gpl
v0.1.4: Giving more hints when throwing exceptions
GPL은 조밀 한 리트리버를 훈련하기위한 감독되지 않은 도메인 적응 방법입니다. 강력한 크로스 코더가있는 쿼리 생성 및 의사 레이블을 기반으로합니다. 도메인 적응 모델을 훈련시키기 위해서는 표지되지 않은 대상 코퍼스 만 필요하며 제로 샷 모델에 비해 상당한 개선을 달성 할 수 있습니다.
자세한 내용은 출판물을 확인하십시오.
재생하려면이 스냅 샷 브랜치를 참조하십시오.
pip 를 통해 GPL을 설치할 수 있습니다
pip install gpl 또는 git clone 통해
git clone https://github.com/UKPLab/gpl.git && cd gpl
pip install -e .한편, Cuda 버전에 따라 올바른 버전의 Pytorch가 설치되었는지 확인하십시오.
GPL은 BEIR- 형식의 데이터를 수락합니다. 예를 들어 Beir가 호스팅하는 FIQA 데이터 세트를 다운로드 할 수 있습니다.
wget https://public.ukp.informatik.tu-darmstadt.de/thakur/BEIR/datasets/fiqa.zip
unzip fiqa.zip
head -n 2 fiqa/corpus.jsonl # One can check this data format. Actually GPL only need this `corpus.jsonl` as data input for training. 그런 다음 python -m 기능을 사용하여 GPL 교육을 직접 실행할 수 있습니다.
export dataset= " fiqa "
python -m gpl.train
--path_to_generated_data " generated/ $dataset "
--base_ckpt " distilbert-base-uncased "
--gpl_score_function " dot "
--batch_size_gpl 32
--gpl_steps 140000
--new_size -1
--queries_per_passage -1
--output_dir " output/ $dataset "
--evaluation_data " ./ $dataset "
--evaluation_output " evaluation/ $dataset "
--generator " BeIR/query-gen-msmarco-t5-base-v1 "
--retrievers " msmarco-distilbert-base-v3 " " msmarco-MiniLM-L-6-v3 "
--retriever_score_functions " cos_sim " " cos_sim "
--cross_encoder " cross-encoder/ms-marco-MiniLM-L-6-v2 "
--qgen_prefix " qgen "
--do_evaluation
# --use_amp # Use this for efficient training if the machine supports AMP
# One can run `python -m gpl.train --help` for the information of all the arguments
# To reproduce the experiments in the paper, set `base_ckpt` to "GPL/msmarco-distilbert-margin-mse" (https://huggingface.co/GPL/msmarco-distilbert-margin-mse)또는 파이썬 스크립트에서 GPL의 훈련 방법을 가져옵니다.
import gpl
dataset = 'fiqa'
gpl . train (
path_to_generated_data = f"generated/ { dataset } " ,
base_ckpt = "distilbert-base-uncased" ,
# base_ckpt='GPL/msmarco-distilbert-margin-mse',
# The starting checkpoint of the experiments in the paper
gpl_score_function = "dot" ,
# Note that GPL uses MarginMSE loss, which works with dot-product
batch_size_gpl = 32 ,
gpl_steps = 140000 ,
new_size = - 1 ,
# Resize the corpus to `new_size` (|corpus|) if needed. When set to None (by default), the |corpus| will be the full size. When set to -1, the |corpus| will be set automatically: If QPP * |corpus| <= 250K, |corpus| will be the full size; else QPP will be set 3 and |corpus| will be set to 250K / 3
queries_per_passage = - 1 ,
# Number of Queries Per Passage (QPP) in the query generation step. When set to -1 (by default), the QPP will be chosen automatically: If QPP * |corpus| <= 250K, then QPP will be set to 250K / |corpus|; else QPP will be set 3 and |corpus| will be set to 250K / 3
output_dir = f"output/ { dataset } " ,
evaluation_data = f"./ { dataset } " ,
evaluation_output = f"evaluation/ { dataset } " ,
generator = "BeIR/query-gen-msmarco-t5-base-v1" ,
retrievers = [ "msmarco-distilbert-base-v3" , "msmarco-MiniLM-L-6-v3" ],
retriever_score_functions = [ "cos_sim" , "cos_sim" ],
# Note that these two retriever model work with cosine-similarity
cross_encoder = "cross-encoder/ms-marco-MiniLM-L-6-v2" ,
qgen_prefix = "qgen" ,
# This prefix will appear as part of the (folder/file) names for query-generation results: For example, we will have "qgen-qrels/" and "qgen-queries.jsonl" by default.
do_evaluation = True ,
# use_amp=True # One can use this flag for enabling the efficient float16 precision
)코드의 작동 방식을 더 잘 이해하려면 Google Colab 의이 장난감 예제를 참조 할 수도 있습니다.
GPL의 워크 플로우는 다음과 같이 표시됩니다. 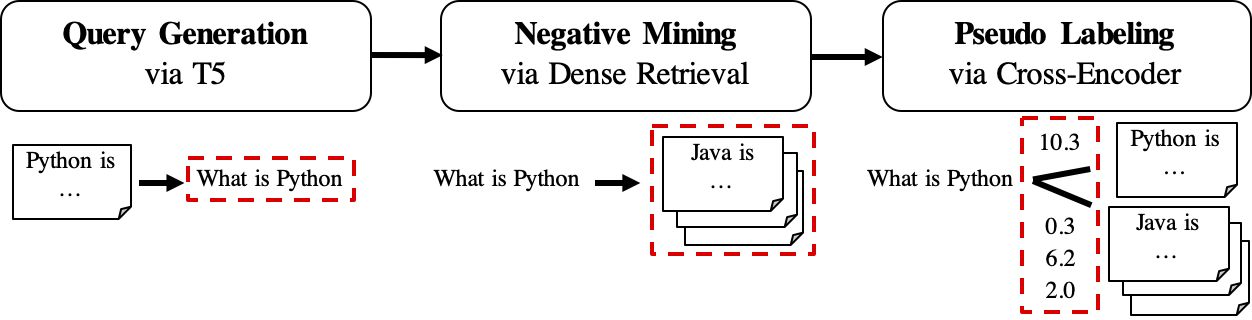
queries_per_passage 쿼리를 생성합니다. 쿼리 패스 쌍은 훈련을위한 긍정적 인 예로 간주됩니다.결과 파일 (Path
$path_to_generated_data아래) : (1)${qgen}-qrels/train.tsv, (2)${qgen}-queries.jsonl및 (3)corpus.jsonl($evaluation_data/);
retrievers 로 사용합니다.결과 파일 (Path
$path_to_generated_data아래) : hard-negatives.jsonl;
결과 파일 (Path
$path_to_generated_data아래) :gpl-training-data.tsv. 총 (gpl_steps*batch_size_gpl) 튜플이 포함되어 있습니다.
지금까지 실제 교육 데이터가 준비되어 있습니다. 데이터 형식에 대한 빠른 예를 위해 샘플 데이터/생성/fiqa를 볼 수 있습니다. 마지막 단계는 여백 손실을 적용하여 학생 리트리버에게 마진 점수, CE (Query, Positive) -CE (쿼리, 부정)를 모방하도록 교사 모델 (Cross -Encoder, CE)을 모방하는 것입니다. 물론, 마진 단계는 GPL에 포함되어 있으며 자동으로 수행됩니다 :). marginmse는 도트 제품과 함께 작동하므로 GPL로 훈련 된 최종 모델은 도트 제품과 함께 작동합니다 .
추신 : --retrievers 는 부정적인 채굴을위한 것입니다. 일반 도메인 (예 : MS Marco)에서 훈련 된 밀도가 높은 리트리버 일 수 있으며 대상 작업/도메인에 대해 강할 필요가 없습니다 . 자세한 내용은 논문을 참조하십시오 (표 7 참조).
또한 경로 $path_to_generated_data 의 중간 단계에 대해 맞춤형 데이터를 동일한 이름 패션으로 교체/배치 할 수도 있습니다. GPL은 제공된 데이터를 사용하여 중간 단계를 건너 뜁니다.
전형적인 워크 플로로서, (영어) 라벨이없는 코퍼스 만 가지고 있으며이 코퍼스를 위해 좋은 모델을 잘 수행하고 싶을 수도 있습니다. 그러한 조건에서 GPL 교육을 실행하려면 다음 단계 만 필요합니다.
corpus.jsonl 을 폴더 아래에 두십시오 (예 : GPL의 데이터로드 및 데이터 생성에 대한”생성”으로 명명되었습니다.python -m gpl.train
--path_to_generated_data " generated "
--output_dir " output "
--new_size -1
--queries_per_passage -1이제 https://huggingface.co/gpl을 통해 미리 훈련 된 GPL 모델을 출시합니다. 현재 5 가지 유형의 모델이 있습니다.
GPL/${dataset}-msmarco-distilbert-gpl : (1) msmarco의 marginmse-> (2) gpl on ${dataset} ;GPL/${dataset}-tsdae-msmarco-distilbert-gpl : (1) ${dataset} -> (2) msmarco-> (3) gpl on ${dataset} ;GPL/msmarco-distilbert-margin-mse : MSMARCO에 대한 MARGINMSE로 훈련 된 모델;GPL/${dataset}-tsdae-msmarco-distilbert-margin-mse : (1) 훈련 순서가있는 모델 $ {dataset}-> (2) msmarco의 marginmse;GPL/${dataset}-distilbert-tas-b-gpl-self_miner : TAS-B 모델에서 시작하여 모델은 기본 모델 자체와 함께 대상 코퍼스 ${dataset} 에서 GPL로 교육을 받았습니다 (여기서 "self_miner"). 모델 1과 2.는 실제로 모델 3과 4. resp. 모든 GPL 모델은 new_size 및 queries_per_passage 의 자동 설정 ( -1 로 설정하여)의 자동 설정을 교육했습니다. 이 자동 설정은 성능을 효율적으로 유지할 수 있습니다. 자세한 내용은 논문의 4.1 절을 참조하십시오.
이러한 모델 중 GPL/${dataset}-distilbert-tas-b-gpl-self_miner ONE은 BEIR 벤치 마크에서 가장 잘 작동합니다. 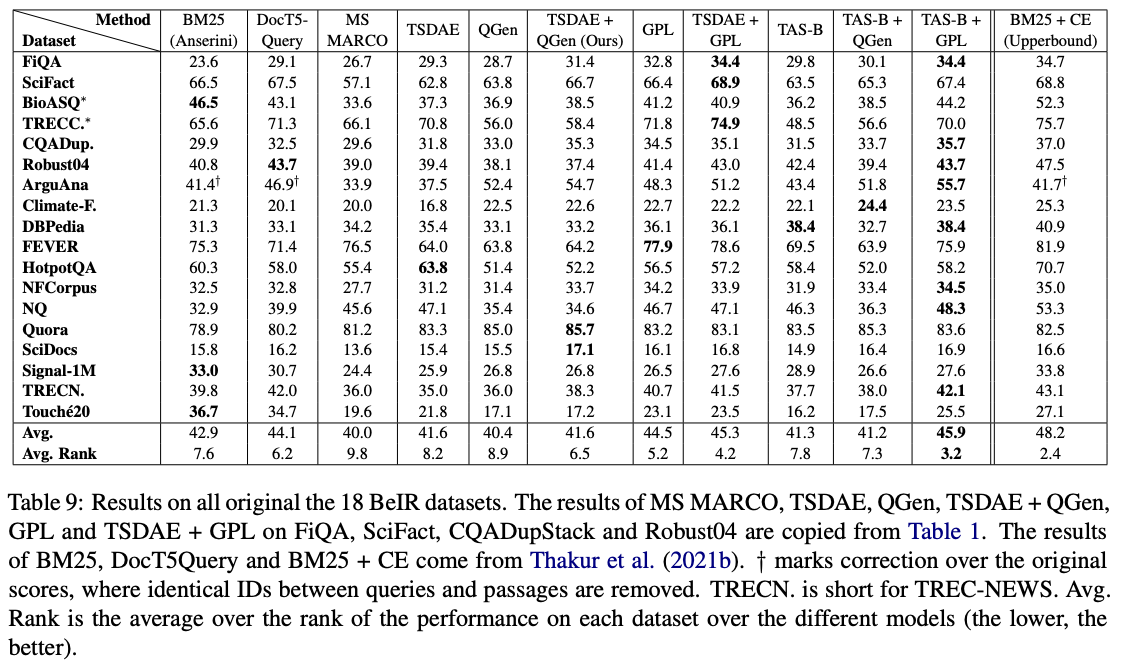
실험에 사용 된 것과 동일한 패키지 버전으로 결과를 재현하려면 Conda 환경 파일 인 Environment.yml을 참조하십시오.
이제 GPL 용지 실험에 사용 된 생성 된 데이터를 발표합니다.
bioasq , robust04 , trec-news 및 signal1m 의 4 개의 데이터 세트는 원래 공식 당국에 등록한 후에 만 사용할 수 있습니다. 파일 이름 corpus.doc_ids.txt 와 함께이 corpora의 문서 ID 만 해제합니다. 자세한 내용은 Beir 저장소를 참조하십시오.
평가를 위해 코드를 사용하는 경우, 공개되지 않은 도메인 적응에 대한 발행물 GPL : Generative Pseudo 라벨링을 자유롭게 인용하십시오.
@article { wang2021gpl ,
title = " GPL: Generative Pseudo Labeling for Unsupervised Domain Adaptation of Dense Retrieval " ,
author = " Kexin Wang and Nandan Thakur and Nils Reimers and Iryna Gurevych " ,
journal = " arXiv preprint arXiv:2112.07577 " ,
month = " 4 " ,
year = " 2021 " ,
url = " https://arxiv.org/abs/2112.07577 " ,
}담당자 및 주요 기고자 : Kexin Wang, [email protected]
https://www.ukp.tu-darmstadt.de/
https://www.tu-darmstadt.de/
주저하지 말고 이메일을 보내거나 문제가 발생하거나 추가 질문이있는 경우 문제를보고하십시오.
이 저장소에는 실험 소프트웨어가 포함되어 있으며 각 간행물에 대한 추가 배경 세부 정보를 제공 할 목적으로만 게시됩니다.


