gpl
v0.1.4: Giving more hints when throwing exceptions
GPL es un método de adaptación de dominio no supervisado para capacitar a los retrievers densos. Se basa en la generación de consultas y el etiquetado de pseudo con potentes codificadores transversales. Para entrenar un modelo adaptado al dominio, solo necesita el corpus objetivo sin etiquetar y puede lograr una mejora significativa sobre los modelos de disparo cero.
Para obtener más información, consulte nuestra publicación:
Para la reproducción, consulte esta rama de instantáneas.
Uno puede instalar GPL a través de pip
pip install gpl o a través de git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .Mientras tanto, asegúrese de que la versión correcta de Pytorch se haya instalado de acuerdo con su versión CUDA.
GPL acepta datos en el formato Beir. Por ejemplo, podemos descargar el conjunto de datos FIQA alojado por Beir:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. Entonces podemos usar la función python -m para ejecutar el entrenamiento GPL directamente:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)o Importar el método de entrenamiento de GPL en un script de Python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)También se puede consultar este ejemplo de juguete en Google Colab para comprender mejor cómo funciona el código.
El flujo de trabajo de GPL se muestra de la siguiente manera: 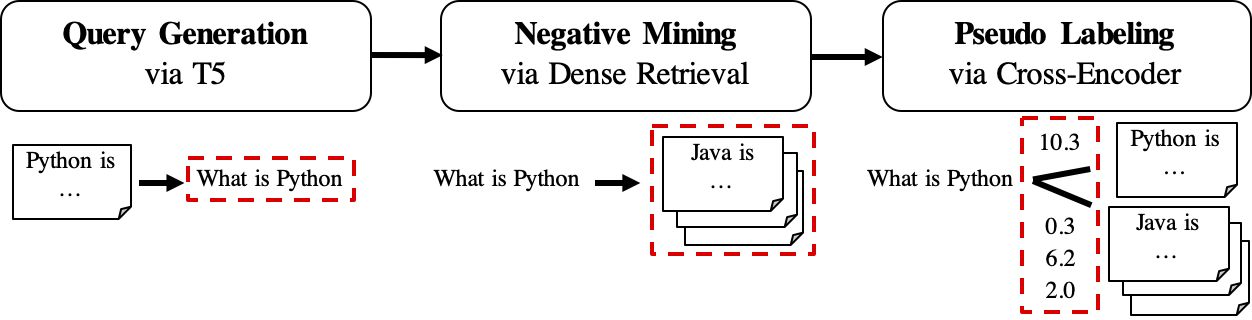
queries_per_passage para cada pasaje en el corpus sin etiquetar. Los pares de consulta de paso se consideran ejemplos positivos para el entrenamiento.Archivos de resultados (en ruta
$path_to_generated_data): (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonly también (3)corpus.jsonl(copiado de$evaluation_data/);
retrievers de argumento como el minero negativo.Archivo de resultados (en ruta
$path_to_generated_data): hard-negates.jsonl;
Archivo de resultados (en ruta
$path_to_generated_data):gpl-training-data.tsv. Contiene (gpl_steps*batch_size_gpl) tuples en total.
Hasta ahora, tenemos los datos de entrenamiento reales listos. Uno puede mirar los datos de muestra/generado/FIQA para un ejemplo rápido sobre el formato de datos. El último paso es aplicar la pérdida de marginmse para enseñarle al estudiante a imitar las puntuaciones de margen, CE (consulta, positivo) - CE (consulta, negativo) etiquetado por el modelo de maestro (entrelazador, CE). Y, por supuesto, el paso MarginMSE se incluye en GPL y se realizará automáticamente :). Tenga en cuenta que MarginMSE funciona con Producto DOT y, por lo tanto, los modelos finales entrenados con GPL funciona con Producto DOT .
PD: Los --retrievers son para minería negativa. Pueden ser cualquier denso retriever capacitado en el dominio general (por ejemplo, la Sra. Marco) y no necesitan ser fuertes para la tarea/dominio objetivo . Consulte el documento para obtener más detalles (cf. Tabla 7).
También se puede reemplazar/poner los datos personalizados para cualquier paso intermedio en la ruta $path_to_generated_data con la misma moda de nombre. GPL omitirá los pasos intermedios utilizando estos datos proporcionados.
Como flujo de trabajo típico, uno podría solo tener el corpus (inglés) sin etiquetar y querer que un buen modelo funcione bien para este corpus. Para ejecutar el entrenamiento de GPL en tal condición, uno solo necesita estos pasos:
corpus.jsonl en una carpeta, por ejemplo, llamado "generado" para la carga de datos y la generación de datos por GPL;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1Ahora lanzamos los modelos GPL previamente entrenados a través de https://huggingface.co/gpl. Actualmente hay cinco tipos de modelos:
GPL/${dataset}-msmarco-distilbert-gpl : modelo con orden de entrenamiento de (1) marginmse en msmarco-> (2) GPL en ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : modelo con orden de entrenamiento de (1) tsdae en ${dataset} -> (2) marginmse en msmarco-> (3) GPL en ${dataset} ;GPL/msmarco-distilbert-margin-mse : Modelo entrenado en Msmarco con MarginMse;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : modelo con orden de entrenamiento de (1) tsdae en $ {dataSet}-> (2) marginmse en msmarco;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : Comenzando desde el modelo TAS-B, los modelos se entrenaron con GPL en el Corpus de Target ${dataset} con el modelo base en sí como el minero negativo (aquí se señaló como "Self_Miner"). Modelos 1. Y 2. En realidad fueron entrenados en la parte superior de los modelos 3. Y 4. Resp. Todos los modelos GPL fueron capacitados en la configuración automática de new_size y queries_per_passage (configurándolos en -1 ). Esta configuración automática puede mantener el rendimiento mientras es eficiente. Para obtener más detalles, consulte la Sección 4.1 en el documento.
Entre estos modelos, GPL/${dataset}-distilbert-tas-b-gpl-self_miner funcionan mejor en el punto de referencia Beir: 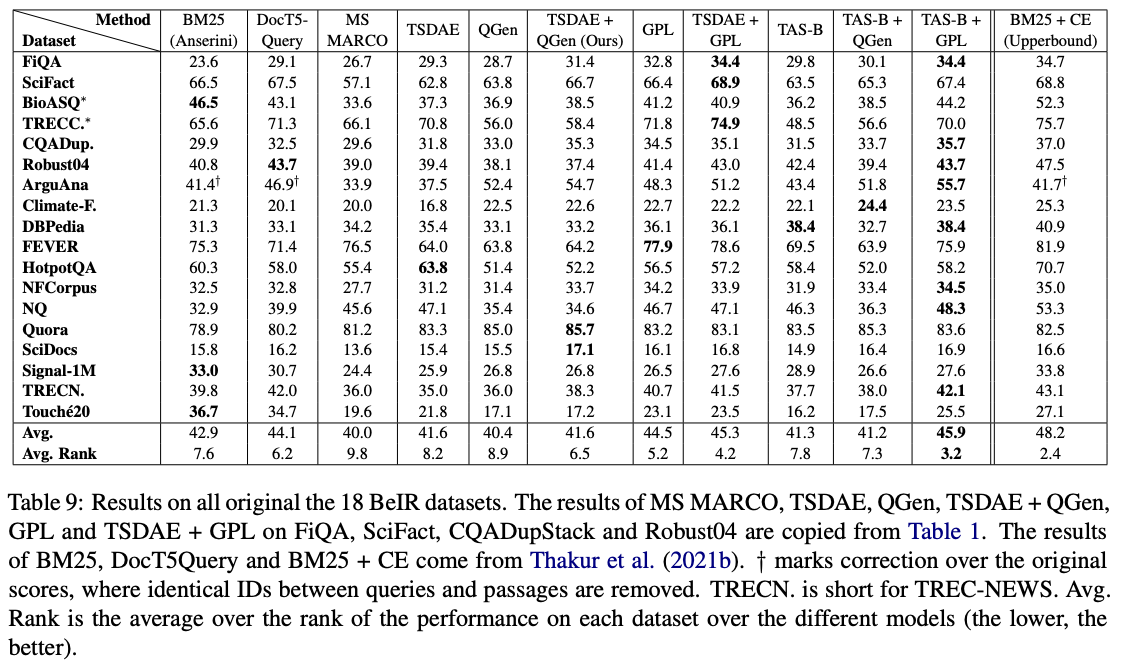
Para reproducir los resultados con las mismas versiones de paquete utilizadas en los experimentos, consulte el archivo de entorno Conda, entorno.yml.
Ahora lanzamos los datos generados utilizados en los experimentos del papel GPL:
Tenga en cuenta que los 4 conjuntos de datos de bioasq , robust04 , trec-news y signal1m solo están disponibles después del registro con las autoridades oficiales originales. Solo lanzamos las ID de documento para estos corpus con el nombre del archivo corpus.doc_ids.txt . Para obtener más detalles, consulte el repositorio de Beir.
Si usa el código para la evaluación, no dude en citar nuestra publicación GPL: etiquetado de pseudo generativo para adaptación de dominio no supervisado de recuperación densa:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}Persona de contacto y colaborador principal: Kexin Wang, [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
No dude en enviarnos un correo electrónico o informar un problema, si algo está roto (y no debería estarlo) o si tiene más preguntas.
Este repositorio contiene software experimental y se publica con el único propósito de dar detalles de antecedentes adicionales sobre la publicación respectiva.


