qa_match
1.0.0
QA_MATCH adalah alat pencocokan tanya jawab berbasis pembelajaran yang mendalam yang mendukung basis pengetahuan struktur satu dan dua lapis Q&A. QA_MATCH mendukung basis pengetahuan struktural satu lapis Q&A melalui model pencocokan niat, dan mendukung basis pengetahuan struktural dua lapis Q&A melalui hasil model klasifikasi domain fusi dan model pencocokan niat. QA_MATCH juga mendukung fungsi pra-pelatihan tanpa pengawasan, dan melalui model bahasa pra-terlatih yang ringan (SPTM, model pra-terlatih sederhana) dapat meningkatkan efektivitas tugas hilir seperti pertanyaan dan jawaban basis pengetahuan.
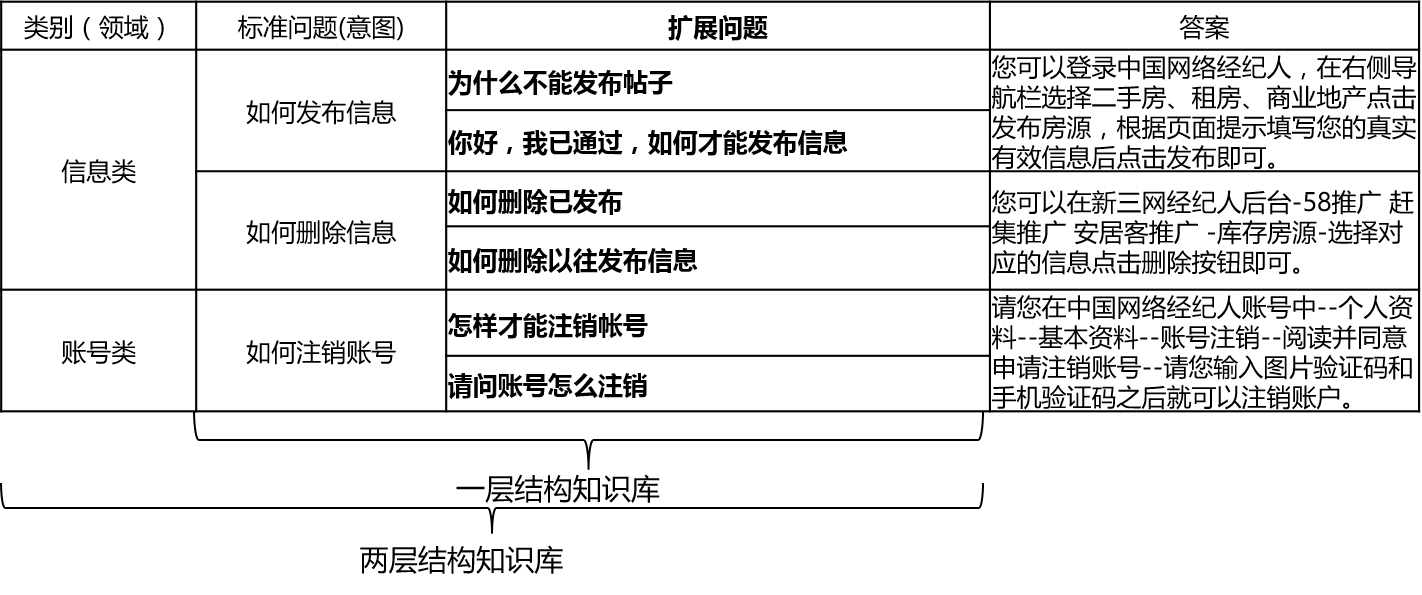
Dalam skenario aktual, basis pengetahuan umumnya dibangun melalui ringkasan manual, anotasi, penambangan mesin, dll. Basis pengetahuan berisi sejumlah besar pertanyaan standar, setiap pertanyaan standar memiliki jawaban standar dan beberapa pertanyaan yang diperluas. Kami menyebut pertanyaan yang diperluas ini pertanyaan yang diperluas. Untuk basis pengetahuan struktural satu lapis yang hanya berisi pertanyaan standar dan pertanyaan ekstensi, kami menyebut pertanyaan standar. Untuk basis pengetahuan struktural dua lapis, setiap masalah standar dan masalah yang diperluas memiliki kategori, yang kami sebut domain, dan satu domain berisi banyak maksud.
QA_Match mendukung struktur basis pengetahuan sebagai berikut:
Untuk pertanyaan input, QA_MATCH dapat memberikan tiga jawaban dalam kombinasi dengan basis pengetahuan:
Di bawah dua struktur basis pengetahuan, ada perbedaan dalam penggunaan QA_MATCH, yang dijelaskan di bawah ini:
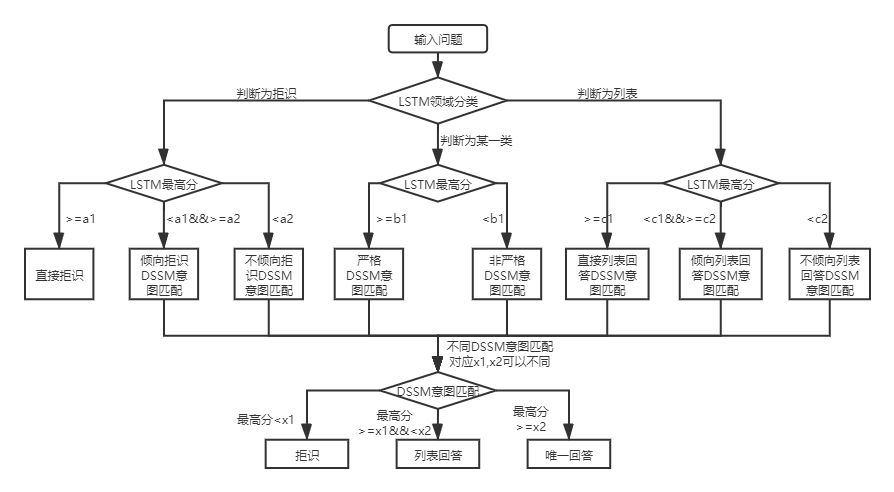
Untuk basis pengetahuan struktur dua lapis T&J, QA_MATCH akan pertama-tama mengklasifikasikan dan mengidentifikasi pertanyaan pengguna dalam domain dan niat, dan kemudian mengintegrasikan hasil keduanya untuk mendapatkan niat dan jawaban yang sebenarnya pengguna sesuai (jawaban unik, daftar jawaban, jawaban penolakan). Sebagai contoh: seperti yang ditunjukkan dalam diagram struktur basis pengetahuan dalam pertanyaan dan jawaban basis pengetahuan di atas, kami memiliki basis pengetahuan struktur dua lapis, yang mencakup "informasi" dan "akun" dua bidang. Bidang "Informasi" berisi dua niat: "Cara menerbitkan informasi", "Cara Menghapus Informasi", dan bidang "Akun" berisi niat: "Cara Membatalkan Akun". Ketika pengguna memasukkan pertanyaan: "Bagaimana cara menerbitkan posting? Kapan", QA_Match akan melakukan logika T&J berikut:
Dalam skenario aktual, kami juga akan menemukan lapisan Basis Pengetahuan Struktural Pertanyaan Tanya Jawab. Menggunakan model pencocokan niat DSSM dan model bahasa pra-terlatih SPTM dapat menyelesaikan masalah semacam ini. Perbandingan keduanya:
| Model | Cara menggunakan | keuntungan | kekurangan |
|---|---|---|---|
| Model pencocokan niat dssm | Model pencocokan DSSM secara langsung cocok | ① mudah digunakan, model ini mengambil sedikit ruang pelatihan/prediksi cepat | Tidak dapat memanfaatkan informasi konteks |
| SPTM Model Bahasa Pra-Terlatih SPTM | Model bahasa LSTM/Transformer Pra-terlatih + Fine-Tune LSTM/Model Pencocokan Transformer | ① Dapat memanfaatkan sepenuhnya data pra-pelatihan tanpa pengawasan untuk meningkatkan efek ② model bahasa dapat digunakan untuk tugas hilir lainnya | ① Pra-pelatihan membutuhkan sejumlah besar data bebas label ② Operasi ini lebih rumit (dua langkah diperlukan untuk mendapatkan model pencocokan) |
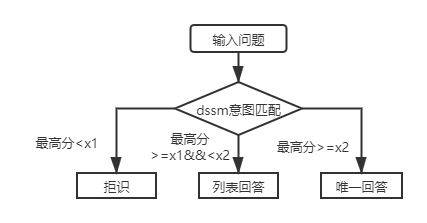
Untuk basis pengetahuan struktur lapisan pertama T&J, Anda hanya perlu menggunakan model pencocokan niat DSSM untuk mencetak pertanyaan input, dan membandingkan skor tertinggi dari pencocokan niat dengan X1 dan X2 pada gambar di atas untuk menentukan jenis jawaban (jawaban unik, daftar jawaban, penolakan).
Mempertimbangkan bahwa sering ada sejumlah besar data yang tidak berlabel dalam penggunaan aktual, ketika data basis pengetahuan terbatas, model bahasa pra-terlatih tanpa pengawasan dapat digunakan untuk meningkatkan efektivitas model pencocokan. Mengacu pada proses pra-pelatihan Bert, pada Mei 2019, kami mengembangkan model SPTM. Dibandingkan dengan Bert, model ini terutama telah meningkatkan tiga aspek: pertama, ini menghilangkan NSP (prediksi kalimat berikutnya) dengan efek yang tidak signifikan, kedua, untuk meningkatkan kinerja inferensi online, transformator diganti dengan LSTM, dan ketiga, untuk memastikan bahwa efek model mengurangi kuantitas parameter, ia juga menyediakan transformator dengan parameter yang dibagikan antara blok. Prinsip model adalah sebagai berikut:
Ketika pra-pelatihan model, data pelatihan perlu dihasilkan menggunakan kalimat tunggal Labelless sebagai set data, dan Bert digunakan untuk membangun sampel: setiap kalimat tunggal digunakan sebagai sampel, 15% dari kata-kata dalam kalimat berpartisipasi dalam prediksi, 80% dari kata yang berpartisipasi dalam prediksi ditopang, 10% tidak diganti dengan kata lain, dan tidak ada yang diganti.
Struktur model tahap pra-pelatihan ditunjukkan pada gambar di bawah ini:
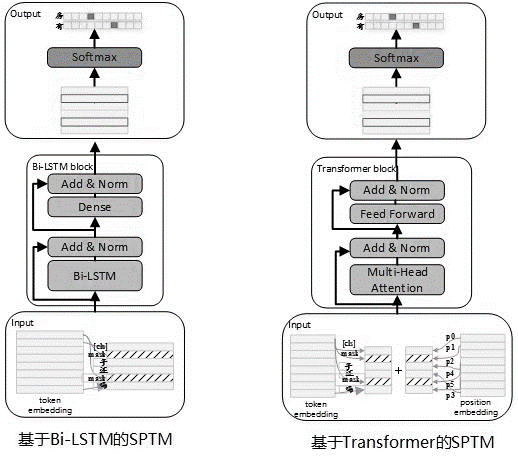
Untuk meningkatkan kemampuan ekspresi model dan mempertahankan informasi yang lebih dangkal, jaringan bi-LSTM residual (residual LSTM) diperkenalkan sebagai badan model. Jaringan menormalkan input dari setiap lapisan BI-LSTM dan output dari lapisan ini, dan hasilnya digunakan sebagai input dari lapisan berikutnya. Selain itu, output BI-LSTM lapisan terakhir digunakan sebagai input dari lapisan yang sepenuhnya terhubung. Setelah menjumlahkan dan menormalkannya dengan output dari lapisan yang sepenuhnya terhubung, hasilnya digunakan sebagai output dari seluruh jaringan.
Contoh tugas pra-pelatihan yang memakan waktu ditunjukkan pada tabel berikut:
| Nama metrik | Nilai indikator | Nilai indikator | Nilai indikator |
|---|---|---|---|
| Struktur model | LSTM | Transformator untuk berbagi parameter | Transformator untuk berbagi parameter |
| Ukuran dataset pretrained | 10 juta | 10 juta | 10 juta |
| Sumber Daya Pra-Pelatihan | 10 NVIDIA K40 / 12G memori | 10 NVIDIA K40 / 12G memori | 10 NVIDIA K40 / 12G memori |
| Parameter pra-pelatihan | Langkah = 100000 / Ukuran Batch = 128 | Langkah = 100000 / Ukuran Batch = 128/1 Lapisan / 12 Kepala | Langkah = 100000 / Ukuran Batch = 128/12 Lapisan / 12 Kepala |
| Memakan waktu pra-pelatihan | 8,9 jam | 13,5 jam | 32,9 jam |
| Ukuran model pretrained | 81m | 80.6m | 121m |
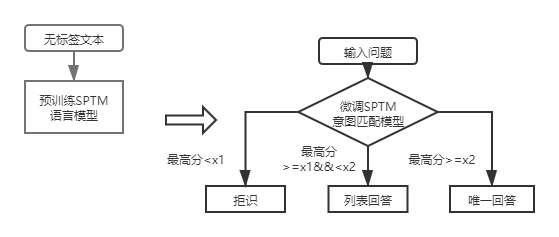
Setelah pengenalan SPTM, untuk basis pengetahuan struktur lapisan pertama Q&A, pertanyaan input pertama kali dinilai menggunakan model pencocokan niat berdasarkan fine-tuning model bahasa, dan kemudian jenis jawaban (jawaban unik, jawaban daftar, penolakan) ditentukan berdasarkan strategi yang sama dengan model pencocokan niat DSSM.
Format file data (di bawah folder data_demo) yang perlu digunakan adalah sebagai berikut. Agar tidak membocorkan data, kami telah mengkodekan teks asli dari masalah standar dan masalah yang diperluas, dan dalam skenario aplikasi yang sebenarnya, cukup persiapkan data dalam format berikut.
<PAD> 、 `) Data dipisahkan oleh t, pengkodean masalah dipisahkan oleh spasi, dan kata -kata dipisahkan oleh ruang. Perhatikan bahwa dalam contoh data proyek ini, teks asli dikodekan dan setiap kata diganti dengan angka. Misalnya, bagaimana teks aktual yang sesuai dengan 205 19 90 417 41 44如何删除信息, dan operasi pengkodean ini tidak diperlukan saat benar -benar digunakan ; Jika struktur basis pengetahuan adalah satu level, semua ID kategori dalam file STD_DATA perlu diatur ke __label__0 .
Proses penambangan semi-otomatis dari basis pengetahuan adalah seperangkat solusi penambangan semi-otomatis untuk basis pengetahuan yang dibangun di atas QA Match Automatic Question and Jawaban Proses (lihat pertanyaan dan jawaban otomatis berdasarkan struktur basis pengetahuan satu lapis), yang membantu meningkatkan skala basis pengetahuan dan kualitas basis pengetahuan. Di satu sisi, ini meningkatkan kemampuan untuk mencocokkan secara online; Di sisi lain, ini meningkatkan kualitas data pelatihan model offline, dan dengan demikian meningkatkan kinerja model. Proses penambangan semi-otomatis dari basis pengetahuan dapat digunakan untuk dua skenario: penambangan awal dingin dan penambangan berulang setelah model diluncurkan. Untuk detailnya, silakan merujuk ke instruksi penambangan basis pengetahuan.
Lihat instruksi operasi untuk detailnya
batch_size >= negitive_size , jika tidak model tidak dapat dilatih secara efektif. tensorflow 版本>r1.8 <r2.0, python3
V1.0: https://github.com/wuba/qa_match/tree/v1.0
V1.1: https://github.com/wuba/qa_match/tree/v1.1
V1.2: https://github.com/wuba/qa_match/tree/v1.2
V1.3: https://github.com/wuba/qa_match/tree/v1.3
Di masa depan, kami akan terus mengoptimalkan dan memperluas kemampuan QA_MATCH, dan rencananya adalah untuk membuka sumber sebagai berikut:
Kami dengan tulus berharap bahwa pengembang akan memberi kami pendapat dan saran yang berharga. Anda dapat memilih cara berikut untuk memberi saran dan pertanyaan kepada kami:


