gpl
v0.1.4: Giving more hints when throwing exceptions
GPL adalah metode adaptasi domain yang tidak diawasi untuk pelatihan retriever padat. Ini didasarkan pada generasi kueri dan pelabelan semu dengan cross-encoder yang kuat. Untuk melatih model yang diadaptasi domain, hanya perlu corpus target yang tidak berlabel dan dapat mencapai peningkatan yang signifikan dibandingkan model nol-shot.
Untuk informasi lebih lanjut, checkout publikasi kami:
Untuk reproduksi, silakan merujuk ke cabang snapshot ini.
Seseorang dapat menginstal GPL melalui pip
pip install gpl atau melalui git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .Sementara itu, pastikan versi Pytorch yang benar telah diinstal sesuai dengan versi CUDA Anda.
GPL menerima data dalam format Beir. Misalnya, kami dapat mengunduh dataset FIQA yang dihosting oleh Beir:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. Kemudian kita dapat menggunakan fungsi python -m untuk menjalankan pelatihan GPL secara langsung:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)Atau impor metode pelatihan GPL dalam skrip Python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)Seseorang juga dapat merujuk pada contoh mainan ini di Google Colab untuk pemahaman yang lebih baik bagaimana kode bekerja.
Alur kerja GPL ditampilkan sebagai berikut: 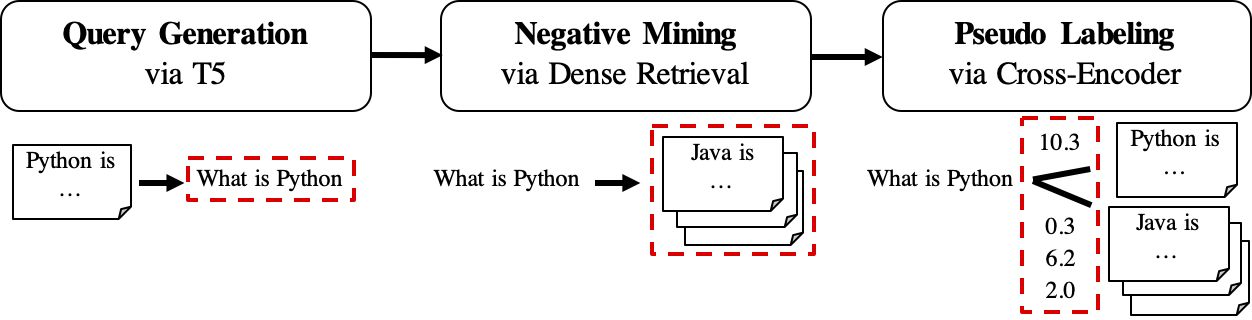
queries_per_passage untuk setiap bagian dalam korpus yang tidak berlabel. Pasangan kueri-passage dipandang sebagai contoh positif untuk pelatihan.File hasil (di bawah path
$path_to_generated_data): (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonldan juga (3)corpus.jsonl(disalin dari$evaluation_data/);
retrievers argumen sebagai penambang negatif.File hasil (di bawah path
$path_to_generated_data): hard-negatives.jsonl;
File hasil (di bawah path
$path_to_generated_data):gpl-training-data.tsv. Ini berisi (gpl_steps*batch_size_gpl) Total tupel.
Hingga saat ini, kami memiliki data pelatihan yang sebenarnya siap. Seseorang dapat melihat sampel-data/yang dihasilkan/fiqa untuk contoh cepat tentang format data. Langkah terakhir adalah menerapkan kehilangan marginmse untuk mengajar siswa retriever untuk meniru skor margin, CE (kueri, positif) - CE (kueri, negatif) yang diberi label oleh model guru (Cross -Encoder, CE). Dan tentu saja, langkah marginmse termasuk dalam GPL dan akan dilakukan secara otomatis :). Perhatikan bahwa MarginMSE bekerja dengan produk DOT dan dengan demikian model akhir yang dilatih dengan GPL bekerja dengan produk DOT .
PS: --retrievers adalah untuk penambangan negatif. Mereka dapat berupa retriever padat yang dilatih pada domain umum (misalnya MS Marco) dan tidak perlu kuat untuk tugas/domain target . Silakan merujuk ke makalah ini untuk detail lebih lanjut (lih. Tabel 7).
Seseorang juga dapat mengganti/meletakkan data yang disesuaikan untuk setiap langkah perantara di bawah PATH $path_to_generated_data dengan nama yang sama. GPL akan melewatkan langkah -langkah perantara dengan menggunakan data yang disediakan ini.
Sebagai alur kerja yang khas, orang mungkin hanya memiliki (bahasa Inggris) corpus tanpa label dan menginginkan model yang baik berkinerja baik untuk korpus ini. Untuk menjalankan pelatihan GPL dalam kondisi seperti itu, seseorang hanya membutuhkan langkah -langkah ini:
corpus.jsonl Anda di bawah folder, misalnya dinamai sebagai "dihasilkan" untuk pemuatan data dan pembuatan data oleh GPL;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1Kami sekarang merilis model GPL pra-terlatih melalui https://huggingface.co/gpl. Saat ini ada lima jenis model:
GPL/${dataset}-msmarco-distilbert-gpl : model dengan urutan pelatihan (1) marginmse pada msmarco-> (2) gpl pada ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : model dengan urutan pelatihan (1) tsdae pada ${dataset} -> (2) marginmse pada msmarco-> (3) gpl pada ${dataset} ;GPL/msmarco-distilbert-margin-mse : Model yang dilatih di Msmarco dengan marginmse;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : model dengan urutan pelatihan (1) tsdae pada $ {dataset}-> (2) marginmse pada msmarco;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : Mulai dari model TAS-B, model dilatih dengan GPL pada corpus target ${dataset} dengan model dasar itu sendiri sebagai penambang negatif (di sini dicatat sebagai "self_miner"). Model 1. Dan 2. Sebenarnya dilatih di atas model 3. Dan 4. Resp. Semua model GPL dilatih pengaturan otomatis new_size dan queries_per_passage (dengan mengaturnya ke -1 ). Pengaturan otomatis ini dapat menjaga kinerja sambil menjadi efisien. Untuk detail lebih lanjut, silakan merujuk ke bagian 4.1 di koran.
Di antara model-model ini, GPL/${dataset}-distilbert-tas-b-gpl-self_miner bekerja paling baik di benchmark beir: 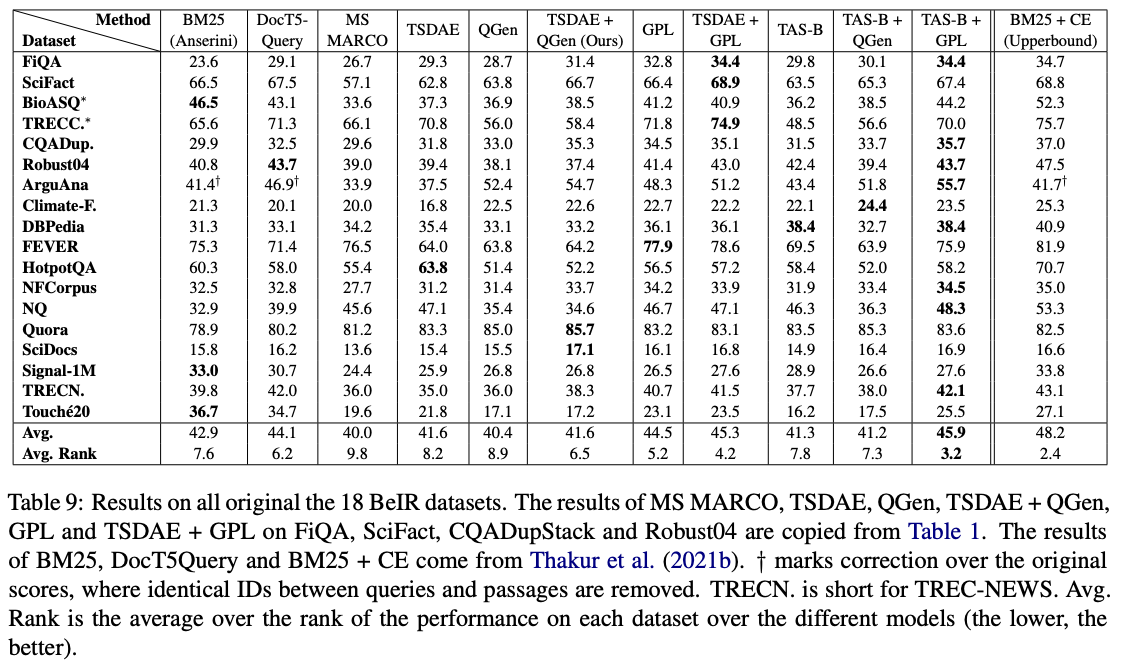
Untuk mereproduksi hasil dengan versi paket yang sama yang digunakan dalam percobaan, silakan merujuk ke file lingkungan CONDA, lingkungan.yml.
Kami sekarang melepaskan data yang dihasilkan yang digunakan dalam percobaan kertas GPL:
Harap dicatat bahwa 4 kumpulan data bioasq , robust04 , trec-news dan signal1m hanya tersedia setelah pendaftaran dengan otoritas resmi asli. Kami hanya merilis ID dokumen untuk korpora ini dengan nama file corpus.doc_ids.txt . Untuk detail lebih lanjut, silakan merujuk ke Repositori Beir.
Jika Anda menggunakan kode untuk evaluasi, jangan ragu untuk mengutip publikasi kami GPL: Pelabelan semu generatif untuk adaptasi domain yang tidak diawasi dari pengambilan padat:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}Hubungi Person dan Kontributor Utama: Kexin Wang, [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
Jangan ragu untuk mengirimi kami email atau melaporkan masalah, jika ada sesuatu yang rusak (dan seharusnya tidak) atau jika Anda memiliki pertanyaan lebih lanjut.
Repositori ini berisi perangkat lunak eksperimental dan diterbitkan untuk tujuan tunggal memberikan rincian latar belakang tambahan pada publikasi masing -masing.


