qa_match
1.0.0
QA_MATCは、1つおよび2層構造の知識ベースQ&Aをサポートする、深い学習ベースの質問と回答のマッチングツールです。 QA_MATCは、意図マッチングモデルを介して1層の構造知識ベースのQ&Aをサポートし、Fusion Domain分類モデルと意図マッチングモデルの結果を通じて2層構造知識ベースのQ&Aをサポートします。 QA_MATCは、監視されていない訓練前機能もサポートしており、軽量の事前訓練を受けた言語モデル(SPTM、単純な訓練モデル)を介して、知識ベースの質問や回答などのダウンストリームタスクの有効性を改善できます。
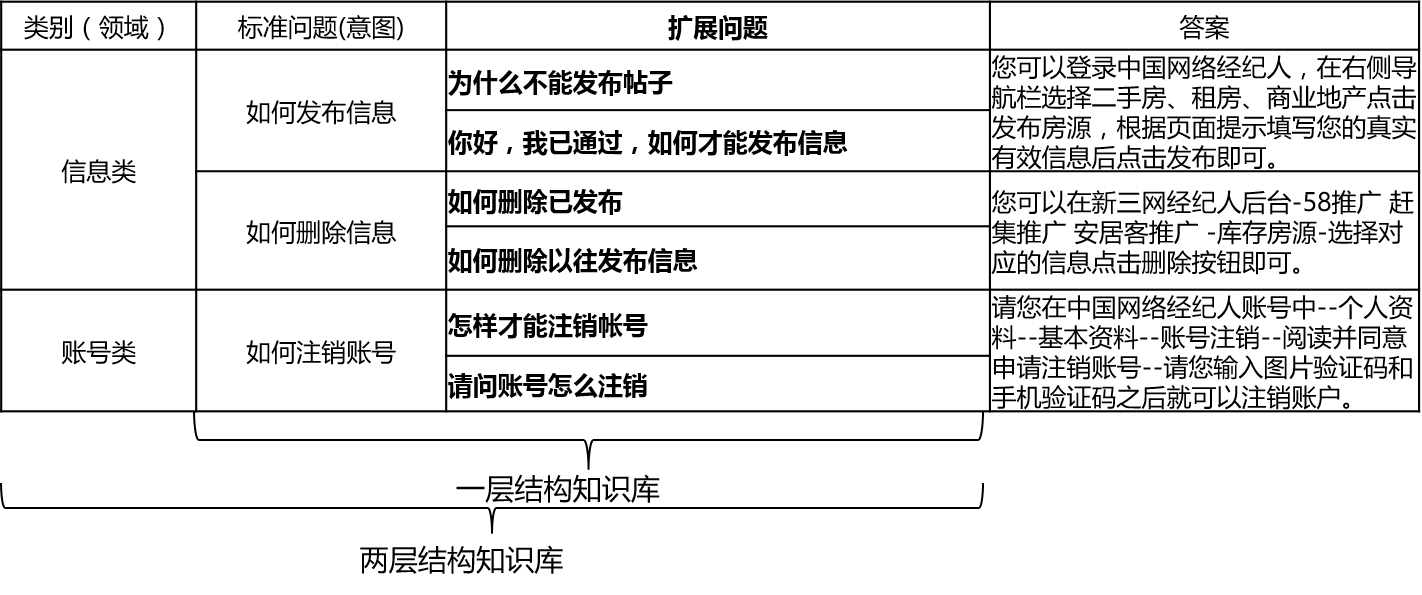
実際のシナリオでは、ナレッジベースは一般に手動の要約、注釈、機械採掘などを通じて構築されます。知識ベースには多数の標準的な質問が含まれており、各標準的な質問には標準的な答えがあり、いくつかの拡張質問があります。これらの拡張された質問を拡張された質問は、拡張された質問と呼びます。標準的な質問と拡張質問のみを含む1層構造知識ベースの場合、標準的な質問を意図と呼びます。 2層構造知識ベースの場合、各標準問題とその拡張された問題には、ドメインと呼ばれるカテゴリがあり、1つのドメインには複数の意図が含まれています。
QA_MATCは、次のように知識ベースの構造をサポートしています。
入力の質問の場合、QA_MATCは知識ベースと組み合わせて3つの回答を提供できます。
2つの知識ベース構造の下では、QA_MATCの使用に違いがあります。これについては、以下に説明します。
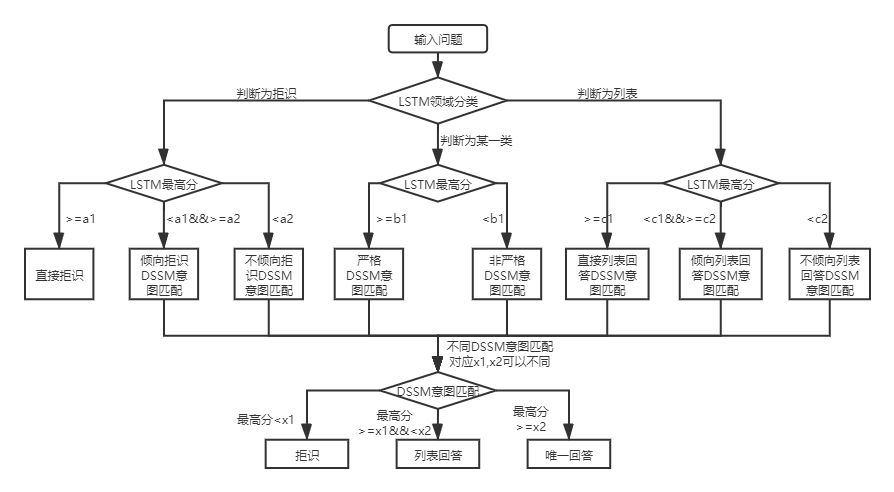
2層構造の知識ベースのQ&Aの場合、QA_MATCは最初にドメインと意図のユーザーの質問を分類および識別し、次に2つの結果を統合してユーザーの真の意図を取得し、それに応じて回答します(一意の回答、リスト、拒否の回答)。例:上記の知識ベースの質問と回答の知識ベース構造図に示されているように、「情報」と「アカウント」2つのフィールドを含む2層構造の知識ベースがあります。 「情報」フィールドには、「情報の公開方法」、「情報の削除方法」、および「アカウント」フィールドには、「アカウントのキャンセル方法」という意図が含まれています。ユーザーが「投稿を公開するにはどうすればよいですか?」という質問を入力したとき、QA_Matchは次のQ&Aロジックを実行します。
実際のシナリオでは、構造知識ベースのQ&A質問の層にも遭遇します。 DSSM意図マッチングモデルとSPTMの軽量化前言語モデルを使用すると、この種の問題を解決できます。 2つの比較:
| モデル | 使い方 | アドバンテージ | 欠点 |
|---|---|---|---|
| DSSM意図マッチングモデル | DSSMマッチングモデルは直接一致します | 使用するのが簡単で、モデルはほとんどスペースを占めていません②高速トレーニング/予測速度 | コンテキスト情報を利用できません |
| SPTM軽量訓練を受けた言語モデル | 事前に訓練されたLSTM/トランス語モデル + LSTM/トランスマッチングモデルを微調整します | cor教師なしの事前トレーニングデータを最大限に活用して効果を改善することができます②言語モデルは他のダウンストリームタスクに使用できます | training訓練前には大量のラベルなしのデータが必要です②操作はより複雑です(マッチングモデルを取得するには2つのステップが必要です) |
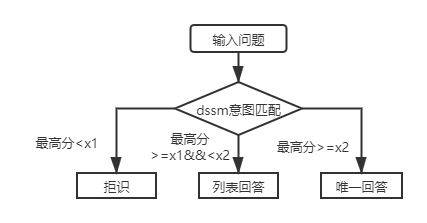
ファーストレイヤー構造の知識ベースのQ&Aの場合、DSSM意図マッチングモデルを使用して入力の質問を採点するだけで、上記の図のX1およびX2との意図マッチングの最高スコアを比較して、回答タイプ(一意の回答、リストの回答、拒否)を決定する必要があります。
多くの場合、実際の使用には大量のラベルのないデータがあることを考慮して、知識ベースのデータが制限されている場合、監督されていない事前訓練された言語モデルを使用して、一致モデルの有効性を改善できます。 2019年5月に、Bert Pre-Trainingプロセスを参照して、SPTMモデルを開発しました。 BERTと比較して、このモデルは主に3つの側面を改善しました。1つ目は、NSP(次の文予測)を取るに足らない効果で除去し、次に除去します。2つ目は、オンライン推論パフォーマンスを改善するために、変圧器をLSTMに置き換え、3番目にモデル効果がパラメーター量を減らすことを保証し、ブロック間の共有パラメーターを持つトランスも提供します。モデルの原則は次のとおりです。
モデルを事前にトレーニングする場合、トレーニングデータはデータセットとしてLabellessの単一文を使用して生成する必要があり、BERTはサンプルを作成するために使用されます。各単一文はサンプルとして使用され、文の単語の15%は予測に参加し、予測に参加する単語の80%がマスクされ、10%はDictionaryの別の単語に置き換えられません。
トレーニング前の段階のモデル構造を以下の図に示します。
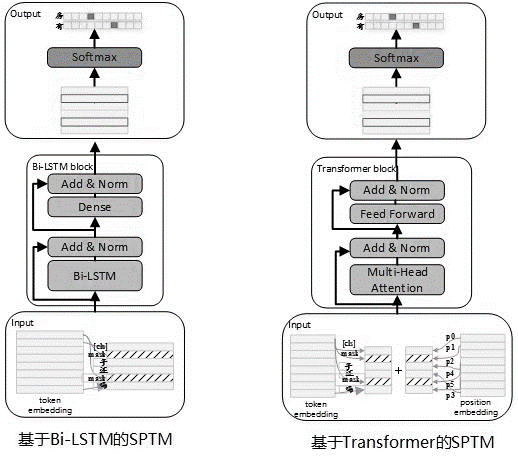
モデルの表現能力を改善し、より浅い情報を保持するために、残差Bi-LSTMネットワーク(残差LSTM)がモデル本体として導入されました。ネットワークは、Bi-LSTMの各層の入力とこのレイヤーの出力を正規化し、結果は次のレイヤーの入力として使用されます。さらに、最後のレイヤーBI-LSTM出力は、完全に接続されたレイヤーの入力として使用されます。完全に接続されたレイヤーの出力で合計および正規化した後、結果はネットワーク全体の出力として使用されます。
トレーニング前のタスクの時間のかかる例を次の表に示します。
| メトリック名 | インジケータ値 | インジケータ値 | インジケータ値 |
|---|---|---|---|
| モデル構造 | LSTM | パラメーターを共有するためのトランス | パラメーターを共有するためのトランス |
| 事前に保護されたデータセットサイズ | 1000万 | 1000万 | 1000万 |
| トレーニング前のリソース | 10 NVIDIA K40 / 12Gメモリ | 10 NVIDIA K40 / 12Gメモリ | 10 NVIDIA K40 / 12Gメモリ |
| トレーニング前のパラメーター | ステップ= 100000 /バッチサイズ= 128 | ステップ= 100000 /バッチサイズ= 128 /1レイヤー / 12ヘッド | ステップ= 100000 /バッチサイズ= 128/12レイヤー / 12ヘッド |
| トレーニング前の時間がかかります | 8.9時間 | 13.5時間 | 32.9時間 |
| 事前に保護されたモデルサイズ | 81m | 80.6m | 121m |
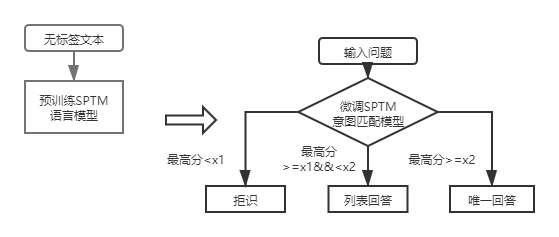
SPTMの導入後、ファーストレイヤー構造の知識ベースQ&Aの場合、言語モデルの微調整に基づいて意図マッチングモデルを使用して入力質問は最初に採点され、次に回答タイプ(一意の回答、リスト回答、拒否)は、DSSM意図マッチングモデルと同じ戦略に基づいて決定されます。
使用する必要があるデータファイル(data_demoフォルダーの下)の形式は次のとおりです。データを漏らしないために、標準問題と拡張された問題の元のテキストをエンコードし、実際のアプリケーションシナリオでは、次の形式でデータを準備するだけです。
<PAD> 、 `が含まれている必要があります)データは tで区切られ、問題のエンコーディングはスペースで区切られ、単語はスペースで区切られます。このプロジェクトのデータ例では、元のテキストがエンコードされ、各単語が数字に置き換えられることに注意してください。たとえば、 205 19 90 417 41 44に対応する実際のテキストが如何删除信息方法、およびこのエンコード操作は実際に使用する場合は必要ありません。ナレッジベースの構造が1つのレベルの場合、std_dataファイルのすべてのカテゴリIDを__label__0に設定する必要があります。
知識ベースの半自動マイニングプロセスは、QAマッチの自動質問と回答プロセスに基づいて構築された知識ベースの半自動マイニングソリューションのセットです(1層の知識ベース構造に基づく自動質問と回答を参照)。一方では、オンラインで一致させる機能が向上します。一方、オフラインモデルトレーニングデータの品質を向上させるため、モデルのパフォーマンスが向上します。ナレッジベースの半自動マイニングプロセスは、モデルが起動した後のコールドスタートマイニングと反復マイニングの2つのシナリオに使用できます。詳細については、知識ベースのマイニング手順を参照してください。
詳細については、操作手順を参照してください
batch_size >= negitive_sizeを満たす必要があります。そうしないと、モデルを効果的にトレーニングできません。 tensorflow 版本>r1.8 <r2.0, python3
V1.0:https://github.com/wuba/qa_match/tree/v1.0
V1.1:https://github.com/wuba/qa_match/tree/v1.1
V1.2:https://github.com/wuba/qa_match/tree/v1.2
V1.3:https://github.com/wuba/qa_match/tree/v1.3
将来的には、QA_MATCの機能を最適化および拡張し続けます。計画は、次のようにオープンソースになります。
開発者が貴重な意見や提案を私たちに与えることを心から願っています。提案や質問をフィードバックする次の方法を選択できます。


