sense2vec
v2.0.2
Sense2vec(Trasket。Al、2015)は、より興味深い詳細なWordベクターを学ぶことができるWord2vecの素晴らしいひねりです。このライブラリは、センス2VECモデルの読み込み、クエリ、トレーニングのためのシンプルなPython実装です。詳細については、ブログ投稿をご覧ください。 2015年と2019年のすべてのRedditコメントでセマンティックな類似点を調査するには、インタラクティブデモを参照してください。
?バージョン2.0(スペイシーV3の場合)が今すぐ!ここでリリースノートを読んでください。

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
ショ和 この例は、Spacy V3での使用法について説明していることに注意してください。 Spacy V2で使用するには、sense2vec==1.0.3をダウンロードして、このレポのv1.xブランチをご覧ください。
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]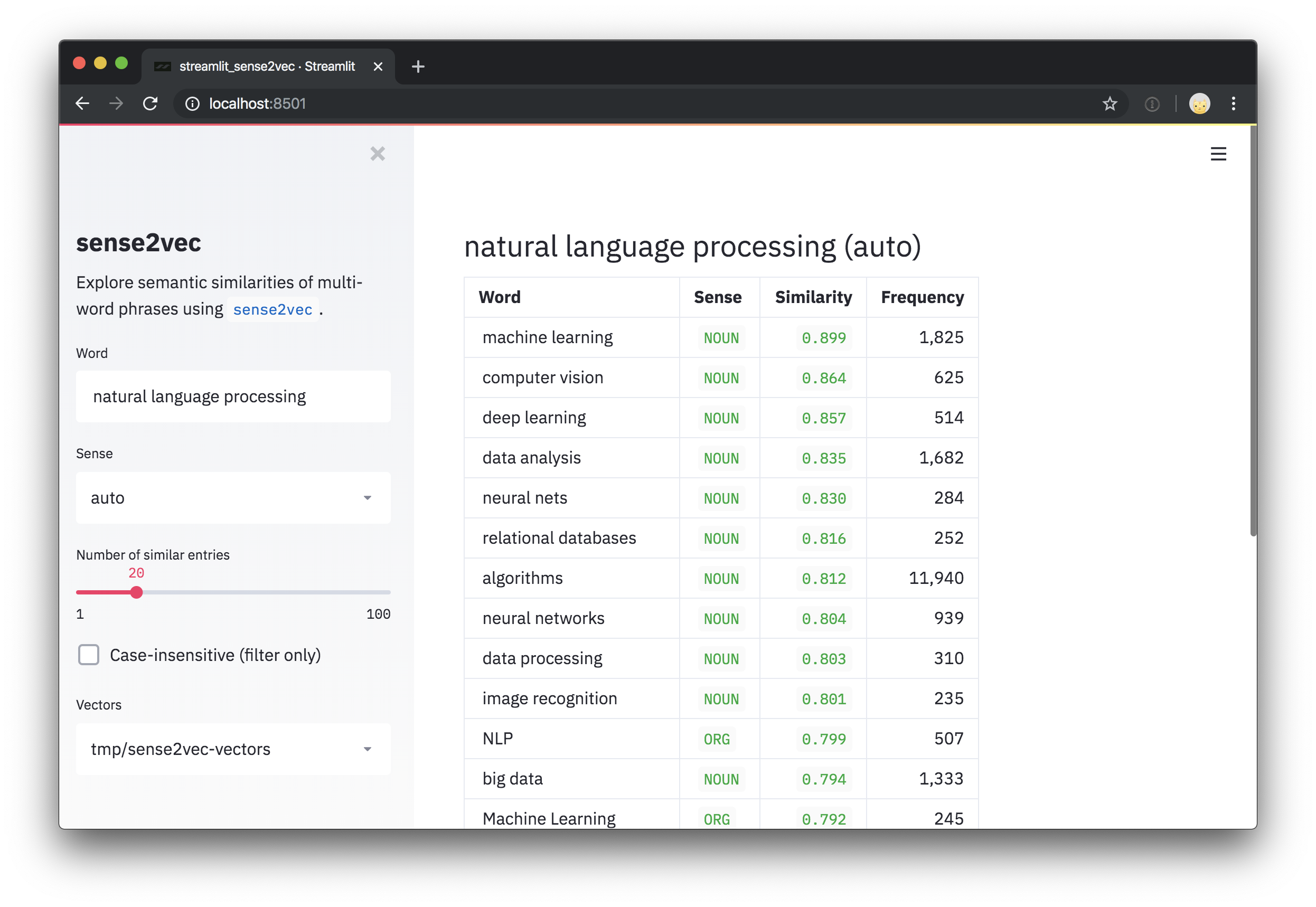
Redditのコメントでトレーニングされた前提条件のベクターを試すには、インタラクティブなSense2Vecデモをご覧ください。
このレポは、ベクターと最も類似したフレーズを探索するための流線のデモスクリプトも含まれています。 streamlitをインストールした後、コマンドラインの位置引数として、 streamlit runと1つ以上のパスを前処理したベクトルへの1つ以上のパスを使用してスクリプトを実行できます。例えば:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectorsベクトルを使用するには、アーカイブをダウンロードし、抽出されたディレクトリをSense2Vec.from_diskまたはSense2VecComponent.from_diskに渡します。ベクトルファイルはGitHubリリースに添付されています。大きなファイルはマルチパートのダウンロードに分割されています。
| ベクトル | サイズ | 説明 | ?ダウンロード(zipped) |
|---|---|---|---|
s2v_reddit_2019_lg | 4ギガバイト | Redditコメント2019(01-07) | パート1、パート2、パート3 |
s2v_reddit_2015_md | 573 MB | Redditコメント2015 | パート1 |
マルチパートアーカイブをマージするには、以下を実行できます。
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzSense2vecリリースはPIPで利用できます。
pip install sense2vec前処理されたベクトルを使用するには、ベクトルパッケージのいずれかをダウンロードし、 .tar.gzアーカイブを抽出したfrom_diskを抽出されたデータディレクトリに解凍します。
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )ライブラリとベクトルを使用する最も簡単な方法は、スペイシーパイプラインに接続することです。 sense2vecパッケージは、 Sense2VecComponentを公開します。Sense2VecComponentは、共有VoCabで初期化し、カスタムパイプラインコンポーネントとしてSpacy Pipelineに追加できます。デフォルトでは、コンポーネントがパイプラインの最後に追加されます。パイプラインは、依存関係の分割にアクセスする必要があり、利用可能な場合は名前付きエンティティにアクセスする必要があるため、このコンポーネントの推奨位置です。
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )コンポーネントは、SpacyのTokenにいくつかの拡張属性とメソッドを追加し、ベクトルと周波数、および最も類似した用語を取得できるオブジェクトをスパンするオブジェクトSpanます。
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )エンティティの場合、エンティティラベルは(トークンのスピーチの一部のタグの代わりに)「センス」として使用されます。
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 )次の拡張属性は、 ._プロパティを介してDocオブジェクトに公開されます。
| 名前 | 属性タイプ | タイプ | 説明 |
|---|---|---|---|
s2v_phrases | 財産 | リスト | 特定のDoc (名詞句、名前付きエンティティ)のすべてのSENSE2VEC互換のフレーズ。 |
次の属性は、 TokenとSpanオブジェクトの._プロパティを介して入手できます。たとえばtoken._.in_s2v :
|名前|属性タイプ|戻りタイプ|説明| | ------------------- | -------------- | ------------------- | ------------------------------------------------------------------------------------- | --------------- | ------- | | in_s2v |プロパティ|ブール|ベクトルマップにキーが存在するかどうか。 | | s2v_key |プロパティ| Unicode |与えられたオブジェクトのsense2vecキー、例: "duck | NOUN" 。 | | s2v_vec |プロパティ| ndarray[float32] |指定されたキーのベクトル。 | | s2v_freq |プロパティ| int |指定されたキーの頻度。 | | s2v_other_senses |プロパティ|リスト| "duck | VERB"の"duck | NOUN"などの他の感覚が利用可能です。 | | s2v_most_similar |方法|リスト| nの最も類似した用語を取得します。 ((word, sense), score)タプルのリストを返します。 | | s2v_similarity |方法|フロート|別のTokenまたはSpanとの類似性を取得します。 |
ショ和 スパン属性に関するメモ:フードの下では、doc.entsのエンティティはSpanオブジェクトです。これが、パイプラインコンポーネントがトークンだけでなくスパンに属性とメソッドを追加する理由です。ただし、モデルにはそれぞれのテキストのキーがない可能性が高いため、ドキュメントの任意のスライスでSense2Vec属性を使用することはお勧めしません。Spanオブジェクトには、スピーチの一部のタグもないため、エンティティラベルが存在しない場合、「センス」はルートの一部のスピーチタグにデフォルトです。
スペイシーパイプラインをトレーニングおよびパッケージ化し、Sense2Vecコンポーネントを含めたい場合は、トレーニング構成の[initialize]ブロックを介してデータにロードできます。
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md "基礎となるSense2Vecクラスを直接使用し、 from_diskメソッドを使用してベクターにロードすることもできます。利用可能なAPIメソッドについては、以下を参照してください。
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
ショ和 重要な注意:ベクトルテーブルでエントリを検索するには、キーはphrase_text|SENSEのスキームに従う必要があります(_の代わりに_に注意し、タグまたはラベルの前に|に注意してください) - たとえば、machine_learning|NOUN。また、基礎となるベクトルテーブルは症例に敏感であることに注意してください。
Sense2Vecベクトル、文字列、周波数を保持するスタンドアロンSense2Vecオブジェクト。
Sense2Vec.__init__ Sense2Vecオブジェクトを初期化します。
| 口論 | タイプ | 説明 |
|---|---|---|
shape | タプル | ベクトル形状。デフォルトは(1000, 128)になります。 |
strings | spacy.strings.StringStore | オプションの文字列ストア。存在しない場合は作成されます。 |
senses | リスト | 利用可能なすべての感覚のオプションのリスト。最良の感覚または他の感覚を生成する方法で使用されます。 |
vectors_name | Unicode | 衝突を防ぐために、 Vectorsテーブルに割り当てるオプション名。デフォルトは"sense2vec"になります。 |
overrides | dict | 使用するオプションのカスタム関数。たとえば、レジストリを介して登録されている名前にマッピングされます{"make_key": "custom_make_key"} 。 |
| 返品 | Sense2Vec | 新しく構築されたオブジェクト。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__ベクトルテーブルの行数。
| 口論 | タイプ | 説明 |
|---|---|---|
| 返品 | int | ベクトルテーブルの行数。 |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__キーがベクトルテーブルにあるかどうかを確認します。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | 見上げる鍵。 |
| 返品 | ブール | キーがテーブルにあるかどうか。 |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__特定のキーのベクトルを取得します。キーがテーブルにない場合、何も返しません。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | 見上げる鍵。 |
| 返品 | numpy.ndarray | ベクトルまたはNone 。 |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__特定のキーのベクトルを設定します。キーが存在しない場合、エラーが発生します。新しいエントリを追加するには、 Sense2Vec.addを使用してください。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | キー。 |
vector | numpy.ndarray | 設定するベクトル。 |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addテーブルに新しいベクトルを追加します。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | 追加する鍵。 |
vector | numpy.ndarray | 追加するベクトル。 |
freq | int | オプションの周波数カウント。最高のマッチング感覚を見つけるために使用されます。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freq特定のキーの周波数カウントを取得します。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | 見上げる鍵。 |
default | - | 頻度が見つからない場合はデフォルト値を返します。 |
| 返品 | int | 周波数カウント。 |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freq特定のキーの周波数カウントを設定します。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | カウントを設定するための鍵。 |
freq | int | 周波数カウント。 |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ 、 Sense2Vec.itemsVectorsテーブルのエントリを反復します。
| 口論 | タイプ | 説明 |
|---|---|---|
| 降伏します | タプル | テーブル内の文字列キーとベクトルのペア。 |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysテーブルのキーを反復します。
| 口論 | タイプ | 説明 |
|---|---|---|
| 降伏します | Unicode | テーブル内の文字列キー。 |
all_keys = list ( s2v . keys ())Sense2Vec.valuesテーブル内のベクトルを反復します。
| 口論 | タイプ | 説明 |
|---|---|---|
| 降伏します | numpy.ndarray | テーブル内のベクトル。 |
all_vecs = list ( s2v . values ())Sense2Vec.sensesテーブル内の利用可能な感覚、例: "NOUN"または"VERB" (初期化時に追加)。
| 口論 | タイプ | 説明 |
|---|---|---|
| 返品 | リスト | 利用可能な感覚。 |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesテーブル内のキーの周波数は、下降順に。
| 口論 | タイプ | 説明 |
|---|---|---|
| 返品 | リスト | (key, freq)は、周波数によるタプル、下降。 |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarity2つのキーまたは2セットのキーのセマンティックな類似性推定値を作成します。デフォルトの推定値は、平均ベクターを使用したCOSINEの類似性です。
| 口論 | タイプ | 説明 |
|---|---|---|
keys_a | Unicode / int / Iterable | 文字列または整数キー。 |
keys_b | Unicode / int / Iterable | 他の文字列または整数キー。 |
| 返品 | フロート | 類似性スコア。 |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarテーブルで最も似たようなエントリを取得します。複数のキーが提供されている場合、ベクトルの平均が使用されます。この方法をより速くするには、最近隣人のキャッシュを事前に計算するためのスクリプトを参照してください。
| 口論 | タイプ | 説明 |
|---|---|---|
keys | Unicode / int / Iterable | 比較する文字列または整数キー。 |
n | int | returnする同様のキーの数。デフォルトは10です。 |
batch_size | int | 使用するバッチサイズ。デフォルトは16です。 |
| 返品 | リスト | 最も類似したベクトルの(key, score)タプル。 |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses "duck|VERB"の"duck|NOUN"など、異なる感覚を持つ同じ単語の他のエントリを見つけます。
| 口論 | タイプ | 説明 |
|---|---|---|
key | Unicode / int | チェックする鍵。 |
ignore_case | ブール | 大文字、小文字、タイトルケースを確認してください。デフォルトはTrueです。 |
| 返品 | リスト | 異なる感覚のある他のエントリの文字列キー。 |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense利用可能な感覚と周波数カウントに基づいて、特定の単語の最適な感覚を見つけます。一致が見つからない場合は、返品しNone 。
| 口論 | タイプ | 説明 |
|---|---|---|
word | Unicode | チェックする言葉。 |
senses | リスト | 検索を制限するための感覚のオプションのリスト。設定 /空でない場合、ベクトル内のすべての感覚が使用されます。 |
ignore_case | ブール | 大文字、小文字、タイトルケースを確認してください。デフォルトはTrueです。 |
| 返品 | Unicode | 最高の一致キーまたはなし。 |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Sense2Vecオブジェクトをバイテストリングにシリアル化します。
| 口論 | タイプ | 説明 |
|---|---|---|
exclude | リスト | 除外するシリアル化フィールドの名前。 |
| 返品 | バイト | シリアル化Sense2Vecオブジェクト。 |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes bytestringからSense2Vecオブジェクトをロードします。
| 口論 | タイプ | 説明 |
|---|---|---|
bytes_data | バイト | ロードするデータ。 |
exclude | リスト | 除外するシリアル化フィールドの名前。 |
| 返品 | Sense2Vec | ロードされたオブジェクト。 |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Sense2Vecオブジェクトをディレクトリにシリアル化します。
| 口論 | タイプ | 説明 |
|---|---|---|
path | ユニコード / Path | パス。 |
exclude | リスト | 除外するシリアル化フィールドの名前。 |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_diskディレクトリからSense2Vecオブジェクトをロードします。
| 口論 | タイプ | 説明 |
|---|---|---|
path | ユニコード / Path | ロードするパスから |
exclude | リスト | 除外するシリアル化フィールドの名前。 |
| 返品 | Sense2Vec | ロードされたオブジェクト。 |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentSense2VecをSpacyパイプラインに追加するパイプラインコンポーネント。
Sense2VecComponent.__init__パイプラインコンポーネントを初期化します。
| 口論 | タイプ | 説明 |
|---|---|---|
vocab | Vocab | 共有Vocab 。主に共有StringStoreに使用されます。 |
shape | タプル | ベクトル形状。 |
merge_phrases | ブール | Sense2Vecフレーズを1つのトークンにマージするかどうか。デフォルトはFalseになります。 |
lemmatize | ブール | ベクターで使用可能な場合は、常に補題を検索します。デフォルトはFalseになります。 |
overrides | 使用するオプションのカスタム関数。たとえば、レジストリを介して登録された名前にマッピングされます{"make_key": "custom_make_key"} 。 | |
| 返品 | Sense2VecComponent | 新しく構築されたオブジェクト。 |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp NLPオブジェクトからコンポーネントを初期化します。主にエントリポイントのコンポーネントファクトリとして使用され(setup.cfgを参照)、 @spacy.componentデコレーターを介して自動登録します。
| 口論 | タイプ | 説明 |
|---|---|---|
nlp | Language | nlpオブジェクト。 |
**cfg | - | オプションの構成パラメーター。 |
| 返品 | Sense2VecComponent | 新しく構築されたオブジェクト。 |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__コンポーネントを使用してDocオブジェクトを処理します。通常、スパシーパイプラインの一部としてのみ呼び出され、直接ではありません。
| 口論 | タイプ | 説明 |
|---|---|---|
doc | Doc | 処理するドキュメント。 |
| 返品 | Doc | 処理されたドキュメント。 |
Sense2Vec.init_componentコンポーネント固有の拡張属性をここで登録し、コンポーネントがパイプラインに追加されて使用されている場合にのみ登録します。そうしないと、コンポーネントが作成されて追加されていない場合でも、トークンは属性を取得します。
Sense2VecComponent.to_bytesコンポーネントをバイテストリングにシリアル化します。コンポーネントがパイプラインに追加され、 nlp.to_bytesを実行した場合にも呼び出されます。
| 口論 | タイプ | 説明 |
|---|---|---|
| 返品 | バイト | シリアル化されたコンポーネント。 |
Sense2VecComponent.from_bytesバイテストリングからコンポーネントをロードします。また、 nlp.from_bytes実行するときにも呼ばれます。
| 口論 | タイプ | 説明 |
|---|---|---|
bytes_data | バイト | ロードするデータ。 |
| 返品 | Sense2VecComponent | ロードされたオブジェクト。 |
Sense2VecComponent.to_diskコンポーネントをディレクトリにシリアル化します。コンポーネントがパイプラインに追加され、 nlp.to_disk実行した場合にも呼び出されます。
| 口論 | タイプ | 説明 |
|---|---|---|
path | ユニコード / Path | パス。 |
Sense2VecComponent.from_diskディレクトリからSense2Vecオブジェクトをロードします。 nlp.from_disk実行したときにも呼ばれます。
| 口論 | タイプ | 説明 |
|---|---|---|
path | ユニコード / Path | ロードするパスから |
| 返品 | Sense2VecComponent | ロードされたオブジェクト。 |
registry関数レジストリ( catalogueを搭載)して、キーとフレーズを生成するために使用される関数を簡単にカスタマイズします。モデルを保存するときに、カスタム関数を飾ってカスタム関数を交換し、カスタム名をシリアル化できます。次のレジストリオプションが利用可能です。
|名前|説明| | ---------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | --------- | | registry.make_key | wordとsenseを考えると、キーの文字列、 "word | sense". | | registry.split_key |文字列キーが与えられた場合、 (word, sense)タプルを返します。 | | registry.make_spacy_key | Spacyオブジェクト( TokenまたはSpan )とブールのprefer_entsキーワード引数(シングルトークンのエンティティラベルを好むかどうか)が与えられた場合、 (word, sense)タプルを返します。トークンとスパンのキーを生成するために拡張属性で使用されます。 | | | registry.get_phrases | Spacy Docが与えられた場合、Sense2Vecフレーズ(通常は名詞句と名前付きエンティティ)に使用されるSpanオブジェクトのリストを返します。 | | registry.merge_phrases |スペイシーDocが与えられた場合、すべてのSENSE2VECフレーズを取得し、それらを単一のトークンに統合します。 |
各レジストリには、関数デコレータとして使用できるregisterメソッドがあり、カスタム関数の名前である1つの引数を取得します。
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Sense2Vecオブジェクトを初期化するときに、カスタム登録機能の名前をオーバーライドの辞書に渡すことができます。
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )これにより、さまざまな戦略を試し、戦略を平易な文字列としてシリアル化することができます(機能自体を通過および/または漬物する代わりに)。
/scriptsディレクトリには、テキストを前処理し、独自のベクトルをトレーニングするためのコマンドラインユーティリティが含まれています。
独自のSense2Vecベクトルをトレーニングするには、次のことが必要です。
doc.noun_chunksに入力する事前に守られたスペイシーモデル。必要な言語が名詞句に組み込まれた構文のイテレーターを提供しない場合は、独自に書く必要があります。 ( doc.noun_chunksとdoc.ents 、Sense2vecがフレーズとは何かを決定するために使用するものです。)makeできるはずです。トレーニングプロセスは、特定のポイントで再開できるように、いくつかのステップに分割されます。スクリプトの処理は、単一のファイルで動作するように設計されているため、作業を簡単に並べることができます。このリポジトリのスクリプトには、クローンとmake必要があるグローブまたはFastTextのいずれかが必要です。
FastTextの場合、スクリプトは作成されたバイナリファイルへのパスが必要です。 Windowsで作業している場合は、 cmakeでビルドするか、Windows用のFastTextバイナリビルドを使用して、この非公式リポジトリの.exeファイルを使用することもできます。
| スクリプト | 説明 | |
|---|---|---|
| 1。 | 01_parse.py | スペイシーを使用して、生のテキストを解析し、 Docオブジェクトのバイナリコレクションを出力します( DocBinを参照)。 |
| 2。 | 02_preprocess.py | 以前のステップで作成された解析されたDocオブジェクトのコレクションをロードし、Sense2Vec形式でテキストファイルを出力します(1行ごとに1つの文と感覚とマージされたフレーズ)。 |
| 3。 | 03_glove_build_counts.py | グローブを使用して、語彙を構築してカウントします。 FastTextを介してWord2Vecを使用している場合は、この手順をスキップします。 |
| 4。 | 04_glove_train_vectors.py04_fasttext_train_vectors.py | グローブまたはファストテキストを使用してベクターをトレーニングします。 |
| 5。 | 05_export.py | ベクトルと周波数をロードし、 Sense2Vec.from_diskを介してロードできるSense2vecコンポーネントを出力します。 |
| 6。 | 06_precompute_cache.py | オプション: Vocab内のすべてのエントリの最寄りのneighborクエリをPrecopute Sense2Vec.most_similarをより速くします。 |
スクリプトのより詳細なドキュメントについては、ソースをチェックするか、 --helpで実行します。たとえば、 python scripts/01_parse.py --help 。
また、このパッケージはProdigy Annotationツールとシームレスに統合され、Sense2Vecベクトルを使用してマルチワードフレーズとブートストラップのリストをすばやく生成するためのレシピを公開します。レシピを使用するには、 sense2vec天才と同じ環境にインストールする必要があります。実際のユースケースの例については、ダウンロード可能なデータセットを使用してこのNERプロジェクトをご覧ください。
以下のレシピが利用可能です。詳細なドキュメントについては、以下を参照してください。
| レシピ | 説明 |
|---|---|
sense2vec.teach | Sense2vecを使用して、用語リストをブートストラップします。 |
sense2vec.to-patterns | フレーズデータセットをトークンベースのマッチパターンに変換します。 |
sense2vec.eval | フレーズトリプルについて尋ねて、Sense2Vecモデルを評価します。 |
sense2vec.eval-most-similar | 最も類似したエントリを修正して、Sense2Vecモデルを評価します。 |
sense2vec.eval-ab | 2つの前提条件2VECベクトルモデルのA/B評価を実行します。 |
sense2vec.teachSense2vecを使用して、用語リストをブートストラップします。 Prodigyは、Sense2vecの最も類似したフレーズに基づいて同様の用語を提案し、同様のフレーズを注釈および受け入れると、提案が調整されます。各シード用語では、Sense2Vecベクトルに従って最適なマッチングセンスが使用されます。
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| 口論 | タイプ | 説明 |
|---|---|---|
dataset | 位置 | 注釈を保存するデータセット。 |
vectors_path | 位置 | 前処理されたSense2Vecベクトルへのパス。 |
--seeds 、 -s | オプション | 1つ以上のコンマ分離された種子フレーズ。 |
--threshold 、 -t | オプション | 類似のしきい値。デフォルトは0.85です。 |
--n-similar 、 -n | オプション | 同様のアイテムの数を一度に取得します。 |
--batch-size 、 -b | オプション | 注釈を送信するためのバッチサイズ。 |
--resume 、 -R | フラグ | 既存のフレーズデータセットから再開します。 |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns sense2vec.teachで収集されたフレーズのデータセットを、SpacyのEntityRulerまたはner.matchなどのレシピで使用できるトークンベースのマッチパターンに変換します。出力ファイルが指定されていない場合、パターンはstdoutに書き込まれます。例は、マルチトークン用語が正しく表されるようにトークン化されています。例: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} 。
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| 口論 | タイプ | 説明 |
|---|---|---|
dataset | 位置 | 変換するフレーズデータセット。 |
spacy_model | 位置 | トークン化のためのスペイシーモデル。 |
label | 位置 | すべてのパターンに適用するラベル。 |
--output-file 、 -o | オプション | オプションの出力ファイル。デフォルトはstdoutです。 |
--case-sensitive 、 -CS | フラグ | パターンをケースに敏感にします。 |
--dry 、 -D | フラグ | ドライランを実行し、何も出力しないでください。 |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalフレーズトリプルについて尋ねてSense2Vecモデルを評価します。単語はWord Bに似ていますか、それとも単語Cに似ていますか?人間がほとんどモデルに同意している場合、ベクターモデルは良好です。レシピでは、同じ感覚を持つベクトルについてのみ尋ね、異なる例の選択戦略をサポートします。
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| 口論 | タイプ | 説明 |
|---|---|---|
dataset | 位置 | 注釈を保存するデータセット。 |
vectors_path | 位置 | 前処理されたSense2Vecベクトルへのパス。 |
--strategy 、 -st | オプション | 選択戦略の例。 most similar (デフォルト)またはrandom 。 |
--senses 、 -s | オプション | 選択を制限するためのコンマ区切りの感覚のリスト。設定しない場合、ベクトル内のすべての感覚が使用されます。 |
--exclude-senses 、 -es | オプション | 除外する感覚のコンマ分離されたリスト。 prodigy_recipes.EVAL_EXCLUDE_SENSESを参照してください。 |
--n-freq 、 -f | オプション | 制限する最も頻繁なエントリの数。 |
--threshold 、 -t | オプション | 例を考慮する最小類似のしきい値。 |
--batch-size 、 -b | オプション | 使用するバッチサイズ。 |
--eval-whole 、 -E | フラグ | 現在のセッションではなく、データセット全体を評価します。 |
--eval-only 、 -O | フラグ | 注釈を付けないでください。現在のデータセットのみを評価します。 |
--show-scores 、 -S | フラグ | デバッグのすべてのスコアを表示します。 |
| 名前 | 説明 |
|---|---|
most_similar | ランダムな感覚からランダムな単語を選択し、同じ感覚の最も類似したエントリを取得します。その選択からの最後と中央のエントリとの類似性について尋ねてください。 |
most_least_similar | ランダムな感覚からランダムな単語を選択し、最も類似したエントリから最も類似したエントリを取得し、その後最も類似したエントリを取得します。 |
random | 同じランダムな感覚から3語のランダムサンプルを選択します。 |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5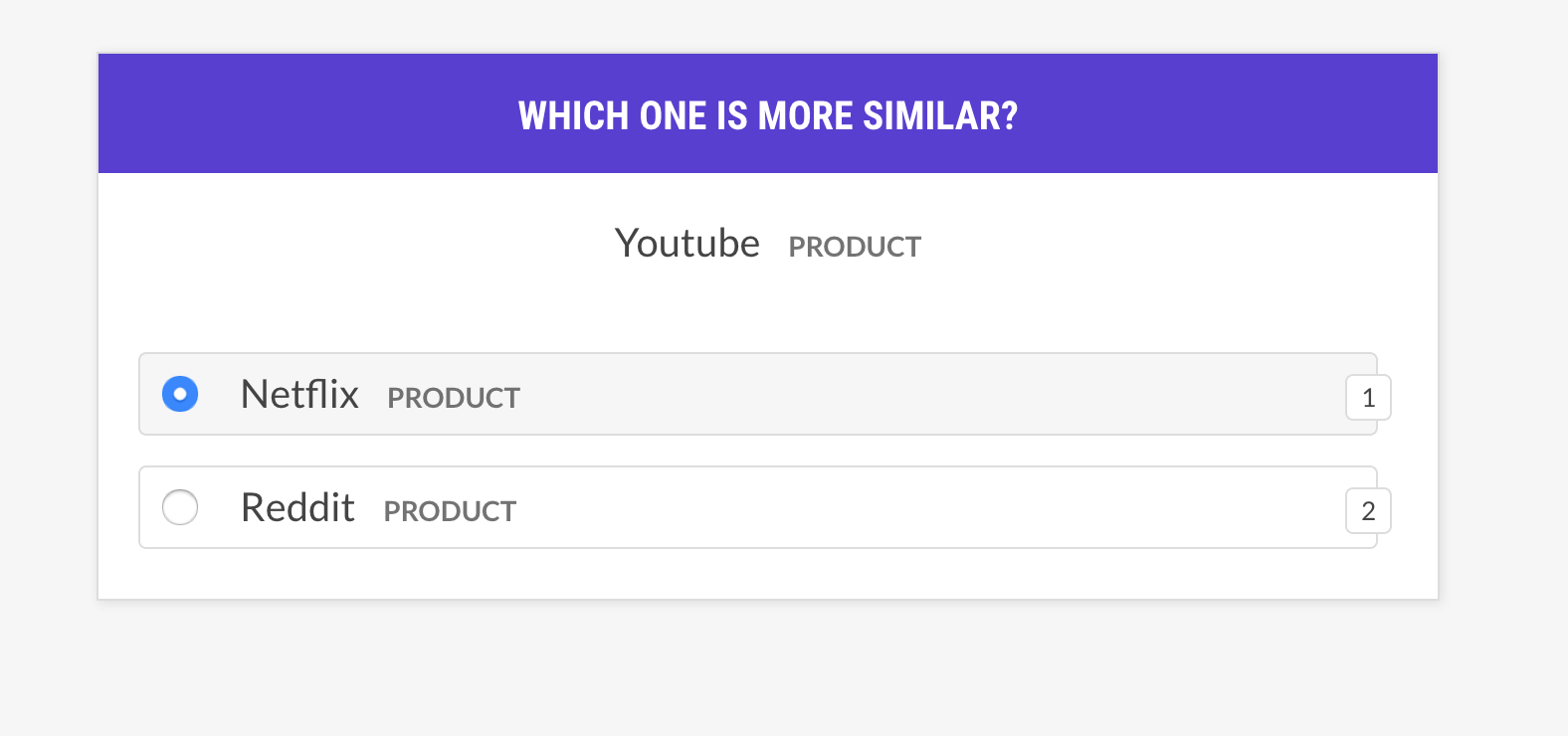
sense2vec.eval-most-similarランダムなフレーズのために返される最も類似したエントリを調べ、間違いを解除することにより、ベクターモデルを評価します。
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| 口論 | タイプ | 説明 |
|---|---|---|
dataset | 位置 | 注釈を保存するデータセット。 |
vectors_path | 位置 | 前処理されたSense2Vecベクトルへのパス。 |
--senses 、 -s | オプション | 選択を制限するためのコンマ区切りの感覚のリスト。設定しない場合、ベクトル内のすべての感覚が使用されます。 |
--exclude-senses 、 -es | オプション | 除外する感覚のコンマ分離されたリスト。 prodigy_recipes.EVAL_EXCLUDE_SENSESを参照してください。 |
--n-freq 、 -f | オプション | 制限する最も頻繁なエントリの数。 |
--n-similar 、 -n | オプション | チェックする同様のアイテムの数。デフォルトは10です。 |
--batch-size 、 -b | オプション | 使用するバッチサイズ。 |
--eval-whole 、 -E | フラグ | 現在のセッションではなく、データセット全体を評価します。 |
--eval-only 、 -O | フラグ | 注釈を付けないでください。現在のデータセットのみを評価します。 |
--show-scores 、 -S | フラグ | デバッグのすべてのスコアを表示します。 |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abランダムなフレーズのために返される最も類似したエントリを比較することにより、2つの前処理されたSense2VECベクトルモデルのA/B評価を実行します。 UIは、各モデルの最も類似したエントリを持つ2つのランダム化オプションを表示し、異なるフレーズを強調します。注釈セッションの終わりには、全体的な統計と優先モデルが表示されます。
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| 口論 | タイプ | 説明 |
|---|---|---|
dataset | 位置 | 注釈を保存するデータセット。 |
vectors_path_a | 位置 | 前処理されたSense2Vecベクトルへのパス。 |
vectors_path_b | 位置 | 前処理されたSense2Vecベクトルへのパス。 |
--senses 、 -s | オプション | 選択を制限するためのコンマ区切りの感覚のリスト。設定しない場合、ベクトル内のすべての感覚が使用されます。 |
--exclude-senses 、 -es | オプション | 除外する感覚のコンマ分離されたリスト。 prodigy_recipes.EVAL_EXCLUDE_SENSESを参照してください。 |
--n-freq 、 -f | オプション | 制限する最も頻繁なエントリの数。 |
--n-similar 、 -n | オプション | チェックする同様のアイテムの数。デフォルトは10です。 |
--batch-size 、 -b | オプション | 使用するバッチサイズ。 |
--eval-whole 、 -E | フラグ | 現在のセッションではなく、データセット全体を評価します。 |
--eval-only 、 -O | フラグ | 注釈を付けないでください。現在のデータセットのみを評価します。 |
--show-mapping 、 -S | フラグ | どのモデルがUIのオプション1とオプション2であるかを示します(デバッグ用)。 |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT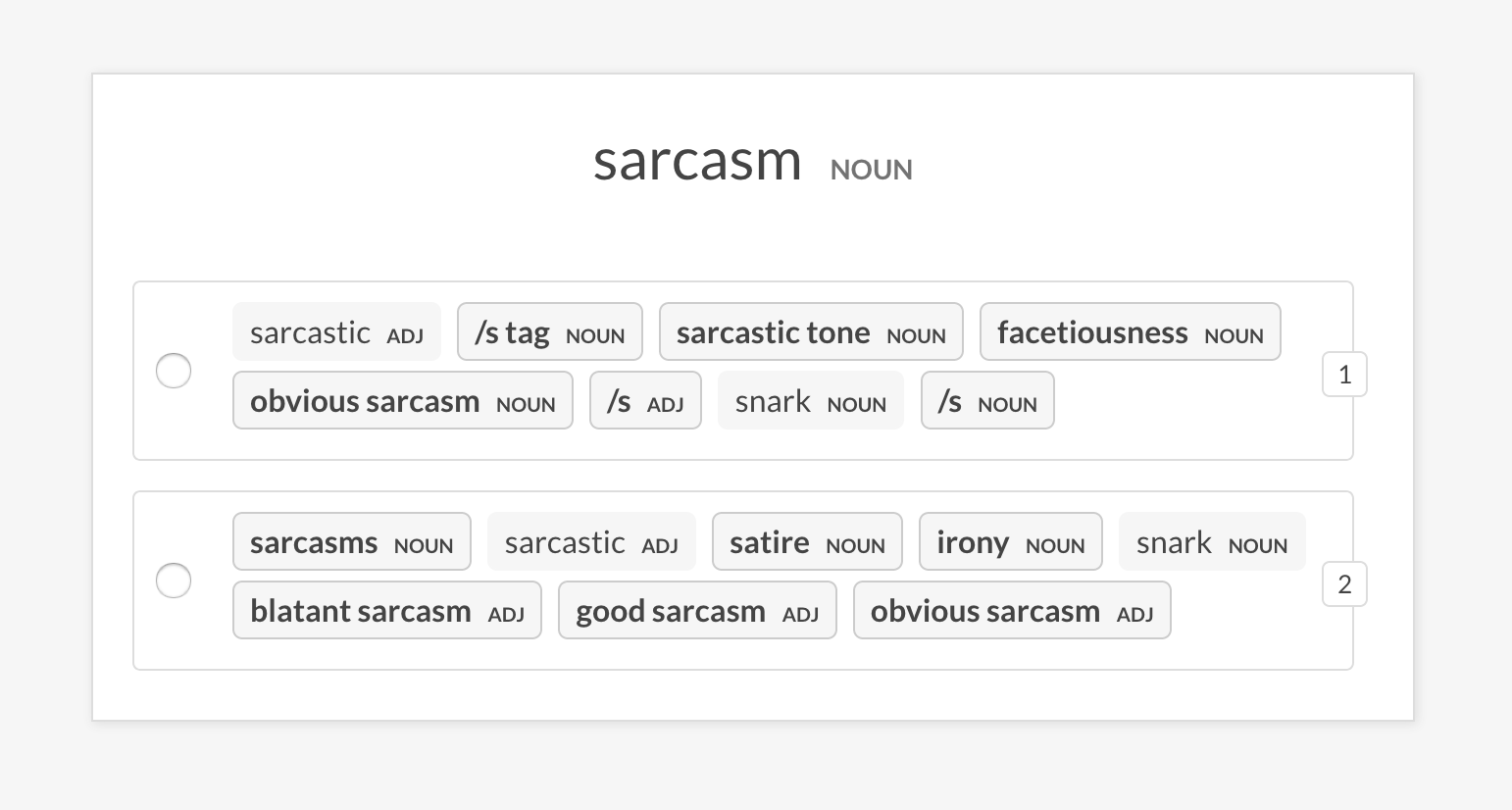
前処理されたRedditベクターは、一部のスピーチタグまたはエンティティラベルのいずれかの次の「感覚」をサポートしています。詳細については、Spacyの注釈スキームの概要を参照してください。
| タグ | 説明 | 例 |
|---|---|---|
ADJ | 形容詞 | 大きく、古い、緑 |
ADP | アドポジション | で、 |
ADV | 副詞 | 非常に、明日、どこで |
AUX | 補助 | is、have(done)、will(do) |
CONJ | 接続詞 | そして、または、しかし |
DET | 決定者 | a、an、 |
INTJ | 間投詞 | PSST、OUCH、BRAVO、こんにちは |
NOUN | 名詞 | 女の子、猫、木、空気、美しさ |
NUM | 数字 | 1、2017、1、77、mmxiv |
PART | 粒子 | そうではありません |
PRON | 代名詞 | 私、あなた、彼、彼女、私自身、誰か |
PROPN | 固有名詞 | メアリー、ジョン、ロンドン、NATO、HBO |
PUNCT | 句読点 | 、? () |
SCONJ | 従属的な接続詞 | もしそうなら、それ |
SYM | シンボル | $、%、=、:)、? |
VERB | 動詞 | 走ったり、走ったり、走ったり、食べたり、食べたり、食べたりします |
| エンティティラベル | 説明 |
|---|---|
PERSON | 架空の人々を含む人々。 |
NORP | 国籍または宗教的または政治グループ。 |
FACILITY | 建物、空港、高速道路、橋など |
ORG | 企業、代理店、機関など |
GPE | 国、都市、州。 |
LOC | 非GPEの場所、山脈、水域。 |
PRODUCT | オブジェクト、車両、食品など(サービスではありません。) |
EVENT | ハリケーン、戦闘、戦争、スポーツイベントなどと名付けられました。 |
WORK_OF_ART | 本、歌などのタイトル |
LANGUAGE | 名前付き言語。 |


