gpl
v0.1.4: Giving more hints when throwing exceptions
GPL เป็นวิธีการปรับตัวของโดเมนที่ไม่ได้รับการดูแลสำหรับการฝึกอบรมการดึงข้อมูลหนาแน่น มันขึ้นอยู่กับการสร้างแบบสอบถามและการติดฉลากหลอกด้วยการเข้ารหัสข้ามที่ทรงพลัง ในการฝึกอบรมโมเดลที่ปรับโดเมนนั้นต้องการเฉพาะคลังเป้าหมายที่ไม่มีป้ายกำกับและสามารถปรับปรุงการปรับปรุงที่สำคัญกว่ารุ่นที่ไม่มีการยิง
สำหรับข้อมูลเพิ่มเติมชำระเงินสิ่งพิมพ์ของเรา:
สำหรับการทำซ้ำโปรดดูสาขาสแน็ปช็อตนี้
หนึ่งสามารถติดตั้ง GPL ผ่าน pip
pip install gpl หรือผ่าน git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .ในขณะเดียวกันโปรดตรวจสอบให้แน่ใจว่ามีการติดตั้ง Pytorch เวอร์ชันที่ถูกต้องตามรุ่น CUDA ของคุณ
GPL รับข้อมูลในรูปแบบ Beir ตัวอย่างเช่นเราสามารถดาวน์โหลดชุดข้อมูล FIQA ที่โฮสต์โดย Beir:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. จากนั้นเราสามารถใช้ฟังก์ชั่น python -m เพื่อเรียกใช้การฝึกอบรม GPL โดยตรง:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)หรือนำเข้าวิธีการฝึกอบรมของ GPL ในสคริปต์ Python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)นอกจากนี้ยังสามารถอ้างถึงตัวอย่างของเล่นนี้บน Google Colab เพื่อทำความเข้าใจวิธีการทำงานของรหัส
เวิร์กโฟลว์ของ GPL แสดงดังนี้: 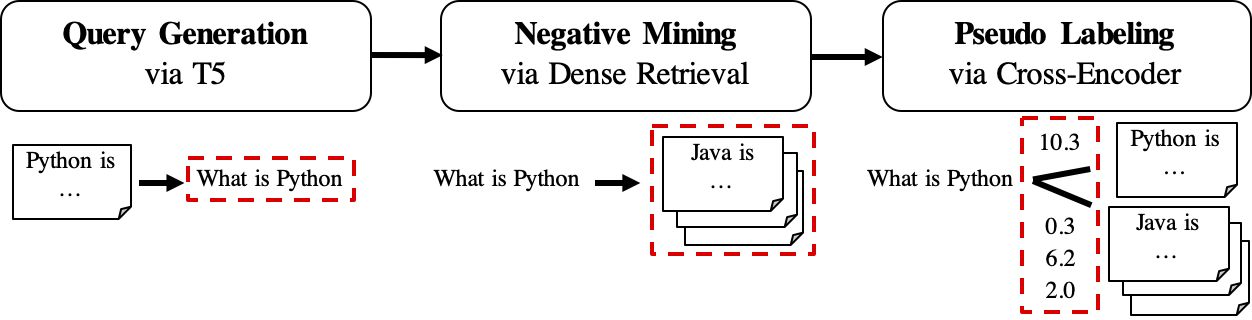
queries_per_passage สำหรับแต่ละข้อความในคลังข้อมูลที่ไม่มีป้ายกำกับ คู่การสืบค้นผ่านถูกมองว่าเป็น ตัวอย่างที่ดี สำหรับการฝึกอบรมไฟล์ผลลัพธ์ (ภายใต้ path
$path_to_generated_data): (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonlและ (3)corpus.jsonl(คัดลอกมาจาก$evaluation_data/);
retrievers อาร์กิวเมนต์ไฟล์ผลลัพธ์ (ภายใต้พา ธ
$path_to_generated_data): hard-negatives.jsonl;
ไฟล์ผลลัพธ์ (ภายใต้พา ธ
$path_to_generated_data):gpl-training-data.tsvมันมี (gpl_steps*batch_size_gpl) รวมทั้งหมด
ถึงตอนนี้เรามีข้อมูลการฝึกอบรมจริงพร้อม หนึ่งสามารถดูตัวอย่างข้อมูล/สร้าง/FIQA สำหรับตัวอย่างอย่างรวดเร็วเกี่ยวกับรูปแบบข้อมูล ขั้นตอนสุดท้ายคือการใช้การสูญเสีย marginmse เพื่อสอน retriever นักเรียนเพื่อเลียนแบบคะแนนระยะขอบ, CE (แบบสอบถาม, บวก) - CE (แบบสอบถาม, ลบ) ที่ติดป้ายกำกับโดยโมเดลครู (Cross -Encoder, CE) และแน่นอน ขั้นตอน marginmse รวมอยู่ใน GPL และจะทำ โดยอัตโนมัติ :) โปรดทราบว่า marginmse ทำงานร่วมกับ DOT-Product และรุ่นสุดท้ายที่ผ่านการฝึกอบรมด้วย GPL จะทำงานร่วมกับ Dot-Product
PS: --retrievers ใช้สำหรับการขุดเชิงลบ พวกเขาสามารถเป็นตัวดึงข้อมูลที่หนาแน่นใด ๆ ที่ได้รับการฝึกฝนเกี่ยวกับโดเมนทั่วไป (เช่น MS Marco) และ ไม่จำเป็นต้องแข็งแกร่งสำหรับงาน/โดเมนเป้าหมาย โปรดดูเอกสารสำหรับรายละเอียดเพิ่มเติม (เปรียบเทียบตารางที่ 7)
นอกจากนี้ยังสามารถแทนที่/วางข้อมูลที่กำหนดเองสำหรับขั้นตอนกลางใด ๆ ภายใต้เส้นทาง $path_to_generated_data ด้วยแฟชั่นชื่อเดียวกัน GPL จะข้ามขั้นตอนกลางโดยใช้ข้อมูลที่ให้ไว้เหล่านี้
ในฐานะที่เป็นเวิร์กโฟลว์ทั่วไปเราอาจมีคลังข้อมูลที่ไม่มีป้ายกำกับ (ภาษาอังกฤษ) เท่านั้นและต้องการรูปแบบที่ดีทำงานได้ดีสำหรับคลังนี้ ในการดำเนินการฝึกอบรม GPL ภายใต้เงื่อนไขดังกล่าวเพียงแค่ต้องการขั้นตอนเหล่านี้:
corpus.jsonl ของคุณภายใต้โฟลเดอร์เช่นชื่อ "สร้าง" สำหรับการโหลดข้อมูลและการสร้างข้อมูลโดย GPL;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1ตอนนี้เราเปิดตัวรุ่น GPL ที่ผ่านการฝึกอบรมมาก่อนผ่าน https://huggingface.co/gpl ปัจจุบันมีรุ่นห้าประเภท:
GPL/${dataset}-msmarco-distilbert-gpl : โมเดลที่มีลำดับการฝึกอบรมของ (1) marginMSE บน mSMARCO-> (2) GPL บน ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : โมเดลที่มีลำดับการฝึกอบรมของ (1) tsdae บน ${dataset} -> (2) marginmse บน msmarco-> (3) gpl บน ${dataset} ;GPL/msmarco-distilbert-margin-mse : รุ่นที่ผ่านการฝึกอบรมเกี่ยวกับ MSMARCO ด้วย marginmse;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : โมเดลที่มีลำดับการฝึกอบรมของ (1) TSDAE บน $ {ชุดข้อมูล}-> (2) marginMSE บน mSmarco;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : เริ่มต้นจากโมเดล TAS-B แบบจำลองได้รับการฝึกฝนด้วย GPL ใน Corpus เป้าหมาย ${dataset} ด้วยโมเดลพื้นฐานของตัวเอง รุ่น 1. และ 2. ได้รับการฝึกฝนจริง ๆ บนรุ่น 3. และ 4. resp รุ่น GPL ทั้งหมดได้รับการฝึกฝนการตั้งค่าอัตโนมัติของ new_size และ queries_per_passage (โดยการตั้งค่าเป็น -1 ) การตั้งค่าอัตโนมัตินี้สามารถรักษาประสิทธิภาพได้ในขณะที่มีประสิทธิภาพ สำหรับรายละเอียดเพิ่มเติมโปรดดูหัวข้อ 4.1 ในกระดาษ
ในบรรดาโมเดลเหล่านี้ GPL/${dataset}-distilbert-tas-b-gpl-self_miner ทำงานได้ดีที่สุดในเกณฑ์มาตรฐาน Beir: 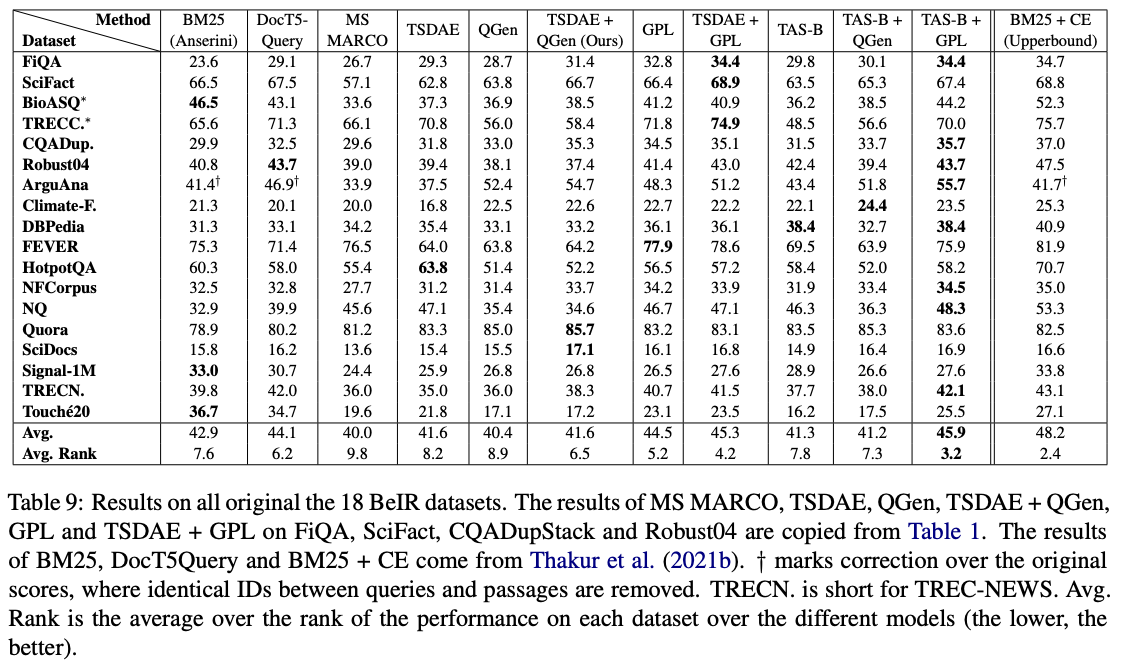
สำหรับการทำซ้ำผลลัพธ์ด้วยแพ็คเกจเดียวกับที่ใช้ในการทดลองโปรดดูไฟล์สภาพแวดล้อม conda, environment.yml
ตอนนี้เราปล่อยข้อมูลที่สร้างขึ้นที่ใช้ในการทดลองของกระดาษ GPL:
โปรดทราบว่าชุดข้อมูล 4 ชุดของ bioasq , robust04 , trec-news และ signal1m มีให้เฉพาะหลังจากการลงทะเบียนกับหน่วยงานทางการเดิม เราปล่อยรหัสเอกสารสำหรับ corpora เหล่านี้ด้วยชื่อไฟล์ corpus.doc_ids.txt สำหรับรายละเอียดเพิ่มเติมโปรดดูที่ที่เก็บ Beir
หากคุณใช้รหัสสำหรับการประเมินผลอย่าลังเลที่จะอ้างถึงสิ่งพิมพ์ GPL ของเรา: การติดฉลากหลอกแบบกำเนิดสำหรับการปรับโดเมนที่ไม่ได้รับการดูแลของการดึงข้อมูลหนาแน่น:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}ผู้ติดต่อและผู้สนับสนุนหลัก: Kexin Wang, [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
อย่าลังเลที่จะส่งอีเมลถึงเราหรือรายงานปัญหาหากมีบางอย่างเสีย (และไม่ควรเป็น) หรือหากคุณมีคำถามเพิ่มเติม
พื้นที่เก็บข้อมูลนี้มีซอฟต์แวร์ทดลองและเผยแพร่เพื่อวัตถุประสงค์เพียงอย่างเดียวในการให้รายละเอียดพื้นหลังเพิ่มเติมเกี่ยวกับสิ่งพิมพ์ที่เกี่ยวข้อง


