qa_match
1.0.0
QA_MATCH-это инструмент сопоставления вопросов и ответов, основанный на глубоком обучении, который поддерживает базу и двое знаний по структуре одной и двухслойной структуры. QA_MATCH поддерживает однослойную структурную базу знаний, посредственную модель соответствия намерения, и поддерживает двухслойные структурные базы знаний, посредством результатов классификационной модели домена Fusion и модели соответствия намерений. QA_MATCH также поддерживает неконтролируемую функцию предварительного обучения, и благодаря легким предварительно обученным языковым моделям (SPTM, простая предварительно обученная модель) могут повысить эффективность задач по нижней части, таких как вопросы базы знаний и ответы.
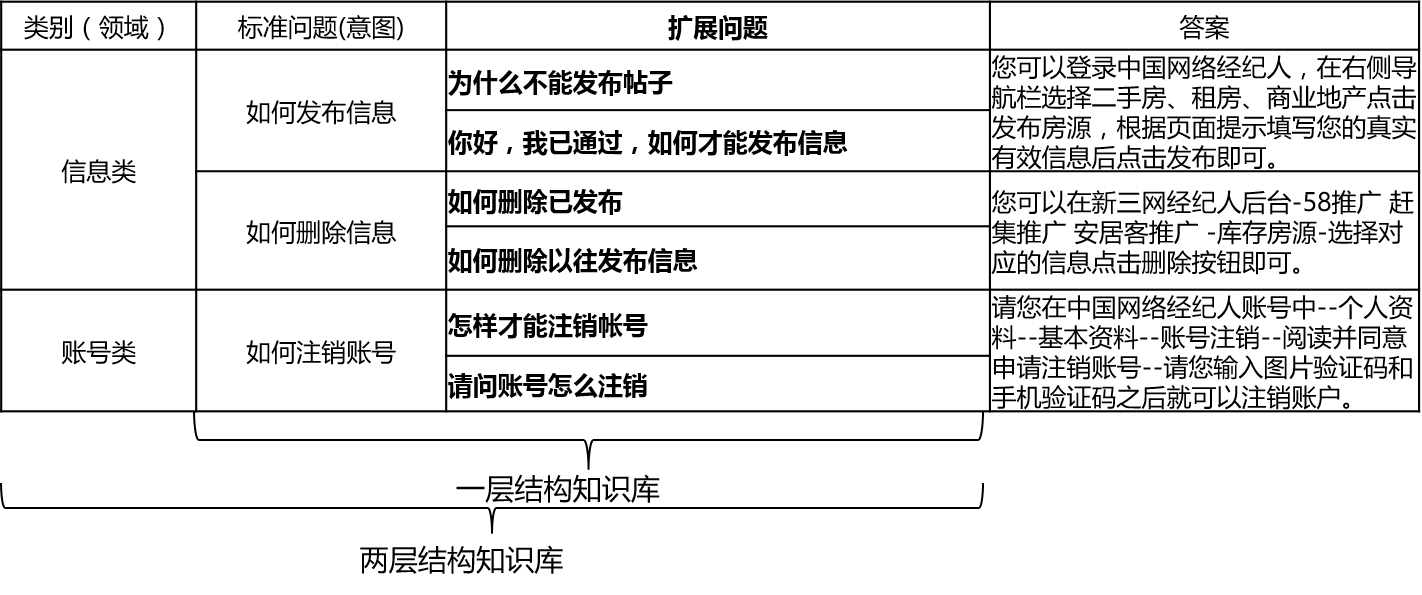
В реальных сценариях база знаний, как правило, строится посредством ручной резюме, аннотации, добычи машины и т. Д. База знаний содержит большое количество стандартных вопросов, каждый стандартный вопрос имеет стандартный ответ и некоторые расширенные вопросы. Мы называем эти расширенные вопросы расширенные вопросы расширенные вопросы. Для однослойной структурной базы знаний, которая содержит только стандартные вопросы и вопросы расширения, мы называем стандартные вопросы намерения. Для двухслойной структурной базы знаний каждая стандартная задача и ее расширенная проблема имеет категорию, которую мы называем домены, а один домен содержит несколько намерений.
QA_MATCH поддерживает структуру базы знаний следующим образом:
Для входных вопросов QA_MATCH может дать три ответа в сочетании с базой знаний:
В соответствии с двумя структурами базы знаний существуют различия в использовании QA_MATCH, которые объясняются ниже:
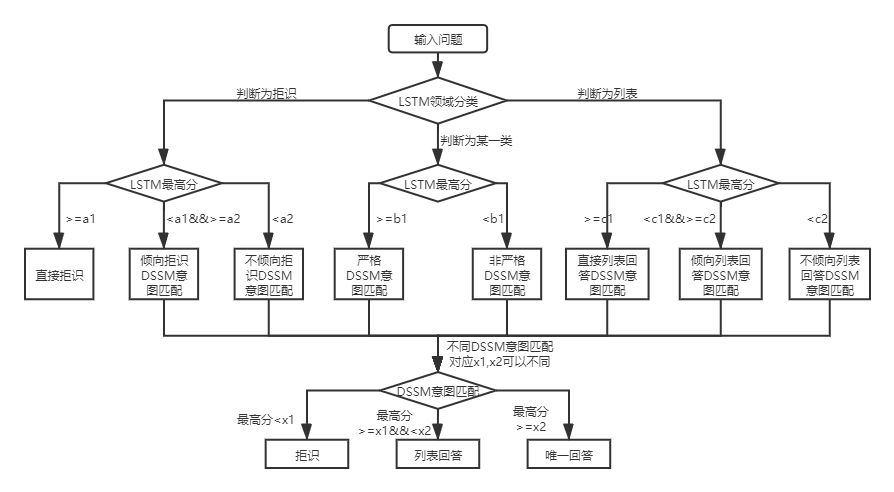
Для двухслойной структуры структуры Q & A Q & A, QA_MATCH сначала классифицирует и определит вопросы пользователя в доменах и намерениях, а затем интегрирует результаты двух, чтобы получить истинное намерение и ответа пользователя (уникальные ответы, ответы на список, ответы отказа). Например: как показано на диаграмме структуры базы знаний в приведенном выше вопросе и ответе базы знаний, у нас есть двухслойная структура, которая включает в себя «информацию» и «учетную запись» два поля. Поле «Информация» содержит два намерения: «Как публиковать информацию», «Как удалить информацию», а поле «учетная запись» содержит намерение: «Как отменить учетную запись». Когда пользователь входит в вопрос: «Как опубликовать сообщение?
В реальных сценариях мы также столкнемся с слоем вопросов структурной базы знаний. Использование модели сопоставления намерений DSSM и легкая предварительно обученная языковая модель SPTM могут решить такую проблему. Сравнение двух:
| Модель | Как использовать | преимущество | недостаток |
|---|---|---|---|
| Модель сопоставления намерений DSSM | Модель сопоставления DSSM напрямую соответствует | ①easy для использования, модель занимает мало места ②fast Training/Speed Progressing Speed | Невозможно использовать контекстную информацию |
| SPTM легкая предварительно обученная языковая модель | Предварительно обученная модель языка LSTM/трансформатора + Mine-Tune LSTM/Модель сопоставления трансформаторов | ① может в полной мере использовать данные предварительного обучения без присмотра для улучшения эффекта ② Языковая модель может использоваться для других задач вниз по течению | ① Предварительное обучение требует большого количества данных без метки ② Операция более сложна (для получения модели соответствующей модели требуются два шага) |
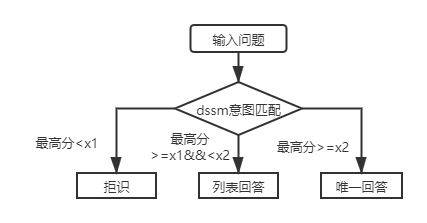
Для первой слойной структуры базы знаний и ответов вам нужно только использовать модель соответствия намерений DSSM, чтобы оценить входные вопросы, и сравнить наивысшую оценку сопоставления намерений с X1 и X2 на рисунке выше, чтобы определить тип ответа (уникальный ответ, список, отказ).
Учитывая, что часто существует большое количество немеченых данных в фактическом использовании, когда данные базы знаний ограничены, неконтролируемые предварительно обученные языковые модели могут использоваться для повышения эффективности соответствующих моделей. Ссылаясь на процесс предварительного обучения BERT, в мае 2019 года мы разработали модель SPTM. По сравнению с BERT эта модель в основном улучшила три аспекта: во -первых, она удаляет NSP (прогноз следующего предложения) с незначительными эффектами, во -вторых, для повышения производительности онлайн -вывода, трансформатор был заменен LSTM и третьим, чтобы гарантировать, что эффект модели уменьшает количество параметров, он также обеспечивает трансформатор с общими параметрами между блоками. Принцип модели заключается в следующем:
При предварительном обучении модели учебные данные должны быть сгенерированы с использованием отдельных предложений Labelless в качестве набора данных, а BERT используется для построения выборки: каждое отдельное предложение используется в качестве выборки, 15% слов в предложении участвуют в предсказании, 80% слов, участвующих в предсказании, замаскируются, 10% случайным образом заменяются другим словом в сложности, а 10%-это не списаются.
Структура модели стадии предварительного обучения показана на рисунке ниже:
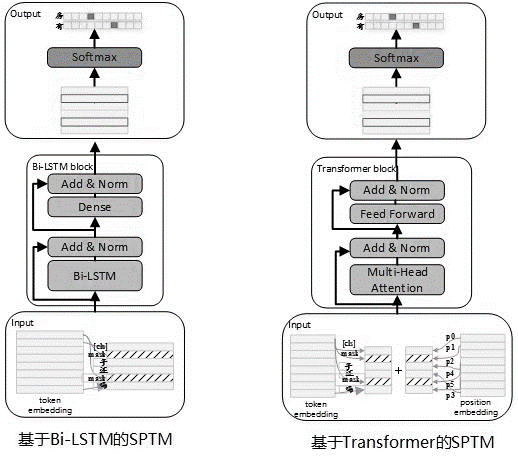
Чтобы улучшить способность выражения модели и сохранить более мелкую информацию, в качестве модели была введена остаточная сеть BISTM (остаточная LSTM). Сеть нормализует вход каждого уровня BI-LSTM и вывода этого уровня, и результат используется в качестве ввода следующего уровня. Кроме того, в качестве входа полностью подключенного слоя используется последний слой Bi-LSTM. После суммирования и нормализации его с выходом полностью подключенного уровня, результат используется в качестве выхода всей сети.
В следующей таблице показан много времени пример предварительных задач предварительного обучения:
| Метрическое название | Значение индикатора | Значение индикатора | Значение индикатора |
|---|---|---|---|
| Структура модели | LSTM | Трансформатор для обмена параметрами | Трансформатор для обмена параметрами |
| Предварительный размер набора данных | 10 миллионов | 10 миллионов | 10 миллионов |
| Предварительные ресурсы | 10 nvidia k40 / 12g память | 10 nvidia k40 / 12g память | 10 nvidia k40 / 12g память |
| Параметры предварительного обучения | Шаг = 100000 / Размер партии = 128 | step = 100000 / размер партии = 128 /1 слои / 12 голов | Шаг = 100000 / Размер партии = 128 /12 слоев / 12 голов |
| Предварительное обучение трудоемкое | 8,9 часа | 13,5 часов | 32,9 часа |
| Предварительный размер модели | 81 м | 80,6 м | 121 м |
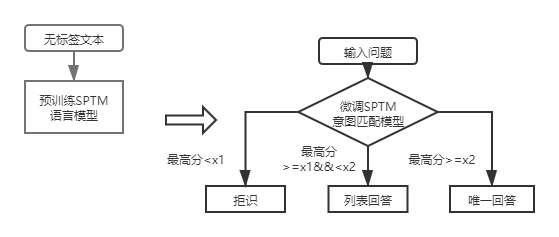
После введения SPTM для базы и ответов в структуре первой слой, входные вопросы сначала оцениваются с использованием модели сопоставления намерений на основе точной настройки языка, а затем тип ответа (уникальный ответ, ответ, отклонение) определяется на основе той же стратегии, что и модель соответствия намерения DSSM.
Формат файла данных (в папке data_demo), который необходимо использовать, заключается в следующем. Чтобы не утекать данные, мы закодировали исходный текст стандартной задачи и расширенной проблемы, а также в фактических сценариях применения, просто подготовим данные в следующем формате.
<PAD> 、 `) Данные разделены t, кодирование проблемы разделяется пространствами, а слова разделены пространствами. Обратите внимание, что в примере данных этого проекта исходный текст кодируется, и каждое слово заменяется номером. Например, как фактический текст, соответствующий 205 19 90 417 41 44如何删除信息, и эта операция кодирования не требуется при фактическом использовании ; Если структура базы знаний составляет один уровень, все идентификаторы категории в файле std_data должны быть установлены на __label__0 .
Полуавтоматический процесс майнинга базы знаний представляет собой набор полуавтоматических решений для майнинга для базовых знаний, основанных на автоматическом процессе вопросов и ответов, которые обращаются к автоматическим вопросам и ответам на основе однослойной структуры базы знаний), что помогает улучшить масштаб базы знаний и качества базы знаний. С одной стороны, это улучшает способность соответствовать онлайн; С другой стороны, это улучшает качество данных о автономном обучении и, таким образом, улучшает производительность модели. Полуавтоматический процесс майнинга базы знаний может использоваться для двух сценариев: Hold Start Mining и итерационная добыча после запуска модели. Для получения подробной информации, пожалуйста, обратитесь к инструкциям по добыче знаний.
Для получения подробной информации см. Инструкции по эксплуатации
batch_size >= negitive_size , в противном случае модель не может быть эффективно подготовлена. tensorflow 版本>r1.8 <r2.0, python3
v1.0: https://github.com/wuba/qa_match/tree/v1.0
v1.1: https://github.com/wuba/qa_match/tree/v1.1
v1.2: https://github.com/wuba/qa_match/tree/v1.2
v1.3: https://github.com/wuba/qa_match/tree/v1.3
В будущем мы будем продолжать оптимизировать и расширять возможности QA_MATCH, и план состоит в том, чтобы открыть исходный код следующим образом:
Мы искренне надеемся, что разработчики дадут нам ценные мнения и предложения. Вы можете выбрать следующие способы обратной связи и вопросов:


