qa_match
1.0.0
qa_match是一款基於深度學習的問答匹配工具,支持一層和兩層結構知識庫問答。 qa_match通過意圖匹配模型支持一層結構知識庫問答,通過融合領域分類模型和意圖匹配模型的結果支持兩層結構知識庫問答。 qa_match同時支持無監督預訓練功能,通過輕量級預訓練語言模型(SPTM,Simple Pre-trained Model)可以提升基於知識庫問答等下游任務的效果。
在實際場景中,知識庫一般是通過人工總結、標註、機器挖掘等方式進行構建,知識庫中包含大量的標準問題,每個標準問題有一個標準答案和一些擴展問法,我們稱這些擴展問法為擴展問題。對於一層結構知識庫,僅包含標準問題和擴展問題,我們把標準問題稱為意圖。對於兩層結構知識庫,每個標準問題及其擴展問題都有一個類別,我們稱為領域,一個領域包含多個意圖。
qa_match支持知識庫結構如下:
對於輸入的問題,qa_match能夠結合知識庫給出三種回答:
在兩種知識庫結構下,qa_match的使用方式存在差異,以下分別說明:
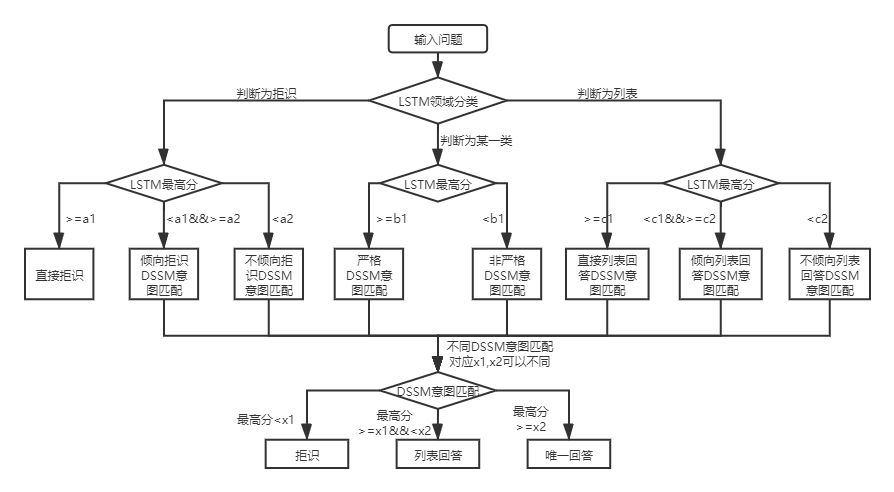
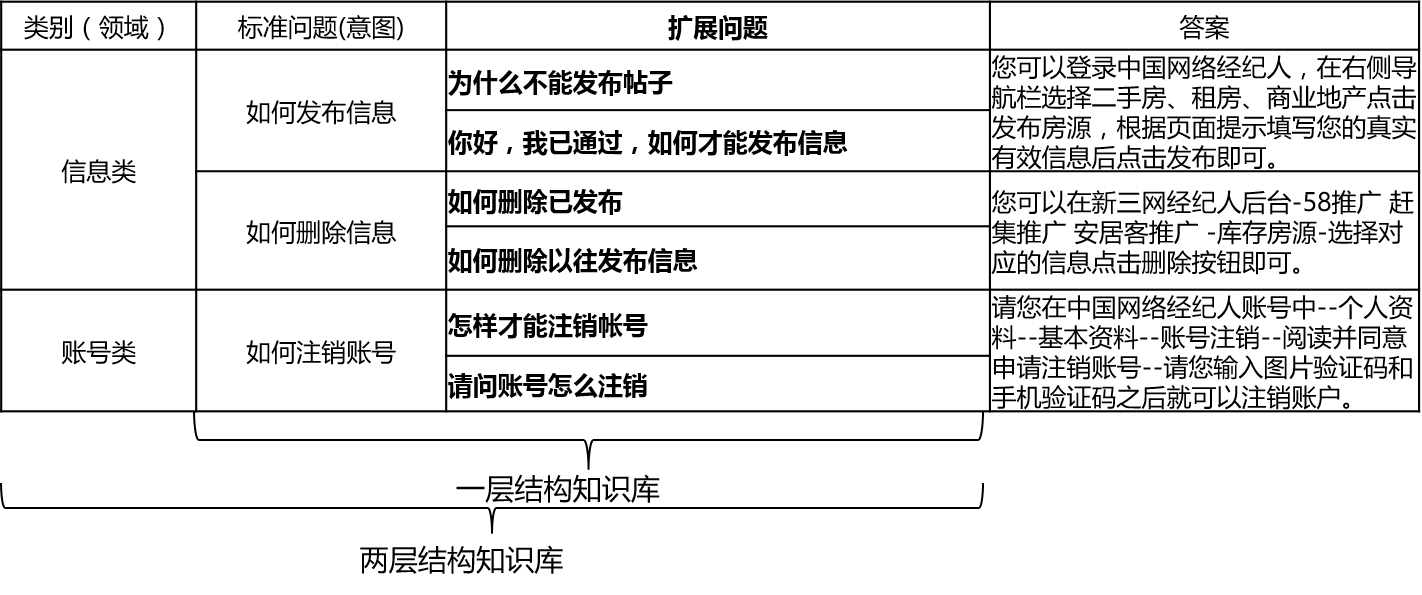
對於兩層結構知識庫問答,qa_match會對用戶問題先進行領域分類和意圖識別,然後對兩者的結果進行融合,獲取用戶的真實意圖進行相應回答(唯一回答、列表回答、拒絕回答)。 舉個例子:如上述知識庫問答中知識庫結構圖所示,我們有一個兩層結構知識庫,它包括”信息“和”賬號“兩個領域”。其中“信息”領域下包含兩個意圖:“如何發布信息”、“如何刪除信息”,“賬號”領域下包含意圖:“如何註銷賬號”。當用戶輸入問題為:“我怎麼發布帖子? ”時,qa_match會進行如下問答邏輯:
實際場景中,我們也會遇到一層結構知識庫問答問題,用DSSM意圖匹配模型與SPTM輕量級預訓練語言模型均可以解決此類問題,兩者對比:
| 模型 | 使用方法 | 優點 | 缺點 |
|---|---|---|---|
| DSSM意圖匹配模型 | DSSM匹配模型直接匹配 | ①使用簡便,模型占用空間小②訓練/預測速度快 | 無法利用上下文信息 |
| SPTM輕量級預訓練語言模型 | 預訓練LSTM/Transformer語言模型 +微調LSTM/Transformer匹配模型 | ①能夠充分利用無監督預訓練數據提升效果②語言模型可用於其他下游任務 | ①預訓練需要大量無標籤數據②操作較複雜(需兩個步驟得到匹配模型) |
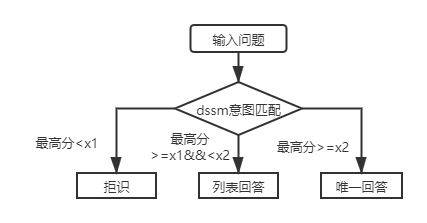
對於一層結構知識庫問答,只需用DSSM意圖匹配模型對輸入問題進行打分,根據意圖匹配的最高分值與上圖中的x1,x2進行比較決定回答類型(唯一回答、列表回答、拒識)。
考慮到實際使用中往往存在大量的無標籤數據,在知識庫數據有限時,可使用無監督預訓練語言模型提升匹配模型的效果。參考BERT預訓練過程,2019年5月我們開發了SPTM模型,該模型相對於BERT主要改進了三方面:一是去掉了效果不明顯的NSP(Next Sentence Prediction),二是為了提高線上推理性能將Transformer替換成了LSTM,三是為了保證模型效果降低參數量也提供了BLOCK間共享參數的Transformer,模型原理如下:
預訓練模型時,生成訓練數據需要使用無標籤單句作為數據集,並參考了BERT來構建樣本:每個單句作為一個樣本,句子中15%的字參與預測,參與預測的字中80%進行mask,10%隨機替換成詞典中一個其他的字,10%不替換。
預訓練階段的模型結構如下圖所示:
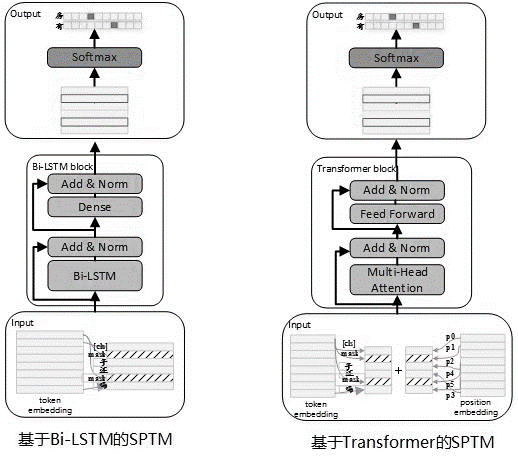
為提升模型的表達能力,保留更多的淺層信息,引入了殘差Bi-LSTM網絡(Residual LSTM)作為模型主體。該網絡將每一層Bi-LSTM的輸入和該層輸出求和歸一化後,結果作為下一層的輸入。此外將最末層Bi-LSTM輸出作為一個全連接層的輸入,與全連接層輸出求和歸一化後,結果作為整個網絡的輸出。
預訓練任務耗時示例如下表所示:
| 指標名稱 | 指標值 | 指標值 | 指標值 |
|---|---|---|---|
| 模型結構 | LSTM | 共享參數的Transformer | 共享參數的Transformer |
| 預訓練數據集大小 | 10Million | 10Million | 10Million |
| 預訓練資源 | 10台Nvidia K40 / 12G Memory | 10台Nvidia K40 / 12G Memory | 10台Nvidia K40 / 12G Memory |
| 預訓練參數 | step = 100000 / batch size = 128 | step = 100000 / batch size = 128 / 1 layers / 12 heads | step = 100000 / batch size = 128 / 12 layers / 12 heads |
| 預訓練耗時 | 8.9 hours | 13.5 hours | 32.9 hours |
| 預訓練模型大小 | 81M | 80.6M | 121M |
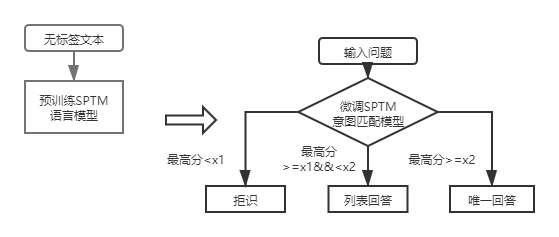
引入SPTM後,對於一層結構知識庫問答,先使用基於語言模型微調的意圖匹配模型對輸入問題進行打分,再根據與DSSM意圖匹配模型相同的策略決定回答類型(唯一回答、列表回答、拒識)。
需要使用到的數據文件(data_demo文件夾下)格式說明如下,這里為了不洩露數據,我們對標準問題和擴展問題原始文本做了編碼,在實際應用場景中直接按照以下格式準備數據即可。
<PAD> 、 、 `)數據以t分隔,問題編碼以空格分隔,字之間以空格分隔。注意在本項目的數據示例中,對原始文本做了編碼,將每個字替換為一個數字, 例如205 19 90 417 41 44對應的實際文本是如何删除信息,在實際使用時不需要做該編碼操作;若知識庫結構為一級,需要把std_data文件中的類別id全部設置為__label__0 。
知識庫半自動挖掘流程,是在qa match自動問答流程的基礎上(參考qa match 基於一層知識庫結構的自動問答)構建的一套知識庫半自動挖掘方案,幫助提升知識庫規模與知識庫質量,一方面提高線上匹配的能力;一方面提高離線模型訓練數據的質量,進而提高模型性能。知識庫半自動挖掘流程可以用於冷啟動挖掘和模型上線後迭代挖掘兩個場景。詳情參見知識庫挖掘說明文檔
詳情見運行說明
batch_size >= negitive_size ,否則模型無法有效訓練。 tensorflow 版本>r1.8 <r2.0, python3
v1.0:https://github.com/wuba/qa_match/tree/v1.0
v1.1:https://github.com/wuba/qa_match/tree/v1.1
v1.2:https://github.com/wuba/qa_match/tree/v1.2
v1.3:https://github.com/wuba/qa_match/tree/v1.3
未來我們會繼續優化擴展qa_match的能力,計劃開源如下:
我們誠摯地希望開發者向我們提出寶貴的意見和建議。您可以挑選以下方式向我們反饋建議和問題:


