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ Processe um objeto Doc com o componente. Normalmente chamado apenas como parte do oleoduto Spacy e não diretamente.
| Argumento | Tipo | Descrição |
|---|---|---|
doc | Doc | O documento para processar. |
| Retorna | Doc | o documento processado. |
Sense2Vec.init_componentRegistre os atributos de extensão específicos do componente aqui e somente se o componente for adicionado ao pipeline e usado-caso contrário, os tokens ainda receberão os atributos, mesmo que o componente seja criado apenas e não seja adicionado.
Sense2VecComponent.to_bytes Serialize o componente para um bytestring. Também chamado quando o componente é adicionado ao pipeline e você executa nlp.to_bytes .
| Argumento | Tipo | Descrição |
|---|---|---|
| Retorna | bytes | O componente serializado. |
Sense2VecComponent.from_bytes Carregue um componente de um bytestring. Também chamado quando você executa nlp.from_bytes .
| Argumento | Tipo | Descrição |
|---|---|---|
bytes_data | bytes | Os dados a serem carregados. |
| Retorna | Sense2VecComponent | O objeto carregado. |
Sense2VecComponent.to_disk Serialize o componente a um diretório. Também chamado quando o componente é adicionado ao pipeline e você executa nlp.to_disk .
| Argumento | Tipo | Descrição |
|---|---|---|
path | unicode / Path | O caminho. |
Sense2VecComponent.from_disk Carregue um objeto Sense2Vec de um diretório. Também chamado quando você executa nlp.from_disk .
| Argumento | Tipo | Descrição |
|---|---|---|
path | unicode / Path | O caminho para carregar de |
| Retorna | Sense2VecComponent | O objeto carregado. |
registry de classe Registro de funções (alimentado pelo catalogue ) para personalizar facilmente as funções usadas para gerar chaves e frases. Permite decorar e nomear funções personalizadas, trocá -las e serializar os nomes personalizados ao salvar o modelo. As seguintes opções de registro estão disponíveis:
| Nome | Descrição | | --------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | -------- | | registry.make_key | Dada uma word e sense , retorne uma sequência da chave, por exemplo, "word | sense". | | registry.split_key | Dada uma chave de string, retorne uma tupla (word, sense) . | | registry.make_spacy_key | Dado um objeto Spacy ( Token ou Span ) e um argumento de palavra -chave prefer_ents boolean (se prefere o rótulo da entidade para tokens únicos), retorne uma tupla (word, sense) . Utilizado em atributos de extensão para gerar uma chave para tokens e vãos. | | | registry.get_phrases | Dado um Doc de spacy, retorne uma lista de objetos Span usados para frases sensoras2vec (normalmente frases substantivas e entidades nomeadas). | | registry.merge_phrases | Dado um Doc de spacy, obtenha todas as frases sensoras2vec e mescle -as em tokens únicos. |
Cada registro possui um método register que pode ser usado como decorador de funções e leva um argumento, o nome da função personalizada.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Ao inicializar o objeto Sense2Vec , agora você pode passar em um dicionário de substituições com os nomes de suas funções registradas personalizadas.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )Isso facilita o experimento de diferentes estratégias e a serialização das estratégias como cordas simples (em vez de ter que passar e/ou consertar as próprias funções).
O diretório /scripts contém utilitários de linha de comando para pré -processamento de texto e treinamento de seus próprios vetores.
Para treinar seus próprios vetores Sense2vec, você precisará do seguinte:
doc.noun_chunks . Se o idioma necessário não fornecer um iterador de sintaxe embutido para frases substantivas, você precisará escrever o seu. (Os doc.noun_chunks e doc.ents são o que o Sense2vec usa para determinar o que é uma frase.)make no respectivo diretório. O processo de treinamento é dividido em várias etapas para permitir que você seja retomado em qualquer ponto. Os scripts de processamento são projetados para operar em arquivos únicos, facilitando o paralelo do trabalho. Os scripts neste repositório exigem luva ou texto rápido que você precisa clonar e make .
Para o FastText, os scripts exigirão o caminho para o arquivo binário criado. Se você estiver trabalhando no Windows, poderá criar com cmake ou, alternativamente, usar o arquivo .exe deste repositório não oficial com compilações binárias FastText para Windows: https://github.com/xiamx/fasttext/releases.
| Script | Descrição | |
|---|---|---|
| 1. | 01_parse.py | Use Spacy para analisar o texto bruto e a saída de coleções binárias dos objetos Doc (consulte DocBin ). |
| 2. | 02_preprocess.py | Carregue uma coleção de objetos Doc analisados produzidos na etapa anterior e os arquivos de texto de saída no formato Sense2vec (uma frase por linha e frases mescladas com sentidos). |
| 3. | 03_glove_build_counts.py | Use luva para construir o vocabulário e a conta. Pule esta etapa se você estiver usando o Word2Vec via FastText. |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | Use luva ou texto rápido para treinar vetores. |
| 5. | 05_export.py | Carregue os vetores e frequências e emitir um componente Sense2vec que pode ser carregado via Sense2Vec.from_disk . |
| 6. | 06_precompute_cache.py | Opcional: consultas pré-computadas no vizinho mais próximo para cada entrada no vocabulário para tornar Sense2Vec.most_similar mais rápido. |
Para uma documentação mais detalhada dos scripts, consulte a fonte ou execute -os com --help . Por exemplo, python scripts/01_parse.py --help .
Este pacote também se integra perfeitamente à ferramenta de anotação Prodigy e expõe receitas para o uso de vetores Sense2vec para gerar rapidamente listas de frases com várias palavras e anotações nervos de bootstrap. Para usar uma receita, sense2vec precisa ser instalado no mesmo ambiente que o Prodigy. Para um exemplo de um caso de uso do mundo real, consulte este projeto NER com conjuntos de dados para download.
As receitas a seguir estão disponíveis - veja abaixo para documentos mais detalhados.
| Receita | Descrição |
|---|---|
sense2vec.teach | Bootstrap uma lista de terminologia usando sense2vec. |
sense2vec.to-patterns | Converta o conjunto de dados de frases em padrões de correspondência baseados em token. |
sense2vec.eval | Avalie um modelo Sense2vec perguntando sobre a frase triplica. |
sense2vec.eval-most-similar | Avalie um modelo Sense2vec corrigindo as entradas mais semelhantes. |
sense2vec.eval-ab | Realize uma avaliação A/B de dois modelos de vetores Sense2vec pré -tenhados. |
sense2vec.teachBootstrap uma lista de terminologia usando sense2vec. O Prodigy sugerirá termos semelhantes com base nas frases mais semelhantes do Sense2vec, e as sugestões serão ajustadas ao anotar e aceitar frases semelhantes. Para cada termo de semente, será usado o melhor sentido correspondente de acordo com os vetores Sense2vec.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| Argumento | Tipo | Descrição |
|---|---|---|
dataset | posicional | Conjunto de dados para salvar anotações para. |
vectors_path | posicional | Caminho para vetores de Sense2vec pré -criados. |
--seeds , -s | opção | Uma ou mais frases de sementes separadas por vírgula. |
--threshold , -t | opção | Limiar de similaridade. Padrões para 0.85 . |
--n-similar , -n | opção | Número de itens semelhantes para obter de uma só vez. |
--batch-size , -b | opção | Tamanho do lote para enviar anotações. |
--resume , -R | bandeira | Retomar de um conjunto de dados de frases existente. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns Converta um conjunto de dados de frases coletadas com os padrões de correspondência sensíveis ao sense2vec.teach em token que podem ser usados com EntityRuler de Spacy ou receitas como ner.match . Se nenhum arquivo de saída for especificado, os padrões serão gravados no stdout. Os exemplos são tokenizados para que os termos com vários toques sejam representados corretamente, por exemplo: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| Argumento | Tipo | Descrição |
|---|---|---|
dataset | posicional | Conjunto de dados da frase para converter. |
spacy_model | posicional | Modelo Spacy para tokenização. |
label | posicional | Rótulo para aplicar a todos os padrões. |
--output-file , -o | opção | Arquivo de saída opcional. Padrões para stdout. |
--case-sensitive , -CS | bandeira | Faça padrões sensíveis ao maiúsculas. |
--dry , -D | bandeira | Realize uma corrida a seco e não produza nada. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalAvalie um modelo Sense2vec perguntando sobre a frase triplos: a palavra é mais semelhante à palavra b ou na palavra c? Se o humano concorda principalmente com o modelo, o modelo de vetores é bom. A receita só perguntará sobre vetores com o mesmo sentido e suporta diferentes estratégias de seleção de exemplo.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| Argumento | Tipo | Descrição |
|---|---|---|
dataset | posicional | Conjunto de dados para salvar anotações para. |
vectors_path | posicional | Caminho para vetores de Sense2vec pré -criados. |
--strategy , -st | opção | Exemplo de estratégia de seleção. most similar (padrão) ou random . |
--senses , -s | opção | Lista de sentidos separada por vírgula para limitar a seleção. Se não for definido, todos os sentidos nos vetores serão usados. |
--exclude-senses , -es | opção | Lista de sentidos separada por vírgula para excluir. Consulte prodigy_recipes.EVAL_EXCLUDE_SENSES dos padrões. |
--n-freq , -f | opção | Número das entradas mais frequentes para limitar. |
--threshold , -t | opção | Limite mínimo de similaridade para considerar exemplos. |
--batch-size , -b | opção | Tamanho do lote a ser usado. |
--eval-whole , -E | bandeira | Avalie todo o conjunto de dados em vez da sessão atual. |
--eval-only , -O | bandeira | Não anote, avalie apenas o conjunto de dados atual. |
--show-scores , -S | bandeira | Mostre todas as pontuações para depuração. |
| Nome | Descrição |
|---|---|
most_similar | Escolha uma palavra aleatória de um sentido aleatório e obtenha suas entradas mais semelhantes do mesmo sentido. Pergunte sobre a semelhança com a última e a entrada do meio dessa seleção. |
most_least_similar | Escolha uma palavra aleatória de um sentido aleatório e obtenha a entrada menos semelhante de suas entradas mais semelhantes e, em seguida, a última entrada mais semelhante disso. |
random | Escolha uma amostra aleatória de 3 palavras do mesmo sentido aleatório. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5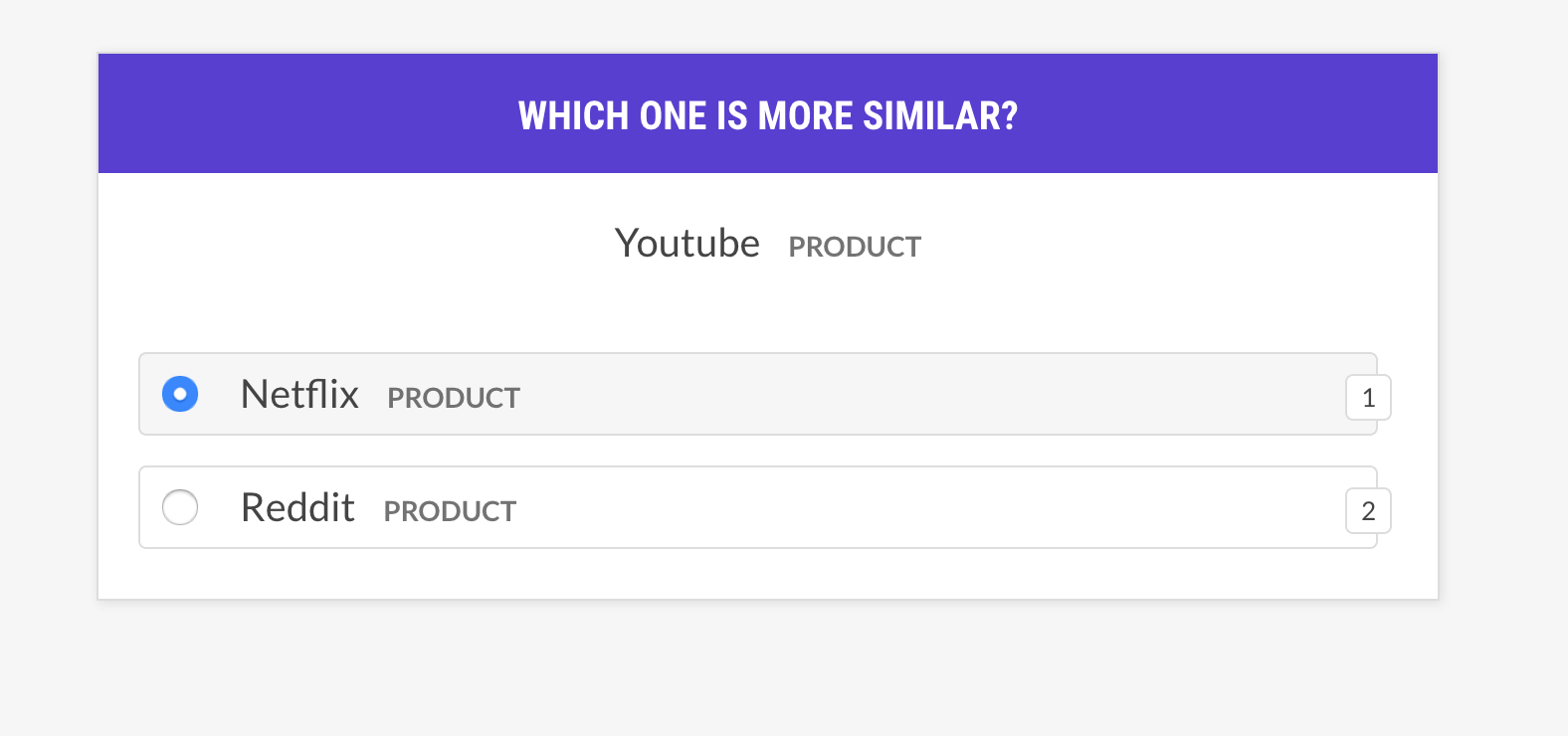
sense2vec.eval-most-similarAvalie um modelo de vetores, observando as entradas mais semelhantes que ele retorna para uma frase aleatória e desmarcando os erros.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| Argumento | Tipo | Descrição |
|---|---|---|
dataset | posicional | Conjunto de dados para salvar anotações para. |
vectors_path | posicional | Caminho para vetores de Sense2vec pré -criados. |
--senses , -s | opção | Lista de sentidos separada por vírgula para limitar a seleção. Se não for definido, todos os sentidos nos vetores serão usados. |
--exclude-senses , -es | opção | Lista de sentidos separada por vírgula para excluir. Consulte prodigy_recipes.EVAL_EXCLUDE_SENSES dos padrões. |
--n-freq , -f | opção | Número das entradas mais frequentes para limitar. |
--n-similar , -n | opção | Número de itens semelhantes para verificar. Padrões para 10 . |
--batch-size , -b | opção | Tamanho do lote a ser usado. |
--eval-whole , -E | bandeira | Avalie todo o conjunto de dados em vez da sessão atual. |
--eval-only , -O | bandeira | Não anote, avalie apenas o conjunto de dados atual. |
--show-scores , -S | bandeira | Mostre todas as pontuações para depuração. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abRealize uma avaliação A/B de dois modelos vetoriais do Sense2VEC pré -terenciados, comparando as entradas mais semelhantes que eles retornam para uma frase aleatória. A interface do usuário mostra duas opções randomizadas com as entradas mais semelhantes de cada modelo e destaca as frases que diferem. No final da sessão de anotação, as estatísticas gerais e o modelo preferido são mostradas.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| Argumento | Tipo | Descrição |
|---|---|---|
dataset | posicional | Conjunto de dados para salvar anotações para. |
vectors_path_a | posicional | Caminho para vetores de Sense2vec pré -criados. |
vectors_path_b | posicional | Caminho para vetores de Sense2vec pré -criados. |
--senses , -s | opção | Lista de sentidos separada por vírgula para limitar a seleção. Se não for definido, todos os sentidos nos vetores serão usados. |
--exclude-senses , -es | opção | Lista de sentidos separada por vírgula para excluir. Consulte prodigy_recipes.EVAL_EXCLUDE_SENSES dos padrões. |
--n-freq , -f | opção | Número das entradas mais frequentes para limitar. |
--n-similar , -n | opção | Número de itens semelhantes para verificar. Padrões para 10 . |
--batch-size , -b | opção | Tamanho do lote a ser usado. |
--eval-whole , -E | bandeira | Avalie todo o conjunto de dados em vez da sessão atual. |
--eval-only , -O | bandeira | Não anote, avalie apenas o conjunto de dados atual. |
--show-mapping , -S | bandeira | Mostre quais modelos são a opção 1 e a opção 2 na interface do usuário (para depuração). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT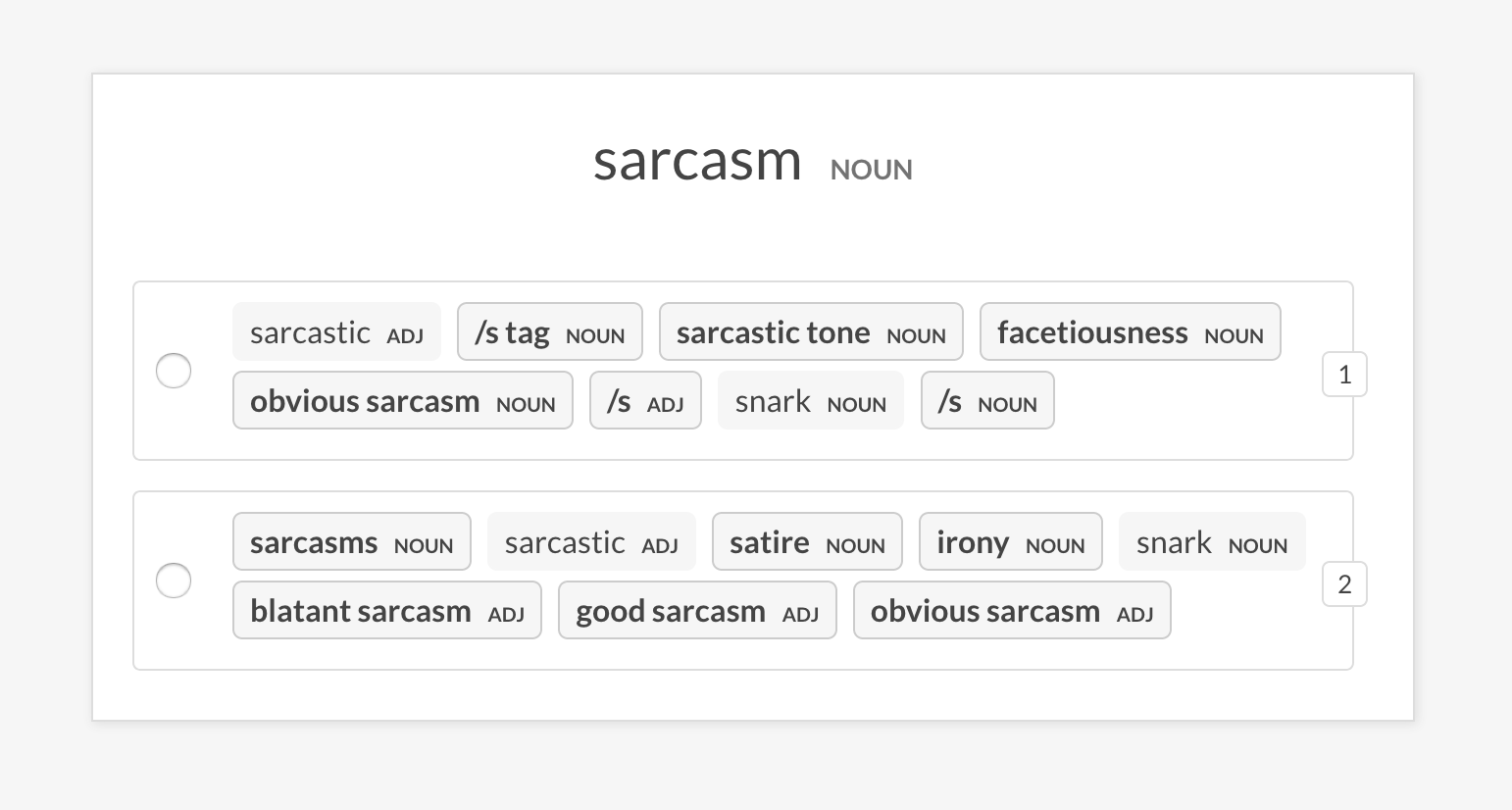
Os vetores do Reddit pré-criados suportam os seguintes "sentidos", etiquetas de parte de fala ou etiquetas de entidade. Para mais detalhes, consulte a visão geral do esquema de anotação de Spacy.
| Marcação | Descrição | Exemplos |
|---|---|---|
ADJ | adjetivo | Grande, velho, verde |
ADP | adposição | em, para, durante |
ADV | advérbio | muito, amanhã, abaixo, onde |
AUX | auxiliar | é, tem (feito), vai (fazer) |
CONJ | conjunção | e, ou, mas |
DET | determinante | A, An, o |
INTJ | interjeição | PSST, ai, bravo, olá |
NOUN | substantivo | Garota, gato, árvore, ar, beleza |
NUM | numeral | 1, 2017, um, setenta e sete, mmxiv |
PART | partícula | S, não |
PRON | pronome | Eu, você, ele, ela, eu mesmo, alguém |
PROPN | substantivo adequado | Mary, John, Londres, OTAN, HBO |
PUNCT | pontuação | ,? () |
SCONJ | conjunção subordinadora | Se, enquanto isso |
SYM | símbolo | $, %, =, :),? |
VERB | verbo | correr, correr, correr, comer, comer, comer |
| Etiqueta de entidade | Descrição |
|---|---|
PERSON | Pessoas, incluindo fictício. |
NORP | Nacionalidades ou grupos religiosos ou políticos. |
FACILITY | Edifícios, aeroportos, rodovias, pontes, etc. |
ORG | Empresas, agências, instituições, etc. |
GPE | Países, cidades, estados. |
LOC | Locais não-GPE, cadeias de montanhas, corpos de água. |
PRODUCT | Objetos, veículos, alimentos, etc. (não serviços.) |
EVENT | Chamados furacões, batalhas, guerras, eventos esportivos, etc. |
WORK_OF_ART | Títulos de livros, músicas, etc. |
LANGUAGE | Qualquer idioma nomeado. |


