qa_match
1.0.0
QA_MATCH เป็นเครื่องมือจับคู่คำถามและคำตอบที่ใช้การเรียนรู้อย่างลึกซึ้งซึ่งรองรับฐานความรู้โครงสร้างความรู้หนึ่งและสองชั้น QA_MATCH รองรับการตอบคำถามฐานความรู้โครงสร้างชั้นเดียวผ่านแบบจำลองการจับคู่ความตั้งใจและรองรับฐานความรู้เชิงโครงสร้างสองชั้น Q&A ผ่านผลลัพธ์ของโมเดลการจำแนกประเภทโดเมนฟิวชั่นและแบบจำลองการจับคู่ความตั้งใจ QA_MATCH ยังรองรับฟังก์ชั่นการฝึกอบรมล่วงหน้าที่ไม่ได้รับการดูแลและผ่านแบบจำลองภาษาที่ได้รับการฝึกฝนมาก่อนที่มีน้ำหนักเบา (SPTM, แบบจำลองที่ผ่านการฝึกอบรมมาก่อน) สามารถปรับปรุงประสิทธิภาพของงานดาวน์สตรีมเช่นคำถามฐานความรู้และคำตอบ
ในสถานการณ์จริงฐานความรู้มักถูกสร้างขึ้นผ่านการสรุปด้วยตนเองคำอธิบายประกอบการขุดเครื่อง ฯลฯ ฐานความรู้มีคำถามมาตรฐานจำนวนมากคำถามแต่ละข้อมีคำตอบมาตรฐานและคำถามเพิ่มเติม เราเรียกคำถามเพิ่มเติมเหล่านี้คำถามเพิ่มเติม สำหรับฐานความรู้เชิงโครงสร้างชั้นเดียวที่มีคำถามมาตรฐานและคำถามขยายเท่านั้นเราเรียกคำถามมาตรฐาน สำหรับฐานความรู้เชิงโครงสร้างสองชั้นปัญหามาตรฐานแต่ละข้อและปัญหาเพิ่มเติมมีหมวดหมู่ซึ่งเราเรียกโดเมนและโดเมนหนึ่งมีหลายเจตนา
QA_Match รองรับโครงสร้างฐานความรู้ดังนี้:
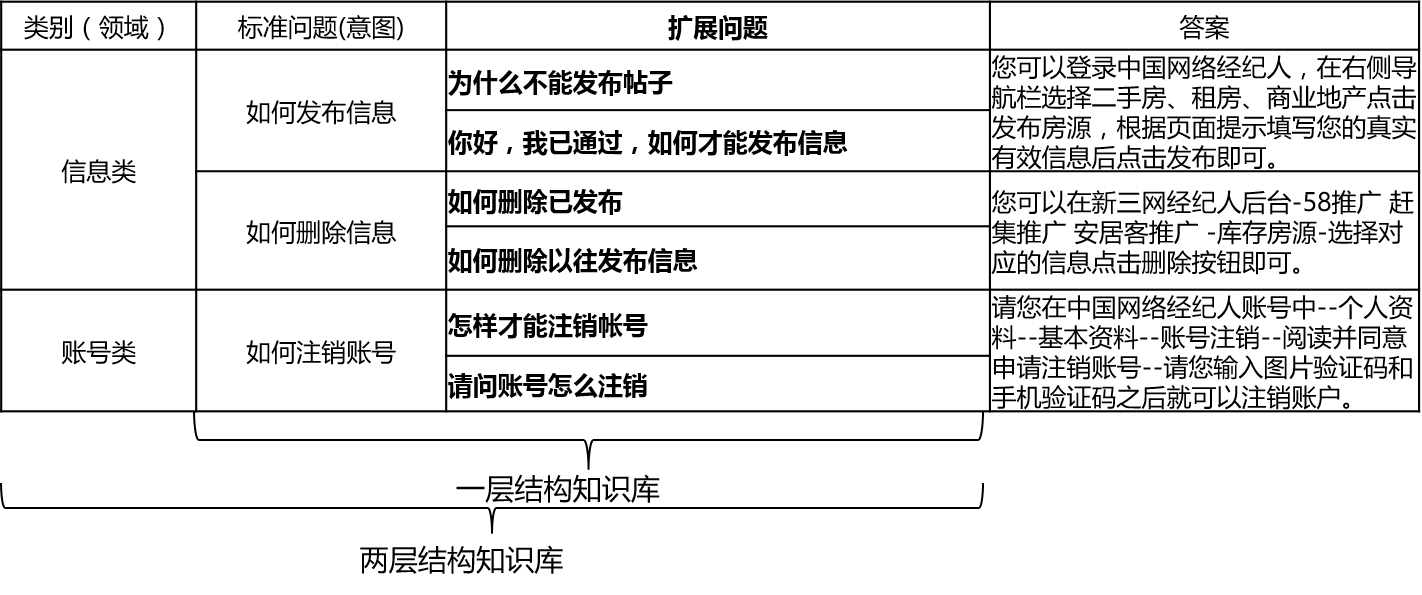
สำหรับคำถามอินพุต QA_MATCH สามารถให้คำตอบสามข้อร่วมกับฐานความรู้:
ภายใต้โครงสร้างฐานความรู้ทั้งสองมีความแตกต่างในการใช้งานของ QA_MATCH ซึ่งอธิบายไว้ด้านล่าง:
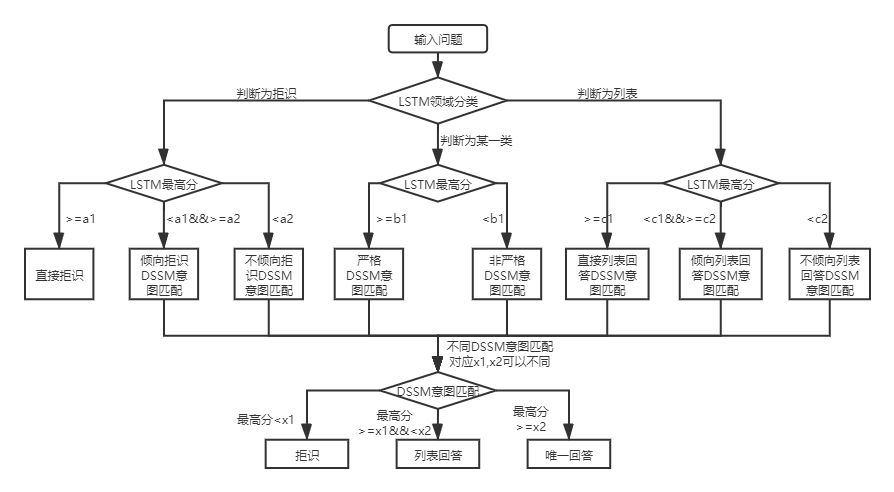
สำหรับ Q&A ฐานความรู้ของโครงสร้างสองชั้น QA_MATCH จะจำแนกและระบุคำถามผู้ใช้ในโดเมนและเจตนาก่อนจากนั้นรวมผลลัพธ์ของทั้งสองเพื่อให้ได้ความตั้งใจและคำตอบที่แท้จริงของผู้ใช้ตามคำตอบที่ไม่ซ้ำกันคำตอบรายการคำตอบการปฏิเสธ) ตัวอย่างเช่นดังที่แสดงในแผนภาพโครงสร้างฐานความรู้ในคำถามและคำตอบพื้นฐานความรู้ด้านบนเรามีฐานความรู้โครงสร้างสองชั้นซึ่งรวมถึง "ข้อมูล" และ "บัญชี" สองสาขา ฟิลด์ "ข้อมูล" มีความตั้งใจสองประการ: "วิธีการเผยแพร่ข้อมูล", "วิธีการลบข้อมูล" และฟิลด์ "บัญชี" มีเจตนา: "วิธีการยกเลิกบัญชี" เมื่อผู้ใช้ป้อนคำถาม: "ฉันจะเผยแพร่โพสต์ได้อย่างไรเมื่อใด" qa_match จะดำเนินการคำถาม & คำตอบต่อไปนี้:
ในสถานการณ์จริงเราจะพบเลเยอร์ของคำถามฐานคำถามความรู้เชิงโครงสร้าง การใช้โมเดลการจับคู่ความตั้งใจ DSSM และแบบจำลองภาษาที่ได้รับการฝึกฝนมาก่อน SPTM สามารถแก้ปัญหาประเภทนี้ได้ การเปรียบเทียบทั้งสอง:
| แบบอย่าง | วิธีใช้ | ข้อได้เปรียบ | ข้อบกพร่อง |
|---|---|---|---|
| รูปแบบการจับคู่ความตั้งใจ DSSM | โมเดลการจับคู่ DSSM ตรงกับโดยตรง | ①ง่ายที่จะใช้โมเดลใช้พื้นที่การฝึกอบรม/ความเร็วในการทำนายที่รวดเร็วเล็กน้อย | ไม่สามารถใช้ข้อมูลบริบทได้ |
| SPTM แบบจำลองภาษาที่ได้รับการฝึกฝนมาก่อน | รูปแบบภาษา LSTM/Transformer ที่ผ่านการฝึกอบรมมาก่อน + ปรับแต่งแบบจำลอง LSTM/Transformer Matching | ①สามารถใช้ประโยชน์จากข้อมูลการฝึกอบรมล่วงหน้าที่ไม่ได้รับการดูแลเพื่อปรับปรุงเอฟเฟกต์②โมเดลภาษาสามารถใช้สำหรับงานดาวน์สตรีมอื่น ๆ | ①การฝึกอบรมล่วงหน้าต้องใช้ข้อมูลที่ปราศจากฉลากจำนวนมากการดำเนินการมีความซับซ้อนมากขึ้น (จำเป็นต้องมีสองขั้นตอนเพื่อให้ได้รูปแบบการจับคู่) |
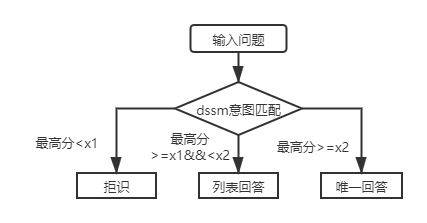
สำหรับ Q&A ฐานความรู้โครงสร้างชั้นแรกคุณจะต้องใช้โมเดลการจับคู่ความตั้งใจ DSSM เพื่อให้คะแนนคำถามอินพุตและเปรียบเทียบคะแนนสูงสุดของการจับคู่ความตั้งใจกับ X1 และ X2 ในรูปด้านบนเพื่อกำหนดประเภทคำตอบ (คำตอบที่ไม่ซ้ำกันรายการคำตอบการปฏิเสธ)
เมื่อพิจารณาว่ามักจะมีข้อมูลที่ไม่มีป้ายกำกับจำนวนมากในการใช้งานจริงเมื่อข้อมูลฐานความรู้มี จำกัด แบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนที่ไม่ได้รับการฝึกอบรมสามารถนำมาใช้เพื่อปรับปรุงประสิทธิภาพของโมเดลการจับคู่ อ้างถึงกระบวนการฝึกอบรมล่วงหน้าของ Bert ในเดือนพฤษภาคม 2562 เราได้พัฒนาโมเดล SPTM เมื่อเทียบกับเบิร์ตโมเดลนี้มีการปรับปรุงสามด้านเป็นหลัก: ประการแรกมันจะลบ NSP (การทำนายประโยคถัดไป) ด้วยเอฟเฟกต์ที่ไม่มีนัยสำคัญที่สองเพื่อปรับปรุงประสิทธิภาพการอนุมานออนไลน์หม้อแปลงถูกแทนที่ด้วย LSTM และที่สามเพื่อให้แน่ใจว่าเอฟเฟกต์แบบจำลองจะลดปริมาณพารามิเตอร์ หลักการของแบบจำลองมีดังนี้:
เมื่อฝึกอบรมแบบจำลองล่วงหน้าข้อมูลการฝึกอบรมจะต้องถูกสร้างขึ้นโดยใช้ประโยคเดี่ยว LaBelless เป็นชุดข้อมูลและ Bert ถูกใช้เพื่อสร้างตัวอย่าง: แต่ละประโยคเดียวจะใช้เป็นตัวอย่าง, 15% ของคำในประโยคมีส่วนร่วมในการทำนาย 80% ของคำที่มีส่วนร่วมในการทำนาย
โครงสร้างแบบจำลองของขั้นตอนการฝึกอบรมก่อนแสดงในรูปด้านล่าง:
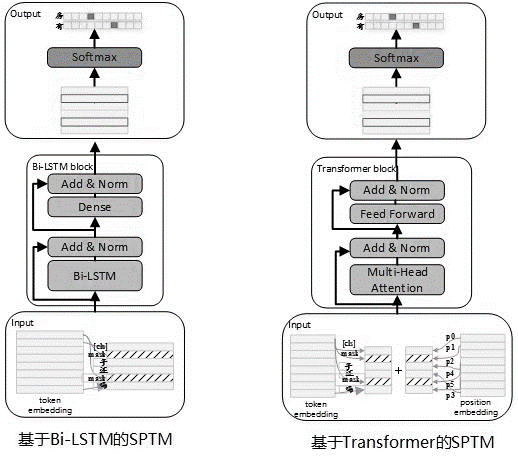
เพื่อปรับปรุงความสามารถในการแสดงออกของแบบจำลองและเก็บข้อมูลตื้นมากขึ้นเครือข่าย BI-LSTM ที่เหลือ (LSTM ที่เหลือ) ได้รับการแนะนำเป็นตัวแบบตัว เครือข่ายทำให้อินพุตของแต่ละชั้นของ BI-LSTM เป็นปกติและเอาต์พุตของเลเยอร์นี้และผลลัพธ์จะใช้เป็นอินพุตของเลเยอร์ถัดไป นอกจากนี้เอาต์พุต Bi-LSTM เลเยอร์สุดท้ายใช้เป็นอินพุตของเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ หลังจากรวมและทำให้เป็นมาตรฐานด้วยเอาต์พุตของเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ผลลัพธ์จะใช้เป็นเอาต์พุตของเครือข่ายทั้งหมด
ตัวอย่างที่ใช้เวลานานของงานฝึกอบรมก่อนจะแสดงในตารางต่อไปนี้:
| ชื่อเมตริก | ค่าตัวบ่งชี้ | ค่าตัวบ่งชี้ | ค่าตัวบ่งชี้ |
|---|---|---|---|
| โครงสร้างแบบจำลอง | LSTM | หม้อแปลงสำหรับการแชร์พารามิเตอร์ | หม้อแปลงสำหรับการแชร์พารามิเตอร์ |
| ขนาดชุดข้อมูลก่อนหน้า | 10 ล้าน | 10 ล้าน | 10 ล้าน |
| ทรัพยากรก่อนการฝึกอบรม | หน่วยความจำ 10 Nvidia K40 / 12G | หน่วยความจำ 10 Nvidia K40 / 12G | หน่วยความจำ 10 Nvidia K40 / 12G |
| พารามิเตอร์ก่อนการฝึกอบรม | ขั้นตอน = 100000 / batch size = 128 | ขั้นตอน = 100000 / batch size = 128/1 ชั้น / 12 หัว | step = 100000 / batch size = 128 /12 เลเยอร์ / 12 หัว |
| ใช้เวลาก่อนการฝึกอบรม | 8.9 ชั่วโมง | 13.5 ชั่วโมง | 32.9 ชั่วโมง |
| ขนาดรุ่นก่อน | 81m | 80.6m | 121m |
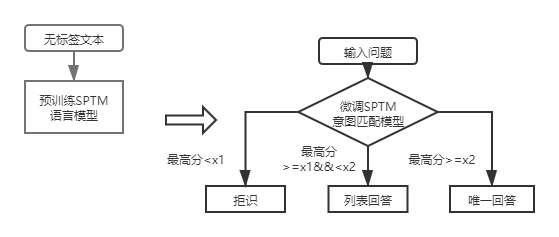
หลังจากการเปิดตัว SPTM สำหรับ Q&A ฐานความรู้โครงสร้างชั้นแรกคำถามอินพุตจะได้รับคะแนนเป็นครั้งแรกโดยใช้แบบจำลองการจับคู่ความตั้งใจตามรูปแบบการปรับแต่งแบบจำลองภาษาจากนั้นประเภทคำตอบ (คำตอบที่ไม่ซ้ำกันรายการคำตอบการปฏิเสธ) จะถูกกำหนดตามกลยุทธ์เดียวกันกับแบบจำลอง
รูปแบบของไฟล์ข้อมูล (ภายใต้โฟลเดอร์ DATA_DEMO) ที่จำเป็นต้องใช้มีดังนี้ เพื่อไม่ให้ข้อมูลรั่วไหลเราได้เข้ารหัสข้อความต้นฉบับของปัญหามาตรฐานและปัญหาเพิ่มเติมและในสถานการณ์แอปพลิเคชันจริงเพียงจัดเตรียมข้อมูลในรูปแบบต่อไปนี้
<PAD> 、 `) ข้อมูลถูกคั่นด้วย t การเข้ารหัสปัญหาจะถูกคั่นด้วยช่องว่างและคำจะถูกคั่นด้วยช่องว่าง โปรดทราบว่าในตัวอย่างข้อมูลของโครงการนี้ข้อความต้นฉบับจะถูกเข้ารหัสและแต่ละคำจะถูกแทนที่ด้วยตัวเลข ตัวอย่างเช่นข้อความจริงที่สอดคล้องกับ 205 19 90 417 41 44如何删除信息และ การดำเนินการเข้ารหัสนี้ไม่จำเป็นเมื่อใช้จริง หากโครงสร้างฐานความรู้คือระดับหนึ่งรหัสหมวดหมู่ทั้งหมดในไฟล์ std_data จะต้องตั้งค่าเป็น __label__0
กระบวนการขุดกึ่งอัตโนมัติของฐานความรู้เป็นชุดของโซลูชันการขุดกึ่งอัตโนมัติสำหรับฐานความรู้ที่สร้างขึ้นบนคำถามและกระบวนการตอบคำถามอัตโนมัติ QA (อ้างอิงจากคำถามและคำตอบอัตโนมัติตามโครงสร้างฐานความรู้หนึ่งชั้น) ซึ่งช่วยปรับปรุงขนาดของฐานความรู้และคุณภาพของฐานความรู้ ในอีกด้านหนึ่งมันช่วยปรับปรุงความสามารถในการจับคู่ออนไลน์ ในทางกลับกันมันปรับปรุงคุณภาพของข้อมูลการฝึกอบรมแบบออฟไลน์และช่วยปรับปรุงประสิทธิภาพของโมเดล กระบวนการขุดกึ่งอัตโนมัติของฐานความรู้สามารถใช้สำหรับสองสถานการณ์: การขุดเริ่มเย็นและการขุดซ้ำหลังจากเปิดตัวโมเดล สำหรับรายละเอียดโปรดดูคำแนะนำการขุดฐานความรู้
ดูคำแนะนำการดำเนินการสำหรับรายละเอียด
batch_size >= negitive_size มิฉะนั้นโมเดลไม่สามารถผ่านการฝึกอบรมได้อย่างมีประสิทธิภาพ tensorflow 版本>r1.8 <r2.0, python3
v1.0: https://github.com/wuba/qa_match/tree/v1.0
v1.1: https://github.com/wuba/qa_match/tree/v1.1
v1.2: https://github.com/wuba/qa_match/tree/v1.2
v1.3: https://github.com/wuba/qa_match/tree/v1.3
ในอนาคตเราจะเพิ่มประสิทธิภาพและขยายขีดความสามารถของ QA_MATCH และแผนคือโอเพนซอร์สดังนี้:
เราหวังเป็นอย่างยิ่งว่านักพัฒนาจะให้ความคิดเห็นและข้อเสนอแนะที่มีค่าแก่เรา คุณสามารถเลือกวิธีการตอบรับข้อเสนอแนะและคำถามต่อไปนี้:


