qa_match
1.0.0
qa_match is a deep learning-based question-and-answer matching tool that supports one- and two-layer structure knowledge base Q&A. qa_match supports one-layer structural knowledge base Q&A through the intent matching model, and supports two-layer structural knowledge base Q&A through the results of the fusion domain classification model and the intent matching model. qa_match also supports unsupervised pre-training function, and through lightweight pre-trained language models (SPTM, Simple Pre-trained Model) can improve the effectiveness of downstream tasks such as knowledge base questions and answers.
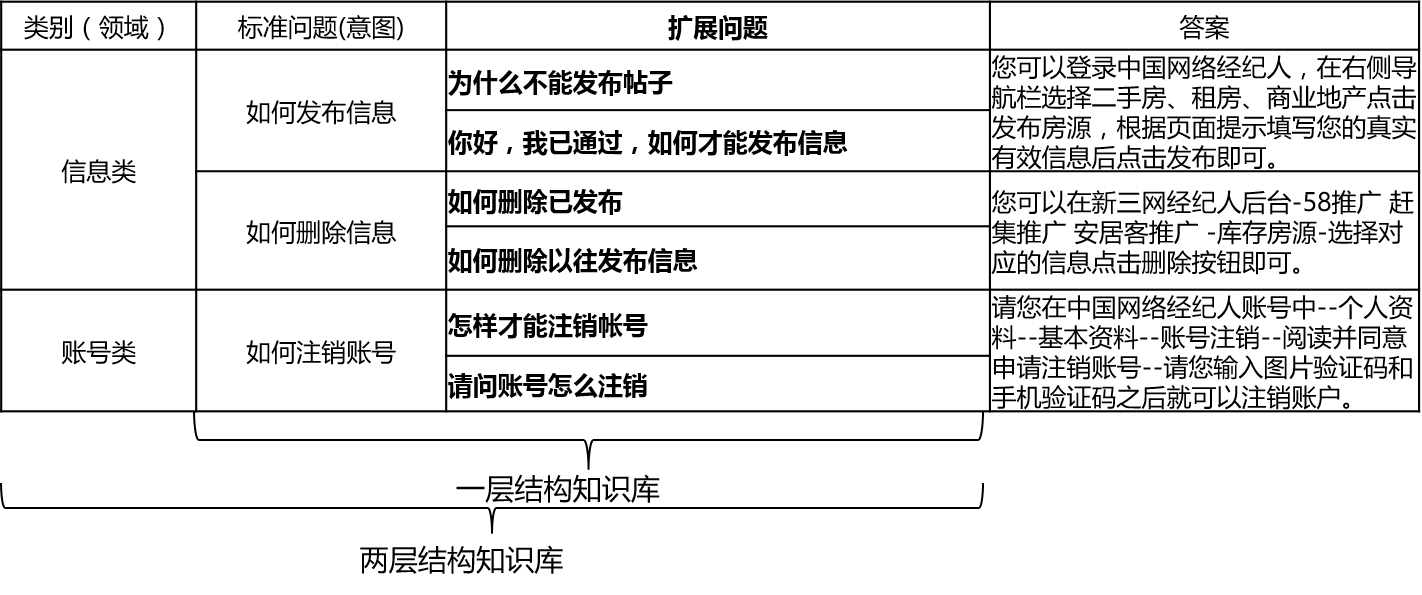
In actual scenarios, the knowledge base is generally constructed through manual summary, annotation, machine mining, etc. The knowledge base contains a large number of standard questions, each standard question has a standard answer and some extended questions. We call these extended questions extended questions extended questions. For a one-layer structural knowledge base that contains only standard questions and extension questions, we refer to standard questions as intentions. For a two-layer structural knowledge base, each standard problem and its extended problem has a category, which we call domains, and one domain contains multiple intents.
The qa_match supports knowledge base structure as follows:
For input questions, qa_match can give three answers in combination with the knowledge base:
Under the two knowledge base structures, there are differences in the usage of qa_match, which are explained below:
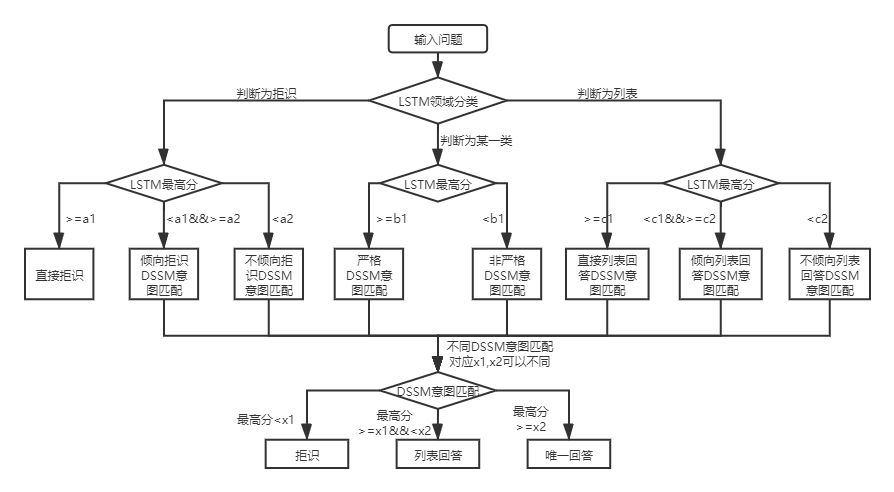
For the two-layer structure knowledge base Q&A, qa_match will first classify and identify user questions in domains and intents, and then integrate the results of the two to obtain the user's true intention and answer accordingly (unique answers, list answers, rejection answers). For example: As shown in the knowledge base structure diagram in the above knowledge base question and answer, we have a two-layer structure knowledge base, which includes "information" and "account" two fields. The "information" field contains two intentions: "How to publish information", "How to delete information", and the "account" field contains intent: "How to cancel the account". When the user enters the question: "How do I publish a post? When ”, qa_match will perform the following Q&A logic:
In actual scenarios, we will also encounter a layer of structural knowledge base Q&A questions. Using DSSM intent matching model and SPTM lightweight pre-trained language model can solve this kind of problem. Comparison of the two:
| Model | How to use | advantage | shortcoming |
|---|---|---|---|
| DSSM Intent Matching Model | DSSM matching model directly matches | ①Easy to use, the model takes up little space ②Fast training/prediction speed | Unable to utilize context information |
| SPTM lightweight pre-trained language model | Pre-trained LSTM/Transformer language model + Fine-tune LSTM/Transformer matching model | ① Can make full use of unsupervised pre-training data to improve the effect ② Language model can be used for other downstream tasks | ① Pre-training requires a large amount of label-free data ② The operation is more complicated (two steps are required to obtain the matching model) |
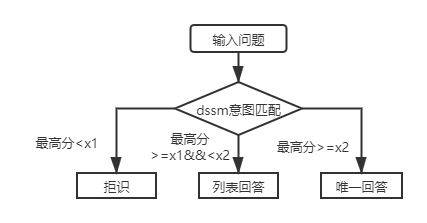
For the first-layer structure knowledge base Q&A, you only need to use the DSSM intent matching model to score the input questions, and compare the highest score of the intent matching with x1 and x2 in the figure above to determine the answer type (unique answer, list answer, rejection).
Considering that there are often a large amount of unlabeled data in actual use, when the knowledge base data is limited, unsupervised pre-trained language models can be used to improve the effectiveness of matching models. Referring to the BERT pre-training process, in May 2019, we developed the SPTM model. Compared with BERT, this model has mainly improved three aspects: First, it removes NSP (Next Sentence Prediction) with insignificant effects, second, to improve online inference performance, the Transformer was replaced with LSTM, and third, to ensure that the model effect reduces the parameter quantity, it also provides a Transformer with shared parameters between BLOCKs. The model principle is as follows:
When pre-training the model, the training data needs to be generated using labelless single sentences as the data set, and BERT is used to construct the sample: each single sentence is used as a sample, 15% of the words in the sentence participate in the prediction, 80% of the words participating in the prediction are masked, 10% are randomly replaced with another word in the dictionary, and 10% are not replaced.
The model structure of the pre-training stage is shown in the figure below:
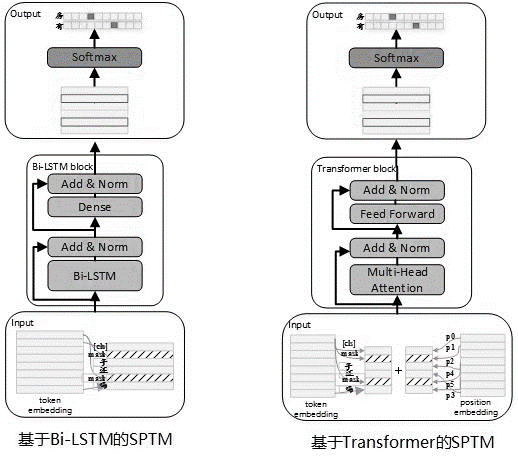
In order to improve the expression ability of the model and retain more shallow information, the residual Bi-LSTM network (Residual LSTM) was introduced as the model body. The network normalizes the input of each layer of Bi-LSTM and the output of this layer, and the result is used as the input of the next layer. In addition, the last layer Bi-LSTM output is used as the input of a fully connected layer. After summing and normalizing it with the output of the fully connected layer, the result is used as the output of the entire network.
The time-consuming example of pre-training tasks is shown in the following table:
| Metric Name | Indicator value | Indicator value | Indicator value |
|---|---|---|---|
| Model structure | LSTM | Transformer for sharing parameters | Transformer for sharing parameters |
| Pretrained dataset size | 10Million | 10Million | 10Million |
| Pre-training resources | 10 Nvidia K40 / 12G Memory | 10 Nvidia K40 / 12G Memory | 10 Nvidia K40 / 12G Memory |
| Pre-training parameters | step = 100000 / batch size = 128 | step = 100000 / batch size = 128 / 1 layers / 12 heads | step = 100000 / batch size = 128 / 12 layers / 12 heads |
| Pre-training time consuming | 8.9 hours | 13.5 hours | 32.9 hours |
| Pretrained model size | 81M | 80.6M | 121M |
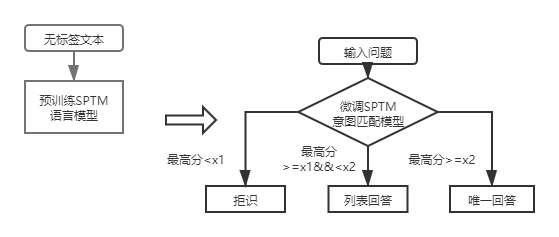
After the introduction of SPTM, for the first-layer structure knowledge base Q&A, the input questions are first scored using the intent matching model based on the language model fine-tuning, and then the answer type (unique answer, list answer, rejection) is determined based on the same strategy as the DSSM intent matching model.
The format of the data file (under the data_demo folder) that needs to be used is as follows. In order not to leak data, we have encoded the original text of the standard problem and the extended problem, and in actual application scenarios, just prepare the data in the following format.
<PAD> , 、 `) The data is separated by t, the problem encoding is separated by spaces, and the words are separated by spaces. Note that in the data example of this project, the original text is encoded and each word is replaced with a number. For example, how the actual text corresponding to 205 19 90 417 41 44如何删除信息, and this encoding operation is not required when actually used ; if the knowledge base structure is one level, all the category ids in the std_data file need to be set to __label__0 .
The semi-automatic mining process of the knowledge base is a set of semi-automatic mining solutions for knowledge bases built on the QA match automatic question and answer process (refer to the automatic question and answer based on a one-layer knowledge base structure), which helps improve the scale of the knowledge base and the quality of the knowledge base. On the one hand, it improves the ability to match online; on the other hand, it improves the quality of offline model training data, and thus improves the model performance. The semi-automatic mining process of the knowledge base can be used for two scenarios: cold start mining and iterative mining after the model is launched. For details, please refer to the knowledge base mining instructions.
See the operation instructions for details
batch_size >= negitive_size , otherwise the model cannot be effectively trained. tensorflow 版本>r1.8 <r2.0, python3
v1.0: https://github.com/wuba/qa_match/tree/v1.0
v1.1: https://github.com/wuba/qa_match/tree/v1.1
v1.2: https://github.com/wuba/qa_match/tree/v1.2
v1.3: https://github.com/wuba/qa_match/tree/v1.3
In the future, we will continue to optimize and expand the capabilities of qa_match, and the plan is to open source as follows:
We sincerely hope that developers will give us valuable opinions and suggestions. You can choose the following ways to feedback suggestions and questions to us:


