gpl
v0.1.4: Giving more hints when throwing exceptions
GPLは、密集したレトリバーをトレーニングするための監視されていないドメイン適応方法です。これは、強力なクロスエンコーダーによるクエリ生成と擬似ラベル付けに基づいています。ドメインに適応したモデルをトレーニングするには、非標識ターゲットコーパスのみが必要であり、ゼロショットモデルよりも大幅な改善を達成できます。
詳細については、出版物をチェックアウトしてください。
複製については、このスナップショットブランチを参照してください。
pip経由でGPLをインストールできます
pip install gplまたはgit cloneを介して
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .一方、CUDAバージョンに従って、Pytorchの正しいバージョンがインストールされていることを確認してください。
GPLは、Beir-Formatのデータを受け入れます。たとえば、BeirがホストするFIQAデータセットをダウンロードできます。
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training.その後、 python -m関数を使用してGPLトレーニングを直接実行できます。
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)または、PythonスクリプトにGPLのトレーニングメソッドをインポートします。
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)コードの仕組みをよりよく理解するために、Google Colabのこのおもちゃの例を参照することもできます。
GPLのワークフローは次のように表示されます。 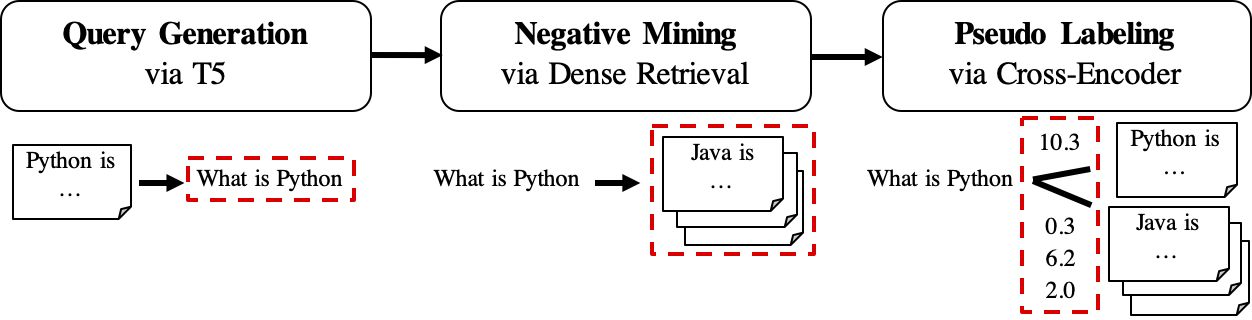
queries_per_passageクエリを生成します。クエリパサージペアは、トレーニングのポジティブな例と見なされます。結果ファイル(PATH
$path_to_generated_dataの下):(1)${qgen}-qrels/train.tsv、(2)${qgen}-queries.jsonlおよび(3)corpus.jsonl($evaluation_data/からコピー);
retrieversに指定できます。結果ファイル(PATH
$path_to_generated_dataの下):hard-negatives.jsonl;
結果ファイル(PATH
$path_to_generated_dataの下):gpl-training-data.tsv。合計でタプルが含まれています(gpl_steps*batch_size_gpl)。
これまで、実際のトレーニングデータを準備しています。データ形式に関する簡単な例を得るために、Sample-Data/generated/fiqaを見ることができます。最後のステップは、マージンムスの損失を適用して、生徒レトリバーにマージンスコア、CE(クエリ、ポジティブ) - CE(クエリ、ネガティブ)が教師モデル(Cross -Encoder、CE)にラベルを付けることを模倣するように教えることです。そしてもちろん、マージンマスステップはGPLに含まれており、自動的に行われます:)。 MarginmseはDOT-Productで動作するため、 GPLでトレーニングされた最終モデルはDOT-Productで動作することに注意してください。
PS: --retrieversは否定的なマイニング用です。それらは、一般的なドメイン(MS MARCOなど)で訓練された密なレトリバーであり、ターゲットタスク/ドメインに強力である必要はありません。詳細については、論文を参照してください(表7を参照)。
また、同じ名前のファッションでパス$path_to_generated_dataの下にある中間ステップのカスタマイズされたデータを交換/配置することもできます。 GPLは、これらの提供されたデータを使用して中間ステップをスキップします。
典型的なワークフローとして、(英語の)無ーなコーパスしか持っておらず、このコーパスに適したパフォーマンスを発揮する良いモデルを望んでいるかもしれません。このような状態でGPLトレーニングを実行するには、これらの手順が必要です。
corpus.jsonlフォルダーの下に置きます。たとえば、GPLによるデータ読み込みとデータ生成のために「生成された」と名付けられました。python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1https://huggingface.co/gplを介して、事前に訓練されたGPLモデルをリリースします。現在、5つのタイプのモデルがあります。
GPL/${dataset}-msmarco-distilbert-gpl :MSMARCO->(2)gpl on ${dataset}の(2)gplのトレーニング順序付きモデル。GPL/${dataset}-tsdae-msmarco-distilbert-gpl : ${dataset} - >(2)msmarco->(3)gpl on $ {dataset} on(2)Magrimse on ${dataset} - >(2)Marginmseのトレーニング順序付きモデル。GPL/msmarco-distilbert-margin-mse :MARGINMSEでMSMARCOで訓練されたモデル。GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse :$ {dataset} - >(2)msmarcoのマージンマスの(1)tsdaeのトレーニング順序付きモデル。GPL/${dataset}-distilbert-tas-b-gpl-self_miner :tas-bモデルから始まると、モデルはターゲットコーパス${dataset}のgplでネガティブマイナーとしてトレーニングされました(ここでは「self_miner」として記載されています)。モデル1および2。モデル3。および4の上部で実際に訓練されました。すべてのGPLモデルは、 new_sizeとqueries_per_passageの自動設定( -1に設定することにより)をトレーニングしました。この自動設定は、効率的である間、パフォーマンスを維持できます。詳細については、論文のセクション4.1を参照してください。
これらのモデルの中で、 GPL/${dataset}-distilbert-tas-b-gpl-self_minerのものは、Beirベンチマークで最も効果的です。 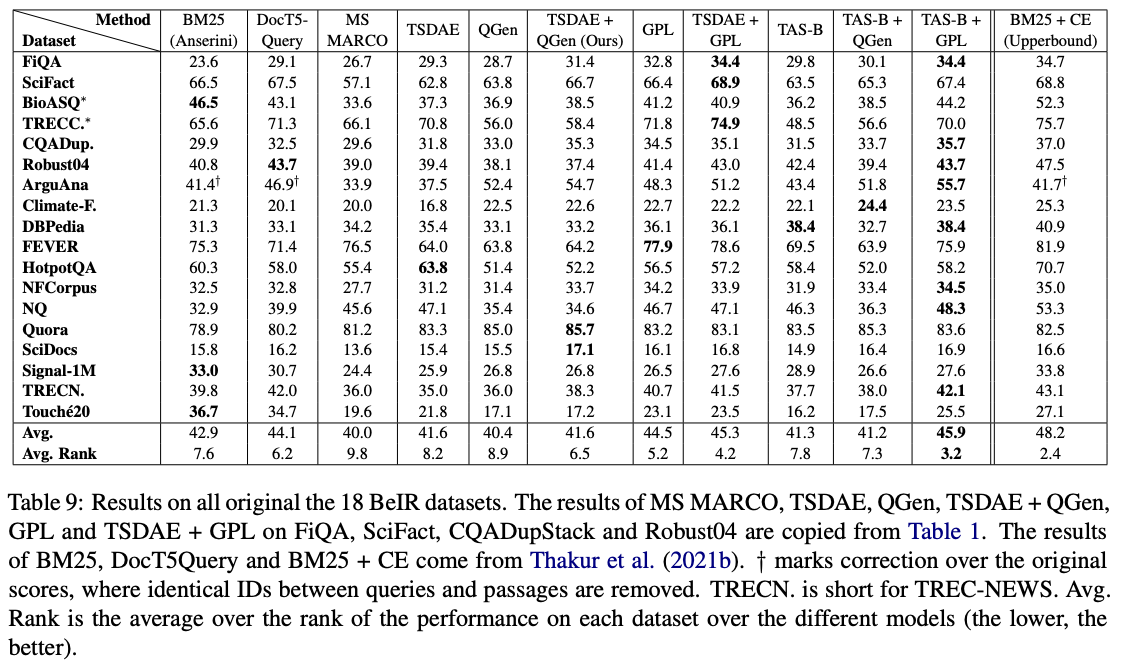
実験で使用されている同じパッケージバージョンで結果を再現するには、Conda Environment File、Environment.ymlを参照してください。
GPLペーパーの実験で使用されている生成されたデータをリリースしました。
bioasq 、 robust04 、 trec-news 、 signal1mの4つのデータセットは、元の公式当局との登録後にのみ利用可能であることに注意してください。ファイル名corpus.doc_ids.txtを使用して、これらのコーパスのドキュメントIDのみをリリースします。詳細については、Beirリポジトリを参照してください。
評価にコードを使用する場合は、公開GPL:監視されていないドメイン適応のための生成的擬似ラベリングをお気軽に引用してください。
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}連絡先と主な寄稿者:Kexin Wang、[email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
何かが壊れている場合(そしてそうすべきではない)、またはさらに質問がある場合、電子メールを送信したり、問題を報告したりすることを躊躇しないでください。
このリポジトリには実験ソフトウェアが含まれており、それぞれの出版物に追加の背景詳細を提供することを目的として公開されています。


