qa_match
1.0.0
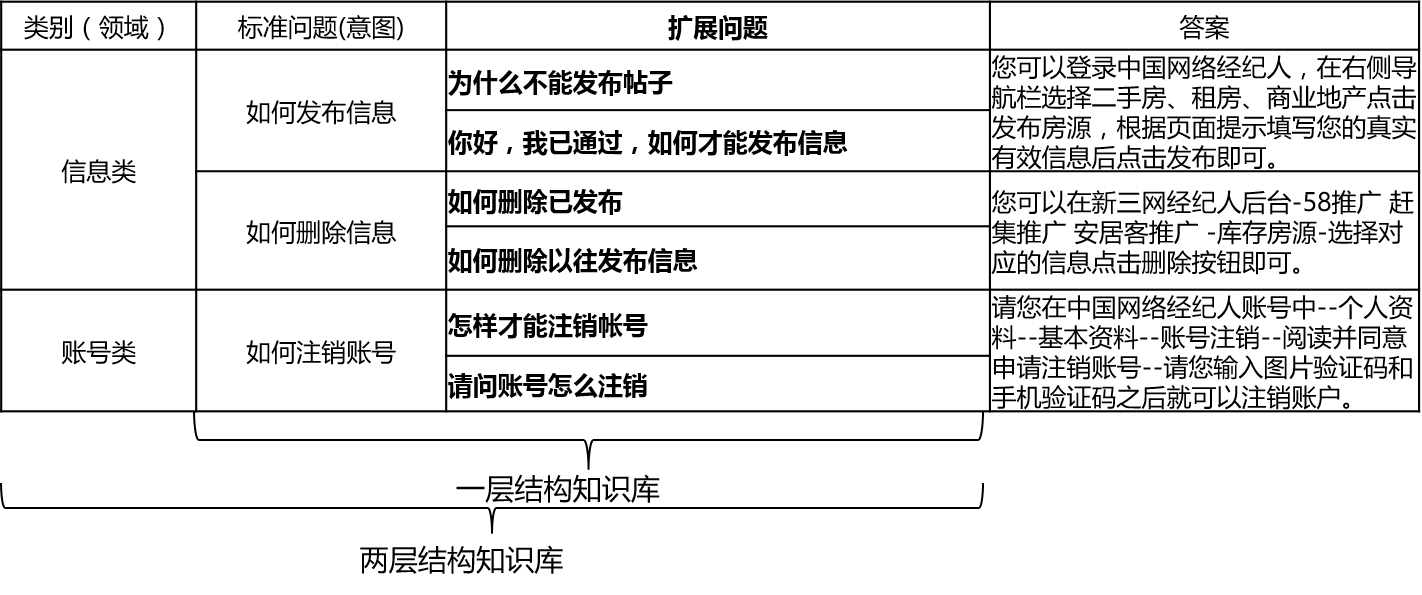
qa_match是一款基于深度学习的问答匹配工具,支持一层和两层结构知识库问答。qa_match通过意图匹配模型支持一层结构知识库问答,通过融合领域分类模型和意图匹配模型的结果支持两层结构知识库问答。qa_match同时支持无监督预训练功能,通过轻量级预训练语言模型(SPTM,Simple Pre-trained Model)可以提升基于知识库问答等下游任务的效果。
在实际场景中,知识库一般是通过人工总结、标注、机器挖掘等方式进行构建,知识库中包含大量的标准问题,每个标准问题有一个标准答案和一些扩展问法,我们称这些扩展问法为扩展问题。对于一层结构知识库,仅包含标准问题和扩展问题,我们把标准问题称为意图。对于两层结构知识库,每个标准问题及其扩展问题都有一个类别,我们称为领域,一个领域包含多个意图。
qa_match支持知识库结构如下:
对于输入的问题,qa_match能够结合知识库给出三种回答:
在两种知识库结构下,qa_match的使用方式存在差异,以下分别说明:
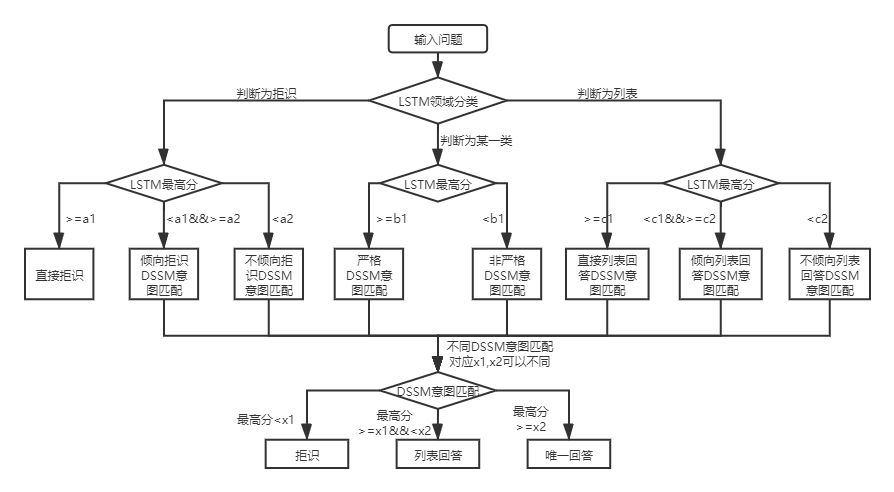
对于两层结构知识库问答,qa_match会对用户问题先进行领域分类和意图识别,然后对两者的结果进行融合,获取用户的真实意图进行相应回答(唯一回答、列表回答、拒绝回答)。 举个例子:如上述知识库问答中知识库结构图所示,我们有一个两层结构知识库,它包括”信息“和”账号“两个领域”。其中“信息”领域下包含两个意图:“如何发布信息”、“如何删除信息”,“账号”领域下包含意图:“如何注销账号”。当用户输入问题为:“我怎么发布帖子?”时,qa_match会进行如下问答逻辑:
实际场景中,我们也会遇到一层结构知识库问答问题,用DSSM意图匹配模型与SPTM轻量级预训练语言模型均可以解决此类问题,两者对比:
| 模型 | 使用方法 | 优点 | 缺点 |
|---|---|---|---|
| DSSM意图匹配模型 | DSSM匹配模型直接匹配 | ①使用简便,模型占用空间小 ②训练/预测速度快 |
无法利用上下文信息 |
| SPTM轻量级预训练语言模型 | 预训练LSTM/Transformer语言模型 +微调LSTM/Transformer匹配模型 |
①能够充分利用无监督预训练数据提升效果 ②语言模型可用于其他下游任务 |
①预训练需要大量无标签数据 ②操作较复杂(需两个步骤得到匹配模型) |
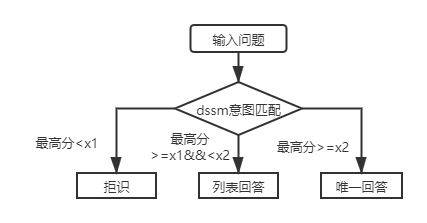
对于一层结构知识库问答,只需用DSSM意图匹配模型对输入问题进行打分,根据意图匹配的最高分值与上图中的x1,x2进行比较决定回答类型(唯一回答、列表回答、拒识)。
考虑到实际使用中往往存在大量的无标签数据,在知识库数据有限时,可使用无监督预训练语言模型提升匹配模型的效果。参考BERT预训练过程,2019年5月我们开发了SPTM模型,该模型相对于BERT主要改进了三方面:一是去掉了效果不明显的NSP(Next Sentence Prediction),二是为了提高线上推理性能将Transformer替换成了LSTM,三是为了保证模型效果降低参数量也提供了BLOCK间共享参数的Transformer,模型原理如下:
预训练模型时,生成训练数据需要使用无标签单句作为数据集,并参考了BERT来构建样本:每个单句作为一个样本,句子中15%的字参与预测,参与预测的字中80%进行mask,10%随机替换成词典中一个其他的字,10%不替换。
预训练阶段的模型结构如下图所示:
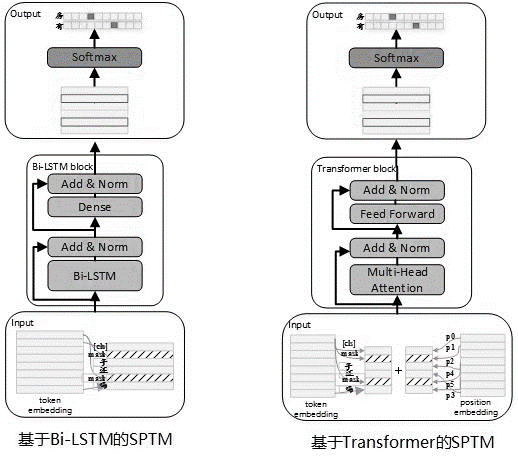
为提升模型的表达能力,保留更多的浅层信息,引入了残差Bi-LSTM网络(Residual LSTM)作为模型主体。该网络将每一层Bi-LSTM的输入和该层输出求和归一化后,结果作为下一层的输入。此外将最末层Bi-LSTM输出作为一个全连接层的输入,与全连接层输出求和归一化后,结果作为整个网络的输出。
预训练任务耗时示例如下表所示:
| 指标名称 | 指标值 | 指标值 | 指标值 |
|---|---|---|---|
| 模型结构 | LSTM | 共享参数的Transformer | 共享参数的Transformer |
| 预训练数据集大小 | 10Million | 10Million | 10Million |
| 预训练资源 | 10台Nvidia K40 / 12G Memory | 10台Nvidia K40 / 12G Memory | 10台Nvidia K40 / 12G Memory |
| 预训练参数 | step = 100000 / batch size = 128 | step = 100000 / batch size = 128 / 1 layers / 12 heads | step = 100000 / batch size = 128 / 12 layers / 12 heads |
| 预训练耗时 | 8.9 hours | 13.5 hours | 32.9 hours |
| 预训练模型大小 | 81M | 80.6M | 121M |
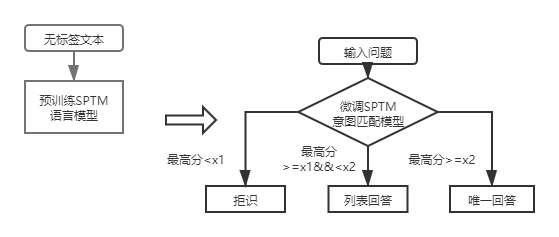
引入SPTM后,对于一层结构知识库问答,先使用基于语言模型微调的意图匹配模型对输入问题进行打分,再根据与DSSM意图匹配模型相同的策略决定回答类型(唯一回答、列表回答、拒识)。
需要使用到的数据文件(data_demo文件夹下)格式说明如下,这里为了不泄露数据,我们对标准问题和扩展问题原始文本做了编码,在实际应用场景中直接按照以下格式准备数据即可。
<PAD>、、`)数据以t分隔,问题编码以空格分隔,字之间以空格分隔。注意在本项目的数据示例中,对原始文本做了编码,将每个字替换为一个数字, 例如205 19 90 417 41 44 对应的实际文本是如何删除信息,在实际使用时不需要做该编码操作;若知识库结构为一级,需要把std_data文件中的类别id全部设置为__label__0。
知识库半自动挖掘流程,是在qa match自动问答流程的基础上(参考qa match 基于一层知识库结构的自动问答)构建的一套知识库半自动挖掘方案,帮助提升知识库规模与知识库质量,一方面提高线上匹配的能力;一方面提高离线模型训练数据的质量,进而提高模型性能。知识库半自动挖掘流程可以用于冷启动挖掘和模型上线后迭代挖掘两个场景。详情参见知识库挖掘说明文档
详情见运行说明
batch_size >= negitive_size,否则模型无法有效训练。tensorflow 版本>r1.8 <r2.0, python3
v1.0:https://github.com/wuba/qa_match/tree/v1.0
v1.1:https://github.com/wuba/qa_match/tree/v1.1
v1.2:https://github.com/wuba/qa_match/tree/v1.2
v1.3:https://github.com/wuba/qa_match/tree/v1.3
未来我们会继续优化扩展qa_match的能力,计划开源如下:
我们诚挚地希望开发者向我们提出宝贵的意见和建议。您可以挑选以下方式向我们反馈建议和问题:


