gpl
v0.1.4: Giving more hints when throwing exceptions
GPL - это метод адаптации без присмотра для обучения плотных ретриверов. Он основан на генерации запросов и псевдо маркировке с мощными перекрестными кодерами. Чтобы обучить модель, адаптированную доменом, ей требуется только немеченые целевое корпус и может достичь значительного улучшения по сравнению с моделями с нулевым выстрелом.
Для получения дополнительной информации проверьте нашу публикацию:
Для воспроизведения, пожалуйста, обратитесь к этой ветви снимка.
Можно либо установить GPL через pip
pip install gpl или через git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .Между тем, пожалуйста, убедитесь, что правильная версия Pytorch была установлена в соответствии с вашей версией CUDA.
GPL принимает данные в BEIR-формате. Например, мы можем скачать набор данных FIQA, размещенный BEIR:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. Затем мы можем либо использовать функцию python -m для напряжения подготовки GPL:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)или импортировать метод обучения GPL в сценарий Python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)Можно также обратиться к этому примеру игрушек в Google Colab для лучшего понимания того, как работает код.
Рабочий процесс GPL показан следующим образом: 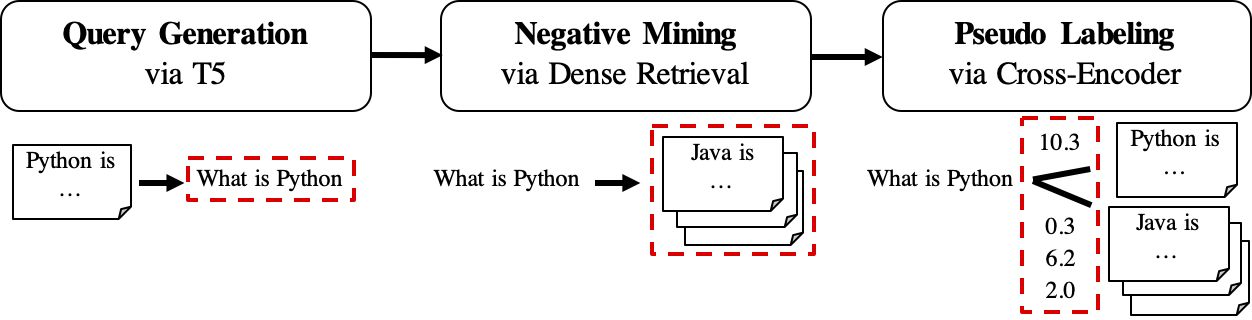
queries_per_passage для каждого отрывка в немеченном корпусе. Пары прохождения запросов рассматриваются как положительные примеры для обучения.Файлы результатов (под путем
$path_to_generated_data): (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonl, а также (3)corpus.jsonl(скопированный из$evaluation_data/);
retrievers аргументов в качестве негативного шахтера.Файл результата (под путем
$path_to_generated_data): жесткие точки зрения.jsonl;
Файл результата (по пути
$path_to_generated_data):gpl-training-data.tsv. Он содержит (gpl_steps*batch_size_gpl) в целом.
До сих пор у нас есть реальные данные обучения. Можно посмотреть на образцы-даты/сгенерированные/fiqa для быстрого примера о формате данных. Самым последним шагом является применение потери MarginMse, чтобы научить студентов -ретривера имитировать оценки маржи, CE (запрос, положительный) - CE (запрос, отрицательный), помеченный моделью учителя (Cross -Encoder, CE). И, конечно же, шаг Marginmse включен в GPL и будет выполняться автоматически :). Обратите внимание, что MARGINMSE работает с DOT-продуктом, и, следовательно, окончательные модели, обученные GPL, работают с DOT-продуктом .
PS: --retrievers для негативной добычи. Это могут быть любые плотные ретриверы, обученные общему домену (например, MS MARCO), и не должны быть сильными для целевой задачи/домена . Пожалуйста, обратитесь к статье для получения более подробной информации (ср. Таблица 7).
Можно также заменить/поместить настраиваемые данные для любого промежуточного шага под пути $path_to_generated_data с тем же именем. GPL пропустит промежуточные шаги, используя эти предоставленные данные.
В качестве типичного рабочего процесса можно иметь только (английский) корпус нераверного и нужен хорошую модель, хорошо выполняющую для этого корпуса. Чтобы провести обучение GPL в соответствии с такими условиями, нужно просто эти шаги:
corpus.jsonl в папку, например, как «генерируемый» для загрузки данных и генерации данных с помощью GPL;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1Теперь мы отпускаем предварительно обученные модели GPL через https://huggingface.co/gpl. В настоящее время есть пять типов моделей:
GPL/${dataset}-msmarco-distilbert-gpl : модель с учебным порядком (1) marginmse на msmarco-> (2) gpl on ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : модель с порядок обучения (1) tsdae на ${dataset} -> (2) MarginMse на msmarco-> (3) gpl on ${dataset} ;GPL/msmarco-distilbert-margin-mse : модель, обученная MSMARCO с MARGINMSE;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : модель с порядок обучения (1) tsdae на $ {набор данных}-> (2) marginmse на msmarco;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : начиная с модели TAS-B, модели были обучены GPL на целевом корпусе ${dataset} с самой базовой моделью как отрицательный шахтер (здесь отмеченный как «Self_miner»). Модели 1. И 2. На самом деле были обучены сверх моделей 3. И 4. соответственно. Все модели GPL были обучены автоматической настройке new_size и queries_per_passage (установив их на -1 ). Эта автоматическая настройка может сохранить производительность, будучи эффективной. Для получения более подробной информации, пожалуйста, обратитесь к разделу 4.1 в статье.
Среди этих моделей GPL/${dataset}-distilbert-tas-b-gpl-self_miner Ones работает лучше всего на тесте BEIR: 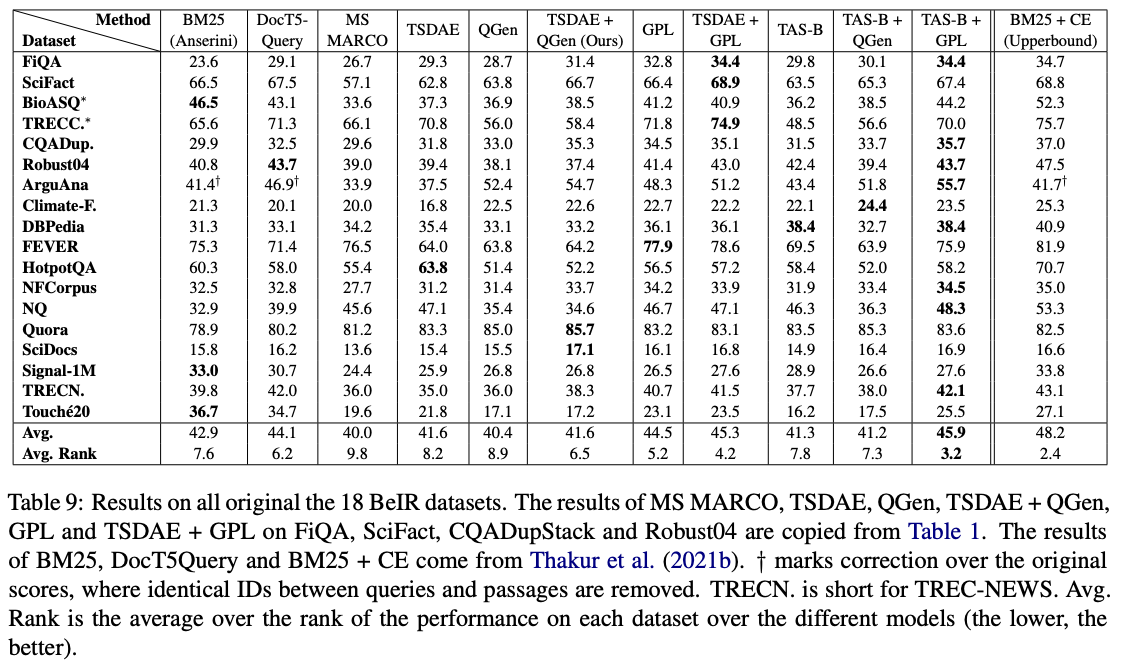
Для воспроизведения результатов с теми же версиями пакетов, которые использовались в экспериментах, пожалуйста, см. Файл среды Conda, Environment.yml.
Теперь мы отпускаем сгенерированные данные, используемые в экспериментах бумаги GPL:
Обратите внимание, что 4 набора данных bioasq , robust04 , trec-news и signal1m доступны только после регистрации с первоначальными официальными органами. Мы выпускаем только идентификаторы документа для этих корпораций с помощью имени файла corpus.doc_ids.txt . Для получения более подробной информации, пожалуйста, обратитесь к репозиторию BEIR.
Если вы используете код для оценки, не стесняйтесь цитировать нашу публикацию GPL: генеративная псевдо -маркировка для неконтролируемой доменной адаптации плотного поиска:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}Контактное лицо и основной участник: Kexin Wang, [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
Не стесняйтесь отправлять нам электронное письмо или сообщать о проблеме, если что-то сломано (и это не должно быть) или если у вас есть дополнительные вопросы.
Этот репозиторий содержит экспериментальное программное обеспечение и опубликовано с единственной целью предоставить дополнительные данные о соответствующей публикации.


