qa_match
1.0.0
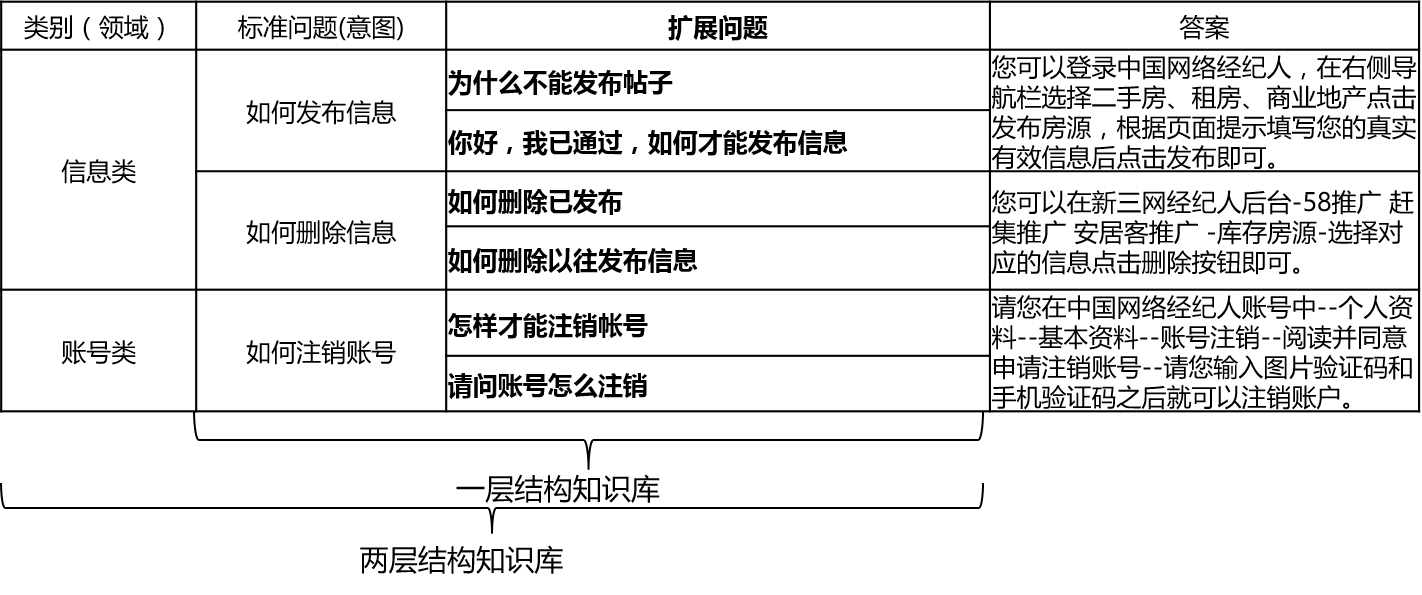
QA_MATCH es una herramienta de coincidencia de preguntas y respuestas basada en el aprendizaje profundo que admite preguntas y respuestas de la base de conocimiento de una estructura de una y dos capas. QA_Match admite preguntas y respuestas de la base de conocimiento estructural de una capa a través del modelo de coincidencia de intenciones, y admite preguntas y respuestas de la base de conocimiento estructural de dos capas a través de los resultados del modelo de clasificación de dominio de fusión y el modelo de coincidencia de intentos. QA_Match también admite la función de pre-entrenamiento no supervisada, y a través de modelos livianos livianos previamente capacitados (SPTM, modelo simple previamente capacitado) puede mejorar la efectividad de las tareas aguas abajo, como preguntas y respuestas de la base de conocimiento.
En escenarios reales, la base de conocimiento generalmente se construye a través de resumen manual, anotación, minería de máquinas, etc. La base de conocimiento contiene una gran cantidad de preguntas estándar, cada pregunta estándar tiene una respuesta estándar y algunas preguntas extendidas. Llamamos a estas preguntas extendidas preguntas extendidas. Para una base de conocimiento estructural de una capa que contiene solo preguntas estándar y preguntas de extensión, llamamos a las preguntas estándar intenciones. Para una base de conocimiento estructural de dos capas, cada problema estándar y su problema extendido tienen una categoría, que llamamos dominios, y un dominio contiene múltiples intentos.
El QA_Match admite la estructura de la base de conocimiento de la siguiente manera:
Para preguntas de entrada, QA_Match puede dar tres respuestas en combinación con la base de conocimiento:
Según las dos estructuras de base de conocimiento, existen diferencias en el uso de QA_Match, que se explican a continuación:
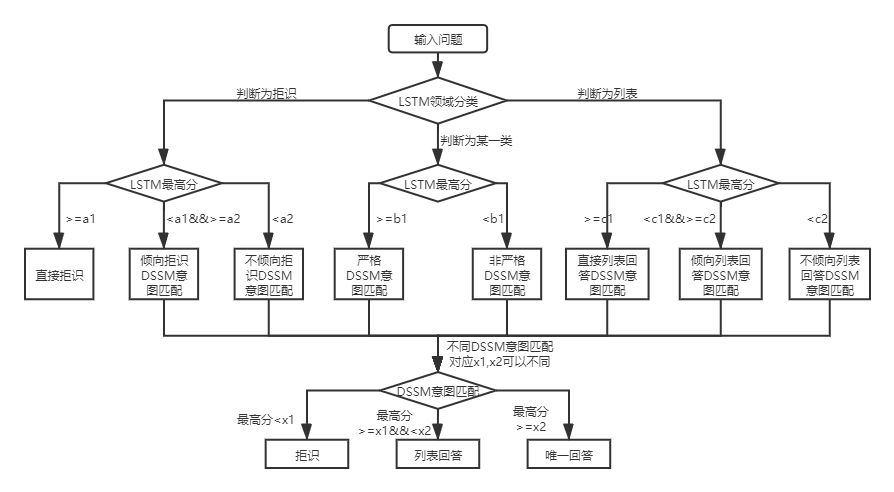
Para las preguntas y respuestas de la base de conocimiento de la estructura de dos capas, QA_Match primero clasificará e identificará las preguntas del usuario en dominios e intentos, y luego integrará los resultados de los dos para obtener la verdadera intención del usuario y la respuesta en consecuencia (respuestas únicas, respuestas de lista, respuestas de rechazo). Por ejemplo: como se muestra en el diagrama de la estructura de la base de conocimiento en la pregunta y respuesta de la base de conocimiento anterior, tenemos una base de conocimiento de estructura de dos capas, que incluye "información" y "cuenta" dos campos. El campo "Información" contiene dos intenciones: "Cómo publicar información", "Cómo eliminar la información", y el campo "Cuenta" contiene intención: "Cómo cancelar la cuenta". Cuando el usuario ingresa a la pregunta: "¿Cómo publico una publicación? Cuándo", Qa_Match realizará la siguiente lógica de preguntas y respuestas:
En escenarios reales, también encontraremos una capa de preguntas de preguntas y respuestas de la base de conocimiento estructural. El uso del modelo de coincidencia de intención DSSM y el modelo de lenguaje pretrontrado liviano SPTM pueden resolver este tipo de problema. Comparación de los dos:
| Modelo | Cómo usar | ventaja | defecto |
|---|---|---|---|
| Modelo de coincidencia de intención DSSM | El modelo de coincidencia DSSM coincide directamente | ① ① ① Útil Usar, el modelo ocupa poco espacio ② velocidad de entrenamiento/predicción rápida | No se puede utilizar la información de contexto |
| SPTM Modelo de lenguaje previamente priorizado con peso ligero | Modelo de lenguaje LSTM/transformador previamente capacitado + Modelo de coincidencia de transformador/LSTM/transformador | ① Puede hacer uso completo de datos de pre-entrenamiento no supervisados para mejorar el efecto ② El modelo de lenguaje se puede utilizar para otras tareas aguas abajo | ① Pre-entrenamiento requiere una gran cantidad de datos sin etiqueta ② La operación es más complicada (se requieren dos pasos para obtener el modelo de coincidencia) |
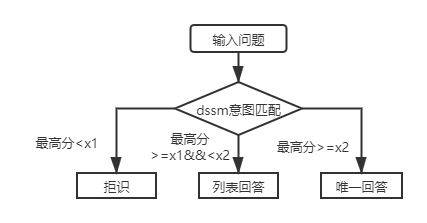
Para las preguntas y respuestas de la base de conocimiento de la estructura de la primera capa, solo necesita usar el modelo de coincidencia de intención DSSM para calificar las preguntas de entrada y comparar la puntuación más alta de la intención que coincida con x1 y x2 en la figura anterior para determinar el tipo de respuesta (respuesta única, respuesta de lista, rechazo).
Teniendo en cuenta que a menudo hay una gran cantidad de datos no etiquetados en el uso real, cuando los datos de la base de conocimiento son limitados, se pueden utilizar modelos de lenguaje previamente capacitados no supervisados para mejorar la efectividad de los modelos coincidentes. Refiriéndose al proceso de pre-entrenamiento de Bert, en mayo de 2019, desarrollamos el modelo SPTM. En comparación con Bert, este modelo ha mejorado principalmente tres aspectos: primero, elimina NSP (la siguiente predicción de oraciones) con efectos insignificantes, segundo, para mejorar el rendimiento de la inferencia en línea, el transformador se reemplazó con LSTM y tercero, para garantizar que el efecto del modelo reduzca la cantidad de parámetros, también proporciona un transformador con los parámetros compartidos entre los bloques. El principio del modelo es el siguiente:
Al prevenir el modelo, los datos de capacitación deben generarse utilizando oraciones individuales de Labellos como el conjunto de datos, y Bert se usa para construir la muestra: cada oración única se usa como una muestra, el 15% de las palabras en la oración participan en la predicción, el 80% de las palabras que participan en la predicción, el 10% se reemplazan al azar con otra palabra en el diccionario y el 10% no se reemplazan.
La estructura del modelo de la etapa previa a la capacitación se muestra en la figura a continuación:
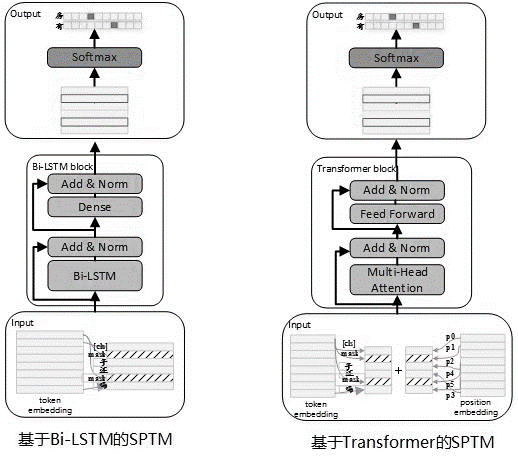
Para mejorar la capacidad de expresión del modelo y retener información más superficial, la red residual de BI-LSTM (LSTM residual) se introdujo como el cuerpo del modelo. La red normaliza la entrada de cada capa de BI-LSTM y la salida de esta capa, y el resultado se usa como entrada de la siguiente capa. Además, la salida BI-LSTM de la última capa se usa como la entrada de una capa totalmente conectada. Después de sumarlo y normalizarlo con la salida de la capa totalmente conectada, el resultado se usa como salida de toda la red.
El ejemplo que requiere mucho tiempo de tareas de pre-entrenamiento se muestra en la siguiente tabla:
| Nombre métrico | Valor indicador | Valor indicador | Valor indicador |
|---|---|---|---|
| Estructura modelo | LSTM | Transformador para compartir parámetros | Transformador para compartir parámetros |
| Tamaño del conjunto de datos previamente | 10 millones | 10 millones | 10 millones |
| Recursos de pre-entrenamiento | 10 NVIDIA K40 / 12G Memoria | 10 NVIDIA K40 / 12G Memoria | 10 NVIDIA K40 / 12G Memoria |
| Parámetros previos al entrenamiento | paso = 100000 / tamaño por lotes = 128 | paso = 100000 / tamaño por lotes = 128/1 capas / 12 cabezas | paso = 100000 / tamaño por lotes = 128/12 capas / 12 cabezas |
| Consumidor de tiempo previo a la capacitación | 8.9 horas | 13.5 horas | 32.9 horas |
| Tamaño del modelo previamente | 81m | 80.6m | 121m |
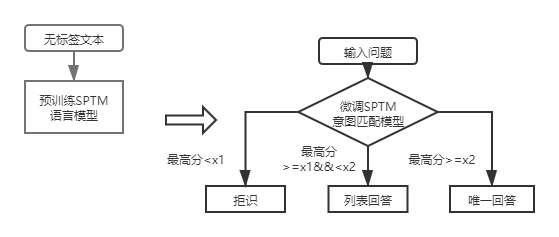
Después de la introducción de SPTM, para las preguntas y respuestas de la base de conocimiento de la estructura de la primera capa, las preguntas de entrada se califican primero utilizando el modelo de coincidencia de intenciones basado en el modelo de lenguaje ajustado, y luego el tipo de respuesta (respuesta única, respuesta de lista, rechazo) se determina en función de la misma estrategia que el modelo de coincidencia de intención DSSM.
El formato del archivo de datos (en la carpeta data_demo) que debe usarse es el siguiente. Para no filtrar datos, hemos codificado el texto original del problema estándar y el problema extendido, y en escenarios de aplicación reales, simplemente prepare los datos en el siguiente formato.
<PAD> 、 `) Los datos están separados por t, la codificación del problema está separada por espacios y las palabras están separadas por espacios. Tenga en cuenta que en el ejemplo de datos de este proyecto, el texto original está codificado y cada palabra se reemplaza con un número. Por ejemplo, cómo el texto real correspondiente a 205 19 90 417 41 44如何删除信息, y esta operación de codificación no se requiere cuando realmente se usa ; Si la estructura de la base de conocimiento es de un nivel, todas las ID de categoría en el archivo std_data deben establecerse en __label__0 .
El proceso de minería semiautomática de la base de conocimiento es un conjunto de soluciones mineras semiautomáticas para bases de conocimiento basadas en el proceso automático de preguntas y preguntas automáticas de QA (consulte la pregunta automática y la respuesta basada en una estructura de base de conocimiento de una capa), que ayuda a mejorar la escala de la base de conocimiento y la calidad de la base de conocimiento. Por un lado, mejora la capacidad de igualar en línea; Por otro lado, mejora la calidad de los datos de entrenamiento del modelo fuera de línea y, por lo tanto, mejora el rendimiento del modelo. El proceso de minería semiautomática de la base de conocimiento se puede utilizar para dos escenarios: minería de inicio en frío y minería iterativa después de que se lance el modelo. Para más detalles, consulte las instrucciones de minería de la base de conocimiento.
Consulte las instrucciones de operación para más detalles
batch_size >= negitive_size , de lo contrario, el modelo no puede ser capacitado de manera efectiva. tensorflow 版本>r1.8 <r2.0, python3
V1.0: https://github.com/wuba/qa_match/tree/v1.0
V1.1: https://github.com/wuba/qa_match/tree/v1.1
V1.2: https://github.com/wuba/qa_match/tree/v1.2
V1.3: https://github.com/wuba/qa_match/tree/v1.3
En el futuro, continuaremos optimizando y expandiendo las capacidades de QA_Match, y el plan es abrir el código de la siguiente manera:
Esperamos sinceramente que los desarrolladores nos den opiniones y sugerencias valiosas. Puede elegir las siguientes formas de retroalimentación de sugerencias y preguntas:


