qa_match
1.0.0
QA_MATCH é uma ferramenta de correspondência de perguntas e respostas baseada em aprendizado profundo que suporta perguntas e respostas da base de conhecimento de estrutura de uma e duas camadas. O QA_MATCH suporta perguntas e respostas da base de conhecimento estrutural de uma camada de uma camada através do modelo de correspondência de intenções e suporta perguntas e respostas da base de conhecimento estrutural de duas camadas através dos resultados do modelo de classificação de domínio de fusão e do modelo de correspondência de intenção. O QA_MATCH também suporta a função pré-treinamento não supervisionada e, por meio de modelos de idiomas pré-treinados leves (SPTM, modelo simples pré-treinado) podem melhorar a eficácia de tarefas a jusante, como perguntas e respostas base do conhecimento.
Nos cenários reais, a base de conhecimento é geralmente construída por meio de resumo manual, anotação, mineração de máquinas etc. A base de conhecimento contém um grande número de perguntas padrão, cada pergunta padrão tem uma resposta padrão e algumas perguntas estendidas. Chamamos essas perguntas estendidas para perguntas estendidas. Perguntas estendidas. Para uma base de conhecimento estrutural de uma camada que contém apenas questões padrão e perguntas de extensão, chamamos de intenção de perguntas padrão. Para uma base de conhecimento estrutural de duas camadas, cada problema padrão e seu problema estendido têm uma categoria, que chamamos de domínios, e um domínio contém várias intenções.
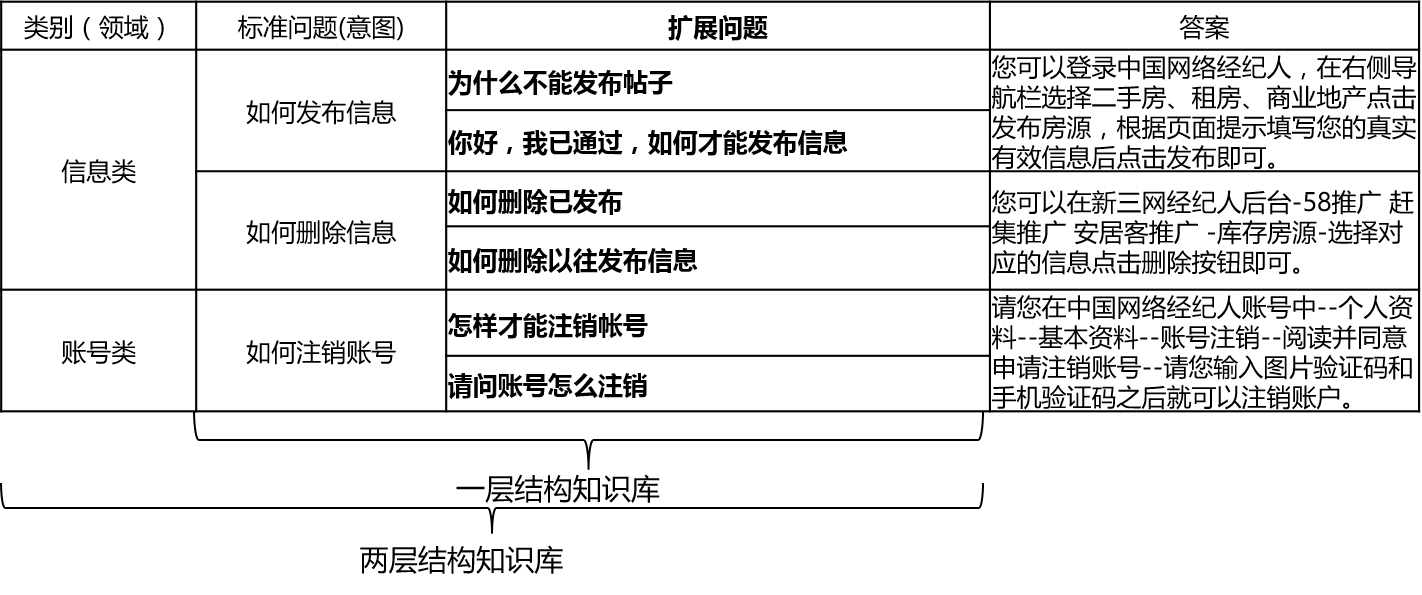
O QA_MATCH suporta a estrutura da base do conhecimento da seguinte maneira:
Para perguntas de entrada, o Qa_Match pode fornecer três respostas em combinação com a base de conhecimento:
Sob as duas estruturas da base de conhecimento, existem diferenças no uso de Qa_match, que são explicadas abaixo:
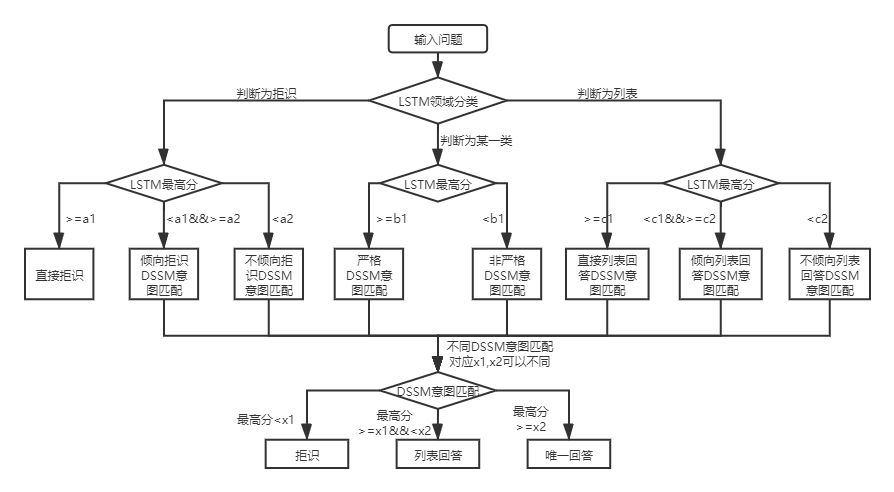
Para as perguntas e respostas da Base de Conhecimento da Base de Conhecimento da Estrutura de duas camadas, QA_MATCH primeiro classificará e identificará as perguntas do usuário em domínios e intenções e depois integrará os resultados dos dois para obter a verdadeira intenção e responder de acordo (respostas únicas, respostas de listar, respostas de rejeição). Por exemplo: Conforme mostrado no diagrama da estrutura da base de conhecimento na pergunta e resposta da base de conhecimento acima, temos uma base de conhecimento de estrutura de duas camadas, que inclui "informações" e "conta" dois campos. O campo "Informações" contém duas intenções: "Como publicar informações", "como excluir informações" e o campo "Conta" contém intenção: "Como cancelar a conta". Quando o usuário insere a pergunta: "Como publico uma postagem?
Nos cenários reais, também encontraremos uma camada de perguntas e respostas da Base de Conhecimento Estrutural. O uso do modelo de correspondência de intenção do DSSM e o modelo de linguagem pré-treinado leve SPTM pode resolver esse tipo de problema. Comparação dos dois:
| Modelo | Como usar | vantagem | falha |
|---|---|---|---|
| Modelo de correspondência de intenção dssm | O modelo de correspondência do DSSM corresponde diretamente | ± | Incapaz de utilizar informações de contexto |
| Modelo de idioma pré-treinado leve SPTM | Modelo de linguagem LSTM/transformador pré-treinado + Modelo de correspondência de LSTM/transformador fino Tune | ① Pode fazer pleno uso de dados pré-treinamento não supervisionados para melhorar o modelo de idioma do efeito pode ser usado para outras tarefas a jusante | ① O pré-treinamento requer uma grande quantidade de dados sem rótulo ② A operação é mais complicada (são necessárias duas etapas para obter o modelo de correspondência) |
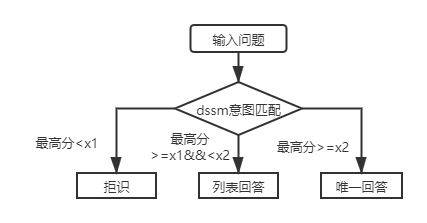
Para as perguntas e respostas da Base de Conhecimento da Base de Conhecimento da Estrutura da Primeira camada, você só precisa usar o modelo de correspondência de intenção do DSSM para marcar as perguntas de entrada e comparar a pontuação mais alta da correspondência de intenções com X1 e X2 na figura acima para determinar o tipo de resposta (resposta única, resposta da lista, rejeição).
Considerando que geralmente há uma grande quantidade de dados não marcados no uso real, quando os dados da base de conhecimento são limitados, modelos de idiomas pré-treinados não supervisionados podem ser usados para melhorar a eficácia dos modelos correspondentes. Referindo-se ao processo de pré-treinamento BERT, em maio de 2019, desenvolvemos o modelo SPTM. Comparado com Bert, esse modelo melhorou principalmente três aspectos: primeiro, ele remove o NSP (previsão da próxima frase) com efeitos insignificantes, segundo, para melhorar o desempenho da inferência on -line, o transformador foi substituído pelo LSTM e o terceiro, para garantir que o efeito do modelo reduz a quantidade de parâmetros, também fornece um transformador com parâmetros compartilhados entre os blocos. O princípio do modelo é o seguinte:
Ao pré-treinamento do modelo, os dados de treinamento precisam ser gerados usando frases únicas com etiqueta como conjunto de dados, e Bert é usado para construir a amostra: cada frase única é usada como uma amostra, 15% das palavras na sentença participam da previsão, 80% das palavras que participam da previsão são mascaradas, 10% são replicadas aleatoriamente.
A estrutura do modelo do estágio de pré-treinamento é mostrada na figura abaixo:
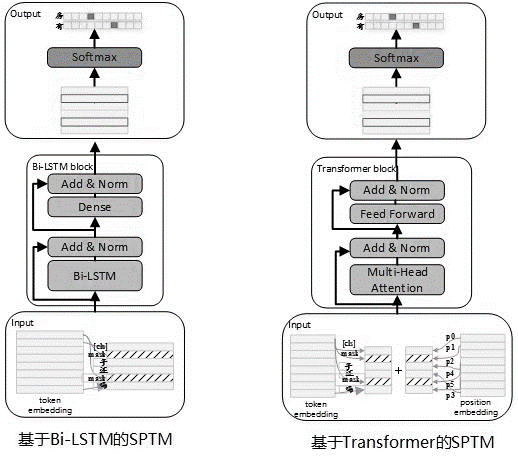
Para melhorar a capacidade de expressão do modelo e reter informações mais superficiais, a rede residual BI-LSTM (LSTM residual) foi introduzida como o corpo do modelo. A rede normaliza a entrada de cada camada de BI-LSTM e a saída dessa camada, e o resultado é usado como entrada da próxima camada. Além disso, a última saída BI-LSTM da camada é usada como entrada de uma camada totalmente conectada. Após resumir e normalizá -lo com a saída da camada totalmente conectada, o resultado é usado como a saída de toda a rede.
O exemplo demorado de tarefas de pré-treinamento é mostrado na tabela a seguir:
| Nome métrico | Valor indicador | Valor indicador | Valor indicador |
|---|---|---|---|
| Estrutura do modelo | LSTM | Transformador para compartilhar parâmetros | Transformador para compartilhar parâmetros |
| Tamanho pré -terenciado do conjunto de dados | 10 milhões | 10 milhões | 10 milhões |
| Recursos pré-treinamento | 10 Nvidia K40 / 12G Memória | 10 Nvidia K40 / 12G Memória | 10 Nvidia K40 / 12G Memória |
| Parâmetros de pré-treinamento | Etapa = 100000 / tamanho do lote = 128 | Etapa = 100000 / tamanho do lote = 128/1 camadas / 12 cabeças | Etapa = 100000 / tamanho do lote = 128/12 camadas / 12 cabeças |
| Pré-treinamento demorado | 8,9 horas | 13,5 horas | 32,9 horas |
| Tamanho do modelo pré -terenciado | 81m | 80,6m | 121m |
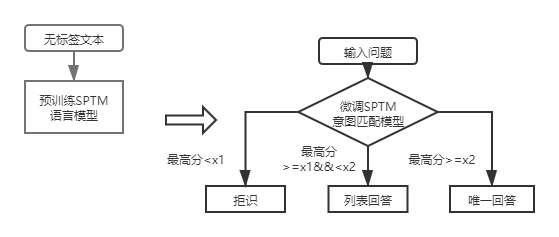
Após a introdução do SPTM, para as perguntas e respostas da base de conhecimento da estrutura de primeira camada, as perguntas de entrada são pontuadas pela primeira vez usando o modelo de correspondência de intenções com base no modelo de ajuste fino do modelo de idioma e, em seguida, o tipo de resposta (resposta exclusiva, resposta da lista, rejeição) é determinada com base na mesma estratégia que o modelo de correspondência de intenção do DSSM.
O formato do arquivo de dados (na pasta Data_Demo) que precisa ser usada é a seguinte. Para não vazar dados, codificamos o texto original do problema padrão e do problema estendido e, nos cenários de aplicação reais, basta preparar os dados no formato a seguir.
<PAD> 、 `) Os dados são separados por t, a codificação do problema é separada por espaços e as palavras são separadas por espaços. Observe que, no exemplo de dados deste projeto, o texto original é codificado e cada palavra é substituída por um número. Por exemplo, como o texto real correspondente a 205 19 90 417 41 44如何删除信息, e essa operação de codificação não é necessária quando realmente usada ; Se a estrutura da base de conhecimento for um nível, todos os IDs de categoria no arquivo std_data precisam ser definidos como __label__0 .
O processo de mineração semi-automático da base de conhecimento é um conjunto de soluções semi-automáticas de mineração para bases de conhecimento construídas no processo de perguntas e respostas automáticas de correspondência de controle de qualidade (consulte a pergunta e resposta automáticas com base em uma estrutura de base de conhecimento de uma camada), que ajuda a melhorar a escala da base de conhecimento e a qualidade da base de conhecimento. Por um lado, melhora a capacidade de combinar online; Por outro lado, melhora a qualidade dos dados de treinamento de modelos offline e, assim, melhora o desempenho do modelo. O processo de mineração semi-automático da base de conhecimento pode ser usado para dois cenários: a mineração de partida a frio e a mineração iterativa após o lançamento do modelo. Para detalhes, consulte as instruções de mineração da base de conhecimento.
Veja as instruções de operação para obter detalhes
batch_size >= negitive_size , caso contrário, o modelo não poderá ser efetivamente treinado. tensorflow 版本>r1.8 <r2.0, python3
v1.0: https://github.com/wuba/qa_match/tree/v1.0
v1.1: https://github.com/wuba/qa_match/tree/v1.1
v1.2: https://github.com/wuba/qa_match/tree/v1.2
v1.3: https://github.com/wuba/qa_match/tree/v1.3
No futuro, continuaremos a otimizar e expandir os recursos do QA_MATCH, e o plano é abrir o código -fonte da seguinte maneira:
Esperamos sinceramente que os desenvolvedores nos dão opiniões e sugestões valiosas. Você pode escolher as seguintes maneiras de obter sugestões e perguntas de feedback para nós:


