qa_match
1.0.0
QA_Match는 1 층 및 2 층 구조 지식 기반 Q & A를 지원하는 딥 러닝 기반 질문 및 응답 일치 도구입니다. QA_MATCH는 의도 일치 모델을 통해 1 층 구조 지식 기반 Q & A를 지원하고 Fusion Domain Classification 모델 및 의도 매칭 모델의 결과를 통해 2 층 구조 지식 기반 Q & A를 지원합니다. QA_MATCH는 감독되지 않은 사전 훈련 기능을 지원하며 가벼운 미리 훈련 된 언어 모델 (SPTM, 간단한 미리 훈련 된 모델)을 통해 지식 기반 질문 및 답변과 같은 다운 스트림 작업의 효과를 향상시킬 수 있습니다.
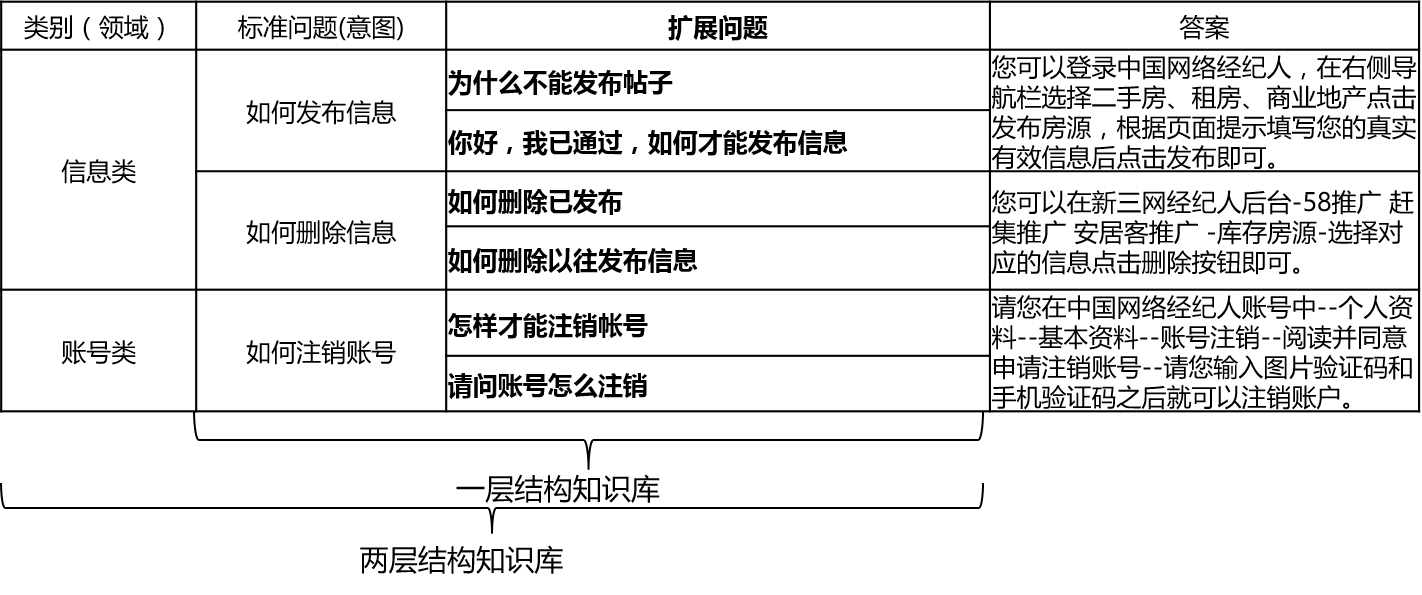
실제 시나리오에서 지식 기반은 일반적으로 수동 요약, 주석, 기계 광업 등을 통해 구성됩니다. 지식 기반에는 많은 표준 질문이 포함되어 있으며 각 표준 질문에는 표준 답변과 일부 확장 된 질문이 있습니다. 우리는이 연장 된 질문을 연장 된 질문을 연장 한 질문이라고 부릅니다. 표준 질문과 확장 질문 만 포함하는 1 층 구조 지식 기반의 경우 표준 질문 의도를 호출합니다. 2 층 구조 지식 기반의 경우 각 표준 문제와 확장 된 문제는 도메인을 호출하는 범주가 있으며 하나의 도메인에는 여러 개의 의도가 포함되어 있습니다.
qa_match는 다음과 같이 지식 기반 구조를 지원합니다.
입력 질문의 경우 QA_Match는 지식 기반과 함께 세 가지 답변을 제공 할 수 있습니다.
두 지식 기반 구조 하에서 QA_Match 사용에는 차이가 있으며 다음과 같습니다.
2 층 구조 지식 기반 Q & A의 경우 QA_Match는 먼저 도메인 및 의도에서 사용자 질문을 분류하고 식별 한 다음 사용자의 진정한 의도를 얻고 그에 따라 답변 (고유 한 답변, 답변 목록)을 얻기 위해 두 가지 결과를 통합합니다. 예를 들어, 위의 지식 기반 질문 및 답변의 지식 기반 구조 다이어그램에 표시된 것처럼 "정보"및 "계정"두 분야를 포함하는 2 층 구조 지식 기반이 있습니다. "정보"필드에는 "정보를 게시하는 방법", "정보를 삭제하는 방법"및 "계정"필드에는 "계정을 취소하는 방법"이 포함됩니다. 사용자가 "게시물을 어떻게 게시합니까? 언제", qa_match는 다음 Q & A 로직을 수행합니다.
실제 시나리오에서는 구조 지식 기반 Q & A 질문의 계층도 만나게됩니다. DSSM 의도 일치 모델과 SPTM 경량 사전 훈련 된 언어 모델을 사용하면 이러한 종류의 문제를 해결할 수 있습니다. 둘의 비교 :
| 모델 | 사용 방법 | 이점 | 결점 |
|---|---|---|---|
| DSSM 의도 일치 모델 | DSSM 매칭 모델이 직접 일치합니다 | 사용하기가 좋으면이 모델은 작은 공간을 차지합니다. | 컨텍스트 정보를 활용할 수 없습니다 |
| SPTM 경량 사전 훈련 된 언어 모델 | 미리 훈련 된 LSTM/변압기 언어 모델 + 미세 조정 LSTM/변압기 일치 모델 | ∎ 효과를 향상시키기 위해 감독되지 않은 사전 훈련 데이터를 최대한 활용할 수 있습니다. 다른 다운 스트림 작업에 언어 모델을 사용할 수 있습니다. | ① 사전 훈련에는 많은 양의 라벨이없는 데이터가 필요합니다. |
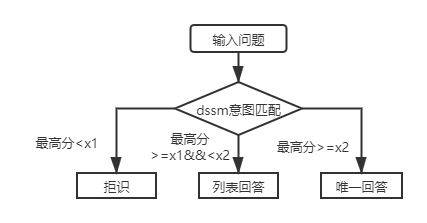
첫 번째 계층 구조 지식 기반 Q & A의 경우 DSSM 의도 일치 모델을 사용하여 입력 질문을 점수를 매기고 위 그림에서 X1 및 X2와 일치하는 의도의 최고 점수를 비교하여 답변 유형 (고유 한 답변, 목록 답변, 거부)을 비교해야합니다.
실제 사용에 종종 표지되지 않은 데이터가 많이 있다는 점을 고려할 때, 지식 기반 데이터가 제한 될 때 감독되지 않은 미리 훈련 된 언어 모델을 사용하여 일치하는 모델의 효과를 향상시킬 수 있습니다. Bert 사전 훈련 프로세스를 참조하여 2019 년 5 월 SPTM 모델을 개발했습니다. Bert와 비교 하여이 모델은 주로 세 가지 측면을 개선했습니다. 첫째, 온라인 추론 성능을 향상시키기 위해 미미한 효과로 NSP (다음 문장 예측)를 제거하고, 변압기는 LSTM으로 대체되었고, 세 번째는 모델 효과가 매개 변수를 줄이도록 보장하고 블록 사이의 공유 파라미터와 변압기를 제공합니다. 모델 원칙은 다음과 같습니다.
모델을 사전 훈련 할 때, 훈련 데이터는 데이터 세트로 Labelless 단일 문장을 사용하여 생성해야하며, Bert는 샘플을 구성하는 데 사용됩니다. 각 단일 문장은 샘플로 사용되며 문장의 단어의 15%는 예측에 참여하고, 참가에 참여하는 단어의 80%는 사전으로 다른 단어로 무작위로 대체되며, 10%는 교체되지 않습니다.
사전 훈련 단계의 모델 구조는 다음 그림에 나와 있습니다.
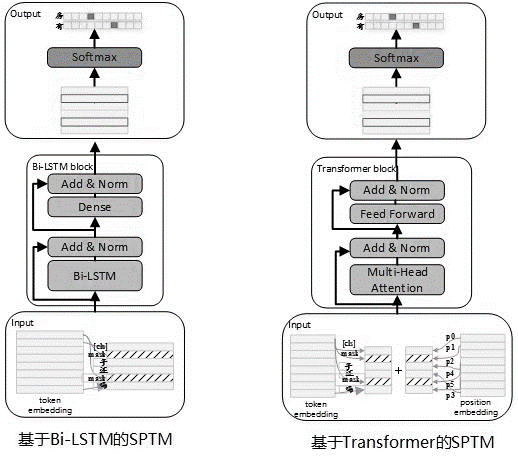
모델의 발현 능력을 향상시키고 더 얕은 정보를 유지하기 위해 잔류 Bi-LSTM 네트워크 (잔류 LSTM)가 모델 본문으로 도입되었습니다. 네트워크는 BI-LSTM의 각 계층의 입력 과이 레이어의 출력을 정규화하고 결과는 다음 레이어의 입력으로 사용됩니다. 또한, 마지막 층 BI-LSTM 출력은 완전히 연결된 층의 입력으로 사용됩니다. 완전히 연결된 레이어의 출력으로 합산 및 정규화 한 후 결과는 전체 네트워크의 출력으로 사용됩니다.
사전 훈련 작업의 시간 소모 예는 다음 표에 나와 있습니다.
| 메트릭 이름 | 표시기 값 | 표시기 값 | 표시기 값 |
|---|---|---|---|
| 모델 구조 | lstm | 매개 변수를 공유하기위한 변압기 | 매개 변수를 공유하기위한 변압기 |
| 사전 예방 된 데이터 세트 크기 | 10 백만 | 10 백만 | 10 백만 |
| 사전 훈련 자원 | 10 NVIDIA K40 / 12G 메모리 | 10 NVIDIA K40 / 12G 메모리 | 10 NVIDIA K40 / 12G 메모리 |
| 사전 훈련 매개 변수 | 단계 = 100000 / 배치 크기 = 128 | step = 100000 / 배치 크기 = 128 / 1 레이어 / 12 헤드 | STEP = 100000 / 배치 크기 = 128 / 12 레이어 / 12 헤드 |
| 사전 훈련 시간 소모 | 8.9 시간 | 13.5 시간 | 32.9 시간 |
| 사전 예방 된 모델 크기 | 81m | 80.6m | 121m |
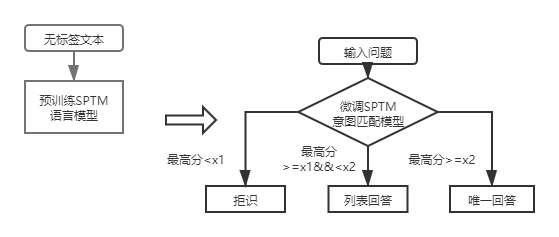
SPTM이 도입 된 후, 첫 번째 계층 구조 지식 기반 Q & A에 대해, 입력 질문은 언어 모델 미세 조정을 기반으로 한 의도 일치 모델을 사용하여 먼저 점수를 매긴 다음 답변 유형 (고유 한 답변, 목록 답변, 거부)은 DSSM 의도 일치 모델과 동일한 전략을 기반으로 결정됩니다.
사용해야하는 데이터 파일 (data_demo 폴더 아래)의 형식은 다음과 같습니다. 데이터가 누출되지 않기 위해 표준 문제의 원본 텍스트와 확장 된 문제를 인코딩했으며 실제 응용 시나리오에서는 다음 형식으로 데이터를 준비합니다.
<PAD> 、 `) 데이터는 t에 의해 분리되고, 문제 인코딩은 공백으로 분리되고 단어는 공백으로 분리됩니다. 이 프로젝트의 데이터 예에서는 원본 텍스트가 인코딩되고 각 단어는 숫자로 대체됩니다. 예를 들어, 실제 텍스트가 205 19 90 417 41 44 에 해당하는 방법如何删除信息실제로 사용하는 경우이 인코딩 작업이 필요하지 않습니다 . 지식 기반 구조가 한 레벨 인 경우 STD_DATA 파일의 모든 카테고리 ID를 __label__0 으로 설정해야합니다.
지식 기반의 반자동 마이닝 프로세스는 지식 기반의 규모와 지식 기반의 품질을 향상시키는 데 도움이되는 QA 매치 자동 질문 및 답변 프로세스 (1 층 지식 기반 구조를 기반으로 한 자동 질문 및 답변을 참조)를 기반으로 한 지식 기반을위한 반자동 마이닝 솔루션 세트입니다. 한편으로는 온라인 일치 능력을 향상시킵니다. 반면 오프라인 모델 교육 데이터의 품질을 향상시켜 모델 성능을 향상시킵니다. 지식 기반의 반자동 마이닝 프로세스는 두 가지 시나리오에 사용될 수 있습니다. 콜드 스타트 마이닝 및 모델이 시작된 후 반복 광업. 자세한 내용은 지식 기반 마이닝 지침을 참조하십시오.
자세한 내용은 작업 지침을 참조하십시오
batch_size >= negitive_size 충족해야합니다. 그렇지 않으면 모델을 효과적으로 훈련시킬 수 없습니다. tensorflow 版本>r1.8 <r2.0, python3
v1.0 : https://github.com/wuba/qa_match/tree/v1.0
v1.1 : https://github.com/wuba/qa_match/tree/v1.1
v1.2 : https://github.com/wuba/qa_match/tree/v1.2
v1.3 : https://github.com/wuba/qa_match/tree/v1.3
앞으로 QA_Match의 기능을 계속 최적화하고 확장 할 것이며 계획은 다음과 같이 오픈 소스입니다.
우리는 개발자들이 우리에게 귀중한 의견과 제안을 제공하기를 진심으로 바랍니다. 제안과 질문을 피드백 할 수있는 다음 방법을 선택할 수 있습니다.


