gpl
v0.1.4: Giving more hints when throwing exceptions
GPL是一種無監督的域適應方法,用於訓練緻密獵犬。它基於與功能強大的跨編碼器的查詢產生和偽標記。要訓練由域適應的模型,它只需要未標記的目標語料庫,並且可以對零射擊模型實現顯著改進。
有關更多信息,請查看我們的出版物:
要復制,請參閱此快照分支。
一個可以通過pip安裝GPL
pip install gpl或通過git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .同時,請確保根據您的CUDA版本安裝了Pytorch的正確版本。
GPL接受Beir-Format中的數據。例如,我們可以下載Beir託管的FIQA數據集:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training.然後,我們可以使用python -m功能直接運行GPL培訓:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)或在Python腳本中導入GPL的火車方法:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)還可以在Google Colab上參考此玩具示例,以更好地了解代碼的工作原理。
GPL的工作流如下: 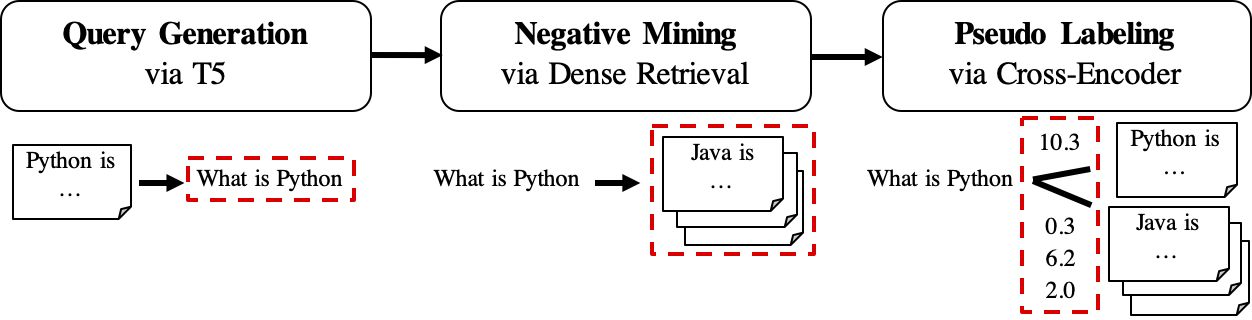
queries_per_passage查詢。查詢對接對被視為訓練的積極例子。結果文件(在路徑
$path_to_generated_data下):(1)${qgen}-qrels/train.tsv,(2)${qgen}-queries.jsonl以及(3)corpus.jsonl(從$evaluation_data/copus.jsonl(複製)
retrievers作為負礦工。結果文件(在路徑
$path_to_generated_data下):hard-negative.jsonl;
結果文件(在路徑
$path_to_generated_data下):gpl-training-data.tsv。它總共包含(gpl_steps*batch_size_gpl)元組。
到目前為止,我們已經準備好實際培訓數據。可以查看Sample-DATA/生成/FIQA,以獲取有關數據格式的快速示例。最後一步是應用邊緣損失,以教導學生獵犬模仿保證金分數,ce(查詢,正) - CE(查詢,負)由教師模型(Cross -nocoder,CE)標記。當然,GPL中包含邊距步驟,將自動完成:)。請注意,Marginmse與DOT產品合作,因此使用GPL訓練的最終模型可與DOT產品一起使用。
PS: --retrievers是用於負面採礦的。它們可以是在通用域中訓練的任何密集的檢索器(例如MS MARCO),並且不需要對目標任務/域進行強大。請參閱論文以獲取更多詳細信息(參見表7)。
一個人還可以以相同名稱時尚的方式替換/將任何中間步驟的自定義數據替換/放置在路徑$path_to_generated_data下的任何中間步驟。 GPL將使用這些提供的數據跳過中間步驟。
作為典型的工作流程,可能只有(英語)Unlabeld語料庫,並且希望一個好的模型為此語料庫表現良好。要在這種情況下進行GPL培訓,只需要以下步驟:
corpus.jsonl放在一個文件夾下,例如,命名為“生成”,用於GPL的數據加載和數據生成;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1現在,我們通過https://huggingface.co/gpl發布了預訓練的GPL模型。當前有五種類型的模型:
GPL/${dataset}-msmarco-distilbert-gpl :在${dataset}上的訓練訂單(1)ribgl的訓練順序的模型;GPL/${dataset}-tsdae-msmarco-distilbert-gpl :型號,培訓順序為(1)tsdae on ${dataset} - >(2)MSMARCO上的Marginmse在${dataset}上的MSMARCO->(3)GPL上的MASMARCO->(3);GPL/msmarco-distilbert-margin-mse :在MSMARCO培訓的模型;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse :$ {dataSet} - >(2)MSMARCO上的Marginmse;GPL/${dataset}-distilbert-tas-b-gpl-self_miner :從TAS-B模型開始,模型在目標語料庫${dataset}上接受了基本模型本身作為負礦工的培訓(此處稱為“ self_miner”)。實際上,模型1和2。在模型3和4。所有GPL型號均經過new_size和queries_per_passage的自動設置(通過將它們設置為-1 )。這種自動設置可以在高效的同時保持性能。有關更多詳細信息,請參閱論文中的第4.1節。
在這些模型中, GPL/${dataset}-distilbert-tas-b-gpl-self_miner Ones在Beir基准上的表現最好: 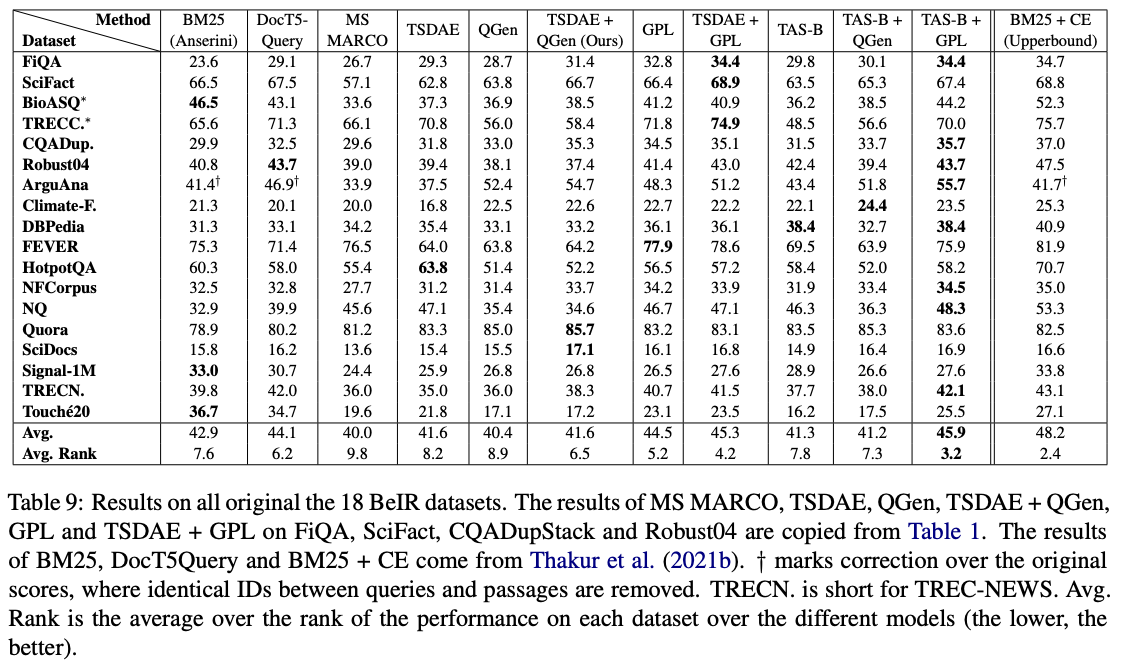
要使用實驗中使用的相同軟件包版本重現結果,請參閱conda環境文件,環境。
現在,我們發布了GPL紙實驗中使用的生成數據:
請注意,只有在與原始正式當局註冊後,僅可用於bioasq , robust04 , trec-news和signal1m的4個數據集。我們僅使用文件名corpus.doc_ids.txt發布這些語料庫的文檔ID。有關更多詳細信息,請參考貝爾存儲庫。
如果您使用該代碼進行評估,請隨時引用我們的出版物GPL:生成偽標籤,以適應密集檢索的無監督域:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}聯繫人和主要貢獻者:Kexin Wang,[email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
請隨時向我們發送電子郵件或報告問題,如果某件事被打破(不應該是),或者您還有其他問題。
該存儲庫包含實驗軟件,並出於唯一目的發布了有關該出版物的其他背景詳細信息。


