sense2vec
v2.0.2
Sense2vec (Trask et. Al, 2015) adalah twist yang bagus pada Word2Vec yang memungkinkan Anda mempelajari vektor kata yang lebih menarik dan terperinci. Perpustakaan ini adalah implementasi Python sederhana untuk memuat, menanyakan dan melatih model SENSE2VEC. Untuk detail lebih lanjut, lihat posting blog kami. Untuk mengeksplorasi kesamaan semantik di semua komentar Reddit tahun 2015 dan 2019, lihat demo interaktif.
? Versi 2.0 (untuk Spacy v3) keluar sekarang! Baca catatan rilis di sini.

from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" )
query = "natural_language_processing|NOUN"
assert query in s2v
vector = s2v [ query ]
freq = s2v . get_freq ( query )
most_similar = s2v . most_similar ( query , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)]
️ Perhatikan bahwa contoh ini menjelaskan penggunaan dengan Spacy V3. Untuk penggunaan dengan Spacy V2, unduhsense2vec==1.0.3dan lihat cabangv1.xdari repo ini.
import spacy
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" )
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )
# [(('machine learning', 'NOUN'), 0.8986967),
# (('computer vision', 'NOUN'), 0.8636297),
# (('deep learning', 'NOUN'), 0.8573361)]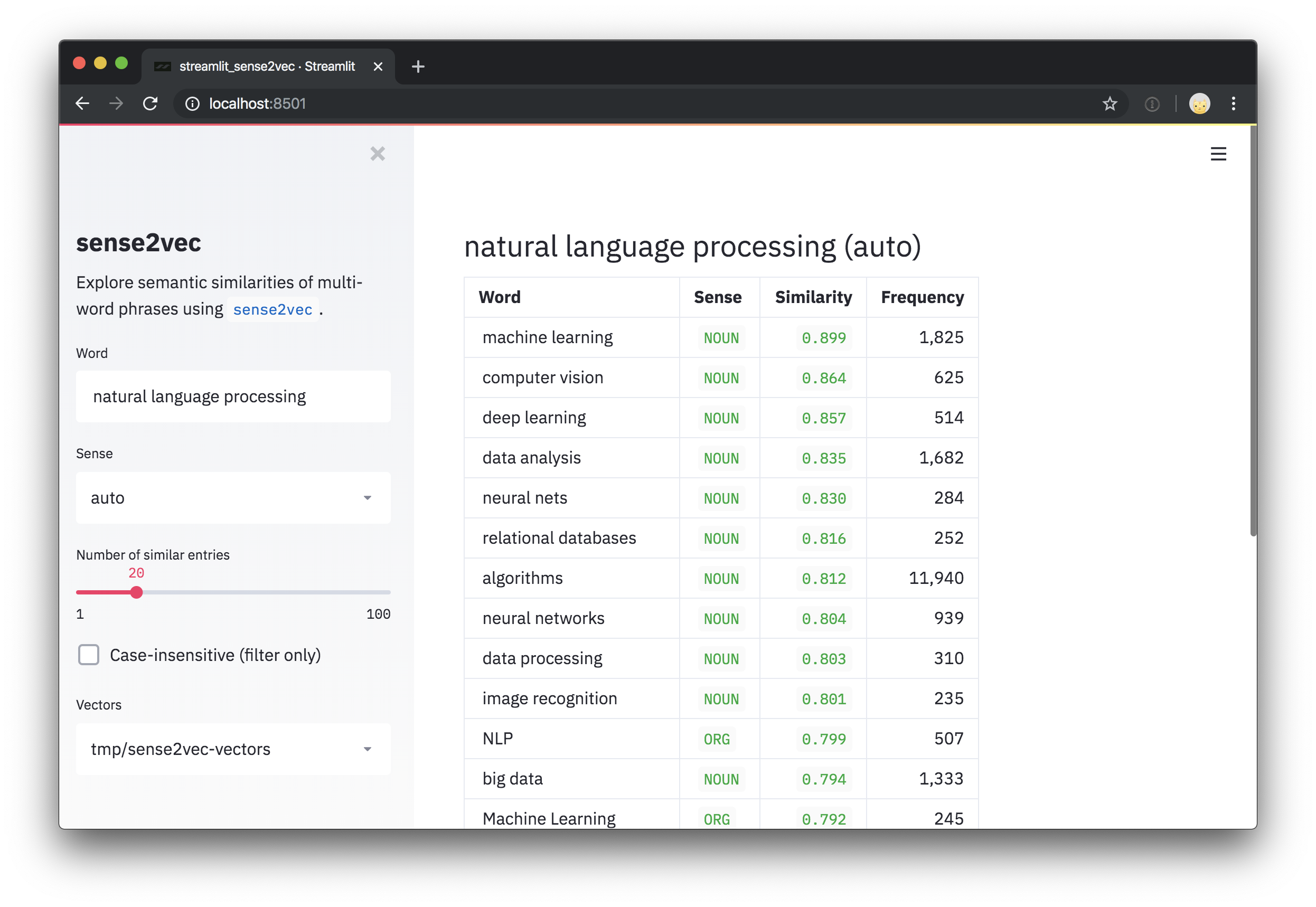
Untuk mencoba vektor pretrained kami yang dilatih pada komentar Reddit, lihat demo SENSE2VEC interaktif.
Repo ini juga mencakup skrip demo yang diintong -aliran untuk mengeksplorasi vektor dan frasa yang paling mirip. Setelah menginstal streamlit , Anda dapat menjalankan skrip dengan streamlit run dan satu atau lebih jalur ke vektor pretrained sebagai argumen posisi pada baris perintah. Misalnya:
pip install streamlit
streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors Untuk menggunakan vektor, unduh arsip dan berikan direktori yang diekstraksi ke Sense2Vec.from_disk atau Sense2VecComponent.from_disk . File vektor dilampirkan pada rilis GitHub . File besar telah dibagi menjadi unduhan multi-bagian.
| Vektor | Ukuran | Keterangan | ? Unduh (Zip) |
|---|---|---|---|
s2v_reddit_2019_lg | 4 GB | Komentar Reddit 2019 (01-07) | Bagian 1, Bagian 2, Bagian 3 |
s2v_reddit_2015_md | 573 MB | Komentar Reddit 2015 | Bagian 1 |
Untuk menggabungkan arsip multi-bagian, Anda dapat menjalankan yang berikut:
cat s2v_reddit_2019_lg.tar.gz. * > s2v_reddit_2019_lg.tar.gzRilis SENSE2VEC tersedia di PIP:
pip install sense2vec Untuk menggunakan vektor pretrained, unduh salah satu paket vektor, buka arsip .tar.gz dan titik from_disk ke direktori data yang diekstraksi:
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/s2v_reddit_2015_md" ) Cara termudah untuk menggunakan perpustakaan dan vektor adalah dengan memasukkannya ke pipa spacy Anda. Paket sense2vec memperlihatkan Sense2VecComponent , yang dapat diinisialisasi dengan vocab bersama dan ditambahkan ke pipa spacy Anda sebagai komponen pipa khusus. Secara default, komponen ditambahkan ke ujung pipa , yang merupakan posisi yang disarankan untuk komponen ini, karena membutuhkan akses ke parse ketergantungan dan, jika tersedia, entitas yang disebutkan.
import spacy
from sense2vec import Sense2VecComponent
nlp = spacy . load ( "en_core_web_sm" )
s2v = nlp . add_pipe ( "sense2vec" )
s2v . from_disk ( "/path/to/s2v_reddit_2015_md" ) Komponen akan menambahkan beberapa atribut ekstensi dan metode ke Token dan Span objek Spacy yang memungkinkan Anda mengambil vektor dan frekuensi, serta istilah yang paling mirip.
doc = nlp ( "A sentence about natural language processing." )
assert doc [ 3 : 6 ]. text == "natural language processing"
freq = doc [ 3 : 6 ]. _ . s2v_freq
vector = doc [ 3 : 6 ]. _ . s2v_vec
most_similar = doc [ 3 : 6 ]. _ . s2v_most_similar ( 3 )Untuk entitas, label entitas digunakan sebagai "indera" (bukan tag part-of-speech token):
doc = nlp ( "A sentence about Facebook and Google." )
for ent in doc . ents :
assert ent . _ . in_s2v
most_similar = ent . _ . s2v_most_similar ( 3 ) Atribut ekstensi berikut diekspos pada objek Doc melalui properti ._ :
| Nama | Jenis atribut | Jenis | Keterangan |
|---|---|---|---|
s2v_phrases | milik | daftar | Semua frasa yang kompatibel dengan SENSE2VEC dalam Doc yang diberikan (frasa kata benda, entitas bernama). |
Atribut berikut tersedia melalui properti ._ Objek Token dan Span - misalnya token._.in_s2v :
| Nama | Tipe Atribut | Tipe Pengembalian | Deskripsi | | ------------------ -------------- | ------------------ ---------------------------------------------------------------------------------- --------------- | ------- | | in_s2v | Properti | bool | Apakah ada kunci di peta vektor. | | s2v_key | Properti | Unicode | Kunci Sense2Vec dari objek yang diberikan, misalnya "duck | NOUN" . | | s2v_vec | Properti | ndarray[float32] | Vektor kunci yang diberikan. | | s2v_freq | Properti | int | Frekuensi kunci yang diberikan. | | s2v_other_senses | Properti | Daftar | Tersedia indera lain, misalnya "duck | VERB" untuk "duck | NOUN" . | | s2v_most_similar | Metode | Daftar | Dapatkan n istilah yang paling mirip. Mengembalikan daftar ((word, sense), score) tupel. | | s2v_similarity | Metode | float | Dapatkan kesamaan dengan Token atau Span lain. |
️ Catatan tentang Atribut SPAN: Di Bawah Tudung, Entitas didoc.entsadalah objekSpan. Inilah sebabnya mengapa komponen pipa juga menambahkan atribut dan metode untuk rentang dan bukan hanya token. Namun, tidak disarankan untuk menggunakan atribut Sense2VEC pada irisan dokumen yang sewenang -wenang, karena model tersebut kemungkinan tidak akan memiliki kunci untuk teks masing -masing. ObjekSpanjuga tidak memiliki tag bagian-of-speech, jadi jika tidak ada label entitas, "indera" default ke tag bagian-of-speech root.
Jika Anda melatih dan mengemas pipa spacy dan ingin memasukkan komponen Sense2Vec di dalamnya, Anda dapat memuat dalam data melalui blok [initialize] konfigurasi pelatihan:
[initialize.components]
[initialize.components.sense2vec]
data_path = " /path/to/s2v_reddit_2015_md " Anda juga dapat menggunakan kelas Sense2Vec yang mendasarinya secara langsung dan memuat vektor menggunakan metode from_disk . Lihat di bawah untuk metode API yang tersedia.
from sense2vec import Sense2Vec
s2v = Sense2Vec (). from_disk ( "/path/to/reddit_vectors-1.1.0" )
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 10 )
️ Catatan Penting: Untuk mencari entri dalam tabel vektor, tombol perlu mengikuti skemaphrase_text|SENSE(perhatikan_alih -alih spasi dan|sebelum tag atau label) - misalnya,machine_learning|NOUN. Perhatikan juga bahwa tabel vektor yang mendasarinya peka terhadap kasus.
Sense2Vec Objek Sense2Vec mandiri yang menampung vektor, string, dan frekuensi.
Sense2Vec.__init__ Inisialisasi objek Sense2Vec .
| Argumen | Jenis | Keterangan |
|---|---|---|
shape | tuple | Bentuk vektor. Default ke (1000, 128) . |
strings | spacy.strings.StringStore | Toko string opsional. Akan dibuat jika tidak ada. |
senses | daftar | Daftar opsional dari semua indera yang tersedia. Digunakan dalam metode yang menghasilkan indera terbaik atau indera lain. |
vectors_name | Unicode | Nama opsional untuk ditetapkan ke tabel Vectors , untuk mencegah bentrokan. Default ke "sense2vec" . |
overrides | dikt | Fungsi khusus opsional untuk digunakan, dipetakan ke nama yang terdaftar melalui registri, misalnya {"make_key": "custom_make_key"} . |
| Kembali | Sense2Vec | Objek yang baru dibangun. |
s2v = Sense2Vec ( shape = ( 300 , 128 ), senses = [ "VERB" , "NOUN" ])Sense2Vec.__len__Jumlah baris dalam tabel vektor.
| Argumen | Jenis | Keterangan |
|---|---|---|
| Kembali | int | Jumlah baris dalam tabel vektor. |
s2v = Sense2Vec ( shape = ( 300 , 128 ))
assert len ( s2v ) == 300 Sense2Vec.__contains__Periksa apakah kunci ada di tabel vektor.
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk melihat ke atas. |
| Kembali | bool | Apakah kuncinya ada di tabel. |
s2v = Sense2Vec ( shape = ( 10 , 4 ))
s2v . add ( "avocado|NOUN" , numpy . asarray ([ 4 , 2 , 2 , 2 ], dtype = numpy . float32 ))
assert "avocado|NOUN" in s2v
assert "avocado|VERB" not in s2v Sense2Vec.__getitem__Mengambil vektor untuk kunci yang diberikan. Mengembalikan tidak ada jika kunci tidak ada dalam tabel.
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk melihat ke atas. |
| Kembali | numpy.ndarray | Vektor atau None . |
vec = s2v [ "avocado|NOUN" ]Sense2Vec.__setitem__ Atur vektor untuk kunci yang diberikan. Akan menimbulkan kesalahan jika kunci tidak ada. Untuk menambahkan entri baru, gunakan Sense2Vec.add .
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kuncinya. |
vector | numpy.ndarray | Vektor untuk mengatur. |
vec = s2v [ "avocado|NOUN" ]
s2v [ "avacado|NOUN" ] = vec Sense2Vec.addTambahkan vektor baru ke tabel.
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk ditambahkan. |
vector | numpy.ndarray | Vektor untuk ditambahkan. |
freq | int | Jumlah frekuensi opsional. Digunakan untuk menemukan indera pencocokan terbaik. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )Sense2Vec.get_freqDapatkan jumlah frekuensi untuk kunci yang diberikan.
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk melihat ke atas. |
default | - | Nilai default untuk dikembalikan jika tidak ada frekuensi yang ditemukan. |
| Kembali | int | Jumlah frekuensi. |
vec = s2v [ "avocado|NOUN" ]
s2v . add ( "?|NOUN" , vec , 1234 )
assert s2v . get_freq ( "?|NOUN" ) == 1234 Sense2Vec.set_freqTetapkan jumlah frekuensi untuk kunci yang diberikan.
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk mengatur jumlah. |
freq | int | Jumlah frekuensi. |
s2v . set_freq ( "avocado|NOUN" , 104294 )Sense2Vec.__iter__ , Sense2Vec.itemsIterasi di atas entri di tabel vektor.
| Argumen | Jenis | Keterangan |
|---|---|---|
| Hasil | tuple | Tombol string dan pasangan vektor di tabel. |
for key , vec in s2v :
print ( key , vec )
for key , vec in s2v . items ():
print ( key , vec )Sense2Vec.keysIterasi di atas kunci di meja.
| Argumen | Jenis | Keterangan |
|---|---|---|
| Hasil | Unicode | Tombol string di tabel. |
all_keys = list ( s2v . keys ())Sense2Vec.valuesIterasi di atas vektor di meja.
| Argumen | Jenis | Keterangan |
|---|---|---|
| Hasil | numpy.ndarray | Vektor di meja. |
all_vecs = list ( s2v . values ())Sense2Vec.senses Indera yang tersedia dalam tabel, misalnya "NOUN" atau "VERB" (ditambahkan pada inisialisasi).
| Argumen | Jenis | Keterangan |
|---|---|---|
| Kembali | daftar | Indera yang tersedia. |
s2v = Sense2Vec ( senses = [ "VERB" , "NOUN" ])
assert "VERB" in s2v . senses Sense2vec.frequenciesFrekuensi kunci dalam tabel, dalam urutan menurun.
| Argumen | Jenis | Keterangan |
|---|---|---|
| Kembali | daftar | (key, freq) tupel dengan frekuensi, turun. |
most_frequent = s2v . frequencies [: 10 ]
key , score = s2v . frequencies [ 0 ]Sense2vec.similarityBuat perkiraan kesamaan semantik dari dua kunci atau dua set kunci. Perkiraan default adalah kesamaan kosinus menggunakan rata -rata vektor.
| Argumen | Jenis | Keterangan |
|---|---|---|
keys_a | unicode / int / iterable | Kunci String atau Integer. |
keys_b | unicode / int / iterable | String atau kunci integer lainnya. |
| Kembali | mengambang | Skor kesamaan. |
keys_a = [ "machine_learning|NOUN" , "natural_language_processing|NOUN" ]
keys_b = [ "computer_vision|NOUN" , "object_detection|NOUN" ]
print ( s2v . similarity ( keys_a , keys_b ))
assert s2v . similarity ( "machine_learning|NOUN" , "machine_learning|NOUN" ) == 1.0 Sense2Vec.most_similarDapatkan entri yang paling mirip di tabel. Jika lebih dari satu kunci disediakan, rata -rata vektor digunakan. Untuk membuat metode ini lebih cepat, lihat skrip untuk menghitung cache dari tetangga terdekat.
| Argumen | Jenis | Keterangan |
|---|---|---|
keys | unicode / int / iterable | Kunci string atau integer untuk dibandingkan dengan. |
n | int | Jumlah kunci serupa untuk dikembalikan. Default ke 10 . |
batch_size | int | Ukuran batch untuk digunakan. Default ke 16 . |
| Kembali | daftar | (key, score) dari vektor yang paling mirip. |
most_similar = s2v . most_similar ( "natural_language_processing|NOUN" , n = 3 )
# [('machine_learning|NOUN', 0.8986967),
# ('computer_vision|NOUN', 0.8636297),
# ('deep_learning|NOUN', 0.8573361)] Sense2Vec.get_other_senses Temukan entri lain untuk kata yang sama dengan pengertian yang berbeda, misalnya "duck|VERB" untuk "duck|NOUN" .
| Argumen | Jenis | Keterangan |
|---|---|---|
key | unicode / int | Kunci untuk memeriksa. |
ignore_case | bool | Periksa huruf besar, huruf kecil, dan titlecase. Default ke True . |
| Kembali | daftar | Kunci string entri lain dengan indera yang berbeda. |
other_senses = s2v . get_other_senses ( "duck|NOUN" )
# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ'] Sense2Vec.get_best_sense Temukan pengertian yang paling cocok untuk kata yang diberikan berdasarkan indera dan jumlah frekuensi yang tersedia. Tidak mengembalikan None jika tidak ada kecocokan ditemukan.
| Argumen | Jenis | Keterangan |
|---|---|---|
word | Unicode | Kata untuk memeriksa. |
senses | daftar | Daftar indera opsional untuk membatasi pencarian. Jika tidak diatur / kosong, semua indera dalam vektor digunakan. |
ignore_case | bool | Periksa huruf besar, huruf kecil, dan titlecase. Default ke True . |
| Kembali | Unicode | Kunci pencocokan terbaik atau tidak sama sekali. |
assert s2v . get_best_sense ( "duck" ) == "duck|NOUN"
assert s2v . get_best_sense ( "duck" , [ "VERB" , "ADJ" ]) == "duck|VERB" Sense2Vec.to_bytes Serialisasi objek Sense2Vec ke bytestring.
| Argumen | Jenis | Keterangan |
|---|---|---|
exclude | daftar | Nama bidang serialisasi untuk dikecualikan. |
| Kembali | byte | Objek Sense2Vec serial. |
s2v_bytes = s2v . to_bytes ()Sense2Vec.from_bytes Muat objek Sense2Vec dari bytestring.
| Argumen | Jenis | Keterangan |
|---|---|---|
bytes_data | byte | Data untuk dimuat. |
exclude | daftar | Nama bidang serialisasi untuk dikecualikan. |
| Kembali | Sense2Vec | Objek yang dimuat. |
s2v_bytes = s2v . to_bytes ()
new_s2v = Sense2Vec (). from_bytes ( s2v_bytes )Sense2Vec.to_disk Serialisasi objek Sense2Vec ke direktori.
| Argumen | Jenis | Keterangan |
|---|---|---|
path | Unicode / Path | Jalannya. |
exclude | daftar | Nama bidang serialisasi untuk dikecualikan. |
s2v . to_disk ( "/path/to/sense2vec" )Sense2Vec.from_disk Muat objek Sense2Vec dari direktori.
| Argumen | Jenis | Keterangan |
|---|---|---|
path | Unicode / Path | Jalur untuk memuat dari |
exclude | daftar | Nama bidang serialisasi untuk dikecualikan. |
| Kembali | Sense2Vec | Objek yang dimuat. |
s2v . to_disk ( "/path/to/sense2vec" )
new_s2v = Sense2Vec (). from_disk ( "/path/to/sense2vec" )Sense2VecComponentKomponen pipa untuk menambahkan SENSE2VEC ke pipa spacy.
Sense2VecComponent.__init__Inisialisasi komponen pipa.
| Argumen | Jenis | Keterangan |
|---|---|---|
vocab | Vocab | Vocab bersama. Sebagian besar digunakan untuk StringStore bersama. |
shape | tuple | Bentuk vektor. |
merge_phrases | bool | Apakah akan menggabungkan frasa Sense2Vec menjadi satu token. Default ke False . |
lemmatize | bool | Selalu cari lemma jika tersedia di vektor, sebaliknya default ke kata asli. Default ke False . |
overrides | Fungsi Kustom Opsional untuk Digunakan, Dipetakan ke Nama yang Didaftarkan melalui Registry, Misalnya {"make_key": "custom_make_key"} . | |
| Kembali | Sense2VecComponent | Objek yang baru dibangun. |
s2v = Sense2VecComponent ( nlp . vocab )Sense2VecComponent.from_nlp Inisialisasi komponen dari objek NLP. Sebagian besar digunakan sebagai pabrik komponen untuk titik masuk (lihat setup.cfg) dan untuk mendaftar secara otomatis melalui @spacy.component Decorator.
| Argumen | Jenis | Keterangan |
|---|---|---|
nlp | Language | Objek nlp . |
**cfg | - | Parameter konfigurasi opsional. |
| Kembali | Sense2VecComponent | Objek yang baru dibangun. |
s2v = Sense2VecComponent . from_nlp ( nlp )Sense2VecComponent.__call__ Proses objek Doc dengan komponen. Biasanya hanya disebut sebagai bagian dari pipa spacy dan tidak secara langsung.
| Argumen | Jenis | Keterangan |
|---|---|---|
doc | Doc | Dokumen untuk diproses. |
| Kembali | Doc | dokumen yang diproses. |
Sense2Vec.init_componentDaftarkan atribut ekstensi khusus komponen di sini dan hanya jika komponen ditambahkan ke pipa dan digunakan-jika tidak, token masih akan mendapatkan atribut bahkan jika komponen hanya dibuat dan tidak ditambahkan.
Sense2VecComponent.to_bytes Serialize komponen ke bytestring. Juga dipanggil saat komponen ditambahkan ke pipa dan Anda menjalankan nlp.to_bytes .
| Argumen | Jenis | Keterangan |
|---|---|---|
| Kembali | byte | Komponen serial. |
Sense2VecComponent.from_bytes Muat komponen dari bytestring. Juga dipanggil saat Anda menjalankan nlp.from_bytes .
| Argumen | Jenis | Keterangan |
|---|---|---|
bytes_data | byte | Data untuk dimuat. |
| Kembali | Sense2VecComponent | Objek yang dimuat. |
Sense2VecComponent.to_disk Serial komponen ke direktori. Juga dipanggil ketika komponen ditambahkan ke pipa dan Anda menjalankan nlp.to_disk .
| Argumen | Jenis | Keterangan |
|---|---|---|
path | Unicode / Path | Jalannya. |
Sense2VecComponent.from_disk Muat objek Sense2Vec dari direktori. Juga dipanggil saat Anda menjalankan nlp.from_disk .
| Argumen | Jenis | Keterangan |
|---|---|---|
path | Unicode / Path | Jalur untuk memuat dari |
| Kembali | Sense2VecComponent | Objek yang dimuat. |
registry kelas Fungsi registri (ditenagai oleh catalogue ) untuk dengan mudah menyesuaikan fungsi yang digunakan untuk menghasilkan kunci dan frasa. Memungkinkan Anda untuk menghias dan memberi nama fungsi kustom, menukarnya dan membuat serial nama khusus saat Anda menyimpan model. Opsi registri berikut tersedia:
| Nama | Deskripsi | | ------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------- | | registry.make_key | Diberi word dan sense , kembalikan serangkaian kunci, misalnya "word | sense". | | registry.split_key | Diberikan tombol string, kembalikan tuple (word, sense) . | | registry.make_spacy_key | Diberikan objek spacy ( Token atau Span ) dan argumen kata kunci boolean prefer_ents (apakah akan lebih suka label entitas untuk token tunggal), kembalikan tuple (word, sense) . Digunakan dalam atribut ekstensi untuk menghasilkan kunci untuk token dan rentang. | | | registry.get_phrases | Diberikan Doc spacy, kembalikan daftar objek Span yang digunakan untuk frasa Sense2Vec (biasanya frasa kata benda dan entitas yang disebutkan). | | registry.merge_phrases | Diberi Doc spacy, dapatkan semua frasa Sense2Vec dan gabungkan menjadi satu token. |
Setiap registri memiliki metode register yang dapat digunakan sebagai dekorator fungsi dan mengambil satu argumen, nama fungsi khusus.
from sense2vec import registry
@ registry . make_key . register ( "custom" )
def custom_make_key ( word , sense ):
return f" { word } ### { sense } "
@ registry . split_key . register ( "custom" )
def custom_split_key ( key ):
word , sense = key . split ( "###" )
return word , sense Saat menginisialisasi objek Sense2Vec , Anda sekarang dapat melewati kamus overrides dengan nama fungsi yang terdaftar kustom Anda.
overrides = { "make_key" : "custom" , "split_key" : "custom" }
s2v = Sense2Vec ( overrides = overrides )Hal ini memudahkan untuk bereksperimen dengan strategi yang berbeda dan membuat serial strategi sebagai string polos (alih -alih harus melewati dan/atau acar fungsi itu sendiri).
Direktori /scripts berisi utilitas baris perintah untuk preprocessing teks dan melatih vektor Anda sendiri.
Untuk melatih vektor SENSE2VEC Anda sendiri, Anda akan membutuhkan yang berikut:
doc.noun_chunks . Jika bahasa yang Anda butuhkan tidak memberikan sintaks iterator bawaan untuk frasa kata benda, Anda harus menulis sendiri. ( doc.noun_chunks dan doc.ents adalah apa yang digunakan Sense2Vec untuk menentukan apa itu frasa.)make di direktori masing -masing. Proses pelatihan dibagi menjadi beberapa langkah untuk memungkinkan Anda melanjutkan pada titik tertentu. Script pemrosesan dirancang untuk beroperasi pada file tunggal, membuatnya mudah untuk memparallikan pekerjaan. Skrip dalam repo ini membutuhkan sarung tangan atau fasttext yang perlu Anda klon dan make .
Untuk FastText, skrip akan membutuhkan jalur ke file biner yang dibuat. Jika Anda mengerjakan Windows, Anda dapat membangun dengan cmake , atau sebagai alternatif menggunakan file .exe dari repo tidak resmi ini dengan fasttext biner Builds untuk windows: https://github.com/xiamx/fasttext/releases.
| Naskah | Keterangan | |
|---|---|---|
| 1. | 01_parse.py | Gunakan Spacy untuk menguraikan teks mentah dan output koleksi biner objek Doc (lihat DocBin ). |
| 2. | 02_preprocess.py | Muat kumpulan objek Doc parsed yang diproduksi pada langkah sebelumnya dan file teks output dalam format Sense2VEC (satu kalimat per baris dan menggabungkan frasa dengan indera). |
| 3. | 03_glove_build_counts.py | Gunakan sarung tangan untuk membangun kosakata dan hitungan. Lewati langkah ini jika Anda menggunakan Word2Vec melalui FastText. |
| 4. | 04_glove_train_vectors.py04_fasttext_train_vectors.py | Gunakan sarung tangan atau fasttext untuk melatih vektor. |
| 5. | 05_export.py | Muat vektor dan frekuensi dan output komponen SENSE2VEC yang dapat dimuat melalui Sense2Vec.from_disk . |
| 6. | 06_precompute_cache.py | Opsional: Mempersomputasi permintaan tetangga terdekat untuk setiap entri dalam vocab untuk membuat Sense2Vec.most_similar lebih cepat. |
Untuk dokumentasi skrip yang lebih terperinci, lihat sumbernya atau jalankan dengan --help . Misalnya, python scripts/01_parse.py --help .
Paket ini juga dengan mulus terintegrasi dengan alat anotasi ajaib dan memperlihatkan resep untuk menggunakan vektor Sense2Vec untuk dengan cepat menghasilkan daftar frasa multi-kata dan anotasi bootstrap ner. Untuk menggunakan resep, sense2vec perlu dipasang di lingkungan yang sama dengan keajaiban. Untuk contoh kasus penggunaan dunia nyata, lihat proyek NER ini dengan set data yang dapat diunduh.
Resep -resep berikut tersedia - lihat di bawah untuk dokumen yang lebih rinci.
| Resep | Keterangan |
|---|---|
sense2vec.teach | Bootstrap Daftar Terminologi Menggunakan Sense2Vec. |
sense2vec.to-patterns | Konversi frasa dataset ke pola kecocokan berbasis token. |
sense2vec.eval | Evaluasi model SENSE2VEC dengan bertanya tentang frasa tiga kali lipat. |
sense2vec.eval-most-similar | Mengevaluasi model SENSE2VEC dengan memperbaiki entri yang paling mirip. |
sense2vec.eval-ab | Lakukan evaluasi A/B dari dua model vektor SENSE2VEC pretrained. |
sense2vec.teachBootstrap Daftar Terminologi Menggunakan Sense2Vec. Prodigy akan menyarankan istilah serupa berdasarkan frasa yang paling mirip dari SENSE2VEC, dan saran akan disesuaikan saat Anda membuat anotasi dan menerima frasa yang sama. Untuk setiap istilah benih, indera pencocokan terbaik menurut vektor Sense2VEC akan digunakan.
prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
[--n-similar] [--batch-size] [--resume]| Argumen | Jenis | Keterangan |
|---|---|---|
dataset | posisi | Dataset untuk menyimpan anotasi ke. |
vectors_path | posisi | Jalan menuju vektor Sense2Vec pretrained. |
--seeds , -s | pilihan | Satu atau lebih frasa benih yang dipisahkan koma. |
--threshold , -t | pilihan | Ambang kesamaan. Default ke 0.85 . |
--n-similar , -n | pilihan | Jumlah item serupa untuk didapat sekaligus. |
--batch-size , -b | pilihan | Ukuran batch untuk mengirimkan anotasi. |
--resume , -R | bendera | Melanjutkan dari set data yang ada. |
prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
--seeds " natural language processing, machine learning, artificial intelligence "sense2vec.to-patterns Konversi set data frasa yang dikumpulkan dengan sense2vec.teach ke pola pertandingan berbasis token yang dapat digunakan dengan EntityRuler spacy atau resep seperti ner.match . Jika tidak ada file output yang ditentukan, polanya ditulis ke stdout. Contoh-contohnya di-tokenisasi sehingga istilah multi-token diwakili dengan benar, misalnya: {"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]} .
prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
[--case-sensitive] [--dry]| Argumen | Jenis | Keterangan |
|---|---|---|
dataset | posisi | Dataset frasa untuk dikonversi. |
spacy_model | posisi | Model spacy untuk tokenisasi. |
label | posisi | Label untuk diterapkan pada semua pola. |
--output-file , -o | pilihan | File output opsional. Default ke stdout. |
--case-sensitive , -CS | bendera | Membuat pola-sensitif. |
--dry , -D | bendera | Lakukan lari kering dan jangan menghasilkan apa pun. |
prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
--output-file /path/to/patterns.jsonlsense2vec.evalEvaluasi model Sense2Vec dengan bertanya tentang frasa tiga: Apakah kata lebih mirip dengan kata B, atau kata c? Jika manusia sebagian besar setuju dengan model, model vektor baik. Resep ini hanya akan bertanya tentang vektor dengan pengertian yang sama dan mendukung strategi seleksi contoh yang berbeda.
prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
[--eval-only] [--show-scores]| Argumen | Jenis | Keterangan |
|---|---|---|
dataset | posisi | Dataset untuk menyimpan anotasi ke. |
vectors_path | posisi | Jalan menuju vektor Sense2Vec pretrained. |
--strategy , -st | pilihan | Contoh strategi seleksi. most similar (default) atau random . |
--senses , -s | pilihan | Daftar indera yang dipisahkan secara koma untuk membatasi pemilihan. Jika tidak diatur, semua indera dalam vektor akan digunakan. |
--exclude-senses , -es | pilihan | Daftar indra yang dipisahkan secara koma untuk dikecualikan. Lihat prodigy_recipes.EVAL_EXCLUDE_SENSES dari default. |
--n-freq , -f | pilihan | Jumlah entri yang paling sering terjadi. |
--threshold , -t | pilihan | Ambang kesamaan minimum untuk mempertimbangkan contoh. |
--batch-size , -b | pilihan | Ukuran batch untuk digunakan. |
--eval-whole , -E | bendera | Evaluasi seluruh dataset alih -alih sesi saat ini. |
--eval-only , -O | bendera | Jangan anotasi, hanya mengevaluasi dataset saat ini. |
--show-scores , -S | bendera | Tunjukkan semua skor untuk debugging. |
| Nama | Keterangan |
|---|---|
most_similar | Pilih kata acak dari pengertian acak dan dapatkan entri yang paling mirip dengan pengertian yang sama. Tanyakan tentang kesamaan dengan entri terakhir dan tengah dari pilihan itu. |
most_least_similar | Pilih kata acak dari akal acak dan dapatkan entri paling tidak serupa dari entri yang paling mirip, dan kemudian entri terakhir yang paling mirip. |
random | Pilih sampel acak 3 kata dari pengertian acak yang sama. |
prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCT --threshold 0.5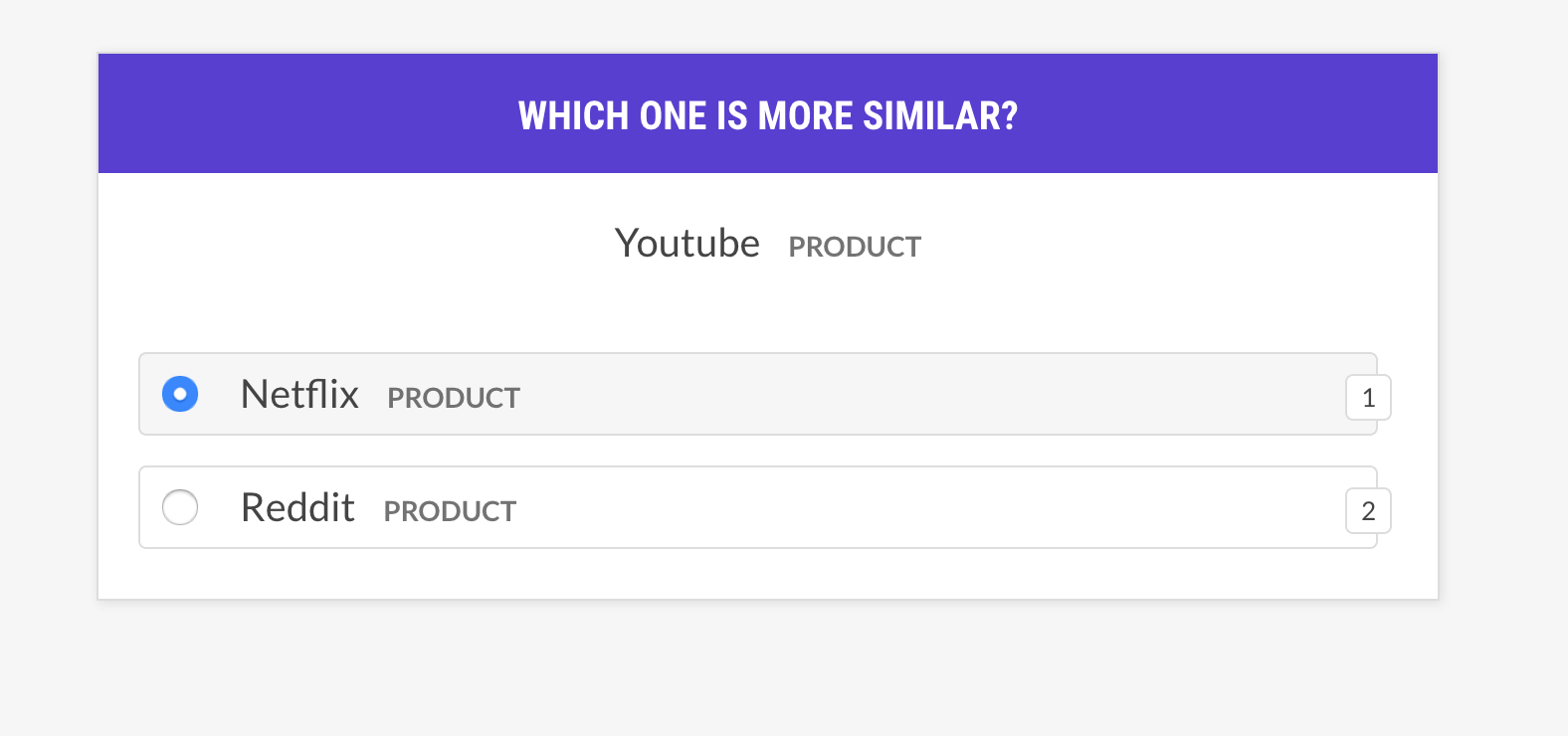
sense2vec.eval-most-similarMengevaluasi model vektor dengan melihat entri yang paling mirip yang dikembalikan untuk frasa acak dan tidak memilih kesalahan.
prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
[--show-scores]| Argumen | Jenis | Keterangan |
|---|---|---|
dataset | posisi | Dataset untuk menyimpan anotasi ke. |
vectors_path | posisi | Jalan menuju vektor Sense2Vec pretrained. |
--senses , -s | pilihan | Daftar indera yang dipisahkan secara koma untuk membatasi pemilihan. Jika tidak diatur, semua indera dalam vektor akan digunakan. |
--exclude-senses , -es | pilihan | Daftar indra yang dipisahkan secara koma untuk dikecualikan. Lihat prodigy_recipes.EVAL_EXCLUDE_SENSES dari default. |
--n-freq , -f | pilihan | Jumlah entri yang paling sering terjadi. |
--n-similar , -n | pilihan | Jumlah item serupa untuk diperiksa. Default ke 10 . |
--batch-size , -b | pilihan | Ukuran batch untuk digunakan. |
--eval-whole , -E | bendera | Evaluasi seluruh dataset alih -alih sesi saat ini. |
--eval-only , -O | bendera | Jangan anotasi, hanya mengevaluasi dataset saat ini. |
--show-scores , -S | bendera | Tunjukkan semua skor untuk debugging. |
prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
--senses NOUN,ORG,PRODUCTsense2vec.eval-abLakukan evaluasi A/B dari dua model vektor SENSE2VEC pretrained dengan membandingkan entri yang paling mirip yang mereka kembalikan untuk frasa acak. UI menunjukkan dua opsi acak dengan entri paling mirip dari masing -masing model dan menyoroti frasa yang berbeda. Pada akhir sesi anotasi, statistik keseluruhan dan model yang disukai ditampilkan.
prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
[--eval-only] [--show-mapping]| Argumen | Jenis | Keterangan |
|---|---|---|
dataset | posisi | Dataset untuk menyimpan anotasi ke. |
vectors_path_a | posisi | Jalan menuju vektor Sense2Vec pretrained. |
vectors_path_b | posisi | Jalan menuju vektor Sense2Vec pretrained. |
--senses , -s | pilihan | Daftar indera yang dipisahkan secara koma untuk membatasi pemilihan. Jika tidak diatur, semua indera dalam vektor akan digunakan. |
--exclude-senses , -es | pilihan | Daftar indra yang dipisahkan secara koma untuk dikecualikan. Lihat prodigy_recipes.EVAL_EXCLUDE_SENSES dari default. |
--n-freq , -f | pilihan | Jumlah entri yang paling sering terjadi. |
--n-similar , -n | pilihan | Jumlah item serupa untuk diperiksa. Default ke 10 . |
--batch-size , -b | pilihan | Ukuran batch untuk digunakan. |
--eval-whole , -E | bendera | Evaluasi seluruh dataset alih -alih sesi saat ini. |
--eval-only , -O | bendera | Jangan anotasi, hanya mengevaluasi dataset saat ini. |
--show-mapping , -S | bendera | Tunjukkan model mana yang merupakan opsi 1 dan opsi 2 di UI (untuk debugging). |
prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT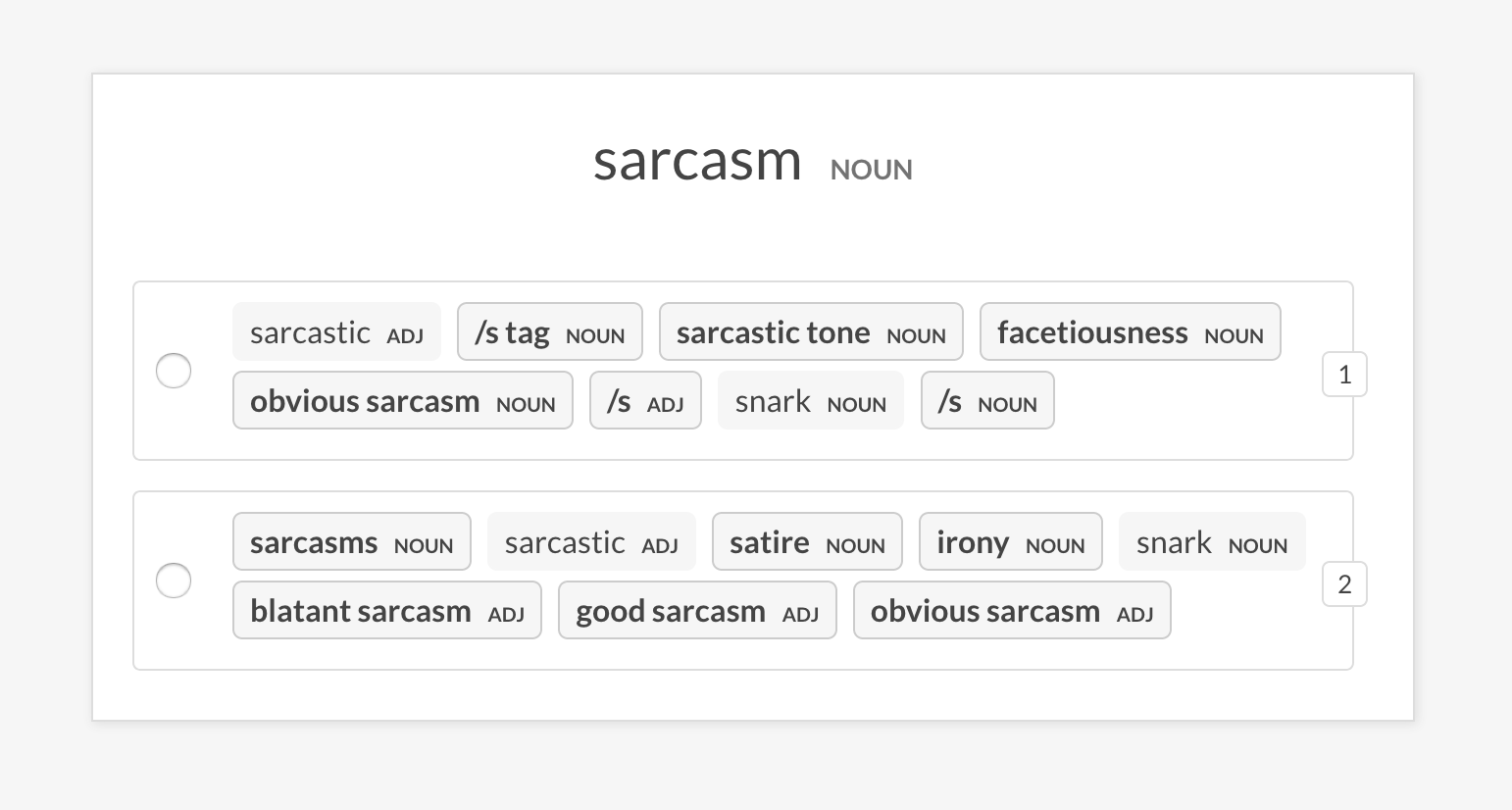
Vektor reddit pretrained mendukung "indera" berikut, baik tag bagian-dari-ucapan atau label entitas. Untuk detail lebih lanjut, lihat Tinjauan Skema Anotasi Spacy.
| Menandai | Keterangan | Contoh |
|---|---|---|
ADJ | kata sifat | Besar, tua, hijau |
ADP | Adposisi | di, ke, selama |
ADV | kata keterangan | sangat, besok, turun, di mana |
AUX | bantu | IS, telah (selesai), akan (lakukan) |
CONJ | konjungsi | dan, atau, tapi |
DET | penentu | a, an, the |
INTJ | kata seru | psst, aduh, bravo, halo |
NOUN | kata benda | Gadis, kucing, pohon, udara, kecantikan |
NUM | angka | 1, 2017, satu, tujuh puluh tujuh, mmxiv |
PART | partikel | S, bukan |
PRON | kata ganti | Aku, kamu, dia, dia, diriku sendiri, seseorang |
PROPN | kata benda yang tepat | Mary, John, London, NATO, HBO |
PUNCT | tanda baca | ,? () |
SCONJ | konjungsi bawahan | Jika, sementara itu |
SYM | simbol | $, %, =, :),? |
VERB | kata kerja | berlari, berlari, berlari, makan, makan, makan |
| Label Entitas | Keterangan |
|---|---|
PERSON | Orang, termasuk fiksi. |
NORP | Kebangsaan atau kelompok agama atau politik. |
FACILITY | Bangunan, bandara, jalan raya, jembatan, dll. |
ORG | Perusahaan, lembaga, lembaga, dll. |
GPE | Negara, kota, negara bagian. |
LOC | Lokasi non-GPE, pegunungan, badan air. |
PRODUCT | Objek, kendaraan, makanan, dll. (Bukan layanan.) |
EVENT | Bernama Badai, Pertempuran, Perang, Acara Olahraga, dll. |
WORK_OF_ART | Judul buku, lagu, dll. |
LANGUAGE | Bahasa apa pun yang disebutkan. |


