qa_match
1.0.0
QA_Match est un outil de correspondance de questions-réponses basé sur l'apprentissage en profondeur qui prend en charge les questions de base de connaissances de la structure à une et deux couches. QA_Match prend en charge la base de base de connaissances structurelles à une couche à travers le modèle de correspondance d'intention et prend en charge la base de base de la base de connaissances structurelles à deux couches à travers les résultats du modèle de classification du domaine de fusion et le modèle d'appariement de l'intention. QA_Match prend également en charge la fonction pré-formation non supervisée, et grâce à des modèles de langage pré-formé légers (SPTM, modèle pré-entraîné simple) peut améliorer l'efficacité des tâches en aval telles que les questions et réponses de la base de connaissances.
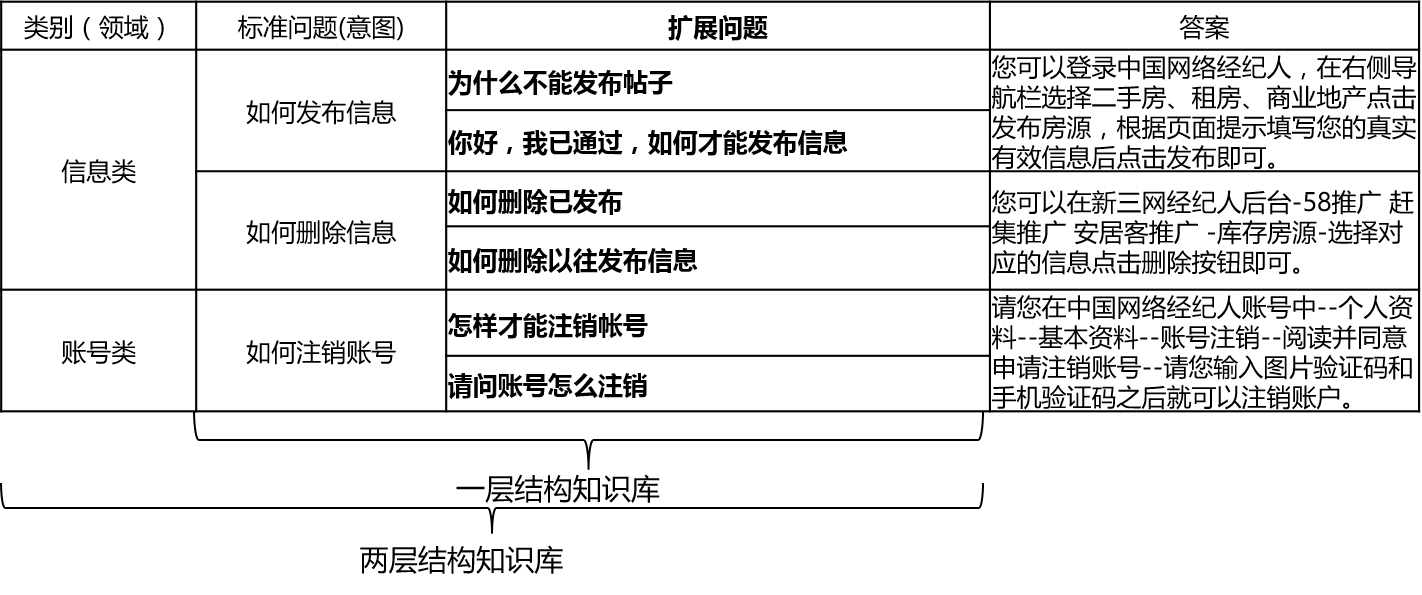
Dans les scénarios réels, la base de connaissances est généralement construite par un résumé manuel, l'annotation, l'exploration de machines, etc. La base de connaissances contient un grand nombre de questions standard, chaque question standard a une réponse standard et quelques questions étendues. Nous appelons ces questions étendues questions étendues de questions étendues. Pour une base de connaissances structurelles à une couche qui ne contient que des questions standard et des questions d'extension, nous appelons les questions standard dans l'intention. Pour une base de connaissances structurelles à deux couches, chaque problème standard et son problème étendu ont une catégorie, que nous appelons des domaines, et un domaine contient plusieurs intentions.
Le QA_Match prend en charge la structure de la base de connaissances comme suit:
Pour les questions d'entrée, QA_Match peut donner trois réponses en combinaison avec la base de connaissances:
Dans les deux structures de base de connaissances, il existe des différences dans l'utilisation de QA_Match, qui sont expliquées ci-dessous:
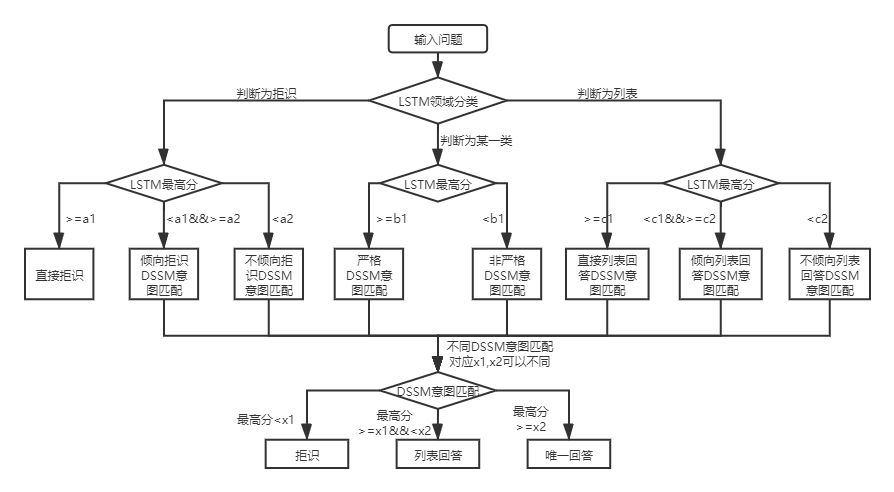
Pour les questions de base de connaissances à deux couches de la structure de la structure, QA_Match classera et identifiera d'abord les questions de l'utilisateur dans les domaines et les intentions, puis intégrera les résultats des deux pour obtenir la véritable intention et répondre de l'utilisateur en conséquence (réponses uniques, répertorier les réponses, rejeter les réponses). Par exemple: Comme le montre le diagramme de structure de base de connaissances dans la question et la réponse de la base de connaissances ci-dessus, nous avons une base de connaissances à la structure à deux couches, qui comprend des «informations» et «compte» deux champs. Le champ "Information" contient deux intentions: "Comment publier des informations", "Comment supprimer les informations", et le champ "Compte" contient l'intention: "Comment annuler le compte". Lorsque l'utilisateur entre dans la question: "Comment publier un message? Quand", QA_Match effectuera la logique des questions et réponses suivantes:
Dans les scénarios réels, nous rencontrerons également une couche de questions de questions-réponses de base de connaissances structurelles. L'utilisation du modèle de correspondance de l'intention DSSM et du modèle de langage pré-formé léger SPTM peut résoudre ce type de problème. Comparaison des deux:
| Modèle | Comment utiliser | avantage | défaut |
|---|---|---|---|
| Modèle de correspondance de l'intention du DSSM | Le modèle de correspondance DSSM correspond directement | ①aisy à utiliser, le modèle occupe peu d'espace. | Impossible d'utiliser les informations de contexte |
| Modèle de langage pré-formé léger SPTM | Modèle de langue LSTM / Transformateur pré-formé + Modèle de correspondance LSTM / Transformateur Fine-Tune | ① peut utiliser pleinement les données pré-formation non supervisées pour améliorer l'effet ② Le modèle de langue peut être utilisé pour d'autres tâches en aval | ① La pré-formation nécessite une grande quantité de données sans étiquette ② L'opération est plus compliquée (deux étapes sont nécessaires pour obtenir le modèle d'appariement) |
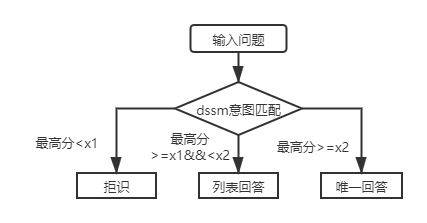
Pour les questions de base de la base de la structure de la première couche, il vous suffit d'utiliser le modèle de correspondance de l'intention DSSM pour marquer les questions d'entrée et de comparer le score le plus élevé de l'intention correspondant à X1 et X2 dans la figure ci-dessus pour déterminer le type de réponse (réponse unique, réponse de liste, rejet).
Étant donné qu'il existe souvent une grande quantité de données non marquées dans une utilisation réelle, lorsque les données de base de connaissances sont limitées, des modèles de langage pré-formés non supervisés peuvent être utilisés pour améliorer l'efficacité des modèles d'appariement. En se référant au processus de pré-formation Bert, en mai 2019, nous avons développé le modèle SPTM. Comparé à Bert, ce modèle a principalement amélioré trois aspects: premièrement, il supprime le NSP (prédiction de phrase suivante) avec des effets insignifiants, deuxièmement, pour améliorer les performances d'inférence en ligne, le transformateur a été remplacé par LSTM et troisièmement pour garantir que l'effet du modèle réduit la quantité de paramètre, il fournit également un transformateur avec des paramètres partagés entre les blocs. Le principe du modèle est le suivant:
Lorsque la pré-formation du modèle, les données de formation doivent être générées à l'aide de phrases uniques sans lié comme ensemble de données, et Bert est utilisé pour construire l'échantillon: chaque phrase unique est utilisée comme échantillon, 15% des mots de la phrase participent à la prédiction, 80% des mots participant à la prédiction ne sont pas masqués, 10% sont remplacés au hasard par un autre mot dans le dictionnaire, et 10% ne sont pas remplacés.
La structure du modèle de l'étape de pré-formation est indiquée dans la figure ci-dessous:
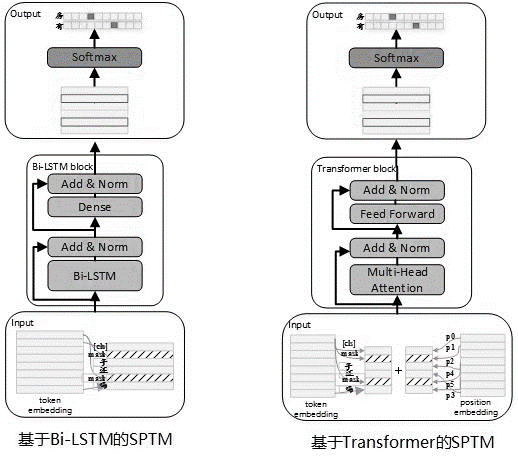
Afin d'améliorer la capacité d'expression du modèle et de conserver des informations plus peu profondes, le réseau résiduel BI-LSTM (LSTM résiduel) a été introduit comme corps du modèle. Le réseau normalise l'entrée de chaque couche de Bi-LSTM et la sortie de cette couche, et le résultat est utilisé comme entrée de la couche suivante. De plus, la dernière sortie Bi-LSTM de couche est utilisée comme entrée d'une couche entièrement connectée. Après l'avoir additionné et normalisé avec la sortie de la couche entièrement connectée, le résultat est utilisé comme sortie de l'ensemble du réseau.
L'exemple de tâches préalable à la formation est illustré dans le tableau suivant:
| Nom métrique | Valeur indicatrice | Valeur indicatrice | Valeur indicatrice |
|---|---|---|---|
| Structure du modèle | LSTM | Transformateur pour le partage des paramètres | Transformateur pour le partage des paramètres |
| Taille de l'ensemble de données pré-entraîné | 10 millions | 10 millions | 10 millions |
| Ressources de pré-formation | 10 NVIDIA K40 / 12G Mémoire | 10 NVIDIA K40 / 12G Mémoire | 10 NVIDIA K40 / 12G Mémoire |
| Paramètres de pré-formation | étape = 100000 / taille de lot = 128 | Étape = 100000 / Taille du lot = 128/1 couches / 12 têtes | Étape = 100000 / Taille du lot = 128/12 couches / 12 têtes |
| Pré-formation de temps en temps | 8,9 heures | 13,5 heures | 32,9 heures |
| Taille du modèle pré-entraîné | 81m | 80,6 m | 121m |
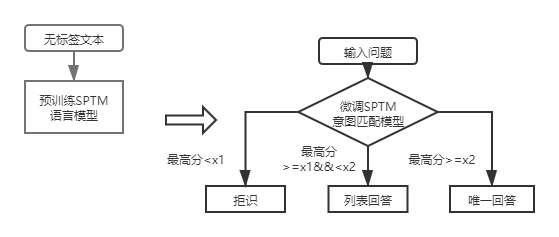
Après l'introduction de SPTM, pour la séance de base de la base de la structure de la première couche, les questions d'entrée sont d'abord notées en utilisant le modèle de correspondance d'intention basé sur le modèle de libellé, puis le type de réponse (réponse unique, réponse de liste, rejet) est déterminée sur la base de la même stratégie que le modèle d'intention d'intention DSSM.
Le format du fichier de données (dans le dossier DATA_DEMO) qui doit être utilisé est le suivant. Afin de ne pas divulguer de données, nous avons codé le texte d'origine du problème standard et du problème étendu, et dans les scénarios d'application réels, préparez simplement les données dans le format suivant.
<PAD> 、 `) Les données sont séparées par t, le codage du problème est séparé par des espaces et les mots sont séparés par des espaces. Notez que dans l'exemple de données de ce projet, le texte d'origine est codé et chaque mot est remplacé par un nombre. Par exemple, comment le texte réel correspondant au 205 19 90 417 41 44如何删除信息, et cette opération de codage n'est pas requise lorsqu'elle est réellement utilisée ; Si la structure de base de connaissances est d'un niveau, tous les ID de catégorie du fichier std_data doivent être définis sur __label__0 .
Le processus minier semi-automatique de la base de connaissances est un ensemble de solutions miniers semi-automatiques pour les bases de connaissances construites sur le processus de question et de réponse automatique de la QA (reportez-vous à la question et à la réponse automatique sur la base d'une structure de base de connaissances à une couche), ce qui contribue à améliorer l'échelle de la base de connaissances et la qualité de la base de connaissances. D'une part, cela améliore la capacité de correspondre en ligne; D'un autre côté, il améliore la qualité des données de formation des modèles hors ligne et améliore ainsi les performances du modèle. Le processus d'extraction semi-automatique de la base de connaissances peut être utilisé pour deux scénarios: l'exploitation à froid de démarrage et l'exploitation itérative après le lancement du modèle. Pour plus de détails, veuillez consulter les instructions d'exploitation de la base de connaissances.
Voir les instructions de fonctionnement pour plus de détails
batch_size >= negitive_size , sinon le modèle ne peut pas être formé efficacement. tensorflow 版本>r1.8 <r2.0, python3
v1.0: https://github.com/wuba/qa_match/tree/v1.0
v1.1: https://github.com/wuba/qa_match/tree/v1.1
v1.2: https://github.com/wuba/qa_match/tree/v1.2
v1.3: https://github.com/wuba/qa_match/tree/v1.3
À l'avenir, nous continuerons d'optimiser et d'élargir les capacités de QA_Match, et le plan est d'open source comme suit:
Nous espérons sincèrement que les développeurs nous donneront des opinions et des suggestions précieuses. Vous pouvez choisir les façons suivantes de faire des commentaires et des questions pour nous:


