gpl
v0.1.4: Giving more hints when throwing exceptions
A GPL é um método de adaptação de domínio não supervisionado para o treinamento de retrievers densos. É baseado na geração de consultas e na rotulagem de pseudo com poderosos codificadores cruzados. Para treinar um modelo adaptado ao domínio, ele precisa de apenas o corpus alvo não marcado e pode obter uma melhoria significativa em relação aos modelos de tiro zero.
Para mais informações, consulte nossa publicação:
Para reprodução, consulte esta filial de instantâneos.
Pode -se instalar GPL via pip
pip install gpl ou via git clone
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .Enquanto isso, verifique se a versão correta do Pytorch foi instalada de acordo com sua versão CUDA.
A GPL aceita dados no formato da Beir. Por exemplo, podemos baixar o conjunto de dados FIQA hospedado pela Beir:
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. Em seguida, podemos usar a função python -m para executar o treinamento GPL diretamente:
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)ou importar o método de treinamento da GPL em um script python:
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)Pode -se também se referir a este exemplo de brinquedo no Google Colab para entender melhor como o código funciona.
O fluxo de trabalho da GPL é mostrado da seguinte maneira: 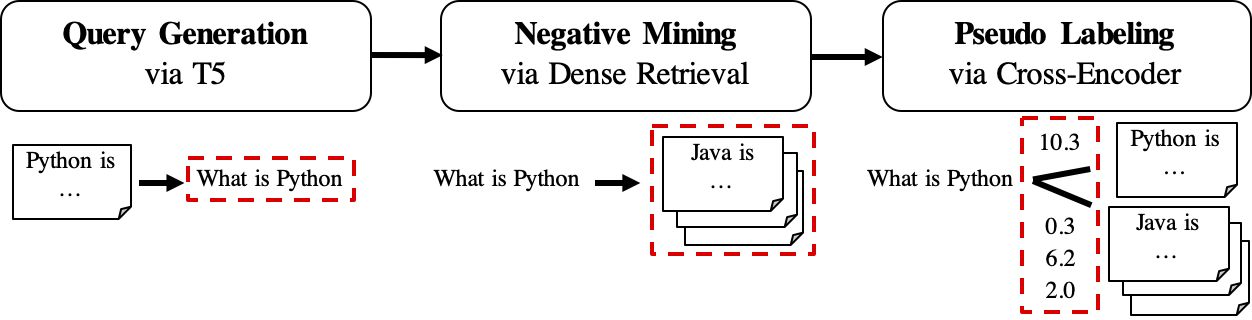
queries_per_passage para cada passagem no corpus não marcado. Os pares de passagem de consulta são vistos como exemplos positivos para o treinamento.Arquivos de resultado (em Path
$path_to_generated_data): (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonle também (3)corpus.jsonl(copiado de$evaluation_data/);
retrievers de argumento como mineiro negativo.Arquivo de resultado (no caminho
$path_to_generated_data): hard-negativos.jsonl;
Arquivo de resultado (em Path
$path_to_generated_data):gpl-training-data.tsv. Ele contém (gpl_steps*batch_size_gpl) tuplas no total.
Até agora, temos os dados de treinamento reais prontos. Pode-se olhar para dados de amostra/gerado/fiqa para um exemplo rápido sobre o formato de dados. A última etapa é aplicar a perda de marginmse para ensinar ao aluno Retriever a imitar as pontuações da margem, CE (consulta, positiva) - CE (consulta, negativa) marcada pelo modelo de professor (cross -coder, CE). E, é claro, a etapa marginmse está incluída no GPL e será feita automaticamente :). Observe que o MarginMSE funciona com o produto de pontos e, portanto, os modelos finais treinados com o GPL trabalha com o produto do DOT .
PS: Os --retrievers são para mineração negativa. Eles podem ser todos os densos retrievers treinados no domínio geral (por exemplo, marco) e não precisam ser fortes para a tarefa/domínio de destino . Consulte o artigo para obter mais detalhes (cf. Tabela 7).
Também é possível substituir/colocar os dados personalizados para qualquer etapa intermediária no caminho $path_to_generated_data com o mesmo nome. A GPL pulará as etapas intermediárias usando esses dados fornecidos.
Como um fluxo de trabalho típico, pode -se ter apenas o corpus (inglês) e deseja um bom modelo com um bom desempenho para este corpus. Para executar o treinamento da GPL nessa condição, basta apenas estas etapas:
corpus.jsonl em uma pasta, por exemplo, nomeada como "gerada" para carregamento de dados e geração de dados pela GPL;python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1Agora lançamos os modelos GPL pré-treinados por meio do https://huggingface.co/gpl. Atualmente, existem cinco tipos de modelos:
GPL/${dataset}-msmarco-distilbert-gpl : Modelo com ordem de treinamento de (1) marginmse no msmarco-> (2) GPL no ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : Modelo com ordem de treinamento de (1) tsdae em ${dataset} -> (2) marginmse no msmarco-> (3) GPL em ${dataset} ;GPL/msmarco-distilbert-margin-mse : Modelo treinado no MSMARCO com marginmse;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : Modelo com ordem de treinamento de (1) tsdae em $ {DATASET}-> (2) marginmse no msmarco;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : A partir do modelo TAS-B, os modelos foram treinados com GPL no corpus alvo ${dataset} com o próprio modelo base como o mineiro negativo (aqui observado como "self_miner"). Os modelos 1. E 2. Foram realmente treinados sobre os modelos 3. E 4. Resp. Todos os modelos GPL foram treinados a configuração automática de new_size e queries_per_passage (definindo -os como -1 ). Essa configuração automática pode manter o desempenho e ser eficiente. Para mais detalhes, consulte a Seção 4.1 no artigo.
Entre esses modelos, GPL/${dataset}-distilbert-tas-b-gpl-self_miner funciona melhor no benchmark da Beir: 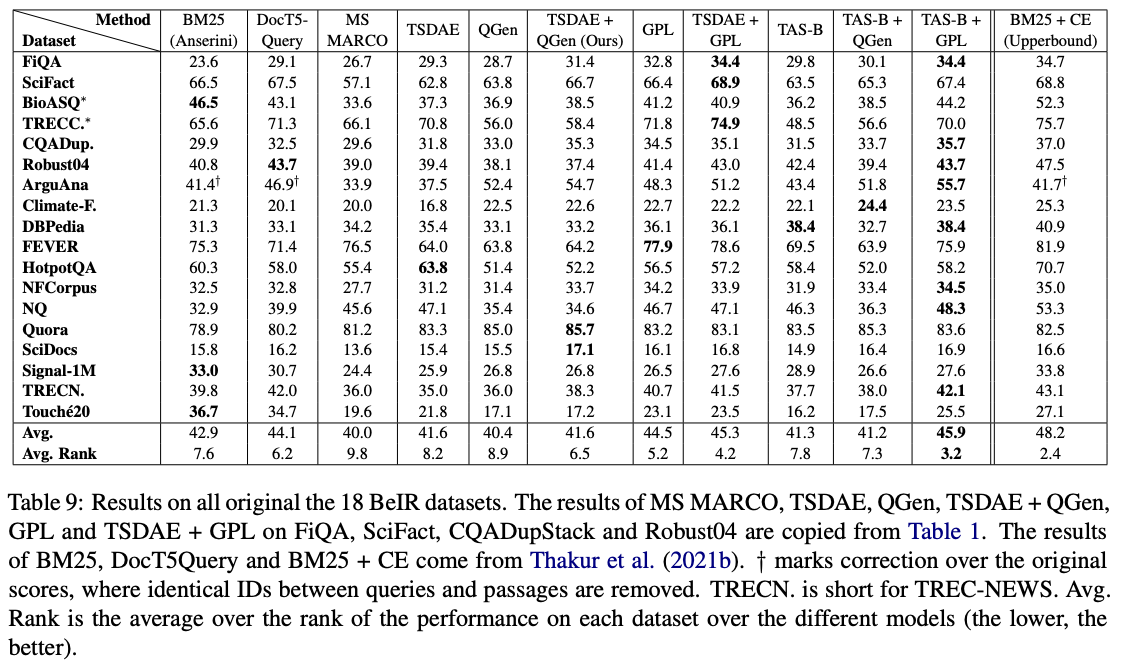
Para reproduzir os resultados com as mesmas versões de embalagem usadas nas experiências, consulte o arquivo de ambiente do CONDA, Environment.yml.
Agora lançamos os dados gerados usados nos experimentos do papel GPL:
Observe que os 4 conjuntos de dados de bioasq , robust04 , trec-news e signal1m estão disponíveis apenas após o registro nas autoridades oficiais originais. Somente lançamos os IDs do documento para esses corpora com o nome do arquivo corpus.doc_ids.txt . Para mais detalhes, consulte o repositório da Beir.
Se você usar o código para avaliação, sinta -se à vontade para citar nossa publicação GPL: Rotulagem de pseudo generativa para adaptação de domínio não supervisionada da recuperação densa:
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}Pessoa de contato e colaborador principal: kexin wang, [email protected]
https://www.ukp.tu-carmstadt.de/
https://www.tu-darmstadt.de/
Não hesite em nos enviar um e-mail ou relatar um problema, se algo estiver quebrado (e não deveria ser) ou se você tiver mais perguntas.
Este repositório contém software experimental e é publicado com o único objetivo de fornecer detalhes adicionais sobre a respectiva publicação.


