sense2vec
v2.0.2
Sense2Vec (Trask et. al ، 2015) هو تطور لطيف على Word2Vec يتيح لك معرفة ناقلات الكلمات الأكثر إثارة للاهتمام والتفصيل. هذه المكتبة عبارة عن تطبيق Python بسيط للتحميل والاستعلام والتدريب على نماذج Sense2Vec. لمزيد من التفاصيل ، تحقق من منشور المدونة لدينا. لاستكشاف أوجه التشابه الدلالية في جميع تعليقات Reddit لعام 2015 و 2019 ، راجع العرض التجريبي التفاعلي.
؟ الإصدار 2.0 (لسباسي V3) خارج الآن! اقرأ ملاحظات الإصدار هنا.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ لاحظ أن هذا المثال يصف الاستخدام مع Spacy V3. للاستخدام مع Spacy V2 ، قم بتنزيلsense2vec==1.0.3وتحقق من فرعv1.xلهذا الريبو.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]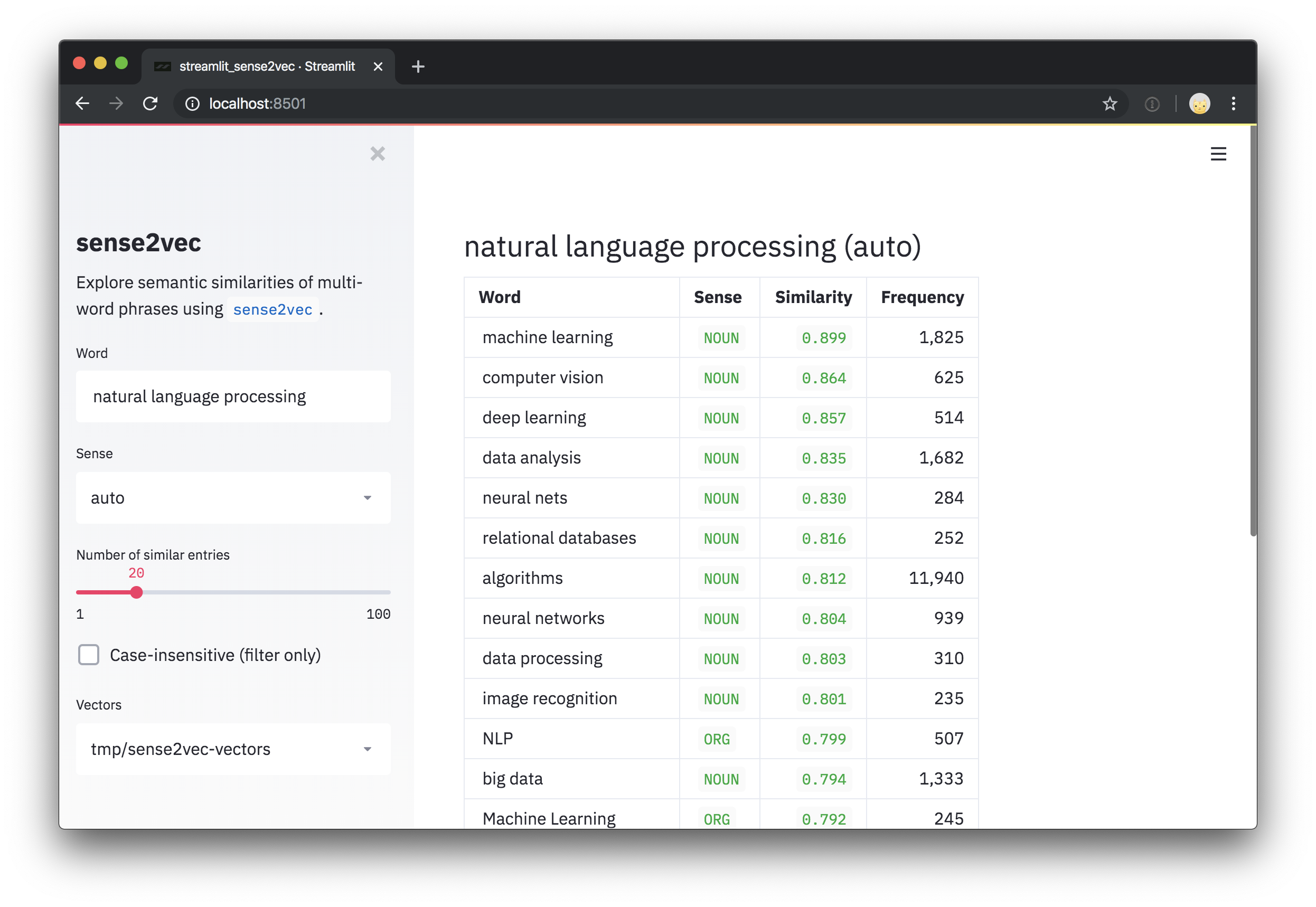
لتجربة ناقلاتنا المسبقة المدربين على تعليقات Reddit ، تحقق من العرض التفاعلي Sense2Vec Demo.
يتضمن هذا الريبو أيضًا نصًا تجريبيًا مبسطًا لاستكشاف المتجهات والعبارات الأكثر تشابهًا. بعد تثبيت streamlit ، يمكنك تشغيل البرنامج النصي مع streamlit run ومسار واحد أو أكثر إلى المتجهات المسبقة كوسائط موضعية على سطر الأوامر. على سبيل المثال:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors لاستخدام المتجهات ، قم بتنزيل الأرشيف (S) وقم بتمرير الدليل المستخرج إلى Sense2Vec.from_disk أو Sense2VecComponent.from_disk . يتم إرفاق ملفات المتجه بإصدار GitHub . تم تقسيم الملفات الكبيرة إلى تنزيلات متعددة الأجزاء.
| المتجهات | مقاس | وصف | ؟ تنزيل (مضغوط) |
|---|---|---|---|
s2v_reddit_2019_lg | 4 غيغابايت | Reddit Comments 2019 (01-07) | الجزء 1 ، الجزء 2 ، الجزء 3 |
s2v_reddit_2015_md | 573 ميغابايت | Reddit تعليقات 2015 | الجزء 1 |
لدمج المحفوظات متعددة الأجزاء ، يمكنك تشغيل ما يلي:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzتتوفر إصدارات Sense2Vec على PIP:
pip install sense2vec لاستخدام المتجهات المسبقة ، قم بتنزيل إحدى حزم المتجهات ، وتفريغ أرشيف .tar.gz وأرشفة from_disk إلى دليل البيانات المستخرج:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) أسهل طريقة لاستخدام المكتبة والمتجهات هي توصيلها في خط أنابيب Spacy الخاص بك. تعرض حزمة sense2vec Sense2VecComponent ، والذي يمكن تهيئة مع المفردات المشتركة وإضافتها إلى خط أنابيب Spacy الخاص بك كمكون لخط أنابيب مخصص. بشكل افتراضي ، تتم إضافة المكونات إلى نهاية خط الأنابيب ، وهو الموضع الموصى به لهذا المكون ، لأنه يحتاج إلى الوصول إلى تحليل التبعية ، وإذا كان متاحًا ، كيانات مسماة.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) سيضيف المكون العديد من سمات التمديد والأساليب إلى كائنات Token Span الخاص بـ Spacy التي تتيح لك استرداد المتجهات والترددات ، وكذلك معظم المصطلحات المتشابهة.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )بالنسبة للكيانات ، يتم استخدام ملصقات الكيانات كـ "المعنى" (بدلاً من علامة الرمز المميز لجزء الكلام):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) يتم كشف سمات التمديد التالية على كائن Doc عبر الخاصية ._ :
| اسم | نوع السمة | يكتب | وصف |
|---|---|---|---|
s2v_phrases | ملكية | قائمة | كل عبارات Sense2VEC المتوافقة في Doc المحدد (عبارات الاسم ، الكيانات المسماة). |
تتوفر السمات التالية عبر خاصية ._ من الكائنات Token Span - على سبيل المثال token._.in_s2v :
| الاسم | نوع السمة | نوع العودة | الوصف | | ------------------ | -------------- | ------------------ | -------------------------------------------------------------------------------- | --------------- | ------- | | in_s2v | خاصية | بول | ما إذا كان هناك مفتاح في خريطة المتجه. | | s2v_key | خاصية | يونيكود | مفتاح Sense2Vec للكائن المحدد ، على سبيل المثال "duck | NOUN" . | | s2v_vec | خاصية | ndarray[float32] | متجه المفتاح المعطى. | | s2v_freq | خاصية | int | تردد المفتاح المعطى. | | s2v_other_senses | خاصية | قائمة | الحواس الأخرى المتاحة ، على سبيل المثال "duck | VERB" لـ "duck | NOUN" . | | s2v_most_similar | طريقة | قائمة | احصل على n شروط متشابهة. إرجاع قائمة ((word, sense), score) tuples. | | s2v_similarity | طريقة | تعويم | احصل على التشابه مع Token آخر أو Span . |
️ ملاحظة حول سمات Span: تحت الغطاء ، فإن الكيانات فيdoc.entsهي كائناتSpan. هذا هو السبب في أن مكون خط الأنابيب يضيف أيضًا سمات وطرق للامتداد وليس فقط الرموز. ومع ذلك ، لا ينصح باستخدام سمات Sense2Vec على شرائح تعسفية للوثيقة ، حيث من المحتمل ألا يكون لدى النموذج مفتاح للنص المعني. لا تحتوي كائناتSpanأيضًا على علامة جزء من الكلام ، لذلك إذا لم تكن تسمية كيان موجودة ، فإن "Sense" الافتراضي لعلامة الجذر جزء الكلام.
إذا كنت تتدرب وتغليف خط أنابيب Spacy وتريد تضمين مكون Sense2Vec فيه ، فيمكنك التحميل في البيانات عبر كتلة [initialize] تكوين التدريب:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " يمكنك أيضًا استخدام فئة Sense2Vec الأساسية مباشرةً وتحميلها في المتجهات باستخدام طريقة from_disk . انظر أدناه للحصول على أساليب API المتاحة.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ ملاحظة مهمة: للبحث عن إدخالات في جدول المتجهات ، تحتاج المفاتيح إلى اتباع مخططphrase_text|SENSE(لاحظ_بدلاً من المسافات و|قبل العلامة أو التسمية) - على سبيل المثال ،machine_learning|NOUN. لاحظ أيضًا أن جدول المتجهات الأساسي حساس للحالة.
Sense2Vec كائن Sense2Vec المستقل الذي يحمل المتجهات والسلاسل والترددات.
Sense2Vec.__init__ تهيئة كائن Sense2Vec .
| دعوى | يكتب | وصف |
|---|---|---|
shape | مترابطة بيانية | شكل المتجه. الإعدادات الافتراضية إلى (1000, 128) . |
strings | spacy.strings.StringStore | متجر سلسلة اختياري. سيتم إنشاؤه إذا لم يكن موجودًا. |
senses | قائمة | قائمة اختيارية لجميع الحواس المتاحة. تستخدم في الأساليب التي تولد أفضل شعور أو غيرها من الحواس. |
vectors_name | يونيكود | الاسم الاختياري لتعيين جدول Vectors ، لمنع الاشتباكات. الإعدادات الافتراضية إلى "sense2vec" . |
overrides | التقليل | وظائف مخصصة اختيارية للاستخدام ، تم تعيينها للأسماء المسجلة عبر السجل ، على سبيل المثال {"make_key": "custom_make_key"} . |
| عودة | Sense2Vec | الكائن الذي شيد حديثا. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__عدد الصفوف في جدول المتجهات.
| دعوى | يكتب | وصف |
|---|---|---|
| عودة | int | عدد الصفوف في جدول المتجهات. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__تحقق مما إذا كان المفتاح في جدول المتجهات.
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح البحث. |
| عودة | بول | ما إذا كان المفتاح في الجدول. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__استرداد ناقل لمفتاح معين. لا يعود أي شيء إذا لم يكن المفتاح في الجدول.
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح البحث. |
| عودة | numpy.ndarray | المتجه أو None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ تعيين ناقل لمفتاح معين. سوف يرفع خطأ إذا لم يكن المفتاح موجودًا. لإضافة إدخال جديد ، استخدم Sense2Vec.add .
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | المفتاح. |
vector | numpy.ndarray | المتجه لتعيين. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addأضف متجهًا جديدًا إلى الجدول.
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح إضافة. |
vector | numpy.ndarray | المتجه لإضافة. |
freq | int | عدد التردد الاختياري. تستخدم للعثور على أفضل الحواس المطابقة. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqالحصول على عدد التردد لمفتاح معين.
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح البحث. |
default | - | القيمة الافتراضية للعودة إذا لم يتم العثور على تردد. |
| عودة | int | عدد التردد. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqتعيين عدد التردد لمفتاح معين.
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح تعيين العد ل. |
freq | int | عدد التردد. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ ، Sense2Vec.itemsتكرار على الإدخالات في جدول المتجهات.
| دعوى | يكتب | وصف |
|---|---|---|
| غلة | مترابطة بيانية | مفتاح السلسلة وأزواج المتجهات في الجدول. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysتكرار على المفاتيح في الجدول.
| دعوى | يكتب | وصف |
|---|---|---|
| غلة | يونيكود | مفاتيح السلسلة في الجدول. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesتكرار على المتجهات في الجدول.
| دعوى | يكتب | وصف |
|---|---|---|
| غلة | numpy.ndarray | المتجهات في الجدول. |
all_vecs = list ( s2v . values ())Sense2Vec.senses الحواس المتاحة في الجدول ، على سبيل المثال "NOUN" أو "VERB" (تمت إضافته عند التهيئة).
| دعوى | يكتب | وصف |
|---|---|---|
| عودة | قائمة | الحواس المتاحة. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesترددات المفاتيح في الجدول ، بترتيب تنازلي.
| دعوى | يكتب | وصف |
|---|---|---|
| عودة | قائمة | (key, freq) tuples عن طريق التردد ، الهبوط. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityقم بعمل تقديري للتشابه الدلالي لمفتاحين أو مجموعتين من المفاتيح. التقدير الافتراضي هو تشابه جيب التمام باستخدام متوسط المتجهات.
| دعوى | يكتب | وصف |
|---|---|---|
keys_a | Unicode / int / itervable | السلسلة أو مفتاح (ق) عدد صحيح. |
keys_b | Unicode / int / itervable | السلسلة الأخرى أو مفتاح (ق). |
| عودة | يطفو | درجة التشابه. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarاحصل على الإدخالات الأكثر تشابهًا في الجدول. إذا تم توفير أكثر من مفتاح واحد ، يتم استخدام متوسط المتجهات. لجعل هذه الطريقة أسرع ، راجع البرنامج النصي لحساب ذاكرة التخزين المؤقت لأقرب الجيران.
| دعوى | يكتب | وصف |
|---|---|---|
keys | Unicode / int / itervable | سلسلة (مفتاح) السلسلة أو عدد صحيح للمقارنة مع. |
n | int | عدد المفاتيح المماثلة للعودة. الافتراضات إلى 10 . |
batch_size | int | حجم الدُفعة للاستخدام. الافتراضات إلى 16 . |
| عودة | قائمة | (key, score) tuples من المتجهات الأكثر تشابها. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses ابحث عن إدخالات أخرى لنفس الكلمة مع شعور مختلف ، على سبيل المثال "duck|VERB" لـ "duck|NOUN" .
| دعوى | يكتب | وصف |
|---|---|---|
key | Unicode / int | مفتاح التحقق. |
ignore_case | بول | تحقق من حصة كبيرة ، صغيرة و titlecase. الافتراضات إلى True . |
| عودة | قائمة | مفاتيح سلسلة من الإدخالات الأخرى مع حواس مختلفة. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense ابحث عن أكثر الإحساس بالتطابق لكلمة معينة بناءً على الحواس المتاحة وتهم التردد. يعود None إذا لم يتم العثور على تطابق.
| دعوى | يكتب | وصف |
|---|---|---|
word | يونيكود | الكلمة للتحقق. |
senses | قائمة | قائمة اختيارية للحواس للحد من البحث. إذا لم يتم تعيين / فارغ ، يتم استخدام جميع الحواس في المتجهات. |
ignore_case | بول | تحقق من حصة كبيرة ، صغيرة و titlecase. الافتراضات إلى True . |
| عودة | يونيكود | أفضل مفتاح أو لا شيء. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes تسلسل كائن Sense2Vec إلى البايت.
| دعوى | يكتب | وصف |
|---|---|---|
exclude | قائمة | أسماء حقول التسلسل لاستبعادها. |
| عودة | بايت | كائن Sense2Vec التسلسلي. |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes تحميل كائن Sense2Vec من البايت.
| دعوى | يكتب | وصف |
|---|---|---|
bytes_data | بايت | البيانات المراد تحميلها. |
exclude | قائمة | أسماء حقول التسلسل لاستبعادها. |
| عودة | Sense2Vec | الكائن المحمّل. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk تسلسل كائن Sense2Vec إلى دليل.
| دعوى | يكتب | وصف |
|---|---|---|
path | Unicode / Path | المسار. |
exclude | قائمة | أسماء حقول التسلسل لاستبعادها. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk تحميل كائن Sense2Vec من دليل.
| دعوى | يكتب | وصف |
|---|---|---|
path | Unicode / Path | المسار إلى التحميل من |
exclude | قائمة | أسماء حقول التسلسل لاستبعادها. |
| عودة | Sense2Vec | الكائن المحمّل. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentمكون خط الأنابيب لإضافة Sense2Vec إلى خطوط الأنابيب Spacy.
Sense2VecComponent.__init__تهيئة مكون خط الأنابيب.
| دعوى | يكتب | وصف |
|---|---|---|
vocab | Vocab | Vocab المشتركة. تستخدم في الغالب ل StringStore المشتركة. |
shape | مترابطة بيانية | شكل المتجه. |
merge_phrases | بول | سواء لدمج عبارات Sense2Vec في رمز واحد. الإعدادات الافتراضية إلى False . |
lemmatize | بول | ابحث دائمًا عن Lemmas إذا كان متاحًا في المتجهات ، وإلا الافتراضي للكلمة الأصلية. الإعدادات الافتراضية إلى False . |
overrides | وظائف مخصصة اختيارية للاستخدام ، تم تعيينها للأسماء المسجلة عبر السجل ، على سبيل المثال {"make_key": "custom_make_key"} . | |
| عودة | Sense2VecComponent | الكائن الذي شيد حديثا. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp تهيئة المكون من كائن NLP. يستخدم في الغالب كمصنع مكون لنقطة الدخول (انظر SETUP.CFG) وللمسجلة التلقائية عبر @spacy.component Decorator.
| دعوى | يكتب | وصف |
|---|---|---|
nlp | Language | كائن nlp . |
**cfg | - | معلمات التكوين الاختيارية. |
| عودة | Sense2VecComponent | الكائن الذي شيد حديثا. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ معالجة كائن Doc مع المكون. عادة ما تسمى فقط كجزء من خط أنابيب Spacy وليس مباشرة.
| دعوى | يكتب | وصف |
|---|---|---|
doc | Doc | وثيقة للمعالجة. |
| عودة | Doc | الوثيقة المصنعة. |
Sense2Vec.init_componentقم بتسجيل سمات الامتداد الخاصة بالمكون هنا وفقط إذا تمت إضافة المكون إلى خط الأنابيب واستخدامه-وإلا ، فإن الرموز ستظل تحصل على السمات حتى إذا تم إنشاء المكون فقط ولم يتم إضافته.
Sense2VecComponent.to_bytes تسلسل المكون إلى البايت. يسمى أيضًا عند إضافة المكون إلى خط الأنابيب وتشغيل nlp.to_bytes .
| دعوى | يكتب | وصف |
|---|---|---|
| عودة | بايت | المكون التسلسلي. |
Sense2VecComponent.from_bytes تحميل مكون من البايت. تسمى أيضًا عند تشغيل nlp.from_bytes .
| دعوى | يكتب | وصف |
|---|---|---|
bytes_data | بايت | البيانات المراد تحميلها. |
| عودة | Sense2VecComponent | الكائن المحمّل. |
Sense2VecComponent.to_disk تسلسل المكون إلى دليل. يسمى أيضًا عند إضافة المكون إلى خط الأنابيب وتشغيل nlp.to_disk .
| دعوى | يكتب | وصف |
|---|---|---|
path | Unicode / Path | المسار. |
Sense2VecComponent.from_disk تحميل كائن Sense2Vec من دليل. تسمى أيضًا عند تشغيل nlp.from_disk .
| دعوى | يكتب | وصف |
|---|---|---|
path | Unicode / Path | المسار إلى التحميل من |
| عودة | Sense2VecComponent | الكائن المحمّل. |
registry الصف سجل الوظيفة (مدعوم من catalogue ) لتخصيص الوظائف المستخدمة بسهولة لإنشاء مفاتيح وعبارات. يتيح لك تزيين وتسمية الوظائف المخصصة ، وتبديلها وتسلسل الأسماء المخصصة عند حفظ النموذج. تتوفر خيارات التسجيل التالية:
| الاسم | الوصف | | ----------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- -------- | | registry.make_key | بالنظر إلى word sense ، أعد سلسلة من المفتاح ، على سبيل المثال "word | sense". | | registry.split_key | بالنظر إلى مفتاح السلسلة ، إرجاع (word, sense) . | | registry.make_spacy_key | بالنظر إلى كائن spacy ( Token أو Span ) و oolean prefer_ents وسيطة الكلمة الرئيسية (سواء كانت تفضل تسمية الكيان للرموز المفردة) ، وإرجاع (word, sense) . تستخدم في سمات التمديد لإنشاء مفتاح للرموز والامتدادات. | | | registry.get_phrases | بالنظر إلى Doc Spacy ، أعد قائمة كائنات Span المستخدمة في عبارات Sense2VEC (عادةً عبارات الاسم والكيانات المسمى). | | registry.merge_phrases | بالنظر إلى Doc Spacy ، احصل على كل عبارات Sense2Vec ودمجها في الرموز المفردة. |
يحتوي كل سجل على طريقة register يمكن استخدامها كديكور دالة ويأخذ وسيطة واحدة ، اسم الوظيفة المخصصة.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense عند تهيئة كائن Sense2Vec ، يمكنك الآن تمريره في قاموس التجاوزات بأسماء وظائفك المسجلة المخصصة.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )هذا يجعل من السهل تجربة استراتيجيات مختلفة وتسلسل الاستراتيجيات كسلاسل عادية (بدلاً من الاضطرار إلى المرور و/أو مخلل الوظائف نفسها).
يحتوي دليل /scripts على مرافق سطر الأوامر لنص المعالجة المسبقة وتدريب المتجهات الخاصة بك.
لتدريب ناقلات Sense2Vec الخاصة بك ، ستحتاج إلى ما يلي:
doc.noun_chunks . إذا كانت اللغة التي تحتاجها لا توفر جهازًا مبنيًا في بناء الجملة لعبارات الاسم ، فستحتاج إلى كتابة بنفسك. ( doc.noun_chunks و doc.ents هي ما يستخدمه Sense2Vec لتحديد ما هي العبارة.)make في الدليل المعني. يتم تقسيم عملية التدريب إلى عدة خطوات للسماح لك بالاستئناف في أي نقطة معينة. تم تصميم البرامج النصية المعالجة للعمل على ملفات واحدة ، مما يجعل من السهل تماثل العمل. تتطلب البرامج النصية في هذا الريبو إما قفازًا أو نصًا تحتاج إلى استنساخ make .
بالنسبة لـ FastText ، ستتطلب البرامج النصية المسار إلى الملف الثنائي الذي تم إنشاؤه. إذا كنت تعمل على Windows ، فيمكنك البناء باستخدام cmake ، أو بدلاً من ذلك ، أو استخدام ملف .exe من هذا الريبو غير الرسمي مع Barinary binary fasttext لنظام التشغيل Windows: https://github.com/xiamx/fasttext/release.
| السيناريو | وصف | |
|---|---|---|
| 1. | 01_parse.py | استخدم Spacy لتحليل النص الخام والمخرجات الثنائية لكائنات Doc (انظر DocBin ). |
| 2. | 02_preprocess.py | قم بتحميل مجموعة من كائنات Doc المحسورة التي تم إنتاجها في الخطوة السابقة وإخراج الملفات النصية بتنسيق SENSE2VEC (جملة واحدة لكل سطر والعبارات المدمجة مع الحواس). |
| 3. | 03_glove_build_counts.py | استخدم القفاز لبناء المفردات والتهم. تخطي هذه الخطوة إذا كنت تستخدم Word2Vec عبر FastText. |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | استخدم القفاز أو fasttext لتدريب المتجهات. |
| 5. | 05_export.py | قم بتحميل المتجهات والترددات وإخراج مكون Sense2Vec الذي يمكن تحميله عبر Sense2Vec.from_disk . |
| 6. | 06_precompute_cache.py | اختياري: استفسارات قريبة من الجوار لكل إدخال في المفردات لإحداث Sense2Vec.most_similar معظمها أسرع. |
للحصول على المزيد من الوثائق التفصيلية للبرامج النصية ، تحقق من المصدر أو تشغيلها مع --help . على سبيل المثال ، python scripts/01_parse.py --help .
تتكامل هذه الحزمة أيضًا بسلاسة مع أداة التعليقات التوضيحية Prodigy وتعرض وصفات لاستخدام ناقلات Sense2VEC لإنشاء قوائم بعبارات متعددة الكلمات بسرعة وشروط التعليقات التوضيحية. لاستخدام وصفة ، يجب تثبيت sense2vec في نفس البيئة مثل Prodigy. للحصول على مثال على حالة استخدام العالم الحقيقي ، تحقق من مشروع NER هذا مع مجموعات البيانات القابلة للتنزيل.
تتوفر الوصفات التالية - انظر أدناه للحصول على مستندات أكثر تفصيلاً.
| وصفة | وصف |
|---|---|
sense2vec.teach | Bootstrap قائمة المصطلحات باستخدام Sense2Vec. |
sense2vec.to-patterns | تحويل عبارات مجموعة البيانات إلى أنماط المطابقة المستندة إلى الرمز المميز. |
sense2vec.eval | تقييم نموذج SENESS2VEC من خلال السؤال عن عبارة ثلاثية. |
sense2vec.eval-most-similar | تقييم نموذج SENSE2VEC من خلال تصحيح الإدخالات الأكثر تشابهًا. |
sense2vec.eval-ab | إجراء تقييم A/B لنماذج متجه Sense2Vec pretrained. |
sense2vec.teachBootstrap قائمة المصطلحات باستخدام Sense2Vec. سوف يقترح Prodigy مصطلحات مماثلة بناءً على أكثر العبارات متشابهة من Sense2Vec ، وسيتم تعديل الاقتراحات أثناء التعليق وقبول عبارات مماثلة. لكل مصطلح بذرة ، سيتم استخدام أفضل معنى مطابق وفقًا لمتجهات Sense2Vec.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| دعوى | يكتب | وصف |
|---|---|---|
dataset | الموضعية | مجموعة البيانات لحفظ التعليقات التوضيحية ل. |
vectors_path | الموضعية | مسار إلى ناقلات Sense2Vec PretRained. |
--seeds ، -s | خيار | واحد أو أكثر من عبارات البذور المفصولة بفاصلة. |
--threshold ، -t | خيار | عتبة التشابه. الافتراضات إلى 0.85 . |
--n-similar ، -n | خيار | عدد العناصر المماثلة للحصول عليها مرة واحدة. |
--batch-size ، -b | خيار | حجم الدُفعة لتقديم التعليقات التوضيحية. |
--resume ، -R | علَم | استئناف من مجموعة بيانات العبارات الموجودة. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns قم بتحويل مجموعة بيانات من العبارات التي تم جمعها باستخدام sense2vec.teach إلى أنماط المطابقة المستندة إلى الرمز المميز والتي يمكن استخدامها مع EntityRuler من Spacy أو وصفات مثل ner.match . إذا لم يتم تحديد ملف إخراج ، يتم كتابة الأنماط إلى stdout. يتم تمثيل الأمثلة المميزة بحيث يتم تمثيل المصطلحات المتعددة بشكل صحيح ، على سبيل المثال: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| دعوى | يكتب | وصف |
|---|---|---|
dataset | الموضعية | مجموعة بيانات العبارة لتحويلها. |
spacy_model | الموضعية | نموذج Spacy للرمز المميز. |
label | الموضعية | تسمية لتطبيق على جميع الأنماط. |
--output-file ، -o | خيار | ملف الإخراج الاختياري. الإعدادات الافتراضية إلى stdout. |
--case-sensitive ، -CS | علَم | جعل الأنماط حساسة للحالة. |
--dry ، -D | علَم | قم بإجراء تشغيل جاف ولا تخرج أي شيء. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalقم بتقييم نموذج SENESS2VEC من خلال السؤال عن عبارة TRIPLES: هل Word A أكثر تشابهًا مع الكلمة B ، أو إلى Word C؟ إذا وافق الإنسان في الغالب على النموذج ، فإن نموذج المتجهات جيد. سوف تسأل الوصفة فقط عن المتجهات بنفس المعنى وتدعم استراتيجيات اختيار مثال مختلفة.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| دعوى | يكتب | وصف |
|---|---|---|
dataset | الموضعية | مجموعة البيانات لحفظ التعليقات التوضيحية ل. |
vectors_path | الموضعية | مسار إلى ناقلات Sense2Vec PretRained. |
--strategy ، -st | خيار | مثال استراتيجية الاختيار. most similar (افتراضي) أو random . |
--senses ، -s | خيار | قائمة مفصل الفاصلة من الحواس للحد من الاختيار إلى. إذا لم يتم ضبطها ، فسيتم استخدام جميع الحواس في المتجهات. |
--exclude-senses ، -es | خيار | قائمة مفصل الفاصلة من الحواس لاستبعاد. انظر prodigy_recipes.EVAL_EXCLUDE_SENSES الافتراضات. |
--n-freq ، -f | خيار | عدد الإدخالات الأكثر شيوعا للحد ل. |
--threshold ، -t | خيار | الحد الأدنى من الحد الأدنى للتشابه للنظر في الأمثلة. |
--batch-size ، -b | خيار | حجم الدُفعة للاستخدام. |
--eval-whole ، -E | علَم | تقييم مجموعة البيانات بأكملها بدلاً من الجلسة الحالية. |
--eval-only ، -O | علَم | لا تشرح ، فقط تقييم مجموعة البيانات الحالية. |
--show-scores ، -S | علَم | إظهار جميع الدرجات لتصحيح الأخطاء. |
| اسم | وصف |
|---|---|
most_similar | اختر كلمة عشوائية من معنى عشوائي واحصل على إدخالاتها الأكثر تشابهًا من نفس المعنى. اسأل عن التشابه مع الإدخال الأخير والوسط من هذا الاختيار. |
most_least_similar | اختر كلمة عشوائية من معنى عشوائي واحصل على إدخال أقل تشابهًا من إدخالاته الأكثر تشابهًا ، ثم آخر إدخال مماثل لذلك. |
random | اختر عينة عشوائية من 3 كلمات من نفس المعنى العشوائي. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5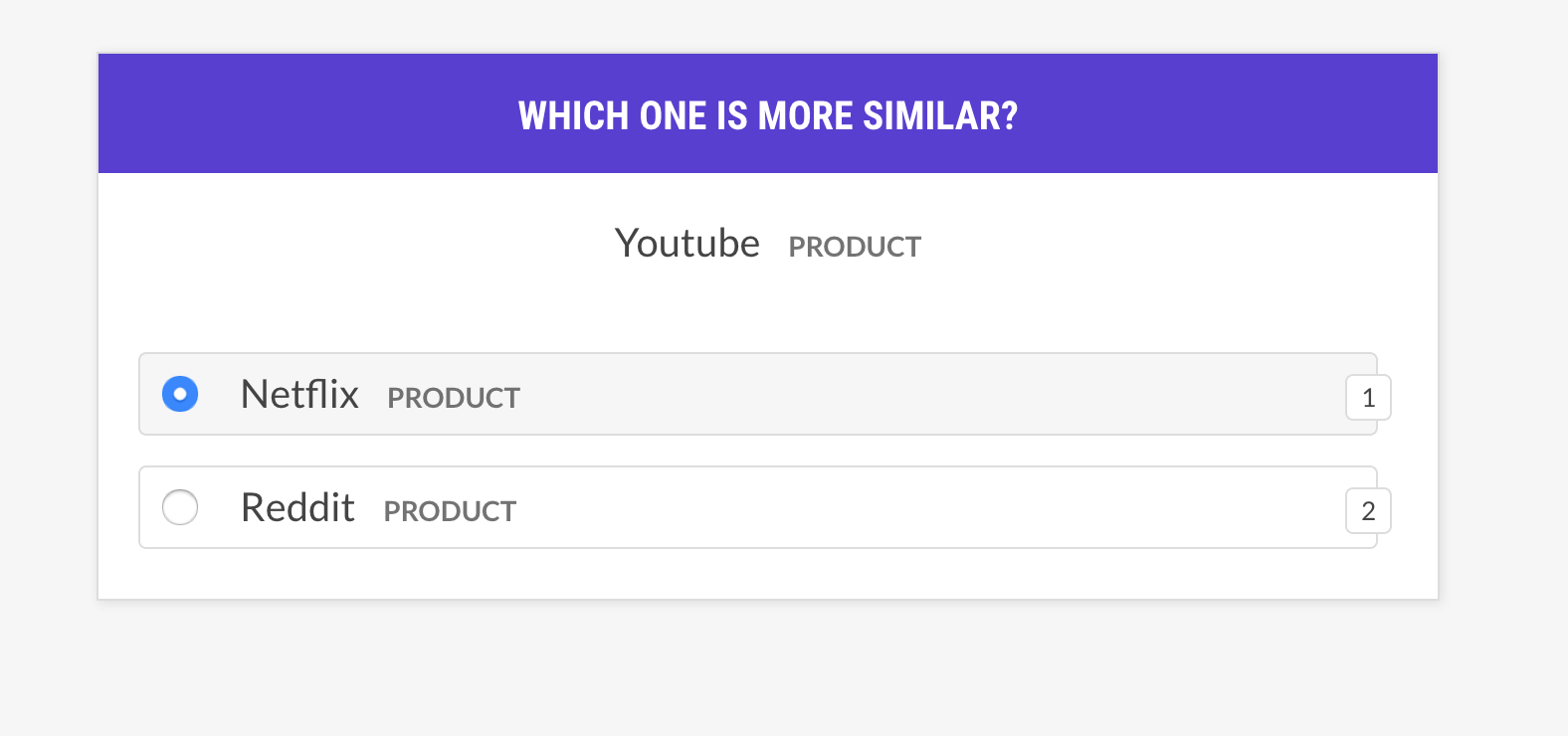
sense2vec.eval-most-similarقم بتقييم نموذج المتجهات من خلال النظر إلى الإدخالات الأكثر تشابهًا التي يعيدها لعبارة عشوائية وإلغاء تحديد الأخطاء.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| دعوى | يكتب | وصف |
|---|---|---|
dataset | الموضعية | مجموعة البيانات لحفظ التعليقات التوضيحية ل. |
vectors_path | الموضعية | مسار إلى ناقلات Sense2Vec PretRained. |
--senses ، -s | خيار | قائمة مفصل الفاصلة من الحواس للحد من الاختيار إلى. إذا لم يتم ضبطها ، فسيتم استخدام جميع الحواس في المتجهات. |
--exclude-senses ، -es | خيار | قائمة مفصل الفاصلة من الحواس لاستبعاد. انظر prodigy_recipes.EVAL_EXCLUDE_SENSES الافتراضات. |
--n-freq ، -f | خيار | عدد الإدخالات الأكثر شيوعا للحد ل. |
--n-similar ، -n | خيار | عدد العناصر المماثلة للتحقق. الافتراضات إلى 10 . |
--batch-size ، -b | خيار | حجم الدُفعة للاستخدام. |
--eval-whole ، -E | علَم | تقييم مجموعة البيانات بأكملها بدلاً من الجلسة الحالية. |
--eval-only ، -O | علَم | لا تشرح ، فقط تقييم مجموعة البيانات الحالية. |
--show-scores ، -S | علَم | إظهار جميع الدرجات لتصحيح الأخطاء. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abقم بتقييم A/B لنماذج ناقلات Sense2Vec pretried من خلال مقارنة الإدخالات الأكثر تشابهًا التي يعودون إلى عبارة عشوائية. تعرض واجهة المستخدم خيارين عشوائيين مع الإدخالات الأكثر تشابهًا لكل نموذج وتسلط الضوء على العبارات التي تختلف. في نهاية جلسة التعليقات التوضيحية ، يتم عرض الإحصائيات الشاملة والنموذج المفضل.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| دعوى | يكتب | وصف |
|---|---|---|
dataset | الموضعية | مجموعة البيانات لحفظ التعليقات التوضيحية ل. |
vectors_path_a | الموضعية | مسار إلى ناقلات Sense2Vec PretRained. |
vectors_path_b | الموضعية | مسار إلى ناقلات Sense2Vec PretRained. |
--senses ، -s | خيار | قائمة مفصل الفاصلة من الحواس للحد من الاختيار إلى. إذا لم يتم ضبطها ، فسيتم استخدام جميع الحواس في المتجهات. |
--exclude-senses ، -es | خيار | قائمة مفصل الفاصلة من الحواس لاستبعاد. انظر prodigy_recipes.EVAL_EXCLUDE_SENSES الافتراضات. |
--n-freq ، -f | خيار | عدد الإدخالات الأكثر شيوعا للحد ل. |
--n-similar ، -n | خيار | عدد العناصر المماثلة للتحقق. الافتراضات إلى 10 . |
--batch-size ، -b | خيار | حجم الدُفعة للاستخدام. |
--eval-whole ، -E | علَم | تقييم مجموعة البيانات بأكملها بدلاً من الجلسة الحالية. |
--eval-only ، -O | علَم | لا تشرح ، فقط تقييم مجموعة البيانات الحالية. |
--show-mapping ، -S | علَم | إظهار النماذج التي هي الخيار 1 والخيار 2 في واجهة المستخدم (لتصحيح الأخطاء). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT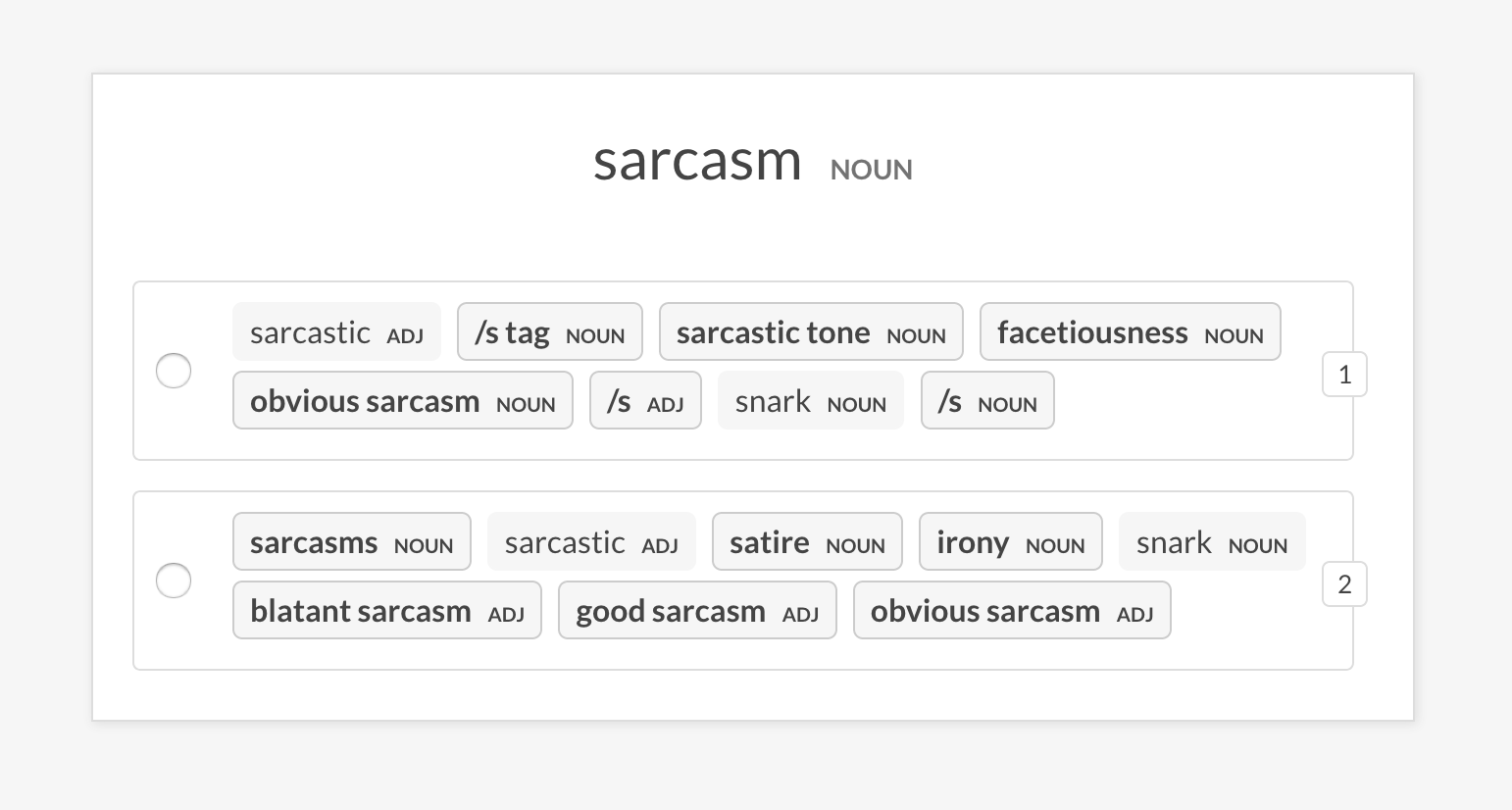
تدعم ناقلات Reddit المسبقة "الحواس" التالية ، إما علامات جزء من الكلام أو ملصقات الكيانات. لمزيد من التفاصيل ، راجع نظرة عامة على مخطط التعليقات التوضيحية لـ Spacy.
| علامة | وصف | أمثلة |
|---|---|---|
ADJ | صفة | كبير ، قديم ، أخضر |
ADP | adposition | في ، إلى ، خلال |
ADV | ظرف | جدا ، غدا ، أسفل ، أين |
AUX | مساعد | هو ، هل (تم) ، سوف (تفعل) |
CONJ | اِقتِران | و ، أو ، ولكن |
DET | المحدد | أ ، و ، و |
INTJ | التدخل | Psst ، Ouch ، Bravo ، مرحبًا |
NOUN | اسم | فتاة ، قط ، شجرة ، الهواء ، الجمال |
NUM | عدد | 1 ، 2017 ، واحد ، سبعة وسبعين ، MMXIV |
PART | الجسيمات | لا |
PRON | ضمير | أنا ، أنت ، هي ، بنفسي ، شخص ما |
PROPN | اسم مناسب | ماري ، جون ، لندن ، الناتو ، HBO |
PUNCT | علامات الترقيم | ،؟ () |
SCONJ | تخصيص التزامن | إذا ، في حين ، ذلك |
SYM | رمز | $ ، ٪ ، = ، :) ،؟ |
VERB | الفعل | الجري ، الجري ، الجري ، تناول الطعام ، أكل ، الأكل |
| تسمية الكيان | وصف |
|---|---|
PERSON | الناس ، بما في ذلك الخيالية. |
NORP | الجنسيات أو الجماعات الدينية أو السياسية. |
FACILITY | المباني ، المطارات ، الطرق السريعة ، الجسور ، إلخ. |
ORG | الشركات ، والوكالات ، والمؤسسات ، إلخ. |
GPE | البلدان والمدن والدول. |
LOC | المواقع غير GPE ، نطاقات الجبال ، أجسام المياه. |
PRODUCT | الكائنات والمركبات والأطعمة وما إلى ذلك (وليس الخدمات.) |
EVENT | اسم الأعاصير والمعارك والحروب والأحداث الرياضية ، إلخ. |
WORK_OF_ART | عناوين الكتب والأغاني وما إلى ذلك |
LANGUAGE | أي لغة تسمي. |


