gpl
v0.1.4: Giving more hints when throwing exceptions
GPL هي طريقة تكييف المجال غير خاضعة للإشراف لتدريب المسترجعين الكثيفين. يعتمد على توليد الاستعلام ووضع العلامات الزائفة مع أدوات متقاطعة قوية. لتدريب نموذج مكيف المجال ، لا يحتاج سوى إلى مجموعة مستهدفة غير مفيدة ويمكن أن تحقق تحسنا كبيرا على نماذج صفرية.
لمزيد من المعلومات ، الخروج عن نشرنا:
للاستنساخ ، يرجى الرجوع إلى فرع اللقطة هذا.
يمكن للمرء إما تثبيت GPL عبر pip
pip install gpl أو عبر git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .وفي الوقت نفسه ، يرجى التأكد من تثبيت الإصدار الصحيح من Pytorch وفقًا لإصدار CUDA الخاص بك.
GPL يقبل البيانات في بير-فورم. على سبيل المثال ، يمكننا تنزيل مجموعة بيانات FIQA التي استضافتها بير:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. ثم يمكننا إما استخدام وظيفة python -m لتشغيل تدريب GPL مباشرة:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)أو استيراد طريقة تدريب GPL في نص Python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)يمكن للمرء أيضًا أن يشير إلى مثال لعبة على Google Colab لفهم أفضل لكيفية عمل الكود.
يظهر سير عمل GPL على النحو التالي: 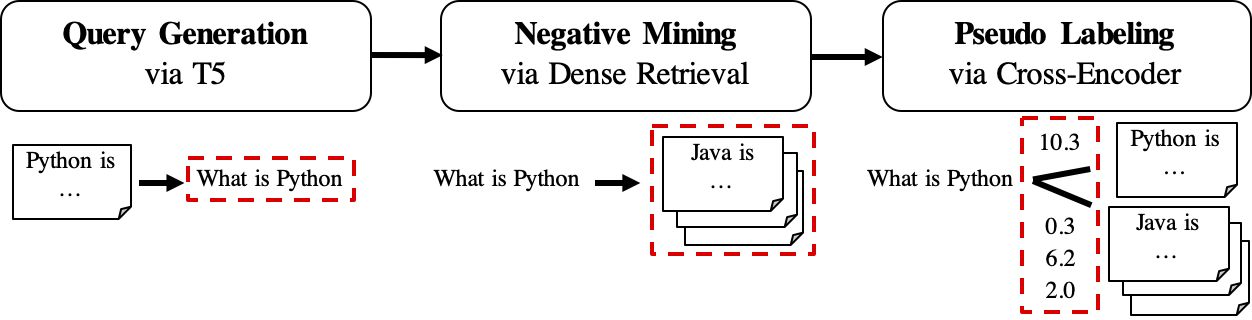
queries_per_passage لكل مقطع في المجموعة غير المُحورة. يُنظر إلى أزواج التماس الاستعلام كأمثلة إيجابية للتدريب.ملفات النتائج (تحت المسار
$path_to_generated_data): (1)${qgen}-qrels/train.tsv، (2)${qgen}-queries.jsonlوأيضًا (3)corpus.jsonl(نسخ من$evaluation_data/) ؛
retrievers الوسيطة كمناجم سالب.ملف النتيجة (تحت المسار
$path_to_generated_data): hard-neginists.jsonl ؛
ملف النتيجة (تحت المسار
$path_to_generated_data):gpl-training-data.tsv. يحتوي على (gpl_steps*batch_size_gpl) في المجموع.
حتى الآن ، لدينا بيانات التدريب الفعلية جاهزة. يمكن للمرء أن ينظر إلى عينة البيانات/تم إنشاؤها/fiqa للحصول على مثال سريع حول تنسيق البيانات. والخطوة الأخيرة هي تطبيق خسارة الهامشين لتدريس المسترد الطالب لتقليد درجات الهامش ، CE (الاستعلام ، الإيجابي) - CE (الاستعلام ، السلبي) المسمى نموذج المعلم (الشفرات المتقاطعة ، CE). وبالطبع ، يتم تضمين خطوة Marginmse في GPL وسيتم تنفيذها تلقائيًا :). لاحظ أن Marginmse يعمل مع منتج DOT وبالتالي فإن النماذج النهائية المدربة مع GPL تعمل مع منتج DOT .
PS: the --retrievers هي من أجل التعدين السلبي. يمكن أن يكونوا أي مسترجعين كثيفون مدربين على المجال العام (على سبيل المثال MS Marco) ولا يحتاجون إلى أن يكونوا قويين للمهمة/المجال المستهدف . يرجى الرجوع إلى الورقة لمزيد من التفاصيل (راجع الجدول 7).
يمكن للمرء أيضًا استبدال/وضع البيانات المخصصة لأي خطوة وسيطة تحت المسار $path_to_generated_data مع نفس الاسم. سيتخطى GPL الخطوات الوسيطة باستخدام هذه البيانات المقدمة.
باعتباره سير عمل نموذجي ، قد يكون للمرء فقط (اللغة الإنجليزية) مجموعة غير مسهرية ويريد نموذجًا جيدًا أداءً جيدًا لهذا المجموعة. لتشغيل تدريب GPL في ظل هذه الحالة ، يحتاج المرء فقط إلى هذه الخطوات:
corpus.jsonl تحت مجلد ، على سبيل المثال اسمه "تم إنشاؤه" لتحميل البيانات وتوليد البيانات بواسطة GPL ؛python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1نقوم الآن بإصدار نماذج GPL التي تم تدريبها مسبقًا عبر https://huggingface.co/GPL. يوجد حاليًا خمسة أنواع من النماذج:
GPL/${dataset}-msmarco-distilbert-gpl : نموذج مع ترتيب تدريب من (1) marginmse على msmarco-> (2) GPL على ${dataset} ؛GPL/${dataset}-tsdae-msmarco-distilbert-gpl : نموذج مع ترتيب تدريب من (1) tsdae على ${dataset} -> (2) marginmse على msmarco-> (3) gpl on ${dataset} ؛GPL/msmarco-distilbert-margin-mse : نموذج تم تدريبه على msmarco مع marginmse ؛GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : نموذج مع ترتيب تدريب (1) tsdae على $ {dataset}-> (2) marginmse على msmarco ؛GPL/${dataset}-distilbert-tas-b-gpl-self_miner : بدءًا من نموذج TAS-B ، تم تدريب النماذج باستخدام GPL على Corpus ${dataset} مع النموذج الأساسي نفسه باعتباره عامل المناجم السلبي (الذي تم الإشارة إليه هنا باسم "self_miner"). تم تدريب النماذج 1. و 2. على قمة النماذج 3. و 4. resp. تم تدريب جميع نماذج GPL على الإعداد التلقائي لـ new_size و queries_per_passage (عن طريق ضبطها على -1 ). يمكن أن يحافظ هذا الإعداد التلقائي على الأداء أثناء الكفاءة. لمزيد من التفاصيل ، يرجى الرجوع إلى القسم 4.1 في الورقة.
من بين هذه النماذج ، تعمل GPL/${dataset}-distilbert-tas-b-gpl-self_miner التي تعمل بشكل أفضل على معيار بير: 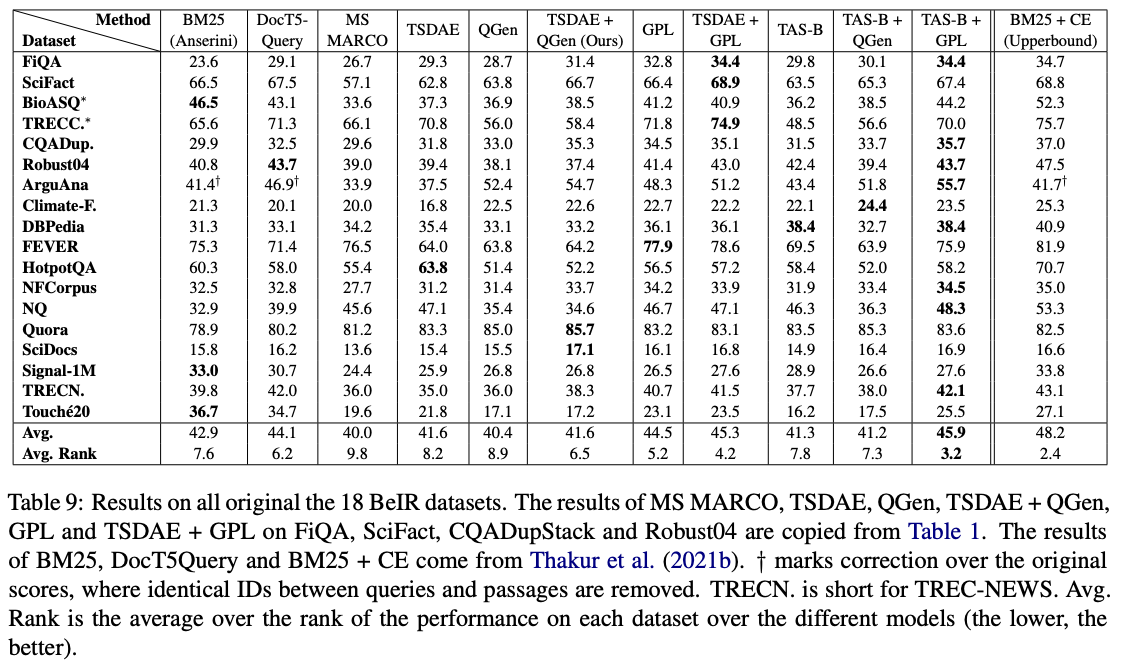
لإعادة إنتاج النتائج باستخدام نسخ الحزمة نفسها المستخدمة في التجارب ، يرجى الرجوع إلى ملف البيئة كوندا ، البيئة.
نطلق الآن البيانات التي تم إنشاؤها المستخدمة في تجارب ورقة GPL:
يرجى ملاحظة أن مجموعات البيانات الأربعة الخاصة بـ bioasq ، و robust04 ، و trec-news و signal1m متاحة فقط بعد التسجيل مع السلطات الرسمية الأصلية. نقوم فقط بإصدار معرفات المستند لهذه الشركات مع اسم الملف corpus.doc_ids.txt . لمزيد من التفاصيل ، يرجى الرجوع إلى مستودع بير.
إذا كنت تستخدم الرمز للتقييم ، فلا تتردد في الاستشهاد بنشرنا GPL: وضع العلامات الزائفة التوليدية لتكييف المجال غير الخاضع للإشراف لاسترجاع كثيف:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}الاتصال الشخص والمساهم الرئيسي: Kexin Wang ، [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
لا تتردد في إرسال بريد إلكتروني إلينا أو الإبلاغ عن مشكلة ، إذا تم كسر شيء ما (ولا ينبغي أن يكون) أو إذا كان لديك المزيد من الأسئلة.
يحتوي هذا المستودع على برنامج تجريبي ويتم نشره لغرض وحيد هو إعطاء تفاصيل خلفية إضافية حول المنشور المعني.


