sense2vec
v2.0.2
Sense2vec (Trask et. al, 2015) เป็นสิ่งที่ดีใน Word2vec ที่ให้คุณเรียนรู้เวกเตอร์คำที่น่าสนใจและมีรายละเอียดมากขึ้น ห้องสมุดนี้เป็นการใช้งาน Python อย่างง่ายสำหรับการโหลดการสอบถามและการฝึกอบรม Sense2VEC แบบจำลอง สำหรับรายละเอียดเพิ่มเติมตรวจสอบโพสต์บล็อกของเรา ในการสำรวจความคล้ายคลึงกันทางความหมายในความคิดเห็นของ Reddit ทั้งหมดของปี 2015 และ 2019 ดูการสาธิตแบบโต้ตอบ
- เวอร์ชัน 2.0 (สำหรับ Spacy v3) ออกตอนนี้! อ่านบันทึกย่อที่นี่

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
โปรดทราบว่าตัวอย่างนี้อธิบายการใช้งานด้วย Spacy V3 สำหรับการใช้งานกับ Spacy V2 ให้ดาวน์โหลด sense2vec==1.0.3และตรวจสอบสาขาv1.xของ repo นี้
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]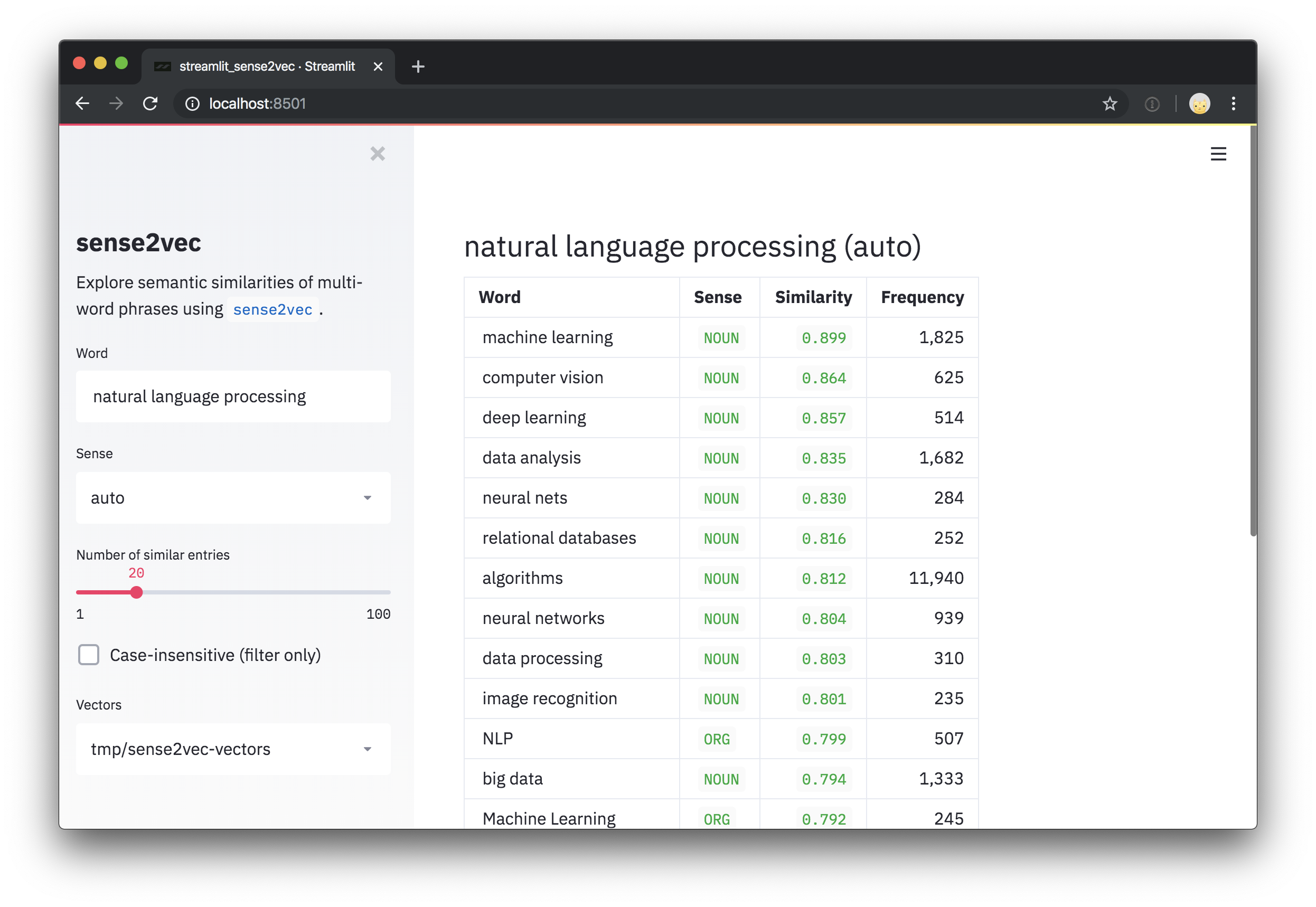
หากต้องการลองใช้เวกเตอร์ที่ได้รับการฝึกฝนเกี่ยวกับความคิดเห็นของ Reddit ให้ตรวจสอบการสาธิต Sense2Vec แบบโต้ตอบ
repo นี้ยังรวมถึงสคริปต์สาธิตสตรีมสำหรับการสำรวจเวกเตอร์และวลีที่คล้ายกันมากที่สุด หลังจากติดตั้ง streamlit คุณสามารถเรียกใช้สคริปต์ด้วย streamlit run และ เส้นทางหนึ่งหรือมากกว่าหนึ่งเส้นทางไปยังเวกเตอร์ที่ได้รับการปรับแต่ง เป็น อาร์กิวเมนต์ตำแหน่ง บนบรรทัดคำสั่ง ตัวอย่างเช่น:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors หากต้องการใช้เวกเตอร์ให้ดาวน์โหลดไฟล์เก็บถาวรและส่งผ่านไดเรกทอรีสกัดไปยัง Sense2Vec.from_disk หรือ Sense2VecComponent.from_disk ไฟล์เวกเตอร์จะ ถูกแนบไปกับการเปิดตัว GitHub ไฟล์ขนาดใหญ่ได้ถูกแบ่งออกเป็นการดาวน์โหลดหลายส่วน
| เวกเตอร์ | ขนาด | คำอธิบาย | - ดาวน์โหลด (ซิป) |
|---|---|---|---|
s2v_reddit_2019_lg | 4 GB | ความคิดเห็น Reddit 2019 (01-07) | ส่วนที่ 1 ส่วนที่ 2 ตอนที่ 3 |
s2v_reddit_2015_md | 573 MB | ความคิดเห็น Reddit 2015 | ส่วนที่ 1 |
ในการรวมคลังเก็บข้อมูลหลายส่วนคุณสามารถเรียกใช้สิ่งต่อไปนี้:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzSense2Vec รุ่นนี้มีอยู่ใน PIP:
pip install sense2vec หากต้องการใช้เวกเตอร์ pretrained ดาวน์โหลดหนึ่งในแพ็คเกจเวกเตอร์แกะกล่อง .tar.gz เก็บถาวรและจุด from_disk ไปยังไดเรกทอรีข้อมูลที่แยกออกมา:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) วิธีที่ง่ายที่สุดในการใช้ห้องสมุดและเวกเตอร์คือการเสียบเข้ากับท่อส่งของคุณ แพ็คเกจ sense2vec เปิดเผย Sense2VecComponent ซึ่งสามารถเริ่มต้นด้วยคำศัพท์ที่ใช้ร่วมกันและเพิ่มลงในท่อ Spacy ของคุณเป็นส่วนประกอบไปป์ไลน์ที่กำหนดเอง โดยค่าเริ่มต้นส่วนประกอบจะถูกเพิ่มไปยัง ส่วนท้ายของไปป์ไลน์ ซึ่งเป็นตำแหน่งที่แนะนำสำหรับส่วนประกอบนี้เนื่องจากจำเป็นต้องเข้าถึงการแยกวิเคราะห์การพึ่งพาและหากมีให้บริการ
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) ส่วนประกอบจะเพิ่มแอตทริบิวต์ส่วนขยายและวิธีการหลายอย่างให้กับ Token ของ Spacy และ Span วัตถุที่ให้คุณดึงเวกเตอร์และความถี่รวมถึงคำที่คล้ายกันมากที่สุด
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )สำหรับเอนทิตีฉลากเอนทิตีถูกใช้เป็น "ความรู้สึก" (แทนที่จะเป็นแท็กส่วนหนึ่งของโทเค็น):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) แอตทริบิวต์ส่วนขยายต่อไปนี้จะถูกเปิดเผยบนวัตถุ Doc ผ่านคุณสมบัติ ._ :
| ชื่อ | ประเภทแอตทริบิวต์ | พิมพ์ | คำอธิบาย |
|---|---|---|---|
s2v_phrases | คุณสมบัติ | รายการ | วลีที่เข้ากันได้กับ Sense2Vec ทั้งหมดใน Doc ที่กำหนด (วลีคำนามชื่อเอนทิตี) |
แอตทริบิวต์ต่อไปนี้มีให้ผ่านคุณสมบัติ ._ ของ Token และ Span วัตถุ - ตัวอย่างเช่น token._.in_s2v :
- ชื่อ | ประเภทแอตทริบิวต์ | Type return | คำอธิบาย | - - - - - - - - in_s2v | ทรัพย์สิน | บูล ไม่ว่าจะเป็นกุญแจสำคัญในแผนที่เวกเตอร์ - - s2v_key | ทรัพย์สิน | Unicode คีย์ Sense2vec ของวัตถุที่กำหนดเช่น "duck | NOUN" - - s2v_vec | ทรัพย์สิน | ndarray[float32] | เวกเตอร์ของคีย์ที่กำหนด - - s2v_freq | ทรัพย์สิน | int | ความถี่ของคีย์ที่กำหนด - - s2v_other_senses | ทรัพย์สิน | รายการ | มีความรู้สึกอื่น ๆ เช่น "duck | VERB" สำหรับ "duck | NOUN" - - s2v_most_similar | วิธีการ | รายการ | รับคำศัพท์ที่คล้ายกันมาก n ส่งคืนรายการของ ((word, sense), score) tuples - - s2v_similarity | วิธีการ | ลอย | รับความคล้ายคลึงกับ Token หรือ Span อื่น -
หมายเหตุเกี่ยวกับแอตทริบิวต์ SPAN: ภายใต้ประทุนเอนทิตีใน doc.entsคือSpanObjects นี่คือเหตุผลที่องค์ประกอบของท่อยังเพิ่มแอตทริบิวต์และวิธีการในช่วงเวลาและไม่เพียง แต่โทเค็น อย่างไรก็ตามไม่แนะนำให้ใช้แอตทริบิวต์ Sense2VEC บนชิ้นส่วนของเอกสารโดยพลการเนื่องจากโมเดลน่าจะไม่มีคีย์สำหรับข้อความที่เกี่ยวข้องSpanObjects ยังไม่มีแท็กส่วนหนึ่งของคำพูดดังนั้นหากไม่มีฉลากเอนทิตีอยู่จะมีค่าเริ่มต้น "ความรู้สึก" ไปยังแท็กส่วนหนึ่งของรูท
หากคุณกำลังฝึกอบรมและบรรจุท่อส่งก๊าซและต้องการรวมองค์ประกอบ Sense2VEC ไว้ในนั้นคุณสามารถโหลดข้อมูลผ่านบล็อก [initialize] ของการฝึกอบรมการกำหนดค่า:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " นอกจากนี้คุณยังสามารถใช้คลาส Sense2Vec พื้นฐานได้โดยตรงและโหลดในเวกเตอร์โดยใช้วิธี from_disk ดูด้านล่างสำหรับวิธี API ที่มีอยู่
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
หมายเหตุสำคัญ: ในการค้นหารายการในตารางเวกเตอร์กุญแจจำเป็นต้องทำตามรูปแบบของ phrase_text|SENSE(หมายเหตุ_แทนช่องว่างและ|ก่อนแท็กหรือฉลาก) - ตัวอย่างเช่นmachine_learning|NOUNโปรดทราบว่าตารางเวกเตอร์พื้นฐานนั้นมีความไวต่อตัวพิมพ์ใหญ่
Sense2Vec วัตถุ Sense2Vec แบบสแตนด์อโลนที่ถือเวกเตอร์สตริงและความถี่
Sense2Vec.__init__ เริ่มต้นวัตถุ Sense2Vec
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
shape | tuple | รูปร่างเวกเตอร์ ค่าเริ่มต้นเป็น (1000, 128) |
strings | spacy.strings.StringStore | ร้านค้าสตริงเสริม จะถูกสร้างขึ้นหากไม่มีอยู่ |
senses | รายการ | รายการเสริมของความรู้สึกที่มีอยู่ทั้งหมด ใช้ในวิธีการที่สร้างความรู้สึกที่ดีที่สุดหรือความรู้สึกอื่น ๆ |
vectors_name | ยูนิคอด | ชื่อเสริมเพื่อกำหนดให้กับตาราง Vectors เพื่อป้องกันการปะทะ ค่าเริ่มต้นเป็น "sense2vec" |
overrides | คำสั่ง | ฟังก์ชั่นที่กำหนดเองที่เป็นตัวเลือกที่จะใช้แมปกับชื่อที่ลงทะเบียนผ่านรีจิสทรีเช่น {"make_key": "custom_make_key"} |
| ผลตอบแทน | Sense2Vec | วัตถุที่สร้างขึ้นใหม่ |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__จำนวนแถวในตารางเวกเตอร์
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลตอบแทน | int | จำนวนแถวในตารางเวกเตอร์ |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__ตรวจสอบว่าคีย์อยู่ในตารางเวกเตอร์หรือไม่
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการค้นหา |
| ผลตอบแทน | บูล | ไม่ว่าจะเป็นคีย์ในตาราง |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__ดึงเวกเตอร์สำหรับคีย์ที่กำหนด ส่งคืนไม่มีถ้าคีย์ไม่ได้อยู่ในตาราง
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการค้นหา |
| ผลตอบแทน | numpy.ndarray | เวกเตอร์หรือ None |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ ตั้งค่าเวกเตอร์สำหรับคีย์ที่กำหนด จะเพิ่มข้อผิดพลาดหากไม่มีคีย์ หากต้องการเพิ่มรายการใหม่ให้ใช้ Sense2Vec.add
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจ |
vector | numpy.ndarray | เวกเตอร์ที่จะตั้งค่า |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addเพิ่มเวกเตอร์ใหม่ลงในตาราง
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการเพิ่ม |
vector | numpy.ndarray | เวกเตอร์ที่จะเพิ่ม |
freq | int | จำนวนความถี่เสริม ใช้เพื่อค้นหาประสาทสัมผัสที่ดีที่สุด |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqรับจำนวนความถี่สำหรับคีย์ที่กำหนด
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการค้นหา |
default | - | ค่าเริ่มต้นที่จะส่งคืนหากไม่พบความถี่ |
| ผลตอบแทน | int | จำนวนความถี่ |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqตั้งค่าจำนวนความถี่สำหรับคีย์ที่กำหนด
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการตั้งค่าการนับ |
freq | int | จำนวนความถี่ |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsวนซ้ำรายการในตารางเวกเตอร์
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลผลิต | tuple | คีย์สตริงและคู่เวกเตอร์ในตาราง |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysวนซ้ำปุ่มในตาราง
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลผลิต | ยูนิคอด | คีย์สตริงในตาราง |
all_keys = list ( s2v . keys ())Sense2Vec.valuesวนซ้ำเวกเตอร์ในตาราง
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลผลิต | numpy.ndarray | เวกเตอร์ในตาราง |
all_vecs = list ( s2v . values ())Sense2Vec.senses ความรู้สึกที่มีอยู่ในตารางเช่น "NOUN" หรือ "VERB" (เพิ่มเมื่อเริ่มต้น)
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลตอบแทน | รายการ | ประสาทสัมผัสที่มีอยู่ |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesความถี่ของปุ่มในตารางตามลำดับจากมากไปน้อย
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลตอบแทน | รายการ | tuples (key, freq) โดยความถี่ลดลง |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityทำการประเมินความคล้ายคลึงกันทางความหมายของปุ่มสองปุ่มหรือสองชุด การประมาณการเริ่มต้นคือความคล้ายคลึงกันของโคไซน์โดยใช้ค่าเฉลี่ยของเวกเตอร์
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
keys_a | Unicode / int / iterable | คีย์สตริงหรือจำนวนเต็ม |
keys_b | Unicode / int / iterable | คีย์สตริงหรือจำนวนเต็มอื่น ๆ |
| ผลตอบแทน | ลอย | คะแนนความคล้ายคลึงกัน |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarรับรายการที่คล้ายกันมากที่สุดในตาราง หากมีคีย์มากกว่าหนึ่งคีย์จะใช้ค่าเฉลี่ยของเวกเตอร์ ในการทำให้วิธีนี้เร็วขึ้นให้ดูสคริปต์สำหรับการคำนวณแคชของเพื่อนบ้านที่ใกล้ที่สุด
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
keys | Unicode / int / iterable | คีย์สตริงหรือจำนวนเต็มเพื่อเปรียบเทียบกับ |
n | int | จำนวนคีย์ที่คล้ายกันที่จะส่งคืน ค่าเริ่มต้นถึง 10 |
batch_size | int | ขนาดแบทช์ที่จะใช้ ค่าเริ่มต้นถึง 16 |
| ผลตอบแทน | รายการ | Tuples (key, score) ของเวกเตอร์ที่คล้ายกันมากที่สุด |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses ค้นหารายการอื่น ๆ สำหรับคำเดียวกันที่มีความรู้สึกที่แตกต่างเช่น "duck|VERB" สำหรับ "duck|NOUN"
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
key | Unicode / int | กุญแจสำคัญในการตรวจสอบ |
ignore_case | บูล | ตรวจสอบตัวพิมพ์ใหญ่ตัวพิมพ์เล็กและ titlecase ค่าเริ่มต้นเป็น True |
| ผลตอบแทน | รายการ | คีย์สตริงของรายการอื่น ๆ ที่มีความรู้สึกที่แตกต่างกัน |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense ค้นหาความรู้สึกที่ดีที่สุดสำหรับคำที่กำหนดขึ้นอยู่กับความรู้สึกและความถี่ที่มีอยู่ None พบหากไม่พบการจับคู่
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
word | ยูนิคอด | คำที่ควรตรวจสอบ |
senses | รายการ | รายการประสาทสัมผัสเสริมเพื่อ จำกัด การค้นหา หากไม่ได้ตั้งค่า / ว่างเปล่าจะใช้ประสาทสัมผัสทั้งหมดในเวกเตอร์ |
ignore_case | บูล | ตรวจสอบตัวพิมพ์ใหญ่ตัวพิมพ์เล็กและ titlecase ค่าเริ่มต้นเป็น True |
| ผลตอบแทน | ยูนิคอด | คีย์การจับคู่ที่ดีที่สุดหรือไม่มีเลย |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes ทำให้วัตถุ Sense2Vec เป็นอนุกรม
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
exclude | รายการ | ชื่อของเขตข้อมูลอนุกรมที่จะแยกออก |
| ผลตอบแทน | ไบต์ | วัตถุ Sense2Vec ที่เป็นอนุกรม |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes โหลดวัตถุ Sense2Vec จากการทดสอบ
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
bytes_data | ไบต์ | ข้อมูลที่จะโหลด |
exclude | รายการ | ชื่อของเขตข้อมูลอนุกรมที่จะแยกออก |
| ผลตอบแทน | Sense2Vec | วัตถุที่โหลด |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk ทำให้วัตถุ Sense2Vec เป็นซีเรียลเป็นไดเรกทอรี
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
path | Unicode / Path | เส้นทาง |
exclude | รายการ | ชื่อของเขตข้อมูลอนุกรมที่จะแยกออก |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk โหลดวัตถุ Sense2Vec จากไดเรกทอรี
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
path | Unicode / Path | เส้นทางที่จะโหลดจาก |
exclude | รายการ | ชื่อของเขตข้อมูลอนุกรมที่จะแยกออก |
| ผลตอบแทน | Sense2Vec | วัตถุที่โหลด |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentส่วนประกอบไปป์ไลน์เพื่อเพิ่ม Sense2vec ไปยัง Spacy Pipelines
Sense2VecComponent.__init__เริ่มต้นส่วนประกอบไปป์ไลน์
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
vocab | Vocab | Vocab ที่ใช้ร่วมกัน ส่วนใหญ่ใช้สำหรับ StringStore ที่ใช้ร่วมกัน |
shape | tuple | รูปร่างเวกเตอร์ |
merge_phrases | บูล | ไม่ว่าจะรวมวลี Sense2vec เข้ากับโทเค็นเดียว ค่าเริ่มต้นเป็น False |
lemmatize | บูล | ค้นหาบทแทรกเสมอหากมีอยู่ในเวกเตอร์มิฉะนั้นจะเริ่มต้นเป็นคำดั้งเดิม ค่าเริ่มต้นเป็น False |
overrides | ฟังก์ชั่นที่กำหนดเองที่เป็นตัวเลือกที่จะใช้แมปกับชื่อที่ลงทะเบียนผ่านรีจิสทรีเช่น {"make_key": "custom_make_key"} | |
| ผลตอบแทน | Sense2VecComponent | วัตถุที่สร้างขึ้นใหม่ |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp เริ่มต้นส่วนประกอบจากวัตถุ NLP ส่วนใหญ่ใช้เป็นโรงงานส่วนประกอบสำหรับจุดเริ่มต้น (ดู setup.cfg) และเพื่อลงทะเบียนอัตโนมัติผ่าน @spacy.component decorator
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
nlp | Language | วัตถุ nlp |
**cfg | - | พารามิเตอร์การกำหนดค่าเสริม |
| ผลตอบแทน | Sense2VecComponent | วัตถุที่สร้างขึ้นใหม่ |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ ประมวลผลวัตถุ Doc ด้วยส่วนประกอบ โดยทั่วไปจะเรียกว่าเป็นส่วนหนึ่งของท่อส่ง Spacy เท่านั้นและไม่ได้โดยตรง
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
doc | Doc | เอกสารที่จะดำเนินการ |
| ผลตอบแทน | Doc | เอกสารที่ประมวลผล |
Sense2Vec.init_componentลงทะเบียนแอตทริบิวต์ส่วนขยายเฉพาะส่วนประกอบที่นี่และเฉพาะในกรณีที่ส่วนประกอบถูกเพิ่มลงในไปป์ไลน์และใช้-มิฉะนั้นโทเค็นจะยังคงได้รับแอตทริบิวต์แม้ว่าส่วนประกอบจะถูกสร้างขึ้นและไม่เพิ่มเท่านั้น
Sense2VecComponent.to_bytes ทำให้ส่วนประกอบเป็นอนุกรมเป็น bytestring เรียกอีกอย่างว่าเมื่อส่วนประกอบถูกเพิ่มลงในไปป์ไลน์และคุณเรียกใช้ nlp.to_bytes
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
| ผลตอบแทน | ไบต์ | องค์ประกอบที่เป็นอนุกรม |
Sense2VecComponent.from_bytes โหลดส่วนประกอบจาก bytestring เรียกอีกอย่างว่าเมื่อคุณเรียกใช้ nlp.from_bytes
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
bytes_data | ไบต์ | ข้อมูลที่จะโหลด |
| ผลตอบแทน | Sense2VecComponent | วัตถุที่โหลด |
Sense2VecComponent.to_disk ทำให้ส่วนประกอบเป็นอนุกรมกับไดเรกทอรี เรียกอีกอย่างว่าเมื่อส่วนประกอบถูกเพิ่มลงในไปป์ไลน์และคุณเรียกใช้ nlp.to_disk
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
path | Unicode / Path | เส้นทาง |
Sense2VecComponent.from_disk โหลดวัตถุ Sense2Vec จากไดเรกทอรี เรียกอีกอย่างว่าเมื่อคุณเรียกใช้ nlp.from_disk
| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
path | Unicode / Path | เส้นทางที่จะโหลดจาก |
| ผลตอบแทน | Sense2VecComponent | วัตถุที่โหลด |
registry ชั้นเรียน ฟังก์ชั่นรีจิสทรี (ขับเคลื่อนโดย catalogue ) เพื่อปรับแต่งฟังก์ชั่นที่ใช้ในการสร้างคีย์และวลีได้อย่างง่ายดาย อนุญาตให้คุณตกแต่งและตั้งชื่อฟังก์ชั่นที่กำหนดเองสลับออกและทำให้ชื่อที่กำหนดเองเป็นอนุกรมเมื่อคุณบันทึกโมเดล มีตัวเลือกรีจิสทรีต่อไปนี้:
- ชื่อ | คำอธิบาย | - - - - - registry.make_key | ให้ word และ sense คืนสตริงของคีย์เช่น "word | sense". - - registry.split_key | ได้รับคีย์สตริงให้ส่งคืน (word, sense) tuple - - registry.make_spacy_key | ได้รับวัตถุ Spacy ( Token หรือ Span ) และอาร์กิวเมนต์คำหลักของบูลี prefer_ents (ไม่ว่าจะชอบฉลากเอนทิตีสำหรับโทเค็นเดี่ยว), ส่งคืน (word, sense) tuple ใช้ในแอตทริบิวต์ส่วนขยายเพื่อสร้างคีย์สำหรับโทเค็นและช่วง - - - registry.get_phrases | ได้รับ Doc Spacy ให้ส่งคืนรายการวัตถุ Span ที่ใช้สำหรับวลี Sense2Vec (โดยทั่วไปแล้ววลีคำนามและเอนทิตีที่มีชื่อ) - - registry.merge_phrases | ได้รับ Doc Spacy รับวลี Sense2vec ทั้งหมดและรวมเข้ากับโทเค็นเดี่ยว -
แต่ละรีจิสตรีมีวิธี register ที่สามารถใช้เป็นนักตกแต่งฟังก์ชั่นและใช้หนึ่งอาร์กิวเมนต์ชื่อของฟังก์ชั่นที่กำหนดเอง
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense เมื่อเริ่มต้นวัตถุ Sense2Vec ตอนนี้คุณสามารถส่งผ่านพจนานุกรมของการแทนที่ด้วยชื่อของฟังก์ชั่นที่ลงทะเบียนที่คุณกำหนดเอง
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )สิ่งนี้ทำให้ง่ายต่อการทดลองกับกลยุทธ์ที่แตกต่างกันและทำให้กลยุทธ์เป็นสตริงธรรมดา (แทนที่จะต้องผ่านและ/หรือดองฟังก์ชั่นด้วยตัวเอง)
ไดเรกทอรี /scripts มียูทิลิตี้บรรทัดคำสั่งสำหรับการประมวลผลข้อความล่วงหน้าและฝึกอบรมเวกเตอร์ของคุณเอง
ในการฝึกอบรมเวกเตอร์ Sense2vec ของคุณเองคุณจะต้องมีสิ่งต่อไปนี้:
doc.noun_chunks หากภาษาที่คุณต้องการไม่ได้จัดเตรียมตัววนซ้ำในตัวในไวยากรณ์สำหรับวลีคำนามคุณจะต้องเขียนของคุณเอง ( doc.noun_chunks และ doc.ents เป็นสิ่งที่ Sense2vec ใช้ในการกำหนดวลีคืออะไร)make ในไดเรกทอรีที่เกี่ยวข้อง กระบวนการฝึกอบรมแบ่งออกเป็นหลายขั้นตอนเพื่อให้คุณสามารถกลับมาทำงานได้ทุกจุด สคริปต์การประมวลผลได้รับการออกแบบมาเพื่อทำงานบนไฟล์เดียวทำให้ง่ายต่อการจัดทำงาน สคริปต์ใน repo นี้ต้องการถุงมือหรือ fasttext ที่คุณต้องโคลนและ make
สำหรับ FastText สคริปต์จะต้องใช้เส้นทางไปยังไฟล์ไบนารีที่สร้างขึ้น หากคุณกำลังทำงานบน Windows คุณสามารถสร้างด้วย cmake หรือใช้ไฟล์ .exe จาก repo ที่ไม่เป็นทางการ นี้ด้วย fasttext binary builds สำหรับ windows: https://github.com/xiamx/fasttext/releases
| สคริปต์ | คำอธิบาย | |
|---|---|---|
| 1. | 01_parse.py | ใช้ Spacy เพื่อแยกวิเคราะห์ข้อความดิบและคอลเลกชันไบนารีของวัตถุ Doc (ดู DocBin ) |
| 2. | 02_preprocess.py | โหลดคอลเลกชันของวัตถุ Doc ที่แยกวิเคราะห์ที่ผลิตในขั้นตอนก่อนหน้าและไฟล์ข้อความเอาต์พุตในรูปแบบ Sense2VEC (หนึ่งประโยคต่อบรรทัดและวลีที่รวมเข้ากับความรู้สึก) |
| 3. | 03_glove_build_counts.py | ใช้ถุงมือเพื่อสร้างคำศัพท์และนับ ข้ามขั้นตอนนี้หากคุณใช้ Word2Vec ผ่าน FastText |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | ใช้ถุงมือหรือ fasttext เพื่อฝึกเวกเตอร์ |
| 5. | 05_export.py | โหลดเวกเตอร์และความถี่และส่งออกส่วนประกอบ Sense2VEC ที่สามารถโหลดได้ผ่าน Sense2Vec.from_disk |
| 6. | 06_precompute_cache.py | ตัวเลือก: การสอบถามล่วงหน้าที่ใกล้ที่สุดสำหรับทุกรายการในคำศัพท์เพื่อให้ Sense2Vec.most_similar เร็วขึ้น |
สำหรับเอกสารรายละเอียดเพิ่มเติมของสคริปต์ให้ตรวจสอบแหล่งที่มาหรือเรียกใช้ด้วย --help ตัวอย่างเช่น python scripts/01_parse.py --help
แพ็คเกจนี้ยังรวมเข้ากับเครื่องมือคำอธิบายประกอบอัจฉริยะอย่างราบรื่นและเปิดเผยสูตรอาหารสำหรับการใช้เวกเตอร์ Sense2VEC เพื่อสร้างรายการวลีหลายคำและคำอธิบายประกอบการบูต ในการใช้สูตรต้องติดตั้ง sense2vec ในสภาพแวดล้อมเดียวกันกับอัจฉริยะ สำหรับตัวอย่างของกรณีการใช้งานจริงลองดูโครงการ NER นี้ด้วยชุดข้อมูลที่ดาวน์โหลดได้
มีสูตรต่อไปนี้ - ดูด้านล่างสำหรับเอกสารรายละเอียดเพิ่มเติม
| สูตรอาหาร | คำอธิบาย |
|---|---|
sense2vec.teach | bootstrap รายการคำศัพท์โดยใช้ Sense2Vec |
sense2vec.to-patterns | แปลงชุดข้อมูลวลีเป็นรูปแบบการจับคู่ที่ใช้โทเค็น |
sense2vec.eval | ประเมินโมเดล Sense2VEC โดยถามเกี่ยวกับวลี TIPLES |
sense2vec.eval-most-similar | ประเมินโมเดล Sense2vec โดยแก้ไขรายการที่คล้ายกันมากที่สุด |
sense2vec.eval-ab | ทำการประเมิน A/B ของโมเดลเวกเตอร์ Sense2VEC สองรุ่น |
sense2vec.teachbootstrap รายการคำศัพท์โดยใช้ Sense2Vec อัจฉริยะจะแนะนำคำศัพท์ที่คล้ายกันตามวลีที่คล้ายกันมากที่สุดจาก Sense2vec และคำแนะนำจะถูกปรับเมื่อคุณใส่คำอธิบายประกอบและยอมรับวลีที่คล้ายกัน สำหรับแต่ละคำศัพท์ความรู้สึกที่ดีที่สุดที่ดีที่สุดตามเวกเตอร์ Sense2VEC จะถูกนำมาใช้
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
dataset | ตำแหน่ง | ชุดข้อมูลเพื่อบันทึกคำอธิบายประกอบเป็น |
vectors_path | ตำแหน่ง | PATH to Pretrained Sense2VEC เวกเตอร์ |
--seeds , -s | ตัวเลือก | วลีเมล็ดพันธุ์ที่คั่นด้วยเครื่องหมายจุลภาคอย่างน้อยหนึ่งวลี |
--threshold , -t | ตัวเลือก | เกณฑ์ความคล้ายคลึงกัน ค่าเริ่มต้นถึง 0.85 |
--n-similar , -n | ตัวเลือก | จำนวนรายการที่คล้ายกันเพื่อรับในครั้งเดียว |
--batch-size -b | ตัวเลือก | ขนาดแบทช์สำหรับการส่งคำอธิบายประกอบ |
--resume , -R | ธง | ดำเนินการต่อจากชุดข้อมูลวลีที่มีอยู่ |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns แปลงชุดข้อมูลของวลีที่รวบรวมด้วย sense2vec.teach เป็นรูปแบบการจับคู่ที่ใช้โทเค็นซึ่งสามารถใช้กับ EntityRuler หรือสูตรอาหารของ Spacy เช่น ner.match หากไม่มีการระบุไฟล์เอาต์พุตรูปแบบจะถูกเขียนไปยัง stdout ตัวอย่างมีความเป็นไปได้เพื่อให้คำศัพท์แบบมัลติเทนมีการแสดงอย่างถูกต้องเช่น: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]}
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
dataset | ตำแหน่ง | ชุดข้อมูลวลีเพื่อแปลง |
spacy_model | ตำแหน่ง | โมเดล Spacy สำหรับโทเค็น |
label | ตำแหน่ง | ติดฉลากเพื่อใช้กับทุกรูปแบบ |
--output-file , -o | ตัวเลือก | ไฟล์เอาต์พุตเสริม ค่าเริ่มต้นเป็น stdout |
--case-sensitive , -CS | ธง | สร้างรูปแบบที่ไวต่อตัวพิมพ์ใหญ่ |
--dry , -D | ธง | ดำเนินการแห้งและอย่าส่งออกอะไรเลย |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalประเมินโมเดล Sense2vec โดยถามเกี่ยวกับวลี Triples: คำนั้นคล้ายกับคำ B หรือคำว่า C หรือไม่? หากมนุษย์ส่วนใหญ่เห็นด้วยกับแบบจำลองโมเดลเวกเตอร์ก็ดี สูตรจะถามเกี่ยวกับเวกเตอร์ที่มีความรู้สึกเดียวกันและสนับสนุนกลยุทธ์การเลือกตัวอย่างที่แตกต่างกัน
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
dataset | ตำแหน่ง | ชุดข้อมูลเพื่อบันทึกคำอธิบายประกอบเป็น |
vectors_path | ตำแหน่ง | PATH to Pretrained Sense2VEC เวกเตอร์ |
--strategy , -st | ตัวเลือก | ตัวอย่างกลยุทธ์การเลือก most similar (เริ่มต้น) หรือ random |
--senses , -s | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อ จำกัด การเลือก หากไม่ได้ตั้งค่าจะใช้ประสาทสัมผัสทั้งหมดในเวกเตอร์ |
--exclude-senses , -es | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อแยกออก ดู prodigy_recipes.EVAL_EXCLUDE_SENSES จากค่าเริ่มต้น |
--n-freq , -f | ตัวเลือก | จำนวนรายการที่พบบ่อยที่สุดที่จะ จำกัด |
--threshold , -t | ตัวเลือก | เกณฑ์ความคล้ายคลึงกันขั้นต่ำเพื่อพิจารณาตัวอย่าง |
--batch-size -b | ตัวเลือก | ขนาดแบทช์ที่จะใช้ |
--eval-whole , -E | ธง | ประเมินชุดข้อมูลทั้งหมดแทนเซสชันปัจจุบัน |
--eval-only , -O | ธง | อย่าใส่คำอธิบายประกอบเพียงประเมินชุดข้อมูลปัจจุบัน |
--show-scores -S | ธง | แสดงคะแนนทั้งหมดสำหรับการดีบัก |
| ชื่อ | คำอธิบาย |
|---|---|
most_similar | เลือกคำสุ่มจากความรู้สึกแบบสุ่มและรับรายการที่คล้ายกันมากที่สุดของความรู้สึกเดียวกัน ถามเกี่ยวกับความคล้ายคลึงกับรายการสุดท้ายและกลางจากการเลือกนั้น |
most_least_similar | เลือกคำสุ่มจากความรู้สึกแบบสุ่มและรับรายการที่คล้ายกันน้อยที่สุดจากรายการที่คล้ายกันที่สุดและจากนั้นรายการที่คล้ายกันที่สุดสุดท้ายของรายการนั้น |
random | เลือกตัวอย่างสุ่ม 3 คำจากความรู้สึกแบบสุ่มเดียวกัน |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5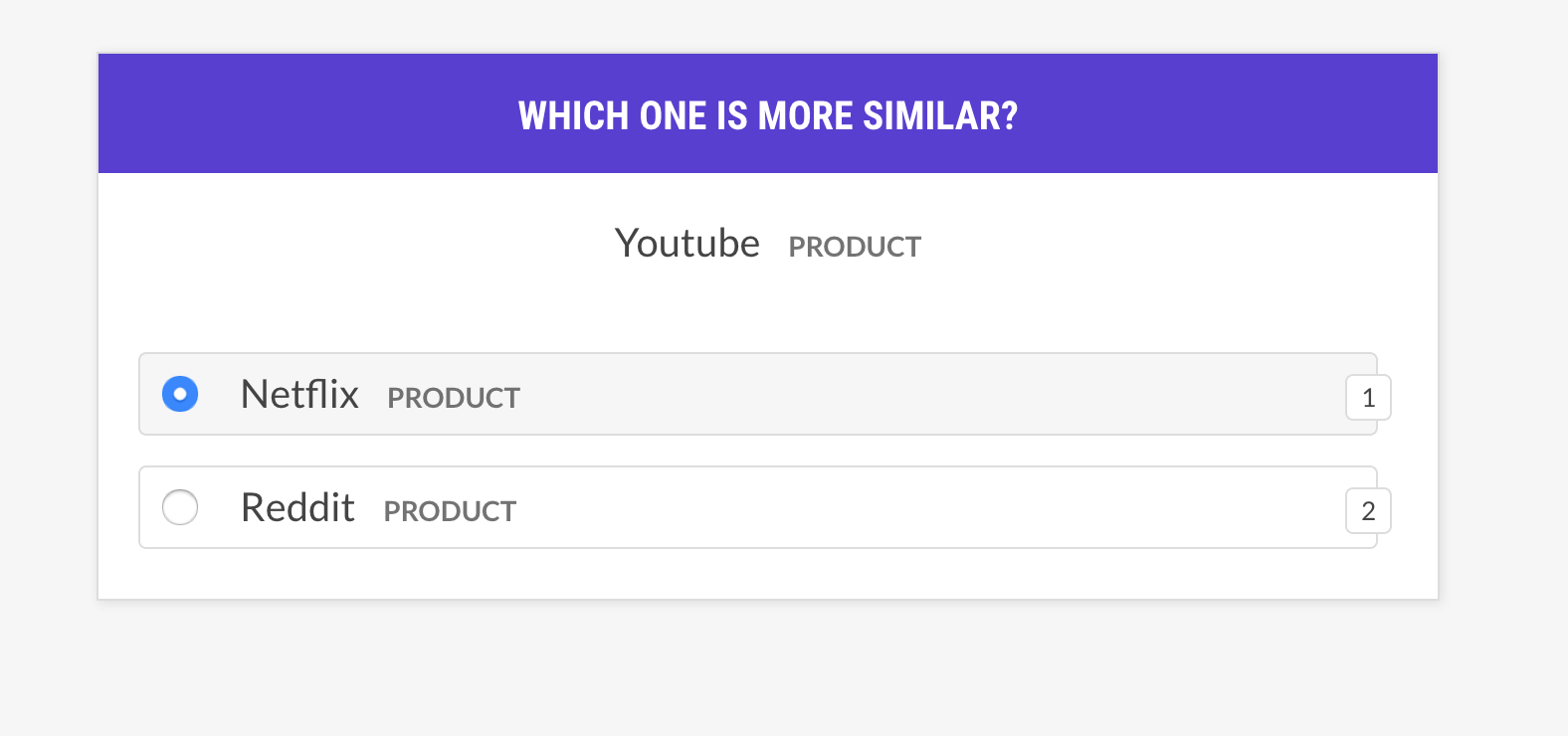
sense2vec.eval-most-similarประเมินโมเดลเวกเตอร์โดยดูที่รายการที่คล้ายกันมากที่สุดมันจะกลับมาสำหรับวลีแบบสุ่มและไม่เลือกความผิดพลาด
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
dataset | ตำแหน่ง | ชุดข้อมูลเพื่อบันทึกคำอธิบายประกอบเป็น |
vectors_path | ตำแหน่ง | PATH to Pretrained Sense2VEC เวกเตอร์ |
--senses , -s | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อ จำกัด การเลือก หากไม่ได้ตั้งค่าจะใช้ประสาทสัมผัสทั้งหมดในเวกเตอร์ |
--exclude-senses , -es | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อแยกออก ดู prodigy_recipes.EVAL_EXCLUDE_SENSES จากค่าเริ่มต้น |
--n-freq , -f | ตัวเลือก | จำนวนรายการที่พบบ่อยที่สุดที่จะ จำกัด |
--n-similar , -n | ตัวเลือก | จำนวนรายการที่คล้ายกันที่จะตรวจสอบ ค่าเริ่มต้นถึง 10 |
--batch-size -b | ตัวเลือก | ขนาดแบทช์ที่จะใช้ |
--eval-whole , -E | ธง | ประเมินชุดข้อมูลทั้งหมดแทนเซสชันปัจจุบัน |
--eval-only , -O | ธง | อย่าใส่คำอธิบายประกอบเพียงประเมินชุดข้อมูลปัจจุบัน |
--show-scores -S | ธง | แสดงคะแนนทั้งหมดสำหรับการดีบัก |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abดำเนินการประเมิน A/B ของโมเดลเวกเตอร์ Sense2VEC สองรุ่นที่ได้รับการฝึกฝนโดยการเปรียบเทียบรายการที่คล้ายกันมากที่สุดที่พวกเขากลับมาสำหรับวลีแบบสุ่ม UI แสดงตัวเลือกแบบสุ่มสองรายการด้วยรายการที่คล้ายกันมากที่สุดของแต่ละรุ่นและเน้นวลีที่แตกต่างกัน ในตอนท้ายของเซสชันคำอธิบายประกอบสถิติโดยรวมและโมเดลที่ต้องการจะปรากฏขึ้น
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| การโต้แย้ง | พิมพ์ | คำอธิบาย |
|---|---|---|
dataset | ตำแหน่ง | ชุดข้อมูลเพื่อบันทึกคำอธิบายประกอบเป็น |
vectors_path_a | ตำแหน่ง | PATH to Pretrained Sense2VEC เวกเตอร์ |
vectors_path_b | ตำแหน่ง | PATH to Pretrained Sense2VEC เวกเตอร์ |
--senses , -s | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อ จำกัด การเลือก หากไม่ได้ตั้งค่าจะใช้ประสาทสัมผัสทั้งหมดในเวกเตอร์ |
--exclude-senses , -es | ตัวเลือก | รายการความรู้สึกที่คั่นด้วยเครื่องหมายจุลภาคเพื่อแยกออก ดู prodigy_recipes.EVAL_EXCLUDE_SENSES จากค่าเริ่มต้น |
--n-freq , -f | ตัวเลือก | จำนวนรายการที่พบบ่อยที่สุดที่จะ จำกัด |
--n-similar , -n | ตัวเลือก | จำนวนรายการที่คล้ายกันที่จะตรวจสอบ ค่าเริ่มต้นถึง 10 |
--batch-size -b | ตัวเลือก | ขนาดแบทช์ที่จะใช้ |
--eval-whole , -E | ธง | ประเมินชุดข้อมูลทั้งหมดแทนเซสชันปัจจุบัน |
--eval-only , -O | ธง | อย่าใส่คำอธิบายประกอบเพียงประเมินชุดข้อมูลปัจจุบัน |
--show-mapping , -S | ธง | แสดงว่ารุ่นใดเป็นตัวเลือก 1 และตัวเลือก 2 ใน UI (สำหรับการดีบัก) |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT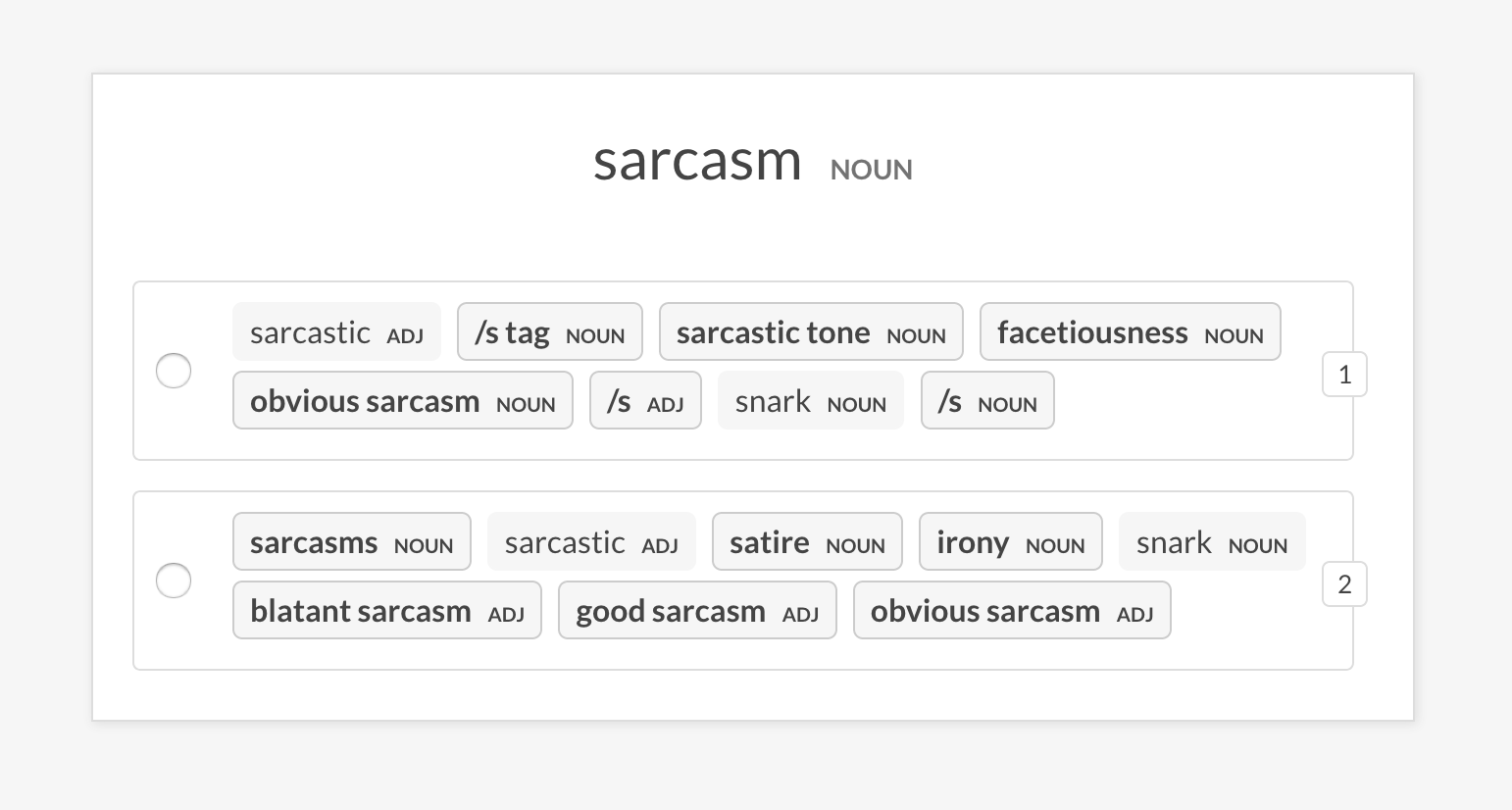
เวกเตอร์ reddit ที่ผ่านการพิสูจน์แล้วสนับสนุน "ประสาทสัมผัส" ต่อไปนี้ไม่ว่าจะเป็นแท็กส่วนหนึ่งของคำพูดหรือฉลากเอนทิตี สำหรับรายละเอียดเพิ่มเติมดูภาพรวมรูปแบบคำอธิบายประกอบของ Spacy
| ติดแท็ก | คำอธิบาย | ตัวอย่าง |
|---|---|---|
ADJ | คุณศัพท์ | ใหญ่เก่าเขียว |
ADP | adposition | ในระหว่าง |
ADV | คำวิเศษณ์ | พรุ่งนี้มากลงที่ไหน |
AUX | เสริม | คือมี (เสร็จแล้ว), จะ (ทำ) |
CONJ | การรวมกัน | และหรือ แต่ |
DET | เครื่องกำหนด | A, A, THE |
INTJ | คำอุทาน | psst, ouch, bravo, สวัสดี |
NOUN | คำนาม | หญิงสาวแมวต้นไม้อากาศความงาม |
NUM | ตัวเลข | 1, 2017, หนึ่ง, เจ็ดสิบเจ็ด, mmxiv |
PART | อนุภาค | ไม่ใช่ |
PRON | คำสรรพนาม | ฉันคุณเขาเธอตัวเองใครบางคน |
PROPN | คำนามที่เหมาะสม | Mary, John, London, Nato, HBO |
PUNCT | วรรคตอน | - - |
SCONJ | การรวมกัน | ถ้าในขณะนั้น |
SYM | เครื่องหมาย | - |
VERB | กริยา | วิ่งวิ่งวิ่งกินกินกิน |
| ฉลากเอนทิตี | คำอธิบาย |
|---|---|
PERSON | ผู้คนรวมถึงตัวละคร |
NORP | เชื้อชาติหรือกลุ่มศาสนาหรือการเมือง |
FACILITY | อาคารสนามบินทางหลวงสะพาน ฯลฯ |
ORG | บริษัท หน่วยงานสถาบัน ฯลฯ |
GPE | ประเทศเมืองรัฐ |
LOC | สถานที่ที่ไม่ใช่ GPE, เทือกเขา, แหล่งน้ำ |
PRODUCT | วัตถุยานพาหนะอาหาร ฯลฯ (ไม่ใช่บริการ) |
EVENT | ตั้งชื่อพายุเฮอริเคนการต่อสู้สงครามกิจกรรมกีฬา ฯลฯ |
WORK_OF_ART | ชื่อหนังสือเพลง ฯลฯ |
LANGUAGE | ภาษาที่มีชื่อใด ๆ |


